With 50+ vendors to choose from, data quality and data observability software has never been more powerful, more plentiful, or more confusing—until now.

With 50+ vendors to choose from, data quality and data observability software has never been more powerful, more plentiful, or more confusing—until now.

Welcome to Analysis-A-Palooza: The Festival No Data Engineer Asked For

AI is changing the world — in this webinar we show how Large Language Model drive the need for DataOps, Data Quality, and Data Observability

When data team leaders hear “data products,” they immediately think of the stuff their team creates. But focusing on the “what” completely misses the mark. Data products aren’t about what you create, but “how” you build, maintain, and continually improve your data deliverables to your customers.

We explore the new generation of open source data quality software that uses AI to police AI, automate test generation at scale, and provides the transparency and control—all while keeping your CFO happy.

This webinar unveils the battle-tested FITT (Functional, Idempotent, Tested, Two-stage) data architecture that eliminates endemic burnout, constant firefighting, and hero-driven development that keeps engineers trapped in operational chaos.

DataOps TestGen Enterprise is now compatible with Google BigQuery and can be used to profile and test file-based data accessible through Redshift Spectrum and Snowflake external tables using Apache Iceberg and other file formats.

When people think of data engineers, the description usually stops at “building high-quality pipelines that deliver analyst-ready data.” That is true, but incomplete. In modern organizations, data engineers hold a deeper responsibility. They are not just the builders of pipelines—they are the curators of the business logic itself.

The manufacturing industry learned decades ago that catching defects early in the production process saves exponentially more money than fixing them after products ship. Today’s data engineering teams face a strikingly similar challenge.
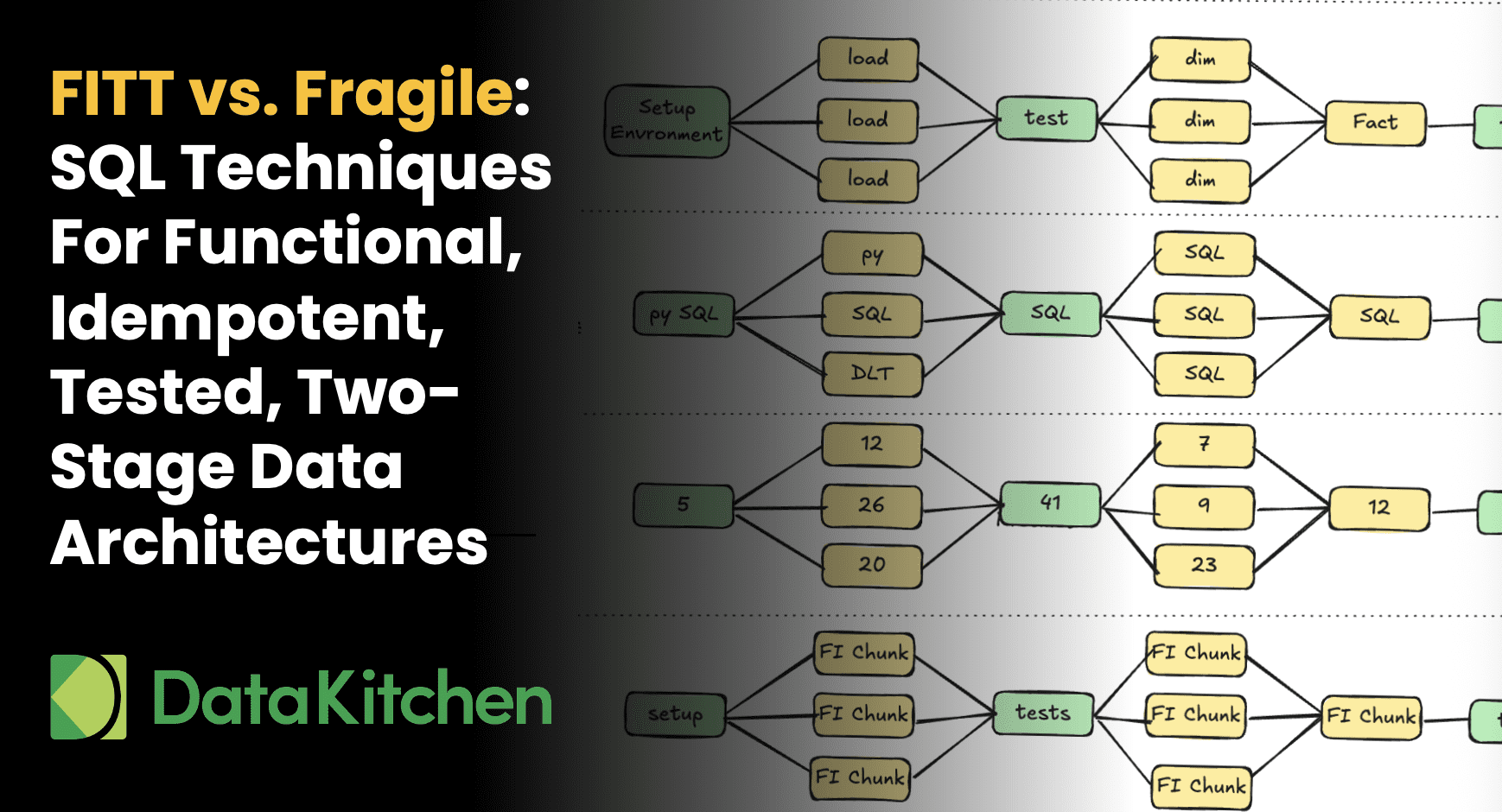
Transform data engineering from a high-stress, “hero saves the day” kind of job into something systematic and predictable that actually scales as your team and business grow. Stop babysitting pipelines: SQL & ELT the FITT Way.

DataOps Data Quality TestGen:
Simple, Fast, Generative Data Quality Testing, Execution, and Scoring.
[Open Source, Enterprise]

DataOps Observability:
Monitor every data pipeline, from source to customer value, & find problems fast
[Open Source, Enterprise]

DataOps Automation:
Orchestrate and automate your data toolchain with few errors and a high rate of change.
[Enterprise]

DataOps Consulting, Coaching, and Transformation
Commercial Data & Analytics Platform for Pharma
Data Production Teams
Data Science/AI
Data Engineering
Data Quality
Business Analytics
Data Products
Data Mesh
Data Contracts
ModelOps / MLOps
DataGovOps
Self-Service Operations
Data Quality Assessments
Data Quality Testing
Data Observability
Data Orchestration


Monitor every Data Journey in an enterprise, from source to customer value, in development and production.
Simple, Fast Data Quality Test Generation and Execution. Your Data Journey starts with verifying that you can trust your data.
Orchestrate and automate your data toolchain to deliver insight with few errors and a high rate of change.