Download as PDF, PPTX





 rdd.saveToCassandra("raw")](https://image.slidesharecdn.com/074mikhailchernetsov-170614192109/75/Building-a-Versatile-Analytics-Pipeline-on-Top-of-Apache-Spark-with-Mikhail-Chernetsov-18-2048.jpg)























![val firstUtmMedium: CalcProp[String] = (E "url").as[Url] .map(_.param("utm_source")) .forEvent("page-visit") .first Enrichment Phase 2: Calculable Props Engine & DSL](https://image.slidesharecdn.com/074mikhailchernetsov-170614192109/75/Building-a-Versatile-Analytics-Pipeline-on-Top-of-Apache-Spark-with-Mikhail-Chernetsov-50-2048.jpg)



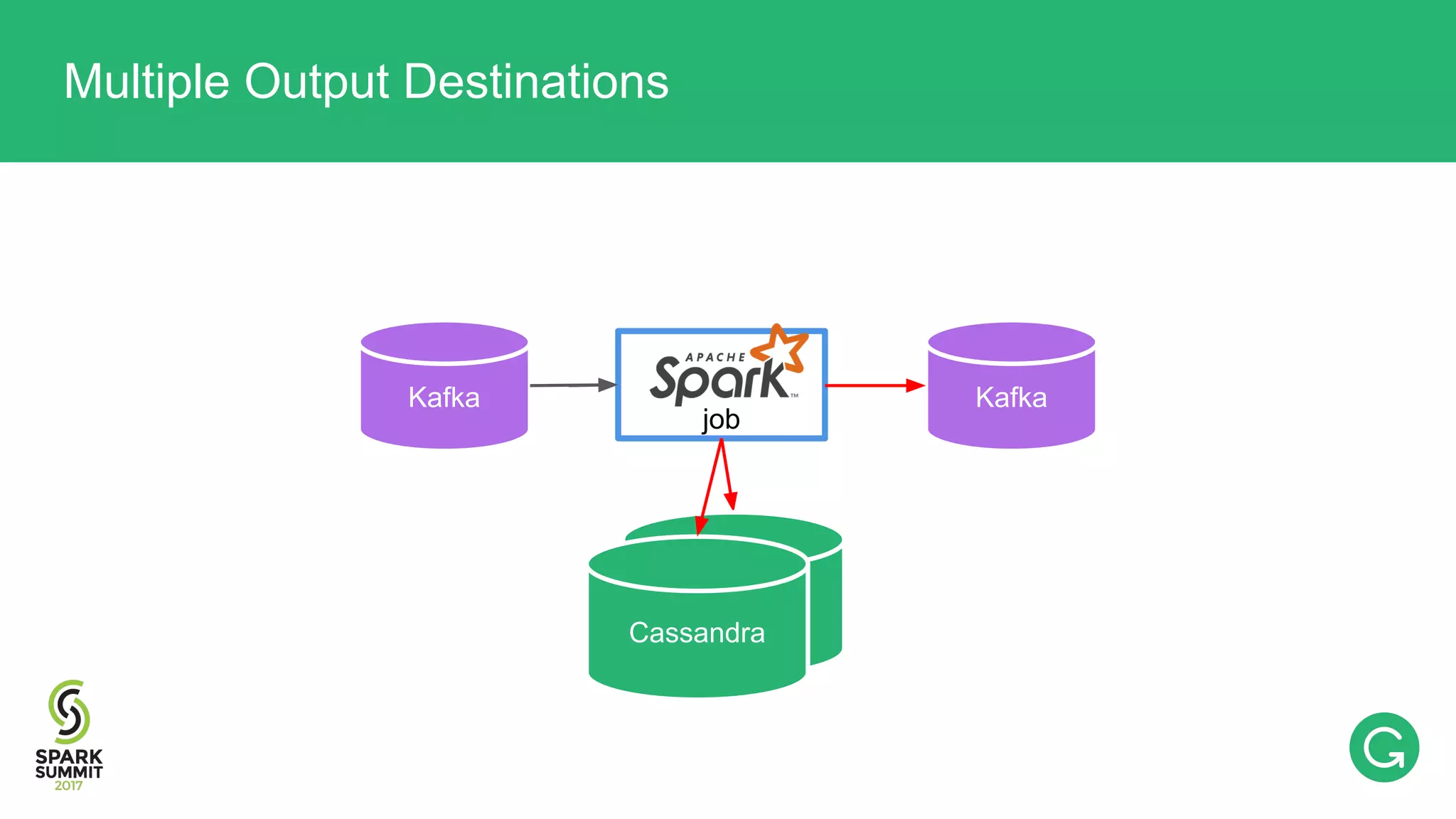
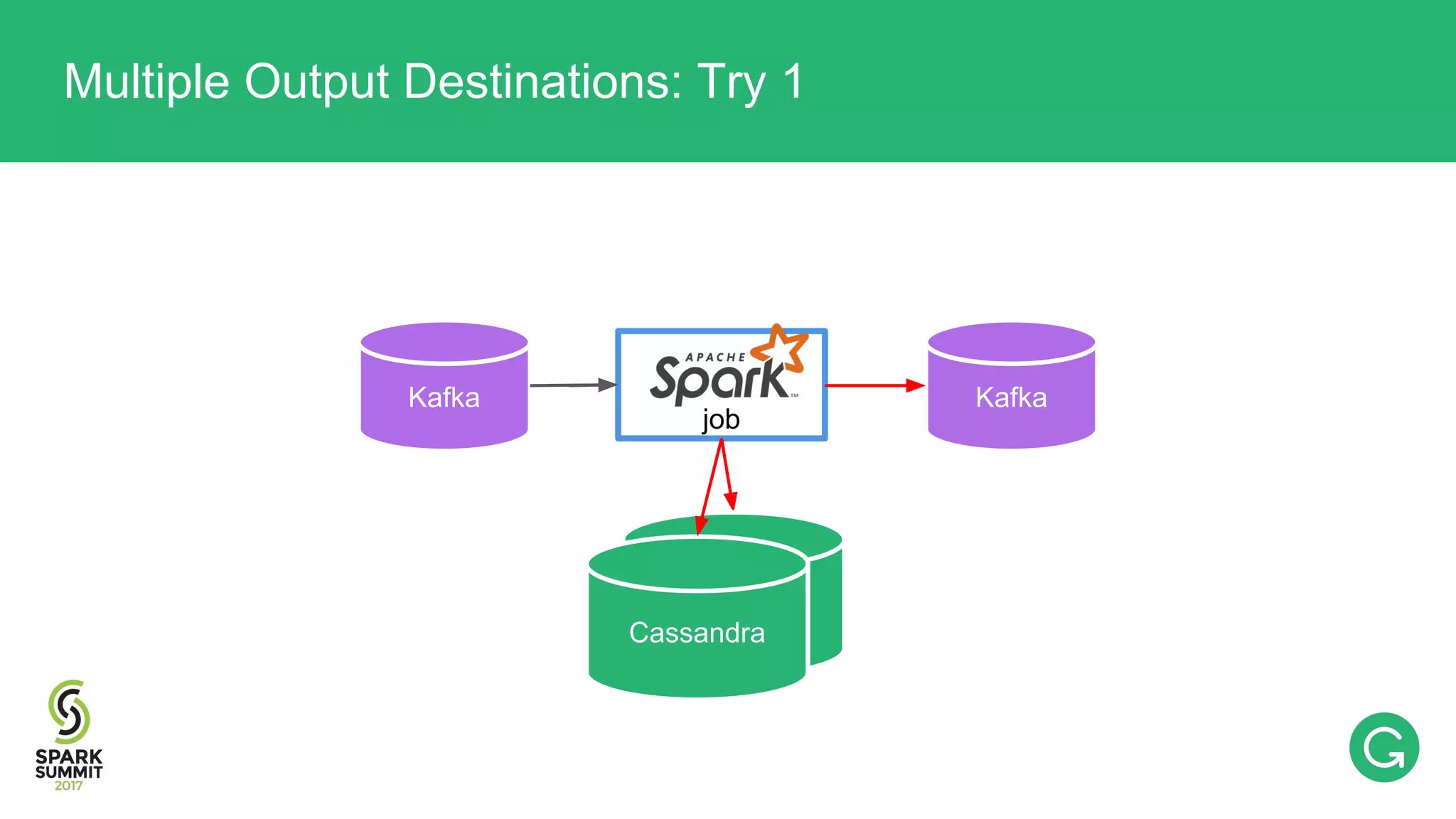
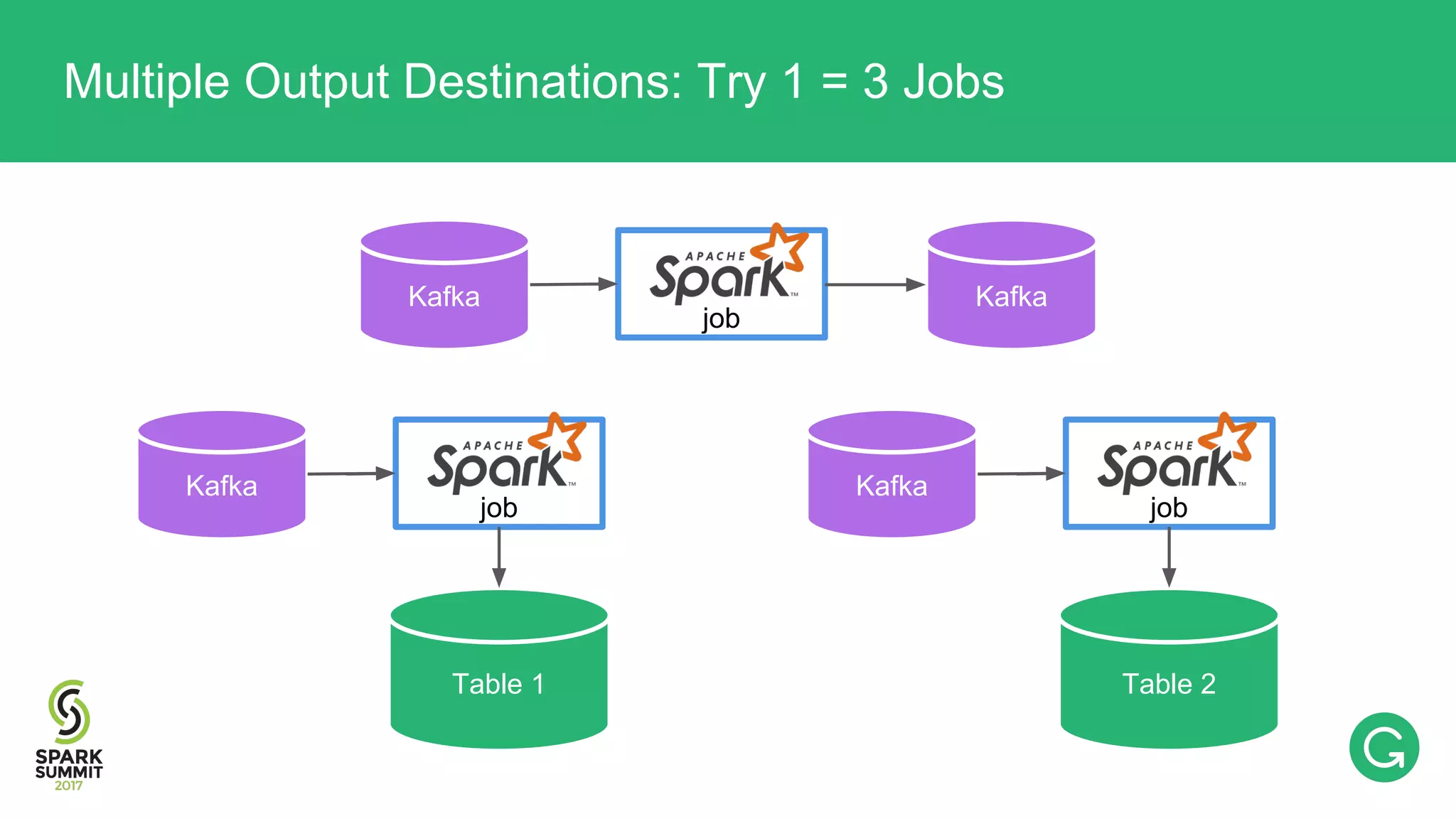
![val rdd: RDD[T] rdd.sendToKafka(“topic_x”) rdd.saveToCassandra(“table_foo”) rdd.saveToCassandra(“table_bar”) Multiple