Download as PDF, PPTX















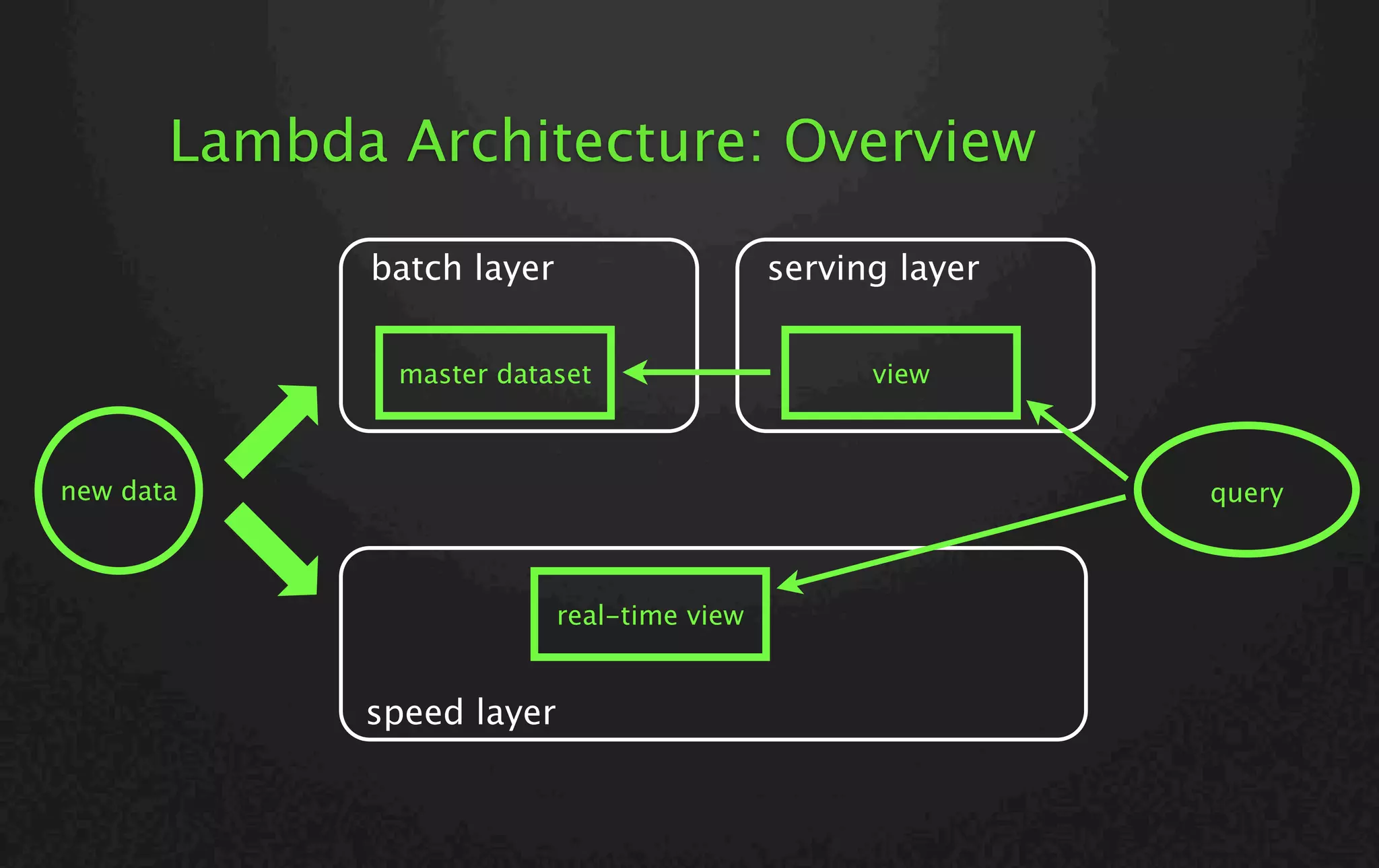
![Twitter Summingbird Lambda architecture library Batch mode: Scalding on Hadoop MapReduce Realtime mode: Storm Word counting by Summingbird (scala): def wordCount[P <: Platform[P]] (source: Producer[P, String], store: P#Store[String, Long]) = source.flatMap { sentence => toWords(sentence).map(_ -> 