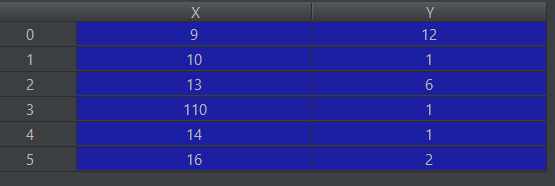
I have 2 column in data frame, X and Y. And I have some string values stored in text, which I want to put in X, Y as shown in the example.
Example :
text=9 10 13 110 14 16 12 1 6 1 1 2 X Y 9 12 10 1 13 6 110 1 14 1 16 2 I have 2 column in data frame, X and Y. And I have some string values stored in text, which I want to put in X, Y as shown in the example.
Example :
text=9 10 13 110 14 16 12 1 6 1 1 2 X Y 9 12 10 1 13 6 110 1 14 1 16 2 If you are looking to hard-code it for only 2 columns, this can be achieved as follows:
import pandas as pd df = pd.DataFrame() text = '9 10 13 110 14 16 12 1 6 1 1 2' text = text.split() df['X'] = text[:int(len(text)/2)] df['Y'] = text[int(len(text)/2):] I will assume your text is in two strings like this:
In [1]: import pandas as pd In [2]: text1 = "9 10 13 110 14 16" In [3]: text2 = "12 1 6 1 1 2" A one-liner solution would be:
In [4] df = pd.DataFrame.from_records(zip(text1.split(" "), text2.split(" "))) A Pandas Dataframe can be created by passing it one list (or tuple) for each row that you want in the table. This is done by using the from_records() method you see above.
So the steps that make the above line work:
split() each string on the spaces, to get a list of strings - one per value.zip does exactly that for us.from_records() method.The final result:
In [7]: df Out[7]: 0 1 0 9 12 1 10 1 2 13 6 3 110 1 4 14 1 5 16 2 Because we just gave the dataframe lists of strings, the values are still strings in teh dataframe. If you want to actually use them as number, you can use the astype() method, like this
df_integers = df.astype(int) # now contains integers df_floats = df.astype(float) # now contains floats, i.e. decimal values If I am understanding the question correctly, the solution should be like this:
import pandas as pd text = "9 10 13 110 14 16 12 1 6 1 1 2" text = text.split() X_part = text[:int(len(text)/2)] Y_part = text[int(len(text)/2):] df = pd.DataFrame(columns=['X', 'Y']) df['X'] = X_part df['Y'] = Y_part Output: