Downloaded 94 times







![Starting the shell ./bin/pyspark OR ./bin/spark-shell [Lots of output] SparkContext available as sc, SQLContext available as sqlContext. >>>](https://image.slidesharecdn.com/alpineacademyapachesparkseries1-introductiontoclustercomputingwithpythonaweebitofscala2-151106044359-lva1-app6891/75/Alpine-academy-apache-spark-series-1-introduction-to-cluster-computing-with-python-a-wee-bit-of-scala-8-2048.jpg)

![Sparkcontext: entry to the world Can be used to create RDDs from many input sources Native collections, local & remote FS Any Hadoop Data Source Also create counters & accumulators Automatically created in the shells (called sc) Specify master & app name when creating Master can be local[*], spark:// , yarn, etc. app name should be human readable and make sense etc.](https://image.slidesharecdn.com/alpineacademyapachesparkseries1-introductiontoclustercomputingwithpythonaweebitofscala2-151106044359-lva1-app6891/75/Alpine-academy-apache-spark-series-1-introduction-to-cluster-computing-with-python-a-wee-bit-of-scala-10-2048.jpg)






![Lets find the lines with the word “Spark” Get started in Python: import os src = "file:///"+os.environ['SPARK_HOME']+"/README.md" lines = sc.textFile(src) Get started in Scala: val src = "file:///" + sys.env("SPARK_HOME") + "/README.md" val lines = sc.textFile(src)](https://image.slidesharecdn.com/alpineacademyapachesparkseries1-introductiontoclustercomputingwithpythonaweebitofscala2-151106044359-lva1-app6891/75/Alpine-academy-apache-spark-series-1-introduction-to-cluster-computing-with-python-a-wee-bit-of-scala-17-2048.jpg)



