Downloaded 116 times

























![CQL List • Ordered by insertion • Use with caution list_example list<text> Collection name Collection type INSERT INTO collections_example (id, list_example) VALUES(1, ['1-one', '2-two']); CQLType](https://image.slidesharecdn.com/introduction-to-data-modeling-with-apache-cassandra-160219183514/75/Introduction-to-Data-Modeling-with-Apache-Cassandra-43-2048.jpg)
![CQL List Operations • Adding an element to the end of a list • Adding an element to the beginning of a list • Deleting an element from a list UPDATE collections_example SET list_example = list_example + ['3-three'] WHERE id = 1; UPDATE collections_example SET list_example = ['0-zero'] + list_example WHERE id = 1; UPDATE collections_example SET list_example = list_example - ['3-three'] WHERE id = 1;](https://image.slidesharecdn.com/introduction-to-data-modeling-with-apache-cassandra-160219183514/75/Introduction-to-Data-Modeling-with-Apache-Cassandra-44-2048.jpg)

![CQL Map Operations • Add an element to the map • Update an existing element in the map • Delete an element in the map UPDATE collections_example SET map_example[3] = 'three' WHERE id = 1; UPDATE collections_example SET map_example[3] = 'tres' WHERE id = 1; DELETE map_example[3] FROM collections_example WHERE id = 1;](https://image.slidesharecdn.com/introduction-to-data-modeling-with-apache-cassandra-160219183514/75/Introduction-to-Data-Modeling-with-Apache-Cassandra-46-2048.jpg)








This document provides an introduction to data modeling with Apache Cassandra. It discusses how Cassandra data models are designed based on the queries an application will perform, unlike relational databases which are designed based on normalization rules. Key aspects covered include avoiding joins by denormalizing data, using a partition key to group related data on nodes, and controlling the clustering order of columns. The document provides examples of modeling time series and tag data in Cassandra.
Introduction to Data Modeling using Apache Cassandra by Patrick McFadin, Chief Evangelist for Apache Cassandra.
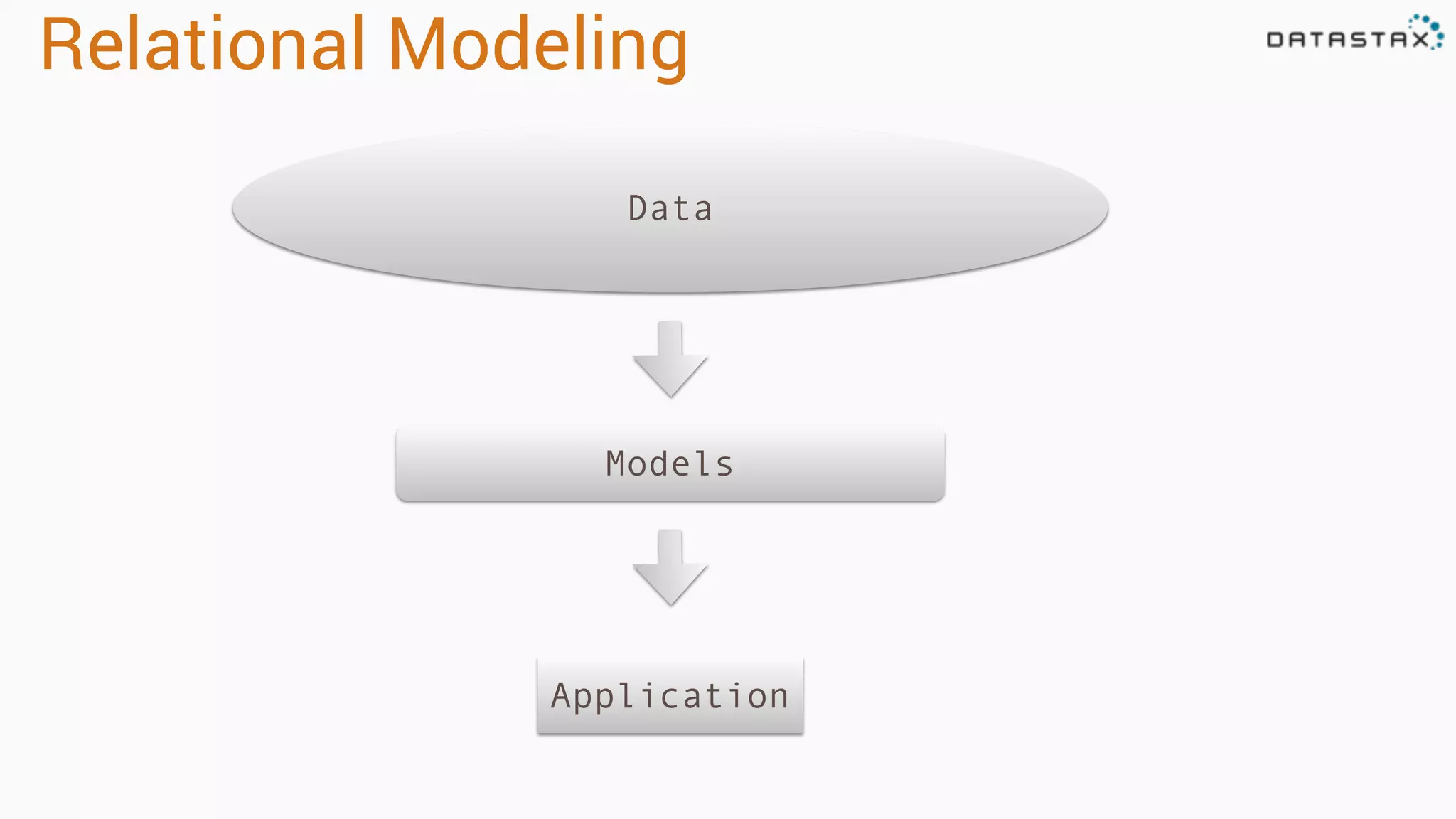
Explains relational data models including normal forms, foreign keys, joins, and relational modeling structures.
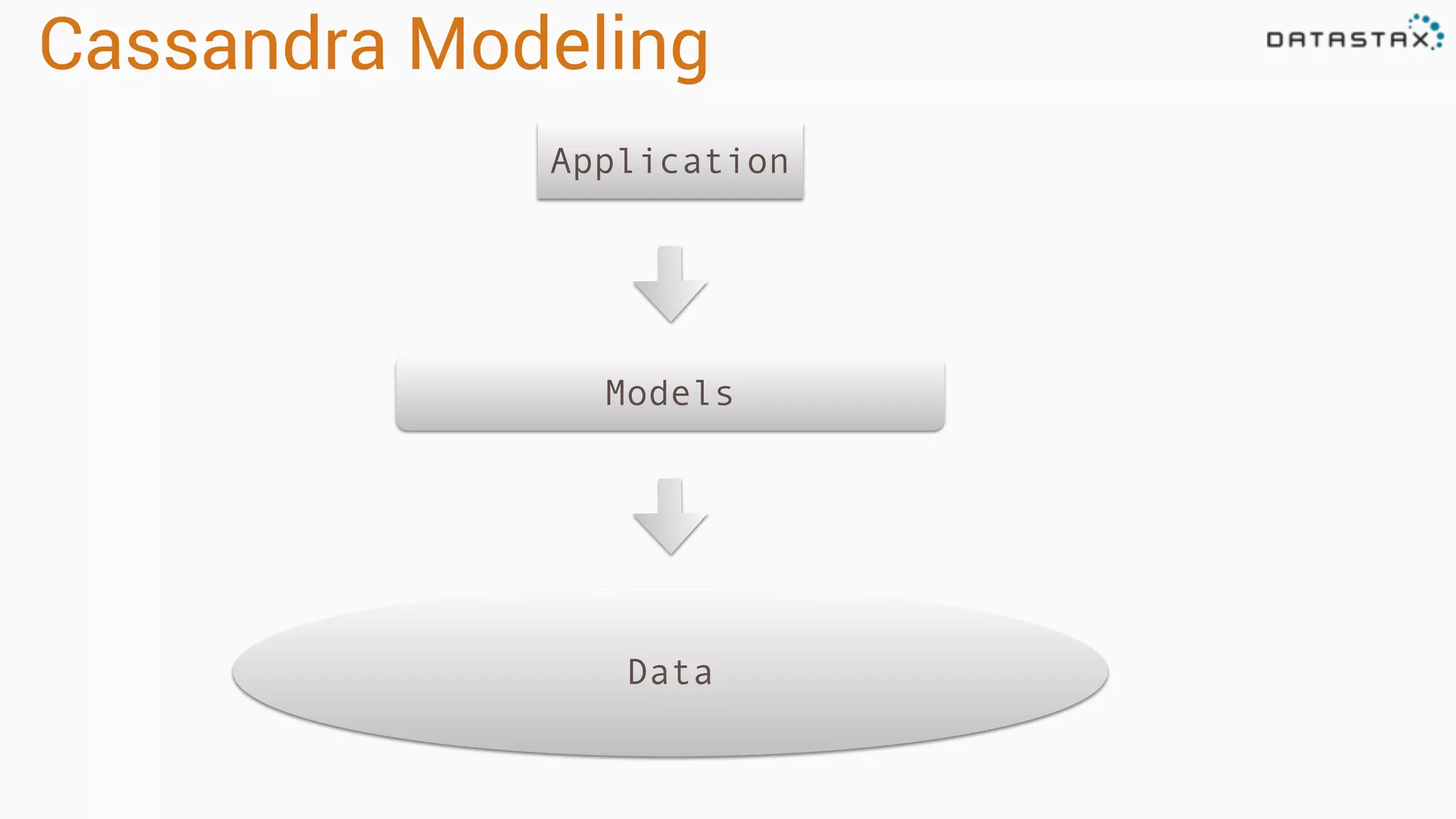
Introduction to Cassandra data models, focusing on application workflows, data access, and the importance of pre-defined queries.
