Download as PDF, PPTX


 with Cassandra { PailSource.source[Search](rootpath, structure, directories).read .mapTo('pailItem -> 'engines) { e: Search ⇒ results(e) } .filter('engines) { e: String ⇒ e.nonEmpty } .groupBy('engines) { _.size('count).sortBy('engines) } .groupBy('engines) { _.sortedReverseTake[(String, Long)](('engines, 'count) -> 'tcount, k) } .flatMapTo('tcount -> ('key, 'engine, 'topCount)) { t: List[(String, Long)] ⇒ t map { case (k, v) ⇒ (jobKey, k, v) }} .write(CassandraSource(connection, "top_searches", Scheme(‘key, ('engine, ‘topCount)))) }](https://image.slidesharecdn.com/lambda-architecture-cassandra-spark-kafka-150408100223-conversion-gate01/75/Lambda-Architecture-with-Spark-Spark-Streaming-Kafka-Cassandra-Akka-and-Scala-3-2048.jpg)











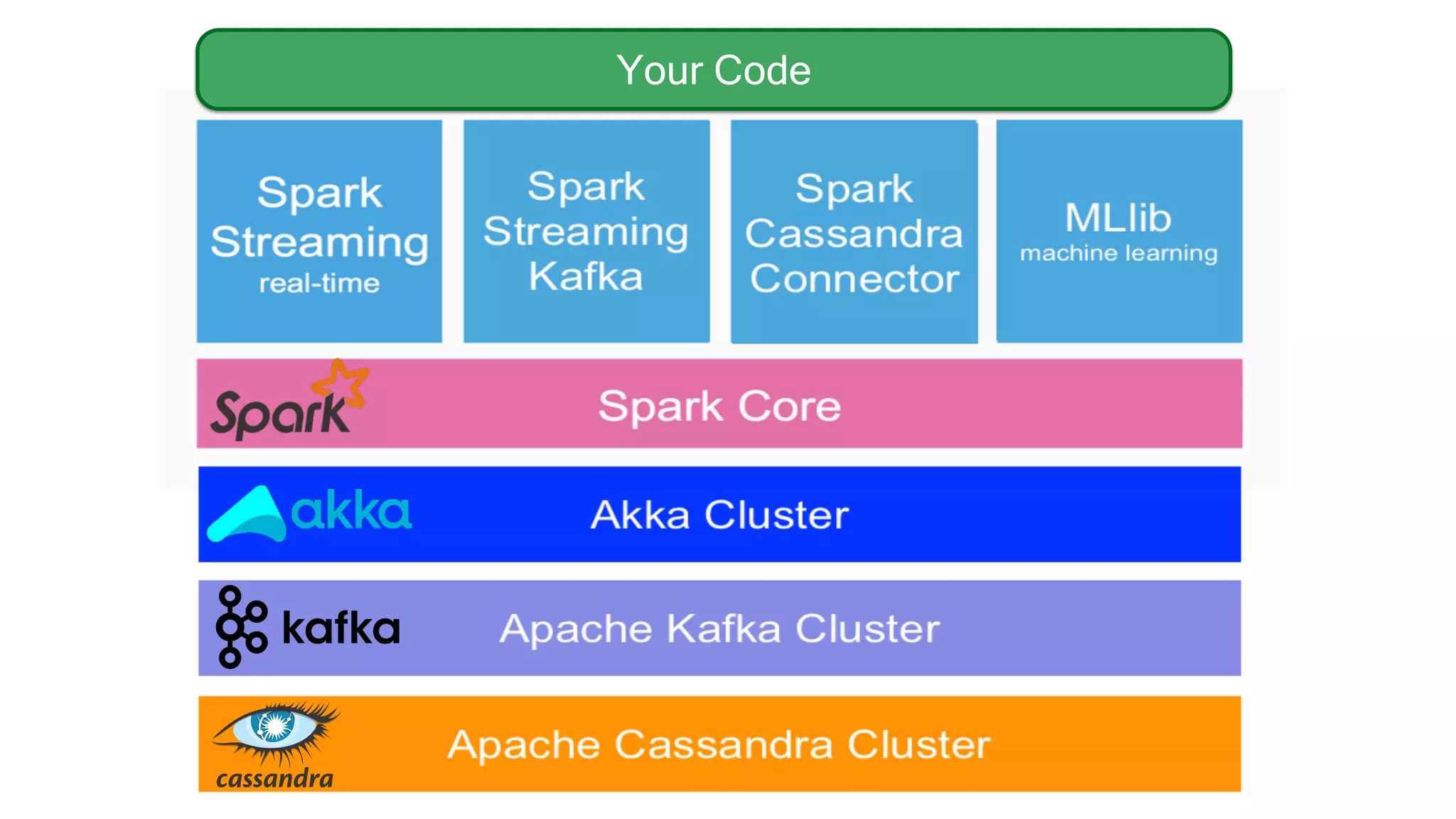
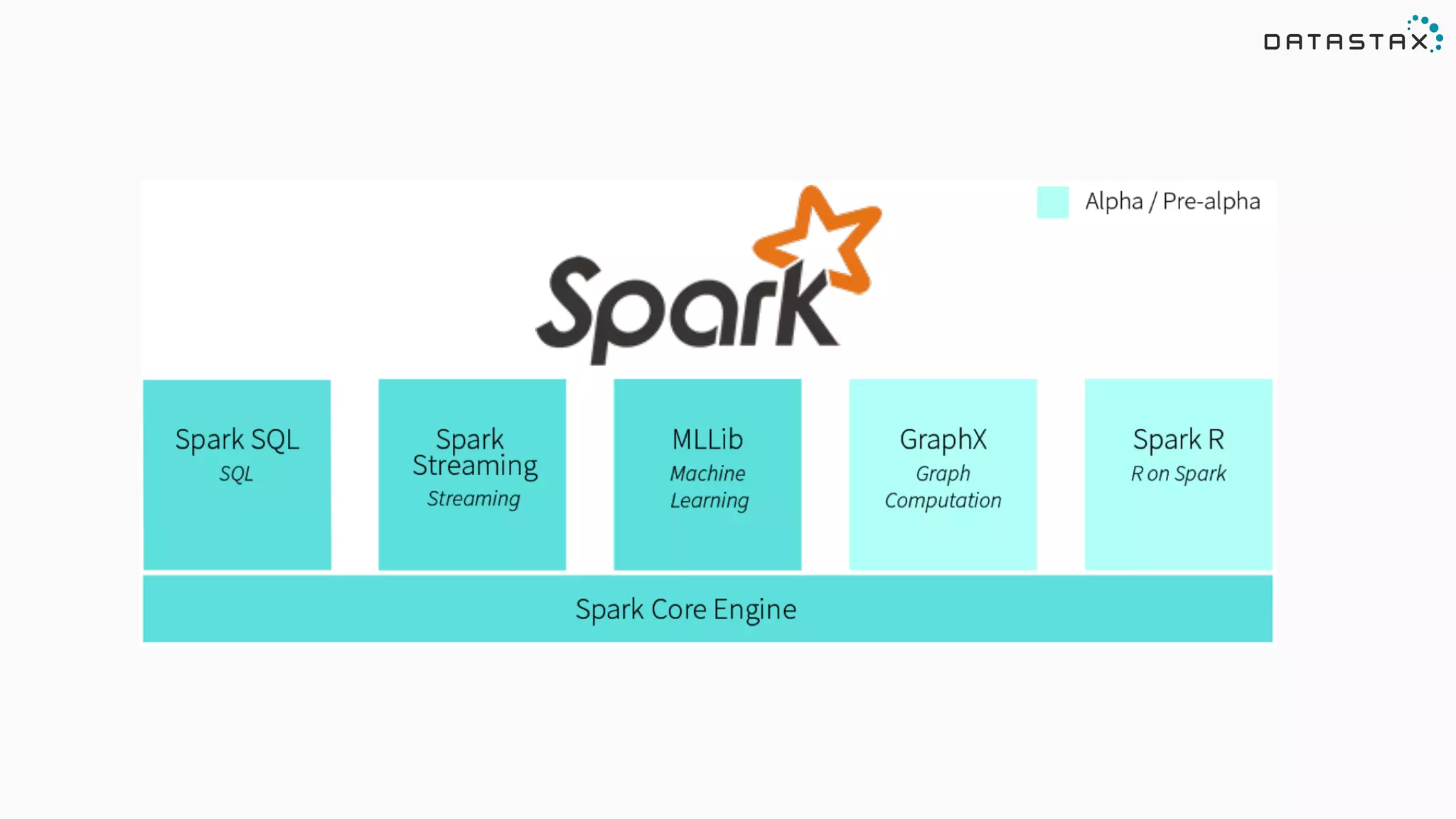
![Apache Spark - Easy to Use API Returns the top (k) highest temps for any location in the year def topK(aggregate: Seq[Double]): Seq[Double] = sc.parallelize(aggregate).top(k).collect Returns the top (k) highest temps … in a Future def topK(aggregate: Seq[Double]): Future[Seq[Double]] = sc.parallelize(aggregate).top(k).collectAsync Analytic Analytic Search](https://image.slidesharecdn.com/lambda-architecture-cassandra-spark-kafka-150408100223-conversion-gate01/75/Lambda-Architecture-with-Spark-Spark-Streaming-Kafka-Cassandra-Akka-and-Scala-23-2048.jpg)


