The document is an introduction to Apache Spark, covering its ecosystem, capabilities, and differences compared to MapReduce. It outlines the essential components like RDDs, Spark SQL, Spark Streaming, and machine learning libraries, along with practical usage examples and code snippets in various programming languages. The presentation emphasizes Spark's advantages, such as performance improvements and its fault-tolerant architecture.
2Page: Agenda • What isApache Spark? • Apache Spark Ecosystem • MapReduce vs. Apache Spark • Core Spark (RDD API) • Apache Spark Concepts • Spark SQL (DataFrame and Dataset API) • Spark Streaming • Use Cases • Next Steps
3.
3Page: Robert Sanders • BigData Manager, Engineer, Architect, etc. • Work for Clairvoyant LLC • 5+ Years of Big Data Experience • Certified Apache Spark Developer • Email: robert.sanders@clairvoyantsoft.com • LinkedIn: https://www.linkedin.com/in/robert-sanders- 61446732
4.
4Page: What is ApacheSpark? • Open source data processing engine that runs on a cluster • https://github.com/apache/spark • Distributed under the Apache License • Provides a number of Libraries for Batch, Streaming and other forms of processing • Very fast in memory processing engine • Primarily written in Scala • Support for Java, Scala, Python, and R • Version: • Most Used Version: 1.6.X • Latest version: 2.0
5.
5Page: Apache Spark EcoSystem •Apache Spark • RDDs • Spark SQL • Once known as “Shark” before completely integrated into Spark • For SQL, structured and semi-structured data processing • Spark Streaming • Processing of live data streams • MLlib/ML • Machine Learning Algorithms Apache Spark, Apache Spark Ecosystem http://spark.apache.org/images/spark-stack.png
7Page: MapReduce Bottlenecks andImprovements • Bottlenecks • MapReduce is a very I/O heavy operation • Map phase needs to read from disk then write back out • Reduce phase needs to read from disk and then write back out • How can we improve it? • RAM is becoming very cheap and abundant • Use RAM for in-data sharing
8.
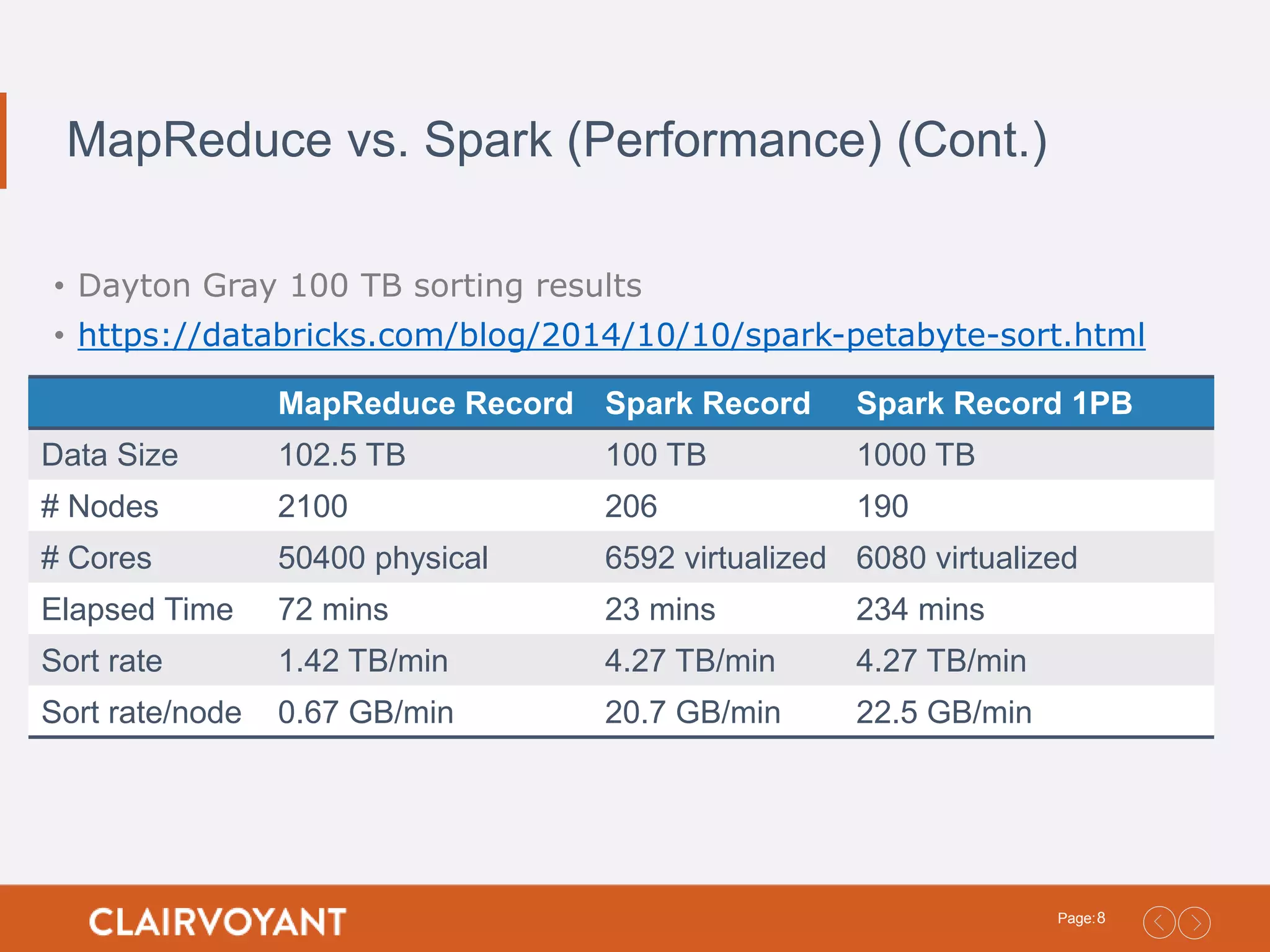
8Page: MapReduce vs. Spark(Performance) (Cont.) • Dayton Gray 100 TB sorting results • https://databricks.com/blog/2014/10/10/spark-petabyte-sort.html MapReduce Record Spark Record Spark Record 1PB Data Size 102.5 TB 100 TB 1000 TB # Nodes 2100 206 190 # Cores 50400 physical 6592 virtualized 6080 virtualized Elapsed Time 72 mins 23 mins 234 mins Sort rate 1.42 TB/min 4.27 TB/min 4.27 TB/min Sort rate/node 0.67 GB/min 20.7 GB/min 22.5 GB/min
9.
