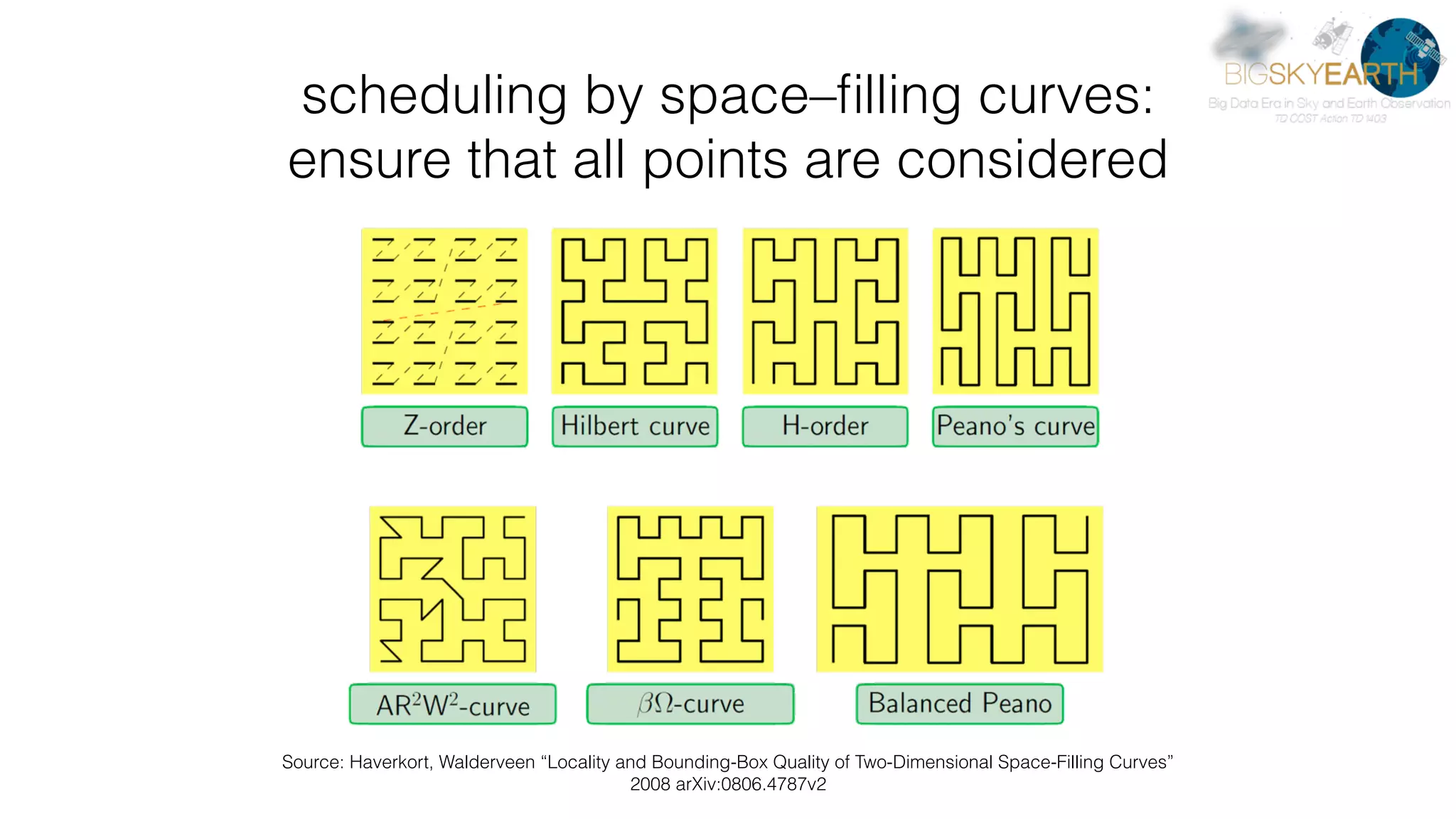
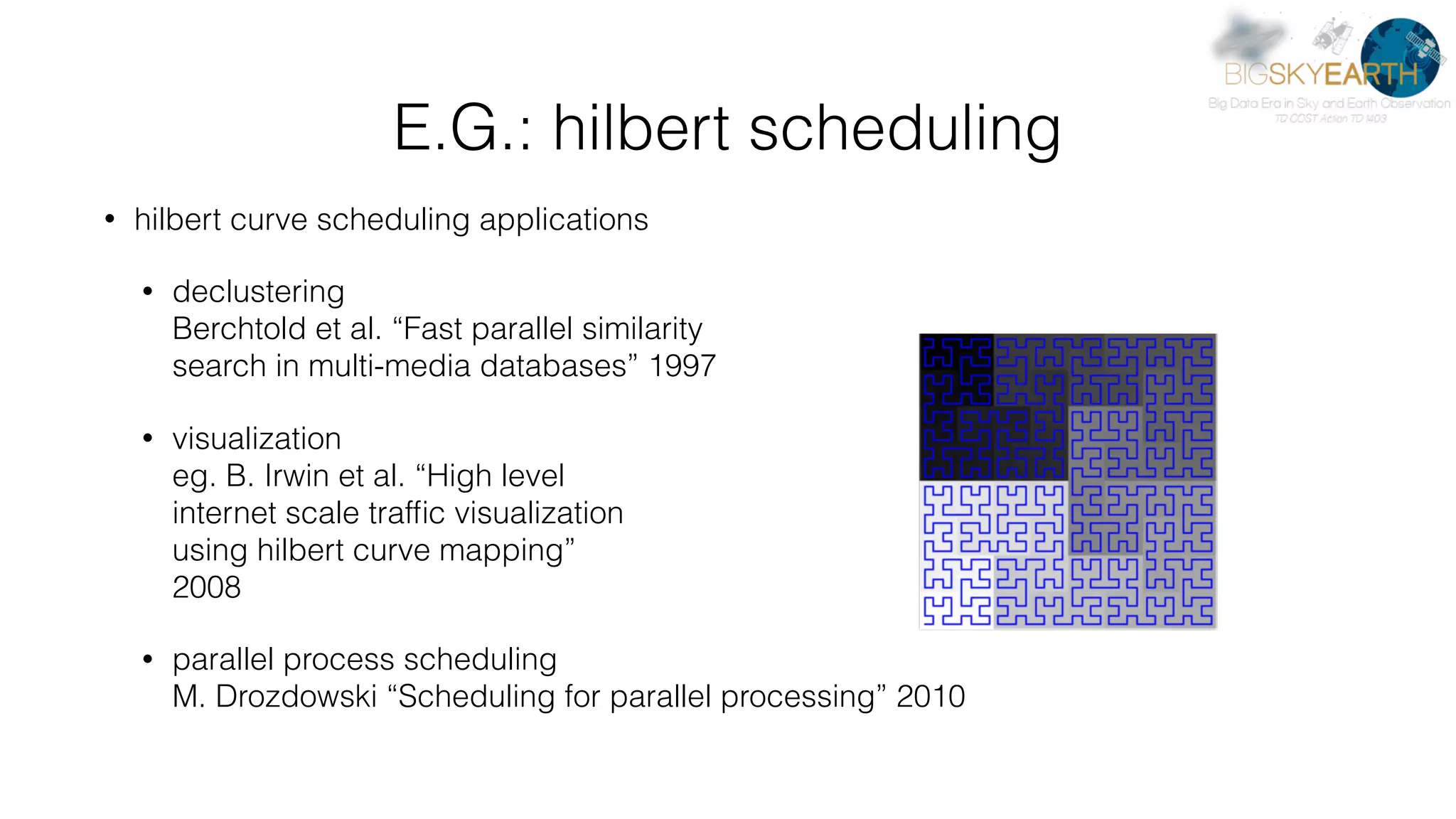
Download as PDF, PPTX













![RASTERIO: RASTER LOADING ➤ high-level interfaces to GDAL fn = “~/Data/all_donosti_croped_16_wgs4326_b.ers” import rasterio, numpy with rasterio.drivers(CPL_DEBUG=True): with rasterio.open(os.path.expanduser(fn)) as src: bands = map(src.read_band, (1, 