Download as PDF, PPTX





















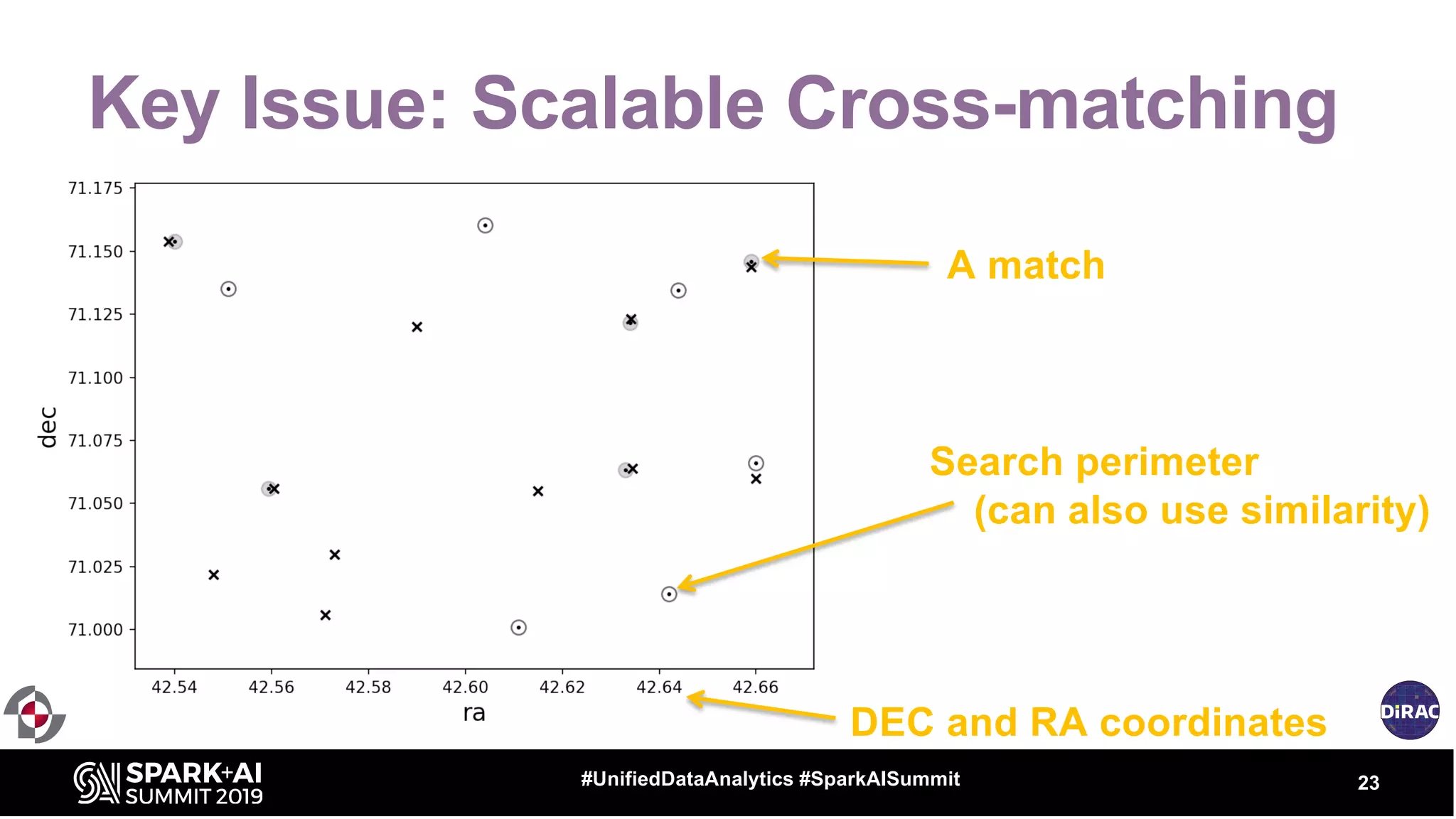

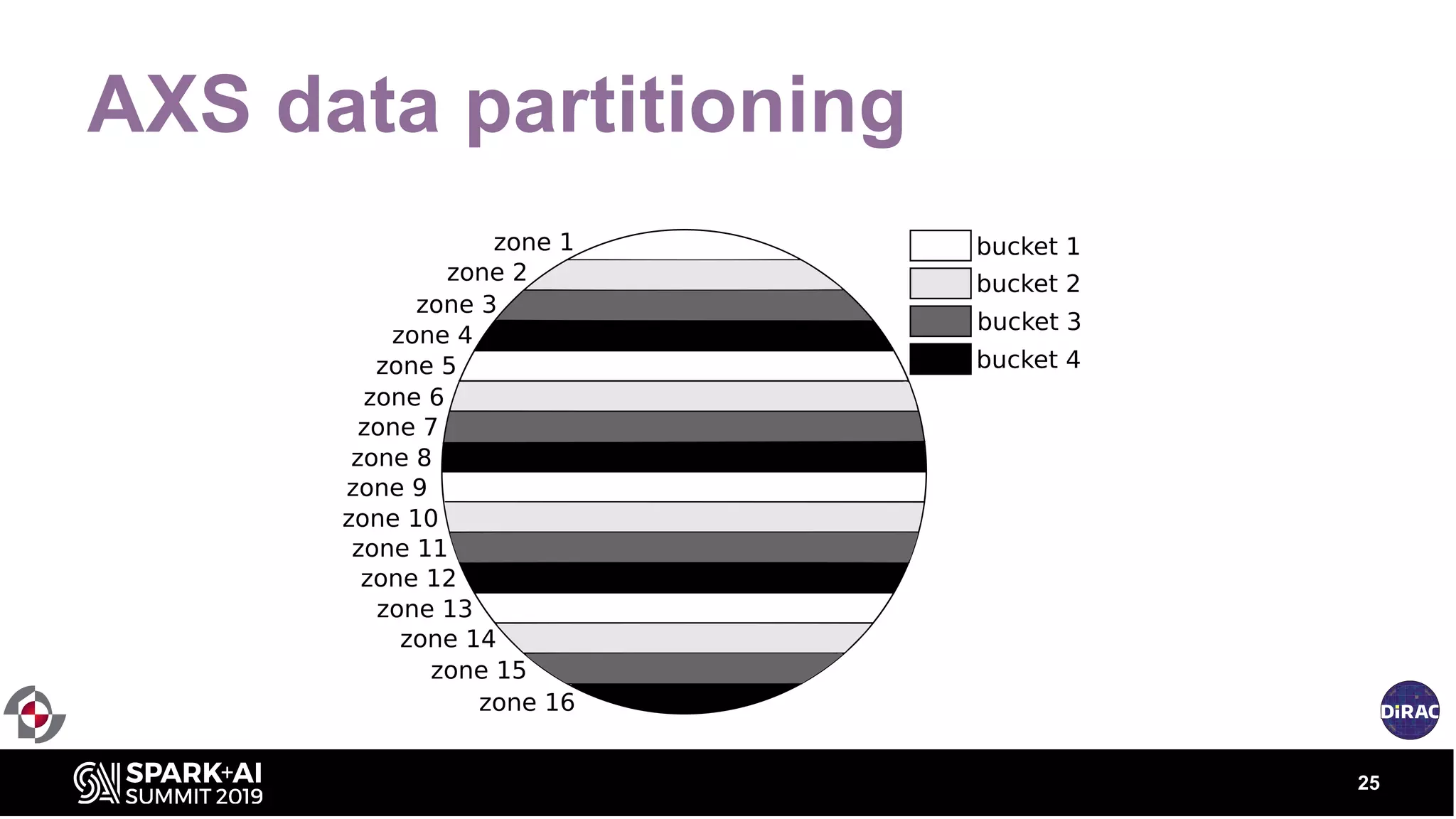