9Page: Running Spark Jobs •Shell • Shell for running Scala Code $ spark-shell • Shell for running Python Code $ pyspark • Shell for running R Code $ sparkR • Submitting (Java, Scala, Python, R) $ spark-submit --class {MAIN_CLASS} [OPTIONS] {PATH_TO_FILE} {ARG0} {ARG1} … {ARGN}
10.
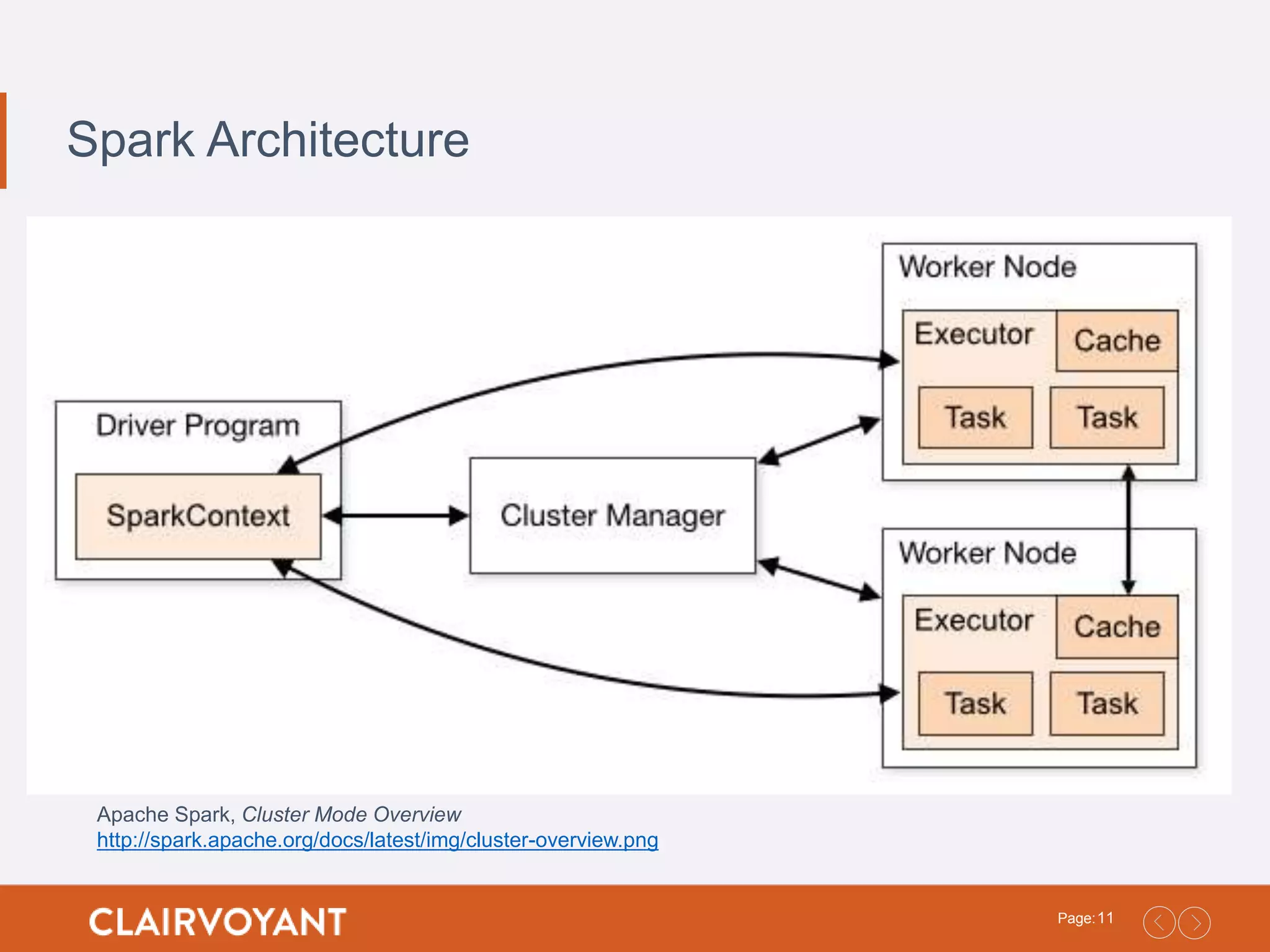
10Page: SparkContext • A Sparkprogram first creates a SparkContext object • Spark Shell automatically creates a SparkContext as the sc variable • Tells spark how and where to access a cluster • Use SparkContext to create RDDs • Documentation • https://spark.apache.org/docs/latest/api/scala/index.html #org.apache.spark.SparkContext
12Page: RDDs • Primary abstractionobject used by Apache Spark • Resilient Distributed Dataset • Fault-tolerant • Collection of elements that can be operated on in parallel • Distributed collection of data from any source • Contained in an RDD: • Set of dependencies on parent RDDs • Lineage (Directed Acyclic Graph – DAG) • Set of partitions • Atomic pieces of a dataset • A function for computing the RDD based on its parents • Metadata about its partitioning scheme and data placement
13.
13Page: RDDs (Cont.) • RDDsare Immutable • Allows for more effective fault tolerance • Intended to support abstract datasets while also maintain MapReduce properties like automatic fault tolerance, locality-aware scheduling and scalability. • RDD API built to resemble the Scala Collections API • Programming Guide • http://spark.apache.org/docs/latest/quick-start.html
14.