![lets use toDebugString un-cached: >>> print word_count.toDebugString() (2) PythonRDD[17] at RDD at PythonRDD.scala:43 [] | MapPartitionsRDD[14] at mapPartitions at PythonRDD.scala:346 [] | ShuffledRDD[13] at partitionBy at NativeMethodAccessorImpl.java:-2 [] +-(2) PairwiseRDD[12] at reduceByKey at <stdin>:3 [] | PythonRDD[11] at reduceByKey at <stdin>:3 [] | MapPartitionsRDD[10] at textFile at NativeMethodAccessorImpl.java:-2 [] | file:////home/holden/repos/spark/README.md HadoopRDD[9] at textFile at NativeMethodAccessorImpl.java:-2 []](https://image.slidesharecdn.com/alpineacademyapachesparkseries1-introductiontoclustercomputingwithpythonaweebitofscala2-151106044359-lva1-app6891/75/Alpine-academy-apache-spark-series-1-introduction-to-cluster-computing-with-python-a-wee-bit-of-scala-21-2048.jpg)
![lets use toDebugString cached: >>> print word_count.toDebugString() (2) PythonRDD[8] at RDD at PythonRDD.scala:43 [] | MapPartitionsRDD[5] at mapPartitions at PythonRDD.scala:346 [] | ShuffledRDD[4] at partitionBy at NativeMethodAccessorImpl.java:-2 [] +-(2) PairwiseRDD[3] at reduceByKey at <stdin>:3 [] | PythonRDD[2] at reduceByKey at <stdin>:3 [] | MapPartitionsRDD[1] at textFile at NativeMethodAccessorImpl.java:-2 [] | CachedPartitions: 2; MemorySize: 2.7 KB; ExternalBlockStoreSize: 0.0 B; DiskSize: 0.0 B | file:////home/holden/repos/spark/README.md HadoopRDD[0] at textFile at NativeMethodAccessorImpl.java:-2 []](https://image.slidesharecdn.com/alpineacademyapachesparkseries1-introductiontoclustercomputingwithpythonaweebitofscala2-151106044