Songlin Wei 魏松林I'm a first-year PhD student at USC Computer Science Department advised by Prof. Yue Wang.Previously, my academic journey took me to Peking University CFCS where I had the privilege of working with Prof. He Wang. I earned a Bachelor's degree in Software Engineering from Xiamen University. Over the years, my career has undergone various transformations. I developed large-scale social media websites, built robots, and started companies. Later, I discovered my passion for research and obtained a Master's degree in Control Science and Technology from Soochow University (which is located near home). My current research interests include:
Email / GitHub / Google Scholar / Wechat |  |
Publications* denotes equal contribution, † denotes corresponding author(s) |
 | Ψ₀: An Open Foundation Model Towards Universal Humanoid Loco-ManipulationSonglin Wei*, Hongyi Jing*, Boqian Li*, Zhenyu Zhao*, Jiageng Mao, Zhenhao Ni, Sicheng He, Jie Liu, Xiawei Liu, Kaidi Kang, Sheng Zang, Marco Pavone, Di Huang, Yue Wang† Arxiv Preprint, 2026 arxiv / website / Ψ0 is an open vision-language-action (VLA) model for dexterous humanoid loco-manipulation. |
 | ICLR: In-Context Imitation Learning with Visual ReasoningToan Nguyen, Weiduo Yuan, Songlin Wei, Hui Li, Daniel Seita†, Yue Wang† Arxiv Preprint, 2026 arxiv / website / We present In-Context Imitation Learning with Visual Reasoning (ICLR), a framework that augments demonstration prompts with structured visual reasoning traces representing anticipated future robot trajectories in image space |