Output Destinations: Try 1](https://image.slidesharecdn.com/074mikhailchernetsov-170614192109/75/Building-a-Versatile-Analytics-Pipeline-on-Top-of-Apache-Spark-with-Mikhail-Chernetsov-58-2048.jpg)

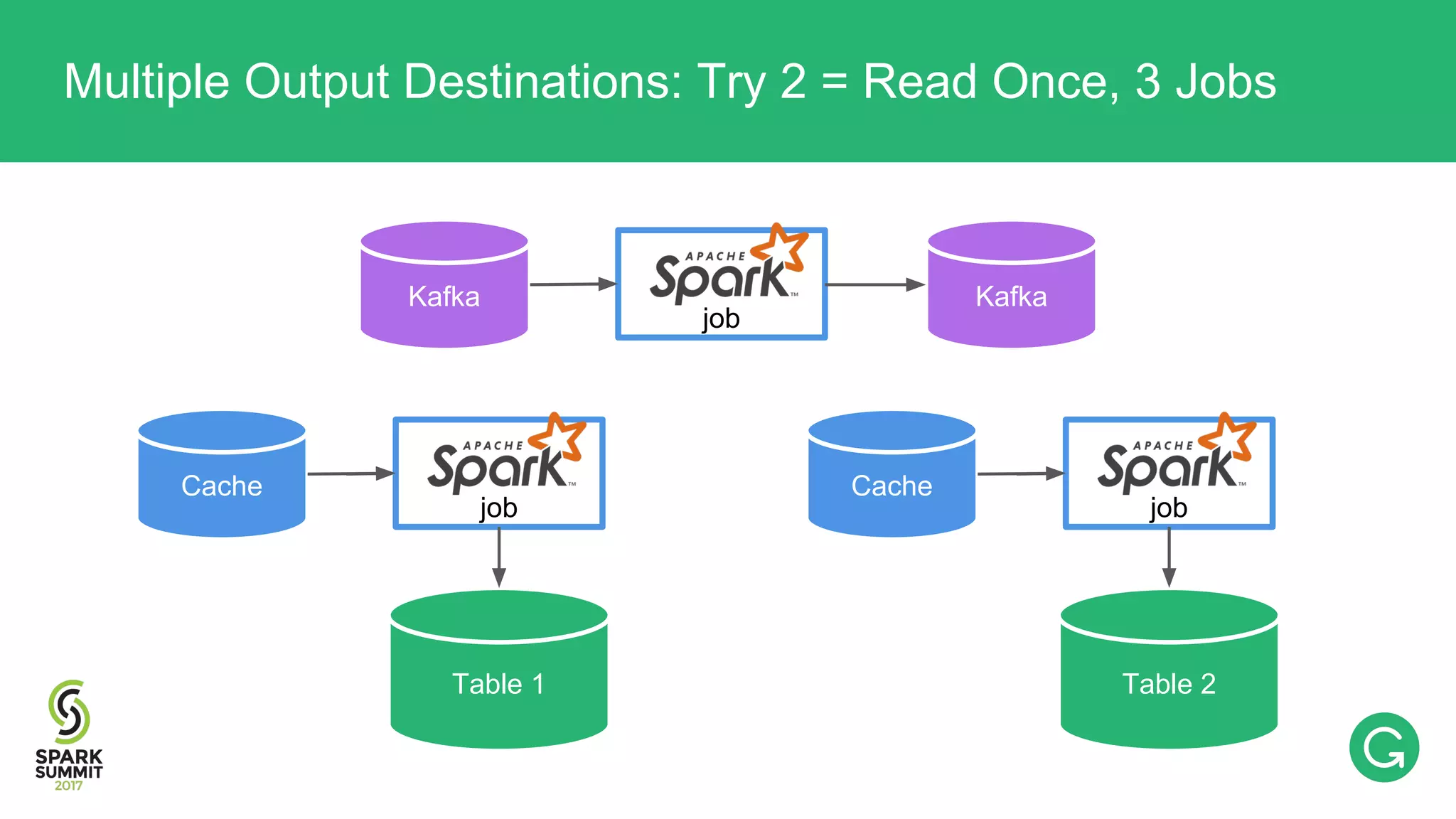
![val rdd: RDD[T] rdd.cache() rdd.sendToKafka(“topic_x”) rdd.saveToCassandra(“table_foo”) rdd.saveToCassandra(“table_bar”) Multiple