Downloaded 39 times



















![wireless sensor nodes to have low-power microcontrollers ensuring that mechanisms such as virtual memory are either unnecessary or too expensive to implement. It is therefore possible to use embedded operating systems such as eCos or uC/OS for sensor networks. However, such operating systems are often designed with real-time properties. TinyOS is perhaps the first operating system specifically designed for wireless sensor networks. TinyOS is based on an event-driven programming model instead of multithreading. TinyOS programs are composed of event handlers and tasks with run-to-completion semantics. When an external event occurs, such as an incoming data packet or a sensor reading, TinyOS signals the appropriate event handler to handle the event. Event handlers can post tasks that are scheduled by the TinyOS kernel some time later. LiteOS is a newly developed OS for wireless sensor networks, which provides UNIX-like abstraction and support for the C programming language. Contiki is an OS which uses a simpler programming style in C while providing advances such as 6LoWPAN and Protothreads. RIOT implements a microkernel architecture. It provides multithreading with standard API and allows for development in C/C++. RIOT supports common IoT protocols such as 6LoWPAN, IPv6, RPL, TCP, and UDP. 1.11.5. Online Collaborative Sensor Data Management Platforms Online collaborative sensor data management platforms are on-line database services that allow sensor owners to register and connect their devices to feed data into an online database for storage and also allow developers to connect to the database and build their own applications based on that data. Examples include Xively and the Wikisensing platform. Such platforms simplify online collaboration between users over diverse data sets ranging from energy and environment data to that collected from transport services. Other services include allowing developers to embed real-time graphs & widgets in websites; analyse and process historical data pulled from the data feeds; send real-time alerts from any data stream to control scripts, devices and environments. The architecture of the Wiki sensing system is described in [21] describes the key components of such systems to include APIs and interfaces for online collaborators, a middleware containing the business logic needed for the sensor data management and processing and a storage model suitable for the efficient storage and retrieval of large volumes of data. 1.11.6. Simulation of WSNs At present, agent-based modelling and simulation is the only paradigm which allows the simulation of complex behaviour in the environments of wireless sensors (such as flocking). Agent-based simulation of wireless sensor and ad hoc networks is a relatively new paradigm. Agent-based modelling was originally based on social simulation.](https://image.slidesharecdn.com/doc1-161112072147/75/LOAD-BALANCED-CLUSTERING-WITH-MIMO-UPLOADING-TECHNIQUE-FOR-MOBILE-DATA-GATHERING-IN-WIRELESS-SENSOR-NETWORK-20-2048.jpg)

























![ϵπ where xϵ[1,M-1]. Now we prove that schedule π for M implies a valid schedule π´ for M+2 cluster heads. Suppose we add two new cluster heads CHa and CHb. If the distance between the two new heads da.b is no longer than √3 Rs, then there exists a valid schedule π´=πỤ(a,b). Otherwise, we can pair (CHx, CHy) where {dx.y ≤ √3 Rs | CHy ϵ {CHa, CHb}}, and pair CH0 with the remaining new cluster head. Based on the above discussion, we can conclude that for any even number M there exists a valid schedule satisfying da.b ≤ √3Rs for any pair (a, b) To successfully choose the selected polling points in a cluster, there should exist at least one possible schedule in which the sets of candidate polling points for all scheduling pairs are non- empty at the same time, i.e., ⱻπ ϵ П such that P´≠ ɸ for all the scheduling pair i ϵ π. This requirement imposes challenges on the distribution of polling points. We study the case that polling points are located at the intersections of grids with each polling point apart from its adjacent neighbors in horizontal and vertical directions in the same distance t, as plotted in Fig. 6a. We have the following property on t to satisfy the above requirement. Property9. If polling points are uniformly distributed as depicted in Fig. 6a, for a CHG with M cluster heads, when t ≤ √2(1-√3/2)Rs, regardless of the value of M, ⱻπ ϵ П, for each scheduling pair(a,b) ϵ π,ƩpϵP Pr(da.p ≤ Rs,db.p ≤ Rs) ≠ 0 where P denotes the set of all polling points, da.p and db.p are the distances between cluster heads a and b in a scheduling pair and the polling point p, respectively. Proof. Under the above specified distribution of polling points, regardless of the orientation of grids, there is at least one polling point located in a circle area with radius √2/2t.For example, in Fig.6a, there are 4 polling points distributed in such an area, which is highlighted in shadow. Moreover, it is known from Property 8 that there exist some schedules, in which the distance between two cluster heads in any scheduling pair is upper bounded by √3Rs. Consider the worst case that there is a scheduling pair (a,b) with da.b =√3Rs (see Fig.6b). A candidate polling point p for (a, b) should be within the transmission range of cluster heads a and b simultaneously. The line shadowed area in Fig.6b, which is the intersection of transmission areas of a and b, indicates the possible distribution region of candidate polling points for (a,b). It is clear that when da.b is shorter; the area of the region would be larger, which corresponds to the lower distribution density requirement on polling points. Hence, considering the case with da,b=√3Rs is sufficient for the proof of the property. It is shown in Fig. 6b that there exists an inscribed circle with radius (1-√3/2)Rs inside the line shadowed area. If t = √2 (1-√3/2)Rs, substituting Rs with the expression of t, the radius of the inscribed circle in the line shadowed area is equal to √2/2t. As mentioned earlier, there is at least one polling point located in such an area. Thus there always exist some candidate polling points for scheduling pair (a, b), i.e. ƩpϵP Pr (da.p ≤ Rs, da.p ≤ Rs)≠ 0.In other words, when t ≤ √2(1-√3/2)Rs, there exist some schedules in which the set of candidate polling points for each scheduling pair is always non- empty. 6.4.2. MU-MIMO Uploading We jointly consider the selections of the schedule pattern and selected polling points for the corresponding scheduling pairs, aiming at achieving the maximum sum of MIMO uplink](https://image.slidesharecdn.com/doc1-161112072147/75/LOAD-BALANCED-CLUSTERING-WITH-MIMO-UPLOADING-TECHNIQUE-FOR-MOBILE-DATA-GATHERING-IN-WIRELESS-SENSOR-NETWORK-52-2048.jpg)





