Download as PDF, PPTX



































This document discusses various performance metrics used to evaluate machine learning models, particularly for classification problems, including confusion matrix, accuracy, precision, recall, specificity, F1 score, log loss, and area under the curve (AUC). It emphasizes the importance of selecting appropriate metrics based on the context of the problem, detailing scenarios where minimizing false positives or false negatives is crucial. Additionally, it provides mathematical formulations and practical examples to illustrate the application and significance of these metrics.
Introduction to performance metrics in machine learning and their significance in evaluating model effectiveness.
Discusses various metrics to evaluate models including Confusion Matrix, Accuracy, Precision, Recall, etc.
Definition of Accuracy in classification and guidance on when it should and shouldn't be used, emphasizing the balance of classes.
Discusses Precision and Recall, their calculations, and their importance in different scenarios alongside when to prioritize each.
Definition of Specificity and its importance compared to Recall, using cancer detection examples for clarity.
Introduction to F1 Score, its calculation, and comparison with Arithmetic Mean, emphasizing its importance in balancing Precision and Recall.
Describes Logarithmic Loss, its calculation and significance in multi-class classification, stressing its relation to accuracy.
Explains AUC, its significance in evaluating model performance, and describes the ROC curve plotting TPR and FPR.
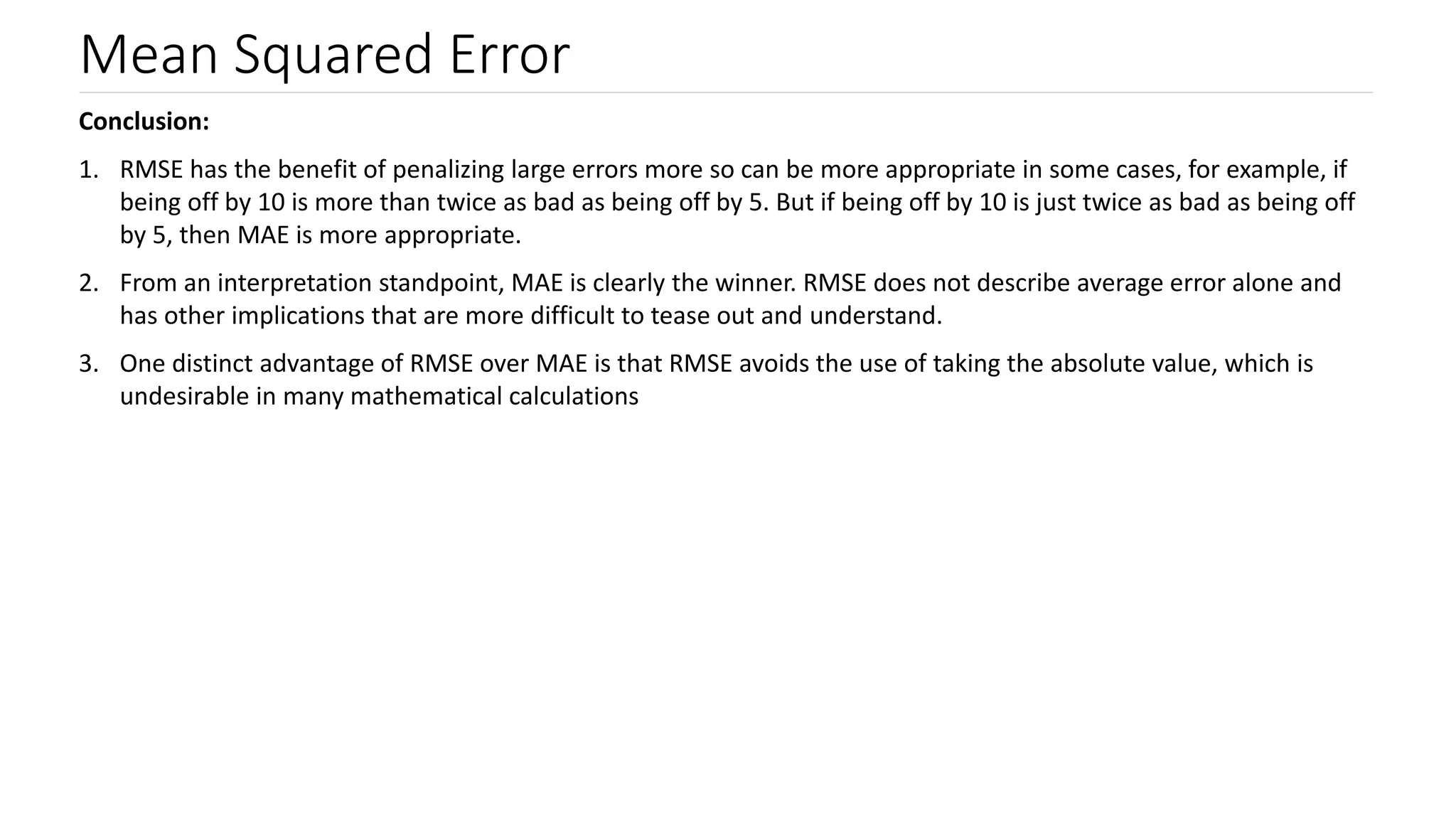
Defines MAE and MSE, compares their calculation methods, benefits, and when each should be used in evaluating model performance.