Downloaded 10 times


![{title: "The Great Gatsby", language: "English", subjects: "Long Island"} {title: "The Great Gatsby", language: "English", subjects: "New York"} {title: "The Great Gatsby", language: "English", subjects: "1920s"} {title: "The Great Gatsby", language: "English", subjects: [ "Long Island", "New York", "1920s"] }, {"$match":{"language":"English"}} $match { _id:"Long Island", count: 1 }, $group { _id: "New York", count: 2 }, $unwind { _id: "1920s", count: 1 }, $sort $skip$limit $project {"$unwind":"$subjects"} {"$group":{"_id":"$subjects", "count":{"$sum:1}} { _id: "Harlem", count: 1 }, { _id:"Long Island", count: 1 }, { _id: "New York", count: 2 }, { _id: "1920s", count: 1 }, {title: "Open City", language: "English", subjects: [ "New York" "Harlem" ] } { title: "The Great Gatsby", language: "English", subjects: [ "Long Island", "New York", "1920s"] }, { title: "War and Peace", language: "Russian", subjects: [ "Russia", "War of 1812", "Napoleon"] }, { title: "Open City", language: "English", subjects: [ "New York", "Harlem" ] }, {title: "Open City", language: "English", subjects: "New York"} {title: "Open City", language: "English", subjects: "Harlem"} { _id: "Harlem", count: 1 }, {"$sort:{"count":-1} {"$limit":3} {"$project":...}](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-6-2048.jpg)





![Update { } OR [ ] [ <aggregation-pipeline> ]](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-16-2048.jpg)

![{ _id: 1 } { _id: 1, a: 10 } { _id: 1, a: 100 } --- { _id: 1, a: "10" } db.coll.update({_id:1}, [ {$set:{a:{$sum:["$a",1]}}} ], {upsert:true}) { _id: 1, a: 1 } { _id: 1, a: 11 } { _id: 1, a: 101 } { _id: 1, a: 1 } { _id: 1, a: 1 }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-18-2048.jpg)
![{ _id: 1 } { _id: 1, a: 10 } { _id: 1, a: 100 } --- { _id: 1, a: "10" } db.coll.update({_id:1}, [ {$set:{a:{$add:["$a",1]}}} ], {upsert:true}) { _id: 1, a: 1 } { _id: 1, a: 11 } { _id: 1, a: 101 } { _id: 1, a: 1 } "errmsg" : "$add only supports numeric or date types, not string"](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-19-2048.jpg)
