How I learned to time travel, or, data pipelining and scheduling with Airflow
The document discusses data pipelining and scheduling using Apache Airflow, presenting its advantages and comparisons with other tools like Luigi, Drakemake, and AWS Data Pipeline. It emphasizes the importance of resilience, complexity handling, and flexibility in data workflows, while detailing the setup and configuration of Airflow for effective task management. Additionally, it introduces 'smart-airflow', a plugin to enhance Airflow's capabilities, particularly in managing file-based intermediate artifacts.
The presentation begins with author Laura Lorenz introducing the topic of data pipelining and scheduling with Airflow.
Discusses the complexities and untrustworthiness of user data, highlighting how traditional scheduling tools like Cron have limitations due to chaos and dependencies.
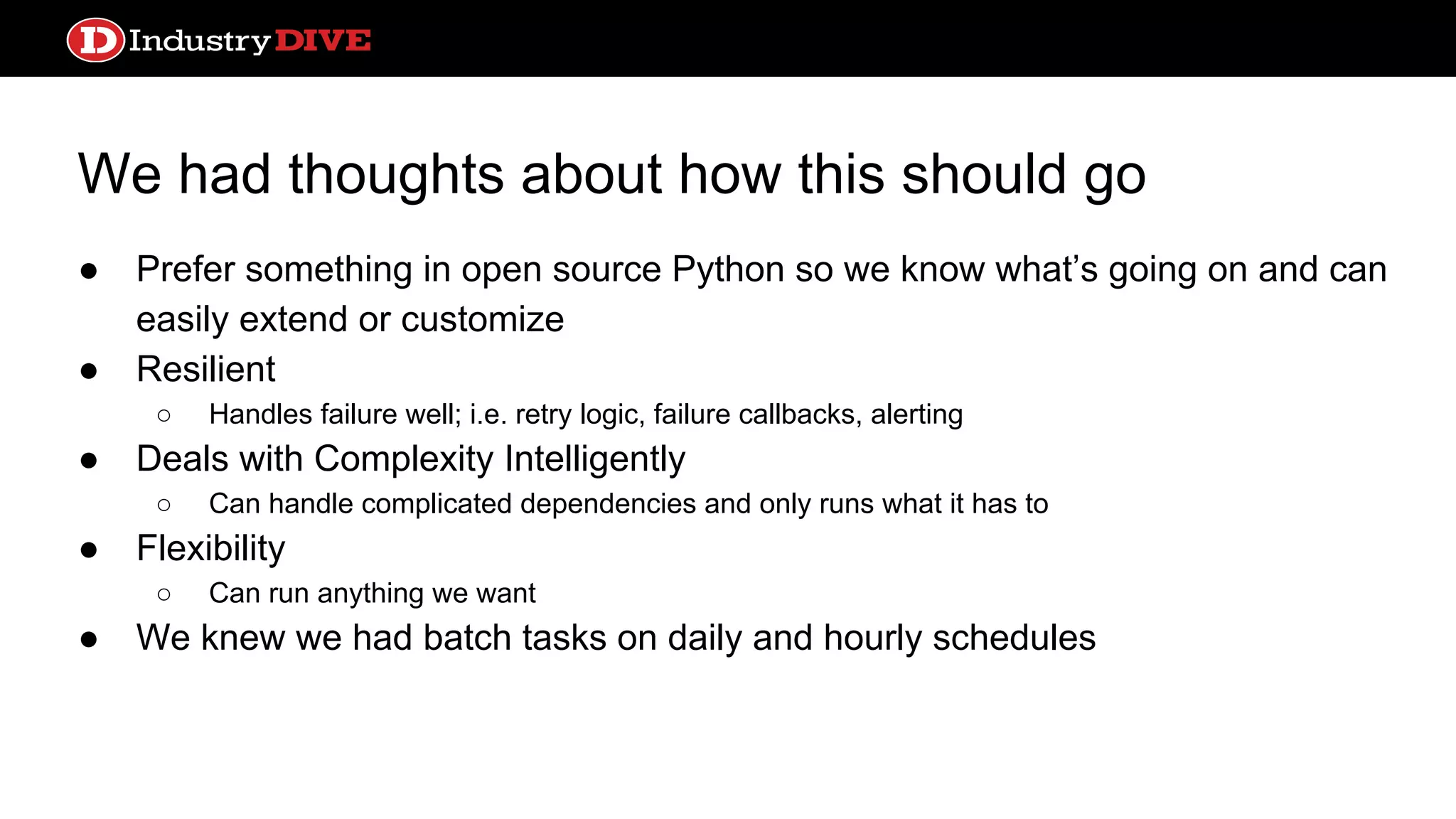
Explores various data pipeline tools, emphasizing the need for open-source Python tools that manage complexity and provide resilience in data orchestration.
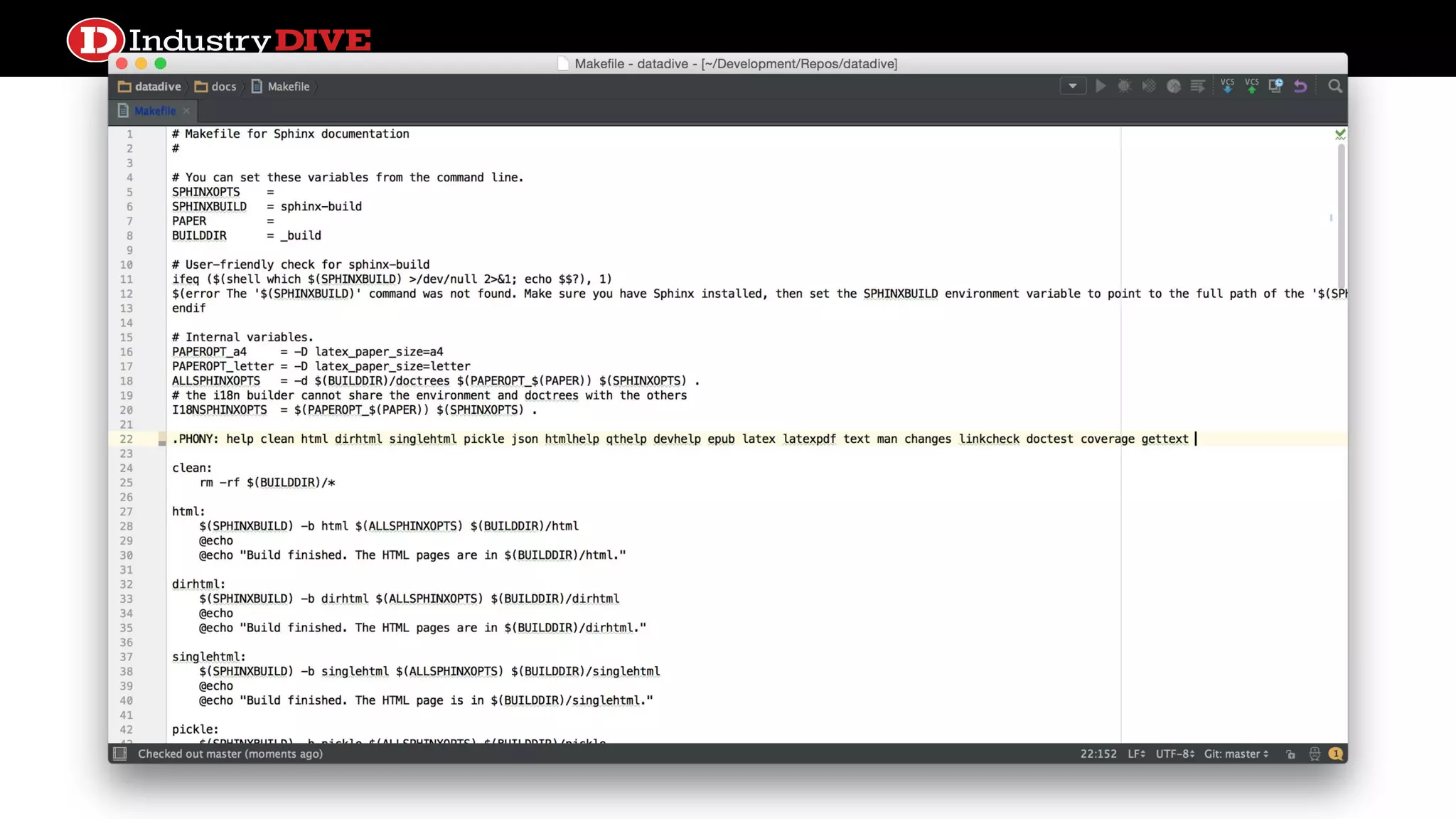
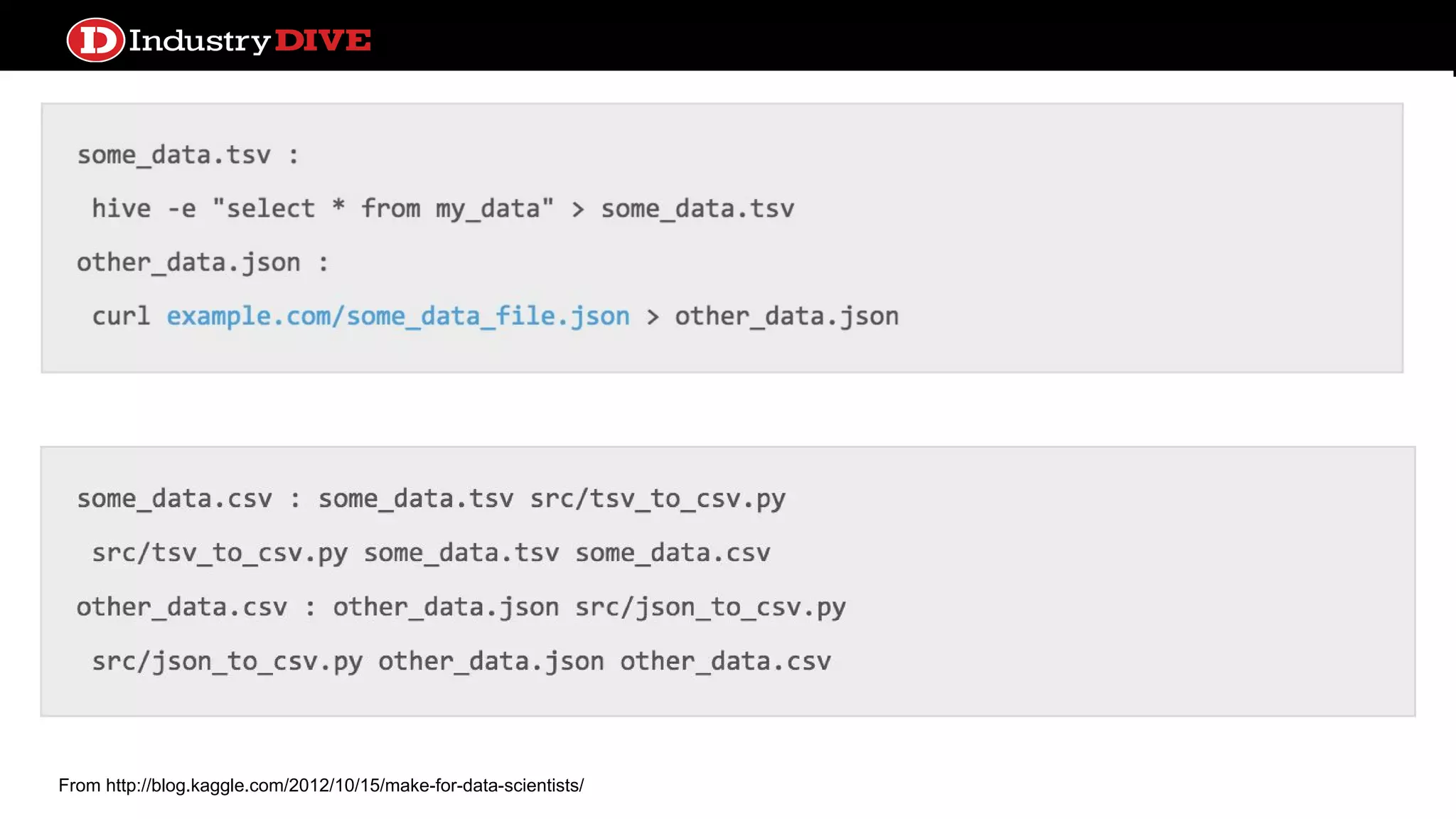
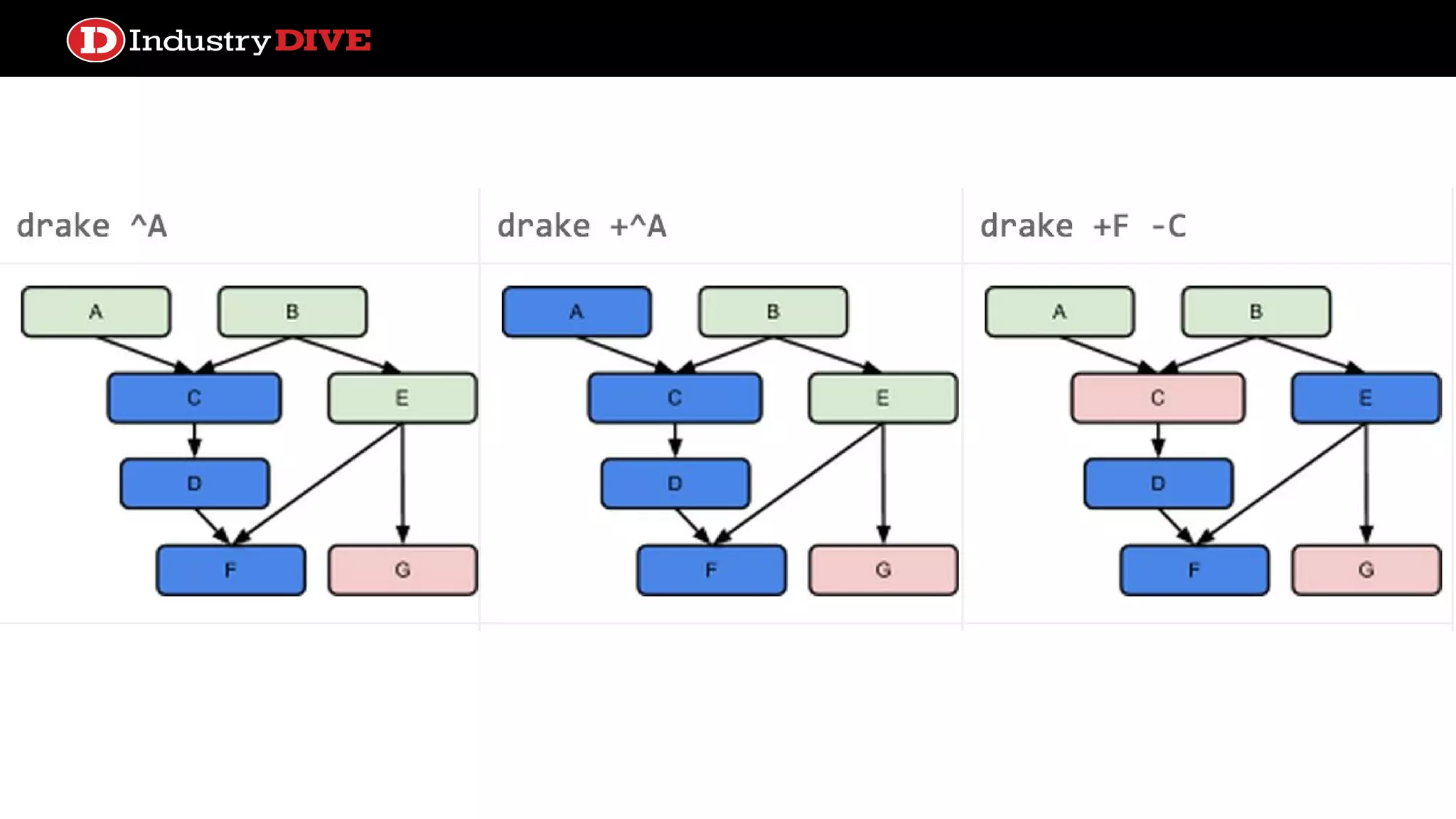
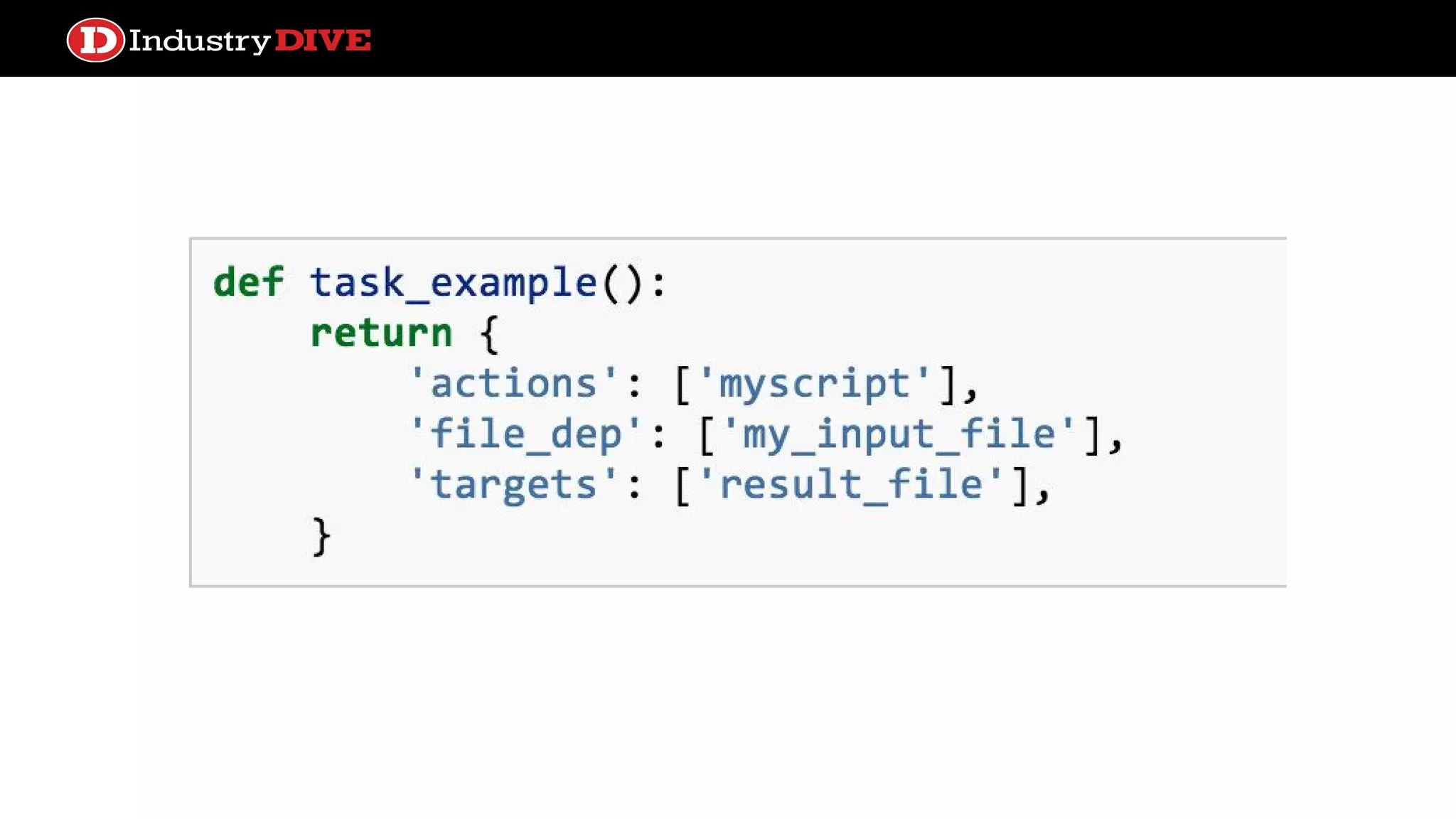
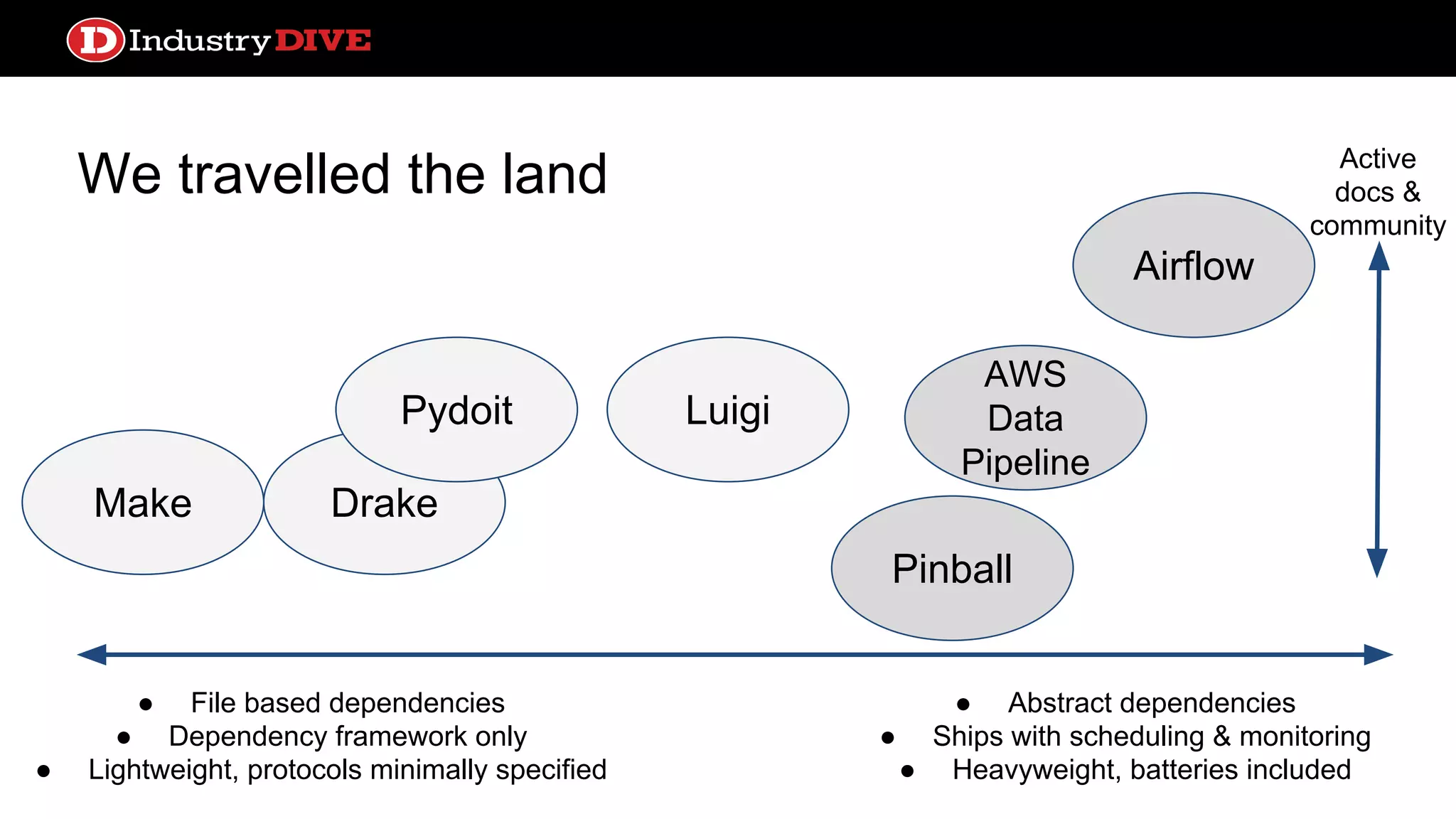
Investigates different frameworks for managing file dependencies, showcasing examples like Makefile, Drakefile, Pydoit, and Luigi.
