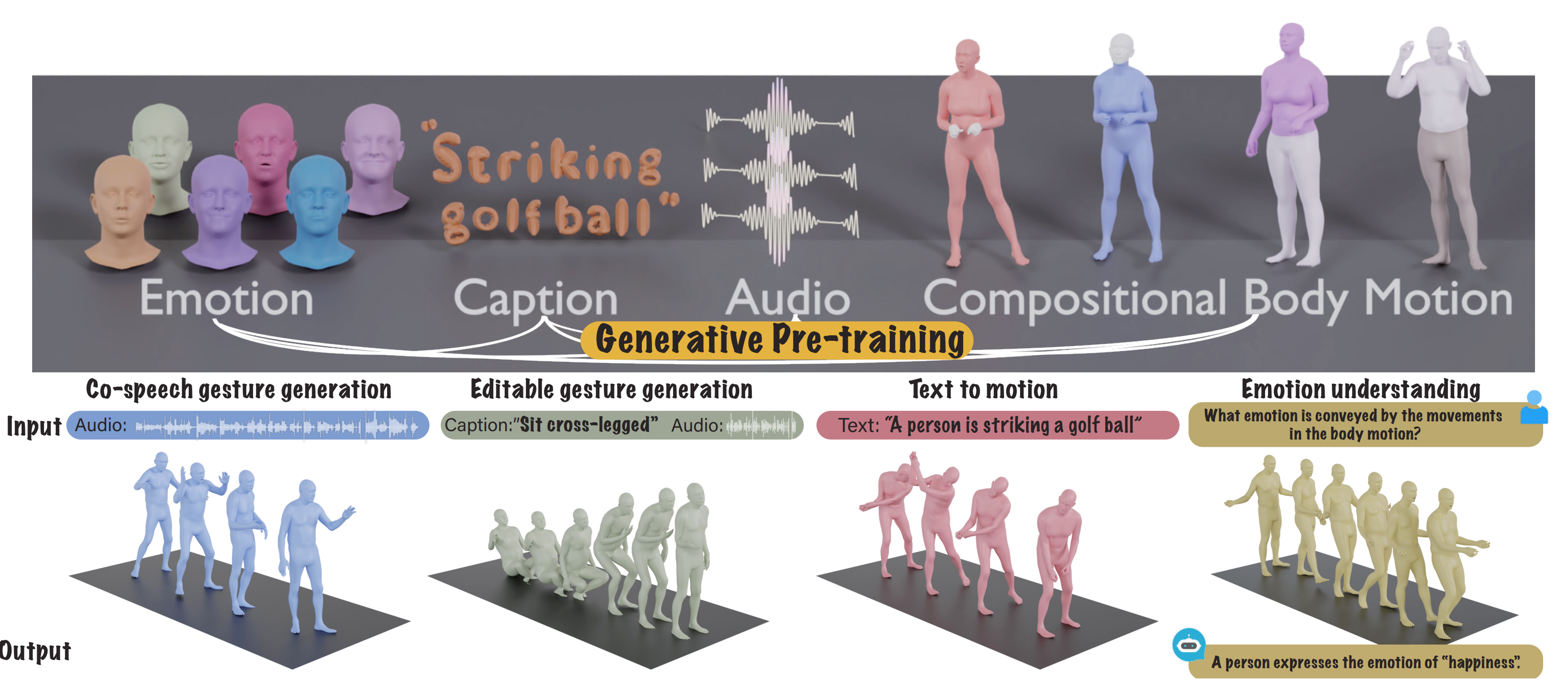
 | The Language of Motion: Unifying Verbal and Non-verbal Language of 3D Human Motion
Changan Chen*, Juze Zhang*, Shrinidhi Kowshika Lakshmikanth*, Yusu Fang, Ruizhi Shao, Gordon Wetzstein, Li Fei-Fei, Ehsan Adeli,
arXiv, 2024
project page / arXiv |  | HOI-M3: Capture Multiple Humans and Objects Interaction within Contextual Environment
Juze Zhang*, Jingyan Zhang*, Zining Song, Zhanhe Shi, Chengfeng Zhao, Ye Shi, Jingyi Yu, Lan Xu, Jingya Wang,
CVPR, 2024, Highlight
project page / arXiv / code / dataset |  | I’M HOI: Inertia-aware Monocular Capture of 3D Human-Object Interactions
