Downloaded 39 times






![Strata + Hadoop World NYC Sept 26-29, 2016 Standardizing Common Data Types • Instead of a Canonical Data Model, we standardize basic building blocks – Feature, Category, Brand – Geospatial – Financial – Time – Contact information Page 15 Address • lines[] • city • subdivision • country • postalCode](https://image.slidesharecdn.com/datamodelingformicroservices20160929-170215161624/75/Data-Modeling-for-Microservices-with-Cassandra-and-Spark-15-2048.jpg)

![Strata + Hadoop World NYC Sept 26-29, 2016 REST Java API GET /types/<id> Type getTypeById() GET /types?<query parameters> Type[] searchType(TypeSearchCriteria) POST /types/ (JSON body) createType(Type) PUT /types/ (JSON body) updateType(Type) DELETE /types/<id> deleteType(TypeId) Java and RESTful APIs – common pattern Page 19](https://image.slidesharecdn.com/datamodelingformicroservices20160929-170215161624/75/Data-Modeling-for-Microservices-with-Cassandra-and-Spark-19-2048.jpg)

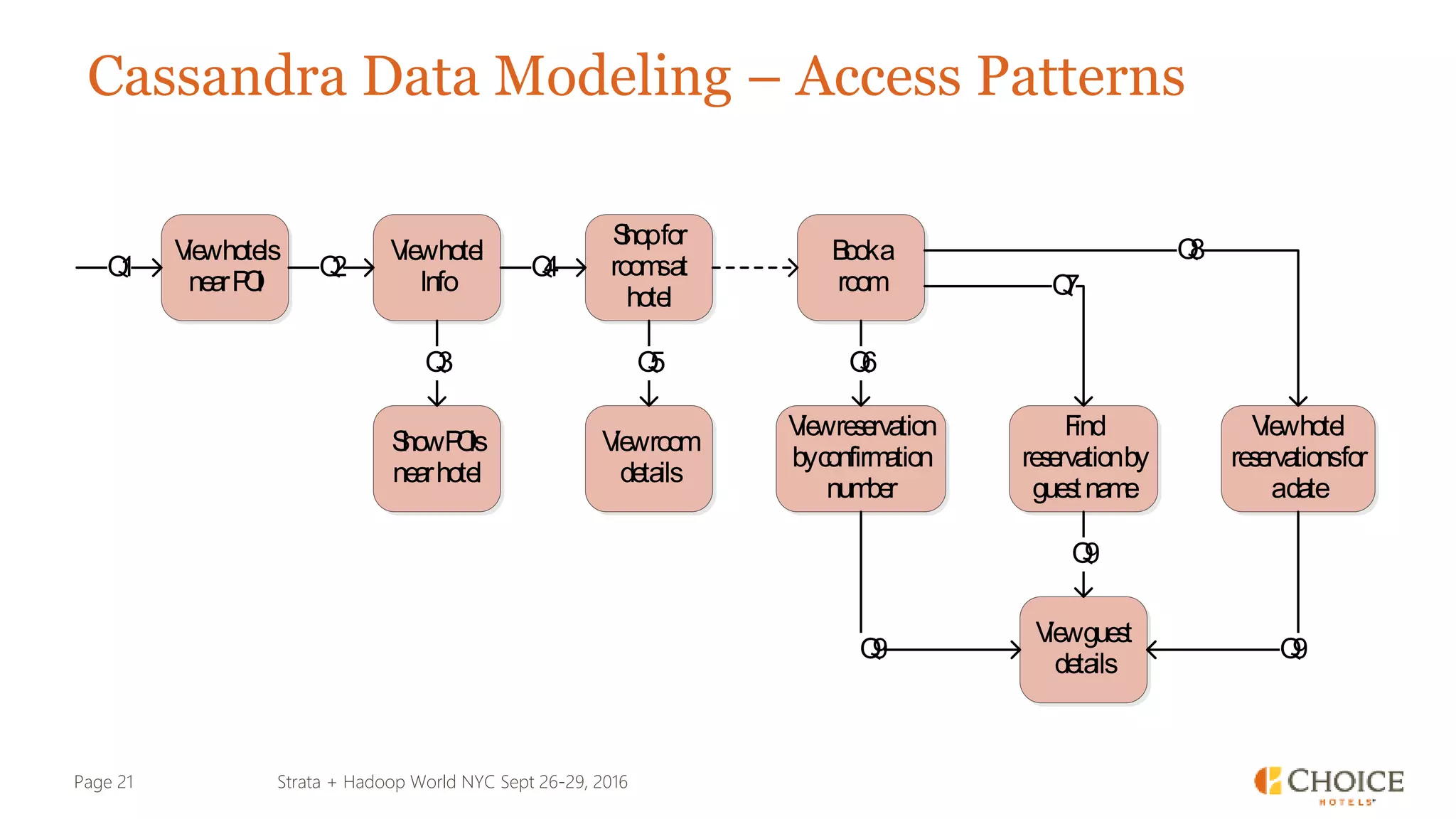
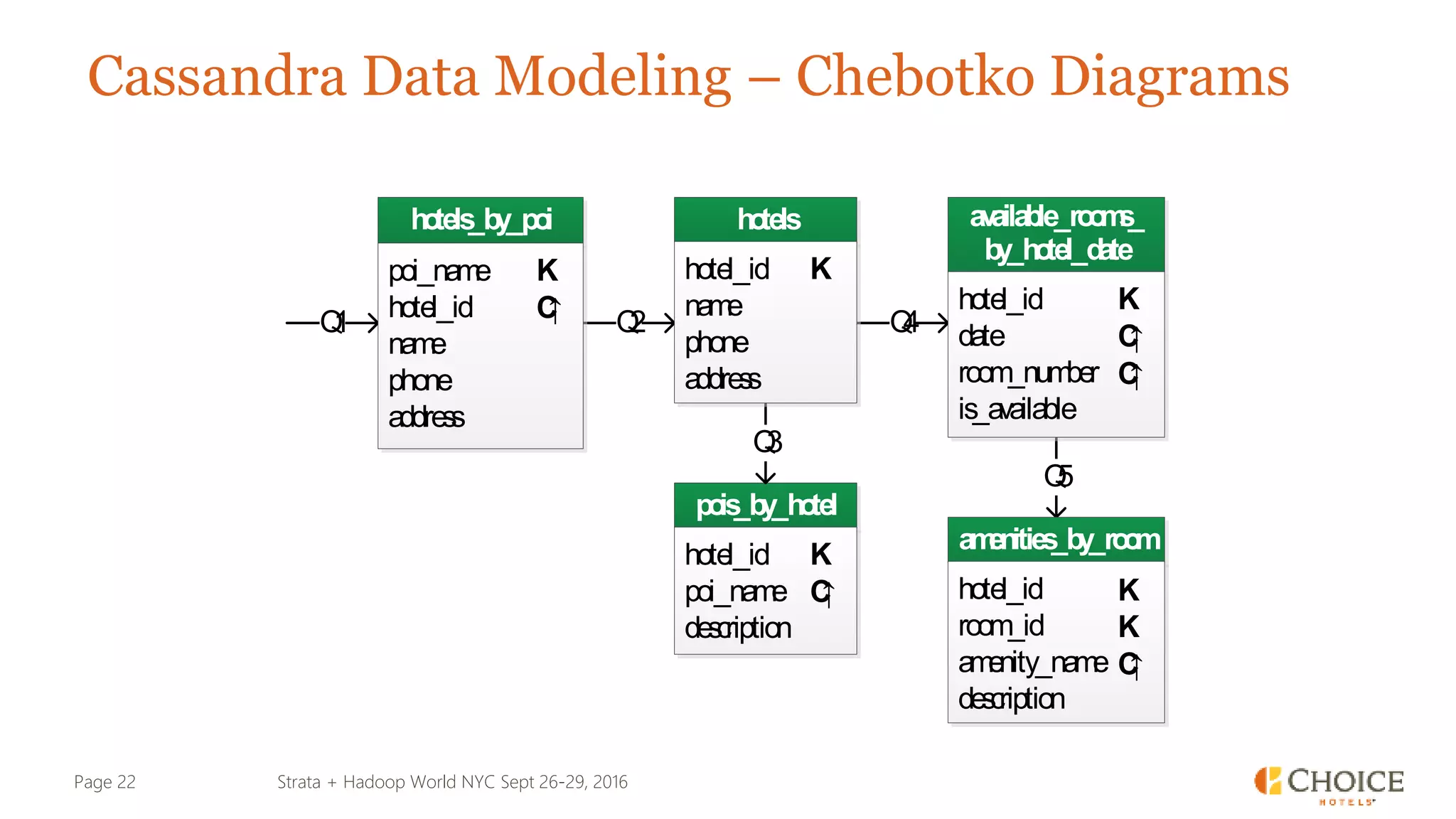
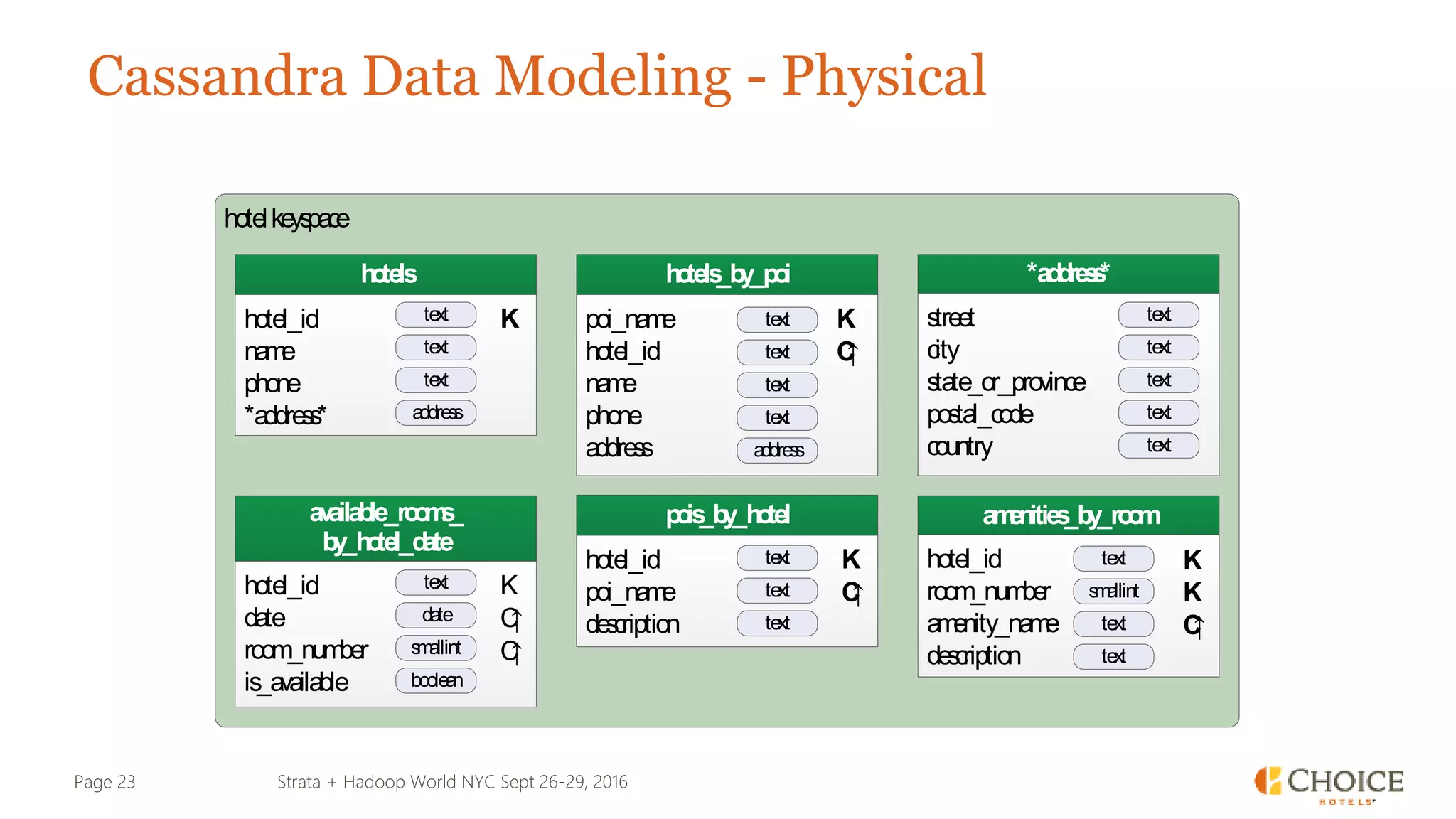
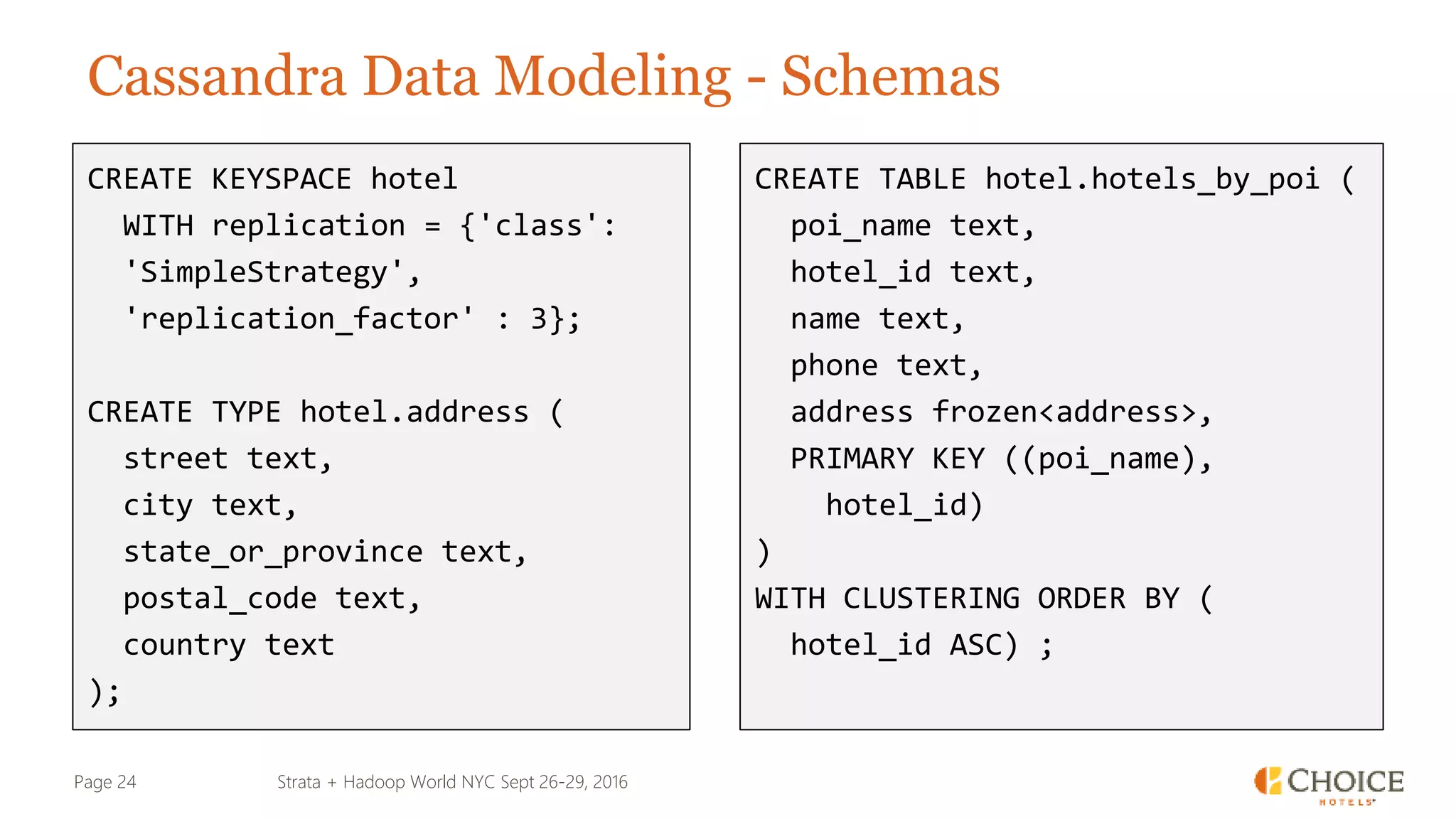