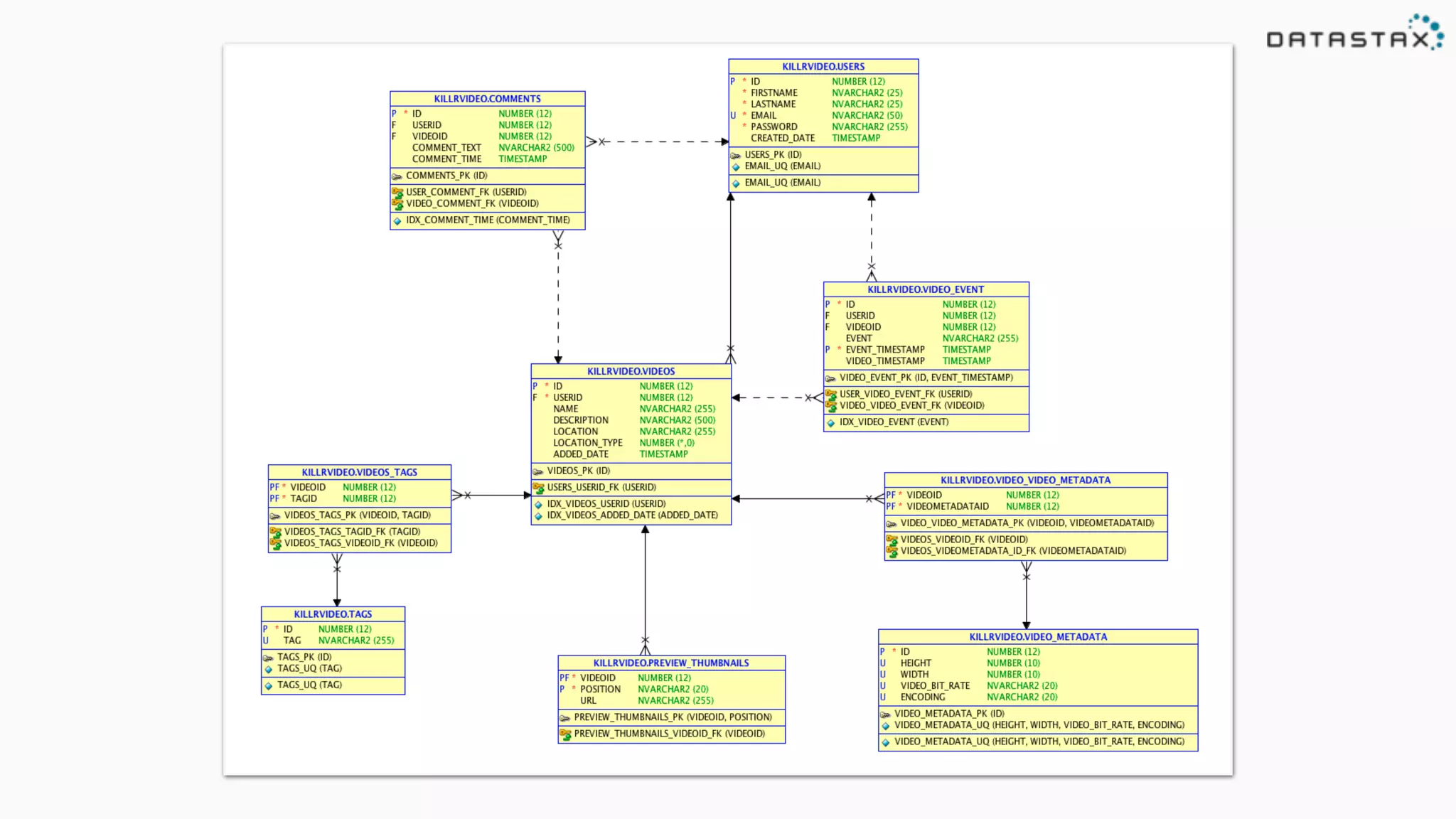
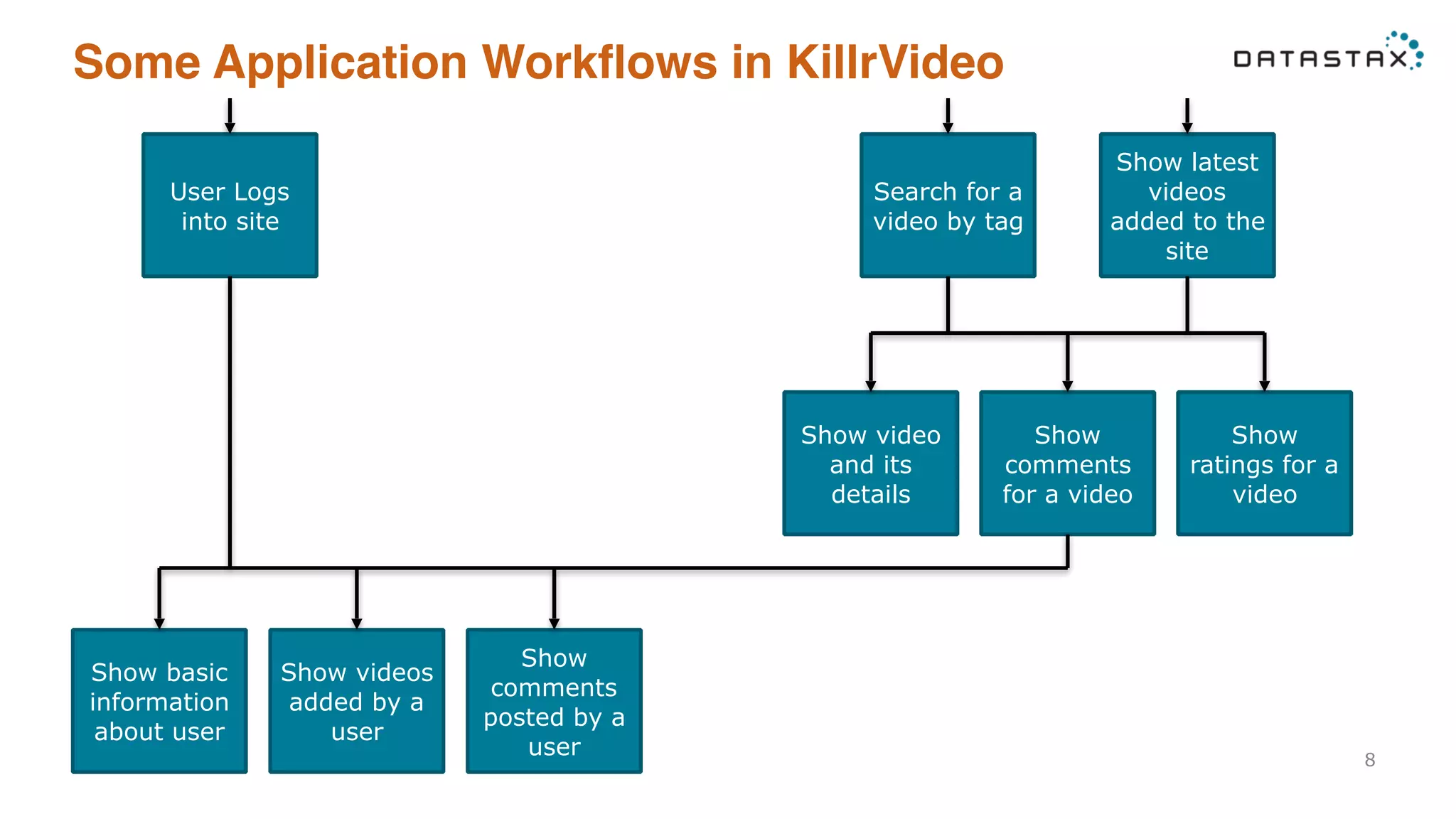
Details user workflows and necessary queries to support the operations of the KillrVideo application.
Contrasts CQL with SQL, highlighting the absence of joins and the concept of denormalization in Cassandra.
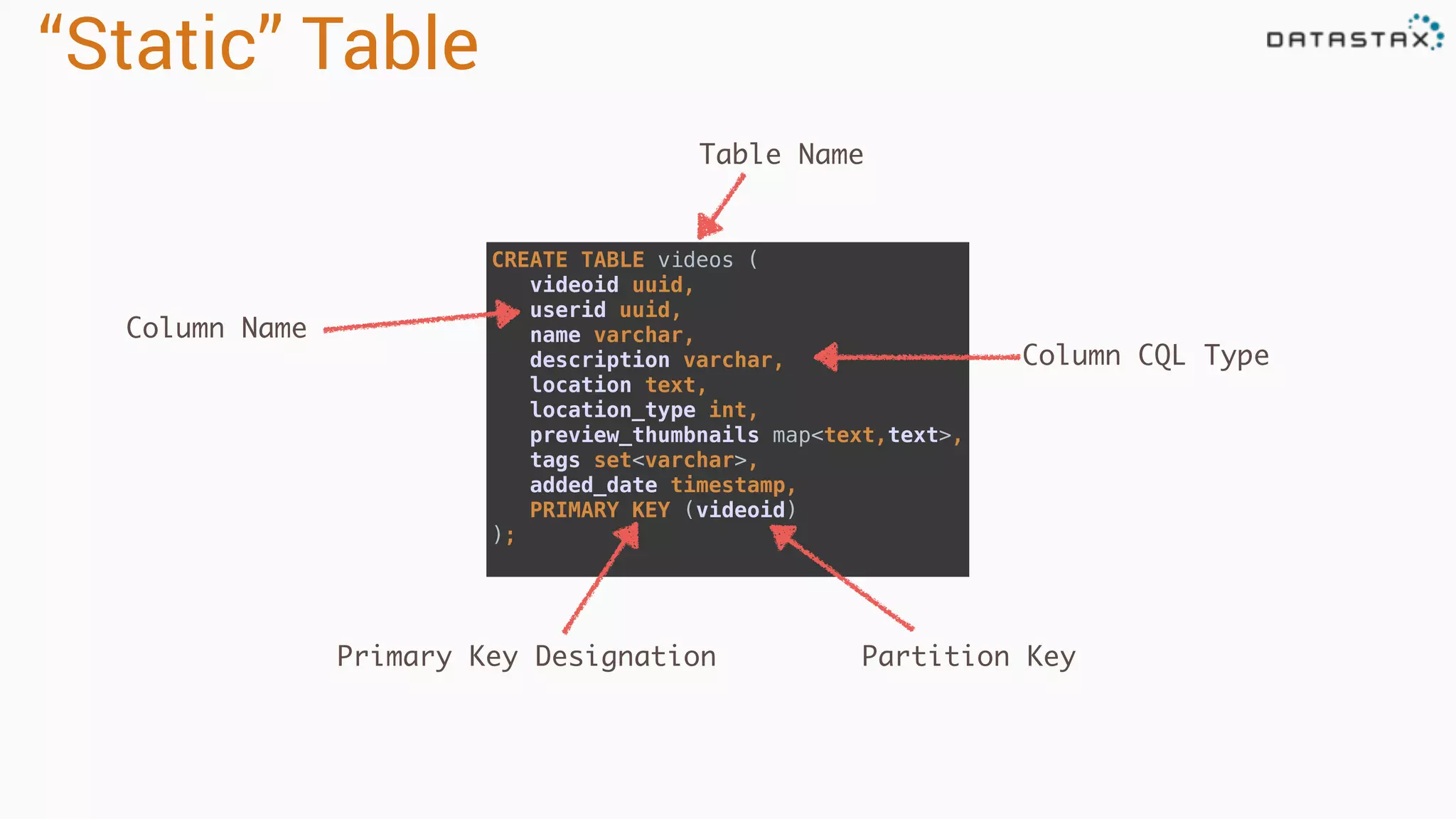
Demonstrates how to create tables in Cassandra, focusing on data types, primary key designations, and insert commands.
