Download to read offline

![IJRET: International Journal of Research in Engineering and Technology eISSN: 2319-1163 | pISSN: 2321-7308 two game plans α=< x1 x2 … xn> and β=< y1 y2 … ym>, then α is known as, meant numbers x1⊆ yj1, x2⊆ yj2,… , and xn⊆yjn . If α and β have the going with courses of gathering catalogues’ evidenced’ in-to th-e’ Table’-1’, this is’ probable’ t’o discover the’ absolute game plan customary sub-grouping. Table 1: Succession’ Data-base’ SID Sequence 10 <l(lmn)(ln)o(nq)> 20 <(lo)n(mn)(lp)> 30 <(pq)(lm)(oq)(nm) 40 <pr(lq)nmo> Each line in-to Table’-1 is a gathering. The progression have course of’ action of segments. Every segment might hold a thing or’a’ course of’action of things (set apart between fenced in area). Things inside a segment be un’ordered’ as well as th-ey’ recorded all together. As case, <l-(-m-n-)-o- n> be the subsequ-ence’ of’- l’(-l-m-n’)’. Rent exist the reinforce constrain slightest support identical to 2, <(lm)n> is a true blue progressive case. A goliath figure of’ likely progressive illustrations be concealed inside data-base’s. In successive case removal issues, th-re-e’ principal classes of cases can be communicated: Periodic or typical cases, truthful cases and vague cases [9]. We depict in the going with portions all the illustration classes. 1.2 Irregular Prototypes These models’s are’ second-hand suspect an occasions of’ a number of occasion (fused into the data’-set’) later on as well as fathom inherent qualities consolidated into it. This model is from time to time too much restrictive, in light of the way that if’ a little of’ it-’s occasions be mis-aligned’ i’t’ fa’ils’ t-o’ recognize a number of entrancing cases. To’ allow a predominant versatile replica’, case be able mostly filled’. The’ rule explanation behind existing in the direction of find the sub-sequen-ces’ show schedule’in-the’ data course of action. Case in point, stipulation to’ contain’ as’ data progressions illustration discontinuous case since this is’ repea-ted’ with’ a-peri-od’ equivalent to’ th-ree’. These past case are described filled discontinuous case in light of the way that every location case demonstrates a schedulings’. An’ occupied irregular illustration be no-t- open just a couple of utilizations, but instead various applications drive information progression anywhere no-t- eve-ry-pos-ition’ demonstrates infrequent case. Case in point, if we have an information plan thusly case broad assortment things as well as readily available be negative filled incidental case by means of distance end to end ‘thr- ee’. This is known as a-par-tial’ irregular case. 1.3 Verifiably Important Prototypes A mainly utilized way’s worn to’ assess dynamic cases be sponsorship as well as sureness. This’meas-ures be negative’ basic intended to everyone livelihoods of’ successive case mining. Fundamental or uncommon representations are the cases missed in the event that we’ utilize th’e’ gauge of’ occasion-s (sorted out backing) a’s-a’-meas-ure’ significance. This issue analyzed by’ different information removal applic-ation’s’. Insi-de-two or three uses, clients are enamored by’-the’ k-mos’t’ essential representations, as well as this errand can be effectively perceived utilizing an edge respect and the top k arranges that have a data grow more basic than the predefined edge ought to be returned. In any case, the issue data get worth is the weakness to see the scope events delineations. Table 2: Compatibility matrix example Real Values Observed Values x y z t x 0.9 0.12 0.0 0.05 y 0.11 0.7 0.1 0.11 z 0.0 0.0 0.88 0..12 t 0.1 0.17 0.0 0.78 For example: if we have tow data outlines courses of action as takes after illustration get in the two progressions, scattered in-S-1-buts goes over successive i-n-S-2’. A couple mechanisms contain be obtainable within’ [9’]’, intended to additional elucidation. 