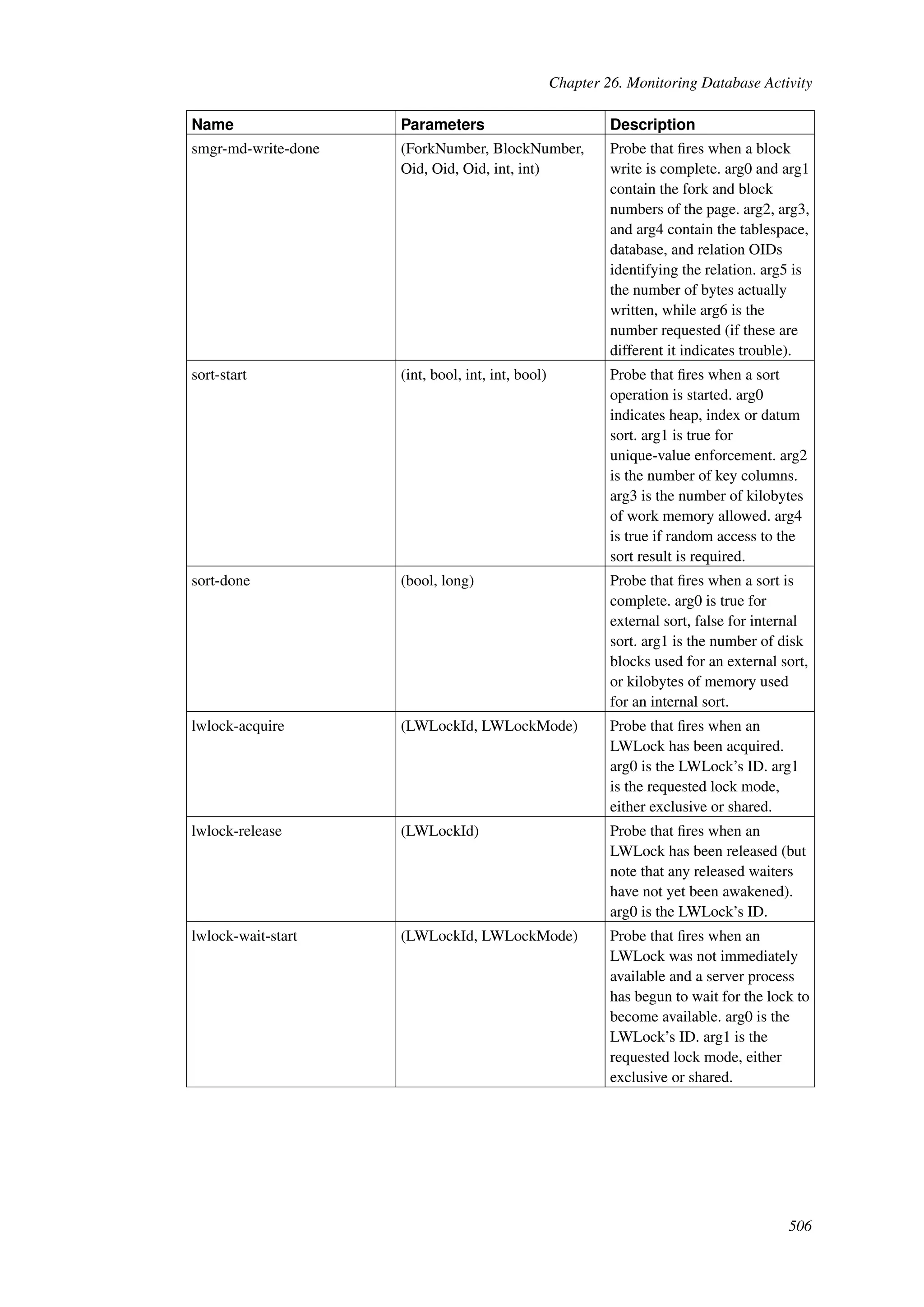
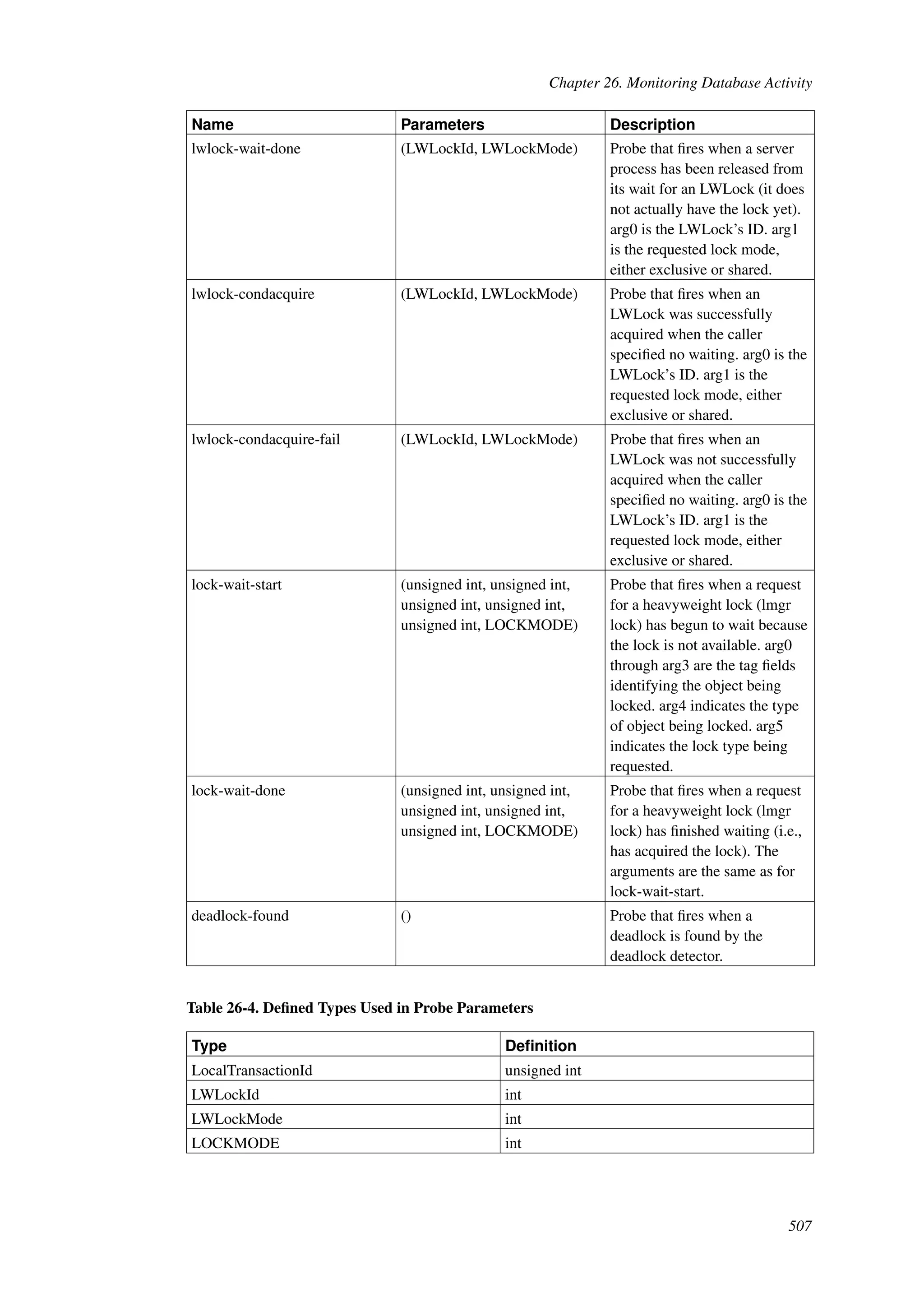
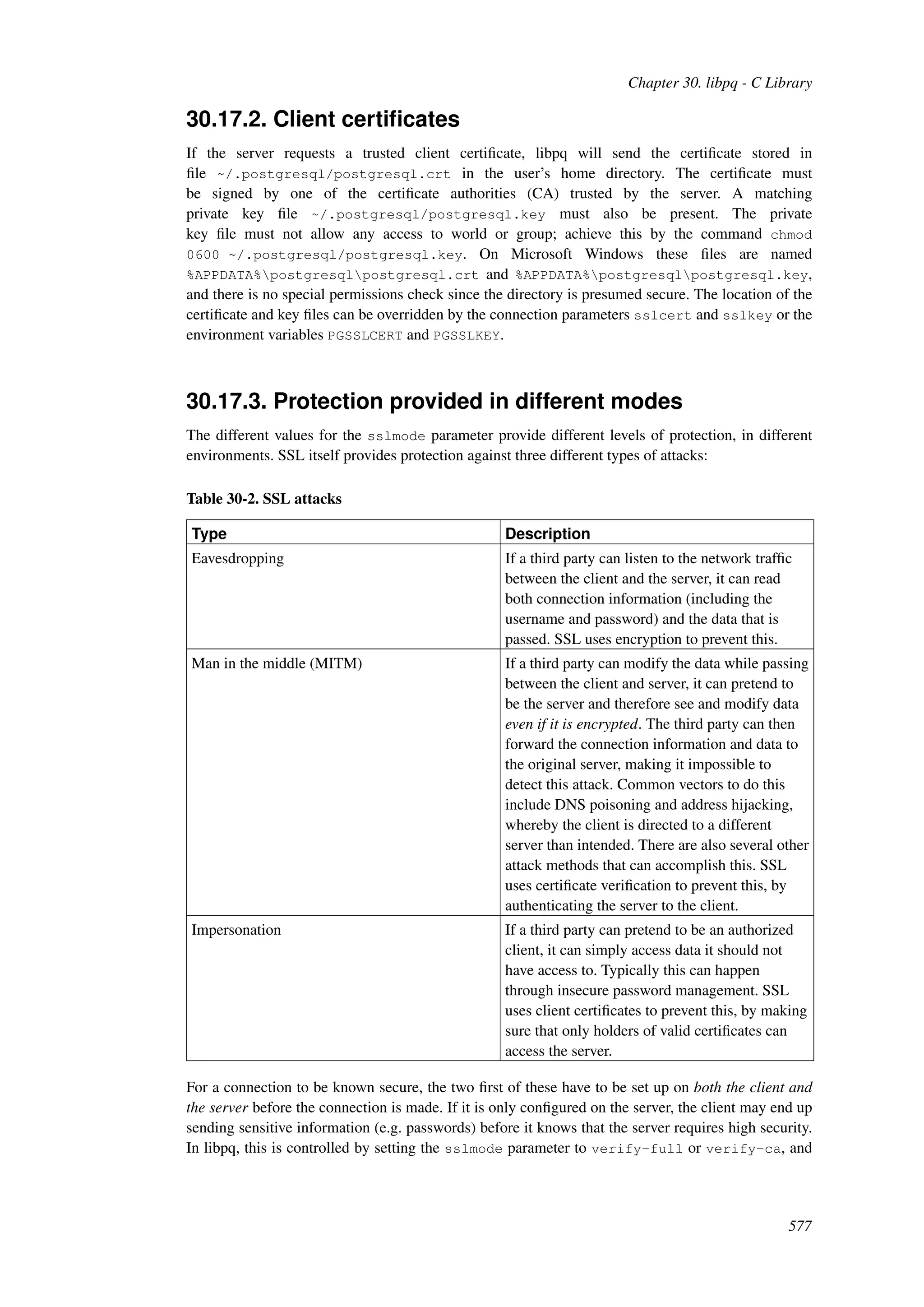