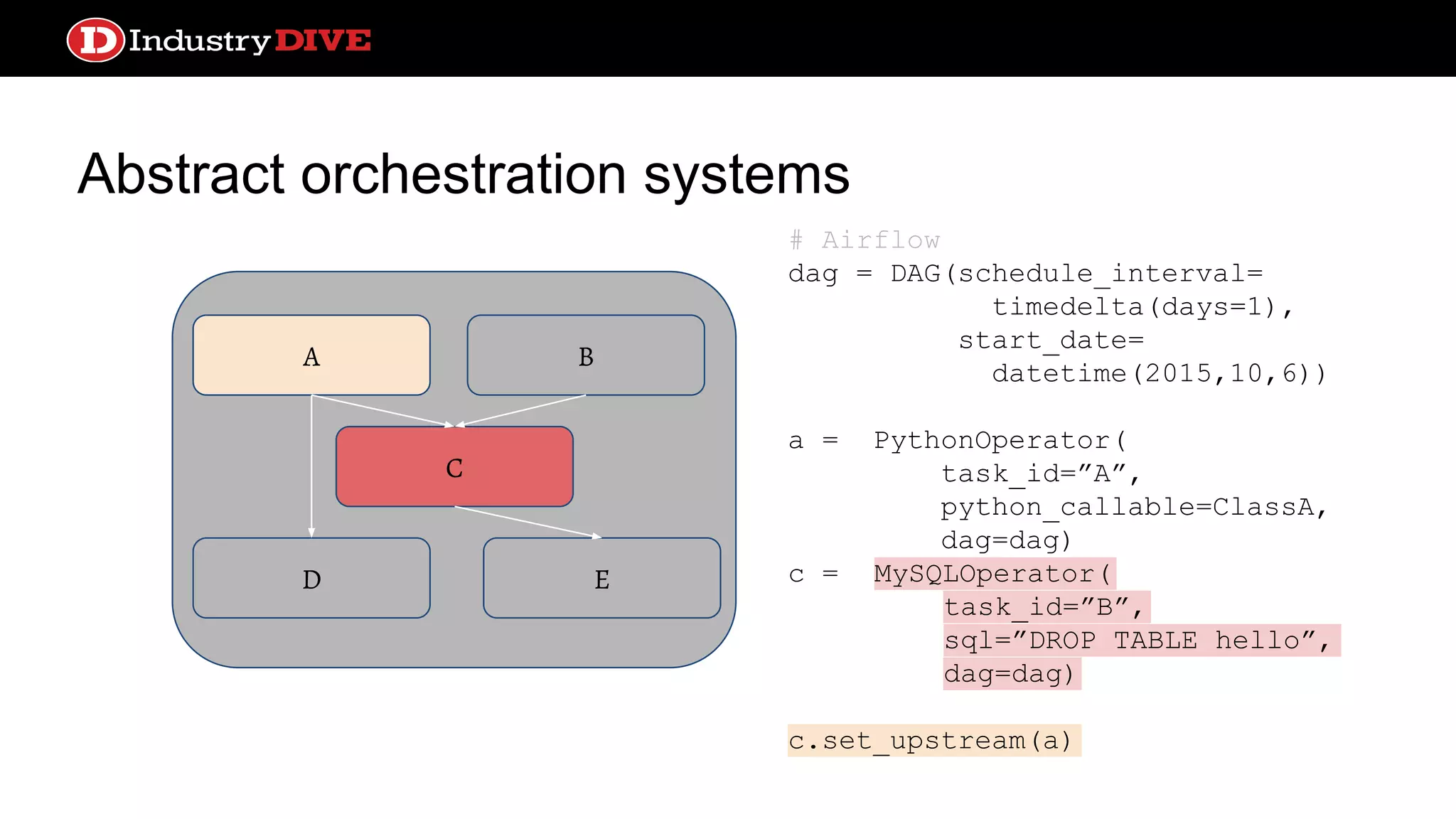
Details abstract orchestration systems' capabilities, particularly how Airflow excels in scheduling, monitoring, and complexity handling while also requiring additional infrastructure.
Shares opinions about the need for sophisticated orchestration along with transparency and independence from ecosystem lock-in.
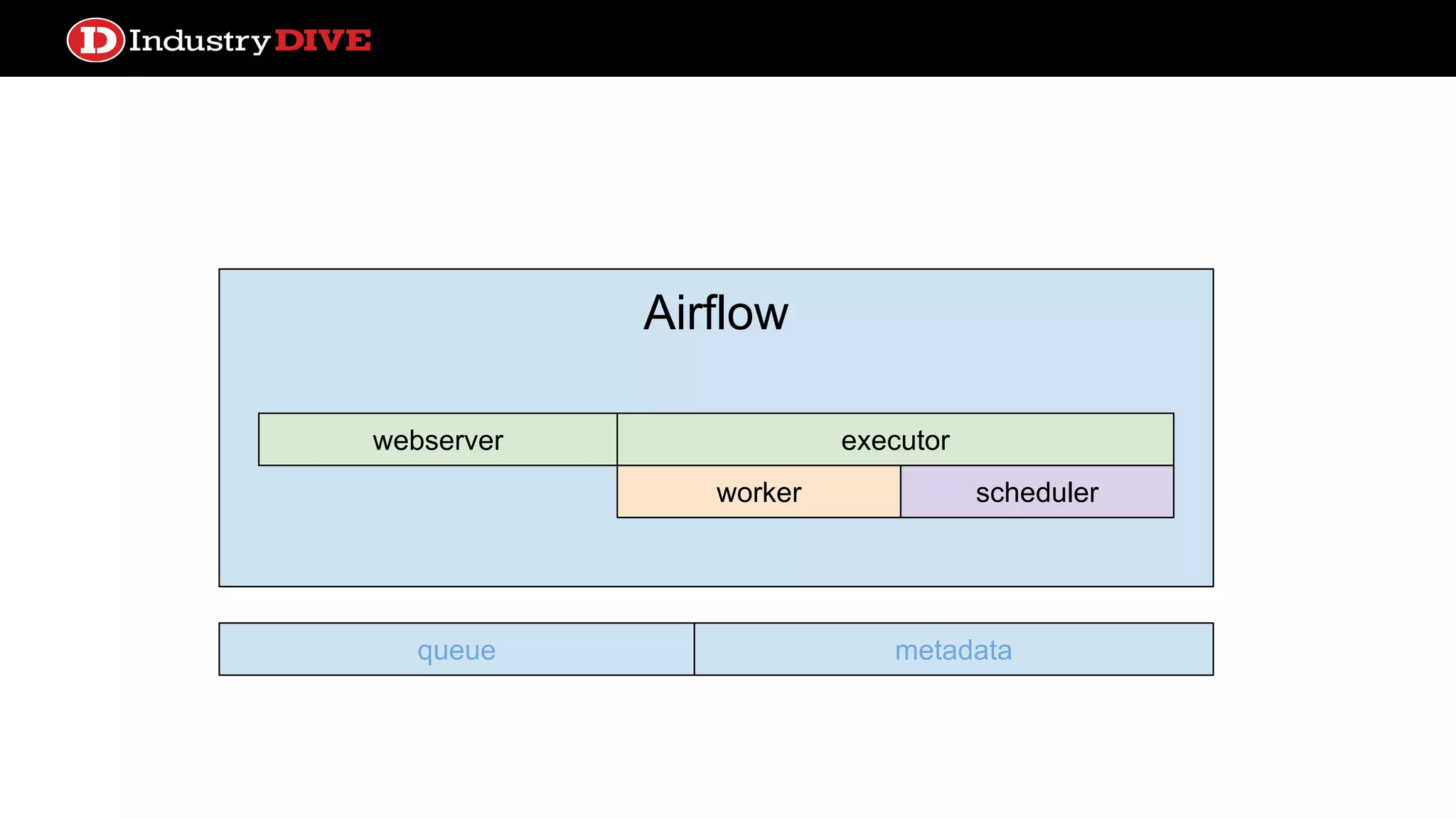
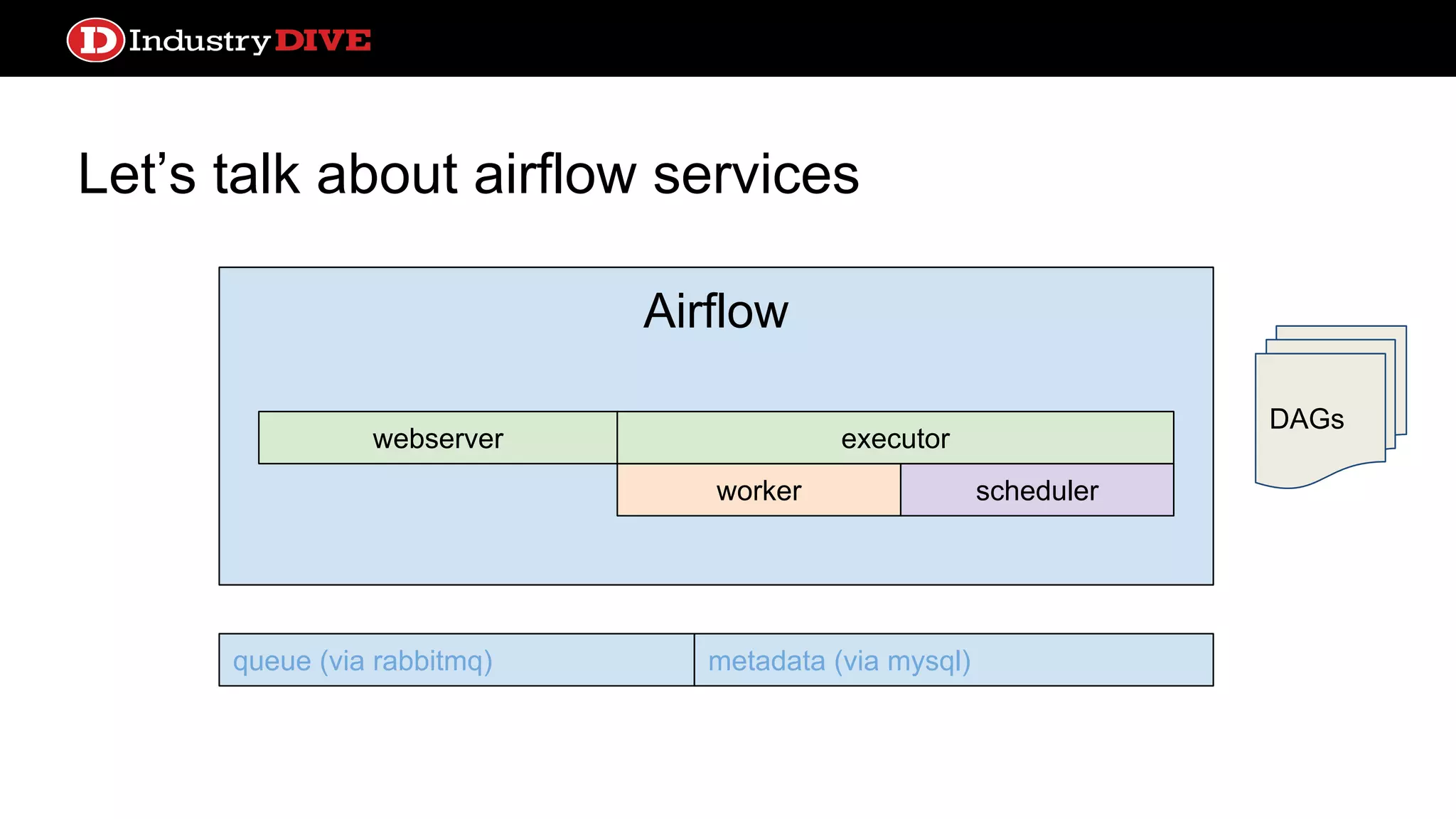
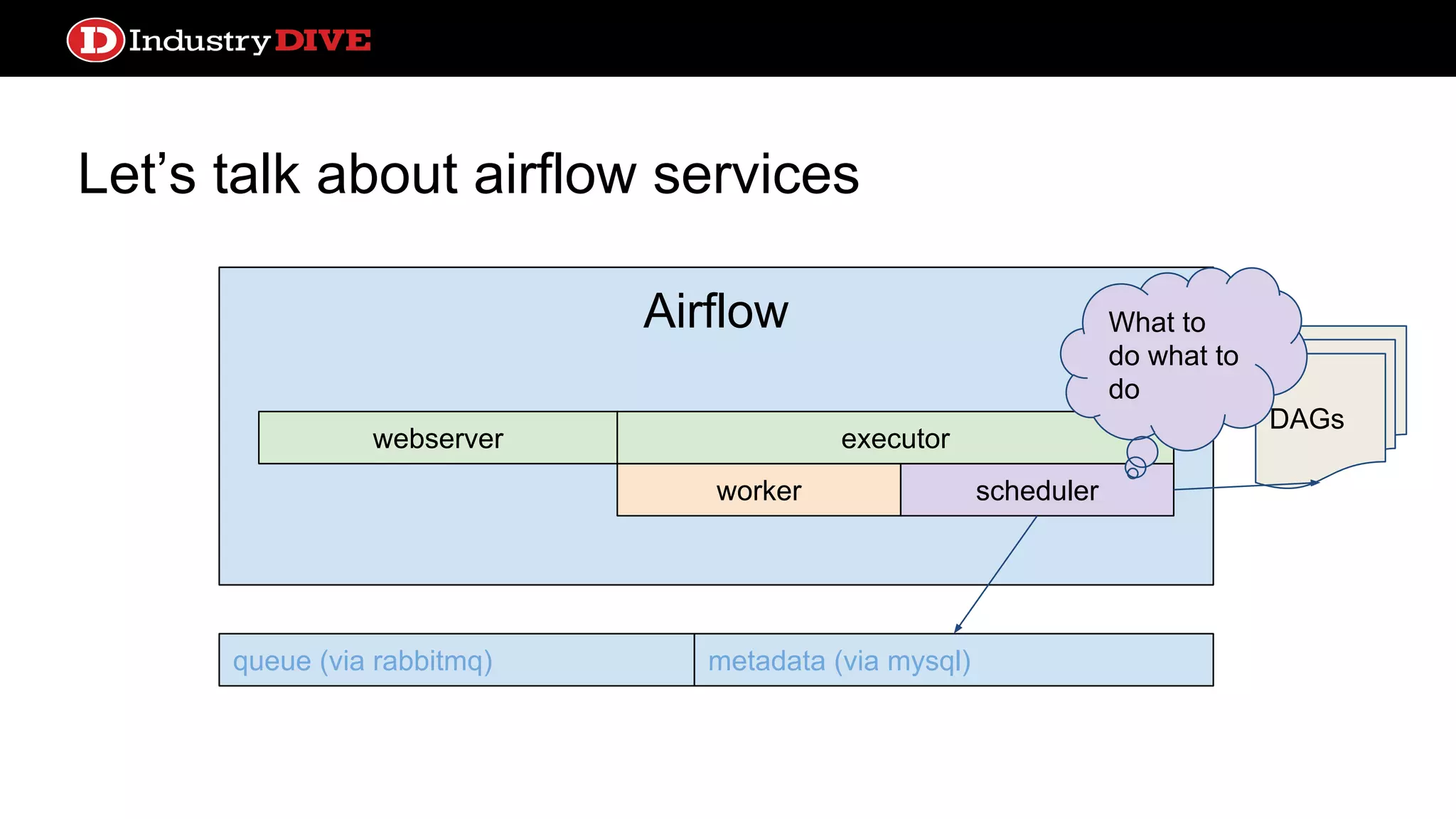
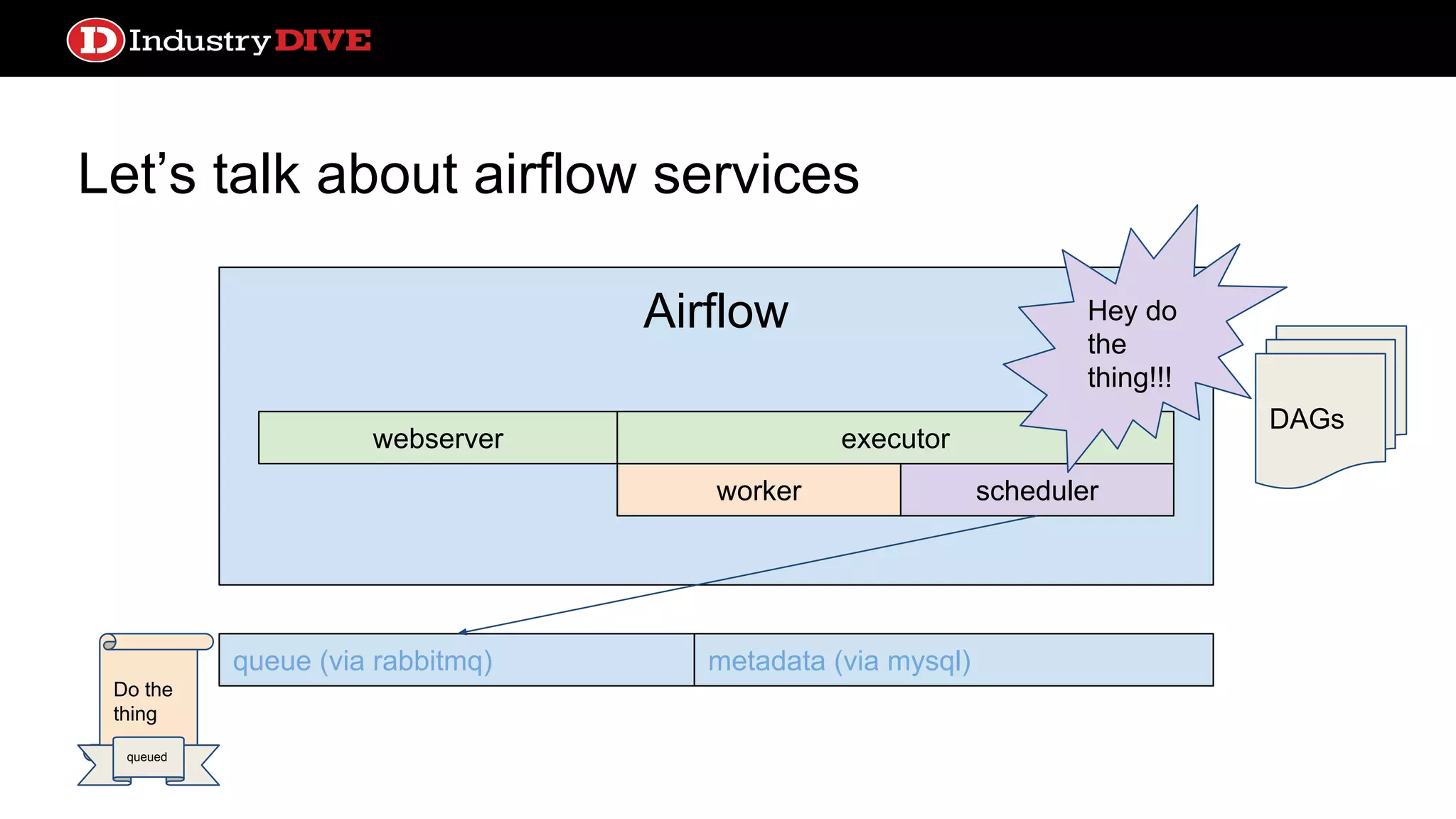