![Analytic Analytic Search Collection To RDD scala> val data = Array(1, 2, 3, 4, 5)
data: Array[Int] = Array(1, 2, 3, 4, 5)
scala> val distributedData = sc.parallelize(data)
distributedData: spark.RDD[Int] = spark.ParallelCollection@10d13e3e](https://image.slidesharecdn.com/lambda-architecture-cassandra-spark-kafka-150408100223-conversion-gate01/75/Lambda-Architecture-with-Spark-Spark-Streaming-Kafka-Cassandra-Akka-and-Scala-26-2048.jpg)

















![CREATE TABLE users ( username varchar, firstname varchar, lastname varchar, email list<varchar>, password varchar, created_date timestamp, PRIMARY KEY (username) ); INSERT INTO users (username, firstname, lastname, email, password, created_date) VALUES ('hedelson','Helena','Edelson', [‘helena.edelson@datastax.com'],'ba27e03fd95e507daf2937c937d499ab','2014-11-15 13:50:00’) IF NOT EXISTS; • Familiar syntax • Many Tools & Drivers • Many Languages • Friendly to programmers • Paxos for locking CQL - Easy](https://image.slidesharecdn.com/lambda-architecture-cassandra-spark-kafka-150408100223-conversion-gate01/75/Lambda-Architecture-with-Spark-Spark-Streaming-Kafka-Cassandra-Akka-and-Scala-49-2048.jpg)

