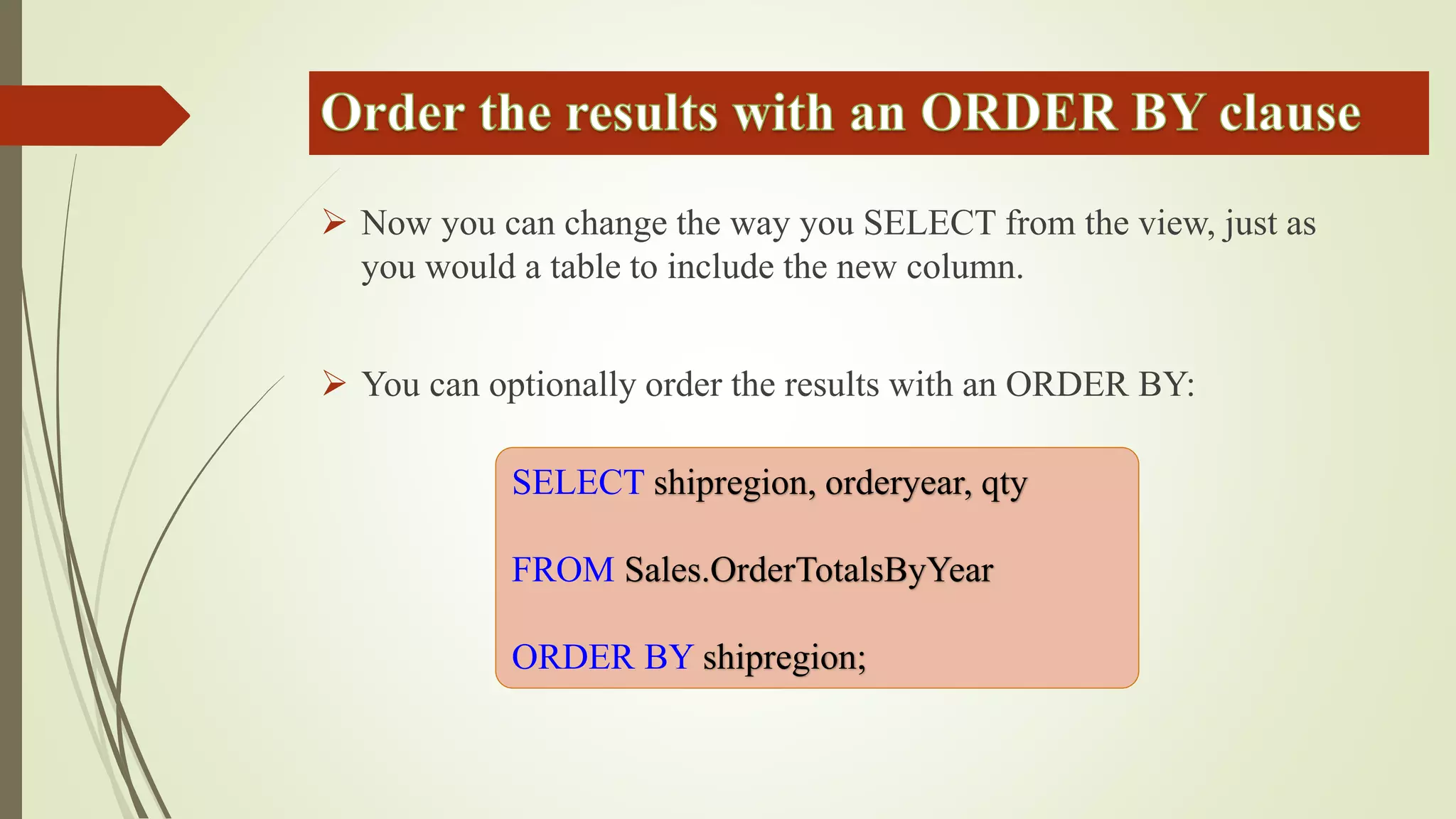
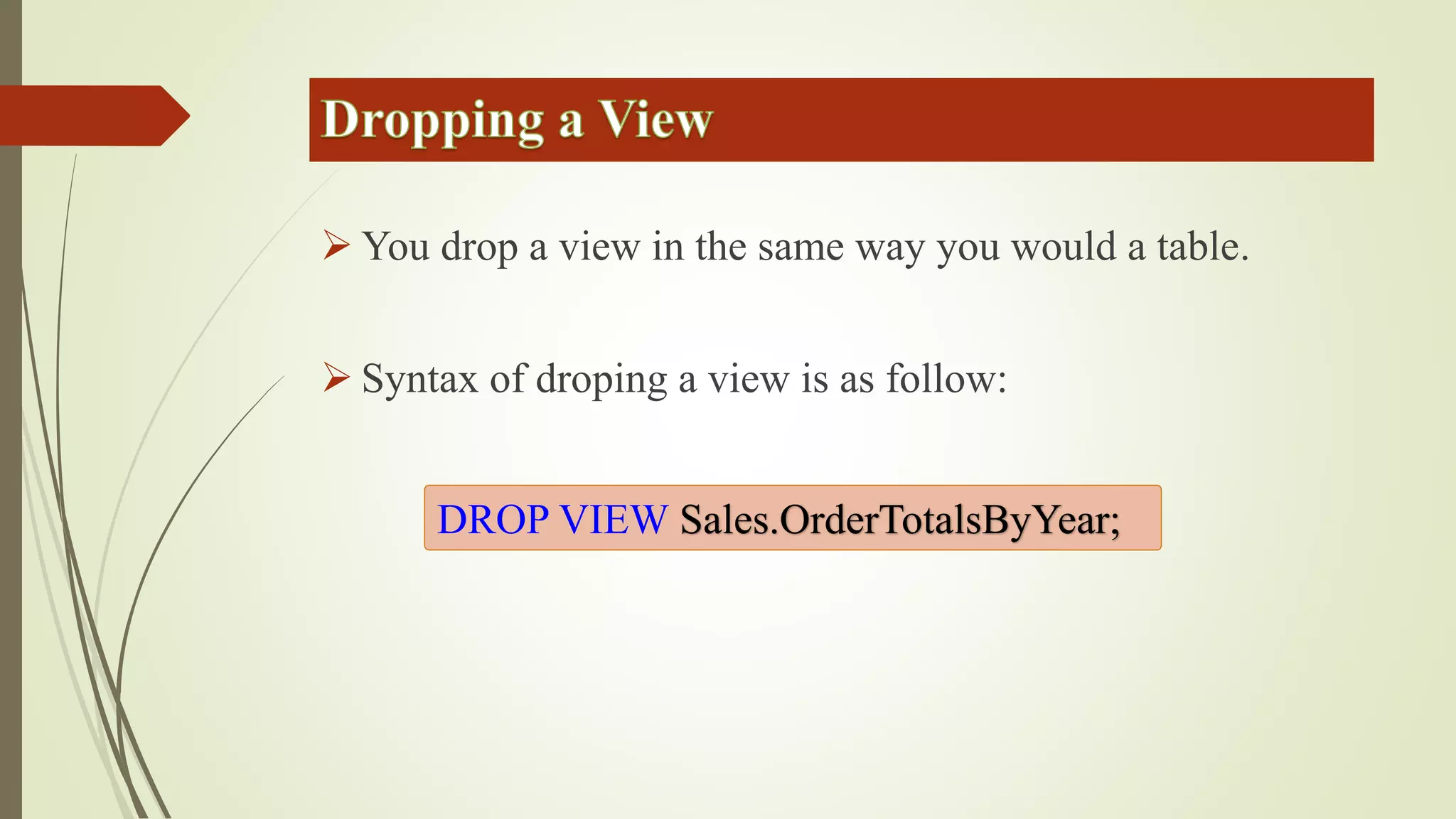
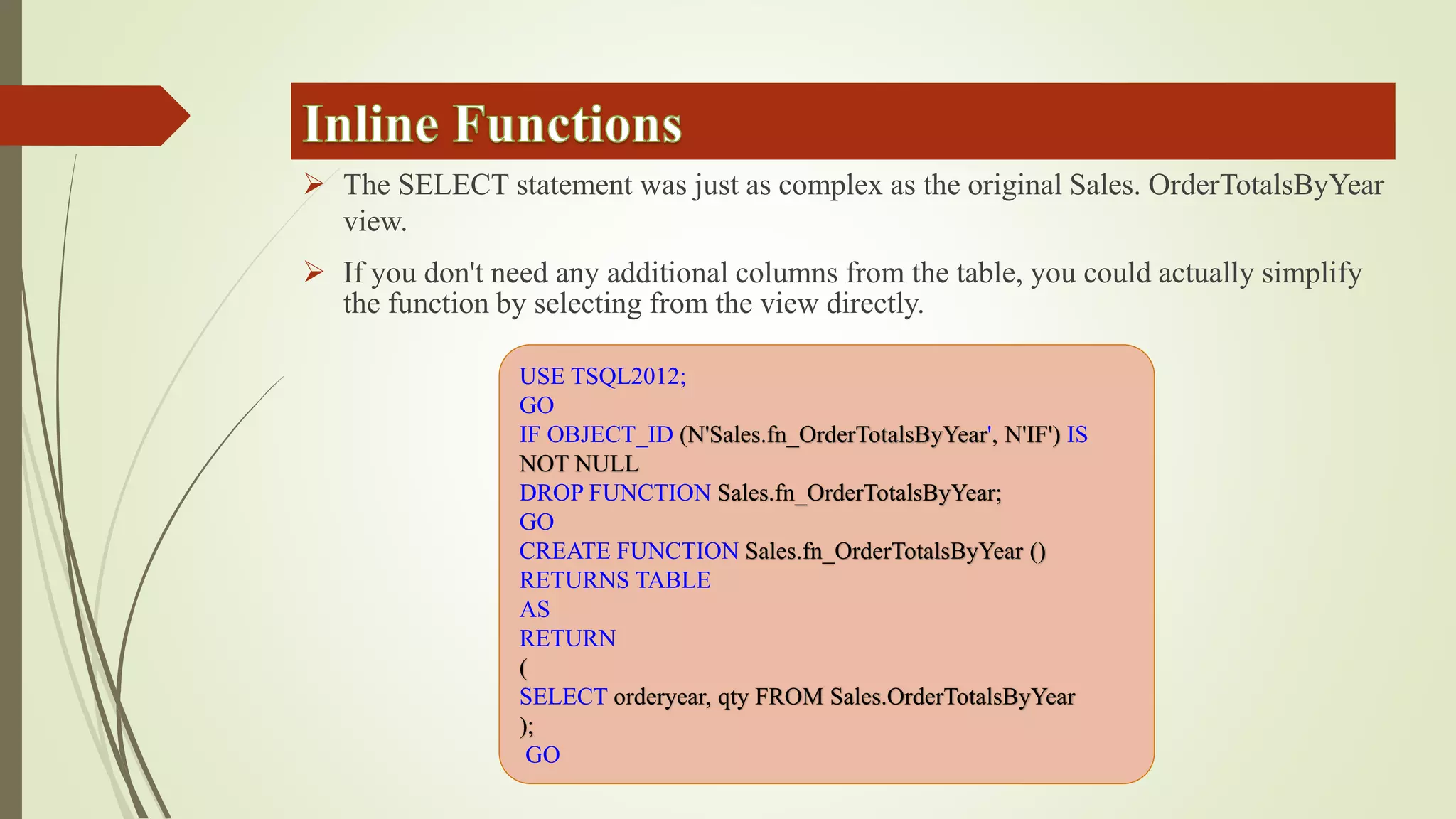