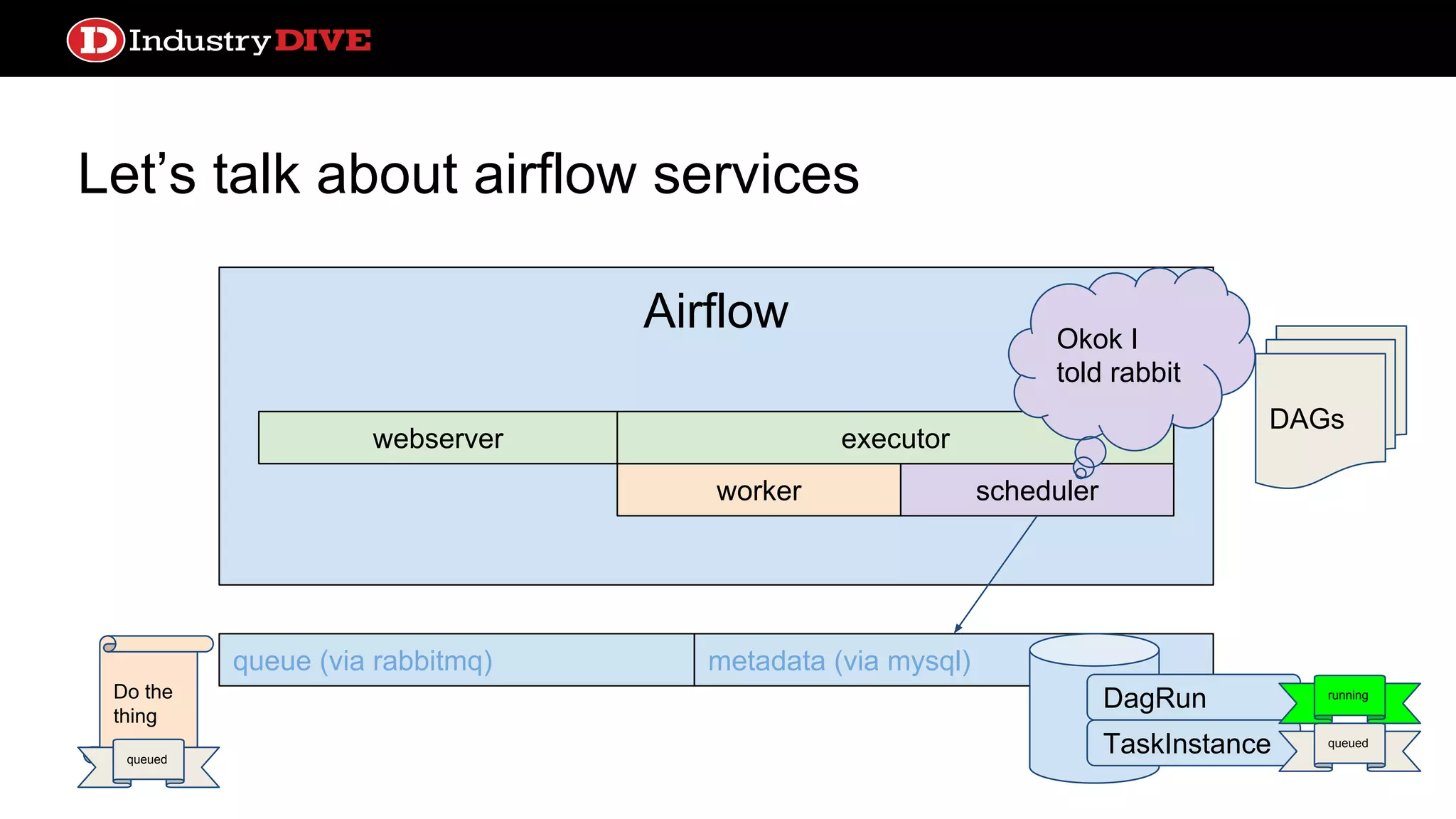
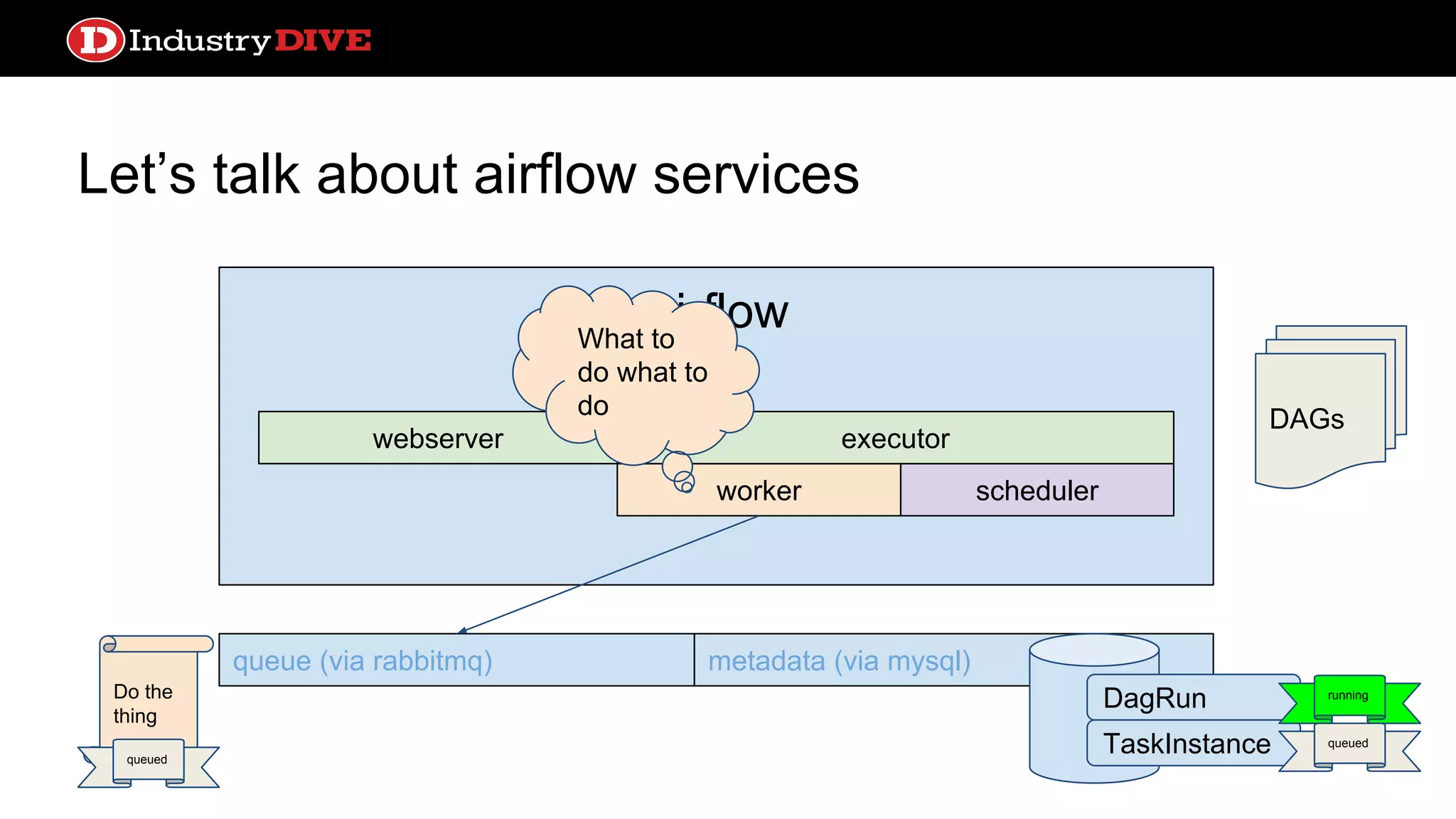
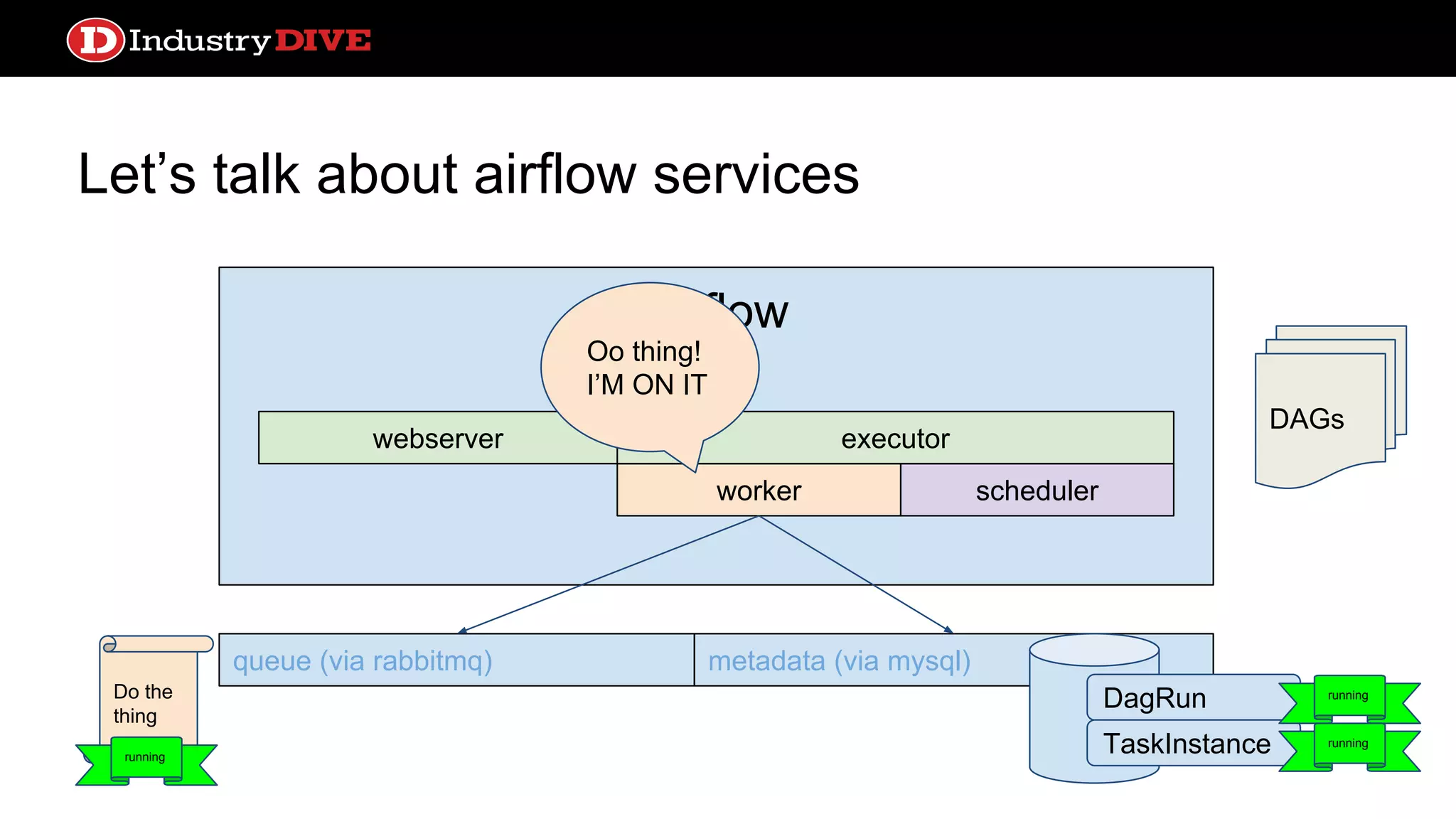
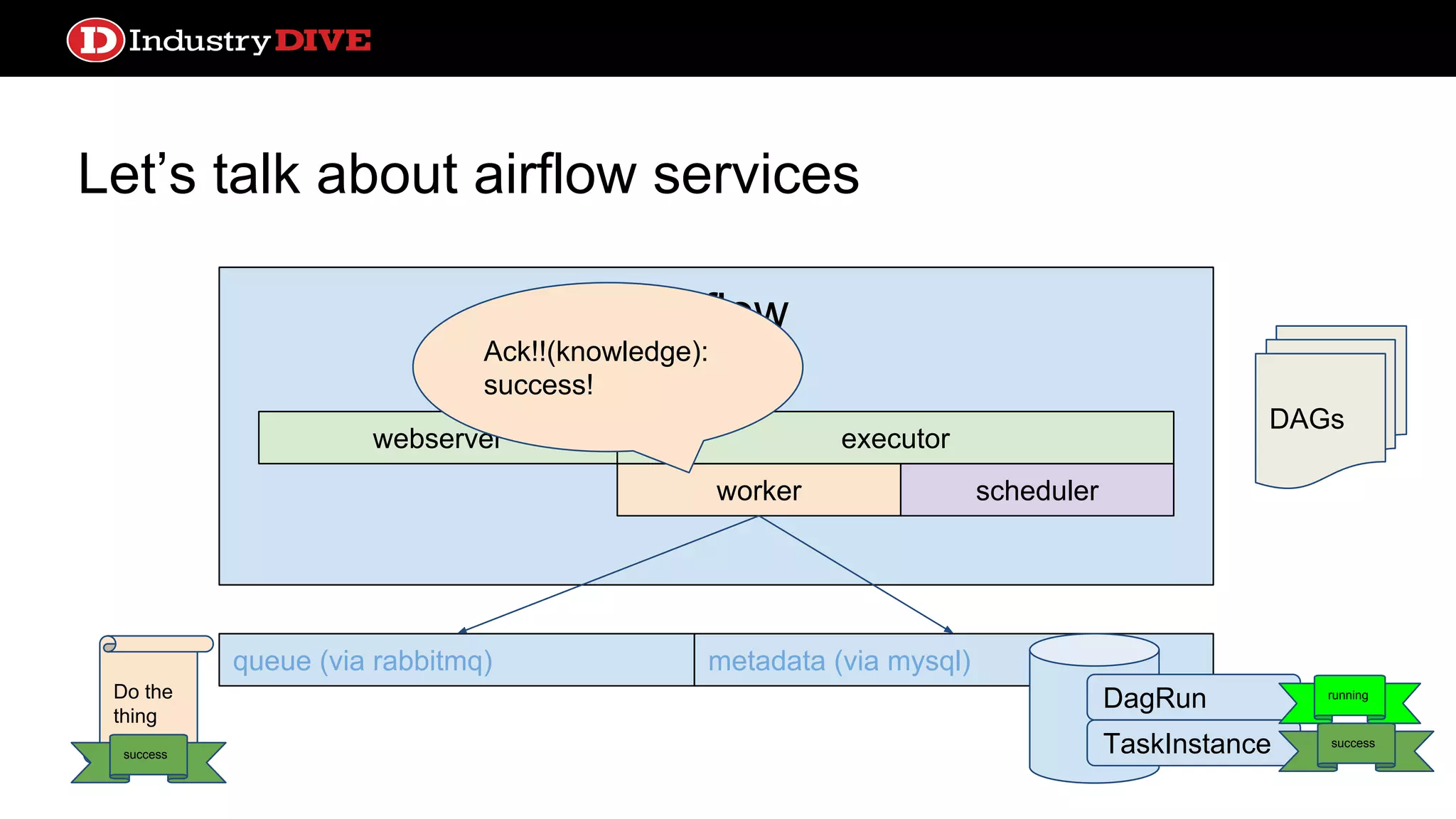
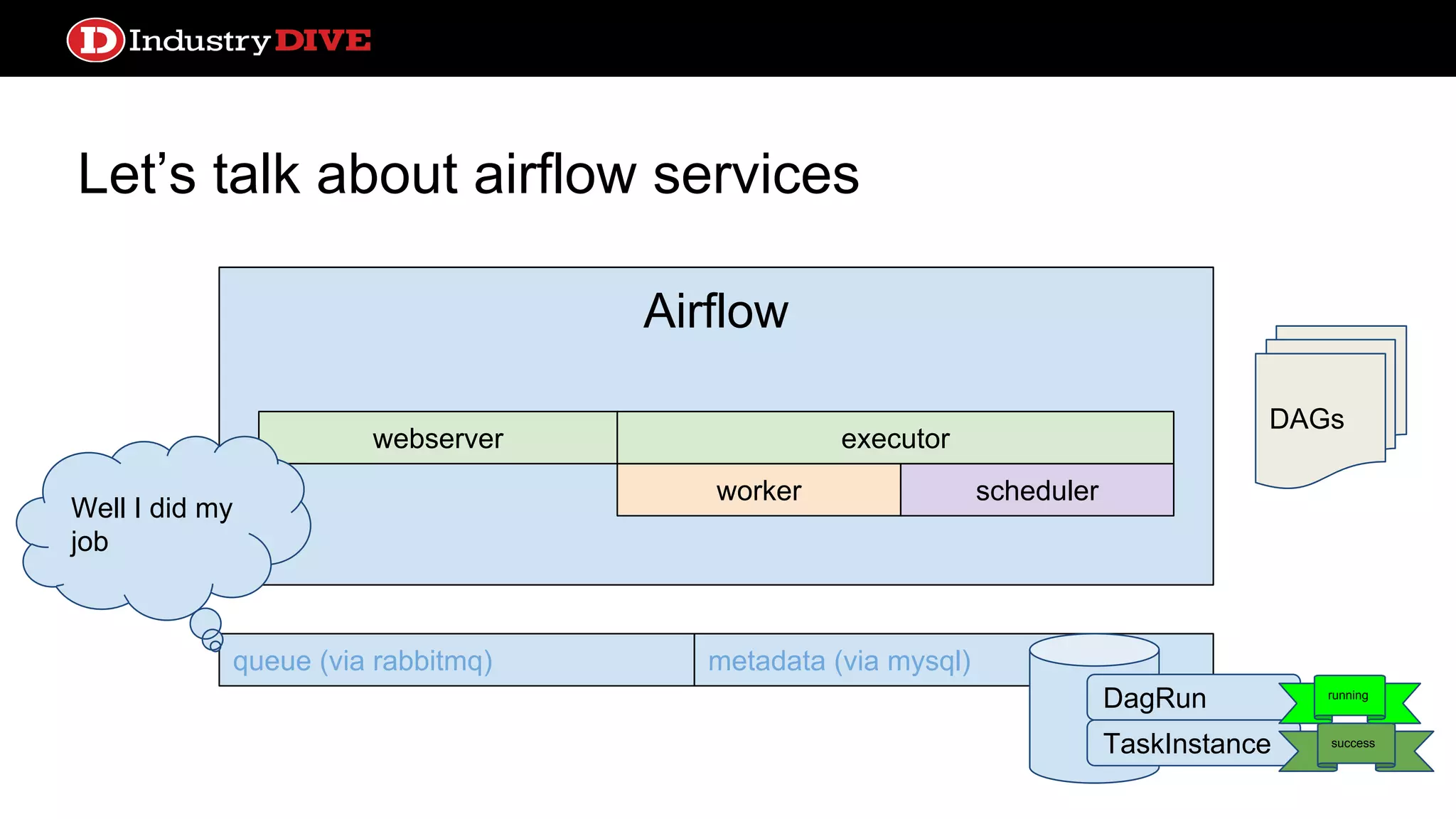
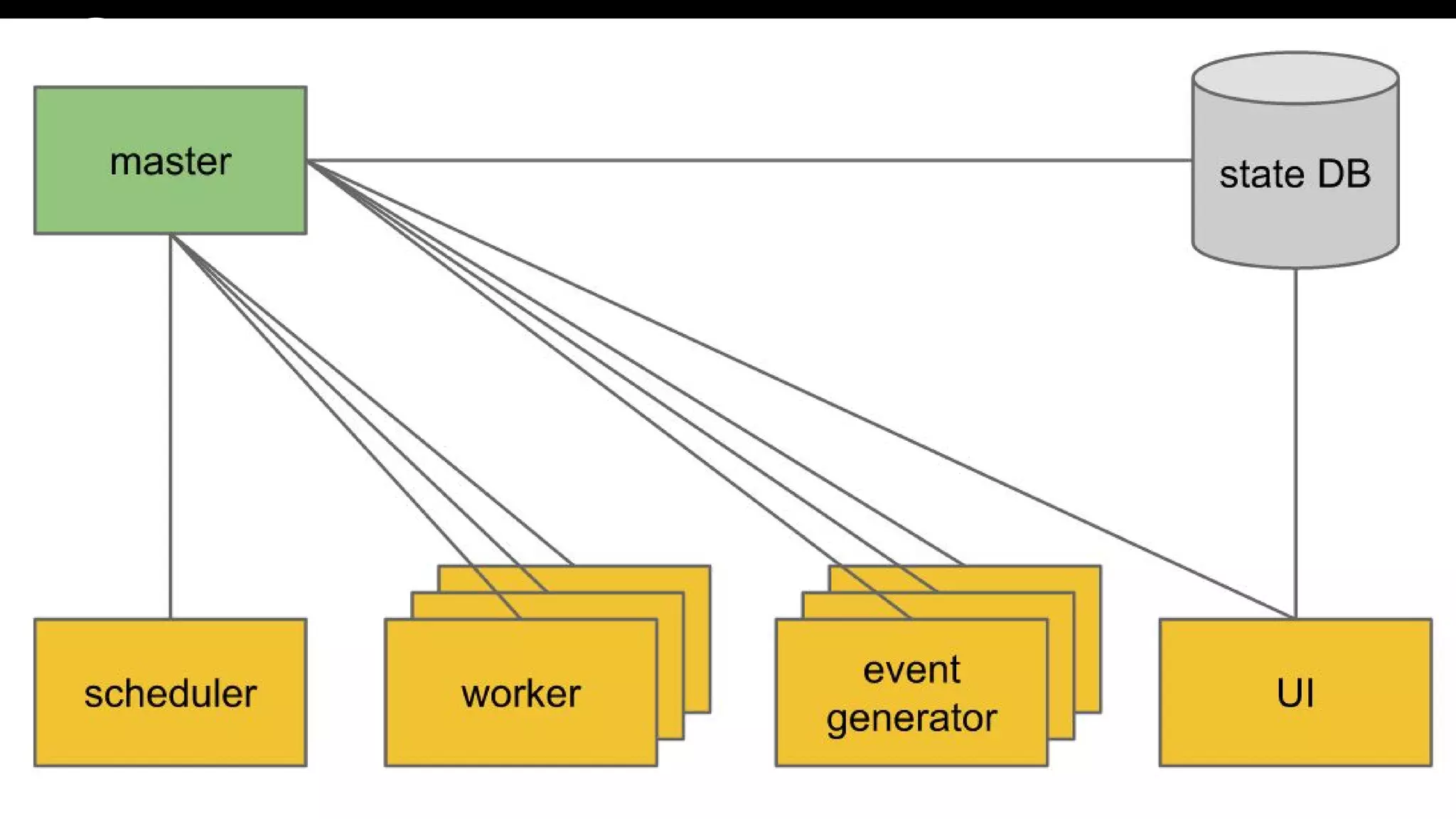
Dives into Airflow’s architecture, explaining its key components, including the scheduler, worker, webserver, and execution mechanisms.
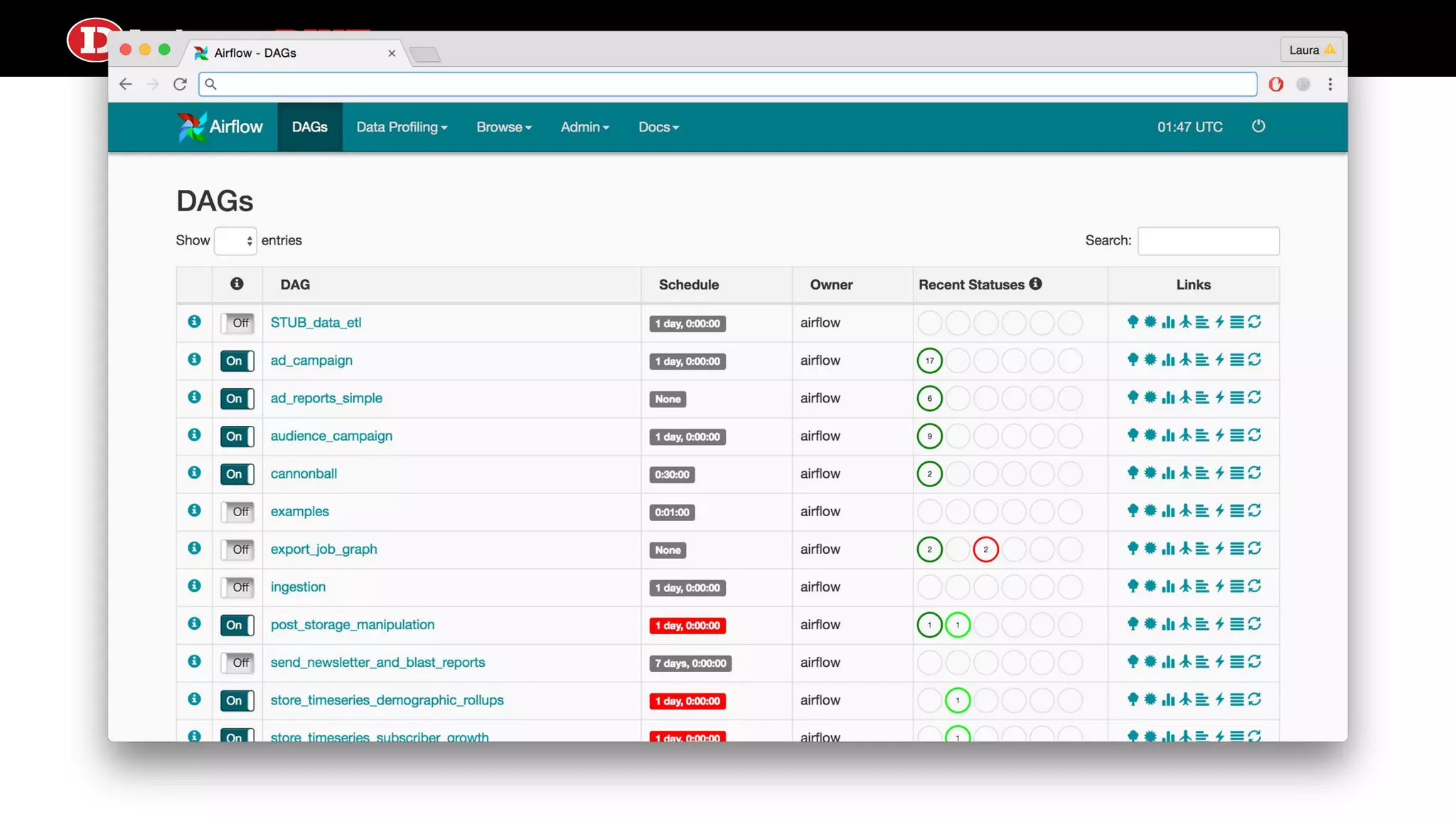
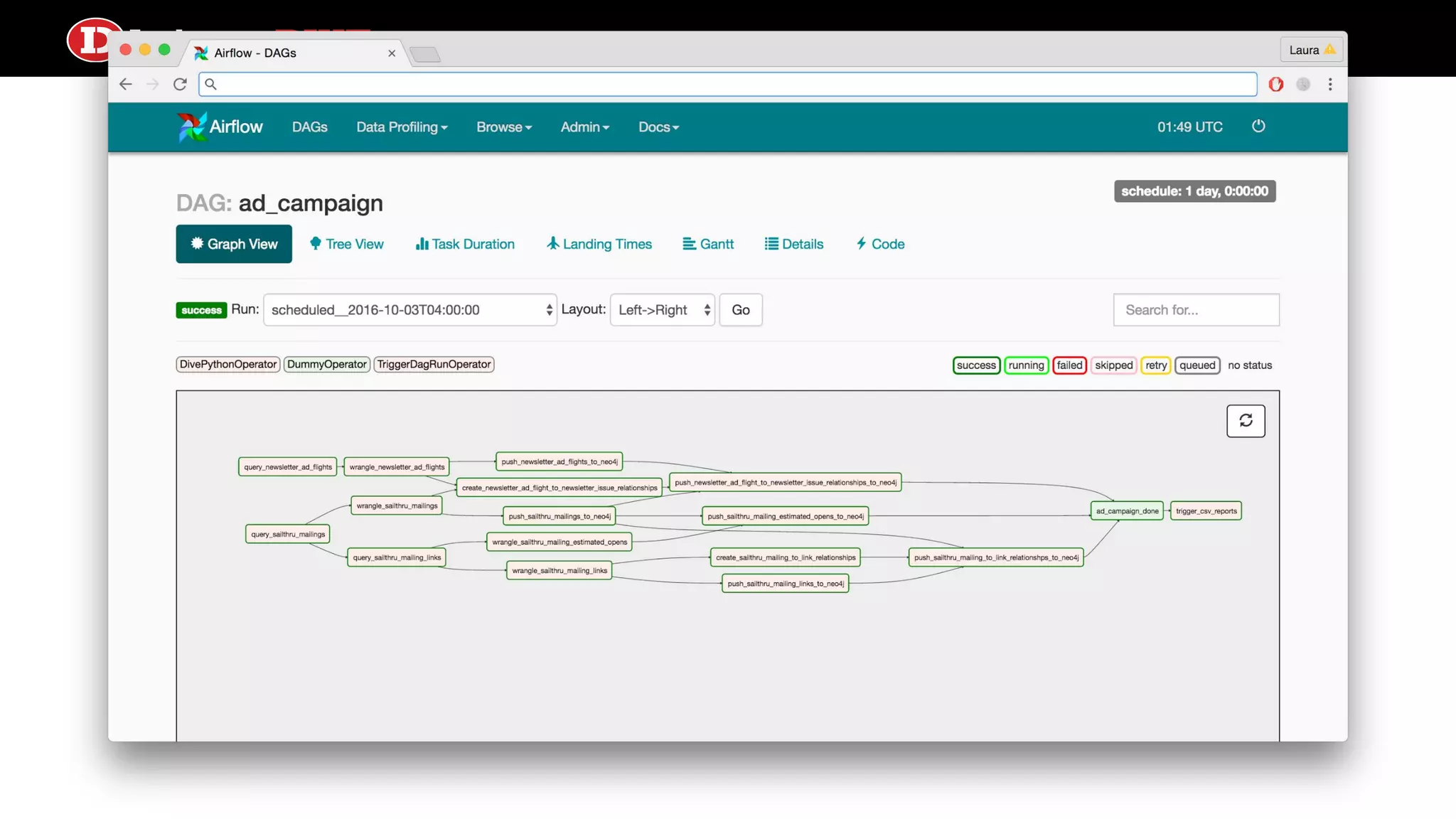
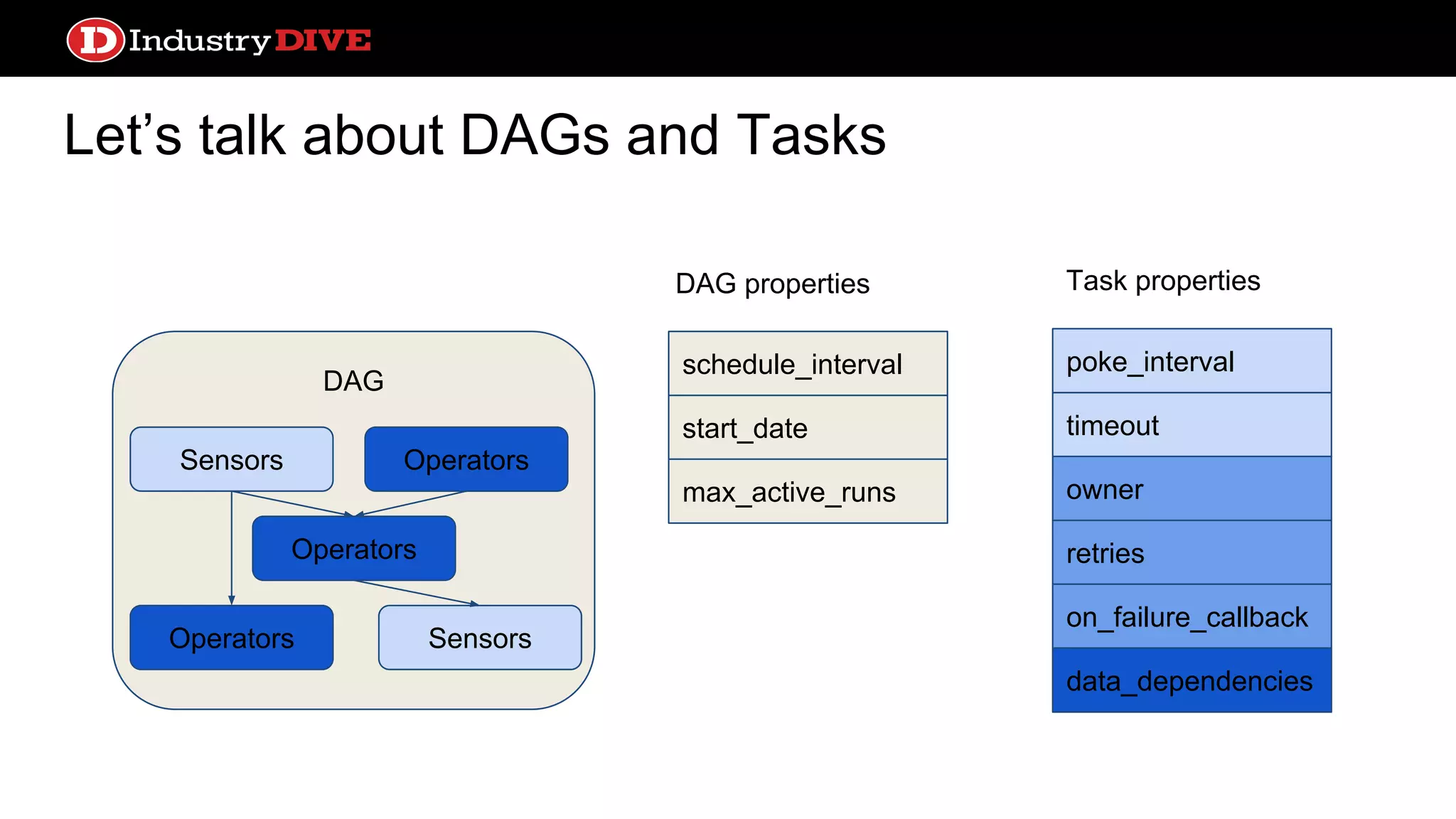