1.4 Harsh Prototypes Boisterous itemsets or flawed information are min-ed’ nearly as flawless itemsets. Flawed data happens in a couple of utilizations if the occasion of a case can't be seen. The two past delineated cases check simply revise competition of’the’ case within-da-ta. An’inaccurate illustration be-a plan pictures which’happens with’a-val-ue more conspicuous tha’n-‘an’ inferred edge within-the-data’ progression. In the direction of deal with issue of evaluated case divulgence, the makers possibility of calculability medium. These networks’ give’ a’ probabilistic relationship from’-the’ watched qualities t’o-the’ certifiable qualities. These-calculability grid methodology proffer’s-the’ probability to’-figure certifiable sponsorship of’- illustrations. Case in point, if we have a likeness matrix as in Table 2: The watched thing t thinks about to a certified occasion, exclusively. An-importance-of’ comparability system ought to be conceivable by the space expert, but there exist a couple of strategies to obtain the sensible estimation of each segment in the grid with a particular level of oversight. 2. LITERATURE REVIEW The pioneer in this customary back to back case mining is Agarwal [1] who exhibited and handled the issue of progressive successive mining. For a given progressive data, _______________________________________________________________________________________________ Volume: 05 Issue: 08 | Aug-2016, Available @ http://ijret.esatjournals.org 35](https://image.slidesharecdn.com/mistreatmentalgorithmicprogramtofindfrequentsequentialpatternswhilenotorderingthestumpssubsequences-161224113512/75/Mistreatment-algorithmic-program-to-find-frequent-sequential-patterns-while-not-ordering-the-stumps-sub-sequences-2-2048.jpg)
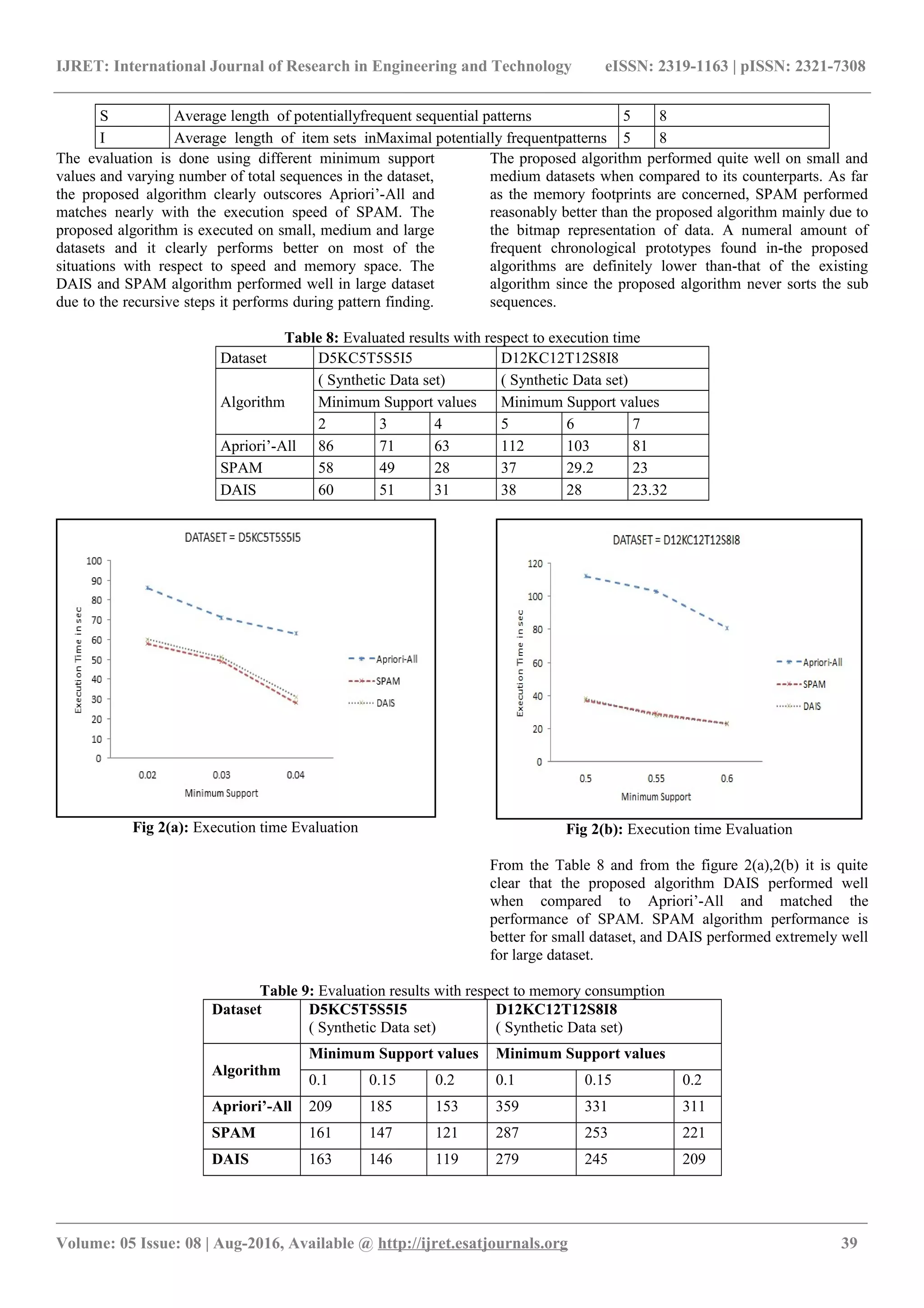
![IJRET: International Journal of Research in Engineering and Technology eISSN: 2319-1163 | pISSN: 2321-7308 the issue is to find each and every sequential case with a customer described slightest sponsorship, moreover named ceaseless back to back illustrations. In any case, Agarwal either considers sorted data or sorts the data before taking care of. A balanced Apriori’ named Apriori’-All [1] was in like manner exhibited by Agarwal however these two counts doesn't discover plans without sorting the data. Different counts in light of the working standard of Apriori’ were introduced by pros yet none was proposed to find the case of unsorted data without sorting the data. The Apriori’-like progressive illustration mining strategies encounter the evil impacts of the costs to handle a possibly enormous course of action of contender illustrations and breadth the data-base’ again and again. The central injury of Apriori’ based philosophy is voluminous confident time especially 2- itemset candidates. The SPAM [2] computation uses bitmap representations to find the I-Extended groupings and Extended progressions yet SPAM estimation expect the dataset courses of action as a sorted one or it explicitly sorts the progressions before finding the successive cases. Continuous illustration mining counts using the vertical association are greatly capable, it can figure the sponsorship of candidate case by avoiding extravagant. Speedy Vertical Mining of Sequential Patterns[3]data-base’ checks. Regardless, the major execution bottleneck of vertical mining figurings is that they generally contribute bundle of vitality evaluating contenders that don't appear in the data data-base’ or are intermittent. This can be used for pruning candidates made by vertical mining figurings. An improved Apriori’ figuring for connection rules [4] is proposed through reducing the time ate up in trades sifting for candidate thing sets by diminishing the amount of trades to be checked. At whatever point the k of k-thing set forms, the opening between our upgraded Apriori’ and the main Apriori’ increases from viewpoint of time ate up, and at whatever point the estimation of minimum support extends, the cleft between our improved Apriori’ and the principal Apriori’ decreases from point of view of time consumed. The time used to make cheerful reinforce number in