Machine Learning Basics and Supervised, unsupervised
1.
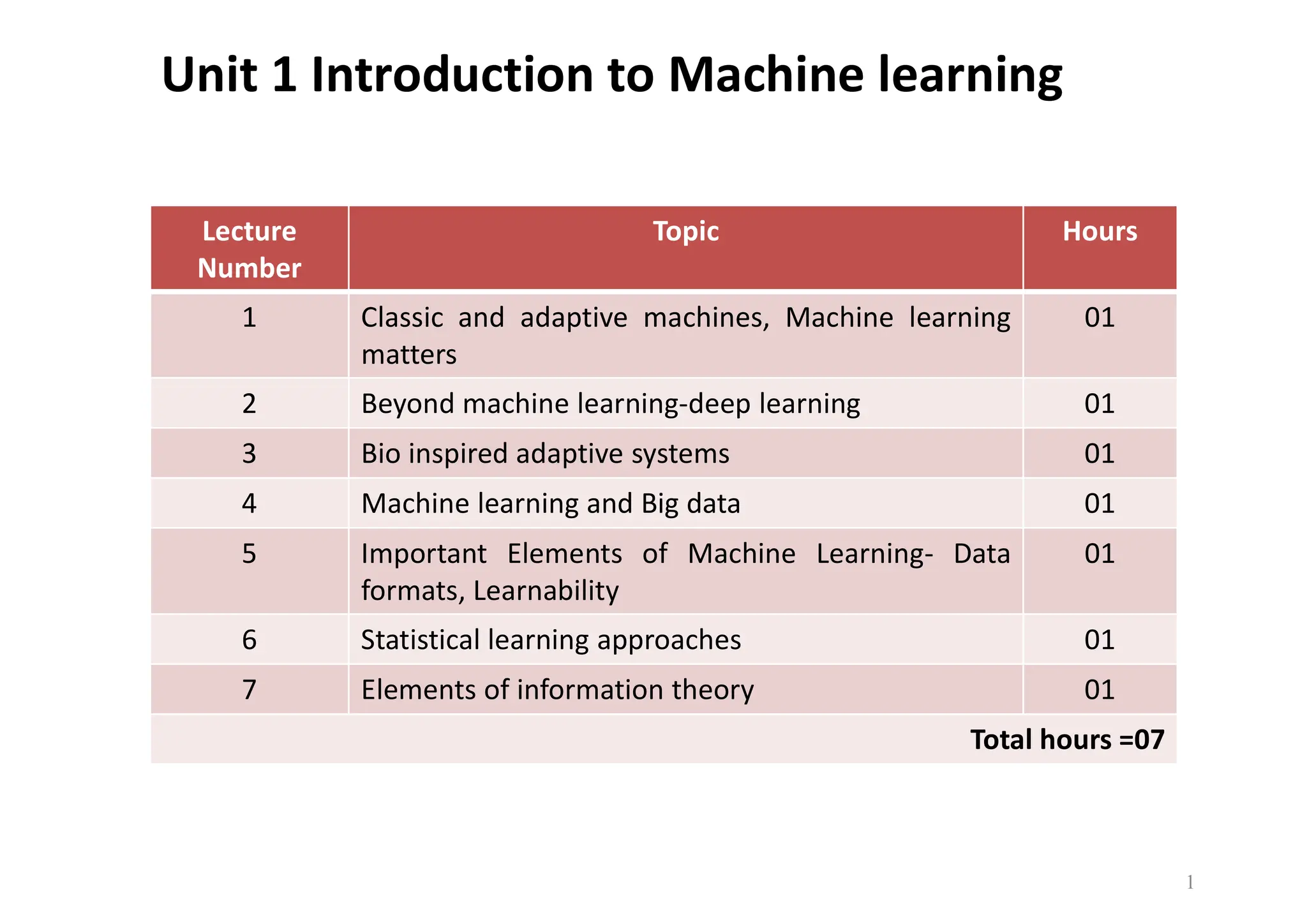
Unit 1 Introductionto Machine learning 1 Lecture Number Topic Hours 1 Classic and adaptive machines, Machine learning matters 01 2 Beyond machine learning-deep learning 01 3 Bio inspired adaptive systems 01 4 Machine learning and Big data 01 5 Important Elements of Machine Learning- Data formats, Learnability 01 6 Statistical learning approaches 01 7 Elements of information theory 01 Total hours =07
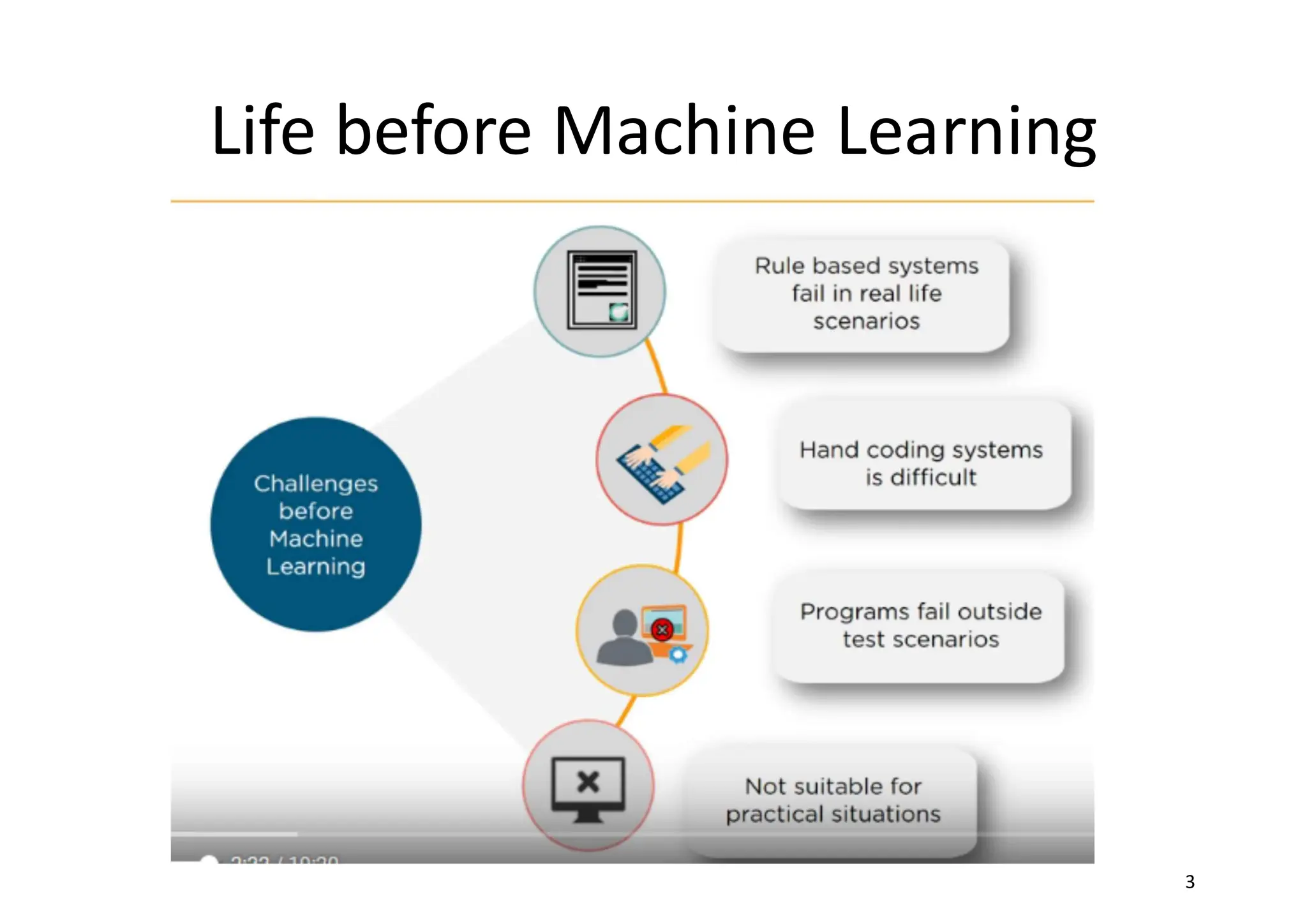
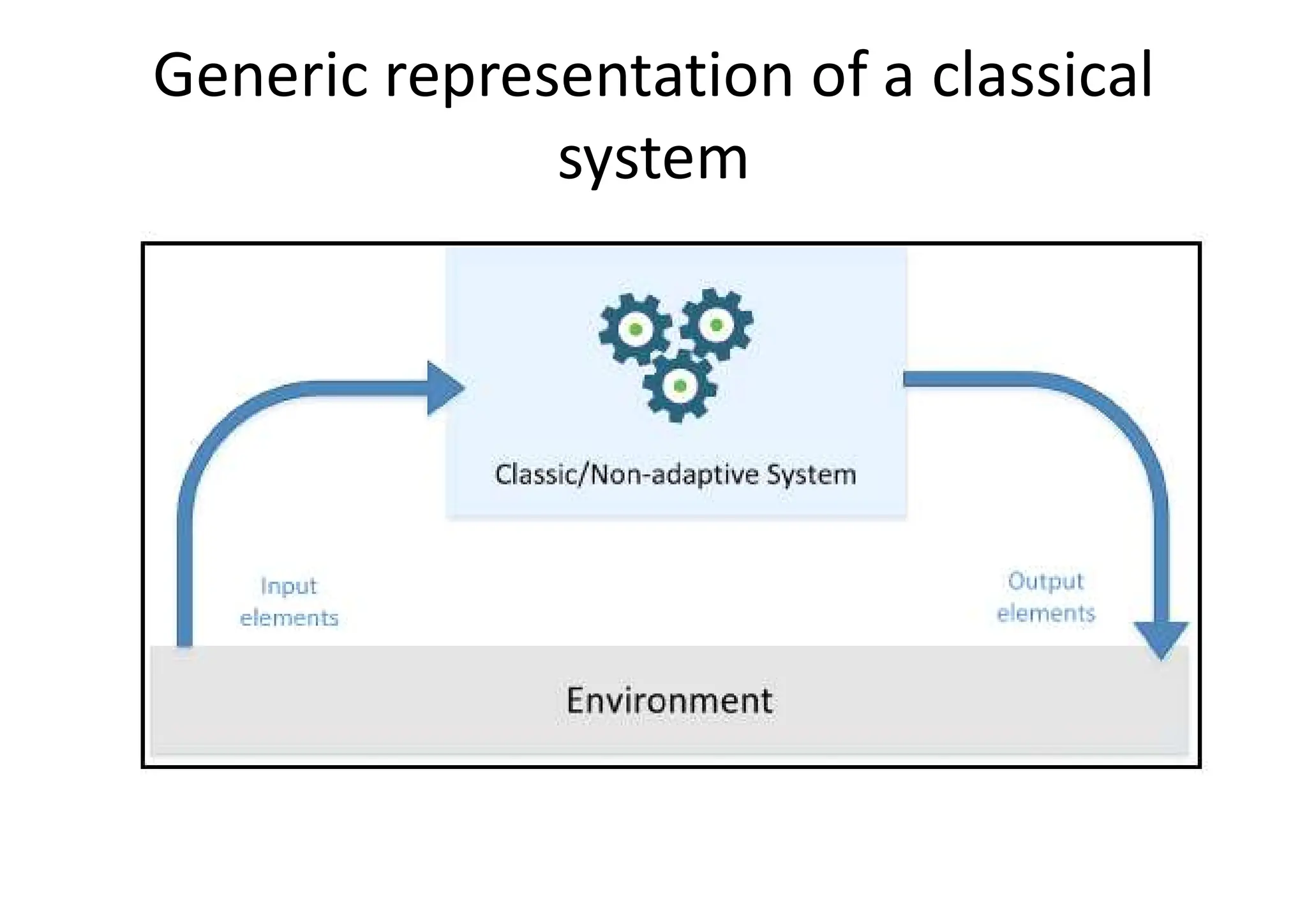