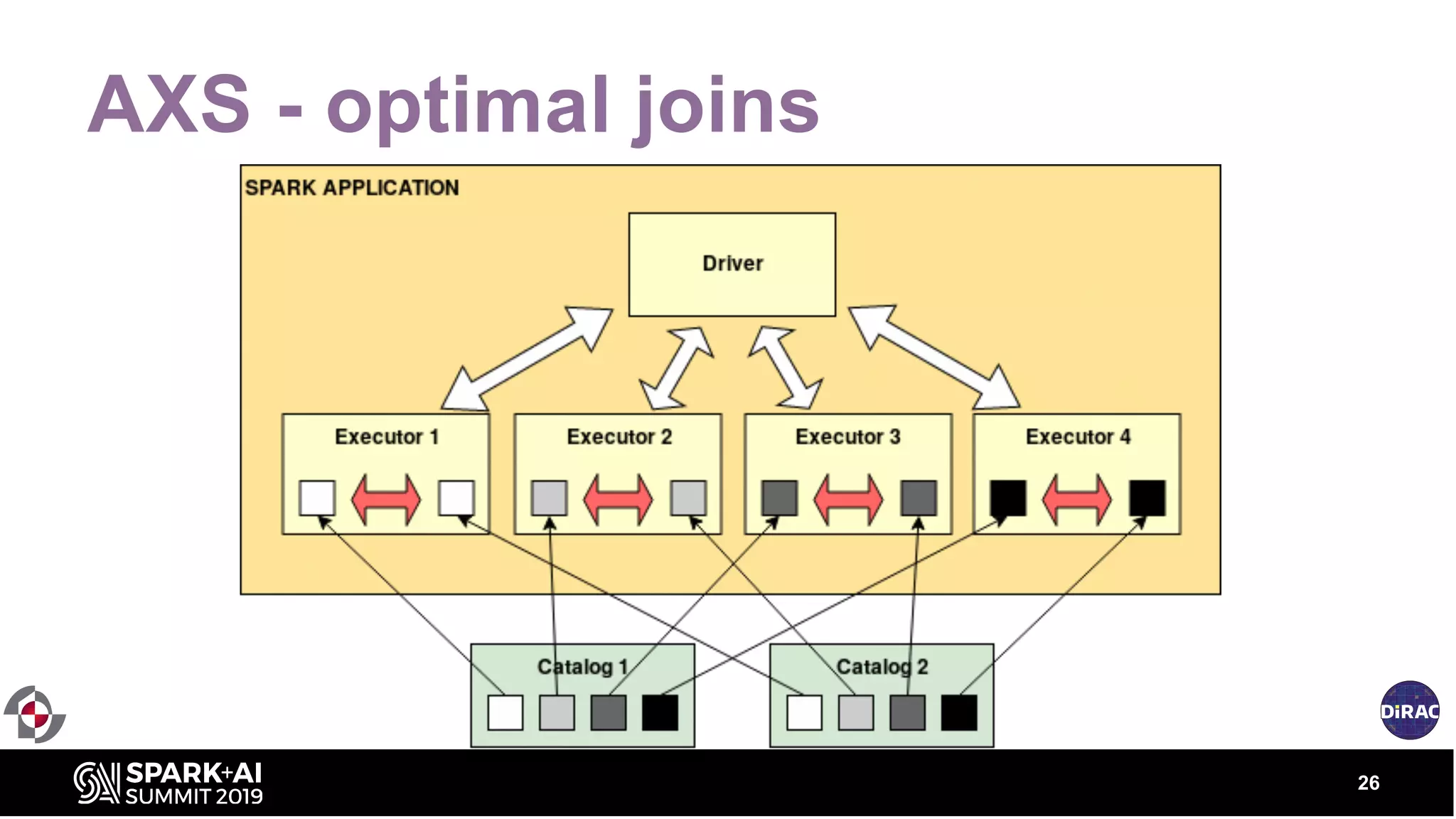
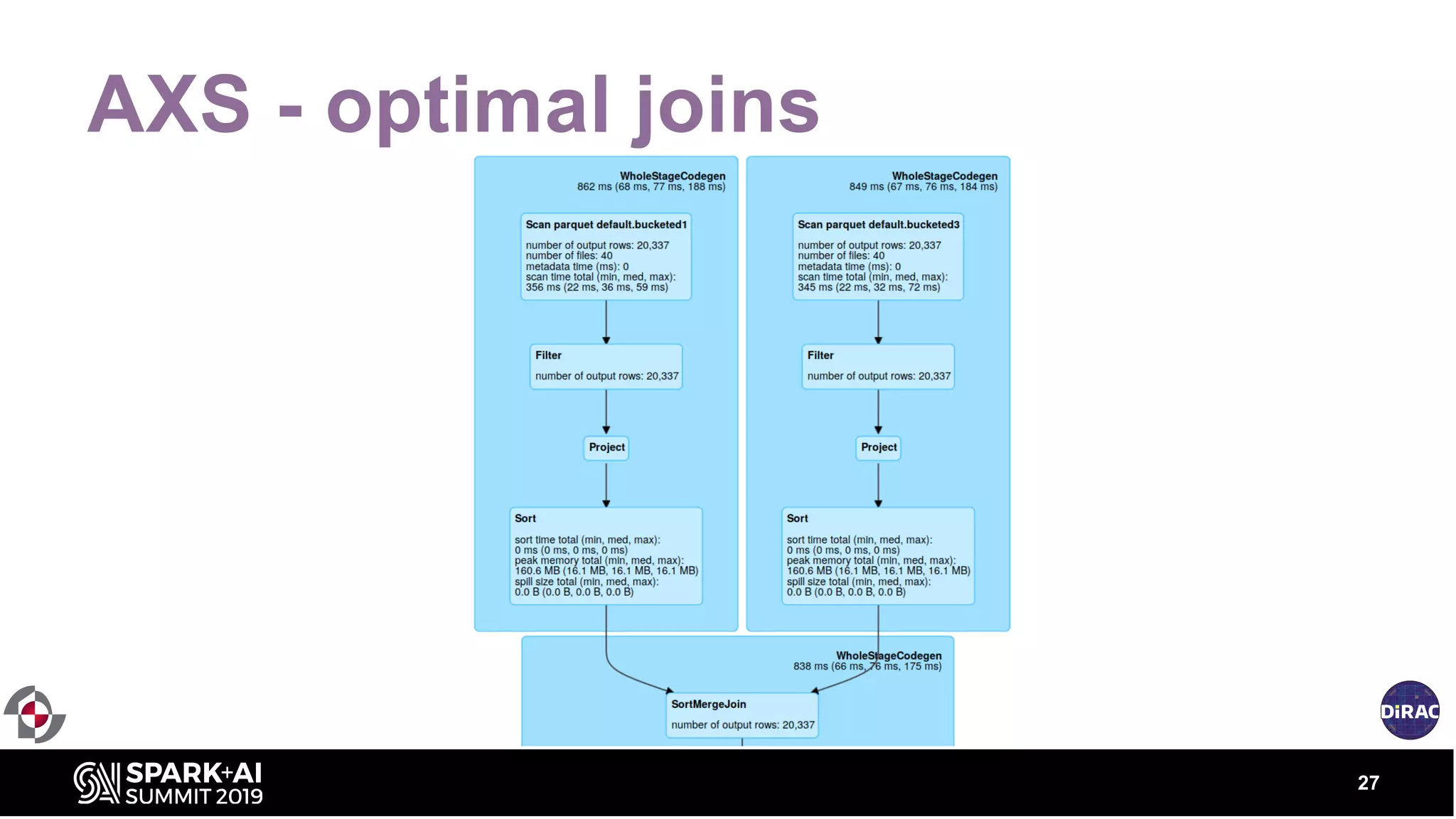
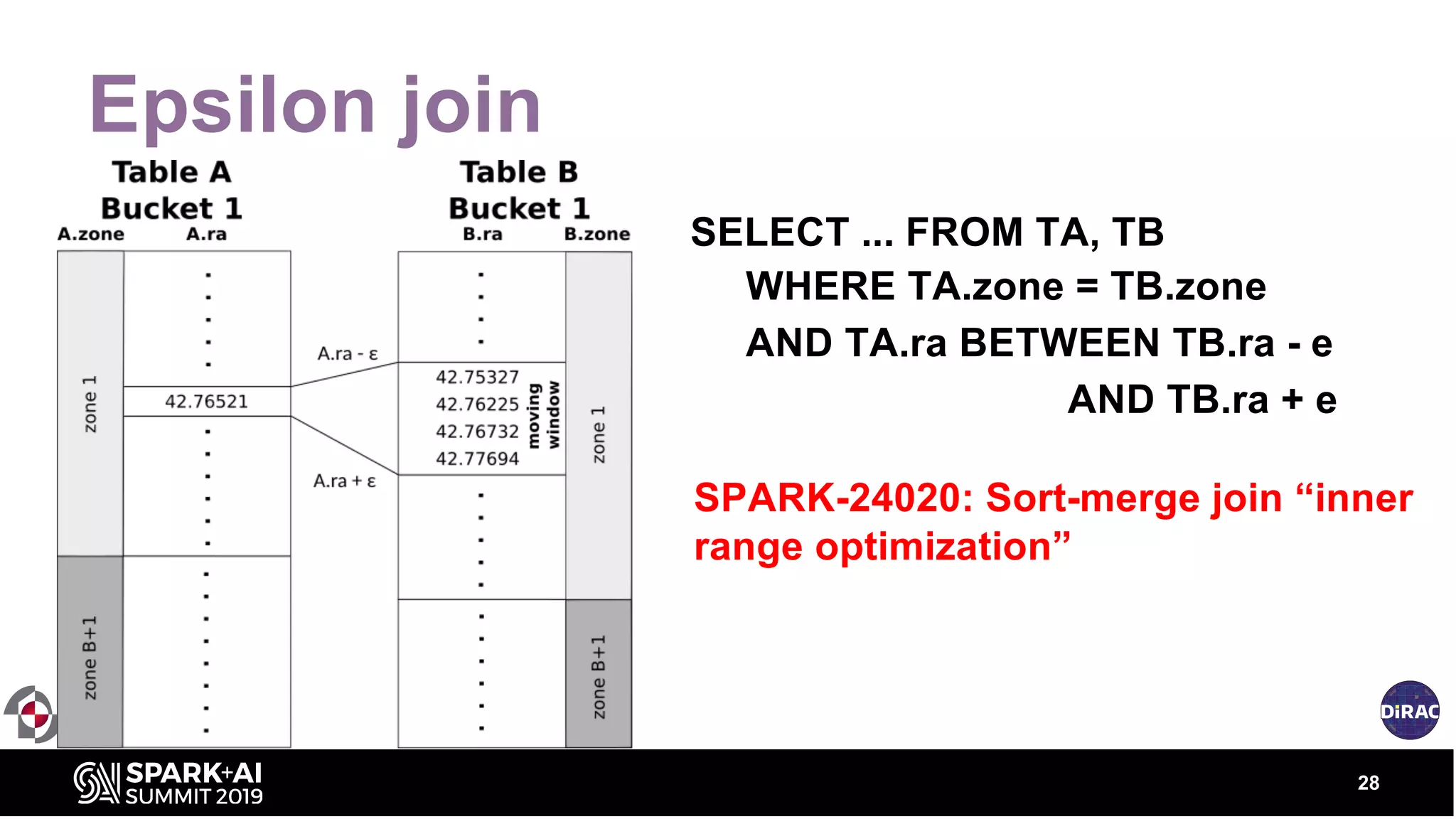

