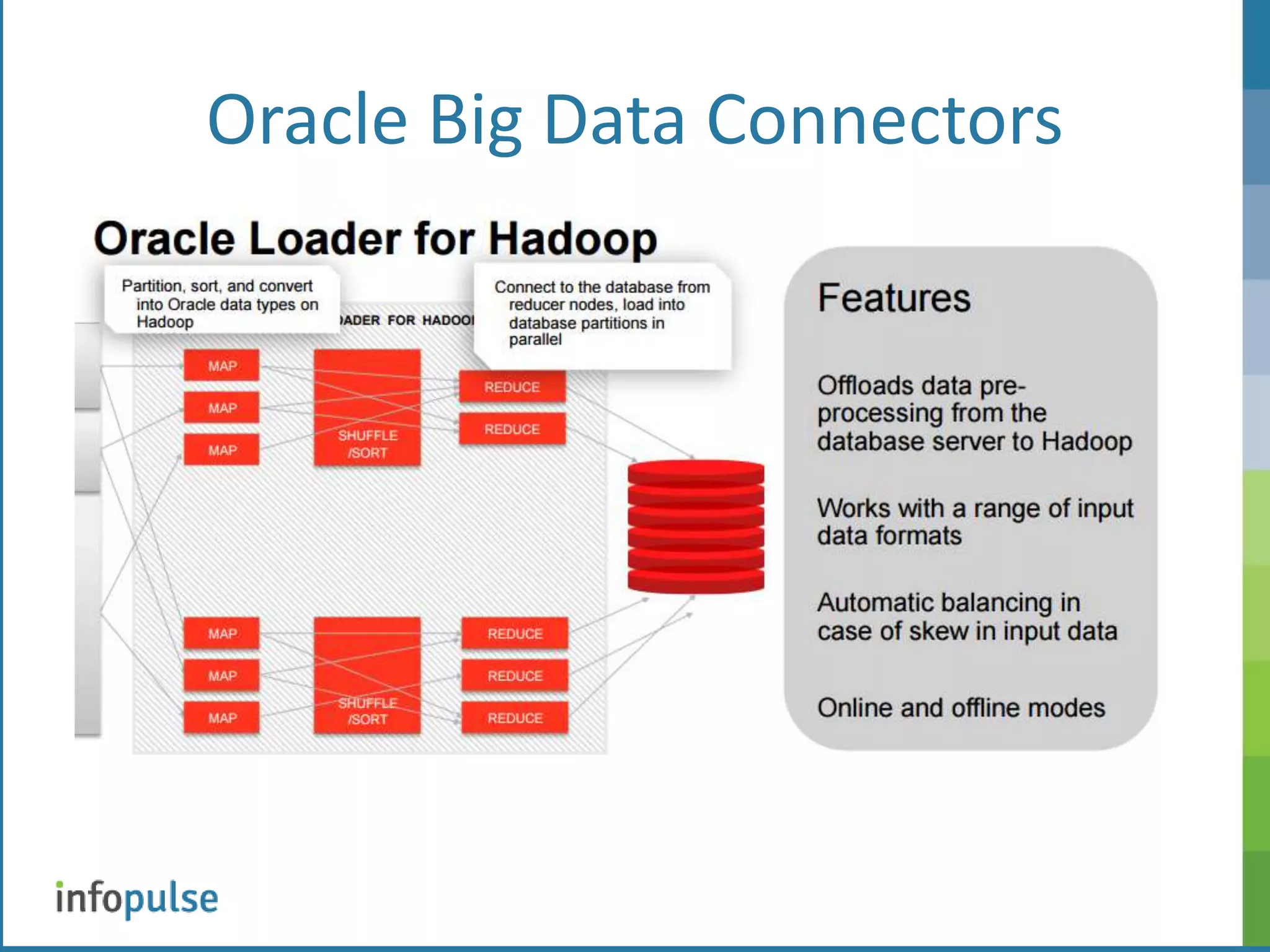
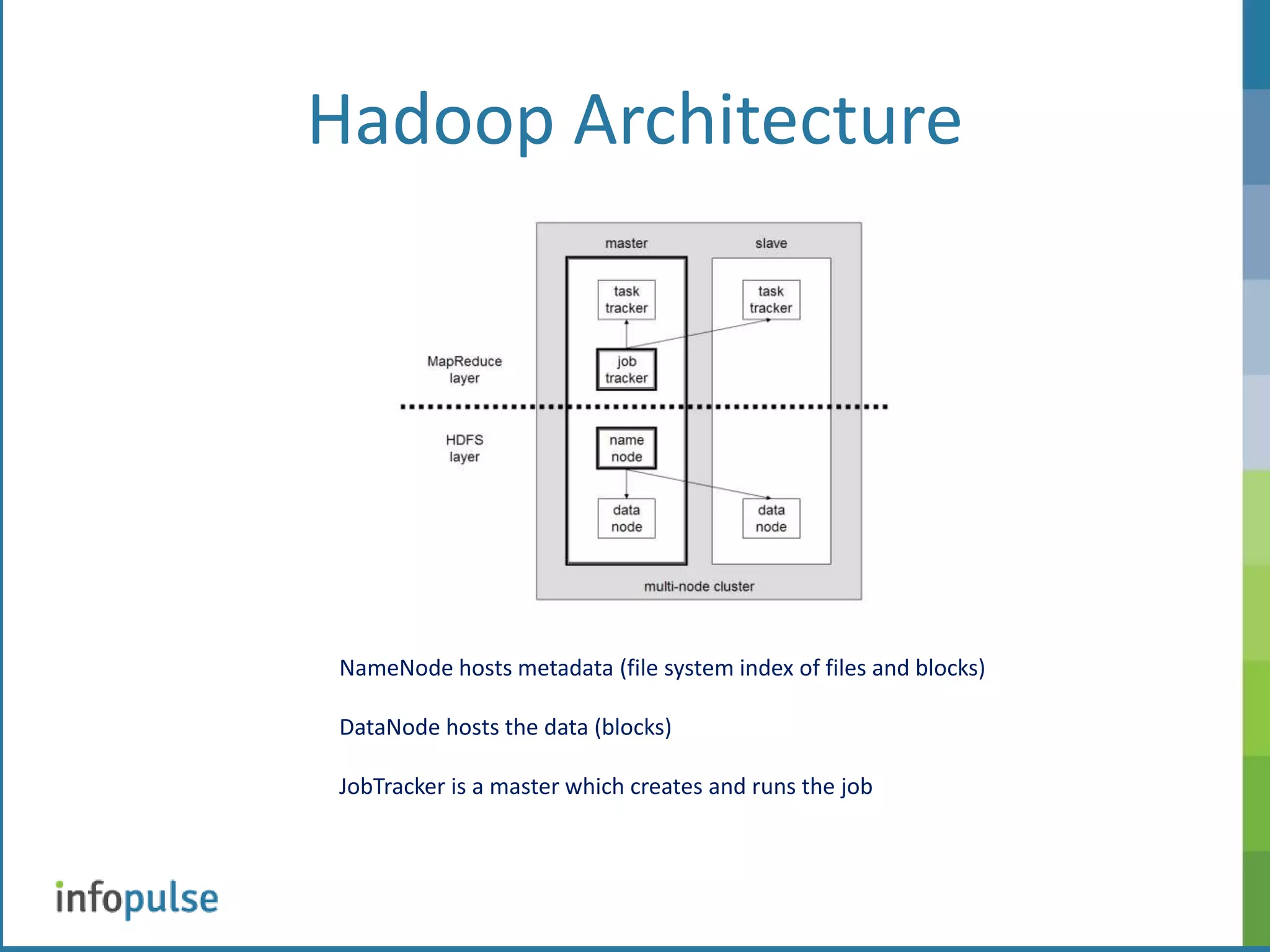
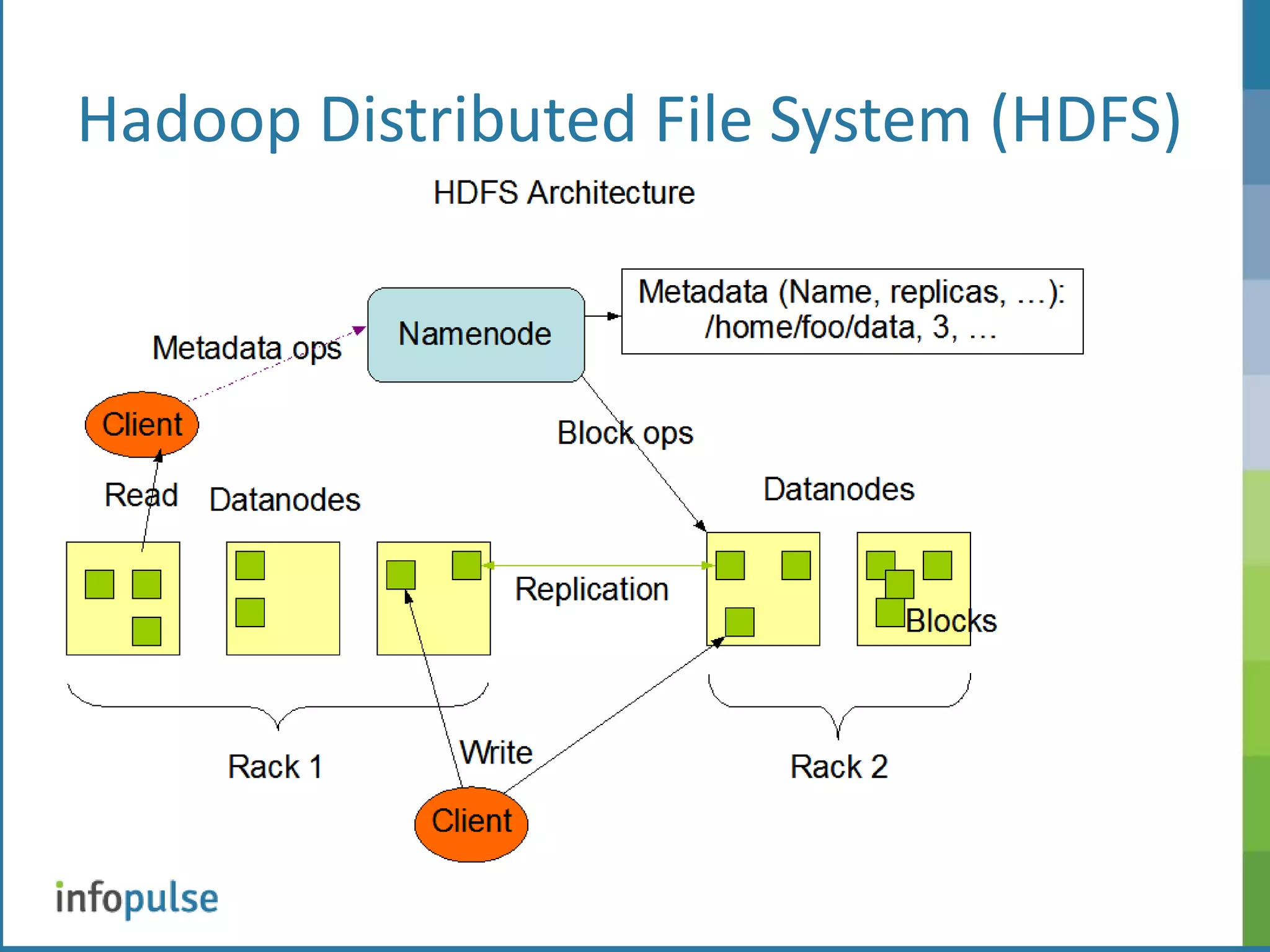
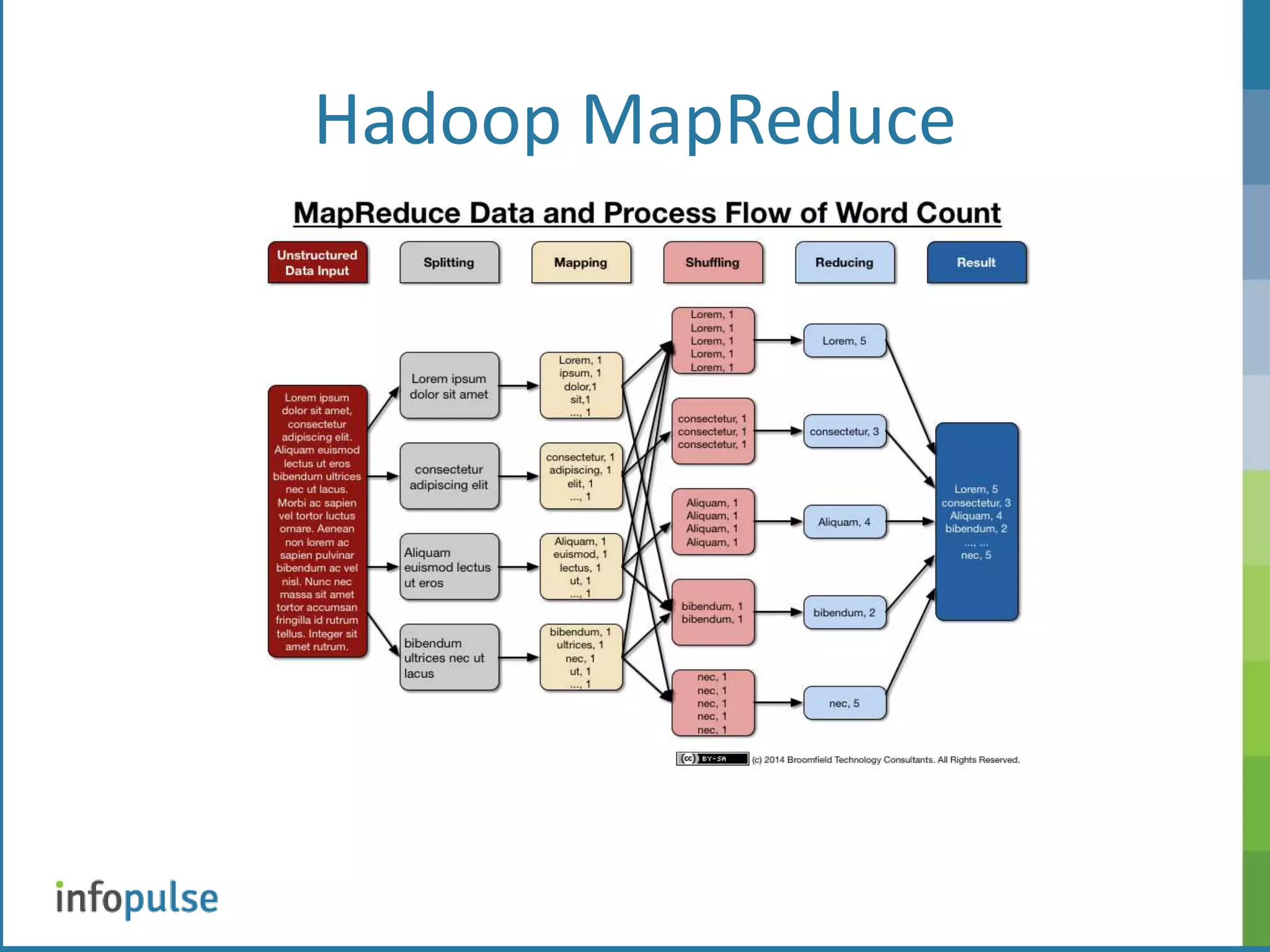
This document provides an overview of Apache Hadoop, including its architecture, components, and applications. Hadoop is an open-source framework for distributed storage and processing of large datasets. It uses Hadoop Distributed File System (HDFS) for storage and MapReduce for processing. HDFS stores data across clusters of nodes and replicates files for fault tolerance. MapReduce allows parallel