Cache 0.1 #81
Description
Summary
Simple cache support for query result in order to speed up loading the same query multiple times. Extensible to more sophisticated design and implementation.
Design-level Explanation Actions
- Investigate existing cache / materialized view solutions for external storage
- Decide the scope of the first version:
- what to cache (admission and eviction)
- how to use the cache
- how to maintain the cache
- Decide the storage engine to store local cache in the first version (sqlite)
- Design the implementation of cache logic
Design-level Explanation
Scope of Cache 0.1
- What to cache
- Manually add query result to cache
- Do not remove cached data (do not consider limited disk space)
- How to use the cache
- Load the entire cache if and only if exactly match on the entire query (without do any filtering or manipulation)
- How to maintain the cache
- Manually force refreshing the cache when issuing query
- Refresh the entire cache (do not consider incremental refresh)
API Design
User Interface
def read_sql(..., enable_cache=True, force_query=False)- enable_cache(string or bool, optional(default
True)) - Whether or not to cache the result data. IfFalseis set, do not cache the result. IfTrueis set, cache the result to/tmpwith connection and sql as name. If a string is set, cache the result to the corresponding path. - force_query(bool, optional(default
False)) - Whether or not to force download the data from database no matter there is a cache or not. IfTrue, also update the local cache.
Logical workflow
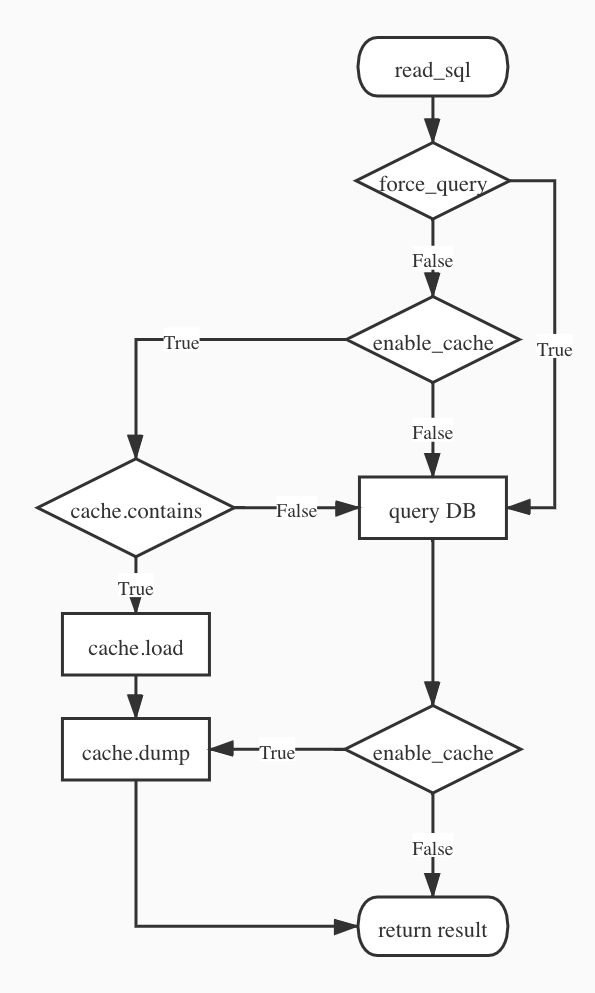
Cache Module Implementation