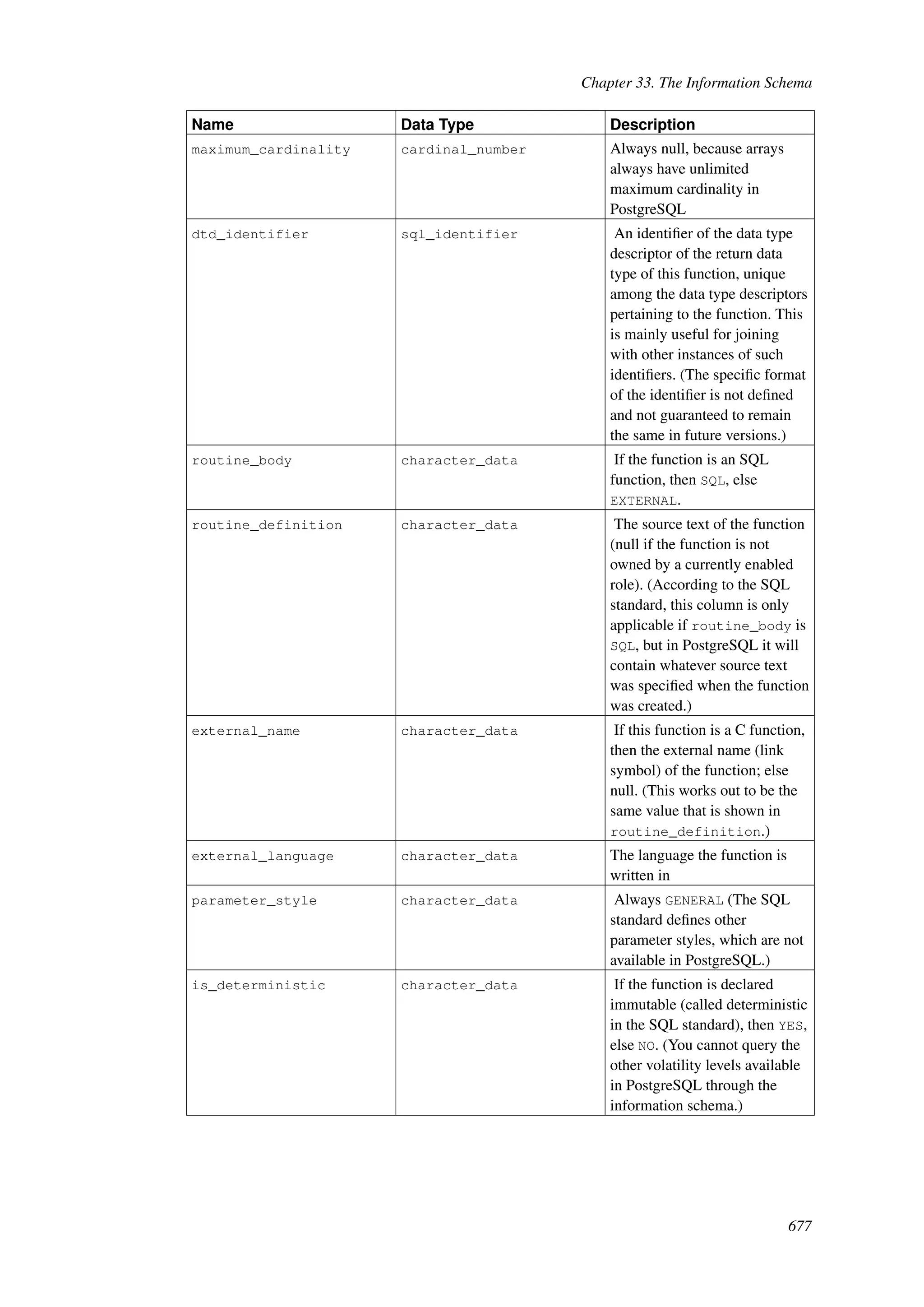
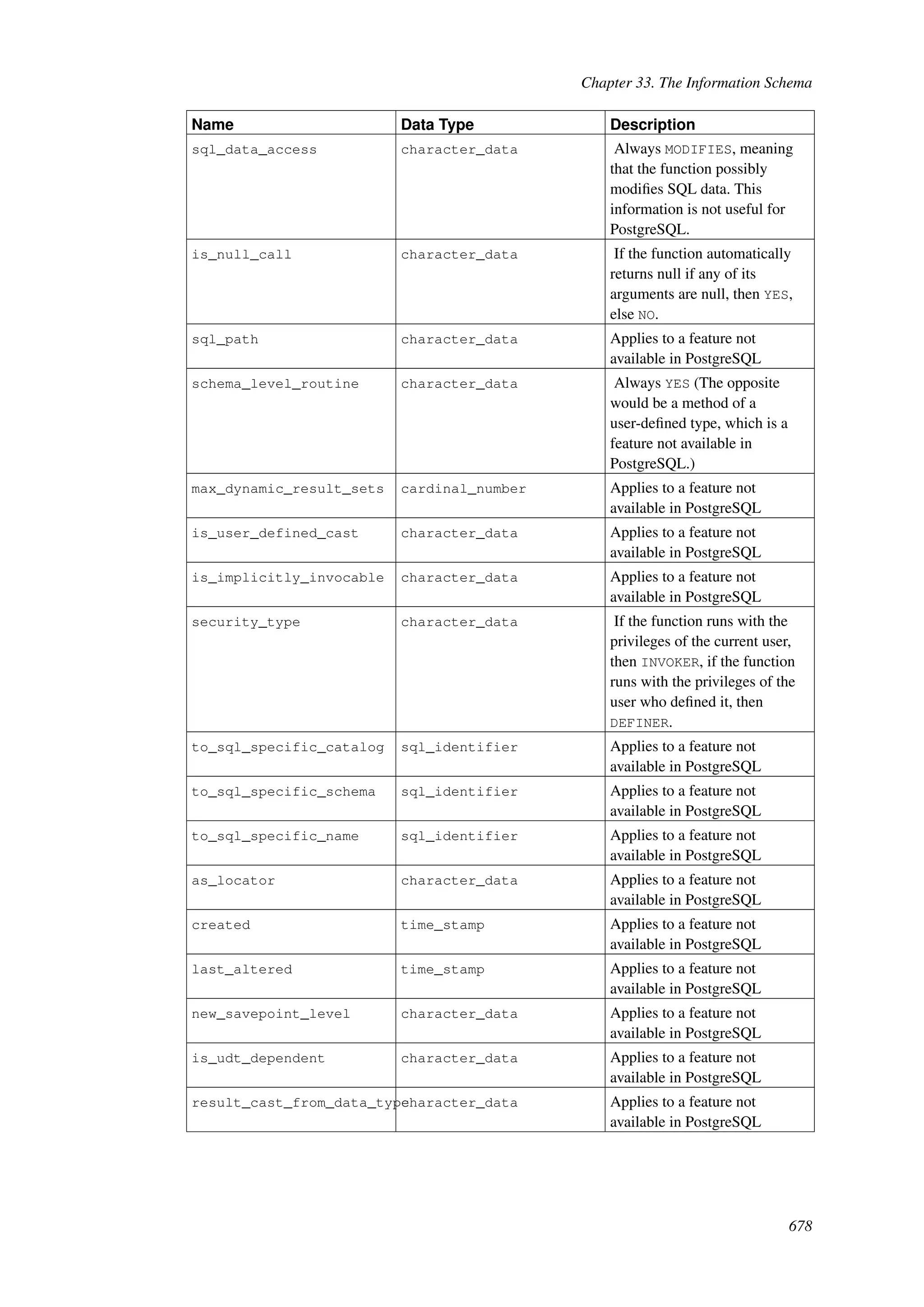