Classic and adaptivemachines • machine is never efficient or trendy without a concrete possibility to use it with pragmatism. • A machine is immediately considered useful and destined to be continuously improved if its users can easily understand what tasks can be completed with less effort or completely automatically
Machine learning matters •learning is the ability to change according to external stimuli and remembering most of all previous experiences • machine learning is an engineering approach that gives maximum importance to every technique that increases or improves the propensity for changing adaptively.
9.
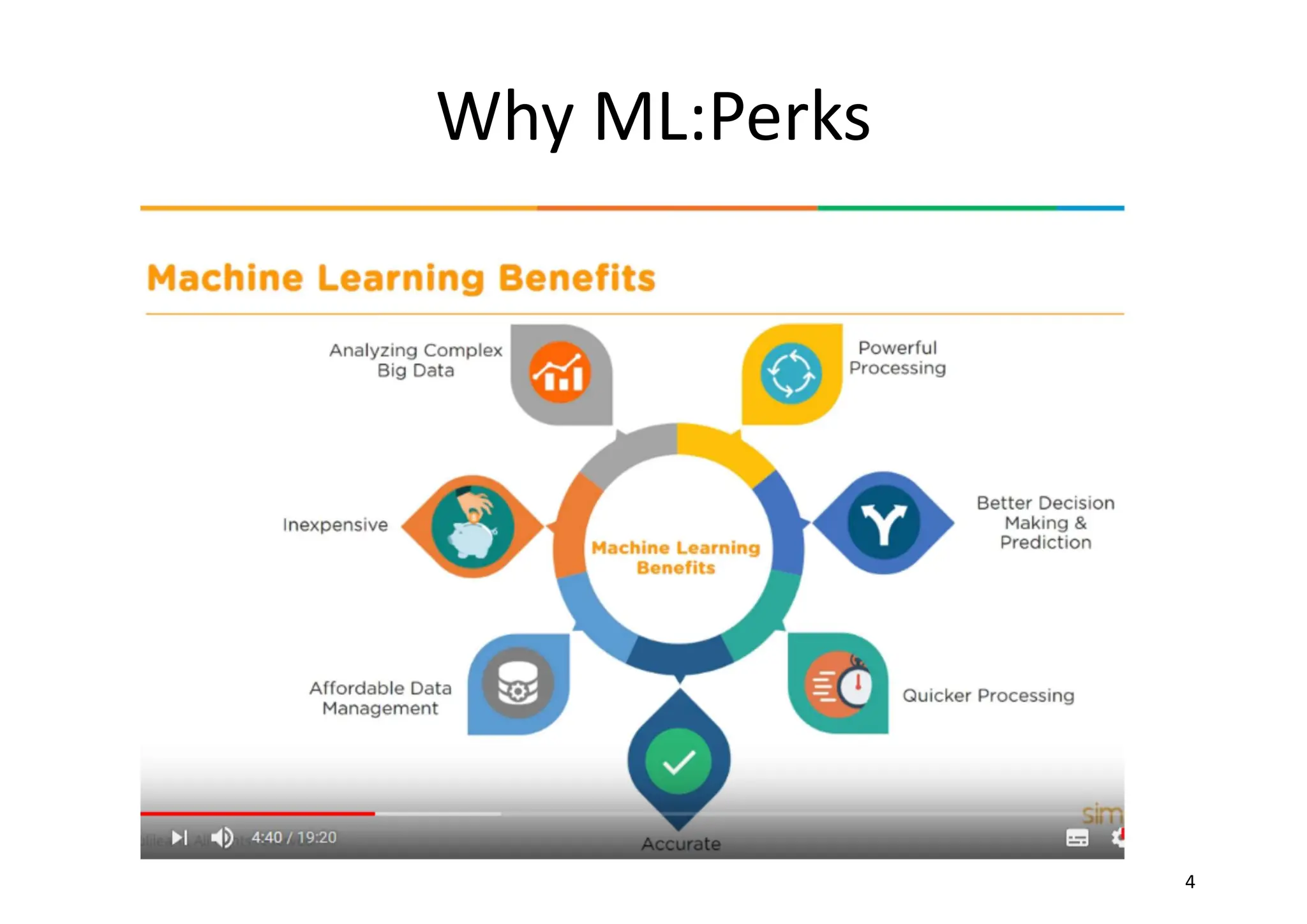
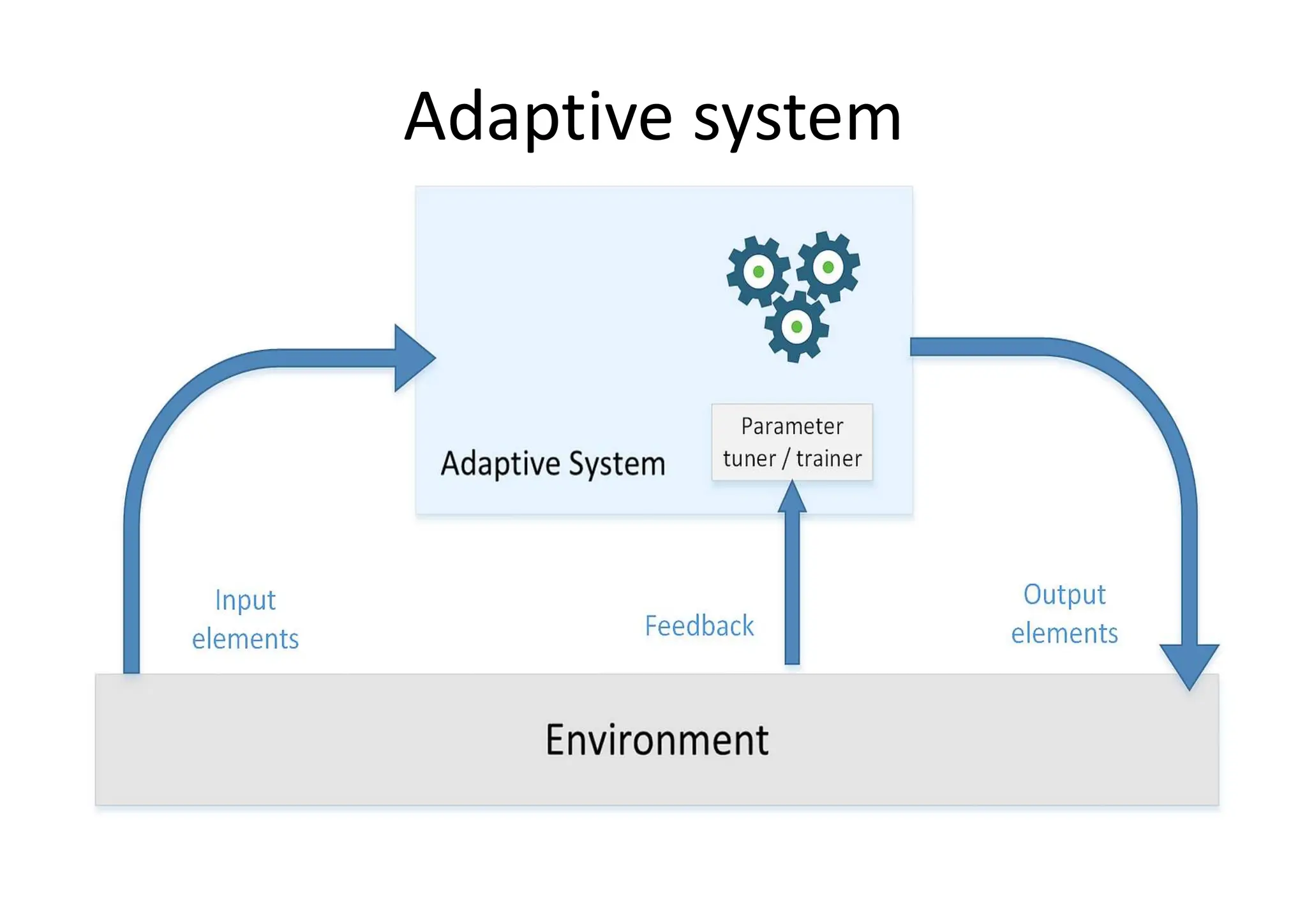
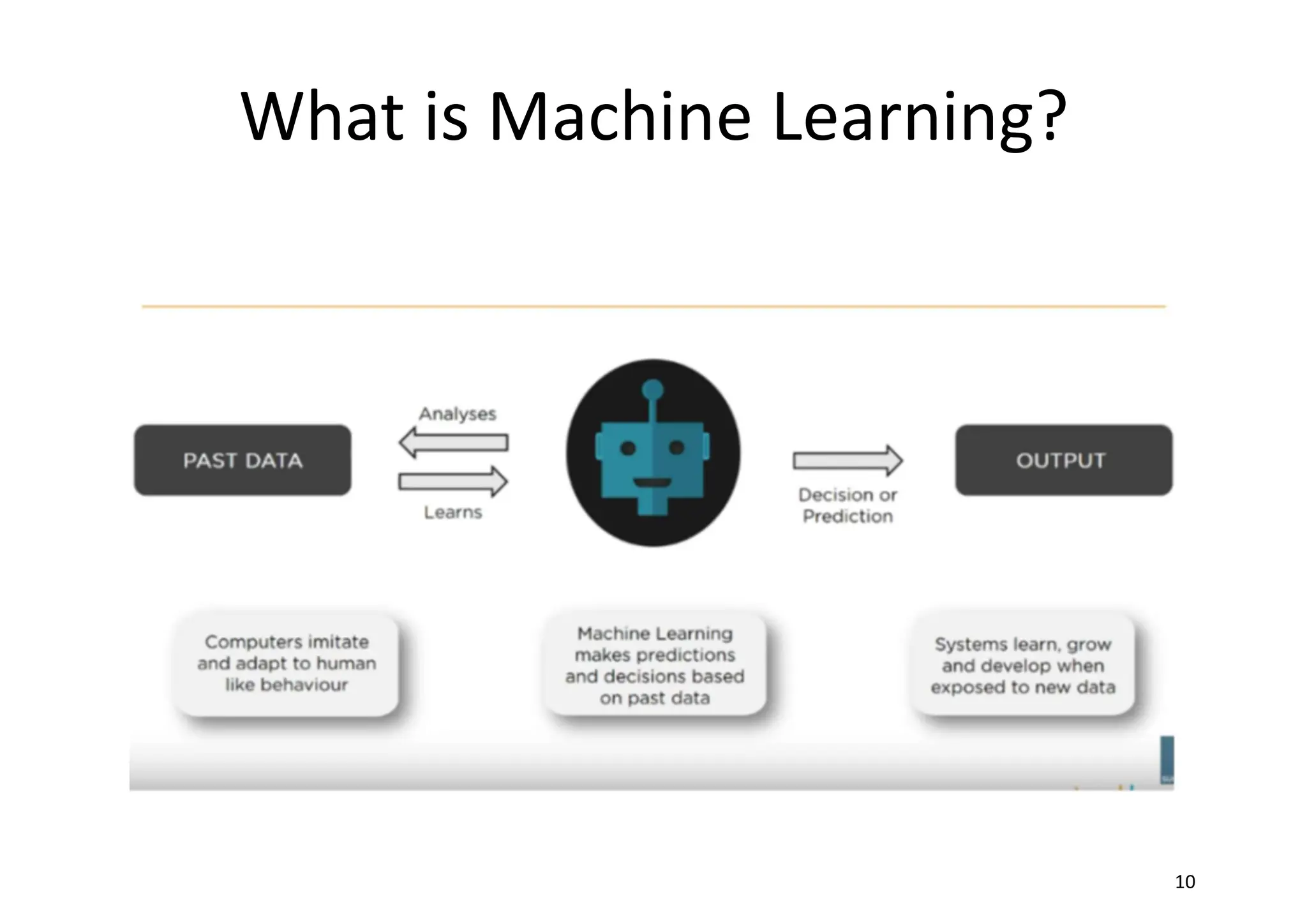
Goal of ML •to study, engineer, and improve mathematical models which can be trained (once or continuously) with context-related data (provided by a generic environment), to infer the future and to make decisions without complete knowledge of all influencing elements (external factors).
Goal of ML •In other words • an agent (which is a software entity that receives information from an environment, picks the best action to reach a specific goal, and observes the results of it) adopts a statistical learning approach, trying to determine the right probability distributions and use them to compute the action (value or decision) that is most likely to be successful (with the least error).
