Downloaded 151 times



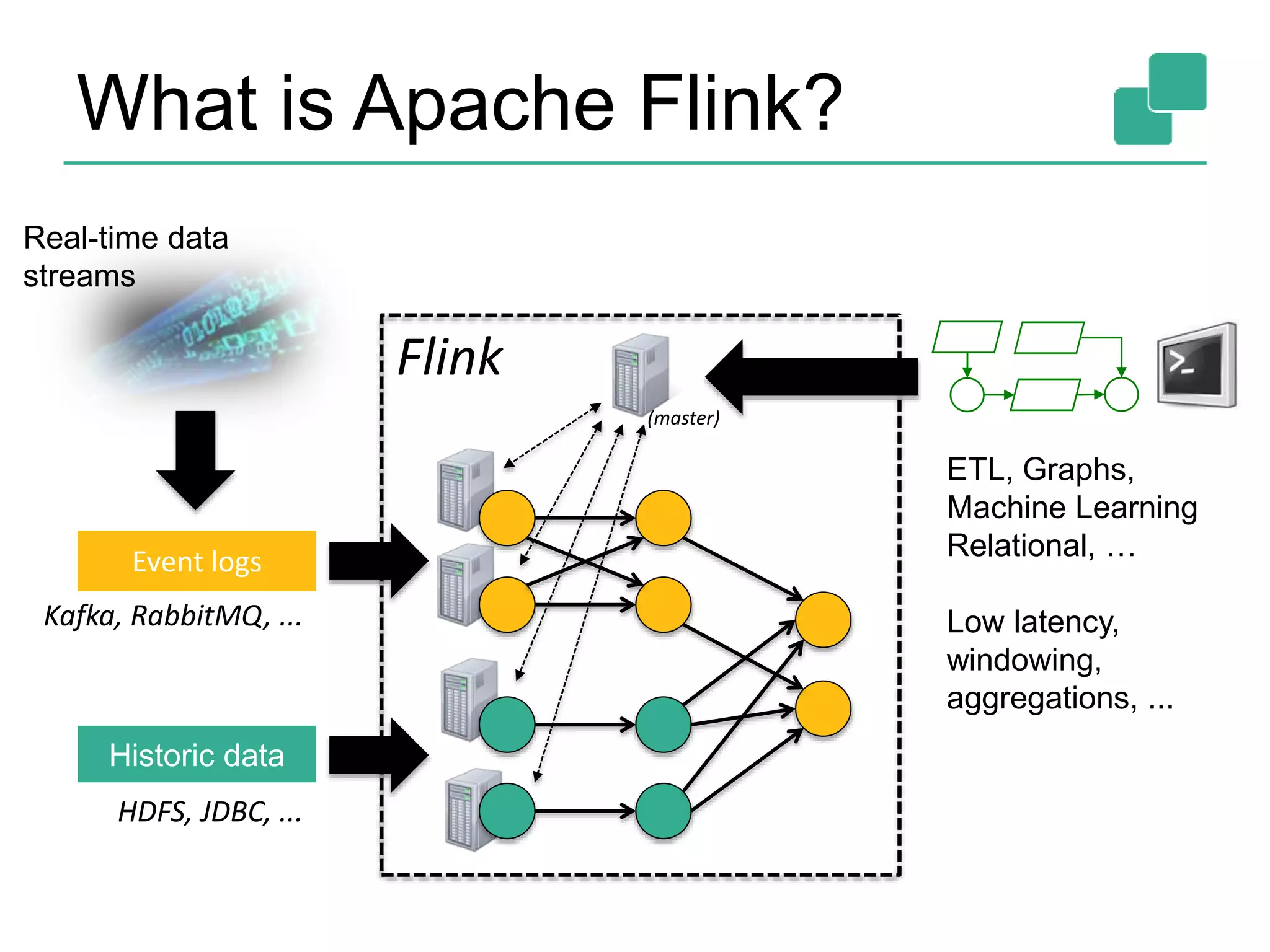
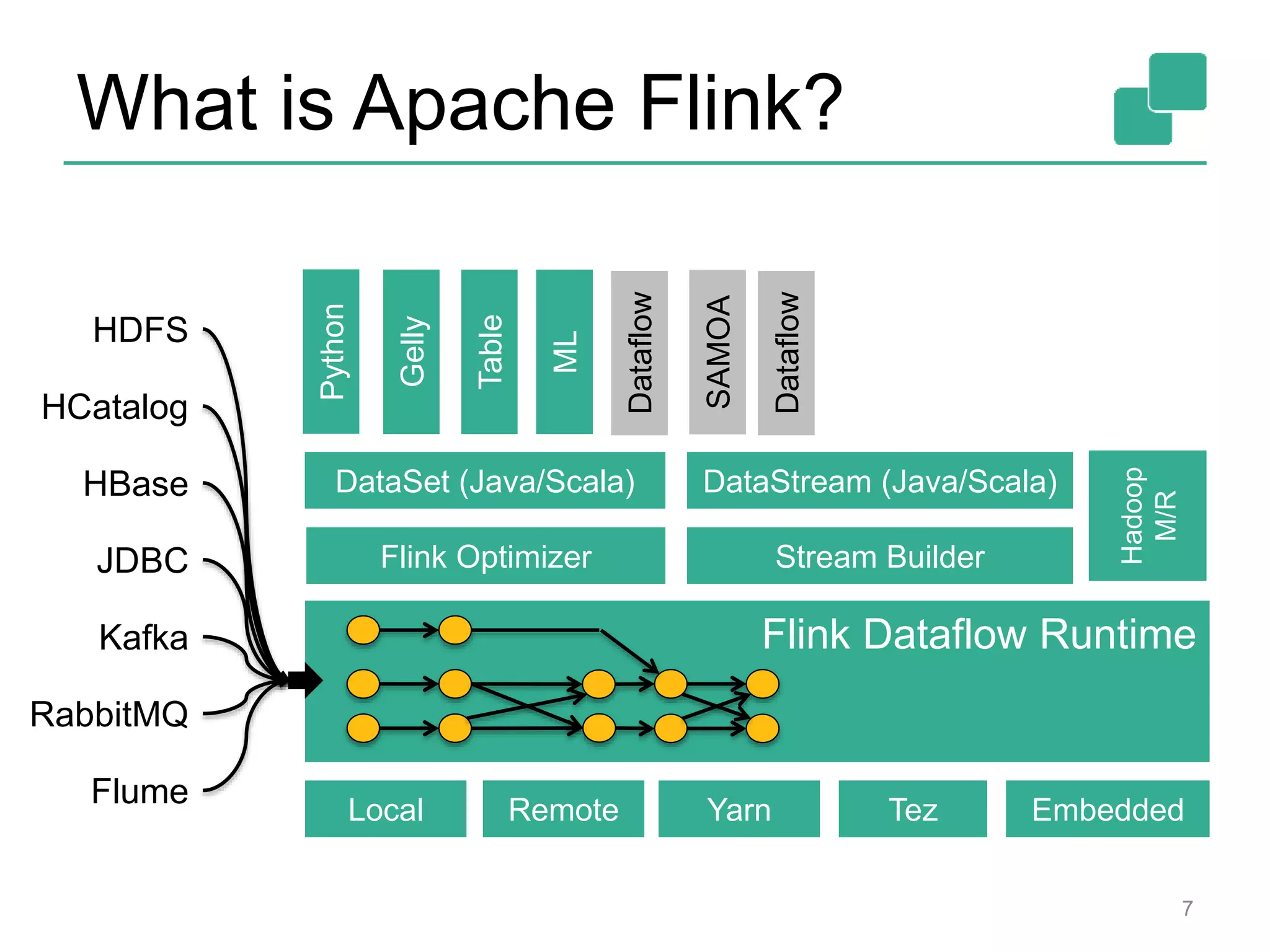
![Batch / Steaming APIs 8 case class Word (word: String, frequency: Int) val lines: DataStream[String] = env.fromSocketStream(...) lines.flatMap {line => line.split(" ") .map(word => Word(word,1))} .window(Count.of(1000)).every(Count.of(100)) .groupBy("word").sum("frequency") .print() val