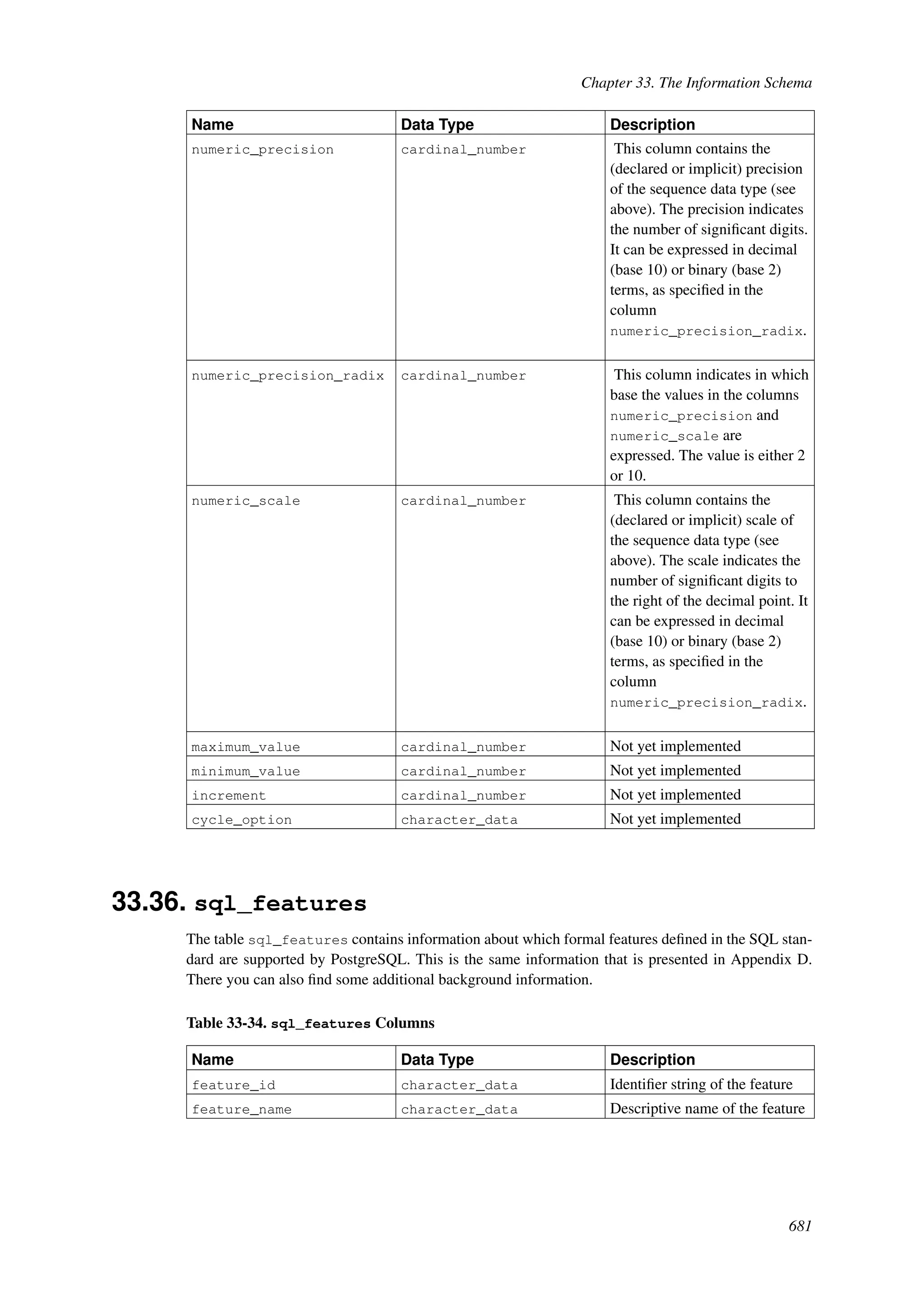
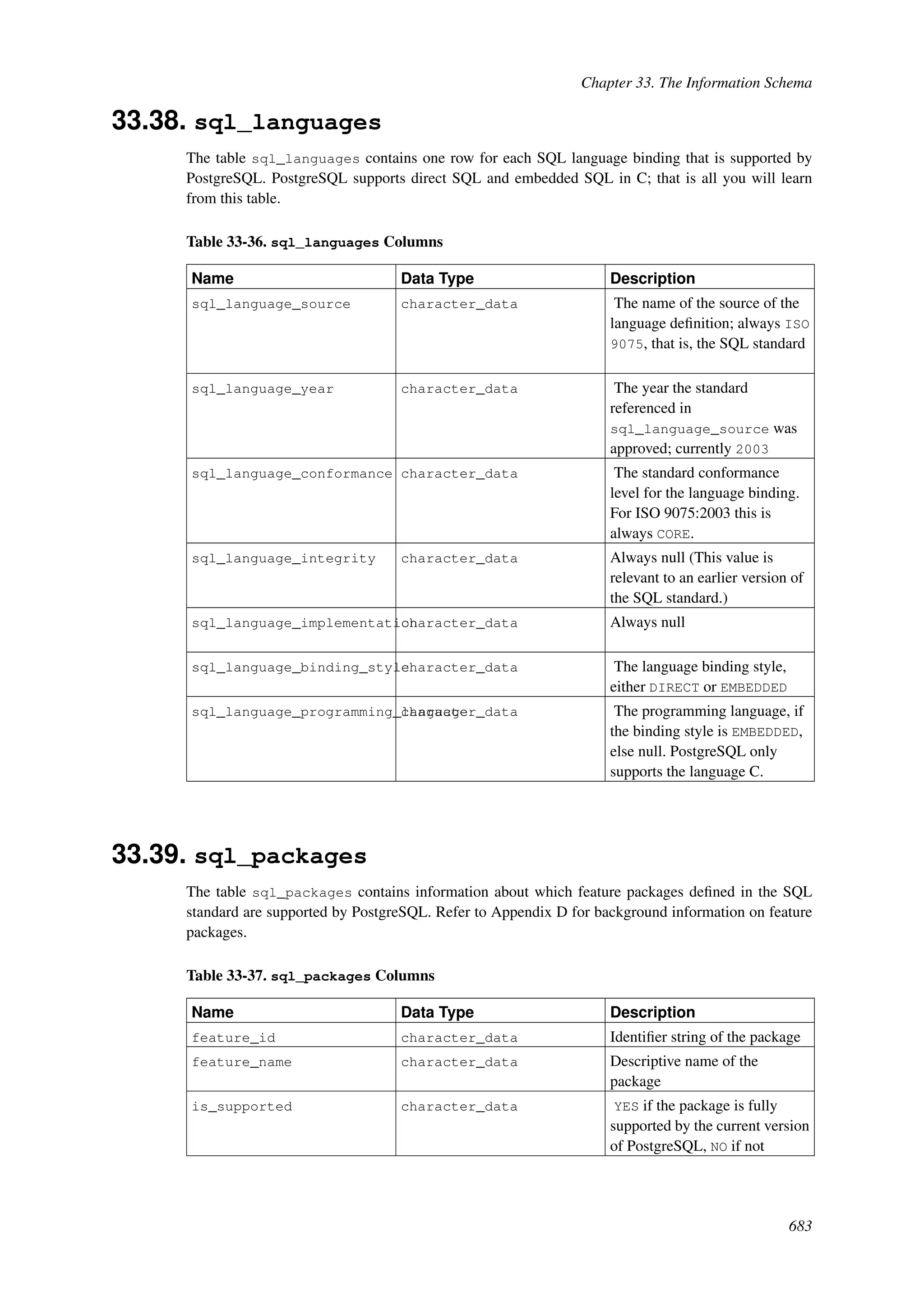
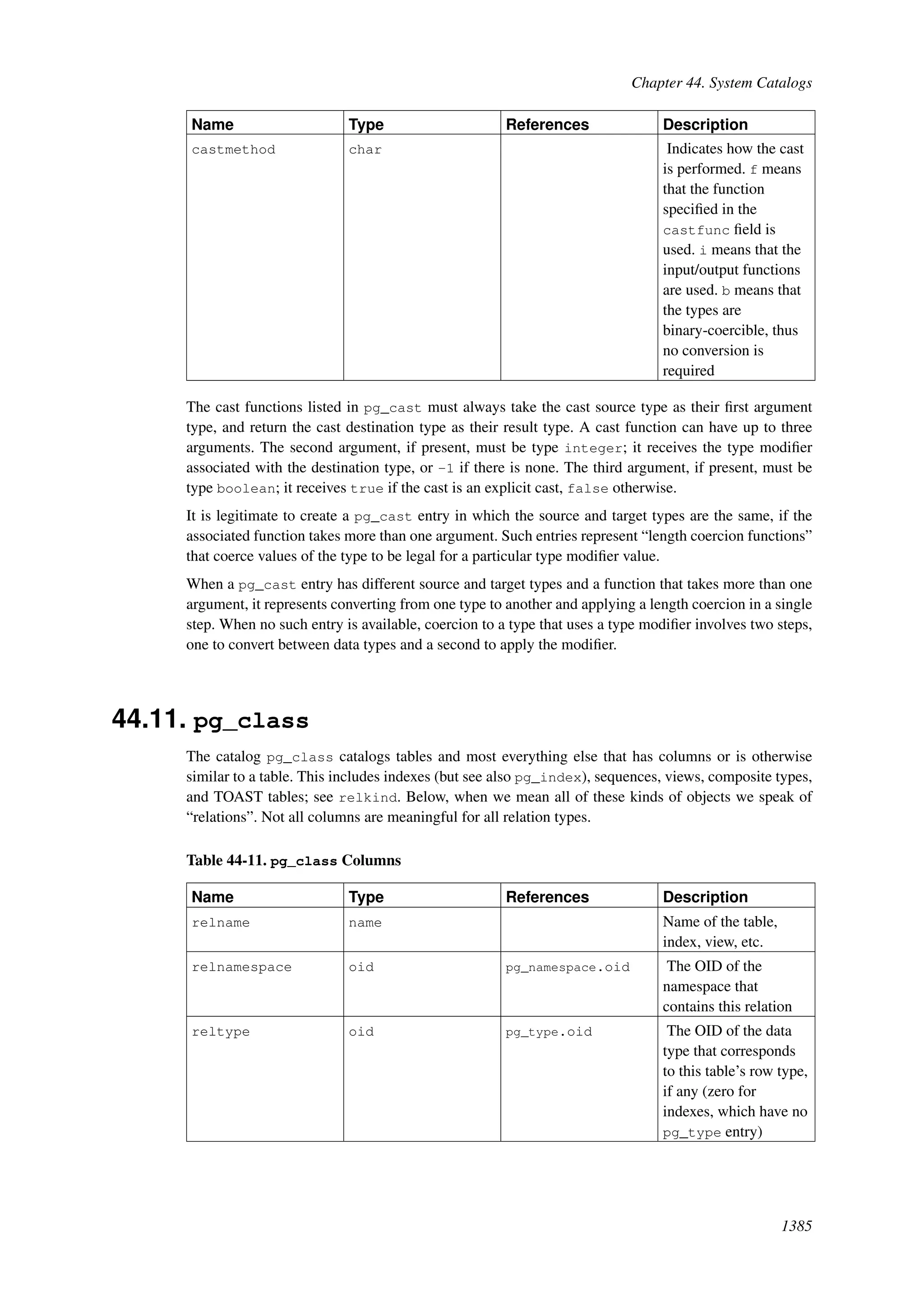