1L) }.sumByKey(store) https://github.com/twitter/summingbird https://blog.twitter.com/2013/streaming-mapreduce-with-summingbird](https://image.slidesharecdn.com/hadoopcontaiwan2014keynote-140915004512-phpapp02/75/Lambda-Architecture-Using-SQL-20-2048.jpg)



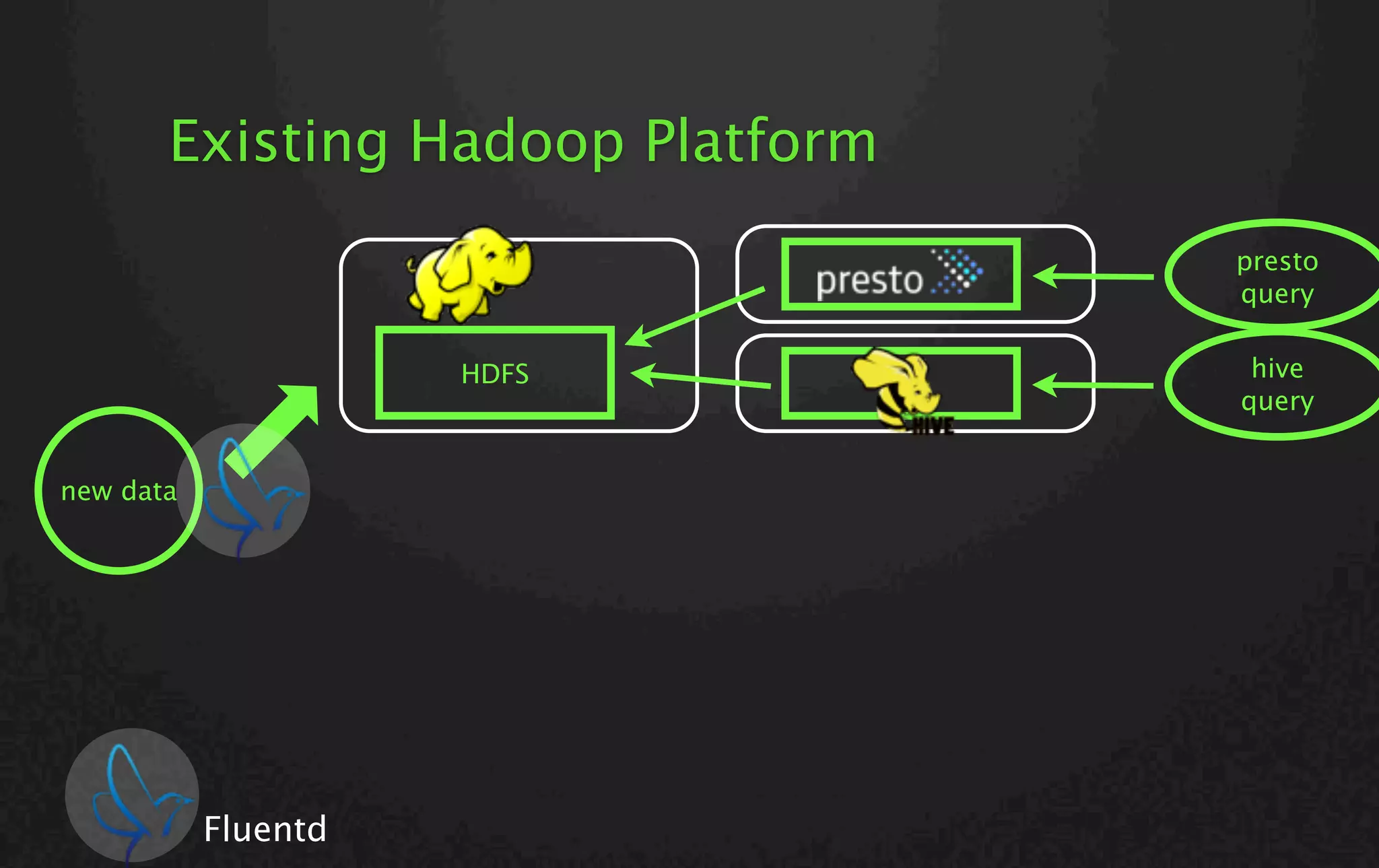

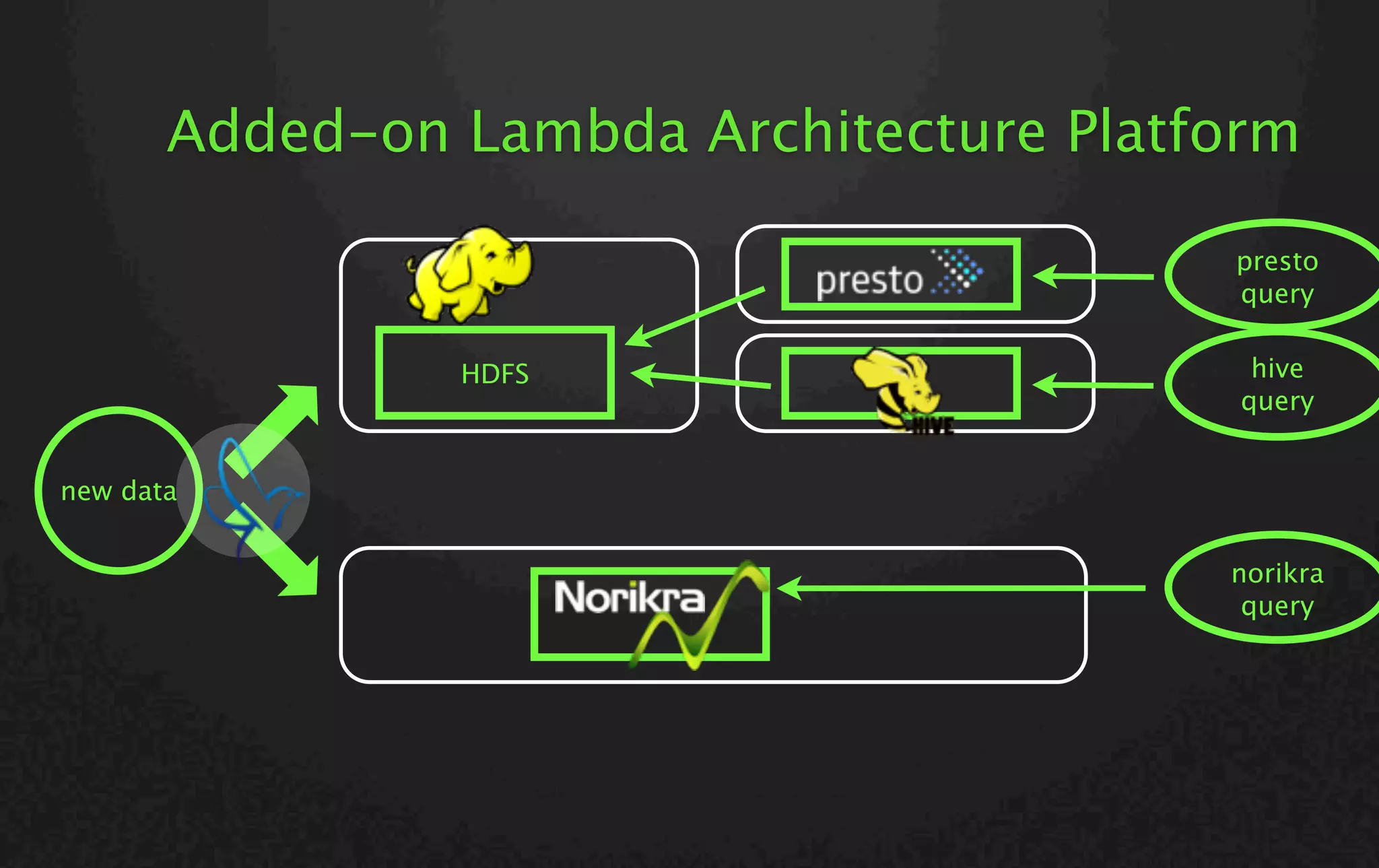







The document discusses a lambda architecture platform using SQL, focusing on data analytics workloads that include batch and stream processing. It highlights the advantages of using stream processing for real-time metrics and prompt reports, as well as the challenges faced in its deployment. The presentation also introduces Norikra, an open-source server software for stream processing with SQL, and emphasizes the ease of learning SQL for non-professionals.