![{ _id: 1 } { _id: 1, a: 10 } { _id: 1, a: 100 } --- { _id: 1, a: "10" } db.coll.update({_id:1}, [ ], {upsert:true}) { _id:1, a: 21 } { _id: 1, a: 11 } { _id: 1, a: 101 } { _id:1, a: 21 }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-20-2048.jpg)
![{ _id: 1 } { _id: 1, a: 10 } { _id: 1, a: 100 } --- { _id: 1, a: "10" } db.coll.update({_id:1}, [ {$set:{a:{$cond:{ if: then: , else: }} }}] {upsert:true}) { _id:1, a: 21 } { _id: 1, a: 11 } { _id: 1, a: 101 } { _id:1, a: 21 }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-21-2048.jpg)
![{ _id: 1 } { _id: 1, a: 10 } { _id: 1, a: 100 } --- { _id: 1, a: "10" } db.coll.update({_id:1}, [ {$set:{a:{$cond:{ if: {$eq:[{$type:"$a"},"missing"]}, then: , else: }} }}], {upsert:true}) { _id:1, a: 21 } { _id: 1, a: 11 } { _id: 1, a: 101 } { _id:1, a: 21 }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-22-2048.jpg)
![{ _id: 1 } { _id: 1, a: 10 } { _id: 1, a: 100 } --- { _id: 1, a: "10" } db.coll.update({_id:1}, [ {$set:{a:{$cond:{ if: {$eq:[{$type:"$a"},"missing"]}, then: 21, else: {$sum:["$a", 1]} }} }}], {upsert:true}) { _id:1, a: 21 } { _id: 1, a: 11 } { _id: 1, a: 101 } { _id:1, a: 21 }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-23-2048.jpg)
![{ _id: 1 } { _id: 1, a: 10 } { _id: 1, a: 100 } --- { _id: 1, a: "10" } db.coll.update({_id:1}, [ {$set:{a:{$cond:{ if: {$eq:[{$type:"$a"},"missing"]}, then: 21, else: {$sum:["$a", 1]} }} }}], {upsert:true}) { _id:1, a: 21 } { _id: 1, a: 11 } { _id: 1, a: 100 } { _id:1, a: 21 }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-24-2048.jpg)
![{ _id: 1 } { _id: 1, a: 10 } { _id: 1, a: 100 } --- { _id: 1, a: "10" } db.coll.update({_id:1}, [ {$set:{a:{$min:[ 100, {$cond:{ if: {$eq:[{$type:"$a"},"missing"]}, then: 21, else: {$sum:["$a", 1]} }}]} }}], {upsert:true}) { _id:1, a: 21 } { _id: 1, a: 11 } { _id: 1, a: 100 } { _id:1, a: 21 }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-25-2048.jpg)
![{ _id: 1 } { _id: 1, a: 10 } { _id: 1, a: 100 } --- { _id: 1, a: "10" } db.coll.update({_id:1}, [ {$set:{a:{$min:[ 100, {$cond:{ if: {$eq:[{$type:"$a"},"missing"]}, then: 21, else: {$sum:["$a", 1]} }}]} }}], {upsert:true}) { _id:1, a: 21 } { _id: 1, a: 11 } { _id: 1, a: 100 } { _id:1, a: 21 } { _id:1, a: 1 }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-26-2048.jpg)