our improved Apriori’ is not precisely the time ate up in the principal Apriori’. Examination back to back illustrations mining[5,6] strategies, for instance, Apriori’-based estimations encounter the issue that various breadths of the data-base’ are required remembering the final objective to make sense of which hopefuls are truly visit. Most by far of the plans gave so far to lessening the computational cost occurring due to the Apriori’ property use a bitmap vertical representation of the passage progression data-base’ and use bitwise operations to figure support at each accentuation. The changed vertical data-base’s, in their turn, present overheads that lower the execution of the proposed estimation, however not as is normally done more terrible than that of illustration advancement figuring. 3. PROBLEM OBJECTIVE AND METHODOLOGY 3.1 Definition Let I={i1; i2… … .,in} be the game plan for goodness' sake. We consider an itemset as a subset of things. A gathering (event) s is set of itemsets and asked for it as demonstrated by time-stamp associated with them. The progression s is implied as s-1-,--s-2-,-......,-s-l-, wheresj of’ s. S-j-i-s- moreover call-ed-a segment gathering, as well as implied a thing. A thing can happen at most once in an itemset yet can display diverse times in various itemsets in a course of action. The amount of events of things in a progression is known as the gathering. The’-gathering with-in len-gth’ l’is known as a l’sS. 3.2 Issue-Statement Given a plan data-base’ and as far as possible regard, the charge of progressive case removal be in the direction of discover the-whole course o-f’ action of back to back case in the data-base’. Four systems specifically GSP, SPADE, PrefixSpan and FreeSpan are used for delivering courses of action and the execution of these estimations are penniless down and took a gander at for finding the as indicated by data mining speculation, successive case digging computation can be generally parceled into three social occasions: Apriori’ based (GSP, SPADE, SPAM), outline advancement (FreeSpan, PrefixSpan) as showed up in Figure1. Fig.1 The system architecture 4. PROPOSED ALGORITHMIC APPROACHES TO THE TASK OF SEQUENCE MINING Right when working up estimation to the attempt of movement mining, the thought is to make it more beneficial to the degree memory necessities and to lessen however much as could be typical the reaction time [10]. That will propose the use of appropriated information structures and the utilization of old and novel algorithmic ways to deal with oversee play out this attempt. The estimation contains different methodology and the _______________________________________________________________________________________________ Volume: 05 Issue: 08 | Aug-2016, Available @ http://ijret.esatjournals.org 36](https://image.slidesharecdn.com/mistreatmentalgorithmicprogramtofindfrequentsequentialpatternswhilenotorderingthestumpssubsequences-161224113512/75/Mistreatment-algorithmic-program-to-find-frequent-sequential-patterns-while-not-ordering-the-stumps-sub-sequences-3-2048.jpg)
![IJRET: International Journal of Research in Engineering and Technology eISSN: 2319-1163 | pISSN: 2321-7308 systems are perceived here, Procedure InitialProcess( Dataset D, min-sup V) Input: Dataset D OutPut: Normalized Converted Data Begin: 1. Load and Scan the Dataset D 2. "DatarowDrÎ D do Mark UniqueItems in InitialTable Mark Numerical Value for UniqueItems in InitialTable Mark Items in ItemLocation Table Find NumberOfEventsnEÎDr Index the Item numerical values to ItemLocation Table IF [nE = 1] Mark 0 Else Mark Numerical Values separated by comma End IF End For 3. Mark Count of UniqueItems, IF[ count <V ] Prune UniqueItem End Procedure Procedure FindProbableCombinations(InitialTableInT) Input: InitialTableInT Output: Probable combinations Begin: Find ThetotalItems Tot in InT "Index I ÎTot " Index I+1 Î Tot ConcateInT[I],InT[I+1]à Combination End For End For Return Combination End procedure Procedure