processing of large datasets using a map and reduce workflow. The document also discusses Hadoop interfaces, Oracle connectors, and resources for further information.




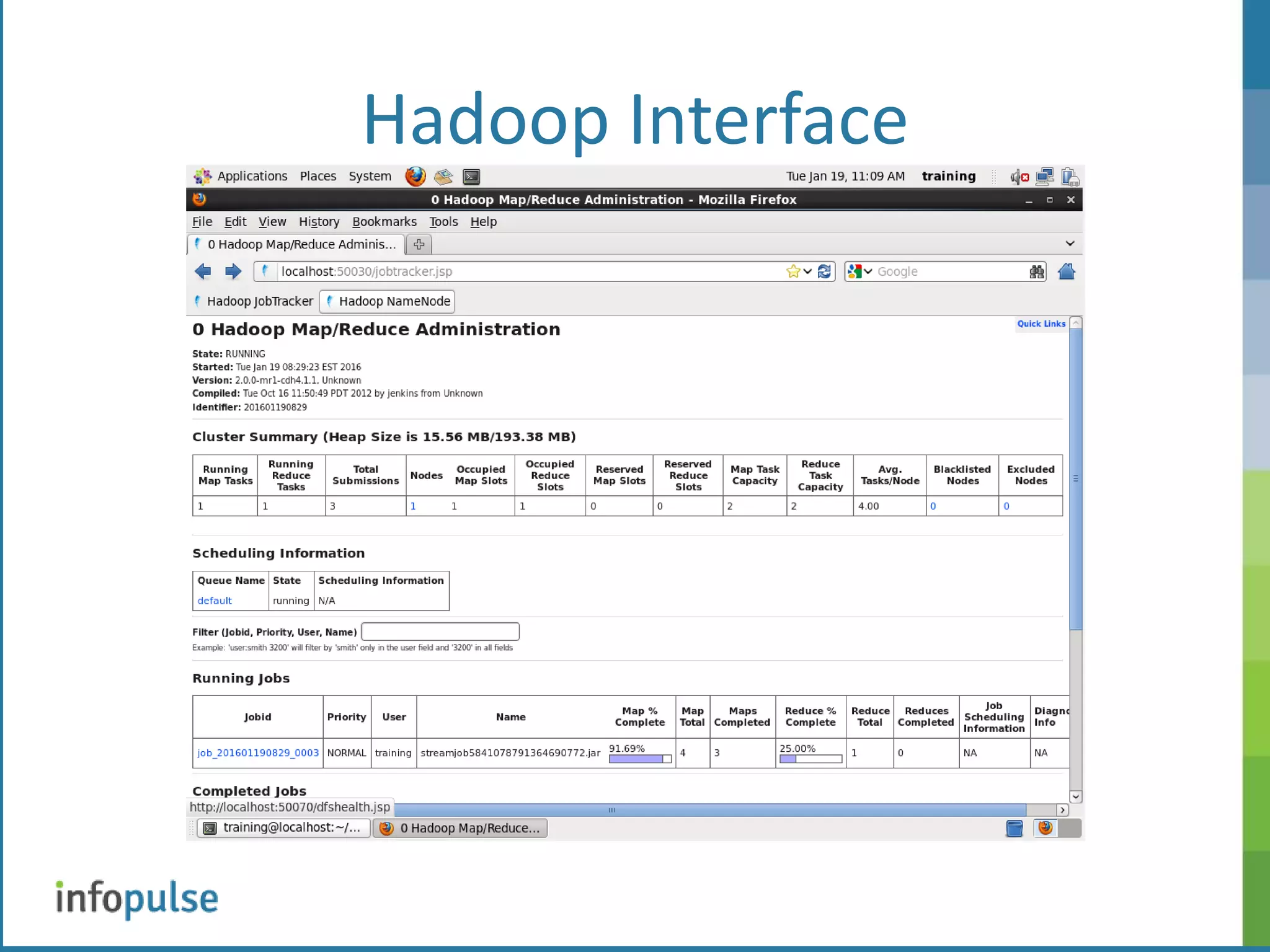
![Hadoop Interface [training@localhost ~]$ hdfs dfsadmin -report Configured Capacity: 15118729216 (14.08 GB) Present Capacity: 10163642368 (9.47 GB) DFS Remaining: 9228095488 (8.59 GB) DFS Used: 935546880 (892.21 MB) DFS Used%: 9.2% Under replicated blocks: 3 Blocks with corrupt replicas: 0 Missing blocks: 0 ------------------------------------------------- Datanodes