


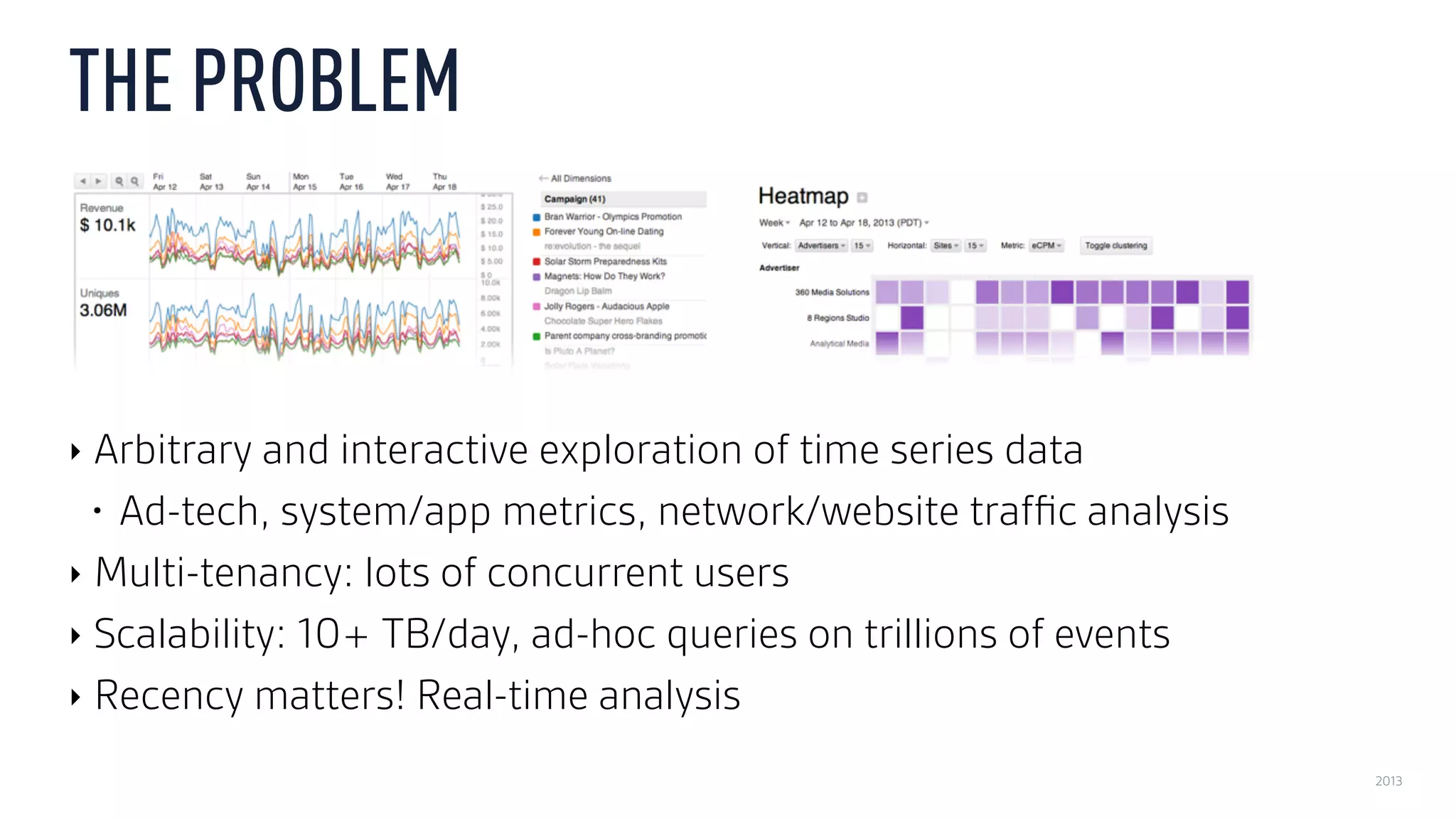



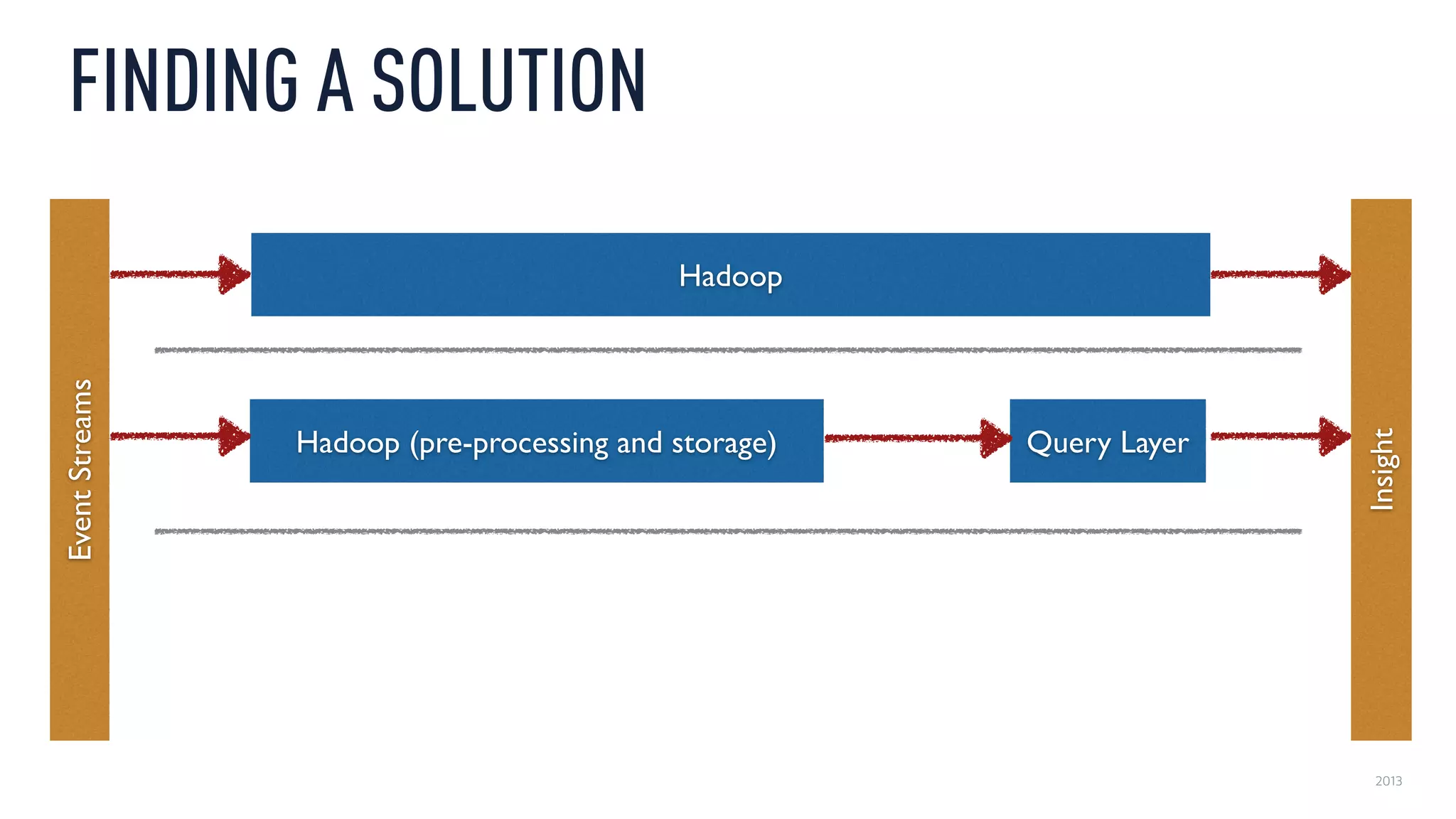


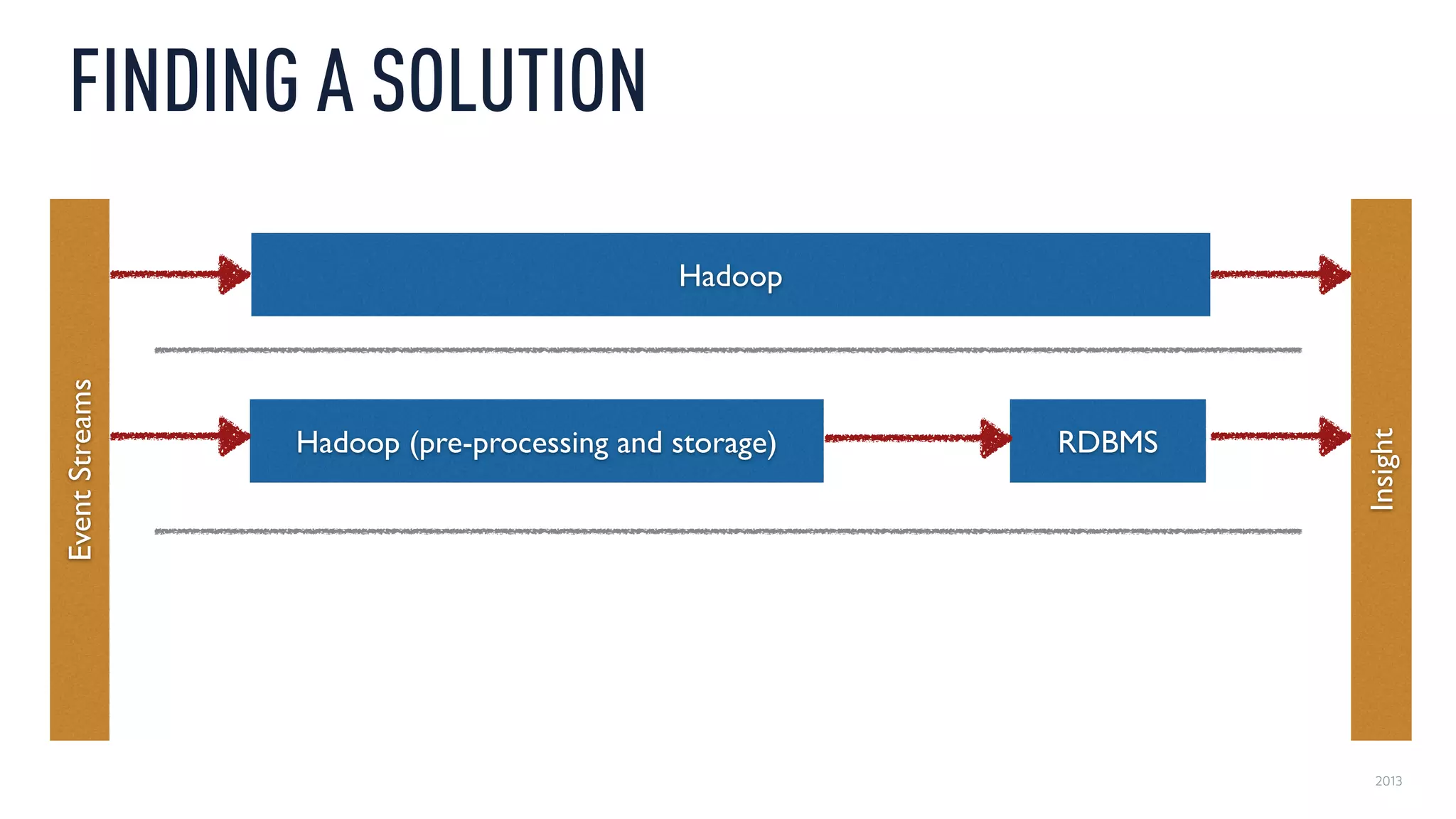
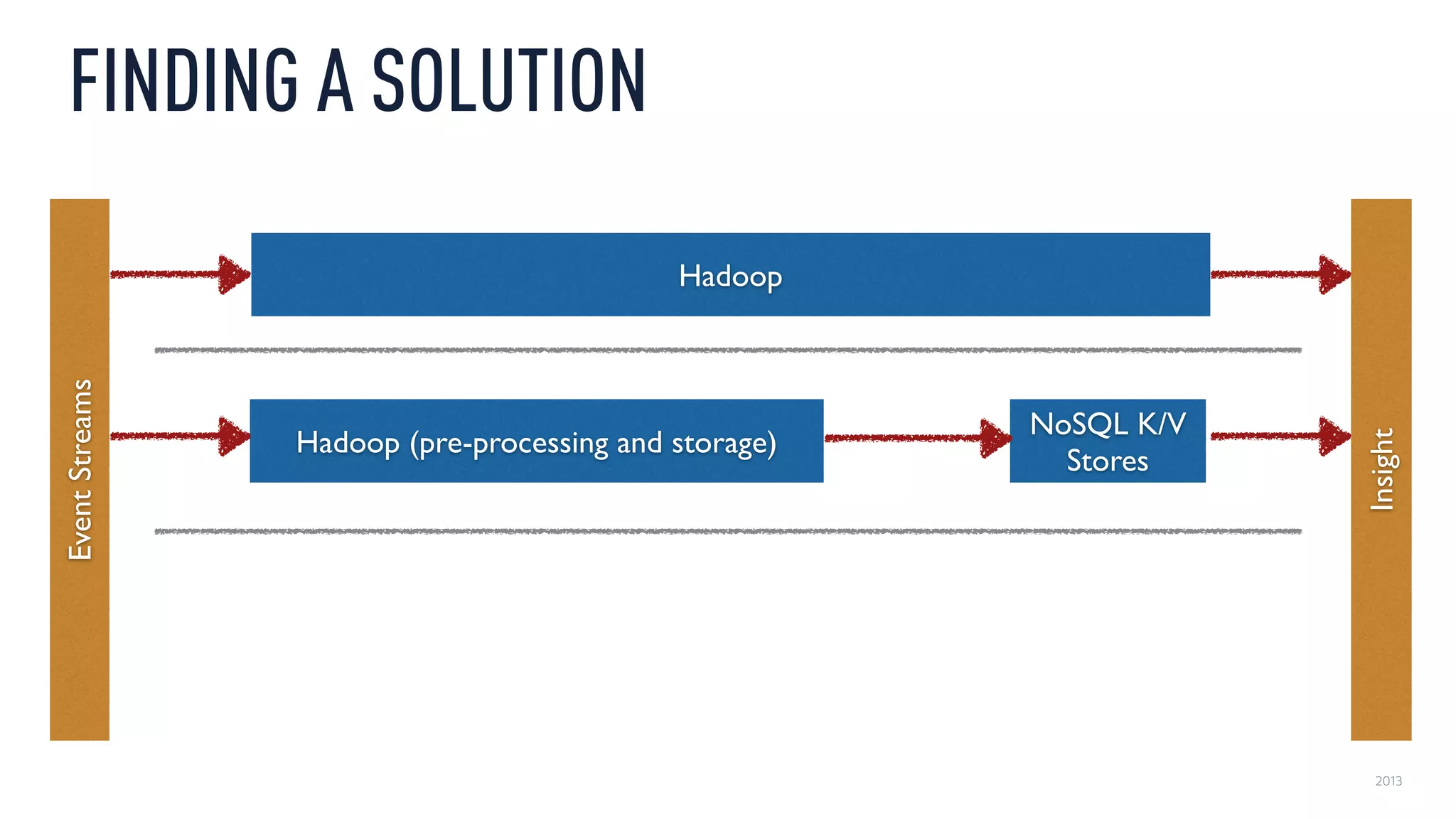
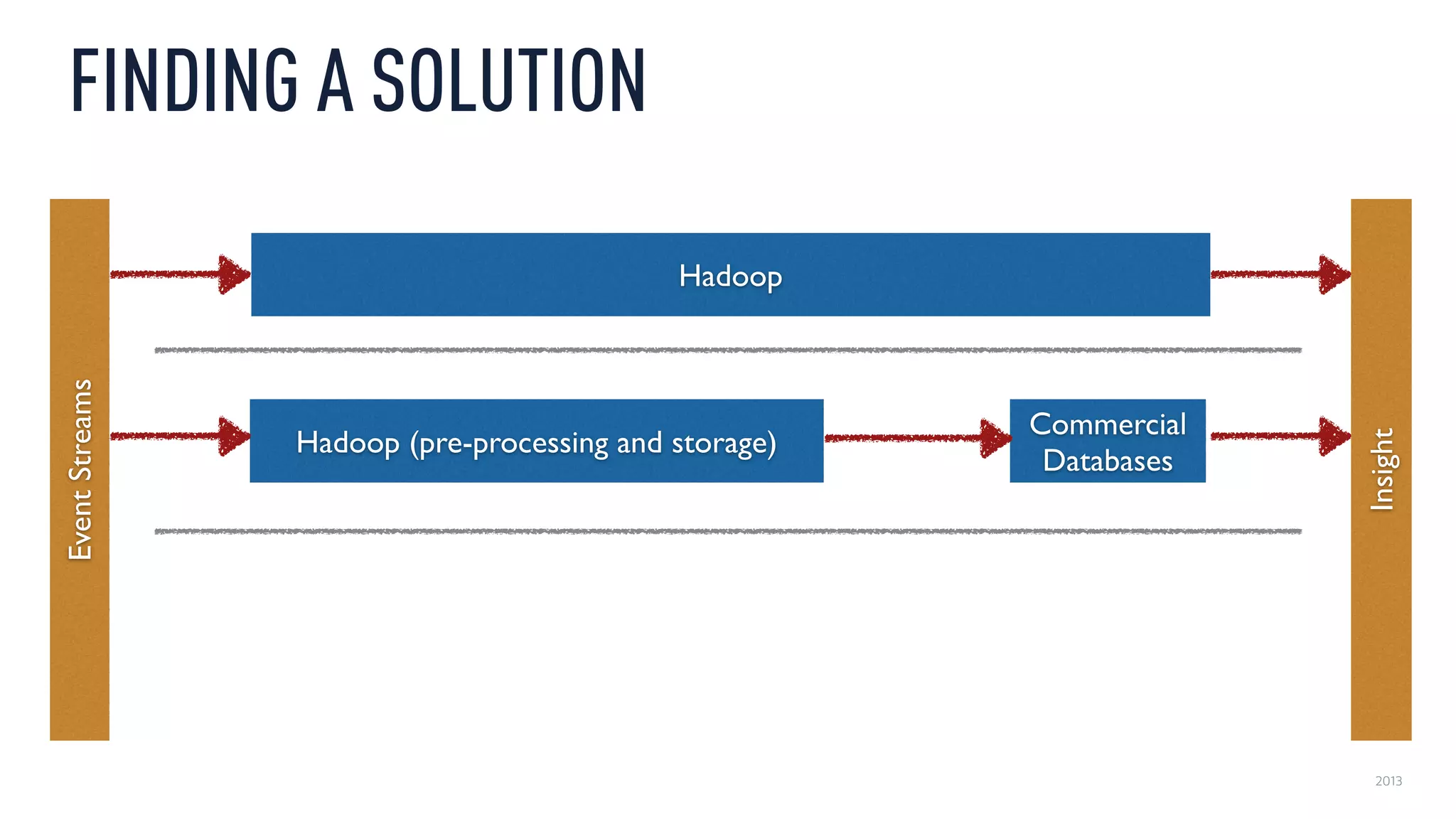