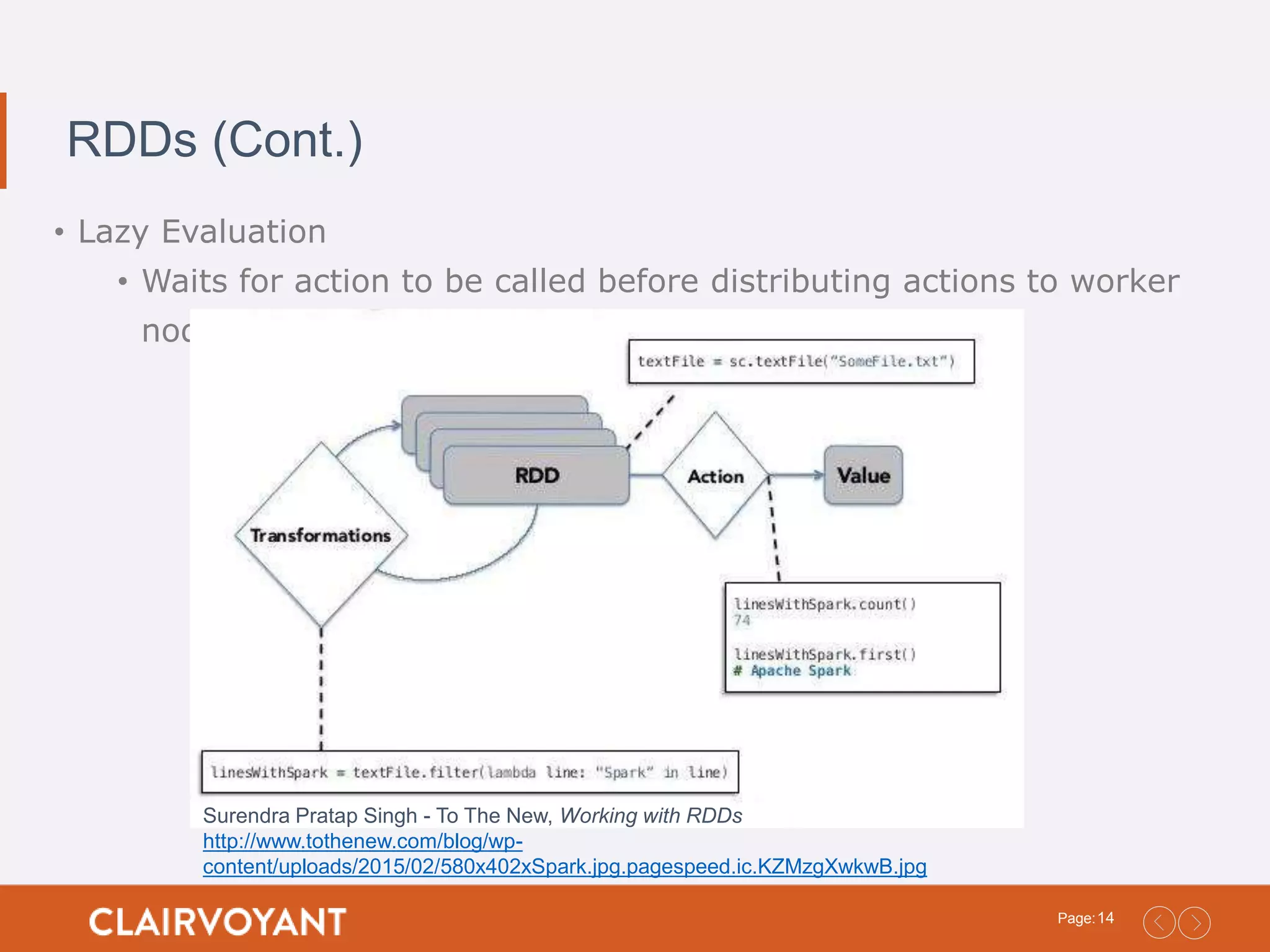
14Page: RDDs (Cont.) • LazyEvaluation • Waits for action to be called before distributing actions to worker nodes Surendra Pratap Singh - To The New, Working with RDDs http://www.tothenew.com/blog/wp- content/uploads/2015/02/580x402xSpark.jpg.pagespeed.ic.KZMzgXwkwB.jpg
15.
15Page: Create RDD • Canonly be created using the SparkContext or by adding a Transformation to an existing RDD • Using the SparkContext: • Parallelized Collections – take an existing collection and run functions on it in parallel rdd = sc.parallelize([ "some", "list", "to", "parallelize"], [numTasks]) • File Datasets – run functions on each record of a file in Hadoop distributed file system or any other storage system supported by Hadoop rdd = sc.textFile("/path/to/file", [numTasks]) rdd = sc.objectFile("/path/to/file", [numTasks])
17Page: Word Count Example Scala valtextFile = sc.textFile("/path/to/file.txt") val counts = textFile .flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _) counts.saveAsTextFile("/path/to/output") Python text_file = sc.textFile("/path/to/file.txt") counts = text_file .flatMap(lambda line: line.split(" ")) .map(lambda word: (word, 1)) .reduceByKey(lambda a, b: a + b) counts.saveAsTextFile("/path/to/output")
18.
18Page: Word Count Example(Java 7) JavaRDD<String> textFile = sc.textFile("/path/to/file.txt"); JavaRDD<String> words = textFile.flatMap(new FlatMapFunction<String, String>() { public Iterable<String> call(String line) { return Arrays.asList(line.split(" ")); } }); JavaPairRDD<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() { public Tuple2<String, Integer> call(String word) { return new Tuple2<String, Integer>(word, 1); } }); JavaPairRDD<String, Integer> counts = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() { public Integer call(Integer a, Integer b) { return a + b; } }); counts.saveAsTextFile("/path/to/output");
19.
19Page: Word Count Example(Java 8) JavaRDD<String> textFile = sc.textFile("/path/to/file.txt"); JavaPairRDD<String, Integer> counts = lines .flatMap(line -> Arrays.asList(line.split(" "))); .mapToPair(w -> new Tuple2<String, Integer>(w, 1)) .reduceByKey((a, b) -> a + b); counts.saveAsTextFile("/path/to/output");
20.
20Page: RDD Lineage Graph valtextFile = sc.textFile("/path/to/file.txt") val counts = textFile.flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _) counts.toDebugString res1: String = (1) ShuffledRDD[7] at reduceByKey at <console>:23 [] +-(1) MapPartitionsRDD[6] at map at <console>:23 [] | MapPartitionsRDD[5] at flatMap at <console>:23 [] | /path/to/file.txt MapPartitionsRDD[3] at textFile at <console>:21 [] | /path/to/file.txt HadoopRDD[2] at textFile at <console>:21 []
21.