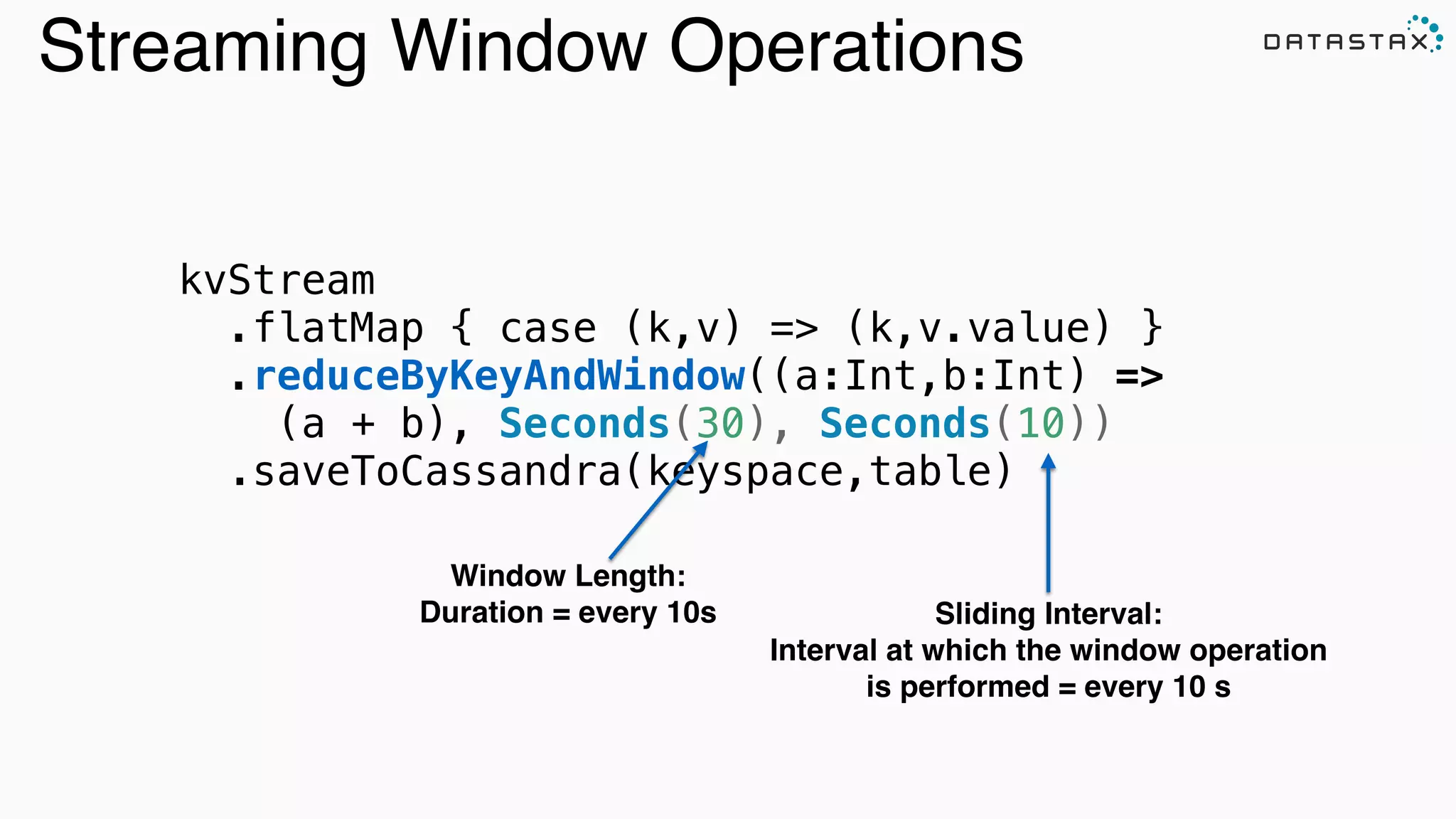
) } streamingContext.union(multipleStreams) .map { httpRequest => TimelineRequestEvent(httpRequest)} .saveToCassandra("requests_ks", "timeline") A record of every event, in order in which it happened, per URL: CREATE TABLE IF NOT EXISTS requests_ks.timeline ( timesegment bigint, url text, t_uuid timeuuid, method text, headers map <text, text>, body text, PRIMARY KEY ((url, timesegment) , t_uuid) ); timeuuid protects from simultaneous events over-writing one another. timesegment protects from writing unbounded partitions.](https://image.slidesharecdn.com/lambda-architecture-cassandra-spark-kafka-150408100223-conversion-gate01/75/Lambda-Architecture-with-Spark-Spark-Streaming-Kafka-Cassandra-Akka-and-Scala-51-2048.jpg)