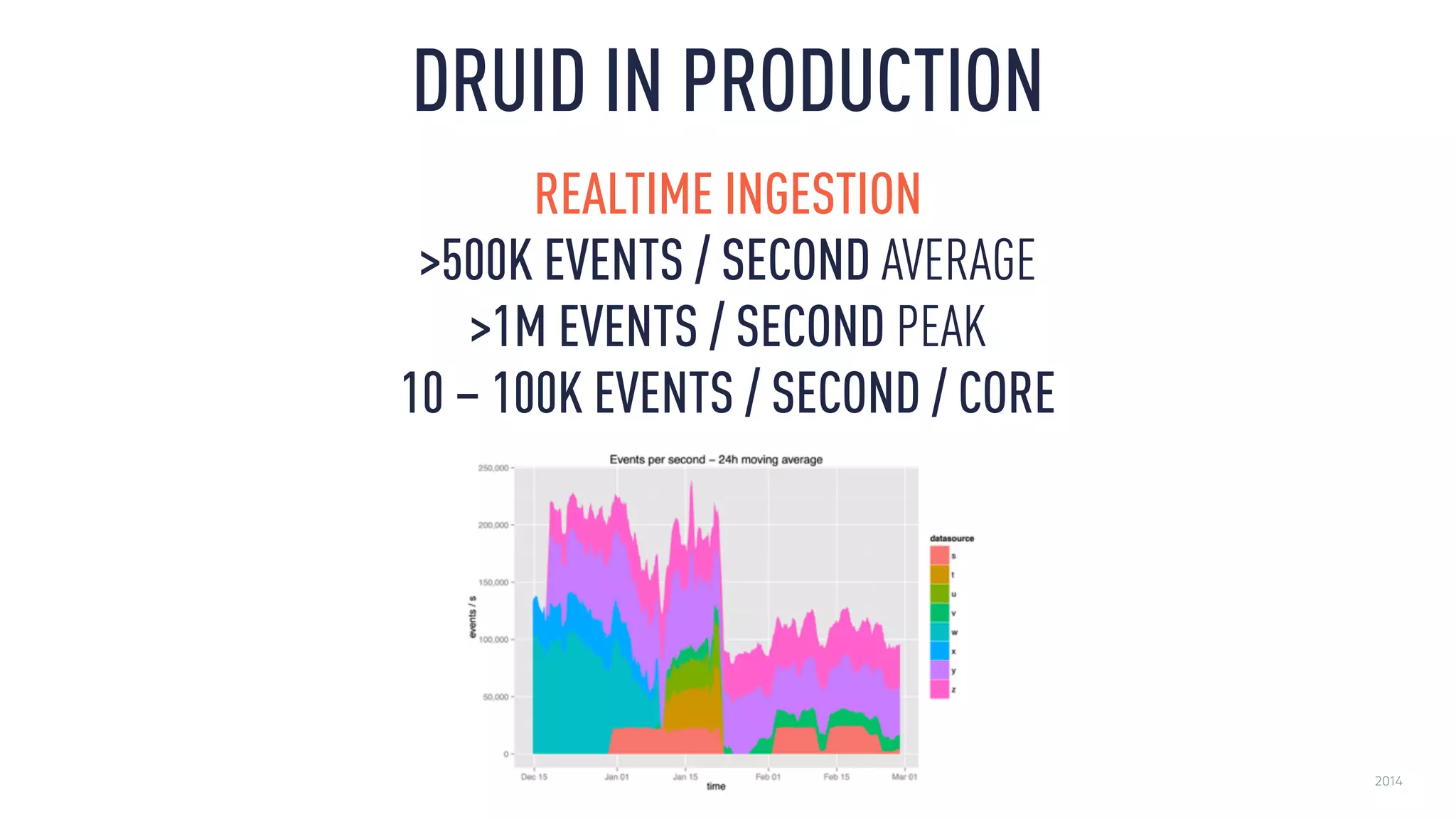
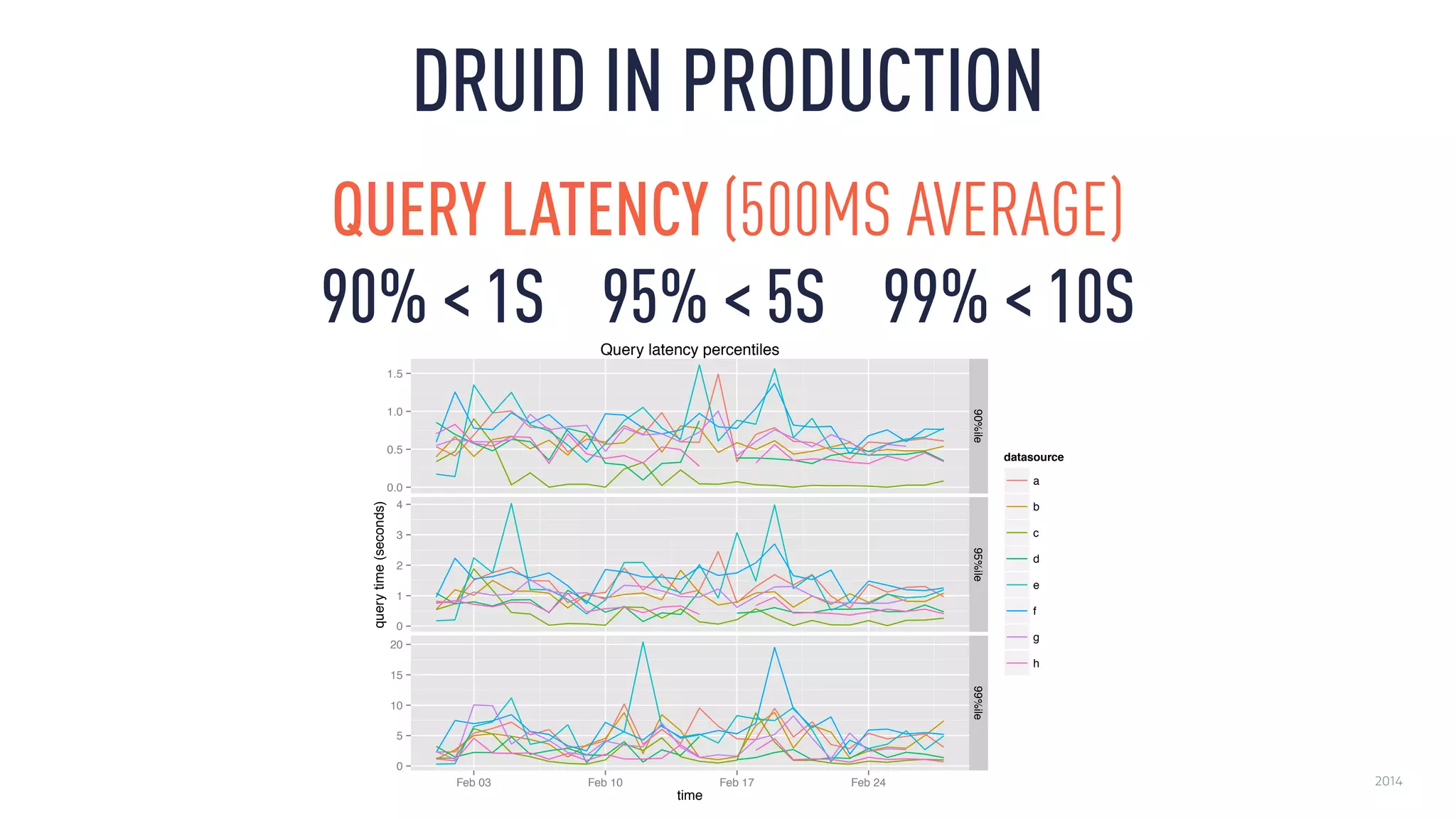






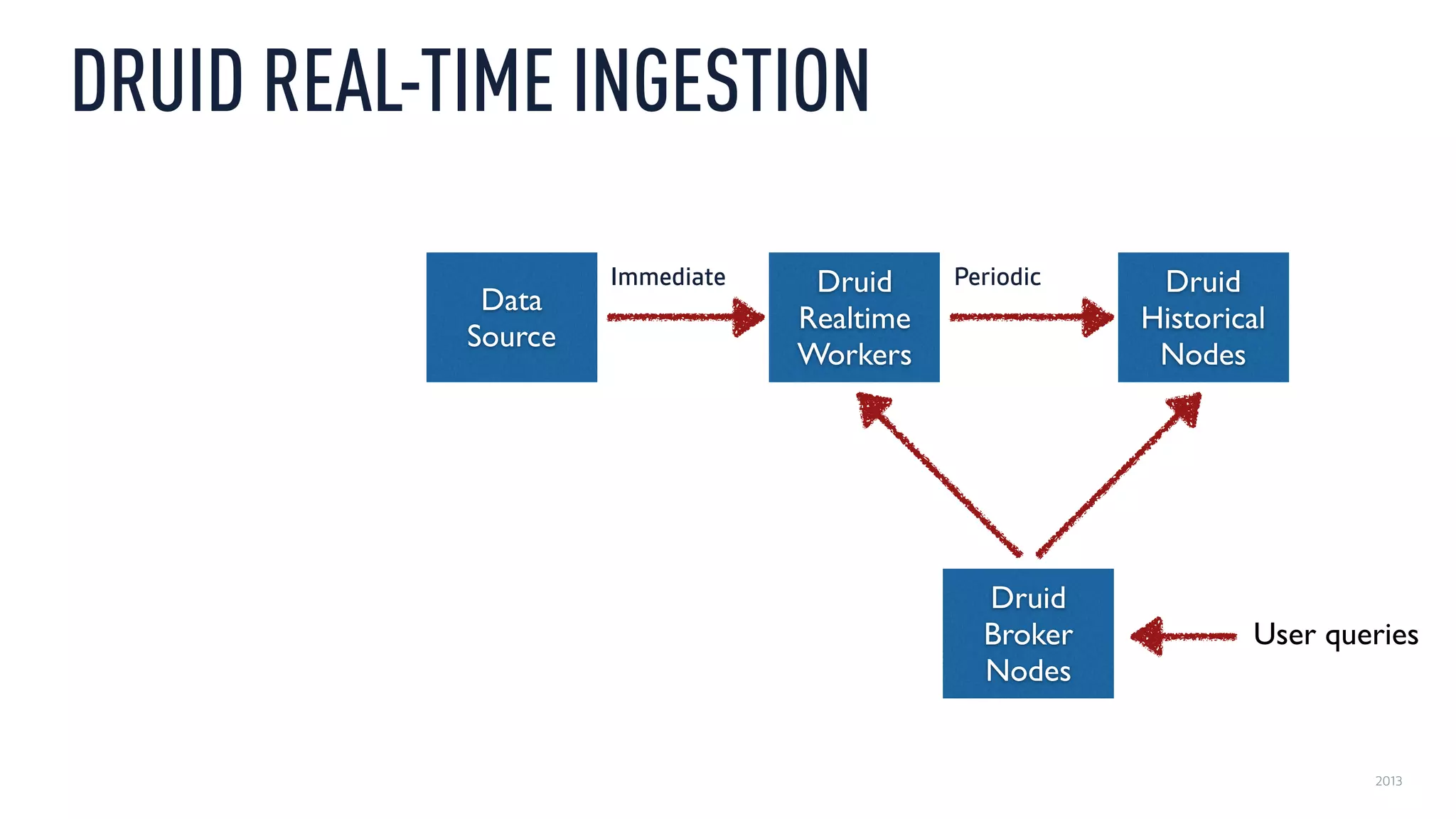
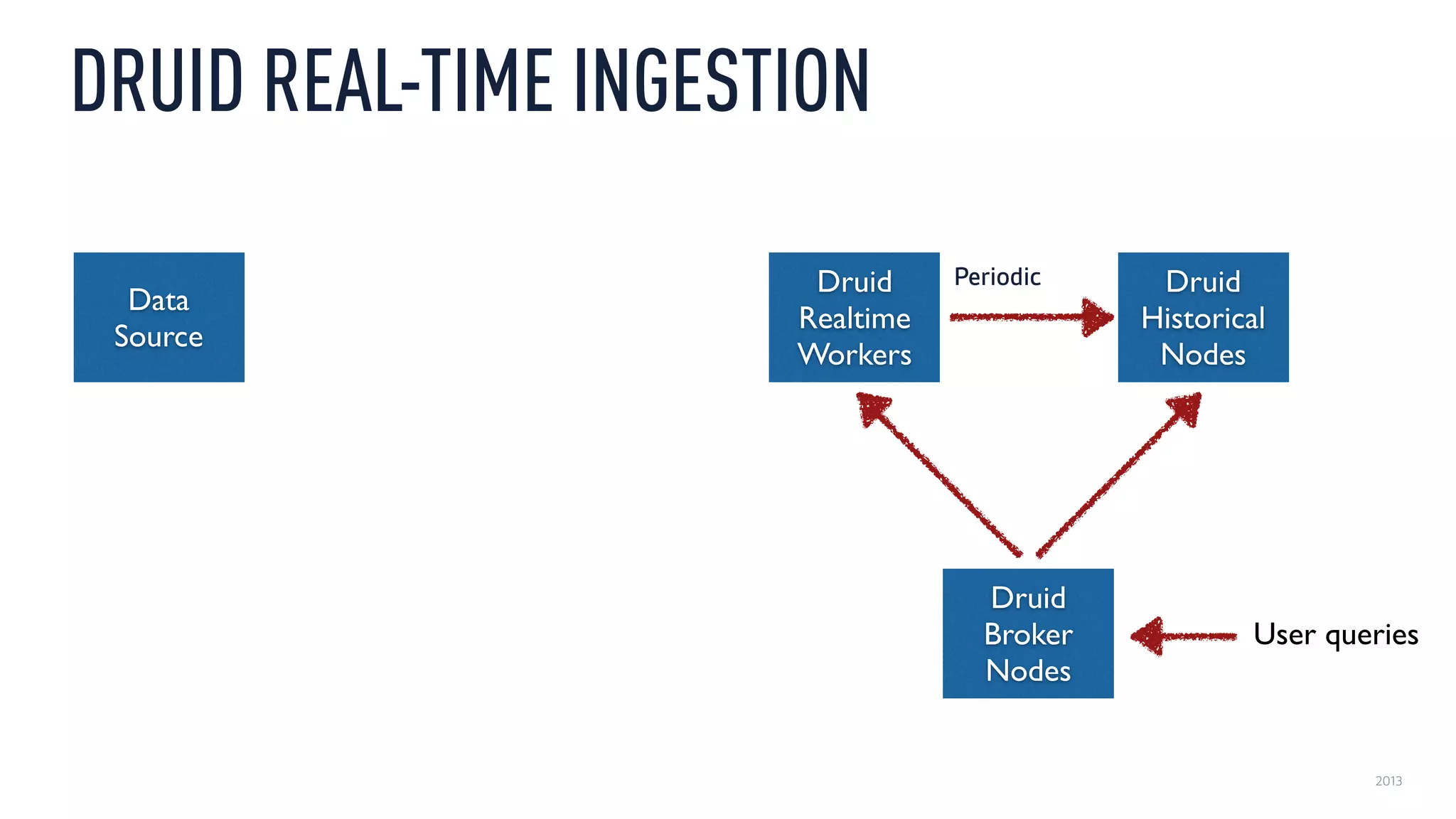