21Page: RDD Persistence • Eachnode stores any partitions of it that it computes in memory and reuses them in other actions on that dataset. • After marking an RDD to be persisted, the first time the dataset is computed in an action, it will be kept in memory on the nodes. • Allows future actions to be much faster (often by more than 10x) since you’re not re-computing some data every time you perform an action. • If data is too big to be cached, then it will spill to disk and memory will gradually degrade • Least Recently Used (LRU) replacement policy
22.
22Page: RDD Persistence (StorageLevels) Storage Level MEANING MEMORY_ONLY Store RDD as deserialized Java objects in the JVM. If the RDD does not fit in memory, some partitions will not be cached and will be recomputed on the fly each time they're needed. This is the default level. MEMORY_AND_DISK Store RDD as deserialized Java objects in the JVM. If the RDD does not fit in memory, store the partitions that don't fit on disk, and read them from there when they're needed. MEMORY_ONLY_SER Store RDD as serialized Java objects (one byte array per partition). This is generally more space-efficient than deserialized objects, especially when using a fast serializer, but more CPU-intensive to read. MEMORY_AND_DISK_SER Similar to MEMORY_ONLY_SER, but spill partitions that don't fit in memory to disk instead of re-computing them on the fly each time they're needed. DISK_ONLY Store the RDD partitions only on disk. MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc. Same as the levels above, but replicate each partition on two cluster nodes.
23.
23Page: RDD Persistence APIs rdd.persist() rdd.persist(StorageLevel) •Persist this RDD with the default storage level (MEMORY_ONLY). • You can override the StorageLevel for fine grain control over persistence rdd.cache() • Persists the RDD with the default storage level (MEMORY_ONLY) rdd.checkpoint() • RDD will be saved to a file inside the checkpoint directory set with SparkContext#setCheckpointDir(“/path/to/dir”) • Used for RDDs with long lineage chains with wide dependencies since it would be expensive to re-compute rdd.unpersist() • Marks it as non-persistent and/or removes all blocks of it from memory and disk
24.
24Page: Fault Tolerance • RDDscontain lineage graphs (coarse grained updates/transformations) to help it rebuild partitions that were lost • Only the lost partitions of an RDD need to be recomputed upon failure. • They can be recomputed in parallel on different nodes without having to roll back the entire app • Also lets a system tolerate slow nodes (stragglers) by running a backup copy of the troubled task. • Original process on straggling node will be killed when new process is complete • Cached/Check pointed partitions are also used to re-compute lost partitions if available in shared memory
25.
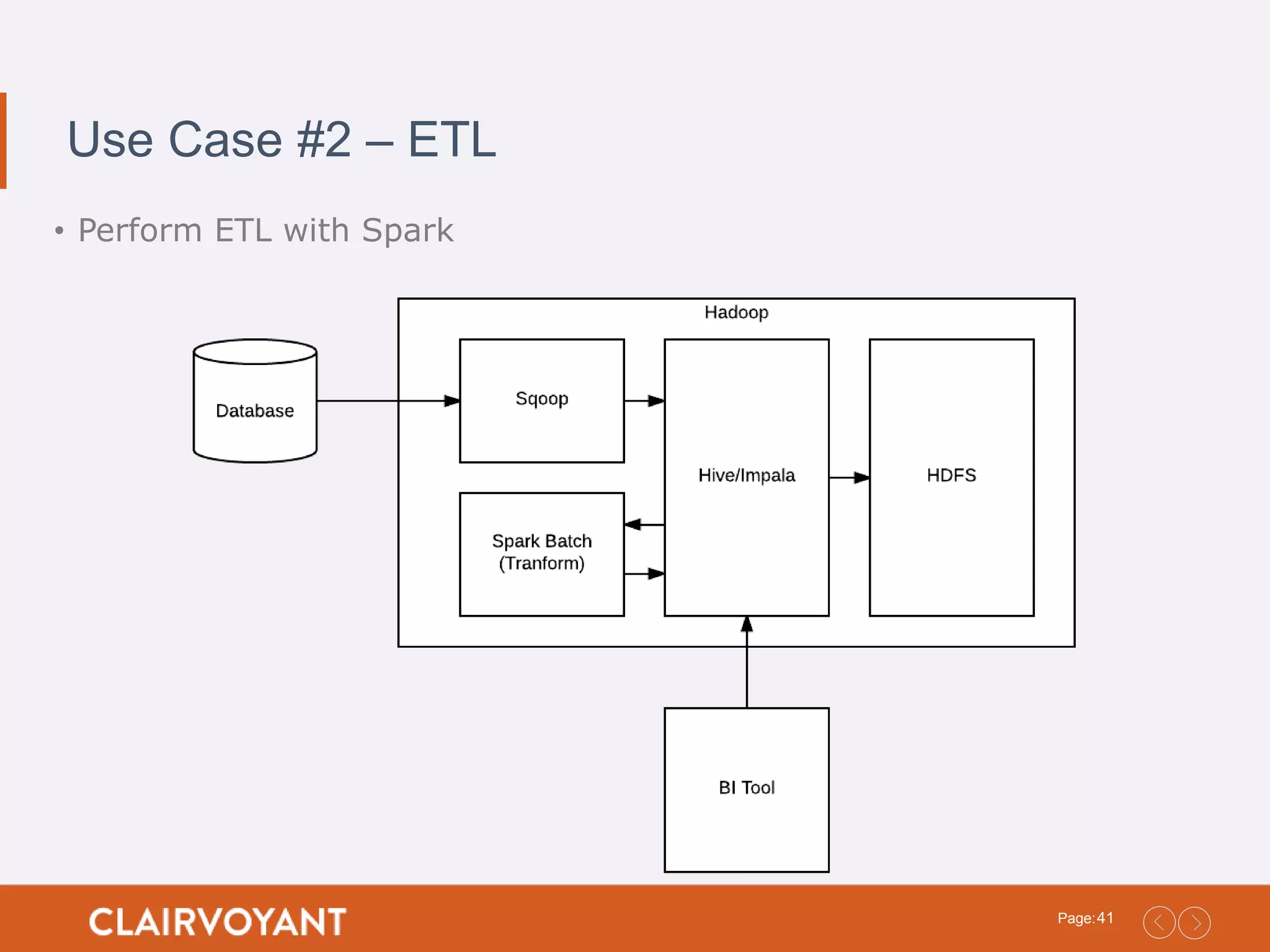
25Page: Spark SQL • Sparkmodule for structured data processing • The most popular Spark Module in the Ecosystem • It is highly recommended to use this the DataFrames or Dataset API because of the performance benefits • Runs SQL/HiveQL Queries, optionally alongside or replacing existing Hive deployments • Use SQLContext to perform operations • Run SQL Queries • Use the DataFrame API • Use the Dataset API • White Paper • http://people.csail.mit.edu/matei/papers/2015/sigmod_spark_sql.pdf • Programming Guide: • https://spark.apache.org/docs/latest/sql-programming-guide.html
26.