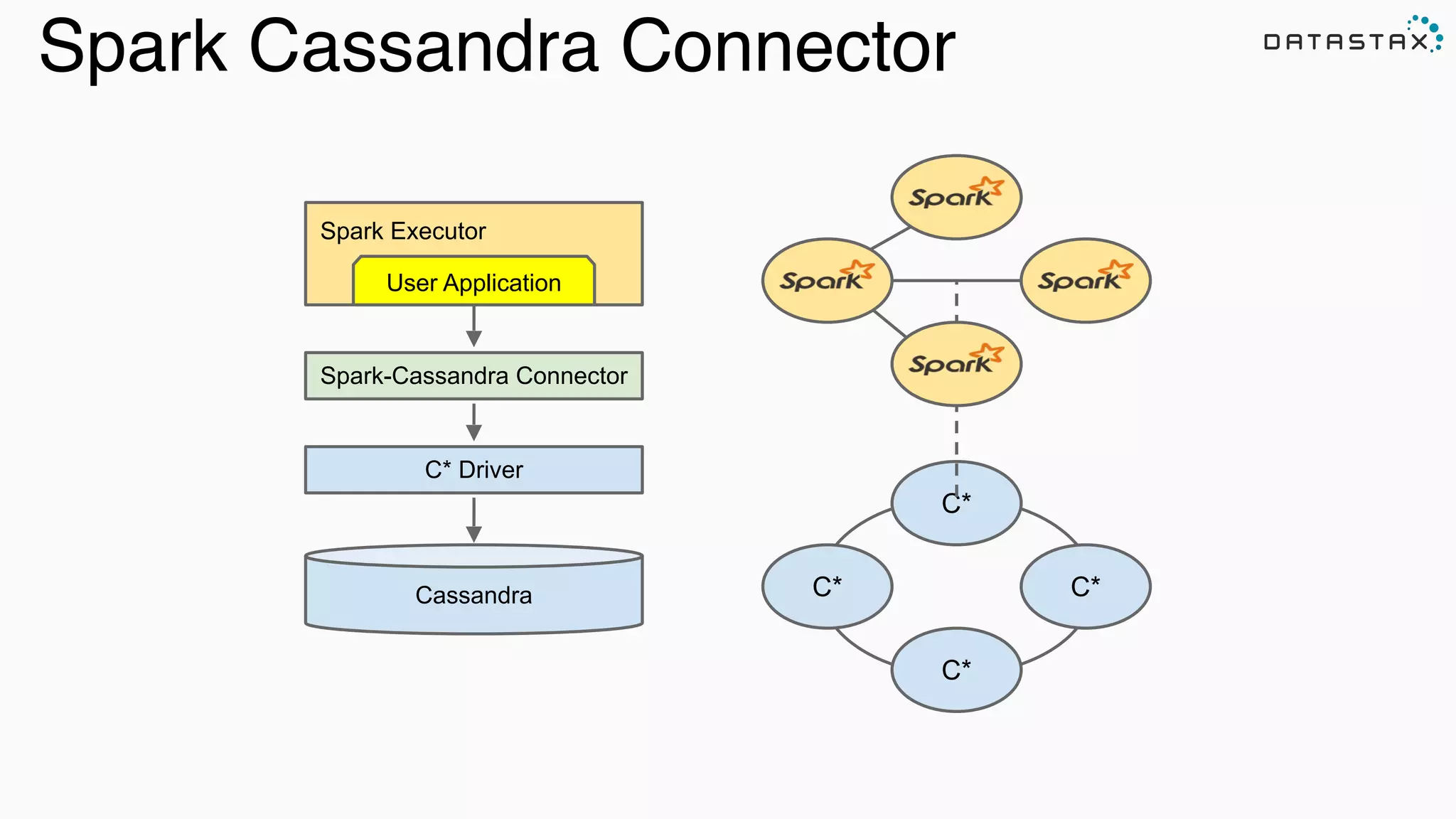



![Read From C* to Spark val rdd = sc.cassandraTable("github", "commits") .select("user","count","year","month") .where("commits >= ? and year = ?", 1000, 2015) CassandraRDD[CassandraRow] Keyspace Table Server-Side Column and Row Filtering SparkContext](https://image.slidesharecdn.com/lambda-architecture-cassandra-spark-kafka-150408100223-conversion-gate01/75/Lambda-Architecture-with-Spark-Spark-Streaming-Kafka-Cassandra-Akka-and-Scala-58-2048.jpg)
 .where("user = ? and project_name = ? and year = ?", "helena", "spark-‐cassandra-‐connector", 2015) CassandraRow Keyspace TableStreamingContext Rows: Custom Objects](https://image.slidesharecdn.com/lambda-architecture-cassandra-spark-kafka-150408100223-conversion-gate01/75/Lambda-Architecture-with-Spark-Spark-Streaming-Kafka-Cassandra-Akka-and-Scala-59-2048.jpg)
 .select("cluster_id","time", "cluster_name") .where("time > ? and time < ?", "2014-‐07-‐12 20:00:01", "2014-‐07-‐12 20:00:03”) val keyValuesPairsRdd = sc.cassandraTable[(Key,Value)](keyspace, table)](https://image.slidesharecdn.com/lambda-architecture-cassandra-spark-kafka-150408100223-conversion-gate01/75/Lambda-Architecture-with-Spark-Spark-Streaming-Kafka-Cassandra-Akka-and-Scala-60-2048.jpg)
 rdd.where("key = 1").limit(10).collect rdd.where("key = 1").take(10).collect val rdd = ssc.cassandraTable[(Int,DateTime,String)]("stats", "clustering_time") .where("key = 1").withAscOrder.collect val rdd = ssc.cassandraTable[(Int,DateTime,String)]("stats", "clustering_time") .where("key = 1").withDescOrder.collect](https://image.slidesharecdn.com/lambda-architecture-cassandra-spark-kafka-150408100223-conversion-gate01/75/Lambda-Architecture-with-Spark-Spark-Streaming-Kafka-Cassandra-Akka-and-Scala-61-2048.jpg)





 cqlsh> CREATE TABLE github_stats.commits_aggr(user VARCHAR PRIMARY KEY, commits INT…); Spark SQL with Cassandra & JSON](https://image.slidesharecdn.com/lambda-architecture-cassandra-spark-kafka-150408100223-conversion-gate01/75/Lambda-Architecture-with-Spark-Spark-Streaming-Kafka-Cassandra-Akka-and-Scala-67-2048.jpg)

