Longest Common Extension / LCE using Segment Tree
Last Updated : 23 Jul, 2025
Prerequisites :
LCE(Set 1) ,
LCE(Set 2) ,
Suffix Array (n Log Log n) ,
Kasai's algorithm and
Segment Tree The Longest Common Extension (LCE) problem considers a string
s
and computes, for each pair (L , R), the longest sub string of
s
that starts at both L and R. In LCE, in each of the query we have to answer the length of the longest common prefix starting at indexes L and R.
Example:
String
: “abbababba”
Queries:
LCE(1, 2), LCE(1, 6) and LCE(0, 5) Find the length of the Longest Common Prefix starting at index given as,
(1, 2), (1, 6) and (0, 5)
. The string highlighted
“green”
are the longest common prefix starting at index- L and R of the respective queries. We have to find the length of the longest common prefix starting at index-
(1, 2), (1, 6) and (0, 5)
.
In this set we will discuss about the Segment Tree approach to solve the LCE problem. In
Set 2, we saw that an LCE problem can be converted into a RMQ problem. To process the RMQ efficiently, we build a segment tree on the lcp array and then efficiently answer the LCE queries. To find low and high, we must have to compute the suffix array first and then from the suffix array we compute the inverse suffix array. We also need lcp array, hence we use
Kasai’s Algorithm to find lcp array from the suffix array. Once the above things are done, we simply find the minimum value in lcp array from index low to high (as proved above) for each query. Without proving we will use the direct result (deduced after mathematical proofs)- LCE (L, R) = RMQ
lcp
(invSuff[R], invSuff[L]-1) The subscript lcp means that we have to perform RMQ on the lcp array and hence we will build a segment tree on the lcp array.
CPP #include<bits/stdc++.h> using namespace std; // Structure to represent a query of form (L,R) struct Query { int L, R; }; // Structure to store information of a suffix struct suffix { int index; // To store the original index int rank[2]; // To store ranks and the next rank pair }; // A utility function to get the minimum of two numbers int minVal(int x, int y) { return (x < y) ? x : y; } // A utility function to get the middle index from // corner indexes. int getMid(int s, int e) { return s + (e - s) / 2; } /* A recursive function to get the minimum value in a given range of array indexes. The following are parameters for this function. st --> Pointer to the segment tree index --> Index of the current node in the segment tree. Initially, 0 is passed as the root is always at index 0 ss & se --> Starting and ending indexes of the segment represented by the current node, i.e., st[index] qs & qe --> Starting and ending indexes of the query range */ int RMQUtil(int *st, int ss, int se, int qs, int qe, int index) { // If the segment of this node is a part of the given range, // then return the min of the segment if (qs <= ss && qe >= se) return st[index]; // If the segment of this node is outside the given range if (se < qs || ss > qe) return INT_MAX; // If a part of this segment overlaps with the given range int mid = getMid(ss, se); return minVal(RMQUtil(st, ss, mid, qs, qe, 2 * index + 1), RMQUtil(st, mid + 1, se, qs, qe, 2 * index + 2)); } // Return the minimum of elements in the range from index qs // (query start) to qe (query end). It mainly uses RMQUtil() int RMQ(int *st, int n, int qs, int qe) { // Check for erroneous input values if (qs < 0 || qe > n - 1 || qs > qe) { cout << "Invalid Input"; return -1; } return RMQUtil(st, 0, n - 1, qs, qe, 0); } // A recursive function that constructs Segment Tree // for array[ss..se]. si is the index of the current node in // the segment tree st int constructSTUtil(int arr[], int ss, int se, int *st, int si) { // If there is one element in the array, store it in // the current node of the segment tree and return if (ss == se) { st[si] = arr[ss]; return arr[ss]; } // If there are more than one element, then recur // for left and right subtrees and store the minimum // of two values in this node int mid = getMid(ss, se); st[si] = minVal(constructSTUtil(arr, ss, mid, st, si * 2 + 1), constructSTUtil(arr, mid + 1, se, st, si * 2 + 2)); return st[si]; } /* Function to construct a segment tree from the given array. This function allocates memory for the segment tree and calls constructSTUtil() to fill the allocated memory */ int *constructST(int arr[], int n) { // Allocate memory for the segment tree // Height of the segment tree int x = (int)(ceil(log2(n))); // Maximum size of the segment tree int max_size = 2 * (int)pow(2, x) - 1; int *st = new int[max_size]; // Fill the allocated memory st constructSTUtil(arr, 0, n - 1, st, 0); // Return the constructed segment tree return st; } // A comparison function used by sort() to compare // two suffixes. Compares two pairs, returns 1 if // the first pair is smaller int cmp(struct suffix a, struct suffix b) { return (a.rank[0] == b.rank[0]) ? (a.rank[1] < b.rank[1] ? 