26Page: SQLContext • Used toCreate DataFrames and Datasets • Spark Shell automatically creates a SparkContext as the sqlContext variable • Implementations • SQLContext • HiveContext • An instance of the Spark SQL execution engine that integrates with data stored in Hive • Documentation • https://spark.apache.org/docs/latest/api/scala/index.html#org. apache.spark.sql.SQLContext • As of Spark 2.0 use SparkSession • https://spark.apache.org/docs/latest/api/scala/index.html#org. apache.spark.sql.SparkSession
27.
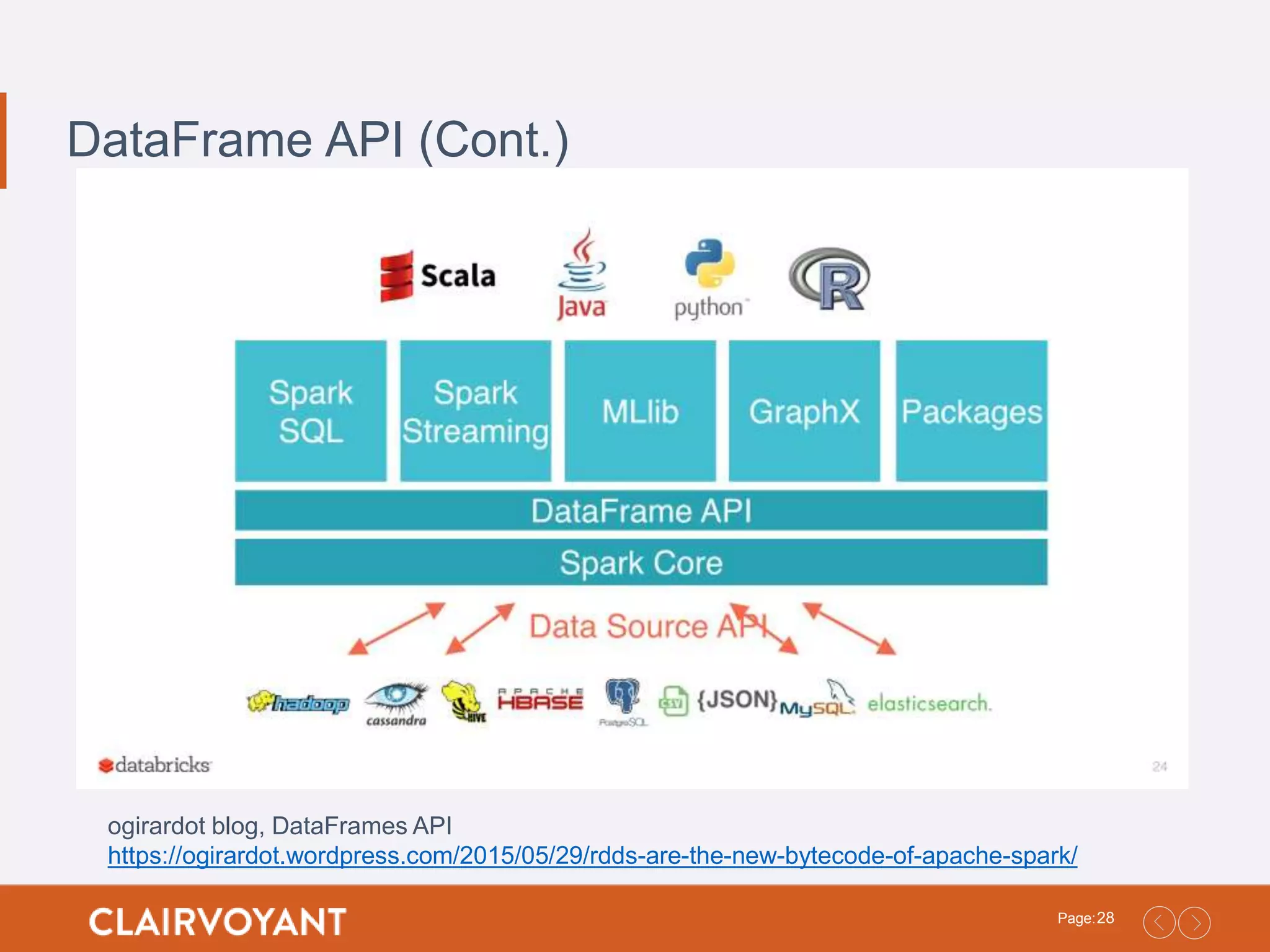
27Page: DataFrame API • Adistributed collection of rows organized into named columns • You know the names of the columns and data types • Like Pandas and R • Unlike RDDs, DataFrame’s keep track of their schema and support various relational operations that lead to more optimized execution • Catalyst Optimizer
29Page: DataFrame API (SQLQueries) • One use of Spark SQL is to execute SQL queries written using either a basic SQL syntax or HiveQL Scala val df = sqlContext.sql(”<SQL>”) Python df = sqlContext.sql(”<SQL>”) Java Dataset<Row> df = sqlContext.sql(”<SQL>");
30.
