
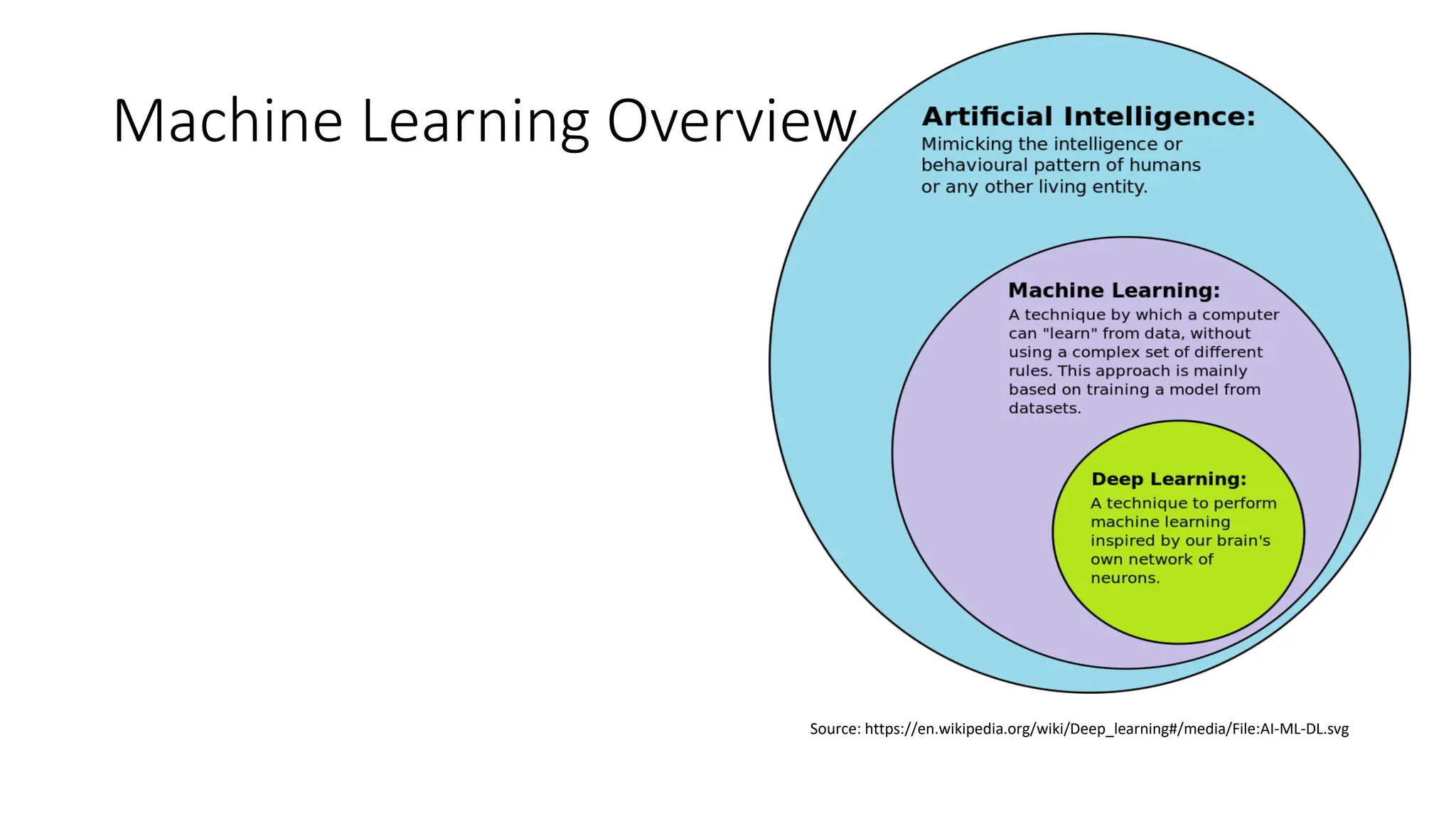








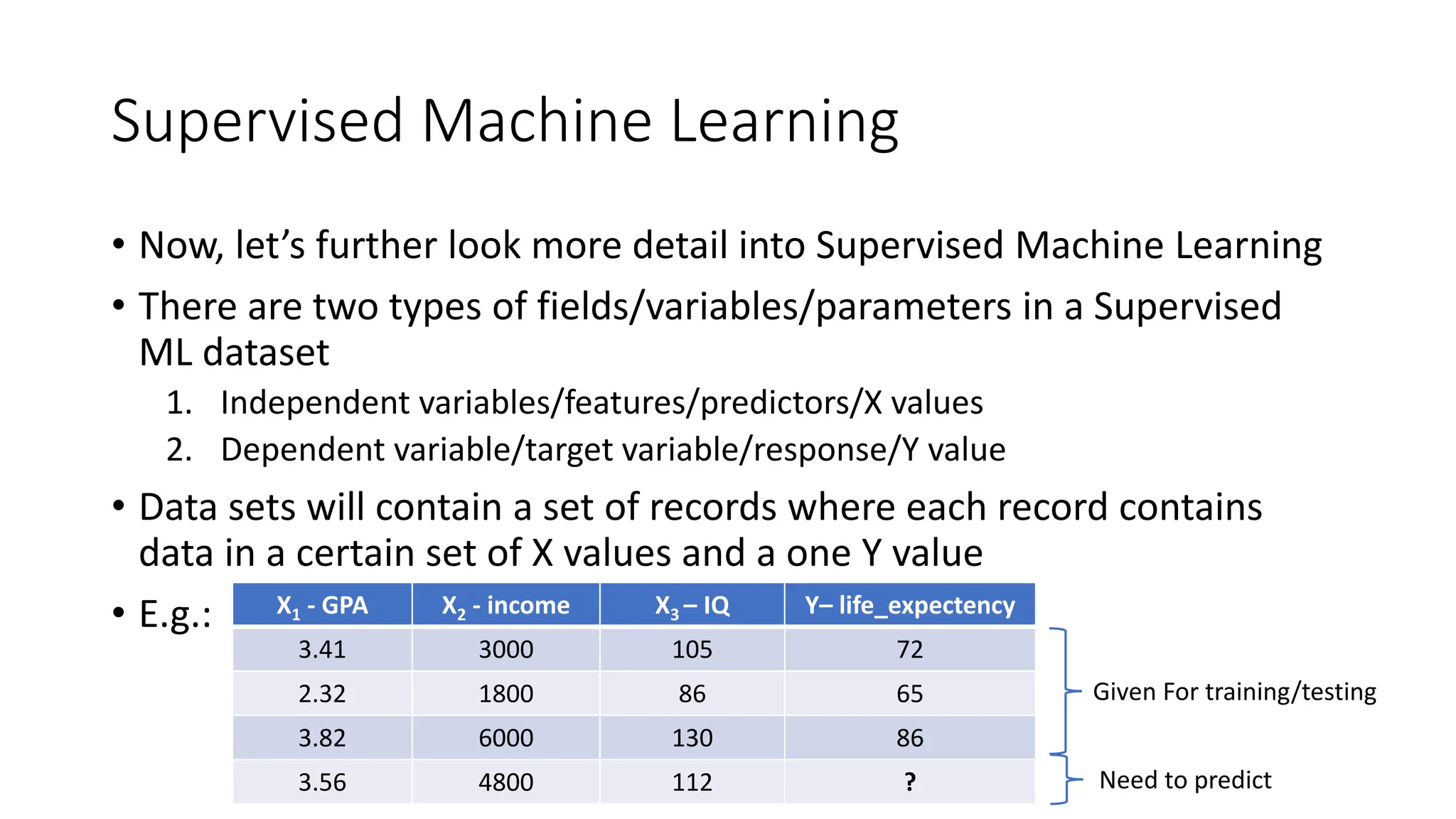
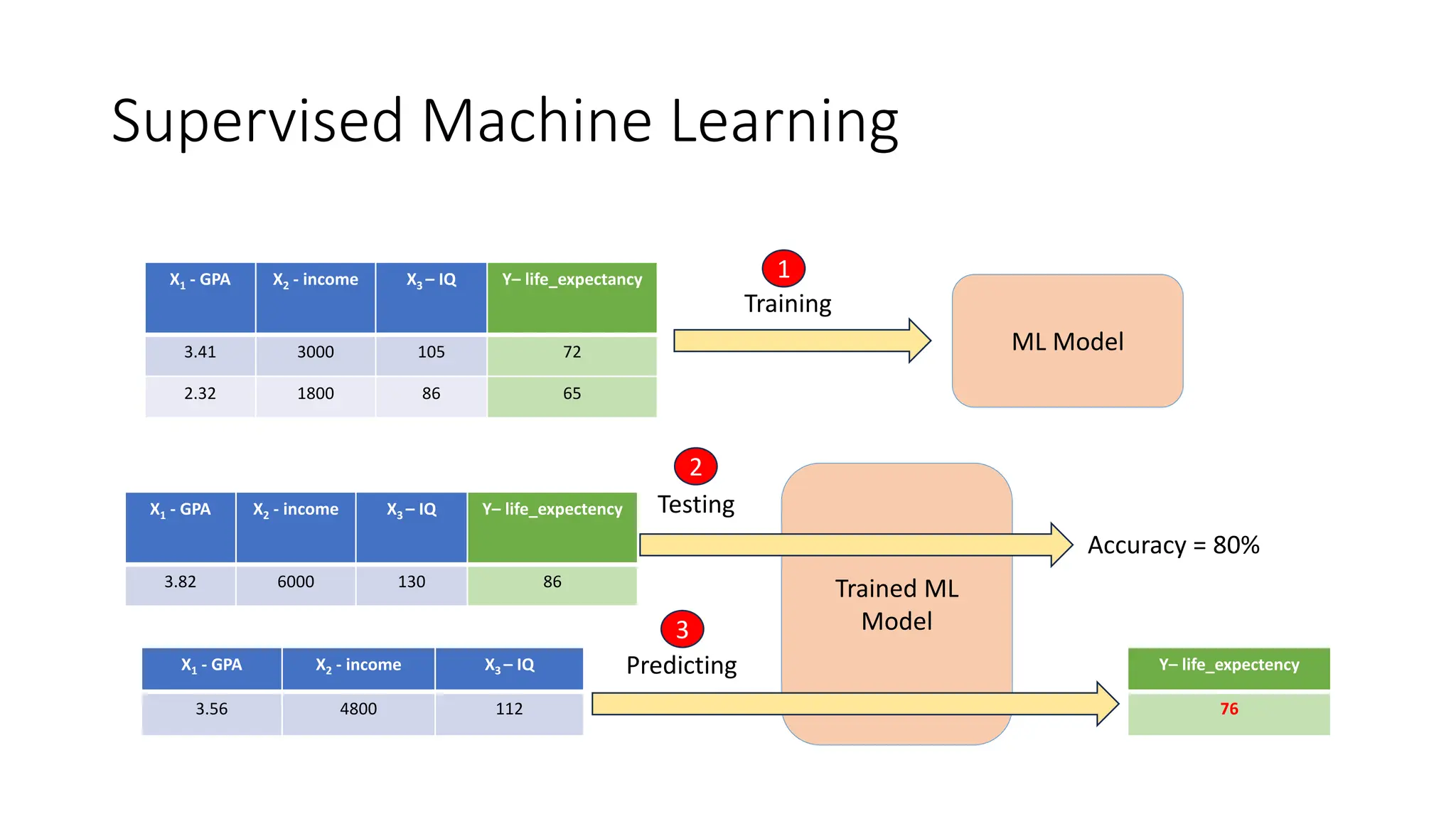








The document provides an overview of statistical learning and machine learning, detailing their definitions, key differences, and applications. It discusses concepts such as supervised and unsupervised learning, model training, and the importance of data in machine learning processes. Additionally, it outlines the course structure for learning machine learning, emphasizing practical skills and the need for a statistical background.