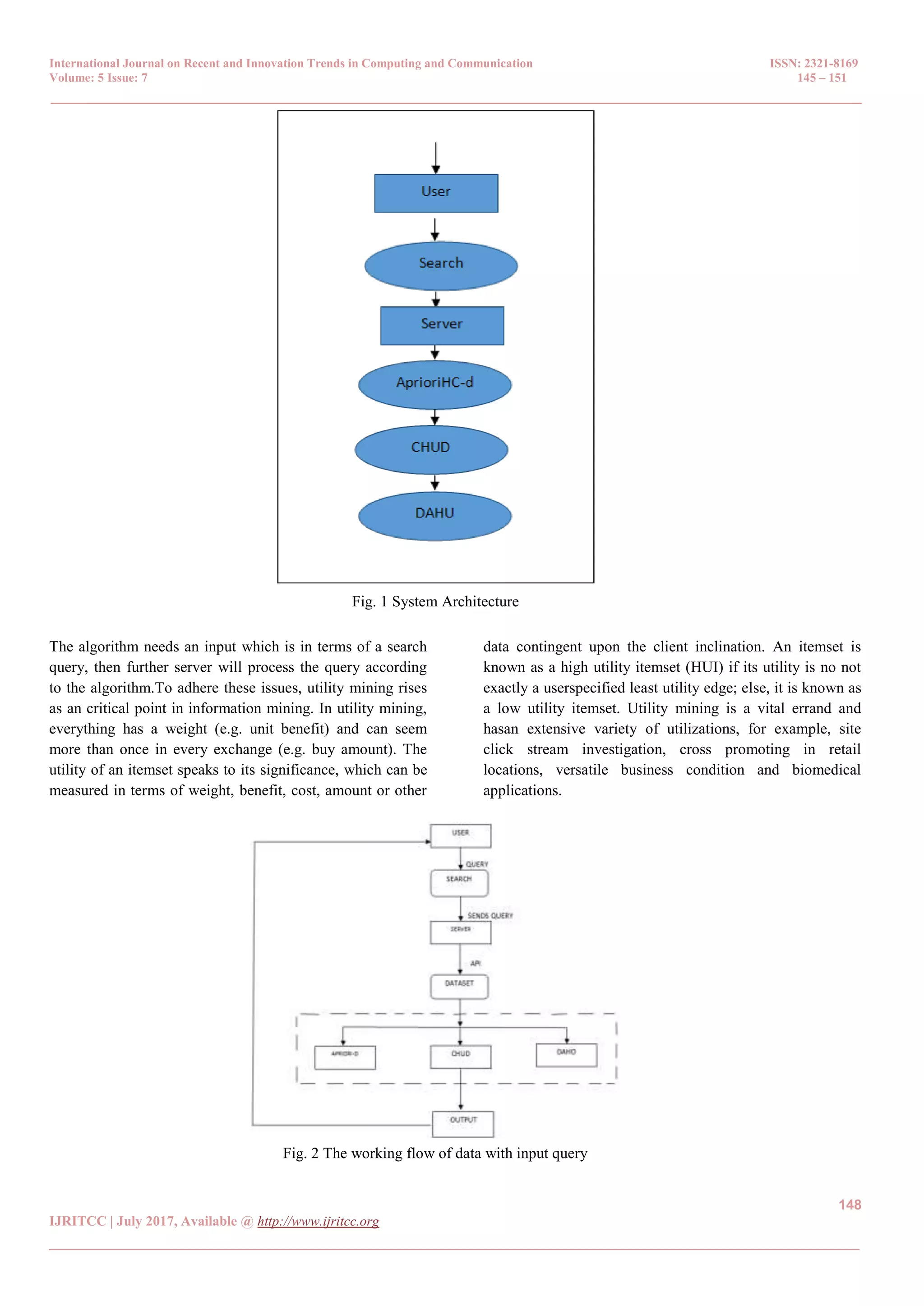
The document discusses techniques for mining high utility item sets (HUIs) using three proposed algorithms: apriorich, apriorihc-d, and chud, which aim to efficiently discover closed high utility itemsets (CHUIs) from large databases. The paper addresses the challenges of frequent item set mining (FIM), including the inefficiency of traditional methods in identifying valuable item sets with low frequencies and presents a novel approach called DAHU for recovering all HUIs effectively. The results indicate a significant reduction in the computational cost and the number of high utility itemsets, enhancing the efficiency of the mining process.