30Page: DataFrame API (DataFrameReader and Writer) DataFrameReader val df = sqlContext.read .format(”json”) .option(“samplingRatio”, “0.1”) .load(“/path/to/file.json”) DataFrameWriter sqlContext.write .format(”parquet”) .mode(“append”) .partitionby(“year”) .saveAsTable(“table_name”)
31.
31Page: DataFrame API SQL Statement: SELECTname, avg(age) FROM people GROUP BY name Can be written as: Scala sqlContext.table(”people”) .groupBy(“name”) .agg(“name”, avg(“age”)) .collect() Python sqlContext.table(”people”) .groupBy(“name”) .agg(“name”, avg(“age”)) .collect() Java Row[] output = sqlContext.table(”<SQL>") .groupBy(“name”) .agg(“name”, avg(“age”)) .collect();
33Page: Dataset API • Datasetis a new interface added in Spark 1.6 that provides the benefits of RDDs with the benefits of Spark SQL’s optimized execution engine • Use the SQLContext • DataFrame is simply a type alias of Dataset[Row] • Support • The unified Dataset API can be used both in Scala and Java • Python does not yet have support for the Dataset API • Easily convert DataFrame Dataset
34.
34Page: Dataset API Scala val df= sqlContext.read.json(”people.json”) case class Person(name: String, age: Long) val ds: Dataset[Person] = df.as[Person] Python Not Supported Java public static class Person implements Serializable { private String name; private long age; /* Getters and Setters */ } Encoder<Person> personEncoder = Encoders.bean(Person.class); Dataset[Row] df = sqlContext.read().json(“people.json”); Dataset<Person> ds = df.as(personEncoder);
35.
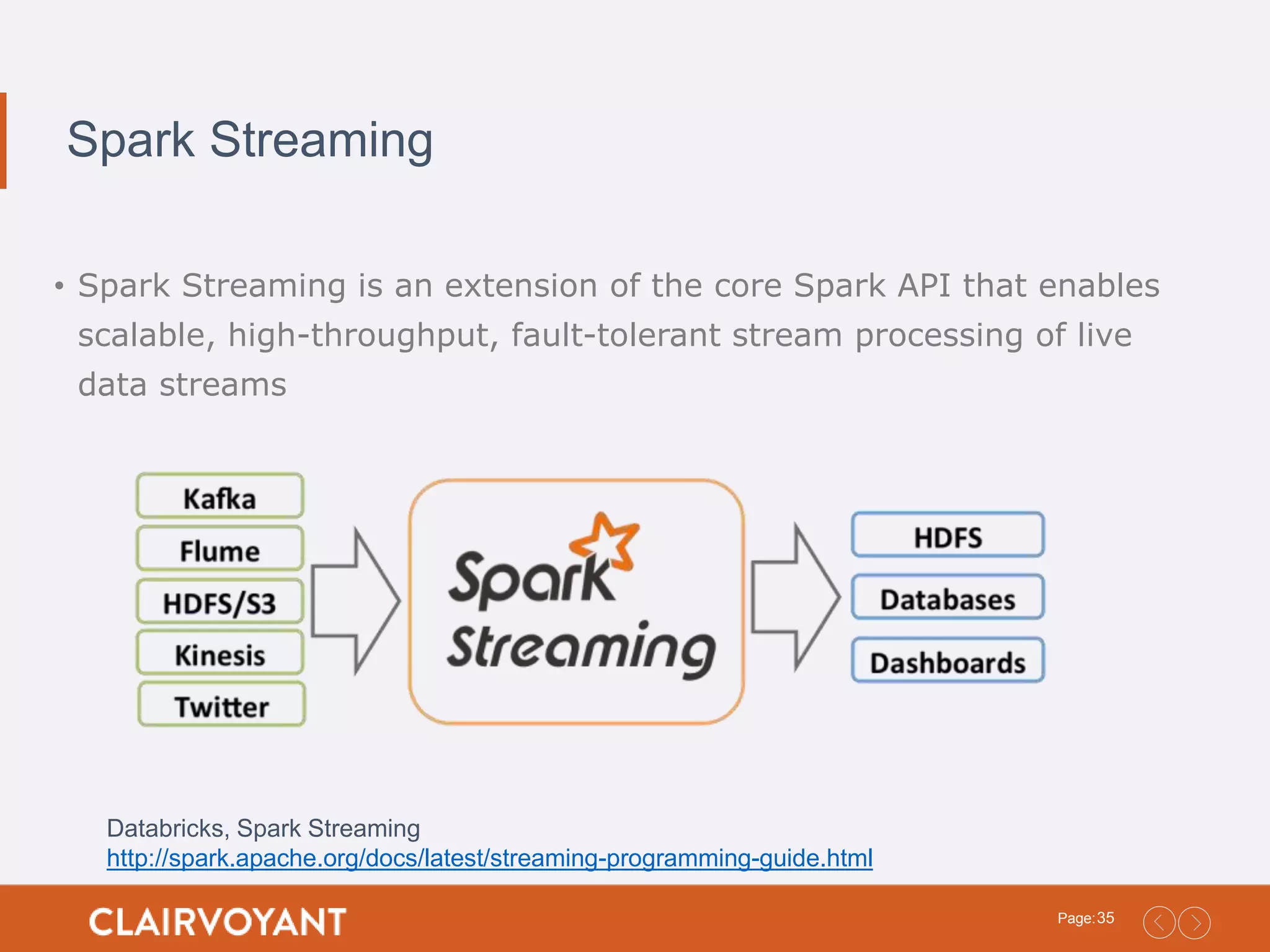
35Page: Spark Streaming • SparkStreaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams Databricks, Spark Streaming http://spark.apache.org/docs/latest/streaming-programming-guide.html
36.
36Page: Spark Streaming (Cont.) •Works off the Micro Batch architecture • Polling ever X Seconds = Batch Interval • Use the StreamingContext to create DStreams • DStream = Discretized Streams • Collection of discrete batches • Represented as a series of RDDs • One for each Block Interval in the Batch Interval • Programming Guide • https://spark.apache.org/docs/latest/streaming-programming- guide.html Databricks, Spark Streaming http://spark.apache.org/docs/latest/streaming-programming-guide.html
37.