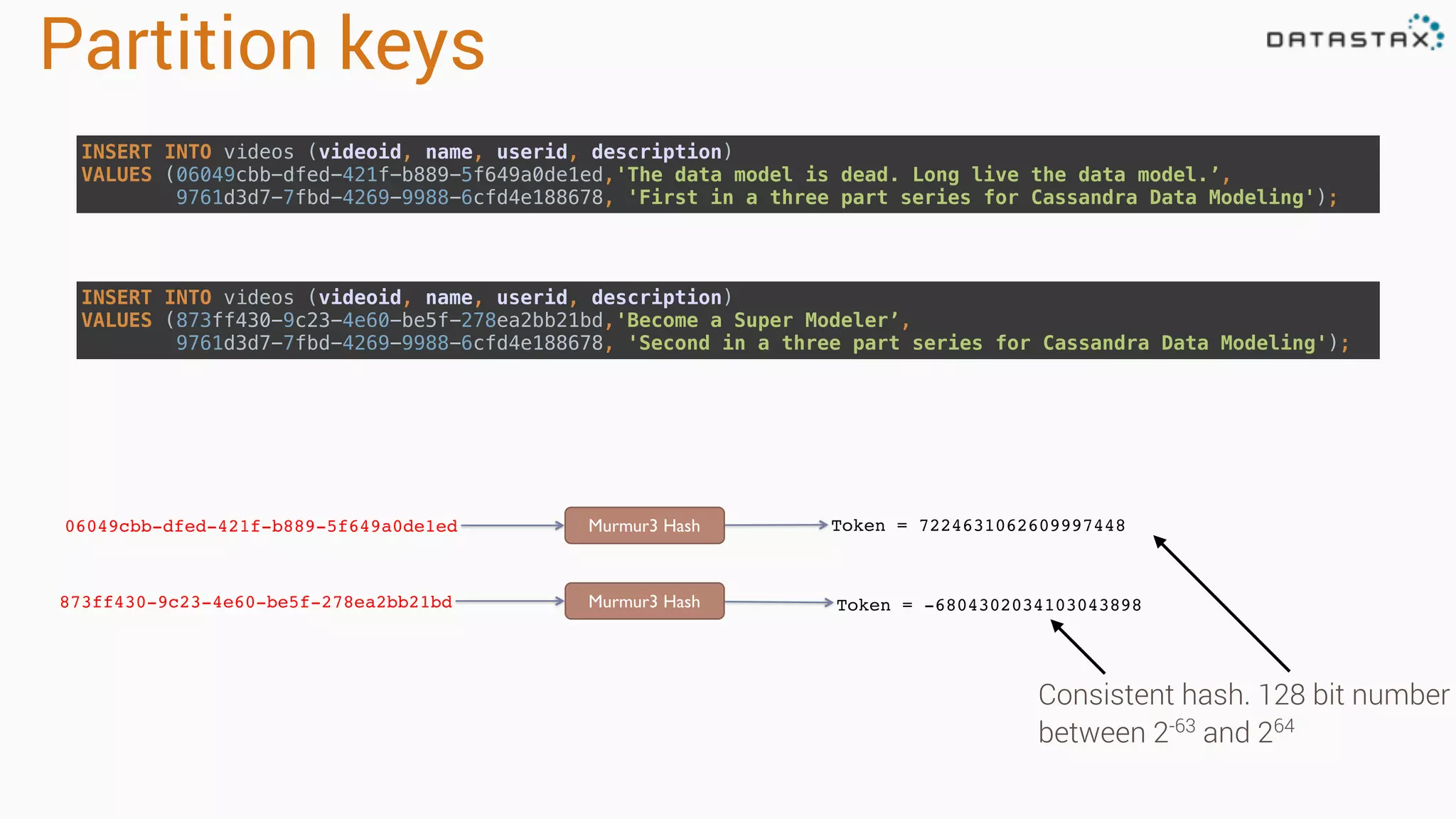
Illustrates partition keys, data insertion, and the significance of UUIDs and natural keys in Cassandra.
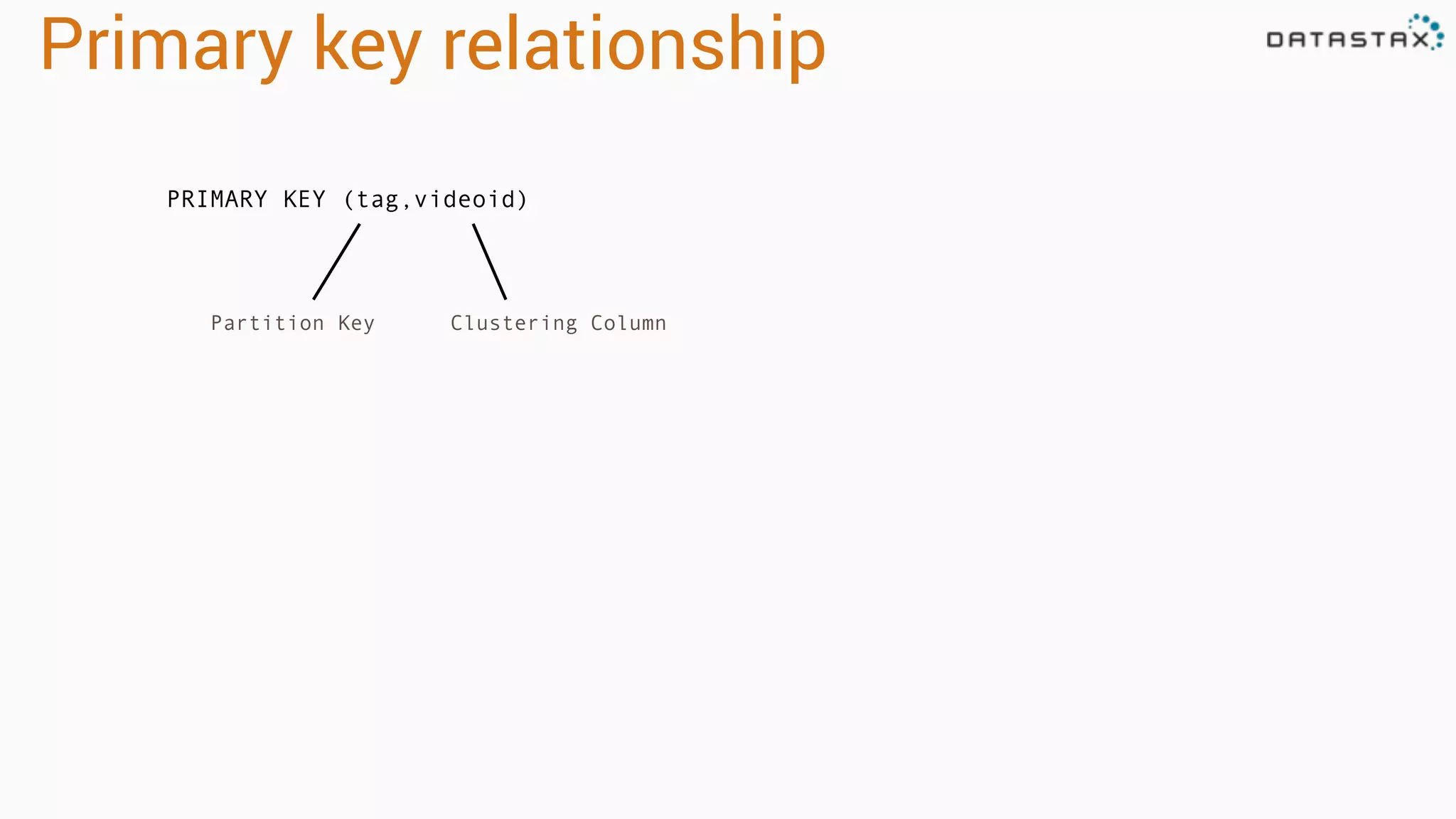
