Downloaded 53 times





![Cassandra Source Connected to Test Cluster at cassandra:9042. [cqlsh 5.0.1 | Cassandra 3.10 | CQL spec 3.4.4 | Native protocol v4] Use HELP for help. cqlsh> use mykeyspace; cqlsh:mykeyspace> create table bonus_table (userid int primary key, bonus_amount decimal); cqlsh:mykeyspace> insert into bonus_table (userid, bonus_amount) values (1, 500.00); cqlsh:mykeyspace> insert into bonus_table (userid, bonus_amount) values (4, 1000.00); cqlsh:mykeyspace> select * from bonus_table; userid | bonus_amount --------+-------------- 1 | 500.00 4 | 1000.00 (2 rows)](https://image.slidesharecdn.com/danmarshalldatafederationwithapachespark-170621200436/75/Data-Federation-with-Apache-Spark-9-2048.jpg)

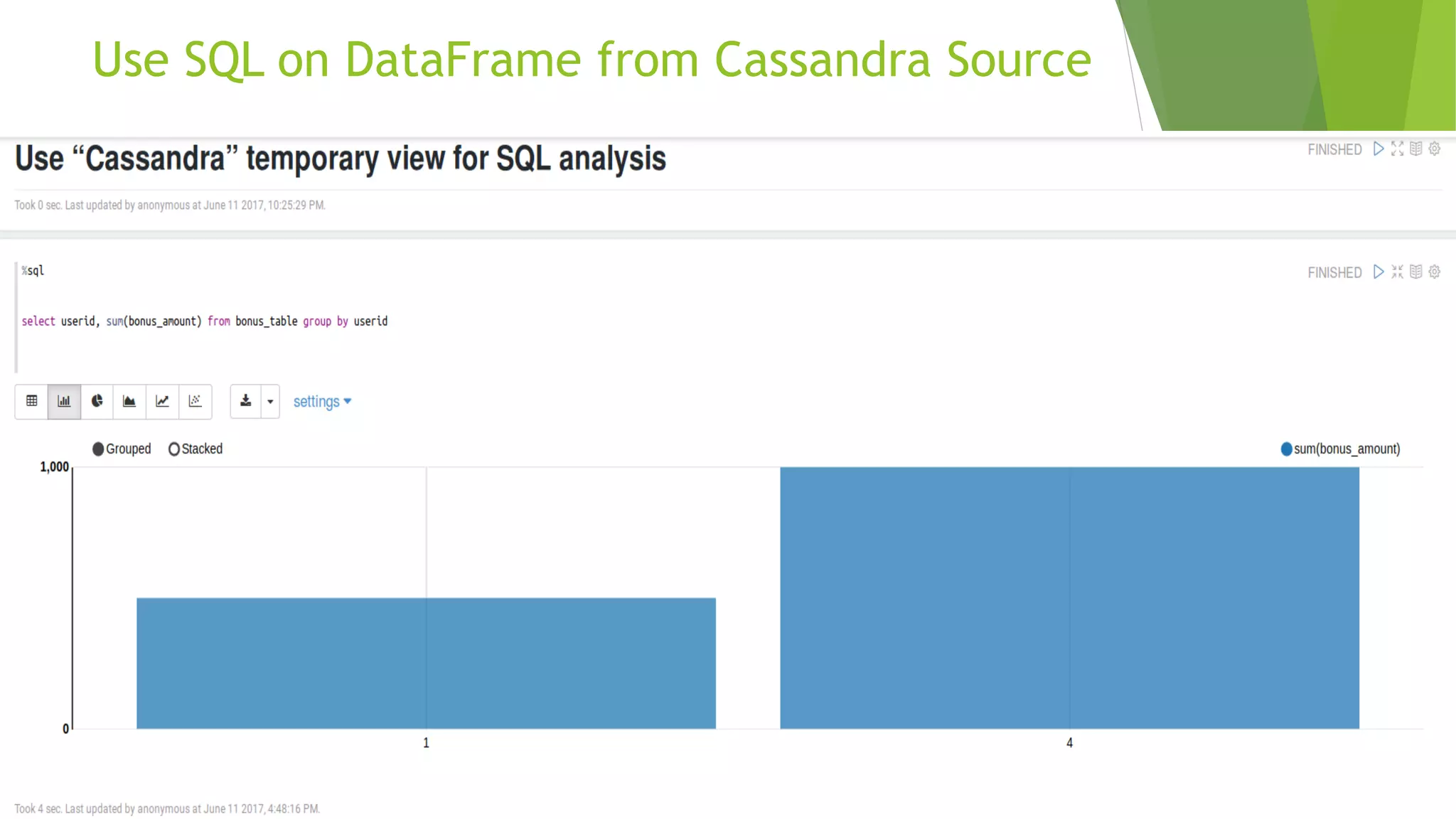
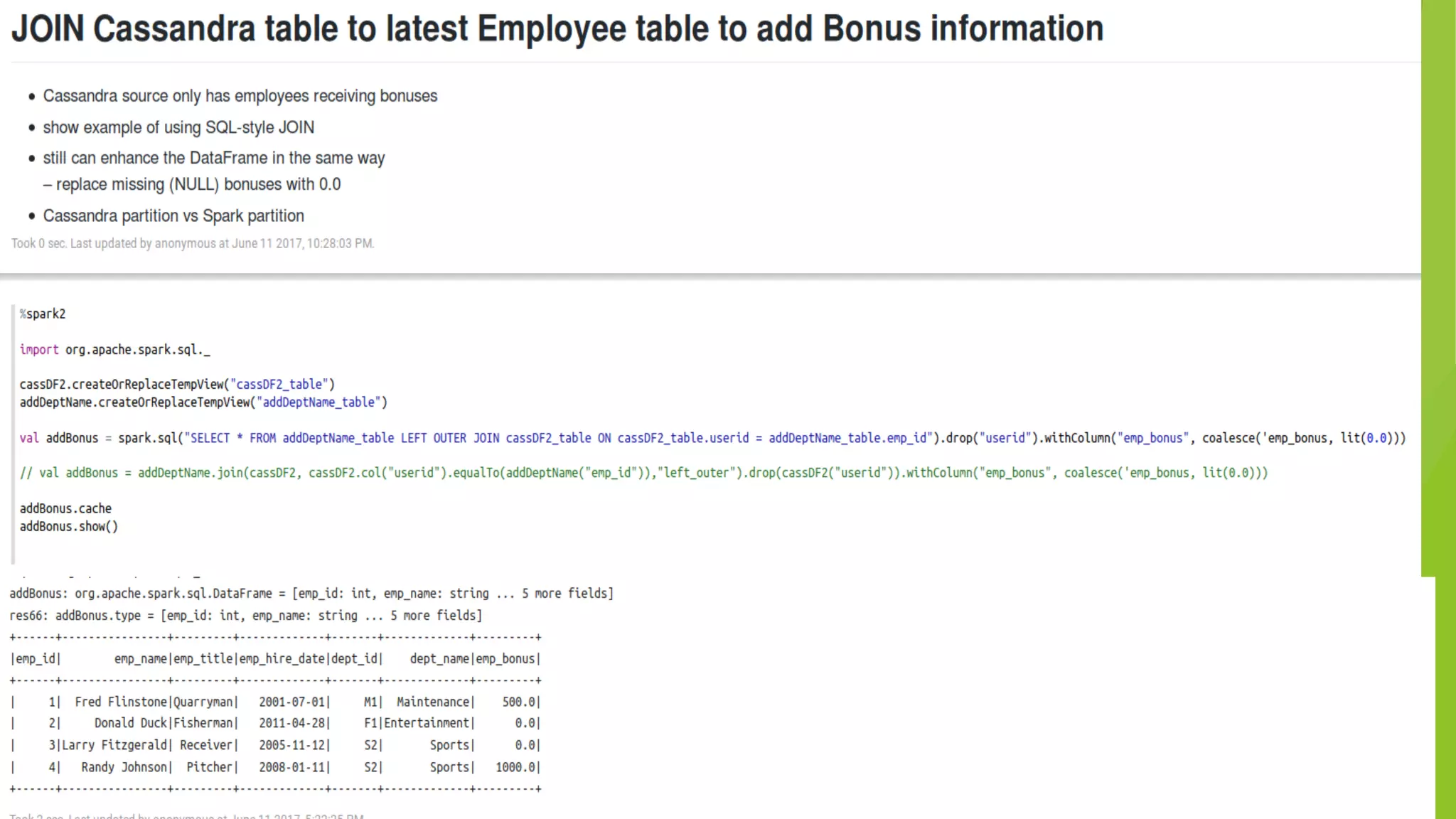



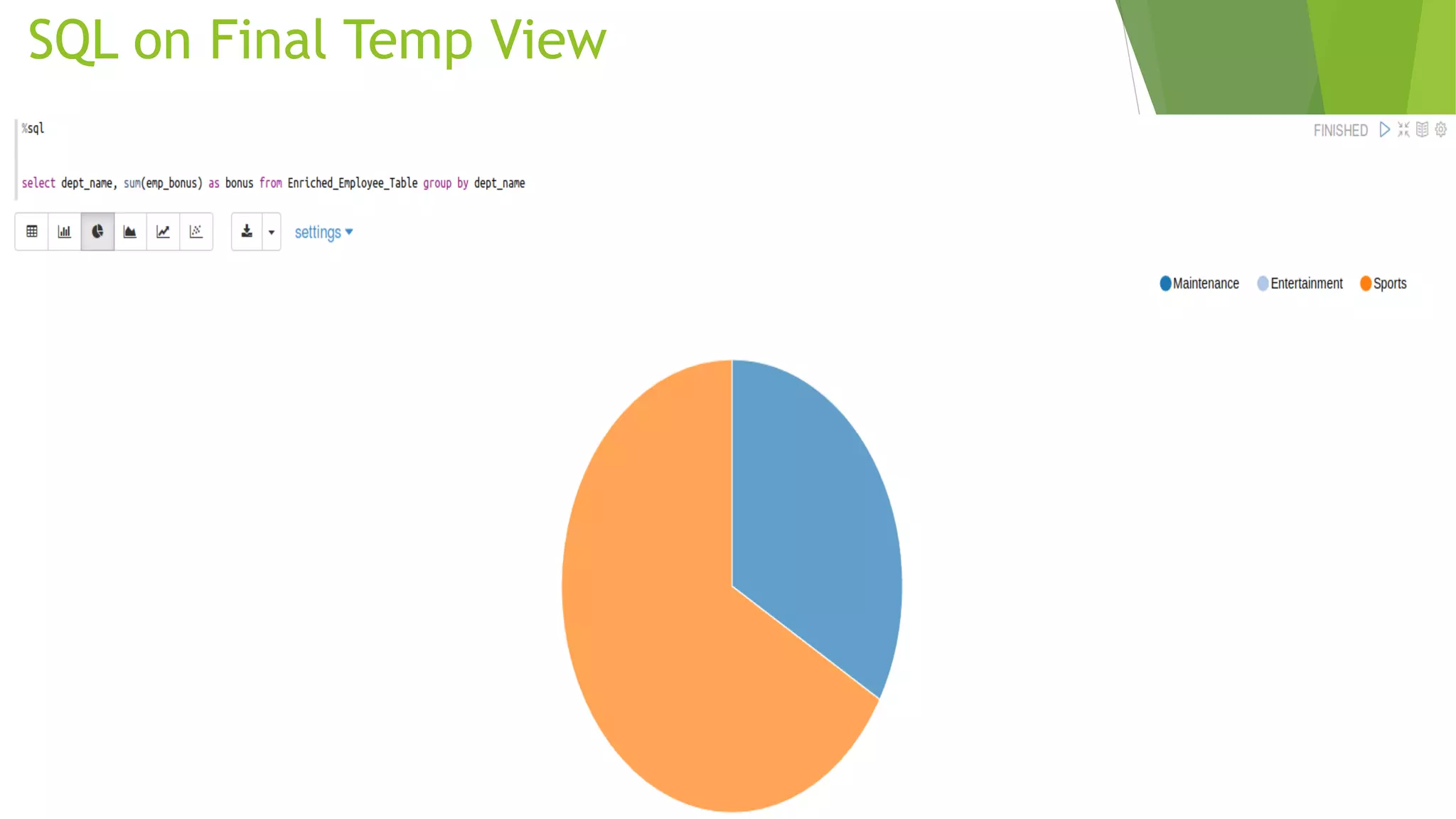

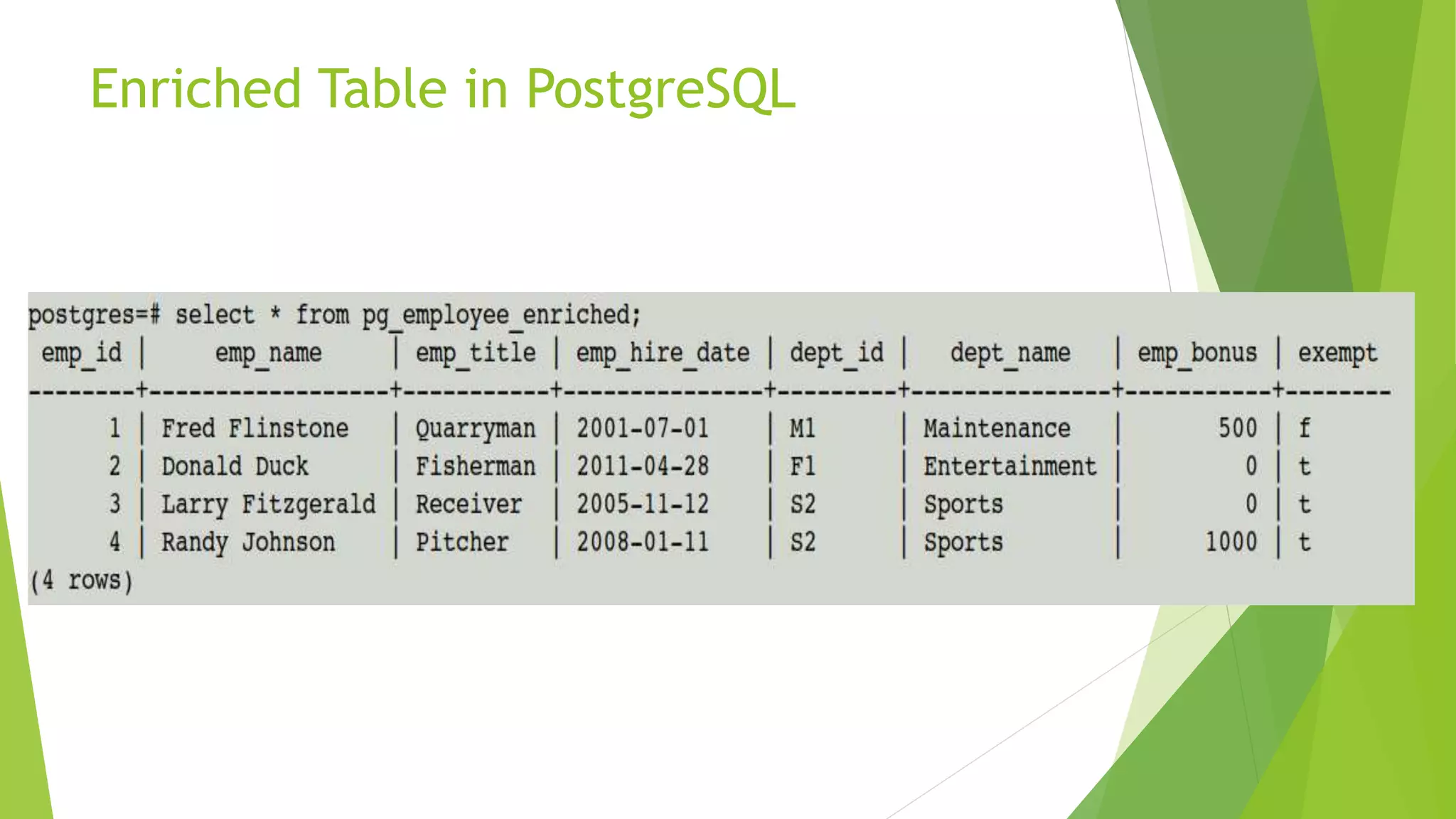


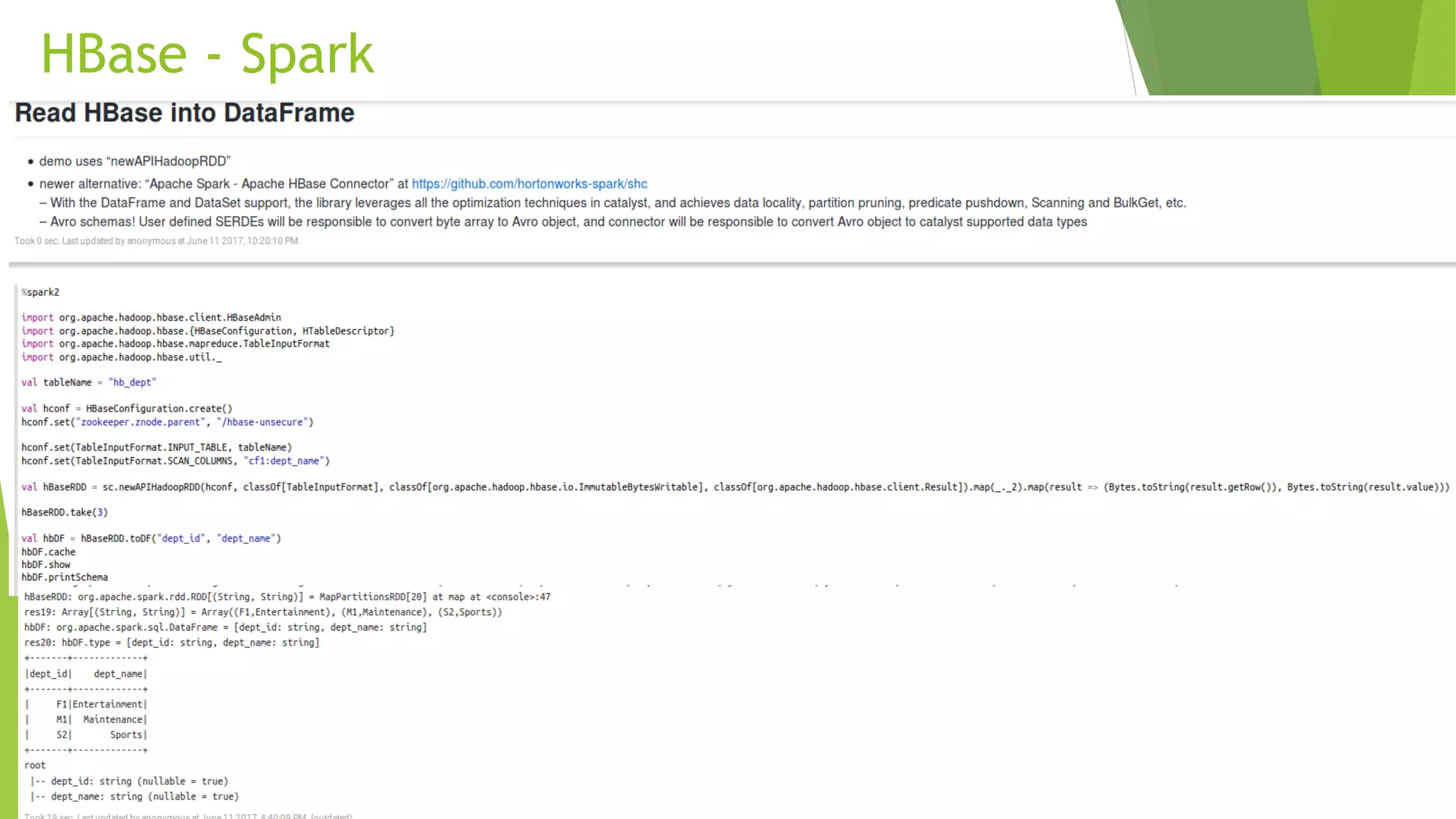