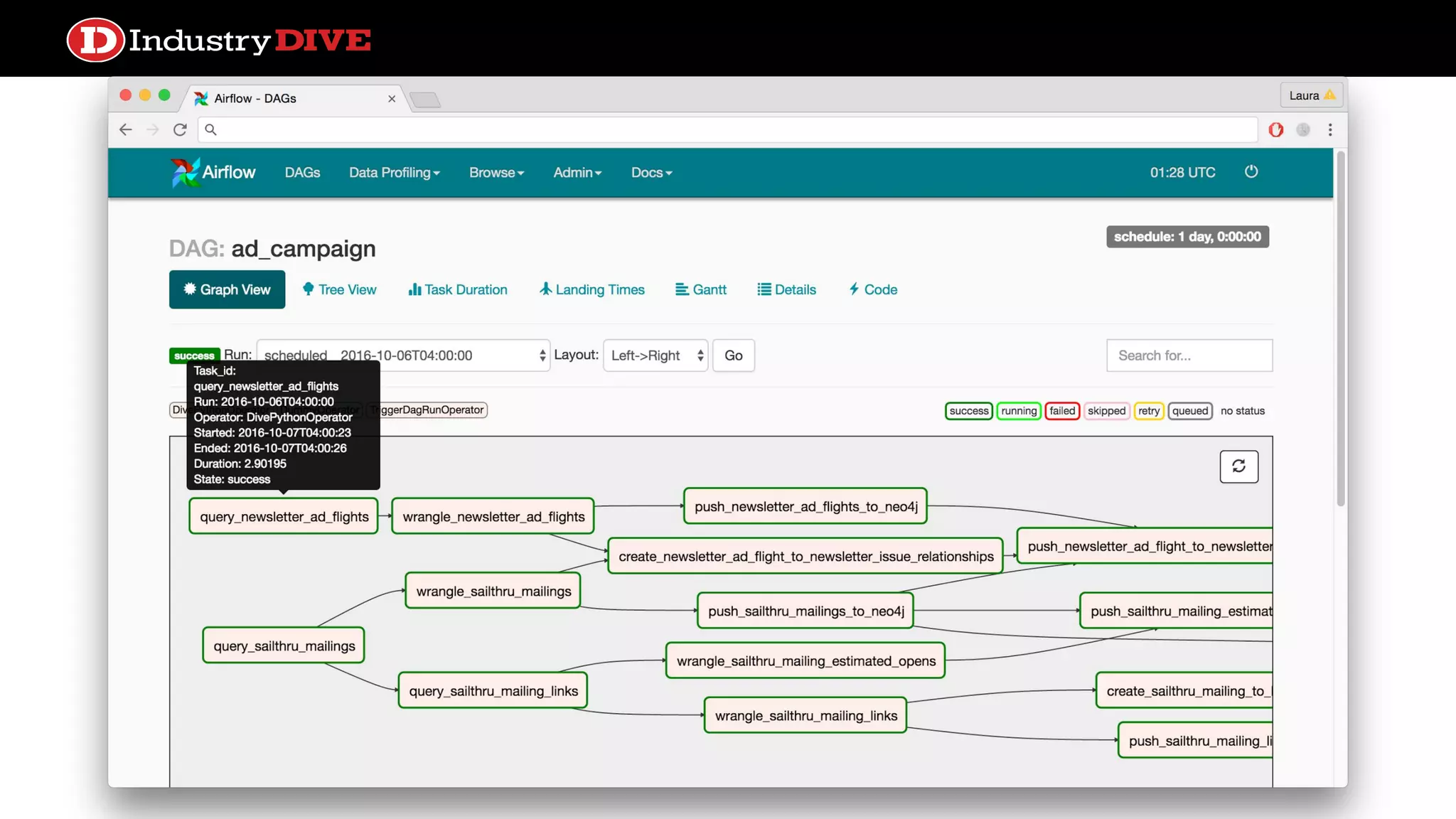
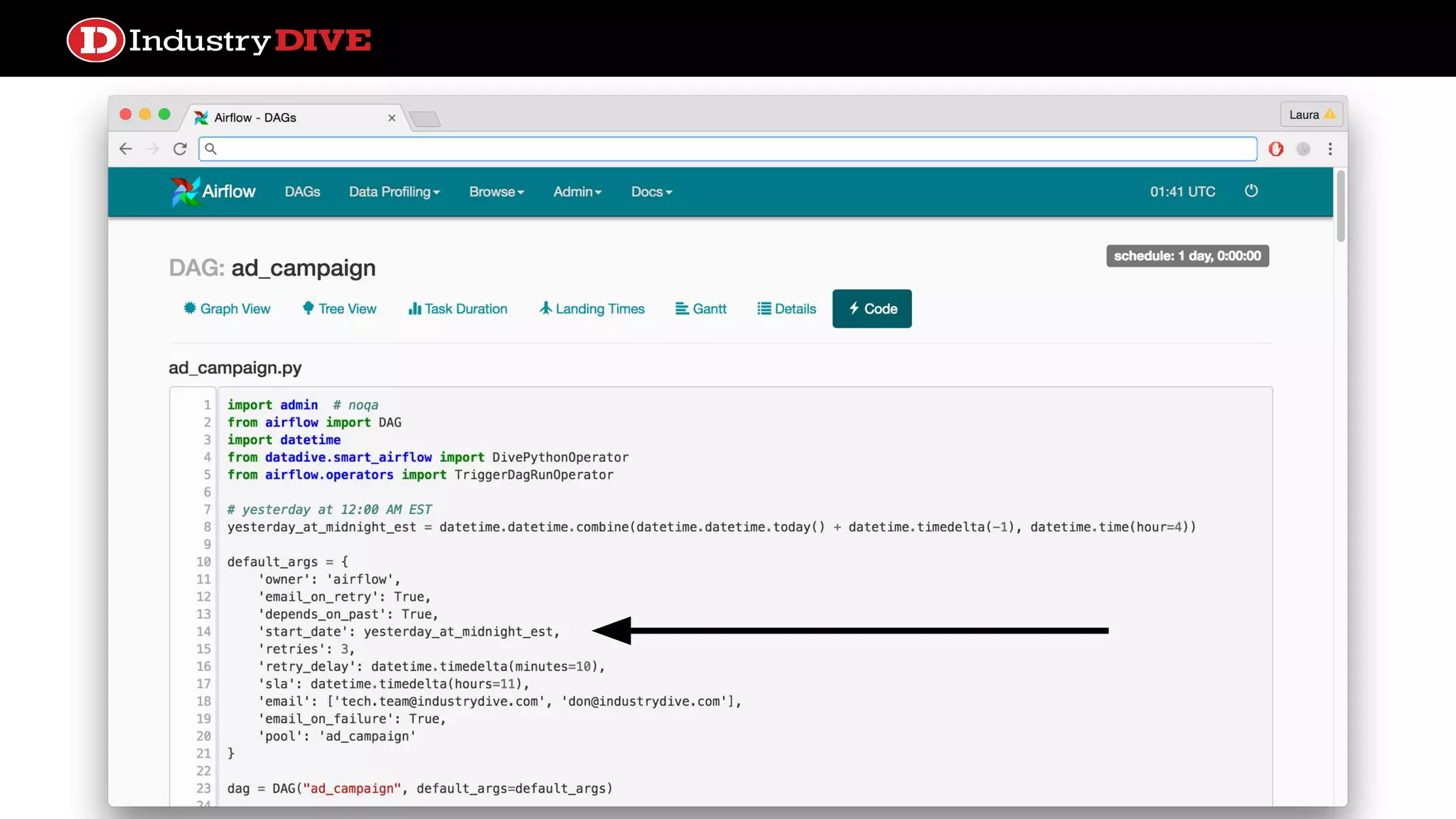
Outlines how Directed Acyclic Graphs (DAGs) and tasks are defined in Airflow, focusing on settings like schedule intervals and task properties.
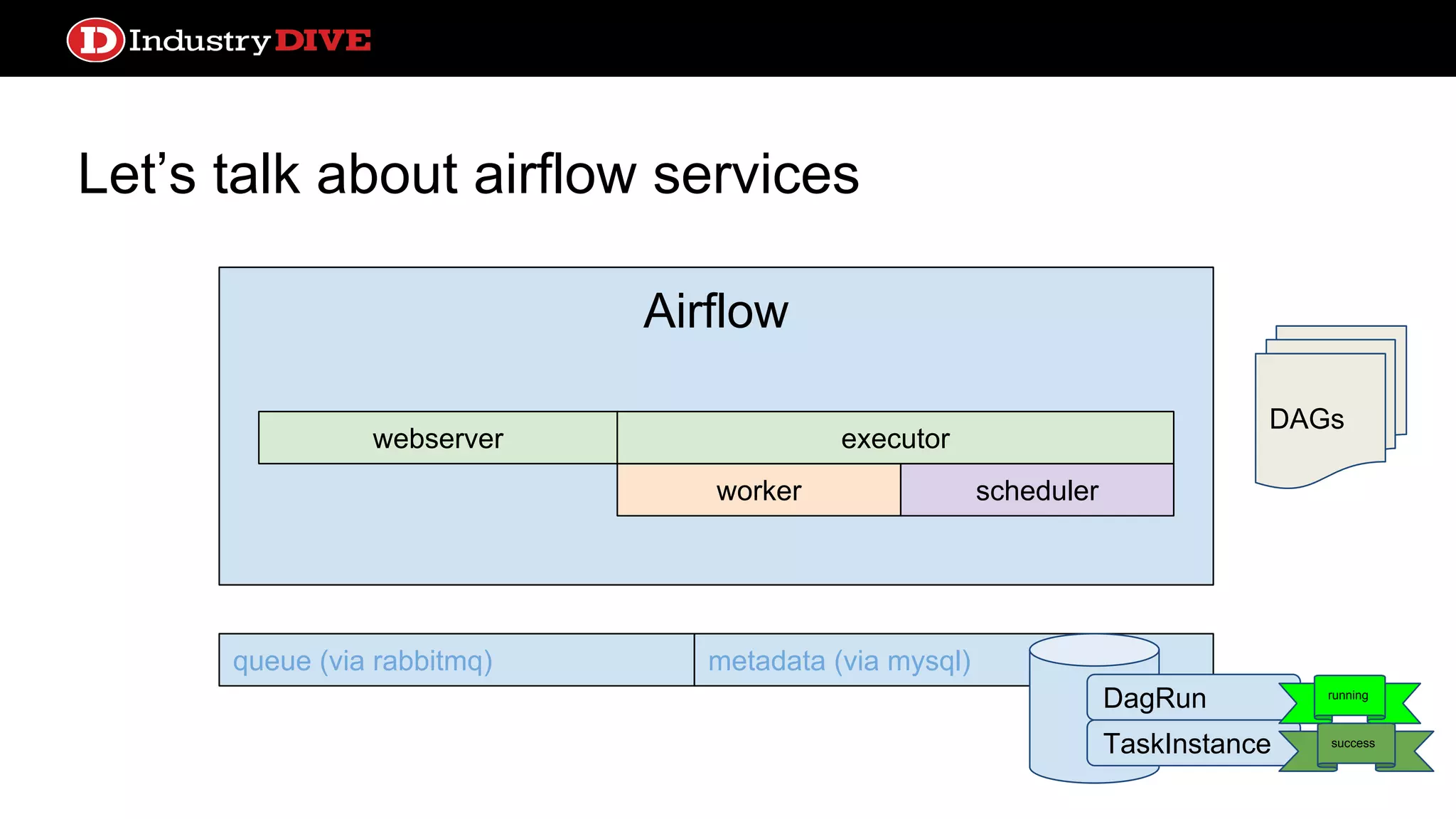
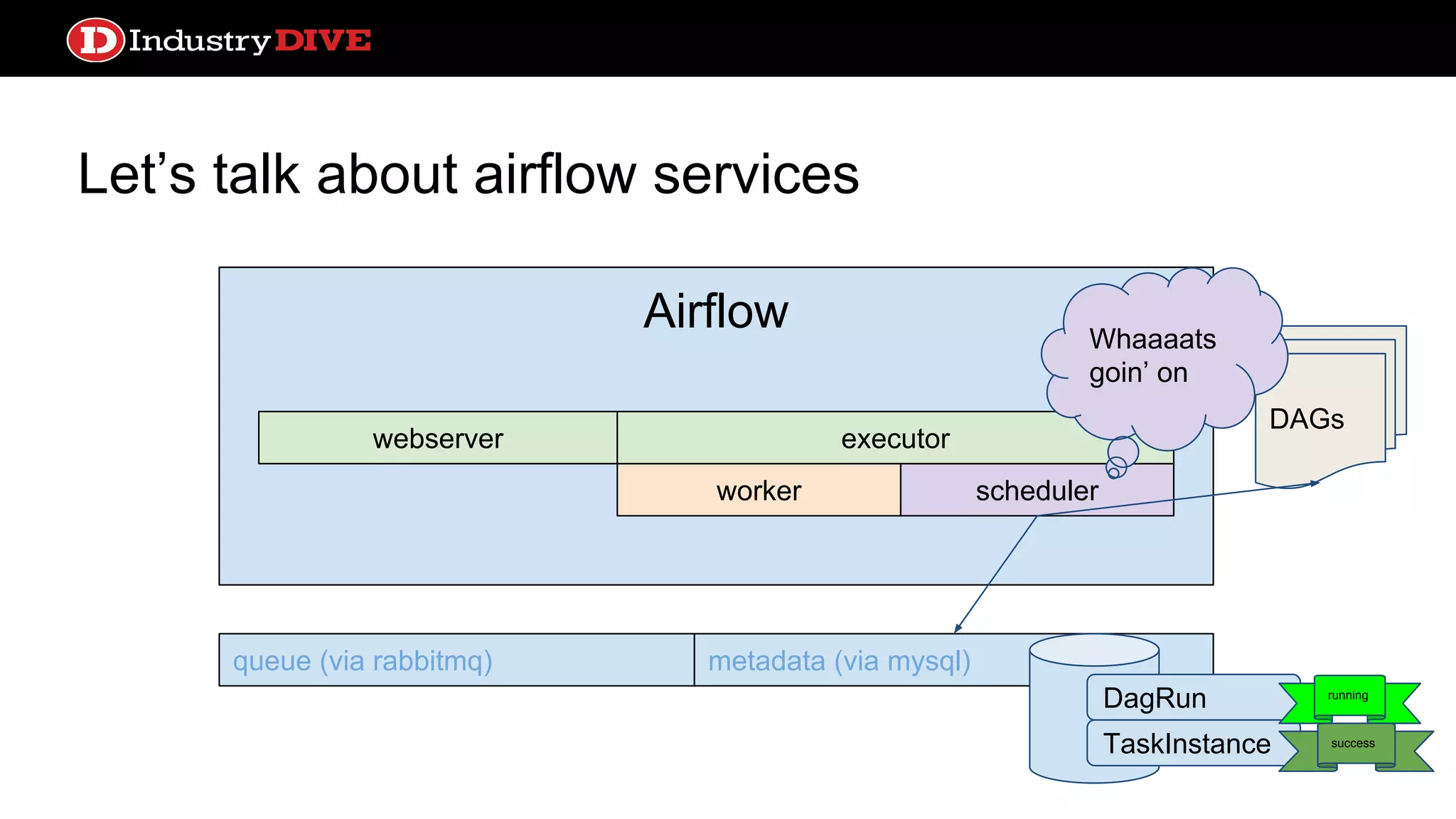
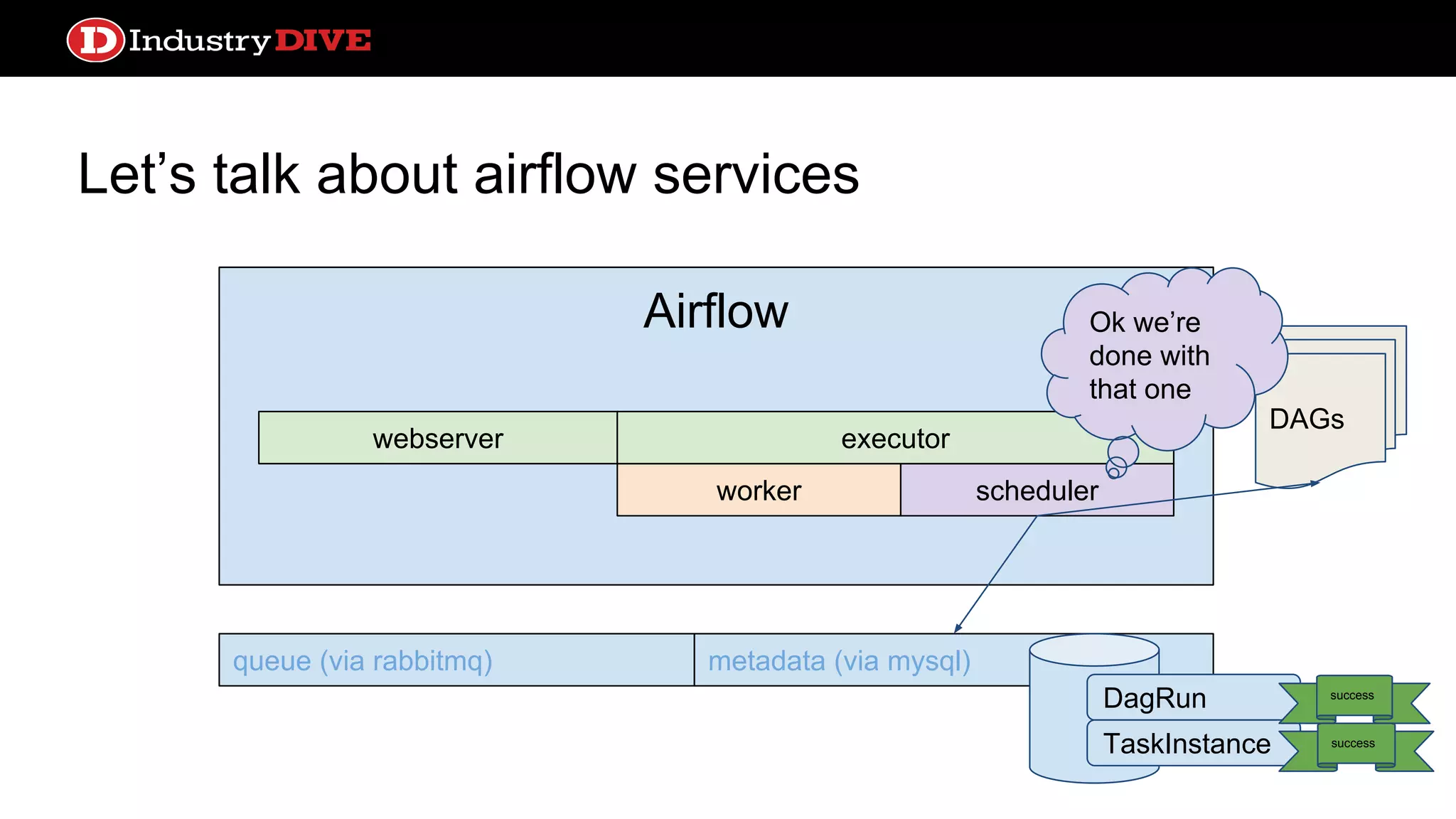
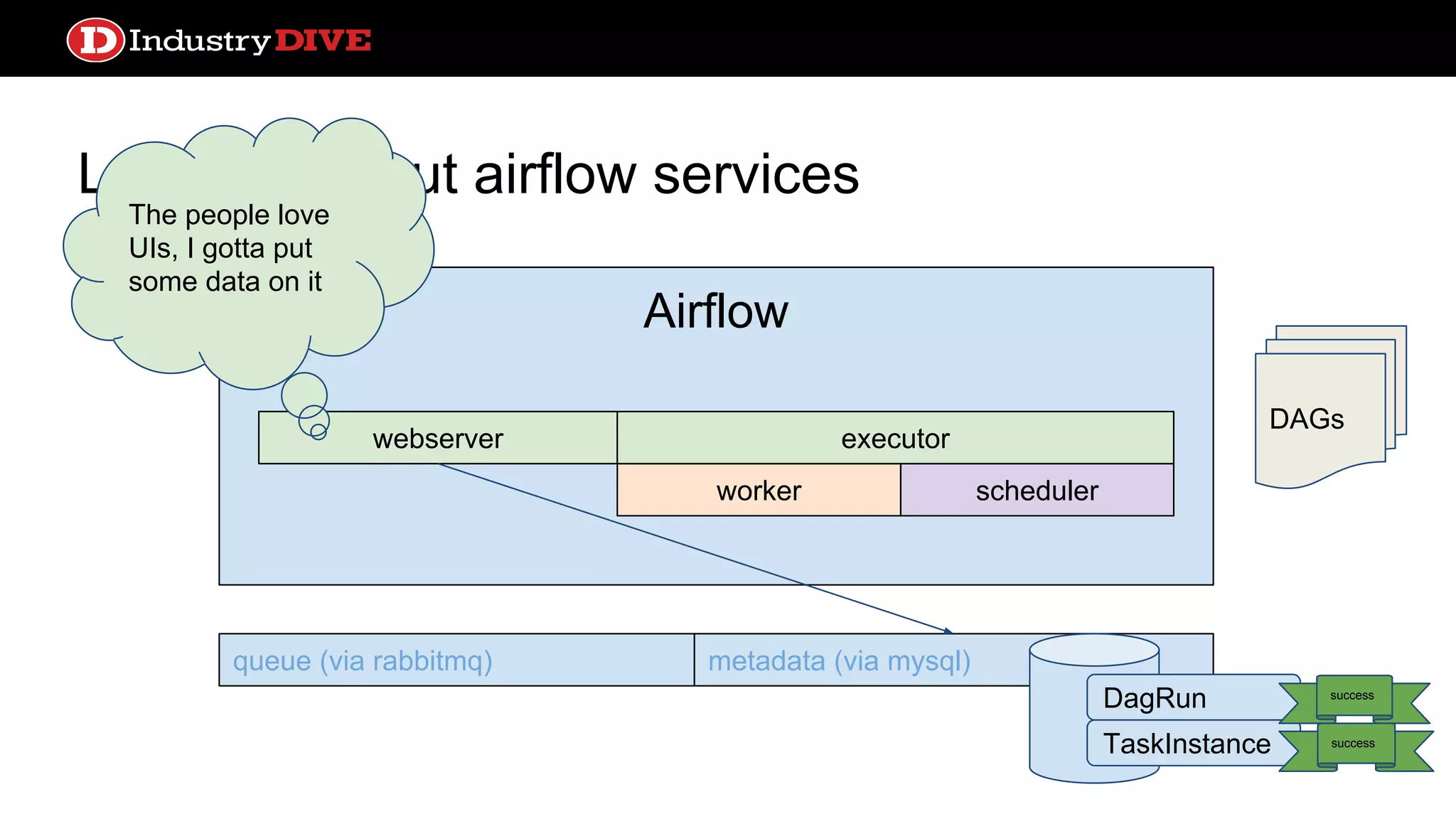
Provides a comprehensive overview of Airflow services across different components like queues, metadata, and execution states.
