Seaborn で ClusterMap を作成する
- Seaborn で
clustermap()メソッドを使用して Clustermap を作成する - Seaborn Clustermap に
row_colorsおよびcol_colorsオプションを追加

このデモンストレーションでは、クラスタ マップとは何か、およびそれを作成して複数のオプションに使用する方法を学習します。
Seaborn で clustermap() メソッドを使用して Clustermap を作成する
seaborn クラスター マップは、マトリックス エンティティをヒート マップで視覚化できるマトリックス プロットですが、行と列のクラスター化も取得します。
必要なライブラリをいくつかインポートしましょう。
コード:
import seaborn as sb import matplotlib.pyplot as plot import numpy as np import pandas as pd ここで、4 人の架空の学生に関するデータを作成します。 彼らの名前、勉強時間、テストの点数、住所が分かります。
コード:
TOY_DATA_DICT = { "Name": ["Andrew", "Victor", "John", "Sarah"], "study_hours": [11, 25, 22, 14], "Score": [11, 30, 28, 19], "Street_Address": [20, 30, 21, 12], } というわけで、このおもちゃのデータは辞書にありますが、これを Pandas のデータフレームに変換し、生徒の名前としてインデックスを設定します。
コード:
TOY_DATA = pd.DataFrame(TOY_DATA_DICT) TOY_DATA.set_index("Name", inplace=True) TOY_DATA したがって、4 人の架空の学生と 3つの異なる列のデータがあります。 ここでわかるように、このデータ セットは意図的に設計されており、各生徒の study_hours と Score がかなり類似しています。
出力:
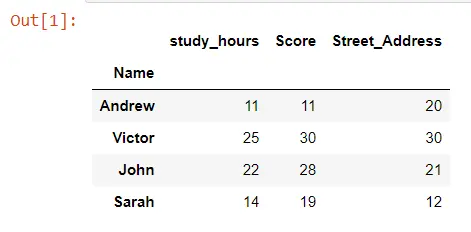
clustermap() メソッドを使用して、このデータ フレームのクラスター マップを作成しましょう。 TOY_DATA というデータ フレーム全体を渡すだけです。
もう 1つのキーワード引数 annot を使用し、True に設定します。 この引数により、クラスター マップのヒート マップ部分に出力された実際の数値を確認できます。
コード:
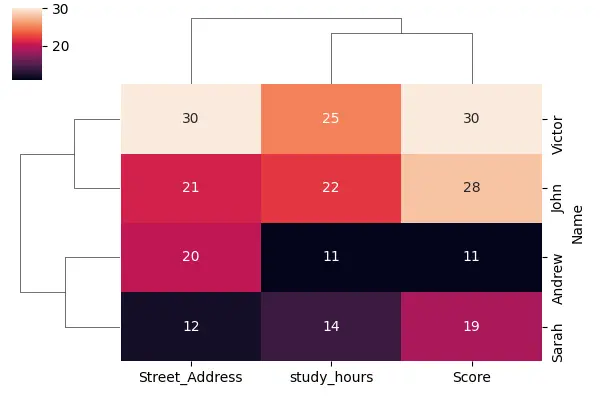