Data-as-it-IS( Dataset D, min-sup ) Input: Dataset D, minimum support Output: Frequent Sequential patterns Begin: Call InitialProcess(D,) Call FindProbableCombinations(T) Combination C Combination do Loop Until (Sequences in C ≠ ) Load Sequence from ItemLocationTable according to C Check for a non-empty value in the first Column IF Row[Column1] = Non-empty, Start from that row Concatenate the non-empty value by moving UP,Right, Down, Diagonal IF (Items found in same Column) Check the EventIndex table to find the numerical values Concatenate according to numerical values as a single sequence End if Store the patterns temp End if End Loop Count the patterns and check Store frequent sequentialpatterns Else Ignore infrequent patterns End For Return Frequent sequential patterns End Procedure The proposed algorithm DAIS is the way to discover the frequent sequential patterns without ordering the items. At first the column 1 is checked for a non-empty value. If the non-empty value found, the process starts from that row. Move from the first column towards right, up or down to identify a non-empty value. After identify the non-empty value, all the items were concatenate and form the sequential patterns. This method employs event item indexing for each sequence and uses numerical values for events which contains more than one item. This methodology efficiently finds and discovers the frequent sequential patterns without disturbing the data present in the events of a sequence. This algorithm proposed a new procedure to find a probable combination of unique items. Step 1 finds the total number of unique item to identify the combination. Step 2 identify the index value to locate the items. In Step 3 the Item combinations are found to check whether the combinations are higher than the minimum support value provided by the user. The result is the combination of items produce a patterns. From the table 3, the data gathering data-base’ S is a course of action of tuples (sid, s), where sid is the progression identifier and s is the data gathering. The amount of tuples in S data-base’ is called base size of the data-base’ S, and demonstrated in gathering Sa, Sais-s. The sponsorship of a plan Sain the data-base’ S be the’amount of tup-le-s during th-e-data-ba’se’ enclosing Sa, implied as sup(Sa). For a given positive entire number m-in’-sup, a’s-t’he’ hold up edge, the’ progression Sais call-e-d-const’ant-seq-uen- tial’ case in data-base’ S, if sup(Sa) m-in’-su-p’. By and large the case is intermittent. Table 3: Sample data-base’ of unordered events SeqID Sequences S1 [ a (dc) ad ] S2 [ acae ] S3 [ cad(cbd) ] S4 [ bbc ] S5 [ (bcd)d ] The proposed approach primaries scrutinize the record-base in the direction of discovering the unique points present into the record-base. A table is constructed to identify whether _______________________________________________________________________________________________ Volume: 05 Issue: 08 | Aug-2016, Available @ http://ijret.esatjournals.org 37](https://image.slidesharecdn.com/mistreatmentalgorithmicprogramtofindfrequentsequentialpatternswhilenotorderingthestumpssubsequences-161224113512/75/Mistreatment-algorithmic-program-to-find-frequent-sequential-patterns-while-not-ordering-the-stumps-sub-sequences-4-2048.jpg)
![IJRET: International Journal of Research in Engineering and Technology eISSN: 2319-1163 | pISSN: 2321-7308 the item is present in the sequence and if the item is present then it is denoted by “1” else denoted by “0”. Along with this the support count of every unique item is calculated and stored. A numerical value for the items are provided and marked in this table as shown in the table 4. Let us consider S1= [a (dc) ad], here there are four sequences and for brevity, the brackets are omitted and [(a) (dc) (a) (d)] is written as [a (dc) ad]. The sequence S1 contains four events and the second event (dc) is unsorted and this event or subsequence is not sorted to discover the recurrent chronological prototypes in the proposed