1 : 0) : (a.rank[0] < b.rank[0] ? 1 : 0); } // This is the main function that takes a string // 'txt' of size n as an argument, builds and returns // the suffix array for the given string vector<int> buildSuffixArray(string txt, int n) { // A structure to store suffixes and their indexes struct suffix suffixes[n]; // Store suffixes and their indexes in an array // of structures. The structure is needed to sort // the suffixes alphabetically and maintain their // old indexes while sorting for (int i = 0; i < n; i++) { suffixes[i].index = i; suffixes[i].rank[0] = txt[i] - 'a'; suffixes[i].rank[1] = ((i + 1) < n) ? (txt[i + 1] - 'a') : -1; } // Sort the suffixes using the comparison function // defined above. sort(suffixes, suffixes + n, cmp); // At this point, all suffixes are sorted according to the first // 2 characters. Let us sort suffixes according to the first 4 // characters, then the first 8 and so on int ind[n]; // This array is needed to get the index // in suffixes[] // from the original index. This mapping is needed to get // the next suffix. for (int k = 4; k < 2 * n; k = k * 2) { // Assigning rank and index values to the first suffix int rank = 0; int prev_rank = suffixes[0].rank[0]; suffixes[0].rank[0] = rank; ind[suffixes[0].index] = 0; // Assigning rank to suffixes for (int i = 1; i < n; i++) { // If the first rank and next ranks are the same as // that of the previous suffix in the array, assign // the same new rank to this suffix if (suffixes[i].rank[0] == prev_rank && suffixes[i].rank[1] == suffixes[i - 1].rank[1]) { prev_rank = suffixes[i].rank[0]; suffixes[i].rank[0] = rank; } else // Otherwise increment rank and assign { prev_rank = suffixes[i].rank[0]; suffixes[i].rank[0] = ++rank; } ind[suffixes[i].index] = i; } // Assign the next rank to every suffix for (int i = 0; i < n; i++) { int nextindex = suffixes[i].index + k / 2; suffixes[i].rank[1] = (nextindex < n) ? suffixes[ind[nextindex]].rank[0] : -1; } // Sort the suffixes according to the first k characters sort(suffixes, suffixes + n, cmp); } // Store indexes of all sorted suffixes in the suffix array vector<int> suffixArr; for (int i = 0; i < n; i++) suffixArr.push_back(suffixes[i].index); // Return the suffix array return suffixArr; } /* To construct and return LCP */ vector<int> kasai(string txt, vector<int> suffixArr, vector<int> &invSuff) { int n = suffixArr.size(); // To store the LCP array vector<int> lcp(n, 0); // Fill values in invSuff[] for (int i = 0; i < n; i++) invSuff[suffixArr[i]] = i; // Initialize the length of the previous LCP int k = 0; // Process all suffixes one by one starting from // the first suffix in txt[] for (int i = 0; i < n; i++) { /* If the current suffix is at n-1, then we don?t have the next substring to consider. So the LCP is not defined for this substring, we put zero. */ if (invSuff[i] == n - 1) { k = 0; continue; } /* j contains the index of the next substring to be considered to compare with the present substring, i.e., the next string in the suffix array */ int j = suffixArr[invSuff[i] + 1]; // Directly start matching from the k'th index as // at least k-1 characters will match while (i + k < n && j + k < n && txt[i + k] == txt[j + k]) k++; lcp[invSuff[i]] = k; // LCP for the present suffix. // Deleting the starting character from the string. if (k > 0) k--; } // return the constructed LCP array return lcp; } // A utility function to find the longest common extension // from index - L and index - R int LCE(int *st, vector<int> lcp, vector<int> invSuff, int n, int L, int R) { // Handle the corner case if (L == R) return (n - L); // Use the formula - // LCE (L, R) = RMQ lcp (invSuff[R], invSuff[L]-1) return (RMQ(st, n, invSuff[R], invSuff[L] - 1)); } // A function to answer queries of the longest common extension void LCEQueries(string str, int n, Query q[], int m) { // Build a suffix array vector<int> suffixArr = buildSuffixArray(str, str.length()); // An auxiliary array to store the inverse of suffix array // elements. For example, if suffixArr[0] is 5, the // invSuff[5] would store 