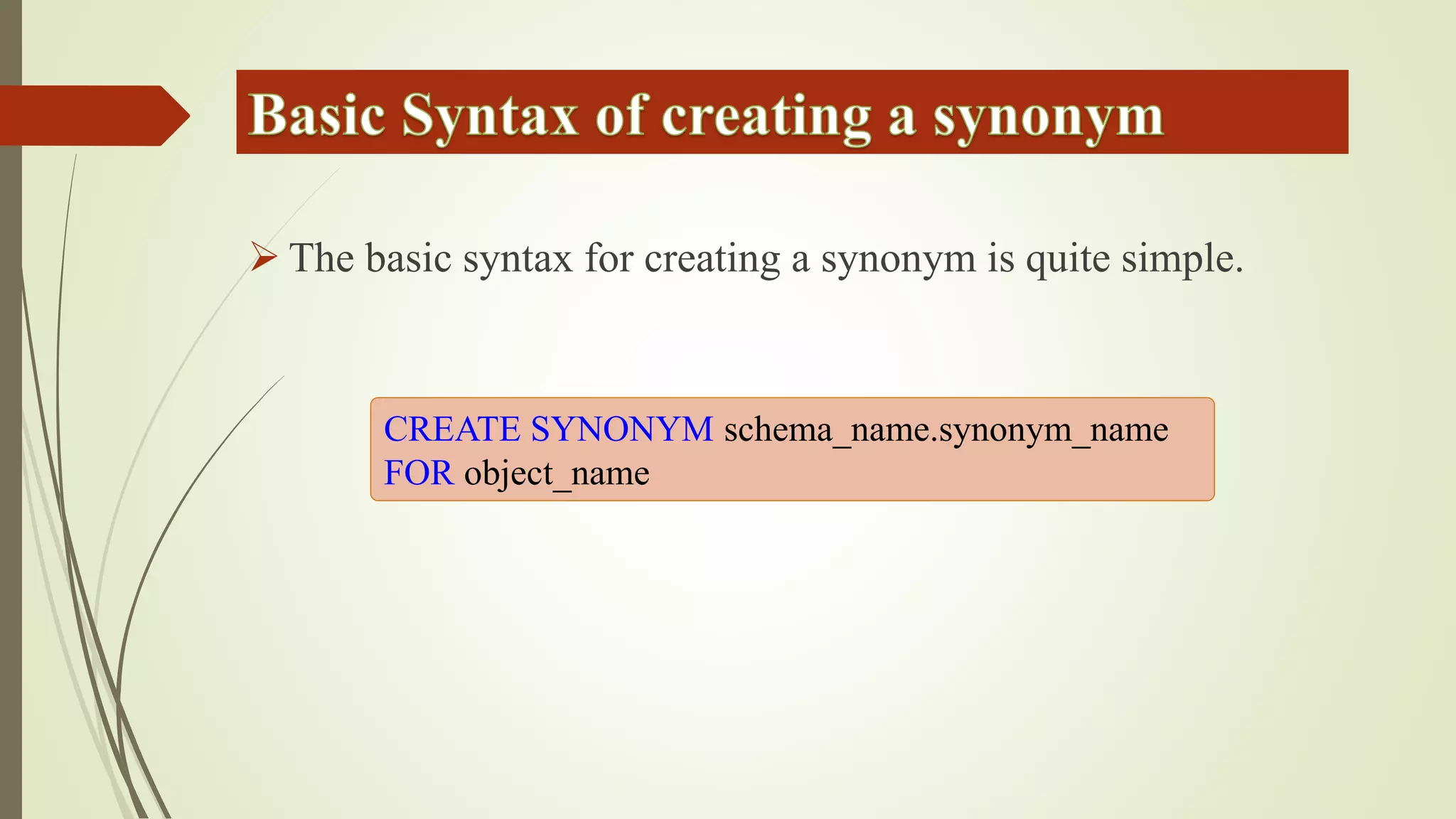
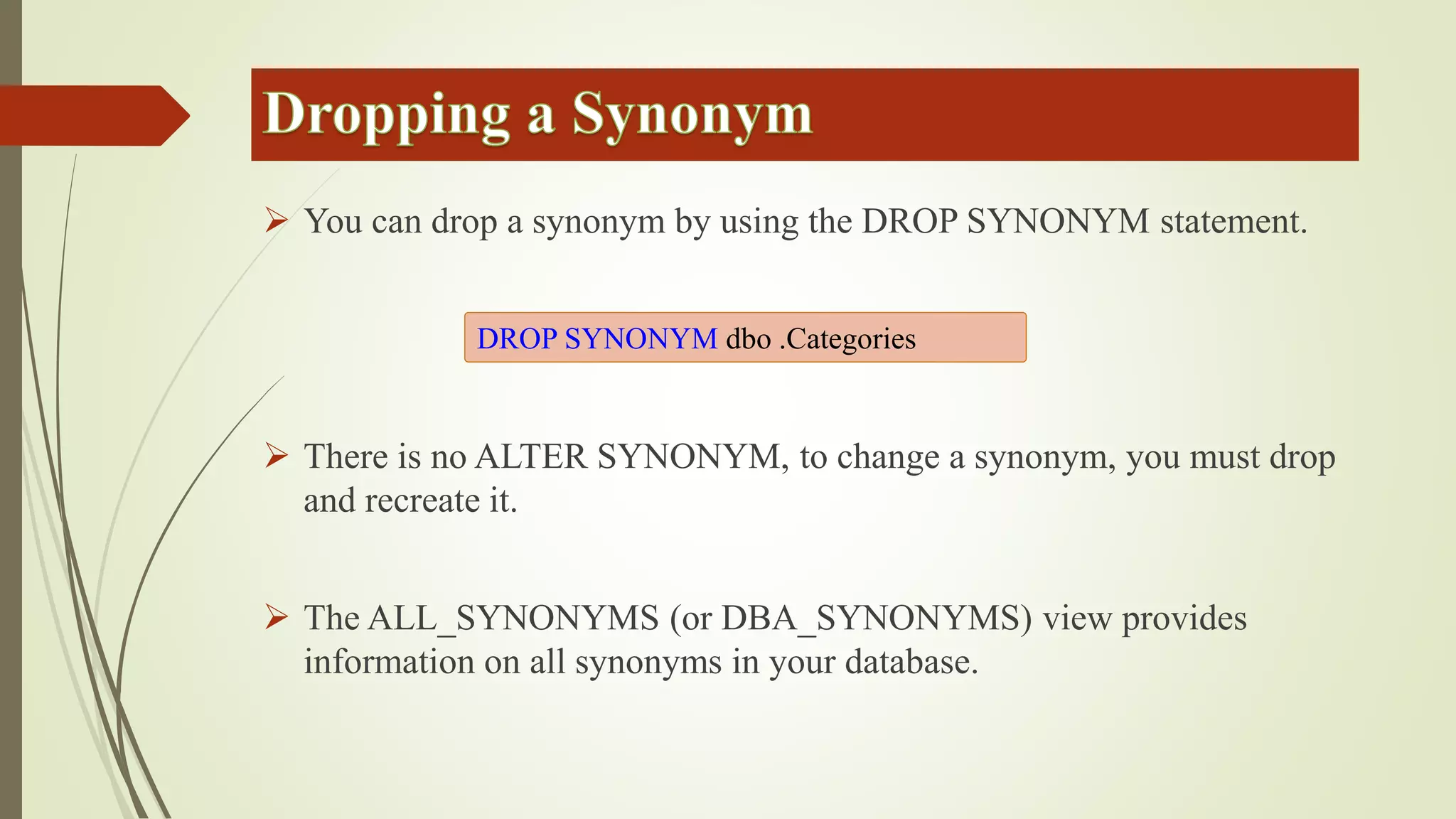
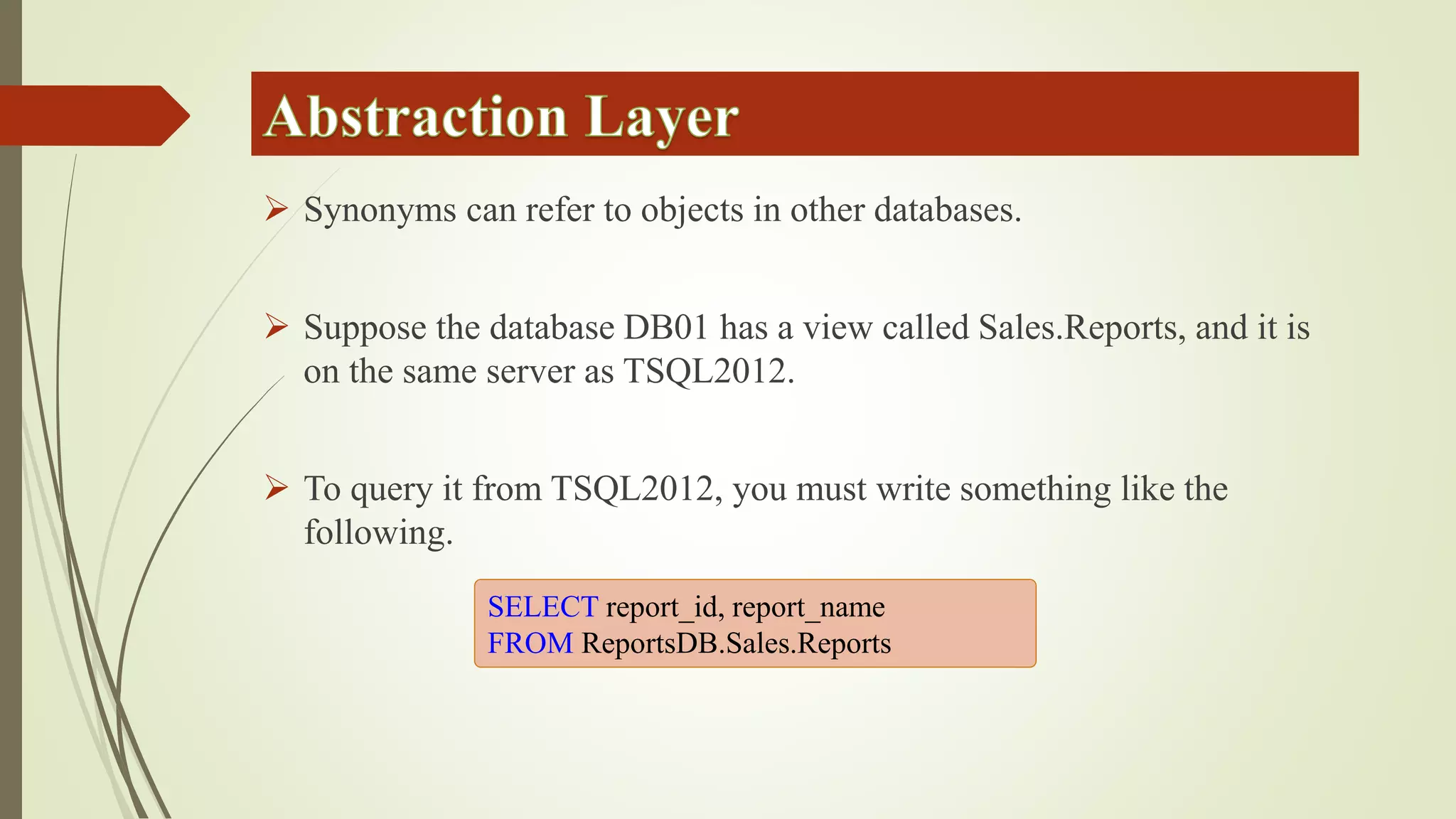
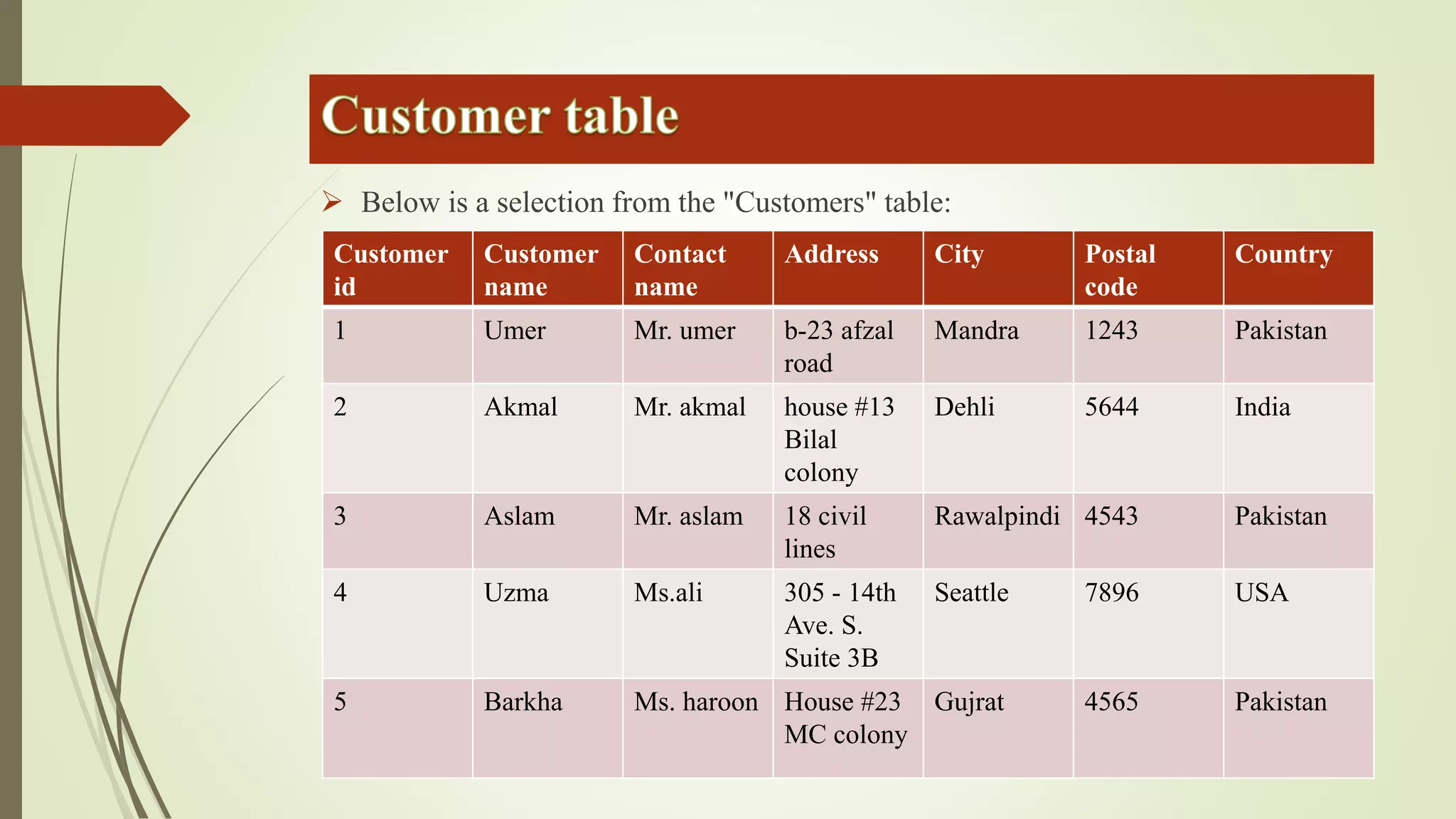
Views allow users to query data from multiple tables while hiding complexity. Views are defined with a SELECT statement and do not store data. Inline functions can be used like parameterized views by accepting parameters. Synonyms provide an abstraction layer and can be used to reference objects in other databases or schemas.









![ The basic syntax for the CREATE VIEW statement: CREATE VIEW [ schema_name . ] view_name [ (column [ ,...n ] ) ] [ WITH <view_attribute> [ ,...n ] ] AS select_statement [ WITH CHECK OPTION ] [ ; ]](https://image.slidesharecdn.com/chapter9and10final-170708121947/75/Designing-and-Creating-Views-Inline-Functions-and-Synonyms-10-2048.jpg)