![{ _id: 1 } { _id: 1, a: 10 } { _id: 1, a: 100 } --- { _id: 1, a: "10" } db.coll.update({_id:1}, [ {$set:{a:{$min:[ 100, {$cond:{ if: {$eq:[{$type:"$a"},"missing"]}, then: 21, else: {$sum:["$a", 1]} }}]}, prev_a: "$a"}}], {upsert:true}) { _id:1, a: 21 } { _id: 1, a: 11 } { _id: 1, a: 100 } { _id:1, a: 21 } { _id:1, a: 1 }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-27-2048.jpg)
![{ _id: 1 } { _id: 1, a: 10 } { _id: 1, a: 100 } --- { _id: 1, a: "10" } db.coll.update({_id:1}, [ {$set:{a:{$min:[ 100, {$cond:{ if: {$eq:[{$type:"$a"},"missing"]}, then: 21, else: {$sum:["$a", 1]} }}]}, prev_a: "$a"}}], {upsert:true}) { _id:1, a: 21 } { _id: 1, a: 11, prev_a: 10 } { _id: 1, a: 100, prev_a: 100 } { _id:1, a: 21 } { _id:1, a: 1, prev_a: "10" }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-28-2048.jpg)

![Set Defaults {_id: 1, a: 5, b: 12} {_id: 2, a: 15, c: "abc"} {_id: 3, b: 99, c: "xyz"} If a or b are missing, set to 0, if c is missing -> "unset" db.coll.update({}, [ {$replaceWith:{ }} ], {multi:true})](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-30-2048.jpg)
![Set Defaults {_id: 1, a: 5, b: 12} {_id: 2, a: 15, c: "abc"} {_id: 3, b: 99, c: "xyz"} If a or b are missing, set to 0, if c is missing -> "unset" db.coll.update({}, [ {$replaceWith:{$mergeObjects:[ ]}} ], {multi:true})](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-31-2048.jpg)
![Set Defaults {_id: 1, a: 5, b: 12} {_id: 2, a: 15, c: "abc"} {_id: 3, b: 99, c: "xyz"} If a or b are missing, set to 0, if c is missing -> "unset" db.coll.update({}, [ {$replaceWith:{$mergeObjects:[ { a:0, b:0, c:"unset" }, "$$ROOT" ]}} ], {multi:true})](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-32-2048.jpg)
![Set Defaults {_id: 1, a: 5, b: 12, c: "unset"} {_id: 2, a: 15, b: 0, c: "abc"} {_id: 3, a: 0, b: 99, c: "xyz"} {_id: 1, a: 5, b: 12} {_id: 2, a: 15, c: "abc"} {_id: 3, b: 99, c: "xyz"} If a or b are missing, set to 0, if c is missing -> "unset" db.coll.update({}, [ {$replaceWith:{$mergeObjects:[ { a:0, b:0, c:"unset" }, "$$ROOT" ]}} ], {multi:true})](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-33-2048.jpg)