![the proposed algorithm we set the message deadline to be uniformly randomly distributed over [0, X] and change X from 60 to 180mins. Therefore, the mean of deadline is from 30 to 90mins. The number of nodes n is set to 200 and the side length of sensing field l varies from 100 to 300 with an increment of 50. In Fig.9a we can see that given a short average deadline and a large field (l=300m, mean deadline equals 30mins), and almost all the messages would miss their deadlines. This is because that the moving time of SenCar to traverse all the polling points exceeds most of the deadlines. Once we relax the deadline constraints (mean deadline equals 40-90mins), the percentage of missing deadlines drops fast. We also observe that when l is between 100 to 200m, the algorithm is able to maintain the percentage of missing deadlines with in 20percent for most cases. Fig.14. Evaluation of data collection with time constraints. (a) Percentage of data messages that miss the deadline. (b) Impact of time constraints on traveling cost of SenCar. To meet dynamic message deadlines, extra moving cost on SenCar is observed. This is because that the cluster with an earlier message deadline may be far from SenCar’s location. We present the traveling cost of SenCar for different cases in Fig.9b and compare it with the traveling cost computed by the nearest neighbor heuristic algorithm in Table 2 (no time constraint on messages). When l=300m and mean deadline equals 90mins, the moving cost on SenCar is over 5,000 m compared to 1,846 m without time constraints. When l=100m and mean deadline equals 90mins, the moving cost on SenCar is 404m compared to 347m without time constraints. The results indicate that higher cost on SenCar is needed with a larger field size. To further reduce traveling cost on SenCar while guaranteeing to meet all the time constraints, multiple SenCar’s are needed to partition the data collection tour and many existing solutions for the Vehicle Routing Problems with Time Windows can be adapted to optimize the data collection routes.](https://image.slidesharecdn.com/doc1-161112072147/75/LOAD-BALANCED-CLUSTERING-WITH-MIMO-UPLOADING-TECHNIQUE-FOR-MOBILE-DATA-GATHERING-IN-WIRELESS-SENSOR-NETWORK-60-2048.jpg)
![CHAPTER-8 CONCLUSIONS AND FUTURE WORKS 8.1. CONCLUSION We have proposed the LBC-MIMO framework for mobile data collection in a WSN. It consists of sensor layer, cluster head layer and SenCar layer. It employs distributed load balanced clustering for sensor self-organization, adopts collaborative inter-cluster communication for energy-efficient transmissions among CHGs, uses dual data uploading for fast data collection, and optimizes SenCar’s mobility to fully enjoy the benefits of MU- MIMO. Our performance study demonstrates the effectiveness of the proposed framework. The results show that LBC-MIMO can greatly reduce energy consumptions by alleviating routing burdens on nodes and balancing workload among cluster heads, which achieves 20 percent less data collection time compared to SISO mobile data gathering and over 60 percent energy saving on cluster heads. We have also justified the energy overhead and explored the results with different numbers of cluster heads in the framework. 8.2. FUTURE WORKS Finally, we would like to point out that there are some interesting problems that may be studied in our future work. The first problem is how to find polling points and compatible pairs for each cluster. A discretization scheme should be developed to partition the continuous space to locate the optimal polling point for each cluster. Then finding the compatible pairs becomes a matching problem to achieve optimal overall spatial diversity. The second problem is how to schedule MIMO uploading from multiple clusters. An algorithm that adapts to the current MIMO-based transmission scheduling algorithms should be studied in future. REFERENCES [1] B. Krishnamachari, Networking Wireless Sensors. Cambridge, U.K.: Cambridge Univ. Press, Dec. 2005. [2] R. Shorey, A. Ananda, M. C. Chan, and W. T. Ooi, Mobile, Wireless, Sensor Networks. Piscataway, NJ, USA: IEEE Press, Mar. 2006. [3] I. F. Akyildiz, W. Su, Y. Sankarasubramaniam, and E. Cayirci, “A survey on sensor networks,” IEEE Commun. Mag., vol. 40, no. 8, pp. 102–114, Aug. 2002. [4] W. C. Cheng, C. Chou, L. Golubchik, S. Khuller, and Y. C. Wan, “A coordinated data collection approach: Design, evaluation, and comparison,” IEEE J. Sel. Areas Commun., vol. 22, no. 10, pp. 2004–2018, Dec. 2004. [5] K. Xu, H. Hassanein, G. Takahara, and Q. Wang, “Relay node deployment strategies in heterogeneous wireless sensor networks,” IEEE Trans. Mobile Compute., vol. 9, no. 2, pp. 145–159, Feb. 2010.](https://image.slidesharecdn.com/doc1-161112072147/75/LOAD-BALANCED-CLUSTERING-WITH-MIMO-UPLOADING-TECHNIQUE-FOR-MOBILE-DATA-GATHERING-IN-WIRELESS-SENSOR-NETWORK-61-2048.jpg)