0. This is used to get the next // suffix string from the suffix array. vector<int> invSuff(n, 0); // Build an LCP vector vector<int> lcp = kasai(str, suffixArr, invSuff); int lcpArr[n]; // Convert to the LCP array for (int i = 0; i < n; i++) lcpArr[i] = lcp[i]; // Build a segment tree from the LCP array int *st = constructST(lcpArr, n); for (int i = 0; i < m; i++) { int L = q[i].L; int R = q[i].R; cout << "LCE (" << L << ", " << R << ") = " << LCE(st, lcp, invSuff, n, L, R) << endl; } return; } // Driver Program to test above functions int main() { string str = "abbababba"; int n = str.length(); // LCA Queries to answer Query q[] = {{1, 2}, {1, 6}, {0, 5}}; int m = sizeof(q) / sizeof(q[0]); LCEQueries(str, n, q, m); return (0); } import java.util.*; // Structure to represent a query of form (L,R) class Query { int L, R; public Query(int L, int R) { this.L = L; this.R = R; } } // Structure to store information of a suffix class Suffix { int index; // To store original index int[] rank = new int[2]; // To store ranks and next rank pair } public class SuffixArrayLCE { // A utility function to get minimum of two numbers static int minVal(int x, int y) { return (x < y) ? x : y; } // A utility function to get the middle index from // corner indexes. static int getMid(int s, int e) { return s + (e - s) / 2; } /* A recursive function to get the minimum value in a given range of array indexes. The following are parameters for this function. st --> Pointer to segment tree index --> Index of current node in the segment tree. Initially 0 is passed as root is always at index 0 ss & se --> Starting and ending indexes of the segment represented by current node, i.e., st[index] qs & qe --> Starting and ending indexes of query range */ static int RMQUtil(int[] st, int ss, int se, int qs, int qe, int index) { // If segment of this node is a part of given range, // then return the min of the segment if (qs <= ss && qe >= se) return st[index]; // If segment of this node is outside the given range if (se < qs || ss > qe) return Integer.MAX_VALUE; // If a part of this segment overlaps with the given // range int mid = getMid(ss, se); return minVal(RMQUtil(st, ss, mid, qs, qe, 2 * index + 1), RMQUtil(st, mid + 1, se, qs, qe, 2 * index + 2)); } // Return minimum of elements in range from index qs // (query start) to qe (query end). It mainly uses RMQUtil() static int RMQ(int[] st, int n, int qs, int qe) { // Check for erroneous input values if (qs < 0 || qe > n - 1 || qs > qe) { System.out.println("Invalid Input"); return -1; } return RMQUtil(st, 0, n - 1, qs, qe, 0); } // A recursive function that constructs Segment Tree // for array[ss..se]. si is index of the current node in // segment tree st static int constructSTUtil(int[] arr, int ss, int se, int[] st, int si) { // If there is one element in the array, store it in // the current node of the segment tree and return if (ss == se) { st[si] = arr[ss]; return arr[ss]; } // If there are more than one elements, then recur // for left and right subtrees and store the minimum // of two values in this node int mid = getMid(ss, se); st[si] = minVal(constructSTUtil(arr, ss, mid, st, si * 2 + 1), constructSTUtil(arr, mid + 1, se, st, si * 2 + 2)); return st[si]; } /* Function to construct a segment tree from the given array. This function allocates memory for the segment tree and calls constructSTUtil() to fill the allocated memory */ static int[] constructST(int[] arr, int n) { // Allocate memory for the segment tree // Height of the segment tree int x = (int) (Math.ceil(Math.log(n) / Math.log(2))); // Maximum size of the segment tree int max_size = 2 * (int) Math.pow(2, x) - 1; int[] st = new int[max_size]; // Fill the allocated memory st constructSTUtil(arr, 0, n - 1, st, 0); // Return the constructed segment tree return st; } // A comparison function used by sort() to compare // two suffixes. Compares two pairs, returns 1 if // the first pair is smaller static int cmp(Suffix a, Suffix b) { return (a.rank[0] == b.rank[0]) ? ((a.rank[1] < b.rank[1]) ? 1 : 0) : ((a.rank[0] < b.rank[0]) ? 