Discusses the alerting capabilities and extensive configuration options in Airflow including various operators and sensors.Introduces the smart-airflow plugin, which enhances Airflow’s handling of file dependencies and intermediate artifact management.
Steps for setting up Airflow, highlighting quick configurations with Docker and best practices for resource management and task idempotency.
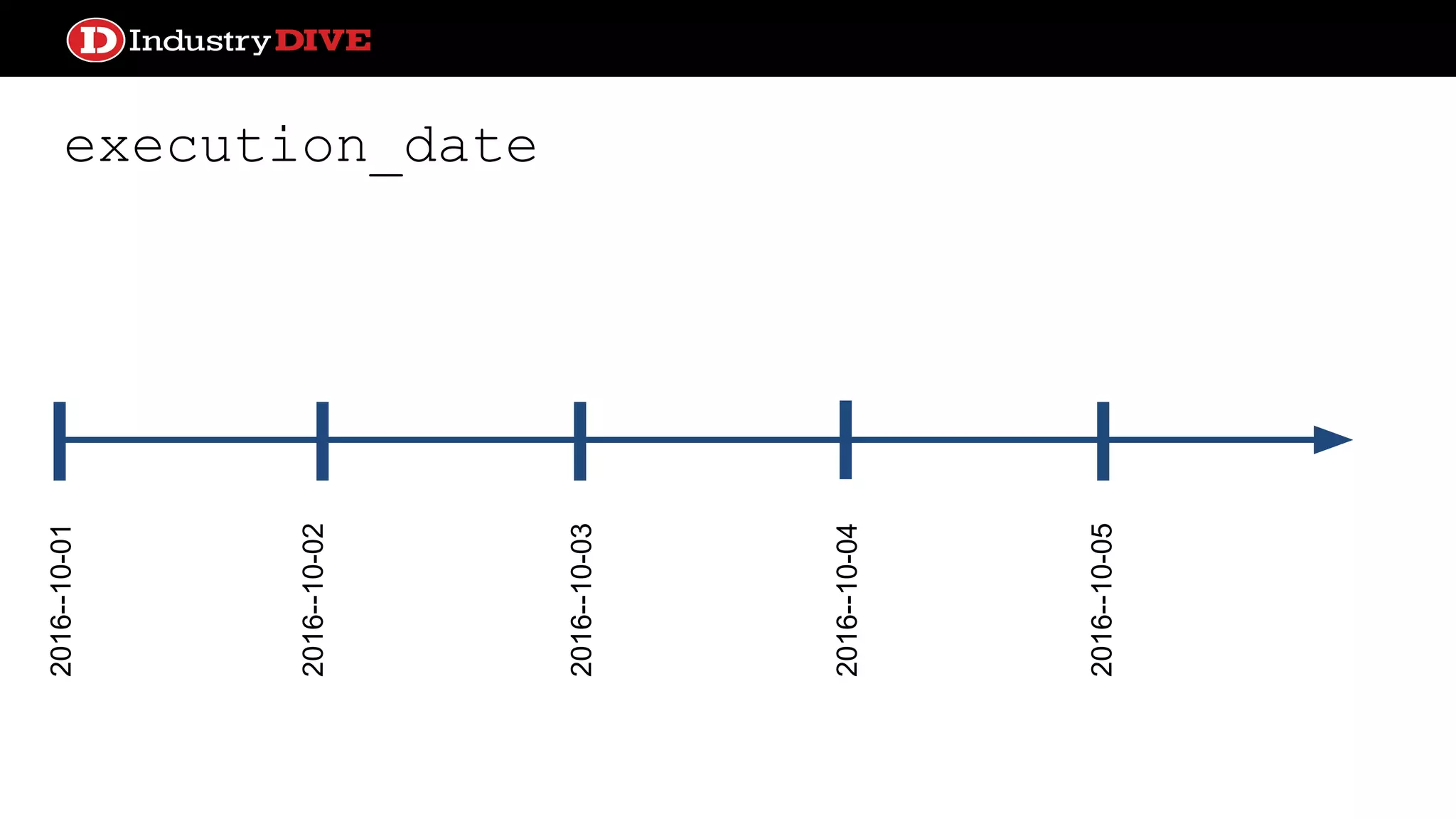
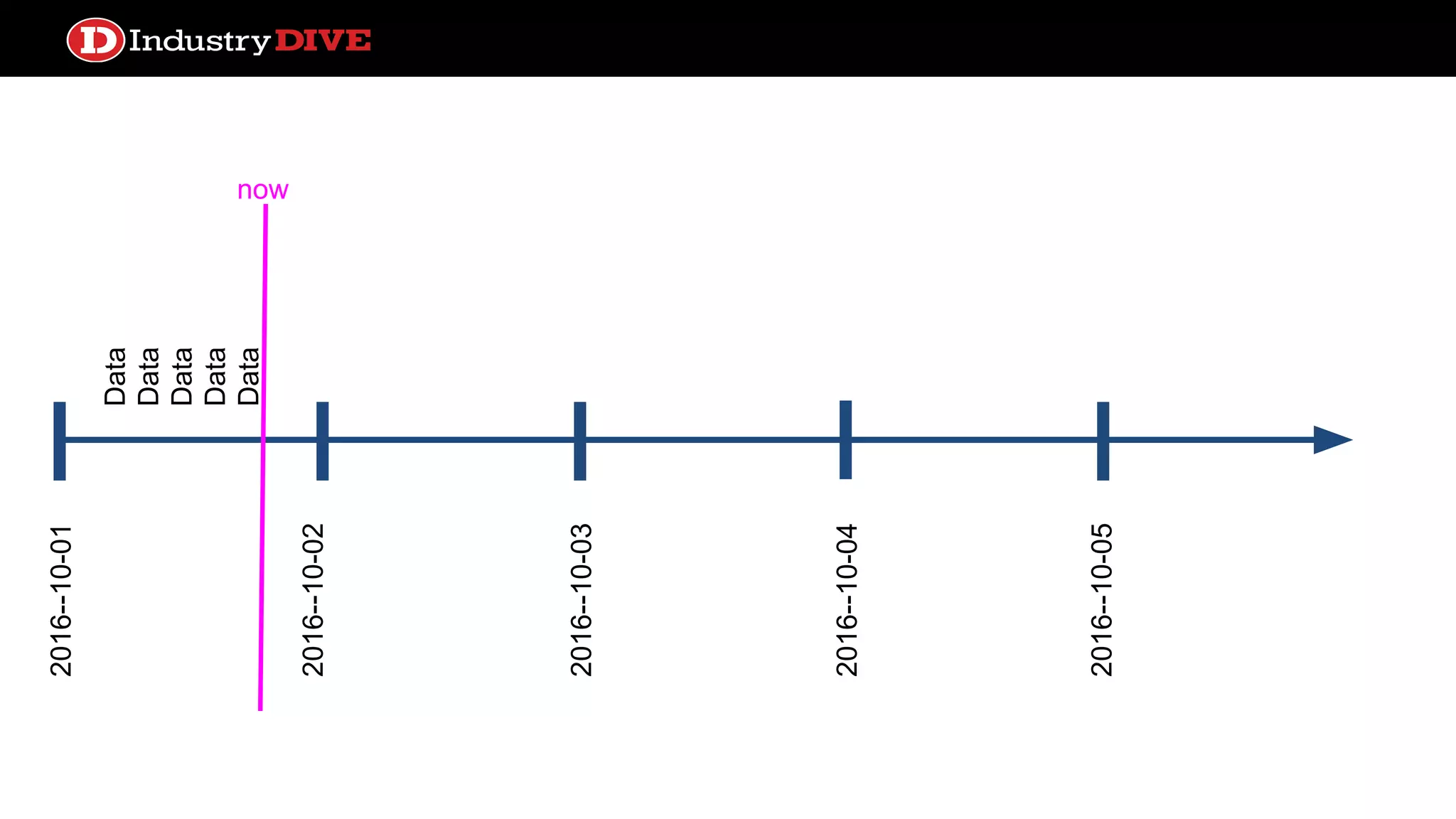
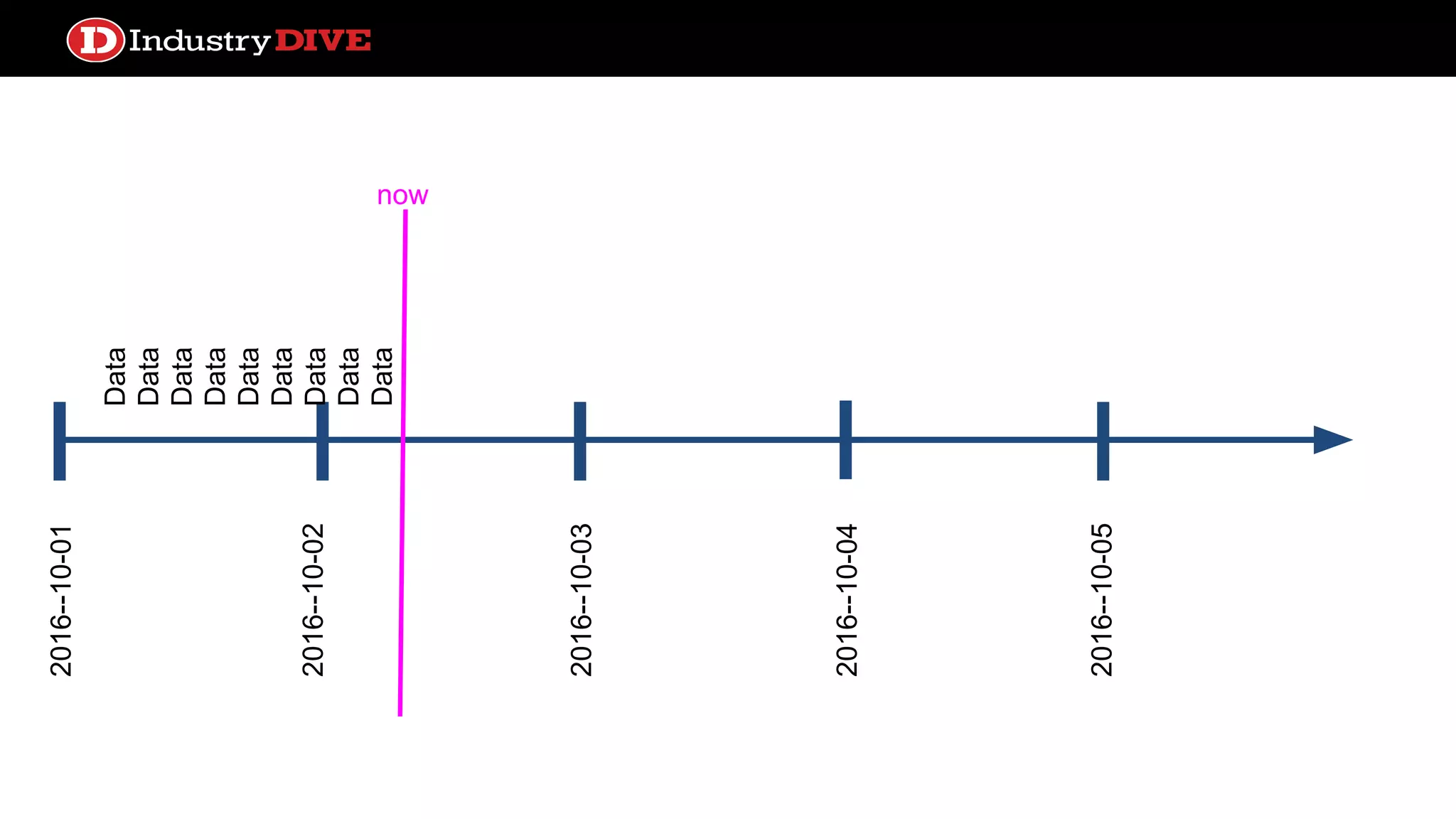
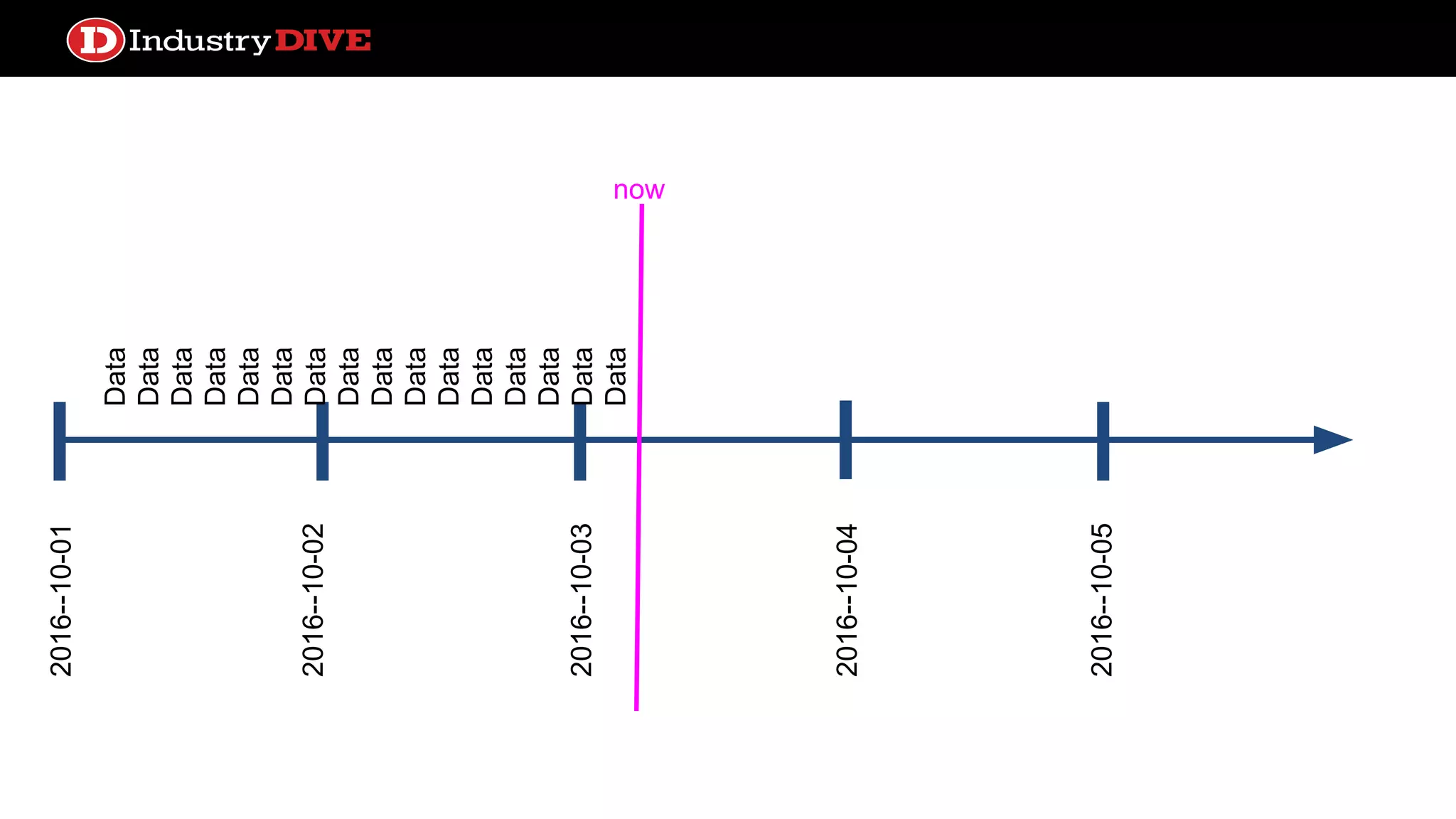
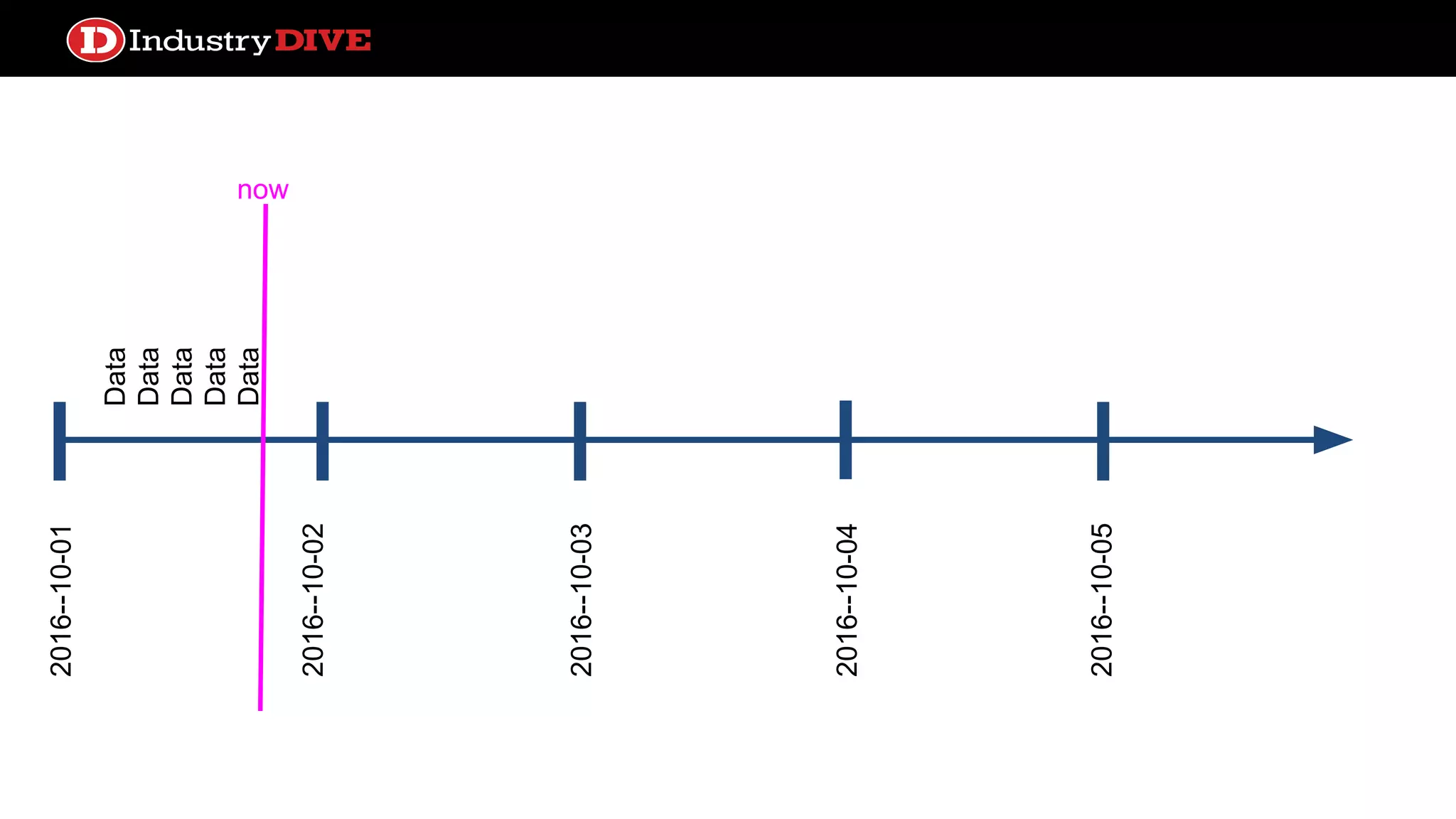
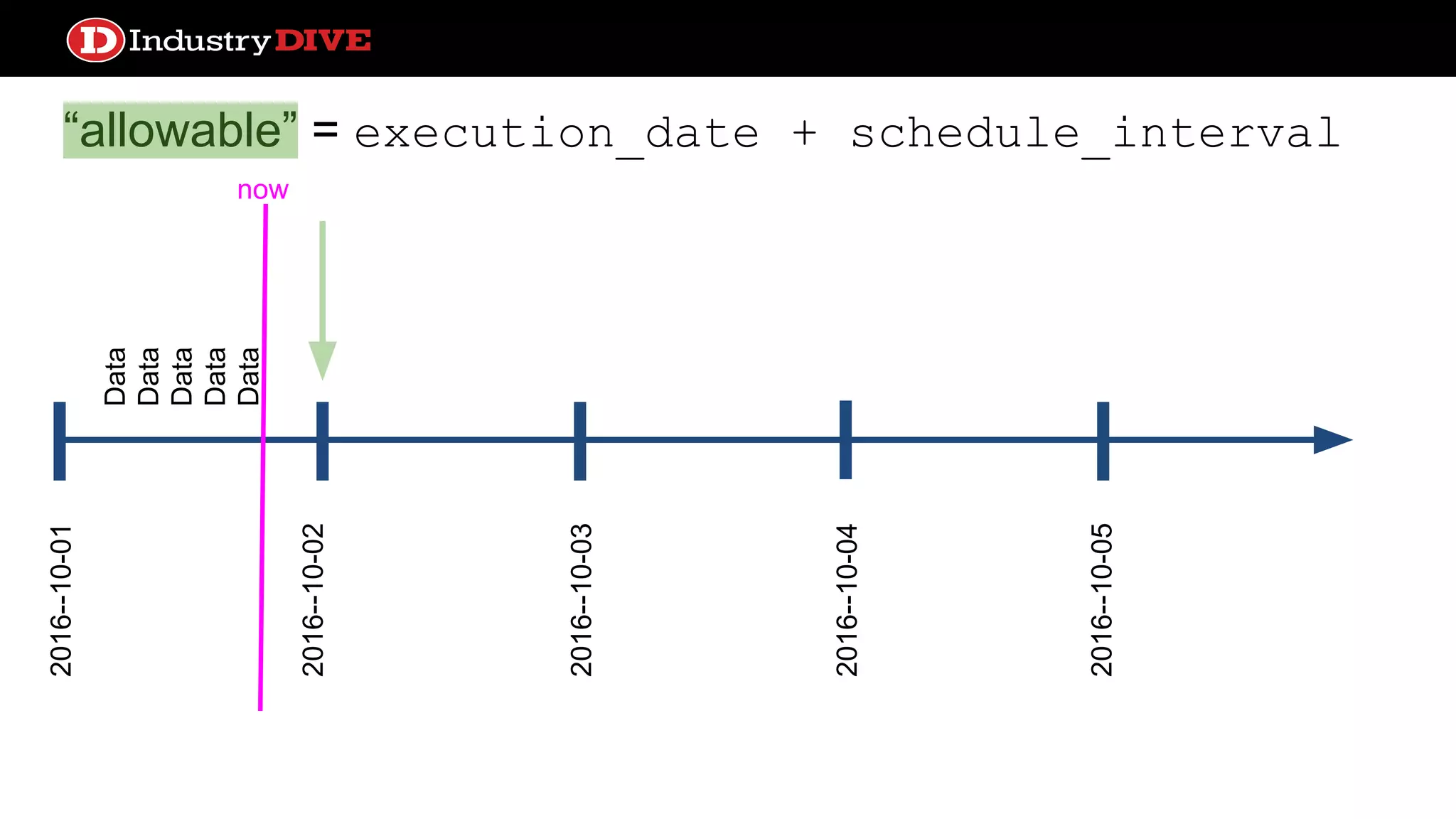
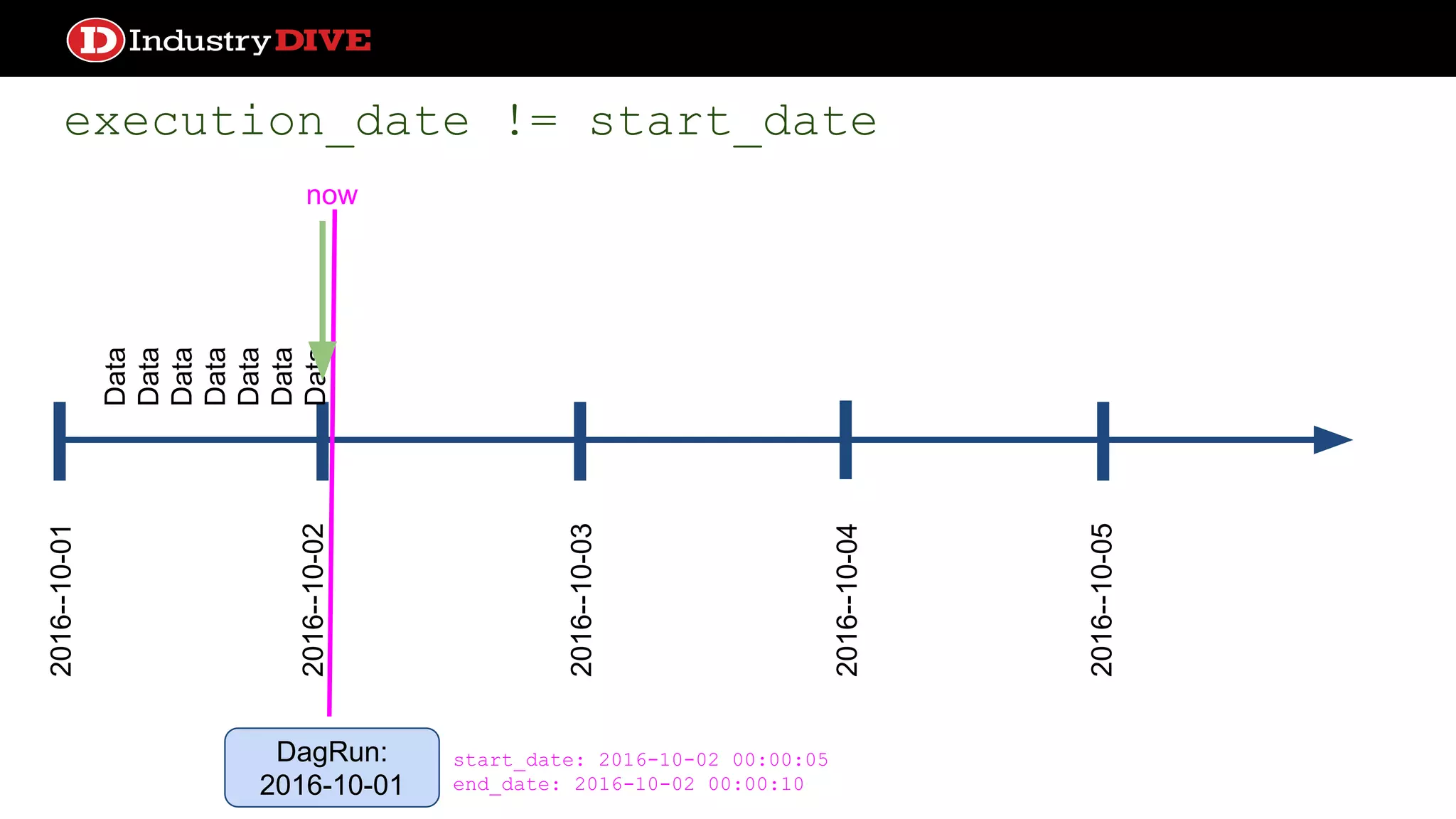
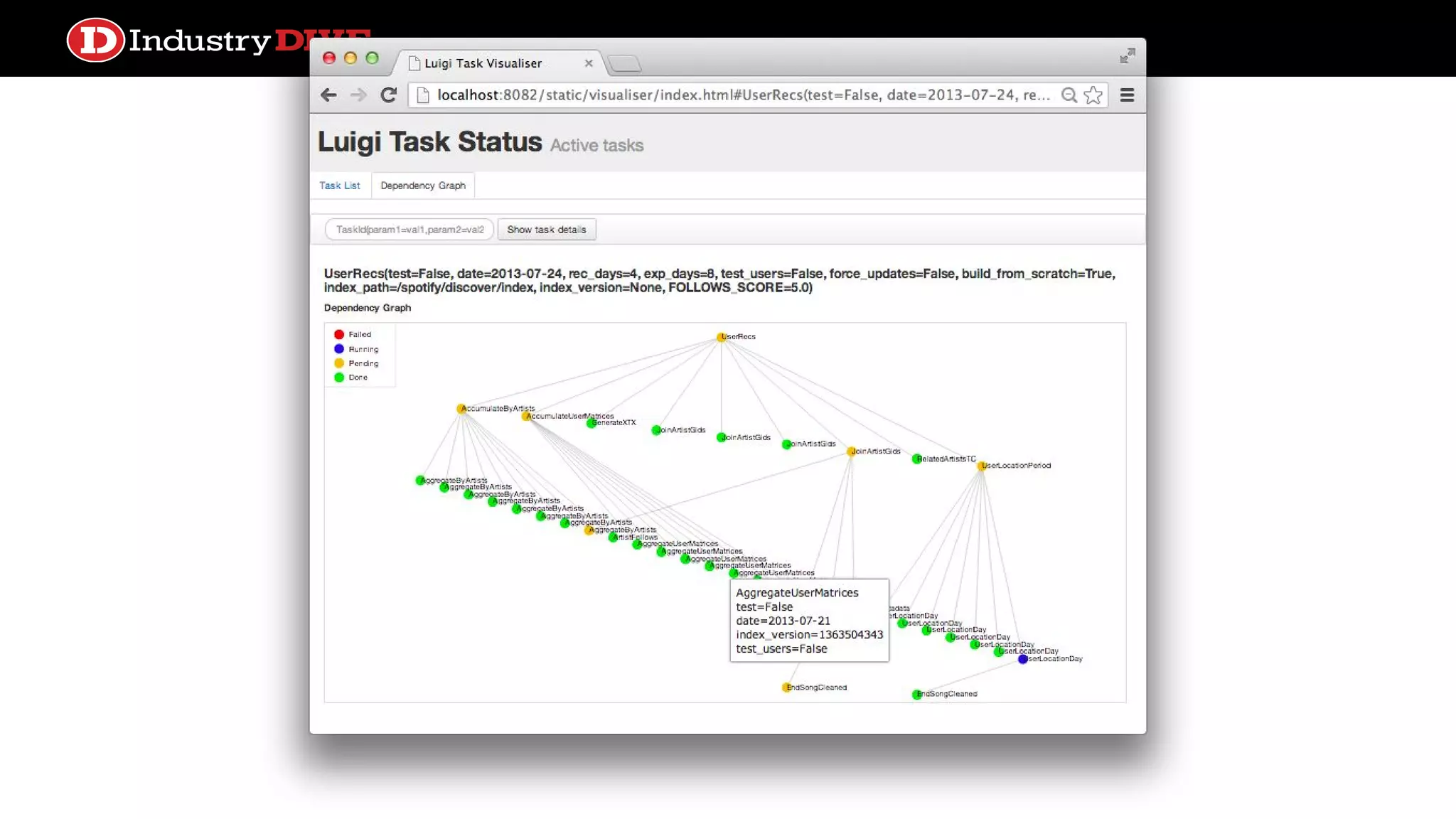
Explains the time travel concept in data pipelines, including execution dates and how they relate to tasks and DAG runs.