import seaborn as sb import matplotlib.pyplot as plot import numpy as np import pandas as pd TOY_DATA_DICT = { "Name": ["Andrew", "Victor", "John", "Sarah"], "study_hours": [11, 25, 22, 14], "Score": [11, 30, 28, 19], "Street_Address": [20, 30, 21, 12], } TOY_DATA = pd.DataFrame(TOY_DATA_DICT) TOY_DATA.set_index("Name", inplace=True) TOY_DATA sb.clustermap(TOY_DATA, figsize=(6, 4), annot=True) plot.show() 値が低いほど色が暗くなり、値が高いほど色が明るくなります。また、このヒート マップの左側と上部に線があることもわかります。 これらの線は樹状図と呼ばれ、seaborn がデータをクラスター化した方法です。
study_hours と score が一緒にクラスター化されており、学習時間からスコアまでの距離を示していることがわかります。 そして、それらの距離が最小であるため、樹状図で最初にクラスター化され、次にこれらの他の 2つの列とあまり似ていない street_address を追加します。
この樹状図は、これらの異なる列のそれぞれが互いにどれだけ離れているかを感じさせ、行でも同じことが起こっていると言えます。 また、Seaborn によって行と列が並べ替えられていることにも気付くでしょう。
出力:
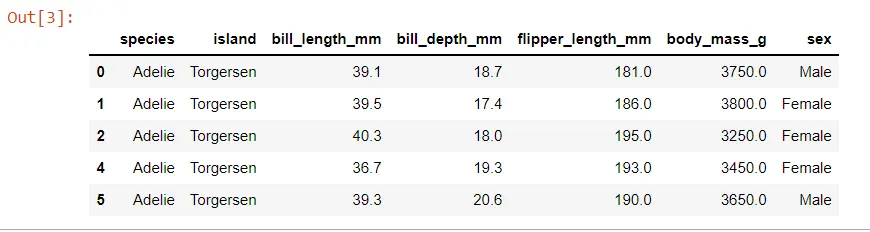
高度なデータ セットでクラスター マップを見てみましょう。 Seaborn ライブラリからいくつかのデータを読み込んでいますが、これらのデータはペンギンに関するものです。
コード:
PENGUINS = sb.load_dataset("penguins").dropna() PENGUINS.head() 出力:
このデータ セットには約 300 種類のペンギンがあり、shape 属性を使用してデータの形状を確認できます。
コード:
print(PENGUINS.shape) 出力:
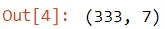
これらのデータのクラスター マップを作成しましょう。 これらのクラスター マップの 1つに渡すデータは数値でなければならないため、このデータ フレームの数値列のみにフィルター処理する必要があります。

高度なクラスター マップを作成しましょう。