.map { case (_,json) => JsonParser.parse(json).extract[MonthlyCommits]}
.saveToCassandra("github_stats","commits_aggr")](https://image.slidesharecdn.com/lambda-architecture-cassandra-spark-kafka-150408100223-conversion-gate01/75/Lambda-Architecture-with-Spark-Spark-Streaming-Kafka-Cassandra-Akka-and-Scala-68-2048.jpg)
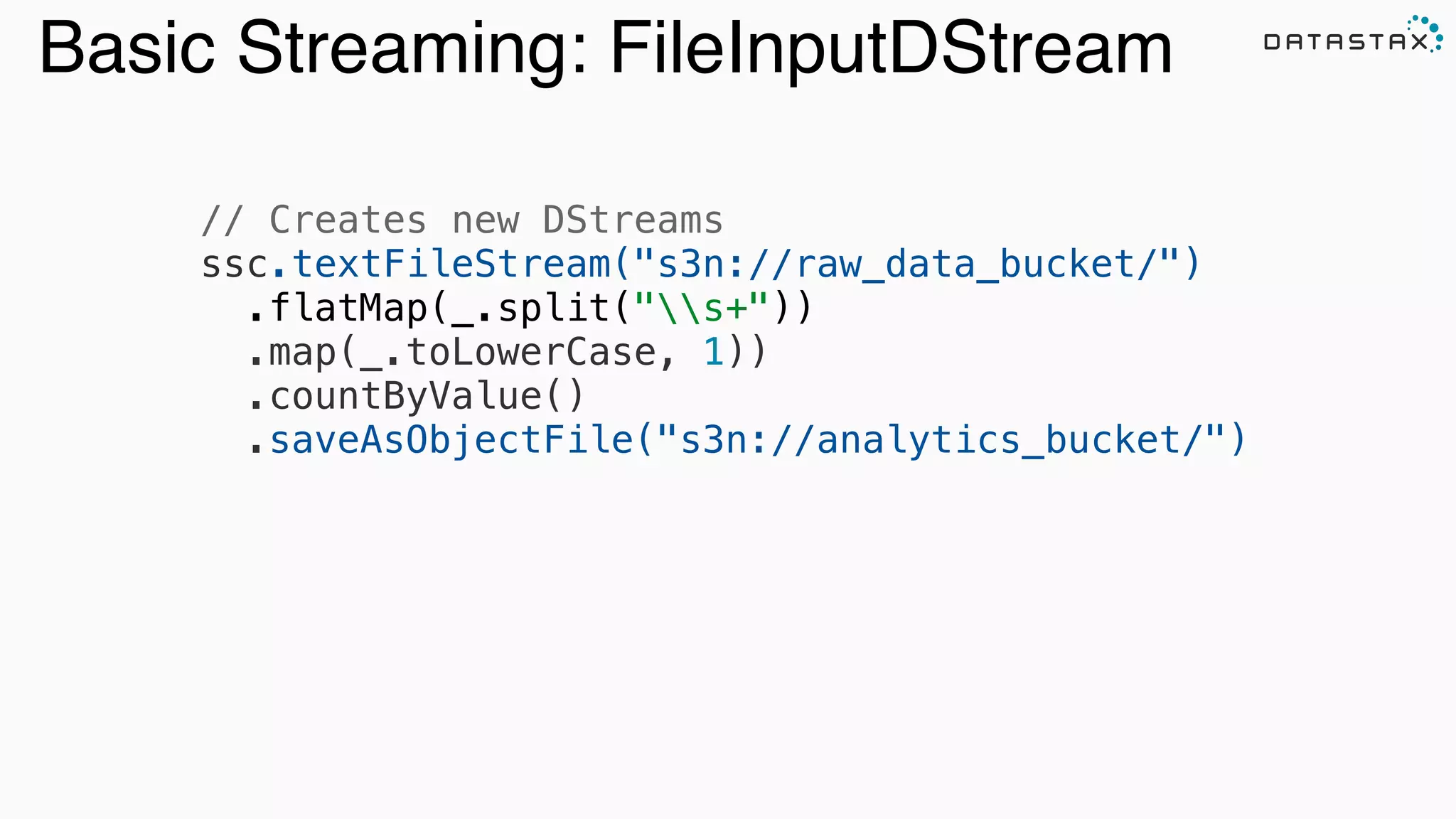
 .map(_._2) .countByValue() .saveToCassandra("my_keyspace","wordcount")](https://image.slidesharecdn.com/lambda-architecture-cassandra-spark-kafka-150408100223-conversion-gate01/75/Lambda-Architecture-with-Spark-Spark-Streaming-Kafka-Cassandra-Akka-and-Scala-69-2048.jpg)

 stream.flatMap { detected => ssc.cassandraTable[AdversaryAttack]("behavior_ks", "observed") .where("adversary = ? and ip = ? and attackType = ?", detected.adversary, detected.originIp, detected.attackType) .collect }.saveToCassandra("profiling_ks", "adversary_profiles")](https://image.slidesharecdn.com/lambda-architecture-cassandra-spark-kafka-150408100223-conversion-gate01/75/Lambda-Architecture-with-Spark-Spark-Streaming-Kafka-Cassandra-Akka-and-Scala-71-2048.jpg)
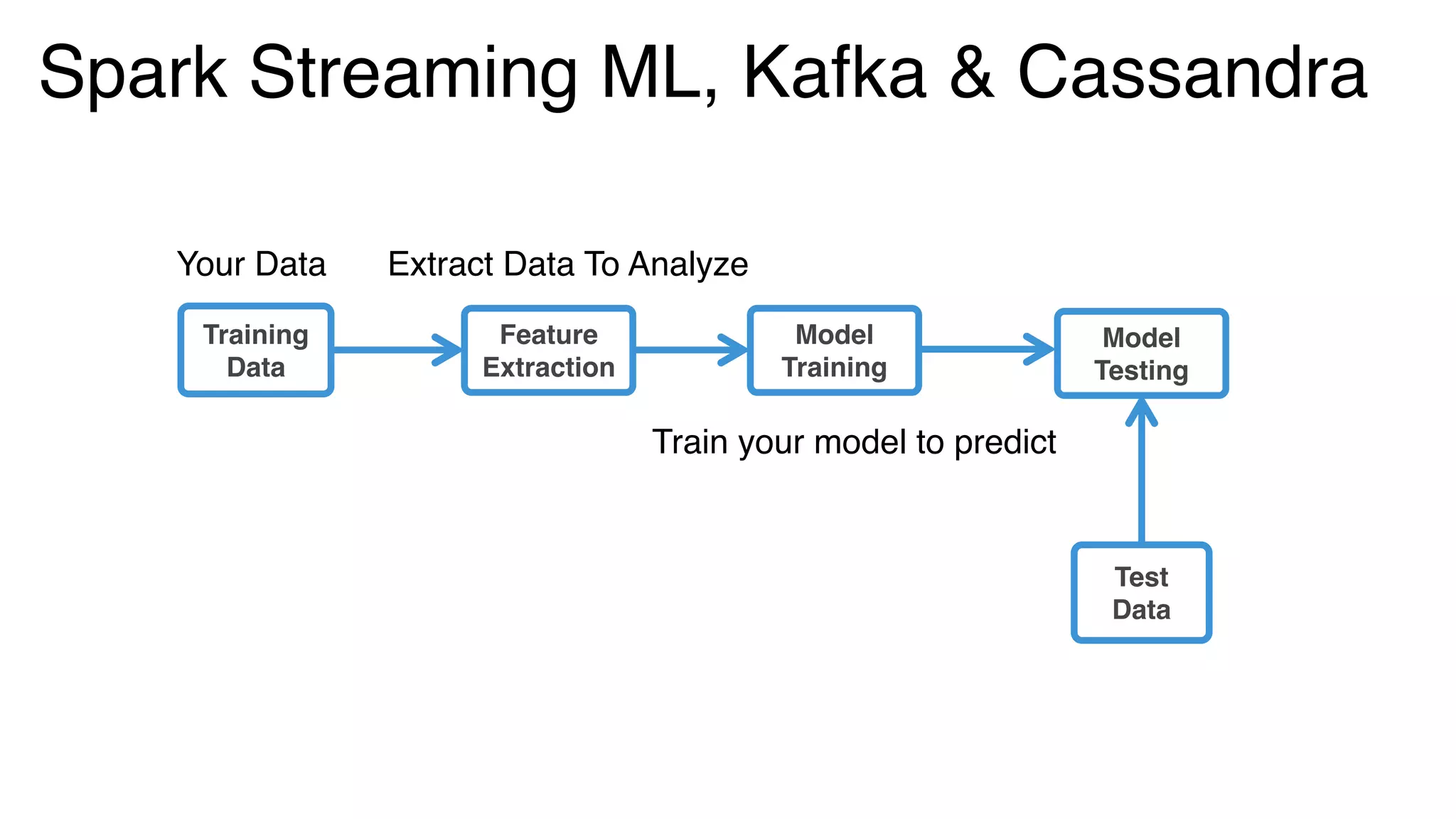
.map(LabeledPoint.parse)
val trainingStream = KafkaUtils.createStream[K, V, KDecoder, VDecoder](
ssc, kafkaParams, topicMap, StorageLevel.MEMORY_ONLY) .map(_._2).map(LabeledPoint.parse) trainingStream.saveToCassandra("ml_keyspace", “raw_training_data")
val model = new StreamingLinearRegressionWithSGD()
.setInitialWeights(Vectors.dense(weights))
.trainOn(trainingStream)
//Making predictions on testData model .predictOnValues(testData.map(lp => (lp.label, lp.features))) .saveToCassandra("ml_keyspace", "predictions") Spark Streaming ML, Kafka & C*](https://image.slidesharecdn.com/lambda-architecture-cassandra-spark-kafka-150408100223-conversion-gate01/75/Lambda-Architecture-with-Spark-Spark-Streaming-Kafka-Cassandra-Akka-and-Scala-73-2048.jpg)