Chengfeng Zhao, Juze Zhang, Jiashen Du, Ziwei Shan, Junye Wang, Jingyi Yu, Jingya Wang, Lan Xu,
CVPR, 2024
project page / arXiv / code / dataset |  | BOTH2Hands: Inferring 3D Hands from Both Text Prompts and Body Dynamics
Wenqian Zhang, Molin Huang, Yuxuan Zhou, Juze Zhang, Jingyi Yu, Jingya Wang, Lan Xu,
CVPR, 2024
project page / arXiv / code / dataset |  | NeuralDome: A Neural Modeling Pipeline on Multi-View Human-Object Interactions
Juze Zhang, Haimin Luo, Hongdi Yang, Xinru Xu, Qianyang Wu, Ye Shi, Jingyi Yu, Lan Xu, Jingya Wang,
CVPR, 2023
project page / arXiv / code / dataset | 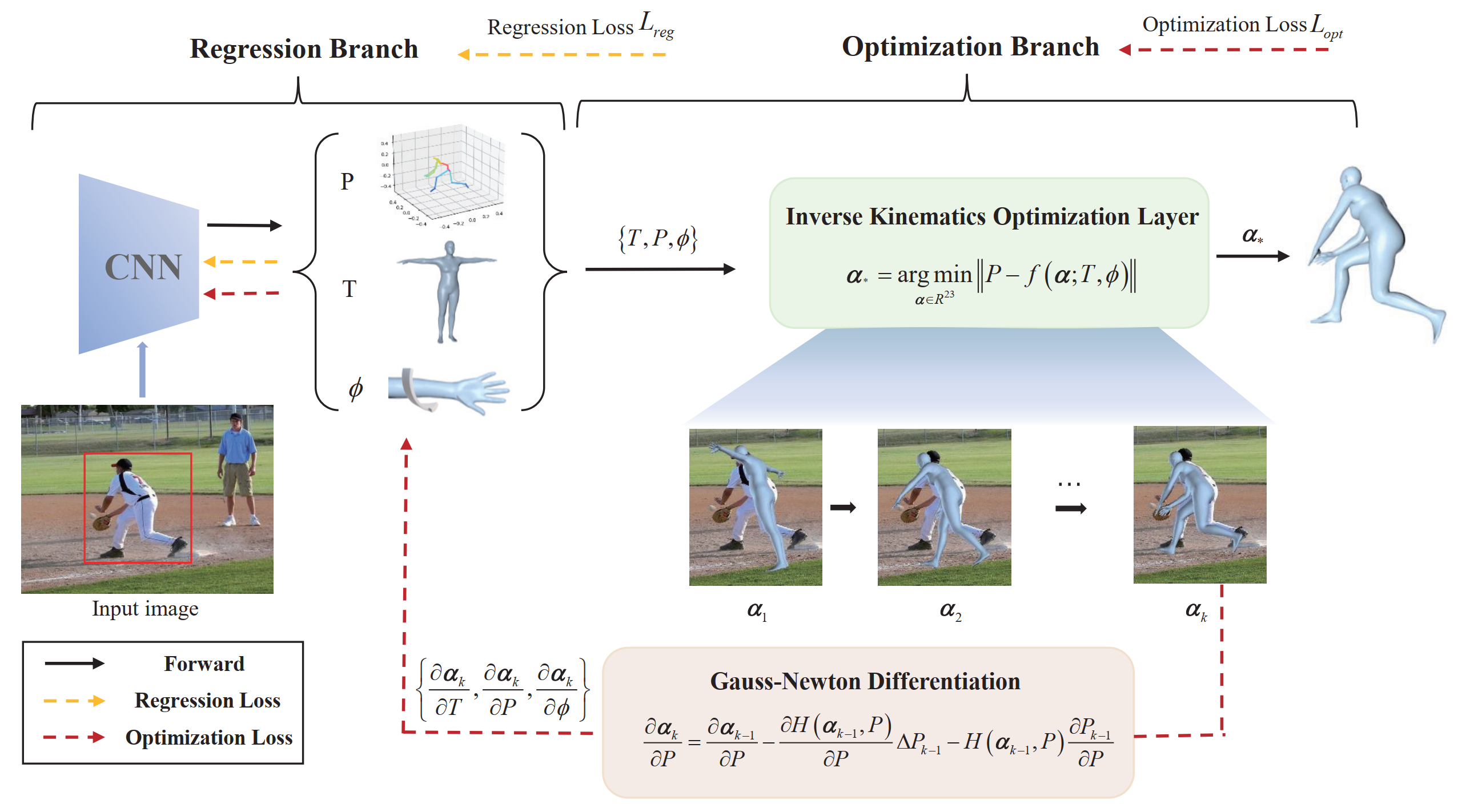 | IKOL: Inverse kinematics optimization layer for 3D human pose and shape estimation via Gauss-Newton differentiation