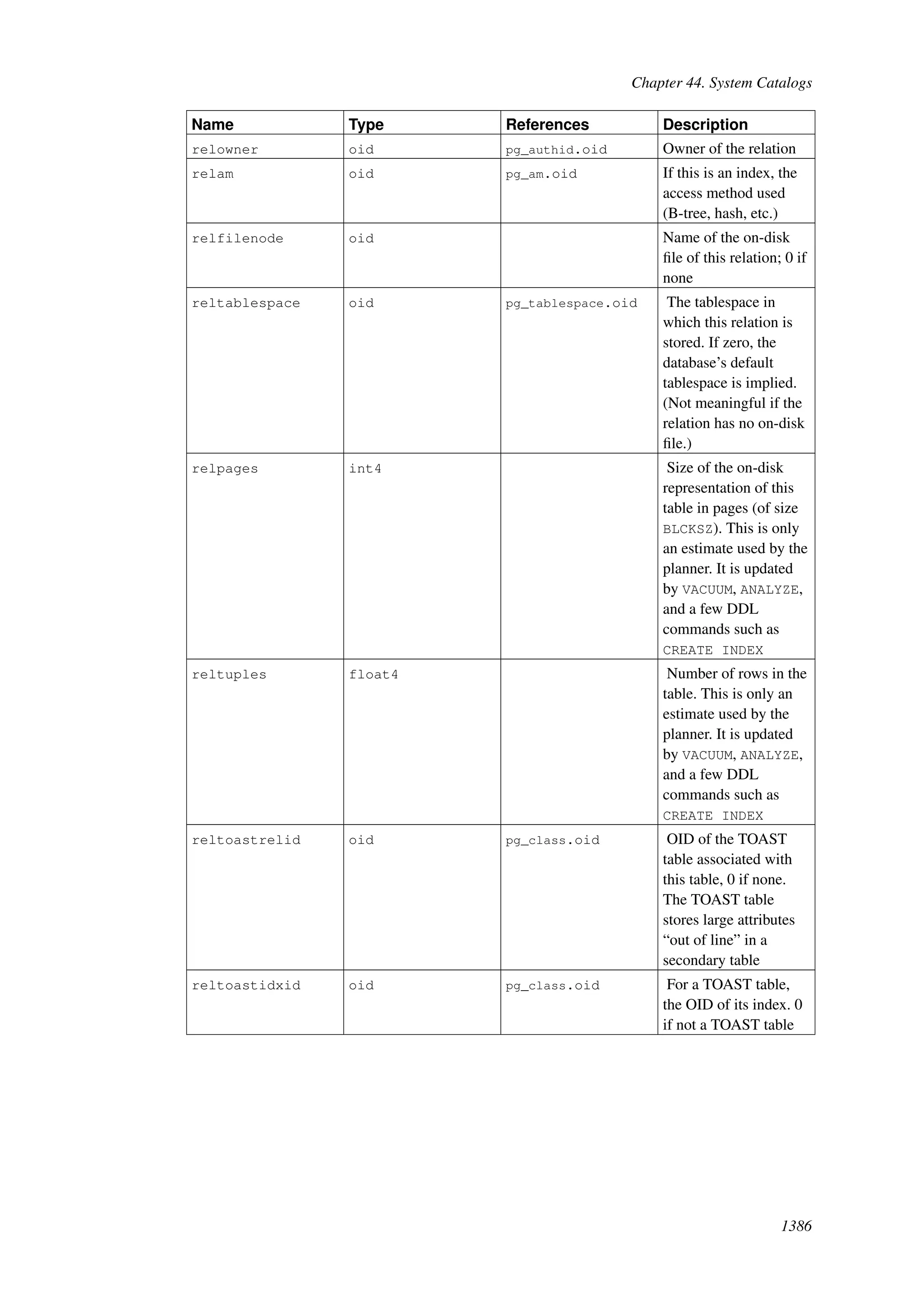
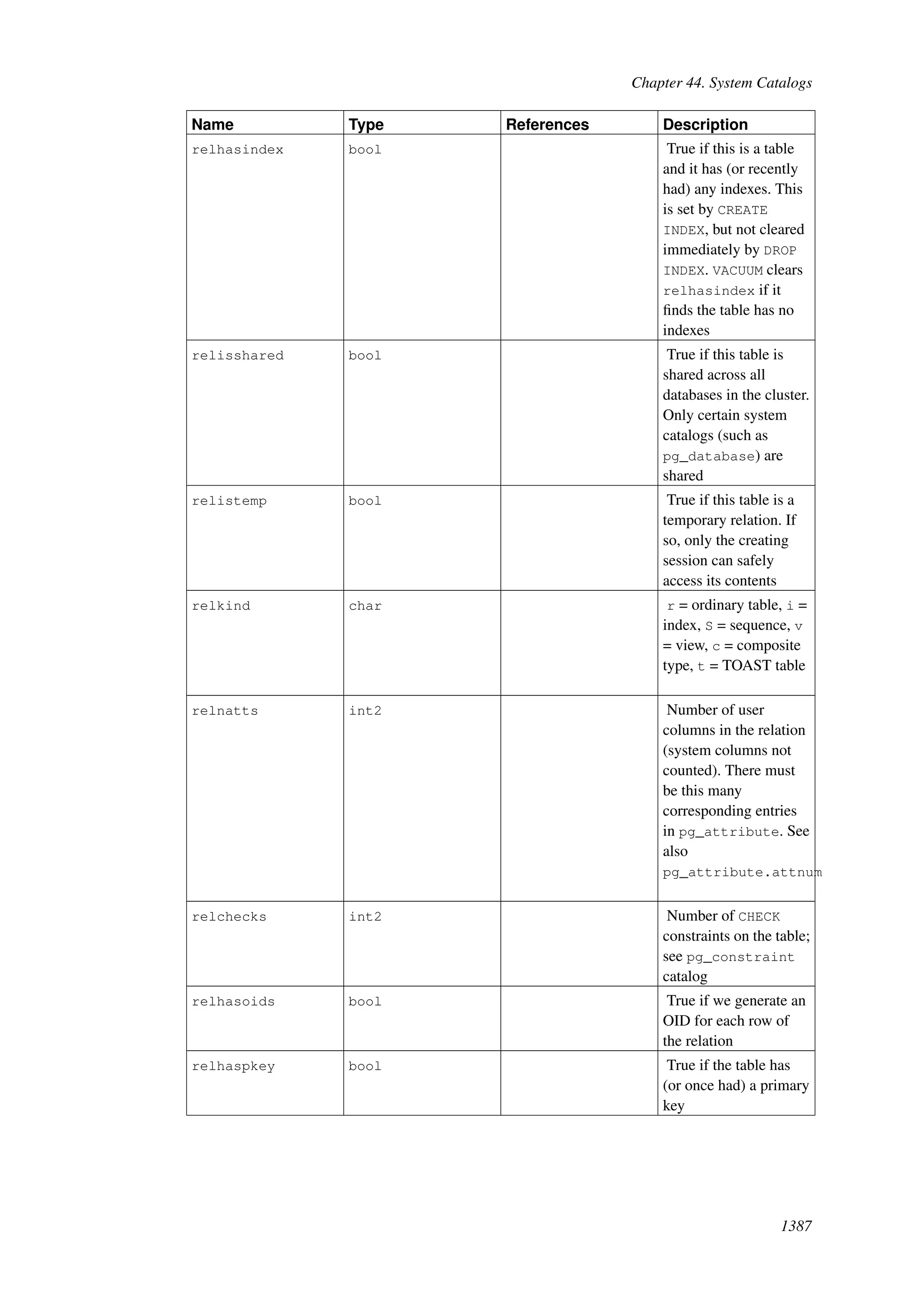