1 : 0); } static int[] buildSuffixArray(String txt, int n) { Suffix[] suffixes = new Suffix[n]; for (int i = 0; i < n; i++) { suffixes[i] = new Suffix(); suffixes[i].index = i; suffixes[i].rank[0] = txt.charAt(i) - 'a'; suffixes[i].rank[1] = (i + 1 < n) ? (txt.charAt(i + 1) - 'a') : -1; } Arrays.sort(suffixes, (a, b) -> { if (a.rank[0] == b.rank[0]) { return Integer.compare(a.rank[1], b.rank[1]); } else { return Integer.compare(a.rank[0], b.rank[0]); } }); int[] ind = new int[n]; for (int k = 4; k < 2 * n; k *= 2) { int rank = 0; int prevRank = suffixes[0].rank[0]; suffixes[0].rank[0] = rank; ind[suffixes[0].index] = 0; for (int i = 1; i < n; i++) { if (suffixes[i].rank[0] == prevRank && suffixes[i].rank[1] == suffixes[i - 1].rank[1]) { prevRank = suffixes[i].rank[0]; suffixes[i].rank[0] = rank; } else { prevRank = suffixes[i].rank[0]; suffixes[i].rank[0] = ++rank; } ind[suffixes[i].index] = i; } for (int i = 0; i < n; i++) { int nextIndex = suffixes[i].index + k / 2; suffixes[i].rank[1] = (nextIndex < n) ? suffixes[ind[nextIndex]].rank[0] : -1; } Arrays.sort(suffixes, (a, b) -> { if (a.rank[0] == b.rank[0]) { return Integer.compare(a.rank[1], b.rank[1]); } else { return Integer.compare(a.rank[0], b.rank[0]); } }); } int[] suffixArr = new int[n]; for (int i = 0; i < n; i++) suffixArr[i] = suffixes[i].index; return suffixArr; } static List<Integer> kasai(String txt, int[] suffixArr, int[] invSuff) { int n = suffixArr.length; List<Integer> lcp = new ArrayList<>(n); for (int i = 0; i < n; i++) lcp.add(0); for (int i = 0; i < n; i++) invSuff[suffixArr[i]] = i; int k = 0; for (int i = 0; i < n; i++) { if (invSuff[i] == n - 1) { k = 0; continue; } int j = suffixArr[invSuff[i] + 1]; while (i + k < n && j + k < n && txt.charAt(i + k) == txt.charAt(j + k)) k++; lcp.set(invSuff[i], k); if (k > 0) k--; } return lcp; } static int LCE(int[] st, List<Integer> lcp, int[] invSuff, int n, int L, int R) { if (L == R) return (n - L); return (RMQ(st, n, invSuff[R], invSuff[L] - 1)); } static void LCEQueries(String str, int n, Query[] q) { // Build a suffix array int[] suffixArr = buildSuffixArray(str, str.length()); // An auxiliary array to store inverse of suffix array // elements. For example, if suffixArr[0] is 5, the // invSuff[5] would store 0. This is used to get the next // suffix string from the suffix array. int[] invSuff = new int[n]; // Build an lcp vector List<Integer> lcp = kasai(str, suffixArr, invSuff); int[] lcpArr = new int[n]; // Convert to lcp array for (int i = 0; i < n; i++) lcpArr[i] = lcp.get(i); // Build segment tree from lcp array int[] st = constructST(lcpArr, n); for (int i = 0; i < q.length; i++) { int L = q[i].L; int R = q[i].R; System.out.printf("LCE (%d, %d) = %d\n", L, R, LCE(st, lcp, invSuff, n, L, R)); } } //Code by Dibyabrata Panja public static void main(String[] args) { String str = "abbababba"; int n = str.length(); // LCA Queries to answer // LCA Queries to answer Query[] q = {new Query(1, 2), new Query(1, 6), new Query(0, 5)}; q[0].L = 1; q[0].R = 2; q[1].L = 1; q[1].R = 6; q[2].L = 0; q[2].R = 5; LCEQueries(str, n, q); } } using System; using System.Collections.Generic; using System.Linq; // Structure to represent a query of form (L,R) class Query { public int L, R; public Query(int L, int R) { this.L = L; this.R = R; } } // Structure to store information of a suffix class Suffix { public int index; // To store original index public int[] rank = new int[2]; // To store ranks and next rank pair } public class SuffixArrayLCE { // A utility function to get minimum of two numbers static int minVal(int x, int y) { return (x < y) ? x : y; } // A utility function to get the middle index from // corner indexes. static int getMid(int s, int e) { return s + (e - s) / 2; } /* A recursive function to get the minimum value in a given range of array indexes. The following are parameters for this function. st --> Pointer to segment tree index --> Index of current node in the segment tree. Initially 0 is passed as root is always at index 0 ss & se --> Starting and ending indexes of the segment represented by current node, i.e., st[index] qs & qe --> Starting and ending indexes of query range */ static int RMQUtil(int[] st, int ss, int se, int qs, int qe, int index) { // If segment of this node is a part of given range, // then return the min of the segment if (qs <= ss && qe >= se) return st[index]; // If segment of this node is outside the given range if (se < qs || ss > qe) return int.MaxValue; // If a part of this segment overlaps with the given // range int mid = getMid(ss, se); return minVal(RMQUtil(st, ss, mid, qs, qe, 2 * index + 1), RMQUtil(st, mid + 1, se, qs, qe, 2 * index + 2)); } // Return minimum of elements in range from index qs // (query start) to qe (query end). It mainly uses RMQUtil() static int RMQ(int[] st, int n, int qs, int qe) { // Check for erroneous input values if (qs < 0 || qe > n - 1 || qs > qe) { Console.WriteLine("Invalid