approach. Table 4: Identification of unique items with count and numerical value S1 S2 S3 S4 S5 SUPPORT COUNT NUMERIC VALUE 1 1 1 0 0 3 1 0 0 1 1 1 3 2 1 1 1 1 1 5 3 1 0 1 0 1 3 4 0 1 0 0 0 1 5 After finding the unique items in the data-base’ the following table is constructed initially to recognize whether the sequences contain a particular item or not. 5. ITEM LOCATION AND EVENT INDEXING Now the unique items exact location in each sequence is found and marked with the item name or simply that location is left empty. Along with this marking of location, the number of items in every event is found and the numerical values corresponding to the items be stocked up into the table-chart like exposed in the figure 2. Table 5: Locating items table for sequence S1, S2, S3, S4, S5 S Sequence Event S1 E1 a * * - 1 0 E2 * c d - 2 4,3 E3 a * * - 1 0 E4 * * d - 1 0 S2 E1 a * * - 1 0 E2 * c * - 1 0 E3 A * * - 1 0 E4 * * e - 1 0 S3 E1 * * c * 1 0 E2 a * * * .3 1.0 E3 * * * d'1 3.1 2.0 E2 b * - - 1 0 E3 * c - - 1 0 E2 * * d - 2,3,4 0 Here in figure 2, the sequence S1 is considered and S1 consists of 4 events [E1,E2,E3,E4] and the unique items in this sequence is identified and located in the corresponding events as shown in the above figure 1. Similarly number of items in each event is found and if it found value exceeds 1, the corresponding item’s numerical value is stored as shown. Here in event indexing 4 denotes “d” and 3 denotes “c”. 6. FORMATION OF ITEM COMBINATIONS After locating the items in the sequence, the item combinations are found to check whether the combinations are higher than smallest amount hold up value provided by the user assuming mun-sup value is 2. First item “a” is considered and the probable combinations are formed for the entire unique items. Here since “e” item hold up tally is less than the least amount carry rate, it is eliminated. To check whether the combination items produce patterns, AND operation is performed as shown below. Table 6: Combination formation of “ab, bc, bcd, abc, acd” to generate frequent patterns Item S1 S2 S3 S4 S5 bcd 0 0 1 0 1 abc 0 0 1 0 0 acd 1 0 1 0 0 Since “ab” support count is 1, the corresponding item sets which contains “ab” will also be 1. So the entire “ab” combinations are eliminated and pruned away. Combination formation of “ac” to generate frequent patterns. Since “e” is eliminated at the first stage, the 4-itemset combination is not considered. Similarly all the unique item combinations are formed and checked whether the count is higher or equal to the minimum support value provided. Those combinations which are leading or equivalent to the lowest amount carry values are further processed top discover the frequent sequential patterns. 7. EXPERIMENTAL RESULTS The proposed DAIS algorithm was implemented Microsoft C#.NET programming language resting up a system by means of 2.66GHz Intel-Pentium core2duo processor with 1GB RAM running on windows 7 ultimate. The evaluations are carried out on artificial information produced with I-B- M artificial marketplace hamper information producer. An input’ed strictures used for comparison are given below in the Table 8. Table 7: Dataset parameters Parameters Description of parameter Dataset utilized for evaluation D No. of successions in thedataset 3K 12K C standard events for each succession 5 12 _______________________________________________________________________________________________ Volume: 05 Issue: 08 | Aug-2016, Available @ http://ijret.esatjournals.org 38](https://image.slidesharecdn.com/mistreatmentalgorithmicprogramtofindfrequentsequentialpatternswhilenotorderingthestumpssubsequences-161224113512/75/Mistreatment-algorithmic-program-to-find-frequent-sequential-patterns-while-not-ordering-the-stumps-sub-sequences-5-2048.jpg)
