Downloaded 191 times




































The document discusses the acceleration of TensorFlow using RDMA (Remote Direct Memory Access) to enhance deep learning performance, highlighting key technologies such as gRPC, TensorFlow, and various high-performance computing (HPC) architectures. It outlines the current trends in deep learning stacks, the importance of big data in analytics, and introduces specific benchmarking efforts to evaluate the integration of RDMA with TensorFlow for optimizing tensor communication. The presentation ultimately aims to explore how native RDMA support can provide significant performance improvements in deep learning applications.
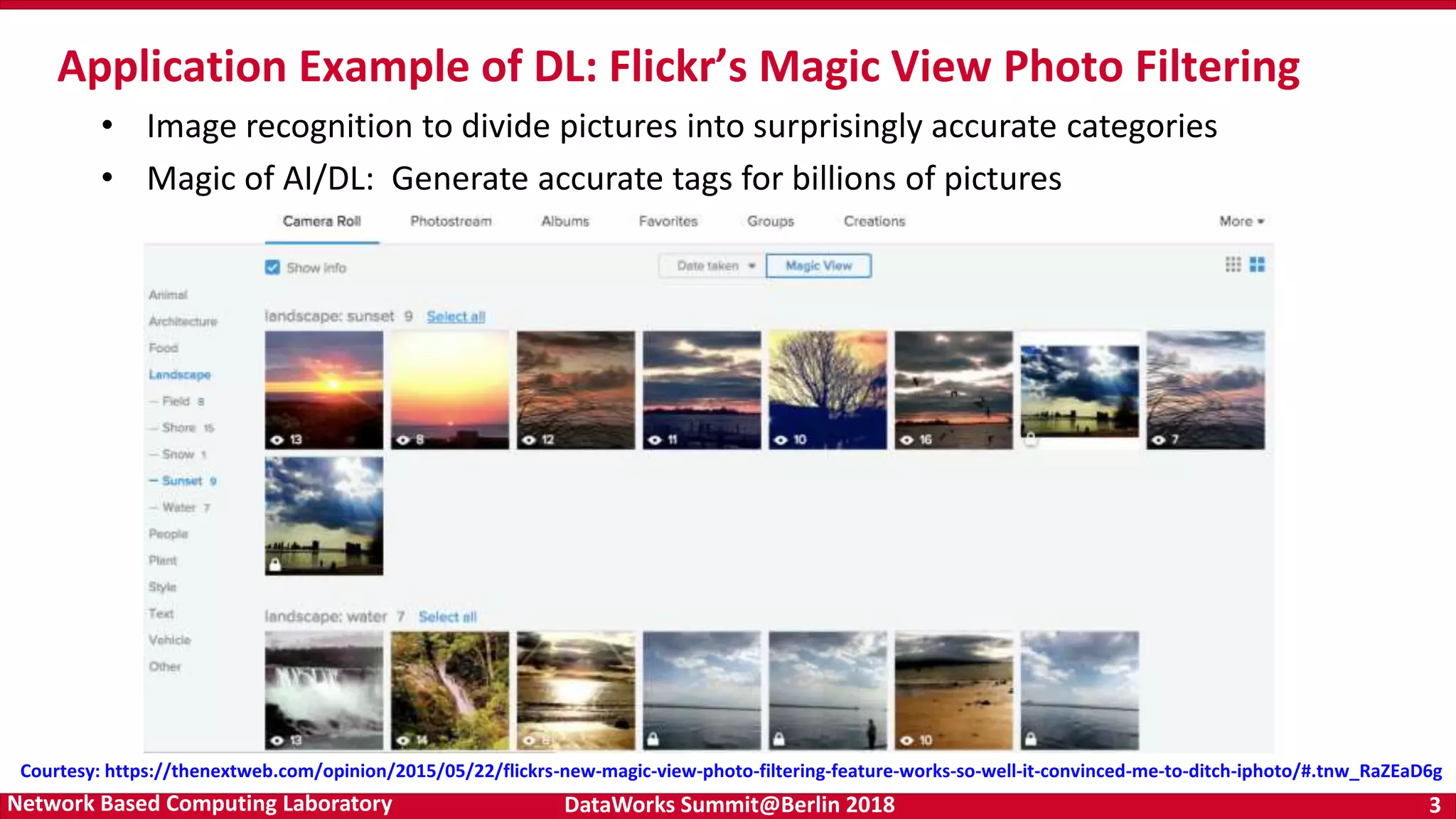
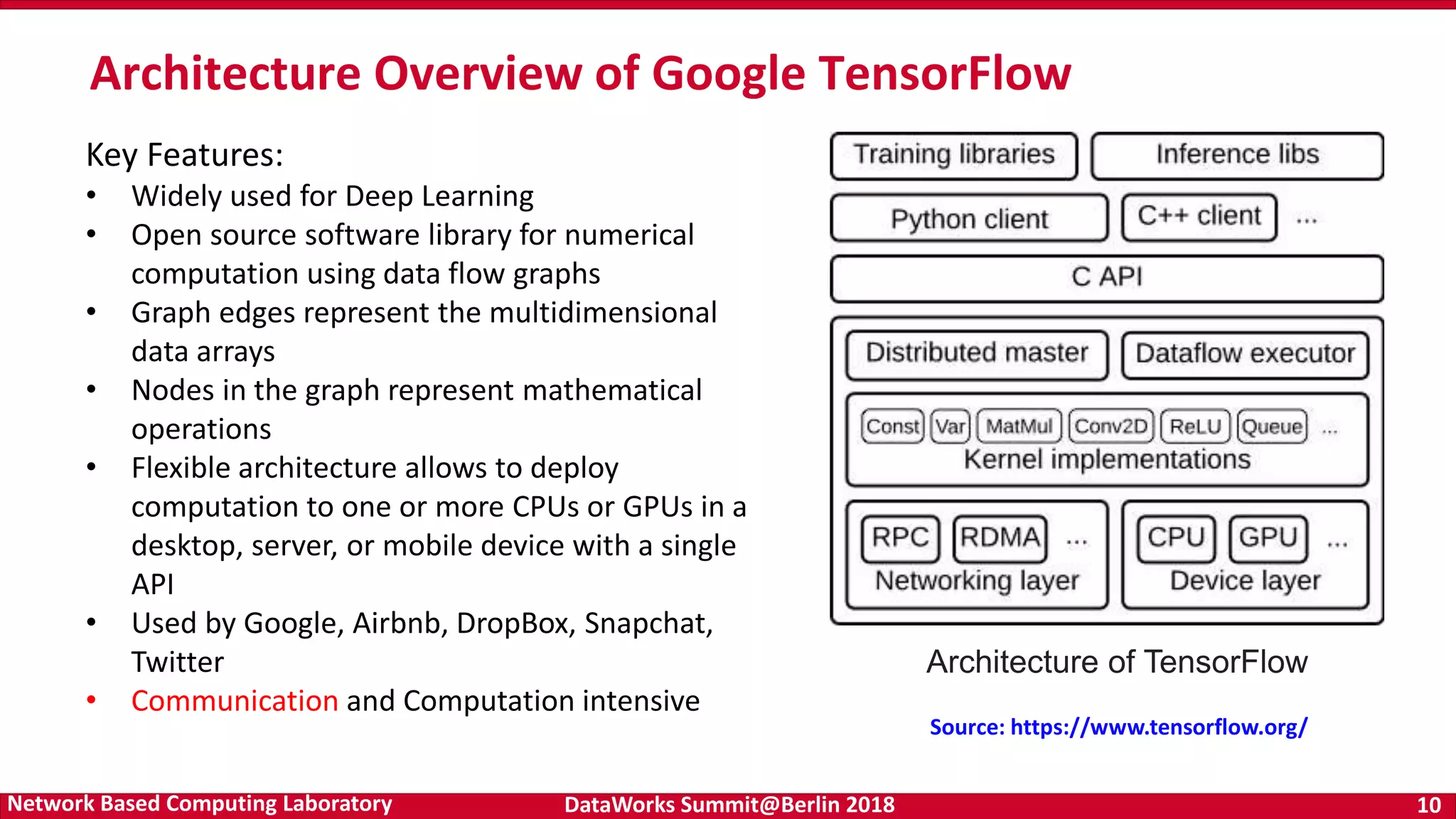
Introduction of TensorFlow and deep learning, and its significance in data analytics. Highlighting trends and the convergence of HPC, Big Data, and Deep Learning.