Input"); return -1; } return RMQUtil(st, 0, n - 1, qs, qe, 0); } // A recursive function that constructs Segment Tree // for array[ss..se]. si is index of the current node in // segment tree st static int constructSTUtil(int[] arr, int ss, int se, int[] st, int si) { // If there is one element in the array, store it in // the current node of the segment tree and return if (ss == se) { st[si] = arr[ss]; return arr[ss]; } // If there are more than one elements, then recur // for left and right subtrees and store the minimum // of two values in this node int mid = getMid(ss, se); st[si] = minVal(constructSTUtil(arr, ss, mid, st, si * 2 + 1), constructSTUtil(arr, mid + 1, se, st, si * 2 + 2)); return st[si]; } /* Function to construct a segment tree from the given array. This function allocates memory for the segment tree and calls constructSTUtil() to fill the allocated memory */ static int[] constructST(int[] arr, int n) { // Allocate memory for the segment tree // Height of the segment tree int x = (int)(Math.Ceiling(Math.Log(n) / Math.Log(2))); // Maximum size of the segment tree int max_size = 2 * (int)Math.Pow(2, x) - 1; int[] st = new int[max_size]; // Fill the allocated memory st constructSTUtil(arr, 0, n - 1, st, 0); // Return the constructed segment tree return st; } // A comparison function used by sort() to compare // two suffixes. Compares two pairs, returns 1 if // the first pair is smaller static int cmp(Suffix a, Suffix b) { return (a.rank[0] == b.rank[0]) ? ((a.rank[1] < b.rank[1]) ? 1 : 0) : ((a.rank[0] < b.rank[0]) ? 1 : 0); } static int[] buildSuffixArray(string txt, int n) { Suffix[] suffixes = new Suffix[n]; for (int i = 0; i < n; i++) { suffixes[i] = new Suffix(); suffixes[i].index = i; suffixes[i].rank[0] = txt[i] - 'a'; suffixes[i].rank[1] = (i + 1 < n) ? (txt[i + 1] - 'a') : -1; } Array.Sort(suffixes, (a, b) => { if (a.rank[0] == b.rank[0]) { return a.rank[1].CompareTo(b.rank[1]); } else { return a.rank[0].CompareTo(b.rank[0]); } }); int[] ind = new int[n]; for (int k = 4; k < 2 * n; k *= 2) { int rank = 0; int prevRank = suffixes[0].rank[0]; suffixes[0].rank[0] = rank; ind[suffixes[0].index] = 0; for (int i = 1; i < n; i++) { if (suffixes[i].rank[0] == prevRank && suffixes[i].rank[1] == suffixes[i - 1].rank[1]) { prevRank = suffixes[i].rank[0]; suffixes[i].rank[0] = rank; } else { prevRank = suffixes[i].rank[0]; suffixes[i].rank[0] = ++rank; } ind[suffixes[i].index] = i; } for (int i = 0; i < n; i++) { int nextIndex = suffixes[i].index + k / 2; suffixes[i].rank[1] = (nextIndex < n) ? suffixes[ind[nextIndex]].rank[0] : -1; } Array.Sort(suffixes, (a, b) => { if (a.rank[0] == b.rank[0]) { return a.rank[1].CompareTo(b.rank[1]); } else { return a.rank[0].CompareTo(b.rank[0]); } }); } int[] suffixArr = new int[n]; for (int i = 0; i < n; i++) suffixArr[i] = suffixes[i].index; return suffixArr; } static List<int> kasai(string txt, int[] suffixArr, int[] invSuff) { int n = suffixArr.Length; List<int> lcp = new List<int>(n); for (int i = 0; i < n; i++) lcp.Add(0); for (int i = 0; i < n; i++) invSuff[suffixArr[i]] = i; int k = 0; for (int i = 0; i < n; i++) { if (invSuff[i] == n - 1) { k = 0; continue; } int j = suffixArr[invSuff[i] + 1]; while (i + k < n && j + k < n && txt[i + k] == txt[j + k]) k++; lcp[invSuff[i]] = k; if (k > 0) k--; } return lcp; } static int LCE(int[] st, List<int> lcp, int[] invSuff, int n, int L, int R) { if (L == R) return (n - L); return (RMQ(st, n, invSuff[R], invSuff[L] - 1)); } static void LCEQueries(string str, int n, Query[] q) { // Build a suffix array int[] suffixArr = buildSuffixArray(str, str.Length); // An auxiliary array to store the inverse of suffix array // elements. For example, if suffixArr[0] is 5, the // invSuff[5] would store 0. This is used to get the next // suffix string from the suffix array. int[] invSuff = new int[n]; // Build an lcp vector List<int> lcp = kasai(str, suffixArr, invSuff); int[] lcpArr = lcp.ToArray(); // Build segment tree from lcp array int[] st = constructST(lcpArr, n); for (int i = 0; i < q.Length; i++) { int L = q[i].L; int R = q[i].R; Console.WriteLine($"LCE ({L}, {R}) = {LCE(st, lcp, invSuff, n, L, R)}"); } } // Code by Dibyabrata Panja public static void Main(string[] args) { string str = "abbababba"; int n = str.Length; // LCA Queries to answer Query[] q = { new Query(1, 2), new Query(1, 6), new Query(0, 5) }; q[0].L = 1; q[0].R = 2; q[1].L = 1; q[1].R = 6; q[2].L = 0; q[2].R = 5; LCEQueries(str, n, q); } } class Query { constructor(L, R) { this.L = L; this.R = R; } } class Suffix { constructor() { this.index = 0; this.rank = [0, 0]; } } function minVal(x, y) { return x < y ? x : y; } function getMid(s, e) { return s + Math.floor((e - s) / 2); } function RMQUtil(st, ss, se, qs, qe, index) { if (qs <= ss && qe >= se) return st[index]; if (se < qs || ss > qe) return Infinity; const mid = getMid(ss, se); return minVal( RMQUtil(st, ss, mid, qs, qe, 2 * index + 1), RMQUtil(st, mid + 1, se, qs, qe, 2 * index + 2) ); } function RMQ(st, n, qs, qe) { if (qs < 0 || qe > n - 1 || qs > qe) { console.log("Invalid Input"); return -1; } return RMQUtil(st, 0, n - 1, qs, qe, 0); } function constructSTUtil(arr, ss, se, st, si) { if (ss === se) { st[si] = arr[ss]; return arr[ss]; } const mid = getMid(ss, se); st[si] = minVal( constructSTUtil(arr, ss, mid, st, si * 2 + 1), constructSTUtil(arr, mid + 1, se, st, si * 2 + 2) ); return st[si]; } function constructST(arr, n) { const x = Math.ceil(Math.log2(n)); const max_size = 2 * 2**x - 1; const st = new Array(max_size).fill(0); constructSTUtil(arr, 0, n - 1, st, 0); return st; } function cmp(a, b) { return a.rank[0] === b.rank[0] ? a.rank[1] - b.rank[1] : a.rank[0] - b.rank[0]; } function buildSuffixArray(txt, n) { const suffixes = new Array(n); for (let i = 0; i < n; i++) { suffixes[i] = new Suffix(); suffixes[i].index = i; suffixes[i].rank[0] = txt[i].charCodeAt(0) - 'a'.charCodeAt(0); suffixes[i].rank[1] = (i + 1 < n) ? (txt[i + 1].charCodeAt(0) - 'a'.charCodeAt(0)) : -1; } suffixes.sort((a, b) => cmp(a, b)); const ind = new Array(n).fill(0); for (let k = 4; k < 2 * n; k *= 2) { let rank = 0; let prevRank = suffixes[0].rank[0]; suffixes[0].rank[0] = rank; ind[suffixes[0].index] = 0; for (let i = 1; i < n; i++) { if (suffixes[i].rank[0] === prevRank && suffixes[i].rank[1] === suffixes[i - 1].rank[1]) { prevRank = suffixes[i].rank[0]; suffixes[i].rank[0] = rank; } else { prevRank = suffixes[i].rank[0]; suffixes[i].rank[0] = ++rank; } ind[suffixes[i].index] = i; } for (let i = 0; i < n; i++) { const nextIndex = suffixes[i].index + k / 2; suffixes[i].rank[1] = (nextIndex < n) ? suffixes[ind[nextIndex]].rank[0] : -1; } suffixes.sort((a, b) => cmp(a, b)); } const suffixArr = suffixes.map(suffix => suffix.index); return suffixArr; } function kasai(txt, suffixArr, invSuff) { const n = suffixArr.length; const lcp = new Array(n).fill(0); for (let i = 0; i < n; i++) invSuff[suffixArr[i]] = i; let k = 0; for (let i = 0; i < n; i++) { if (invSuff[i] === n - 1) { k = 0; continue; } const j = suffixArr[invSuff[i] + 1]; while (i + k < n && j + k < n && txt[i + k] === txt[j + k]) k++; lcp[invSuff[i]] = k; if (k > 0) k--; } return lcp; } function LCE(st, lcp, invSuff, n, L, R) { if (L === R) return n - L; return RMQ(st, n, invSuff[R], invSuff[L] - 1); } function LCEQueries(str, n, queries) { // Build a suffix array const suffixArr = buildSuffixArray(str, str.length); // An auxiliary array to store the inverse of the suffix array // elements. For example, if suffixArr[0] is 5, then // invSuff[5] would store 0. This is used to get the next // suffix string from the suffix array. const invSuff = new Array(n).fill(0); // Build an LCP vector const lcp = kasai(str, suffixArr, invSuff); const lcpArr = [...lcp]; // Build segment tree from LCP array const st = constructST(lcpArr, n); for (let i = 0; i < queries.length; i++) { const L = queries[i].L; const R = queries[i].R; console.log(`LCE (${L}, ${R}) = ${LCE(st, lcp, invSuff, n, L, R)}`); } } const str = "abbababba"; const n = str.length; // LCA Queries to answer const queries = [new Query(1, 2), new Query(1, 6), new Query(0, 5)]; queries[0].L = 1; queries[0].R = 2; queries[1].L = 1; queries[1].R = 6; queries[2].L = 0; queries[2].R = 5; LCEQueries(str, n, queries); import math # Structure to represent a query of form (L,R) class Query: def __init__(self, L, R): self.L = L self.R = R # Structure to store information of a suffix class Suffix: def __init__(self): self.index = 0 # To store the original index self.rank = [0, 0] # To store ranks and the next rank pair # A utility function to get the minimum of two numbers def minVal(x, y): return x if x < y else y # A utility function to get the middle index from corner indexes. def getMid(s, e): return s + (e - s) // 2 # A recursive function to get the minimum value in a given range of array indexes def RMQUtil(st, ss, se, qs, qe, index): # If the segment of this node is a part of the given range, then return the min of the segment if qs <= ss and qe >= se: return