Will saving a trained model this way give me a model trained on every chunk of data or just the last chunk?
df = pd.read_csv(, chunksize=10000) for chunk in df: text = chunk['body'] label = chunk['user_id'] print(text.shape, label.shape) X_train, X_test, y_train, y_test = train_test_split(text, label, test_size=0.3) text_clf.fit(X_train, y_train) filename = 'finalized_model.sav' joblib.dump(text_clf, filename) # load the model from disk loaded_model = joblib.load(filename) For example, if the first chunk had labels 1 and 2, and the second chunk 3 and 4, will the final model be able to predict just 3 and 4? Or 1 and 2 as well, given the testing data has all the labels. Any help?
UPDATE The chunk is used to get text from the csv. I have updated my code.
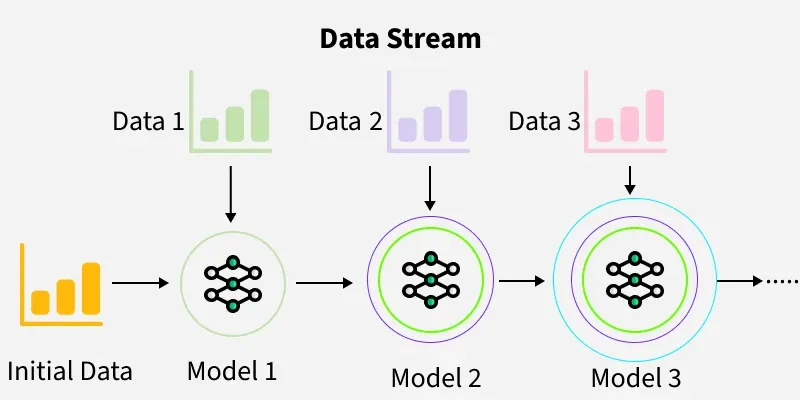
chunksizewhile reading dataframe could have negative impact on saving the updated learning/training (because of different labels in the used chunks) . I was about saying that this is duplication of this post, however OP asked for Save the updated training which I assume is going to be done automatically via.partial_fit()! $\endgroup$