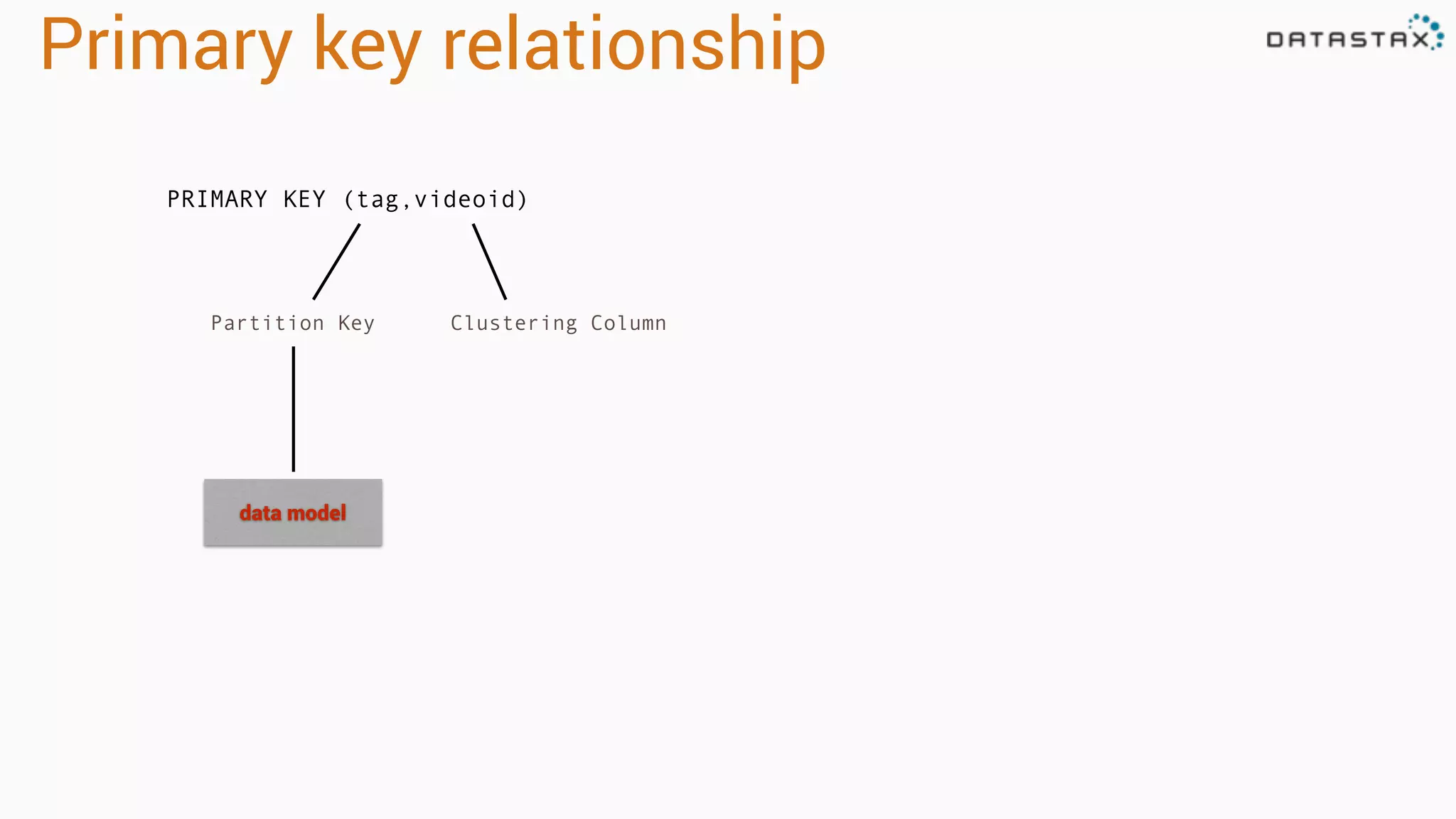
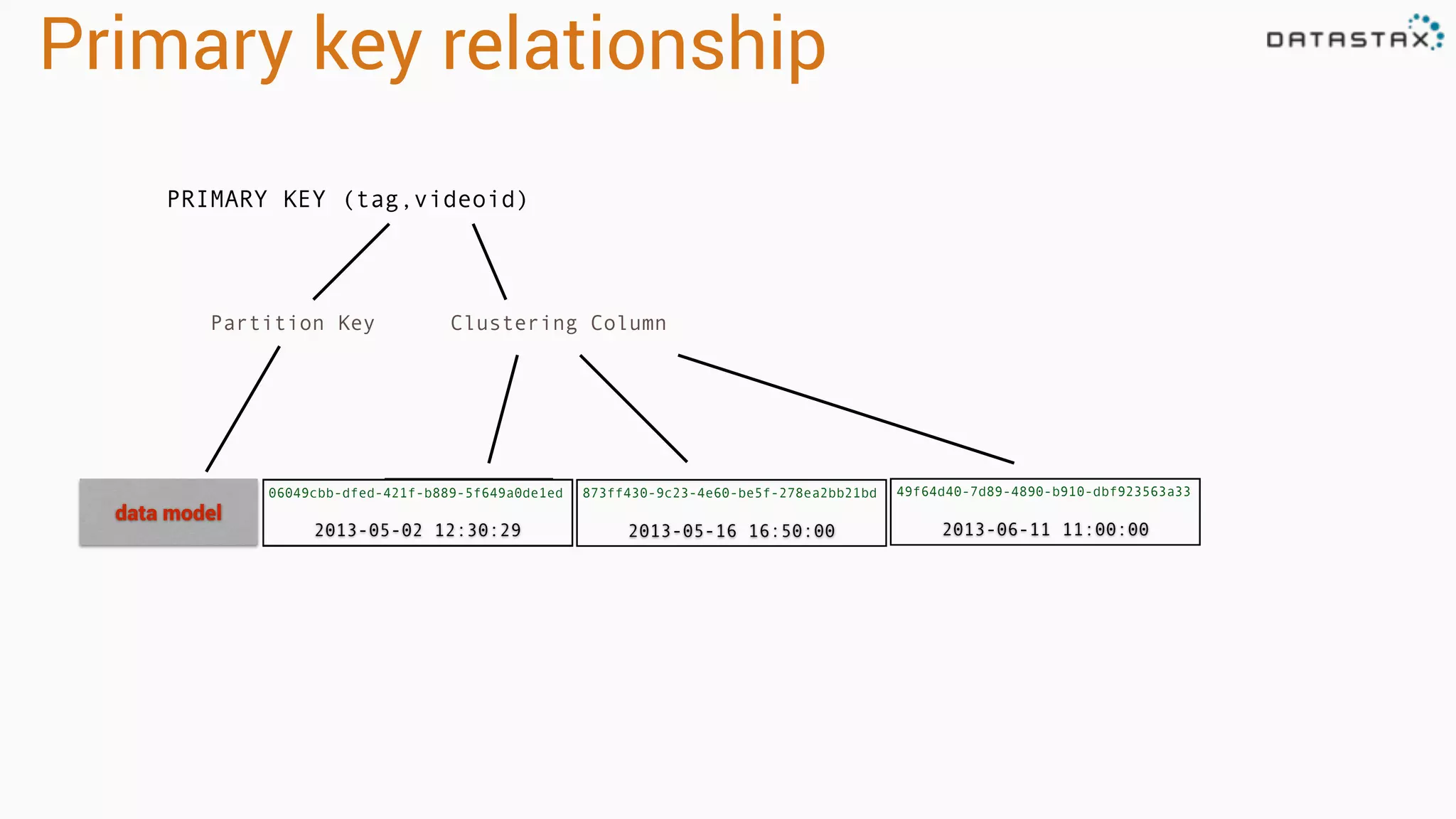
Explains dynamic and 'static' tables in Cassandra, focusing on primary key relationships with partition keys and clustering columns.