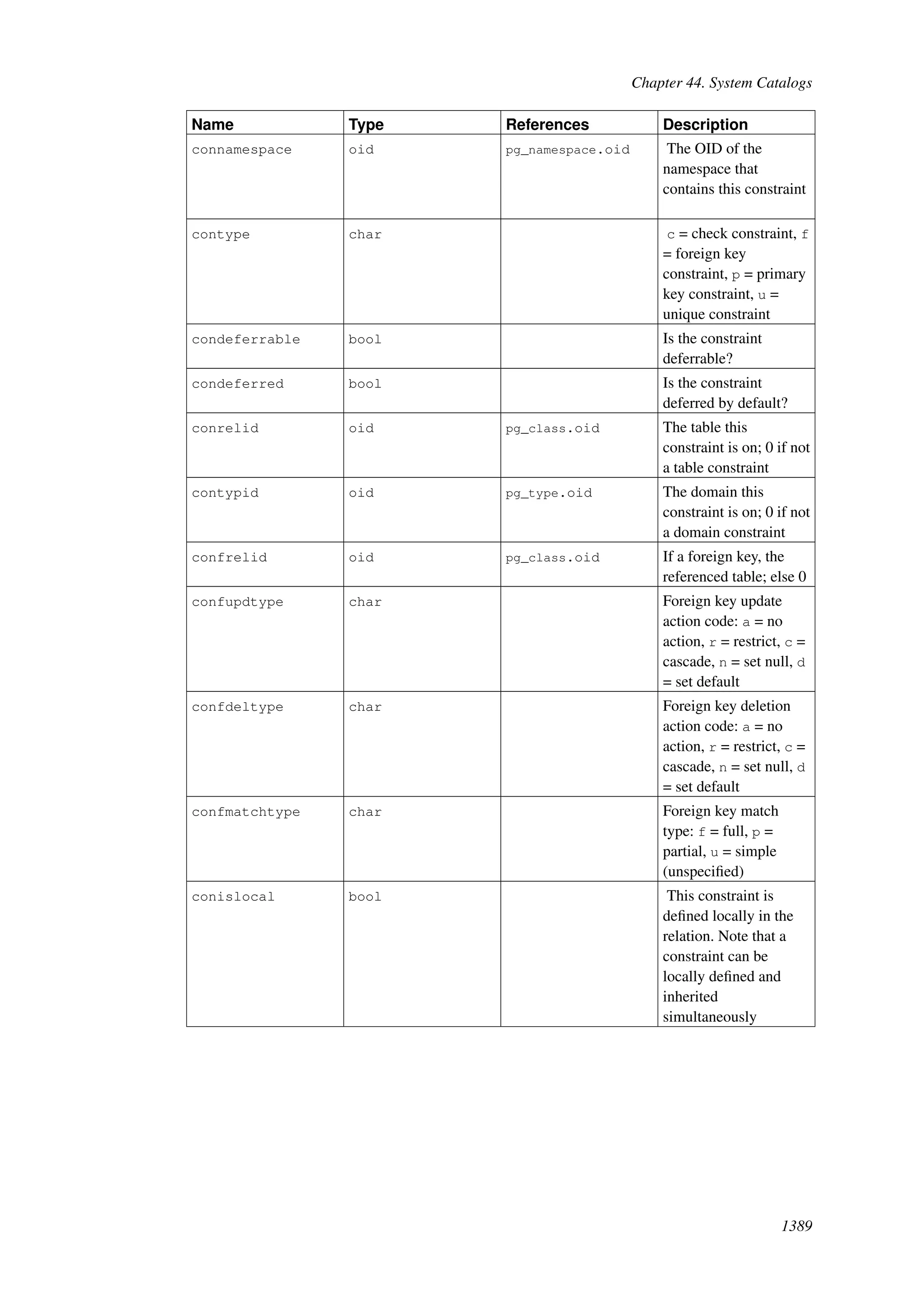
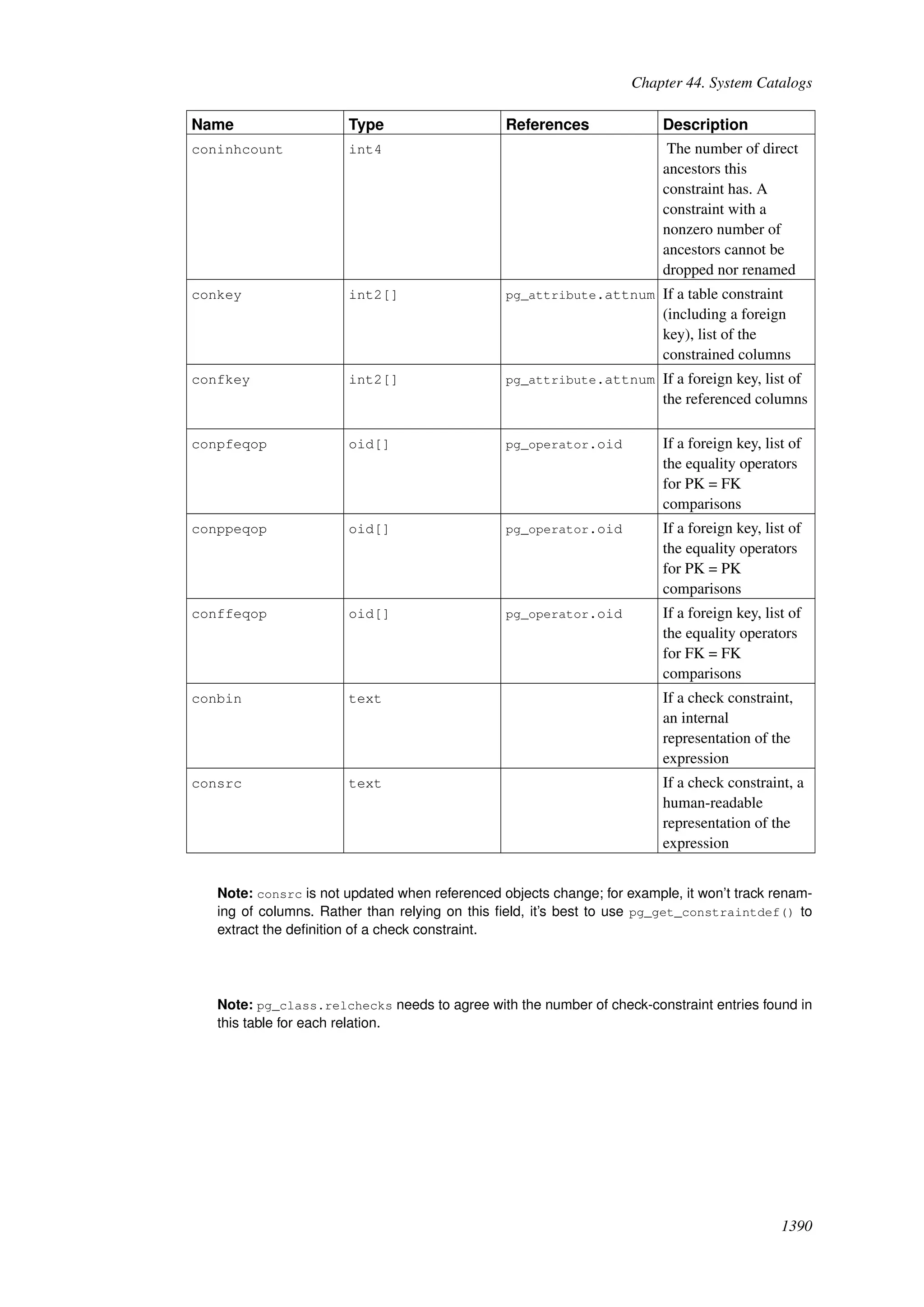
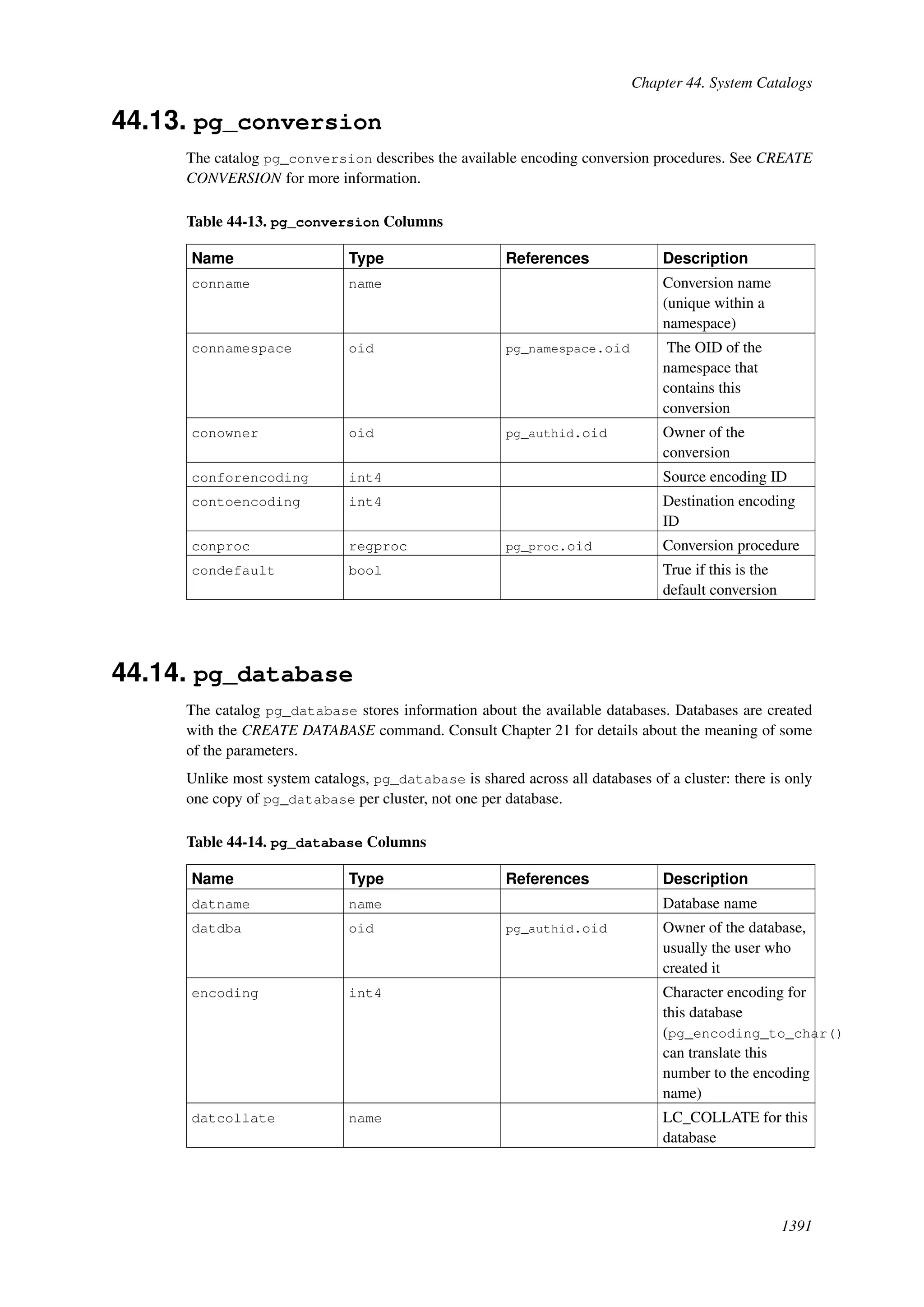
