
































































![Create Schema • • • • • • cassandra-cli -host localhost -port 9160 create keyspace TestsDataStore; show keyspaces; use TestsDataStore; create column family Cars with comparator = UTF8Type; update column family Cars with column_metadata = [ {column_name: make, validation_class: UTF8Type}, {column_name: model, validation_class: UTF8Type}, ];](https://image.slidesharecdn.com/apachecassandra-overview-140109094834-phpapp01/75/Apache-Cassandra-training-Overview-and-Basics-82-2048.jpg)
![Populate With Data • • • • • • • • • assume Cars keys as utf8; set Cars['Cabrio']['make'] = 'bmw' set Cars['Cabrio']['model'] = '640i'; set Cars['Corolla']['make'] = 'toyota'; set Cars['Corolla']['model'] = 'le'; set Cars['fit']['make'] = 'honda'; set Cars['fit']['model'] = 'fit sport'; set Cars['focus']['make'] = 'ford'; set Cars['focus']['model'] = 'sel';](https://image.slidesharecdn.com/apachecassandra-overview-140109094834-phpapp01/75/Apache-Cassandra-training-Overview-and-Basics-83-2048.jpg)
![Data Manipulation • • • • • • • • get Cars['Cabrio']; get Cars['Cabrio']['make']; update column family Cars with comparator=UTF8Type and column_metadata=[{column_name: make, validation_class: UTF8Type, index_type: KEYS}, {column_name: model, validation_class: UTF8Type}]; del Cars['Cabrio']['bmw']; drop column