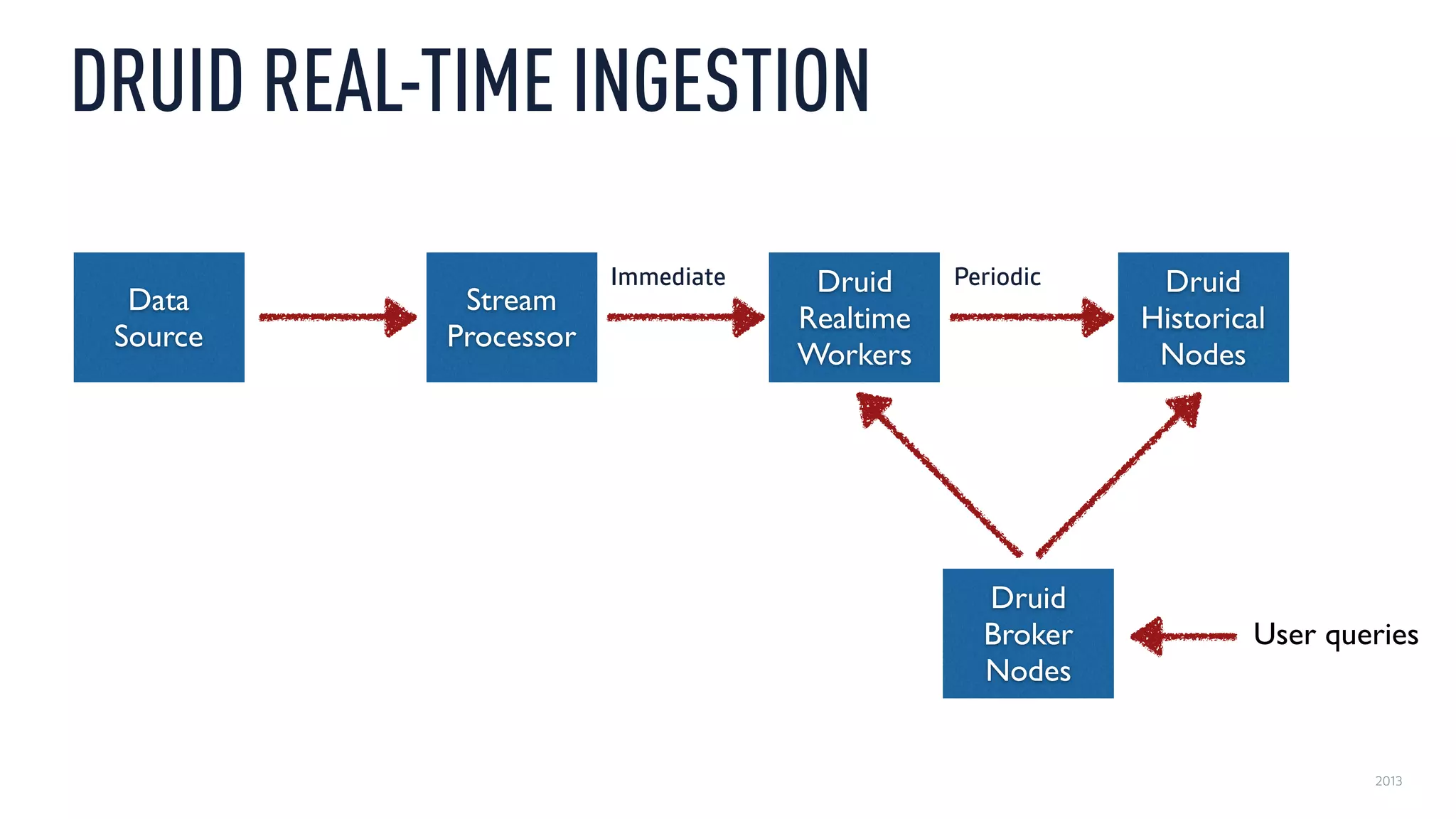
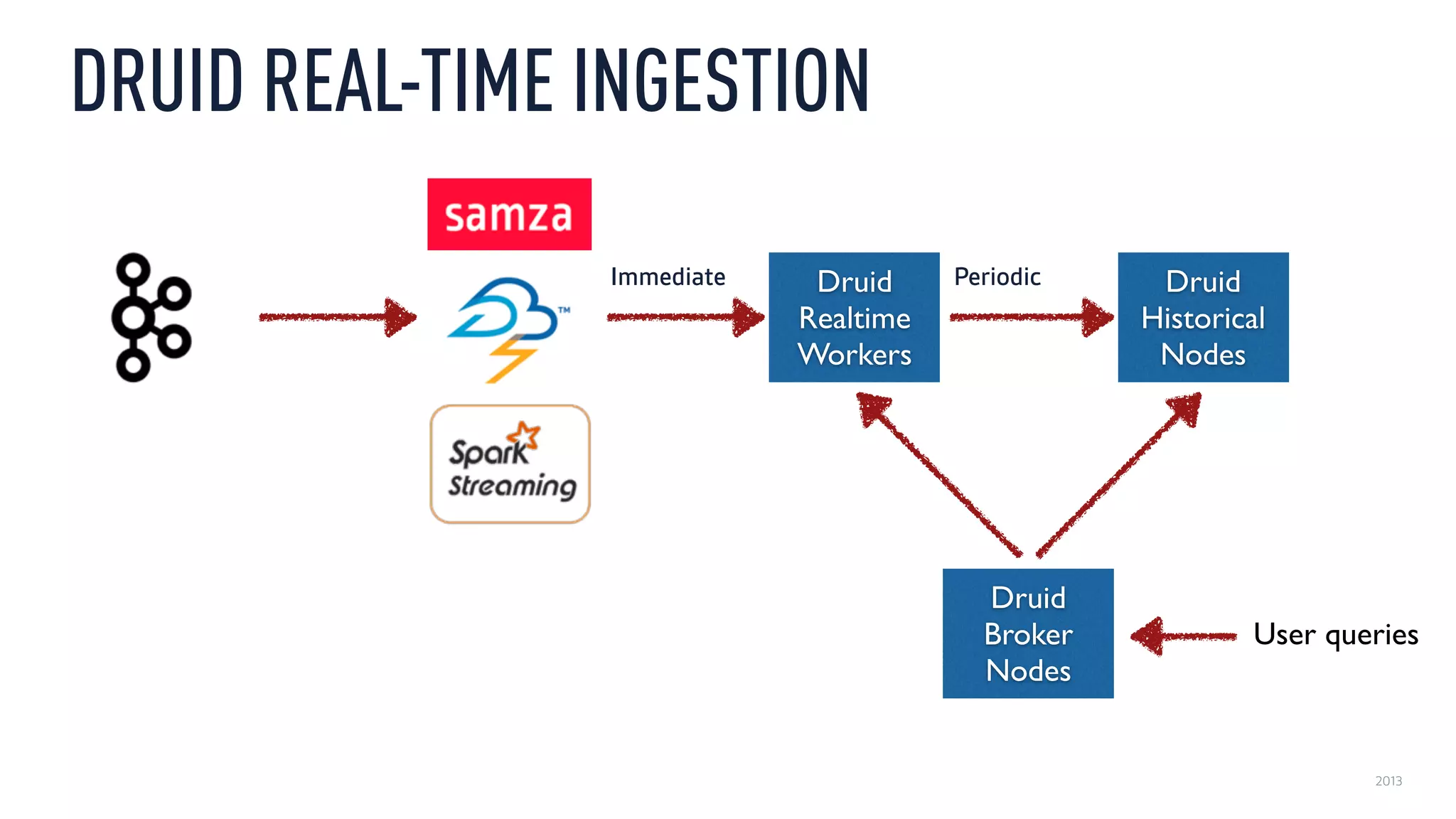


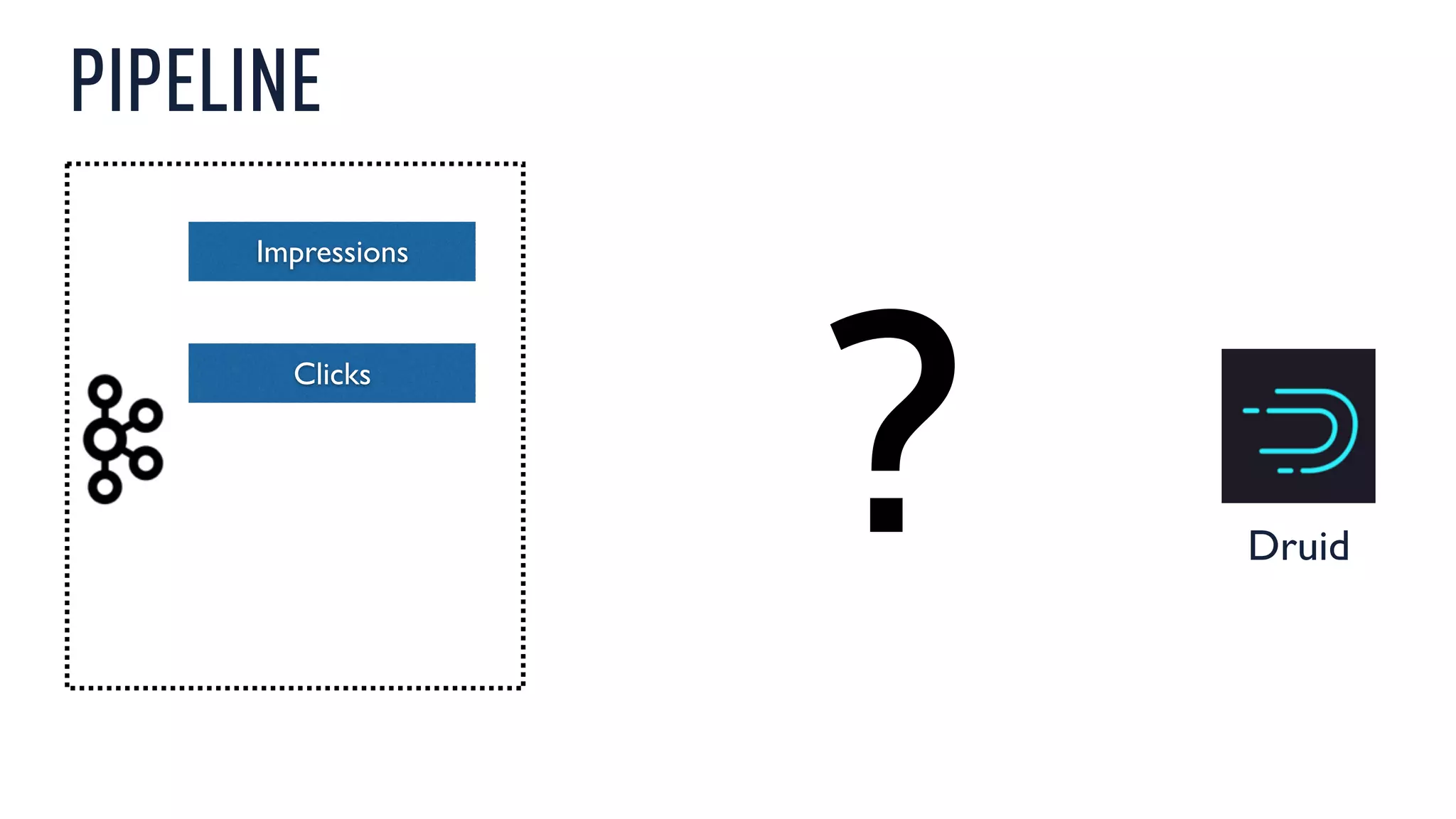

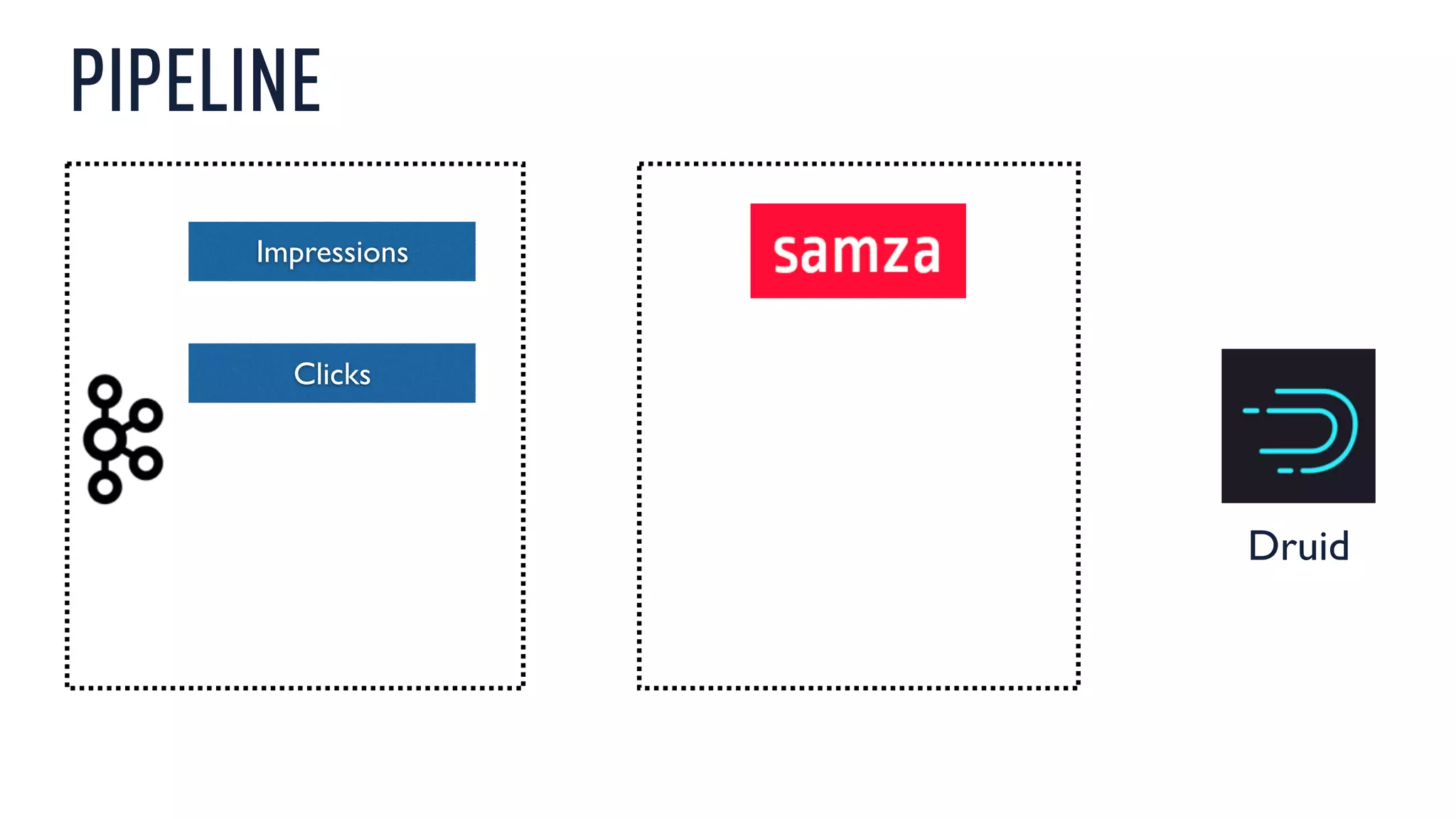
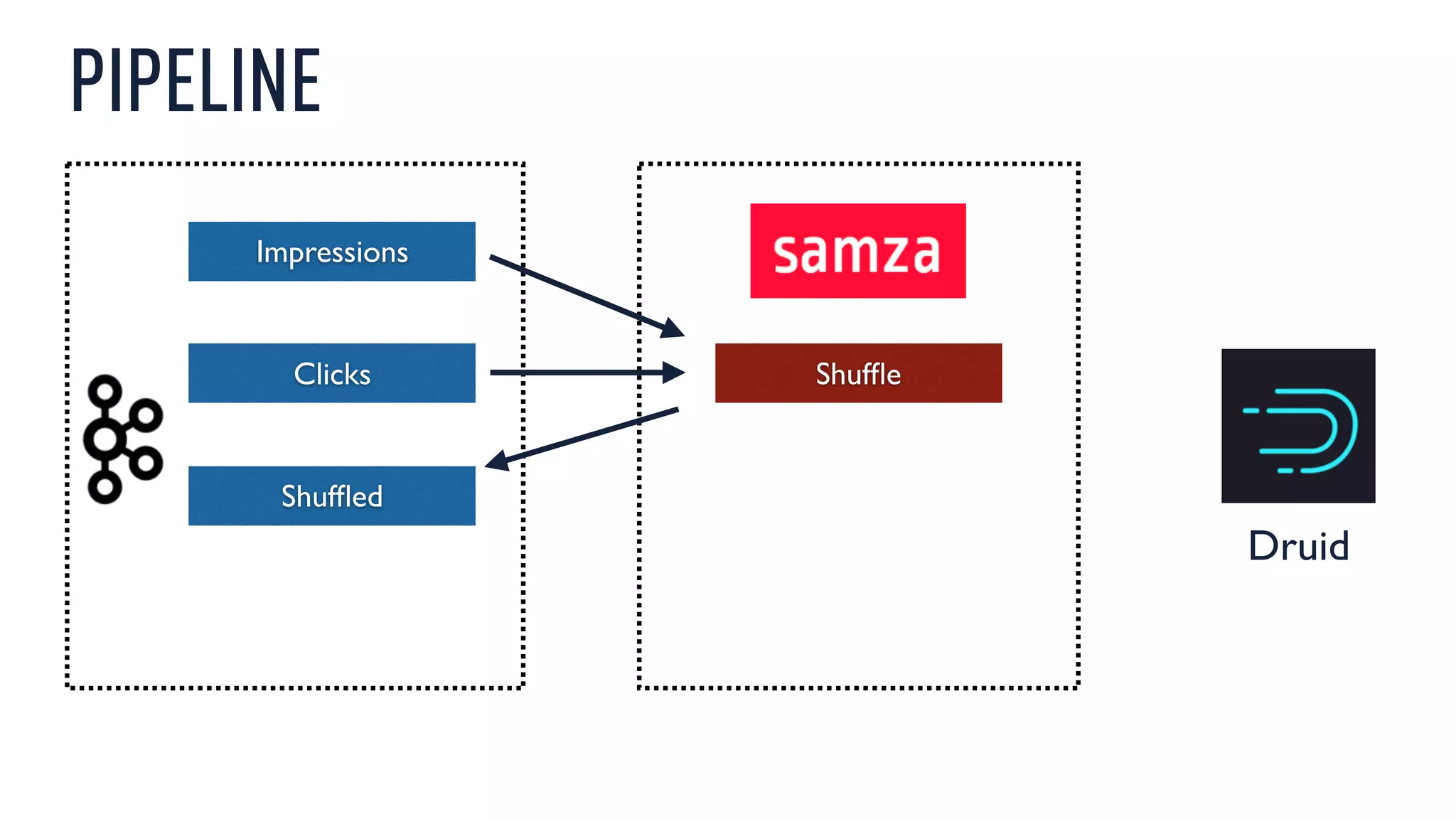