![International Journal on Recent and Innovation Trends in Computing and Communication ISSN: 2321-8169 Volume: 5 Issue: 7 145 – 151 _______________________________________________________________________________________________ 145 IJRITCC | July 2017, Available @ http://www.ijritcc.org _______________________________________________________________________________________ Discovering High Utility Item Sets to Achieve Lossless Mining using Apriori Algorithm Gagan S Purad Assistant Professor, Dept. of CSE, New Horizon College Of Engineering, Bangalore, India. Email-id: gagansp99@gmail.com Abstract —Mining high utility thing sets (HUIs) from databases is a vital information mining errand, which alludes to the disclosure of thing sets with high utilities (e.g. high benefits).The proposal three effective calculations named AprioriCH (Apriori-based calculation for mining High utility Closed þ itemsets), AprioriHC-D (AprioriHC calculation with Discarding unpromising and detached things) and CHUD (Closed þ High Utility itemset Discovery) to discover this portrayal. Further, a strategy called DAHU (Derive All High Utility itemsets) is proposed to recuperate all HUIs from the arrangement of CHUIs without getting to the first database.To accomplish high proficiency for the mining errand and give a succinct mining result to clients, we propose a novel system in this paper for mining closedþ high utility itemsets (CHUIs), which fills in as a reduced and lossless portrayal of HUIs. Keywords— High utility item set, Apriori, item set, Frequent item set _____________________________________________________*****____________________________________________________ I. INTRODUCTION The World Wide Web is a dynamic world continually developing with changing circumstances and developing as far as the information it brings to the table. Frequent Item set Mining (FIM) is a principal examine theme in information mining. One of its prominent applications is showcase market basket investigation, which alludes to the disclosure of sets of things (thing sets) that are regularly bought together by clients. Be that as it may, in this application, the conventional model of FIM may find a lot of incessant yet low income thing sets and lose the data on important thing sets having low offering frequencies.These issues are caused by the truths that (1) FIM regards all things as having a similar significance/unit benefit/weight and (2) it expect that each thing in an exchange shows up in a twofold frame, i.e., a thing can be either present or truant in an exchange, which does not demonstrate its buy amount in the exchange. Consequently, FIM can't fulfill the necessity of clients who craving to find thing sets with high utilities, for example, high benefits. To address these issues, utility mining rises as an essential point in information mining. In utility mining, everything has a weight (e.g. unit benefit) and can seem more than once in every exchange (e.g. buy amount). The utility of a thing set speaks to its significance, which can be measured as far as weight, benefit, cost, amount or other data relying upon the client inclination. A. Background A thing set is known as a high utility item set (HUI) if its utility is no not as much as a client indicated least utility edge; else, it is known as a low utility thing set. Utility mining is an essential assignment and has an extensive variety of utilizations, for example, site click stream investigation cross showcasing in retail locations , portable business condition and biomedical applications [6]. Be that as it may, HUI mining is not a simple undertaking since the descending conclusion property in FIM does not hold in utility mining. At the end of the day, the scan space for mining HUIs can't be straightforwardly decreased as it is done in FIM in light of the fact that a superset of a low utility thing set can be a high utility thing set. Many examinations were proposed for mining HUIs, however they frequently display countless utility thing sets to clients. Countless utility thing sets makes it troublesome for the clients to fathom the outcomes. It might likewise make the calculations end up noticeably wasteful as far as time and memory prerequisite, or even come up short on memory. It is generally perceived that the higher utility thing sets the calculations create, the all the more preparing they expend. The execution of the digging