Download as PDF, PPTX



























![Kafka Streams Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "xxx");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9093");
props.put(StreamsConfig.ZOOKEEPER_CONNECT_CONFIG, "localhost:2182");
props.put(StreamsConfig.KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(StreamsConfig.VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
KStreamBuilder builder = new KStreamBuilder();
KStream<String, String> kafkaInput = builder.stream(“INPUT-TOPIC");
KStream<String, RealtimeXXX> auths = kafkaInput.mapValues(value -> ...);
KStream<String, byte[]> serializedAuths = auths.mapValues(a -> AvroSerializer.serialize(a));
serializedAuths.to(Serdes.String(), Serdes.ByteArray(), “OUTPUT-TOPIC");
KafkaStreams streams = new KafkaStreams(builder, props);
streams.start(); 2/2 Example (Java)](https://image.slidesharecdn.com/sparkandmicroservices-160824162008/75/Lessons-Learned-Using-Spark-and-Microservices-30-2048.jpg)





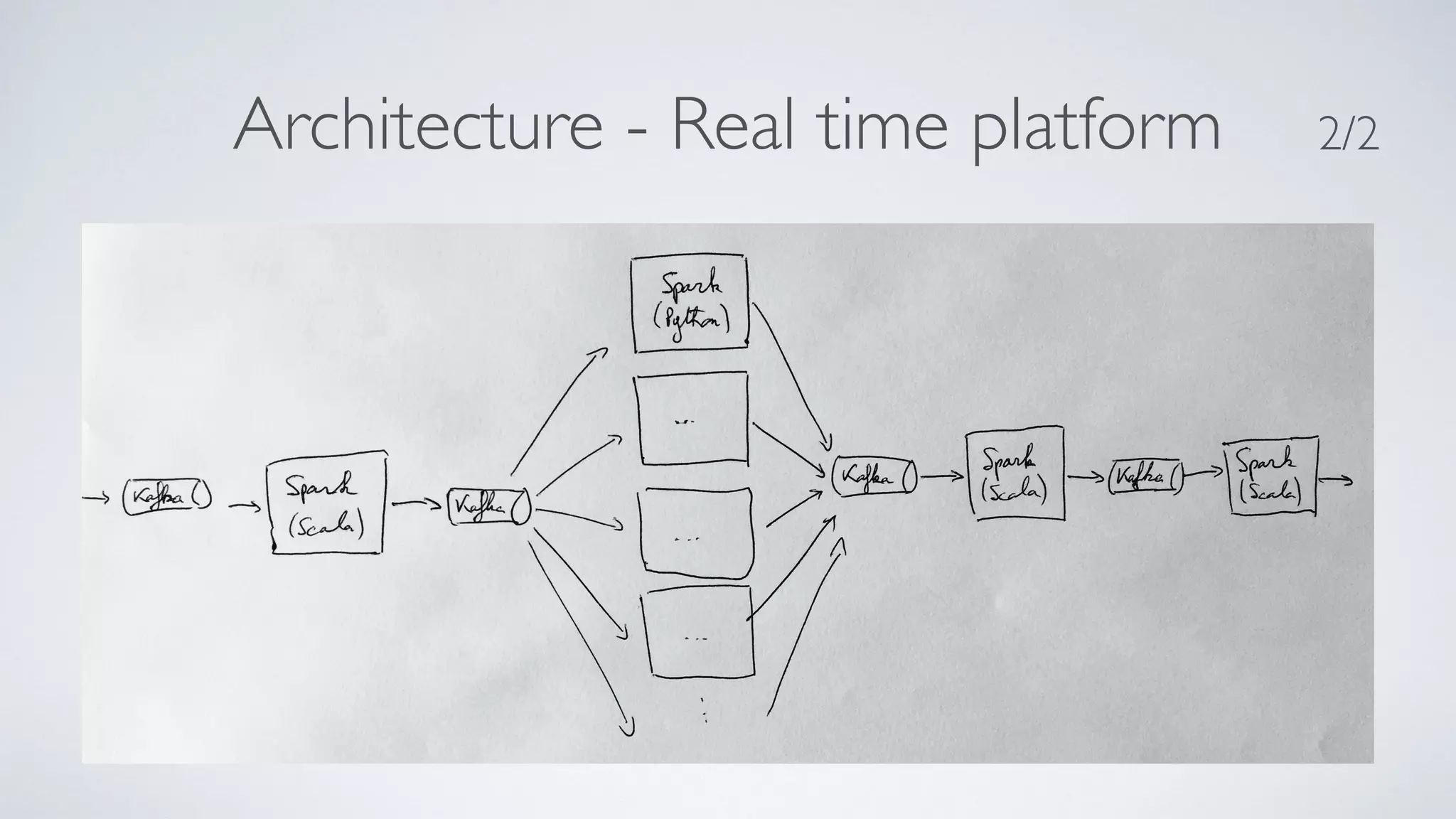
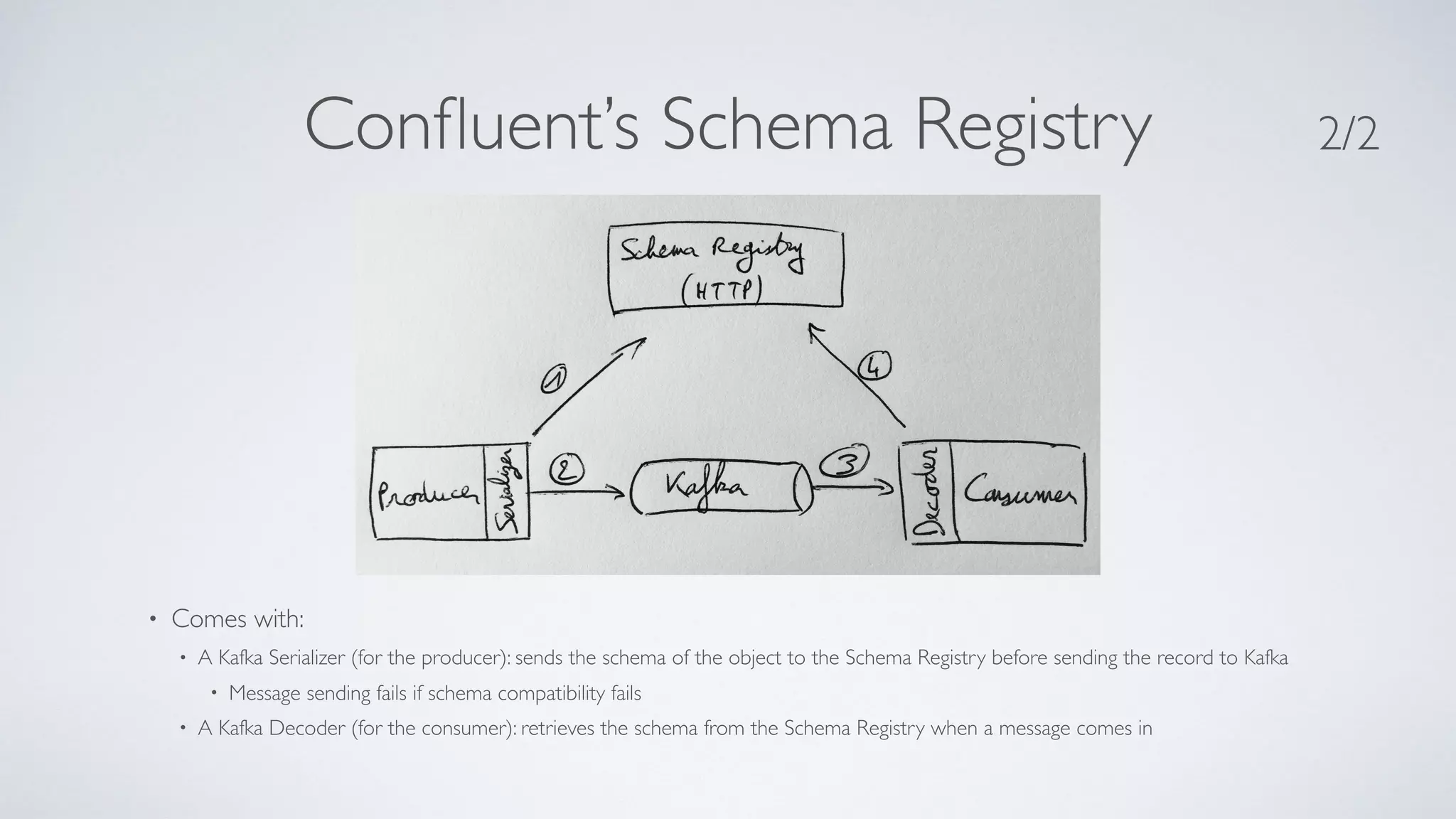
The document discusses lessons learned from building a real-time data processing platform using Spark and microservices. Key aspects include: - A microservices-inspired architecture was used with Spark Streaming jobs processing data in parallel and communicating via Kafka. - This modular approach allowed for independent development and deployment of new features without disrupting existing jobs. - While Spark provided batch and streaming capabilities, managing resources across jobs and achieving low latency proved challenging. - Alternative technologies like Kafka Streams and Confluent's Schema Registry were identified to improve resilience, schemas, and processing latency. - Overall the platform demonstrated strengths in modularity, A/B testing, and empowering data scientists, but faced challenges around