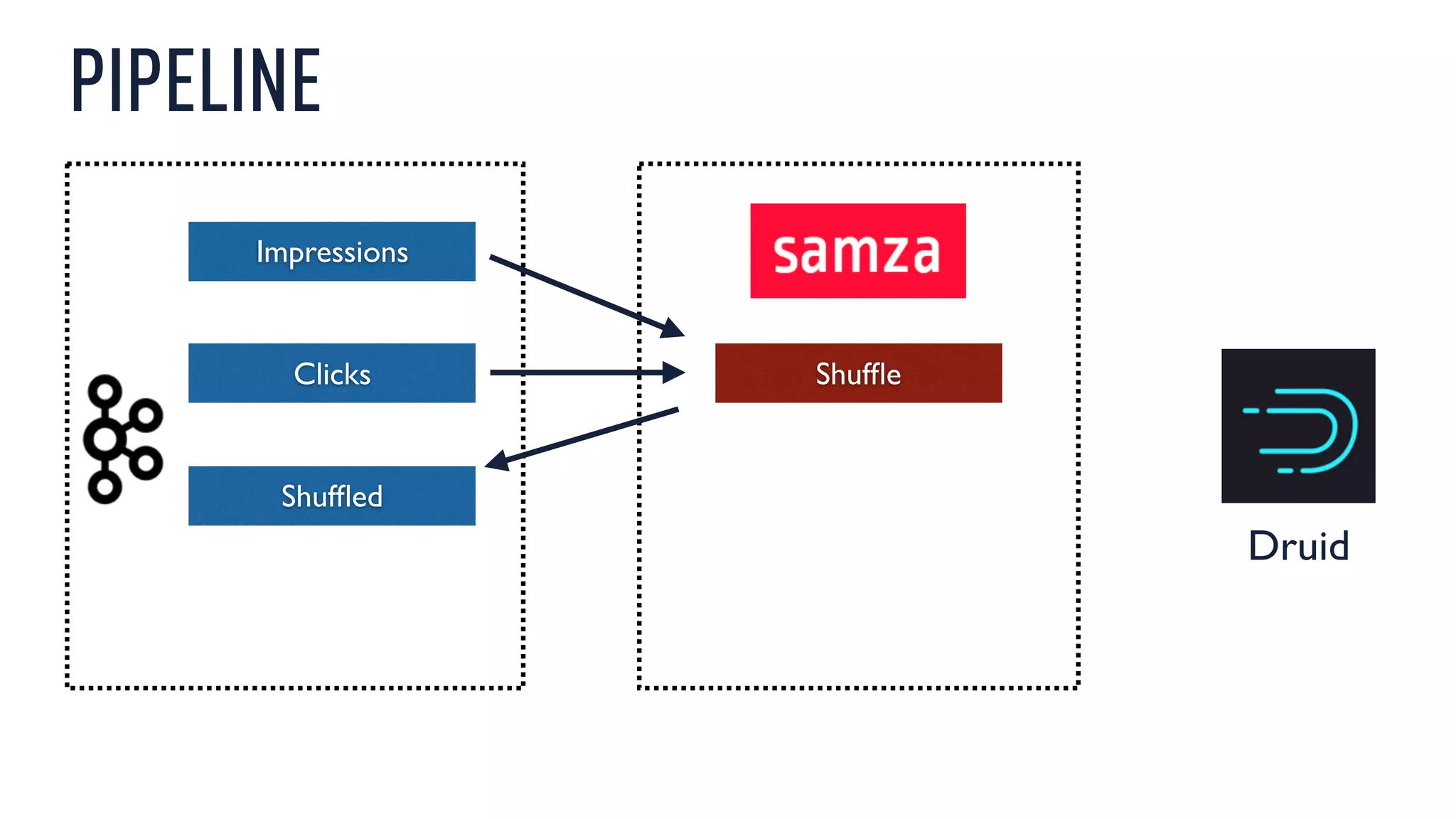
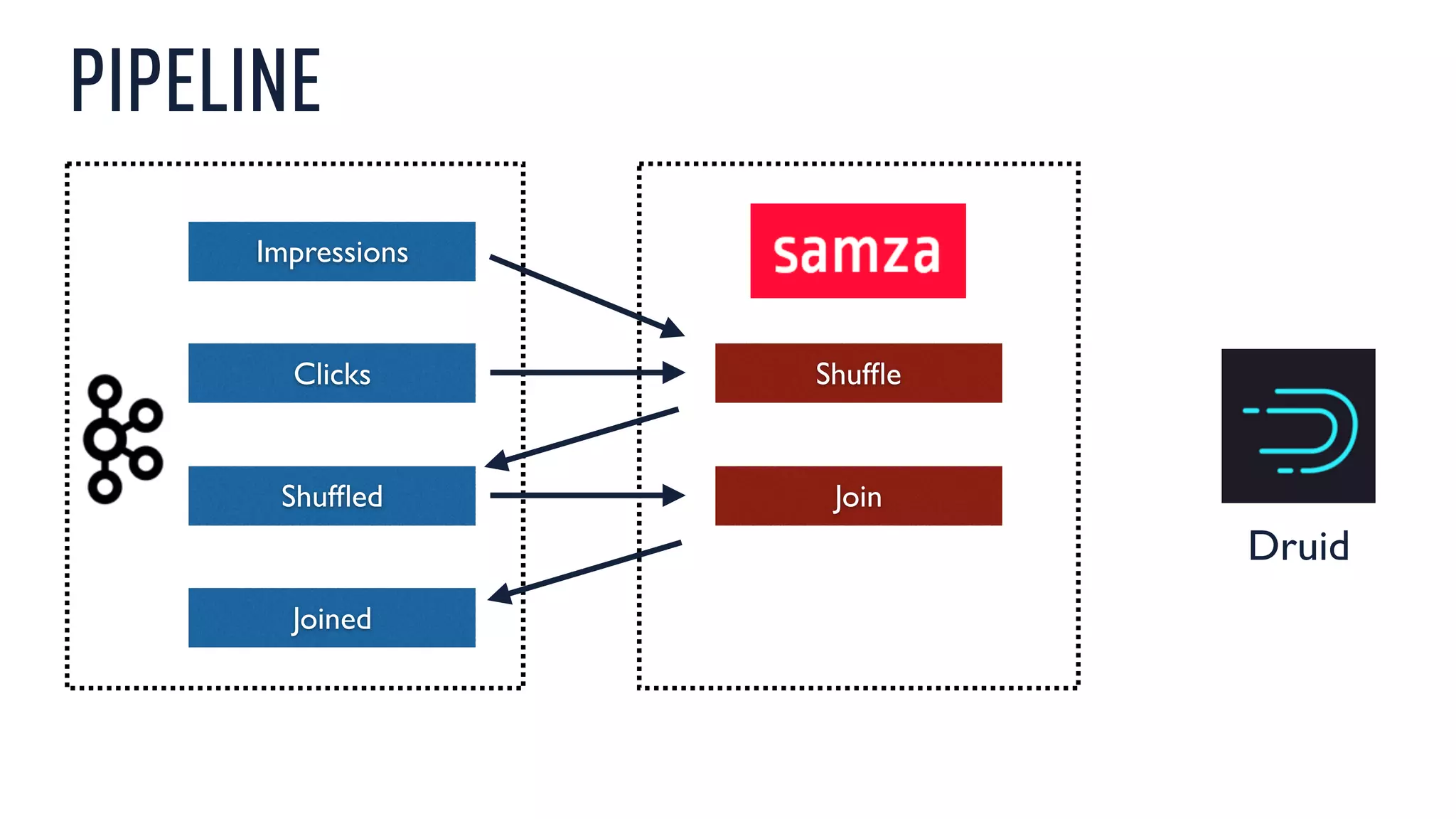

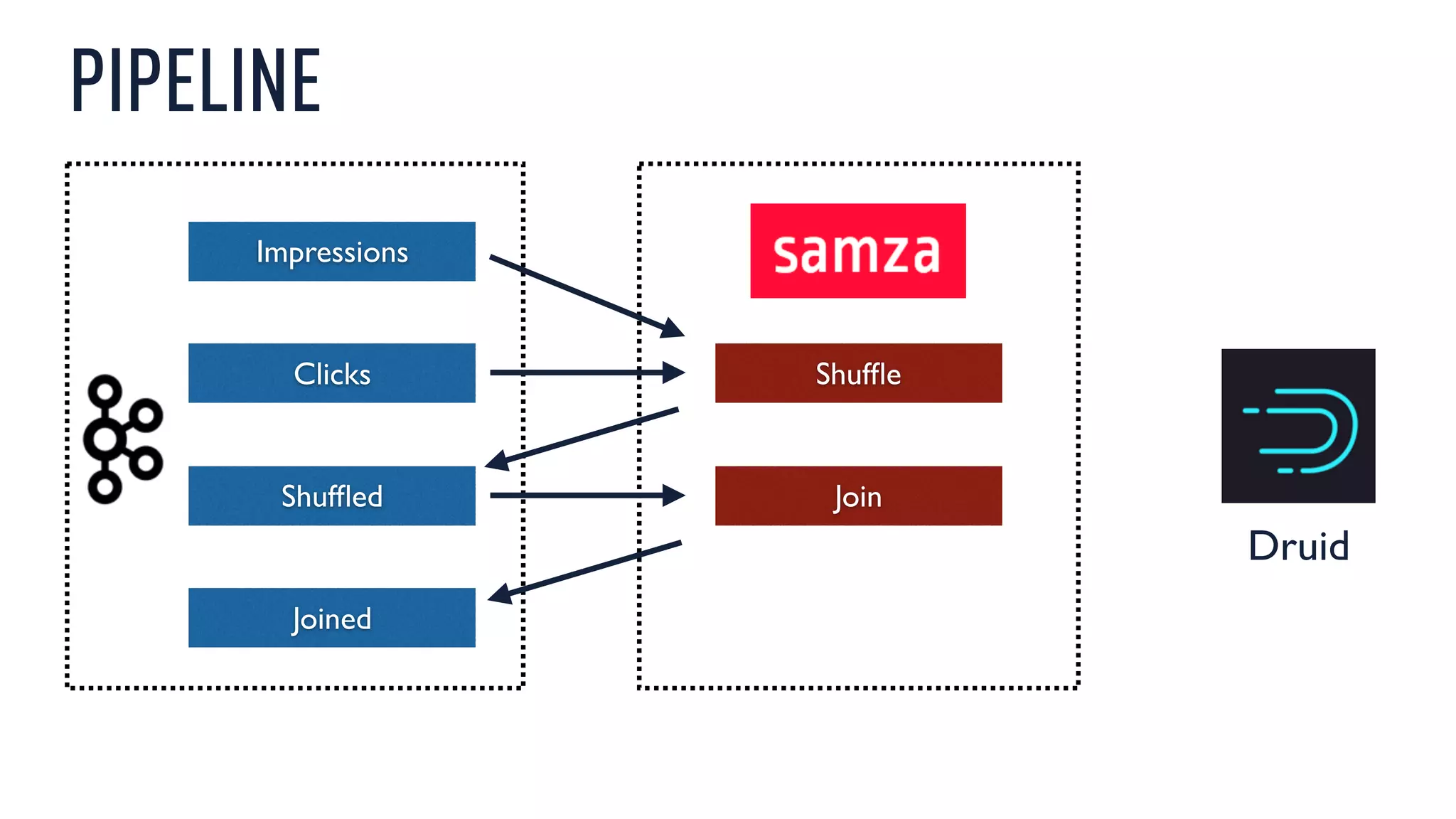
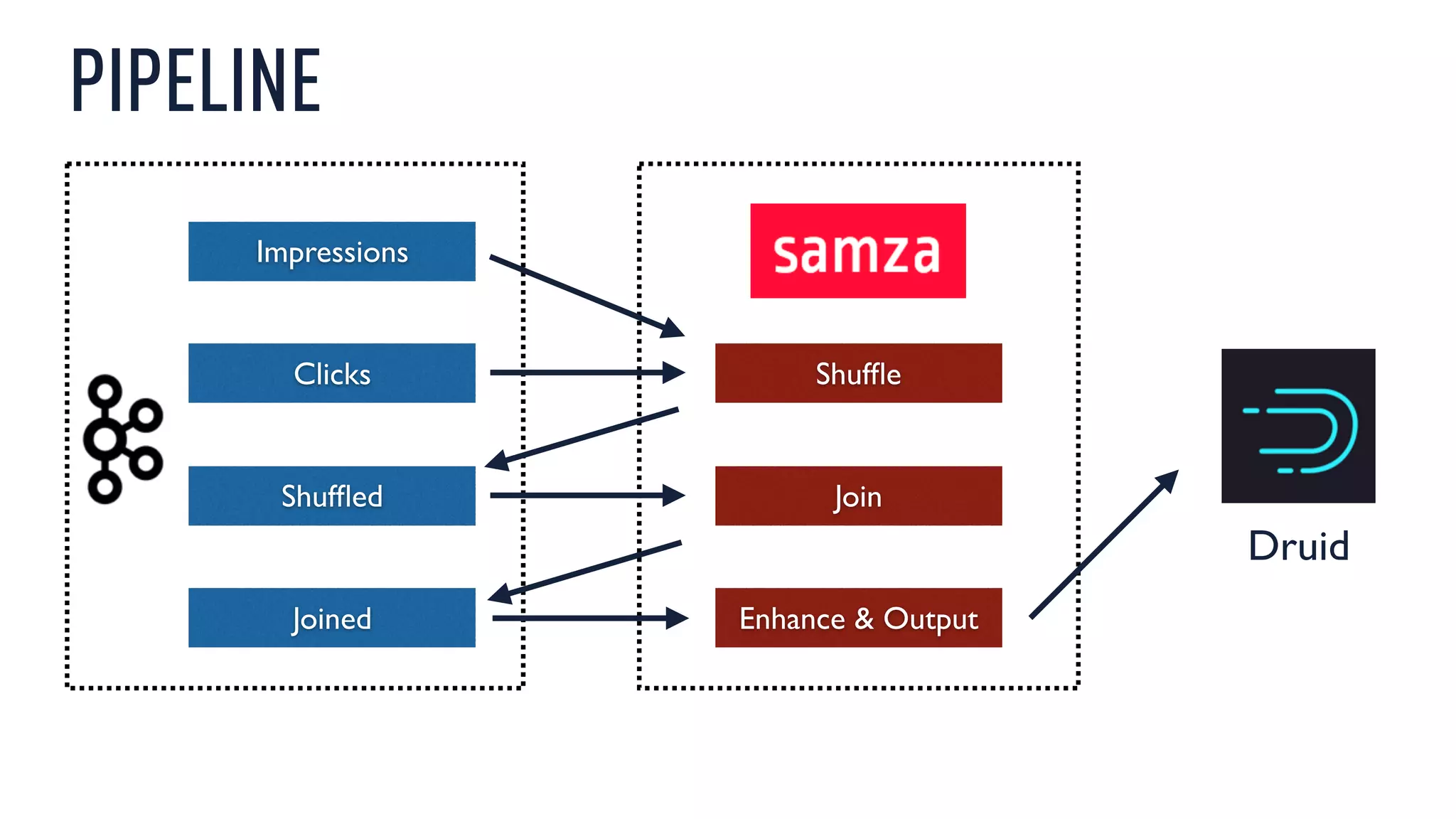
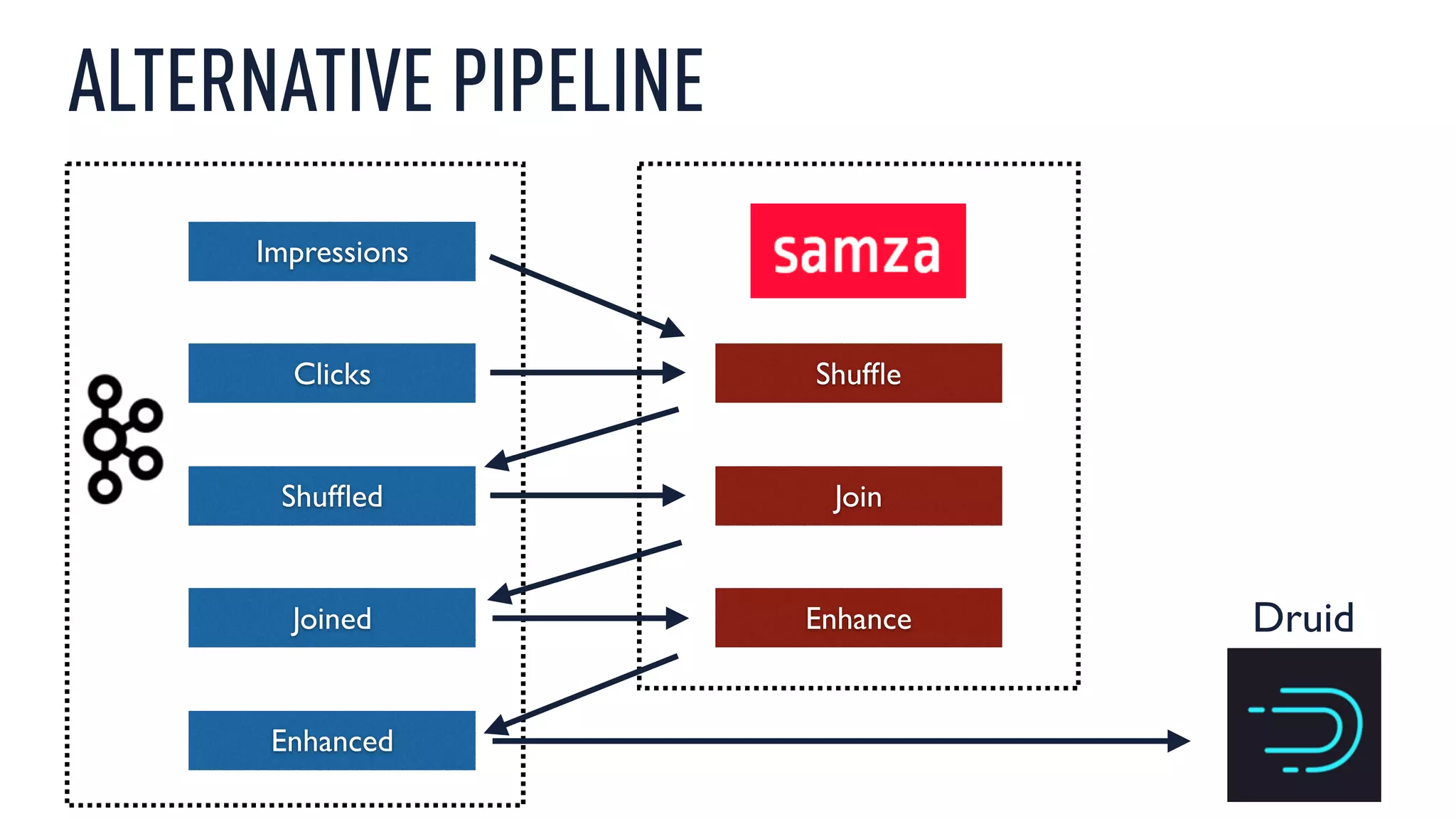