undertaking diminishes enormously for low least utility limits or when managing thick databases. In FIM, to diminish the computational cost of the mining undertaking and present less however more critical examples to clients, many investigations concentrated on creating compact portrayals, for example, free sets [3], non-logical sets [4], chances proportion designs [15], disjunctive shut thing sets [11], maximal thing sets [8] and shut thing sets [20]. These portrayals effectively diminish the quantity of thing sets found, yet they are created for FIM rather than HUI mining. So it is required that we need to make the item sets available without any hassles, and record the hits with some proper measure. Ultimately the intension of this paper is to propose such solution to the problem found during finding item sets for high utilities. In this proclaim the algorithms](https://image.slidesharecdn.com/30150001144514-07-2017-171227110831/75/Discovering-High-Utility-Item-Sets-to-Achieve-Lossless-Mining-using-Apriori-Algorithm-1-2048.jpg)


![International Journal on Recent and Innovation Trends in Computing and Communication ISSN: 2321-8169 Volume: 5 Issue: 7 145 – 151 _______________________________________________________________________________________________ 149 IJRITCC | July 2017, Available @ http://www.ijritcc.org _______________________________________________________________________________________ Given a substantial gathering of exchanges containing things, a fundamental normal information mining issue is to separate the supposed regular itemsets (i.e., sets of things showing up in any event a given number of exchanges). In this paper, we propose a structure called free-sets, from which we can surmised any itemset bolster (i.e., the quantity of exchanges containing the itemset) and we formalize this thought in the system of ²-satisfactory portrayals [10]. We demonstrate that successive free-sets can be effectively extricated utilizing pruning techniques produced for visit itemset disclosure, and that they can be utilized to estimate the help of any incessant itemset. Examinations on genuine thick informational collections demonstrate a critical lessening of the measure of the yield when contrasted and standard incessant itemset extraction. Besides, the trials demonstrate that the extraction of successive free-sets is as yet conceivable when the extraction of incessant itemsets ends up plainly recalcitrant, and that the backings of the continuous free-sets can be utilized to rough intently the backings of the regular itemsets. At long last, we consider the impact of this estimate on affiliation governs (a mainstream sort of examples that can be gotten from visit itemsets) and demonstrate that the relating mistakes stay low by and by. An exceptionally substantial number of high utility item sets makes it troublesome for the clients to appreciate the outcomes. It might likewise cause the calculations to wind up plainly wasteful as far as time and memory prerequisite, or even come up short on memory. It is generally perceived that the all the more high utility item sets the calculations produce, the additionally preparing they devour. The execution of the digging errand diminishes significantly for low least utility edges or when managing thick databases. In FIM, to lessen the computational cost of the mining assignment and present less however more imperative examples to clients, many examinations concentrated on creating compact portrayals, for example, free sets, non- resultant sets, chances proportion designs, disjunctive shut item sets, maximal item sets and shut item sets. Fig.3 User Page Fig. 4 Admin Page](https://image.slidesharecdn.com/30150001144514-07-2017-171227110831/75/Discovering-High-Utility-Item-Sets-to-Achieve-Lossless-Mining-using-Apriori-Algorithm-5-2048.jpg)