Output Destinations: Try 2](https://image.slidesharecdn.com/074mikhailchernetsov-170614192109/75/Building-a-Versatile-Analytics-Pipeline-on-Top-of-Apache-Spark-with-Mikhail-Chernetsov-62-2048.jpg)




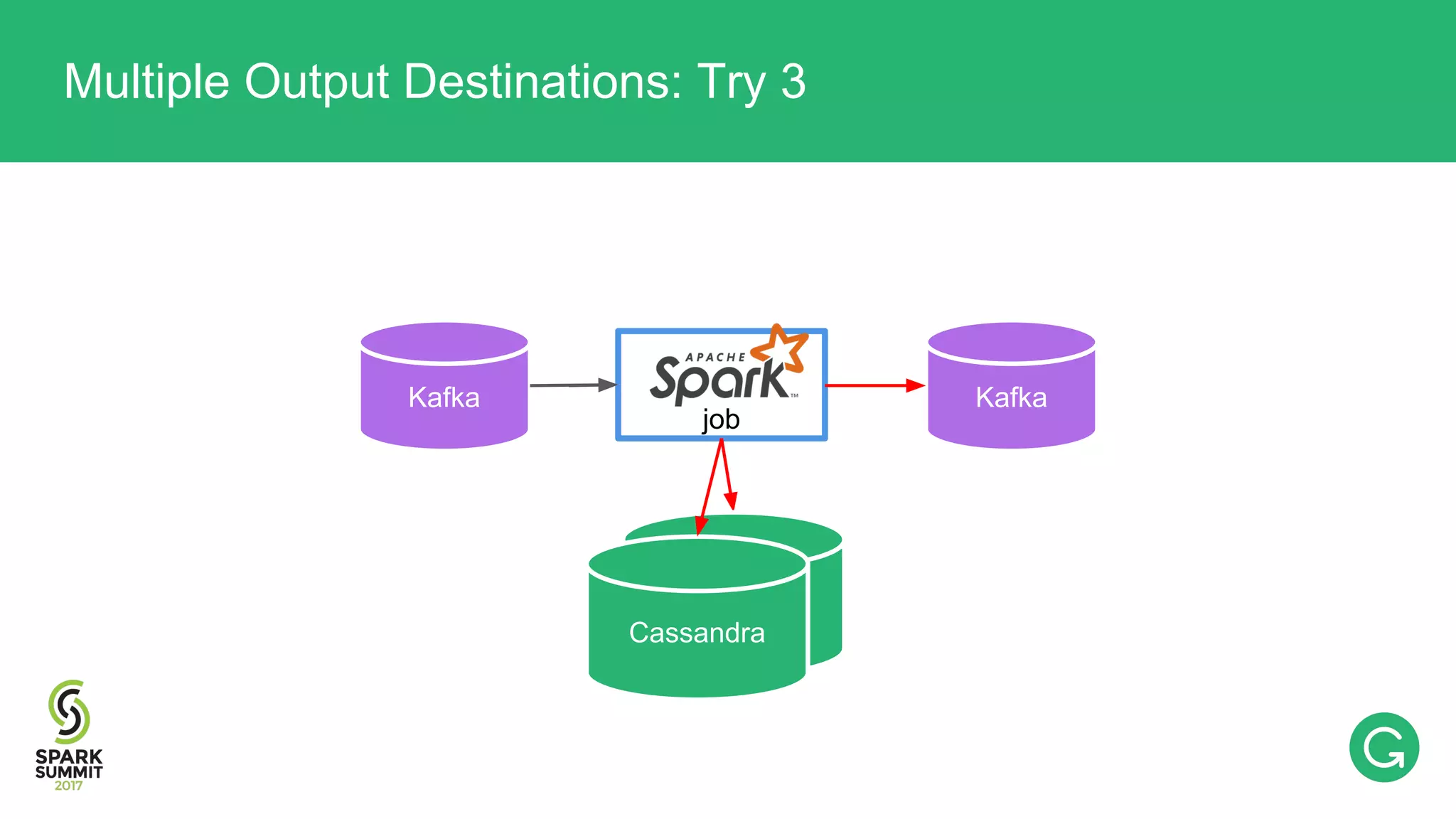
![val rdd: RDD[T] rdd.andSaveToCassandra(“table_foo”) .andSaveToCassandra(“table_bar”) .sendToKafka(“topic_x”) Multiple Output Destinations: Try 3](https://image.slidesharecdn.com/074mikhailchernetsov-170614192109/75/Building-a-Versatile-Analytics-Pipeline-on-Top-of-Apache-Spark-with-Mikhail-Chernetsov-71-2048.jpg)

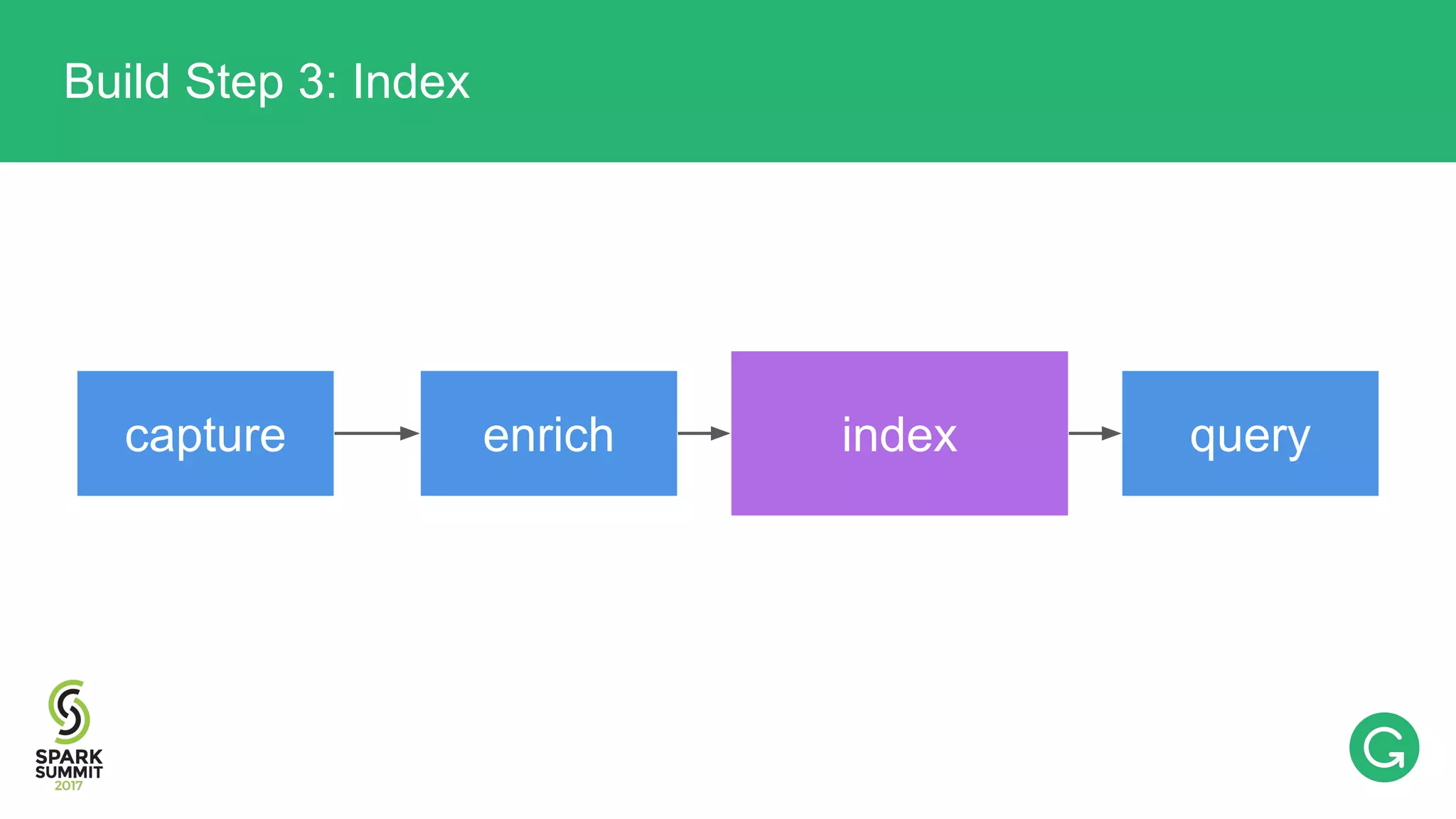

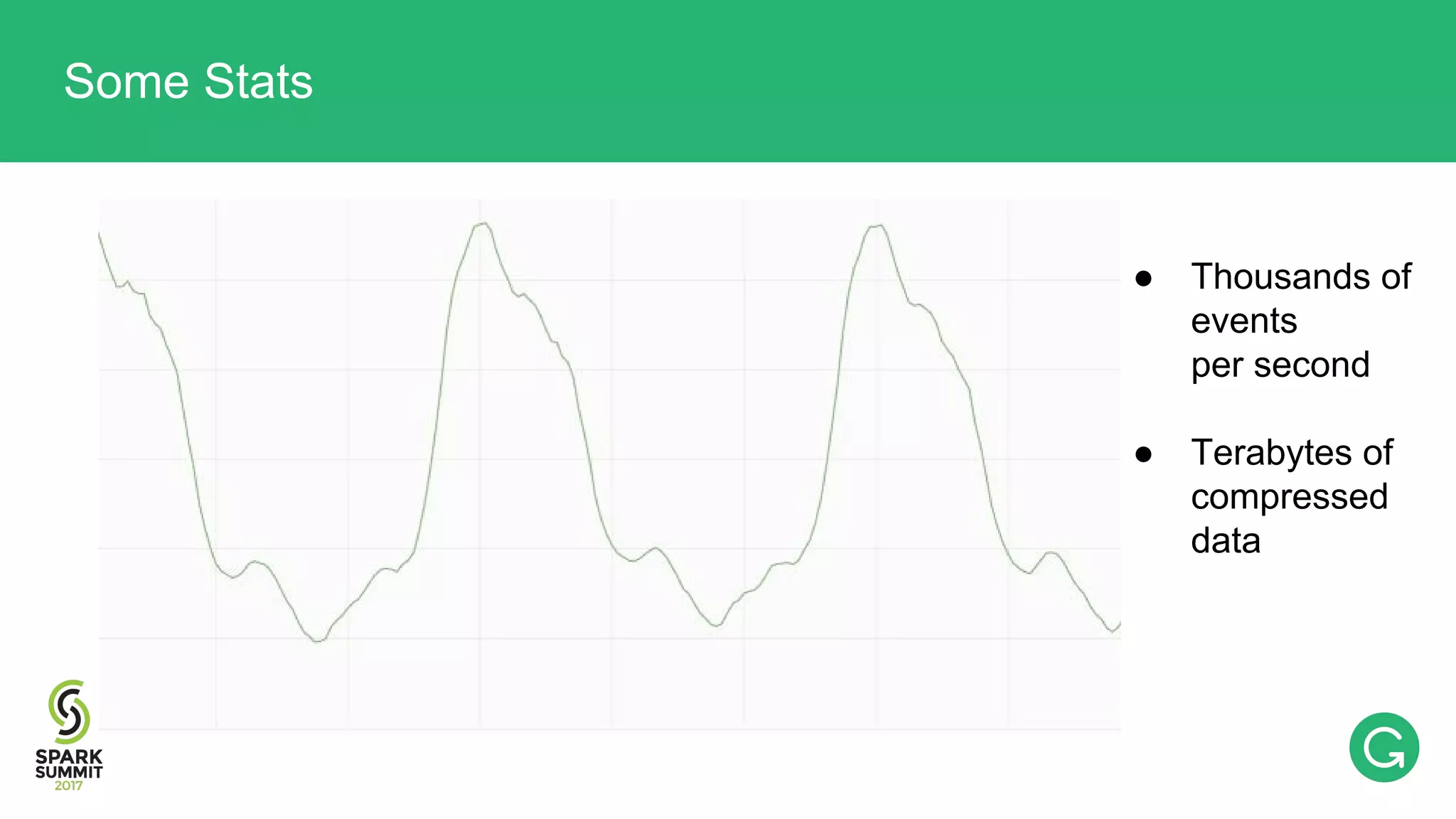
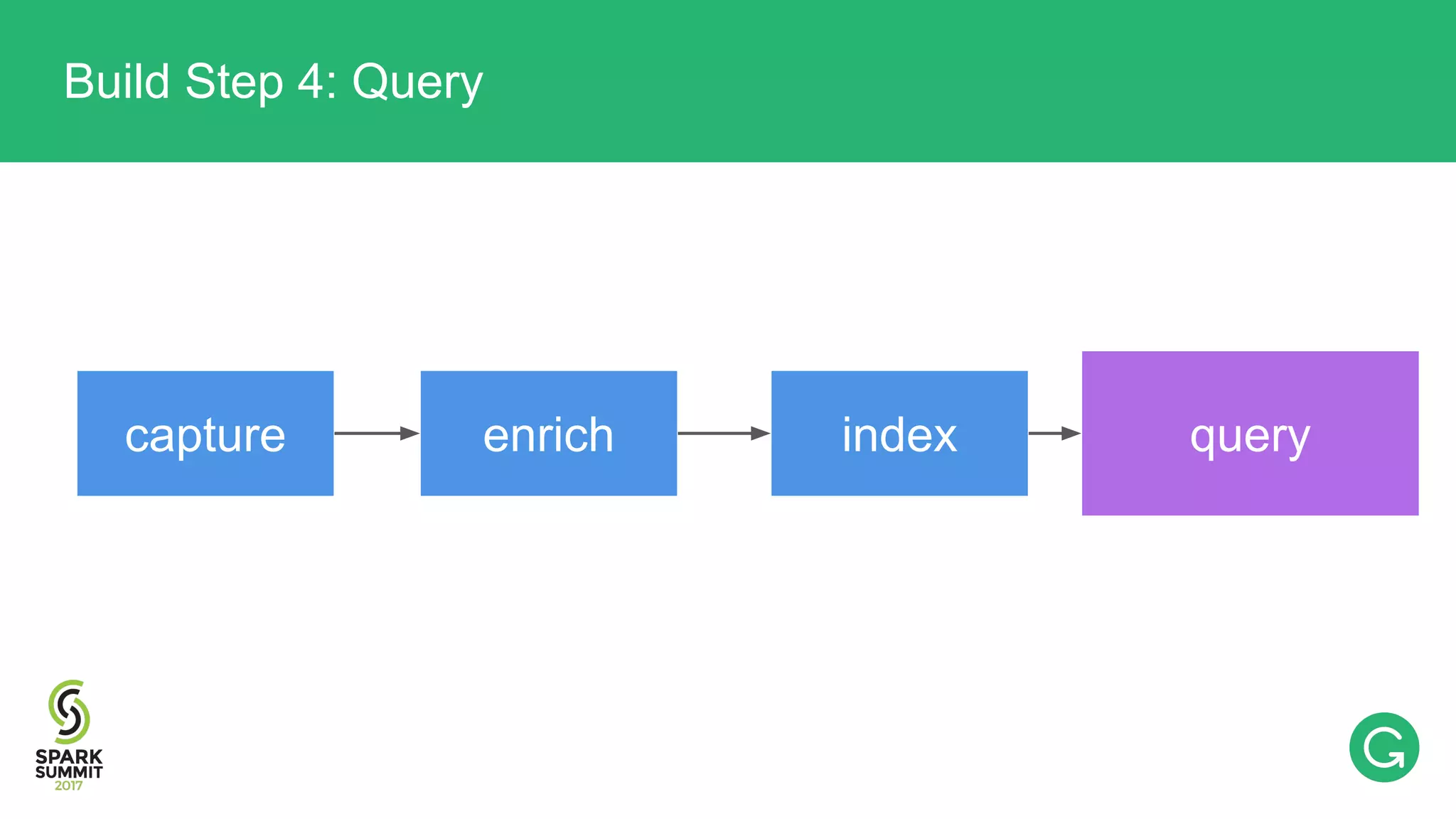



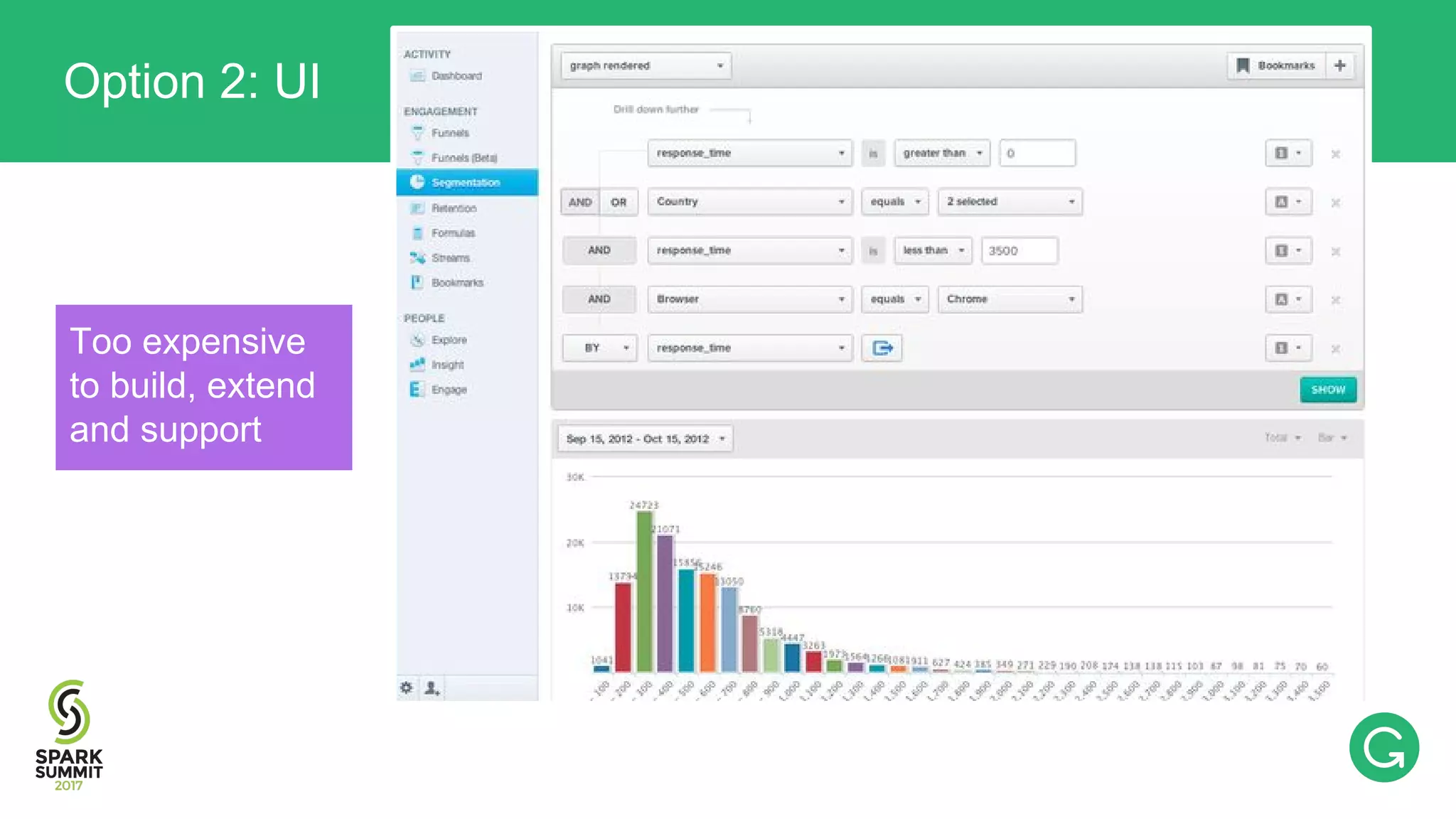







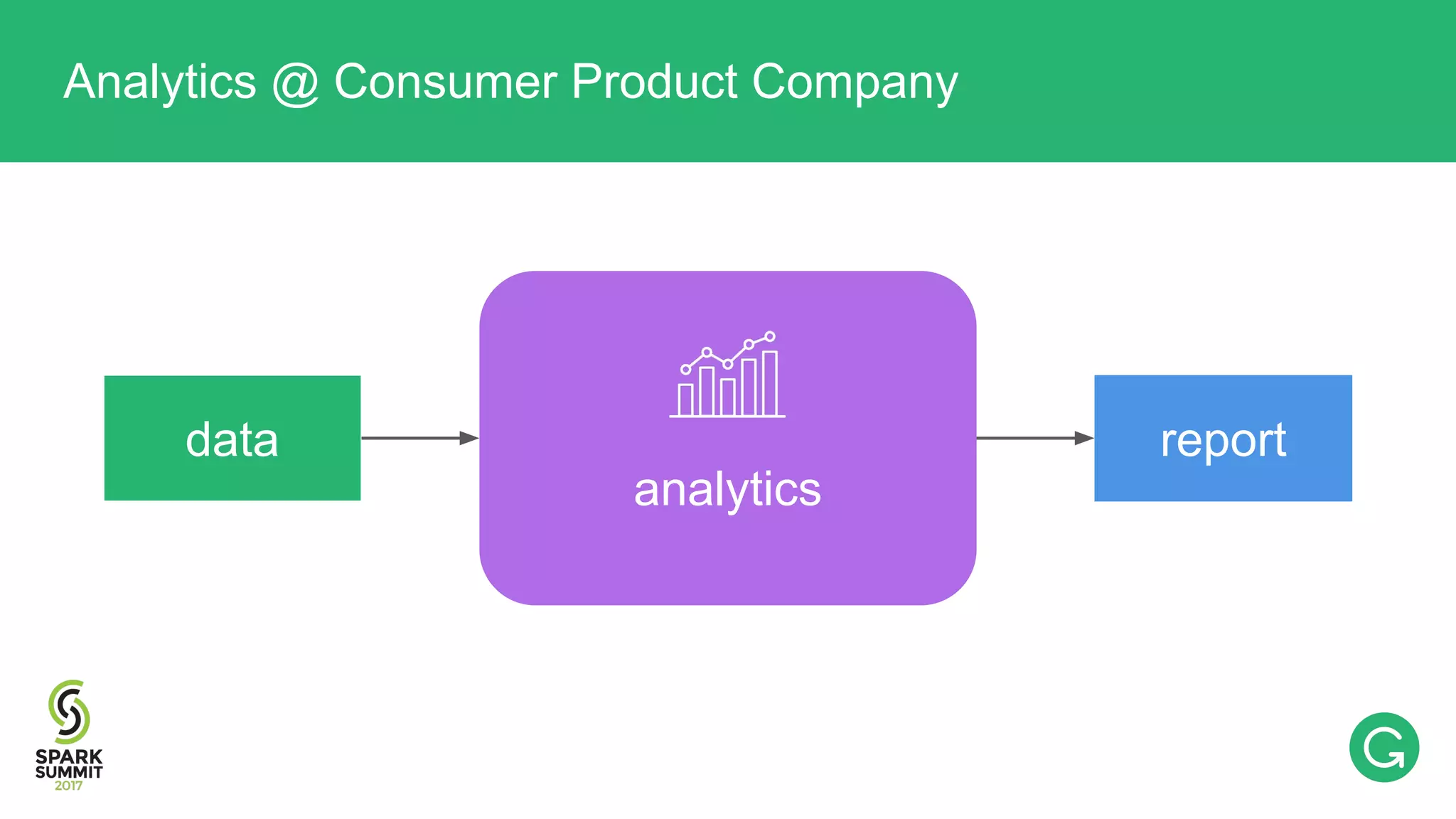