st[index] # If the segment of this node is outside the given range if se < qs or ss > qe: return math.inf # If a part of this segment overlaps with the given range mid = getMid(ss, se) return minVal(RMQUtil(st, ss, mid, qs, qe, 2 * index + 1), RMQUtil(st, mid + 1, se, qs, qe, 2 * index + 2)) # Return the minimum of elements in the range from index qs (query start) to qe (query end). It mainly uses RMQUtil() def RMQ(st, n, qs, qe): # Check for erroneous input values if qs < 0 or qe > n - 1 or qs > qe: print("Invalid Input") return -1 return RMQUtil(st, 0, n - 1, qs, qe, 0) # A recursive function that constructs Segment Tree for array[ss..se]. si is the index of the current node in the segment tree st def constructSTUtil(arr, ss, se, st, si): # If there is one element in the array, store it in the current node of the segment tree and return if ss == se: st[si] = arr[ss] return arr[ss] # If there are more than one element, then recur for left and right subtrees and store the minimum of two values in this node mid = getMid(ss, se) st[si] = minVal(constructSTUtil(arr, ss, mid, st, si * 2 + 1), constructSTUtil(arr, mid + 1, se, st, si * 2 + 2)) return st[si] # Function to construct a segment tree from the given array. def constructST(arr, n): # Height of the segment tree x = math.ceil(math.log2(n)) # Maximum size of the segment tree max_size = 2 * (2 ** x) - 1 st = [0] * max_size # Fill the allocated memory st constructSTUtil(arr, 0, n - 1, st, 0) # Return the constructed segment tree return st # A comparison function used by sort() to compare two suffixes. Compares two pairs, returns 1 if the first pair is smaller def cmp(a, b): if a.rank[0] == b.rank[0]: return 1 if a.rank[1] < b.rank[1] else 0 else: return 1 if a.rank[0] < b.rank[0] else 0 # This is the main function that takes a string 'txt' of size n as an argument, builds and returns the suffix array for the given string def buildSuffixArray(txt, n): # A structure to store suffixes and their indexes suffixes = [Suffix() for _ in range(n)] # Store suffixes and their indexes in an array of structures. The structure is needed to sort the suffixes alphabetically and maintain their old indexes while sorting for i in range(n): suffixes[i].index = i suffixes[i].rank[0] = ord(txt[i]) - ord('a') suffixes[i].rank[1] = ord(txt[i + 1]) - ord('a') if i + 1 < n else -1 # Sort the suffixes using the comparison function defined above. suffixes.sort(key=lambda x: (x.rank[0], x.rank[1])) # At this point, all suffixes are sorted according to the first 2 characters. # Let us sort suffixes according to the first 4 characters, then the first 8 and so on ind = [0] * n # This array is needed to get the index in suffixes[] from the original index. This mapping is needed to get the next suffix. k = 4 while k < 2 * n: # Assigning rank and index values to the first suffix rank = 0 prev_rank = suffixes[0].rank[0] suffixes[0].rank[0] = rank ind[suffixes[0].index] = 0 # Assigning rank to suffixes for i in range(1, n): if suffixes[i].rank[0] == prev_rank and suffixes[i].rank[1] == suffixes[i - 1].rank[1]: prev_rank = suffixes[i].rank[0] suffixes[i].rank[0] = rank else: prev_rank = suffixes[i].rank[0] rank += 1 suffixes[i].rank[0] = rank ind[suffixes[i].index] = i # Assign the next rank to every suffix for i in range(n): nextindex = suffixes[i].index + k // 2 suffixes[i].rank[1] = suffixes[ind[nextindex]].rank[0] if nextindex < n else -1 # Sort the suffixes according to the first k characters suffixes.sort(key=lambda x: (x.rank[0], x.rank[1])) k *= 2 # Store indexes of all sorted suffixes in the suffix array suffixArr = [0] * n for i in range(n): suffixArr[i] = suffixes[i].index # Return the suffix array return suffixArr # To construct and return LCP def kasai(txt, suffixArr, invSuff): n = len(suffixArr) # To store the LCP array lcp = [0] * n # Fill values in invSuff[] for i in range(n): invSuff[suffixArr[i]] = i # Initialize the length of the previous LCP k = 0 # Process all suffixes one by one starting from the first suffix in txt[] for i in range(n): # If the current suffix is at n-1, then we don't have the next substring to consider. # So the LCP is not defined for this substring, we put zero. if invSuff[i] == n - 1: k = 0 continue # j contains the index of the next substring to be considered to compare with the present substring, # i.e., the next string in the suffix array j = suffixArr[invSuff[i] + 1] # Directly start matching from the k'th index as at least k-1 characters will match while i + k < n and j + k < n