2, 3)) data = numpy.dstack(bands) print(type(data)) print(src.bounds) print(src.count, src.shape) print(src.driver) print(str(src.crs)) bounds = src.bounds[::2] + src.bounds[1::2] import skimage.color import matplotlib.pylab as plt data_hsv = skimage.color.rgb2xyz(data) fig = plt.figure(figsize=(8, 8)) ax = plt.imshow(data_hsv, extent=bounds) plt.show()](https://image.slidesharecdn.com/asljvkgssyeh0s5a8nyn-signature-a67e94e385b0f51ee716eaa6622e12490992bac90a7a1bf9ae2be66c7fac4b82-poli-160812071229/75/04-open-source_tools-27-2048.jpg)
![FIONA: VECTOR MASKING ➤ Binary masking by Shapefiles import shapefile, os.path from PIL import Image, ImageDraw sf = shapefile.Reader(os.path.expanduser(“~/masking_shapes.shp")) shapes, src_bbox = sf.shapes(), [ bounds[i] for i in [0, 2, 1, 3] ] # Geographic x & y image sizes xdist, ydist = src_bbox[2] - src_bbox[0], src_bbox[3] - src_bbox[1] # Image width & height iwidth, iheight = feats.shape[1], feats.shape[0] xratio, yratio = iwidth/xdist, iheight/ydist # Masking mask = Image.new("RGB", (iwidth, iheight), "black") draw = ImageDraw.Draw(mask) pixels = { label:[] for label in labels } for i_shape, shape in enumerate(sf.shapes()): draw.polygon([ p[:2] for p in pixels[label] ], outline="rgb(1, 1, 1)", fill="rgb(1, 1, 1)”) import scipy.misc fig = plt.figure(figsize=(8, 8)) ax = plt.imshow(scipy.misc.fromimage(mask)*data, extent=bounds)](https://image.slidesharecdn.com/asljvkgssyeh0s5a8nyn-signature-a67e94e385b0f51ee716eaa6622e12490992bac90a7a1bf9ae2be66c7fac4b82-poli-160812071229/75/04-open-source_tools-28-2048.jpg)




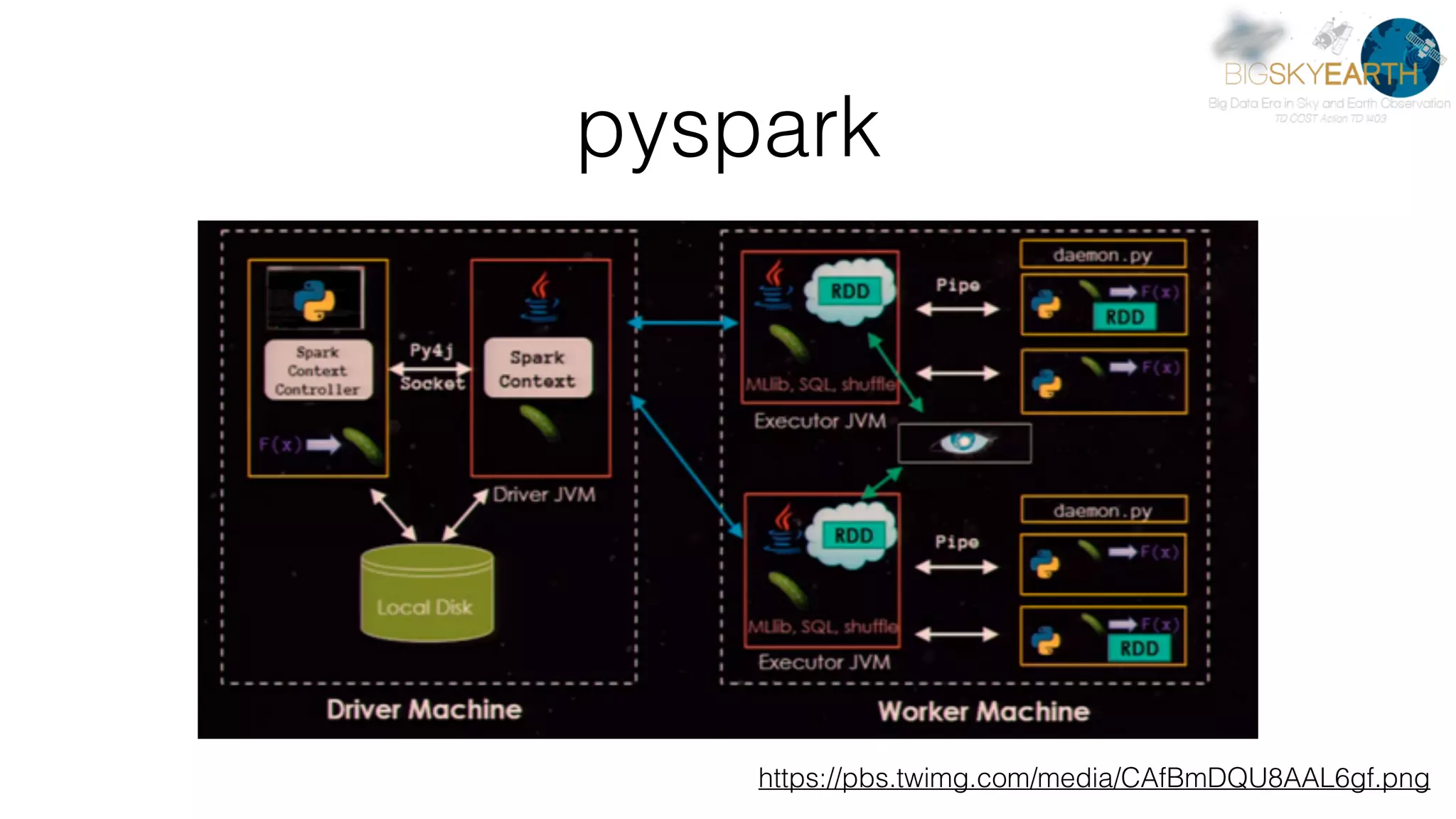


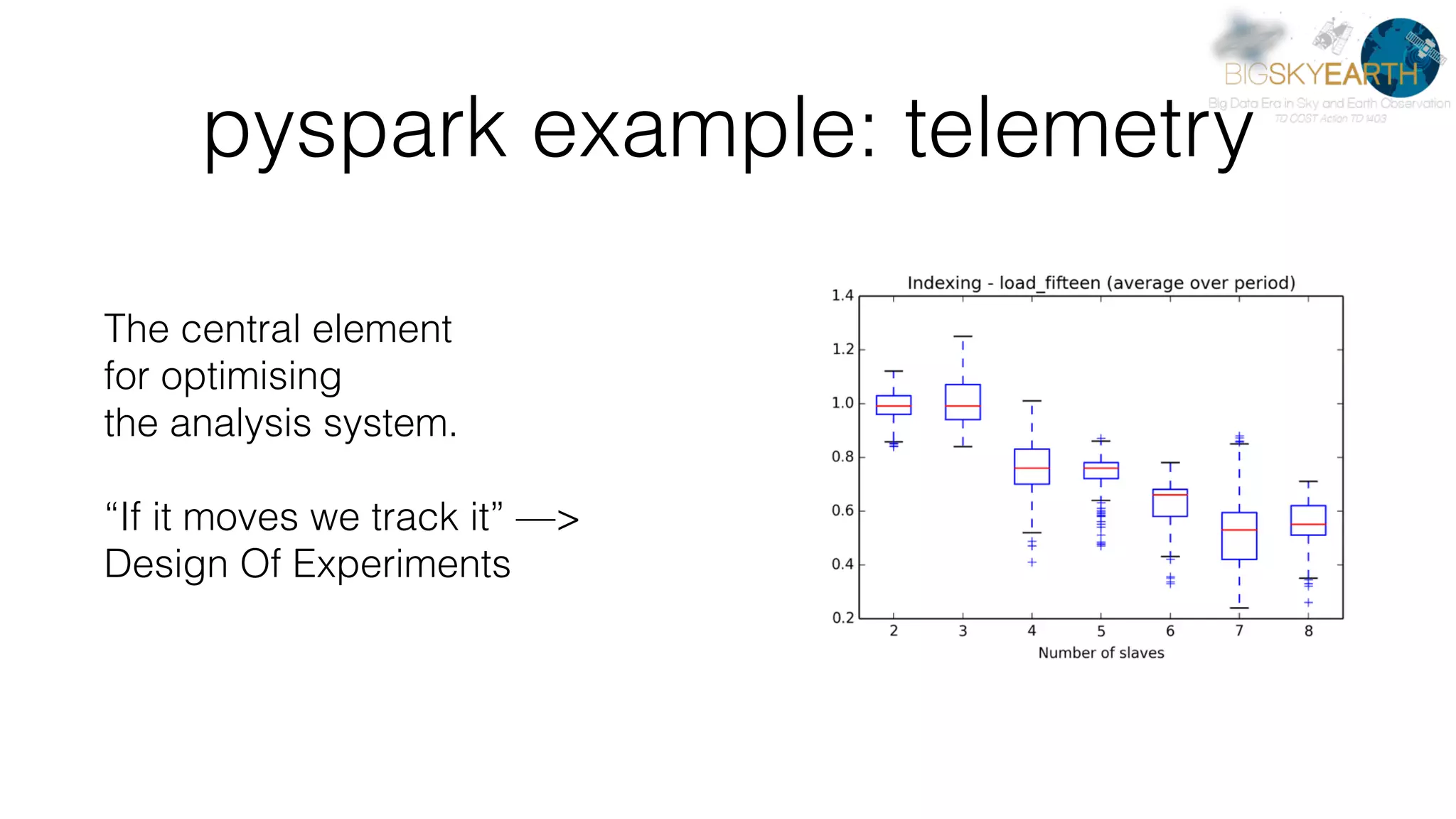








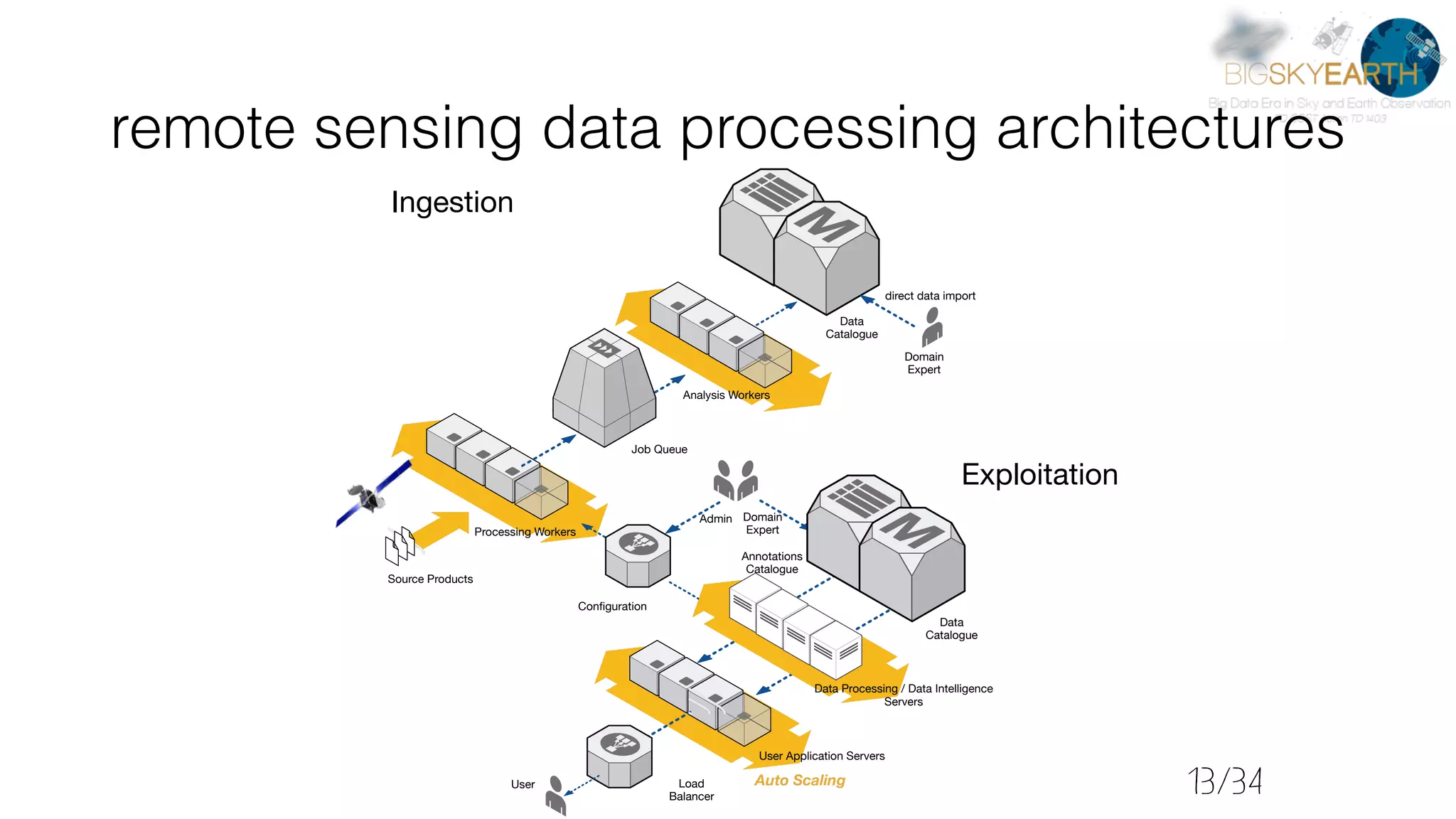
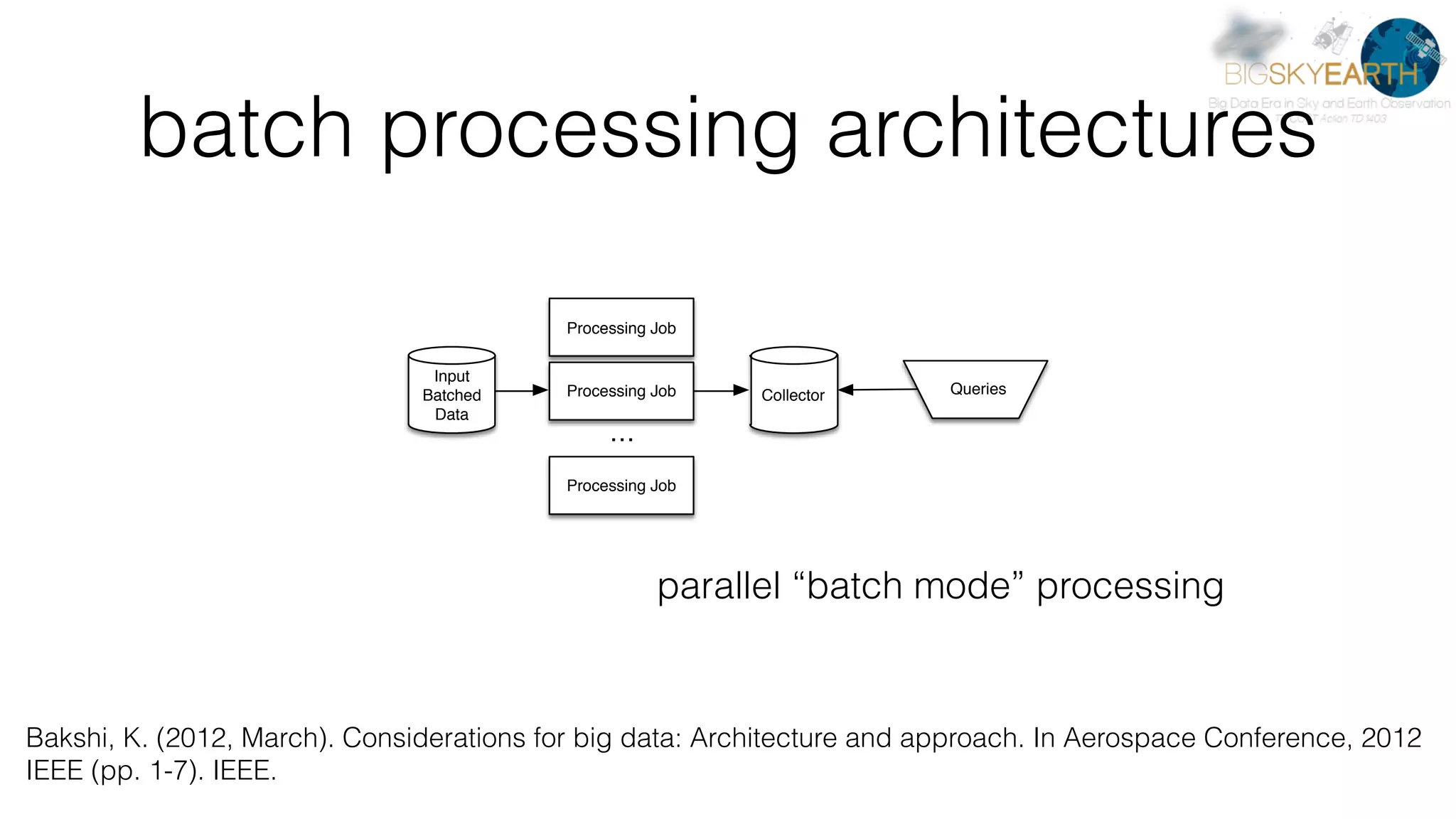
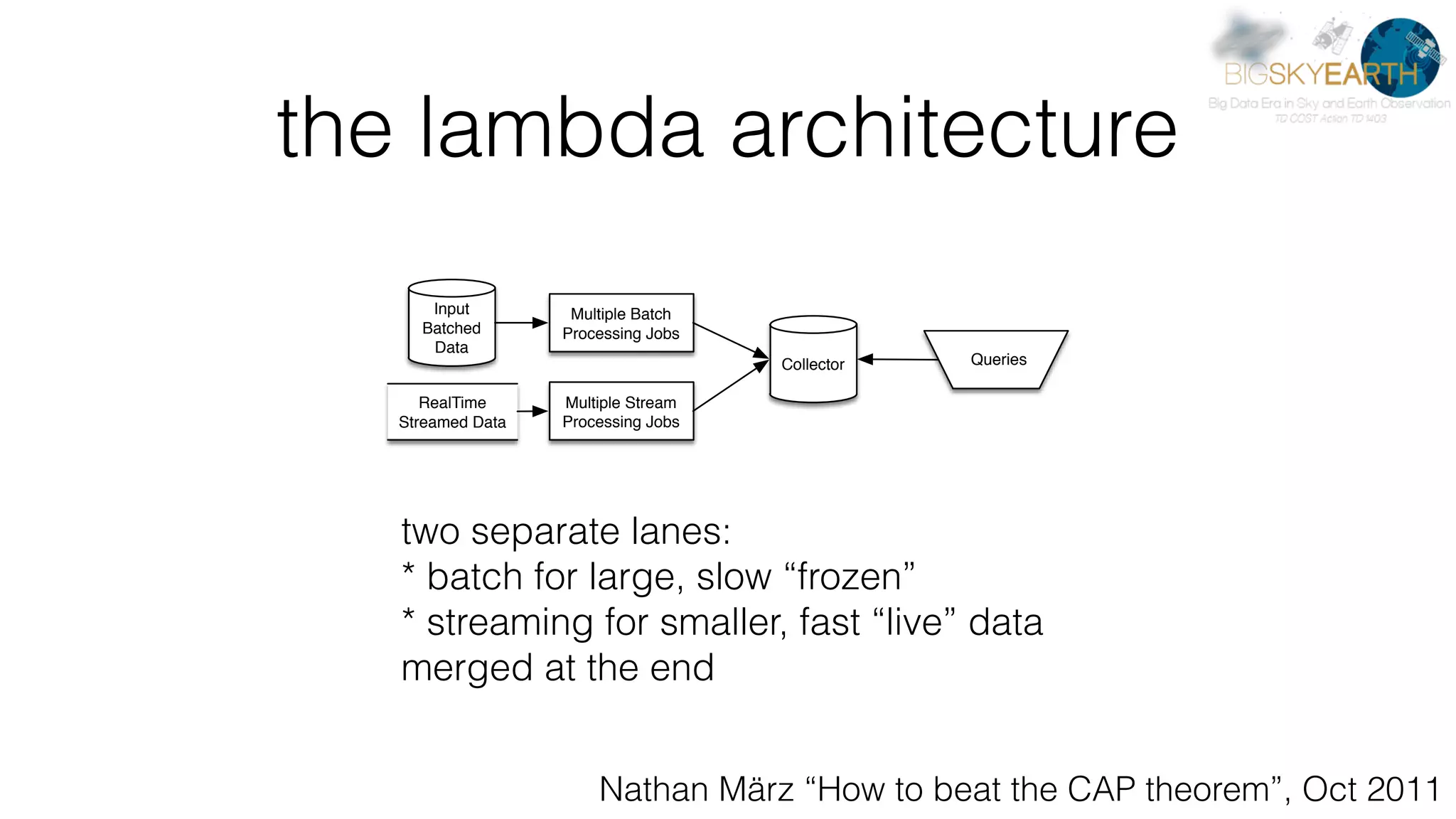