family Cars; drop keyspace TestsDataStore; show keyspaces;](https://image.slidesharecdn.com/apachecassandra-overview-140109094834-phpapp01/75/Apache-Cassandra-training-Overview-and-Basics-84-2048.jpg)




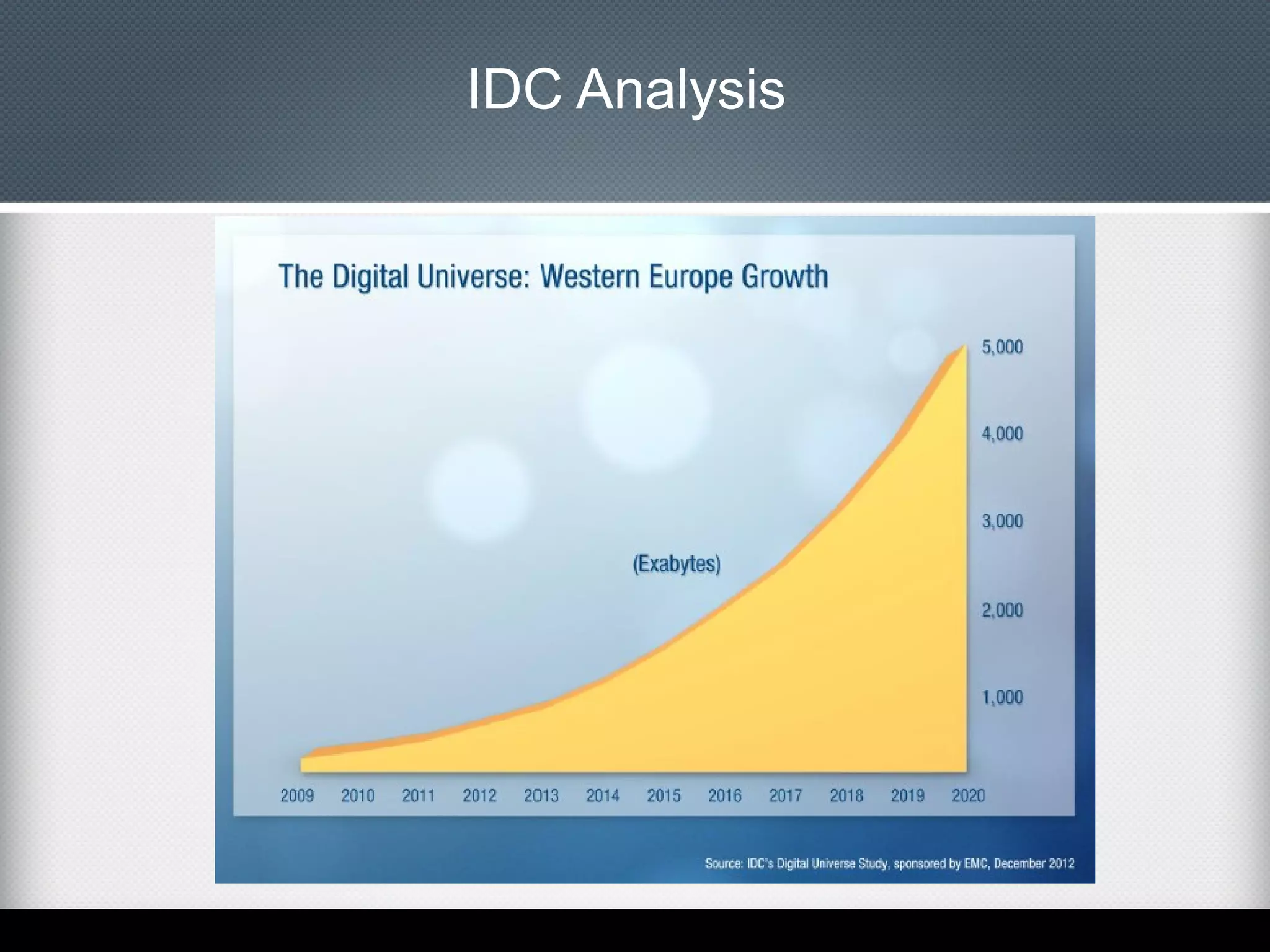
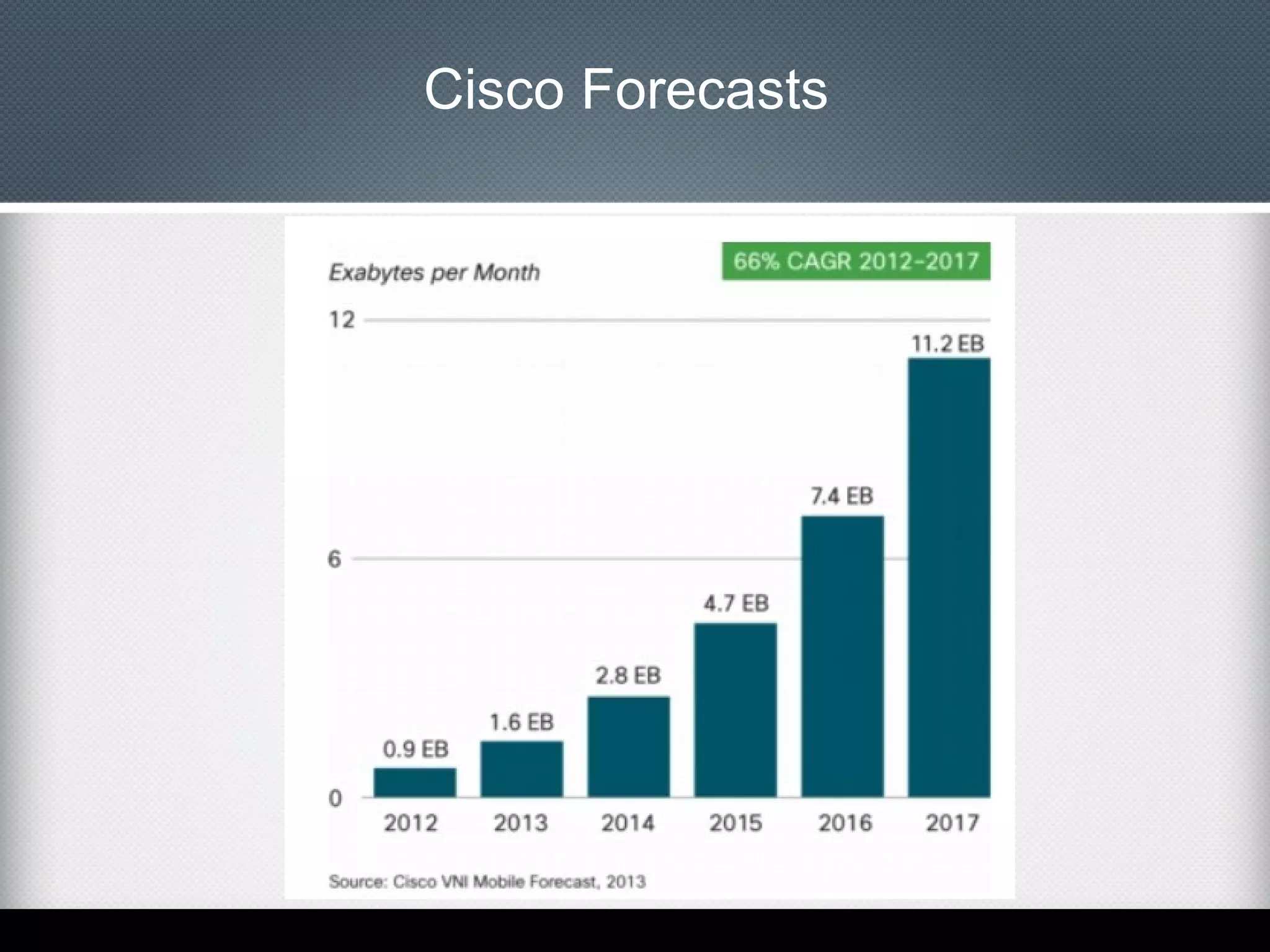
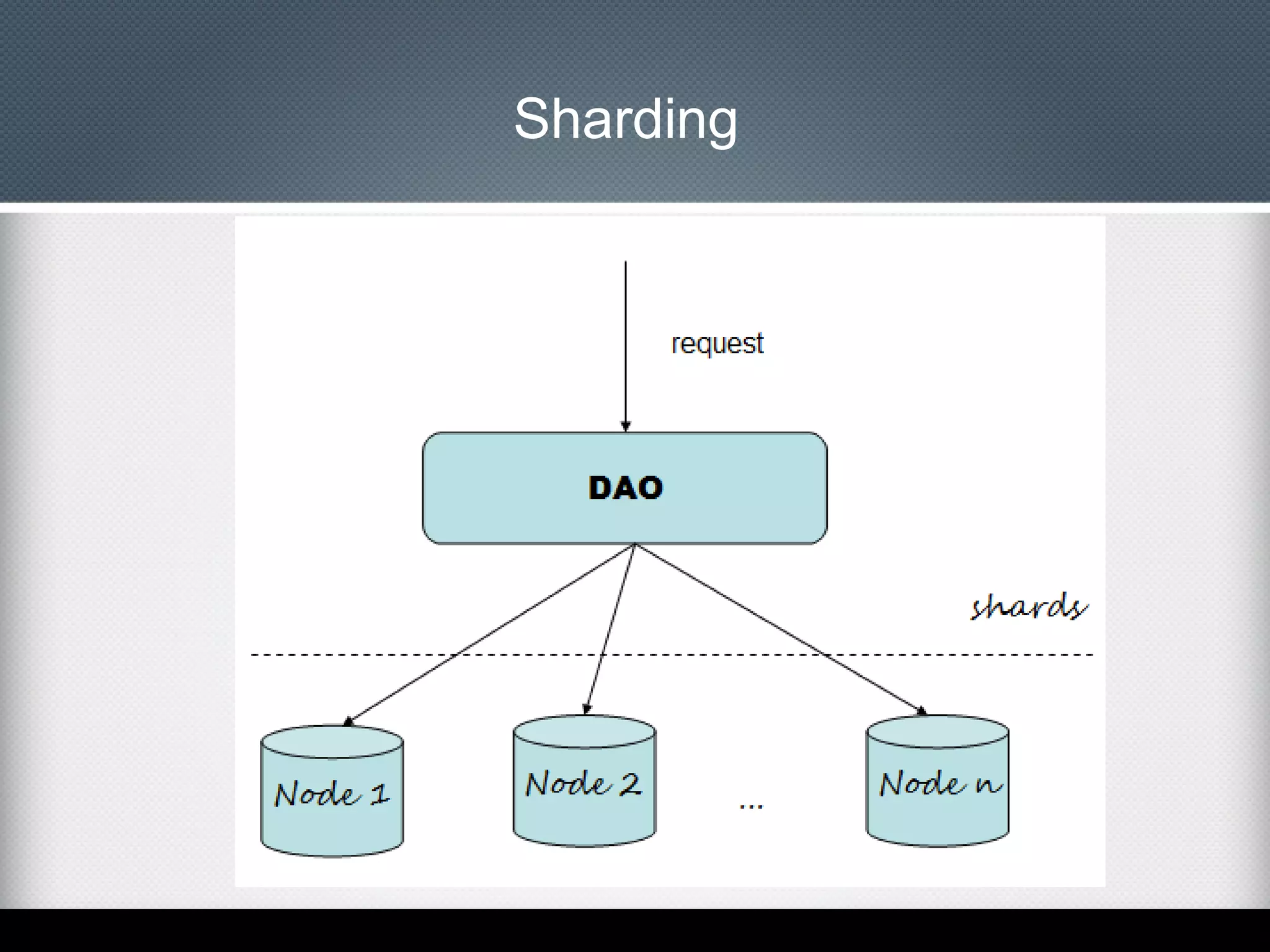
