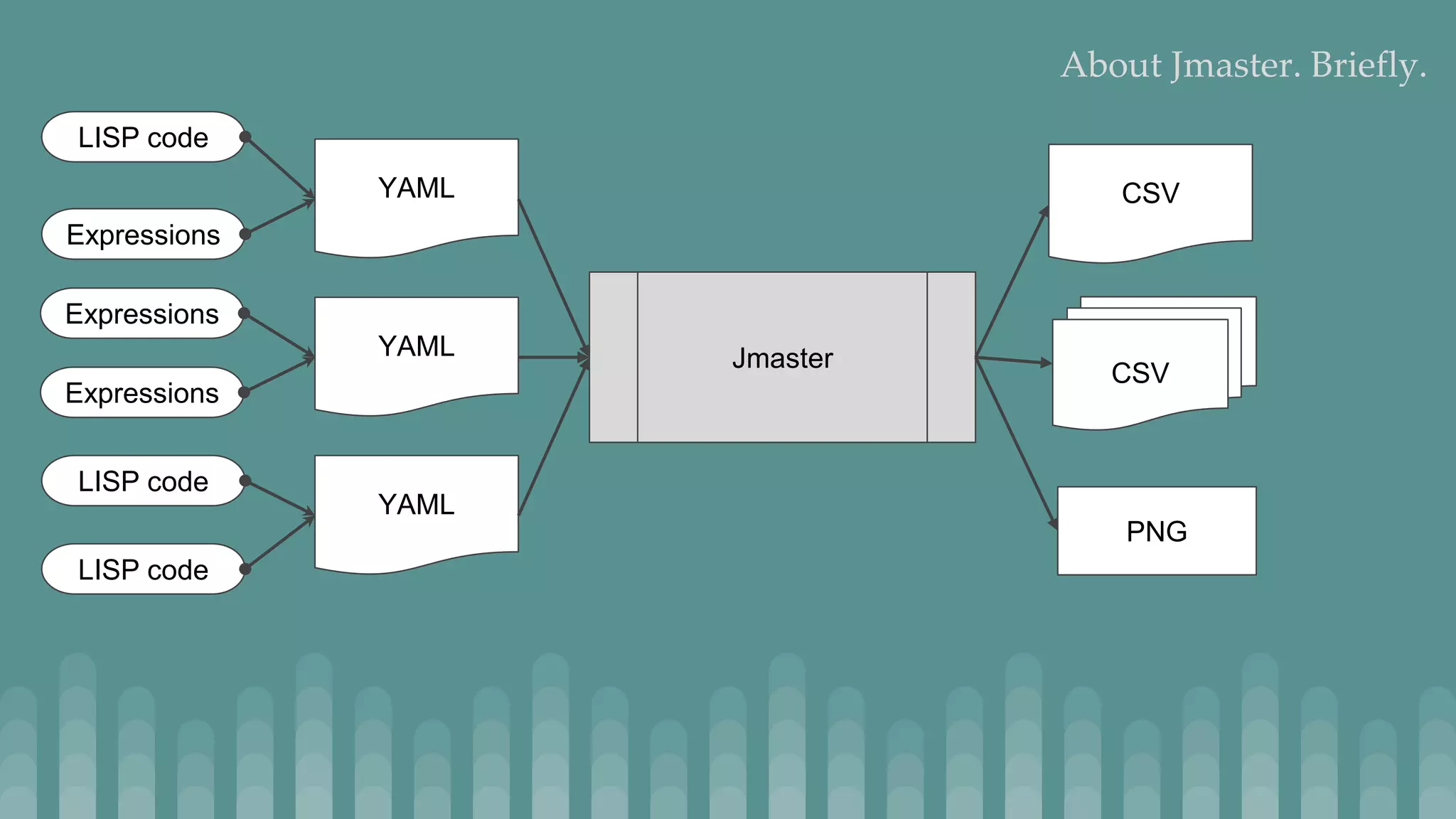
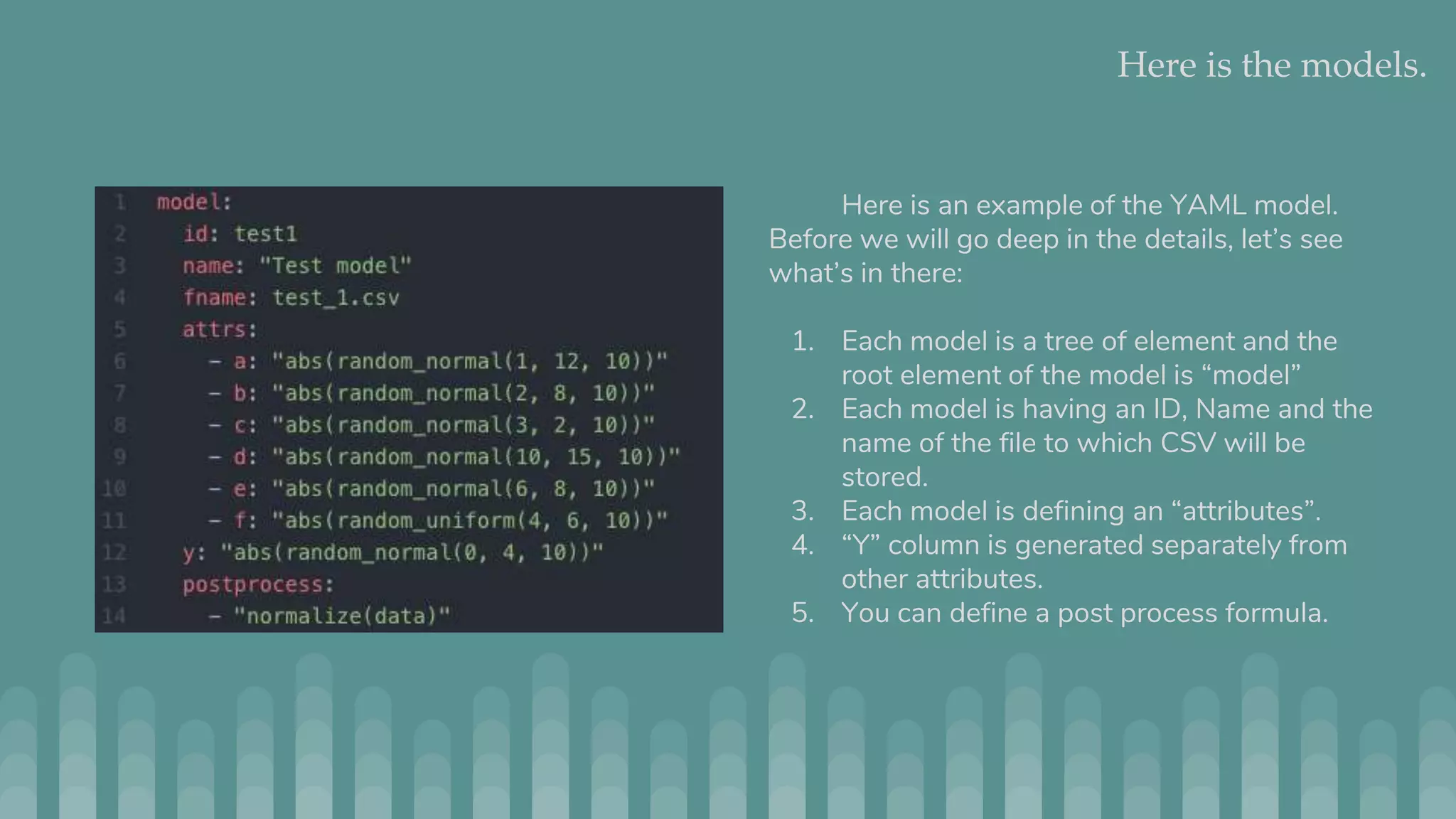
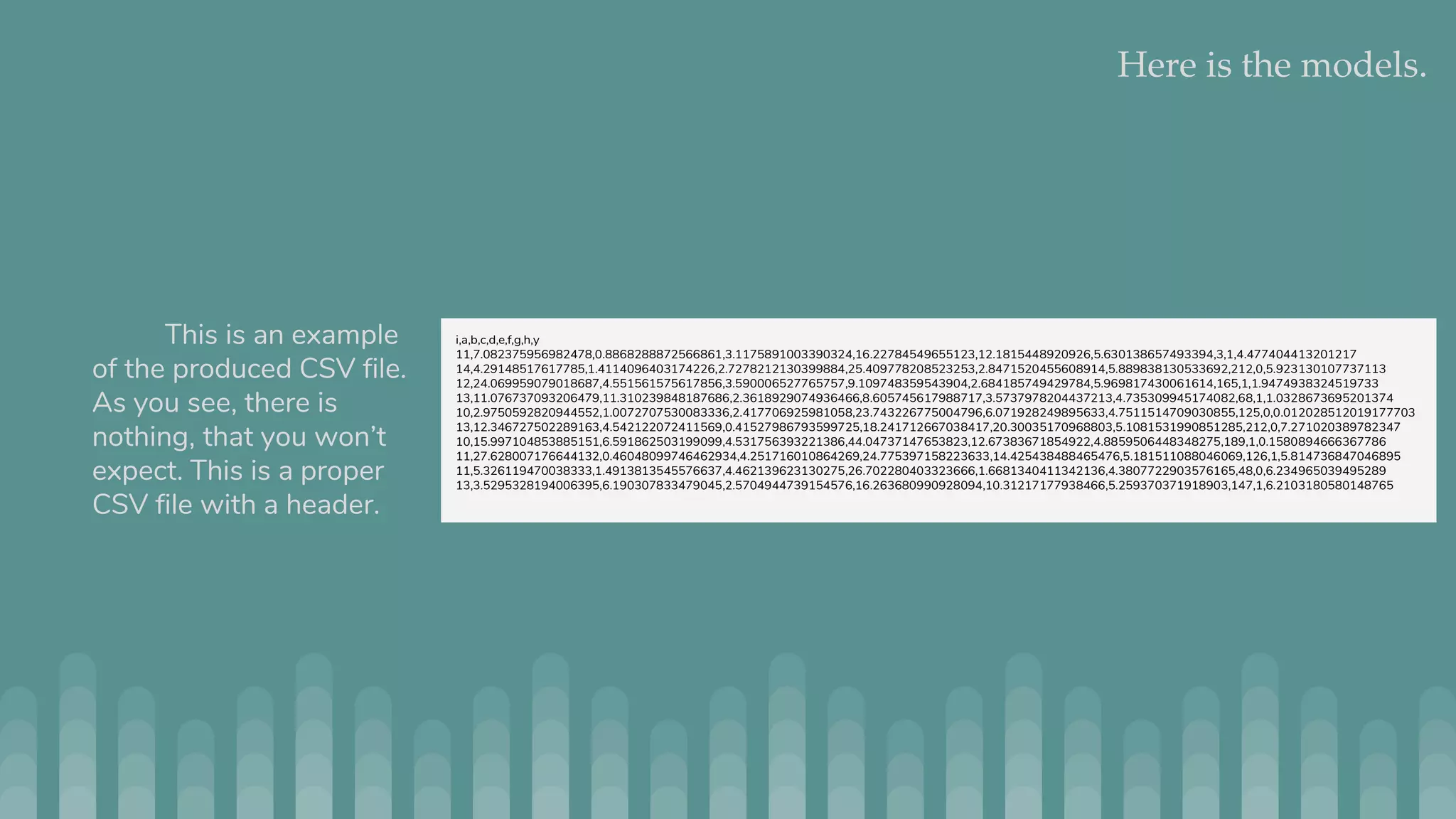
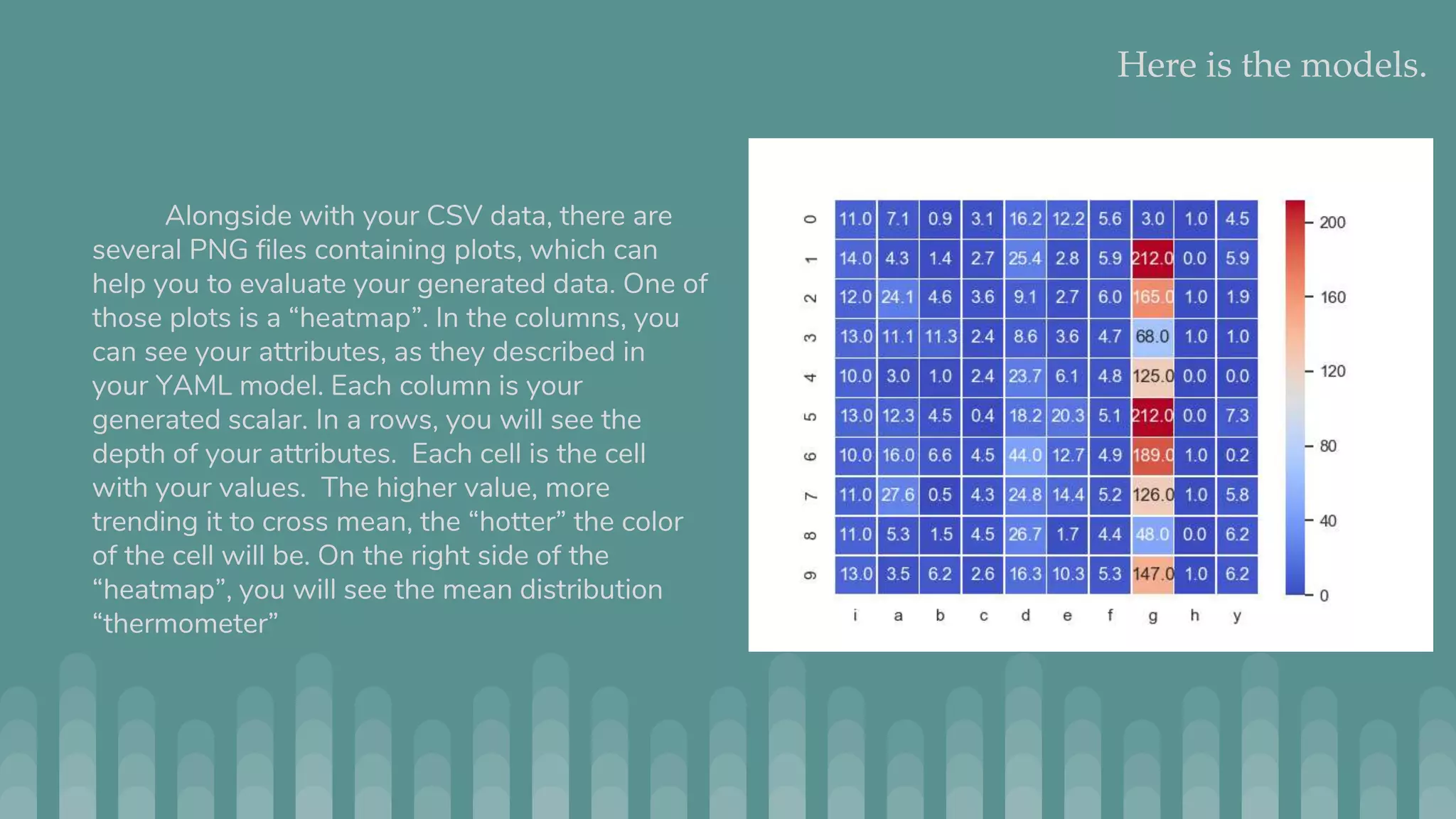