37Page: Spark Streaming Example •Use netcat to stream data from a TCP Socket $ nc -lk 9999 Scala import org.apache.spark._ import org.apache.spark.streaming._ val ssc = new StreamingContext(sc, Seconds(5)) val lines = ssc.socketTextStream("localhost", 9999) val wordCounts = lines.flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _) wordCounts.print() ssc.start() ssc.awaitTermination() Python from pyspark import SparkContext from pyspark.streaming import StreamingContext ssc = new StreamingContext(sc, 5) lines = ssc.socketTextStream("localhost", 9999) wordCounts = text_file .flatMap(lambda line: line.split(" ")) .map(lambda word: (word, 1)) .reduceByKey(lambda a, b: a + b) wordCounts.print() ssc.start() ssc.awaitTermination()
38.
38Page: Spark Streaming Example(Java) import org.apache.spark.*; import org.apache.spark.api.java.function.*; import org.apache.spark.streaming.*; import org.apache.spark.streaming.api.java.*; import scala.Tuple2; JavaStreamingContext jssc = new JavaStreamingContext(sc, Durations.seconds(5)); JavaReceiverInputDStream<String> lines = jssc.socketTextStream("localhost", 9999); JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() { public Iterable<String> call(String line) { return Arrays.asList(line.split(" "));} }); JavaPairRDD<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() { public Tuple2<String, Integer> call(String word) { return new Tuple2<String, Integer>(word, 1); } }); JavaPairRDD<String, Integer> counts = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() { public Integer call(Integer a, Integer b) { return a + b; } }); wordCounts.print(); jssc.start() jssc.awaitTermination();
39.
39Page: Spark Streaming Dangers •SparkStreaming processes one Batch at a time • If the processing of each Batch takes longer then the Batch Interval you could see issues • Back Pressure • Buffering • Eventually you’ll see the Stream crash
40.
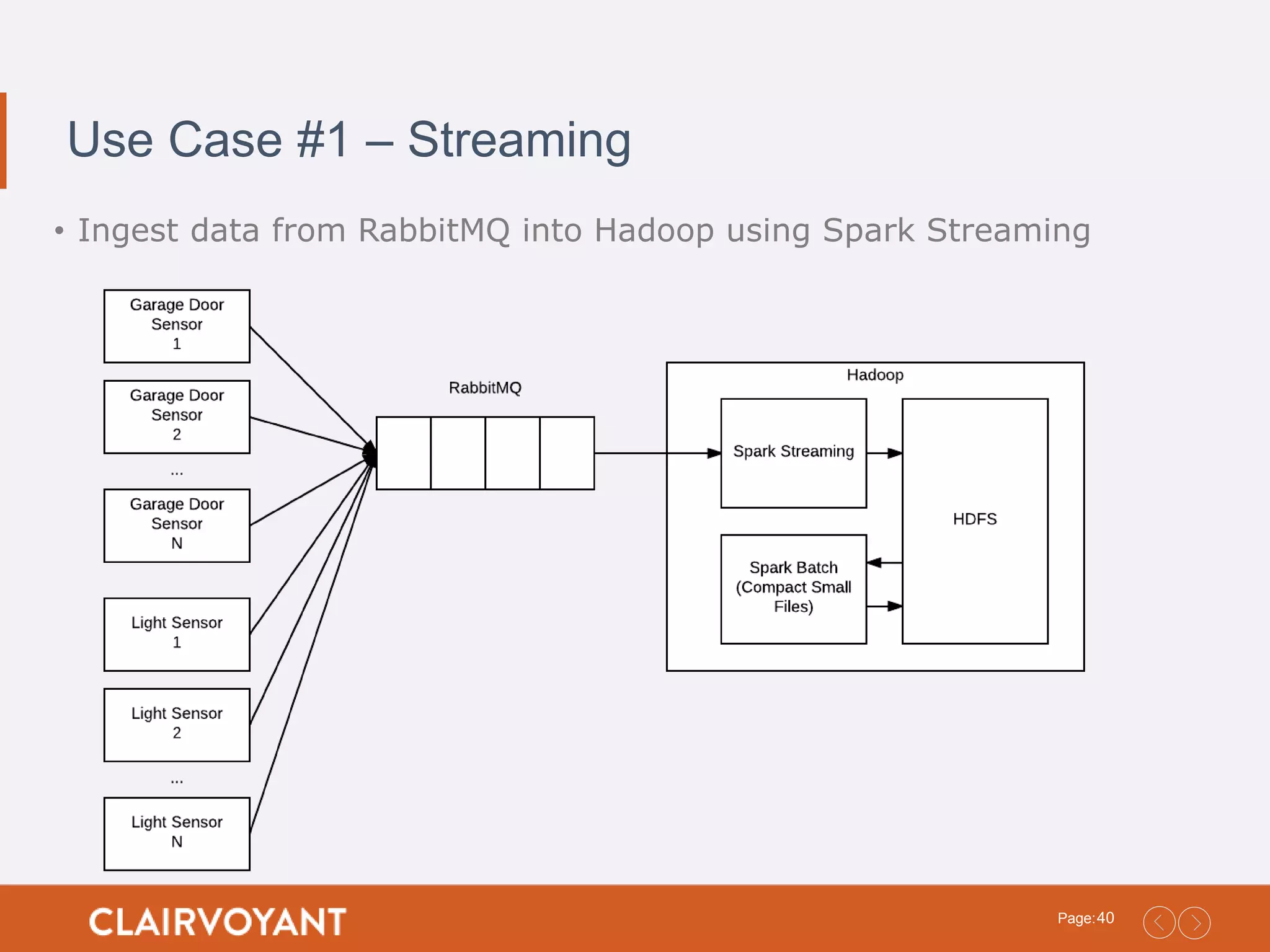
40Page: Use Case #1– Streaming • Ingest data from RabbitMQ into Hadoop using Spark Streaming
Interested in learningmore about SparkSQL? Well here’s an additional Desert Code Camp session to attend: Getting started with SparkSQL Presenter: Avinash Ramineni Room: AH-1240 Time: 4:45 PM – 5:45 PM
#7 MapReduce Fault Tolerance - Videos of early days of mapreduce Jeff Dean 2011 - deployed an app in prod and found the jobs to be running slower. they called down to the data center and found out that the data center was powering down machines, swapping out hardware (racks) and powering them back on and the job still completed but just slower.