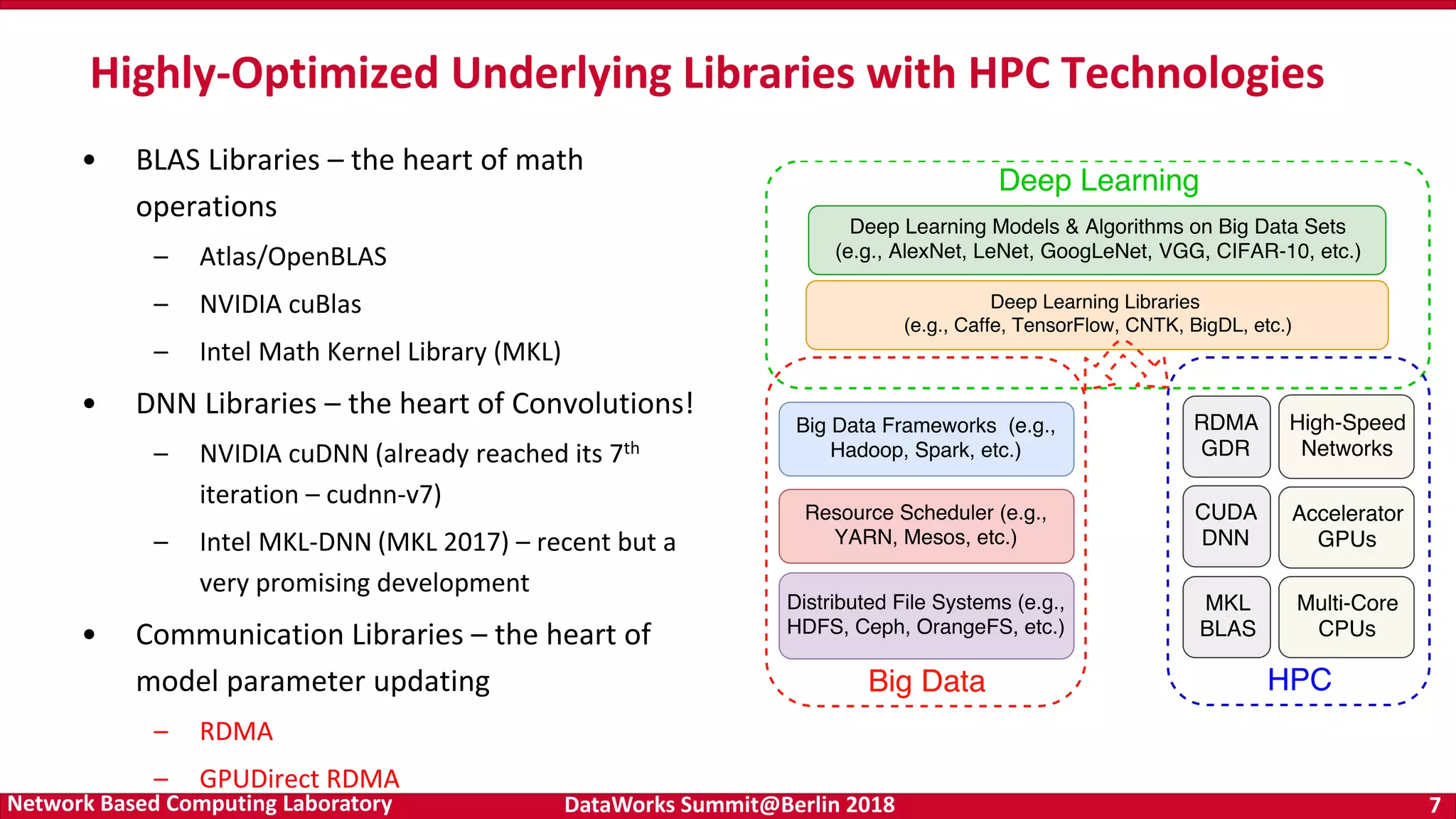
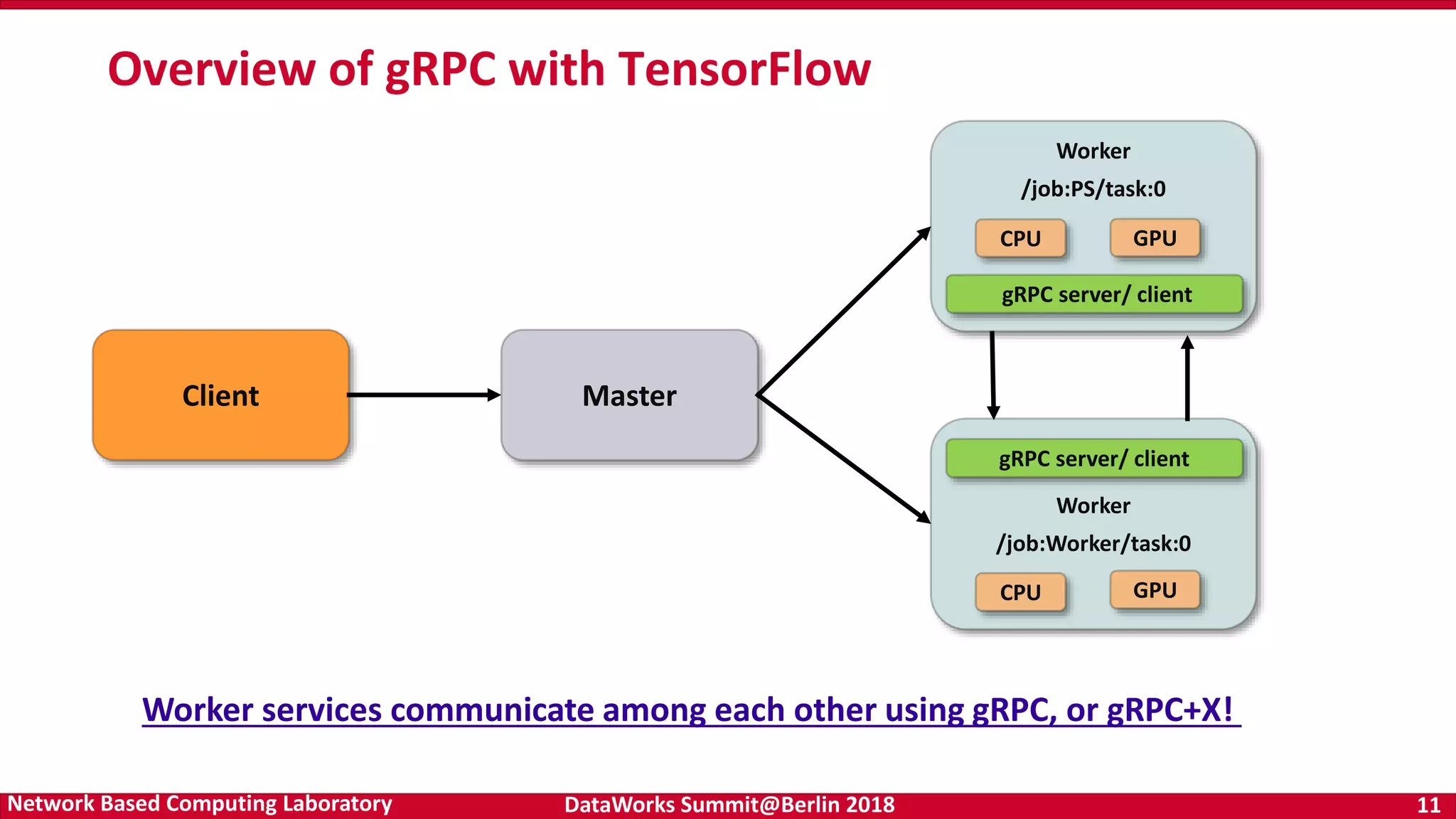
Discussion of optimized libraries for mathematical operations and deep learning, including BLAS and communication libraries central to deep learning frameworks. Key