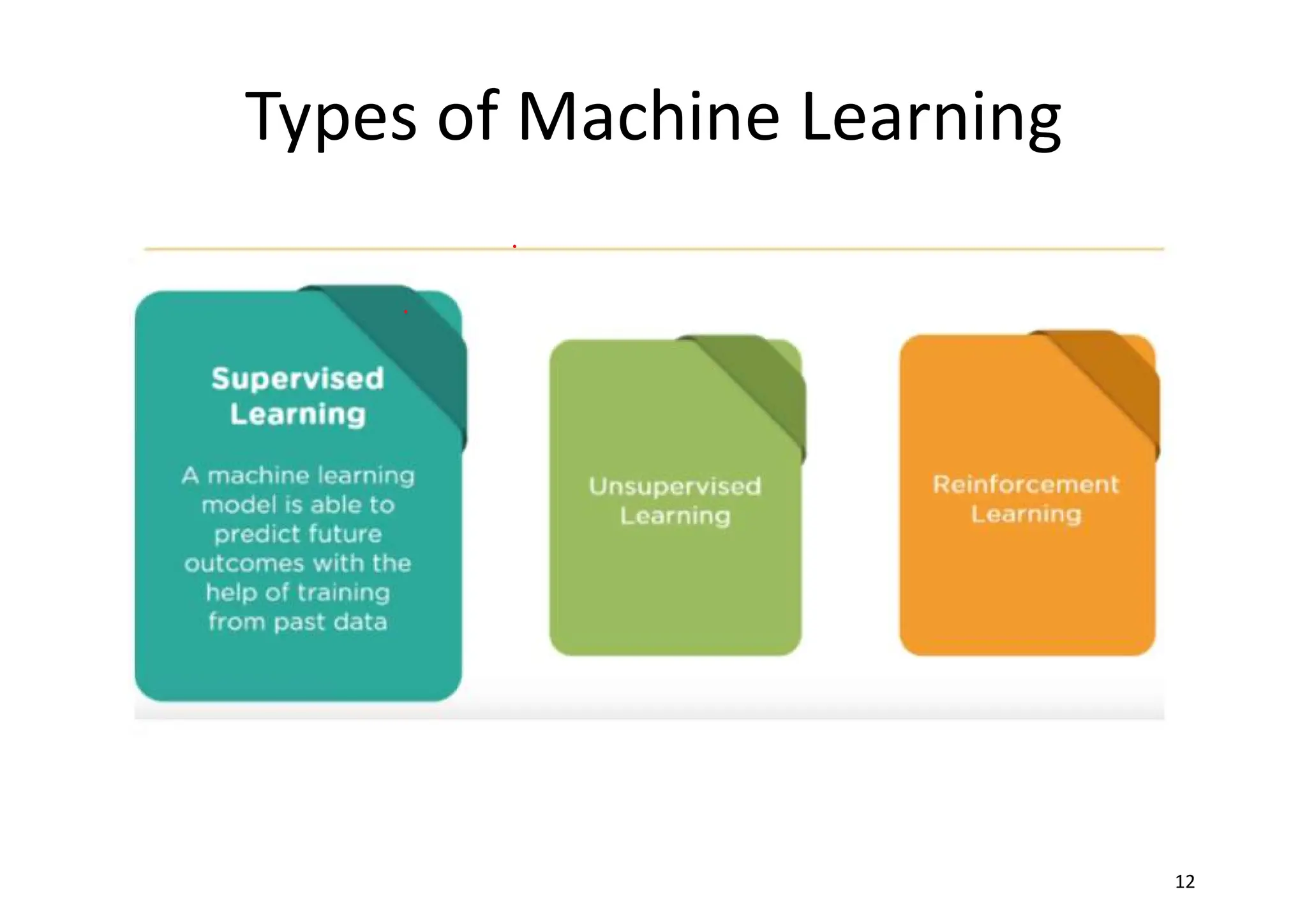
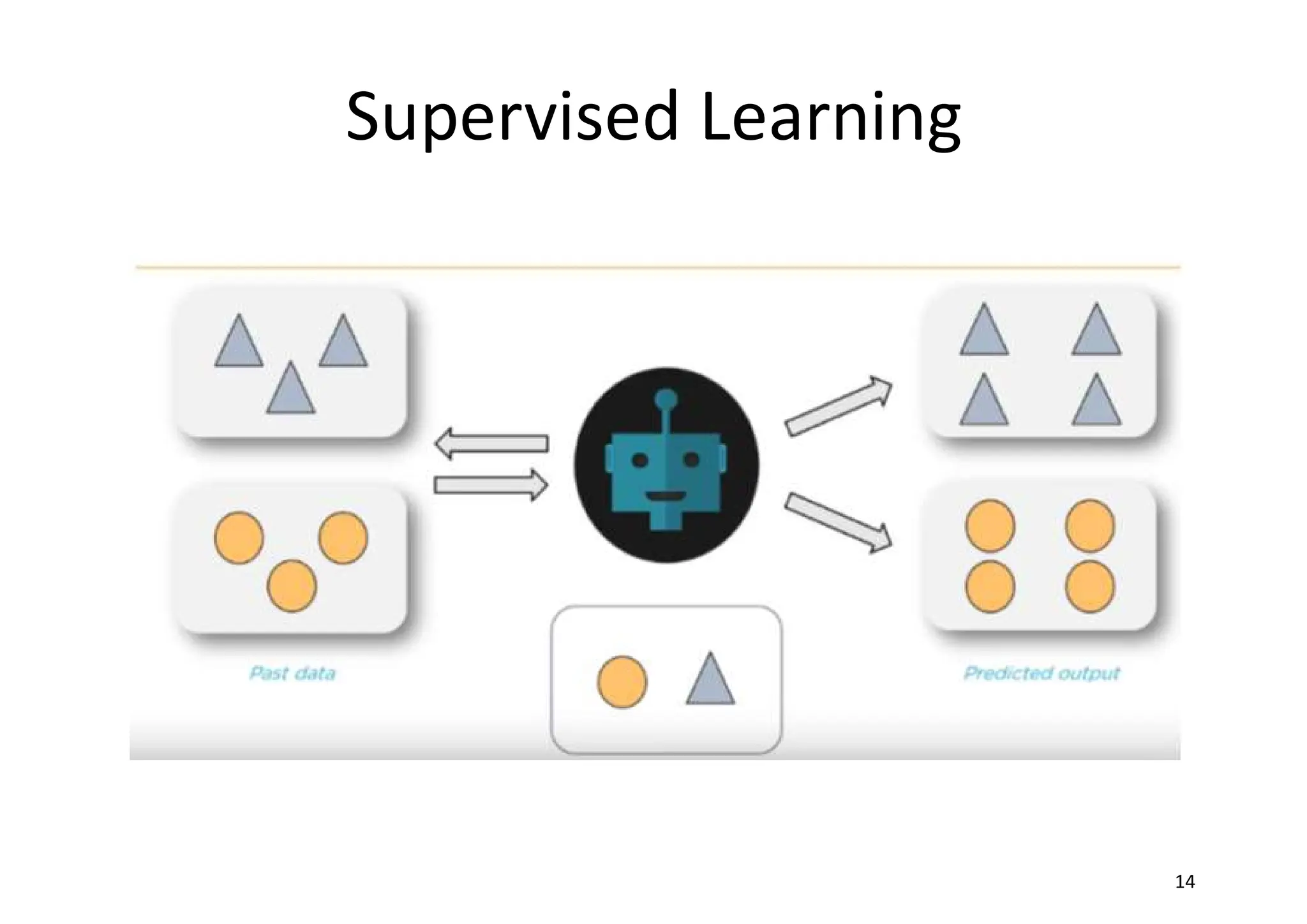
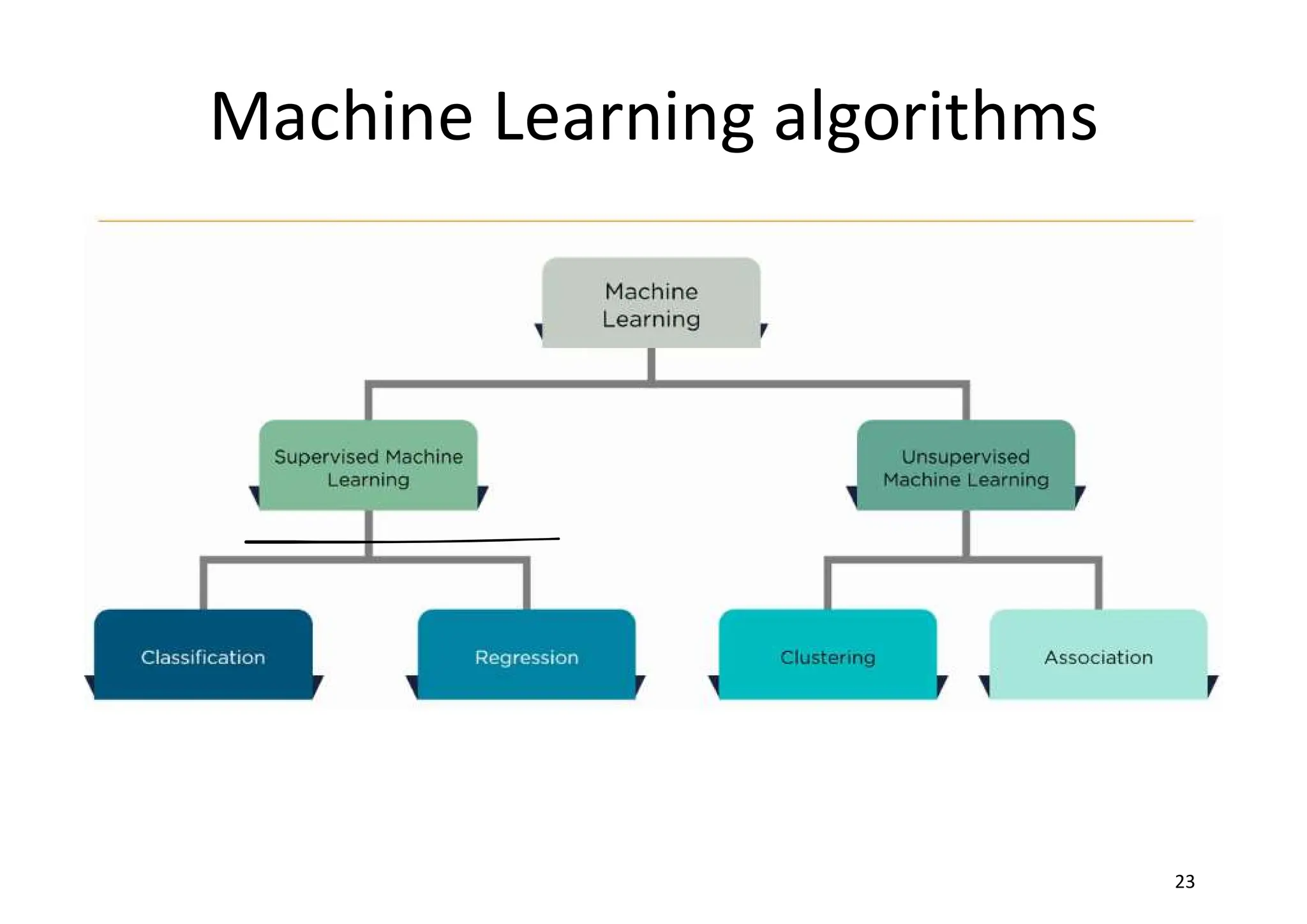
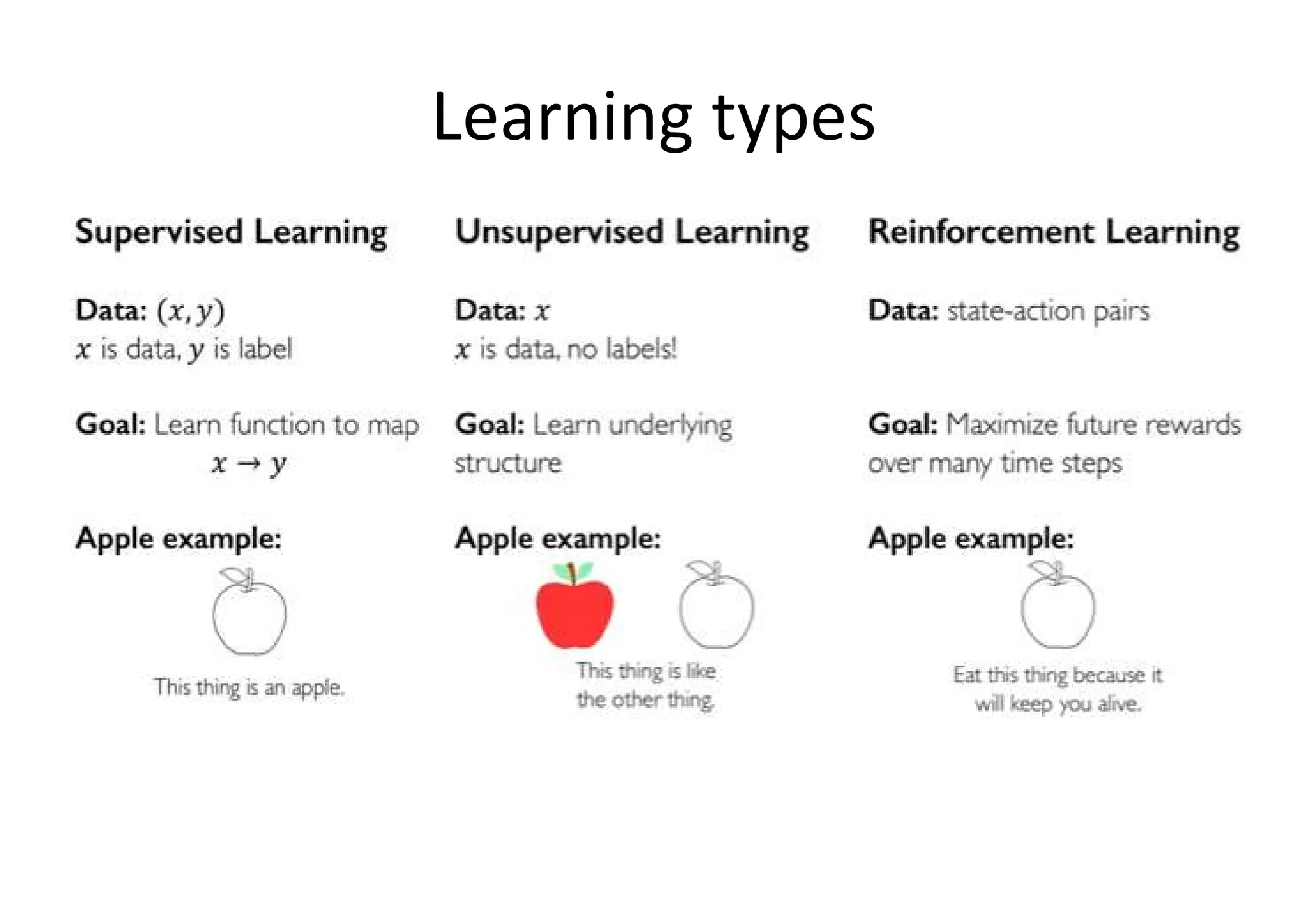
Supervised learning • Asupervised scenario is characterized by the concept of a teacher or supervisor, whose main task is to provide the agent with a precise measure of its error (directly comparable with output values). • In a supervised scenario, the goal is training a system that must also work with samples never seen before. So, it's necessary to allow the model to develop a generalization ability and avoid a common problem called overfitting, which causes an overlearning due to an excessive capacity
Common supervised learningapplications include: • Predictive analysis based on regression or categorical classification • Spam detection • Pattern detection • Natural Language Processing • Sentiment analysis • Automatic image classification • Automatic sequence processing (for example, music or speech)
16.
