Downloaded 251 times
















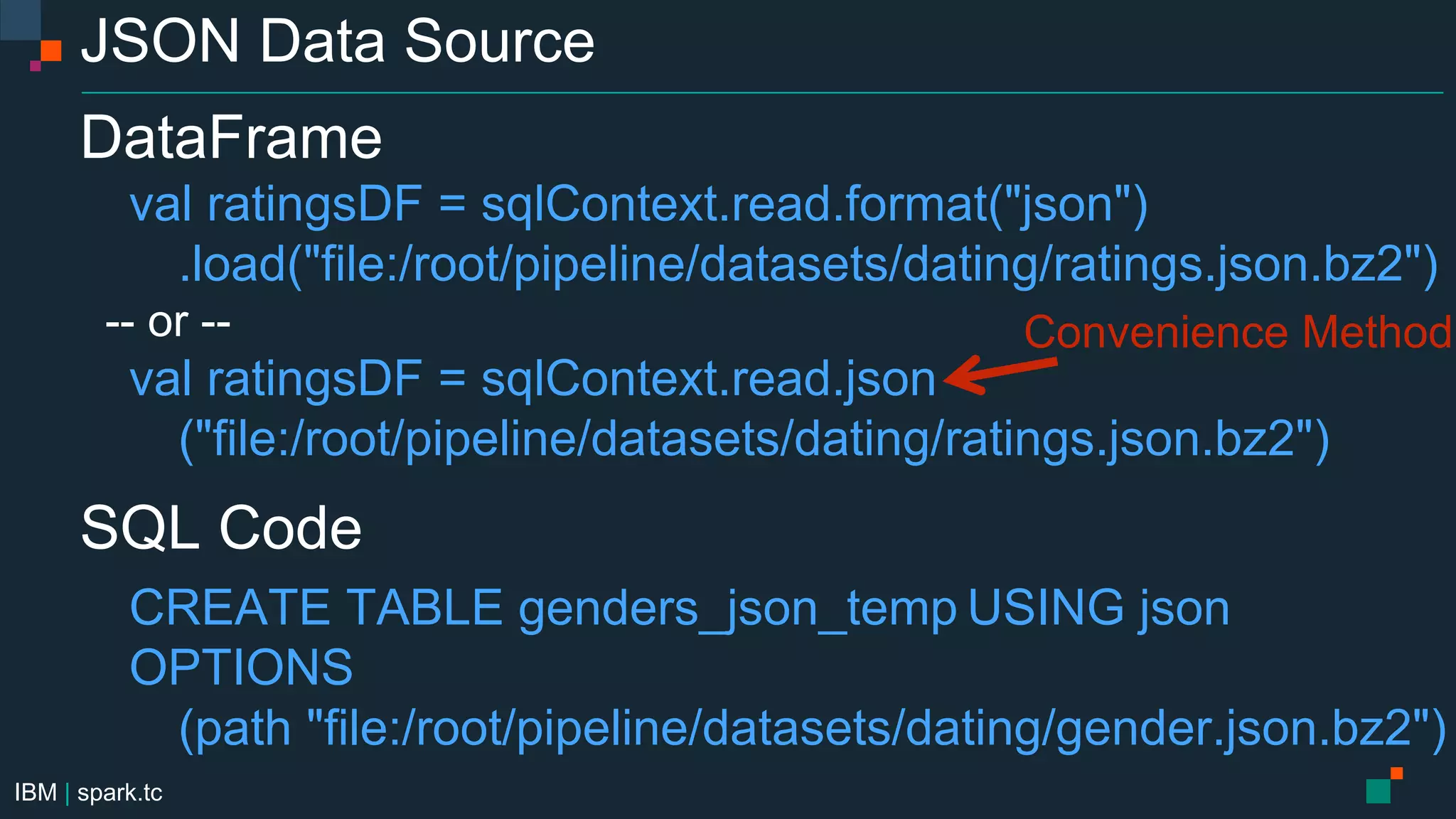

![IBM | spark.tc Parquet Data Source Configuration spark.sql.parquet.filterPushdown=true spark.sql.parquet.mergeSchema=true