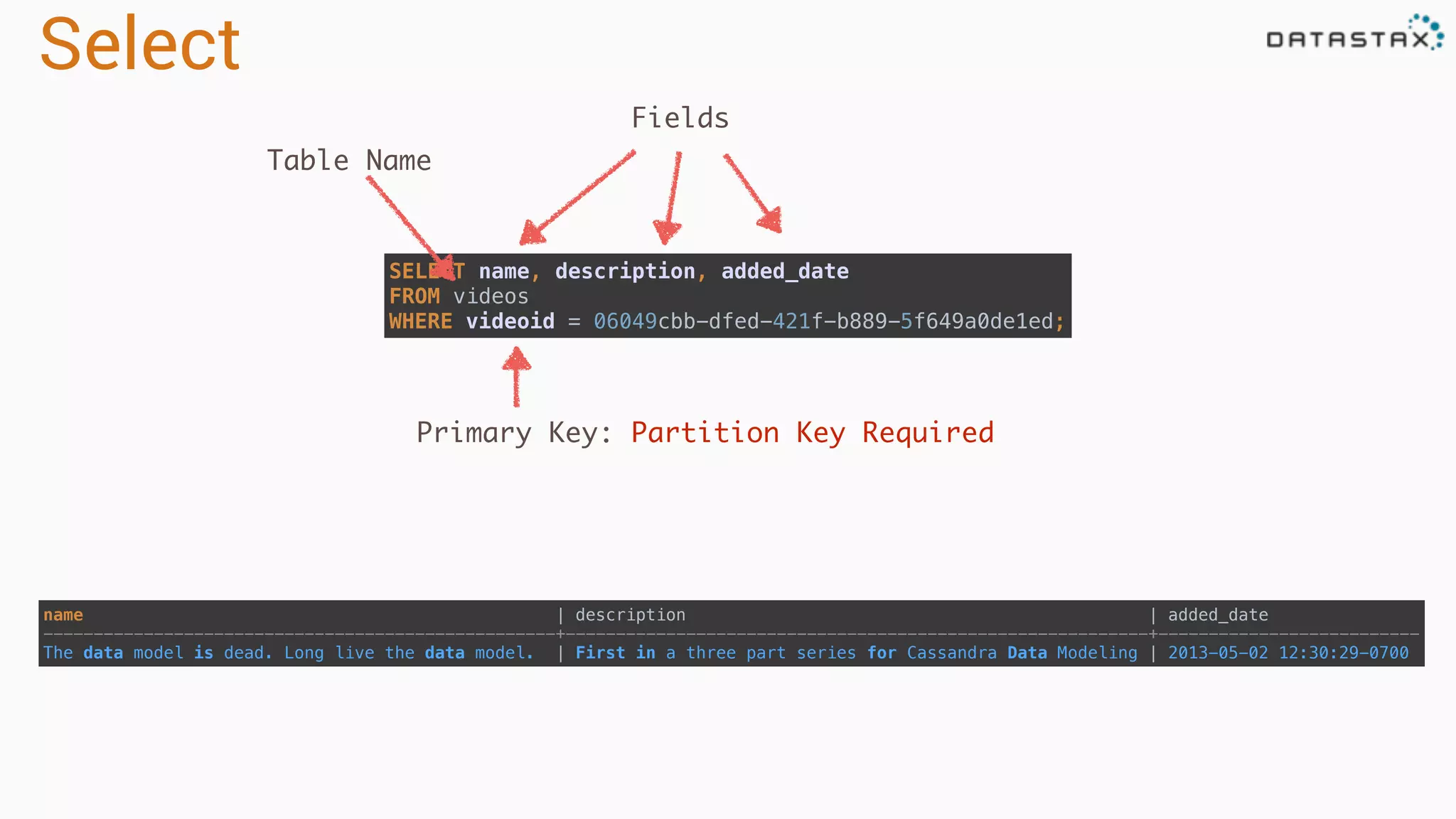
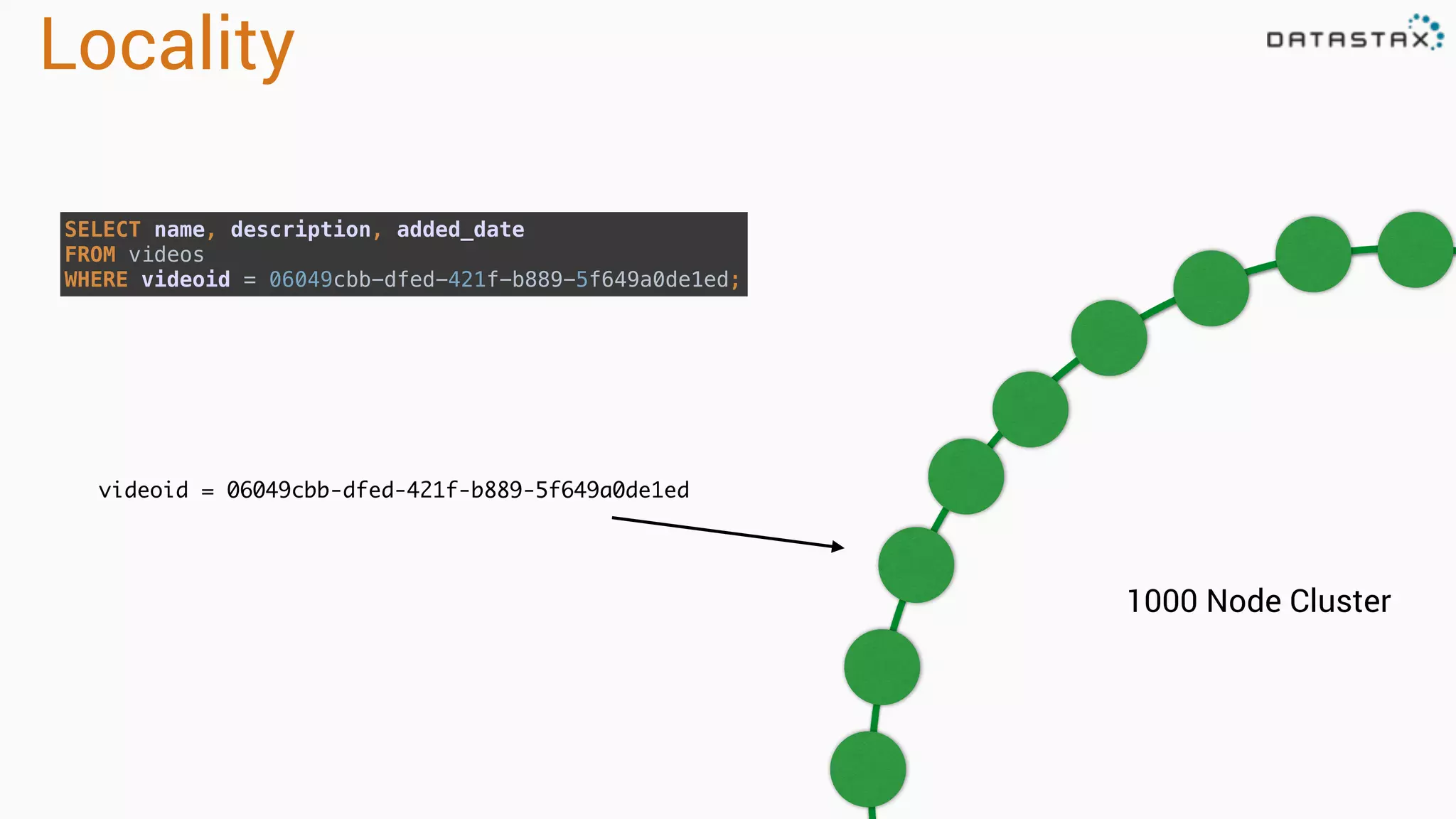
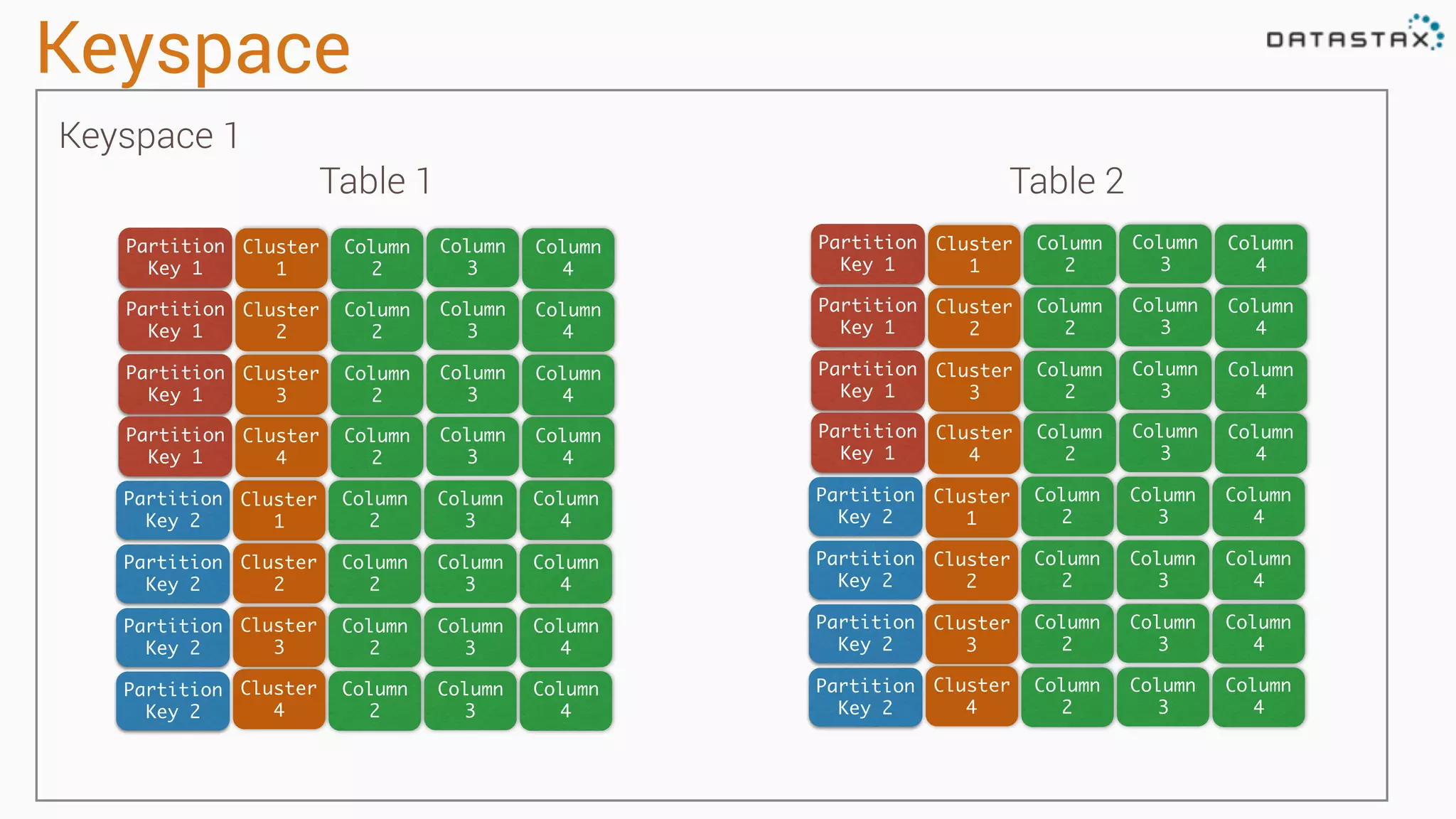
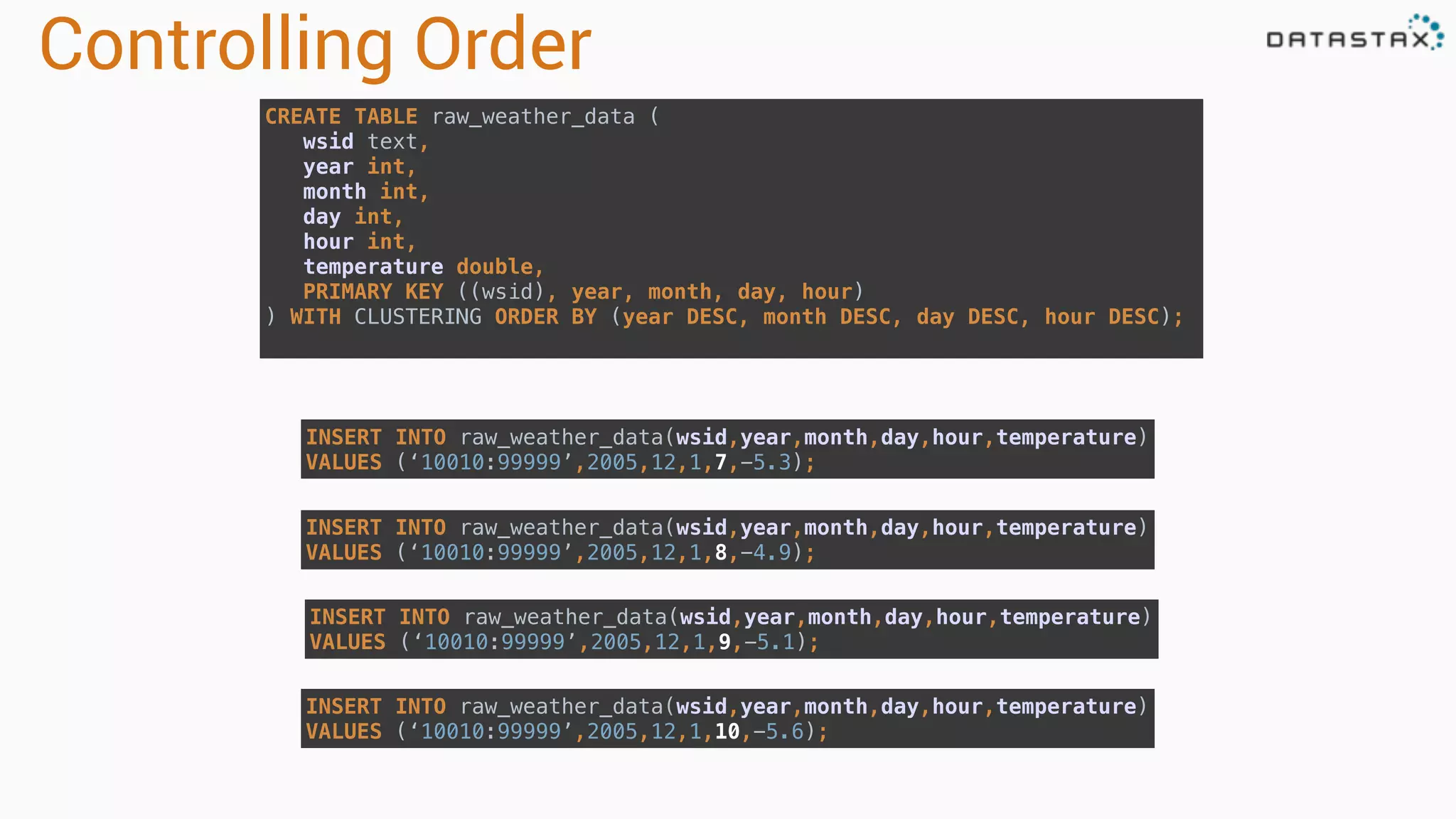
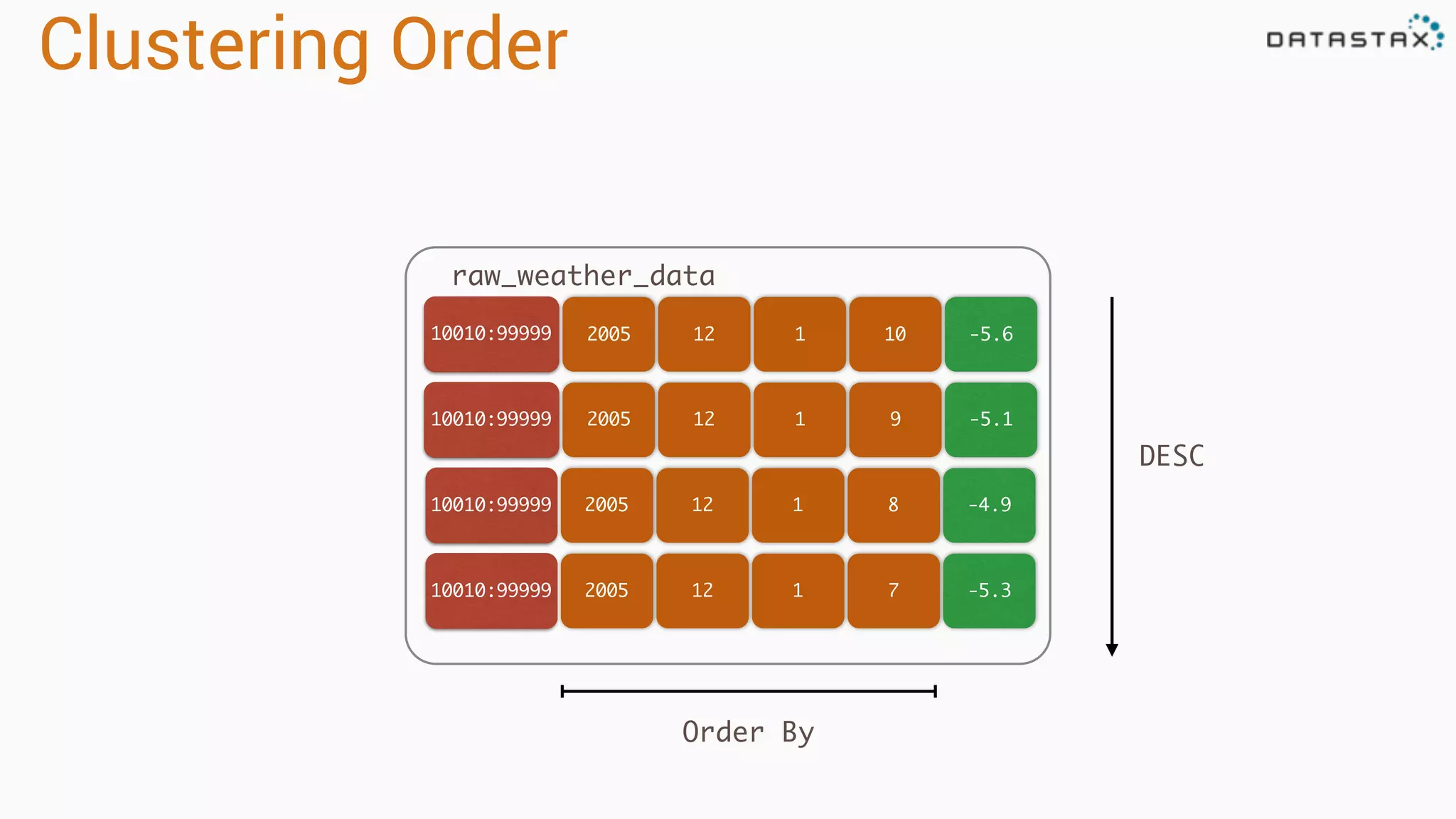
Describes partitioning and clustering in Cassandra, emphasizing the organization of data in tables and clusters.