Unsupervised learning • Thisapproach is based on the absence of any supervisor and therefore of absolute error measures; it's useful when it's necessary to learn how a set of elements can be grouped(clustered) according to their similarity (or distance measure)
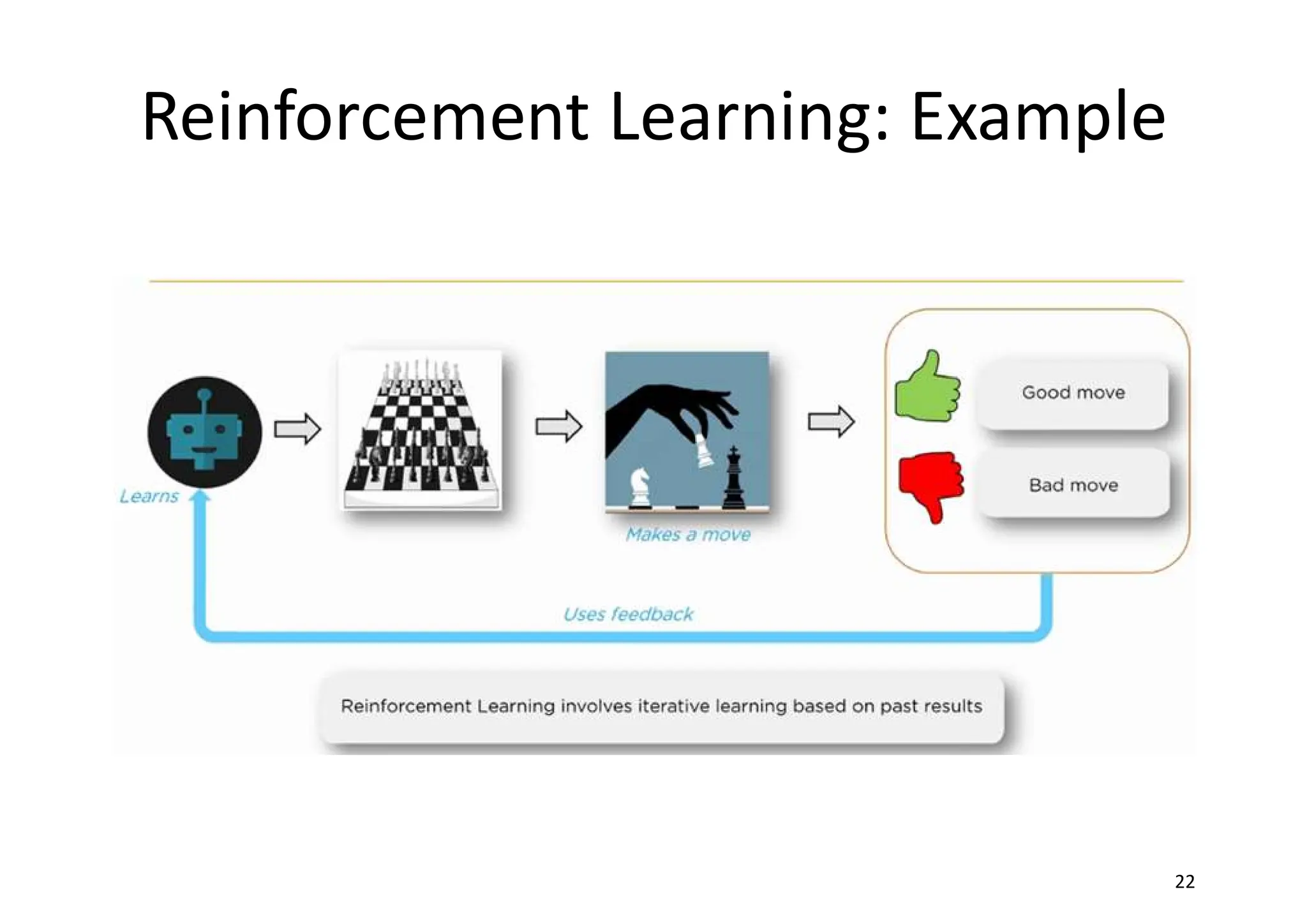
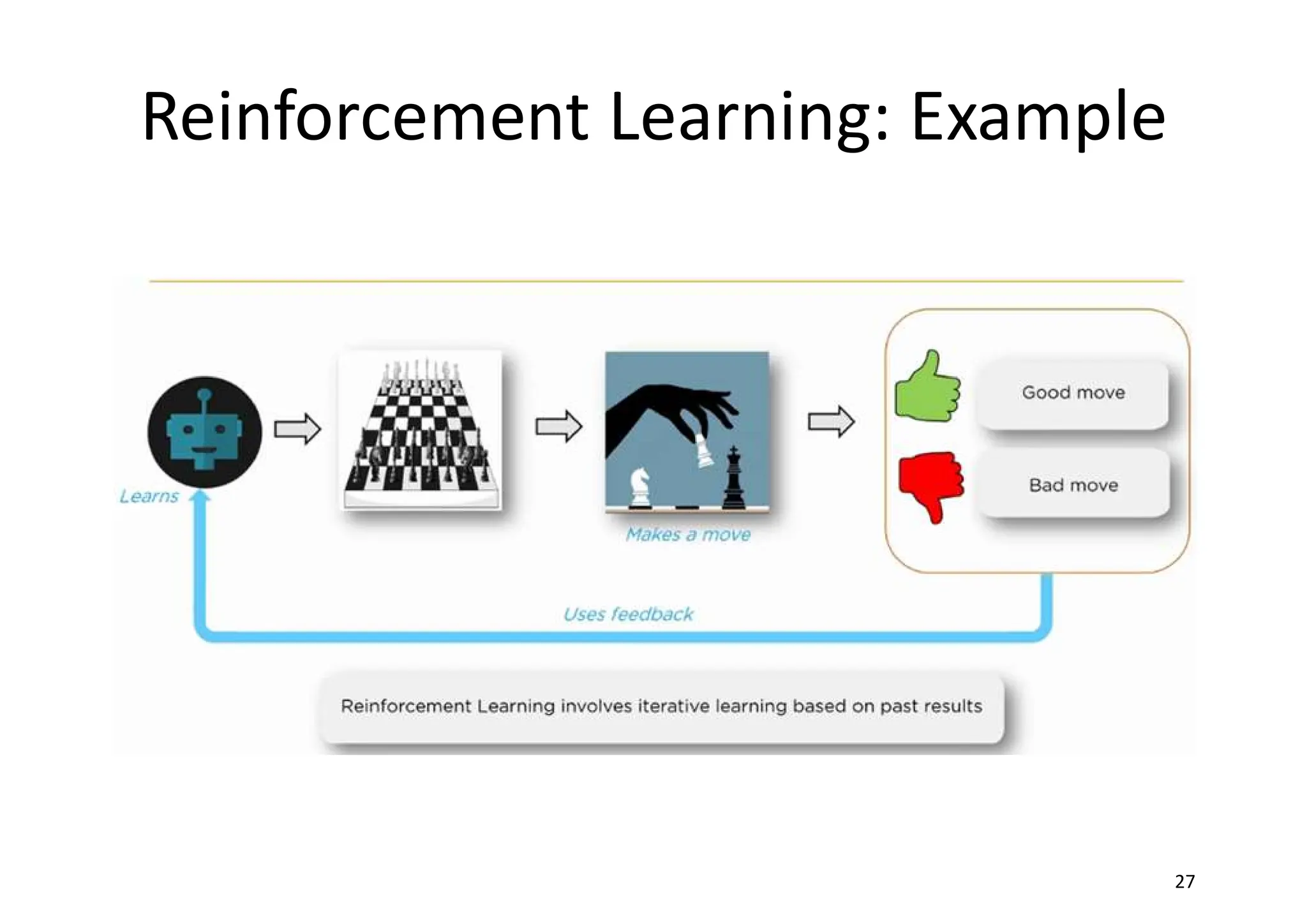
Reinforcement Learning • reinforcementlearning is also based on feedback provided by the environment • the information is more qualitative and doesn't help the agent in determining a precise measure of its error. In reinforcement learning, this feedback is usually called reward (sometimes, a negative one is defined as a penalty) and it's useful to understand whether a certain action performed in a state is positive or not.
21.
Reinforcement Learning • Thesequence of most useful actions is a policy that the agent has to learn, so to be able to make always the best decision in terms of the highest immediate and cumulative reward. In other words, an action can also be imperfect, but in terms of a global policy it has to offer the highest total reward. • Reinforcement learning is particularly efficient when the environment is not completely deterministic, when it's often very dynamic, and when it's impossible to have a precise error measure.
Reinforcement Learning • reinforcementlearning is also based on feedback provided by the environment • the information is more qualitative and doesn't help the agent in determining a precise measure of its error. In reinforcement learning, this feedback is usually called reward (sometimes, a negative one is defined as a penalty) and it's useful to understand whether a certain action performed in a state is positive or not.
26.
Reinforcement Learning • Thesequence of most useful actions is a policy that the agent has to learn, so to be able to make always the best decision in terms of the highest immediate and cumulative reward. In other words, an action can also be imperfect, but in terms of a global policy it has to offer the highest total reward. • Reinforcement learning is particularly efficient when the environment is not completely deterministic, when it's often very dynamic, and when it's impossible to have a precise error measure.
Beyond machine learning deeplearning , bio inspired adaptive systems • complex (deep) neural architectures: deep learning – Rosenblatt invented the first perceptron, interest in neural networks • The idea behind these techniques is to create algorithms that work like a brain • Common deep learning applications include: – Image classification – Real-time visual tracking – Autonomous car driving – Logistic optimization – Bioinformatics – Speech recognition
29.
Machine learning andBig data. • the amount of information managed in different business contexts grew exponentially • opportunity to use it for machine learning purposes arose • it's possible to asynchronously train several local models, periodically share the updates, and re- synchronize them all with a master model • Not every machine learning problem is suitable for big data, and not all big datasets are really useful when training models.