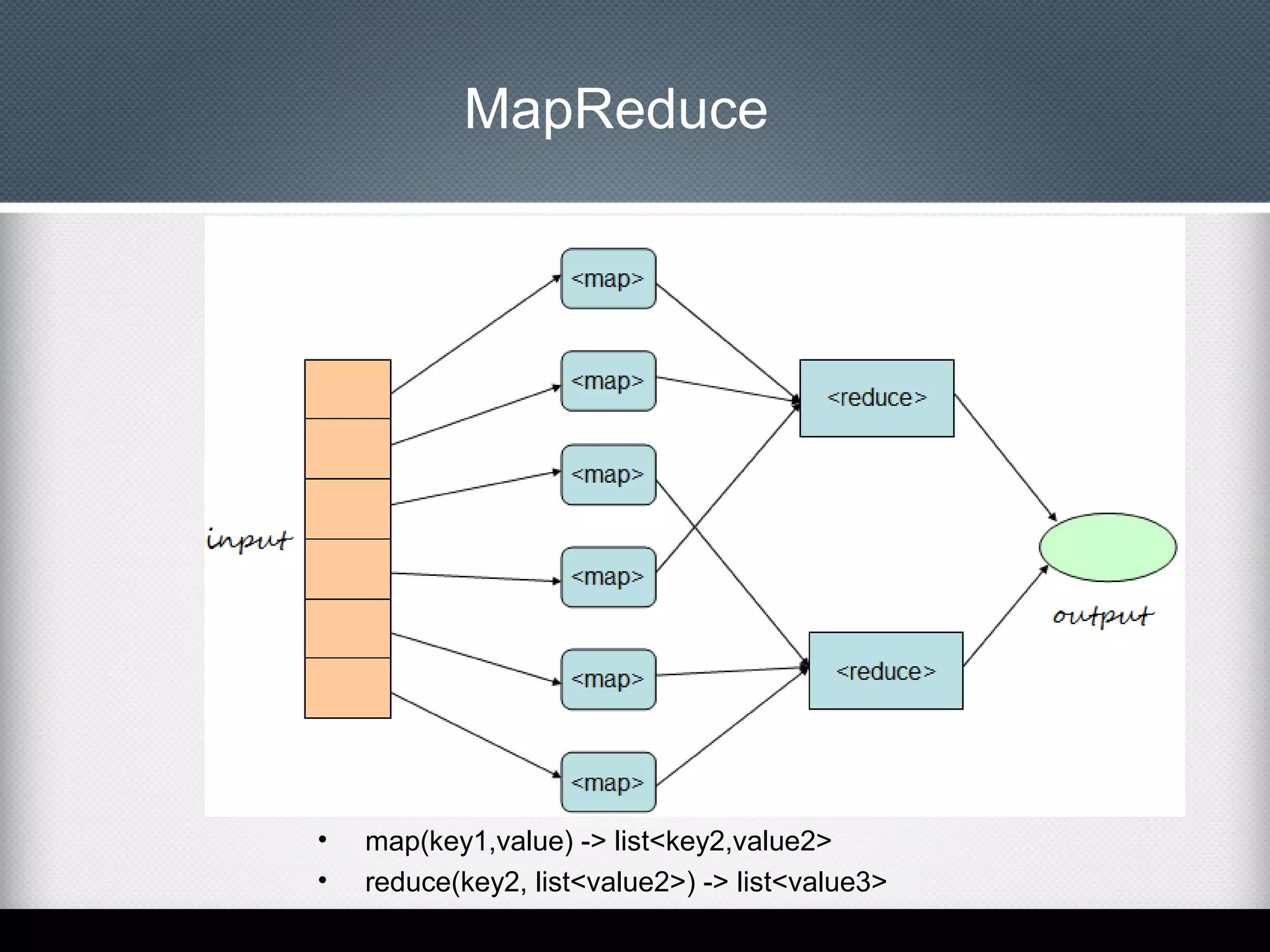
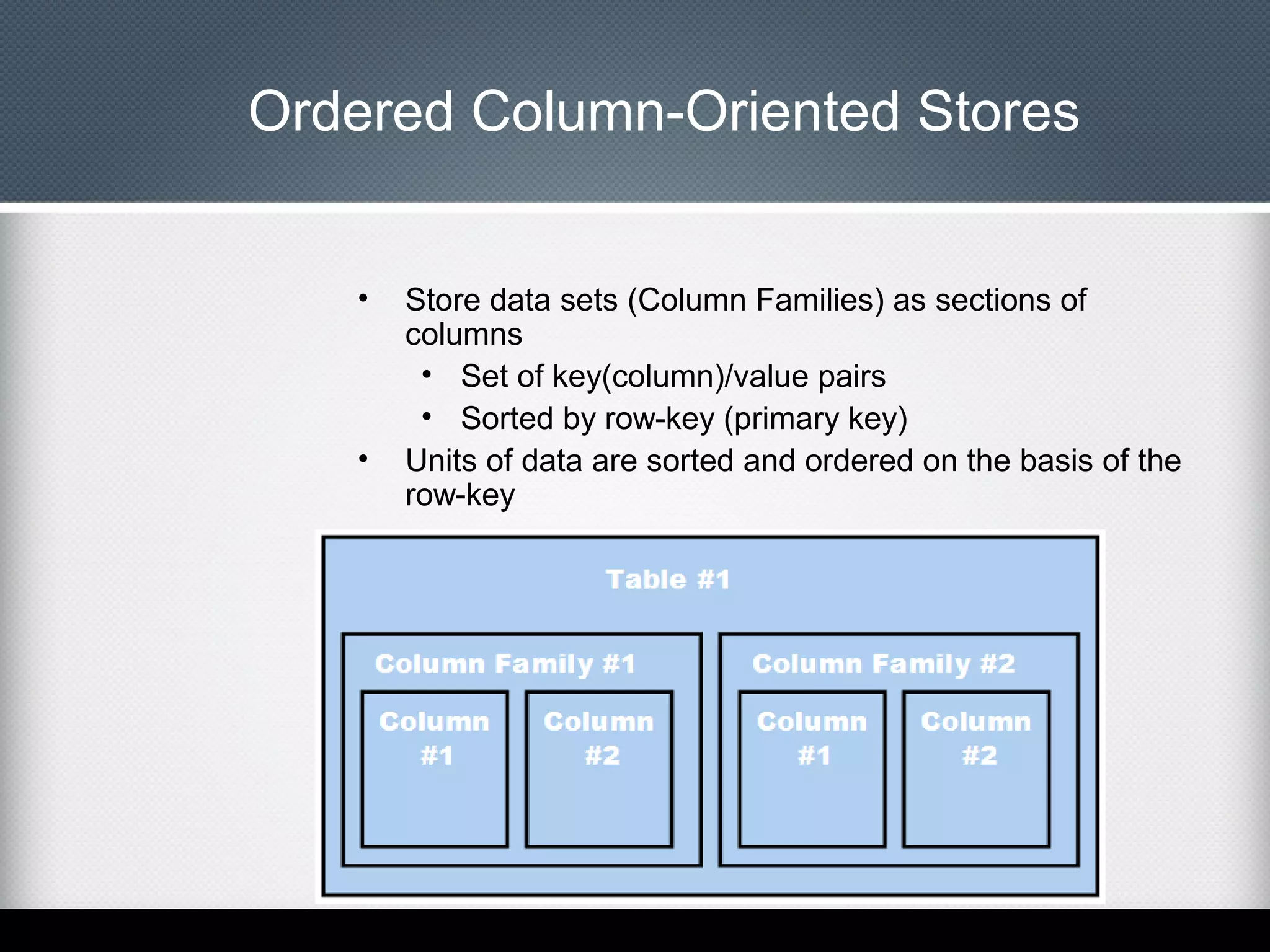
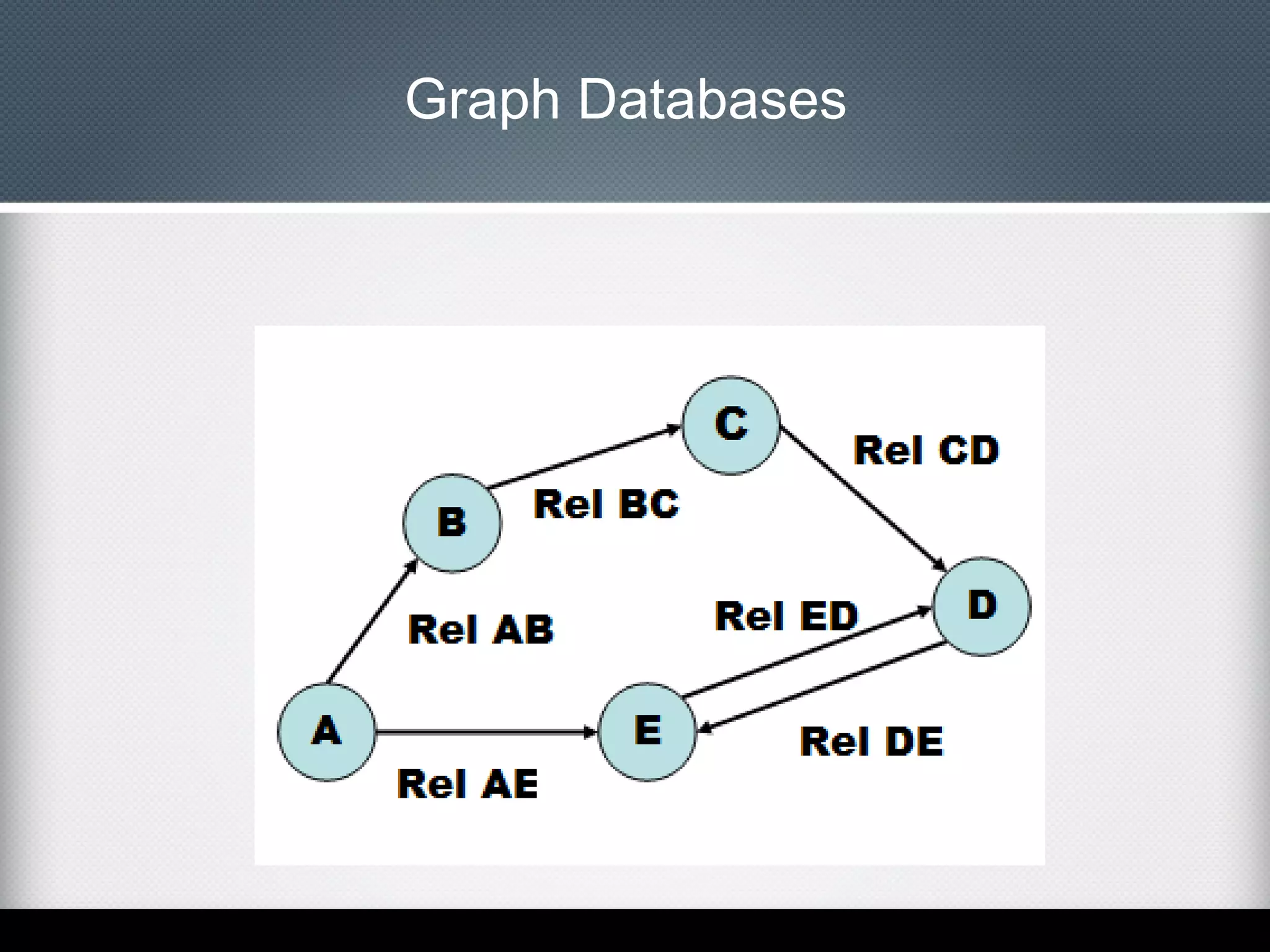
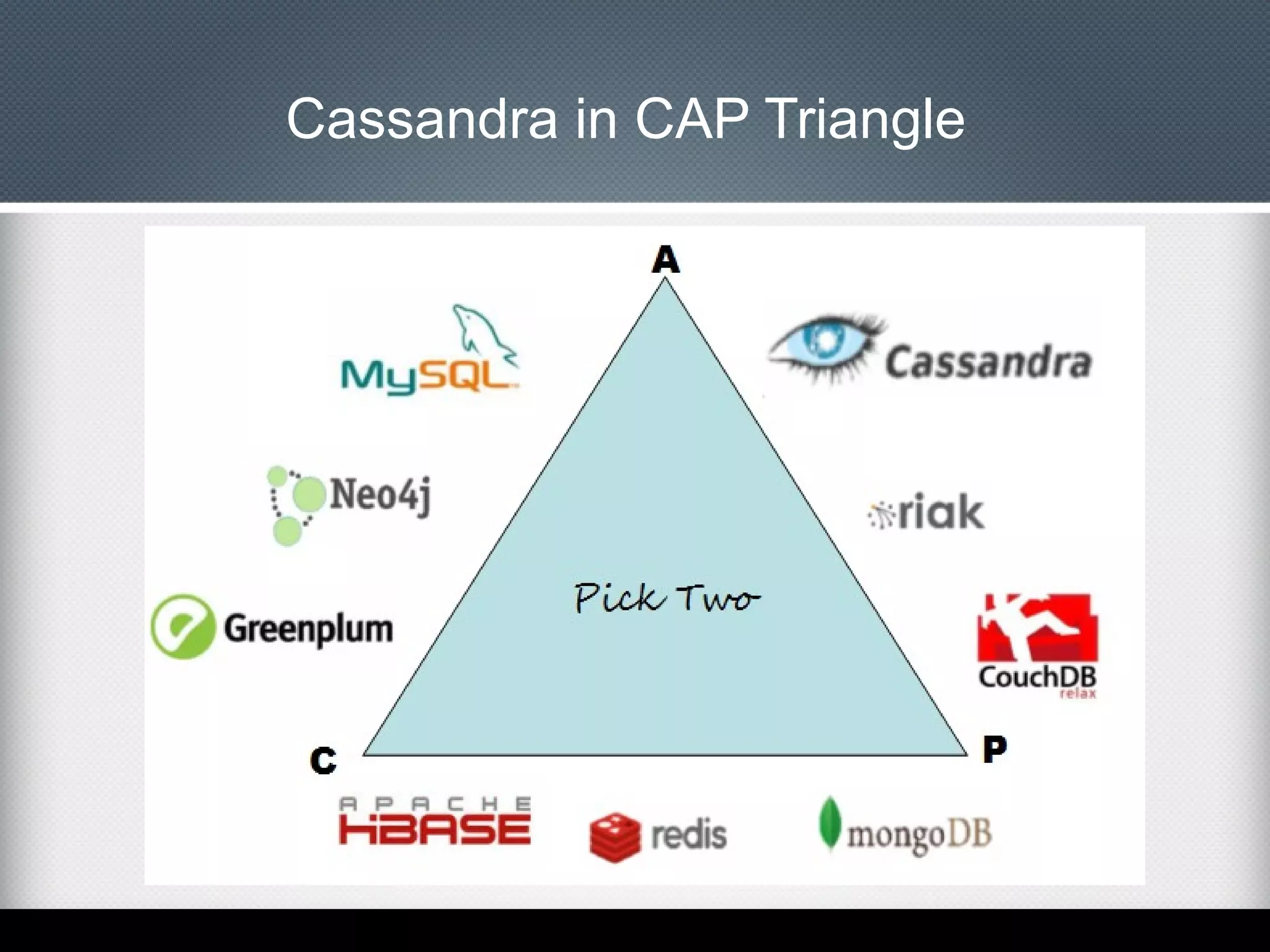
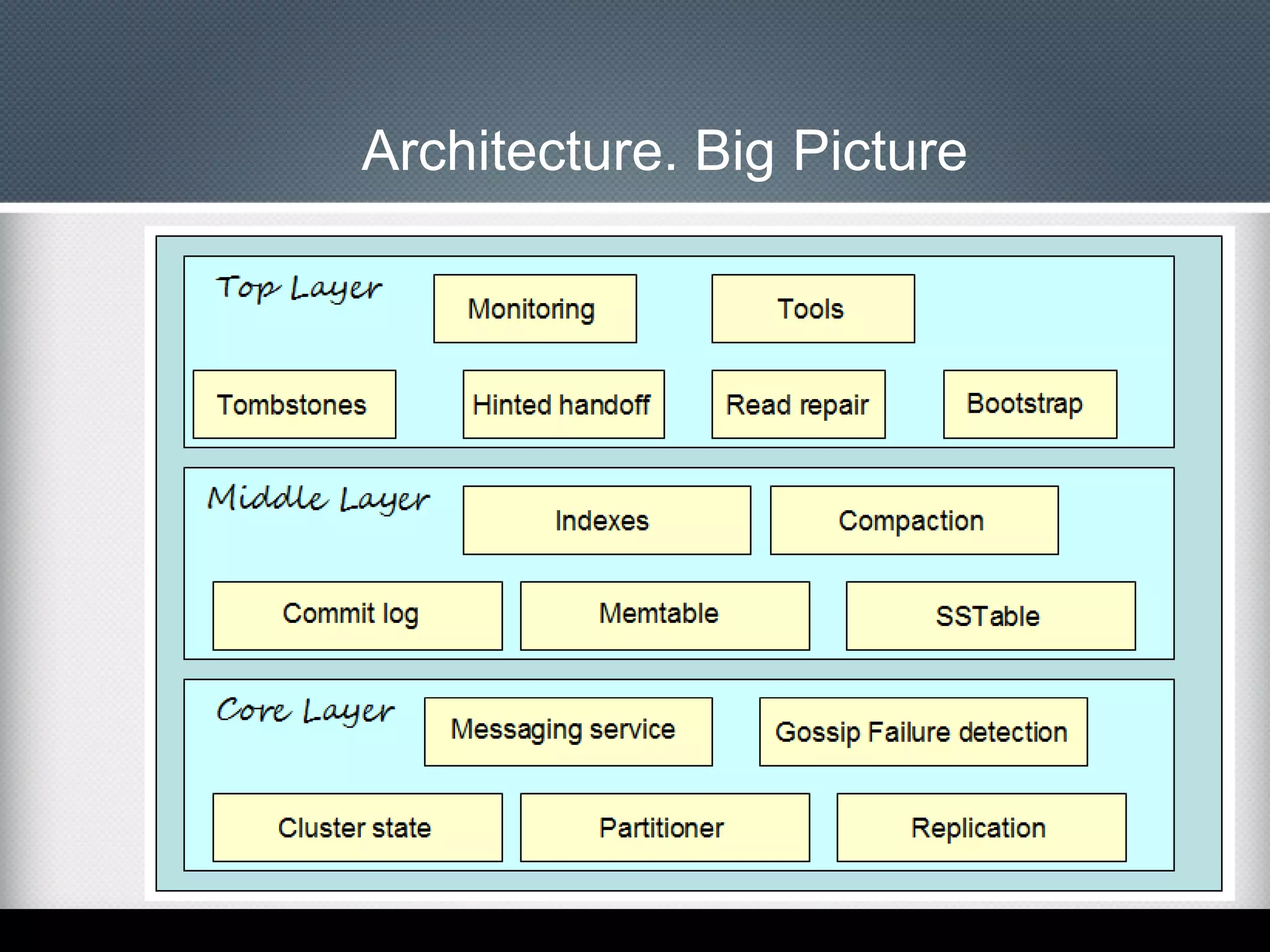
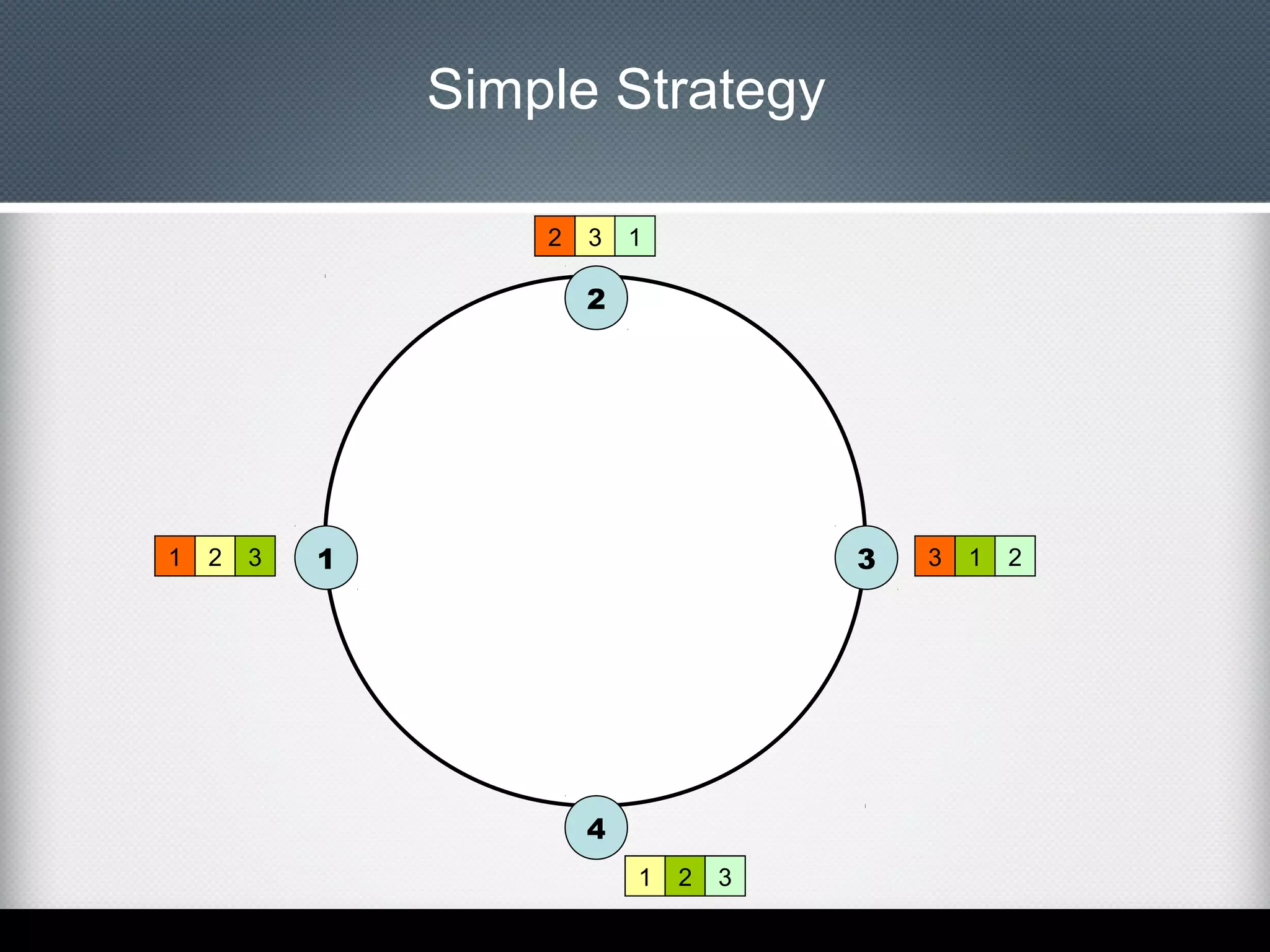
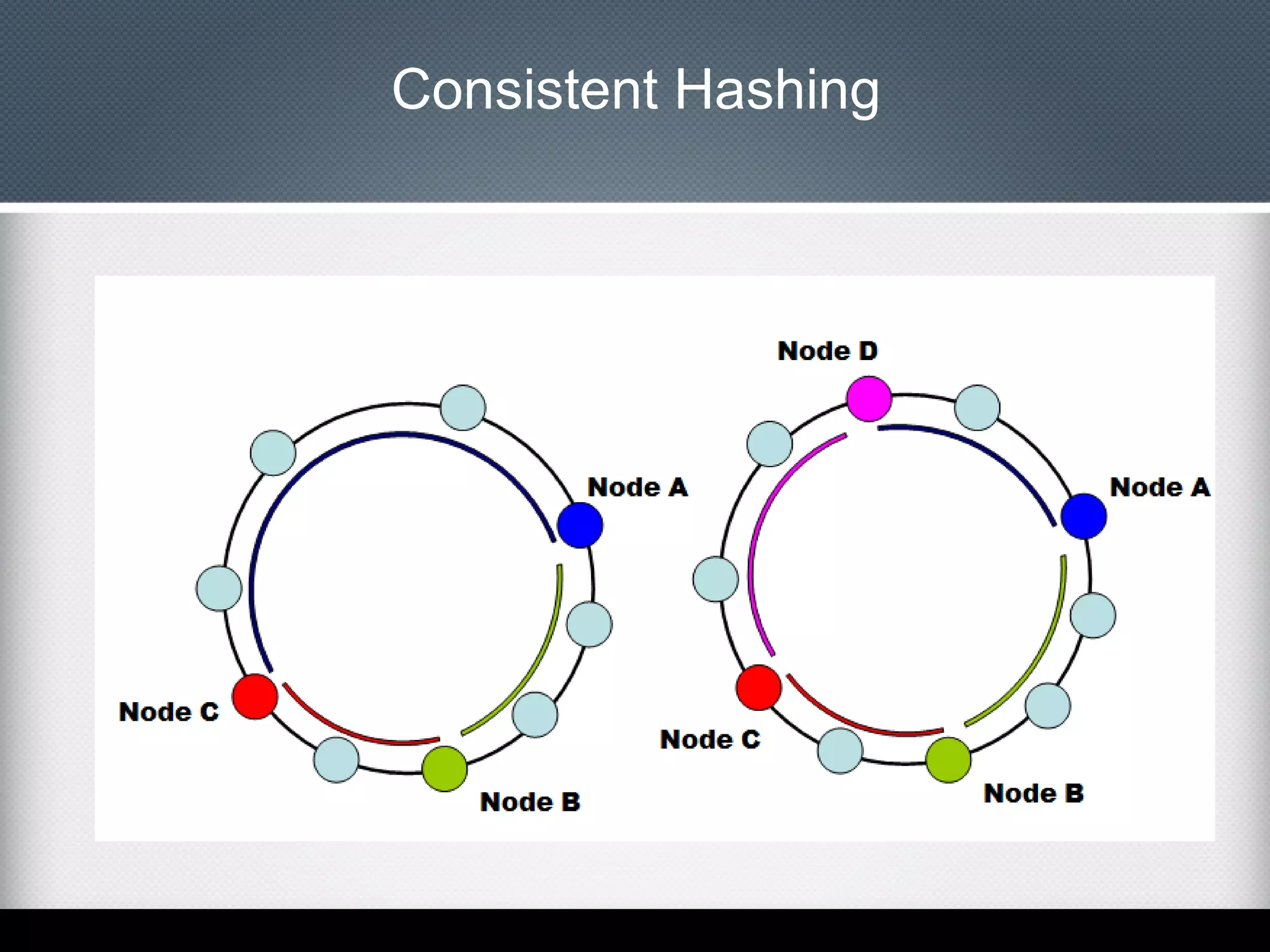
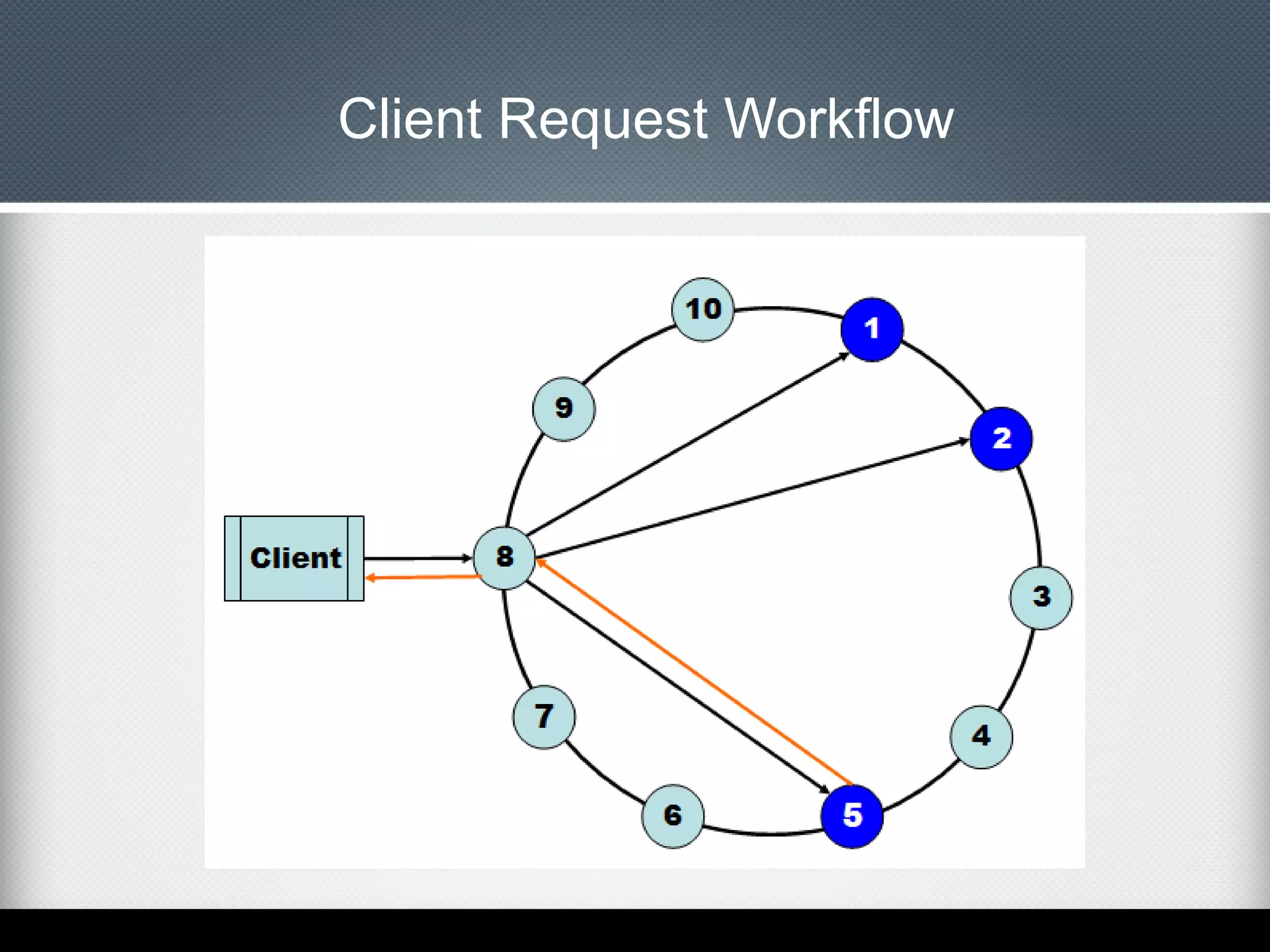
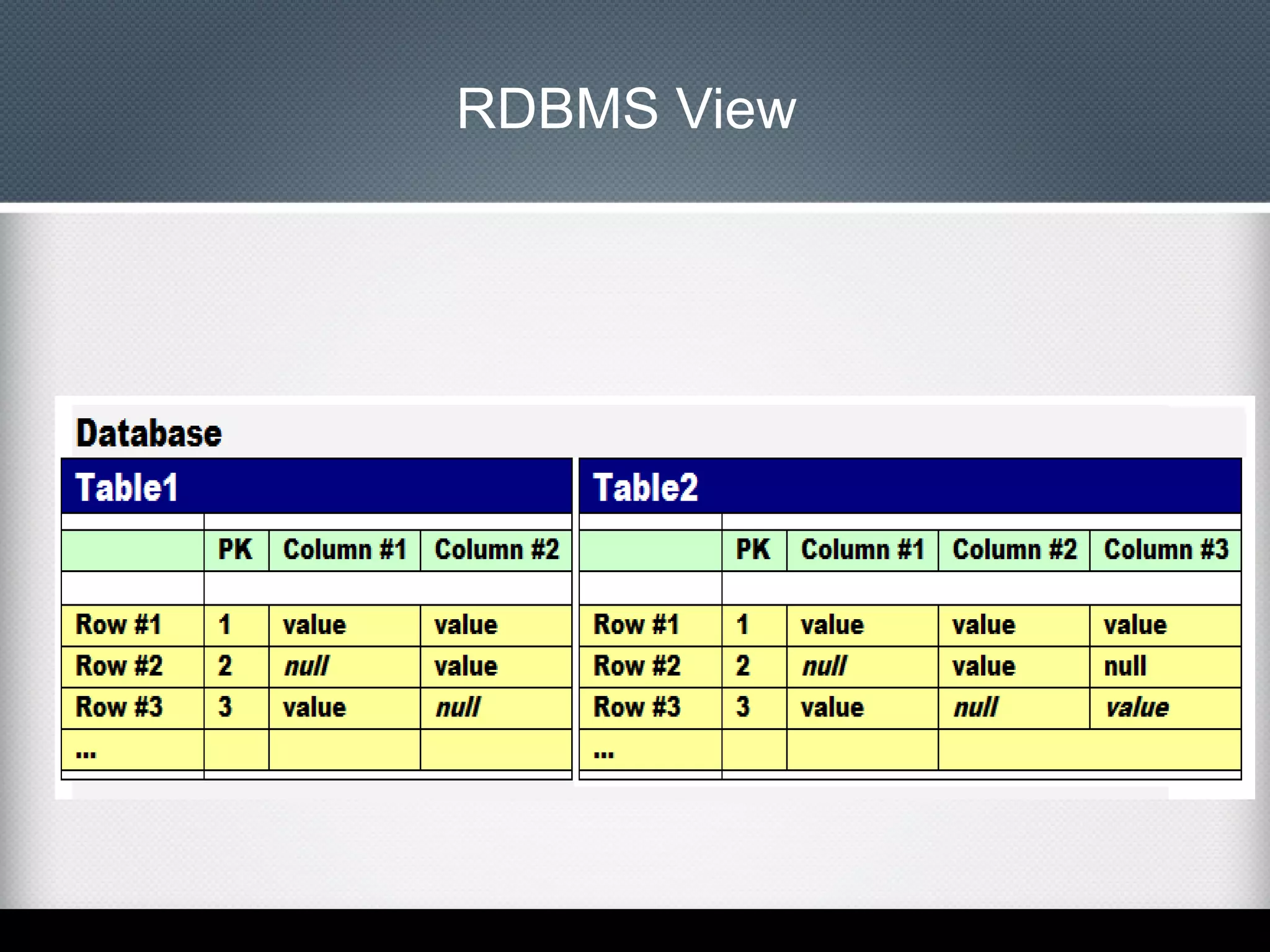