![Set array element upsert append update { id: 1, d: ISODate("2019-06-04T00:00:00"), h: [ { hour:"11", value: 296 }, { hour:"12", value: 300 } ]} id: X, d:Y, hour:Z, value: VAL db.coll.update({id:X, d:Y}, [ {$set:{h:{$cond:{ if: then: else: }}}}], {upsert:true})](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-34-2048.jpg)
![Set array element upsert append update { id: 1, d: ISODate("2019-06-04T00:00:00"), h: [ { hour:"11", value: 296 }, { hour:"12", value: 300 } ]} id: X, d:Y, hour:Z, value: VAL db.coll.update({id:X, d:Y}, [ {$set:{h:{$cond:{ if: {$in:[Z,{$ifNull:["$h.hour",[]]}]}, then:{$map:{ input:"$h", in: {$cond:{ if:{$ne:["$$this.hour",Z]}, then:"$$this", else: {hour: Z, value: {$sum:[ "$$this.value", VAL]}} }} }}, else:{$concatArrays:[{$ifNull:["$h",[]]},[{hour:Z,value:VAL}]]} }}}}], {upsert:true})](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-35-2048.jpg)


![MongoDB 4.2 이전 $out coll new_coll db.coll.aggregate( [ { pipeline }, ….. { $out: “new_coll” } ]) ; new_coll ○ must be unsharded ○ overwrites existing](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-38-2048.jpg)
![MongoDB 4.2 이후 $merge db.coll.aggregate( [ {pipeline}, ..., {$merge: { ... } ]); coll2 can exist same or different 'db' can be sharded coll coll2](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-39-2048.jpg)




![$merge 구문 { $merge: { into: <target>, on: <fields> } } on: "_id" on: [ "_id", "shardkey(s)" ] must be unique](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-44-2048.jpg)


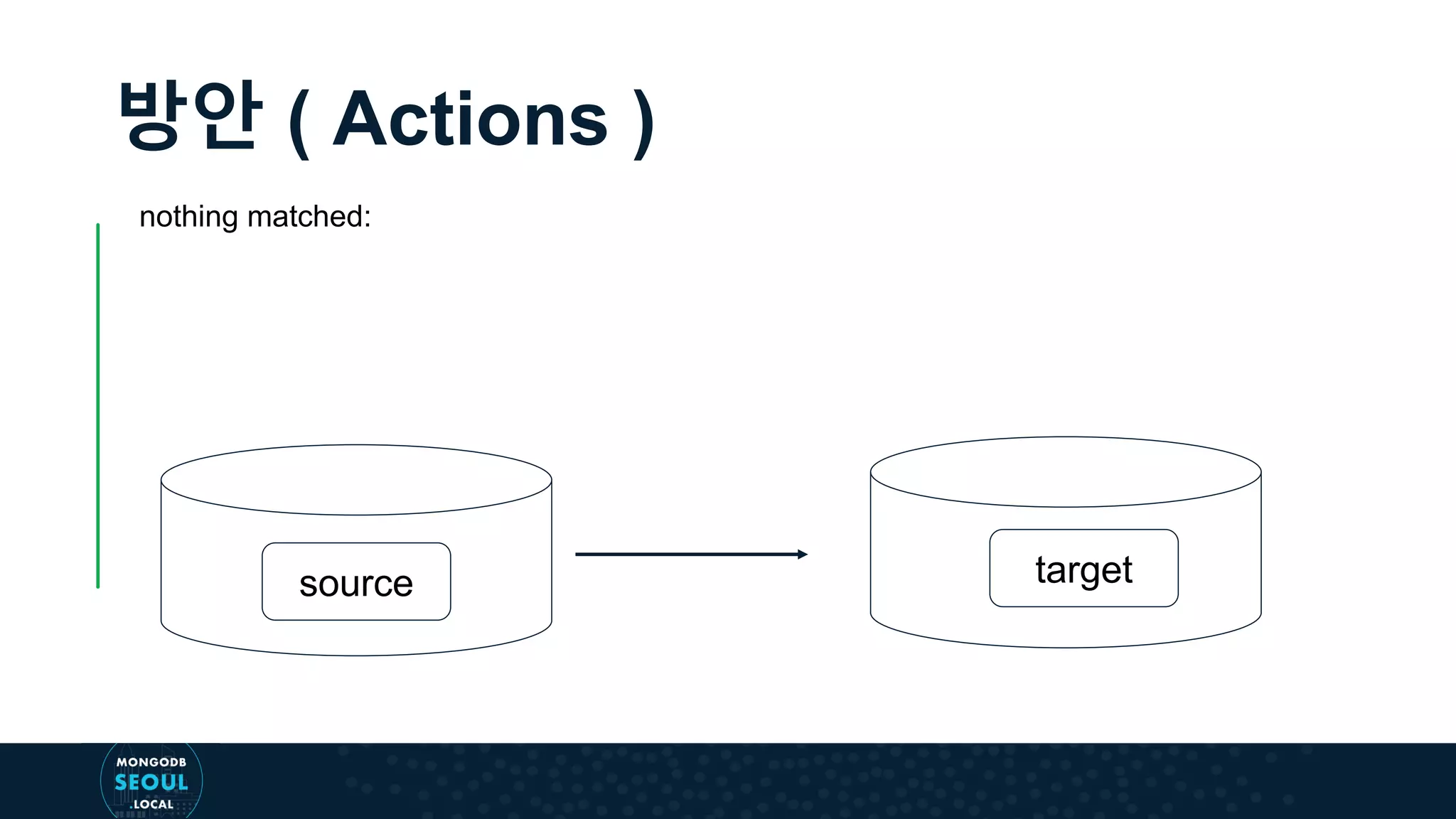





![$merge 구문 { $merge: { into: <target>, whenNotMatched:"insert"|"discard"|"fail", whenMatched:"merge"|"replace"|"keepExisting"|"fail"|[...] } }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-57-2048.jpg)
![$merge 구문 { $merge: { into: <target>, whenMatched:[...] } }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-58-2048.jpg)
![$merge 구문 { $merge: { into: <target>, whenMatched:[<custom pipeline>] } }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-59-2048.jpg)