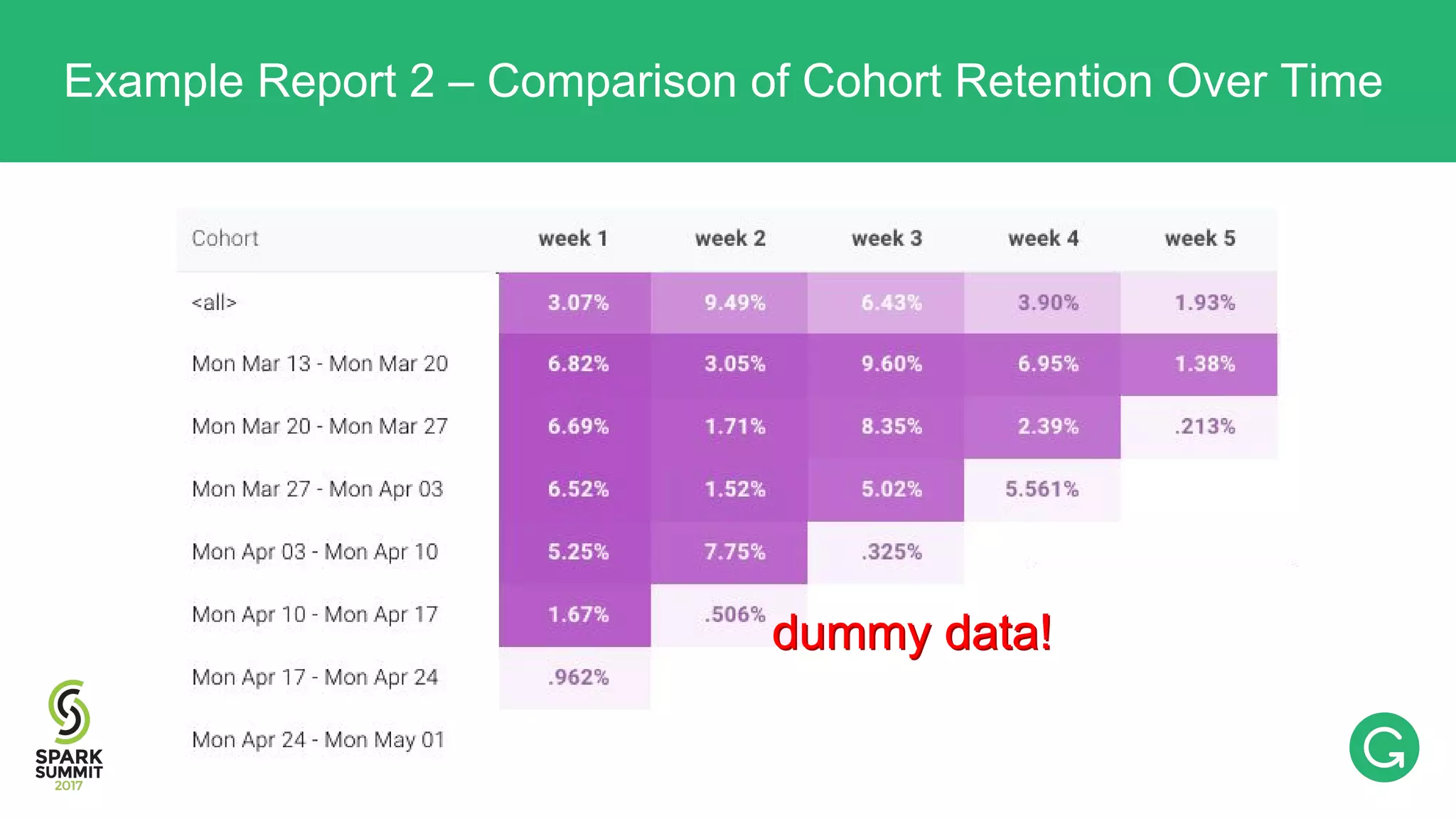
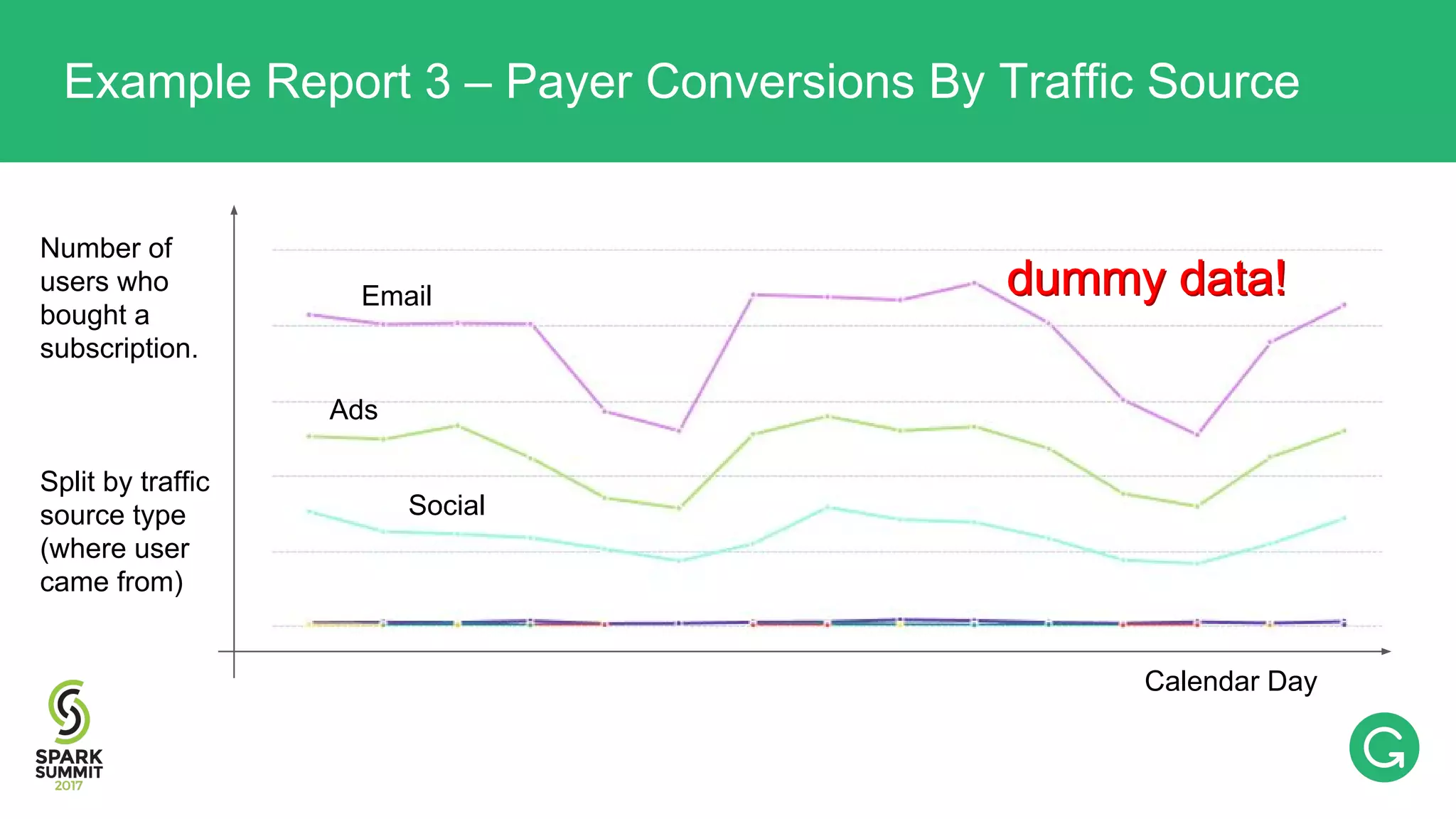
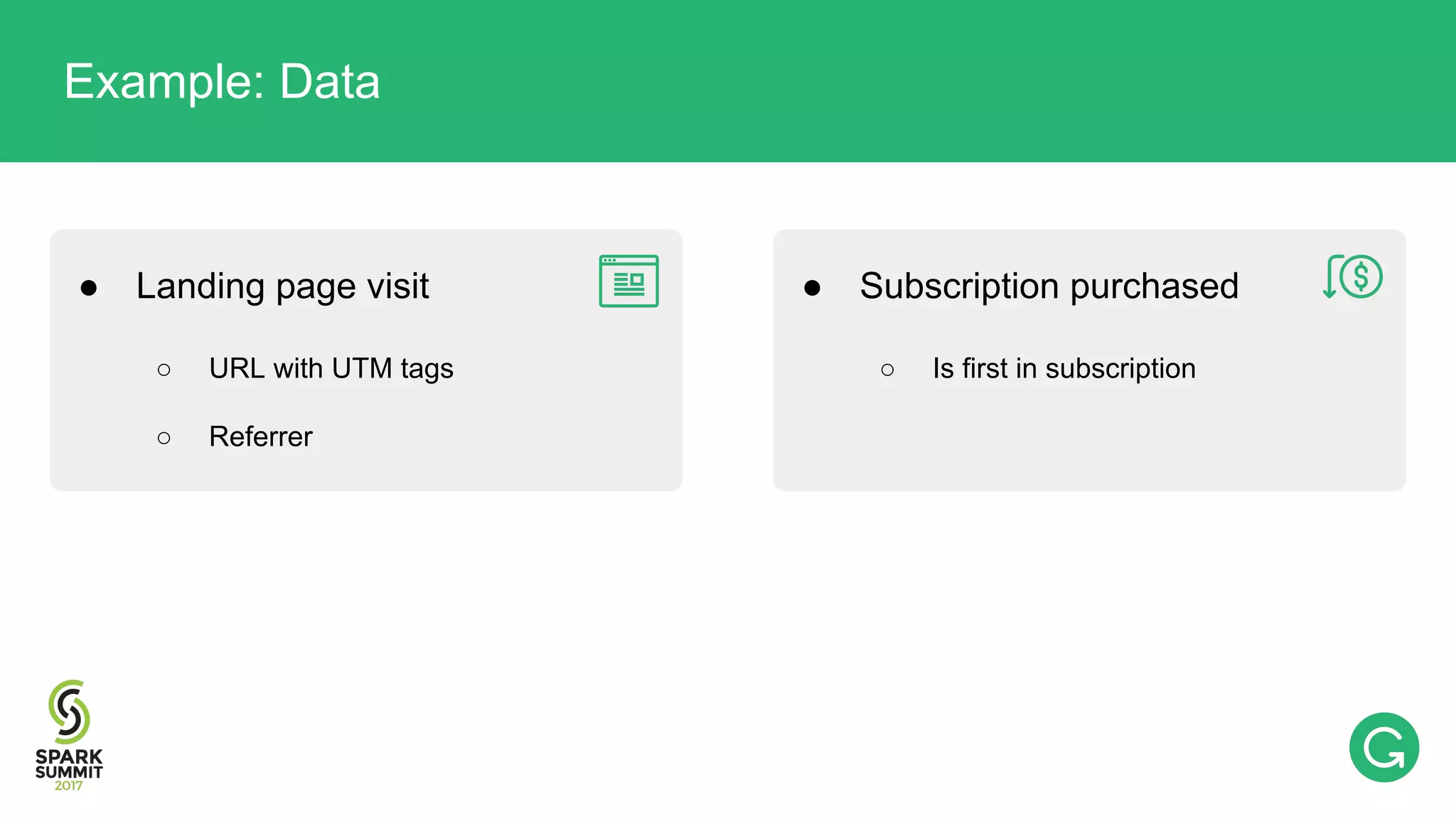
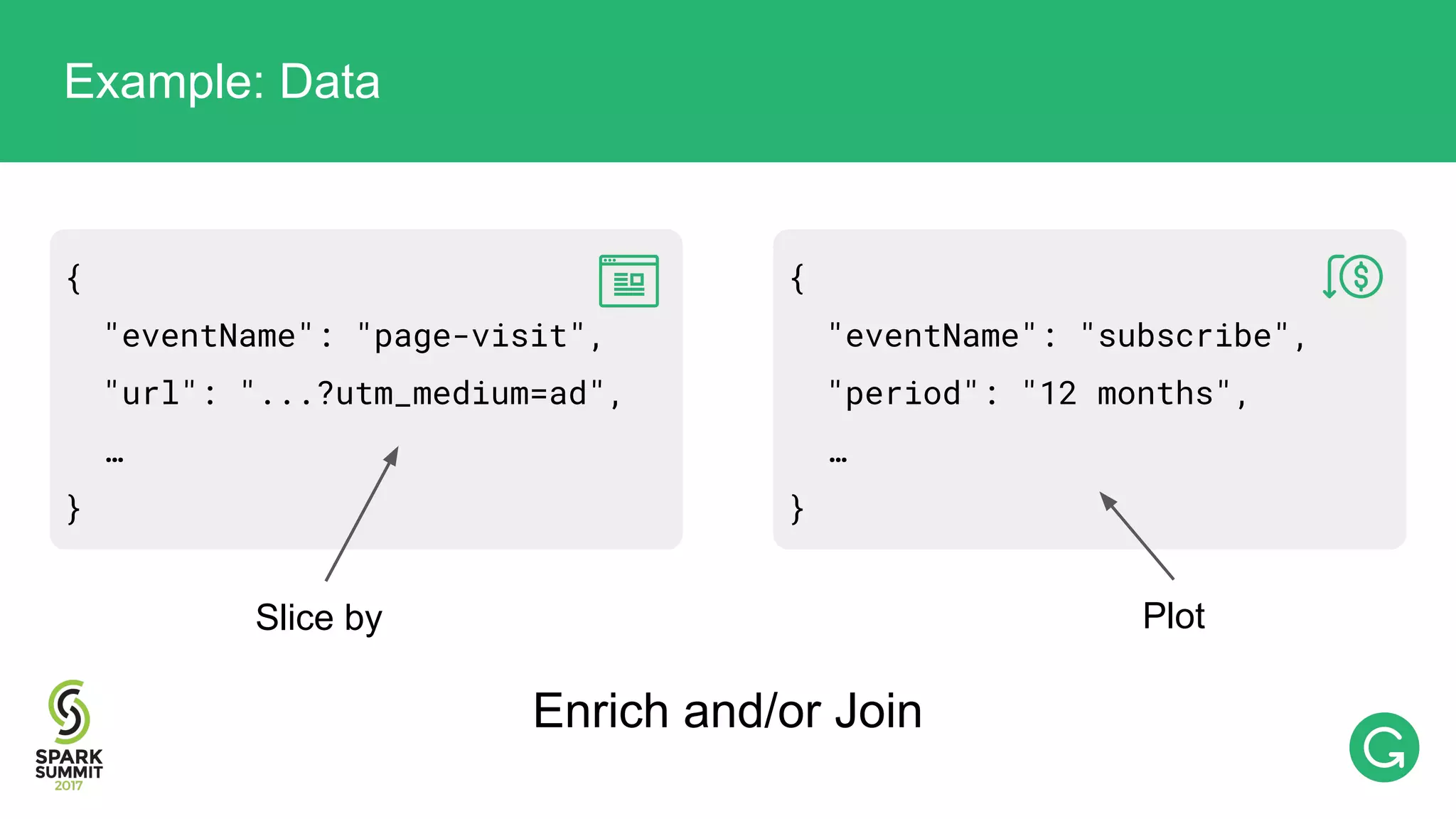
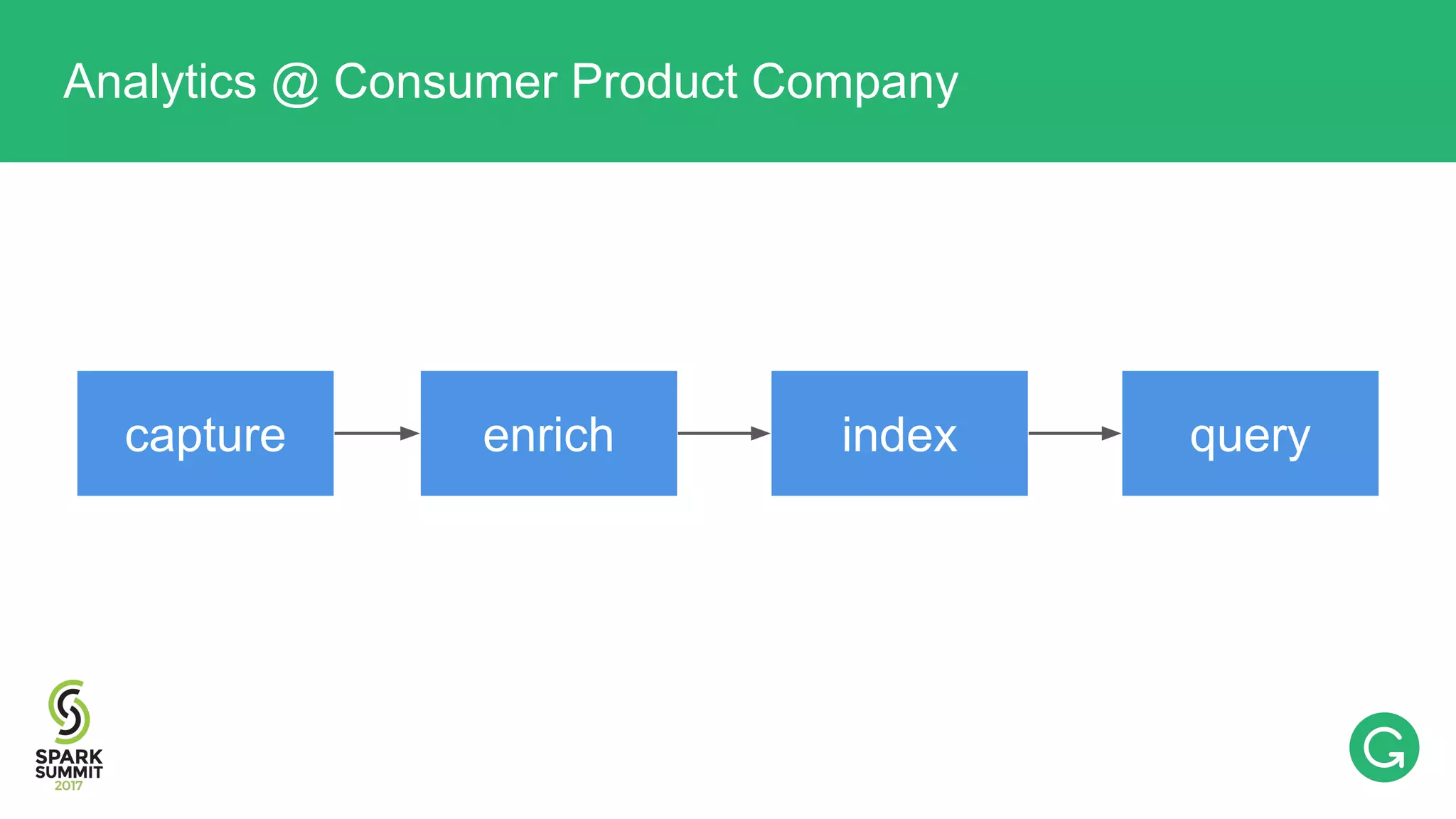
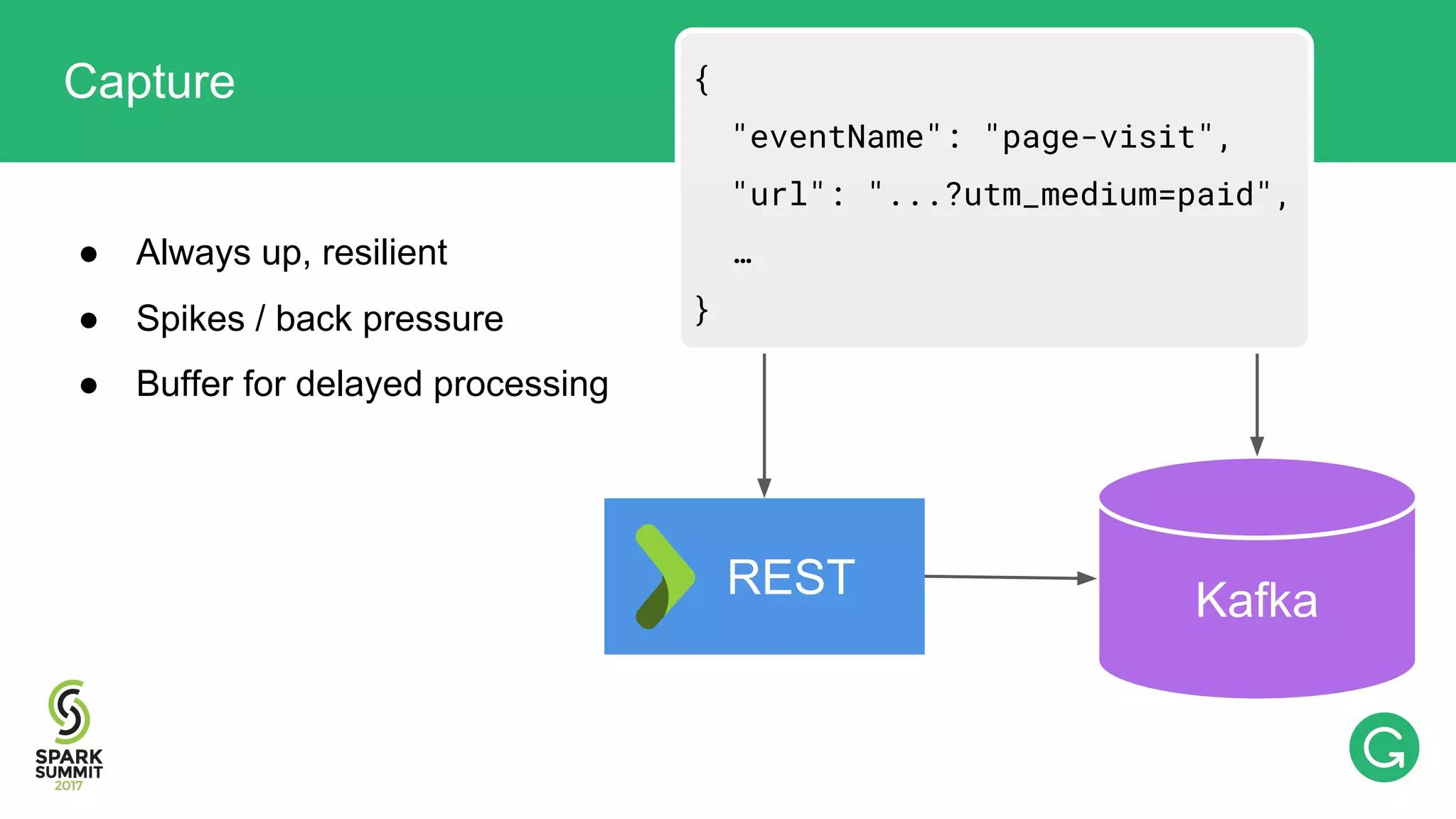
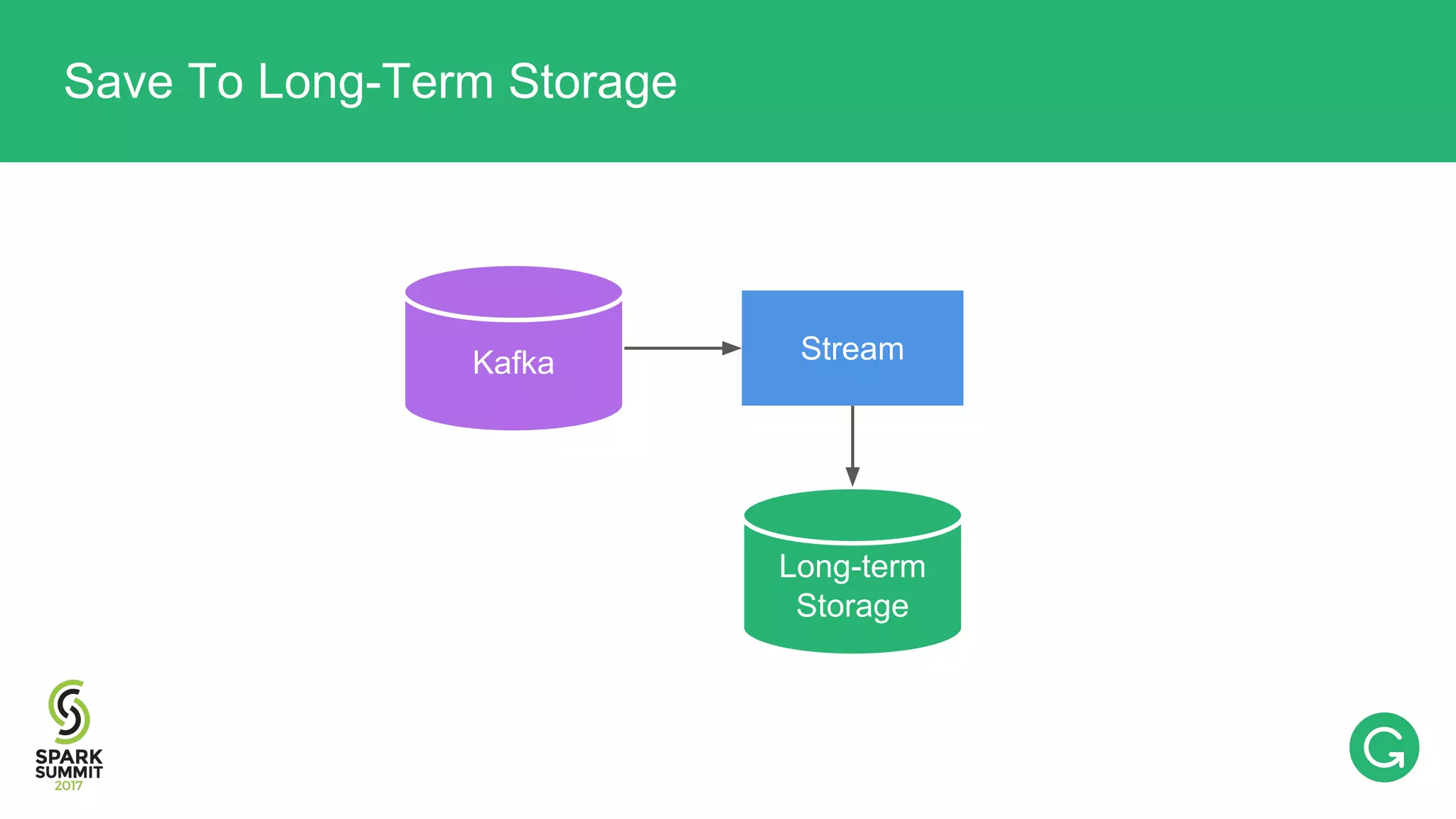
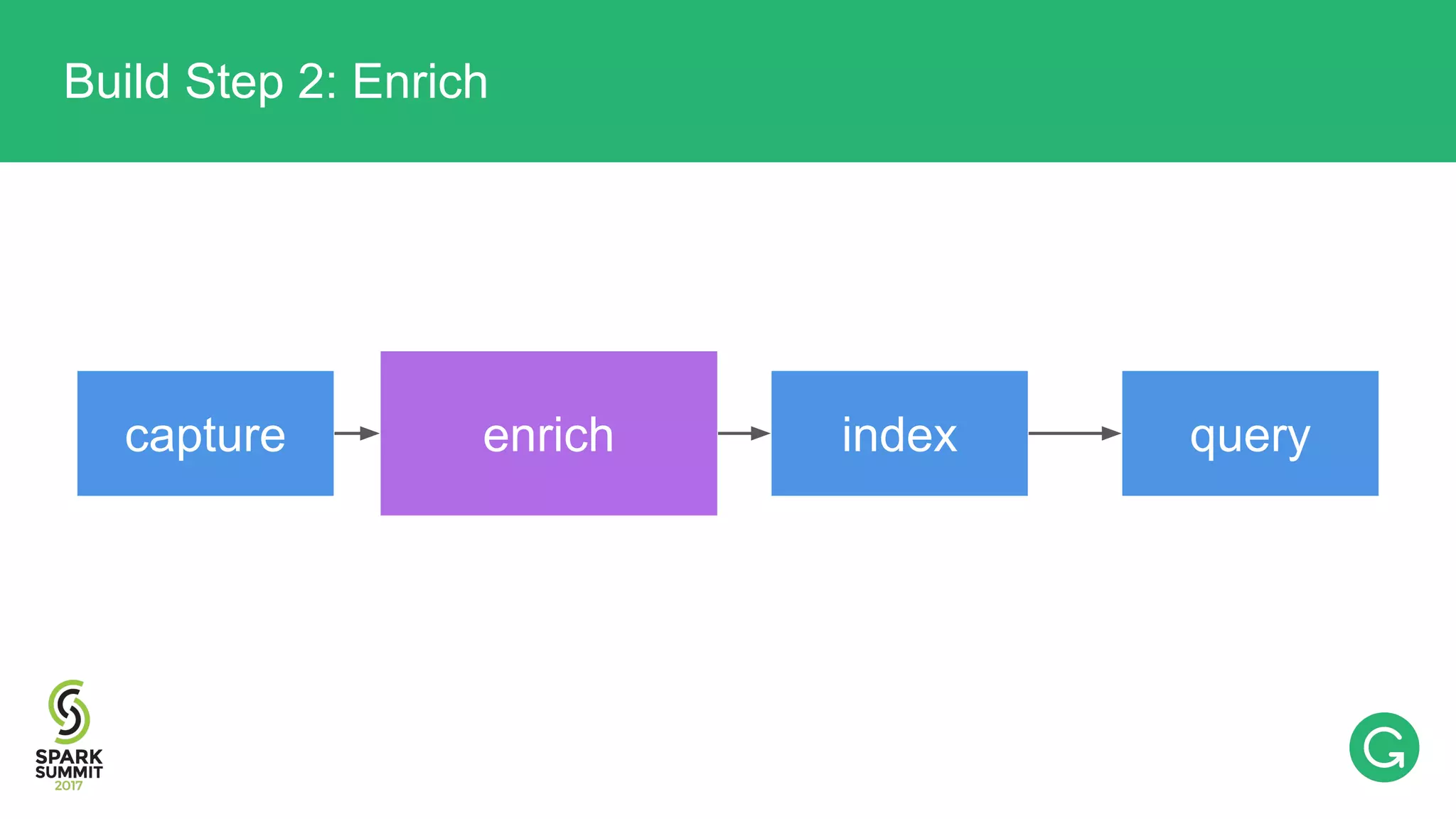
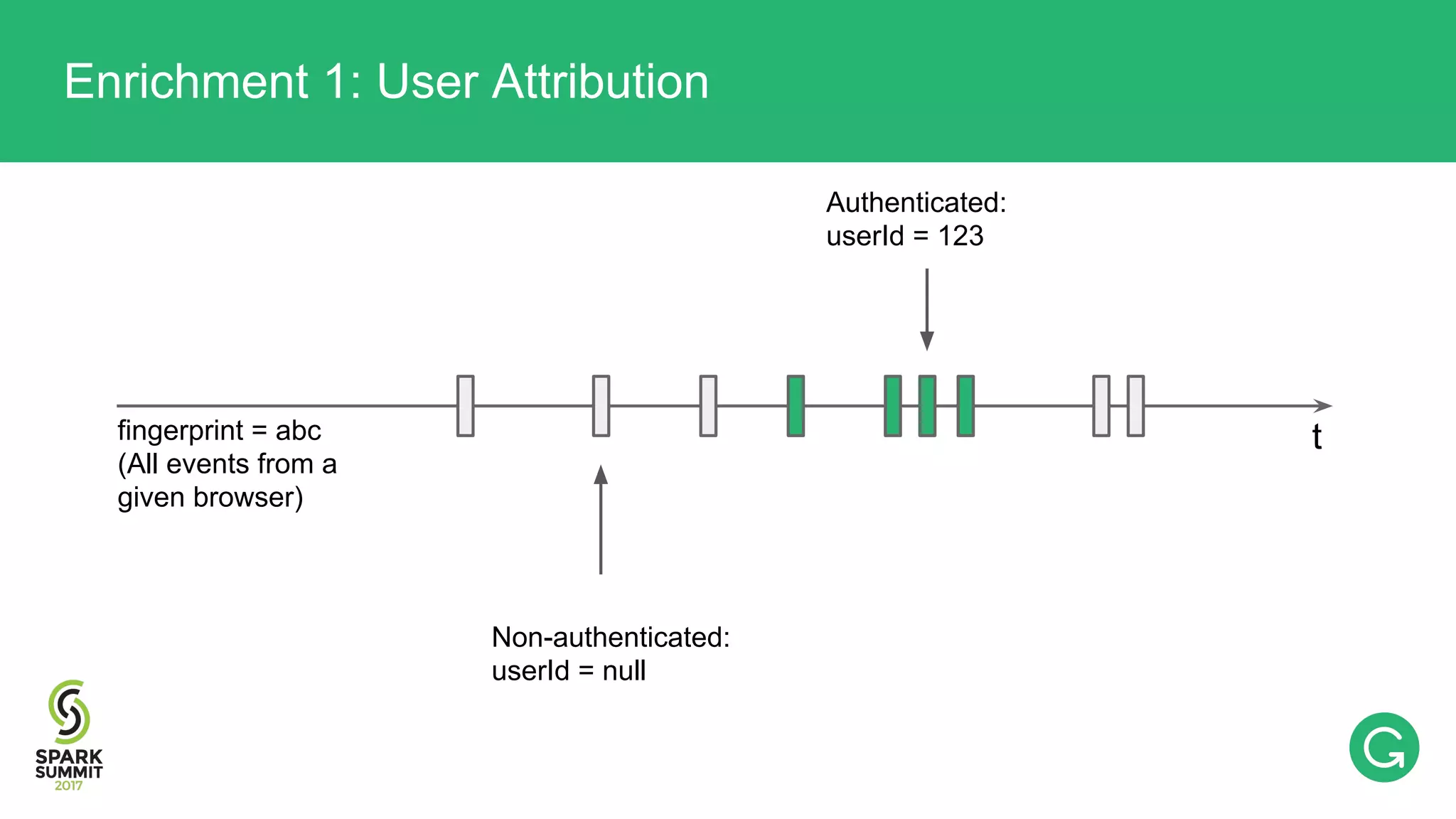
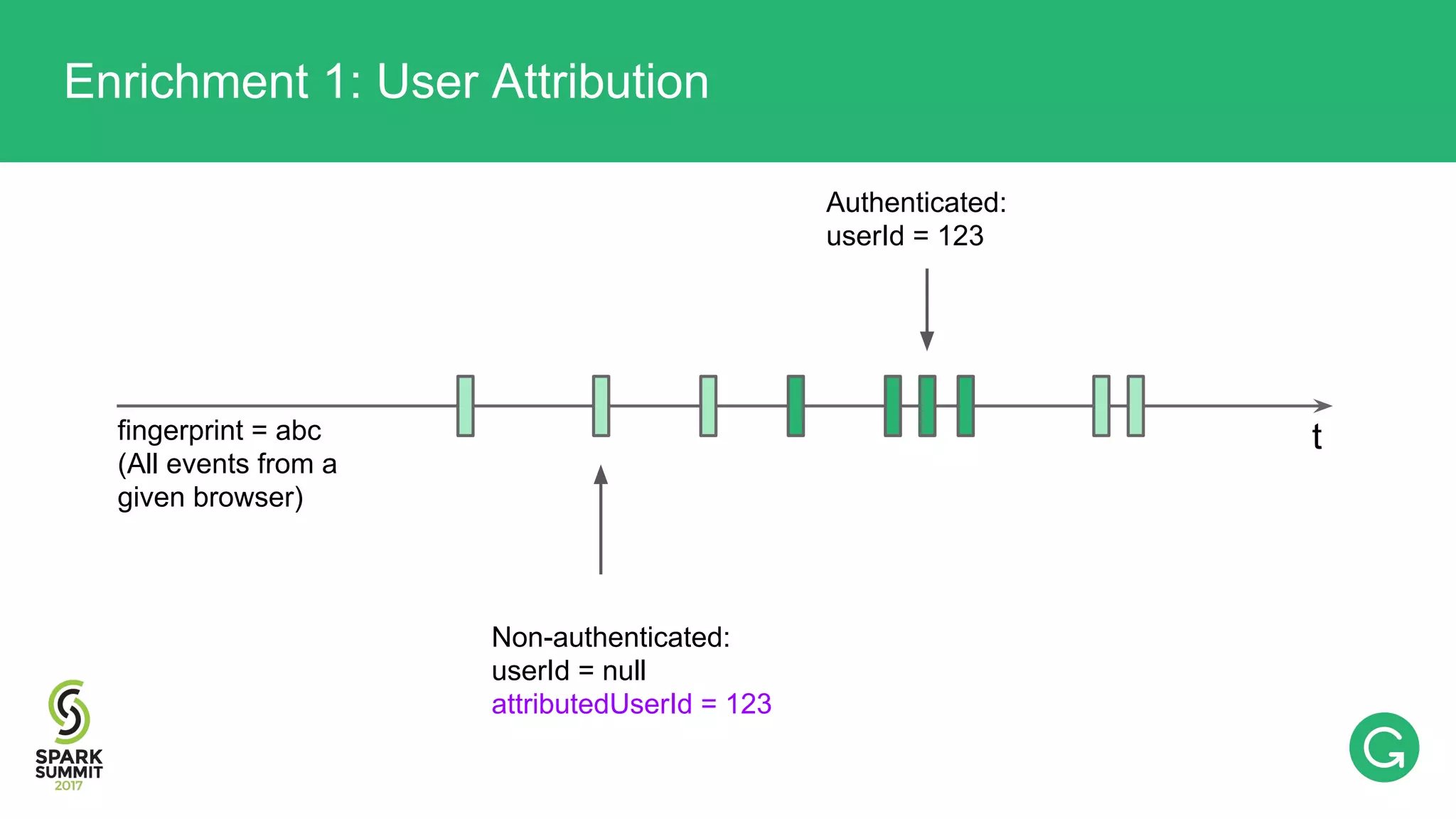