![International Journal on Recent and Innovation Trends in Computing and Communication ISSN: 2321-8169 Volume: 5 Issue: 7 145 – 151 _______________________________________________________________________________________________ 150 IJRITCC | July 2017, Available @ http://www.ijritcc.org _______________________________________________________________________________________ Implementation The implementation part involves the modules for each of the task to be performed for mining the data. The usage period of any venture improvement is the most imperative stage as it yields the last arrangement, which takes care of the current issue. The usage stage includes the real emergence of the thoughts, which are communicated in the investigation archive and created in the outline stage. Usage ought to be ideal mapping of the outline archive in an appropriate programming dialect with a specific end goal to accomplish the essential last item. Frequently the item is demolished because of wrong programming dialect decided for execution or unsatisfactory strategy for programming. It is better for the coding stage to be specifically connected to the outline stage in the sense if the plan is as far as question situated terms then execution ought to be ideally completed in a protest arranged manner.. Fig. 5 in detail flow of analysis of query V. CONCLUSION Here the intention to the issue of excess in high utility itemset mining by proposing a lossless and minimized portrayal named closedþ high utility itemsets, which has not been investigated up until this point. To mine this portrayal, we proposed three effective calculations named AprioriHC (Apriori-based approach for mining High Utility Closed itemset), AprioriHC-D (AprioriHC calculation with disposing of unpromising and separated things) and CHUID (Closedþ High Utility itemset Discovery). AprioriHC-D is an enhanced form of AprioriHC, which joins methodologies DGU [24] and IIDS [19] for pruning hopefuls. AprioriHC and AprioriHCD play out a broadness initially look for mining closedþ high utility itemsets from even database, while CHUD plays out a profundity initially scan for mining closedþ high utility itemsets from vertical database. The systems joined in CHUD are effective and novel. They have never been utilized for vertical mining of high utility itemsets and closedþ high utility itemsets. To effectively recuperate all high utility itemsets from closedþ high utility itemsets, we proposed a proficient strategy named DAHU (Derive All High Utility itemsets). Results on both genuine and engineered datasets demonstrate that the proposed portrayal accomplishes a gigantic decrease in the quantity of high utility itemsets on all genuine datasets (e.g. a decrease of up to 800 times for Mushroom and 32 times for Foodmart). Also, CHUD beats UP Growth, one of the as of now best calculations by a few requests of extent (e.g. CHUD ends in 80 seconds on BMSWebView1 for min utility ¼ 2%, while UP-Growth can't end inside 24 hours). The blend of CHUD and DAHU is additionally quicker than UP-Growth when DAHU could be connected. References [1] J.-F. Boulicaut, A. Bykowski, and C. Rigotti, “Free-sets: A condensed representation of Boolean data for the approximation of frequency queries,” Data Mining Knowl. Discovery, vol. 7, no. 1, pp. 5–22, 2003.](https://image.slidesharecdn.com/30150001144514-07-2017-171227110831/75/Discovering-High-Utility-Item-Sets-to-Achieve-Lossless-Mining-using-Apriori-Algorithm-6-2048.jpg)
![International Journal on Recent and Innovation Trends in Computing and Communication ISSN: 2321-8169 Volume: 5 Issue: 7 145 – 151 _______________________________________________________________________________________________ 151 IJRITCC | July 2017, Available @ http://www.ijritcc.org _______________________________________________________________________________________ [2] R. Chan, Q. Yang, and Y. Shen, “Mining high utility itemsets,” in Proc. IEEE Int. Conf. Data Min., 2003, pp. 19–26. [3] K. Chuang, J. Huang, and M. Chen, “Mining top-k frequent patternsin the presence of the memory constraint,” VLDB J., vol. 17,pp. 1321–1344, 2008. [4] A. Erwin, R. P. Gopalan, and N. R. Achuthan, “Efficient mining of high utility itemsets from large datasets,” in Proc. Int. Conf. Pacific- Asia Conf. Knowl. Discovery Data Mining, 2008, pp. 554–561. 738 ieee transactions on knowledge and data engineering, vol. 27, no. 3, march 2015 [5] R. Agrawal and R. Srikant, “Fast algorithms for mining association rules,” in Proc. 20th Int. Conf. Very Large Data Bases, 1994, pp. 487–499. [6] Pak, Alexander, and Patrick Paroubek. "Twitter as a Corpus for Sentiment Analysis and Opinion Mining." In LREC, vol. 10,2010, pp - 1320-1326. [7] Pang, B., & Lee, L."Opinion mining and sentiment analysis. Foundations and Trends" in Information Retrieval, 2(1-2),2012](https://image.slidesharecdn.com/30150001144514-07-2017-171227110831/75/Discovering-High-Utility-Item-Sets-to-Achieve-Lossless-Mining-using-Apriori-Algorithm-7-2048.jpg)