Downloaded 43 times





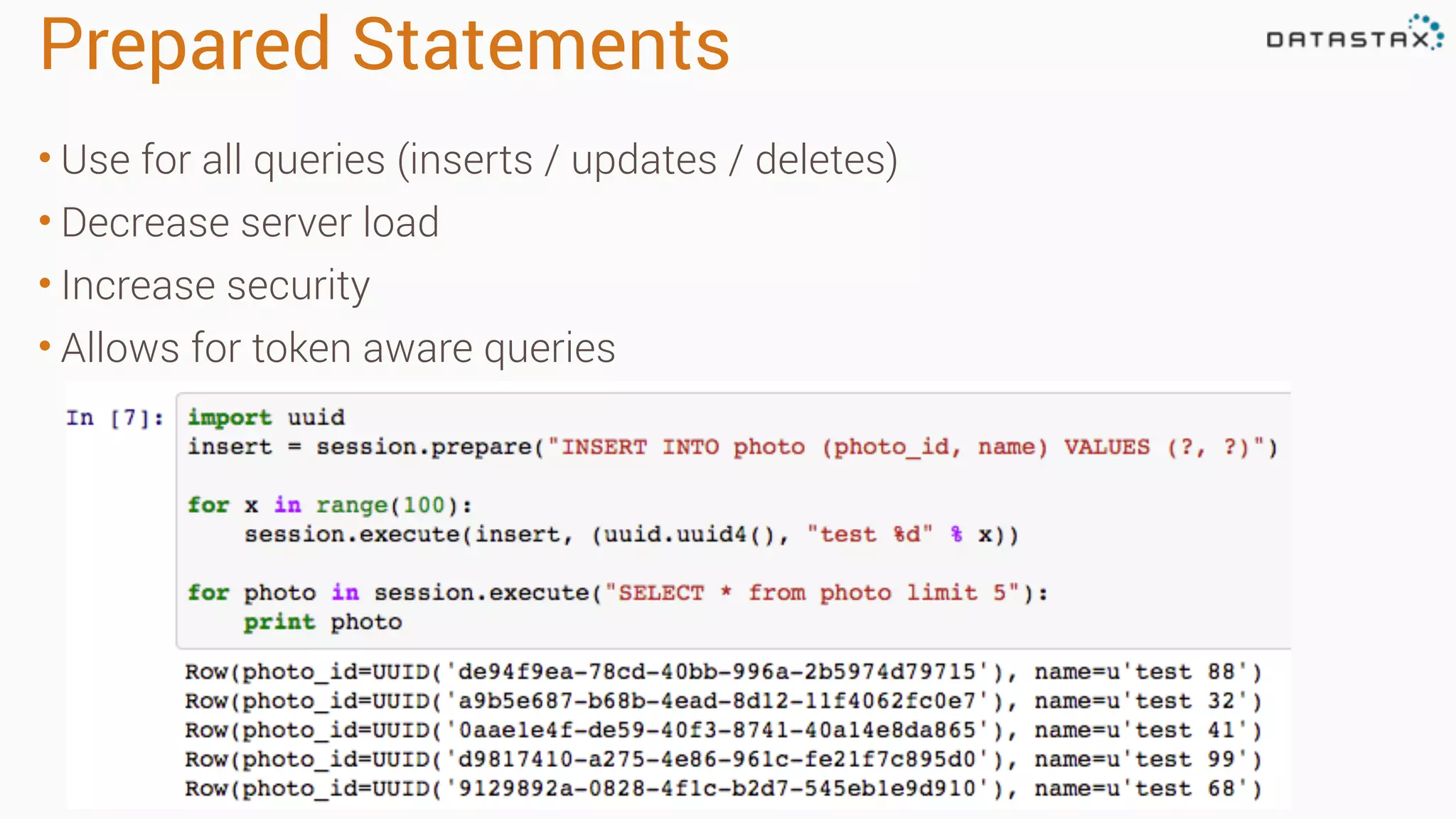

![1 from cassandra.concurrent import execute_concurrent_with_args 2 3 stmt = """SELECT * FROM sensor_data WHERE sensor_id=? 4 ORDER BY created_at DESC LIMIT 1""") 5 6 select_statement = session.prepare(stmt) 7 8 sensor_ids = [["f472d5ff-0c76-404a-8044-038db416685e"], 9 ["940cb741-d5b5-4c5d-82f5-bf1aa61c6d47"], 10 ["497d4b2c-cba2-4d0f-bd80-42de612690fd"], 11 ["1bdeac75-7e12-43ba-80b5-2d38405f9843"] 12 13 result = execute_concurrent_with_args(session, select_statement, sensor_ids) Async Queries (managed) prepared statement automatically manages concurrency](https://image.slidesharecdn.com/apachecassandraandpython-150323173334-conversion-gate01/75/Cassandra-Day-Atlanta-2015-Python-Cassandra-10-2048.jpg)














The document provides a technical overview of using the DataStax native Python driver to interact with Cassandra databases, including concepts such as connection pooling, query execution, and asynchronous operations. It introduces an object mapper (CQL engine) for simplifying the data modeling process and includes examples of defining models, handling concurrency, and managing data inserts. Additionally, it touches on application integration with frameworks like Flask and Django, and offers guidance on best practices for performance optimization.