30.
Parametric learning • avector-values function depend on an internal parameter vector which determines the actual instance of a generic predictor, the approach is called parametric learning:
31.
non-parametric learning • doesn'tmake initial assumptions about the family of predictors • instance-based learning and makes real-time predictions (without pre-computing parameter values) based on hypothesis determined only by the training samples (instance set). • concept of neighborhoods :classification
32.
• In aclassification problem, a new sample is automatically surrounded by classified training elements and the output class is determined considering the preponderant one in the neighborhood • Eg: kernel-based support vector machines
33.
• A genericparametric training process must find the best parameter vector which minimizes the regression/classification error given a specific training dataset and it should also generate a predictor that can correctly generalize when unknown samples are provided.
34.
• Supervised Learning –Regression and classification • Single value /single label • Multi value: multi-label classification and multi-output regression • Unsupervised learning – We only have an input set X with m-length vectors, and we define clustering function (with n target clusters) with the following expression:
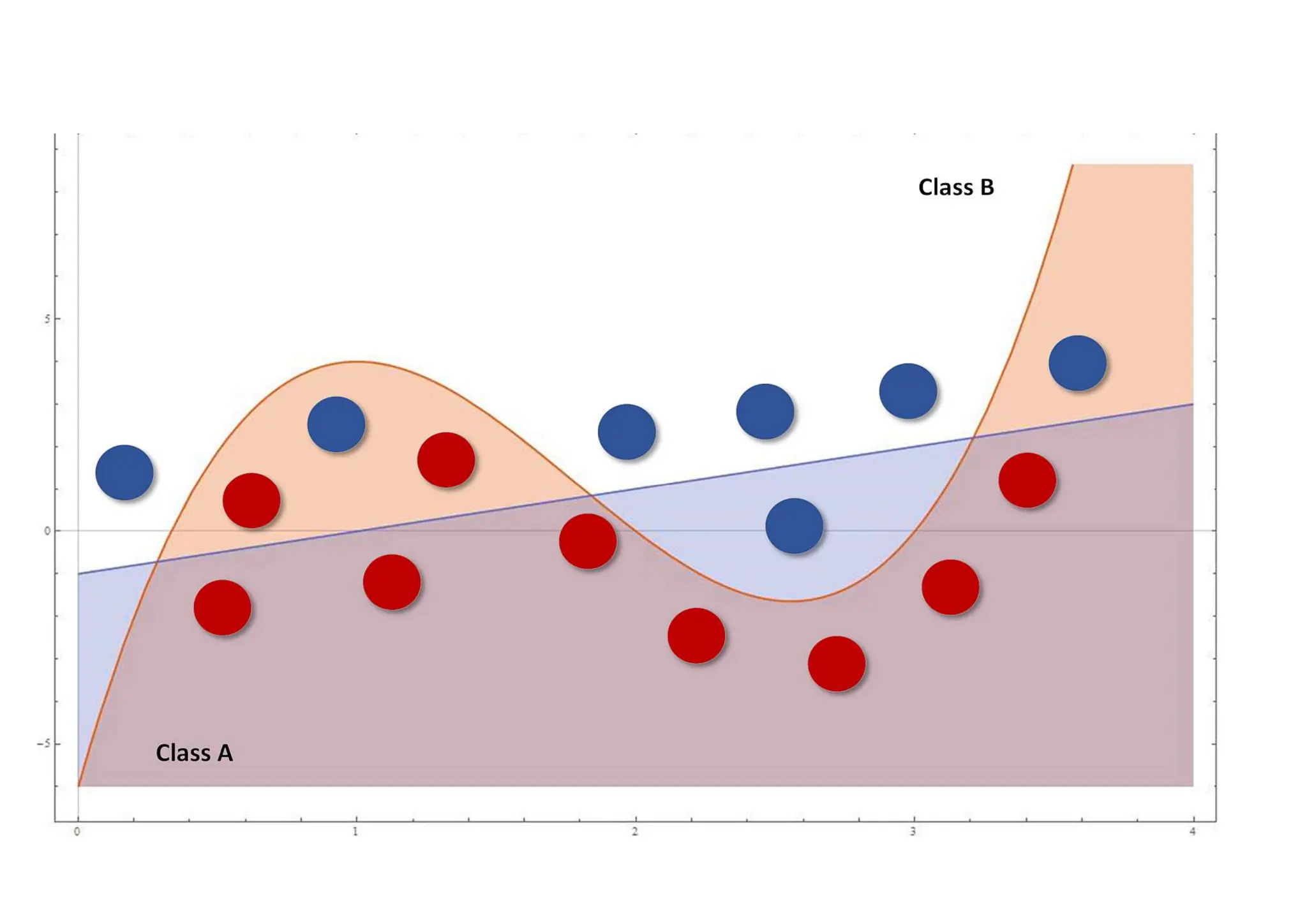
two possibilities • Ifwe expect future data to be exactly distributed as training samples, a more complex model can be a good choice, to capture small variations that a lowerlevel one will discard. In this case, a linear (or lower-level) model will drive to underfitting, because it won't be able to capture an appropriate level of expressivity. • If we think that future data can be locally distributed differently but keeps a global trend, it's preferable to have a higher residual misclassification error as well as a more precise generalization ability. Using a bigger model focusing only on training data can drive to overfitting.
37.
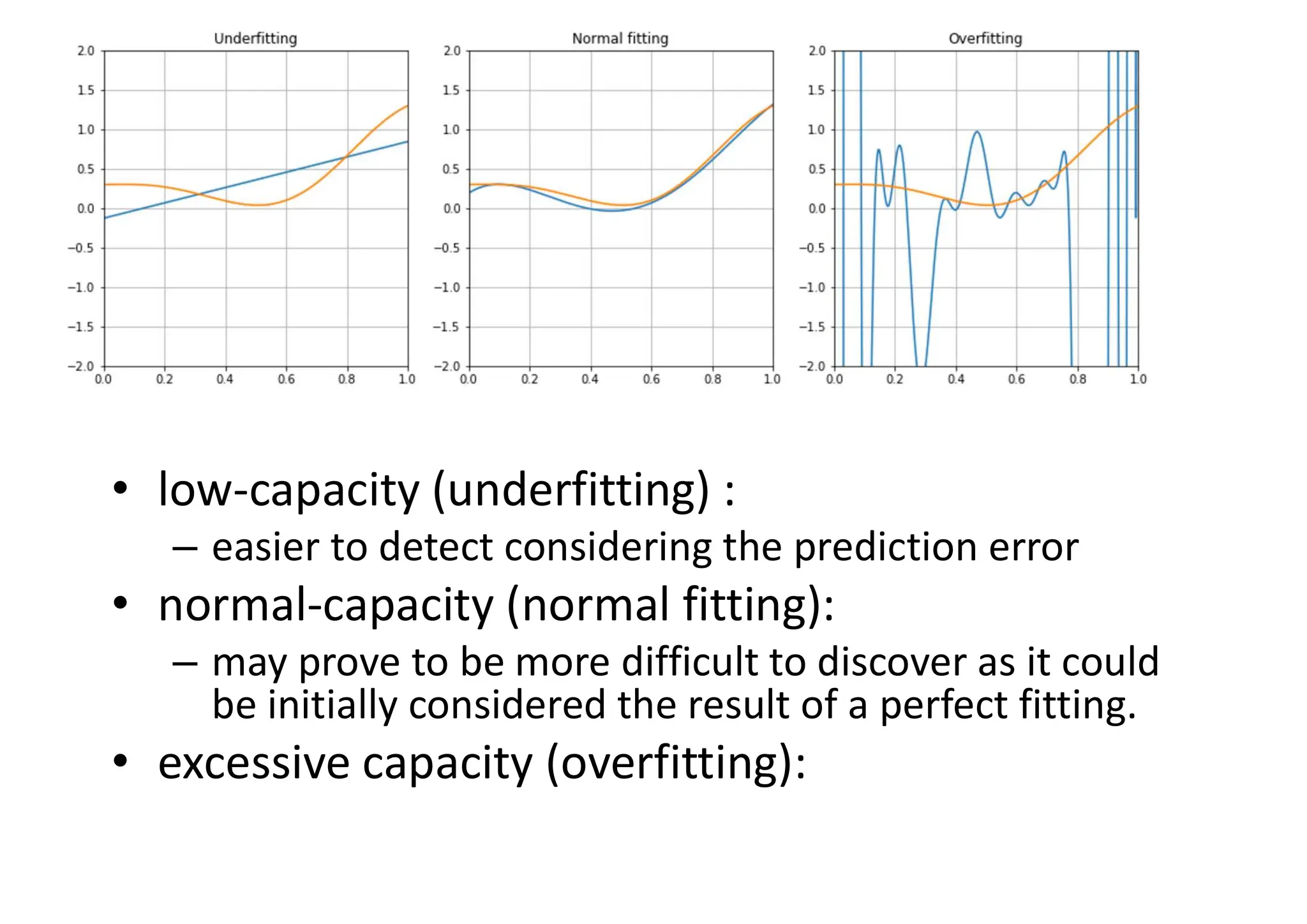
Underfitting and overfitting •The purpose of a machine learning model is to approximate an unknown function that associates input elements to output ones (classes) • Underfitting: It means that the model isn't able to capture the dynamics shown by the same training set (probably because its capacity is too limited). • Overfitting: the model has an excessive capacity and it's not more able to generalize considering the original dynamics provided by the training set. It can associate almost perfectly all the known samples to the corresponding output values, but when an unknown input is presented, the corresponding prediction error can be very high.