lines: DataSet[String] = env.readTextFile(...) lines.flatMap {line => line.split(" ") .map(word => Word(word,1))} .groupBy("word").sum("frequency") .print() DataSet API (batch): DataStream API (streaming):](https://image.slidesharecdn.com/flinkhadoopsummitmeetup-150415045615-conversion-gate01/75/Apache-Flink-Overview-and-Use-cases-of-a-Distributed-Dataflow-System-at-pre-Hadoop-Summit-Meetups-8-2048.jpg)
![Technology inside Flink case class Path (from: Long, to: Long) val tc = edges.iterate(10) { paths: DataSet[Path] => val next = paths .join(edges) .where("to") .equalTo("from") { (path, edge) => Path(path.from, edge.to) } .union(paths) .distinct() next } Cost-based optimizer Type extraction stack Task scheduling Recovery metadata Pre-flight (Client) Master Workers DataSourc e orders.tbl Filter Map DataSourc e lineitem.tbl Join Hybrid Hash build HT probe hash-part [0] hash-part [0] GroupRed sort forward Program Dataflow Graph Memory manager Out-of-core algos Batch & Streaming State & Checkpoints deploy operators track intermediate results](https://image.slidesharecdn.com/flinkhadoopsummitmeetup-150415045615-conversion-gate01/75/Apache-Flink-Overview-and-Use-cases-of-a-Distributed-Dataflow-System-at-pre-Hadoop-Summit-Meetups-9-2048.jpg)





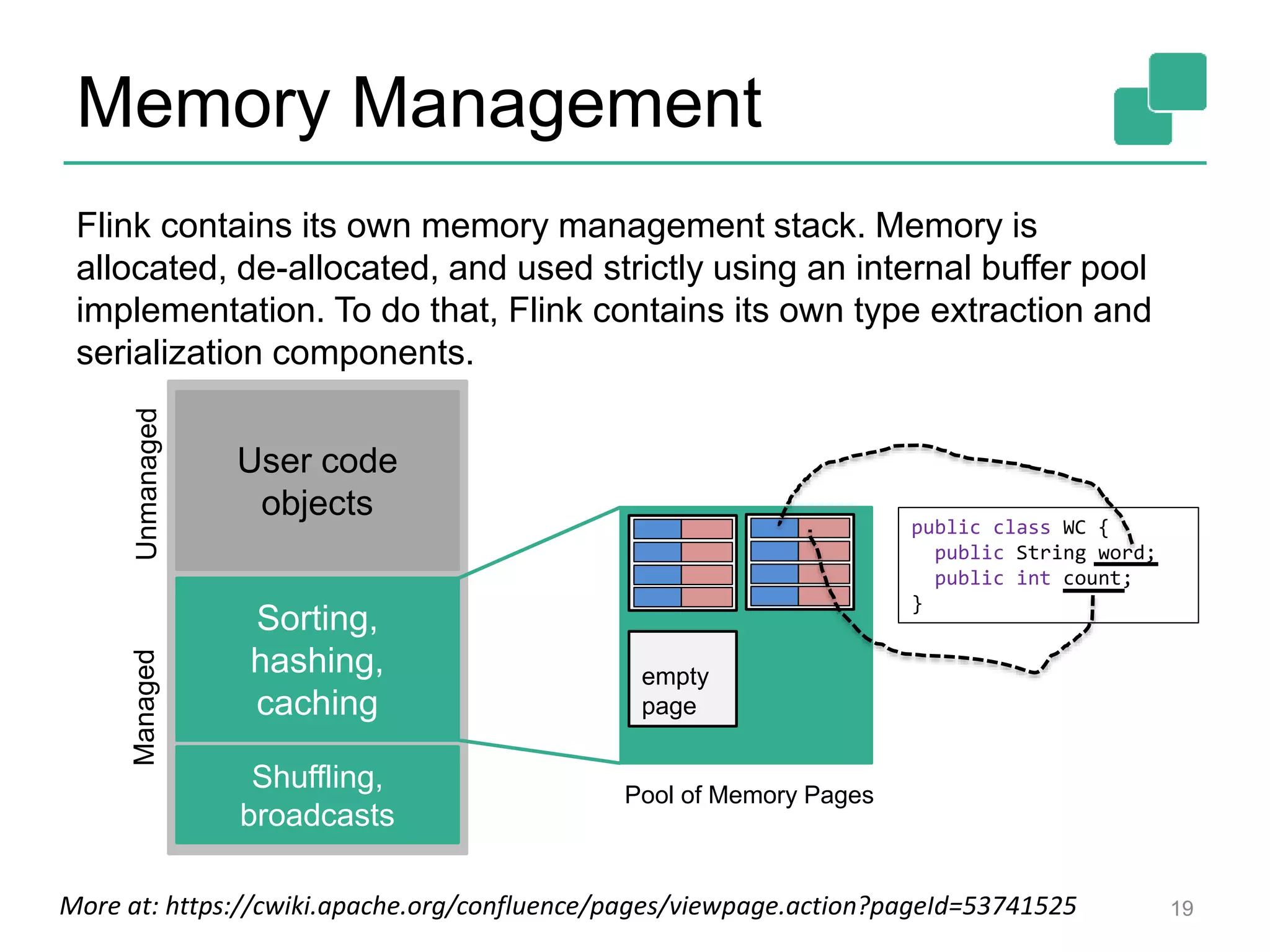
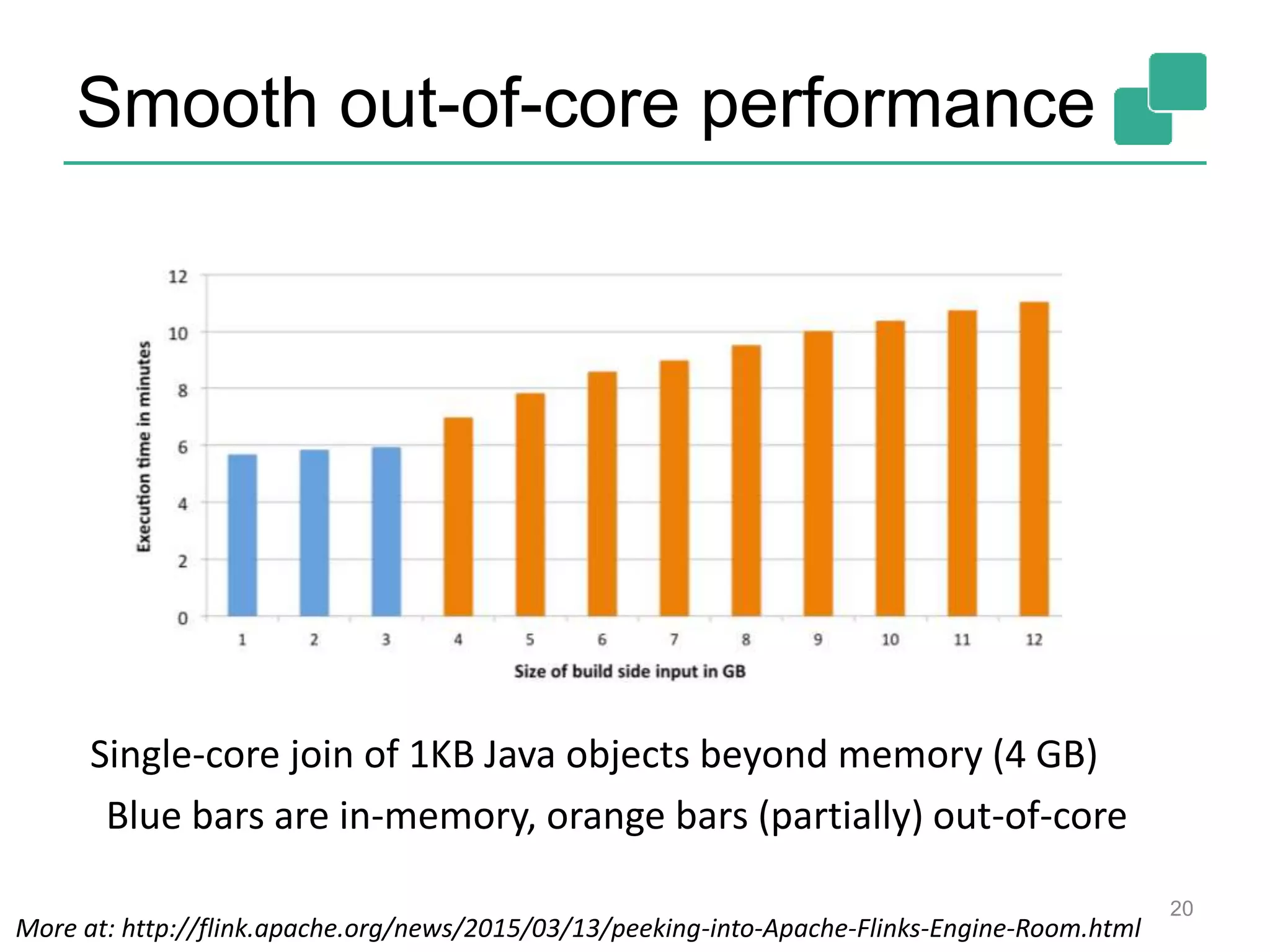
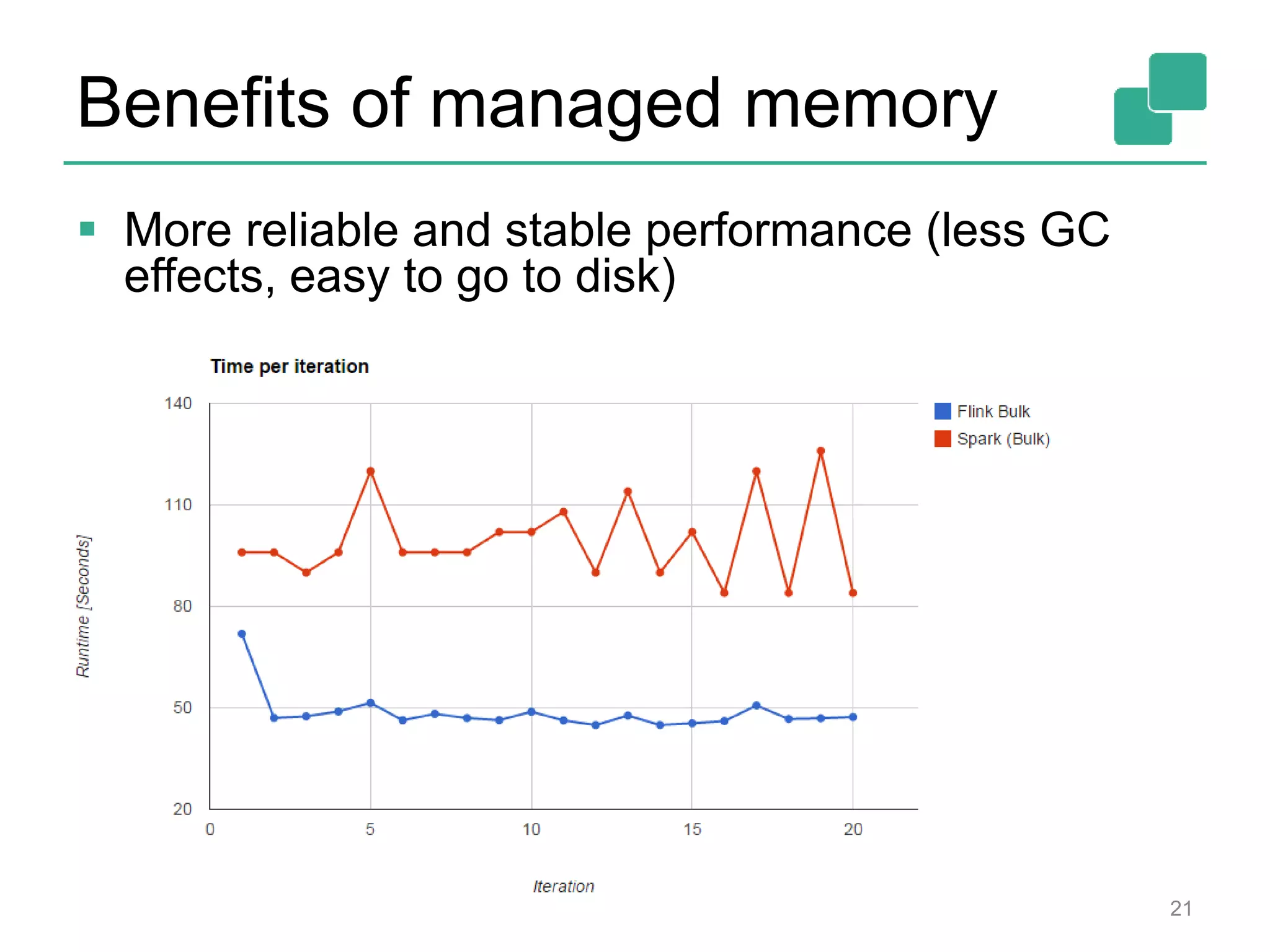


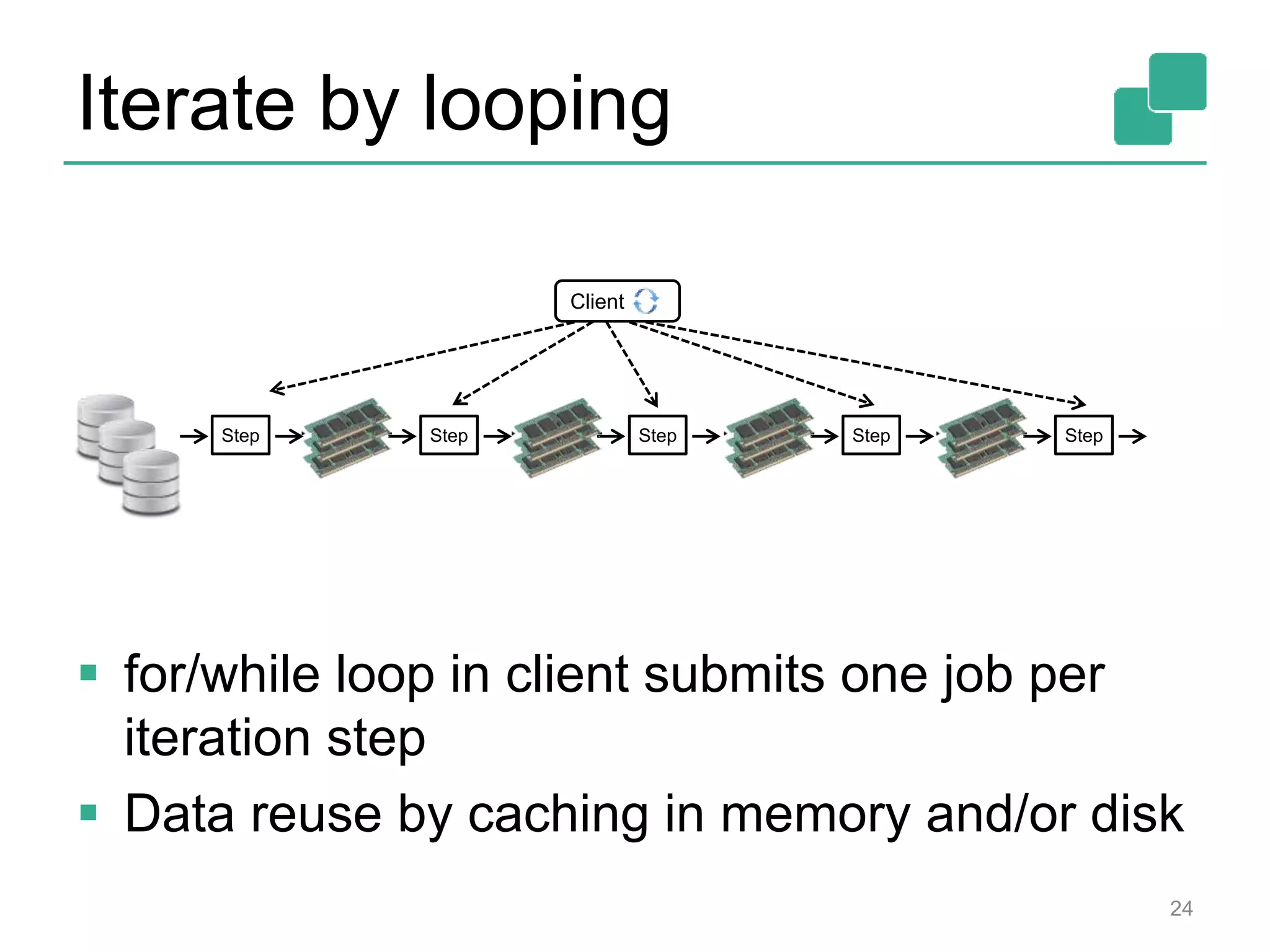
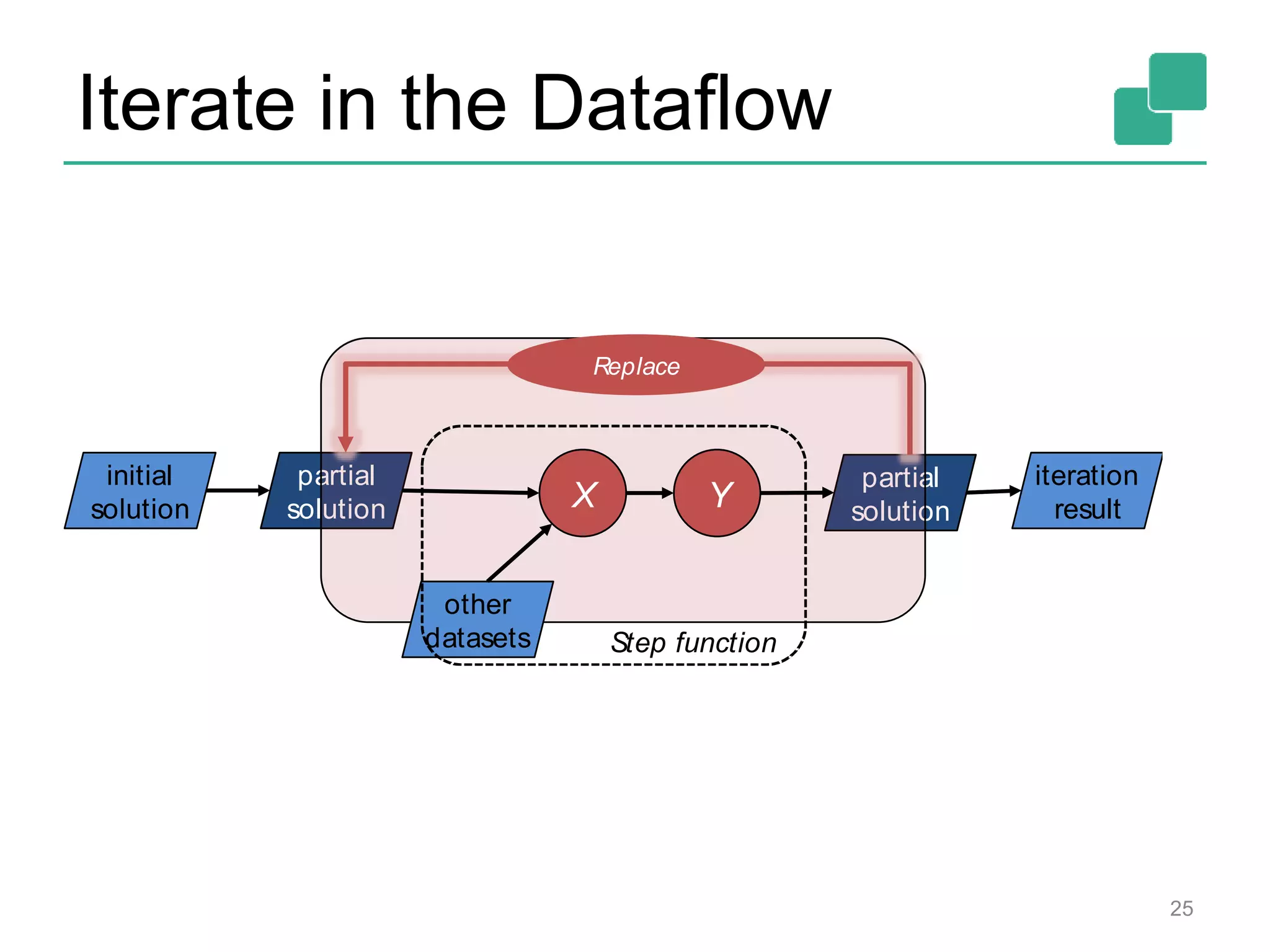