#9 Since Spark won, TritonSort has beaten the old record
#16 val rdd = sc.parallelize(1 to 5) val filteredRDD = rdd.filter(_ > 3) val fileRdd = sc.textFile(“/user/cloudera/”) filteredRDD.count() res2: Long = 2 filteredRDD.collect() res3: Array[Int] = Array(4, 5) rdd.count() res4: Long = 5
#19 Talk more about how to execute functions in Java Types have to be defined with java whereas they are inferred in python and scala
#20 Talk more about how to execute functions in Java Types have to be defined with java whereas they are inferred in python and scala
#25 Two main methods of fault tolerance: checkpointing the data or logging the updates made to it Checkpointing is expensive on a large scale so RDDs implement logging. Logging is through lineage Coarse Grained vs Fine Grained A fine grained update would be an update to one record in a database whereas coarse grained is generally functional operators (like used in spark) for example map, reduce, flatMap, join. Spark's model takes advantage of this because once it saves your small DAG of operations (small compared to the data you are processing) it can use that to recompute as long as the original data is still there. With fine grained updates you cannot recompute because saving the updates could potentially cost as much as saving the data itself, basically if you update each record out of billions separately you have to save the information to compute each update, whereas with coarse grained you can save one function that updates a billion records. Clearly though this comes at the cost of not being as flexible as a fine grained model.






![9Page: Running Spark Jobs • Shell • Shell for running Scala Code $ spark-shell • Shell for running Python Code $ pyspark • Shell for running R Code $ sparkR • Submitting (Java, Scala, Python, R) $ spark-submit --class {MAIN_CLASS} [OPTIONS] {PATH_TO_FILE} {ARG0} {ARG1} … {ARGN}](https://image.slidesharecdn.com/introtoapachespark-desertcodecamp-161008212602/75/Intro-to-Apache-Spark-9-2048.jpg)



![15Page: Create RDD • Can only be created using the SparkContext or by adding a Transformation to an existing RDD • Using the SparkContext: • Parallelized Collections – take an existing collection and run functions on it in parallel rdd = sc.parallelize([ "some", "list", "to", "parallelize"], [numTasks]) • File Datasets – run functions on each record of a file in Hadoop distributed file system or any other storage system supported by Hadoop rdd = sc.textFile("/path/to/file", [numTasks]) rdd = sc.objectFile("/path/to/file", [numTasks])](https://image.slidesharecdn.com/introtoapachespark-desertcodecamp-161008212602/75/Intro-to-Apache-Spark-15-2048.jpg)




![20Page: RDD Lineage Graph val textFile = sc.textFile("/path/to/file.txt") val counts = textFile.flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _) counts.toDebugString res1: String = (1) ShuffledRDD[7] at reduceByKey at <console>:23 [] +-(1) MapPartitionsRDD[6] at map at <console>:23 [] | MapPartitionsRDD[5] at flatMap at <console>:23 [] | /path/to/file.txt MapPartitionsRDD[3] at textFile at <console>:21 [] | /path/to/file.txt HadoopRDD[2] at textFile at <console>:21 []](https://image.slidesharecdn.com/introtoapachespark-desertcodecamp-161008212602/75/Intro-to-Apache-Spark-20-2048.jpg)









![31Page: DataFrame API SQL Statement: SELECT name, avg(age) FROM people GROUP BY name Can be written as: Scala sqlContext.table(”people”) .groupBy(“name”) .agg(“name”, avg(“age”)) .collect() Python sqlContext.table(”people”) .groupBy(“name”) .agg(“name”, avg(“age”)) .collect() Java Row[] output = sqlContext.table(”<SQL>") .groupBy(“name”) .agg(“name”, avg(“age”)) .collect();](https://image.slidesharecdn.com/introtoapachespark-desertcodecamp-161008212602/75/Intro-to-Apache-Spark-31-2048.jpg)
 val df = sqlContext.table(“users”) val newDF = df.withColumn( “birth_year_int”, castToInt(df.birth_year) ) Python castToInt = utf(lambda someStr: int(someStr)) df = sqlContext.table(“users”) newDF = df.withColumn( “birth_year_int”, castToInt(df.birth_year) ) Java UDF1 castToInt = new UDF1<String, Integer>() { public String call(final String someStr) throws Exception { return Integer.valueOf(someStr); } }; sqlContext.udf().register(”castToInt", castToInt, DataTypes.IntegerType); Dataset<Row> df = sqlContext.table(“users”); Dataset<Row> newDF = df.withColumn(“birth_year_int”, callUDF(”castToInt", col(”birth_year")))](https://image.slidesharecdn.com/introtoapachespark-desertcodecamp-161008212602/75/Intro-to-Apache-Spark-32-2048.jpg)
![33Page: Dataset API • Dataset is a new interface added in Spark 1.6 that provides the benefits of RDDs with the benefits of Spark SQL’s optimized execution engine • Use the SQLContext • DataFrame is simply a type alias of Dataset[Row] • Support • The unified Dataset API can be used both in Scala and Java • Python does not yet have support for the Dataset API • Easily convert DataFrame Dataset](https://image.slidesharecdn.com/introtoapachespark-desertcodecamp-161008212602/75/Intro-to-Apache-Spark-33-2048.jpg)
![34Page: Dataset API Scala val df = sqlContext.read.json(”people.json”) case class Person(name: String, age: Long) val ds: Dataset[Person] = df.as[Person] Python Not Supported Java public static class Person implements Serializable { private String name; private long age; /* Getters and Setters */ } Encoder<Person> personEncoder = Encoders.bean(Person.class); Dataset[Row] df = sqlContext.read().json(“people.json”); Dataset<Person> ds = df.as(personEncoder);](https://image.slidesharecdn.com/introtoapachespark-desertcodecamp-161008212602/75/Intro-to-Apache-Spark-34-2048.jpg)