spark.sql.parquet.cacheMetadata=true spark.sql.parquet.compression.codec=[uncompressed,snappy,gzip,lzo] DataFrames val gendersDF = sqlContext.read.format("parquet") .load("file:/root/pipeline/datasets/dating/genders.parquet") gendersDF.write.format("parquet").partitionBy("gender") .save("file:/root/pipeline/datasets/dating/genders.parquet") SQL CREATE TABLE genders USING parquet OPTIONS (path "file:/root/pipeline/datasets/dating/genders.parquet")](https://image.slidesharecdn.com/advancedapachesparkmeetupdatasourcesapicassandrasparkconnectorsept212015-150922225610-lva1-app6891/75/Advanced-Apache-Spark-Meetup-Spark-SQL-DataFrames-Catalyst-Optimizer-Data-Sources-API-27-2048.jpg)
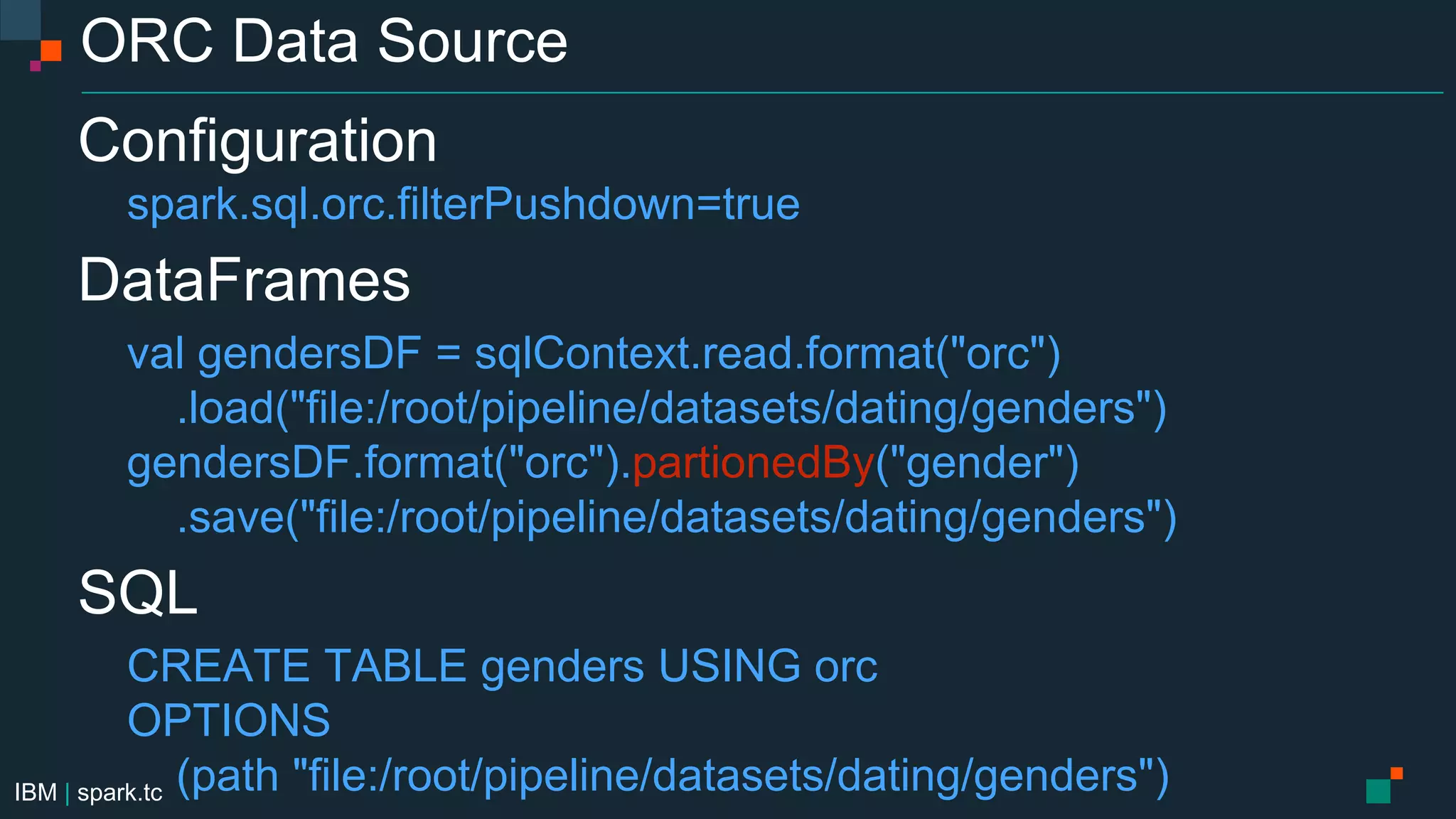

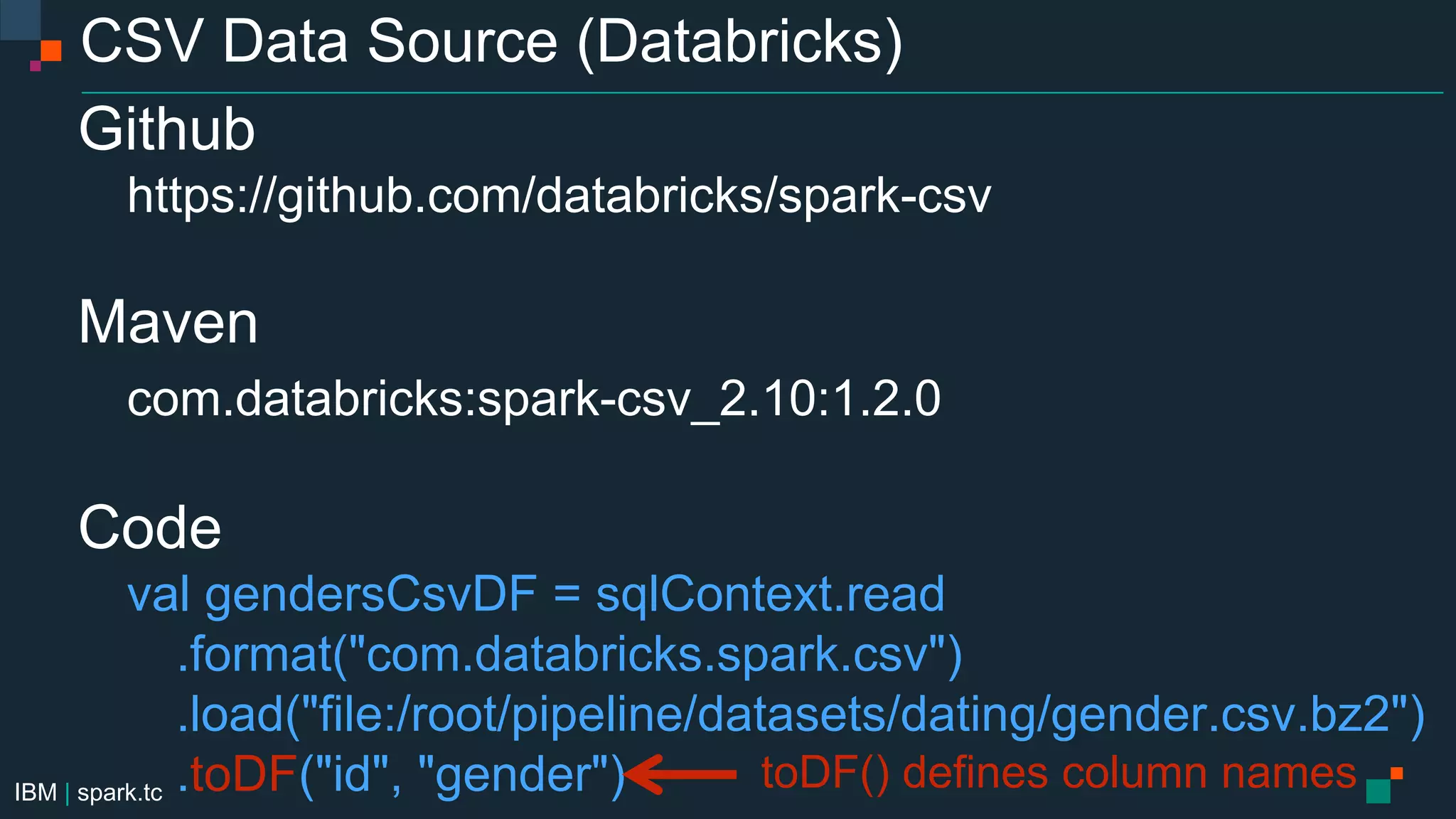
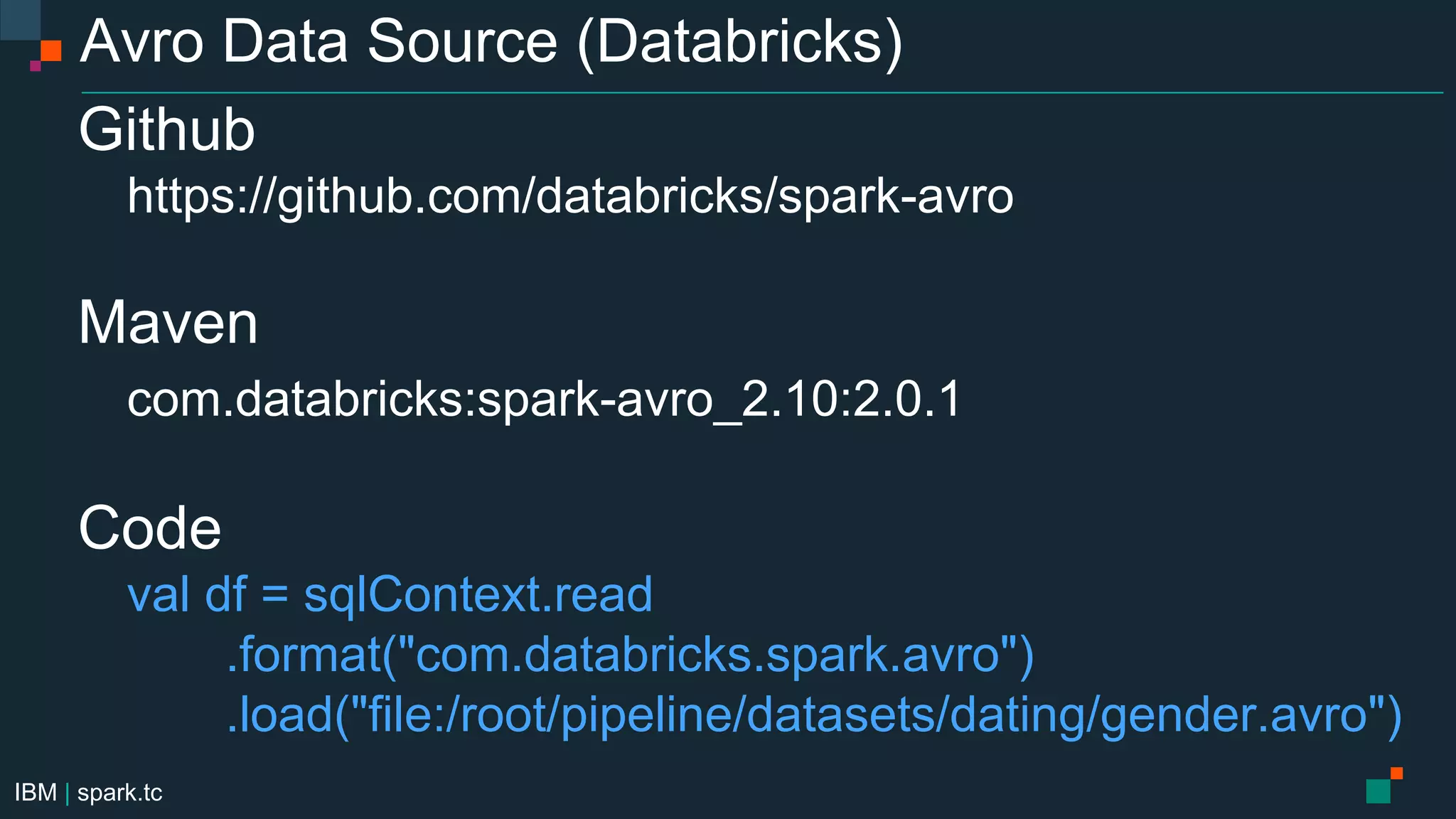