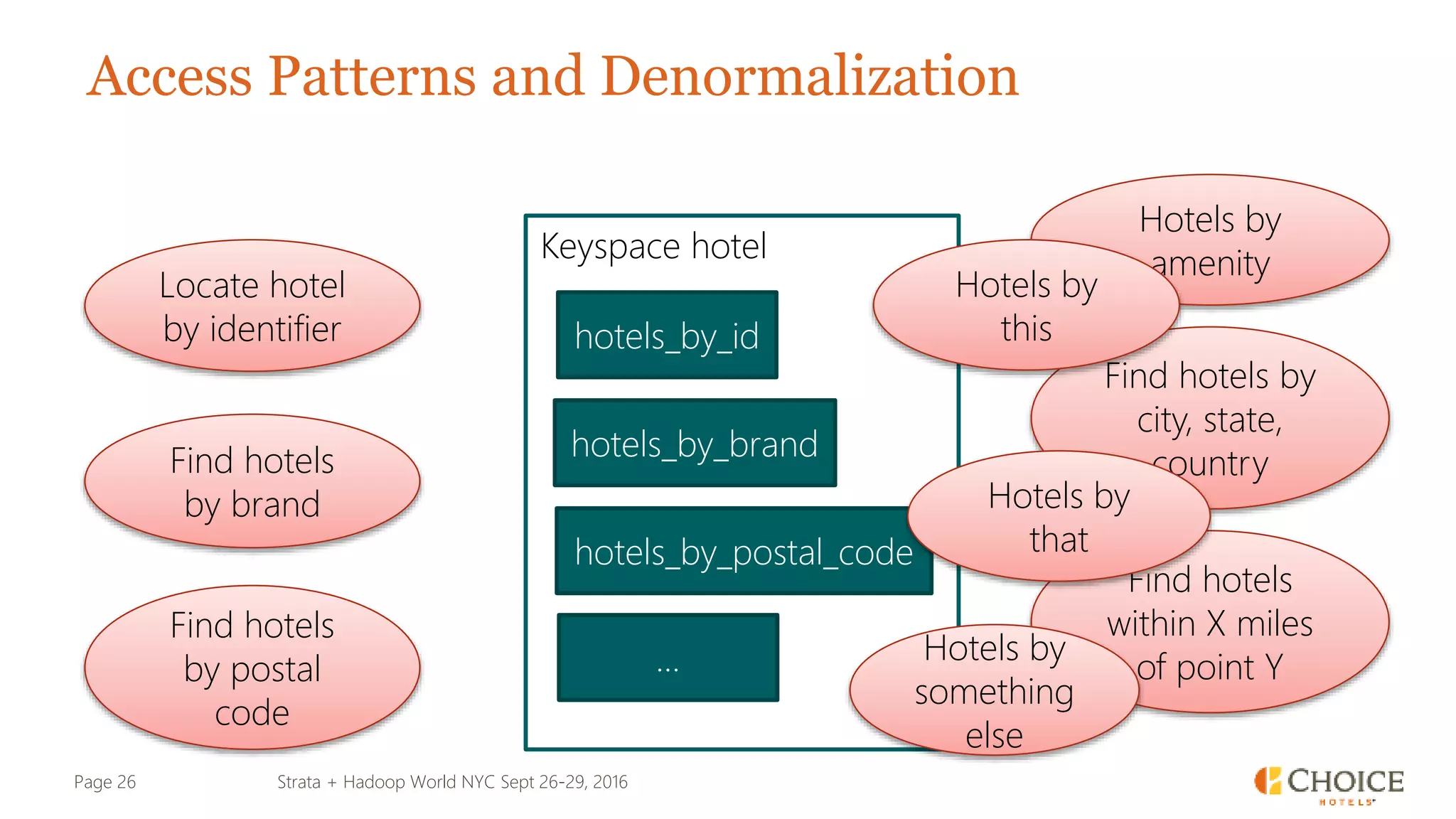
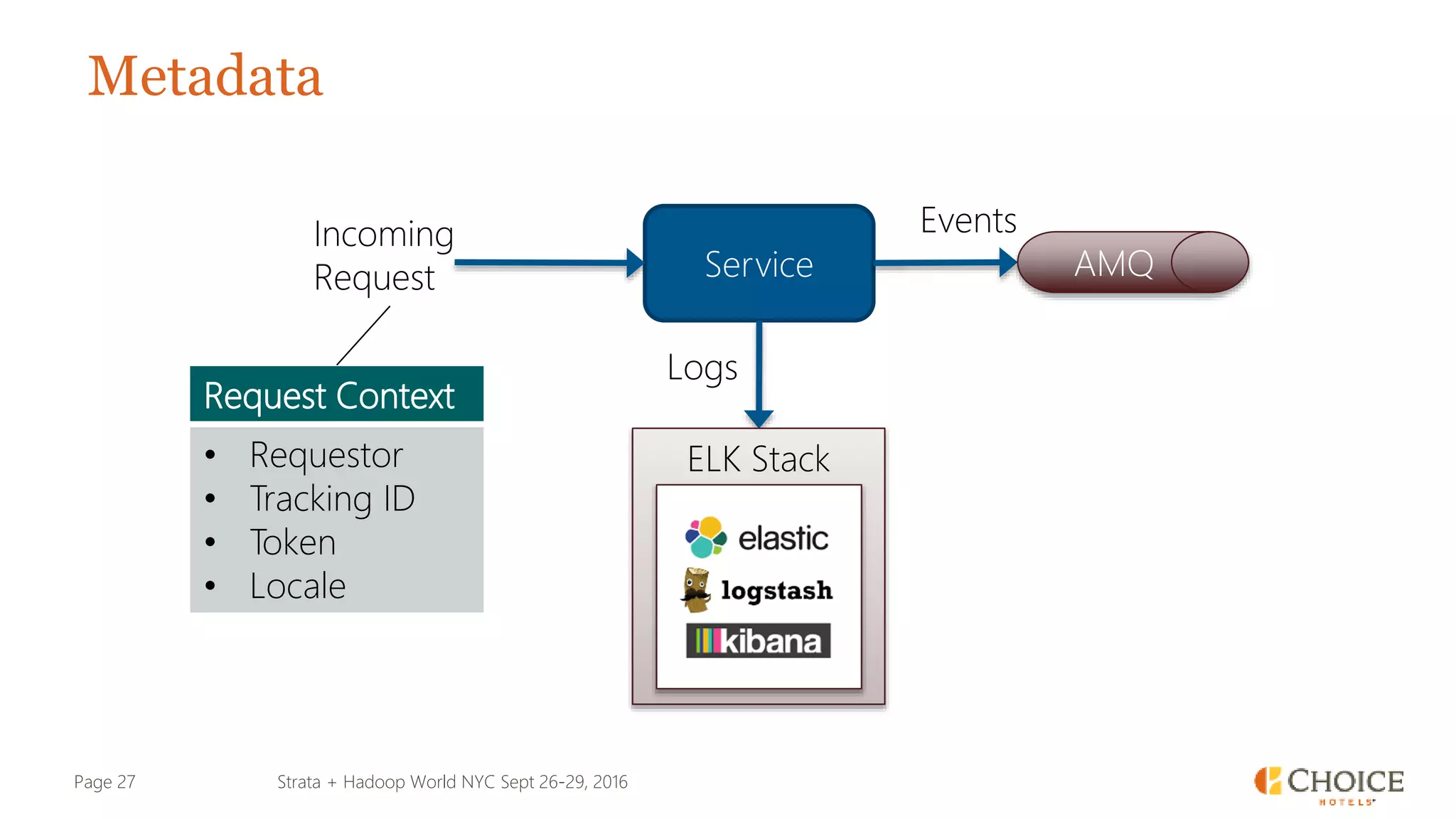

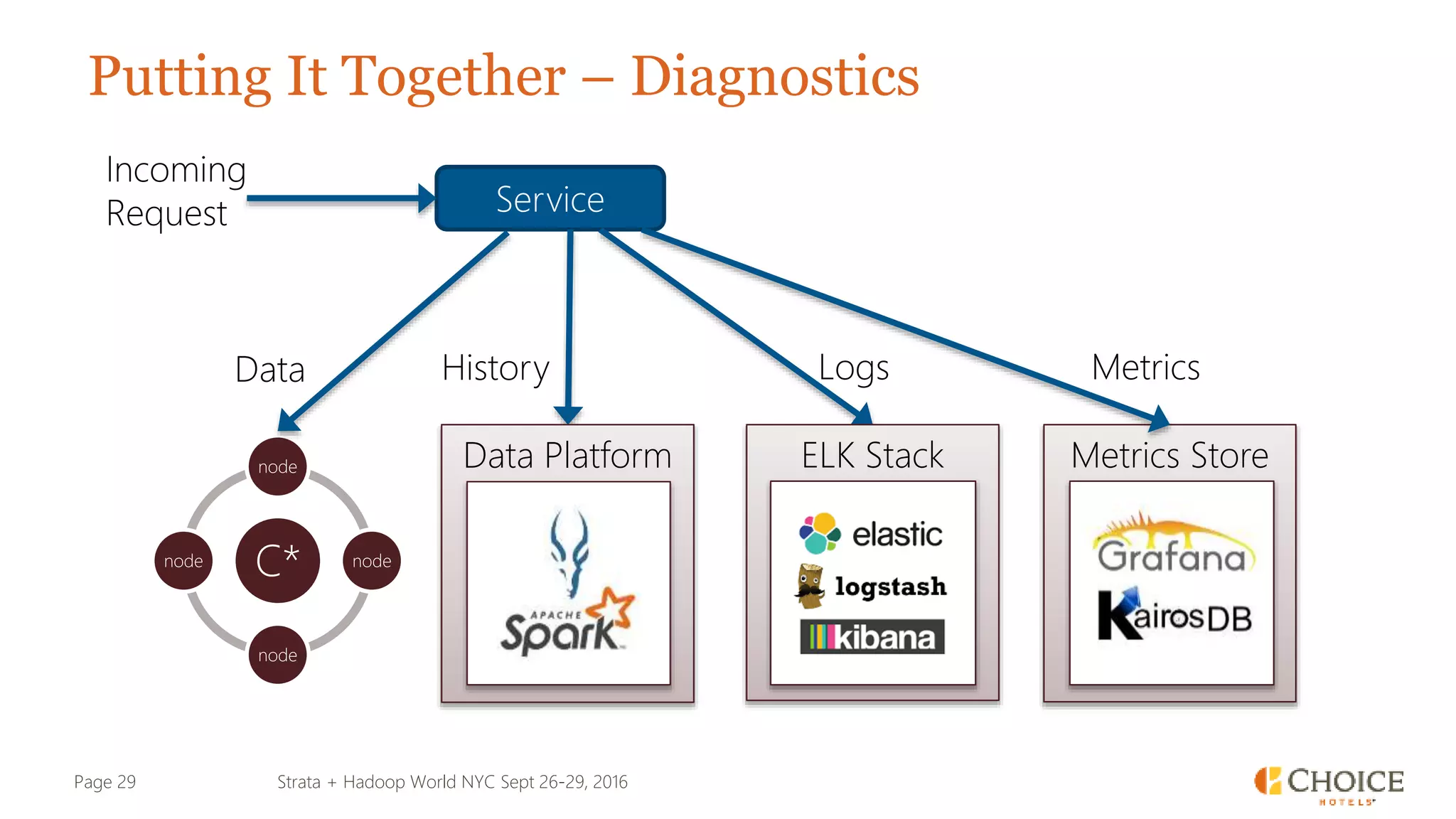
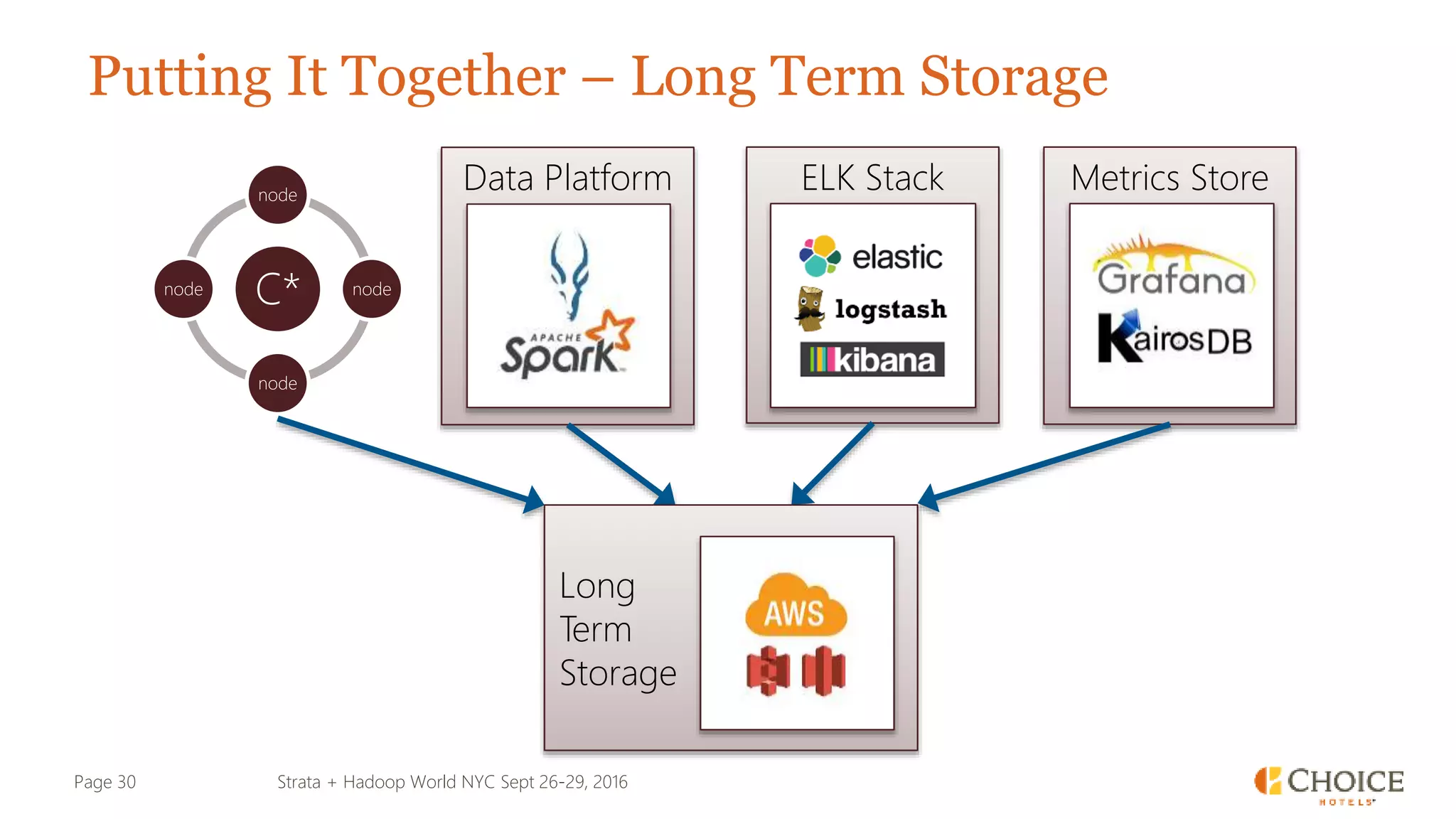
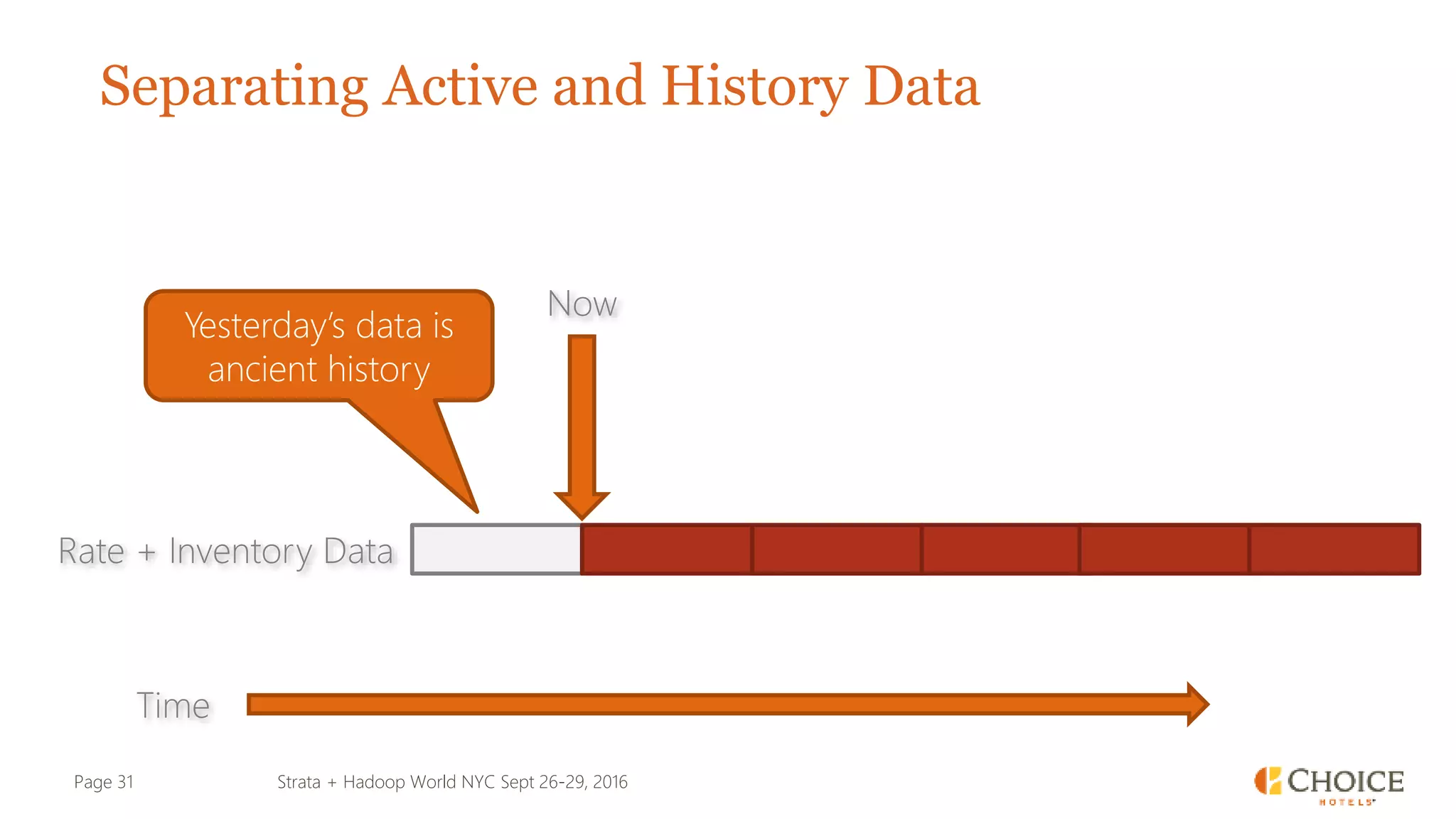
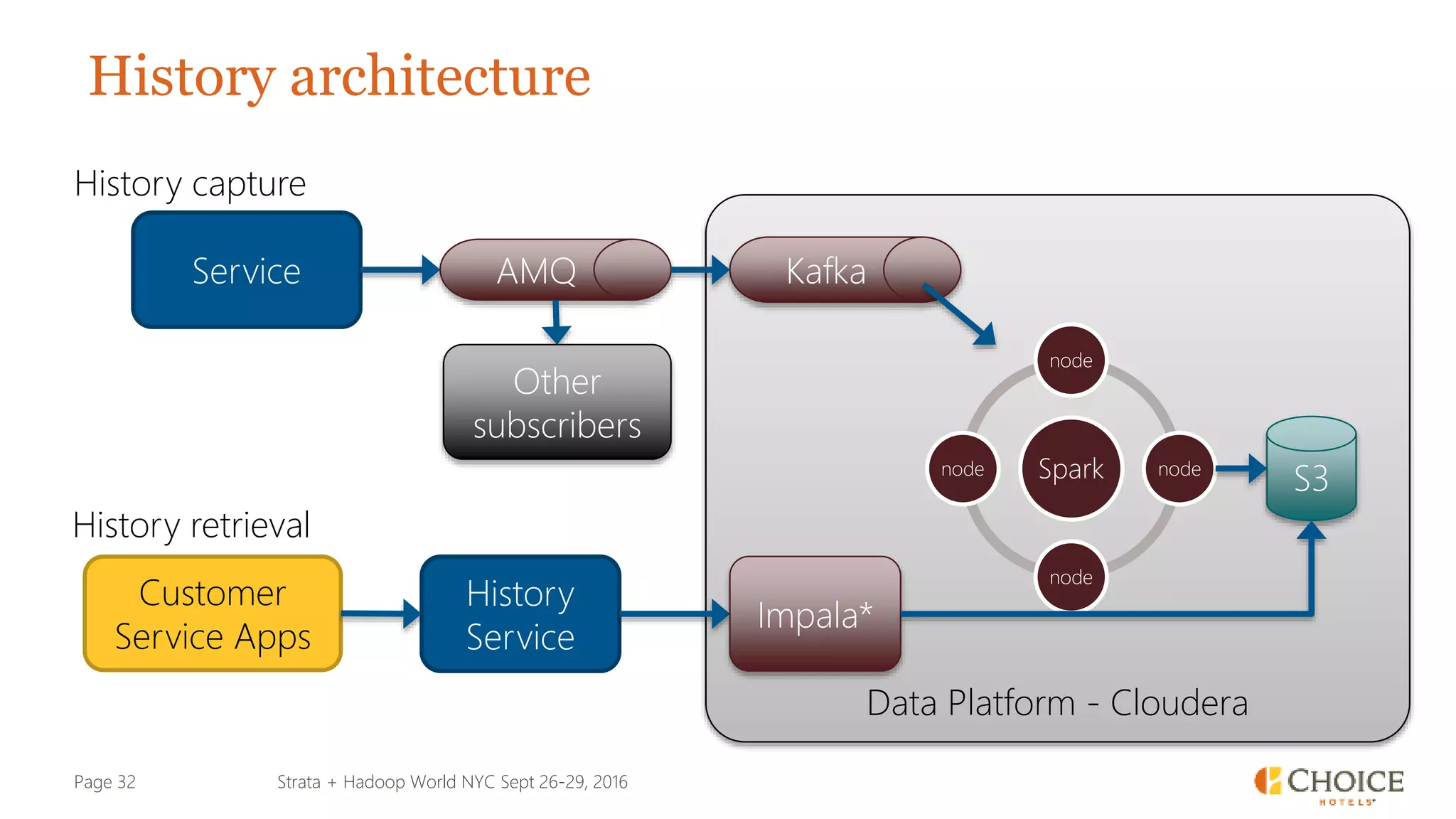

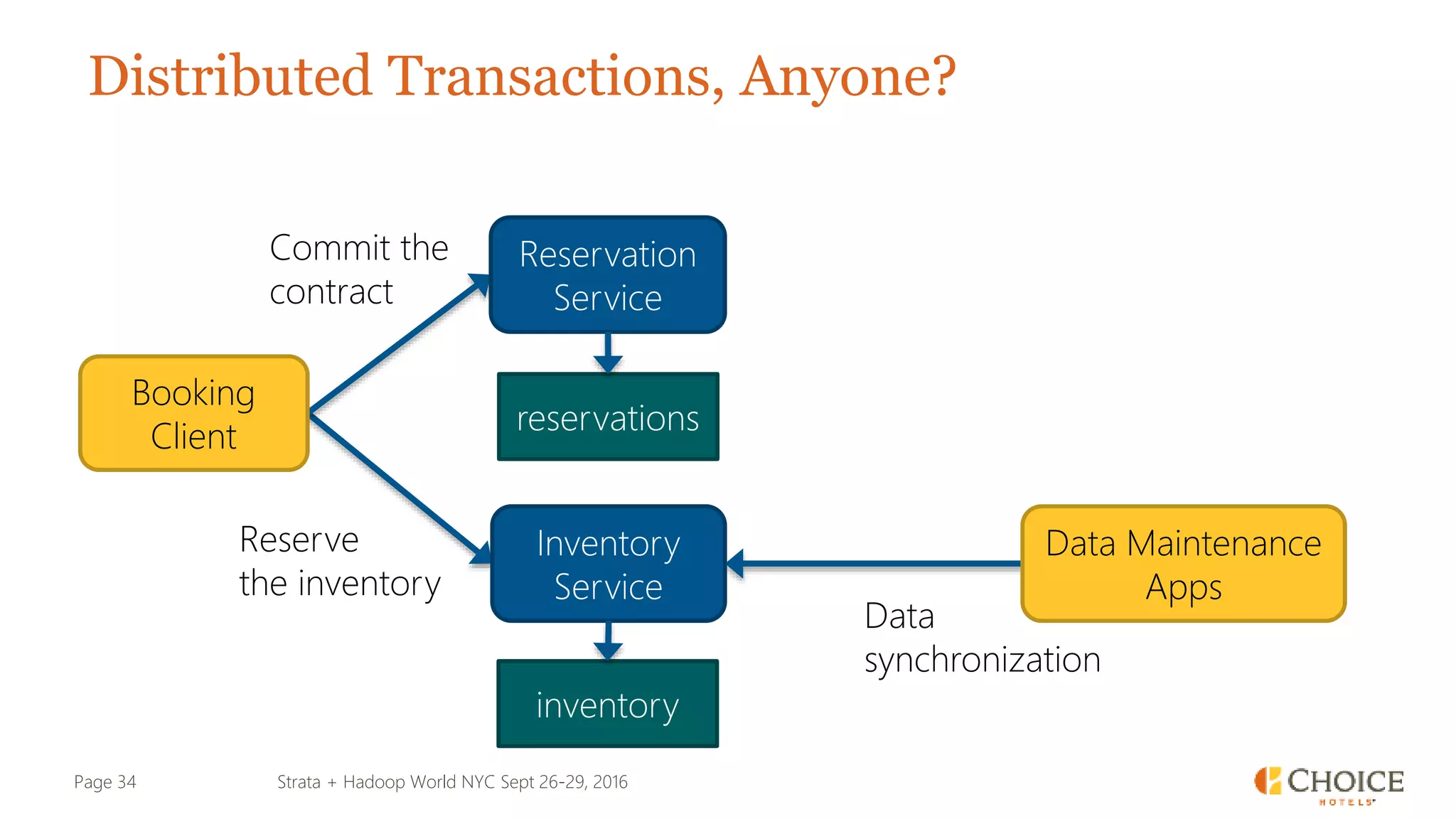