Addresses common misunderstandings about the execution date and start date within Airflow and encourages audience inquiries.
Includes complementary information on various pipeline tools, focusing on Make, Drake, and Pydoit, and their functionalities.
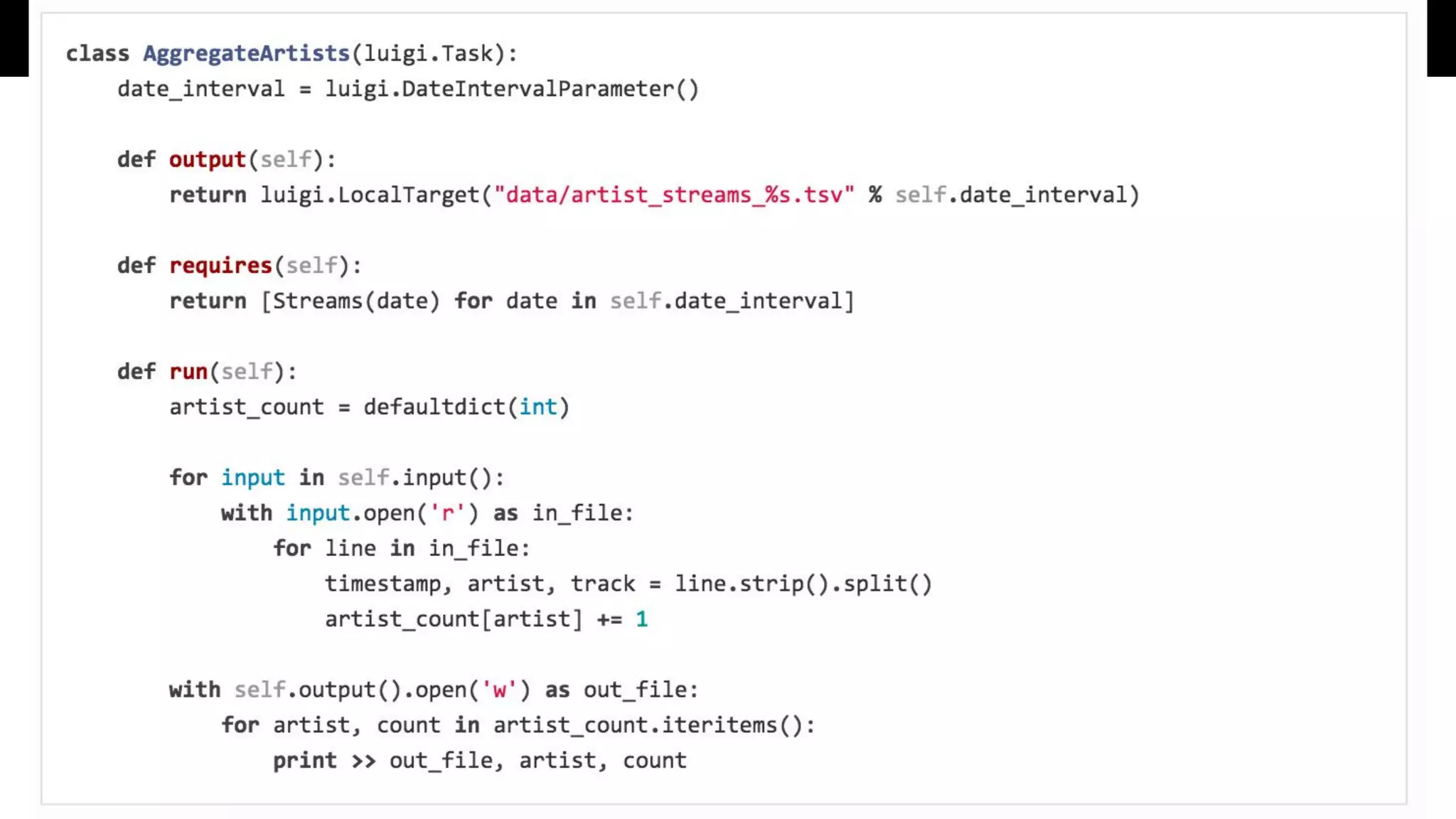
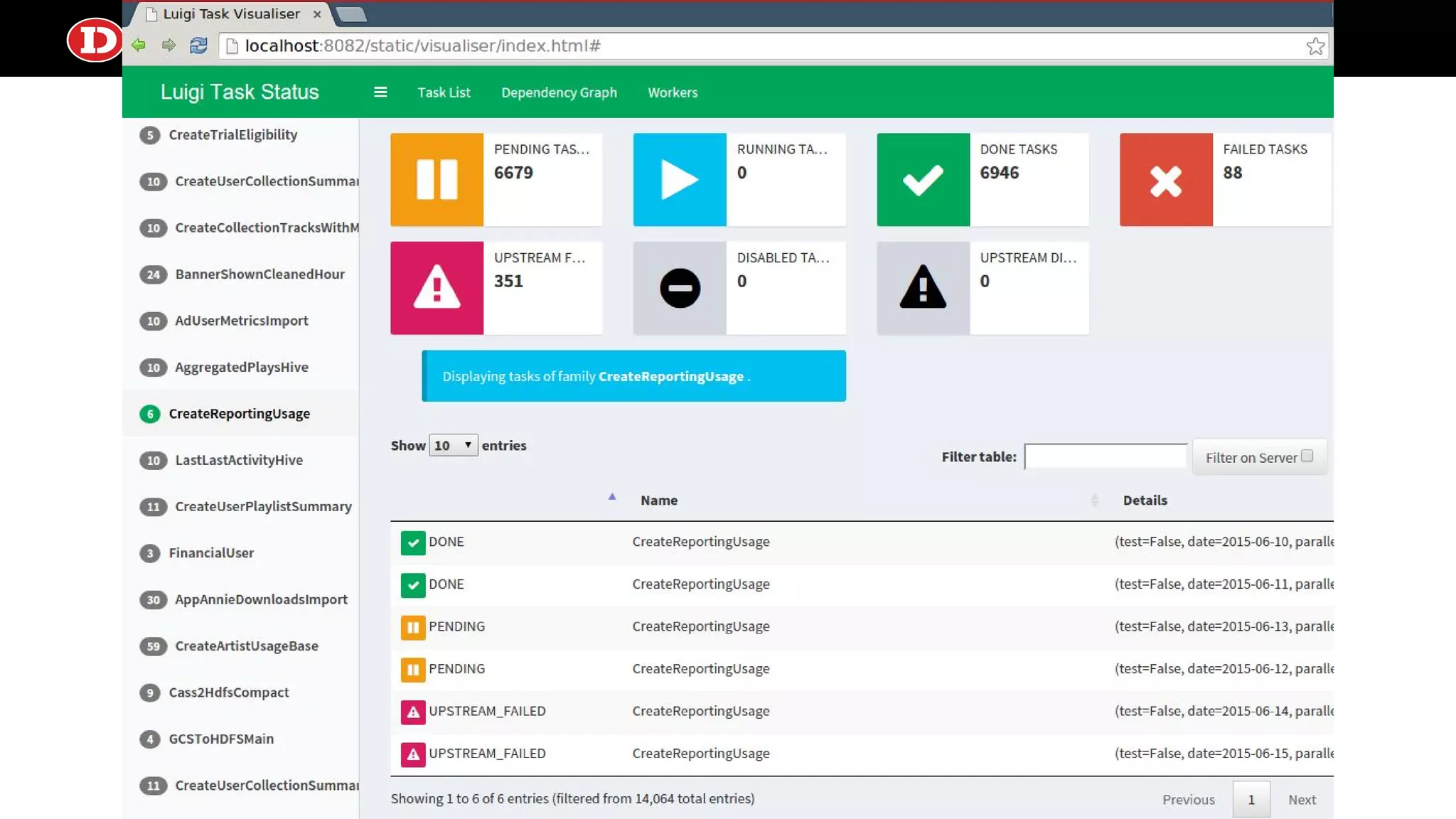
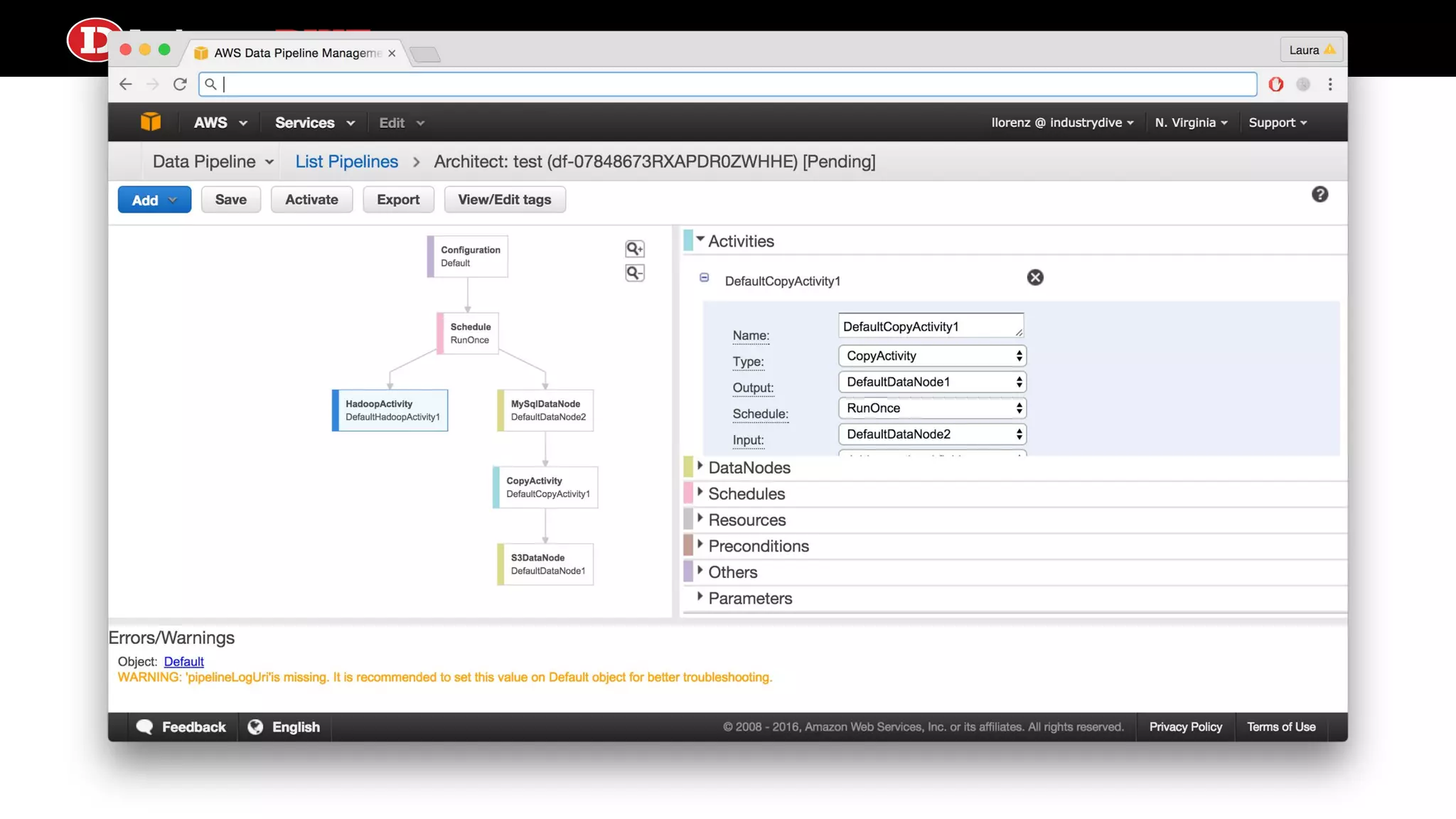
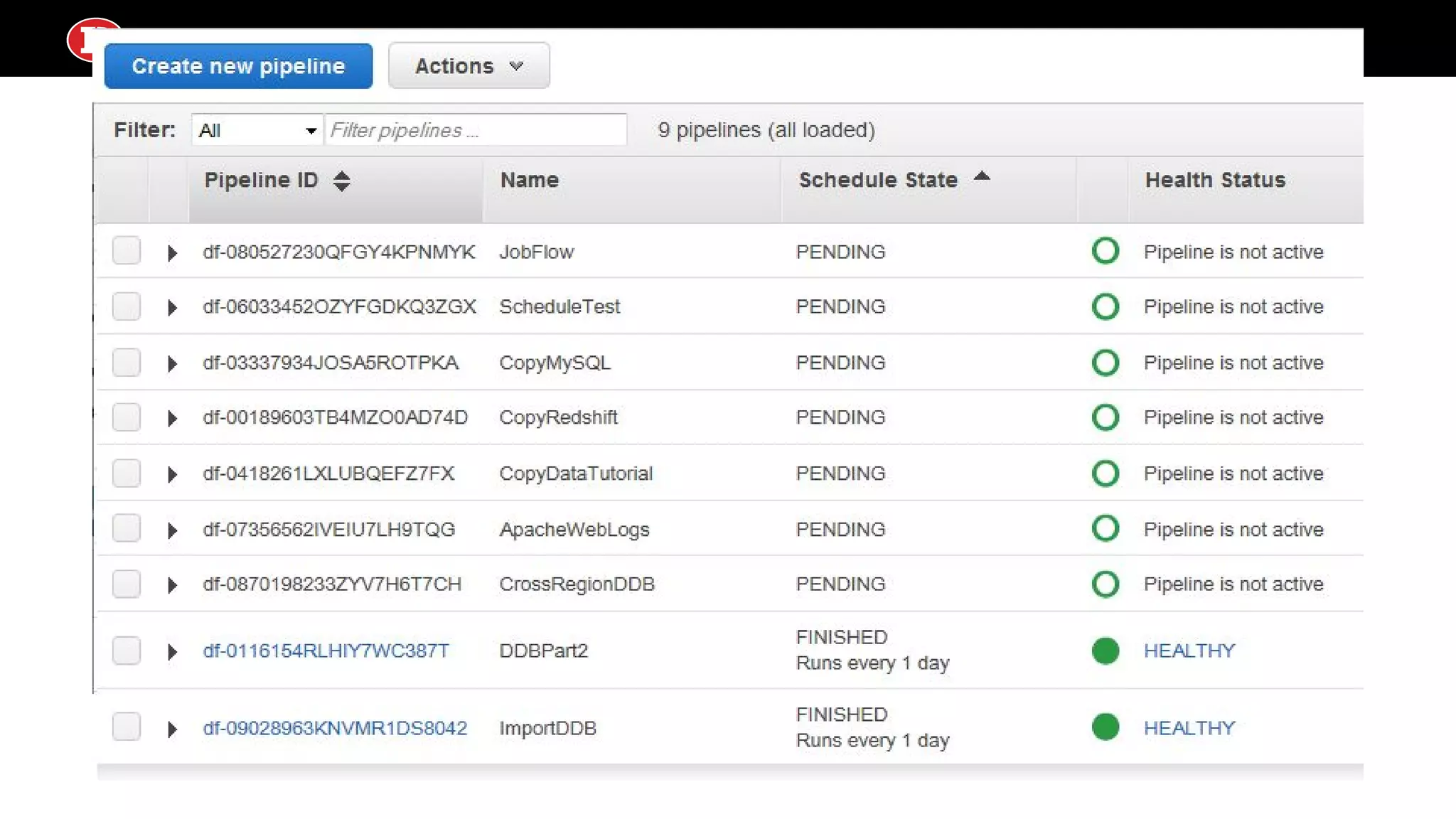
Describes Luigi’s capabilities in batch workflows and AWS Data Pipeline’s cloud-based scheduling, emphasizing job management and dependencies.
“ In thebeginning, there was Cron. We had one job, it ran at 1AM, and it was good. - Pete Owlett, PyData London 2016 from the outline of his talk: “Lessons from 6 months of using Luigi in production”
6.
“ In thebeginning, there was Cron. We had one job, it ran at 1AM, and it was good. - Pete Owlett, PyData London 2016 from the outline of his talk: “Lessons from 6 months of using Luigi in production” ^ 100 ^ depends ^ chaos
We had thoughtsabout how this should go ● Prefer something in open source Python so we know what’s going on and can easily extend or customize ● Resilient ○ Handles failure well; i.e. retry logic, failure callbacks, alerting ● Deals with Complexity Intelligently ○ Can handle complicated dependencies and only runs what it has to ● Flexibility ○ Can run anything we want ● We knew we had batch tasks on daily and hourly schedules
9.