features and architecture of gRPC, its language/platform support, and communication protocols as a basis for tensor communication in TensorFlow.
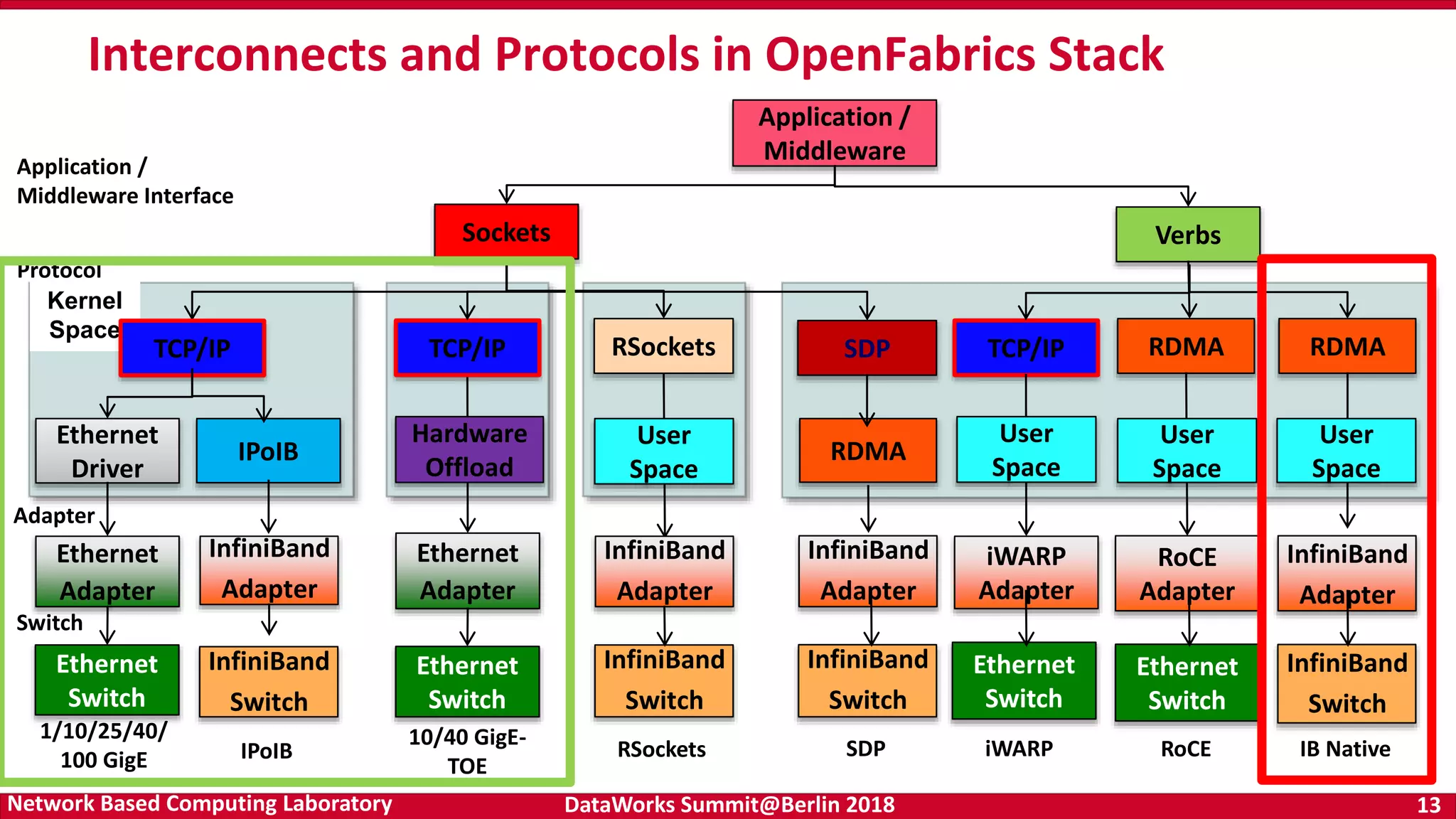
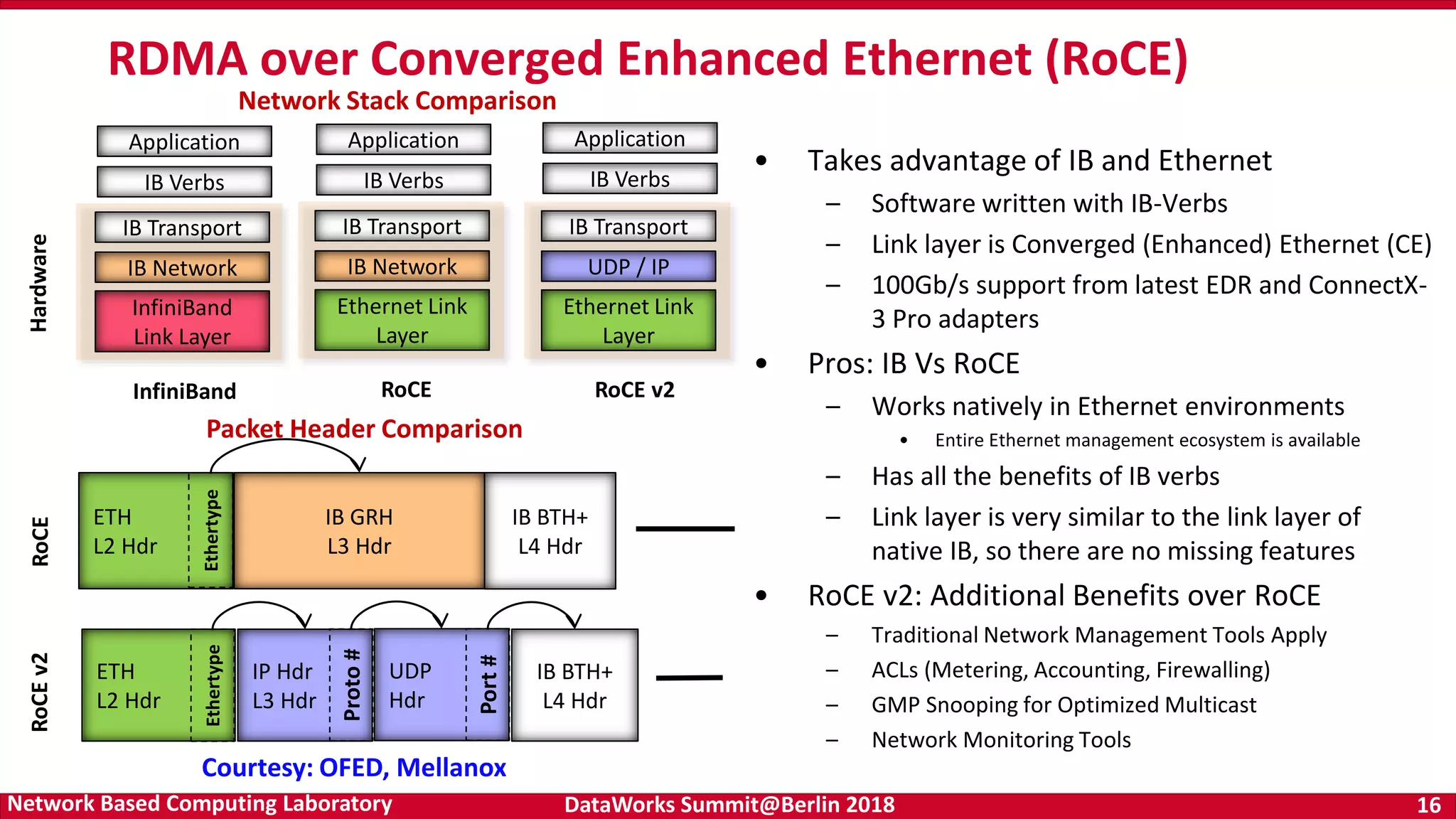
Drivers of HPC architecture including RDMA and SSDs, highlighting its relevance in supporting deep learning workloads and performance. Details on the OpenFabrics stack and InfiniBand technology, demonstrating its significance for high-performance data transfer in computing.