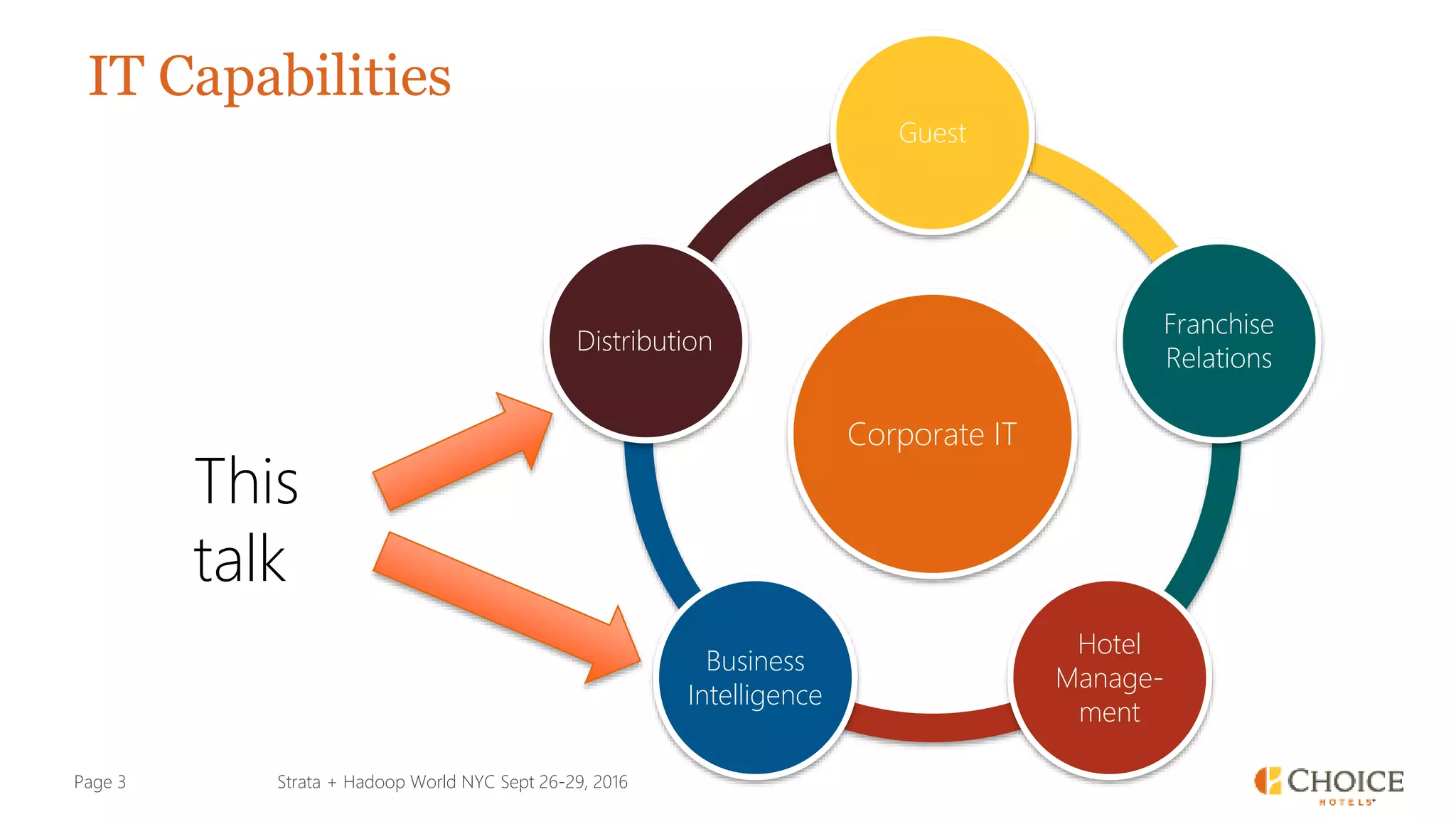
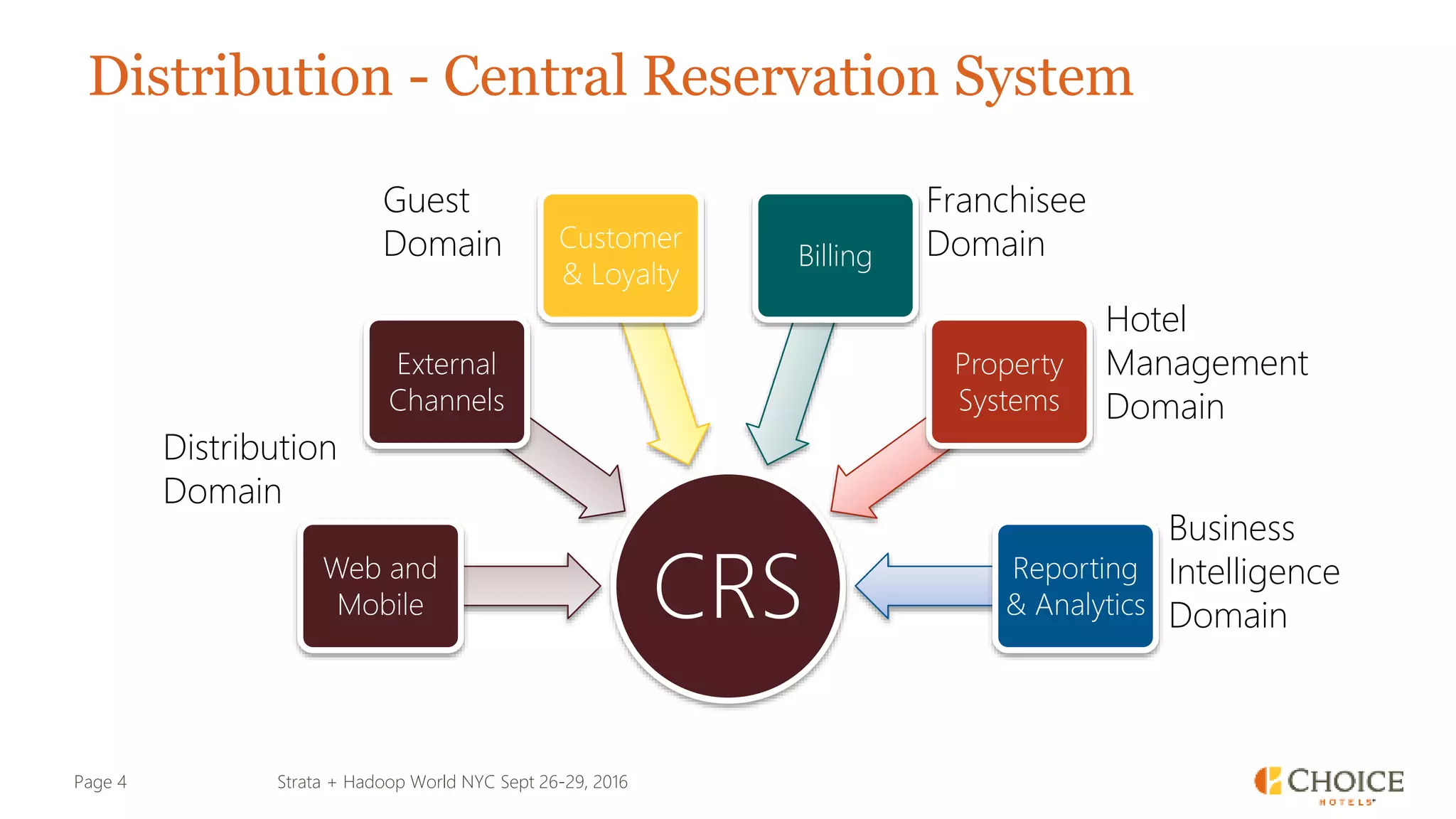
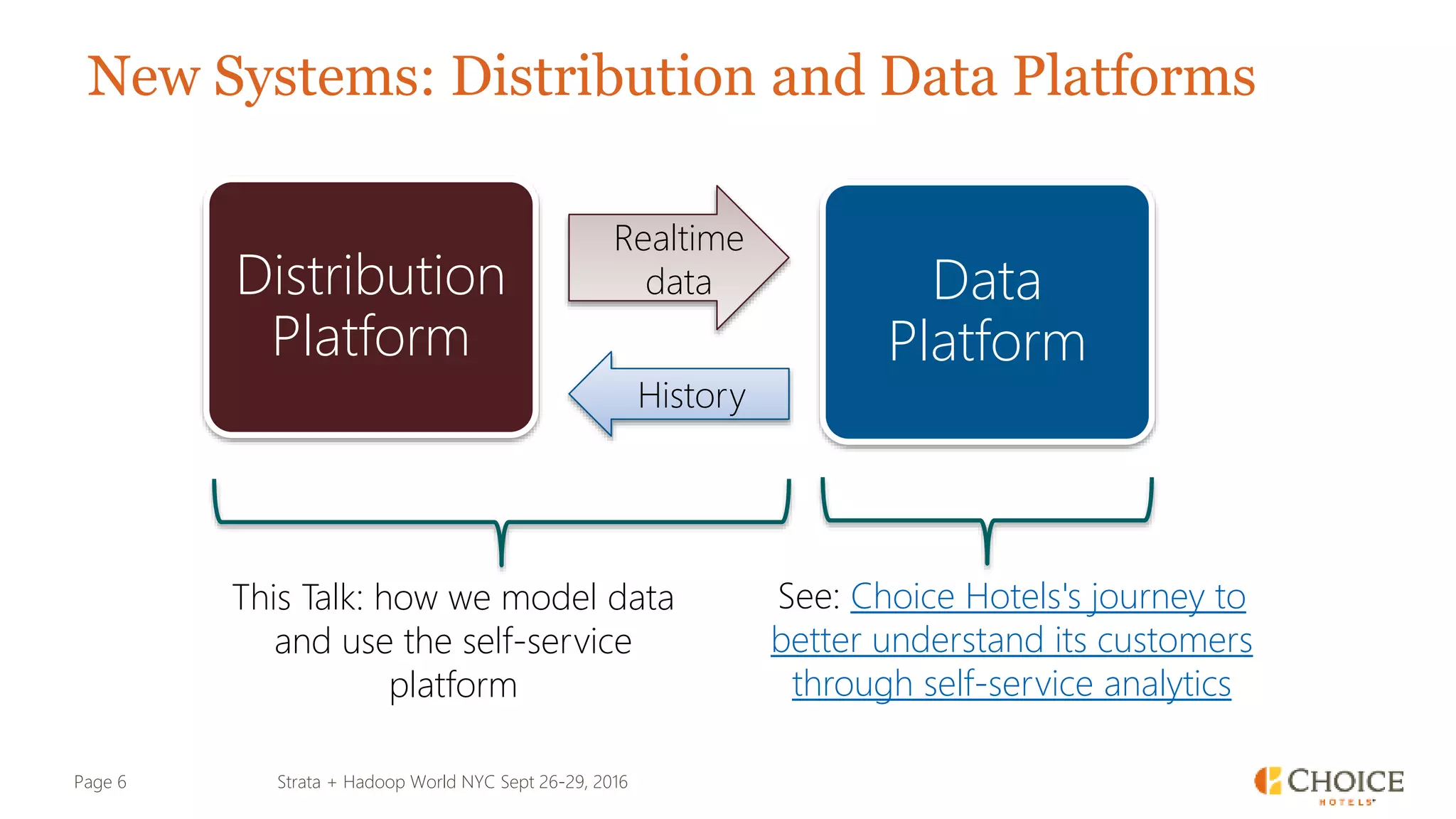
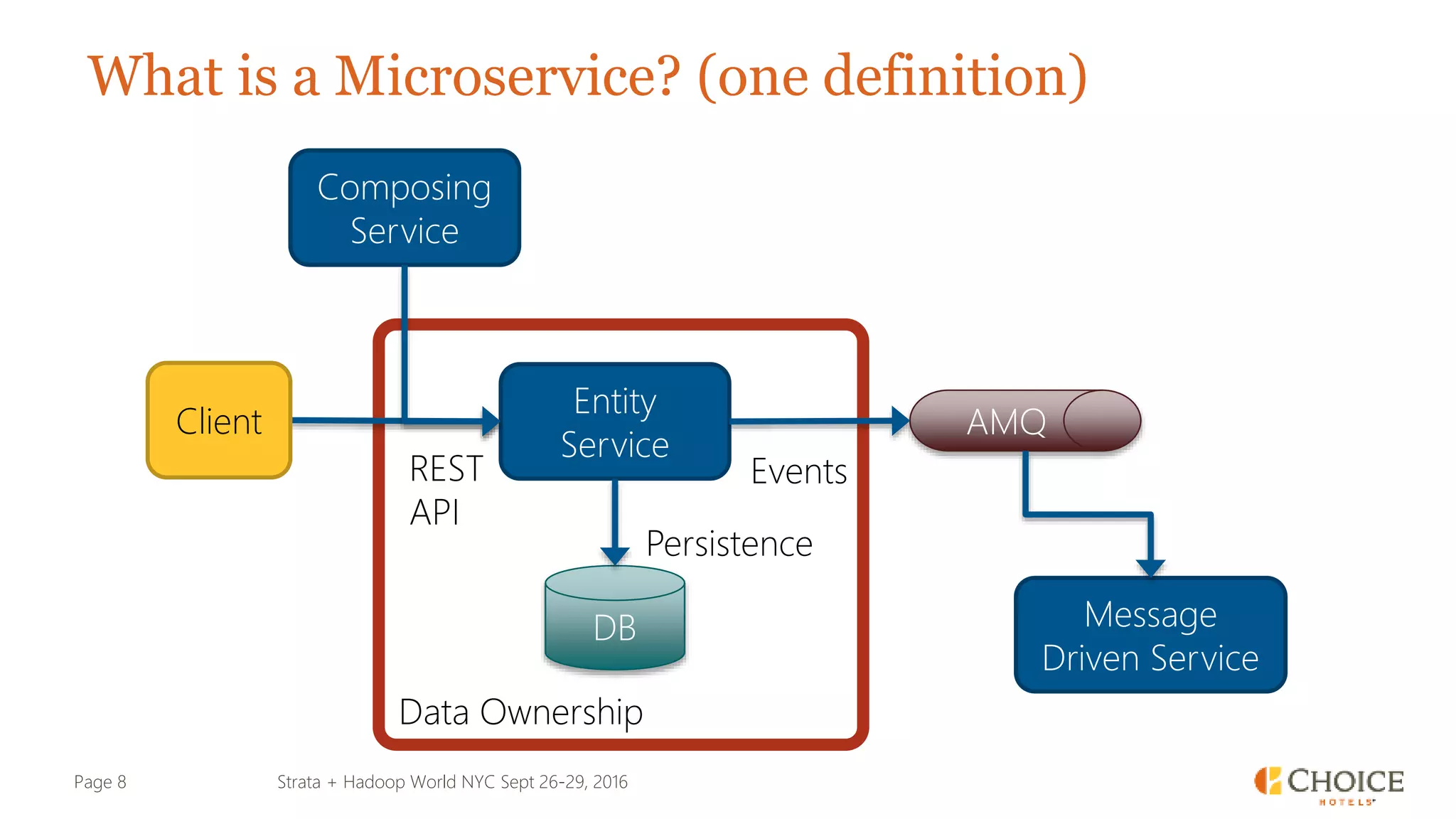
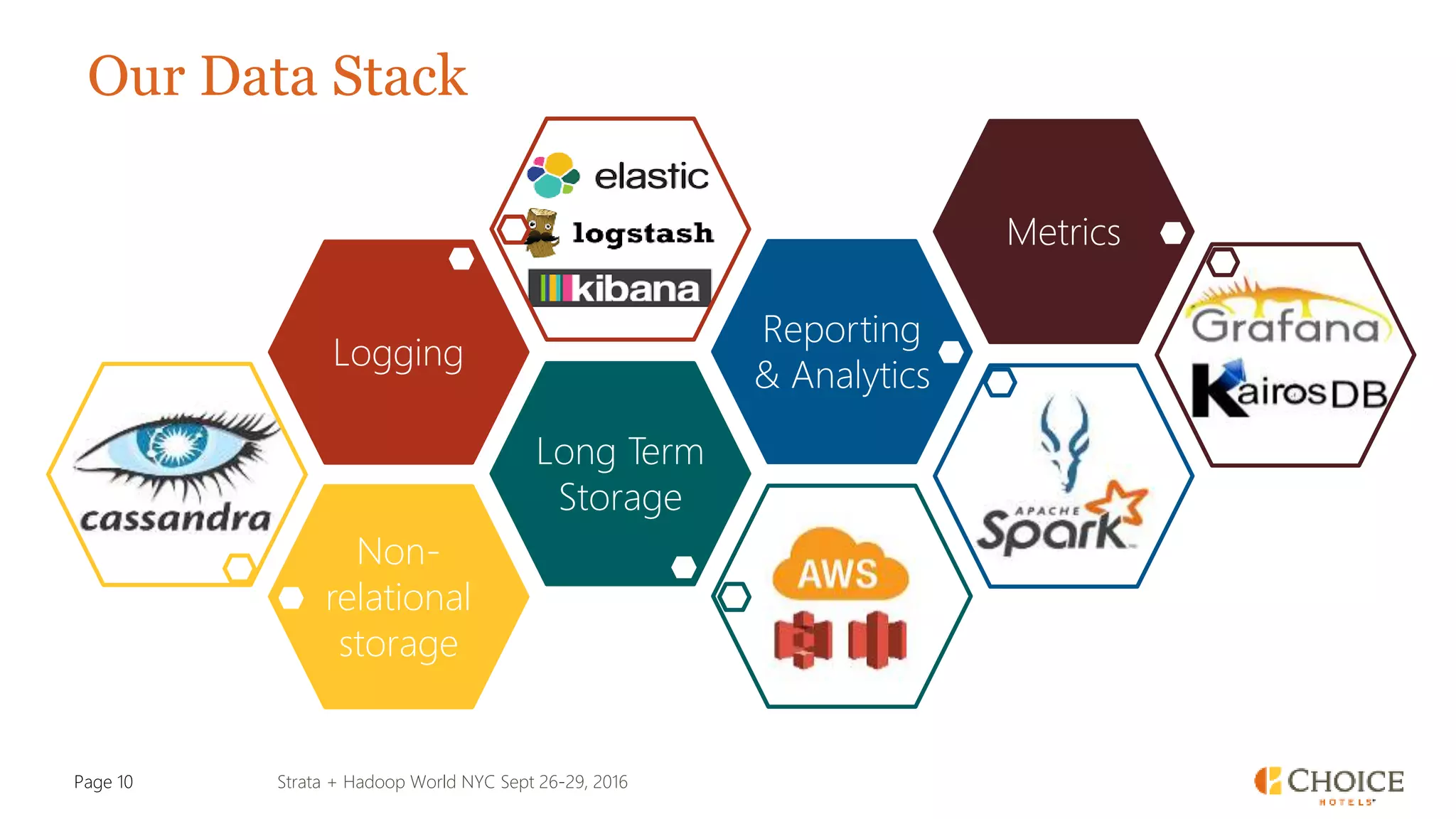
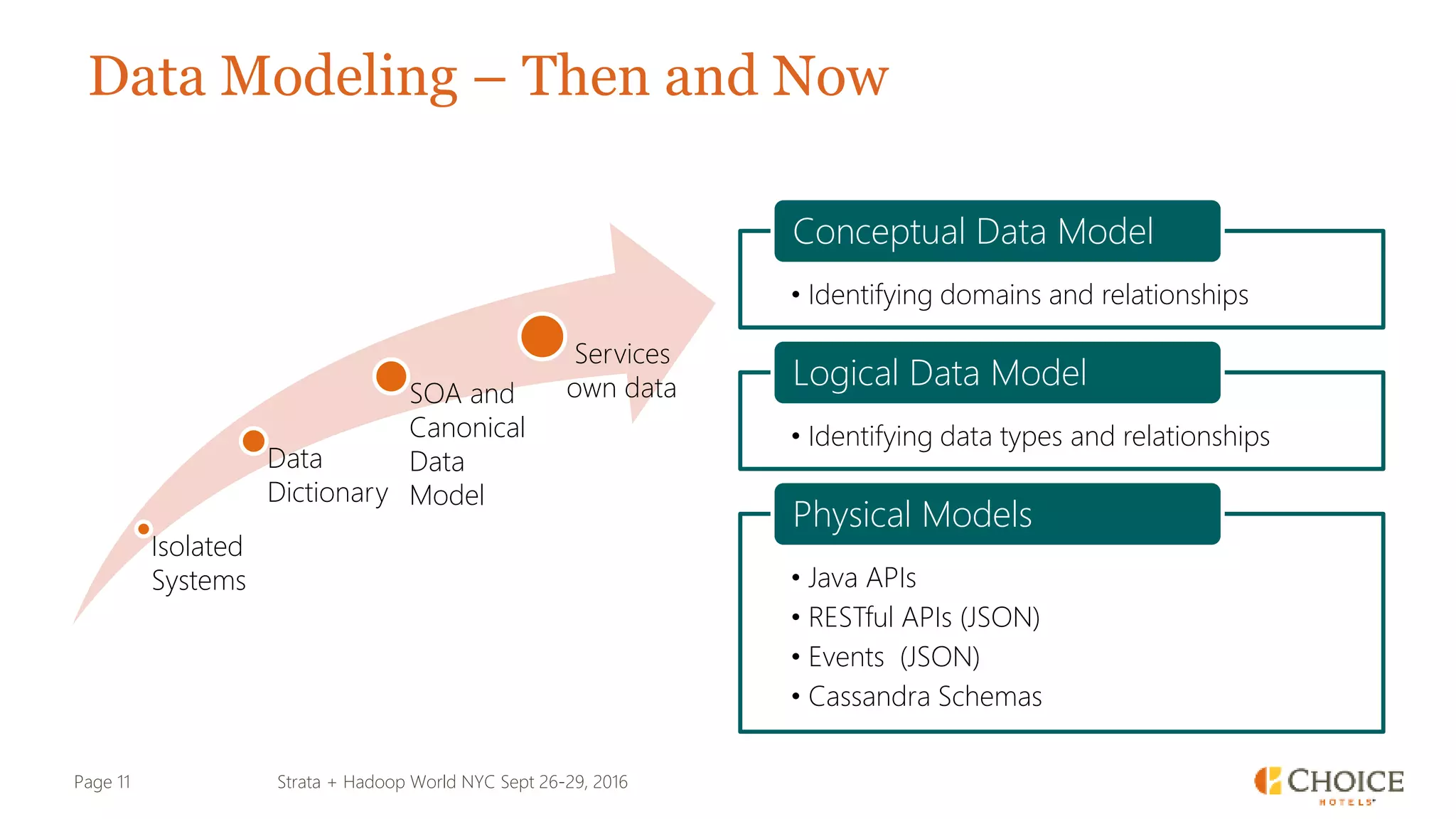
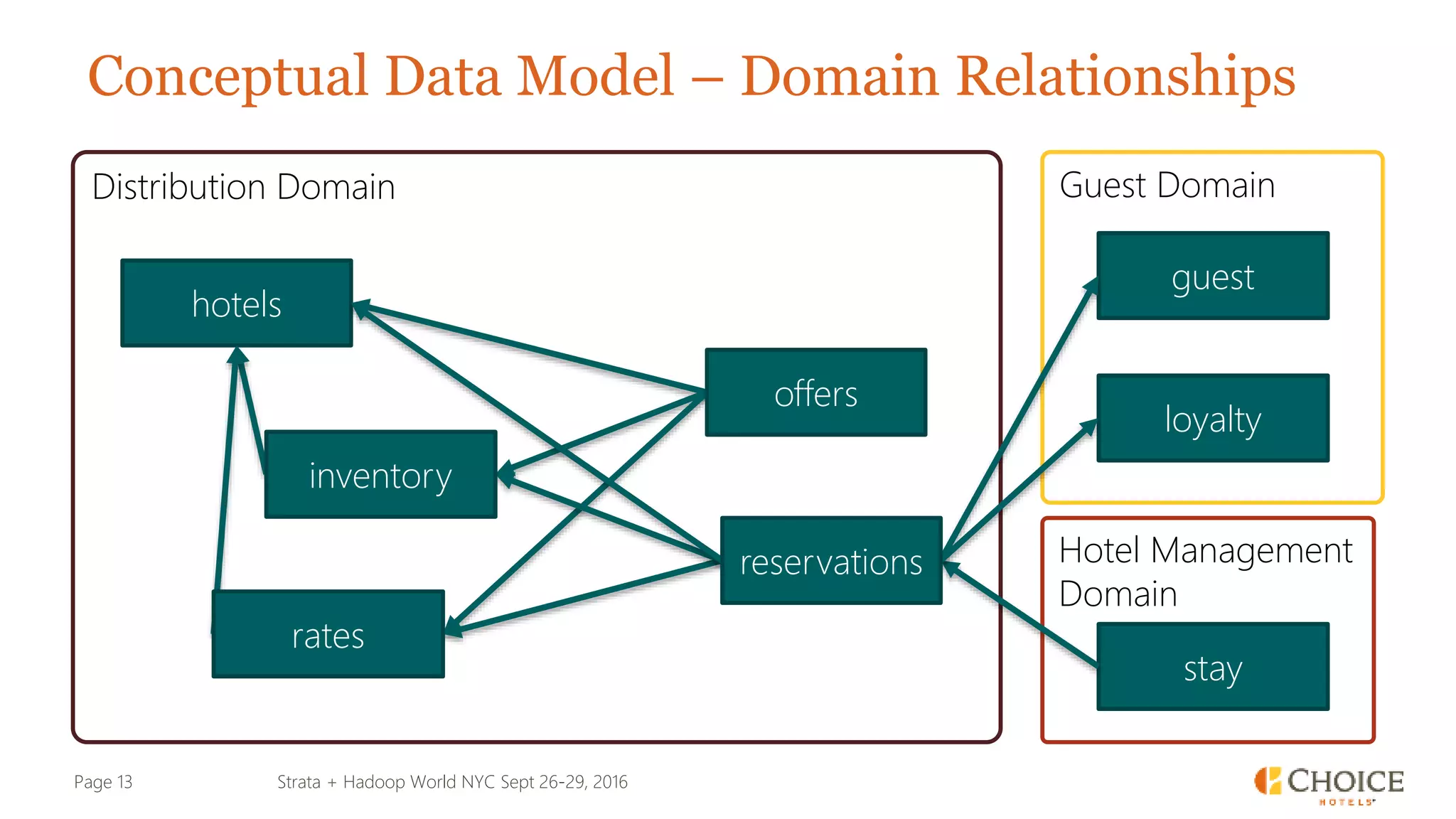