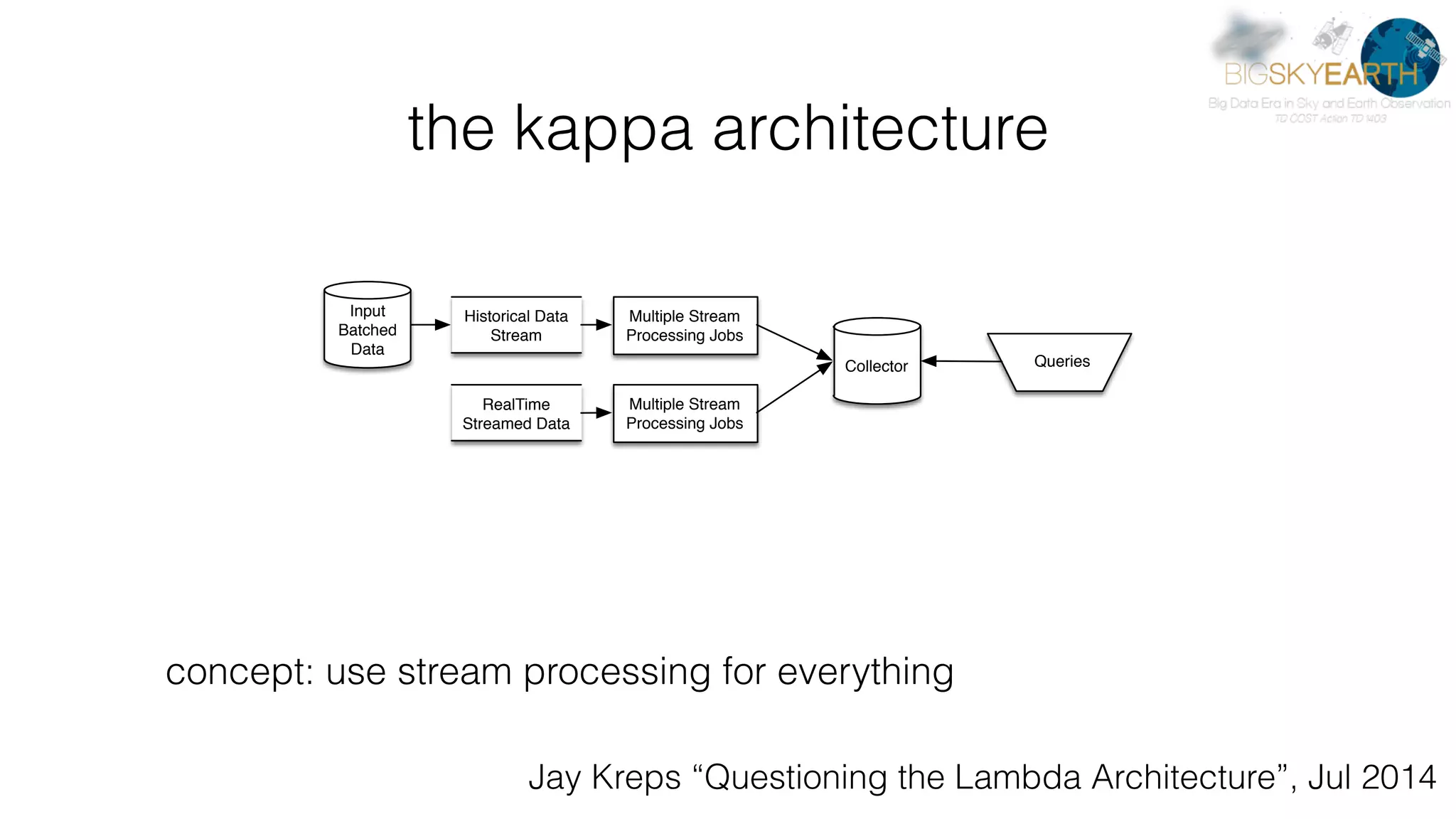
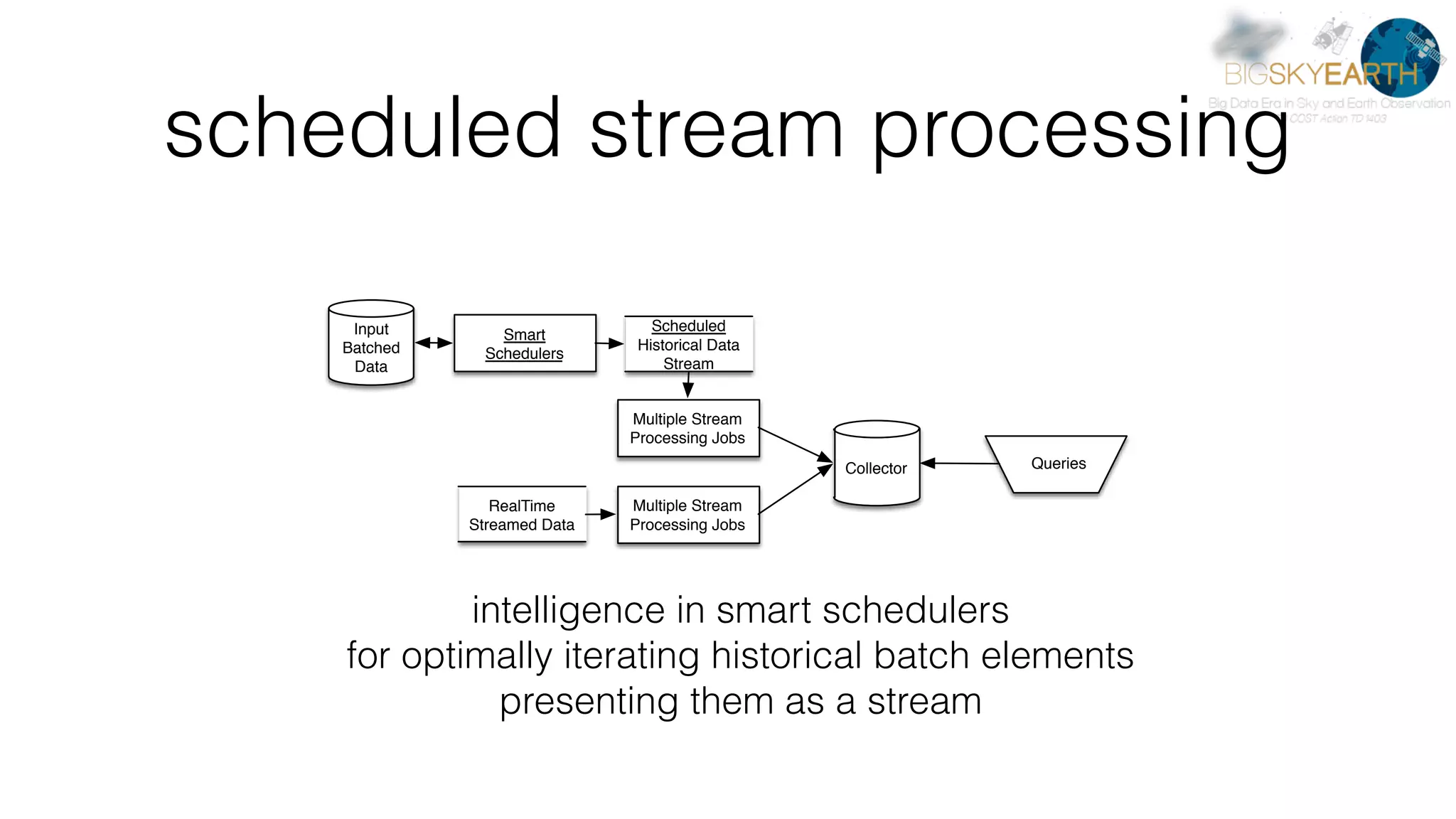
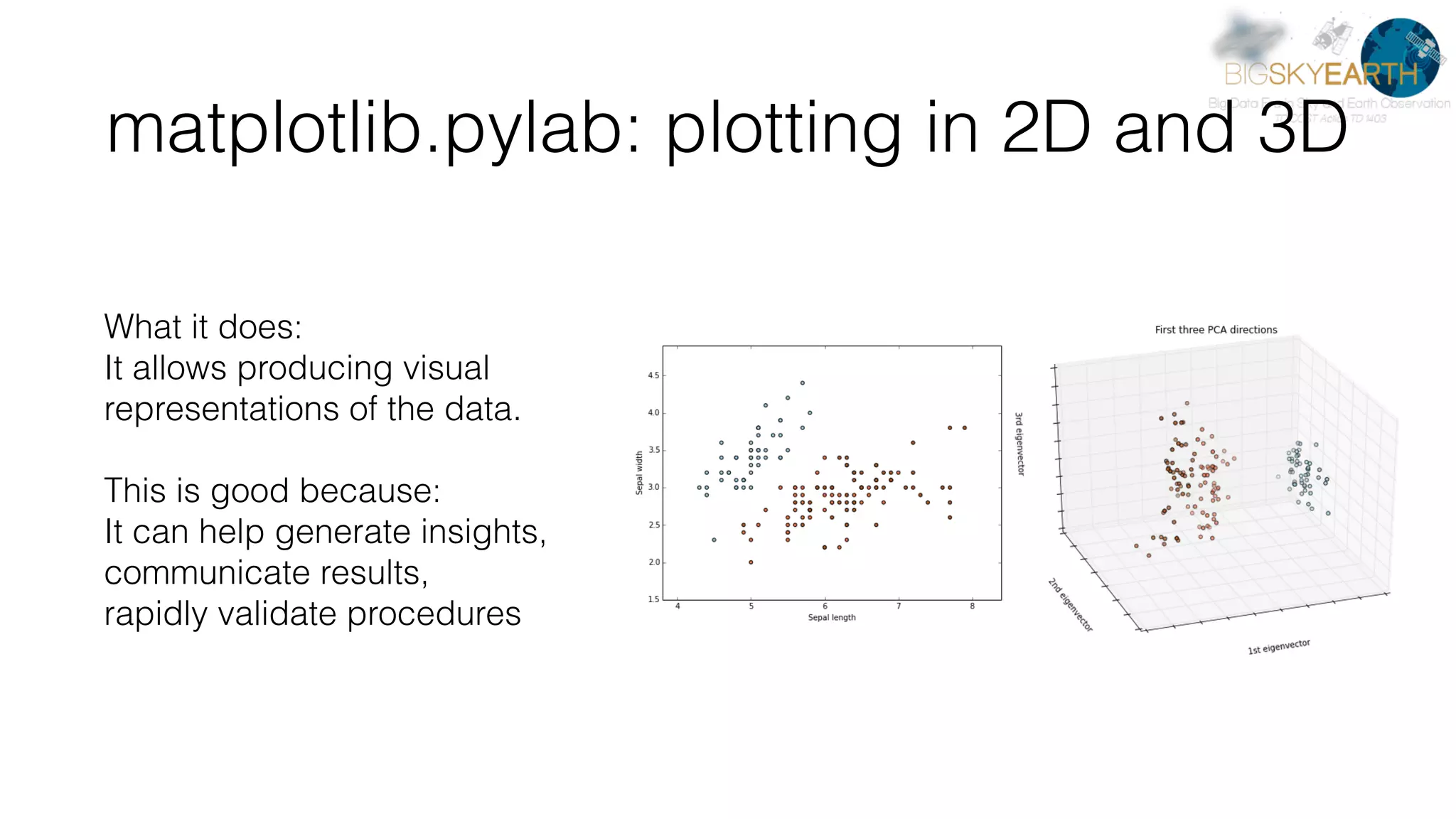
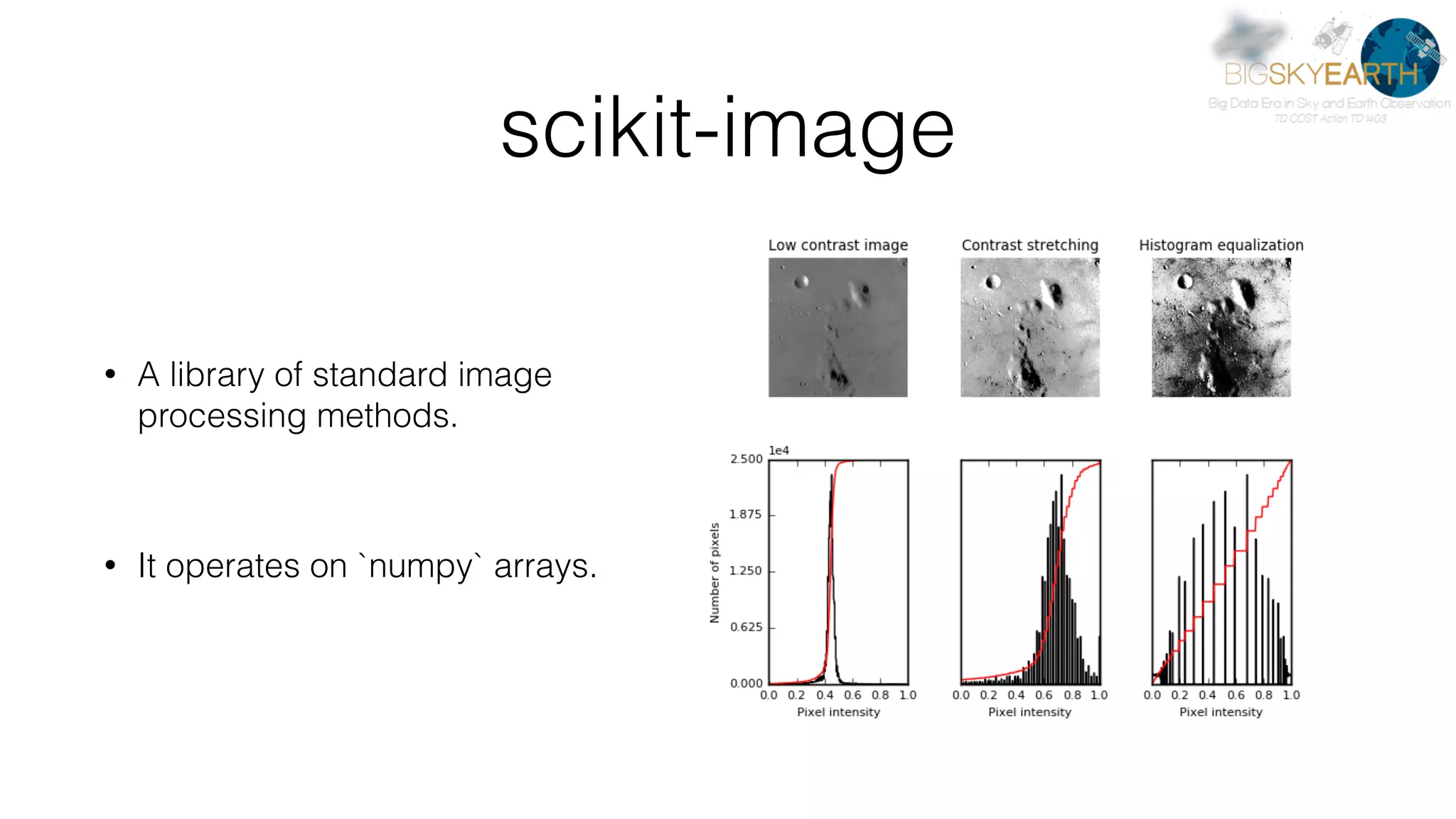
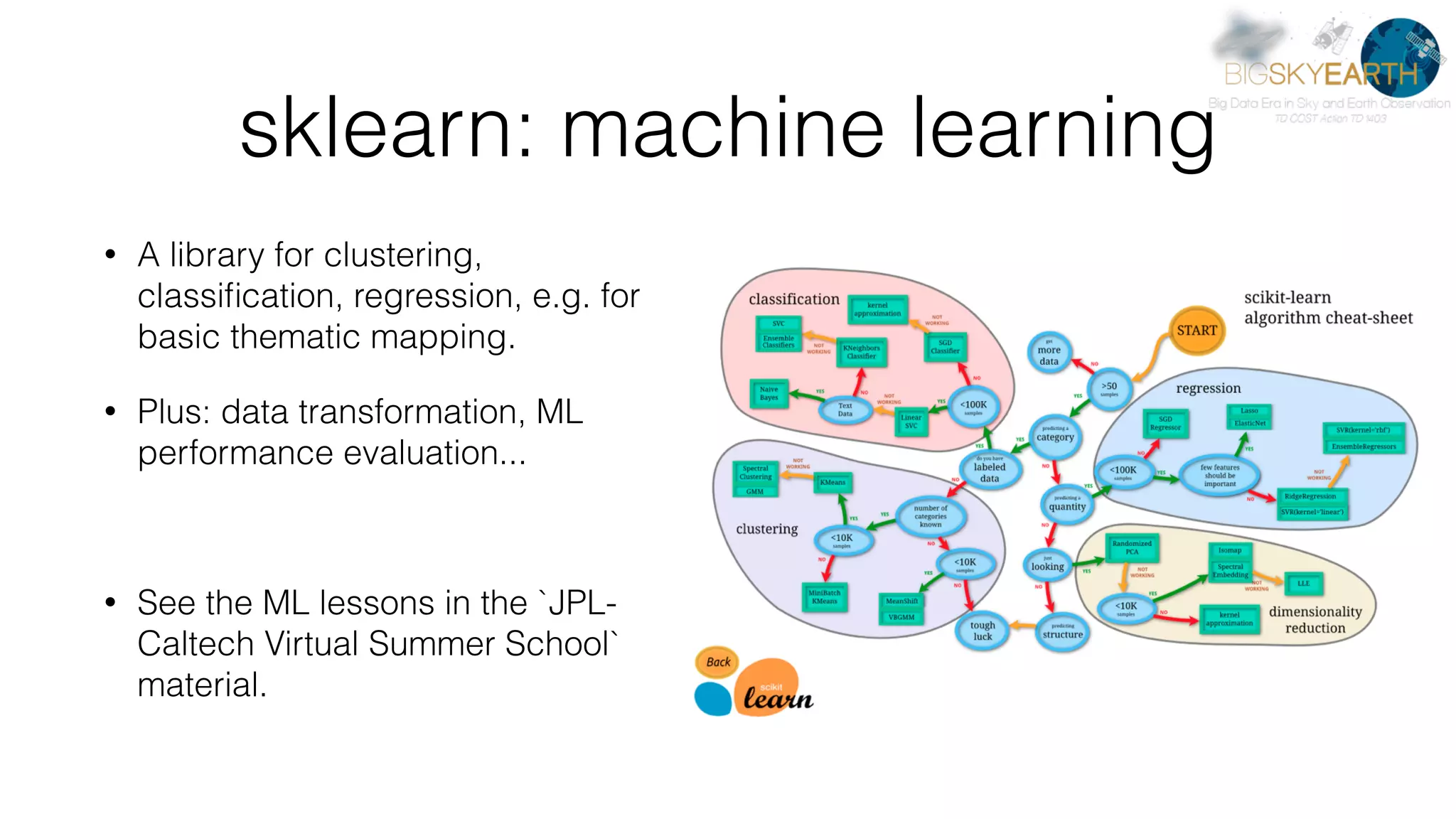
This document discusses tools for distributed data analysis including Apache Spark. It is divided into three parts: 1) An introduction to cluster computing architectures like batch processing and stream processing. 2) The Python data analysis library stack including NumPy, Matplotlib, Scikit-image, Scikit-learn, Rasterio, Fiona, Pandas, and Jupyter. 3) The Apache Spark cluster computing framework and examples of its use including contexts, HDFS, telemetry, MLlib, streaming, and deployment on AWS.