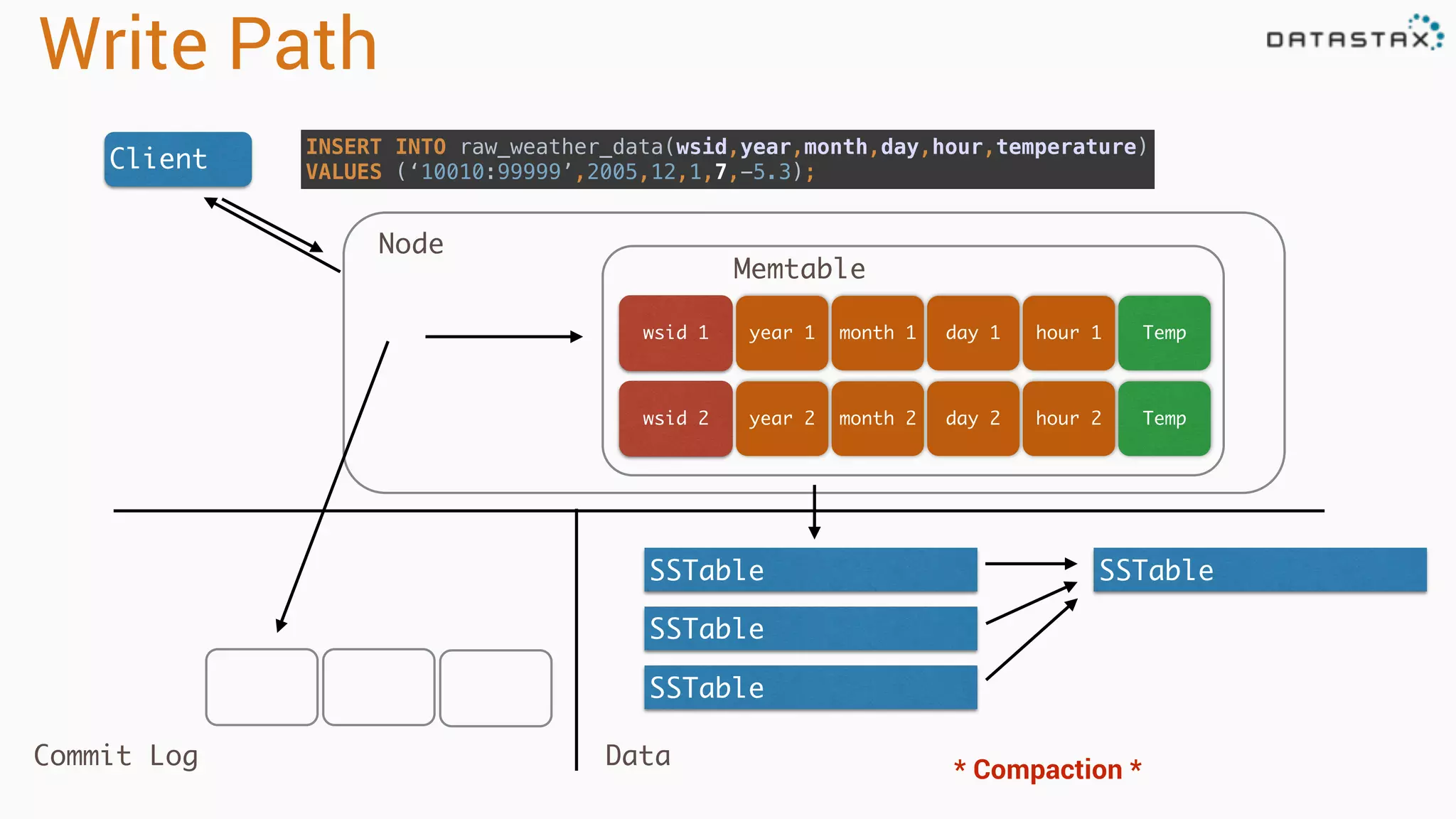
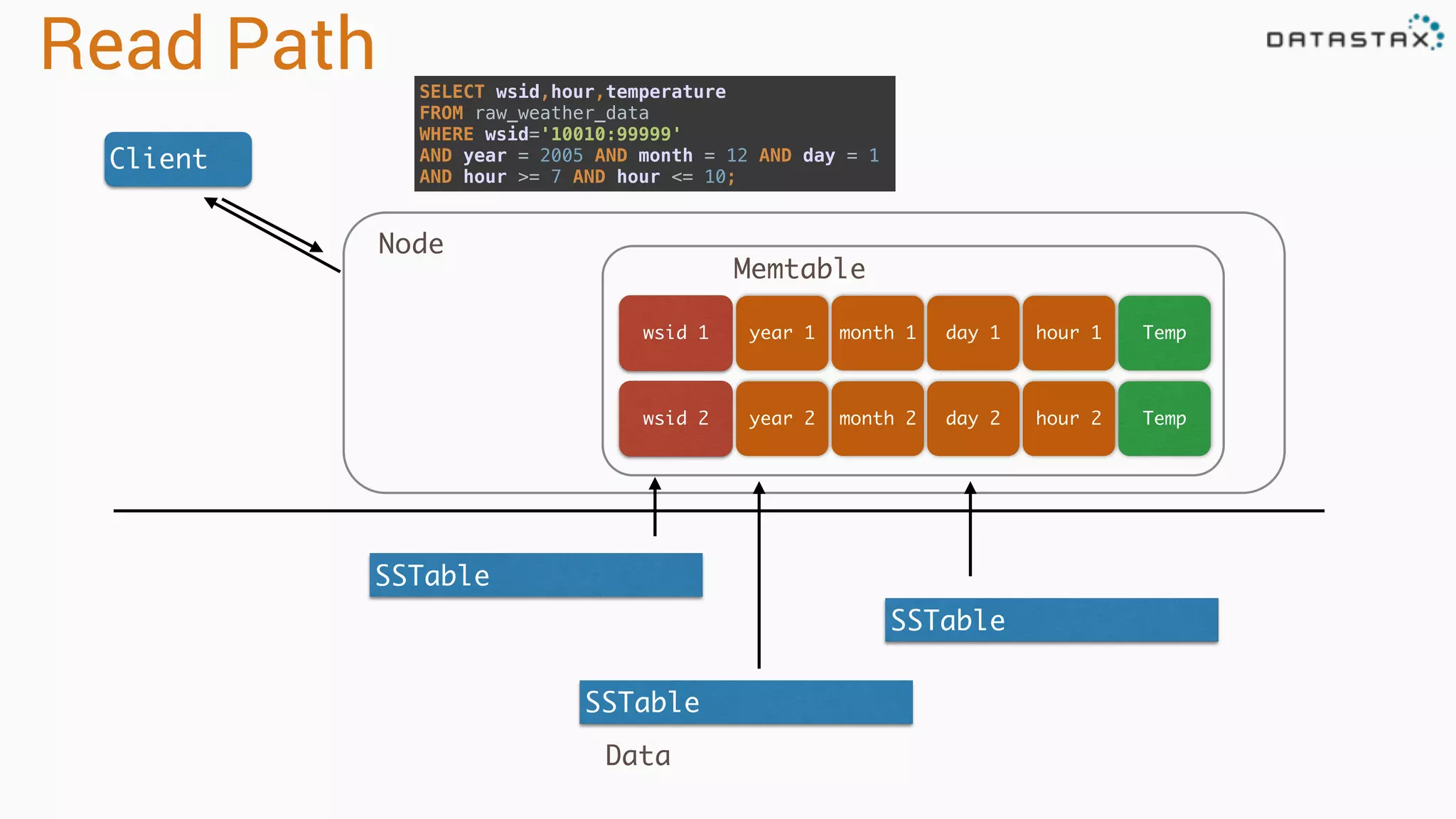
Discusses data storage models, including logical view, disk layout, read and write paths for efficient data retrieval.
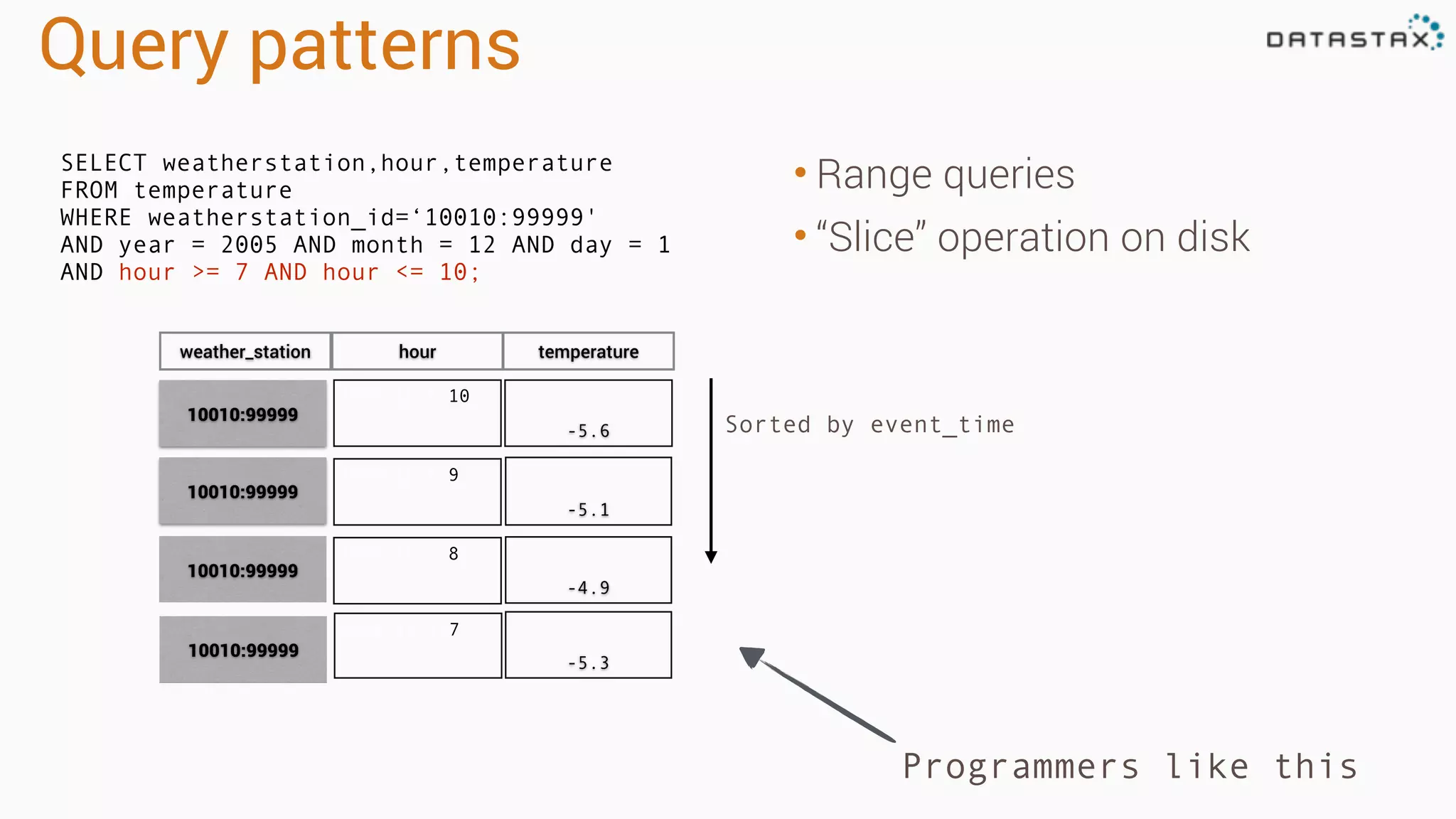
Describes query patterns in Cassandra focusing on range queries and disk operations for data extraction.
Introduces CQL collections, their operations, dynamics, and how they interact with tables in Cassandra.
Demonstrates various operations on CQL sets, lists, and maps, showing how to manipulate collection types.
Discusses entity modeling with collections in Cassandra and the use of index tables for fast data access.