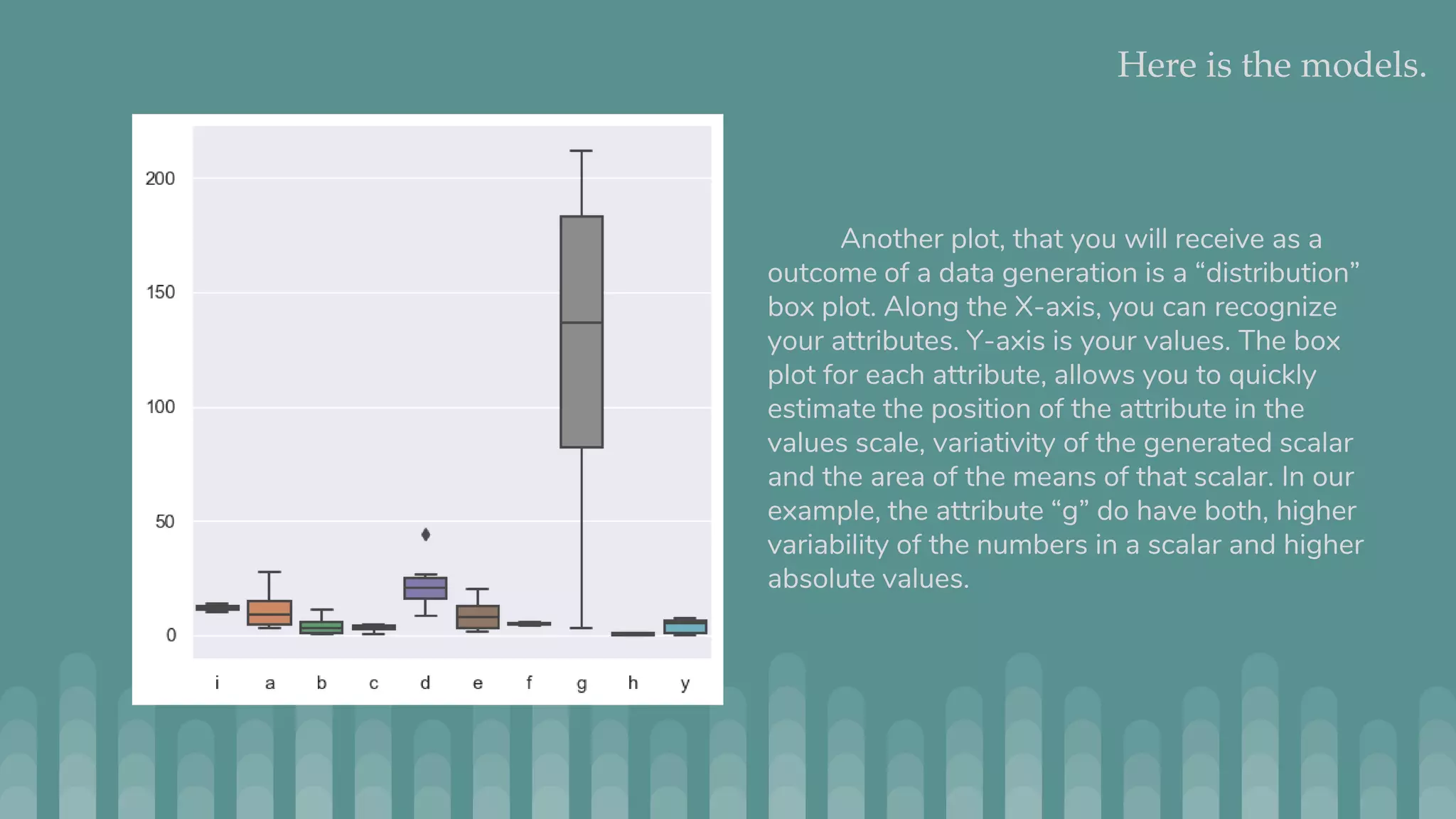
Jmaster is a tool for generating controlled test datasets that can be used for testing machine learning and statistical models. It takes a YAML file as input to define a "model" for how the data is generated. This includes attributes, variable definitions, and optional LISP code. Jmaster then outputs a CSV file with the generated data and PNG files to visualize the data distribution and quality. It has two modes - regular mode which generates absolute values, and time series mode which generates deltas to apply to an initial dataset. The goal is to provide flexible yet predictable ways to generate synthetic data for evaluating models.