available: 1 (1 total, 0 dead) Live datanodes: Name: 127.0.0.1:50010 (localhost.localdomain) Hostname: localhost.localdomain Decommission Status : Normal Configured Capacity: 15118729216 (14.08 GB) DFS Used: 935546880 (892.21 MB) Non DFS Used: 4955086848 (4.61 GB) DFS Remaining: 9228095488 (8.59 GB) DFS Used%: 6.19% DFS Remaining%: 61.04% Last contact: Mon Jan 18 14:05:48 EST 2016](https://image.slidesharecdn.com/hadoop-160127225411/75/BIG-DATA-Apache-Hadoop-6-2048.jpg)
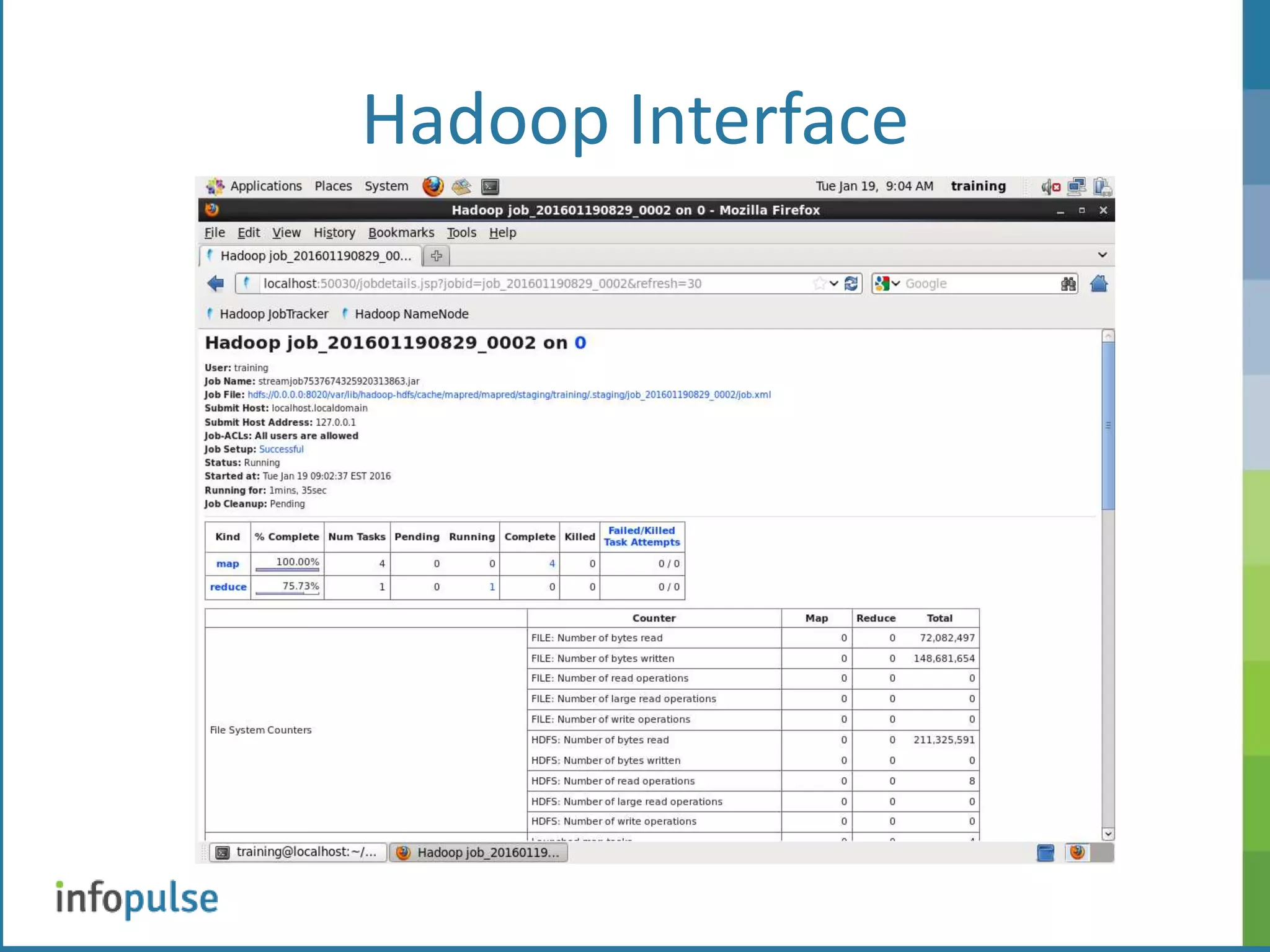