![$merge 예제 { $merge: { into: <target>, whenMatched:[ {$addFields:{ }} ] } }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-60-2048.jpg)
![$merge 예제 { $merge: { into: <target>, whenMatched:[ {$addFields:{ total:{$sum:["$total","$$new.total"]} }} ] } }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-61-2048.jpg)
![$merge 예제 { $merge: { into: <target>, whenMatched:[ {$set:{ total:{$sum:["$total","$$new.total"]} }} ] } }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-62-2048.jpg)
![$merge 예제 { $merge: { into: <target>, whenMatched:[ {$set:{ total:{$sum:["$total","$$new.total"]} }} ] } }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-63-2048.jpg)
![$merge 예제 { $merge: { into: <target>, whenMatched:[ {$set:{ total:{$sum:["$total","$$new.total"]} }} ] } } Incoming Target { _id: "37", total: 64, f1: "x" } { _id: "37", total: 245, f1: "yyy" } Result: { }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-64-2048.jpg)
![$merge 예제 { $merge: { into: <target>, whenMatched:[ {$set:{ total:{$sum:["$total","$$new.total"]} }} ] } } Incoming Target { _id: "37", total: 64, f1: "x" } { _id: "37", total: 245, f1: "yyy" } Result: { _id: "37", total: 309, f1: "yyy" }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-65-2048.jpg)
![$merge 예제 2 { $merge: { into: <target>, whenMatched:[ {$replaceWith:{$mergeObjects:[ "$$new", {total:{$sum:["$$new.total", "$total"]}} ]}} ] } }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-66-2048.jpg)
![$merge 예제 2 { $merge: { into: <target>, whenMatched:[ {$replaceWith:{$mergeObjects:[ "$$new", {total:{$sum:["$$new.total", "$total"]}} ]}} ] } } Incoming Target { _id: "37", total: 64, f1: "x" } { _id: "37", total: 245, f1: "yyy" } Result: { }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-67-2048.jpg)
![$merge 예제 2 { $merge: { into: <target>, whenMatched:[ {$replaceWith:{$mergeObjects:[ "$$new", {total:{$sum:["$$new.total", "$total"]}} ]}} ] } } Incoming Target { _id: "37", total: 64, f1: "x" } { _id: "37", total: 245, f1: "yyy" } Result: { _id: "37", total: 309, f1: "x" }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-68-2048.jpg)