We travelled theland ● File based dependencies ● Dependency framework only ● Lightweight, protocols minimally specified ● Abstract dependencies ● Ships with scheduling & monitoring ● Heavyweight, batteries included DrakeMake Pydoit Pinball Airflow Luigi AWS Data Pipeline Active docs & community
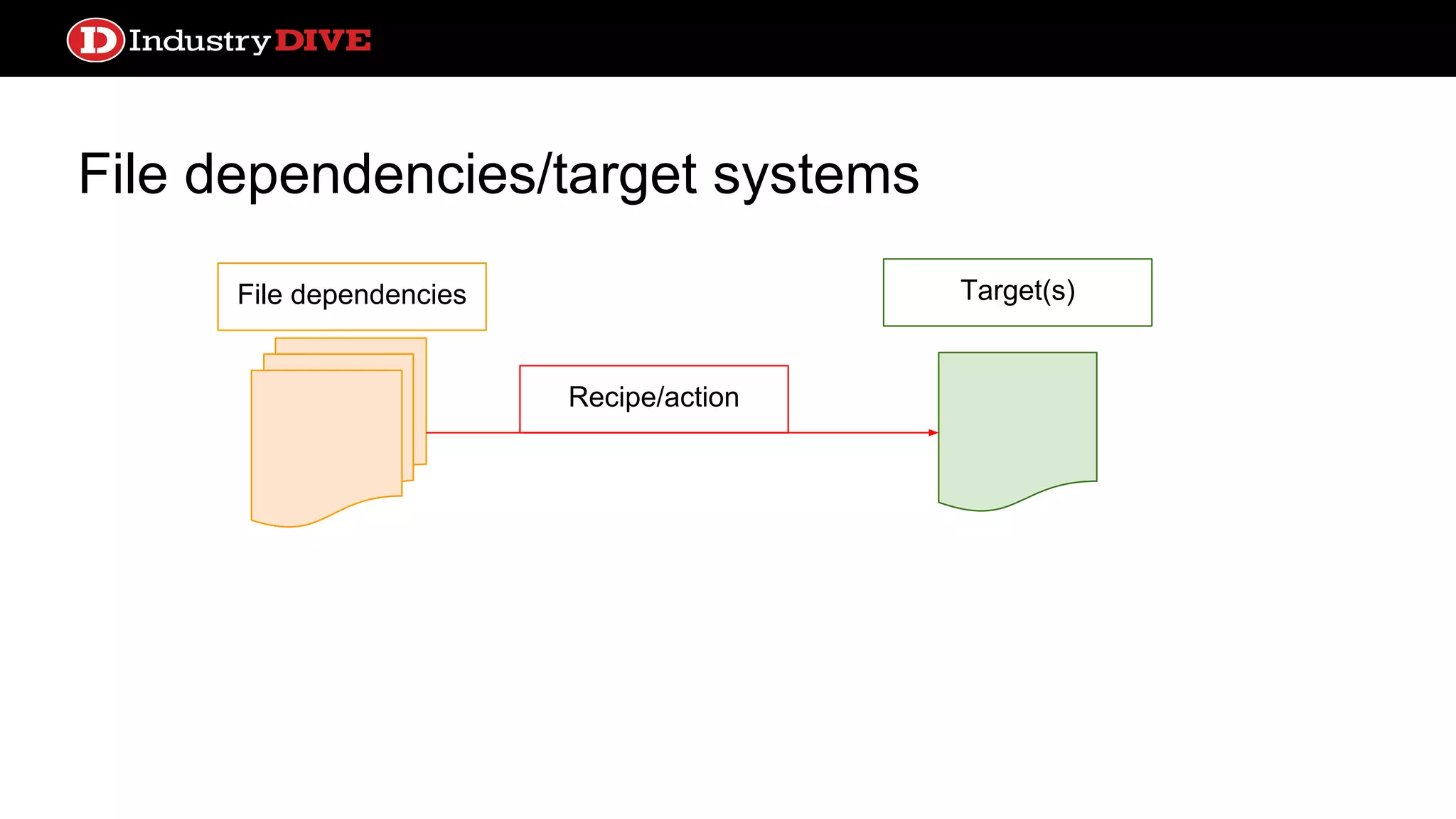
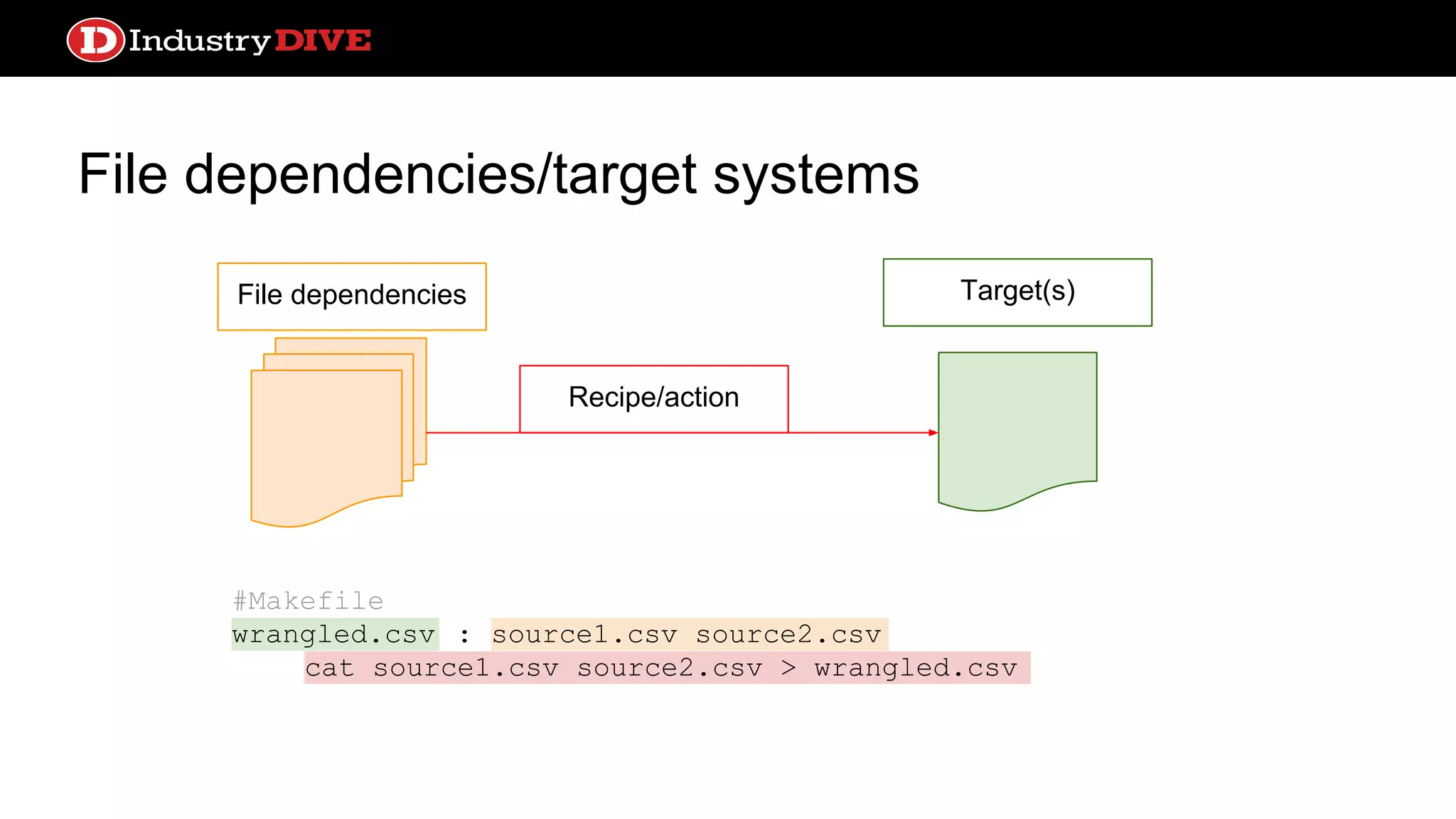
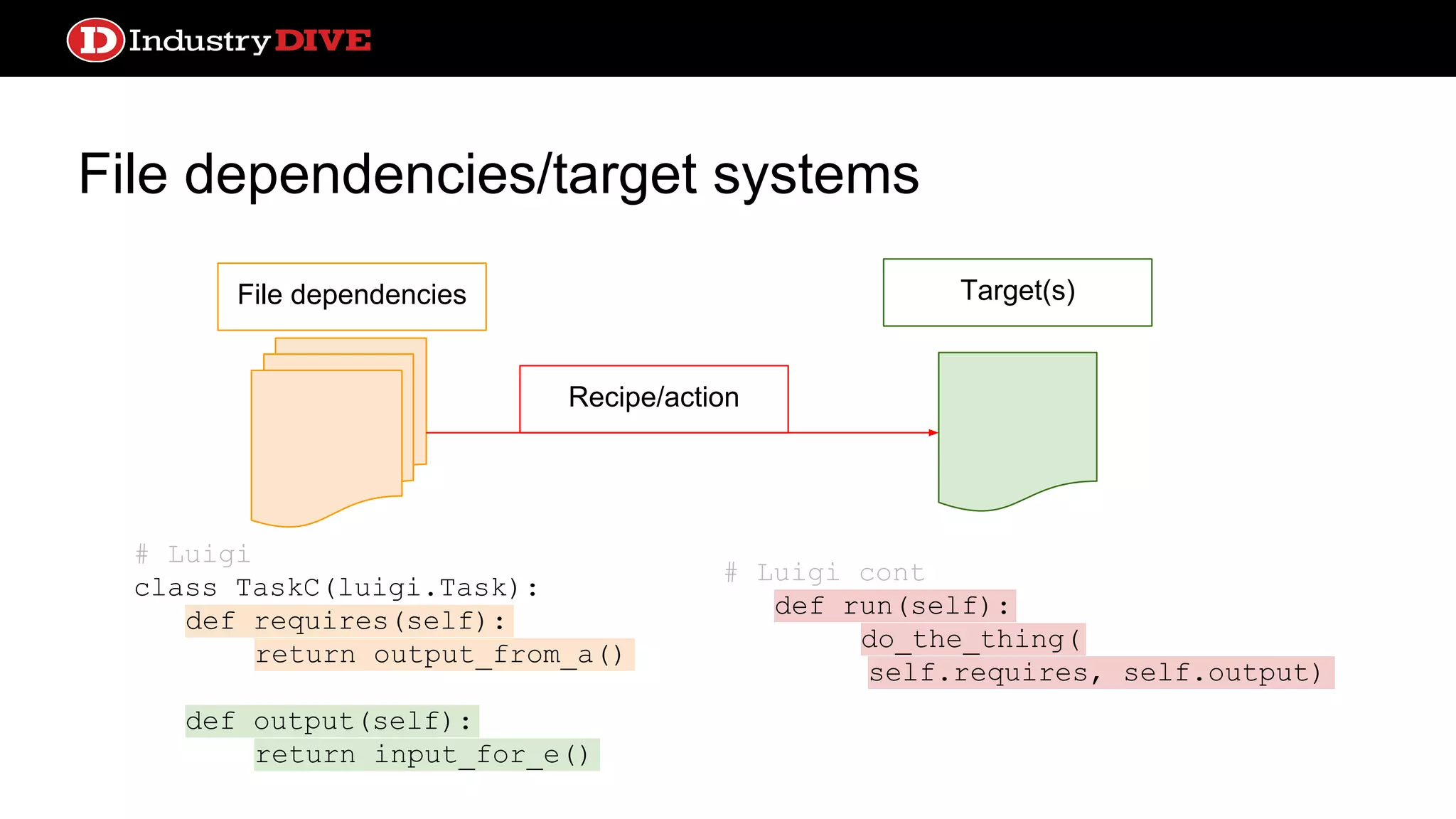
File dependencies/target systems Filedependencies Recipe/action Target(s) # Luigi class TaskC(luigi.Task): def requires(self): return output_from_a() def output(self): return input_for_e() # Luigi cont def run(self): do_the_thing( self.requires, self.output)
15.
File dependencies/target systems ●Work is cached in files ○ Smart rebuilding ● Simple and intuitive configuration especially for data transformations ● No native concept of schedule ○ Luigi is the first to introduce this, but lacks built in polling process ● Alerting systems too basic ● Design paradigm not broadly applicable to non-target operations Pros Cons
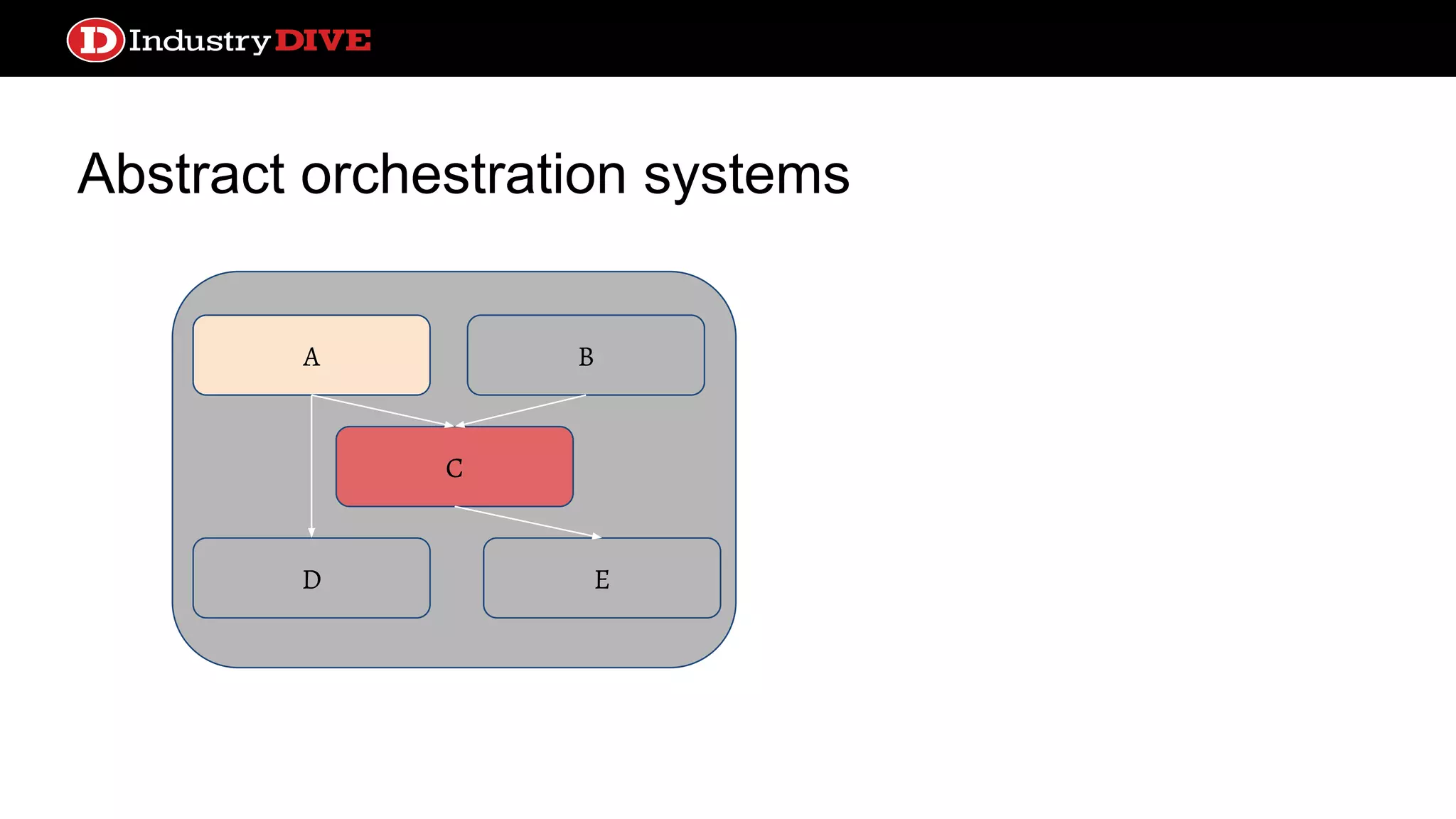
Abstract orchestration systems C AB ED # Pinball WORKFLOW = {“ex”: WorkflowConfig( jobs={ “A”: JobConfig( JobTemplate(A), []), “C”: JobConfig( JobTemplate(C) , [“A”], …, schedule=ScheduleConfig( recurrence=timedelta(days=1), reference_timestamp= datetime( year=2016, day=8, month=10)) …,
18.
Abstract orchestration systems C AB ED # Airflow dag = DAG(schedule_interval= timedelta(days=1), start_date= datetime(2015,10,6)) a = PythonOperator( task_id=”A”, python_callable=ClassA, dag=dag) c = MySQLOperator( task_id=”B”, sql=”DROP TABLE hello”, dag=dag) c.set_upstream(a)
19.
Abstract orchestration systems ●Support many more types of operations out of the box ● Handles more complicated dependency logic ● Scheduling, monitoring, and alerting services built-in and sophisticated ● Caching is per service; loses focus on individual data transformations ● Configuration is more complex ● More infrastructure dependencies ○ Database for state ○ Queue for distribution Pros Cons
20.
Armed with knowledge,we had more opinions ● We like the sophistication of the abstract orchestration systems ● But we also like Drake/Luigi-esque file targeting for transparency and data bug tracking ○ “Intermediate artifacts” ● We (I/devops) don’t want to maintain a separate scheduling service ● We like a strong community and good docs ● We don’t want to be stuck in one ecosystem
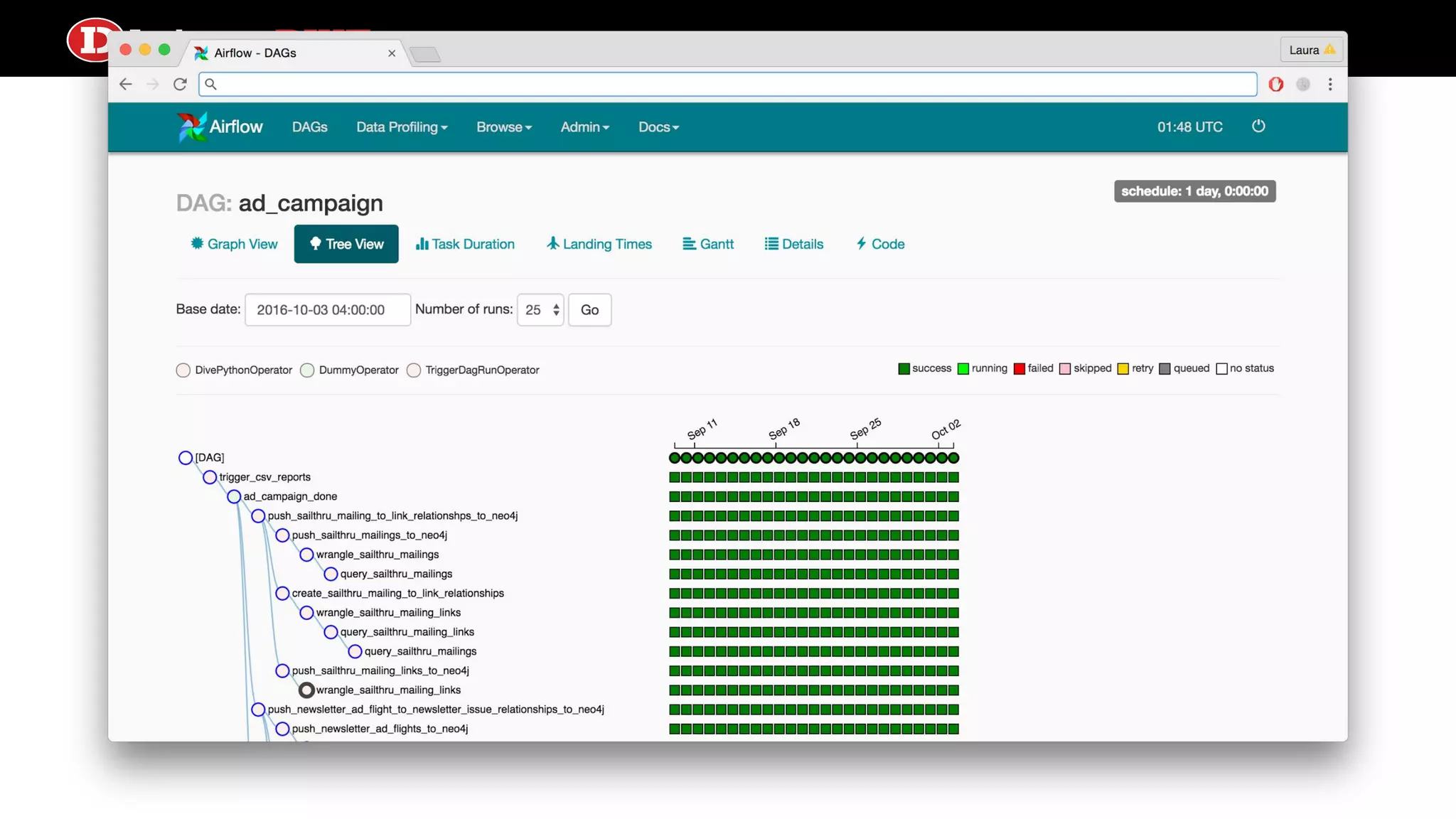
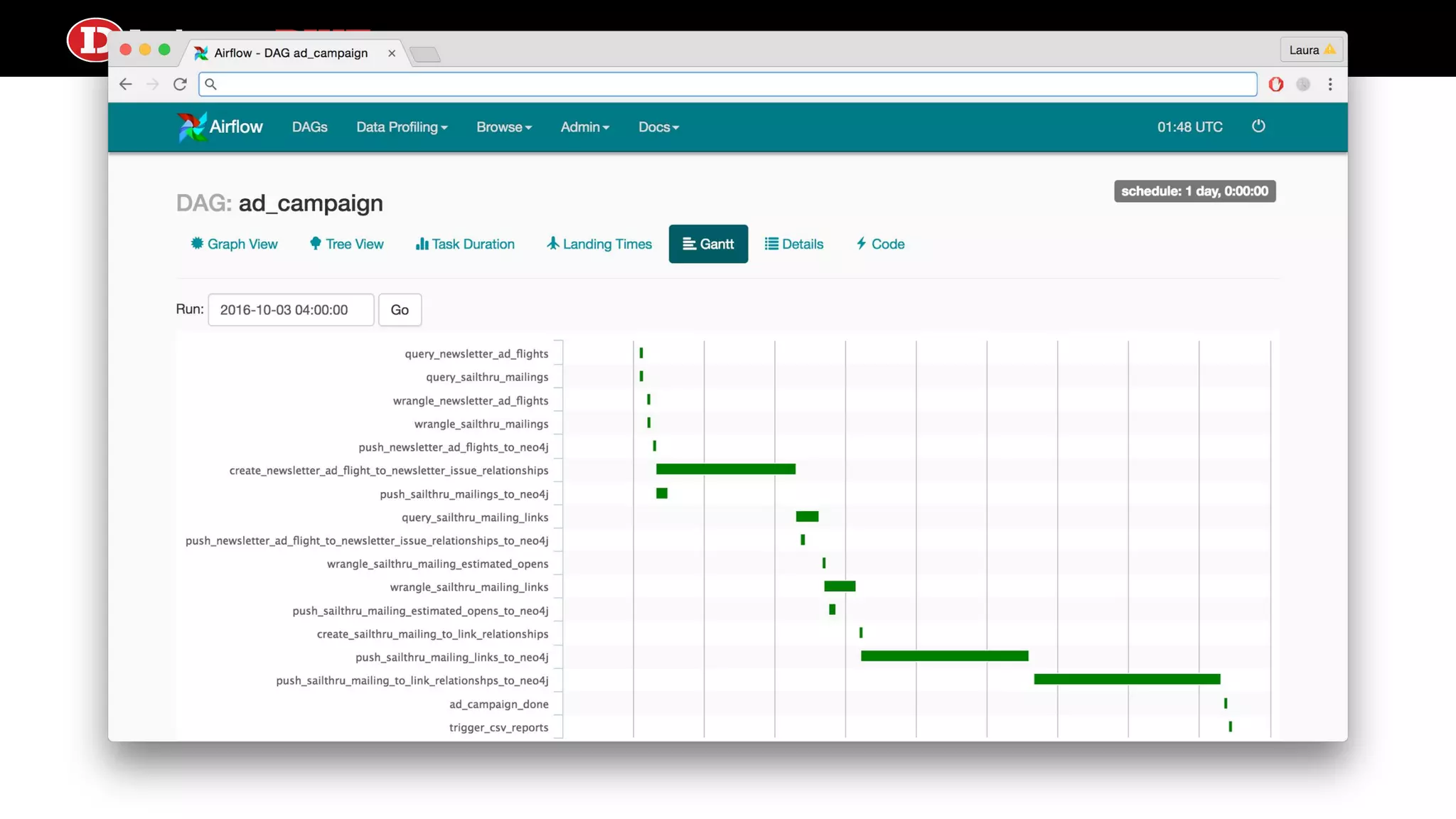
Airflow ● Scheduler processhandles triggering and executing work specified in DAGs on a given schedule ● Built in alerting based on service license agreements or task state ● Lots of sexy profiling visualizations ● test, backfill, clear operations convenient from the CLI ● Operators can come from a number of prebuilt classes like PythonOperator, S3KeySensor, or BaseTransfer, or can obviously extend using inheritance ● Can support local or distributed work execution; distributed needs a celery backend service (RabbitMQ, Redis)
Let’s talk aboutairflow services webserver queue (via rabbitmq) metadata (via mysql) DAGs Airflow worker webserver scheduler executor What to do what to do
33.
Let’s talk aboutairflow services webserver queue (via rabbitmq) metadata (via mysql) DAGs Airflow worker webserver scheduler executor Hey do the thing!!! Do the thing queued
34.
Let’s talk aboutairflow services webserver queue (via rabbitmq) metadata (via mysql) DAGs Airflow worker webserver scheduler executor Okok I told rabbit Do the thing queued DagRun TaskInstance running queued
35.
Let’s talk aboutairflow services webserver queue (via rabbitmq) metadata (via mysql) DAGs Airflow worker webserver scheduler executor Do the thing queued What to do what to do DagRun TaskInstance running queued
36.
Let’s talk aboutairflow services webserver queue (via rabbitmq) metadata (via mysql) DAGs Airflow worker webserver scheduler executor Do the thing Oo thing! I’M ON IT running DagRun TaskInstance running running
Let’s talk aboutairflow services webserver queue (via rabbitmq) metadata (via mysql) DAGs Airflow worker webserver scheduler executor DagRun TaskInstance success success Ok we’re done with that one
42.