359-lva1-app6891/75/Alpine-academy-apache-spark-series-1-introduction-to-cluster-computing-with-python-a-wee-bit-of-scala-22-2048.jpg)


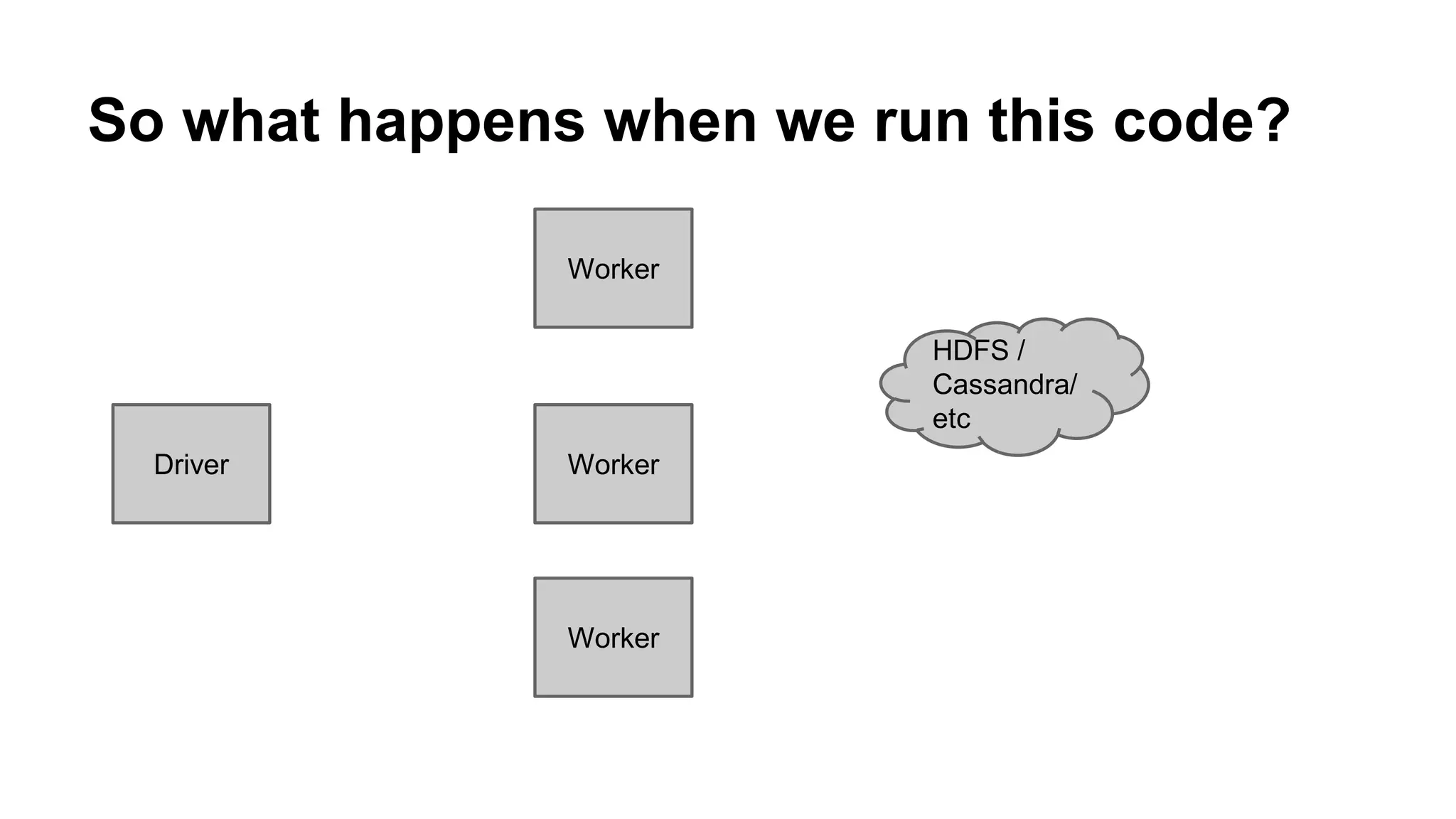
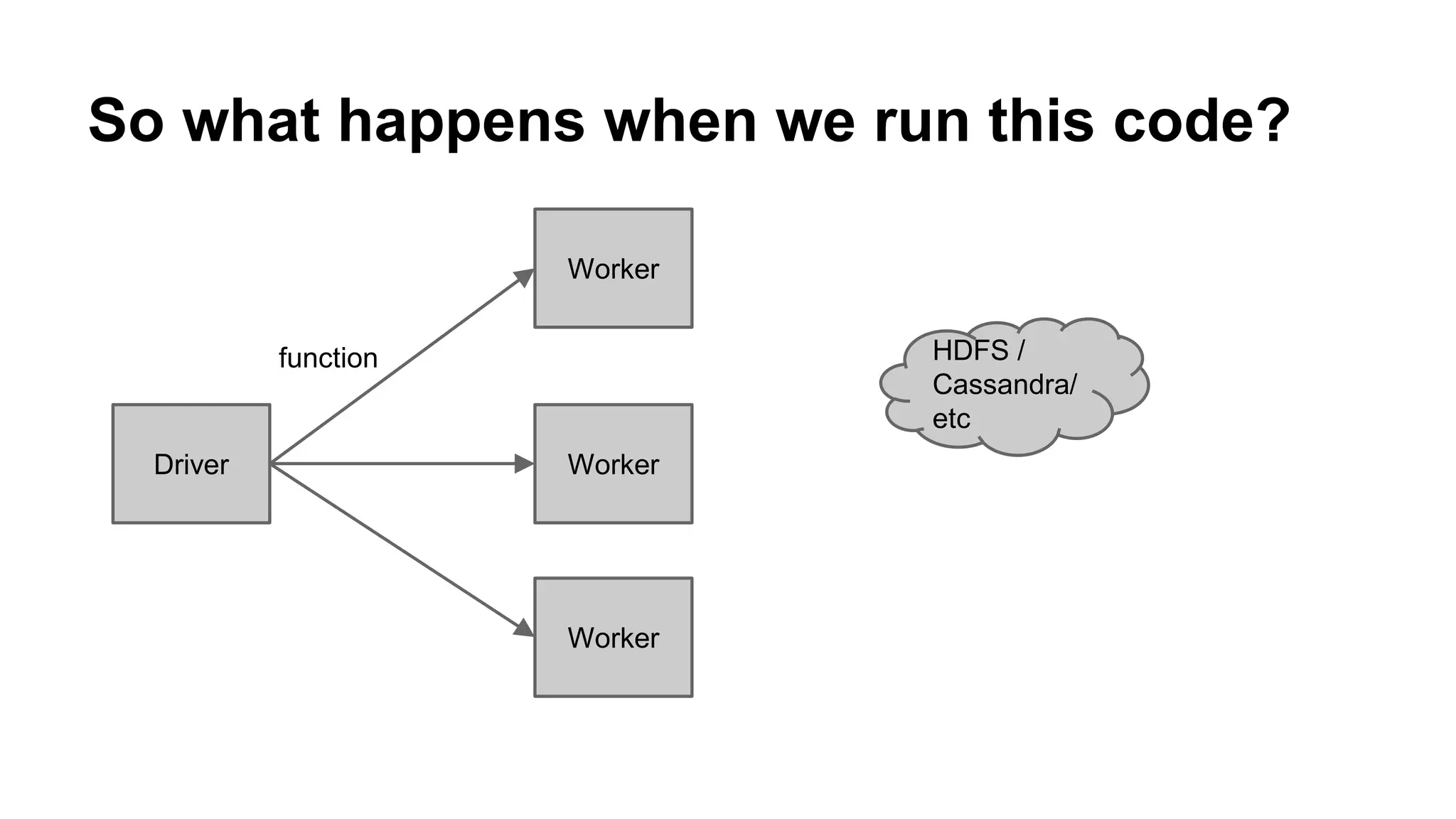
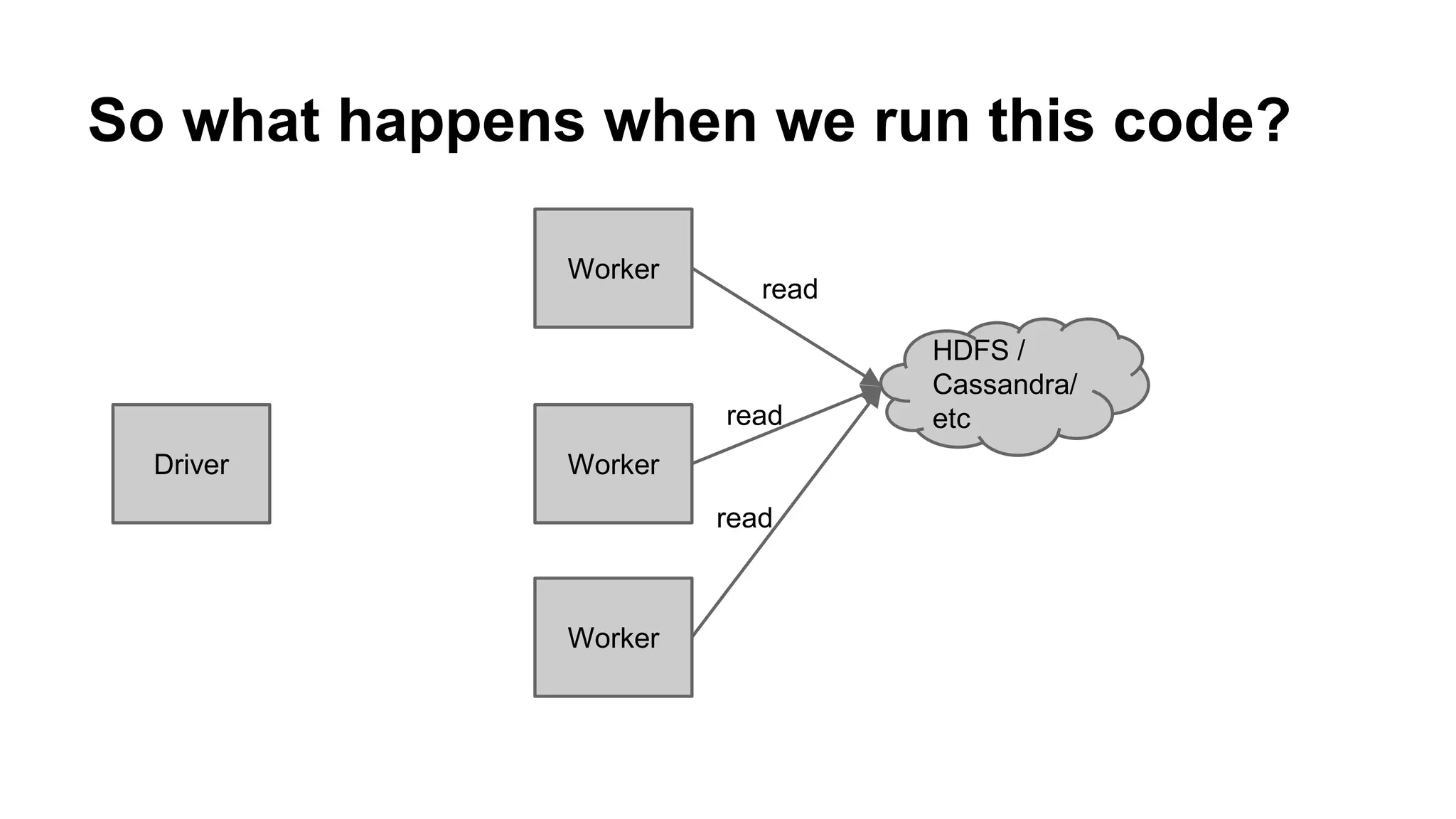
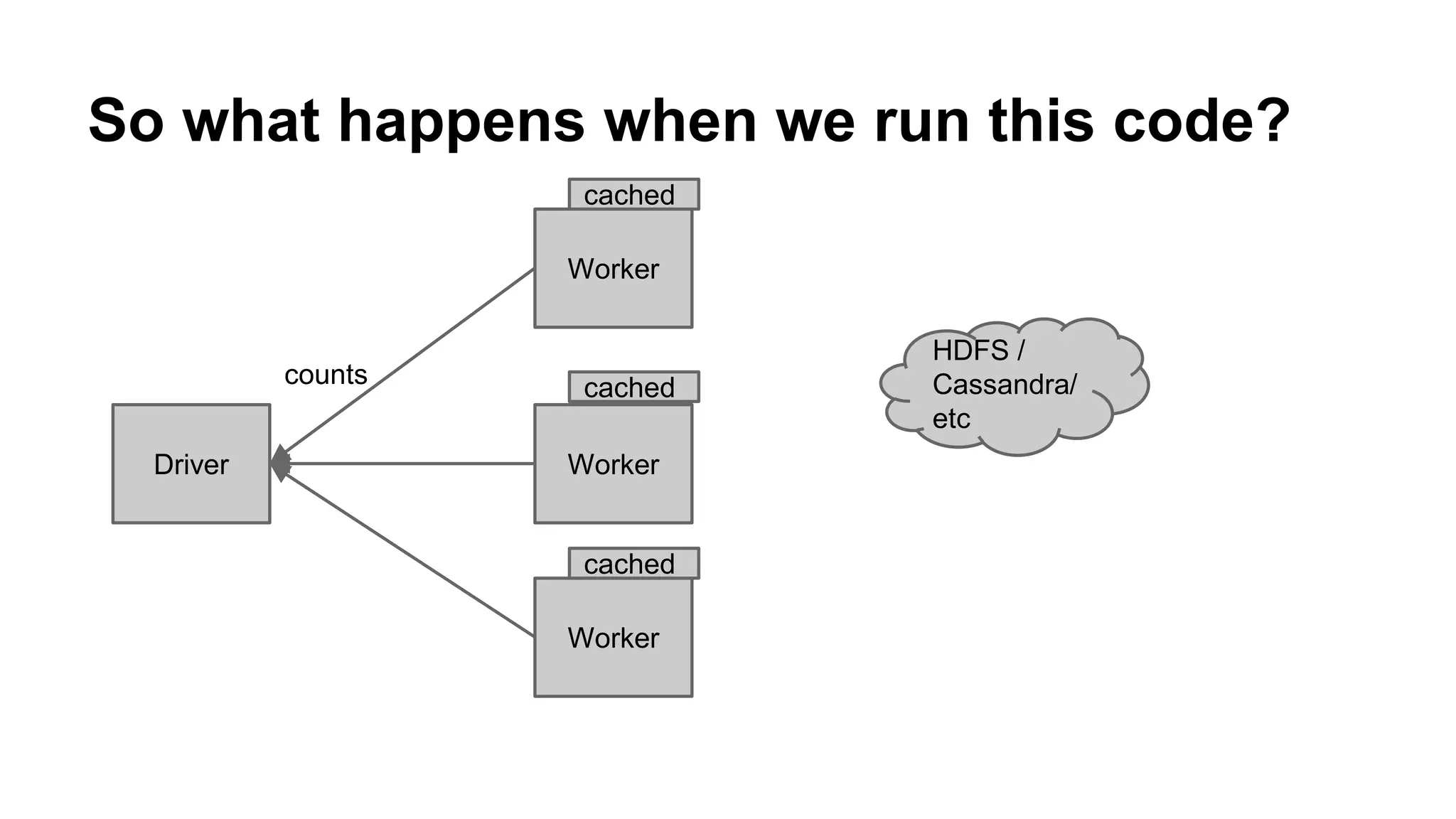













The document is a presentation by Holden Karau that introduces Apache Spark, a fast and general-purpose distributed computing system, emphasizing its capabilities for data processing with Python and Scala. It covers key concepts such as Resilient Distributed Datasets (RDDs), common transformations and actions, as well as Spark SQL and DataFrames for structured data. Additional resources and exercises are provided to help users get hands-on experience with Spark programming.