import seaborn as sb import matplotlib.pyplot as plot import numpy as np import pandas as pd PENGUINS = sb.load_dataset("penguins").dropna() PENGUINS.head() print(PENGUINS.shape) NUMERICAL_COLS = PENGUINS.columns[2:6] print(NUMERICAL_COLS) sb.clustermap(PENGUINS[NUMERICAL_COLS], figsize=(6, 6)) plot.show() このコードを実行すると、非常に暗い値の列が 3つあり、非常に明るい値の列が 1つしかないことがすぐにわかります。 これは、これらの異なる列のスケールが異なるためです。
出力:
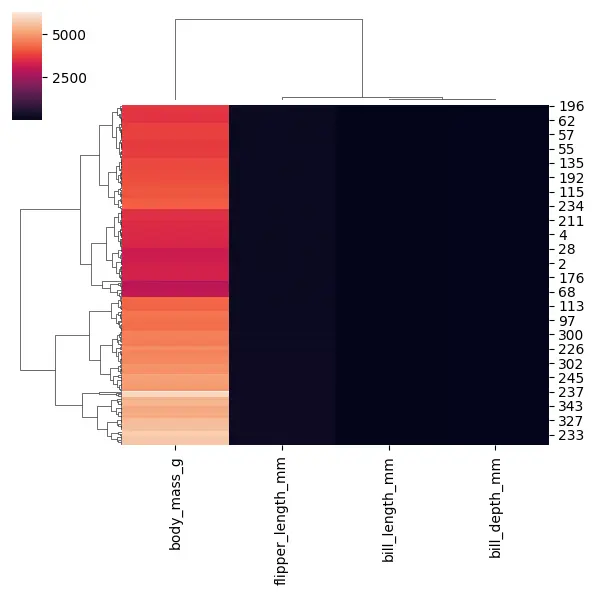
3つの列にはより小さい値があり、1つの列 body_mass_g には非常に大きな値があります。 しかし、これは一種の役に立たないヒート マップになる可能性があるため、データをスケーリングする必要があります。
クラスター マップ内でデータをスケーリングする方法はいくつかありますが、簡単な方法の 1つは、standard_scale と呼ばれるこの引数を使用することです。 この引数の値は、各行をスケーリングする場合は 0 になり、各列をスケーリングする場合は 1 になります。
コード:
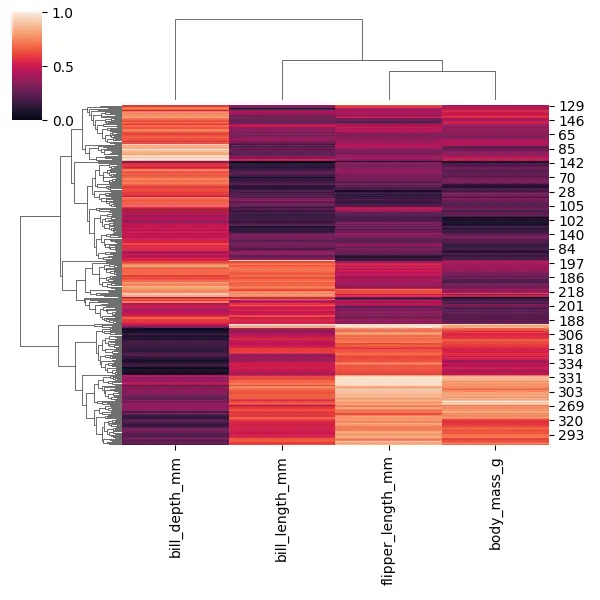
import seaborn as sb import matplotlib.pyplot as plot import numpy as np import pandas as pd PENGUINS = sb.load_dataset("penguins").dropna() PENGUINS.head() print(PENGUINS.shape) NUMERICAL_COLS = PENGUINS.columns[2:6] print(NUMERICAL_COLS) sb.clustermap(PENGUINS[NUMERICAL_COLS], figsize=(6, 6), standard_scale=1) plot.show() これで、すべての値が 0 から 1 の間で表示されます。これにより、これらの各列を同じスケールに配置して、比較しやすくなります。
また、さまざまなペンギンがすべてクラスター化されていることもわかります。これは、どのペンギンが互いに最も似ているかを判断するのに役立ちます。
出力:
seaborn クラスター マップでは、リンケージと距離を判断するマトリックスの両方を変更できるので、method 引数を使用してリンケージを変更してみましょう。 文字列を single と呼ばれる値として渡すことができます。これは最小限のリンケージです。
コード:
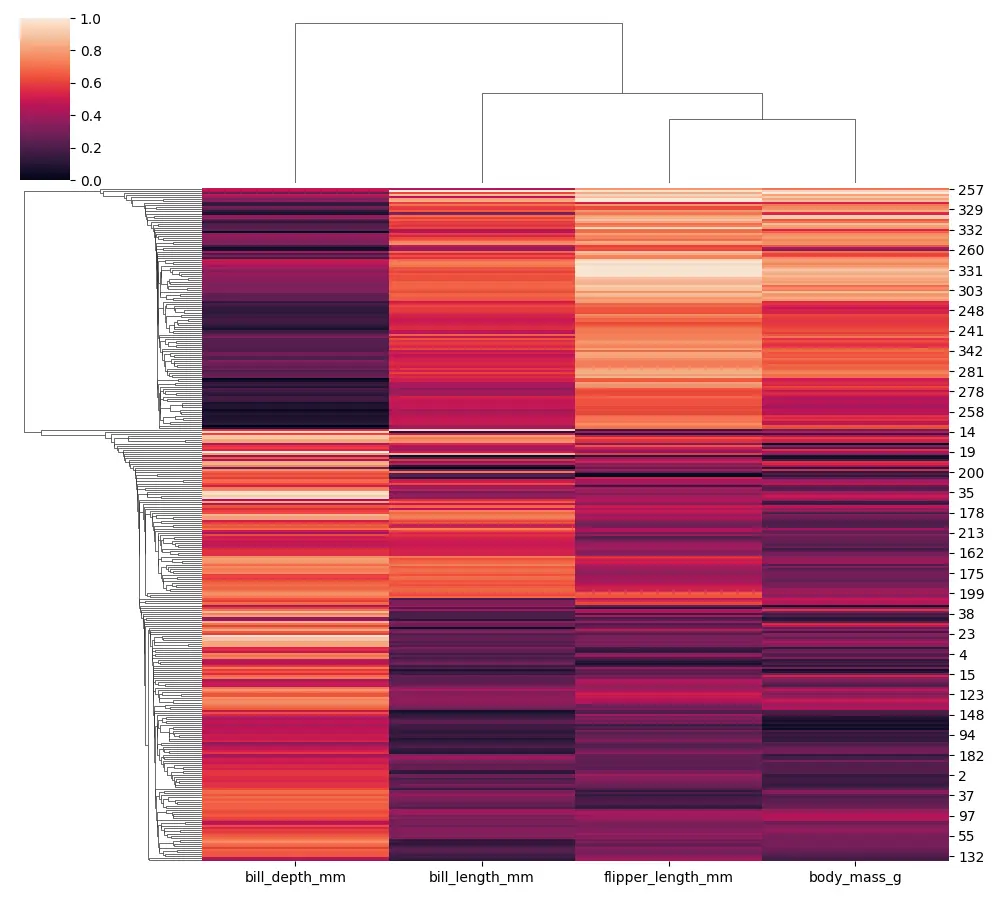