![$merge 구문 { $merge: { into: <target>, whenMatched:[...] } }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-69-2048.jpg)
![$merge 구문 { $merge: { into: <target>, let: { ... }, whenMatched:[ ...] } }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-70-2048.jpg)
![$merge 구문 { $merge: { into: <target>, let: {new: "$$ROOT"}, whenMatched:[ ...] } }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-71-2048.jpg)
![$merge 구문 { $merge: { into: <target>, whenMatched:[ {$set:{ total:{$sum:["$total","$$new.total"]} }} ] } }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-72-2048.jpg)
![$merge 구문 { $merge: { into: <target>, whenMatched:[ {$set:{ total:{$sum:["$total","$$new.total"]} }} ] } } { $merge:{ into:<target>, let:{itotal:"$total"}, whenMatched:[ {$set:{ total:{$sum:["$total","$$itotal"]} }} ] } }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-73-2048.jpg)


![aggregate 'temp' and append valid records to 'data' db.temp.aggregate( [ { ... } /* pipeline to massage and cleanse data in temp */, {$merge:{ into: "data", whenMatched: "fail" }} ]);](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-76-2048.jpg)
![aggregate 'temp' and append valid records to 'data' db.temp.aggregate( [ { ... } /* pipeline to massage and cleanse data in temp */, {$merge:{ into: "data", whenMatched: "fail" }} ]); Similar to SQL's INSERT INTO T1 SELECT * from T2](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-77-2048.jpg)


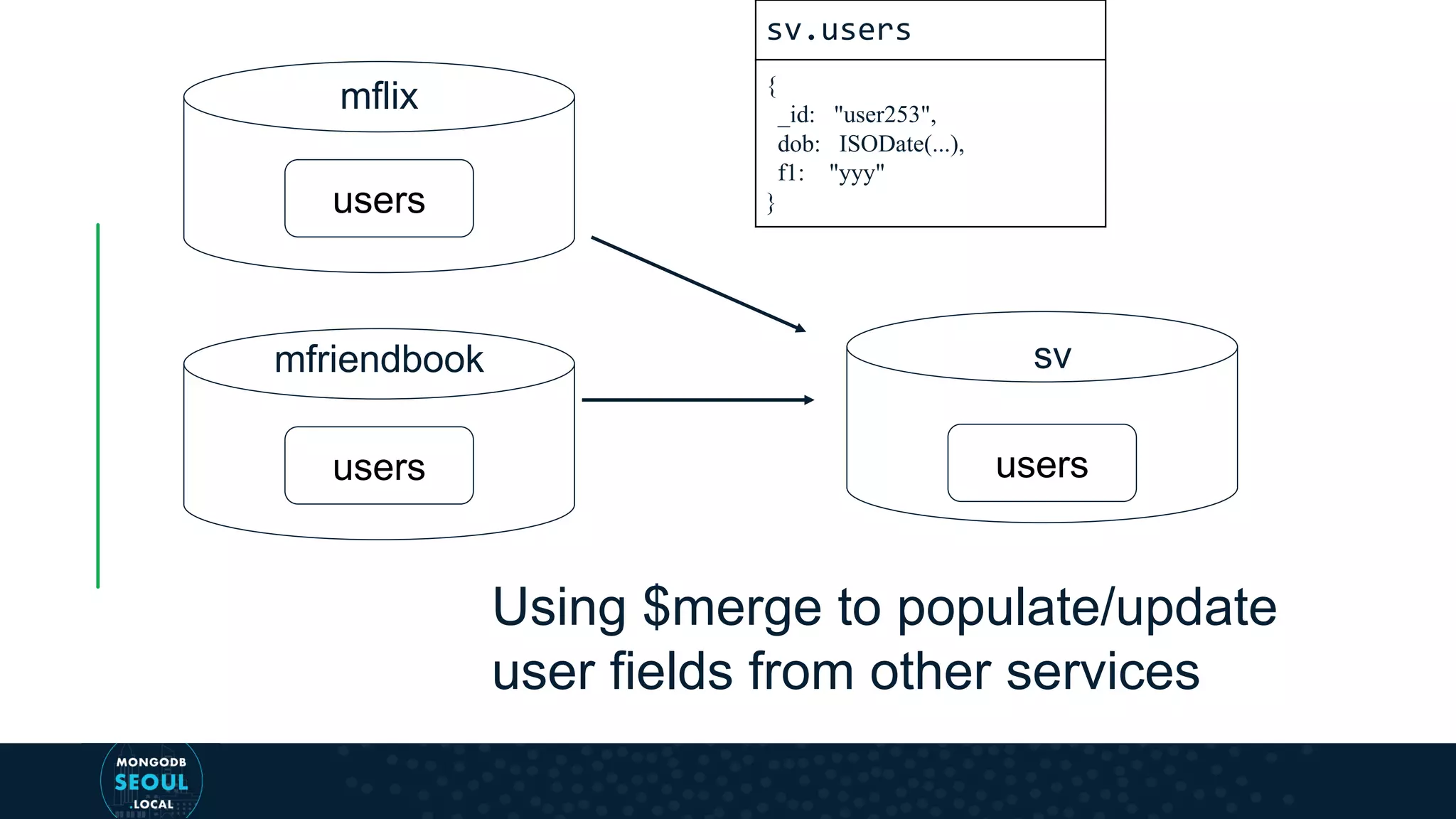
![$merge updates fields from mflix.users collection into sv.users collection. Our "_id" field is unique username mflix_pipeline = [ {"$project" : { "_id" : "$username", "mflix" : "$$ROOT" }}, {"$merge" : { "into" : { "db": "sv", "collection" : "users" }, "whenNotMatched" : "discard" }} ] (in mflix) sv.users { _id: "user253", dob: ISODate(...), f1: "yyy" }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-81-2048.jpg)
