Downloaded 309 times










![ASSOCIATION RULES Wal-Mart customers who purchase Barbie dolls have a 60% likelihood of also purchasing one of three types of candy bars [Forbes, Sept 8, 1997] Customers who purchase maintenance agreements are very likely to purchase large appliances (author experience) When a new hardware store opens, one of the most commonly sold items is toilet bowl cleaners (author experience) So what…](https://image.slidesharecdn.com/armfinal-171227062148/75/Association-rule-mining-and-Apriori-algorithm-12-2048.jpg)






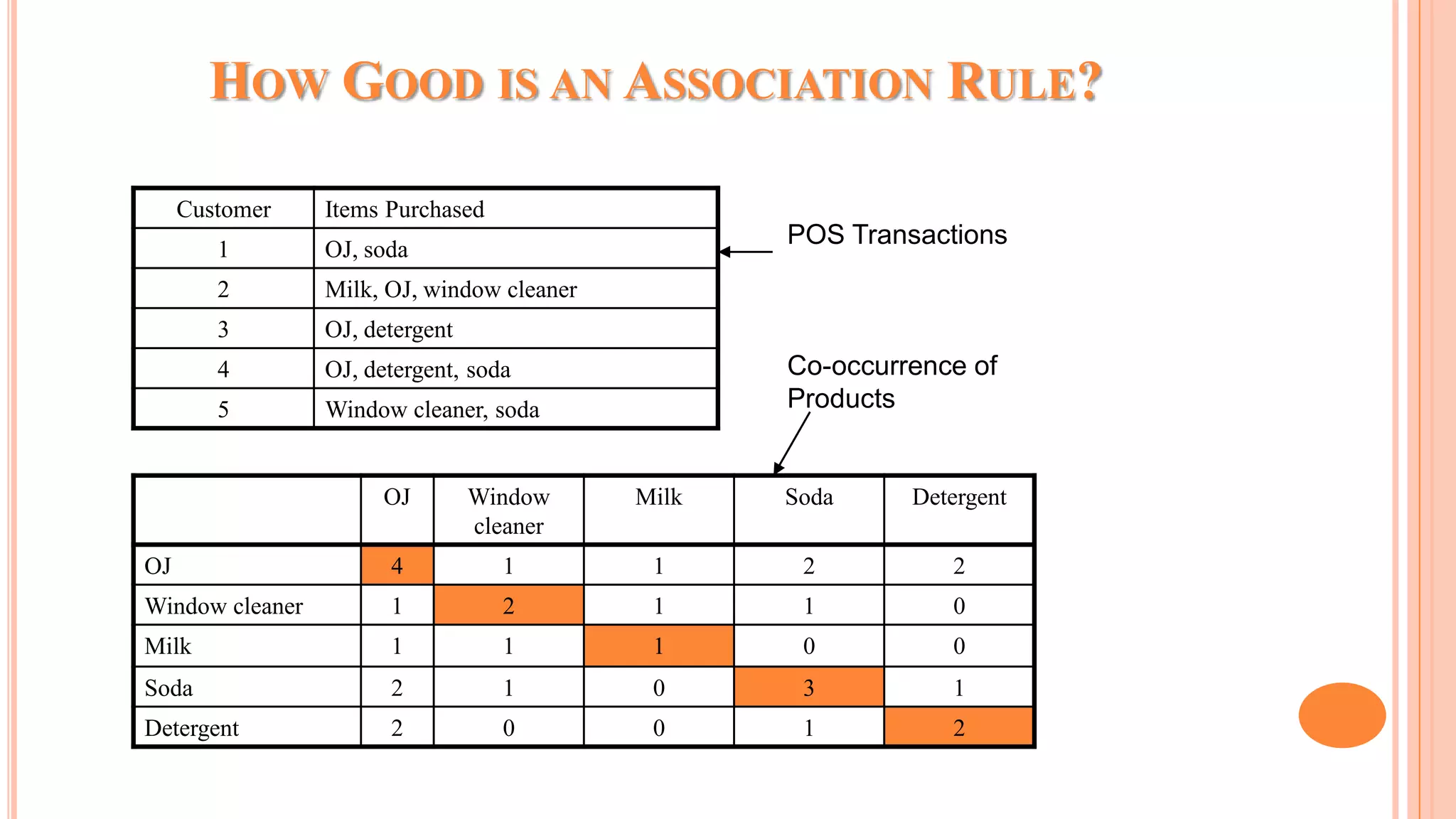
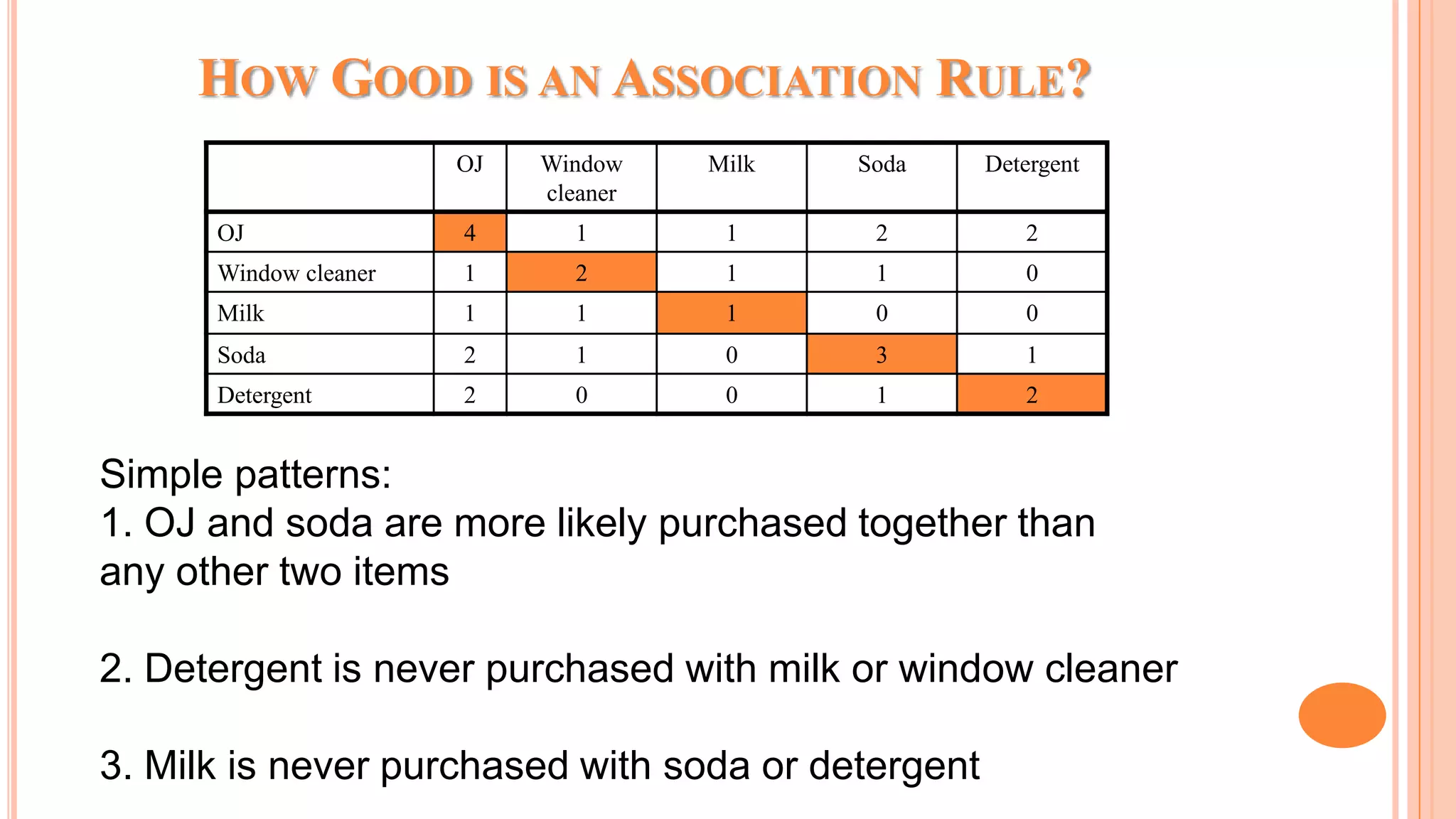