and txt[i + k] == txt[j + k]: k += 1 lcp[invSuff[i]] = k # LCP for the present suffix. # Deleting the starting character from the string. if k > 0: k -= 1 # return the constructed LCP array return lcp # A utility function to find the longest common extension from index - L and index - R def LCE(st, lcp, invSuff, n, L, R): # Handle the corner case if L == R: return (n - L) # Use the formula - LCE (L, R) = RMQ lcp (invSuff[R], invSuff[L]-1) return (RMQ(st, n, invSuff[R], invSuff[L] - 1)) # A function to answer queries of the longest common extension def LCEQueries(txt, n, q, m): # Build a suffix array suffixArr = buildSuffixArray(txt, len(txt)) # An auxiliary array to store the inverse of suffix array elements. invSuff = [0] * n # Build an LCP vector lcp = kasai(txt, suffixArr, invSuff) lcpArr = lcp # Build a segment tree from the LCP array st = constructST(lcpArr, n) for i in range(m): L = q[i].L R = q[i].R print("LCE (", L, ", ", R, ") = ", LCE(st, lcp, invSuff, n, L, R), sep='') # Driver Program to test above functions if __name__ == "__main__": txt = "abbababba" n = len(txt) # LCA Queries to answer q = [Query(1, 2), Query(1, 6), Query(0, 5)] m = len(q) LCEQueries(txt, n, q, m) Output:
LCE (1, 2) = 1
LCE (1, 6) = 3
LCE (0, 5) = 4
Time Complexity :
To construct the lcp and the suffix array it takes O(N.logN) time. To answer each query it takes O(log N). Hence the overall time complexity is O(N.logN + Q.logN)). Although we can construct the lcp array and the suffix array in O(N) time using other algorithms. where, Q = Number of LCE Queries. N = Length of the input string.
Auxiliary Space :
We use O(N) auxiliary space to store lcp, suffix and inverse suffix arrays and segment tree.
Comparison of Performances:
We have seen three algorithm to compute the length of the LCE.
Set 1 :
Naive Method [O(N.Q)]
Set 2 :
RMQ-Direct Minimum Method [O(N.logN + Q. (|invSuff[R] – invSuff[L]|))]
Set 3 :
Segment Tree Method [O(N.logN + Q.logN))] invSuff[] = Inverse suffix array of the input string. From the asymptotic time complexity it seems that the Segment Tree method is most efficient and the other two are very inefficient. But when it comes to practical world this is not the case. If we plot a graph between time vs log((|invSuff[R] – invSuff[L]|) for typical files having random strings for various runs, then the result is as shown below.
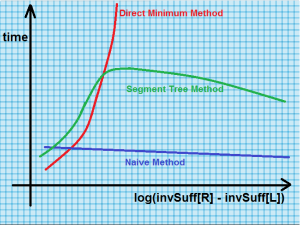
The above graph is taken from
this reference. The tests were run on 25 files having random strings ranging from 0.7 MB to 2 GB. The exact sizes of string is not known but obviously a 2 GB file has a lot of characters in it. This is because 1 character = 1 byte. So, about 1000 characters equal 1 kilobyte. If a page has 2000 characters on it (a reasonable average for a double-spaced page), then it will take up 2K (2 kilobytes). That means it will take about 500 pages of text to equal one megabyte. Hence 2 gigabyte = 2000 megabyte = 2000*500 = 10,00,000 pages of text ! From the above graph it is clear that the Naive Method (discussed in Set 1) performs the best (better than Segment Tree Method). This is surprising as the asymptotic time complexity of Segment Tree Method is much lesser than that of the Naive Method. In fact, the naive method is generally 5-6 times faster than the Segment Tree Method on typical files having random strings. Also not to forget that the Naive Method is an in-place algorithm, thus making it the most desirable algorithm to compute LCE . The bottom-line is that the naive method is the most optimal choice for answering the LCE queries when it comes to average-case performance. Such kind of thinks rarely happens in Computer Science when a faster-looking algorithm gets beaten by a less efficient one in practical tests. What we learn is that the although asymptotic analysis is one of the most effective way to compare two algorithms on paper, but in practical uses sometimes things may happen the other way round.
References:
https://www.sciencedirect.com/science/article/pii/S1570866710000377 If you like GeeksforGeeks and would like to contribute, you can also write an article using
write.geeksforgeeks.org or mail your article to review-team@geeksforgeeks.org. See your article appearing on the GeeksforGeeks main page and help other Geeks. Please write comments if you find anything incorrect, or you want to share more information about the topic discussed above.
Explore
DSA Fundamentals
Data Structures
Algorithms
Advanced
Interview Preparation
Practice Problem