![[6] O. Gnawali, R. Fonseca, K. Jamieson, D. Moss, and P. Levis, “Collection tree protocol,” in Proc. 7th ACM Conf. Embedded Netw. Sensor Syst., 2009, pp. 1–14. [7] E. Lee, S. Park, F. Yu, and S.-H. Kim, “Data gathering mechanism with local sink in geographic routing for wireless sensor networks,” IEEE Trans. Consum. Electron., vol. 56, no. 3, pp. 1433–1441, Aug. 2010. [8] Y. Wu, Z. Mao, S. Fahmy, and N. Shroff, “Constructing maximum- lifetime data- gathering forests in sensor networks,” IEEE/ ACM Trans. Netw., vol. 18, no. 5, pp. 1571– 1584, Oct. 2010. [9] X. Tang and J. Xu, “Adaptive data collection strategies for lifetime- constrained wireless sensor networks,” IEEE Trans. Parallel Distrib. Syst., vol. 19, no. 6, pp. 721–7314, Jun. 2008. [10] W. R. Heinzelman, A.Chandrakasan, and H.Balakrishnan, “An application-specific protocol architecture for wireless microsensor networks,” IEEE Trans. Wireless Commun., vol. 1, no. 4, pp. 660–660, Oct. 2002. [11] O. Younis and S. Fahmy, “Distributed clustering in ad-hoc sensor networks: A hybrid, energy-efficient approach,” in IEEE Conf. Comput. Commun., pp. 366–379, 2004. [12] D. Gong, Y. Yang, and Z. Pan, “Energy-efficient clustering in lossy wireless sensor networks,” J. Parallel Distrib. Comput., vol. 73, no. 9, pp. 1323–1336, Sep. 2013. [13] A. Amis, R. Prakash, D. Huynh, and T. Vuong, “Max-min d-cluster formation in wireless ad hoc networks,” in Proc. IEEE Conf. Comput. Commun., Mar. 2000, pp. 32–41. [14] A. Manjeshwar and D. P. Agrawal, “Teen: A routing protocol for enhanced efficiency in wireless sensor networks,” in Proc. 15th Int. IEEE Parallel Distrib. Process. Symp., Apr. 2001, pp. 2009–2015. [15] Z. Zhang, M. Ma, and Y. Yang, “Energy efficient multi-hop polling in clusters of two- layered heterogeneous sensor networks,” IEEE Trans. Comput., vol. 57. no. 2, pp. 231–245, Feb. 2008. [16] M. Ma and Y. Yang, “SenCar: An energy-efficient data gathering mechanism for large- scale multihop sensor networks,” IEEE Trans. Parallel Distrib. Syst., vol. 18, no. 10, pp. 1476–1488, Oct. 2007. [17] B. Gedik, L. Liu, and P. S. Yu, “ASAP: An adaptive sampling approach to data collection in sensor networks,” IEEE Trans. Parallel Distrib. Syst., vol. 18, no. 12, pp. 1766– 1783, Dec. 2007. [18] C. Liu, K. Wu, and J. Pei, “An energy-efficient data collection framework for wireless sensor networks by exploiting spatiotemporal correlation,” IEEE Trans. Parallel Distrib. Syst., vol. 18, no. 7, pp. 1010–1023, Jul. 2007. [19] R. Shah, S. Roy, S. Jain, and W. Brunette, “Data MULEs: Modeling a three-tier architecture for sparse sensor networks,” Elsevier Ad Hoc Netw. J., vol. 1, pp. 215–233, Sep. 2003. [20] D. Jea, A. A. Somasundara, and M. B. Srivastava, “Multiple controlled mobile elements (data mules) for data collection in sensor networks,” in Proc. IEEE/ACM Int. Conf. Distrib. Comput. Sensor Syst., Jun. 2005, pp. 244–257. [21] M. Ma, Y. Yang, and M. Zhao, “Tour planning for mobile data gathering mechanisms in wireless sensor networks,” IEEE Trans. Veh. Technol., vol. 62, no. 4, pp. 1472–1483, May 2013.](https://image.slidesharecdn.com/doc1-161112072147/75/LOAD-BALANCED-CLUSTERING-WITH-MIMO-UPLOADING-TECHNIQUE-FOR-MOBILE-DATA-GATHERING-IN-WIRELESS-SENSOR-NETWORK-62-2048.jpg)
![[22] M. Zhao and Y. Yang, “Bounded relay hop mobile data gathering in wireless sensor networks,” IEEE Trans. Comput., vol. 61, no. 2, pp. 265–271, Feb. 2012. [23] M. Zhao, M. Ma, and Y. Yang, “Mobile data gathering with spacedivision multiple access in wireless sensor networks,” in Proc. IEEE Conf. Comput. Commun., 2008, pp. 1283–1291. [24] M. Zhao, M. Ma, and Y. Yang, “Efficient data gathering with mobile collectors and space-division multiple access technique in wireless sensor networks,” IEEE Trans. Comput., vol. 60, no. 3, pp. 400–417, Mar. 2011. [25] A. A. Somasundara, A. Ramamoorthy, and M. B. Srivastava,, “Mobile element scheduling for efficient data collection in wireless sensor networks with dynamic deadlines,” in Proc. 25th IEEE Int. Real-Time Syst. Symp., Dec. 2004, pp. 296–305. [26] W. Ajib and D. Haccoun, “An overview of scheduling algorithms in MIMO-based fourth-generation wireless systems,” IEEE Netw., vol. 19, no. 5, Sep./Oct. 2005, pp. 43–48. [27] S. Cui, A. J. Goldsmith, and A. Bahai, “Energy-efficiency of MIMO and cooperative MIMO techniques in sensor networks,” IEEE J. Sel. Areas Commun., vol. 22, no. 6, pp. 1089–1098, Aug. 2004. [28] S. Jayaweera, “Virtual MIMO-based cooperative communication for energy-constrained wireless sensor networks,” IEEE Trans. Wireless Commun., vol. 5, no. 5, pp. 984–989, May 2006. [29] S. Cui, A. J. Goldsmith, and A. Bahai, “Energy-constrained modulation optimization,” IEEE Trans. Wireless Commun., vol. 4, no. 5, pp. 2349–2360, Sep. 2005. [30] I. Rhee, A. Warrier, J. Min, and X. Song, “DRAND: Distributed randomized TDMA scheduling for wireless ad-hoc networks,” in Proc. 7th ACM Int. Symp. Mobile Ad Hoc Netw. Comput., 2006, pp. 190–201. [31] S. C. Ergen and P. Varaiya, “TDMA scheduling algorithms for wireless sensor networks,” Wireless Netw., vol. 16, no. 4, pp. 985– 997, May 2010. [32] I. Rhee, A. Warrier, M. Aia, and J. Min, “Z-MAC: A hybrid MAC for wireless sensor networks,” in Proc. 3rd ACM Int. Conf. Embedded Netw. Sensor Syst., 2005, pp. 90–101. [33] D. M. Blough and P. Santi, “Investigating upper bounds on network lifetime extension for cell-based energy conservation techniques in stationary ad hoc networks,” in Proc. 13th Annu. ACM Int. Conf. Mobile Comput. Netw., 2002, pp. 183–192. [34] F. Ye, G. Zhong, S. Lu, and L. Zhang, “PEAS: A robust energy conserving protocol for long-lived sensor networks,” in Proc. 23rd IEEE Int. Conf. Distrib. Comput. Syst., 2003, pp. 28–37. [35] T. H. Cormen, C. E. Leiserson, R. L. Rivest, and C. Stein, Introduction to Algorithms. Cambridge, MA, USA: MIT Press, 2001. [36] V. Tarokh, H. Jafarkhani, and A. R. Calderbank, “Space-time block codes for orthogonal designs,” IEEE Trans. Info. Theory, vol. 45, no. 5, pp. 1456–1467, Jul. 1999. [37] D. Tse and P. Viswanath, Fundamentals of Wireless Communication. Cambridge, U.K.: Cambridge Univ. Press, May 2005. [38][Online].(2013).Available: http://www.ti.com/product/DAC128S085/technicaldocuments [39] M. M. Solomon, “Algorithm for the vehicle routing and scheduling problems with time window constraints,” Oper. Res., vol. 35, no. 2, pp. 254–265, 1987.](https://image.slidesharecdn.com/doc1-161112072147/75/LOAD-BALANCED-CLUSTERING-WITH-MIMO-UPLOADING-TECHNIQUE-FOR-MOBILE-DATA-GATHERING-IN-WIRELESS-SENSOR-NETWORK-63-2048.jpg)

This project report details a proposed three-layer framework for mobile data collection in wireless sensor networks, utilizing distributed load balanced clustering and dual data uploading techniques, termed lbc-mimo. The framework aims to enhance scalability, extend network lifetime, and reduce data collection latency, with implementations demonstrating significant energy savings compared to traditional methods. The document includes comprehensive explanations of mobile computing concepts, system designs, implementation processes, and performance evaluations.
Project titled 'Load Balanced Clustering with MIMO Uploading Technique' submitted as part of M.Tech degree requirements and certification for project work completion.
Acknowledgments expressed for guidance, support, and infrastructure aid from various individuals and faculty that aided in project completion.
Comprehensive organization of the project document including chapters on Mobile Computing, Literature Review, Existing and Proposed Systems, Design, Implementation, Evaluation, and Conclusions.
An introduction to mobile computing, applications in various scenarios, and benefits including flexibility, productivity, and enhancement in business processes.
Discussion of WSNs, their structure, applications like monitoring and industrial use, characteristics, platforms, and concepts like data integration and in-network processing.
Overview of the current state of research in WSN data collection, energy consumption issues, and proposed new techniques for optimization.
Analysis of existing data collection methods, including relay routing and clustered systems, discussing their limitations in energy consumption and efficiency.
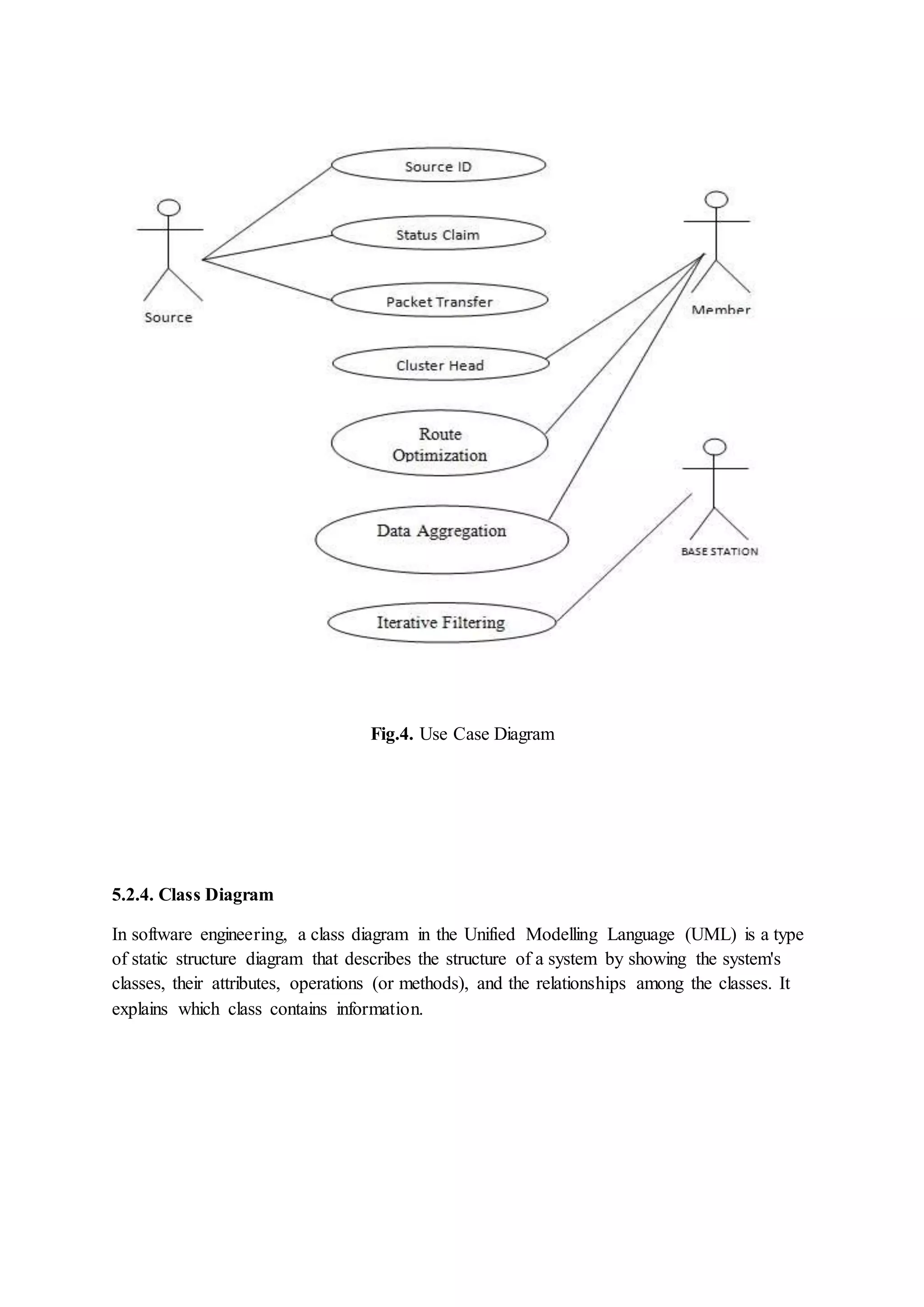
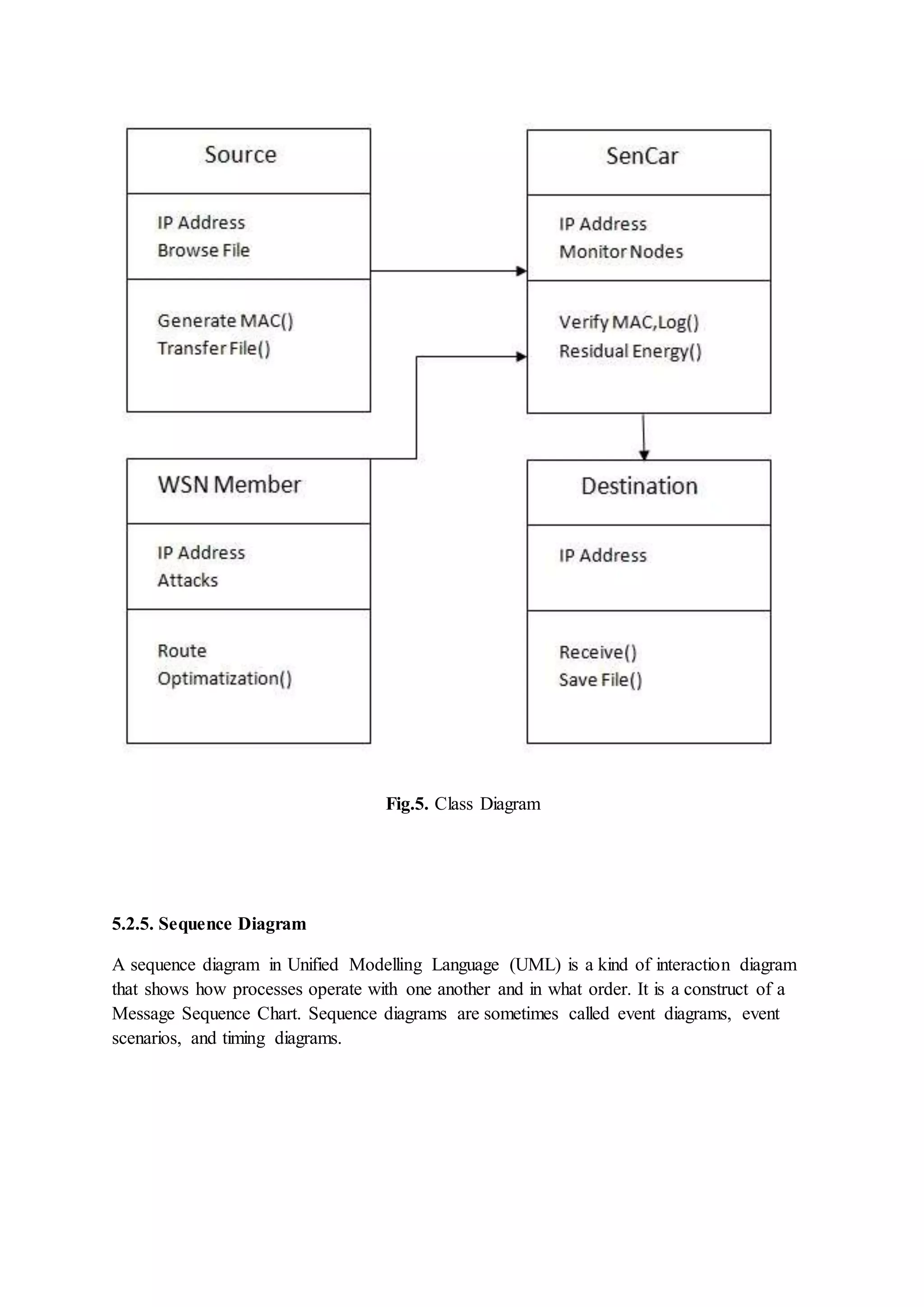
Introduction of the LBC-MIMO framework consisting of three layers focused on efficient mobile data collection, including specifics on clustering and communication methods.
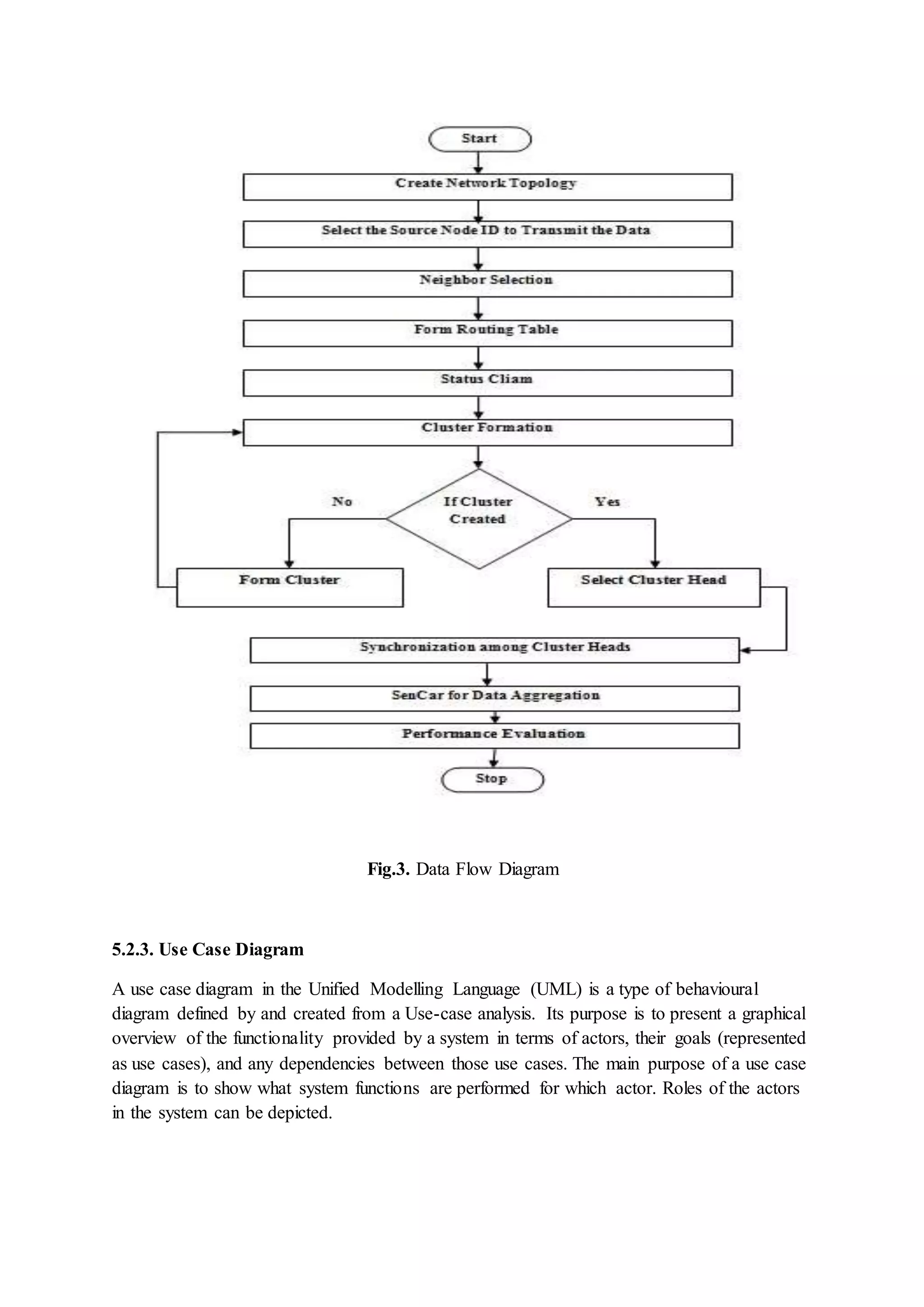
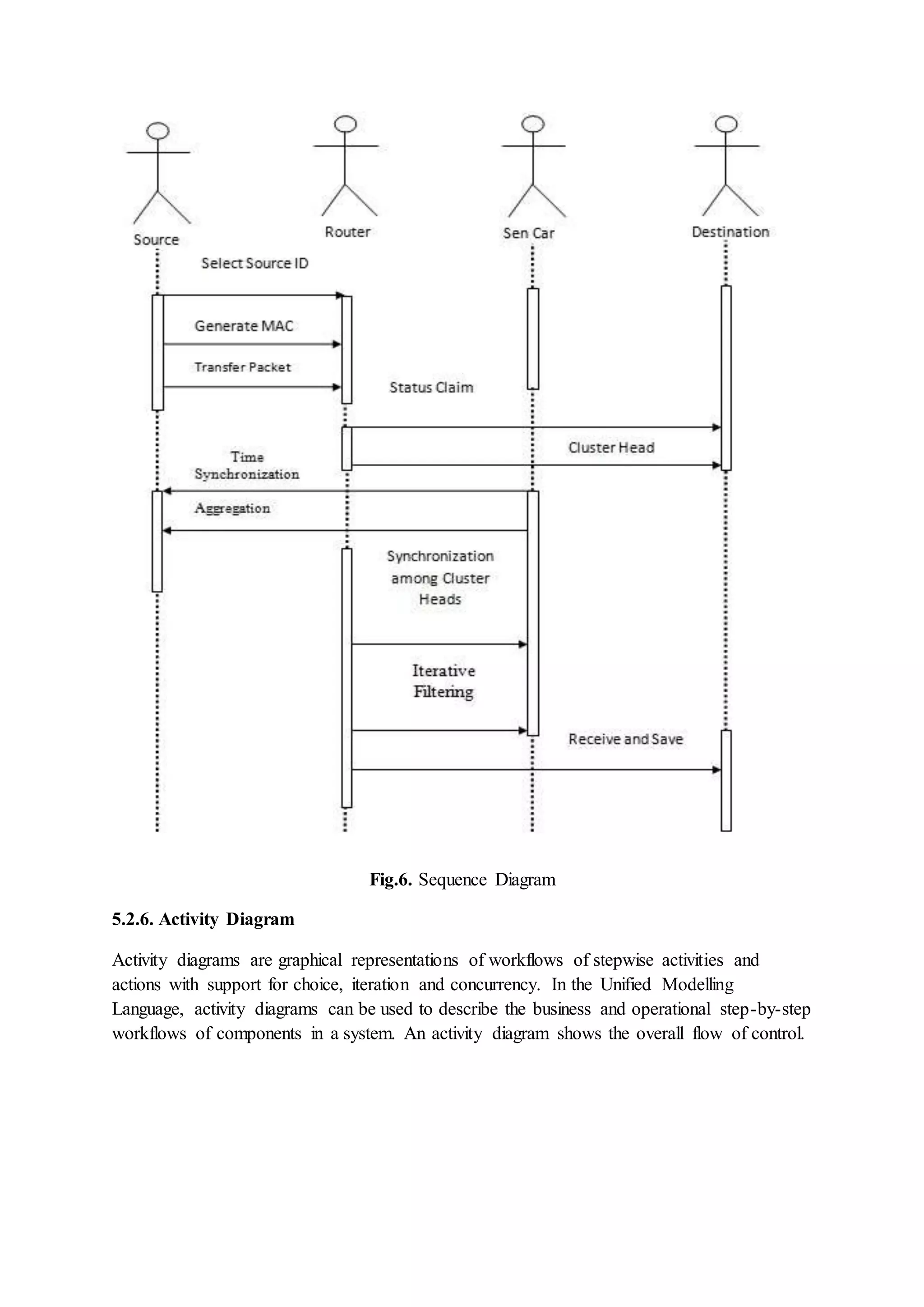
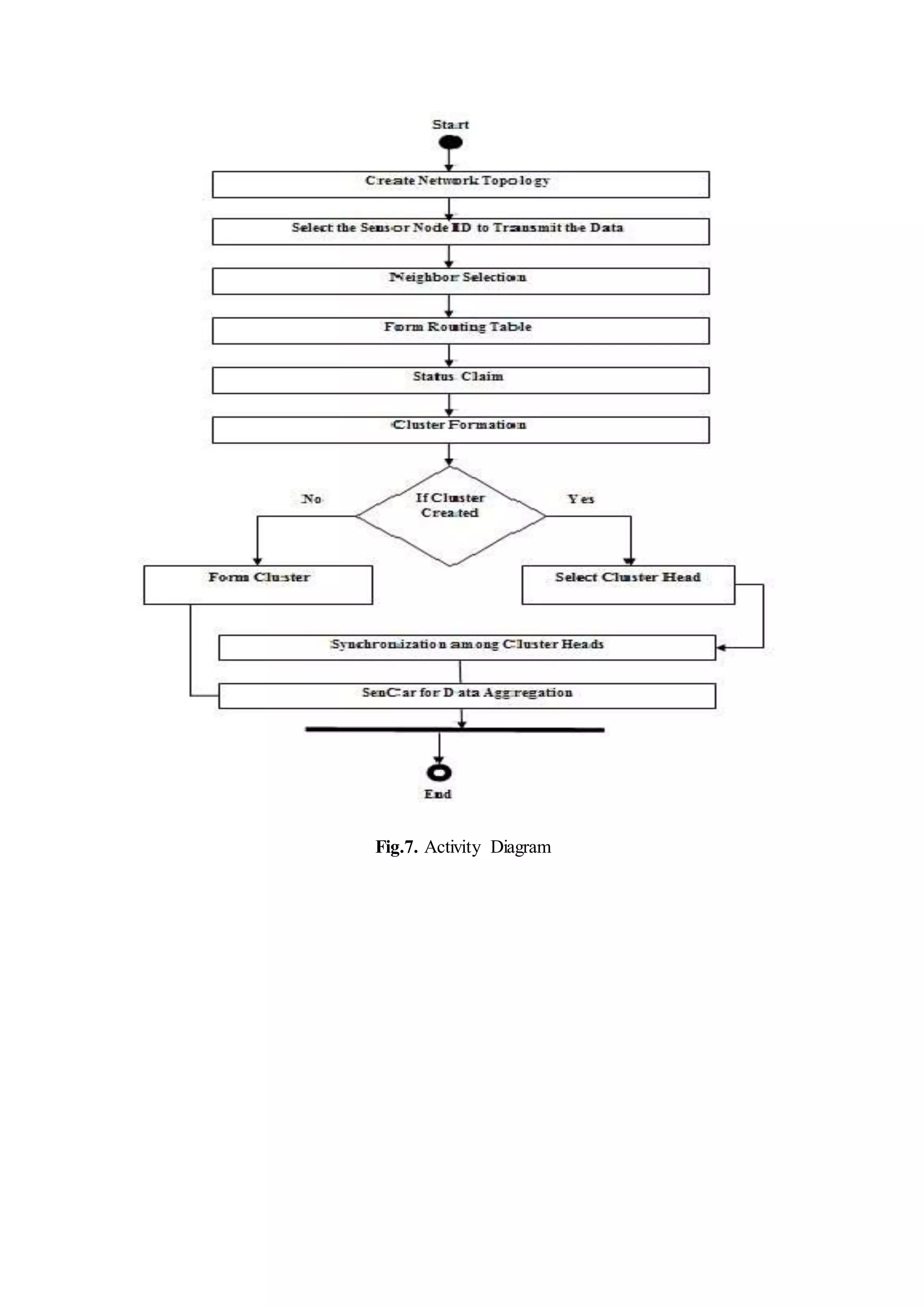
Detailed description of the implementation of the load balanced clustering algorithm, including initialization, status claims, clustering procedures, and synchronization.
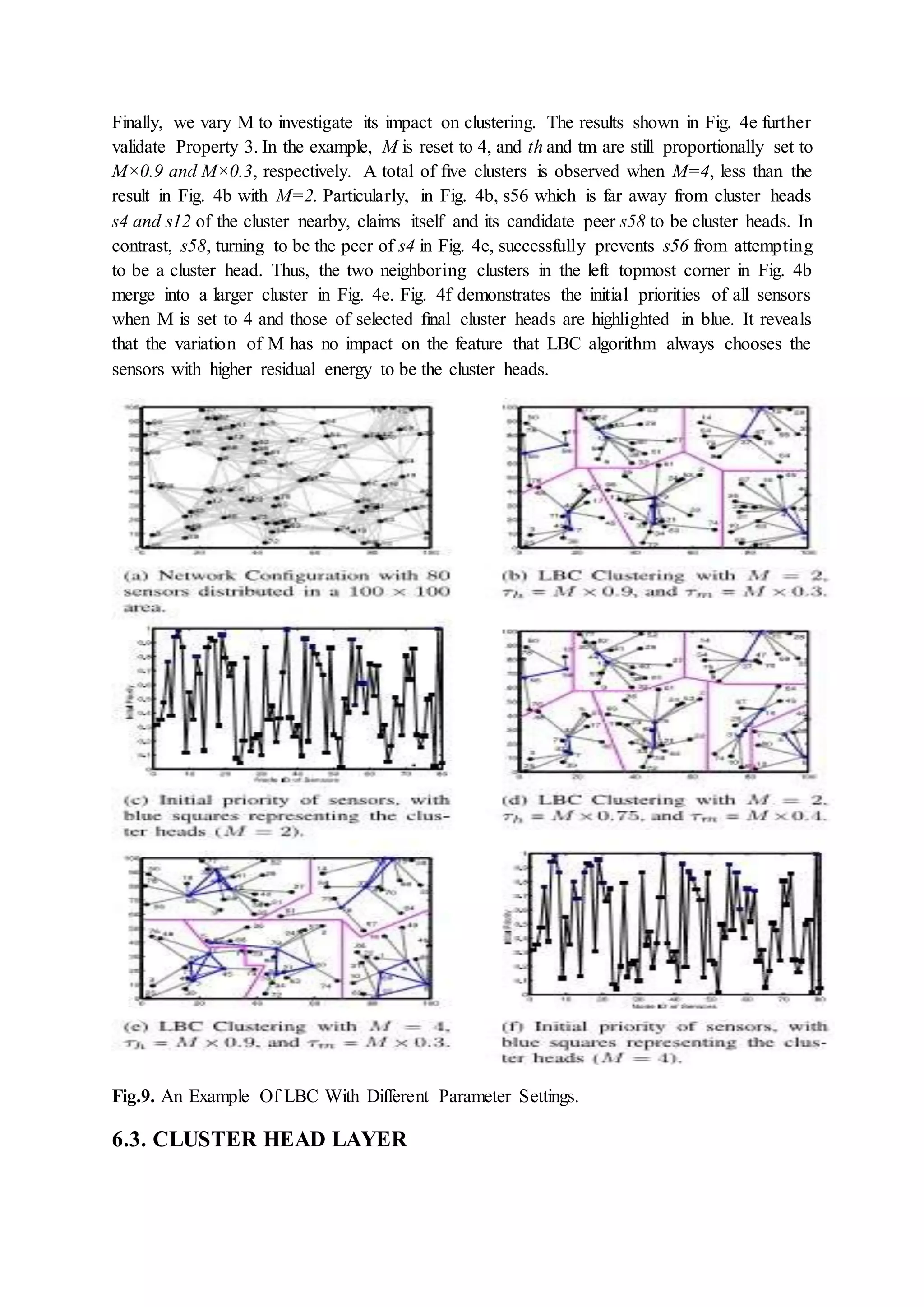
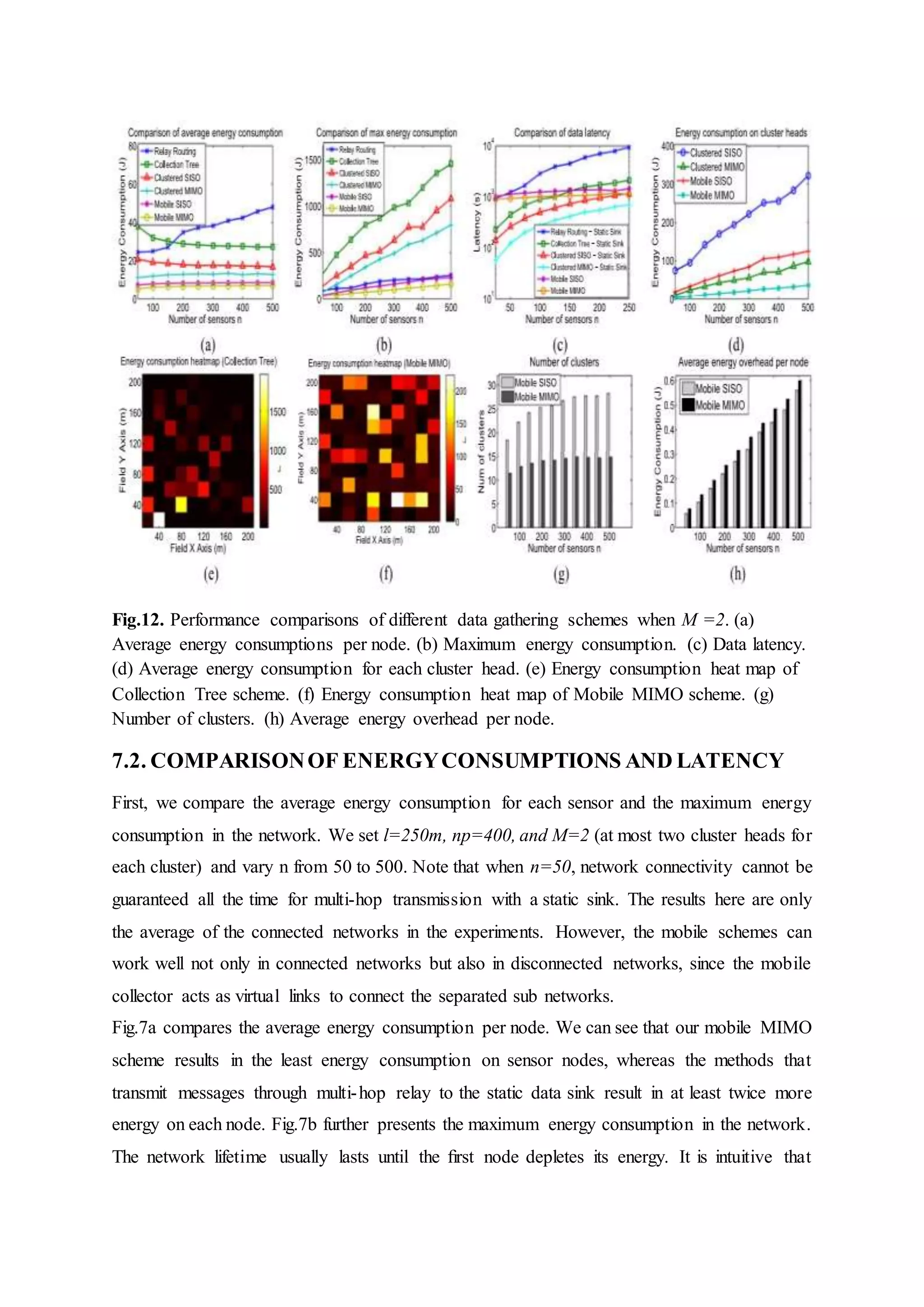
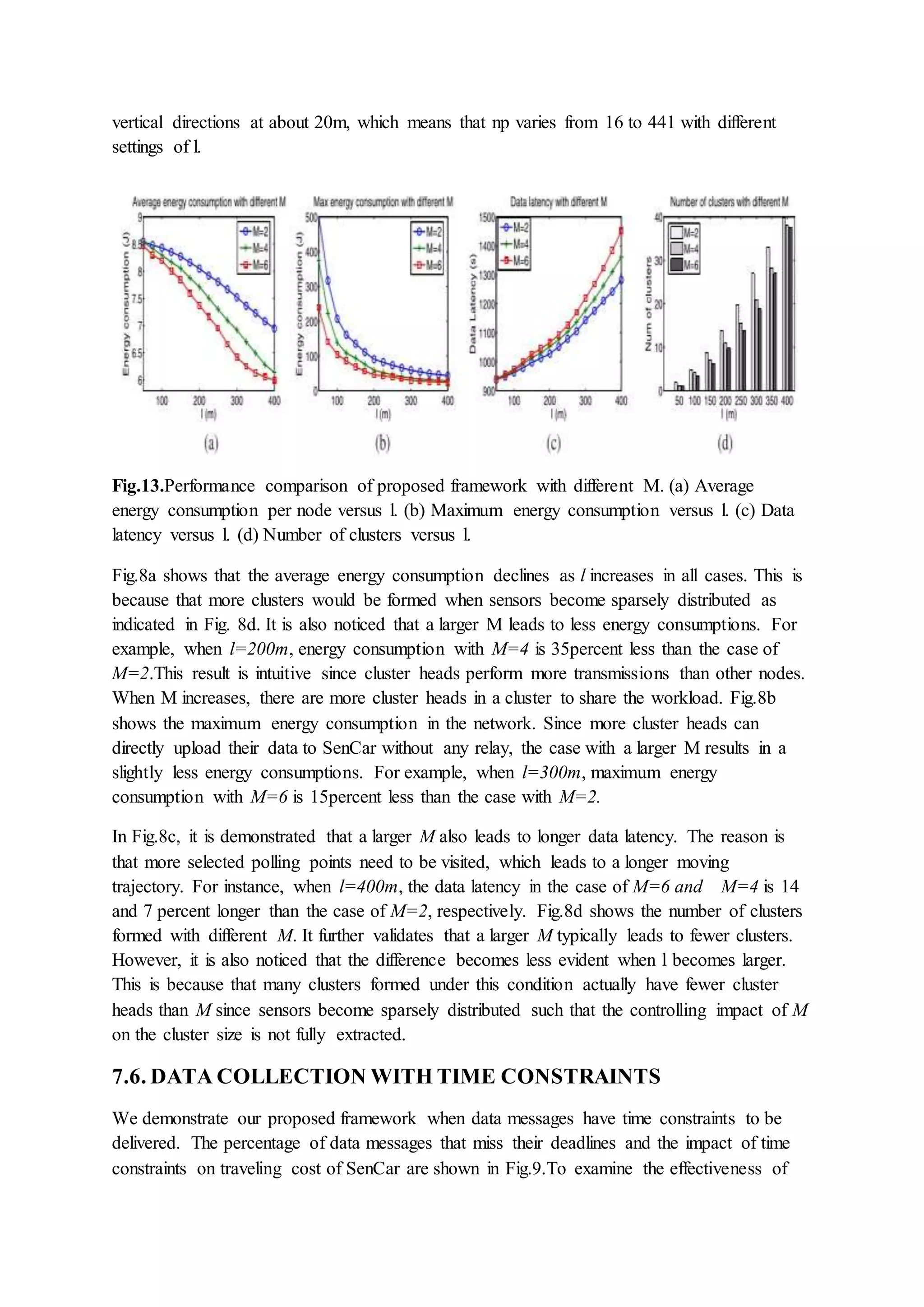
Evaluation of LBC-MIMO's performance including energy savings, data collection latency, effectiveness compared with existing methods, and load distribution among cluster heads.
Concluding remarks on the LBC-MIMO framework's effectiveness and areas for future research, particularly in optimizing polling point selection and MIMO scheduling.