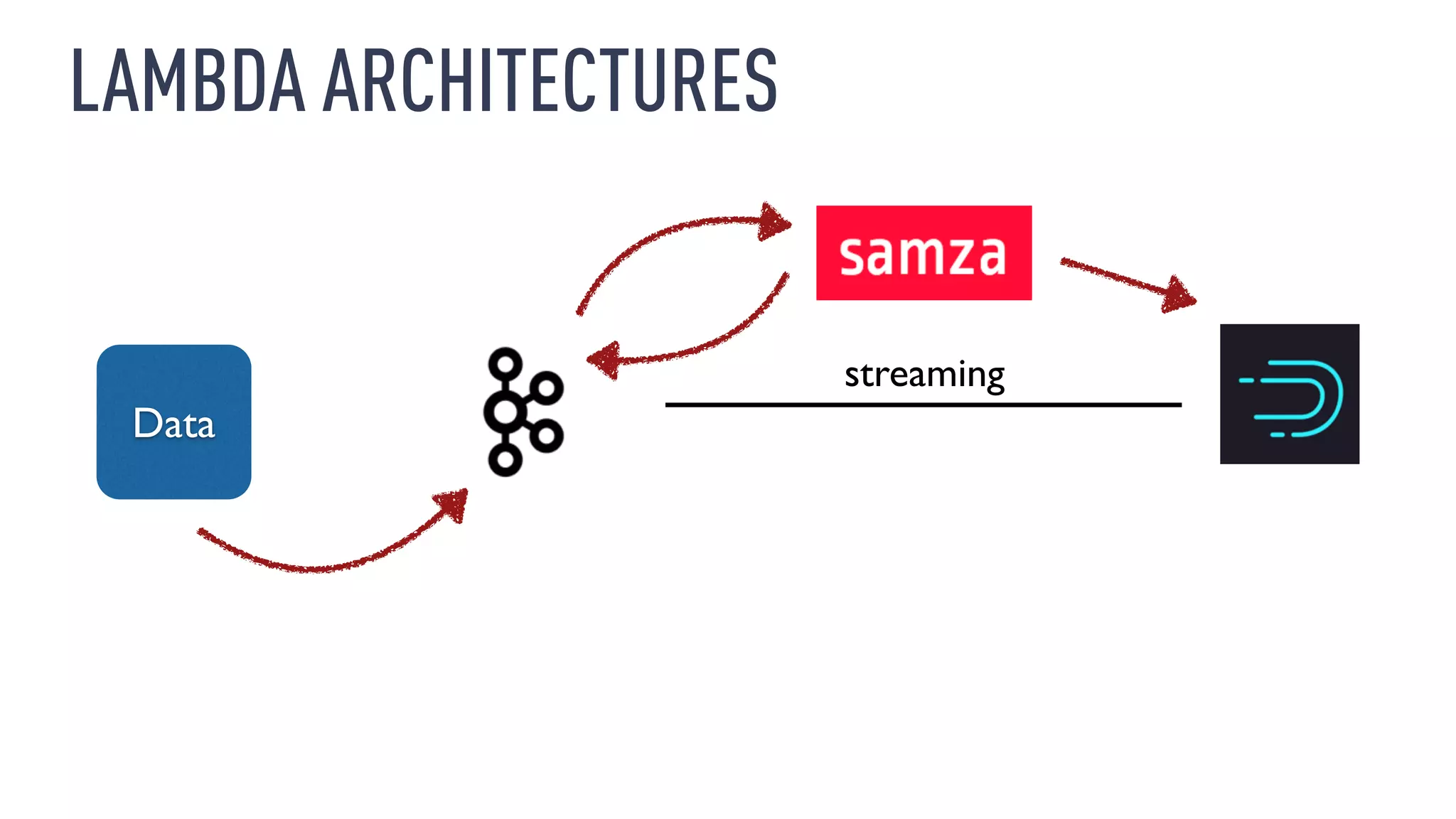
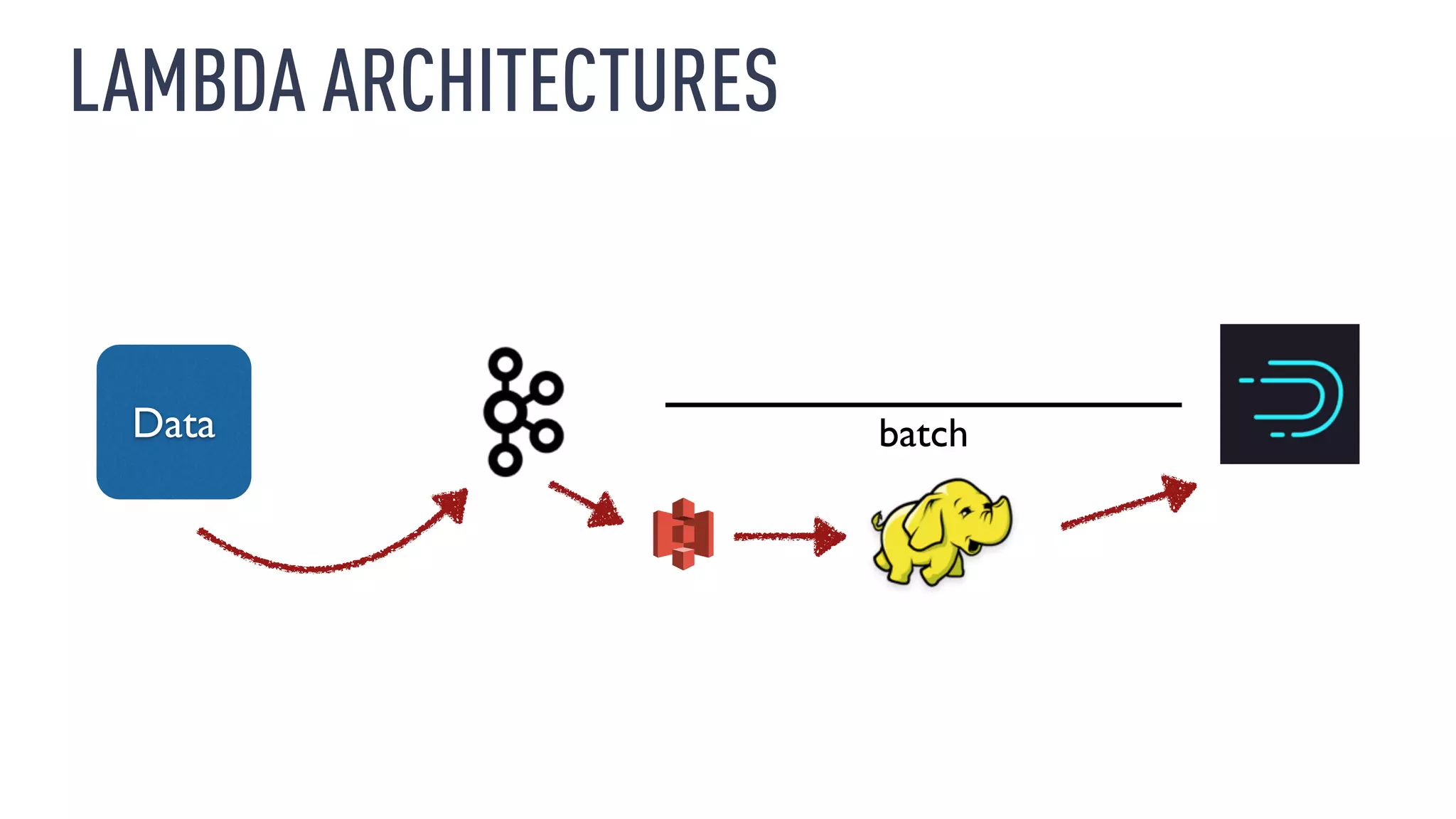
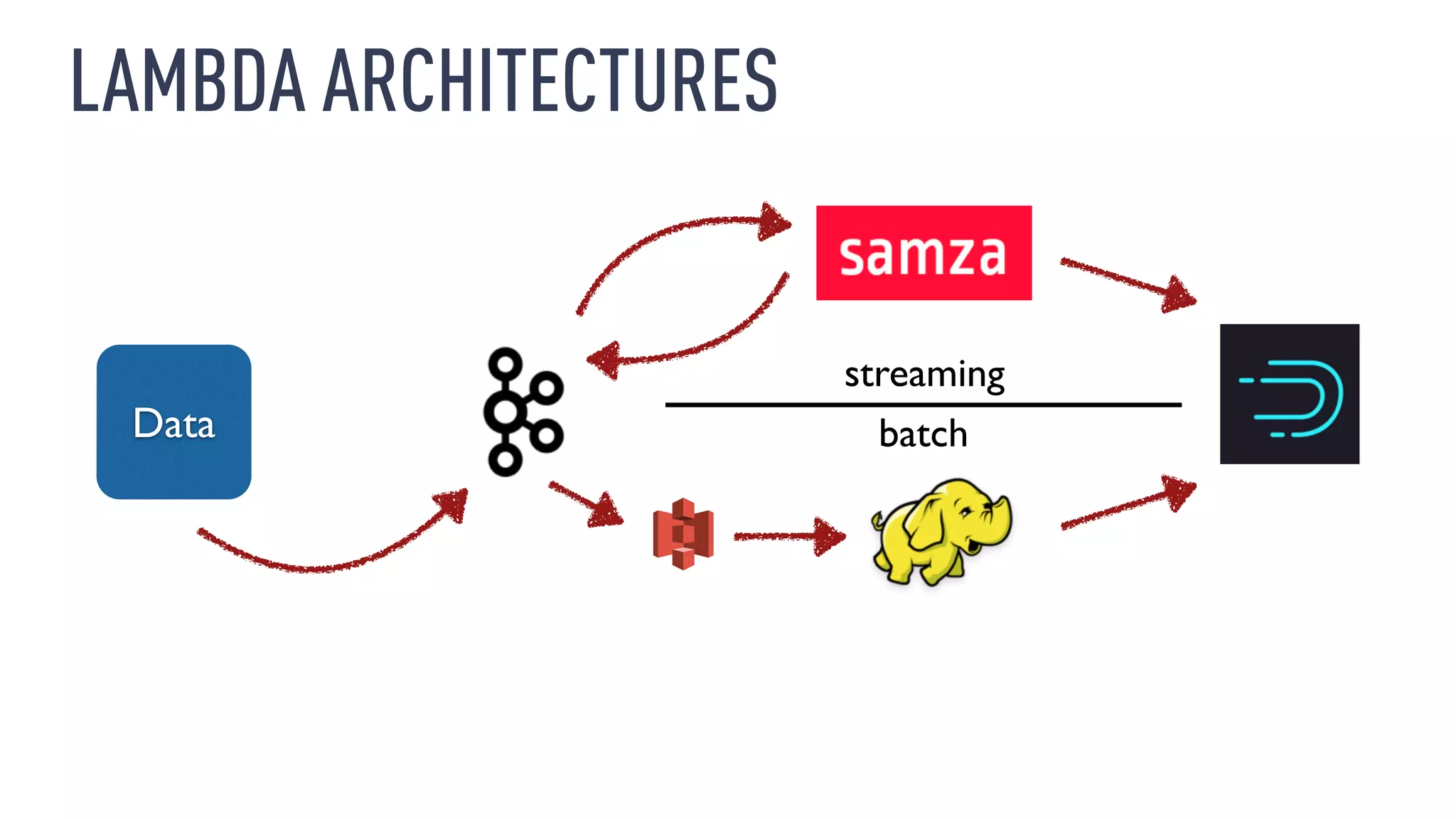







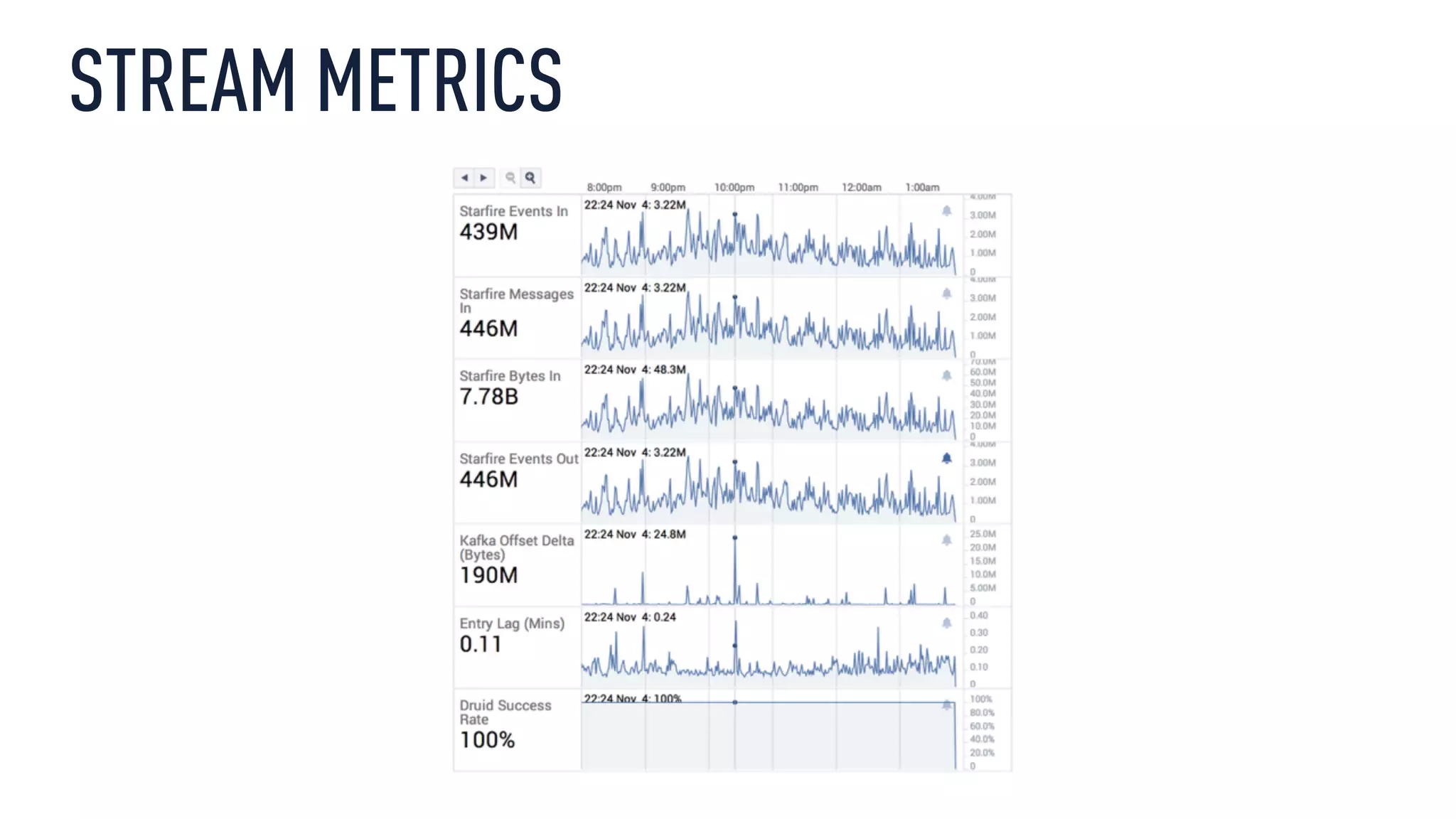
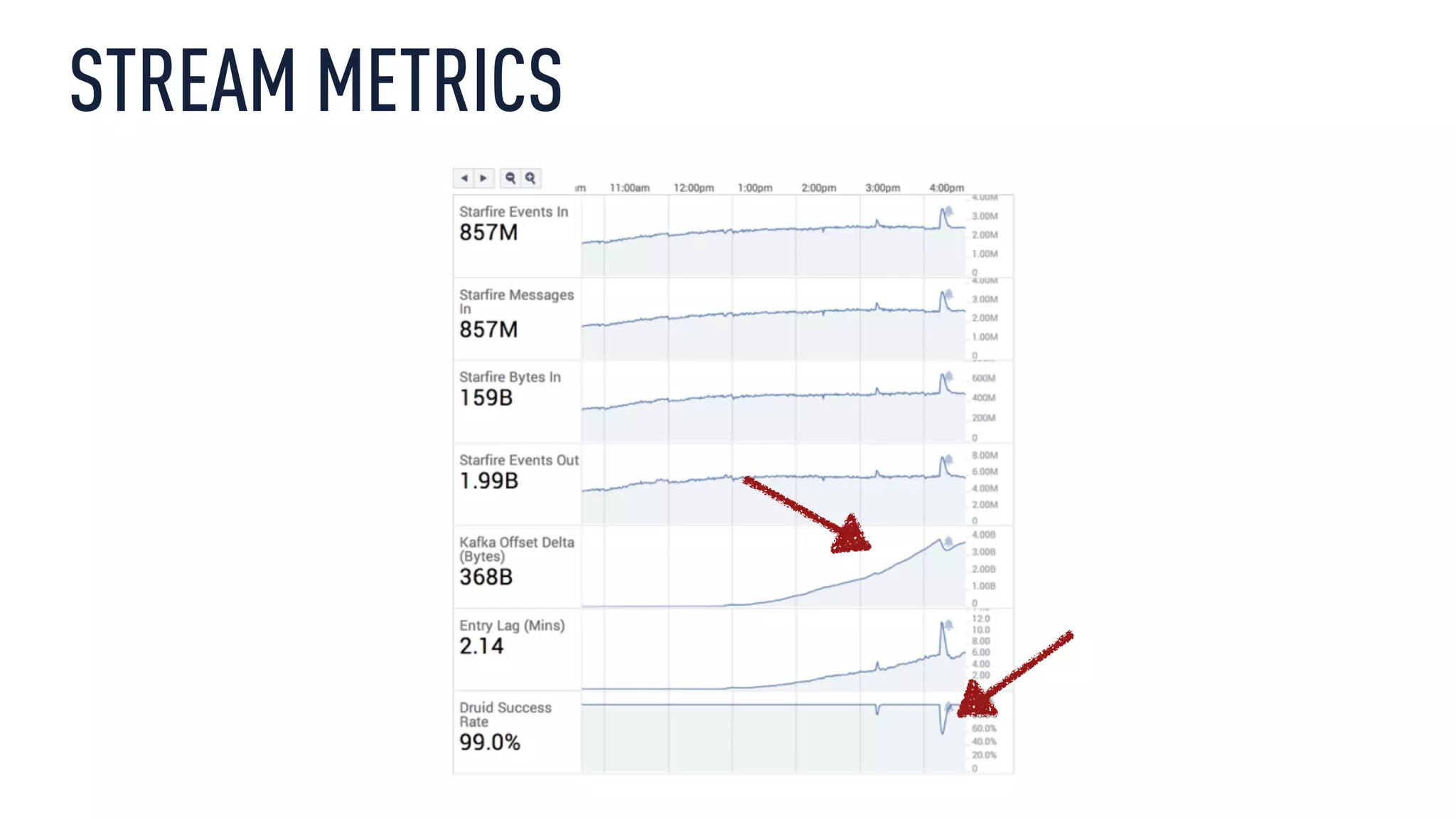