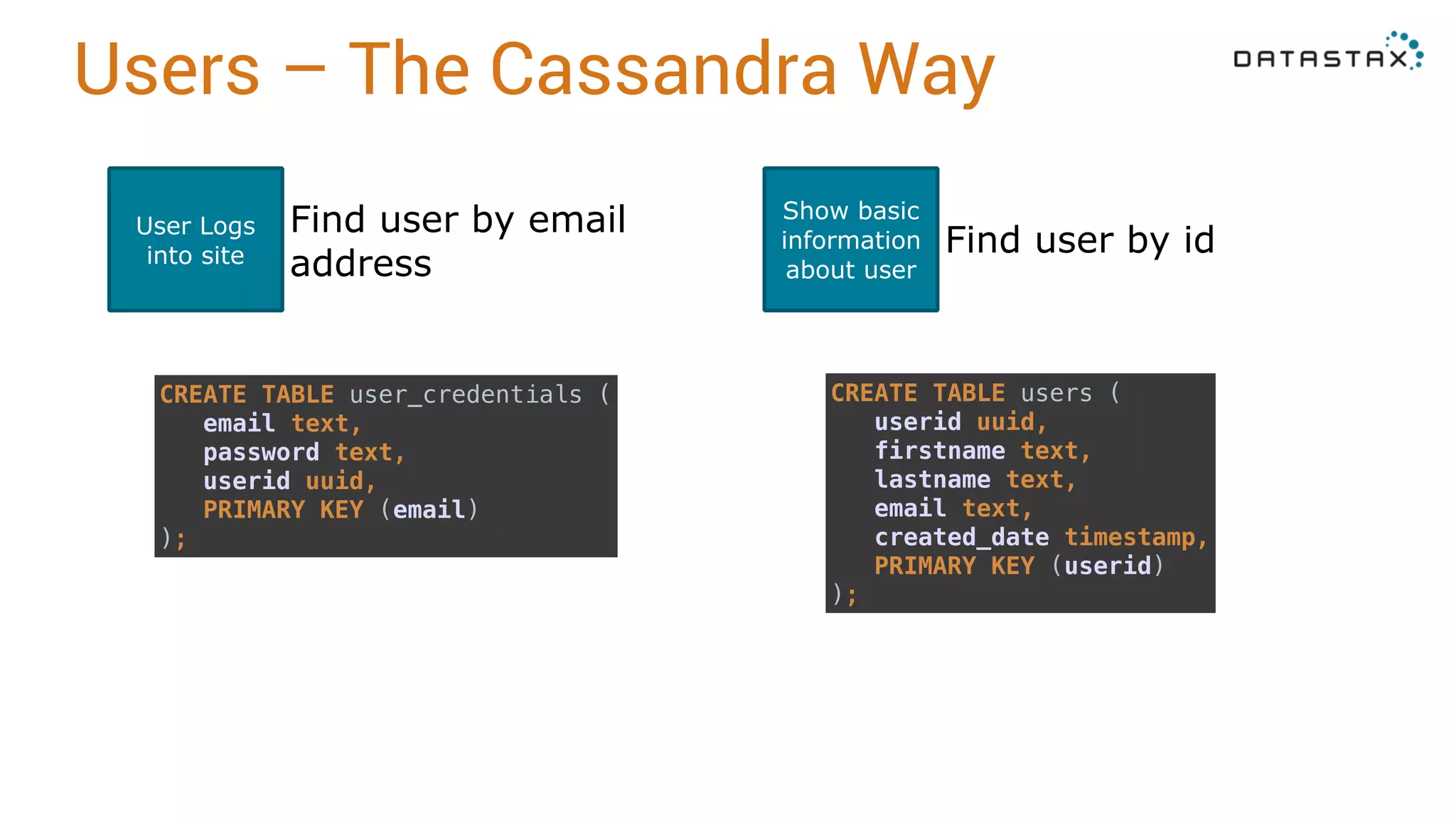
Outlines user management in Cassandra, including table structures for user credentials and video management.
Explains multiple lookup patterns and the implementation of many-to-many relationships in Cassandra.
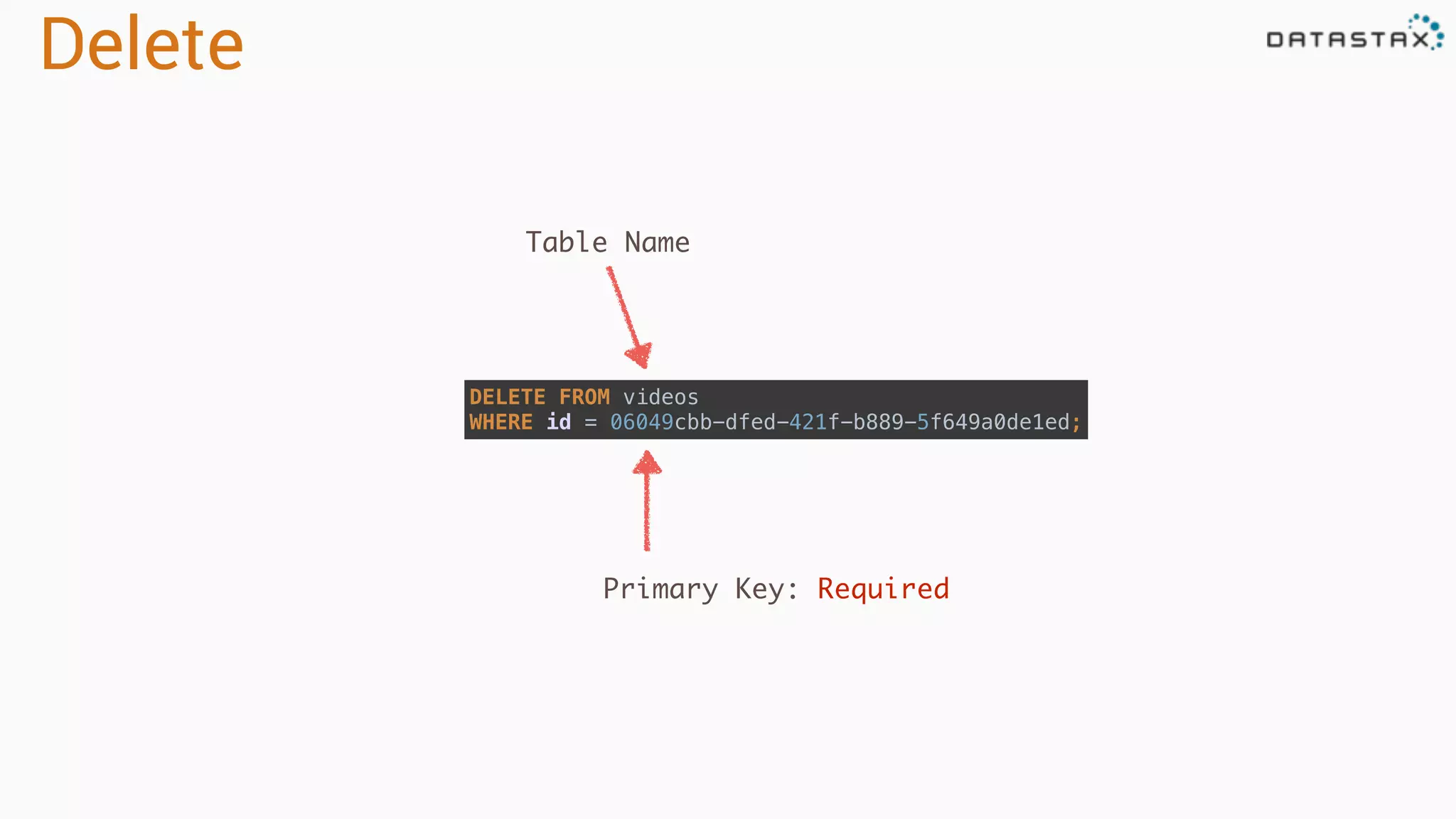
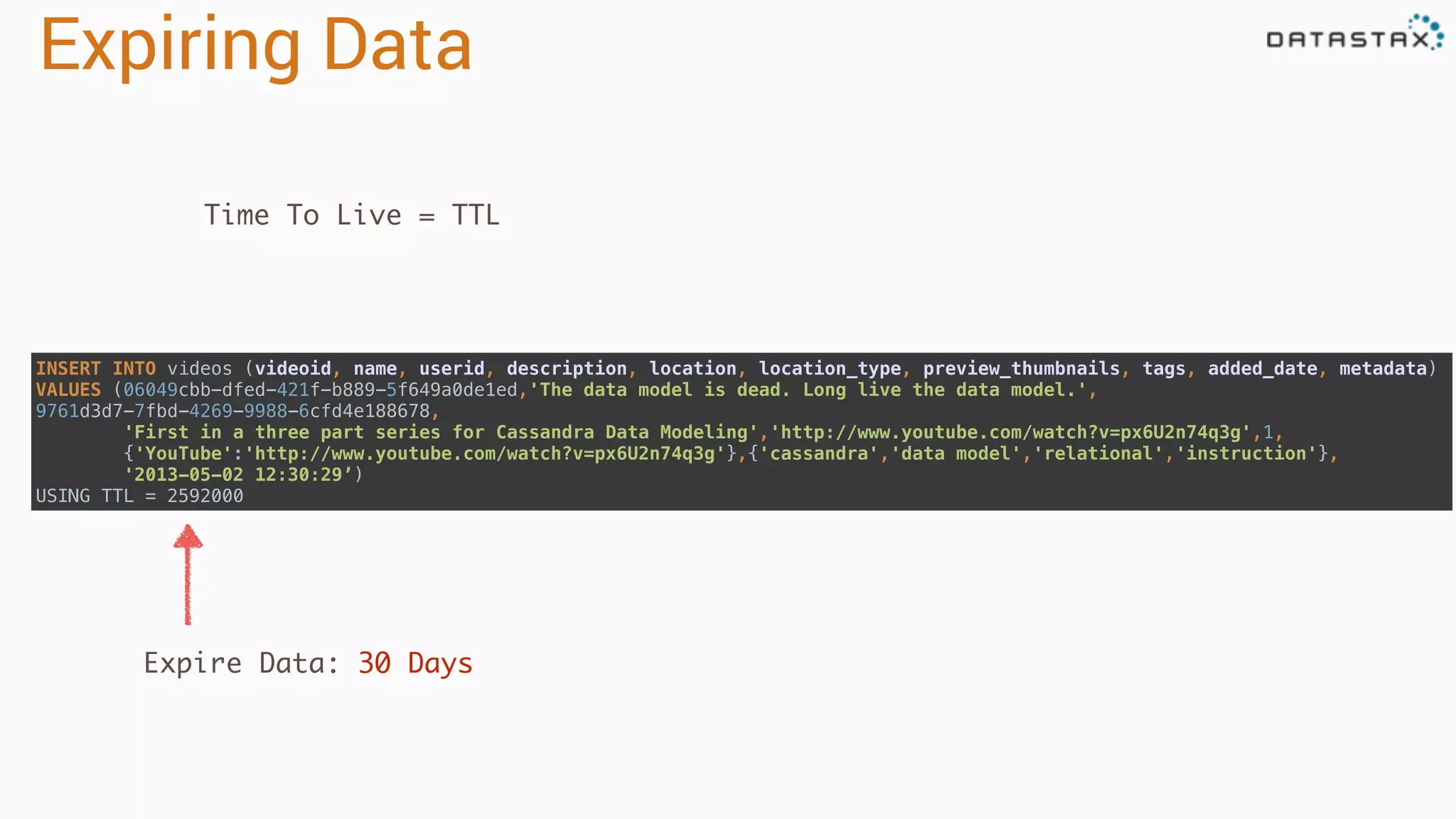
Describes methods for deleting data, handling tombstones, and managing data expiration using TTL in Cassandra.
Ends with a thank you message and invitation for questions, encouraging follow-up on Twitter.