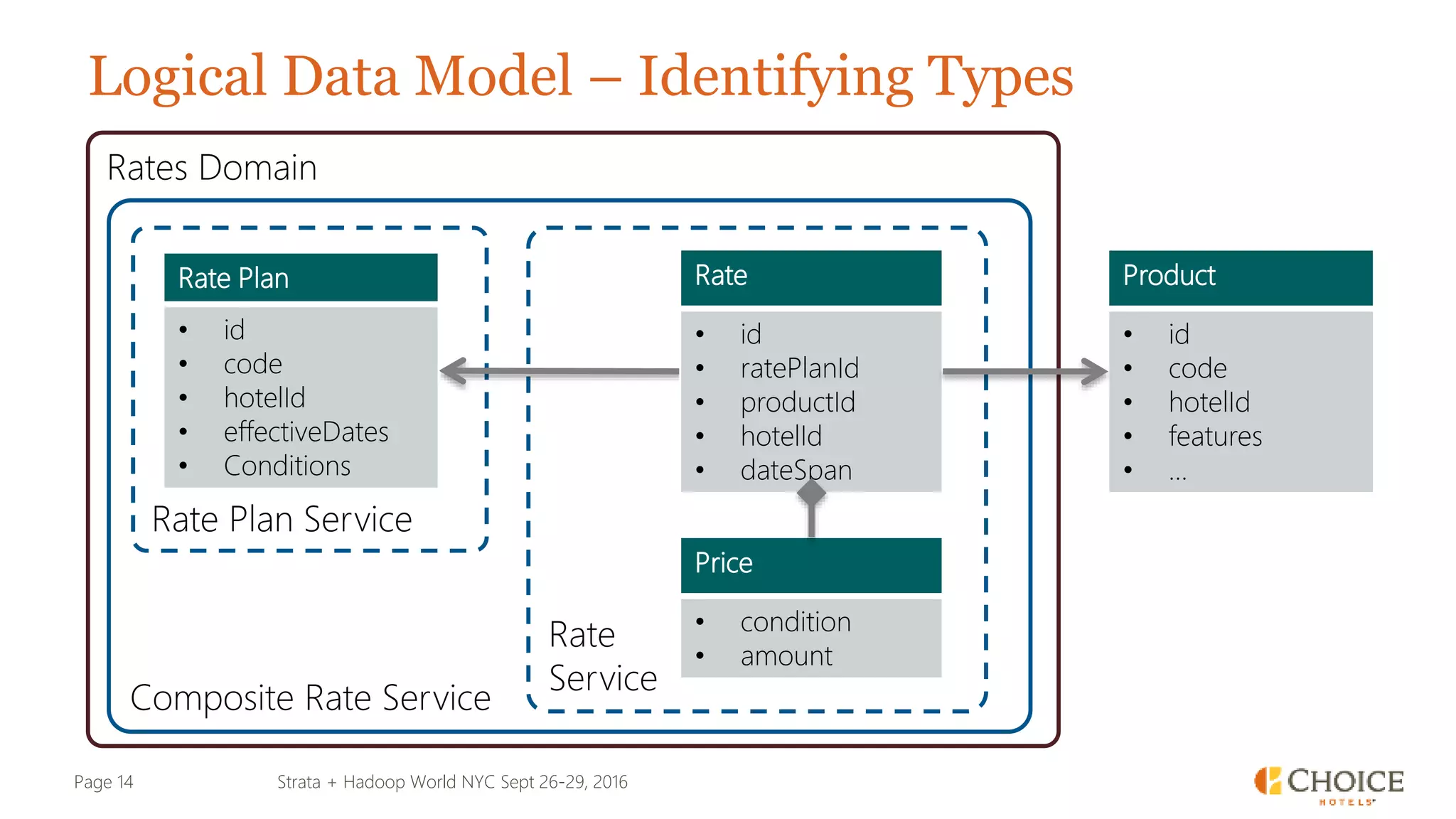
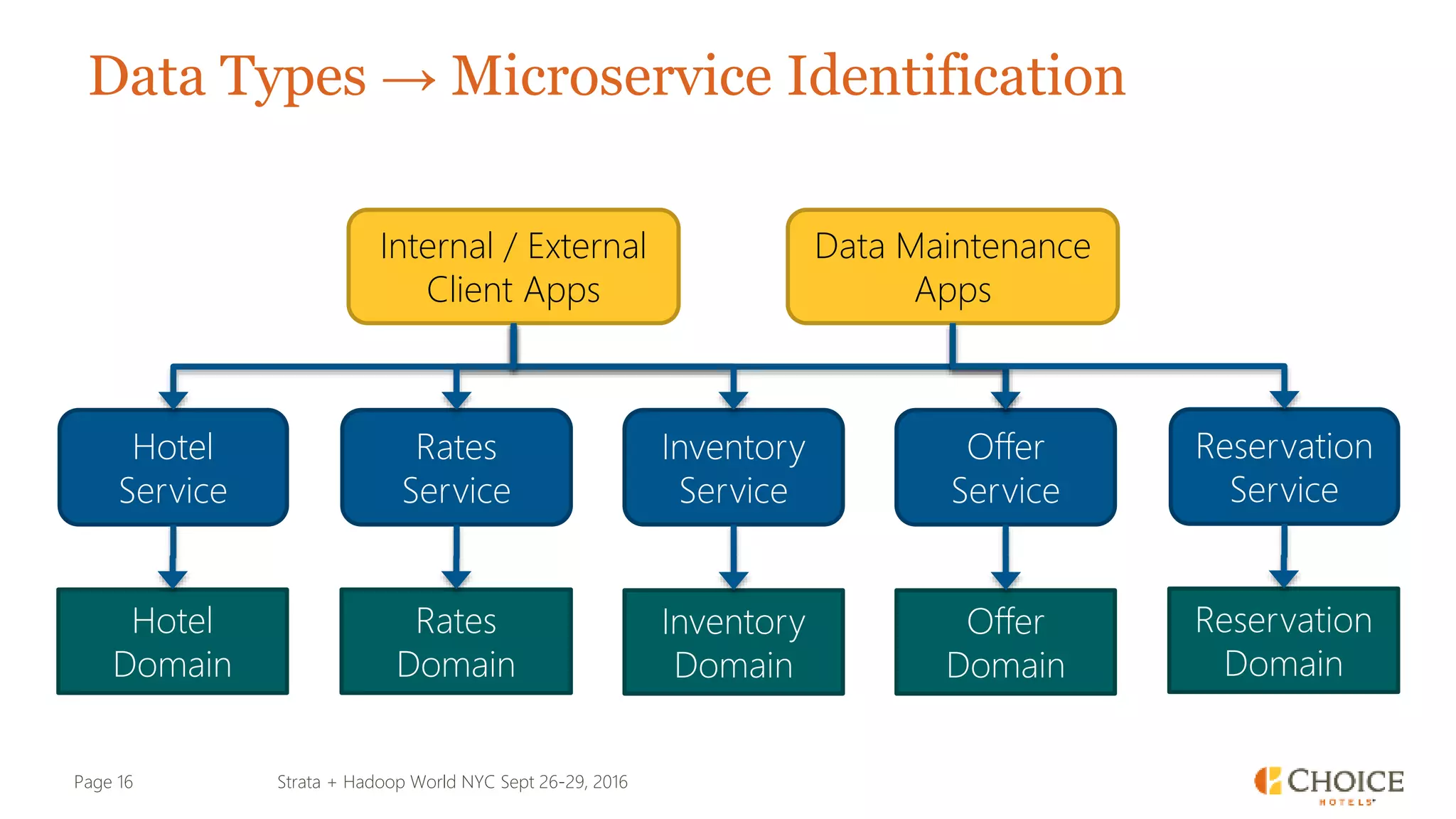
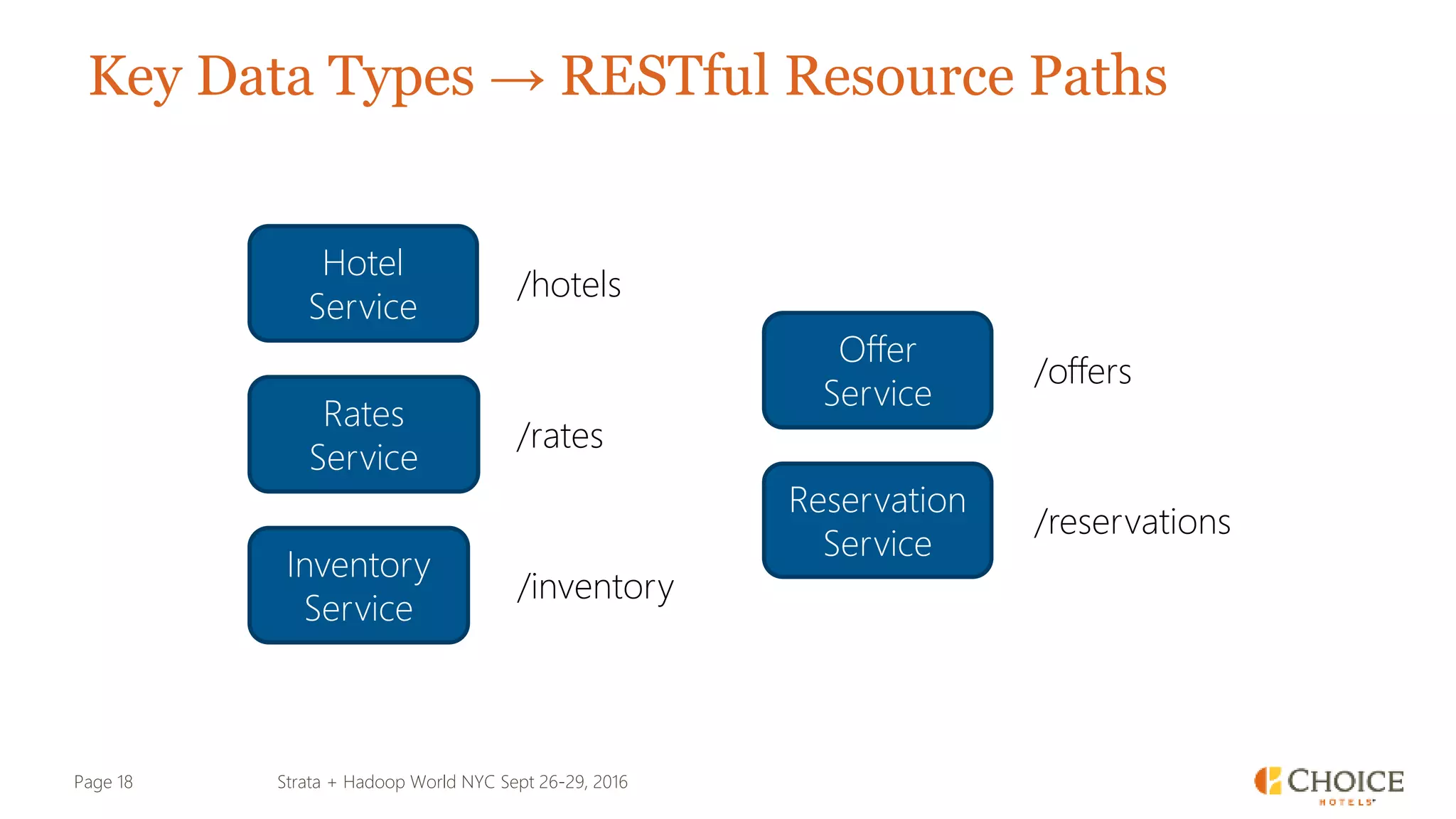
The document details a presentation from Strata + Hadoop World NYC 2016, focusing on data modeling for microservices using Cassandra and Spark. Key topics include the transformation of IT capabilities, architecture for data platforms, the design of scalable and maintainable data structures, and the challenges of distributed transactions. It outlines various data types, RESTful APIs, and practical applications in the context of hotel management and reservation systems.