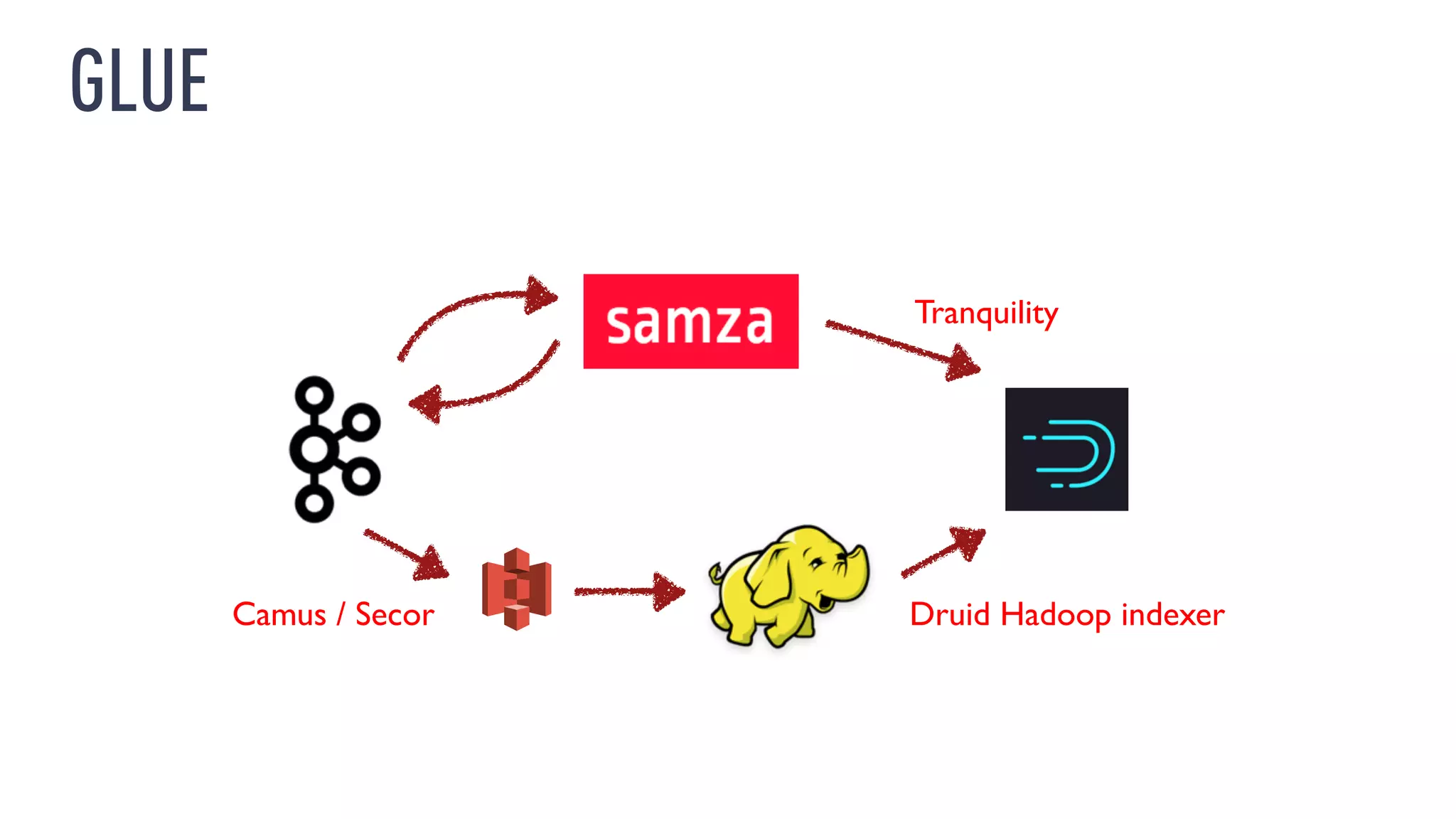
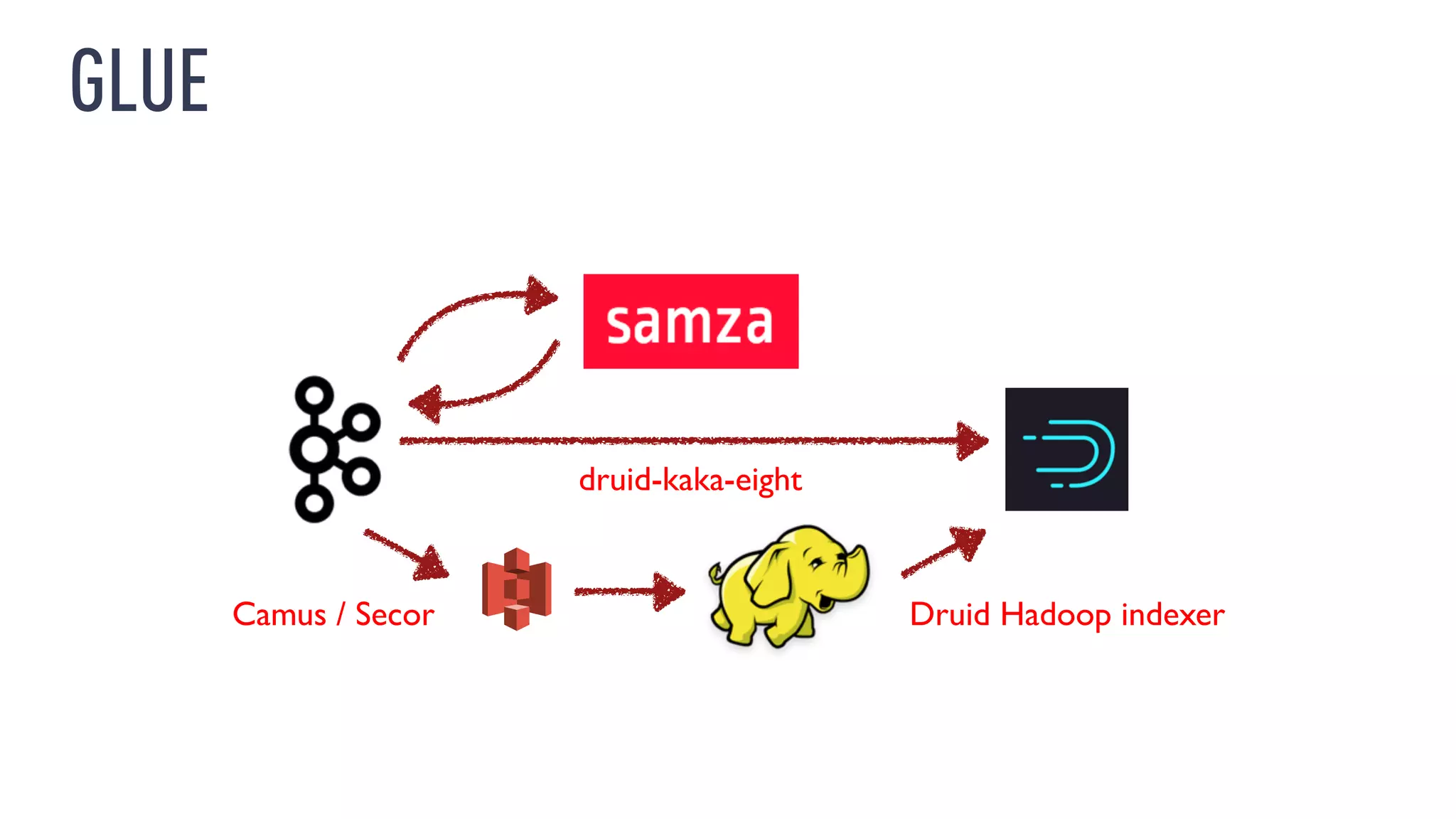



This document discusses using an open source Lambda architecture with Kafka, Hadoop, Samza, and Druid to handle event data streams. It describes the problem of interactively exploring large volumes of time series data. It outlines how Druid was developed as a fast query layer for Hadoop to enable low-latency queries over aggregated data. The architecture ingests raw data streams in real-time via Kafka and Samza, aggregates the data in Druid, and enables reprocessing via Hadoop for reliability.