 | Diffusion Knows Transparency: Repurposing Video Diffusion for Transparent Object Depth and Normal EstimationShaocong Xu, Songlin Wei, Qizhe Wei, Zheng Geng, Hong Li, Licheng Shen, Qianpu Sun, Shu Han, Bin Ma, Bohan Li, Chongjie Ye, Yuhang Zheng, Nan Wang, Saining Zhang, and Hao Zhao† Arxiv Preprint, 2025 arxiv / website / “Diffusion knows transparency.” Generative video priors can be repurposed, efficiently and label-free, into robust, temporally coherent perception for challenging real-world manipulation. |
 | GraspVLA: a Grasping Foundation Model Pre-trained on Billion-scale Synthetic Action DataShengliang Deng*, Mi Yan*, Songlin Wei, Haixin Ma, Yuxin Yang, Jiayi Chen, Zhiqi Zhang, Taoyu Yang, Xuheng Zhang, Heming Cui, Zhizheng Zhang, He Wang† Arxiv Preprint, 2025 arxiv / website / We present GraspVLA, a VLA model pretrained on large-scale synthetic action data as a foundational model for grasping tasks. |
 | Uni-NaVid: A Video-based Vision-Language-Action Model for Unifying Embodied Navigation TasksJiazhao Zhang, Kunyu Wang ,Shaoan Wang ,Minghan Li ,Haoran Liu, Songlin Wei, Zhongyuan Wang ,Zhizheng Zhang† ,He Wang† Arxiv Preprint, 2024 We present Uni-NaVid, the first video-based vision-language-action (VLA) model designed to unify diverse embodied navigation tasks and enable seamless navigation for mixed long-horizon tasks in unseen real-world environments. |
 | RoboHanger: Learning Generalizable Robotic Hanger Insertion for Diverse GarmentsYuxing Chen*, Songlin Wei*, Bowen Xiao, Jiangran Lyu, Jiayi Chen, Feng Zhu, He Wang† Arxiv Preprint, 2024 In this work, we address the problem of inserting a hanger into various unseen garments that are initially laid out flat on a table. |