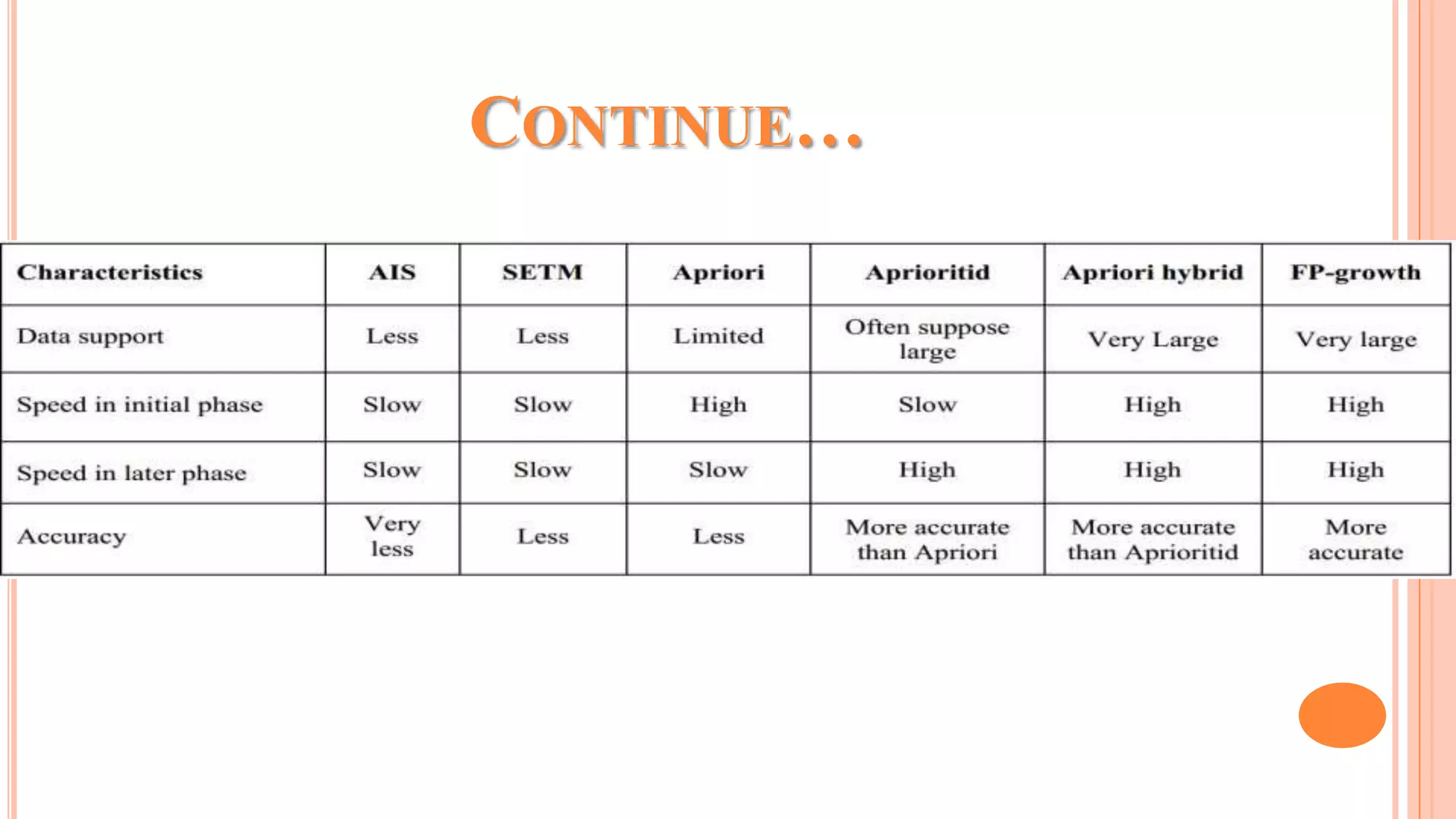


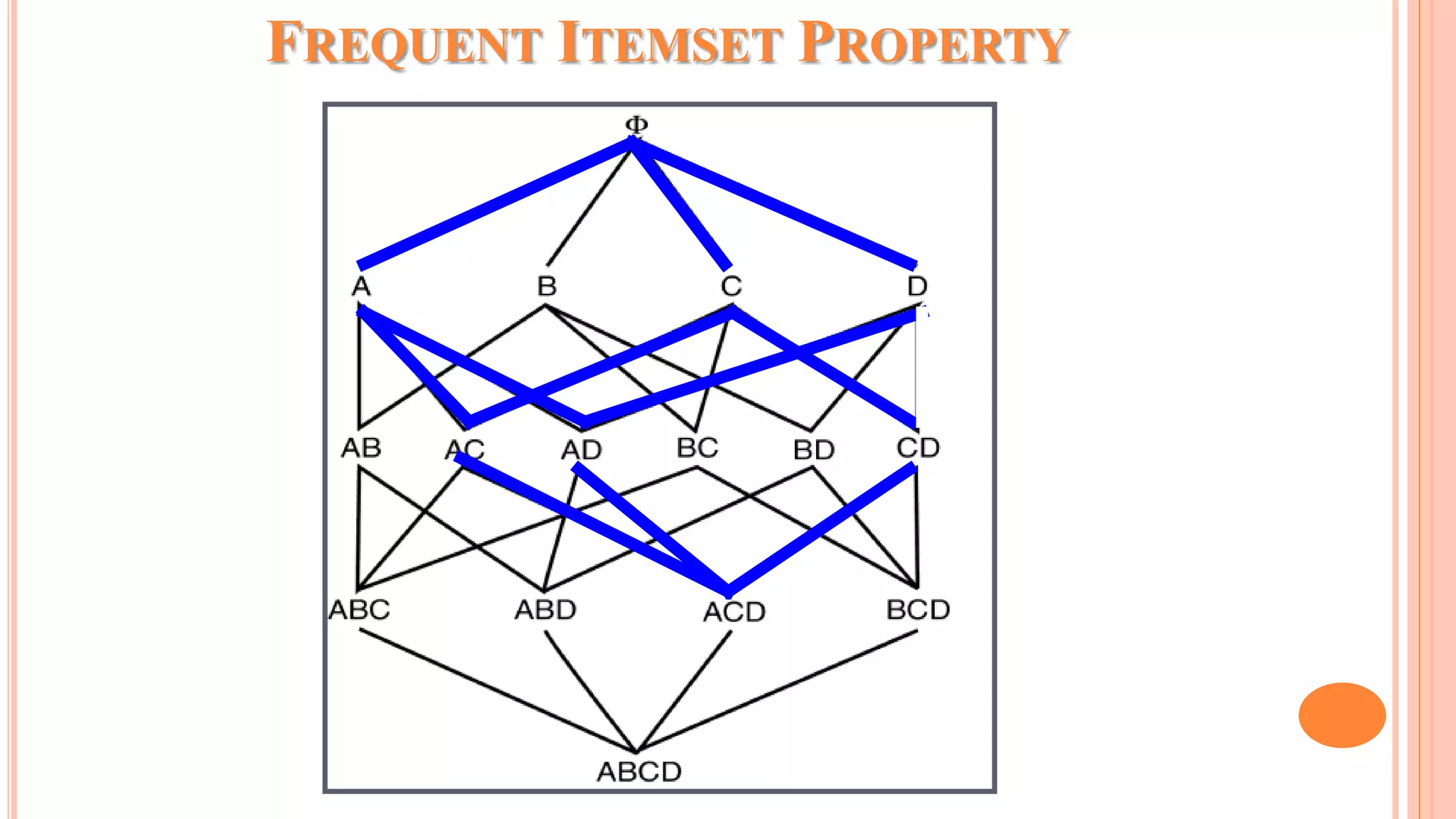

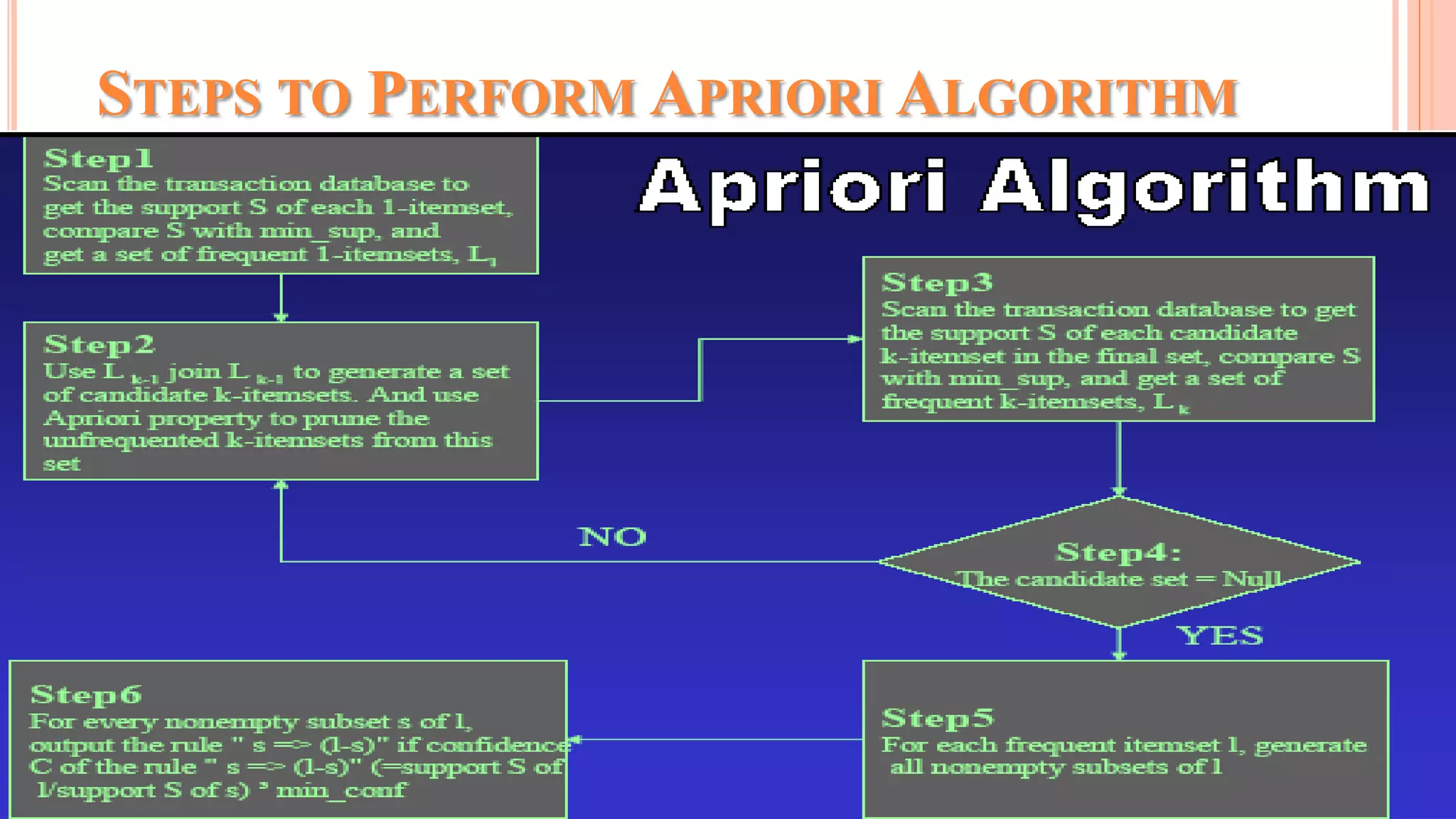


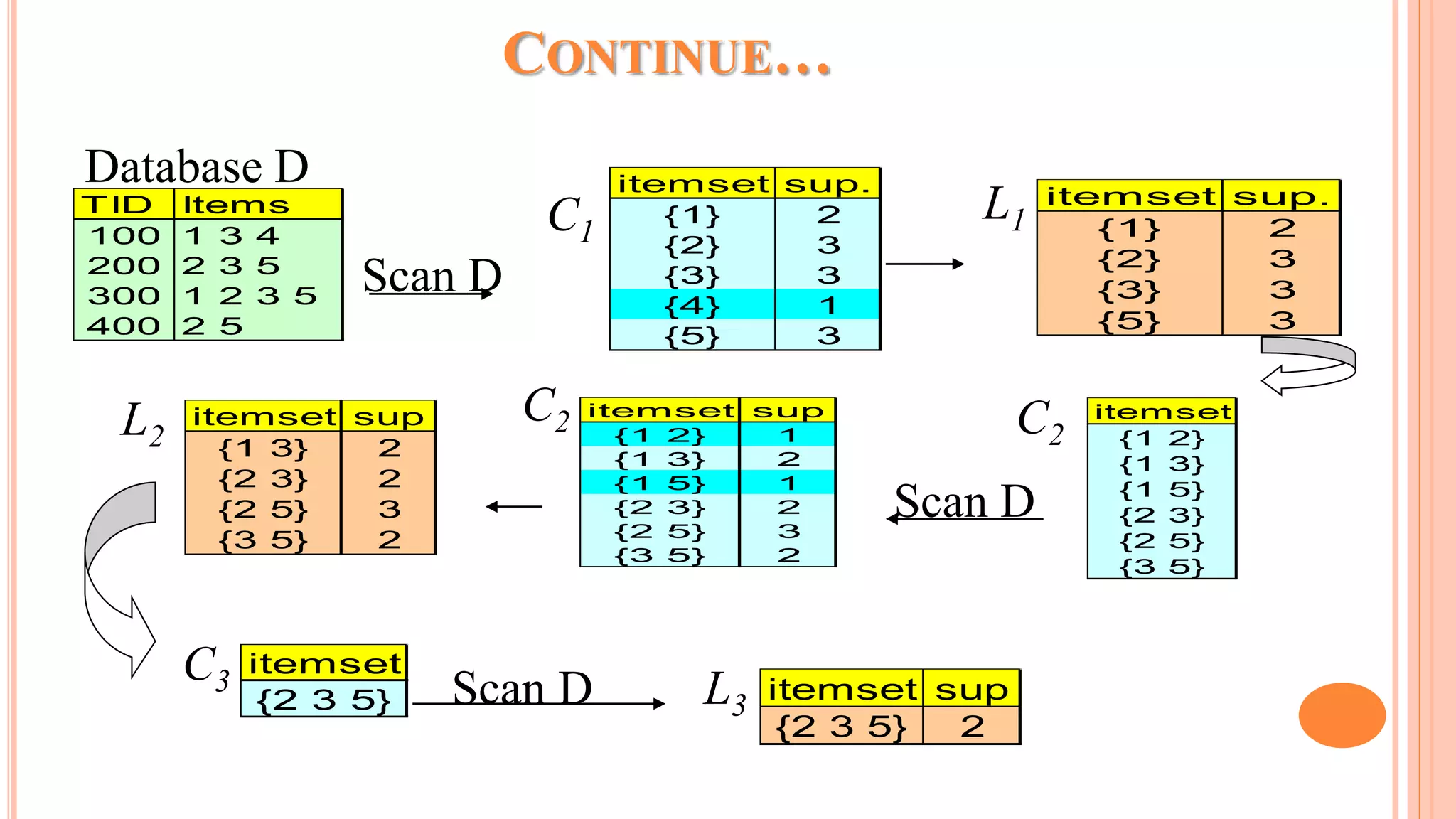
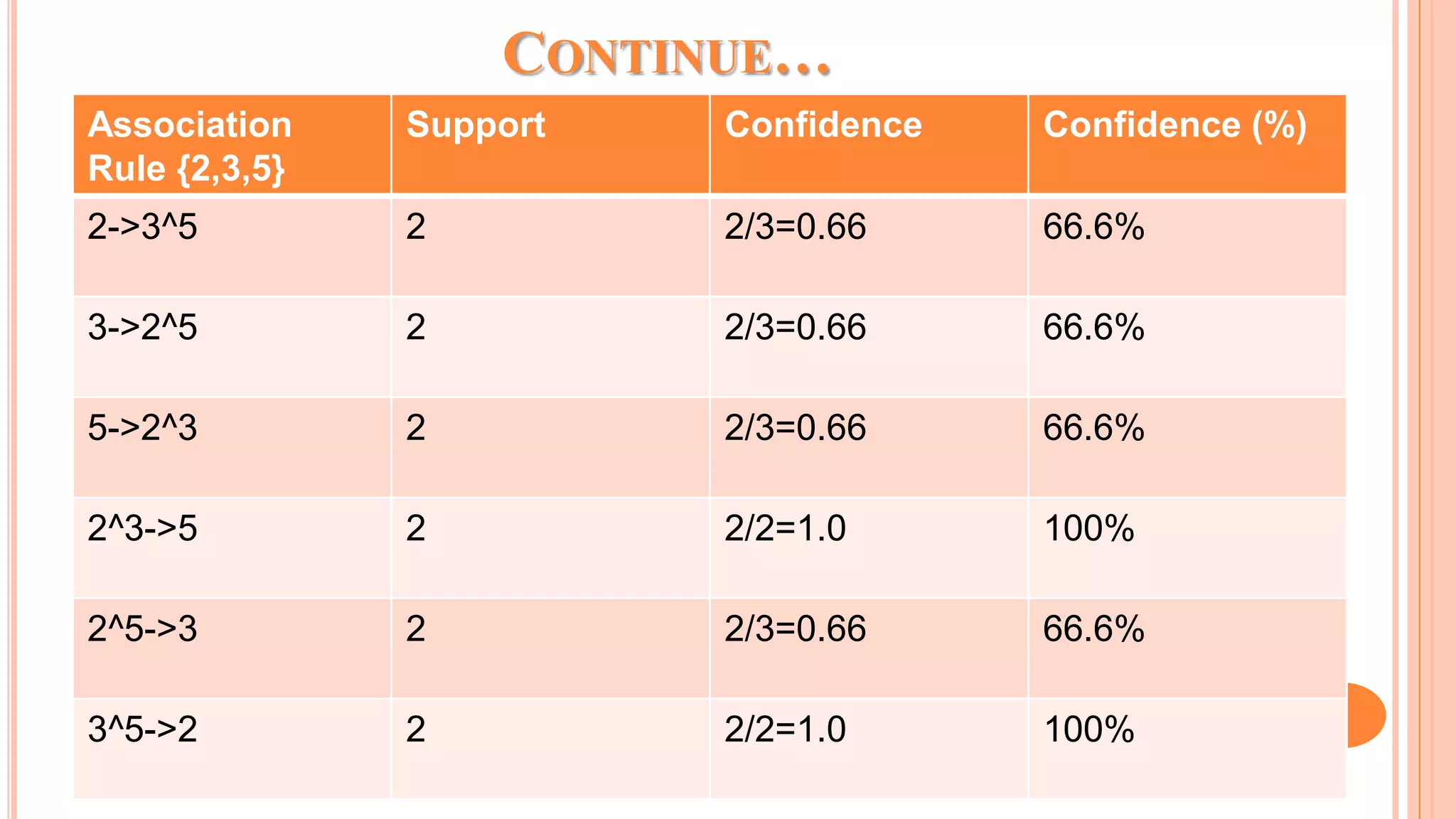







The document discusses association rule mining and the Apriori algorithm. It provides an overview of association rule mining, which aims to discover relationships between variables in large datasets. The Apriori algorithm is then explained as a popular algorithm for association rule mining that uses a bottom-up approach to generate frequent itemsets and association rules, starting from individual items and building up patterns by combining items. The key steps of Apriori involve generating candidate itemsets, counting their support from the dataset, and pruning unpromising candidates to create the frequent itemsets.