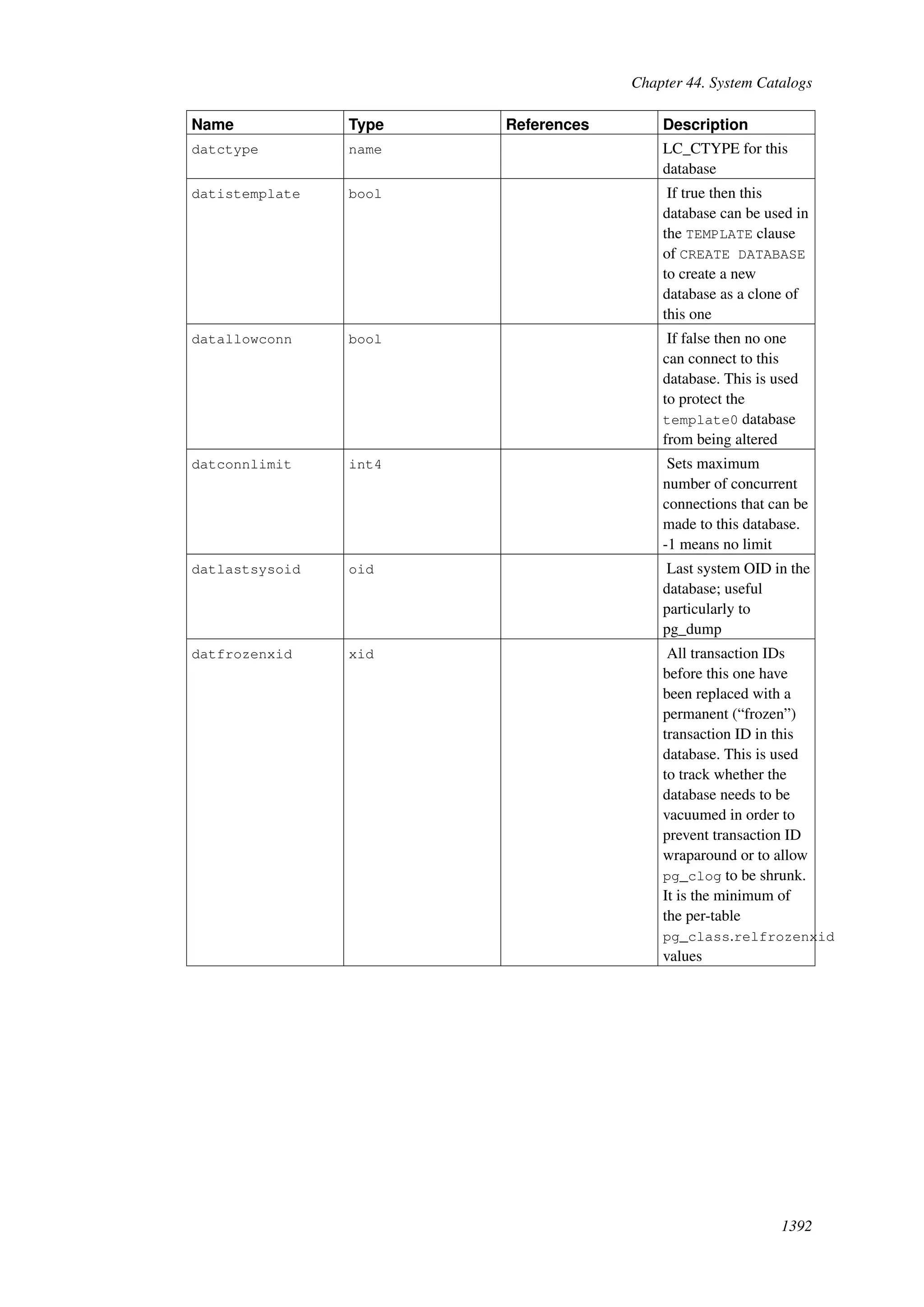
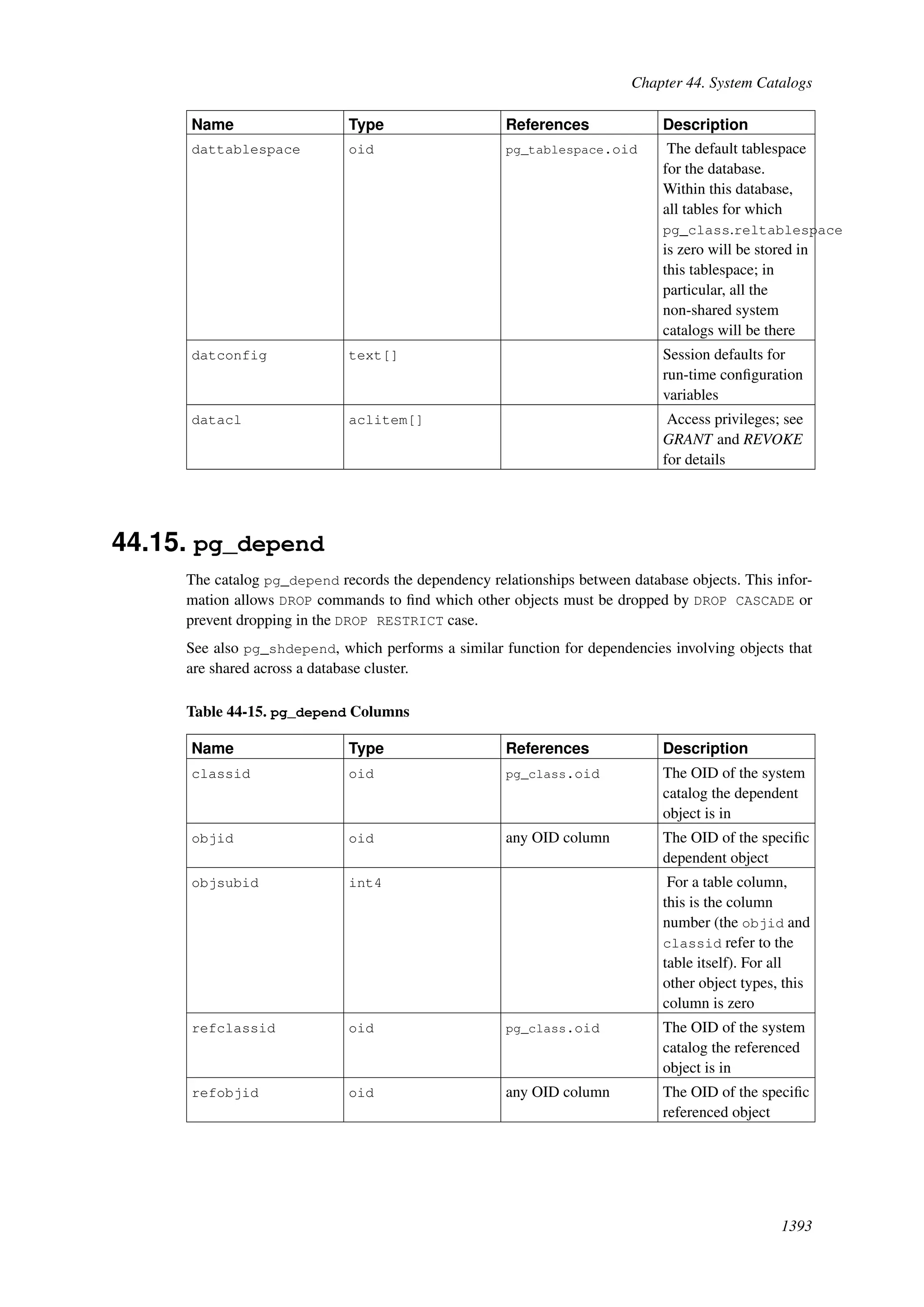
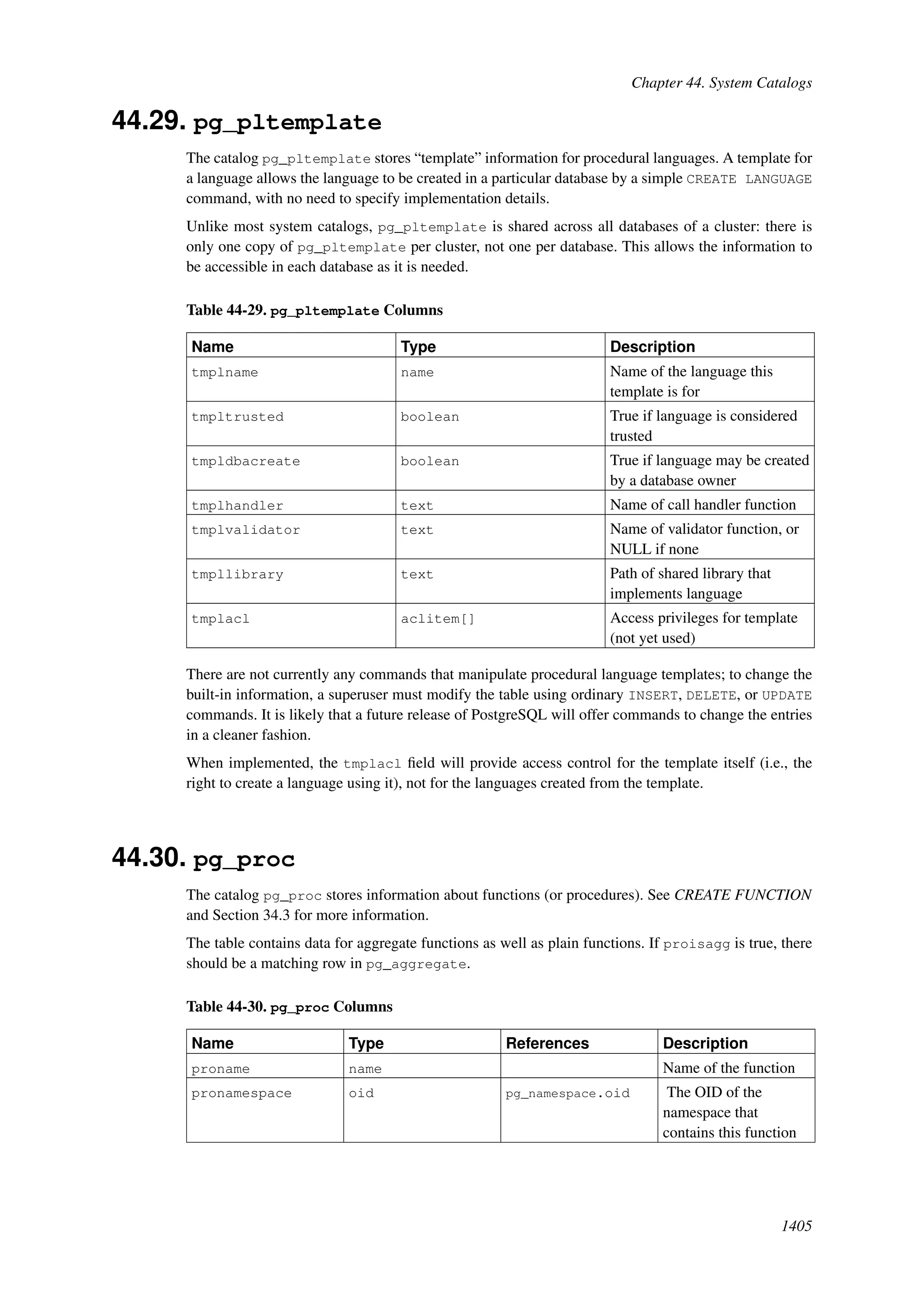