 | GAPartManip: A Large-scale Part-centric Dataset for Material-Agnostic Articulated Object ManipulationWenbo Cui*, Chengyang Zhao*, Songlin Wei*, Jiazhao Zhang, Haoran Geng, Yaran Chen, He Wang† Arxiv Preprint, 2024 arxiv / we introduced a large-scale part-centric dataset for articulated object manipulation that features both photo-realistic material randomizations and detailed annotations of part-oriented, scene-level actionable interaction poses. |
 | D3RoMa: Disparity Diffusion-based Depth Sensing for Material-Agnostic Robotic ManipulationSonglin Wei, Haoran Geng, Jiayi Chen, Congyue Deng, Wenbo Cui, Chengyang Zhao, Xiaomeng Fang, Leonidas Guibas, He Wang† CoRL 2024, Wild3D@ECCV 2024, 2024 arxiv / website / We propose a diffusion model-based depth estimation framework on stereo image pairs for robotic manipulation. |
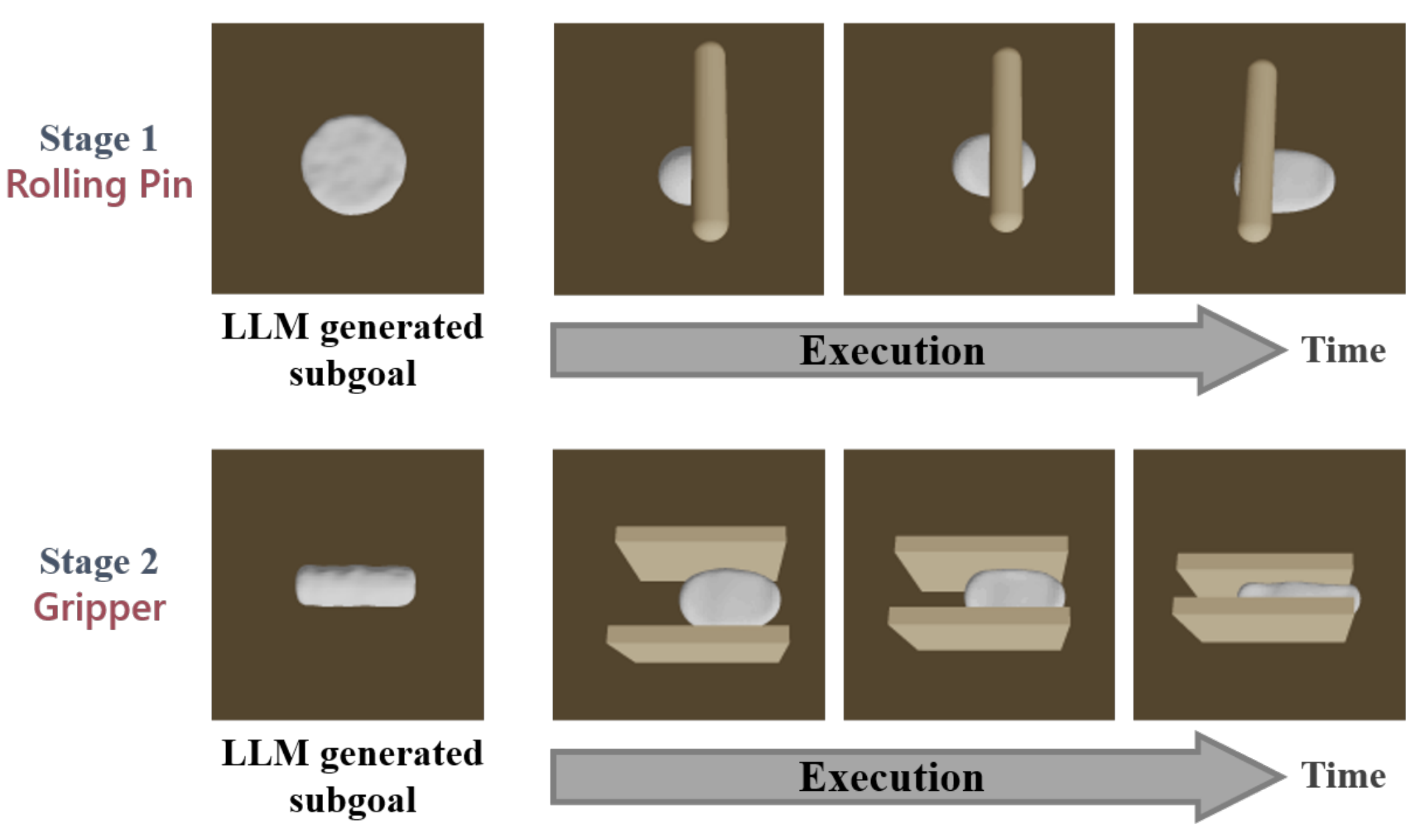 | Make a Donut🍩: Hierarchical EMD-Space Planning for Zero-Shot Deformable Manipulation with ToolsYang You, Bokui Shen, Congyue Deng, Haoran Geng, Songlin Wei, He Wang, Leonidas Guibas† Arxiv, 2024 arxiv / In this work, we introduce a demonstration-free hierarchical planning approach capable of tackling intricate long-horizon tasks without necessitating any training |
 | Open6DOR: Benchmarking Open-instruction 6-DoF Object Rearrangement and A VLM-based ApproachYufei Ding*, Haoran Geng*, Chaoyi Xu, Xiaomeng Fang, Jiazhao Zhang, Songlin Wei, Qiyu Dai, Zhizheng Zhang, He Wang† IROS, 2024 website / We present Open6DOR, a challenging and comprehensive benchmark for open-instruction 6-DoF object rearrangement tasks. Following this, we propose a zero-shot and robust method, Open6DORGPT, which proves effective in demanding simulation environments and real-world scenarios. |