![Hadoop Interface [training@localhost ~]$ hadoop fs -help get -get [-ignoreCrc] [-crc] <src> ... <localdst>: Copy files that match the file pattern <src> to the local name. <src> is kept. When copying multiple, files, the destination must be a directory. hadoop fs –ls hadoop fs -put purchases.txt hadoop fs -put access_log hadoop fs -ls hadoop fs -tail purchases.txt hadoop fs get filename hs {mapper script} {reducer script} {input_file} {output directory} hs mapper.py reducer.py myinput joboutput](https://image.slidesharecdn.com/hadoop-160127225411/75/BIG-DATA-Apache-Hadoop-7-2048.jpg)









![Hadoop MapReduce Usage: $HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar [options] Options: -input <path> DFS input file(s) for the Map step -output <path> DFS output directory for the Reduce step -mapper <cmd|JavaClassName> The streaming command to run -combiner <cmd|JavaClassName> The streaming command to run -reducer <cmd|JavaClassName> The streaming command to run -file <file> File/dir to be shipped in the Job jar file -inputformat TextInputFormat(default)|SequenceFileAsTextInputFormat|JavaClassName Optional. -outputformat TextOutputFormat(default)|JavaClassName Optional. -partitioner JavaClassName Optional. -numReduceTasks <num> Optional. -inputreader <spec> Optional. -cmdenv <n>=<v> Optional. Pass env.var to streaming commands -mapdebug <path> Optional. To run this script when a map task fails -reducedebug <path> Optional. To run this script when a reduce task fails -io <identifier> Optional. -verbose hs {mapper script} {reducer script} {input_file} {output directory} hs mapper.py reducer.py myinput joboutput](https://image.slidesharecdn.com/hadoop-160127225411/75/BIG-DATA-Apache-Hadoop-21-2048.jpg)