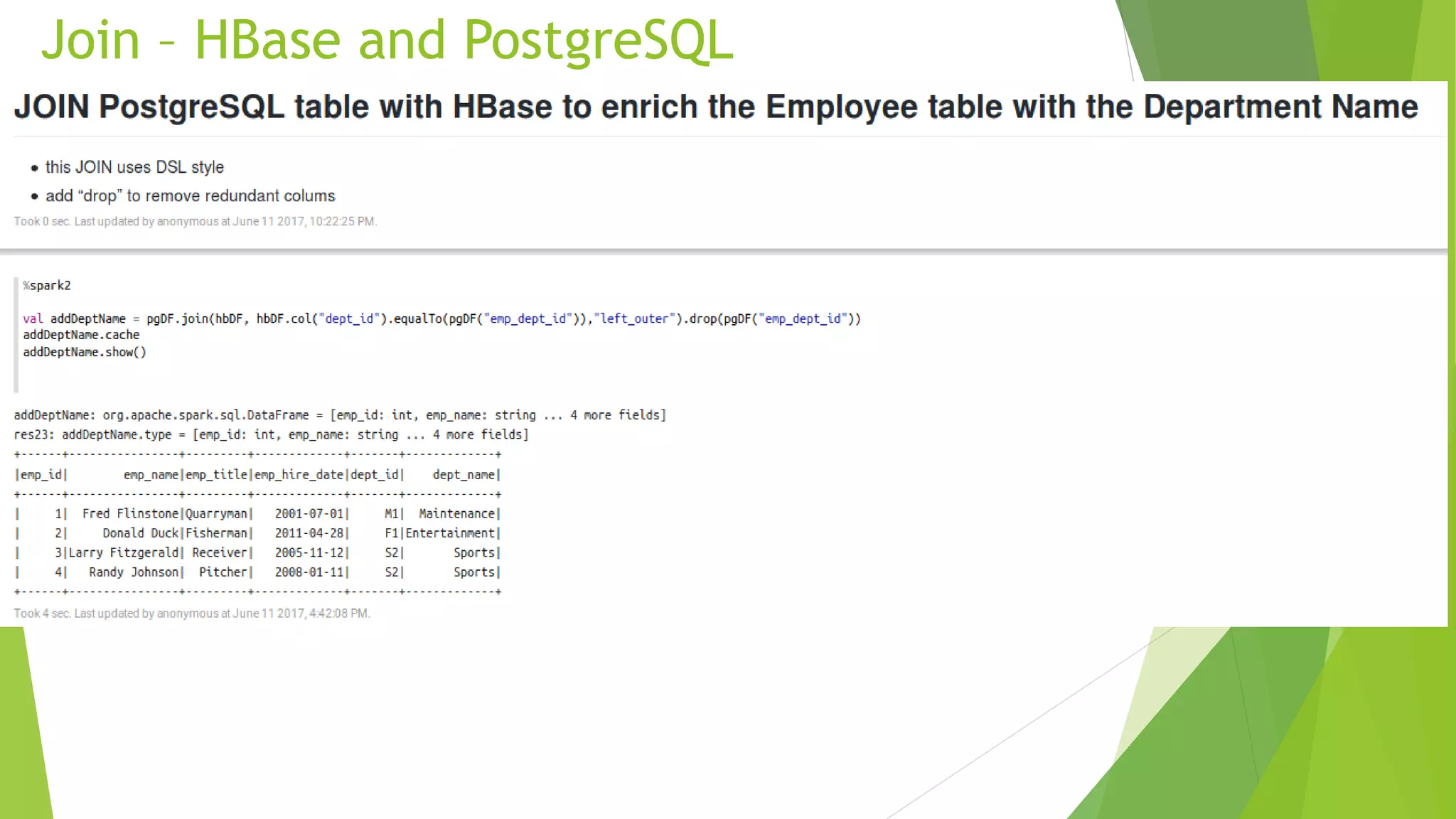
The document details the process of data federation using Apache Spark with multiple data sources including PostgreSQL, HBase, and Cassandra. It includes SQL commands for creating tables and inserting data across these platforms, as well as examples of querying and joining data. The objective of the project is to demonstrate how to combine data from different storage systems into a cohesive analysis framework.