There is already many good answers, I will just add to those that came before mine:
This type of images you are referring to are called adversarial perturbations, (see 1, and it is not limited to images, it has been shown to apply to text too, see Jia & Liang, EMNLP 2017. In text, the introduction of an irrelevant sentence which doesn't contradict the paragraph has been seen to cause the network to come to a completely different answer (see see Jia & Liang, EMNLP 2017).
The reason they work is due to the fact that neural network view images in a different way from us, coupled with the high dimentionality of the problem space. Where we see the whole picture, they see a combination of features which combine to form an object(Moosavi-Dezfooli et al., CVPR 2017). According to perturbation generated against one network has been seen to have high likelihood to work on other networks:
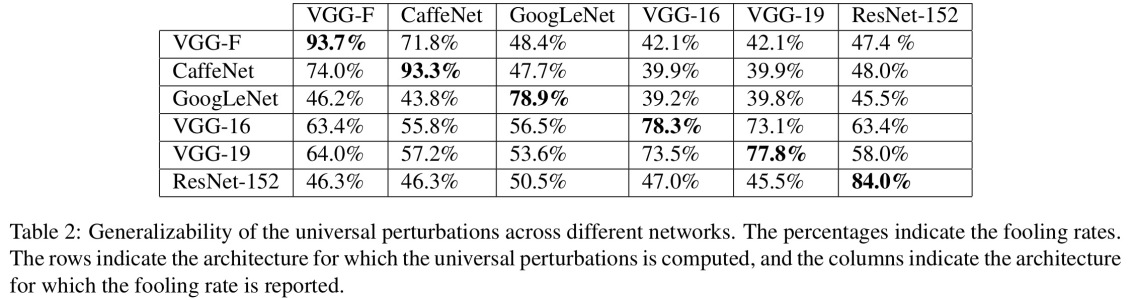
In the figure above, it is seen that The universal perturbations computed for the VGG-19 network, for example, have a fooling ratio above 53% for all other tested architectures.
So how do you deal with the threat of adversarial perturbations? Well, for one, you can try to generate as many perturbations as you can and use them to fine-tune your model. Whist this somewhat solves the problem, it doesn't solve the problem entirely. In (Moosavi-Dezfooli et al., CVPR 2017) the author reported that, repeating the process by computing new perturbations and then fine-tuning again seems to yield no further improvements, regardless of the number of iterations, with the fooling ratio hovering around 80%.
Perturbations are an indication of the shallow pattern matching that neural networks perform, coupled with their minimal lack of in-depth understanding of the problem at hand. More work still needs to be done.