Highlighting the HiBD project utilizing RDMA for various Apache frameworks, focusing on its wide adoption and significant downloads.
Discussion on the potential performance benefits of RDMA with gRPC and TensorFlow and how benchmarking these systems can be approached.
Examining tensor communication over gRPC channels, and discussions on optimizing communication for performance improvements in TensorFlow.
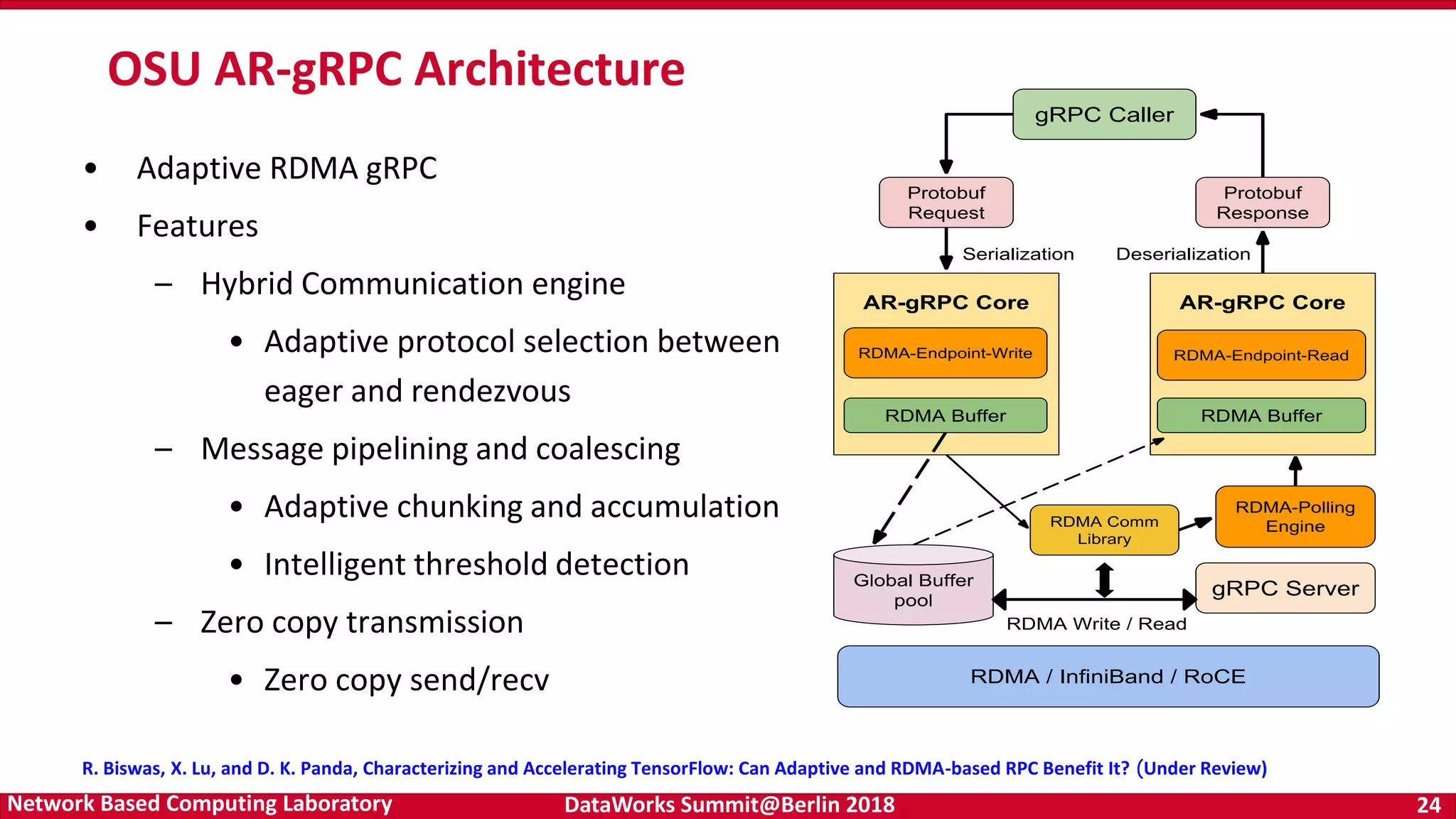
Insights into an adaptive RDMA gRPC architecture aimed at enhancing TensorFlow's communication performance through intelligent optimizations.