 extends Actor {
override val supervisorStrategy =
OneForOneStrategy(maxNrOfRetries = 10, withinTimeRange = 1.minute) {
case _: ActorInitializationException => Stop
case _: FailedToSendMessageException => Restart case _: ProducerClosedException => Restart case _: NoBrokersForPartitionException => Escalate case _: KafkaException => Escalate
case _: Exception => Escalate
}
private val producer = new KafkaProducer[K, V](producerConfig)
override def postStop(): Unit = producer.close()
def receive = {
case e: KafkaMessageEnvelope[K,V] => producer.send(e)
}
} Kafka Producer as Akka Actor](https://image.slidesharecdn.com/lambda-architecture-cassandra-spark-kafka-150408100223-conversion-gate01/75/Lambda-Architecture-with-Spark-Spark-Streaming-Kafka-Cassandra-Akka-and-Scala-80-2048.jpg)

HttpResponse(200, entity = HttpEntity(MediaTypes.`text/html`, s"POST $entity"))
} getOrElse HttpResponse(404, entity = s"Unsupported request") }
def receive : Actor.Receive = {
case Http.ServerBinding(localAddress, stream) => Source(stream).foreach({
case Http.IncomingConnection(remoteAddress, requestProducer, responseConsumer) =>
log.info("Accepted new connection from {}.", remoteAddress)
Source(requestProducer).map(requestHandler).to(Sink(responseConsumer)).run()
}) }} Akka Actor as REST Endpoint](https://image.slidesharecdn.com/lambda-architecture-cassandra-spark-kafka-150408100223-conversion-gate01/75/Lambda-Architecture-with-Spark-Spark-Streaming-Kafka-Cassandra-Akka-and-Scala-81-2048.jpg)


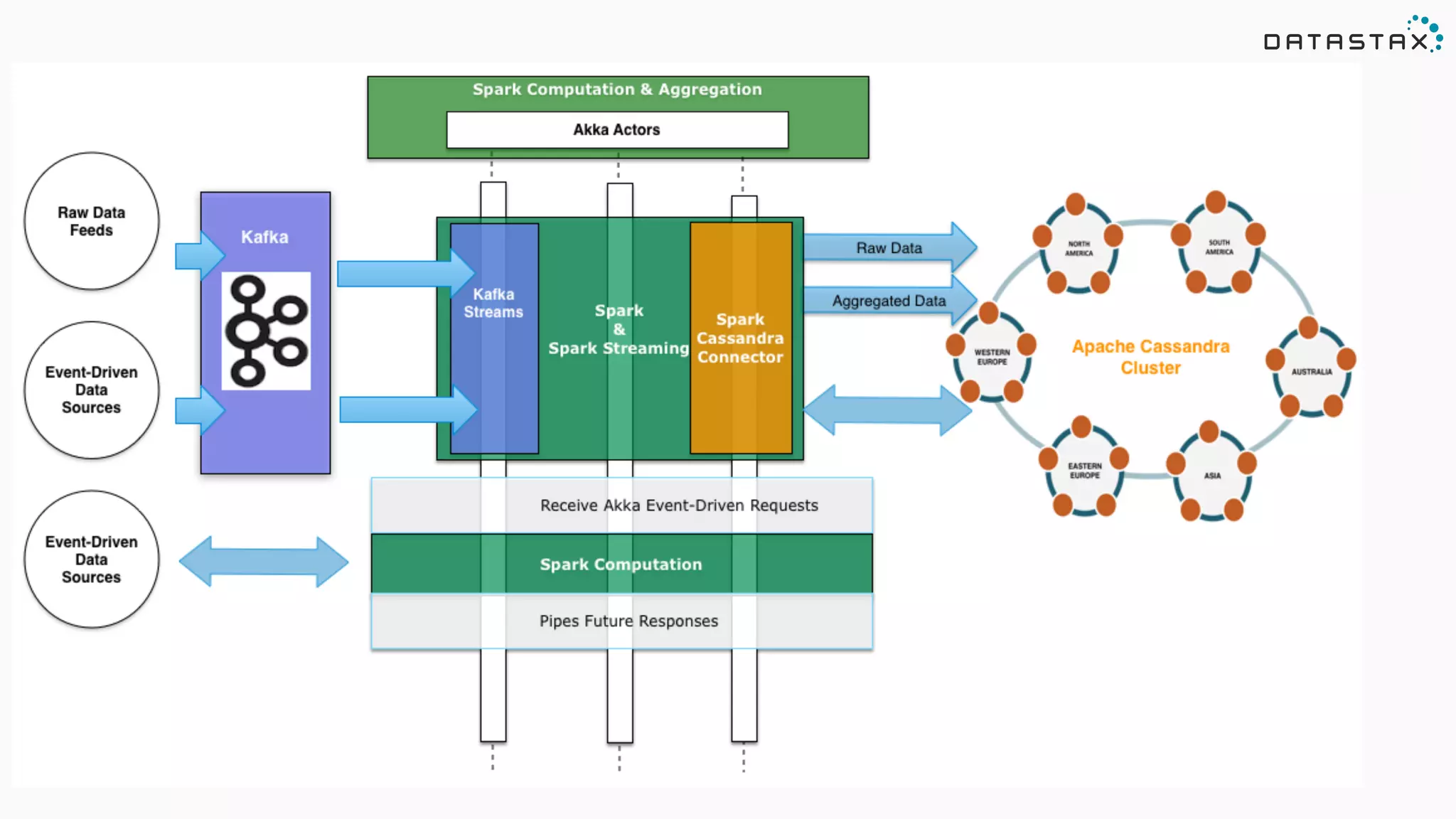
![val kafkaStream = KafkaUtils.createStream[K, V, KDecoder, VDecoder] (ssc, kafkaParams, topicMap, StorageLevel.DISK_ONLY_2)
.map(transform)
.map(RawWeatherData(_))
/** Saves the raw data to Cassandra. */
kafkaStream.saveToCassandra(keyspace, raw_ws_data) Store Raw Data on Ingestion To Cassandra From Kafka Stream /** Now proceed with computations from the same stream.. */ kafkaStream… Now we can replay: on failure, for later computation, etc](https://image.slidesharecdn.com/lambda-architecture-cassandra-spark-kafka-150408100223-conversion-gate01/75/Lambda-Architecture-with-Spark-Spark-Streaming-Kafka-Cassandra-Akka-and-Scala-84-2048.jpg)