import seaborn as sb import matplotlib.pyplot as plot import numpy as np import pandas as pd PENGUINS = sb.load_dataset("penguins").dropna() PENGUINS.head() print(PENGUINS.shape) NUMERICAL_COLS = PENGUINS.columns[2:6] print(NUMERICAL_COLS) sb.clustermap( PENGUINS[NUMERICAL_COLS], figsize=(10, 9), standard_scale=1, method="single" ) plot.show() 単一のリンケージを使用すると、デンドログラムがわずかに異なり始めることに気付くでしょう。
出力:
Seaborn Clustermap に row_colors および col_colors オプションを追加
クラスター マップを作成するときに使用できる追加オプションがいくつかあります。 seaborn クラスター マップの追加オプションは、row_colors または col_colors と呼ばれます。
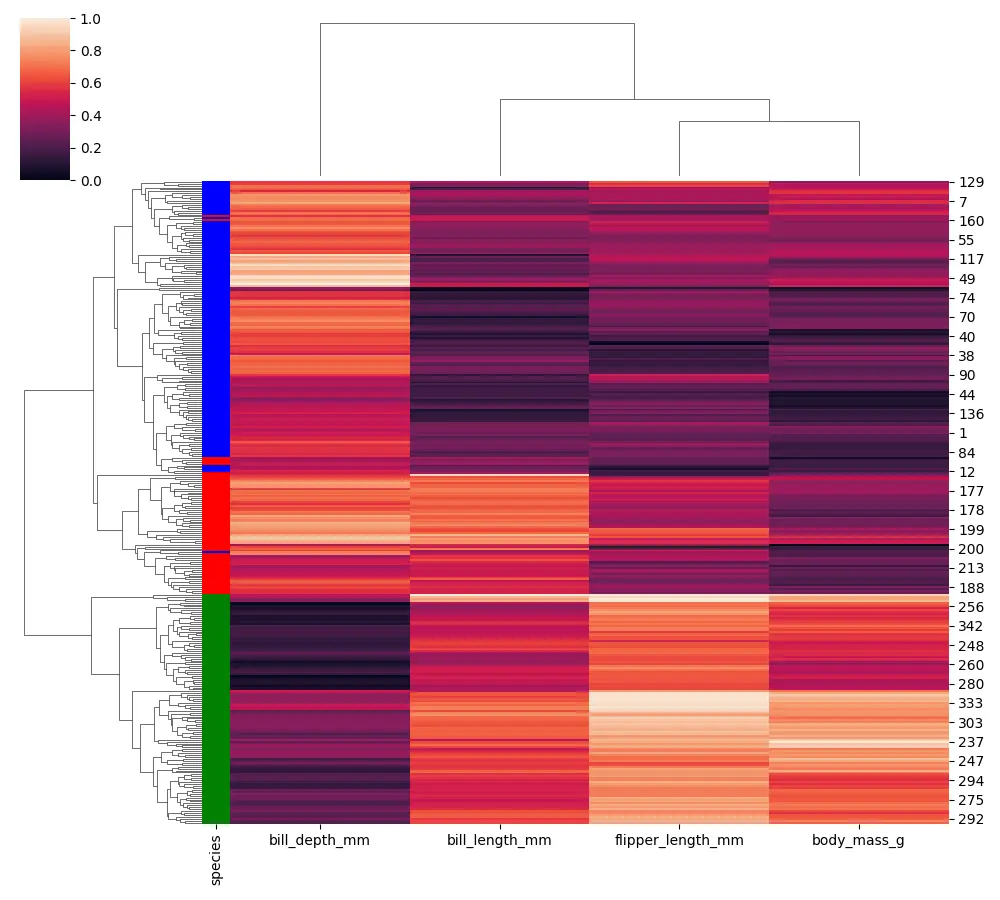
ここで、各色を割り当て、このデータをペンギンの種列 (カテゴリ列) から取得します。
コード:
import seaborn as sb import matplotlib.pyplot as plot import numpy as np import pandas as pd PENGUINS = sb.load_dataset("penguins").dropna() PENGUINS.head() NUMERICAL_COLS = PENGUINS.columns[2:6] SPECIES_COLORS = PENGUINS.species.map( {"Adelie": "blue", "Chinstrap": "red", "Gentoo": "green"} ) sb.clustermap( PENGUINS[NUMERICAL_COLS], figsize=(10, 9), standard_scale=1, row_colors=SPECIES_COLORS, ) plot.show() さまざまな種類のペンギン種のすべての行にフラグが表示されます。
出力:
Seaborn はバックエンドで scipy または高速クラスターを利用しているため、これらの使用可能なリンケージ オプションについて詳しく知りたい場合は、scipy ドキュメント を確認してください。

Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedIn