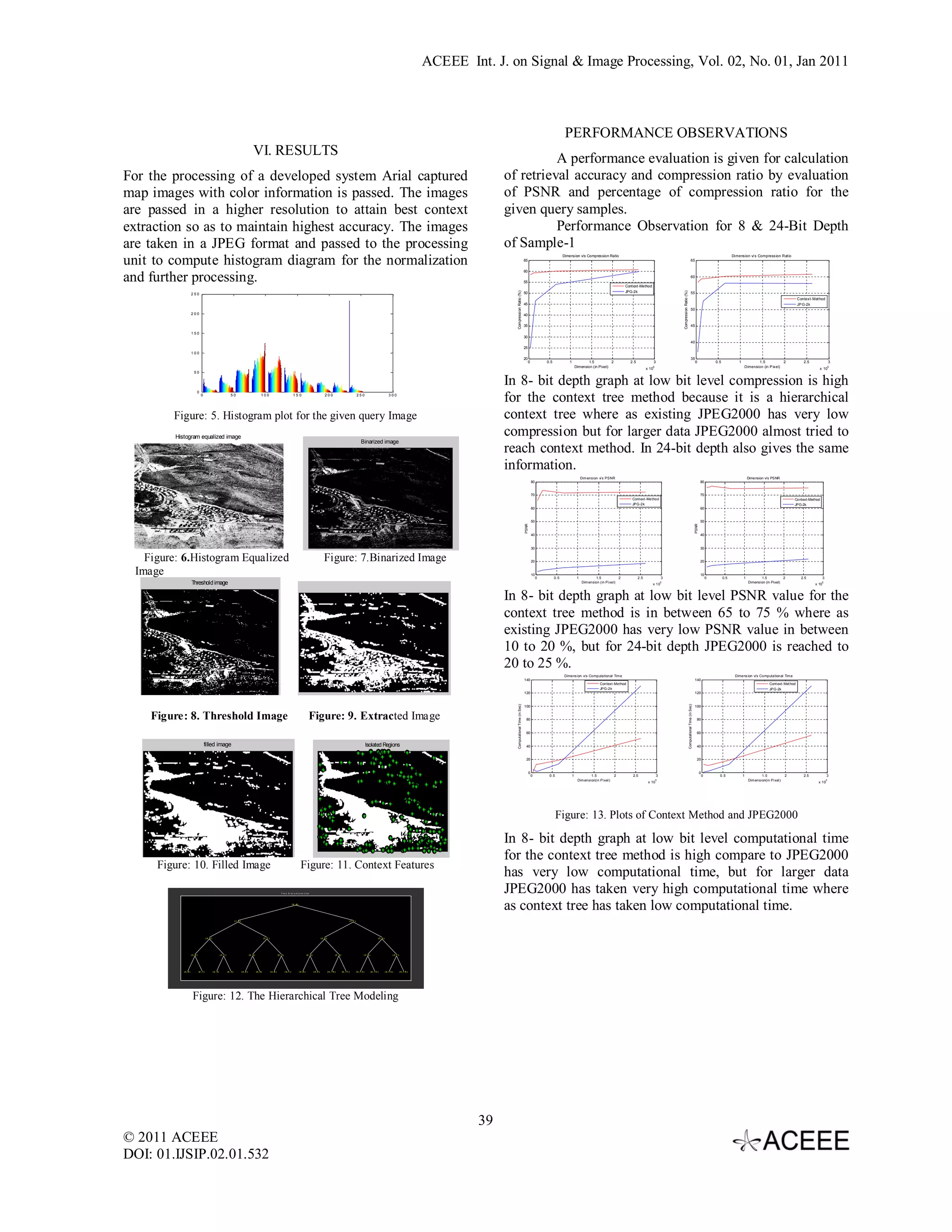
The document discusses a low complexity hierarchical coding compression approach for aerial images focusing on lossless and lossy image compression techniques, including a new context-based statistical model. It highlights the limitations of existing JPEG architectures and introduces a context modeling method aimed at achieving higher compression ratios while maintaining retrieval accuracy. Performance evaluations demonstrate that the proposed method outperforms traditional JPEG2000 in terms of compression ratio and retrieval accuracy for aerial map images.
![ACEEE Int. J. on Signal & Image Processing, Vol. 02, No. 01, Jan 2011 Low Complex-Hierarchical Coding Compression Approach for Arial Images 1 M. Suresh, 2 J. Amulya Kumar 1 Asst. Professor, ECE Dept., CMRCET, Hyderabad, AP-India, suresh1516@gmail.com 2 Project Manager, Centre for Integrated Solutions, Secunderabad, AP-India Abstract: Image compression is an extended research area text compression must be lossless because a very small from a long time. Various compression schemes were difference can result in statements with totally different developed for the compression of image in gray scaling and meanings. While processing with documented images color image compression. Basically the compression is such as digitized map images the compression required are focused for lossy or lossless color image compression based on the need of applications. Where lossy compression are to be totally lossless, as a minor variation in the image higher in compression ratio but are observed to be lower in data may result in a wrong representation of the map retrieval accuracy. Various compression techniques such as information in the case of roads, vegetation, dwelling etc. JPEG and JPEG-2K architectures are developed to realize Various research works were carried out on both lossy and such and method. But with the need in high accuracy lossless image compression[1] in past. The image retreivation these techniques[8] are not suitable. To achieve compression committee has come out with the JPEG nearby lossless compression[1] various other coding methods committee with a release of a new image-coding standard, were suggested like lifting scheme coding. This coding result JPEG 2000 that serves the enhancement to the existing in very high retrieval accuracy but gives low compression JPEG system. The JPEG 2000 implements a new way of ratio. This limitation is a bottleneck in current image compression architectures. So, there is a need in the compressing images based on the wavelet transforms in development of a compressing approach where both higher contrast to the transformations used in JPEG standard. compression as well as higher retrieval accuracy is obtained. There is a majority of today’s Internet bandwidth is estimated to be used for images and video transmission. Keyword: Image Compression, Context Modeling, Arial Recent multimedia applications for handheld and portable Images, PSNR, Compression Ratio devices place a limit on the available wireless bandwidth. I. INTRODUCTION II. STATISTICAL IMAGE CODING Digital imagery has had an enormous impact on A binary image can be considered as a message, industrial, scientific and computer applications. Image generated by an information source. The idea of statistical coding has been a subject of great commercial interest in modeling is to describe the message symbols (pixels) today’s world. Uncompressed digital images require according to the probability distribution of the source considerable storage capacity and transmission bandwidth. alphabet (binary alphabet, in our case). Shannon has Efficient image compression solutions are becoming more shown that the information content of a single symbol critical with the recent growth of data intensive, (pixel) in the message (image) can be measured by its multimedia-based web applications. An image is a entropy: positive function on a plane. The value of this function at H pixel = ─ Log 2 P, each point specifies the luminance or brightness of the Where P is the probability of the pixel. Entropy of the picture at that point. Digital images are sample versions of entire image can be calculated as the average entropy of such functions, where the value of the function is specified all pixels: only at discrete locations on the image plane, known as pixels. During transmission of these pixels the pixel data H image = - 1/n ∑ n i=1 Log2 Pi , must be compressed to match the bit rate of the network. Where Pi is the probability of ith pixel and n is the total In order to be useful, a compression algorithm number of pixels in the image. has a corresponding decompression algorithm[3] that, If the probability distribution of the source alphabet (black given the compressed file, reproduces the original file. and white pixels) is a priori known, the entropy of the There have been many types of compression algorithms probability model can thus be expressed as: developed. These algorithms fall into two broad types, H = ─ Pw Log 2 Pw─ PB Log2 PB , loss less algorithms and lossy algorithms. A lossless Where Pw and PB are the probabilities of the white and algorithm reproduces the original exactly. A lossy black pixels, respectively. The more sophisticated Bayesian sequential estimator calculates probability of the algorithm, as its name implies, loses some data. Data loss pixel on the basis of the observed pixel frequencies as may be unacceptable in many applications. For example, follows: 36 © 2011 ACEEE DOI: 01.IJSIP.02.01.532](https://image.slidesharecdn.com/532-120926234623-phpapp01/75/Low-Complex-Hierarchical-Coding-Compression-Approach-for-Arial-Images-1-2048.jpg)
![ACEEE Int. J. on Signal & Image Processing, Vol. 02, No. 01, Jan 2011 distribution and lower bit-rates. CONSTRUCTION PROCEDURE To construct a context tree, the image is processed and the statistics ntW and ntB are calculated for Where n tW, ntB are the time-dependent counters, ptW, ptB every context in the full tree, including the internal nodes. are the probabilities for white and black colors The tree is then pruned by comparing the children and parents nodes at each level. If compression gain is not respectively, and δ is a constant. Counters ntW and ntB start achieved from using the children nodes instead of their from zero and are updated after the pixel has been coded parent node, the children are removed from the tree and (decoded). As in [JBIGl], we use δ = 0.45. The cumulative equation for entropy is used to estimate the their parent will become a leaf node. The compression average bit rate and calculate the ideal code length. gain is calculated as: Gain ( C, C W, C B )= l( C ) - l( C W ) - l(CB ) – Split Cost , Where C is the parent context and CW and CB are the two III. CONTEXT BASED STATISTICAL MODEL children nodes. The code length l denotes the total number The pixels in an image form geometrical structures of output bits from the pixels coded using the context. The with appropriate spatial dependencies.[2] The cost of storing the tree is integrated into the Split Cost dependencies can be localized to a limited neighborhood, parameter. The code length can be calculated by summing and described by a context-based statistical model. In this up the entropy estimates of the pixels as they occur in the model, the pixel probability is conditioned on the context image: l(C) = ∑t log pt (C) The probability of the pixel is C, which is defined as distinct black-white configuration calculated on the basis of the observed frequencies using a of neighboring pixels within the local template. For Bayesian sequential estimator: binary images, the pixel probability is calculated by counting the number of black (nCB) and white (nCW) pixels appeared in that context in the entire image: Where ntW , ntB are the time-dependent frequencies, and ptW, ptB are the probabilities for white and black colors respectively, and δ = 0.45, as in [JBIG1]. The template form and the pixel order in this example are optimized for topographic images. Here, pCB and pCW are the corresponding probabilities of the black and white pixels. The entropy H(C) of a context C is defined as the average entropy of all pixels within the context: H(C) = - pWC log 2 pWC - p BC log 2 p B C A context with skew probability distribution has smaller entropy and therefore smaller information content. The entropy of an N-level context model is the weighted sum of the entropies of individual contexts: HN = - ∑ N j=1 p(Cj). (p WCj. log2 pWCj + pBCj .log2 pBCj) In principle, a skewed distribution can be obtained through conditioning of larger regions by using larger context Figure: 1. Illustration of a context tree. templates. However, this implies a larger number of In the bottom-up approach, the tree is analyzed from the parameters of the statistical model and, in this way, leaves to the root. A full tree of kMax levels is first constructed increases the model cost, which could offset the entropy by calculating statistics for all contexts in the tree. The tree is then savings. Another consequence is the "context dilution" recursively pruned up to level kMin, using the same criterion as problem occurring when the count statistics are distributed in the top-down approach. The gain is calculated using the over too many contexts, thus affecting the accuracy of the code length equation using l(C). The code lengths from the probability estimates. children contexts l(CW) and l(CB) are derived from the previous level of the recursion. The sub-trees of the nodes that do not deliver positive compression gain are removed IV. ALGORITHM from the tree. A sketch of the implementation is shown in Figure and the algorithm is illustrated in Figure. The context size is a trade-off between the prediction accuracy and learning cost (in dynamic modeling) or model overhead (in semi-adaptive modeling). A larger template size gives us a theoretically better pixel prediction. This results in a skewer probability 37 © 2011 ACEEE DOI: 01.IJSIP.02.01.532](https://image.slidesharecdn.com/532-120926234623-phpapp01/75/Low-Complex-Hierarchical-Coding-Compression-Approach-for-Arial-Images-2-2048.jpg)
![ACEEE Int. J. on Signal & Image Processing, Vol. 02, No. 01, Jan 2011 technique to estimate the required region out of the whole. A mathematical morphology[10] operation is apply to extract the bounding regions and curves in the map image. The extracted regions are then passed to context tree modeling[7] for obtaining the context feature of the obtained regions. A tree model is developed as explained in previous sections for the obtained context features. The contexed features are quite large in count and are required to be reduced for higher compression. To achieve lower context counts a pruning operation is performed. A Pruning is a hierarchical coding technique for dimensionality reduction with a tracing of obtained context features in a hierarchical tree manner with branches and leaf projecting towards high dominative Figure: 2. Illustration of bottom-up tree pruning. context features comparative to lower context features discarding at intermediate level. This pruning process The bottom-up approach can be implemented hence ends out at minimum number of dominative context using only one pass over the whole image. Unfortunately, features resulting in low context information for context high kMAX values will result in huge memory mapping. This results in faster computation of image data consumption. For this reason, a two-stage bottom-up mapping with context feature for entropy encoding. pruning procedure was proposed in. In the first stage, the Context mapping is a process of transforming the tree is constructed from the root to level KSTART and then image coefficient to a context tree model mapping[9] with recursively pruned until level kMin. In the second stage, the reference to obtained pruning output. The image pixels are remaining leaf nodes at the level KSTART are expanded up mapped with pruning output and a binary stream to level kMax and then pruned until level KSTART ' In this indicating the mapping information is generated. This way, the memory consumption depends mainly on the stream is passed to entropy encoder for performing binary choice of the KSTART because only a small proportion of compression using Huffman entropy coding.[4] [14] the nodes at that level remains after the first pruning stage. The dequantized information is passed to the The starting level KSTART is chosen as large as the memory demapping operation. The image coefficients are retrieved resources permit. This approach of modeling & pruning with a demapping of the context information to the results in a higher compression of pixel representation in dequantized data to obtain the original image information given image sample. back. The demapping operation is carried out in a similar fashion as like the mapping operation with the reference of V. SYSTEM DESIGN context table. For the regeneration of pixel coefficient the The suggested context modeling for color image same context tree is used for the reverse tree generated to compression is developed for the evaluation of Arial map retrieve pixel coefficient. The obtained coefficients are images. These images are higher in textural variation with post processed for the final generation of the image. high color contrast. A compression scheme for such an This unit realigns the pixel coefficient to the grid image is designed and the block diagram for this method level based on the generated context index during pre is as shown below, processing. The image retrieved after the computation is evaluated for PSNR value in the evaluator unit for the performance evaluation of suggested architecture with estimation accuracy as the quality factor. Figure: 3. Functional Block Diagram of the proposed method This designed system read the color image information and transform to gray plane with proper data type conversion for the computation. During pre processing operation the map image is equalized with histogram equalization to normalize the intensity distribution to be in uniform level. This equalized image is then processed with binarization by using thresholding 38 © 2011 ACEEE DOI: 01.IJSIP.02.01.532](https://image.slidesharecdn.com/532-120926234623-phpapp01/75/Low-Complex-Hierarchical-Coding-Compression-Approach-for-Arial-Images-3-2048.jpg)
![ACEEE Int. J. on Signal & Image Processing, Vol. 02, No. 01, Jan 2011 OBSERVATION TABLES [2] Samet H. Applications of Spatial Data Structures: Computer Graphics,Image Processing, GIS. MA: Addison-Wesley, Image Bit Depth: 8 - Bit Depth Reading. May 2006 [3] Pajarola R, Widmayer P. Spatial indexing into compressed raster images: how to answer range queries without decompression. Proc. Int. Workshop on Multimedia DBMS (Blue Mountain Lake, NY, USA), 94-100. 1, May 2000 [4] Hunter R., Robinson A.H. International digital facsimile coding standards. Proc. of IEEE, 68 (7), 854-867. 2002 [5] Urban S.J. Review of standards for electronic imaging for facsimile systems. Journal of Electronic Imaging, 1(1): 5-21. 6,May 2008 [6] Salomon D. Data compression: the complete reference. New York: Springer- Verlag.] Arps RB., Truong T.K. Comparison of international standards for lossless still image compression. Proceedings of the IEEE 82: 889-899. 2003 [7] Rissanen J.J., Langdon G.G.) Universal modeling and Image Bit Depth: 24 - Bit Depth coding. IEEE Trans. Inform. TheoryIT-27: 12-23. 2000 [8] Netravali A.N., Mounts F.W. Ordering Techniques for Facsimile Coding: A Review. Proceedings of the IEEE, 68 (7): 796-807. 2003 [9] Capon J. A probabilistic model for run-length coding of pictures. IRE Tran. Information Theory, IT-5: 157-163. 12, March 2007 [10] Shannon c.E. A mathematical theory of communication. Bell System. Tech Journal 27: 398-403. 1, Nov 2001 [11] Vitter J. Design and Analysis of dynamic Huffman codes. Journal of Association for Computing Machinery, 34:825-845. 5, May 2000 [12] Rice RF. Some practical universal noiseless coding techniques. Proc. Data Compression Conference (Snow Bird, Utah, USA), 351360. VII. CONCLUSION [13] Colombo S.W. Run-length encoding. IEEE Trans. Inform This Paper presents a compression approach in image Theory, IT-12: 399-401. 4, Aug 2005 processing applications using a hierarchical context [14] Huffman D.A. A method for the construction of minimum modeling of highly varying color images with practical redundancy codes. Proc. of IEEE, 40 (9): 1098-110 I. 2007 [15] Shannon c. E. A mathematical theory of communication. information of Arial mapping. The developed context tree Bell Syst. Tech Journal 27: 398-403. 5, May 2000 modeling is focused with the objective of attaining [16] Wao Y. Wu Y. J.-M. Vector Run-Length Coding of Bi- minimum error and faster computations in processing Level Images. Proceedings Data Compression Conference, these mapping images for real time applications. For the Snowbird, Utah, USA, 289-298. 5, May 2000 developed system the quality metric of situation accuracy [17]ITU-T (CCITT) Recommendation TA. Kunt M., Johnsen O. with respect to PSNR value is computed and observed to Block Coding: A Tutorial Review. Proceedings of the IEEE, 68 be a higher value giving suggested method as feasible (7): 770-786. 5, May 2000 solutions for fast, high and lossless compression in [18] Franti P., Nevalainen O. Compression of binary images by practical environments. composite methods basically on the block coding. Journal of Visual Communication, Image Representation 6 (4): 366-377. 26, Jun 1999 VIII. REFERENCES [19] Rissanen J.J., Langdon G.G. Arithmetic coding. IBM [1] Alexander Akimov, Alexander Kolesnikov, and Pasi Fränti, Journal of Research, Development 23: 146-162. 2007 “Lossless Compression of Color Map Images by Context Tree [20] Langdon G.G., Rissanen J. Compression of black-white Modeling”, IEEE Transactions On Image Processing, Vol. 16, images with arithmetic coding. IEEE Trans. Communications NO. 1, January 2007. 29(6):858-867.2000 40 © 2011 ACEEE DOI: 01.IJSIP.02.01.532](https://image.slidesharecdn.com/532-120926234623-phpapp01/75/Low-Complex-Hierarchical-Coding-Compression-Approach-for-Arial-Images-5-2048.jpg)