![$merge updates fields from mflix.users collection into sv.users collection. Our "_id" field is unique username mflix_pipeline = [ {"$project" : { "_id" : "$username", "mflix" : "$$ROOT" }}, {"$merge" : { "into" : { "db": "sv", "collection" : "users" }, "whenNotMatched" : "discard" }} ] (in mflix) db.users.aggregate(mflix_pipeline) sv.users { _id: "user253", dob: ISODate(...), f1: "yyy", mflix: { ... } }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-82-2048.jpg)
![$merge updates fields from mfriendbook.users collection into sv.users collection. Our "_id" field is unique username mfriendbook_pipeline = [ {"$project" : { "_id" : "$username", "mfriendbook" : "$$ROOT" }}, {"$merge" : { "into" : { "db": "sv", "collection" : "users" }, "whenNotMatched" : "discard" }} ] (in mfriendbook) sv.users { _id: "user253", dob: ISODate(...), f1: "yyy", mflix: { ... } }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-83-2048.jpg)
![$merge updates fields from mfriendbook.users collection into sv.users collection. Our "_id" field is unique username mfriendbook_pipeline = [ {"$project" : { "_id" : "$username", "mfriendbook" : "$$ROOT" }}, {"$merge" : { "into" : { "db": "sv", "collection" : "users" }, "whenNotMatched" : "discard" }} ] (in mfriendbook) db.users.aggregate(mfriendbook_pipeline) sv.users { _id: "user253", dob: ISODate(...), f1: "yyy", mflix: { ... }, mfriendbook: { ... } }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-84-2048.jpg)



![$merge to create/update periodic rollups in summary collection (for all days) db.regsummary.createIndex({event:1, date:1}, {unique: true}); db.registrations.aggregate([ {$match: {event_id: "MDBW19"}}, {$group:{ _id:{$dateToString:{date:"$date",format:"%Y-%m-%d"}}, count: {$sum:1} }}, {$project: {_id:0,event:"MDBW19",date:"$_id",total:"$count"}}, {$merge: { into: "regsummary", on: ["event", "date"] }} ])](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-88-2048.jpg)
![$merge to create/update periodic rollups in summary collection (for all days) db.regsummary.createIndex({event:1, date:1}, {unique: true}); db.registrations.aggregate([ {$match: {event_id: "MDBW19"}}, {$group:{ _id:{$dateToString:{date:"$date",format:"%Y-%m-%d"}}, count: {$sum:1} }}, {$project: {_id:0,event:"MDBW19",date:"$_id",total:"$count"}}, {$merge: { into: "regsummary", on: ["event", "date"] }} ]) { "event" : "MDBW19", "date" : "2019-05-19", "total" : 33 } { "event" : "MDBW19", "date" : "2019-05-20", "total" : 15 } { "event" : "MDBW19", "date" : "2019-05-21", "total" : 24 }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-89-2048.jpg)