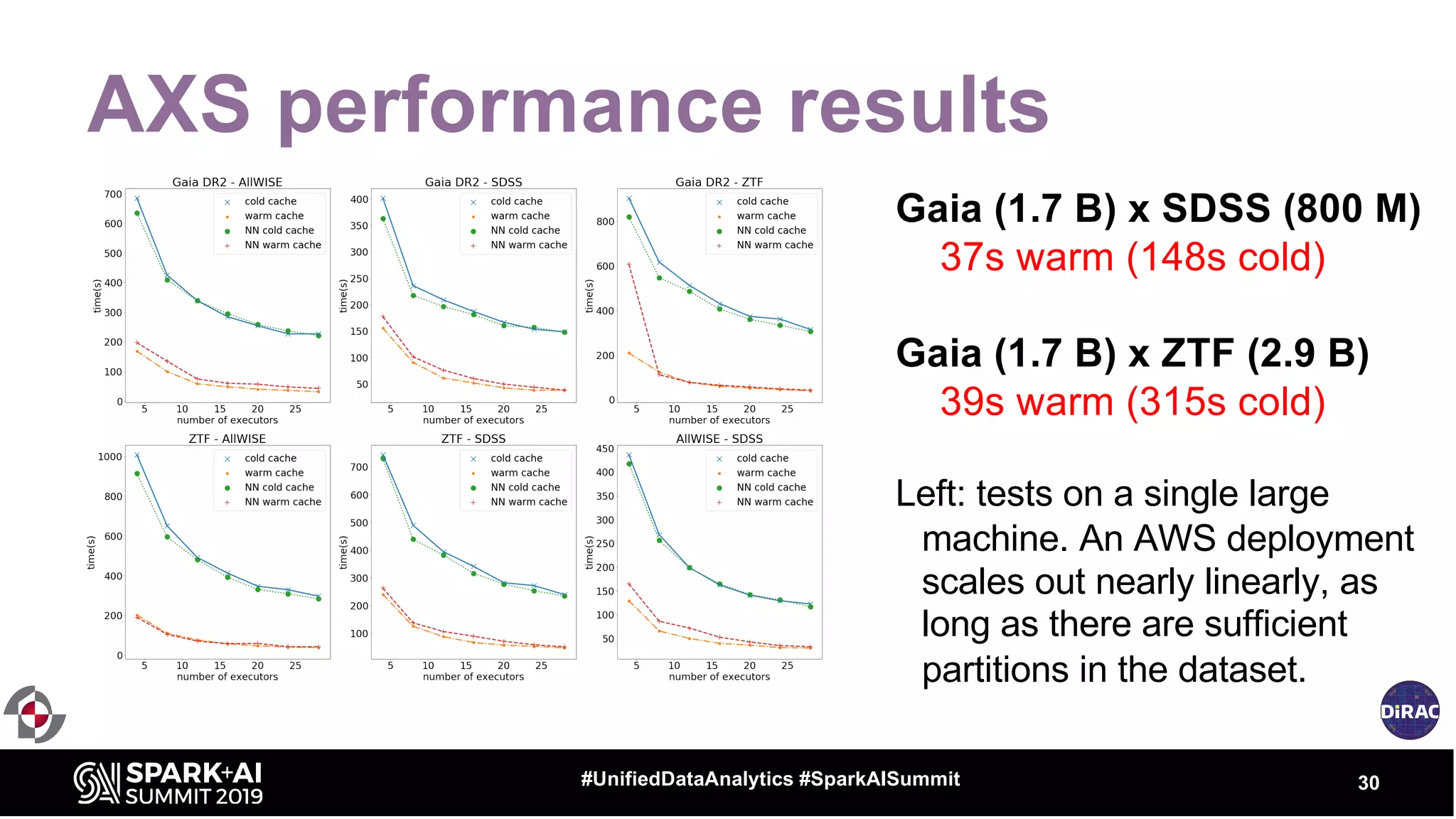
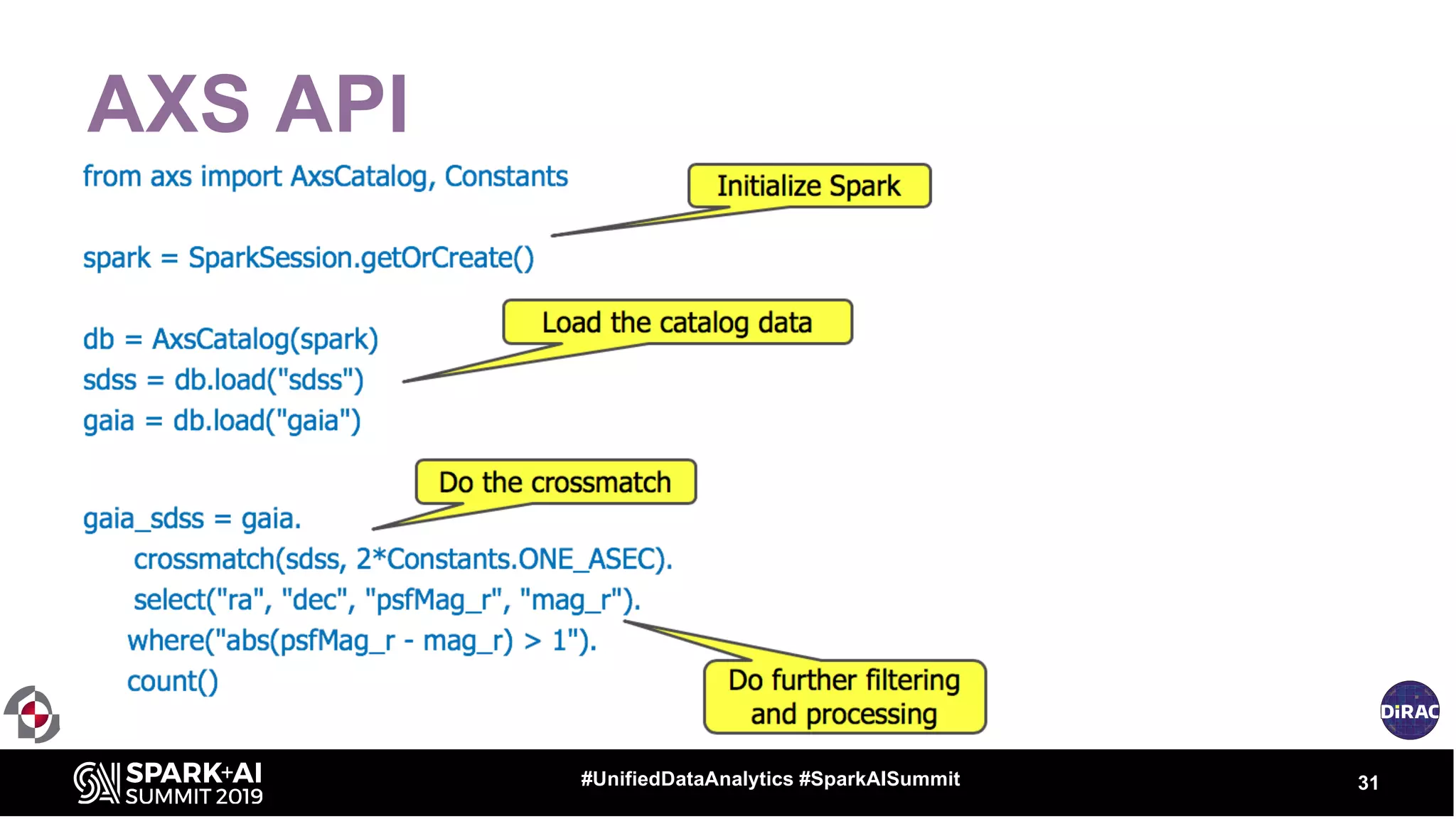









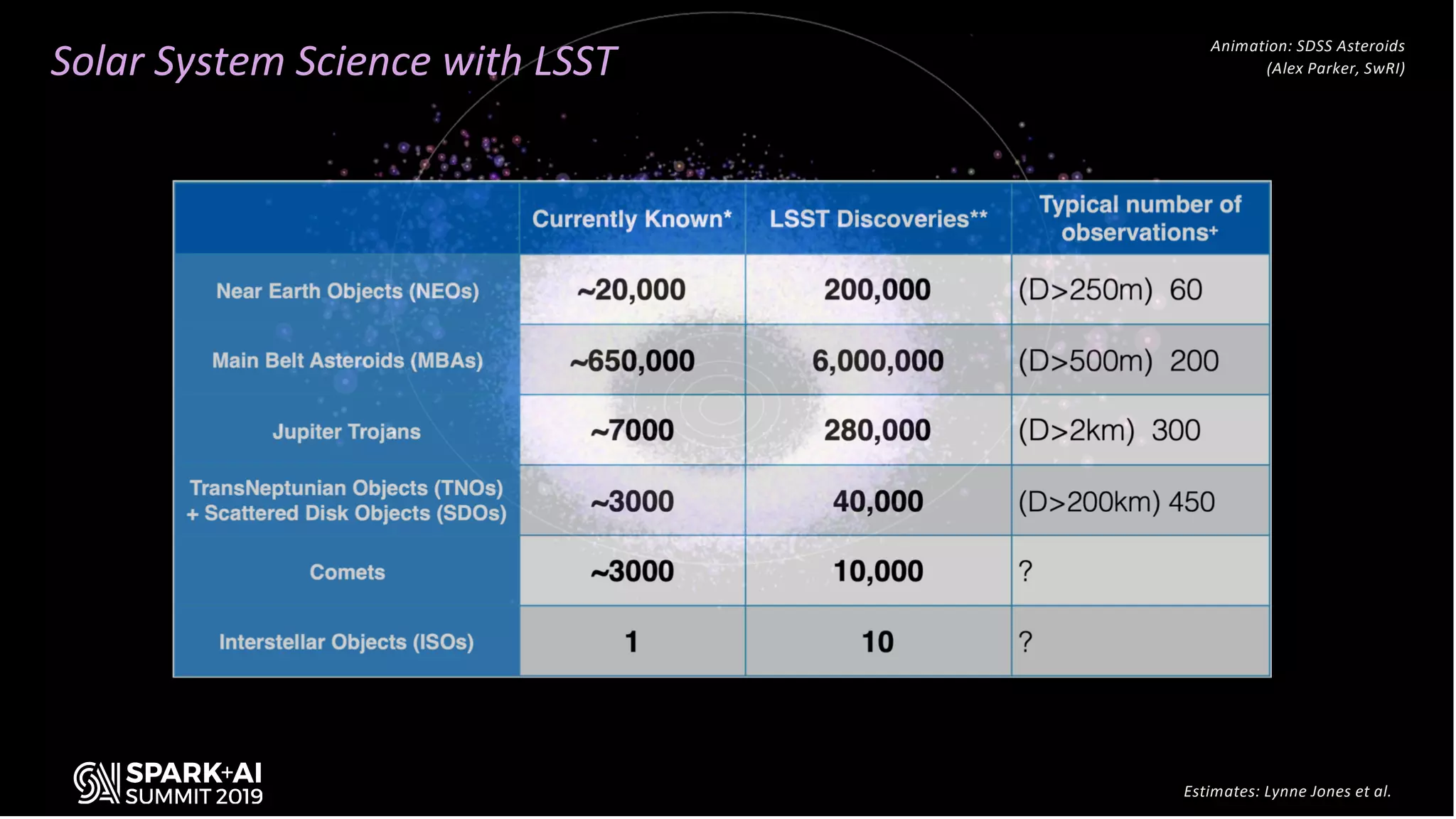