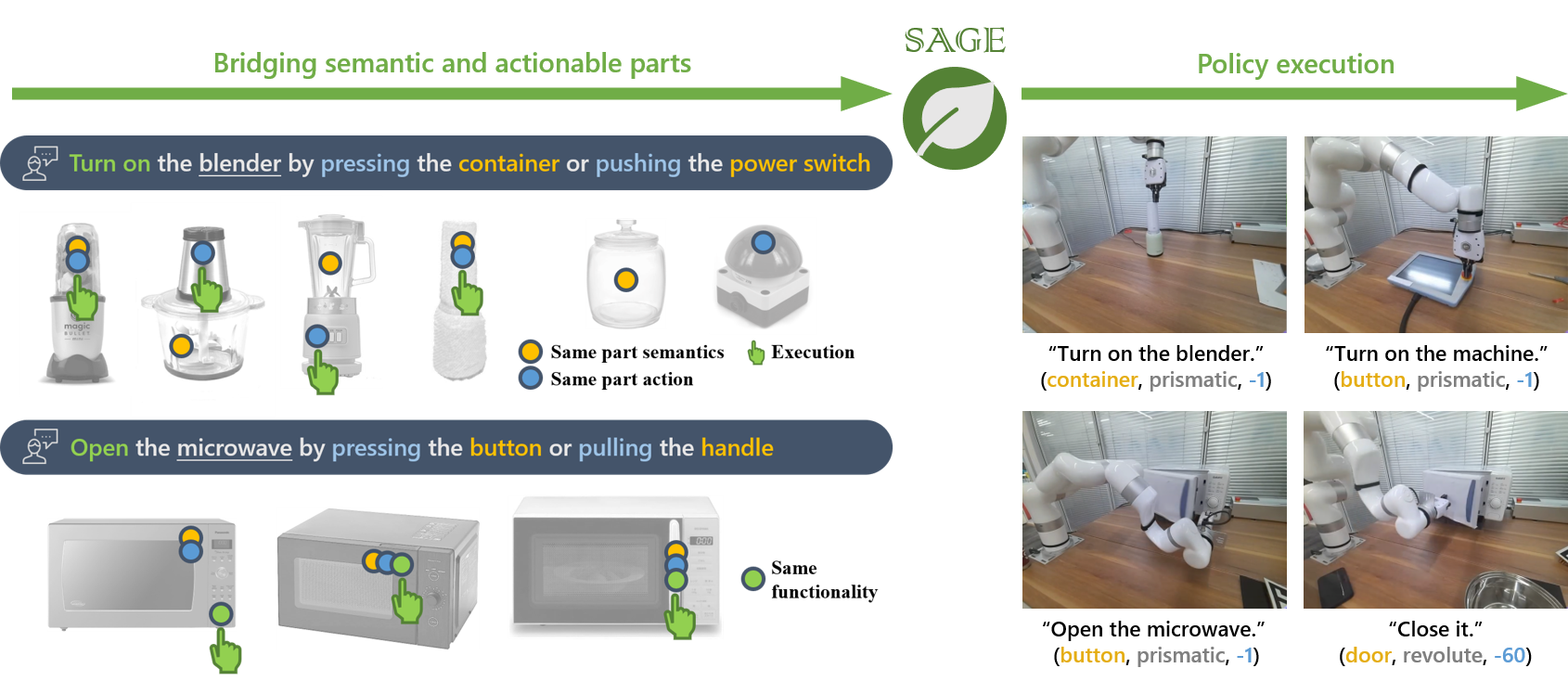 | SAGE🌿: Bridging Semantic and Actionable Parts for Generalizable Manipulation of Articulated ObjectsHaoran Geng*, Songlin Wei*, Congyue Deng, Bokui Shen, He Wang†, Leonidas Guibas† RSS, 2024 arxiv / website / We present SAGE🌿, a framework bridging the understanding of semantic and actionable parts for generalizable manipulation of articulated objects. |
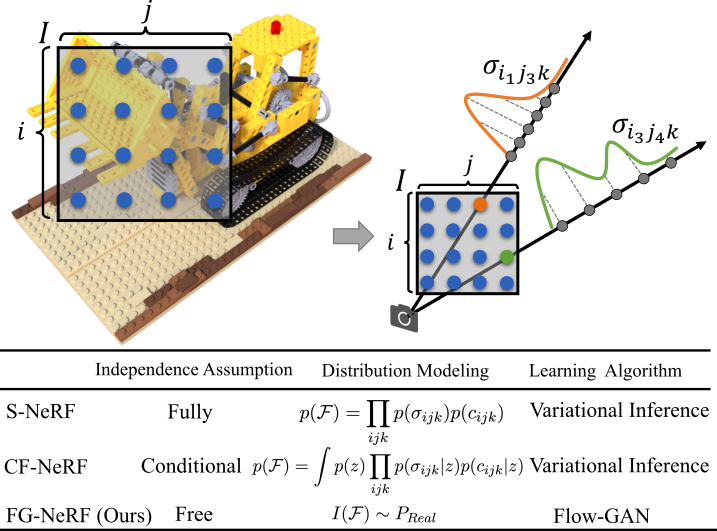 | FG-NeRF: Flow-GAN based Probabilistic Neural Radiance Field for Independence-Assumption-Free Uncertainty EstimationSonglin Wei*, Jiazhao Zhang*, Yang Wang, Fanbo Xiang, Hao Su, He Wang Arxiv, 2023 arxiv / We propose an independence-assumption-free probabilistic neural radiance field based on Flow-GAN. By combining the generative capability of adversarial learning and the powerful expressivity of normalizing flow, our method explicitly models the density-radiance distribution of the whole scene. |
 | 3D Object Aided Self-Supervised Monocular Depth EstimationSonglin Wei, Guodong Chen, Wenzheng Chi, Zhenhua Wang and Lining Sun IROS, 2022 arxiv / video / Self-supervised depth estimation methods rely on static world assumption, which produce inaccurate depths of dynamic objects. In this work, we propose to address dynamic object movements through monocular 3D object detection. |
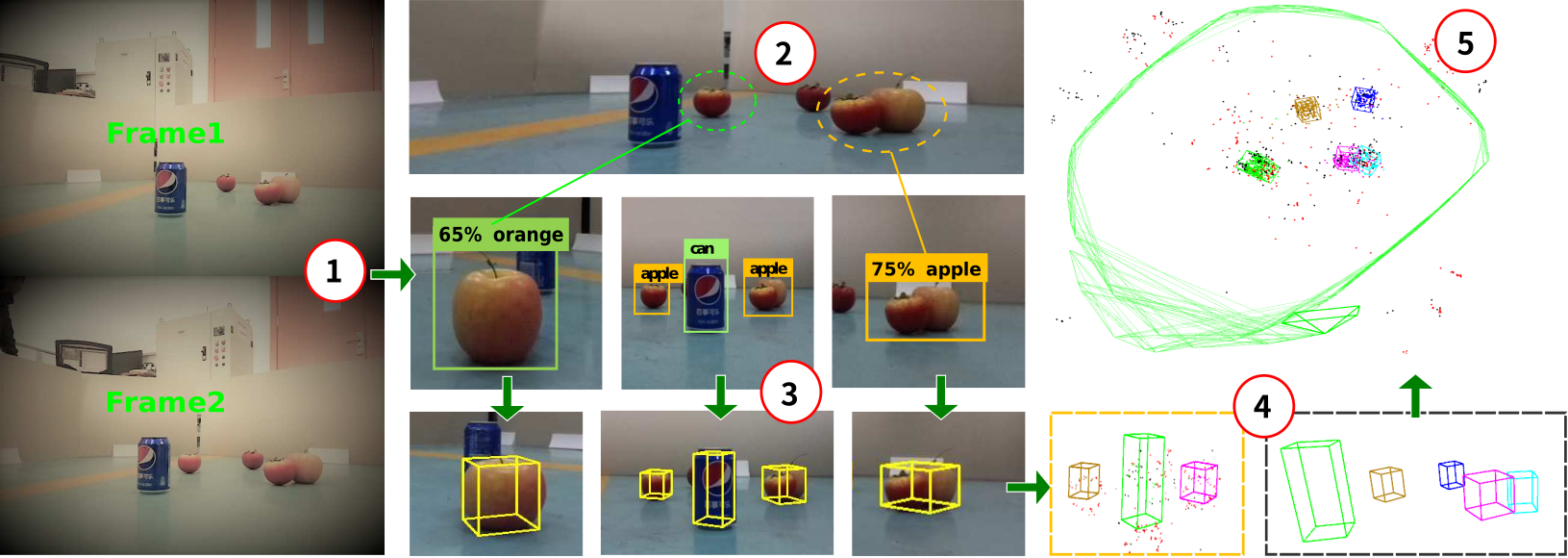 | Object Clustering with Dirichlet Process Mixture Model for Data Association in Monocular SLAMSonglin Wei, Guodong Chen, Wenzheng Chi, Zhenhua Wang and Lining Sun IEEE Transactions on Industrial Electronics, 2022 arxiv / video / We propose a novel data association method for cuboid landmarks based on Dirichlet Process Mixture Model. By jointly considering object class, position, and size, our method can perform data association robustly. |
| Forked from Leonid Keselman's website |