38.
• low-capacity (underfitting): – easier to detect considering the prediction error • normal-capacity (normal fitting): – may prove to be more difficult to discover as it could be initially considered the result of a perfect fitting. • excessive capacity (overfitting):
39.
Data formats • Ina supervised learning problem, there will always be a dataset, defined as a finite set of real vectors with m features each: Considering approach is always probabilistic each X as drawn from a statistical multivariate distribution D.
40.
• dataset X:we expect all samples to be independent and identically distributed (i.i.d). • This means all variables belong to the same distribution D, and considering an arbitrary subset of m values, it happens that: • The corresponding output values can be both numerical- continuous or categorical. • In the first case, the process is called regression, while in the second, it is called classification.
• Generic Regressor: a vector-valued function which associates an input value to a continuous output • Generic Classifier, a vector-values function whose predicted output is categorical (discrete).
43.
Multiclass strategies • numberof output classes is greater than one • two main possibilities to manage a classification problem: – One-vs-all – One-vs-one • the choice is transparent and the output returned to the user will always be the final value or class.
44.
One-vs-one • training amodel for each pair of classes • complexity is O(n2) • the right class is determined by a majority vote. • this choice is more expensive and should be adopted only when a full dataset comparison is not preferable.
45.
One-vs-all • widely adoptedby scikit-learn • If there are n output classes, n classifiers will be trained in parallel considering there is always a separation between an actual class and the remaining ones. • lightweight approach (O(n) complexity)
46.
Learnability • A parametricmodel can be split into two parts: a static structure and a dynamic set of parameters. • a static structure : is determined by choice of a specific algorithm and is normally immutable • dynamic set of parameters is the objective of our optimization
47.
Learnability • Considering nunbounded parameters, they generate an n-dimensional space where each point, together with the immutable part of the estimator function, represents a learning hypothesis H • The goal of a parametric learning process is to find the best hypothesis whose corresponding prediction error is minimum and the residual generalization ability is enough to avoid overfitting.
49.
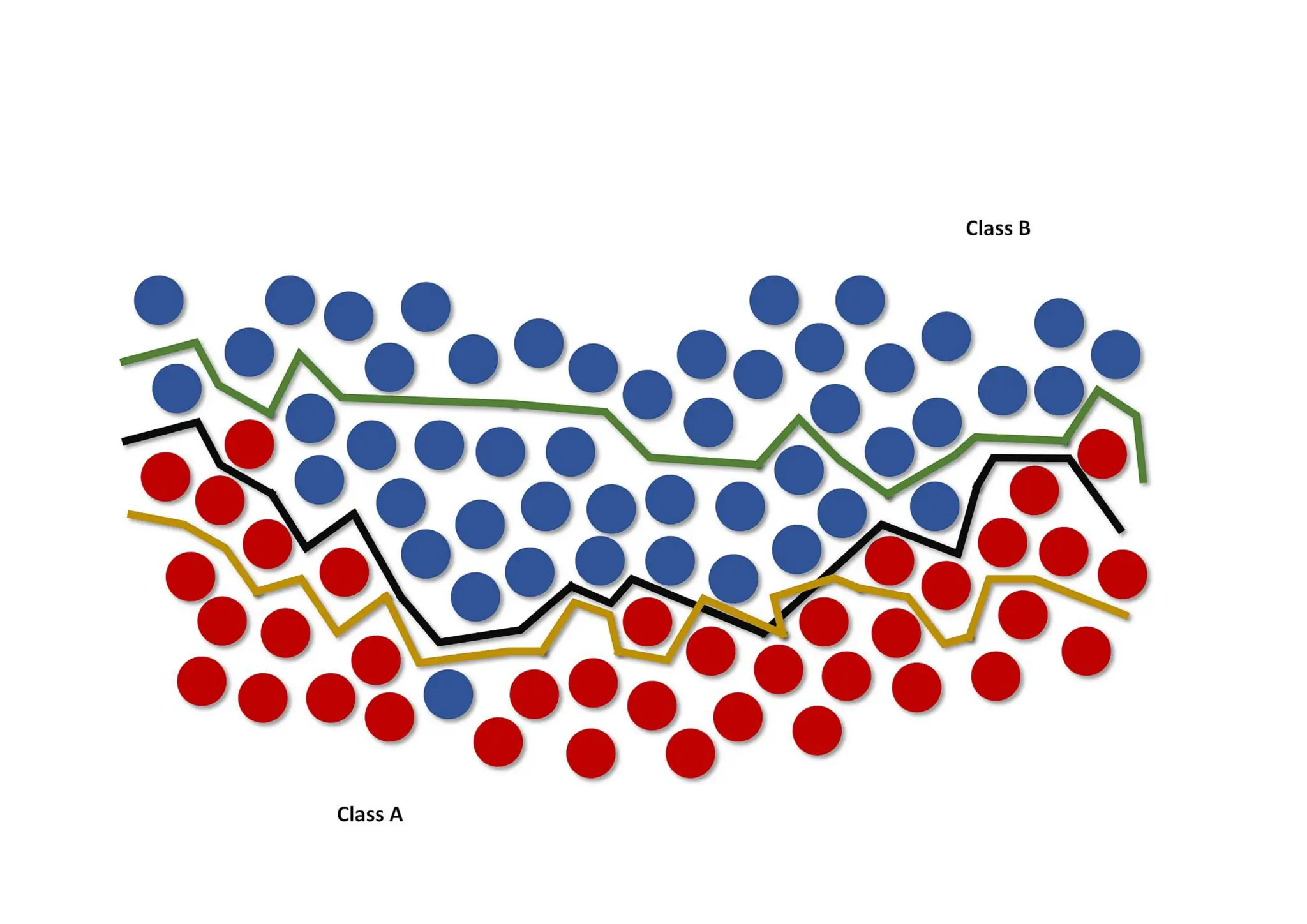
• the datasetX is linearly separable (without transformations) if there exists a hyperplane which divides the space into two subspaces containing only elements belonging to the same class
51.
• Cross-validation andother techniques easily show how our model works with test samples never seen during the training phase. • generic rule of thumb says that a residual error is always necessary to guarantee a good generalization ability, while a model that shows a validation accuracy of 99.999... percent on training samples is almost surely overfitted and will likely be unable to predict correctly when never-seen input samples are provided.
52.
Error measures • Ingeneral, when working with a supervised scenario, we define a non-negative error measure em which takes two arguments (expected and predicted output) and allows us to compute a total error value over the whole dataset (made up of n samples):
53.
loss function • it'suseful to consider the mean square error (MSE): • A generic training algorithm has to find the global minimum or a point quite close to it (there's always a tolerance to avoid an excessive number of iterations and a consequent risk of overfitting). • This measure is also called loss function because its value must be minimized through an optimization problem.
54.
zero-one-loss • efficient forbinary classifications (also for one- vs-rest multiclass strategy): • adopted in loss functions based on the probability of misclassification
55.
Statistical learning approaches •Imagine that you need to design a spam-filtering algorithm starting from this initial (over simplistic) classification based on two parameters: • We have collected 200 email messages (X) : p1 and p2 mutually exclusive • find a couple of probabilistic hypotheses to determine