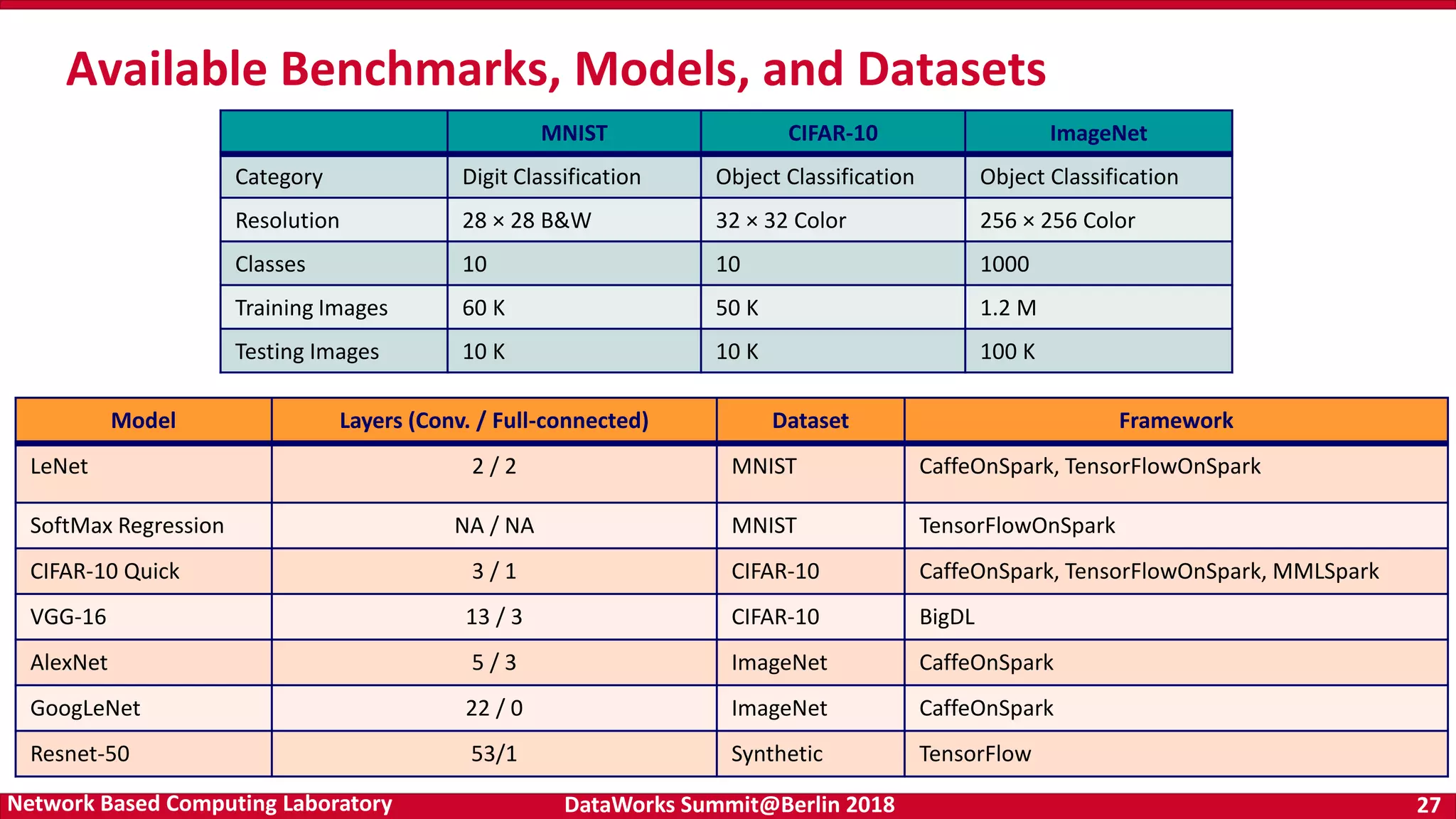
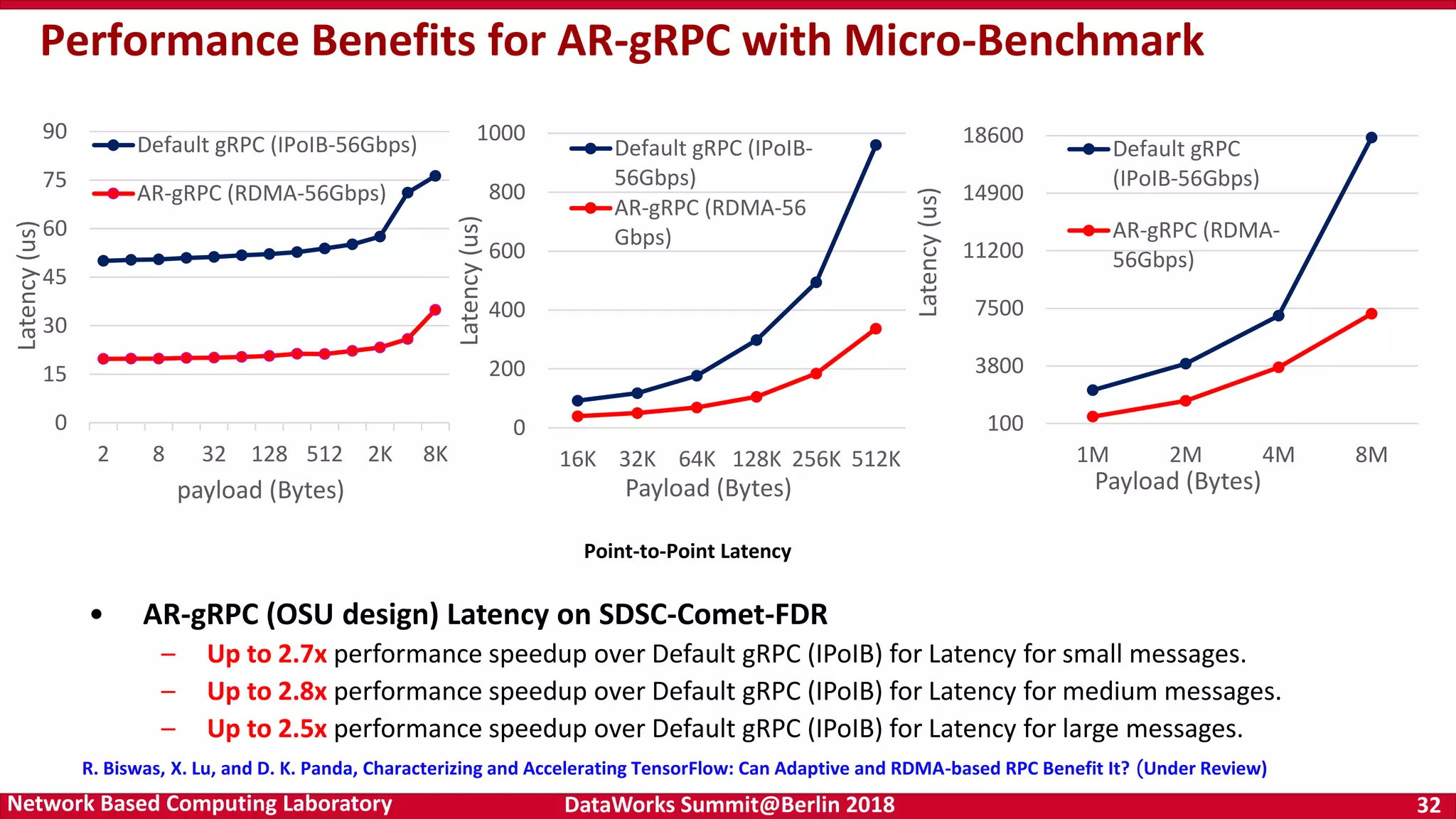
Performance evaluation results of AR-gRPC, showcasing latency and bandwidth improvements compared to default gRPC for various payload sizes. Detailed performance benefits of TensorFlow with AR-gRPC, including significant speedups for various GPU configurations in benchmark tests.
Summary of gRPC, TensorFlow, and RDMA implementation details while emphasizing future challenges and opportunities in the deep learning community.
Acknowledgments of funding and personnel contributions, along with a mention of upcoming workshops related to high-performance big data computing.