![IJRET: International Journal of Research in Engineering and Technology eISSN: 2319-1163 | pISSN: 2321-7308 Fig 3(a): Execution memory usage Fig 3 (b): Execution memory usage From the table 9 and from the figure 3(a),3(b) it is quite clear that the memory usage of the proposed algorithm was compared with the existing algorithms and from the evaluated results, it is quite clear that the DAIS algorithm performed exceedingly well on larger datasets and at the same time the SPAM performed well on both small and larger dataset mainly because of the bitmap representation used in SPAM. 8. CONCLUSION Back to back mining has been attracting thought in late research in the field of data mining. Since the interest space is gigantic and data volume is tremendous, it has made various issues for mining back to back cases. To reasonably mine the continuous illustrations, capable progressive case mining computations are required. Among the back to back case counts GS-P, SPA-DE and Prefix-Span, Prefix-Span, DAIS is a capable illustration improvement technique since it beats the other three computations. Clearly DAIS Algorithm is more capable with respect to running time, space use and adaptability than Apriori’’ based computations. Another estimation to meet the test of discovering progressive case without asking for the events in a gathering is proposed in this paper and the proposed count DAIS performed growing awesome for greater datasets without sorting by using event thing indexing using numerical qualities. The proposed figuring should be executed on denser datasets with little min-sup qualities to test the adequacy and the accuracy. REFERENCES [1]. R. Agarwal and R. Srikant. Mining Sequential Pattern, Fast Algorithm for Mining Association Rule in Large Data- base’s.In Proc.1995,1994 Int. Conf. Data Engineering, pages 3-10, 1995., Int. Conf. Very Large Data-base’s, pp. 487-499, 1994. [2]. J. Ayres, J. Flannick, J. Gehrke, and T. Yiu. Sequential PAttern Mining Using A Bitmap Representation. In Proc. 2002 Int. Conf. Knowledge Discovery and Data Mining, 2002. [3]. Philippe Fournier-Viger1, Antonio Gomariz2,Manuel Campos2, and Rincy Thomas3: In Proc.2014 Fast Vertical Mining of Sequential Patterns Using Co-occurrence Information,University de Moncton [4]. Mohammed Al-Maolegi1: In Proc.2014 An improved Apriori’ algorithm for association rules. International Journal on Natural Language Computing (IJNLC) Vol. 3. [5]. Nikhil Gundawar1, Venkatesh Akolekar2, Piyush Phalak3, Akshay Gujar4 and Bewoor5: In Proc.2014 Analysis of Sequential Pattern Mining: international journal for research in emerging science and technology, volume-1, issue-6. [6]. Bhawna Mallick, Deepak Garg and Preetam Singh Grover. Constraint-Based Sequential Pattern Mining: In Proc. 2014 The International Arab Journal of Information Technology, Vol. 11, No. 1, January 2014. [7]. Goswami, Chaturvedi Anshu, Raghuvanshi: In Proc.2010 An Algorithm for Frequent Pattern Mining Based On Apriori’. International Journal on Computer Science and Eng [9]. Ms Shweta, Dr. Kanwal Garg2:In Proc.2013Mining Efficient Association Rules Through Apriori’ Algorithm Using Attributes and Comparative Analysis of Various Association Rule Algorithms. International journal of advanced research in computer science and software engineering. _______________________________________________________________________________________________ Volume: 05 Issue: 08 | Aug-2016, Available @ http://ijret.esatjournals.org 40](https://image.slidesharecdn.com/mistreatmentalgorithmicprogramtofindfrequentsequentialpatternswhilenotorderingthestumpssubsequences-161224113512/75/Mistreatment-algorithmic-program-to-find-frequent-sequential-patterns-while-not-ordering-the-stumps-sub-sequences-7-2048.jpg)

The document discusses a proposed algorithm called 'data because it is algorithm' aimed at efficiently mining frequent sequential patterns from databases without ordering subsequences. The algorithm addresses challenges in sequence mining by pruning infrequent items early in the process and demonstrates significantly improved performance compared to existing methods. Applications of this approach span various fields, including consumer behavior analysis, bioinformatics, and web mining.