![Gets the partition key: Data Locality Spark C* Connector feeds this to Spark Cassandra Counter column in our schema, no expensive `reduceByKey` needed. Simply let C* do it: not expensive and fast. Efficient Stream Computation val kafkaStream = KafkaUtils.createStream[K, V, KDecoder, VDecoder] (ssc, kafkaParams, topicMap, StorageLevel.DISK_ONLY_2)
.map(transform)
.map(RawWeatherData(_))
kafkaStream.saveToCassandra(keyspace, raw_ws_data) /** Per `wsid` and timestamp, aggregates hourly pricip by day in the stream. */
kafkaStream.map { weather =>
(weather.wsid, weather.year, weather.month, weather.day, weather.oneHourPrecip)
}.saveToCassandra(keyspace, daily_precipitation_aggregations)](https://image.slidesharecdn.com/lambda-architecture-cassandra-spark-kafka-150408100223-conversion-gate01/75/Lambda-Architecture-with-Spark-Spark-Streaming-Kafka-Cassandra-Akka-and-Scala-86-2048.jpg)

.where("wsid = ? AND year = ? AND month = ?", e.wsid, e.year, e.month)
.collectAsync()
.map(MonthlyTemperature(_, e.wsid, e.year, e.month)) pipeTo requester } C* data is automatically sorted by most recent - due to our data model. Additional Spark or collection sort not needed.](https://image.slidesharecdn.com/lambda-architecture-cassandra-spark-kafka-150408100223-conversion-gate01/75/Lambda-Architecture-with-Spark-Spark-Streaming-Kafka-Cassandra-Akka-and-Scala-87-2048.jpg)