![$merge to incrementally update periodic rollups in summary collection (for single day) db.registrations.aggregate([ {$match: { event_id: "MDBW19", date:{$gte:ISODate("2019-05-22"),$lt:ISODate("2019-05-23")} }}, {$count: "total"}, {$addFields: {event:"MDBW19", "date":"2019-05-22"}}, {$merge: { into: "regsummary", on: ["event", "date"] }} ])](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-90-2048.jpg)
![$merge to incrementally update periodic rollups in summary collection (for single day) db.registrations.aggregate([ {$match: { event_id: "MDBW19", date:{$gte:ISODate("2019-05-22"),$lt:ISODate("2019-05-23")} }}, {$count: "total"}, {$addFields: {event:"MDBW19", "date":"2019-05-22"}}, {$merge: { into: "regsummary", on: ["event", "date"] }} ]) { "event" : "MDBW19", "date" : "2019-05-19", "total" : 33 } { "event" : "MDBW19", "date" : "2019-05-20", "total" : 15 } { "event" : "MDBW19", "date" : "2019-05-21", "total" : 24 } { "event" : "MDBW19", "date" : "2019-05-22", "total" : 34 }](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-91-2048.jpg)

![Aggregation Pipeline Power [김준] https://www.research.net/r/AggPipelineSeoul](https://image.slidesharecdn.com/9-190916180938/75/Aggregation-Pipeline-Power-MongoDB-4-2-MongoDB-93-2048.jpg)

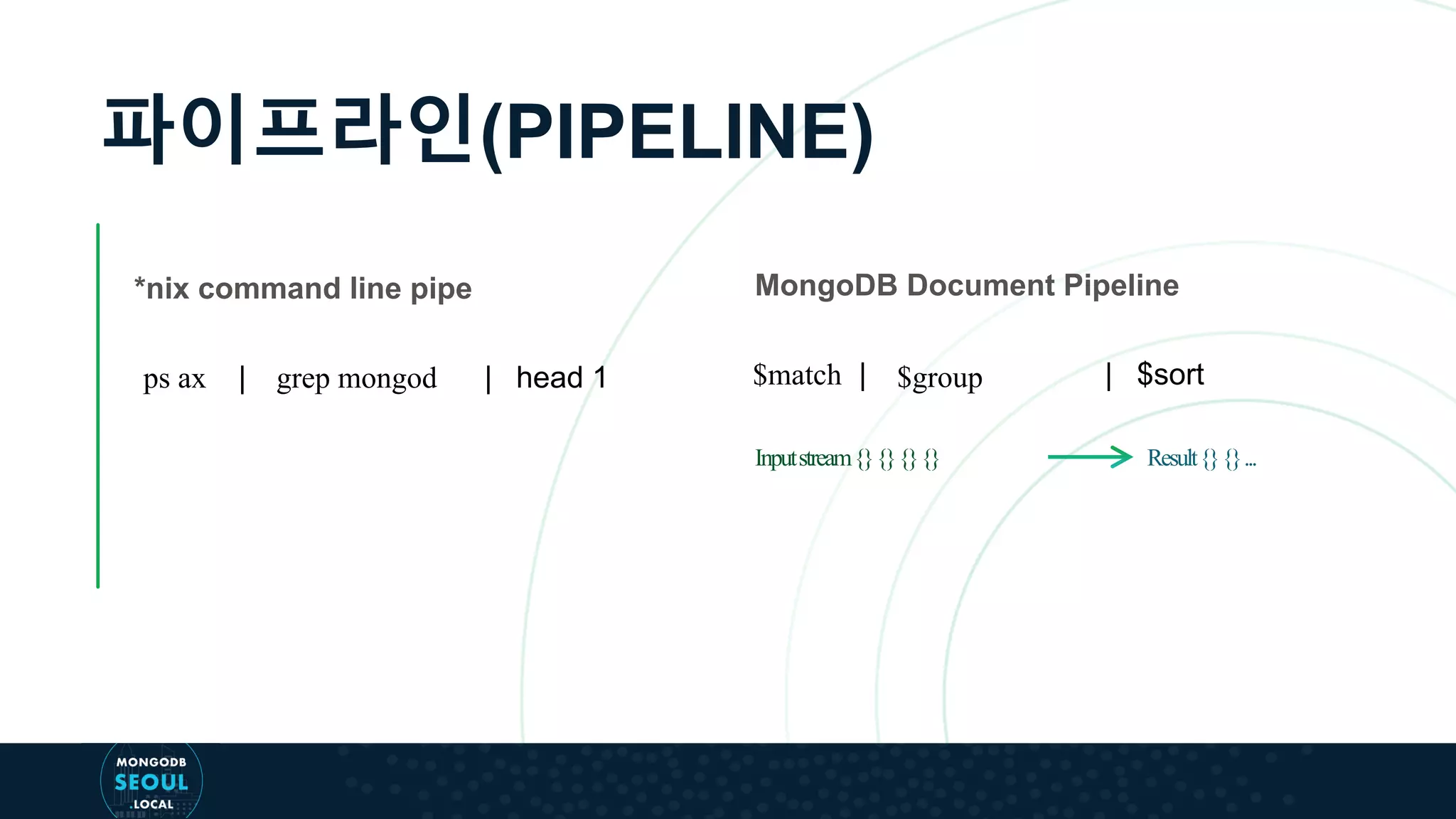
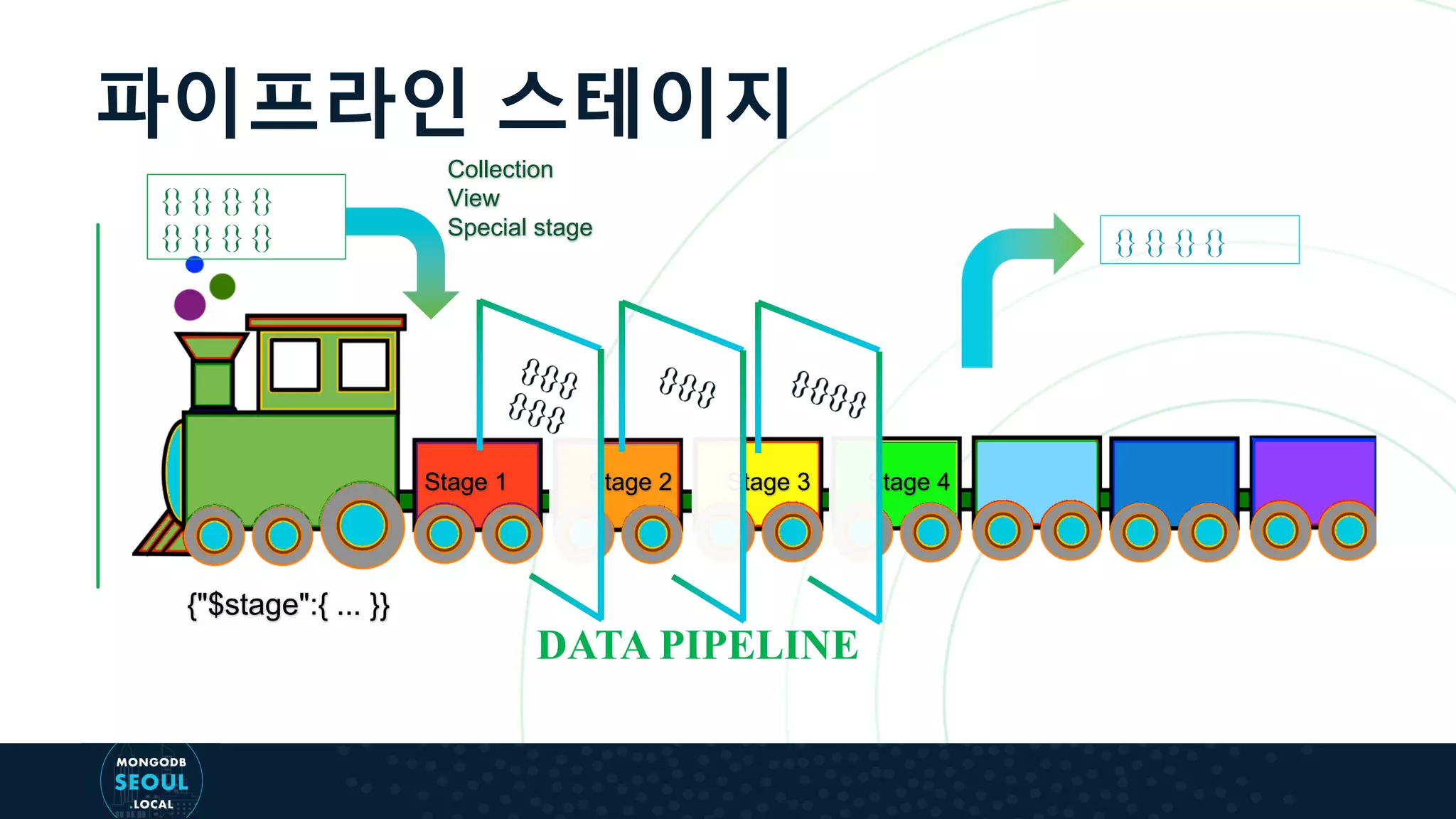
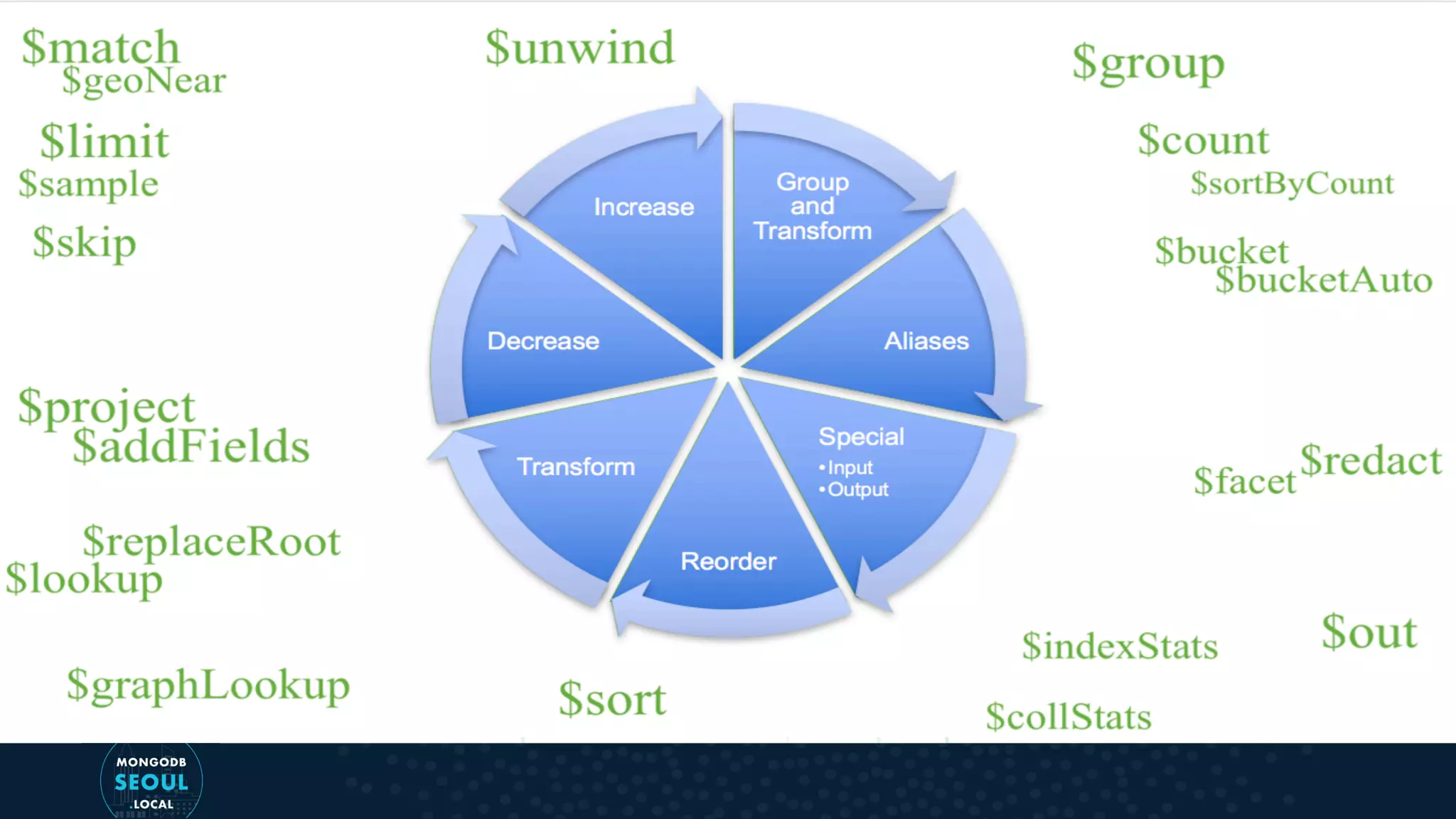
This document provides an overview of the aggregation pipeline in MongoDB 4.2, detailing its use for queries, updates, and specialized views. It explains how different stages of the pipeline work, including $match, $group, $unwind, and $sort, as well as the new $merge stage that allows for more flexible operations during aggregation. Additionally, it describes various update scenarios using aggregation pipelines, illustrating how existing document fields can be accessed and modified.