Juze Zhang, Ye Shi, Yuexin Ma, Lan Xu, Jingyi Yu, Jingya Wang,
AAAI, 2023, oral
project page / arXiv / video / code / | 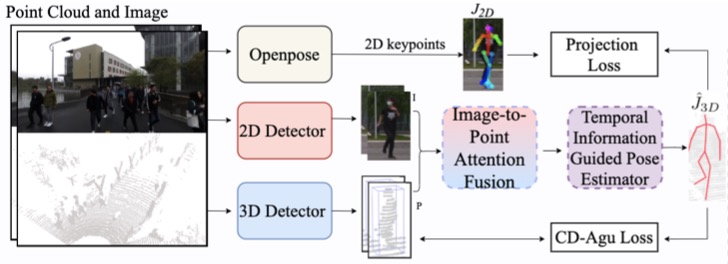 | Weakly Supervised 3D Multi-person Pose Estimation for Large-scale Scenes based on Monocular Camera and Single LiDAR
Peishan Cong, Yiteng Xu, Yiming Ren, Juze Zhang, Lan Xu, Jingya Wang, Jingyi Yu, Yuexin Ma,
AAAI, 2023, oral
project page / arXiv / | 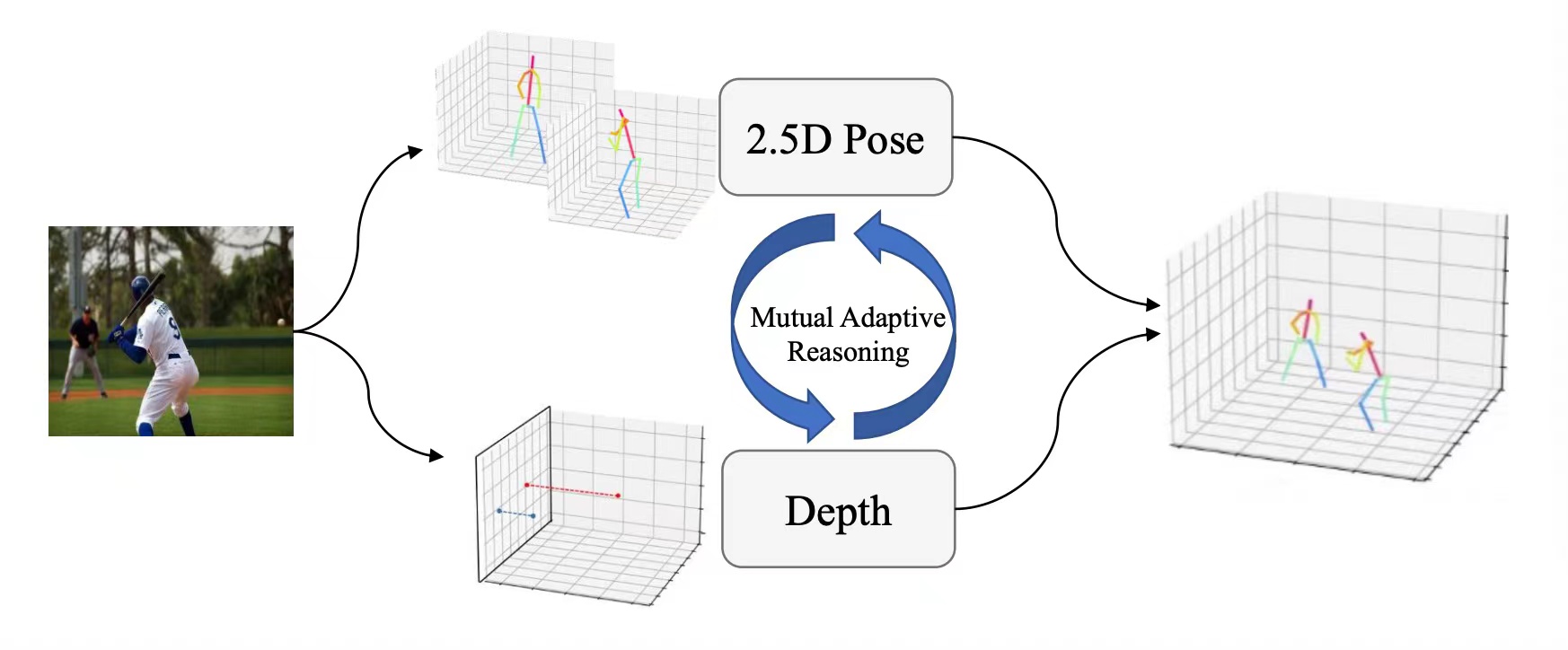 | Mutual Adaptive Reasoning for Monocular 3D Multi-Person Pose Estimations
Juze Zhang, Jingya Wang, Ye Shi, Fei Gao, Lan Xu, Jingyi Yu,
ACMMM, 2022
arXiv / | |