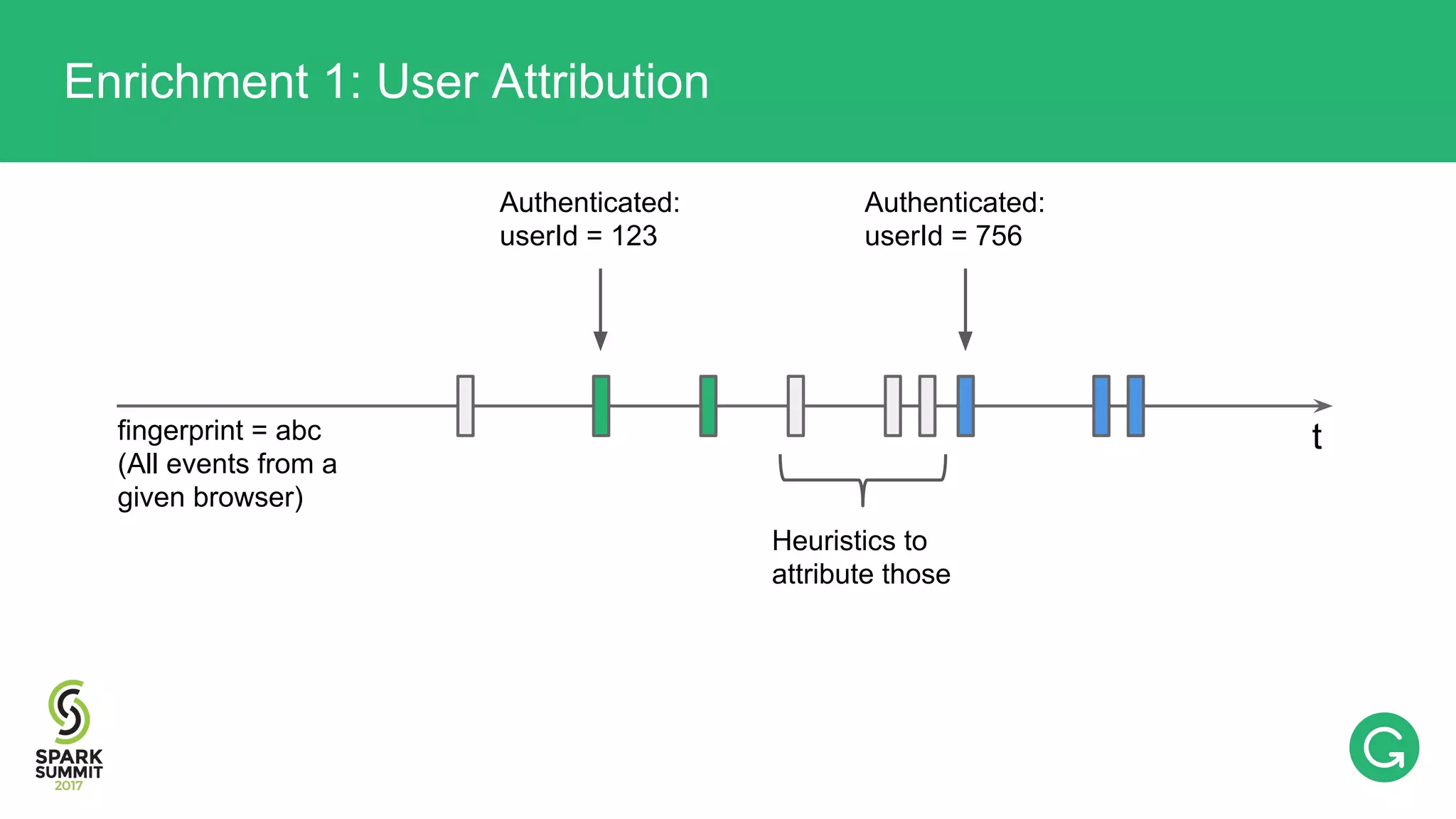
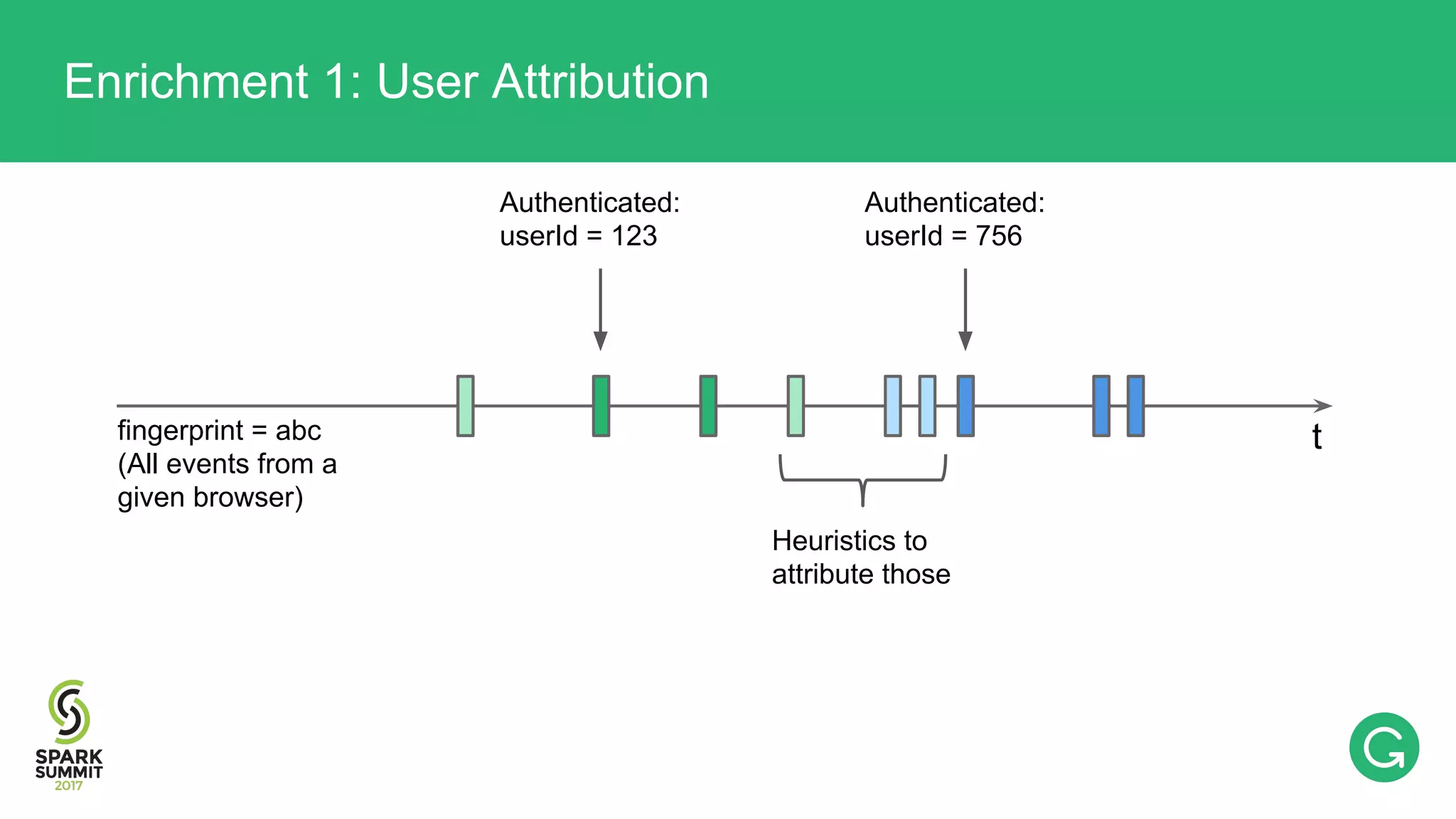
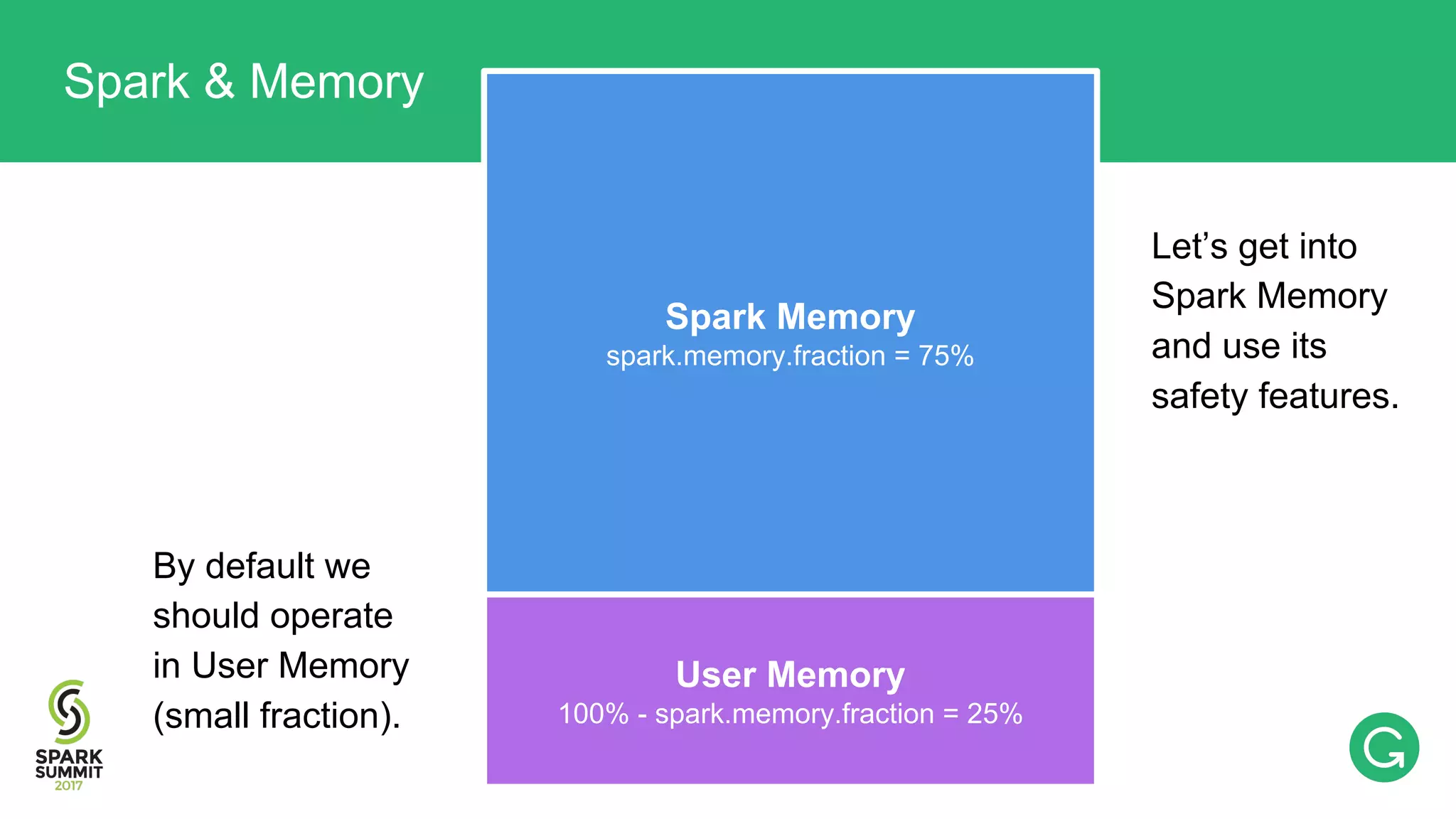
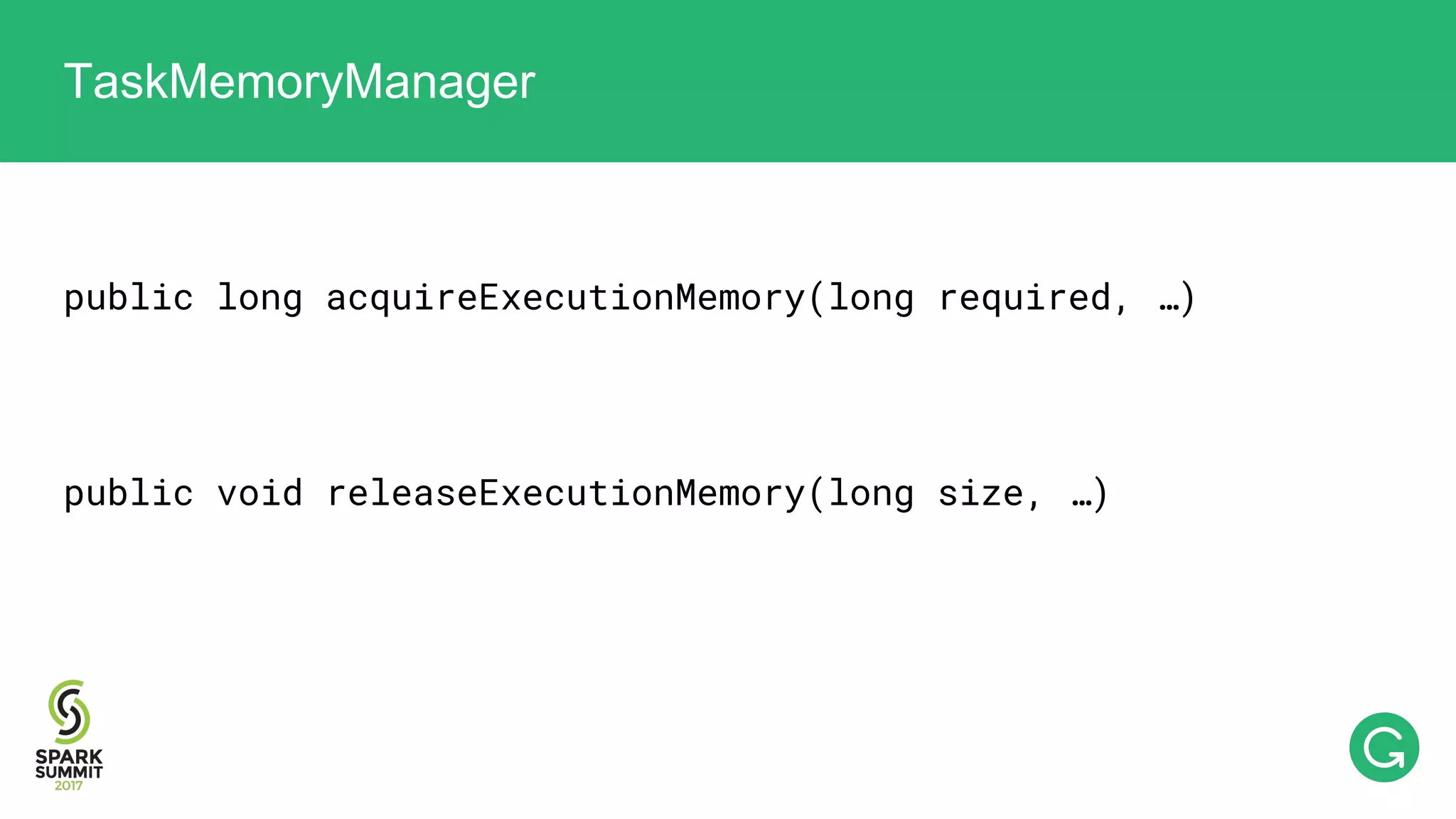
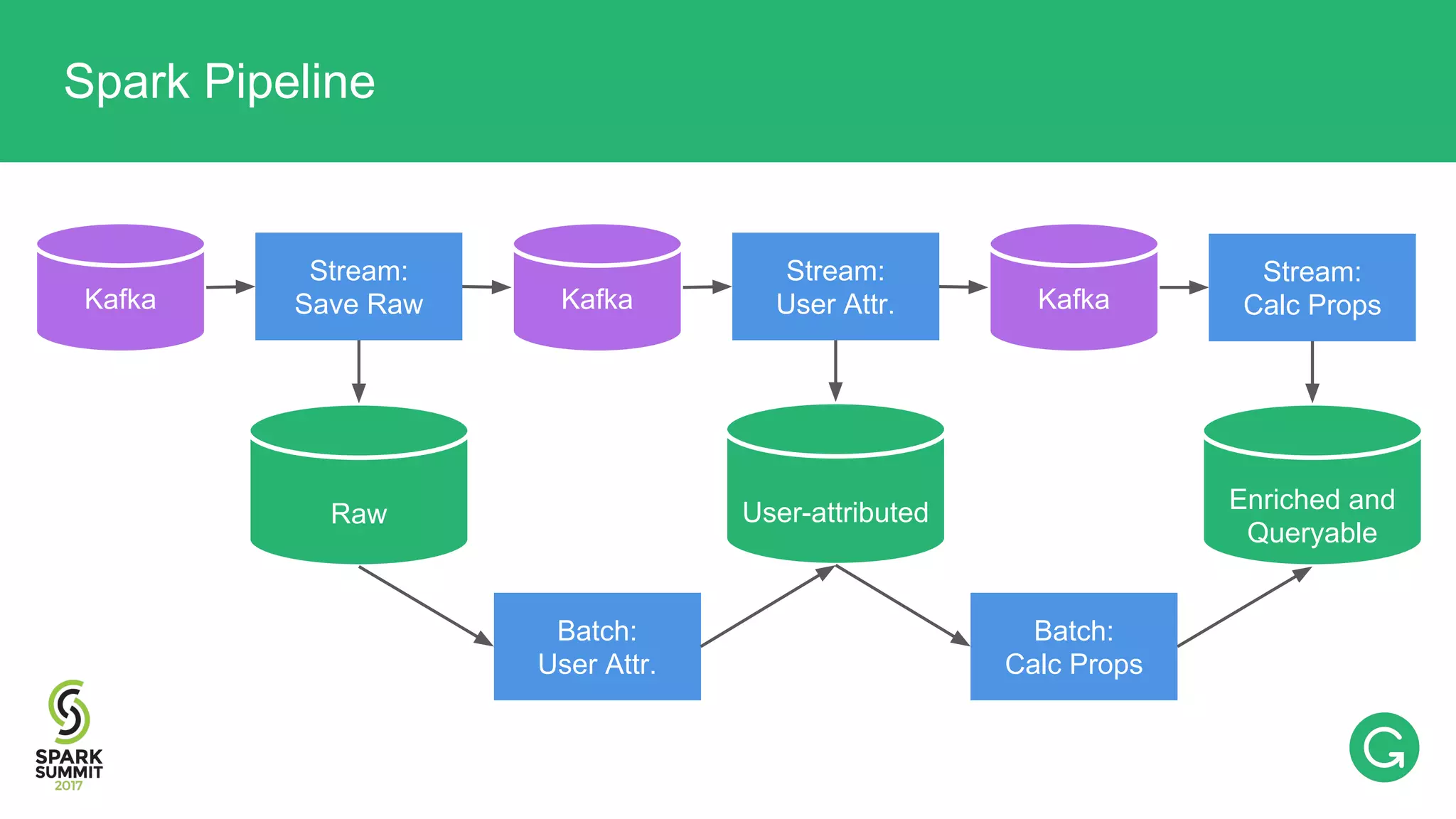
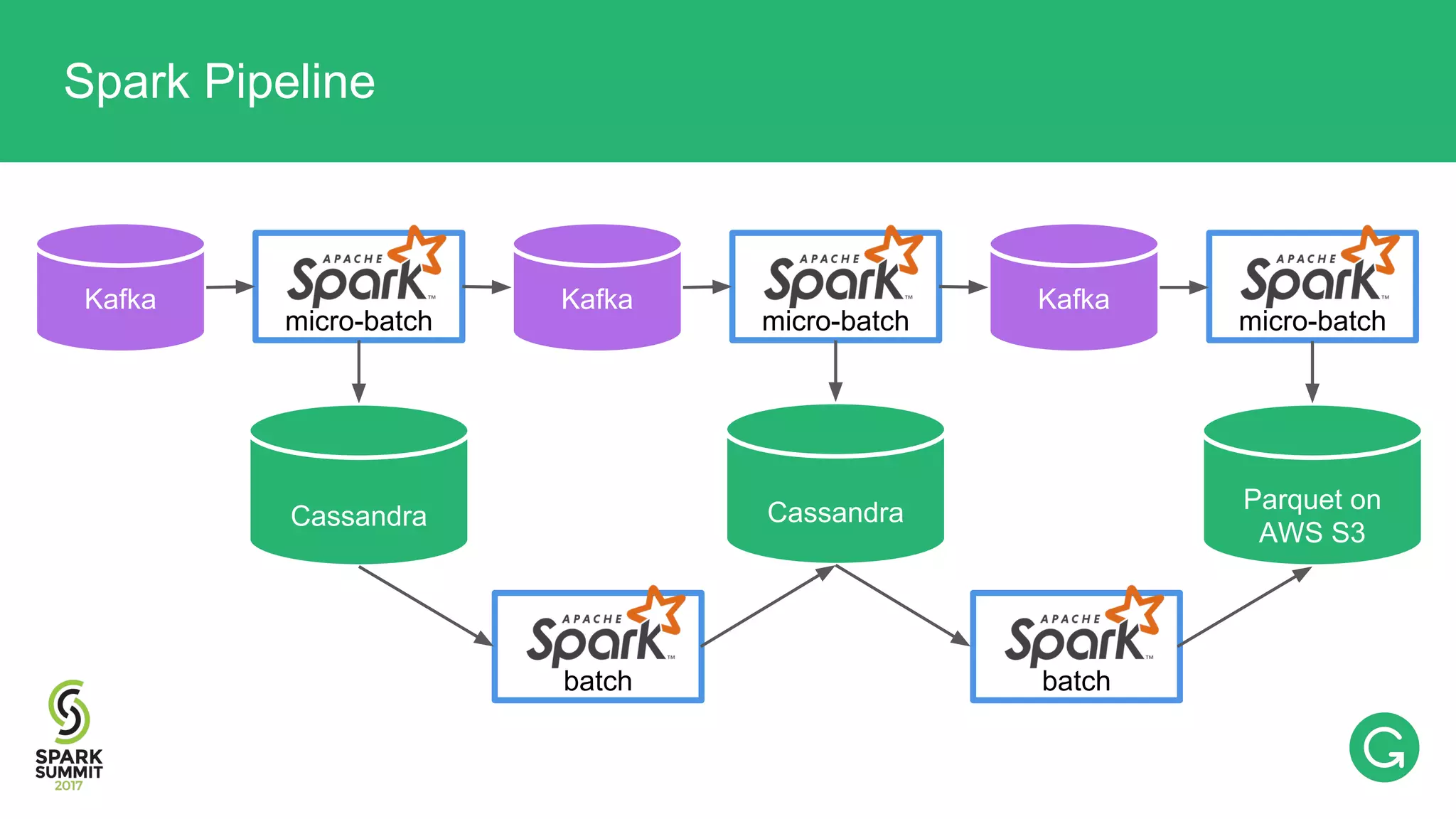
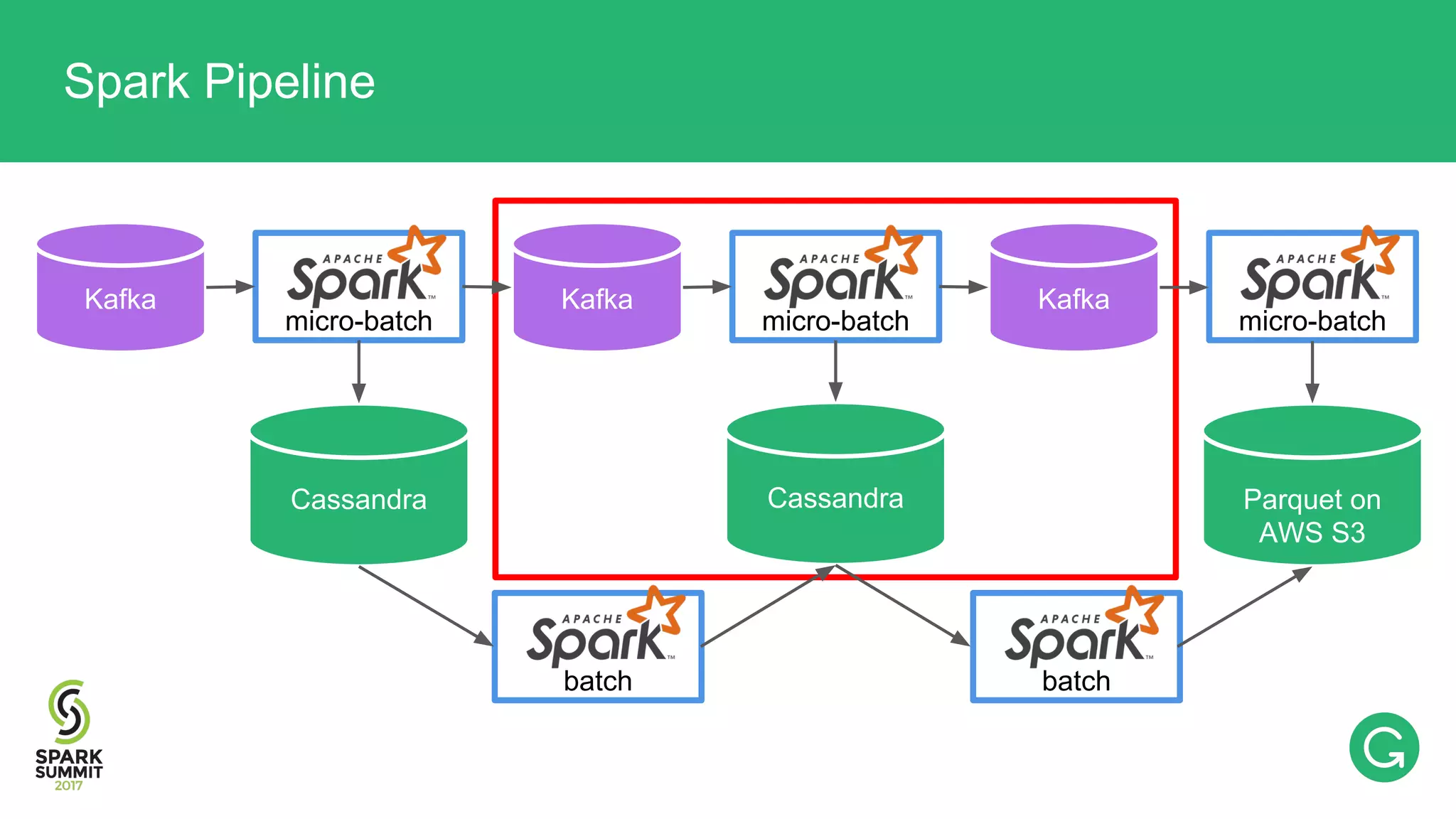
The document presents an intricate framework for building an analytics pipeline using Apache Spark, aimed at enhancing user understanding and engagement for a consumer product company. It details steps such as data capturing, enrichment, indexing, and querying, emphasizing the importance of data-driven decisions and the integration of various tools like Kafka, Cassandra, and S3. The discussion also touches on handling user attribution and system memory management for optimal performance.