pub trait Cache { fn init(conn: str) -> Result<()>; // init cache source, init metadata if not exists fn query_match(query: str) -> Result<(Vec<str>, Vec<str>)>; // lookup metadata, split query into probe query and remainder query, and partition each query fn post_execute(dests: Vec<Box<dyn Destination>>) -> Result<Destination>; // produce final result }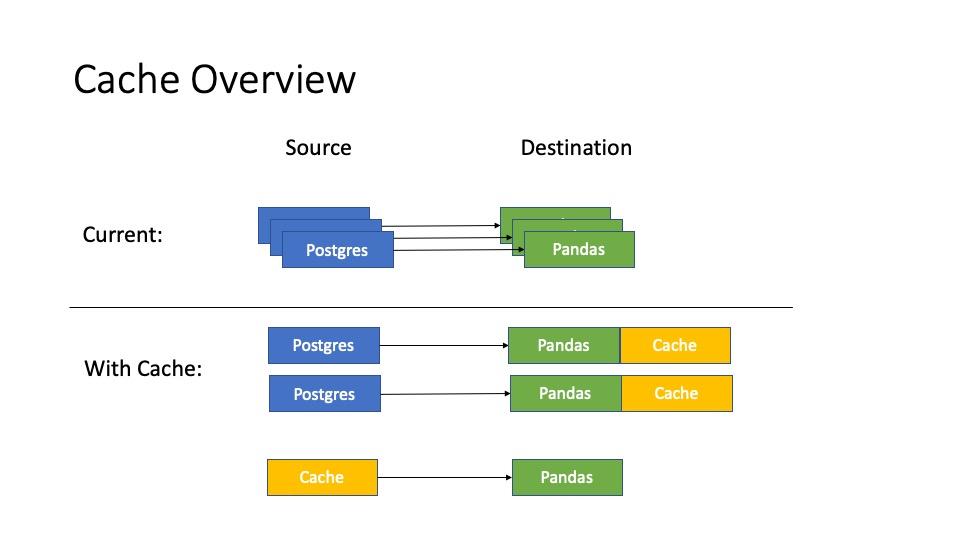
Implementation-level Explanation
Left: current implementation, Right: implementation supporting cache
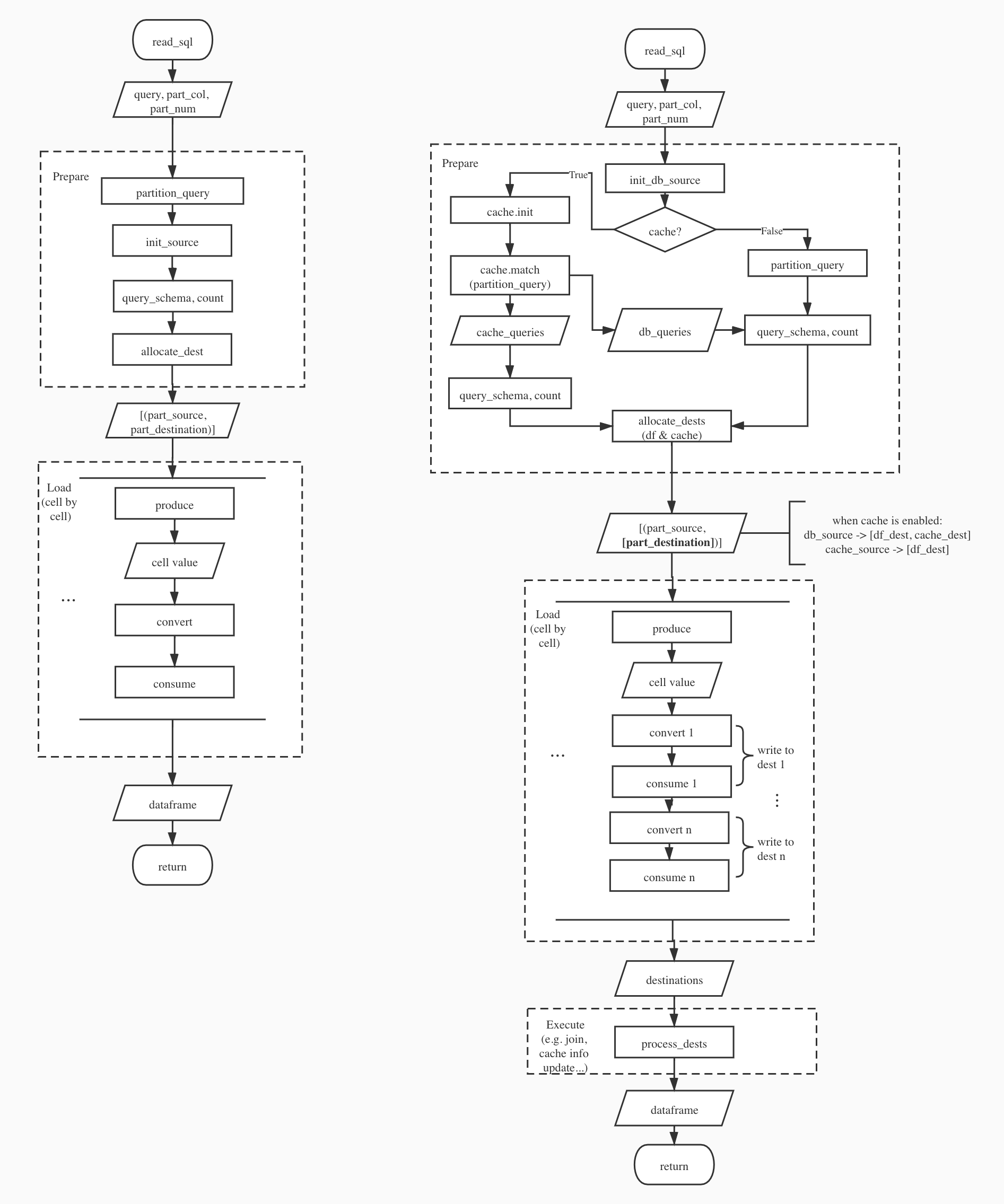
Either cache_queries or db_queries will be empty in the first version that only support exactly match.
Rational and Alternatives
- Able to extend to more cache backends, data format and policies in the future.
- Easy to incorporate in the current workflow of ConnectorX
- Able to make use current loading and writing mechanism in ConnectorX
Prior Art
Some related works:
- cachesql
- torchdata
- joblib.Memory
- flask-caching
- delta-cache
- redshift.MV
- snowflake.MV
- Materialize
- Noria
Future Possibilities
- Support different external storages for cache (e.g. Redis)
- Support using cache on partial match queries
- partial attribute
- partial predicate
- partial table (in join)
- Admission and eviction policy given limited space budget
- Incremental refresh the cache
Implementation-level Actions
- Add cache source on decided storage
- Add cache destination on decided storage
- Support multiple source to multiple destination logic (source partition -> destination partition combinator)
- read_sql API support
- Add tests
- Add documentation
Additional Tasks
- This task is put into a correct pipeline (Development Backlog or In Progress).
- The label of this task is setting correctly.
- The issue is assigned to the correct person.
- The issue is linked to related Epic.
- The documentation is changed accordingly.
- Tests are added accordingly.