Let’s talk aboutairflow services webserver queue (via rabbitmq) metadata (via mysql) DAGs Airflow worker webserver scheduler executor The people love UIs, I gotta put some data on it DagRun TaskInstance success success
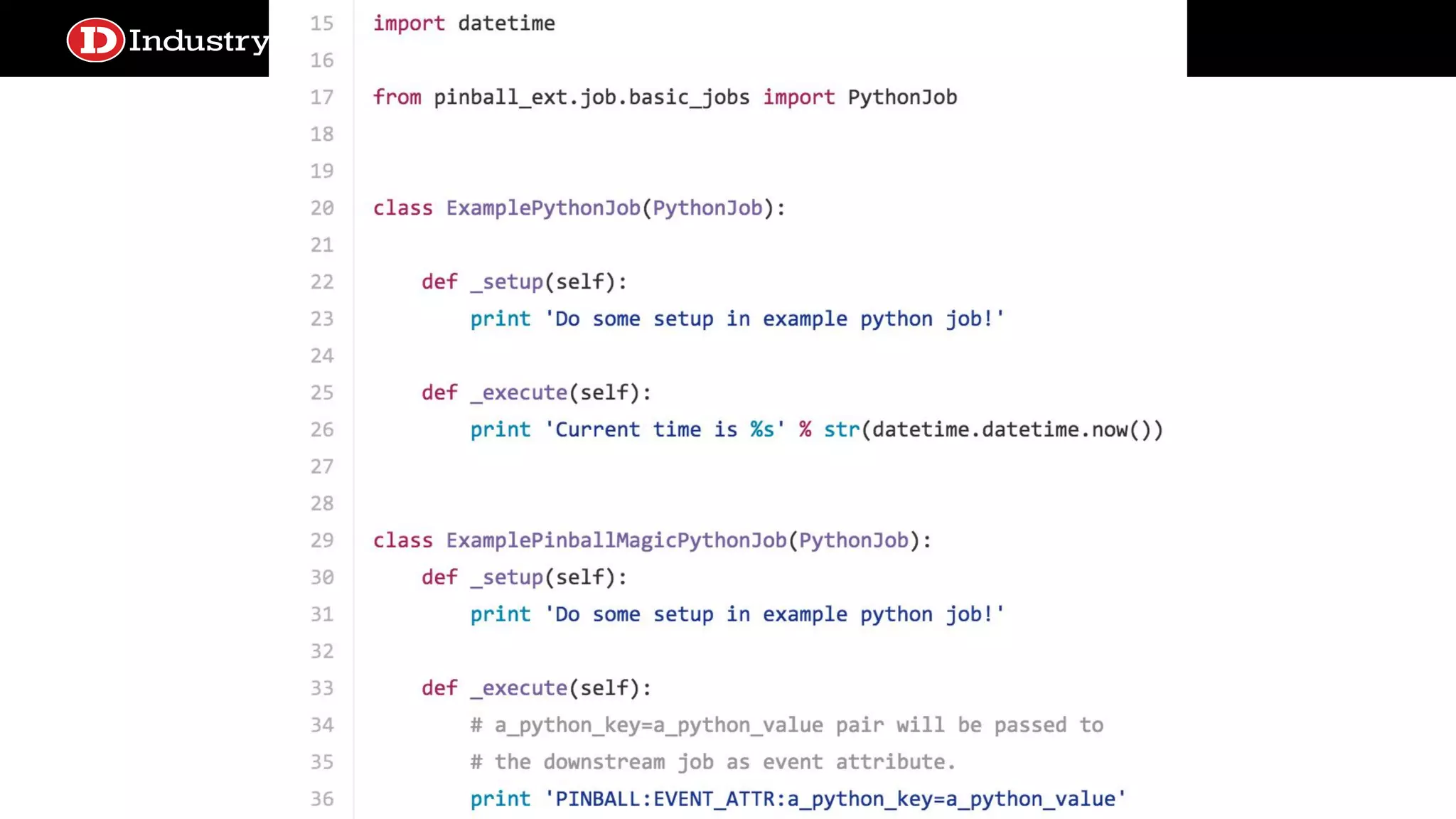
Flexibility ● Operators ○ PythonOperator,BashOperator ○ TriggerDagRunOperator, BranchOperator ○ EmailOperator, MySqlOperator, S3ToHiveTransfer ● Sensors ○ ExternalTaskSensor ○ HttpSensor, S3KeySensor ● Extending your own operators and sensors ○ smart_airflow.DivePythonOperator
46.
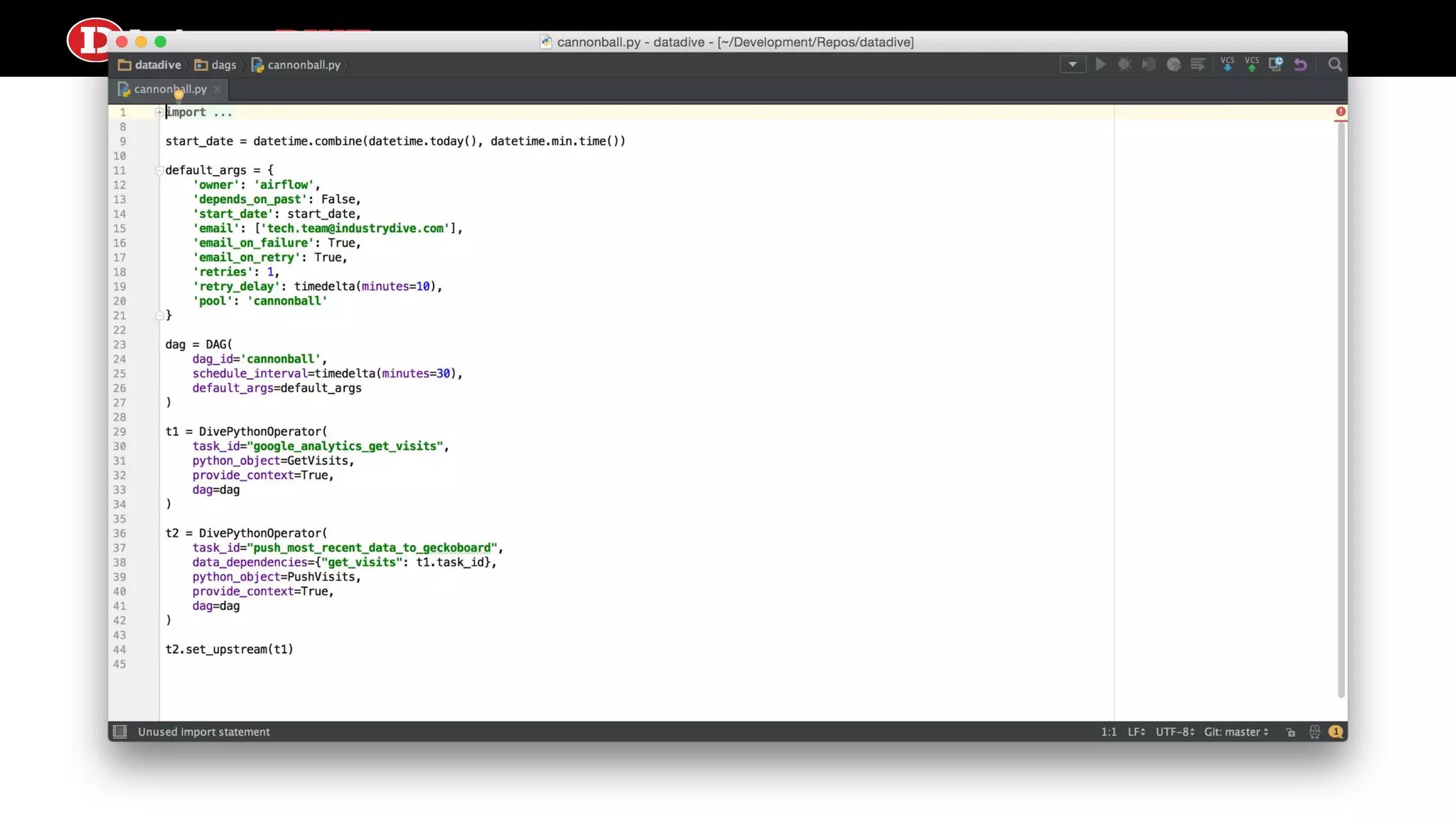
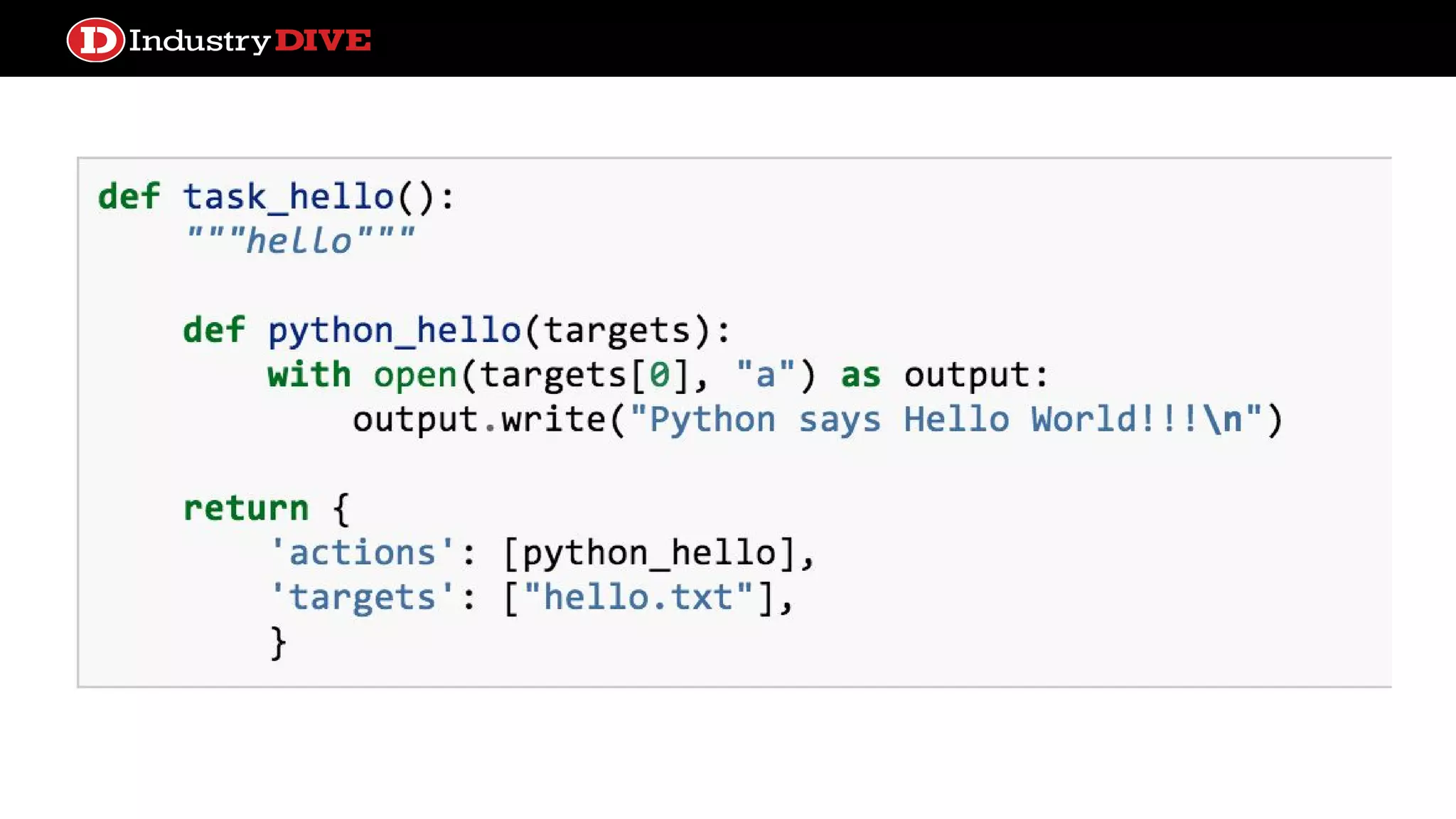
smart-airflow ● Airflow doesn’tsupport much data transfer between tasks out of the box ○ only small pieces of data via XCom ● But we liked the file dependency/target concept of checkpoints to cache data transformations to both save time and provide transparency ● smart-airflow is a plugin to Airflow that supports local file system or S3-backed intermediate artifact storage ● It leverages Airflow concepts to make file location predictable ○ dag_id/task_id/execution_date
48.
Our smart-airflow backedETL paradigm 1. Make each task as small as possible while maintaining readability 2. Preserve output for each task as a file-based intermediate artifact in a format that is consumable by its dependent task 3. Avoid finalizing artifacts for as long as possible (e.g. update a database table as the last and simplest step in a DAG)
50.
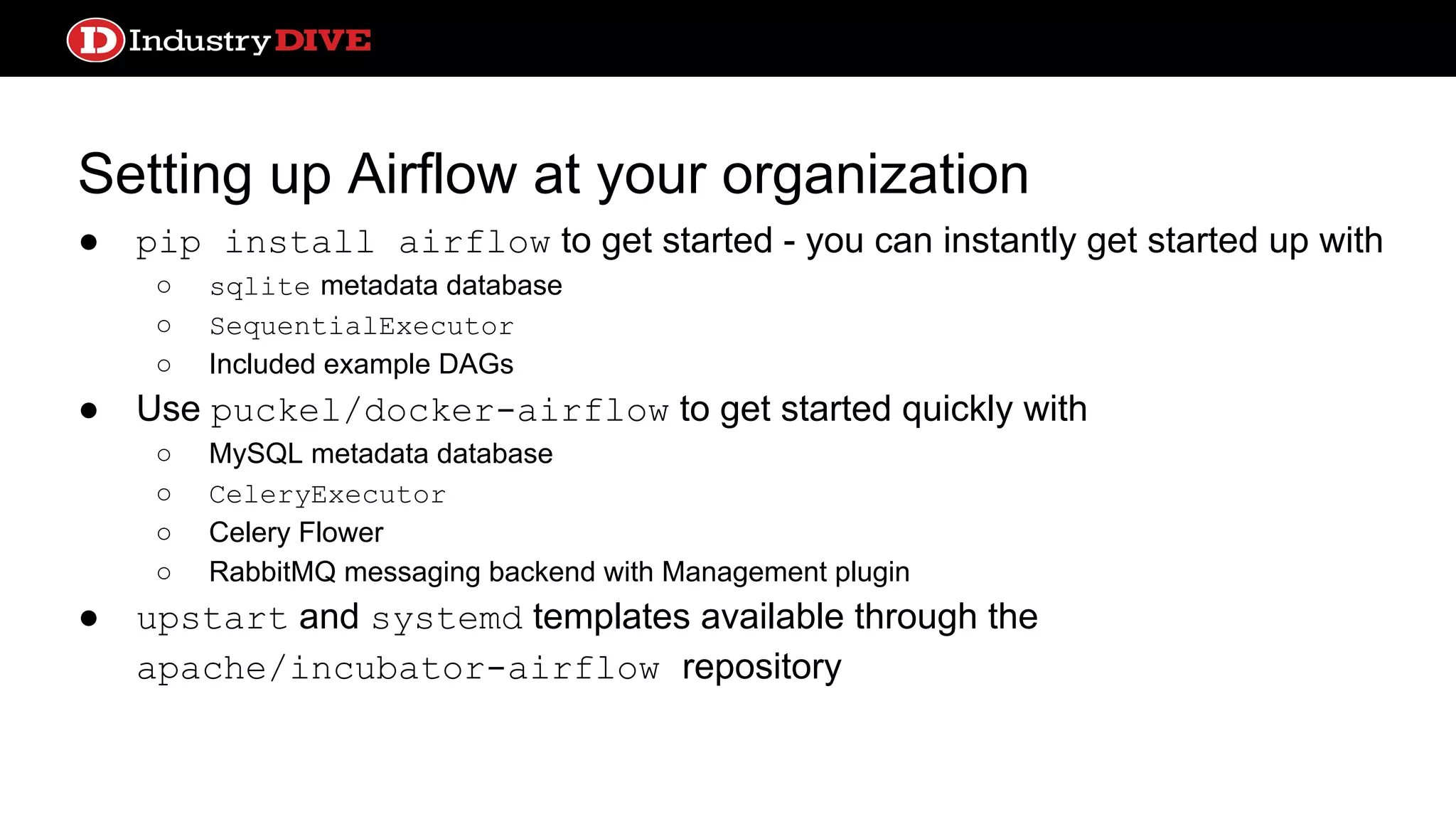
Setting up Airflowat your organization ● pip install airflow to get started - you can instantly get started up with ○ sqlite metadata database ○ SequentialExecutor ○ Included example DAGs ● Use puckel/docker-airflow to get started quickly with ○ MySQL metadata database ○ CeleryExecutor ○ Celery Flower ○ RabbitMQ messaging backend with Management plugin ● upstart and systemd templates available through the apache/incubator-airflow repository
51.
Tips, tricks, andgotchas for Airflow ● Minimize your dev environment with SequentialExecutor and use airflow test {dag_id} {task_id} {execution_date} in early development to test tasks ● To test your DAG with the scheduler, utilize the @once schedule_interval and clear the DagRuns and TaskInstances between tests with airflow clear or the fancy schmancy UI ● Don’t bother with the nascent plugin system, just package your custom operators with your DAGs for deployment ● No built in log rotation - default logging is pretty verbose and if you add your own, this might get surprisingly large. As of Airflow 1.7 you can back them up to S3 with simple configuration
52.
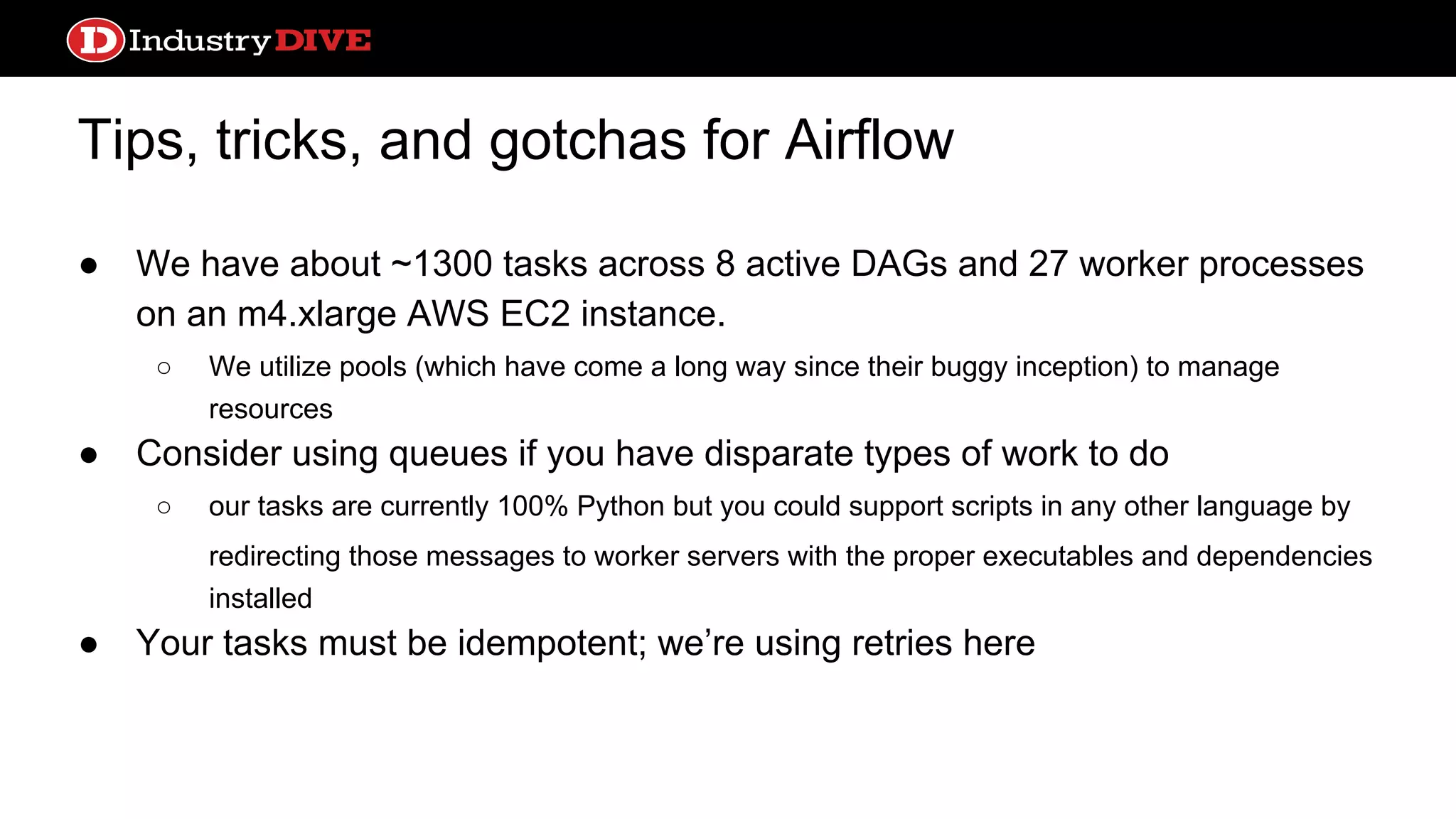
Tips, tricks, andgotchas for Airflow ● We have about ~1300 tasks across 8 active DAGs and 27 worker processes on an m4.xlarge AWS EC2 instance. ○ We utilize pools (which have come a long way since their buggy inception) to manage resources ● Consider using queues if you have disparate types of work to do ○ our tasks are currently 100% Python but you could support scripts in any other language by redirecting those messages to worker servers with the proper executables and dependencies installed ● Your tasks must be idempotent; we’re using retries here
Appendix More details onthe pipeline tools not covered in depth from an earlier draft of this talk
69.
Make ● Originally/often usedto compile source code ● Defines ○ targets and any prerequisites, which are potential file paths ○ recipes that can be executed by your shell environment ● Specify batch workflows in stages with file storage as atomic intermediates (local FS only). ● Rebuilding logic based on target existence and other file dependencies (“prerequisites”) existence/metadata. ● Supports basic conditionals and parallelism
Drake ● “Make fordata” ● Specify batch workflows in stages with file storage as atomic intermediates (backend support for local FS, S3, HDFS, Hive) ● Early support for alternate branches and branch merging ● Smart rebuilding against targets and target metadata, or a quite sophisticated command line specification system ● Parallel execution ● Workflow graph generation ● Expanding protocols support to facilitate common tasks like python, HTTP GET, etc
Pydoit ● “doit comesfrom the idea of bringing the power of build-tools to execute any kind of task” ● flexible build tool used to glue together pipelines ● Similar to Drake but much more support for Python as opposed to bash. ● Specify actions, file_deps, and targets for tasks ● Smart rebuilding based on target/file_deps metadata, or your own custom logic ● Parallel execution ● Watcher process that triggers based on target/file_deps file changes ● Can define failure/success callbacks against the project
79.
Luigi ● Specify batchworkflows with different job type classes including postgres.CopyToTable, hadoop.JobTask, PySparkTask ● Specify depedencies with class requires() method and record via output() method targets against supported backends such as S3, HDFS, local or remote FS, MySQL, Redshift, etc. ● Event system provided to add callbacks to task returns, basic email alerting ● A central task scheduler (luigid) that provides a web frontend for task reporting, prevents duplicate task execution, and basic task history browsing ● Requires a separate triggering mechanism to submit tasks to the central scheduler ● RangeDaily and RangeHourly parameters as a dependency for backfill or recovery from extended downtime
83.
AWS Data Pipeline ●Cloud scheduler and resource instigator on hosted AWS hardware ● Can define data pipeline jobs, some of which come built-in (particularly AWS-to-AWS data transfer, complete with blueprints), but you can run custom scripts by hosting them on AWS ● Get all the AWS goodies: CloudWatch, IAM roles/policies, Security Groups ● Spins up target computing instances to run your pipeline activities per your configuration ● No explicit file based dependencies
86.
Pinball ● Central schedulerserver with monitoring UI built in ● Parses a file based configuration system into JobToken or EventToken instances ● Tokens are checked against Events associated with upstream tokens to determine whether or not they are in a runnable state. ● Tokens specify their dependencies to each other - not file based. ● More of an task manager abstraction than the other tools as it doesn't have a lot of job templates built in. ● Overrun policies deal with dependencies on past successes





![File dependencies/target systems File dependencies Recipe/action Target(s) #Drakefile wrangled.csv <- source1.csv, source2.csv [shell] cat $INPUT0 $INPUT1 > $OUTPUT](https://image.slidesharecdn.com/howilearnedtotimetravel1-161015172123/75/How-I-learned-to-time-travel-or-data-pipelining-and-scheduling-with-Airflow-12-2048.jpg)
![File dependencies/target systems File dependencies Recipe/action Target(s) #Pydoit def task_example(): return {“targets”: [‘wrangled.csv’], “file_deps”: [‘source1.csv’, ‘source2.csv’], “actions”: [concatenate_files_func] }](https://image.slidesharecdn.com/howilearnedtotimetravel1-161015172123/75/How-I-learned-to-time-travel-or-data-pipelining-and-scheduling-with-Airflow-13-2048.jpg)

![Abstract orchestration systems C A B ED # Pinball WORKFLOW = {“ex”: WorkflowConfig( jobs={ “A”: JobConfig( JobTemplate(A), []), “C”: JobConfig( JobTemplate(C) , [“A”], …, schedule=ScheduleConfig( recurrence=timedelta(days=1), reference_timestamp= datetime( year=2016, day=8, month=10)) …,](https://image.slidesharecdn.com/howilearnedtotimetravel1-161015172123/75/How-I-learned-to-time-travel-or-data-pipelining-and-scheduling-with-Airflow-17-2048.jpg)