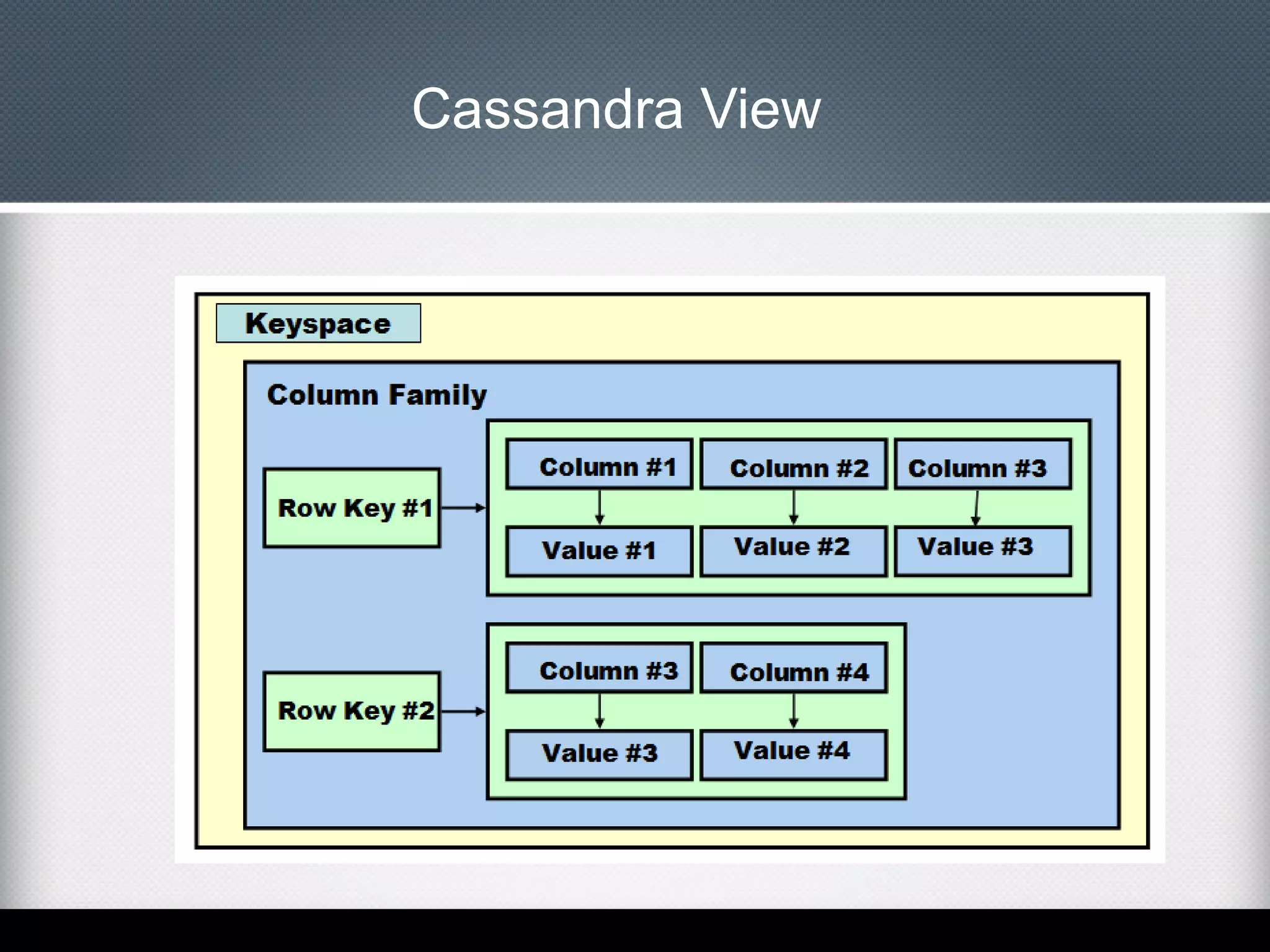
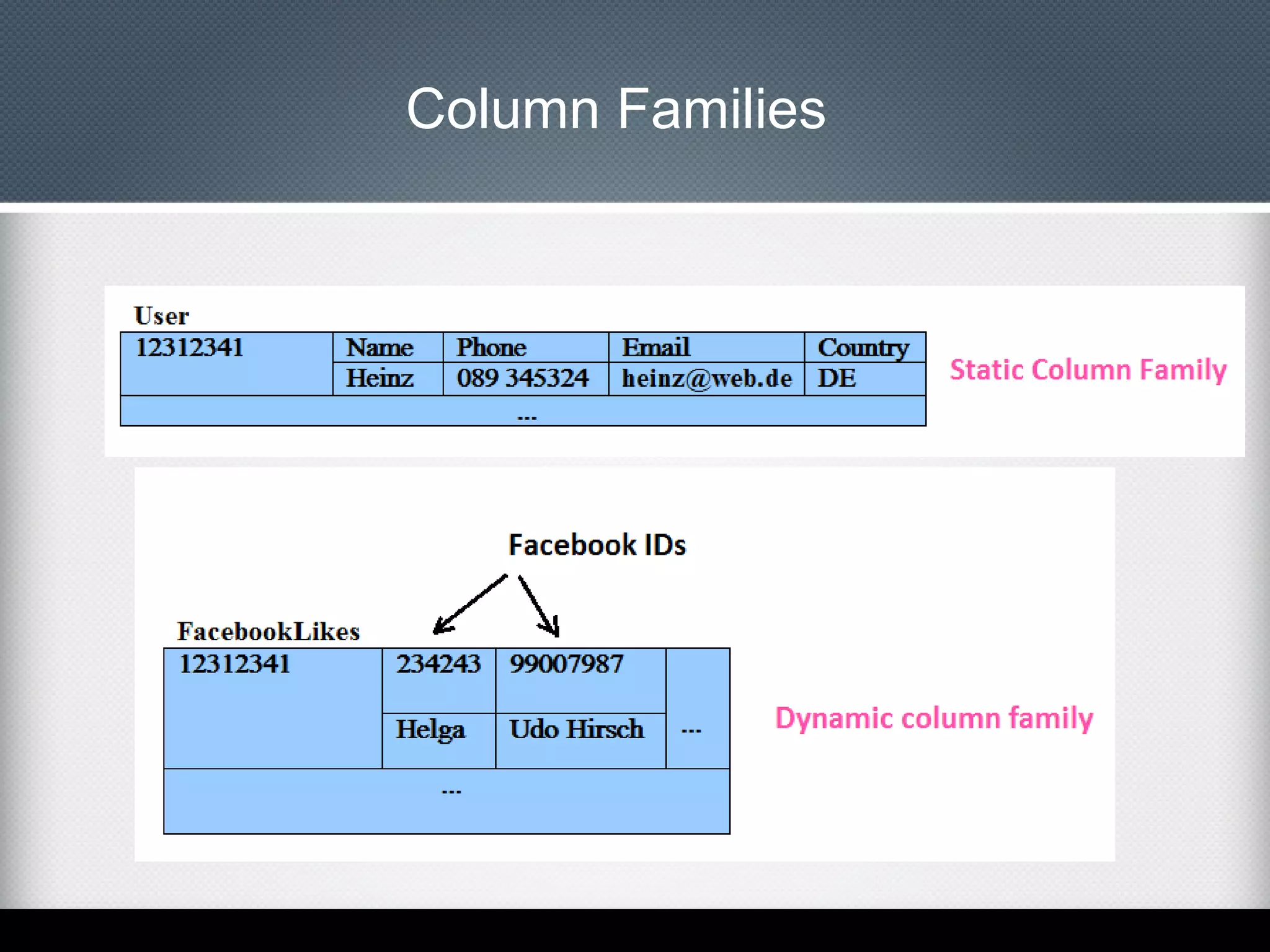
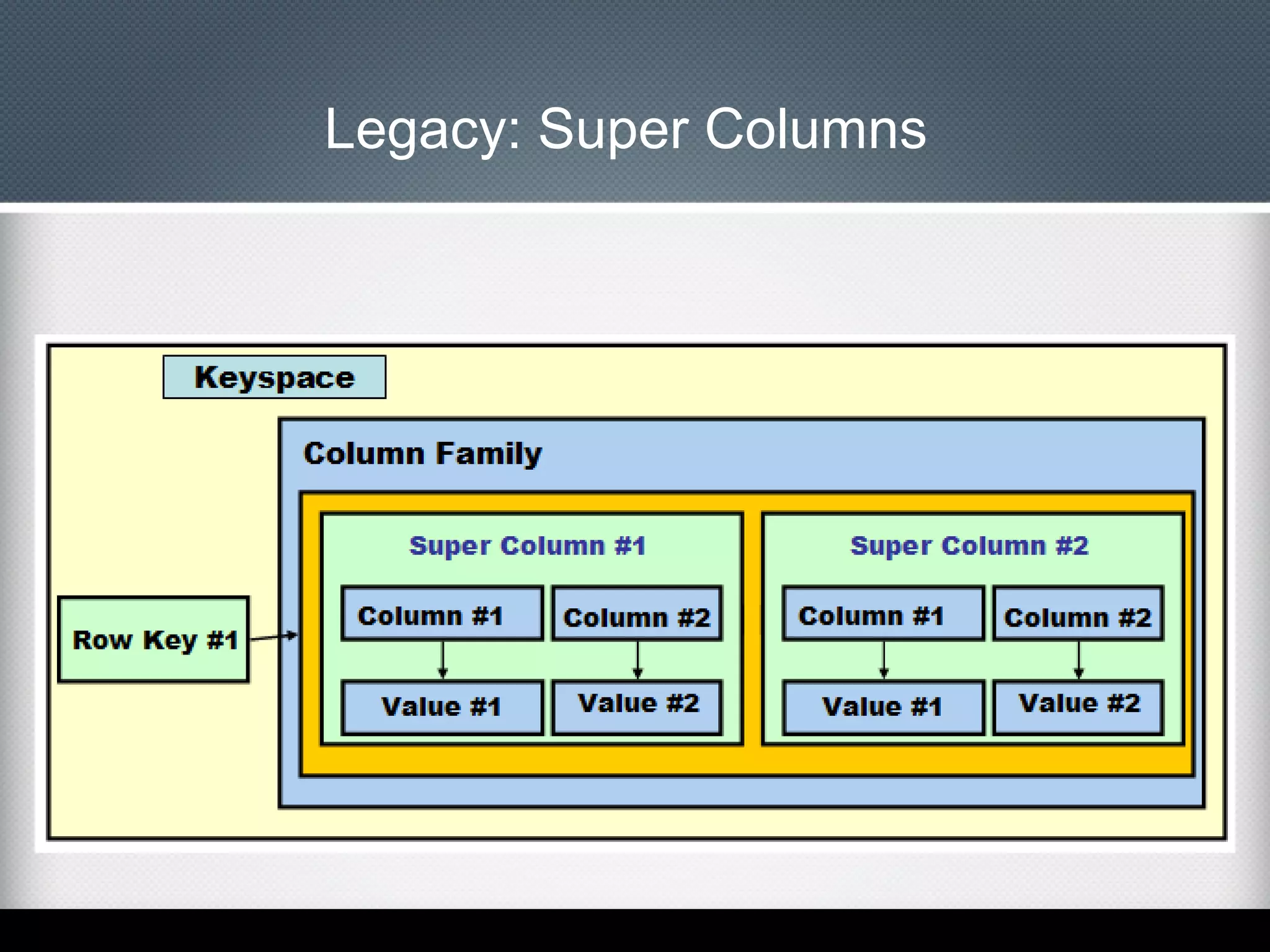
This document provides an overview of Apache Cassandra, including: - Its history originating from Facebook's need to solve an inbox search problem. - Its key features like high availability, linear scalability, fault tolerance and tunable consistency. - Its architecture based on consistent hashing and a ring topology for data distribution. - Its data model using keyspaces, column families, rows, and columns differently than a relational database. - Examples of using the Cassandra CLI to create a schema, insert data, and perform queries.