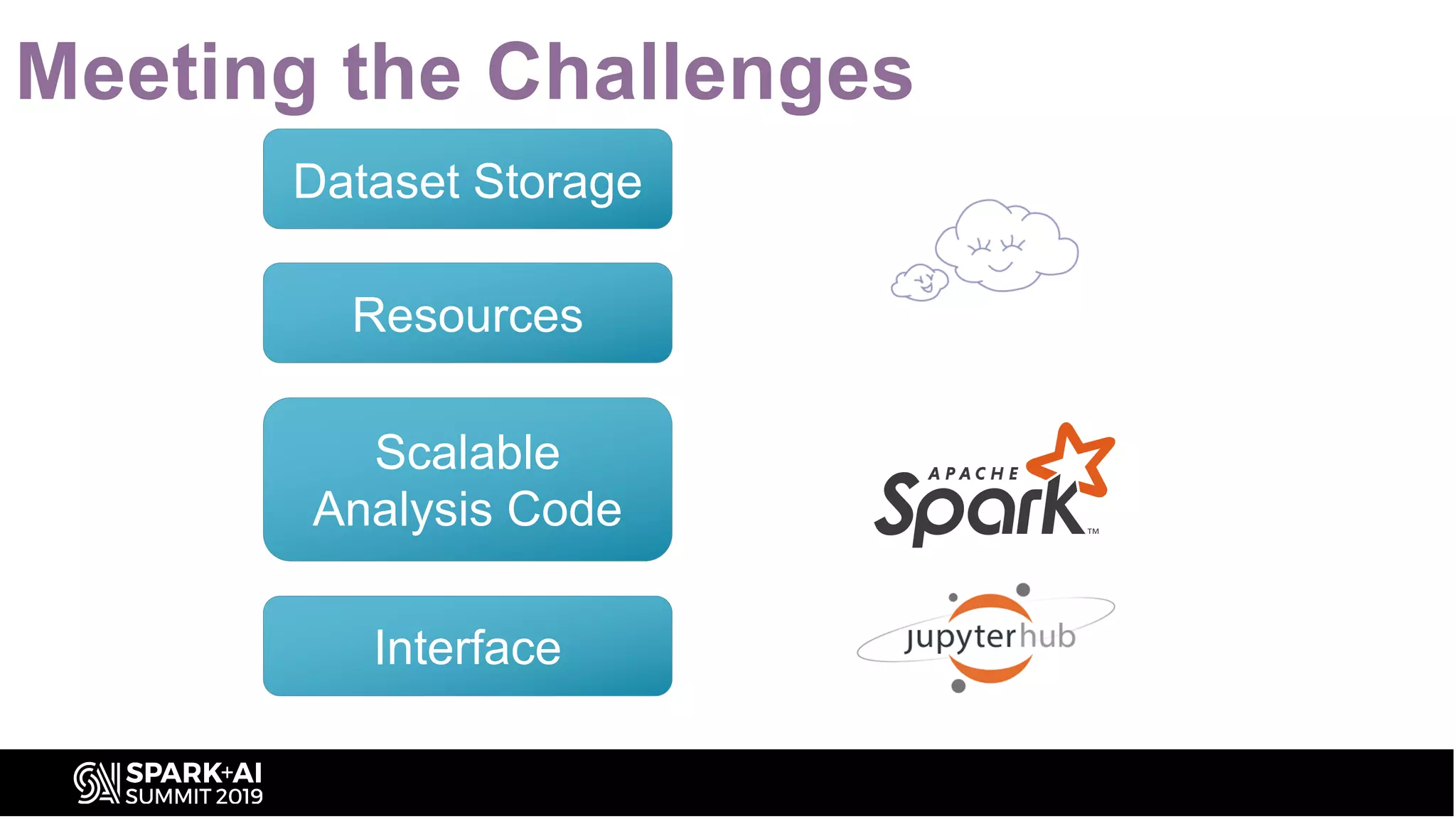

The document discusses the advancements in astronomical data processing, particularly focusing on the use of Apache Spark in handling large datasets, such as those from the Large Synoptic Survey Telescope. It outlines the evolution of astronomical surveys and the need for scalable and efficient tools for data analysis, emphasizing the development of AXS, an astronomy extension for Spark that enhances exploratory data analysis. The document highlights the challenges faced in managing petabyte-scale datasets and presents solutions for cross-matching and data partitioning to improve performance in astronomical research.