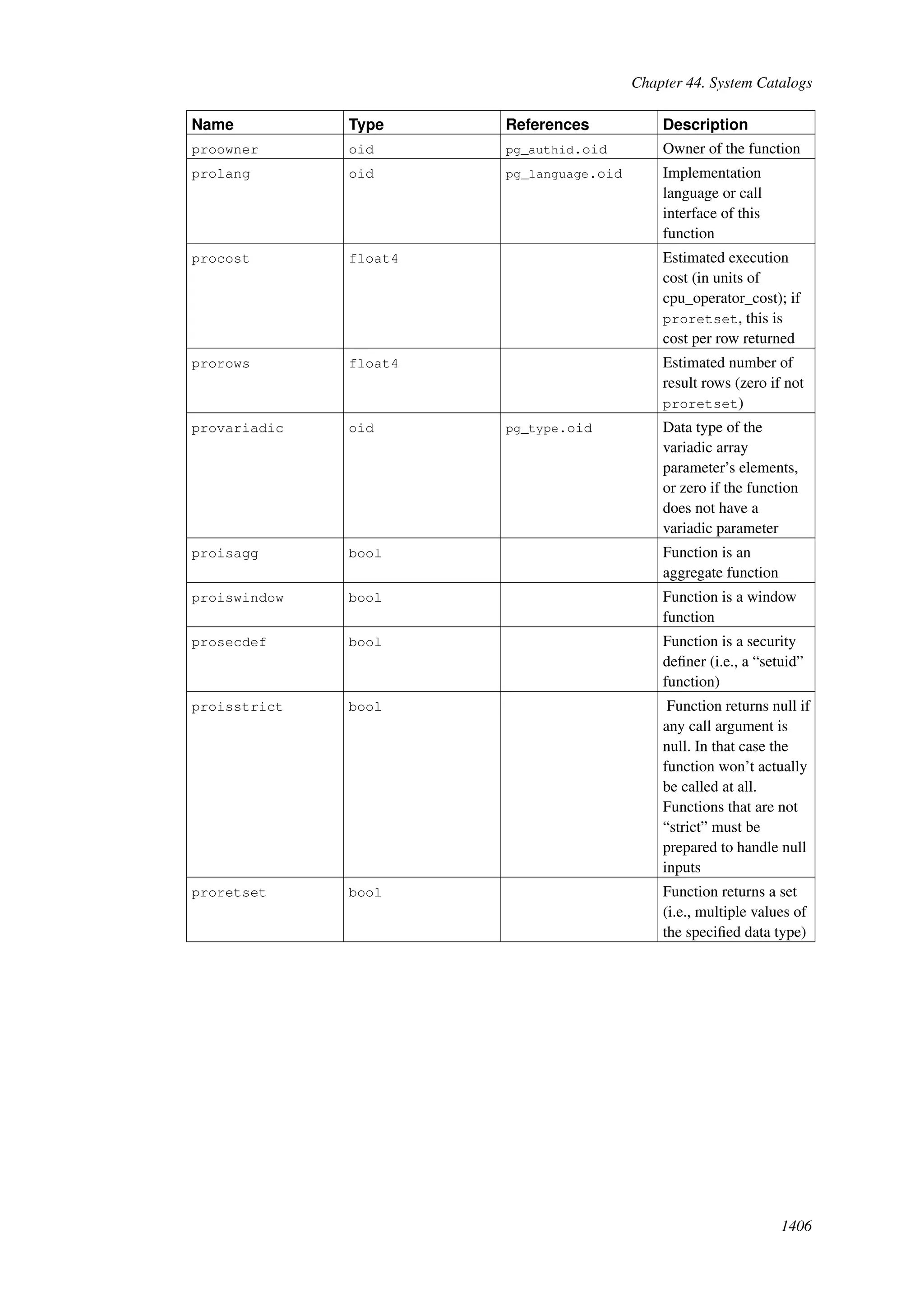
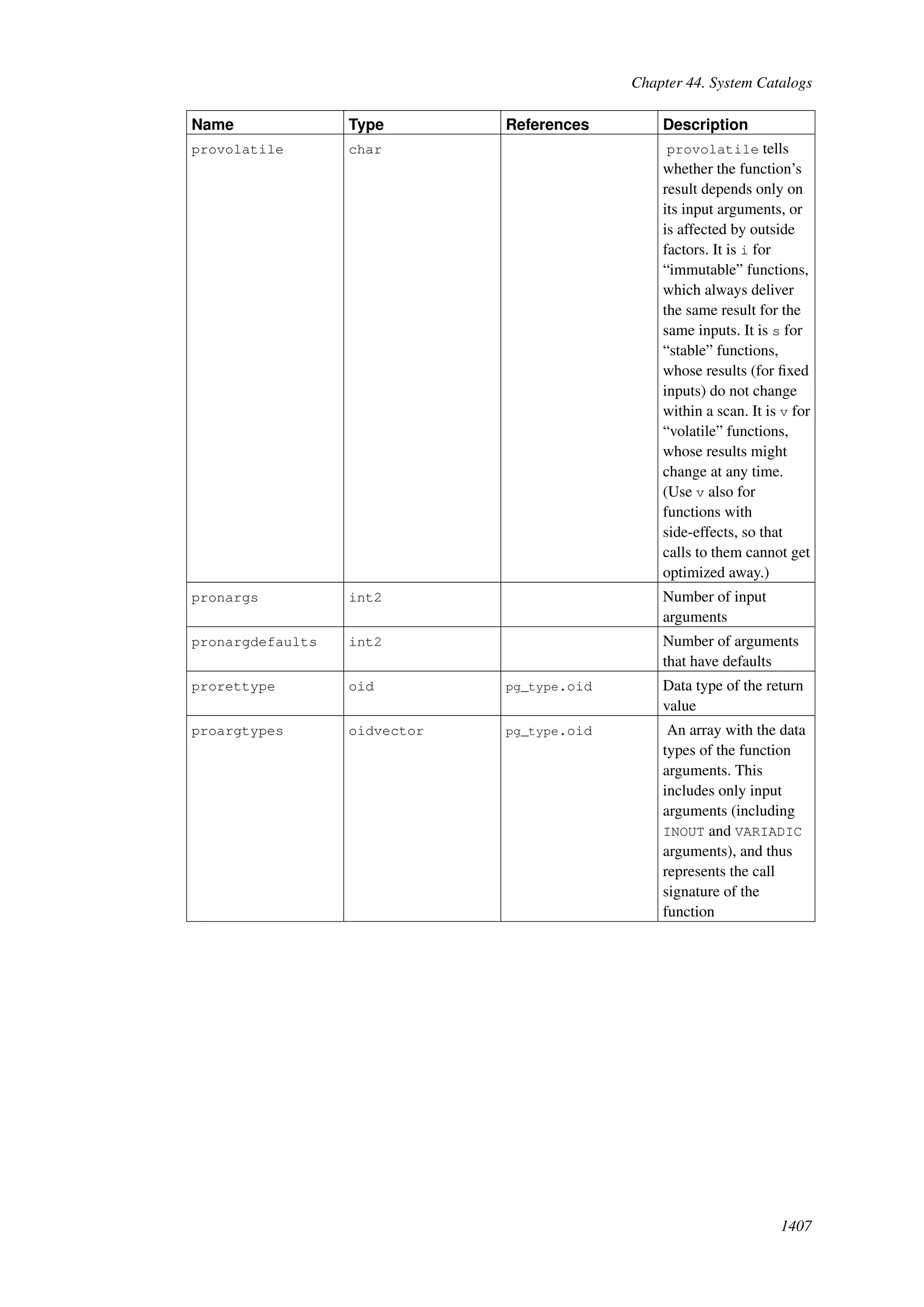