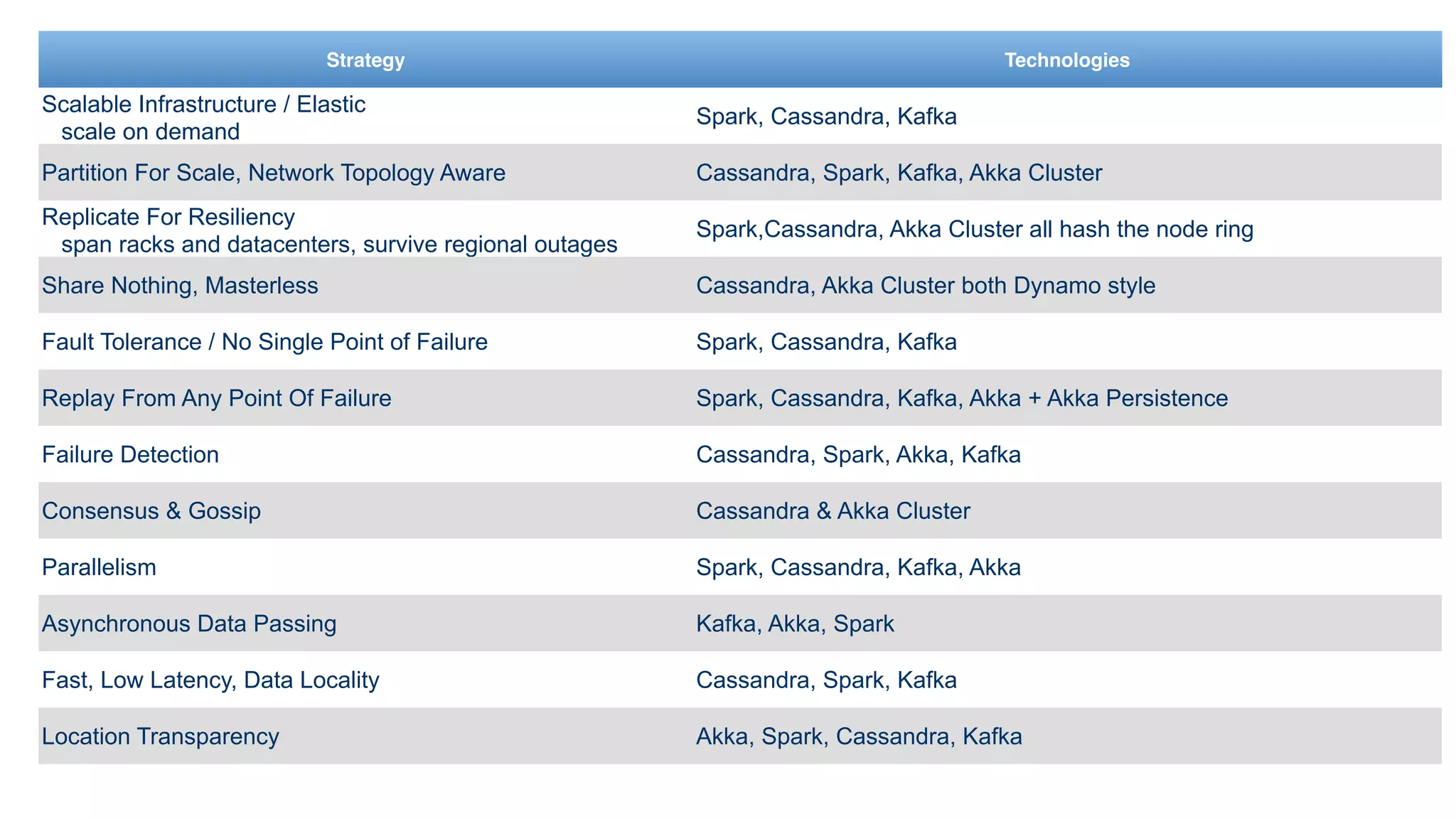
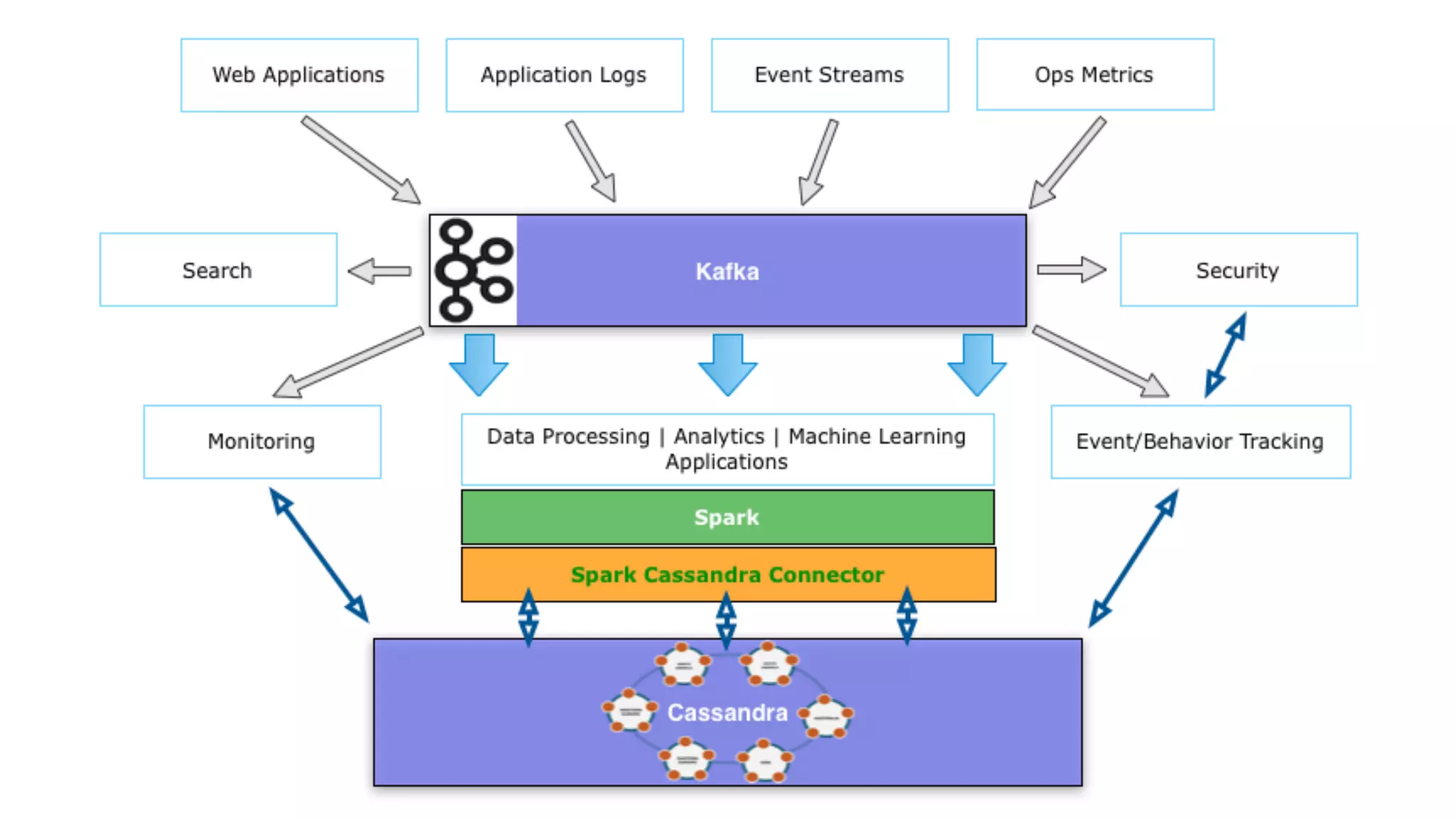
The document outlines a comprehensive overview of the lambda architecture using technologies like Spark, Kafka, Cassandra, and Akka, focusing on scalable and fault-tolerant data processing strategies. It provides various examples of using Spark with Cassandra for real-time data analytics and batch processing, as well as coding snippets demonstrating dataflows and transformations. Additionally, the document discusses key features of the technologies involved, such as operational simplicity, elasticity, and asynchronous messaging.