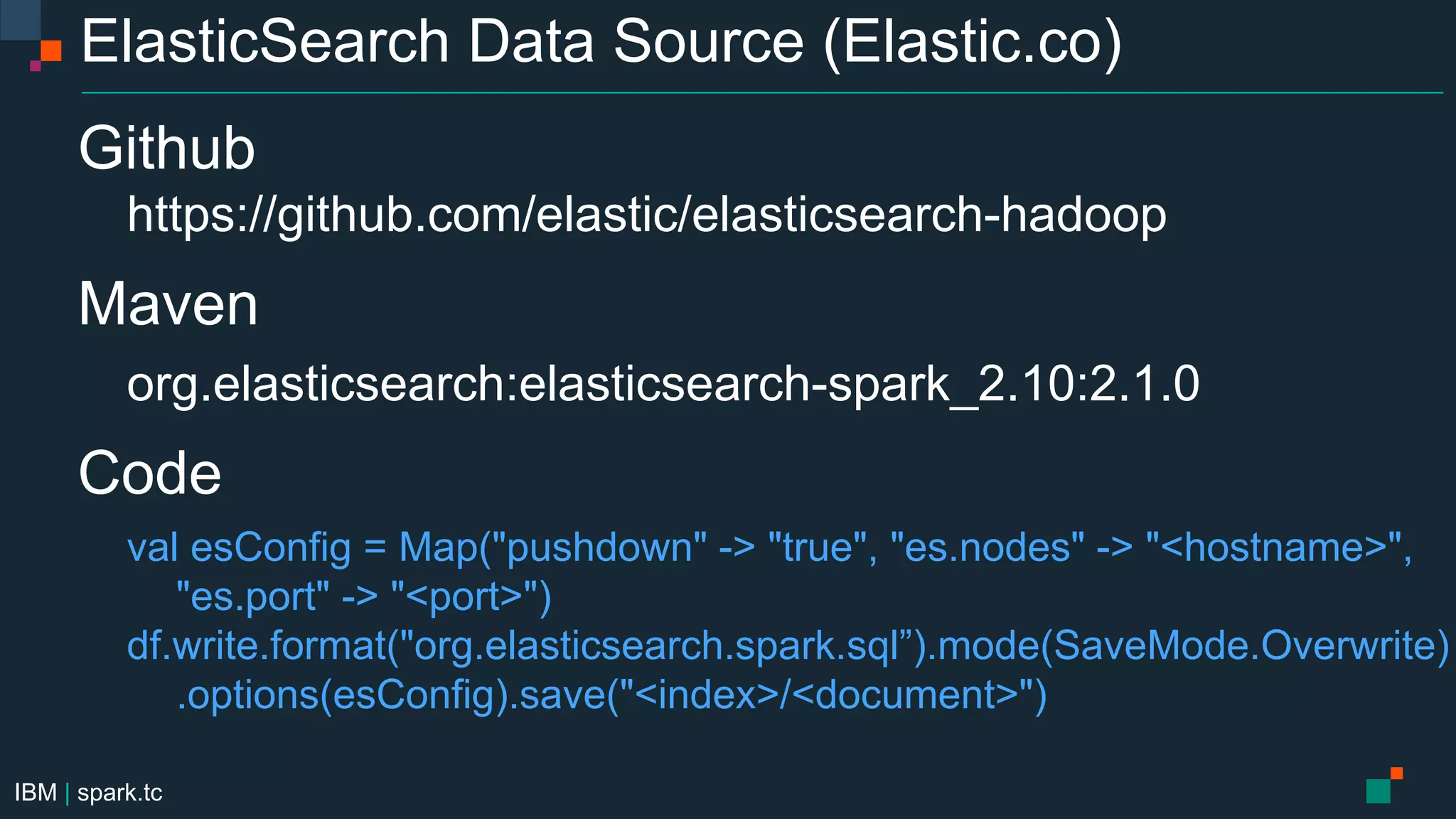









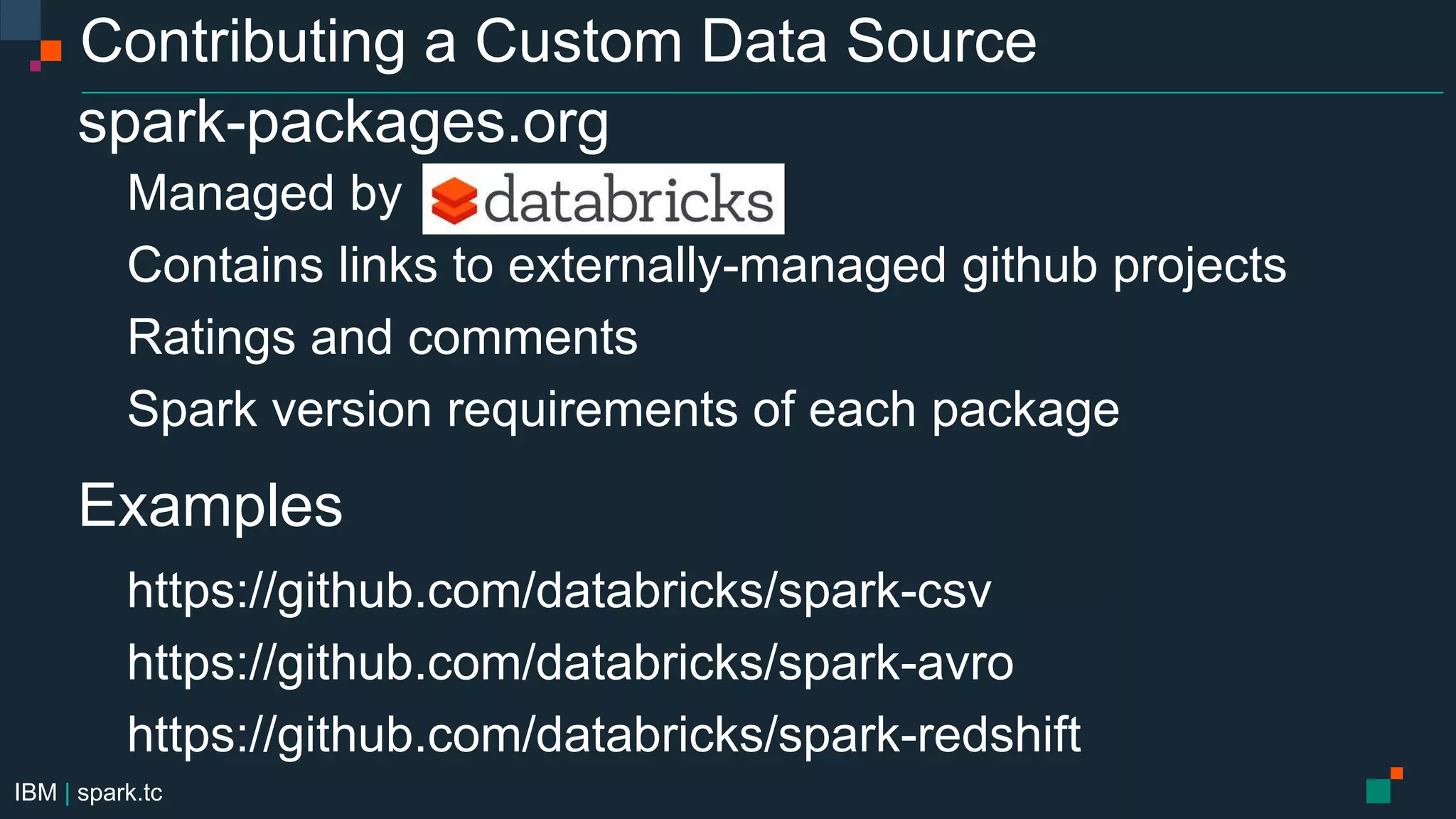
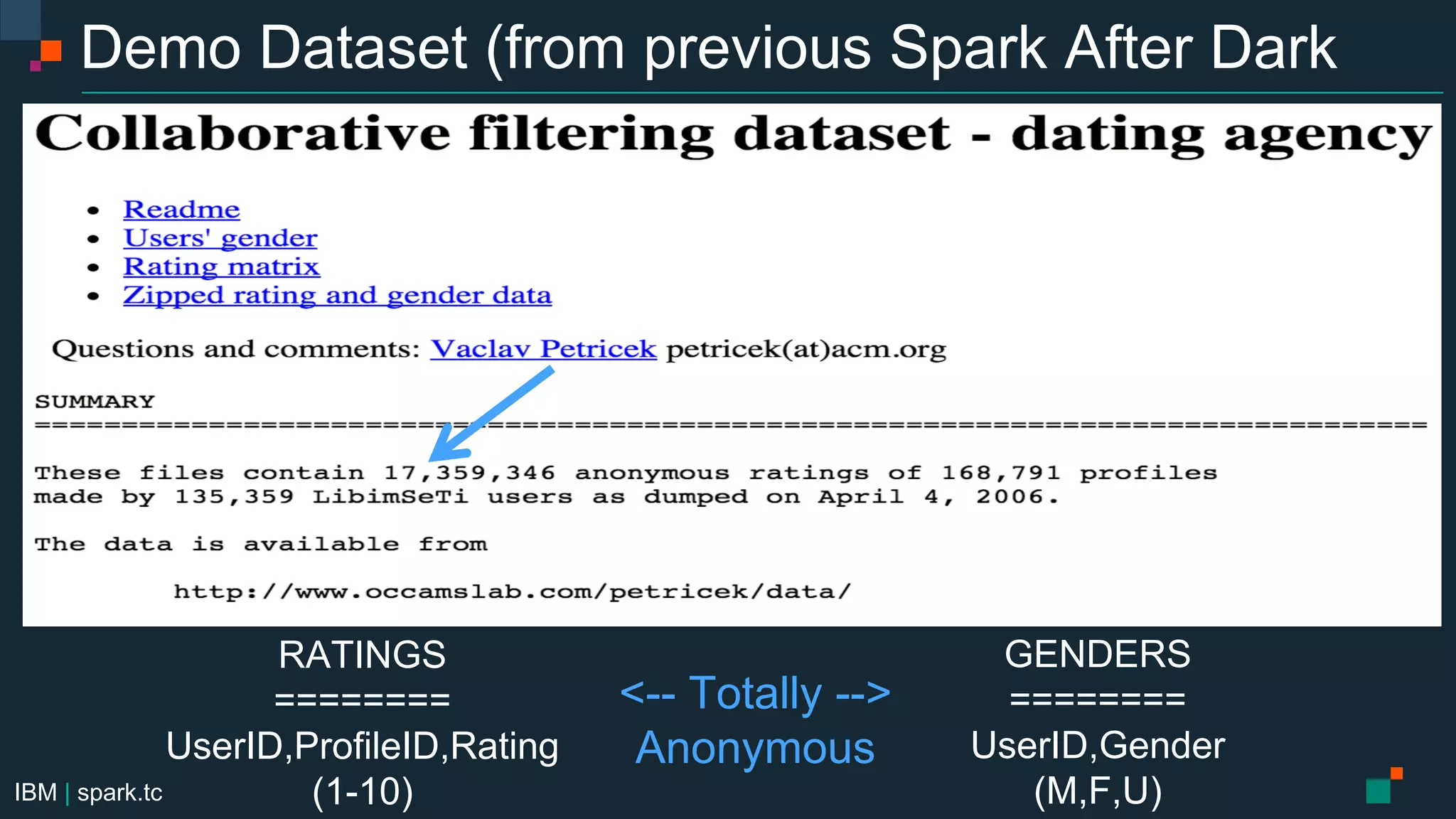
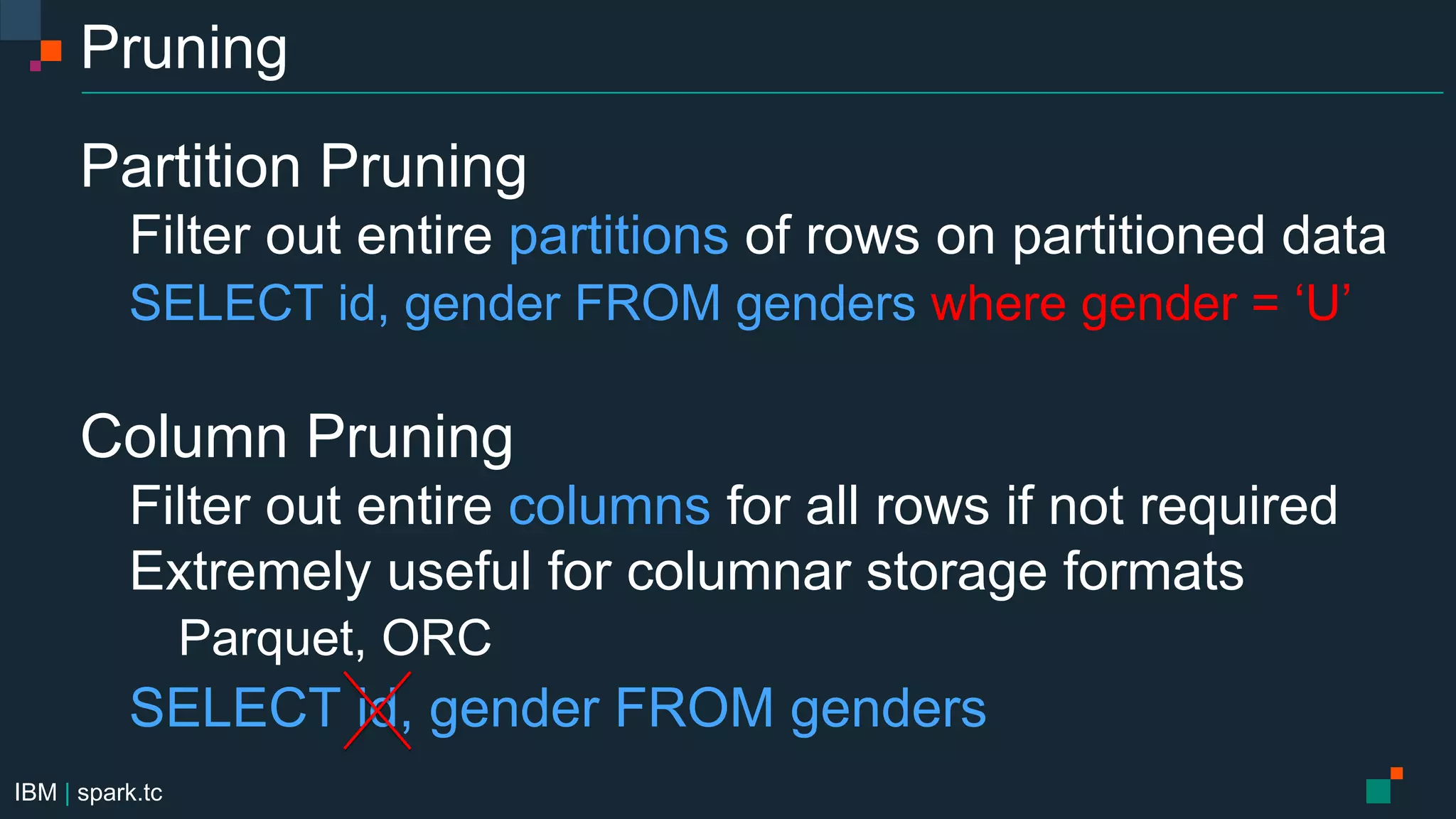
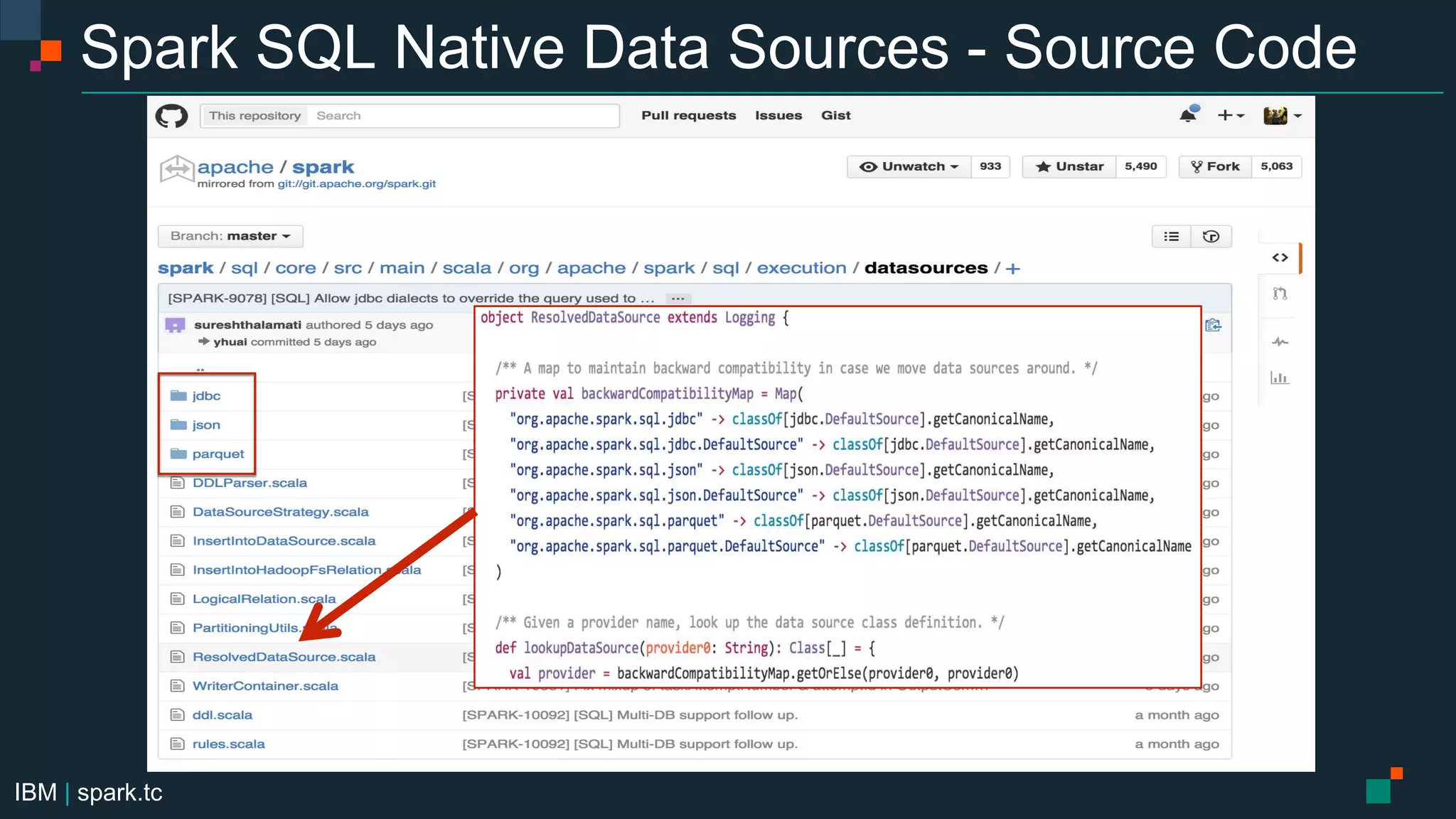
The document details a meetup presentation about advanced Apache Spark, focusing on Spark SQL, DataFrames, and the Catalyst optimizer, delivered by Chris Fregly from IBM. It covers the structure, functionality, and performance tuning of DataFrames and introduces custom data sources, partitioning, and optimization techniques. Additionally, it outlines upcoming meetups and future topics related to Spark technology.