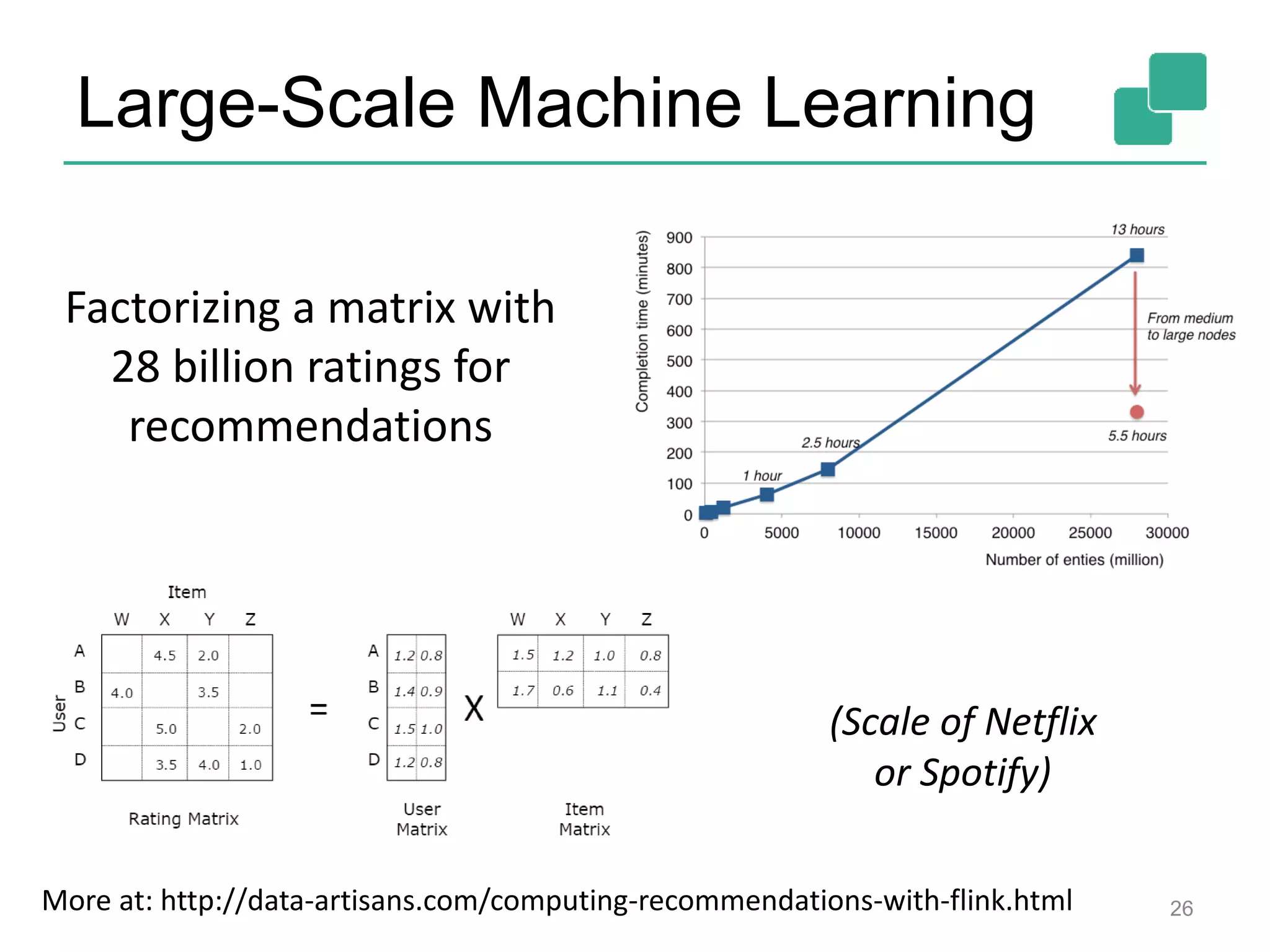

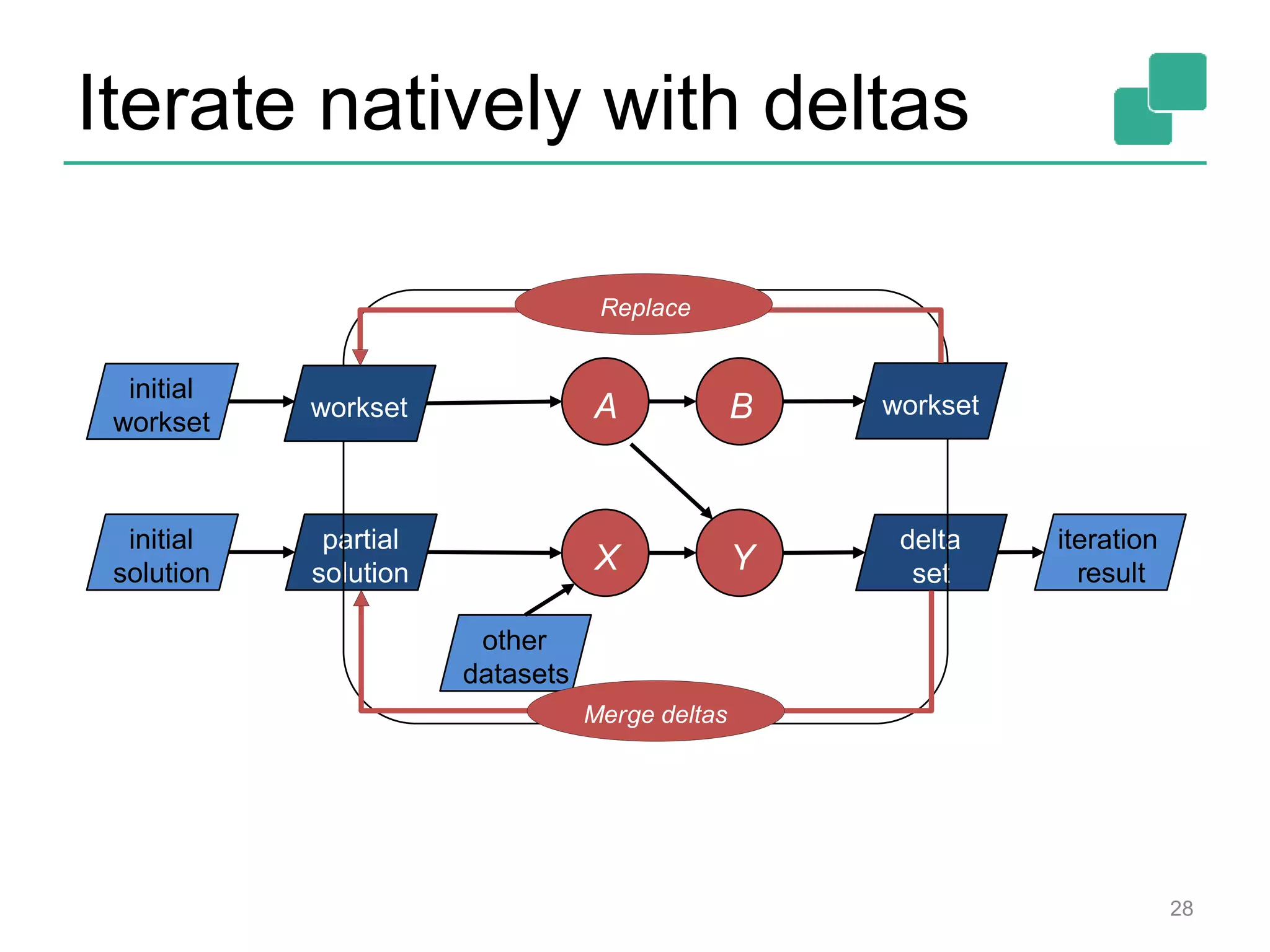
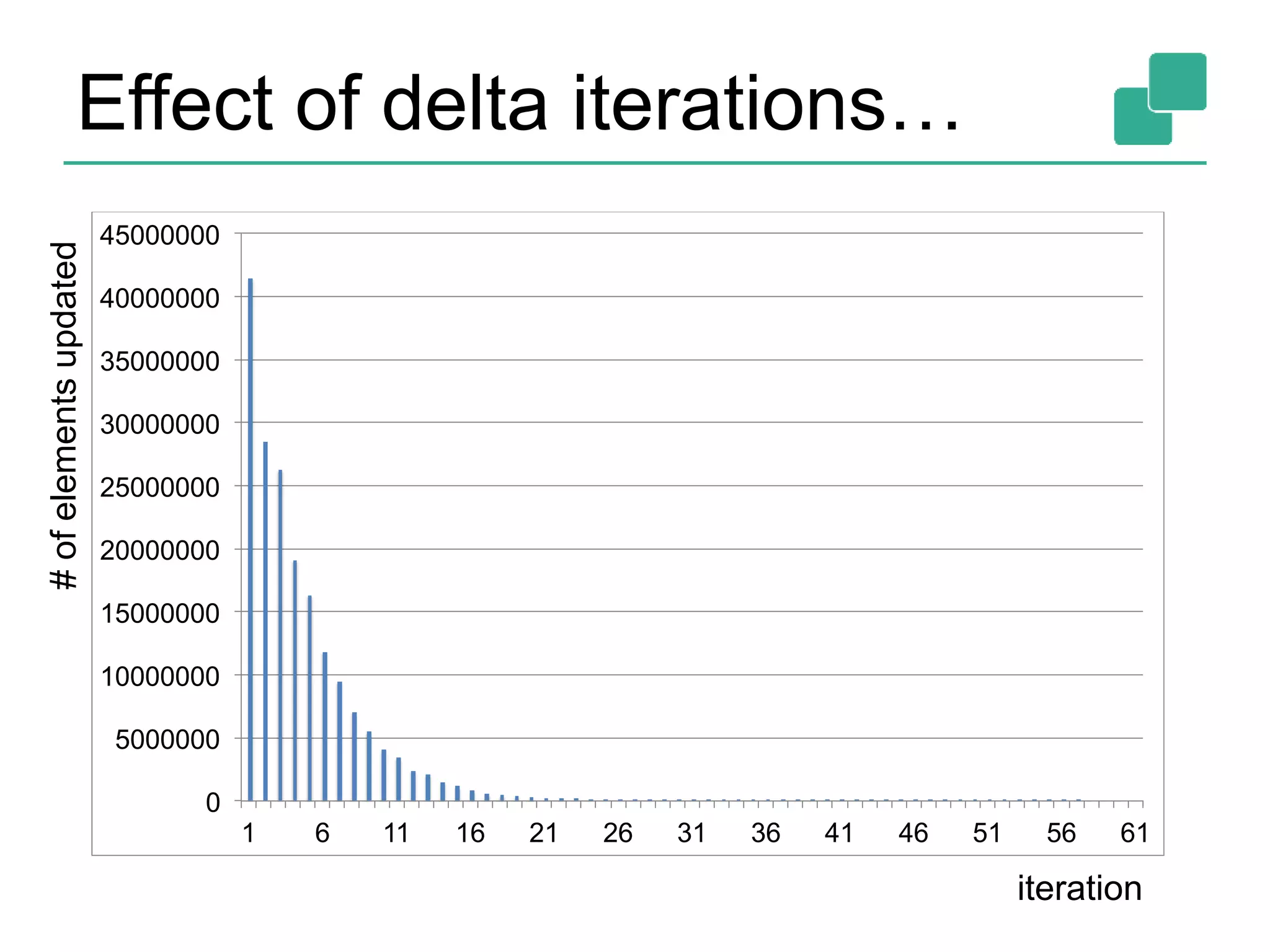






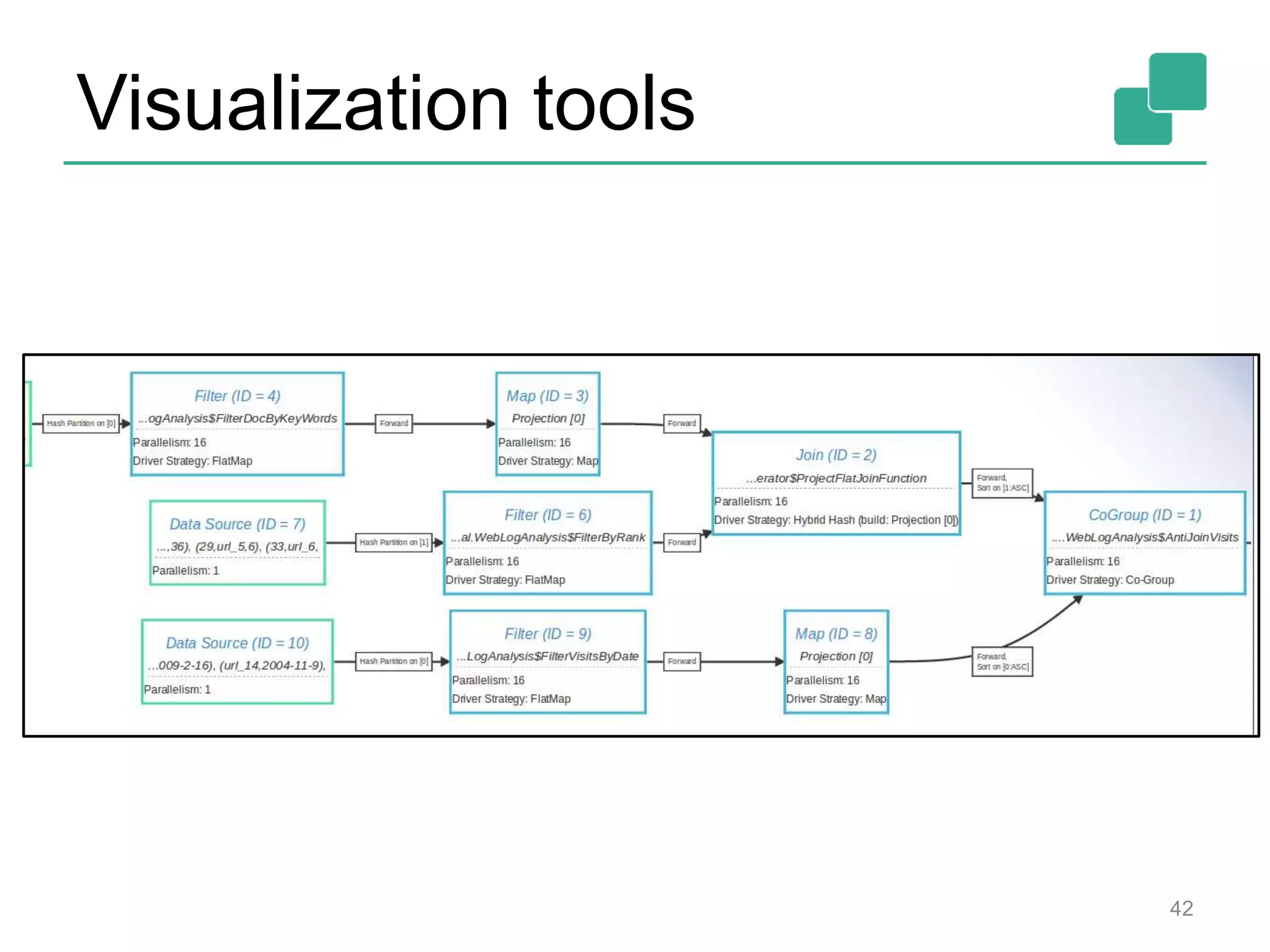
![Two execution plans 39 DataSource orders.tbl Filter Map DataSource lineitem.tbl Join Hybrid Hash buildHT probe broadcast forward Combine GroupRed sort DataSource orders.tbl Filter Map DataSource lineitem.tbl Join Hybrid Hash buildHT probe hash-part [0] hash-part [0] hash-part [0,1] GroupRed sort forwardBest plan depends on relative sizes of input files](https://image.slidesharecdn.com/flinkhadoopsummitmeetup-150415045615-conversion-gate01/75/Apache-Flink-Overview-and-Use-cases-of-a-Distributed-Dataflow-System-at-pre-Hadoop-Summit-Meetups-39-2048.jpg)



The document provides an overview of Apache Flink, focusing on its architecture, features, and capabilities for processing both batch and streaming data. It discusses the various APIs available, memory management, stateful computations, and iteration for machine learning. Additionally, it highlights Flink's roadmap, ongoing community contributions, and future enhancements planned for the platform.