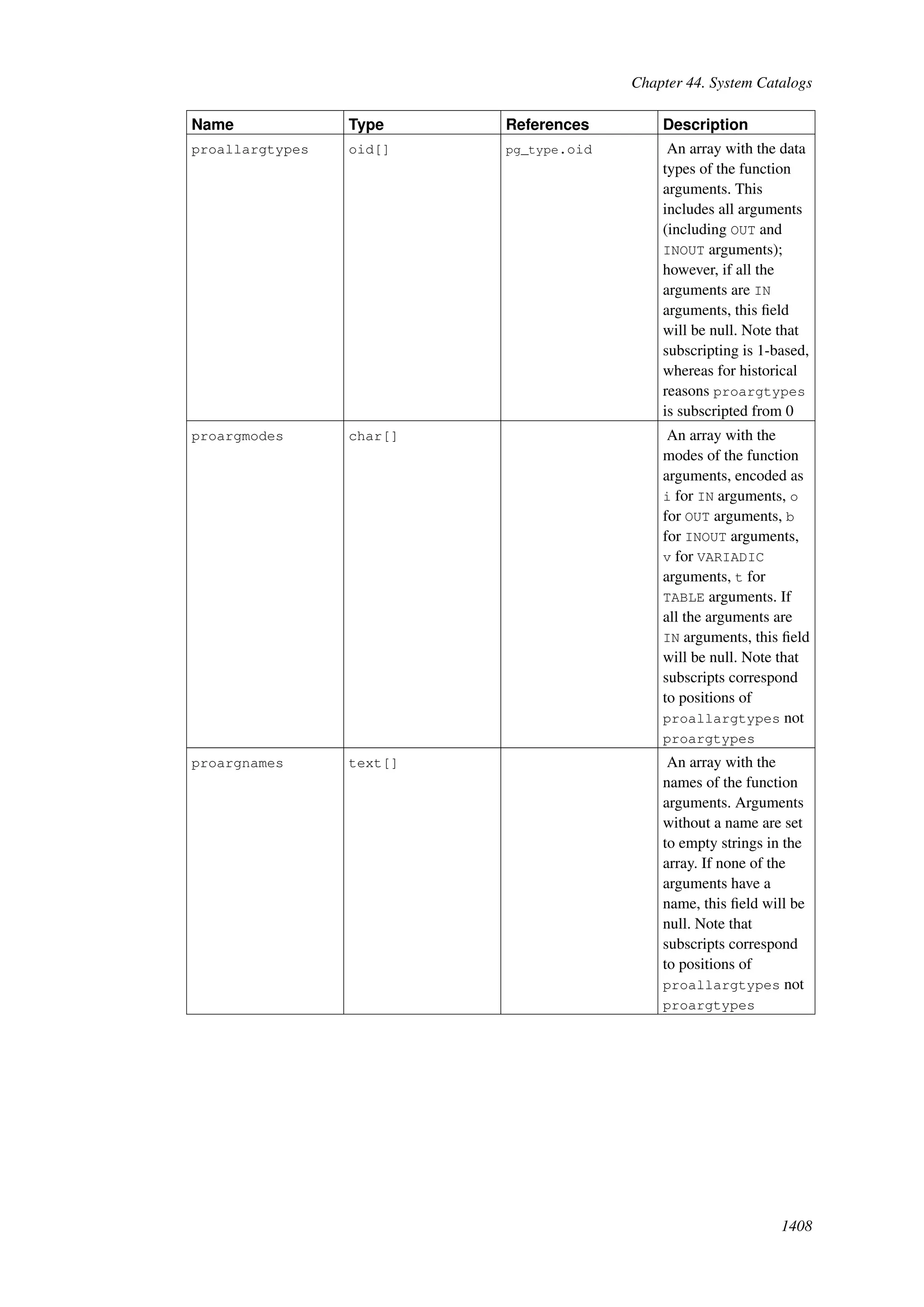
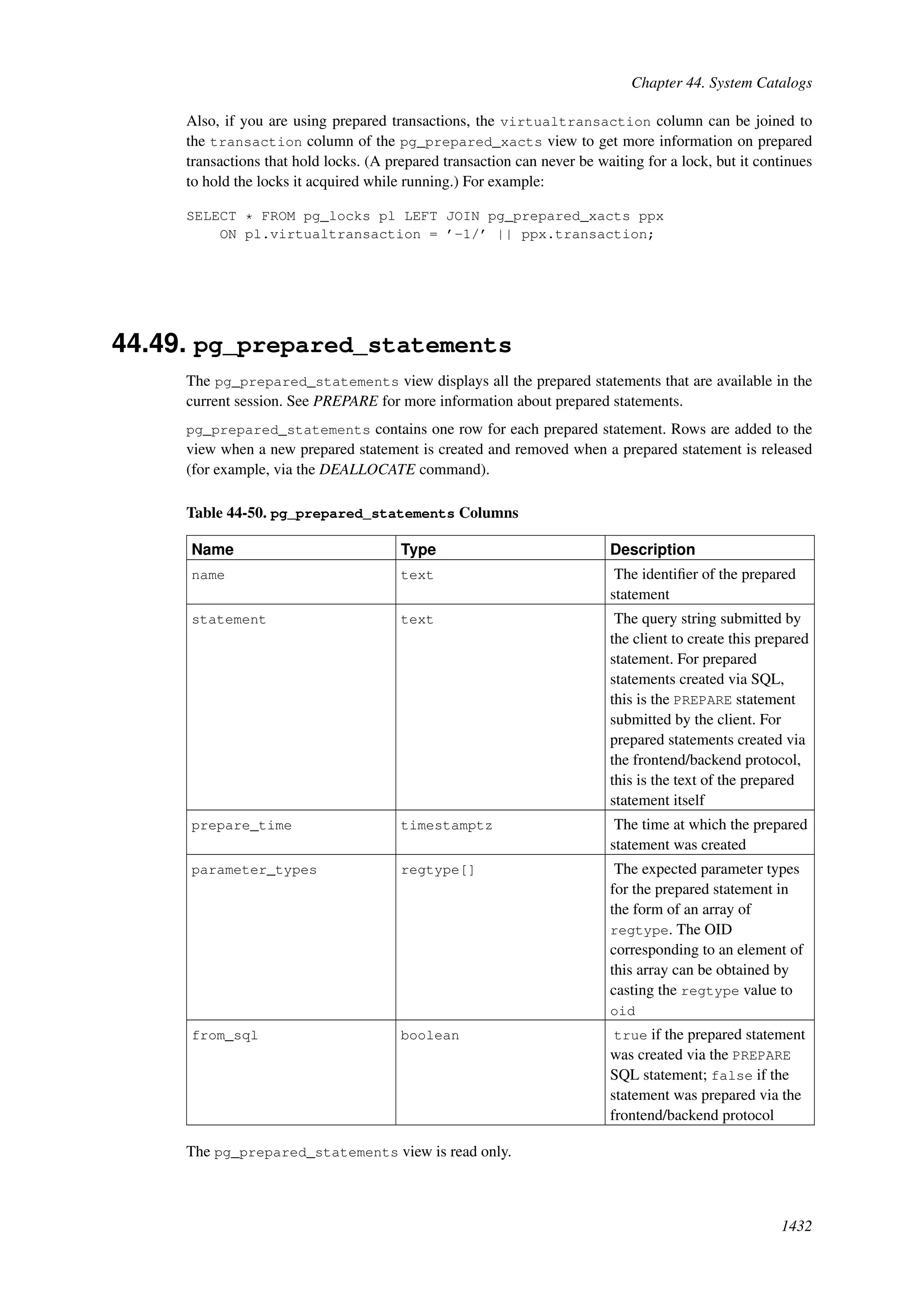
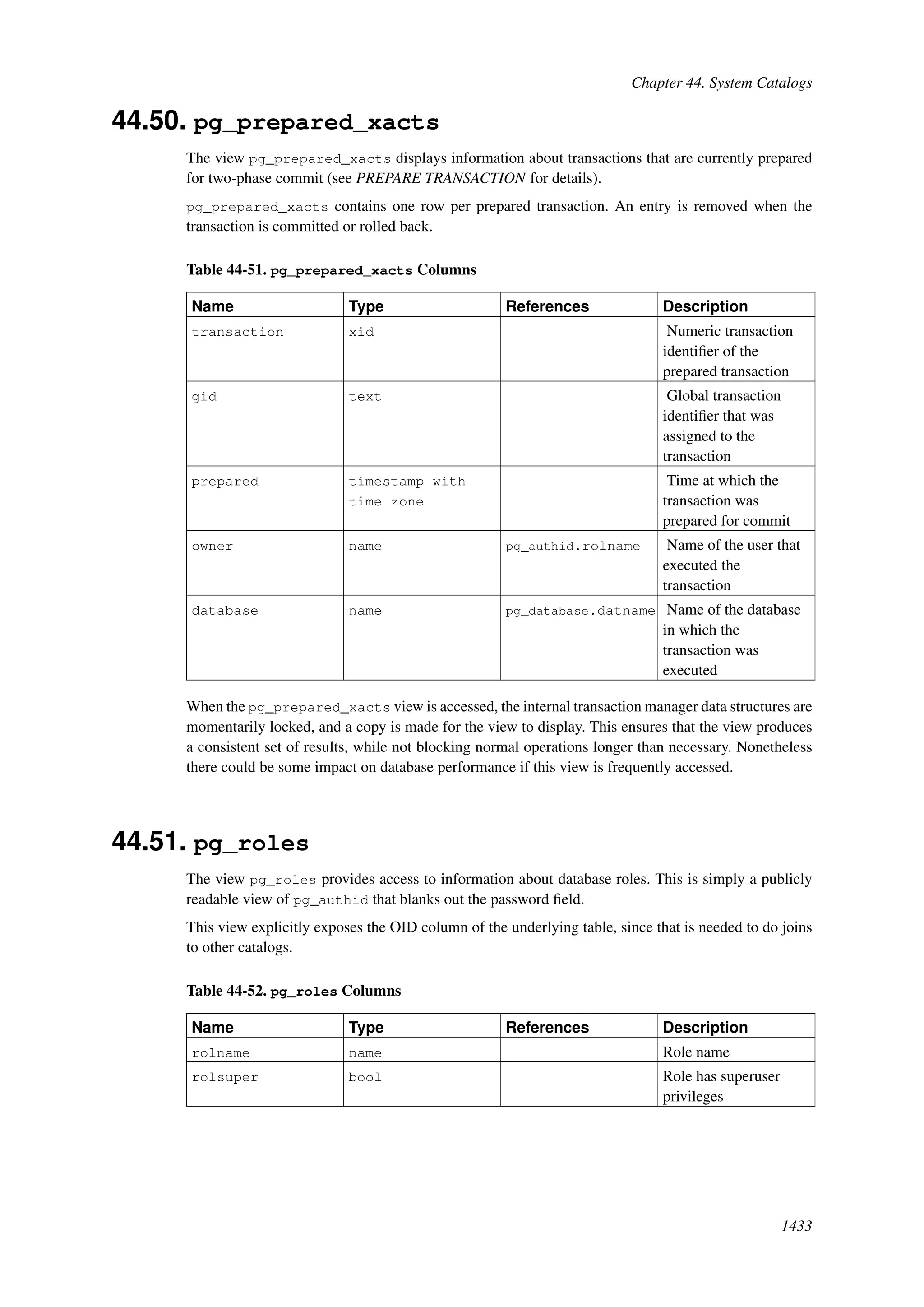
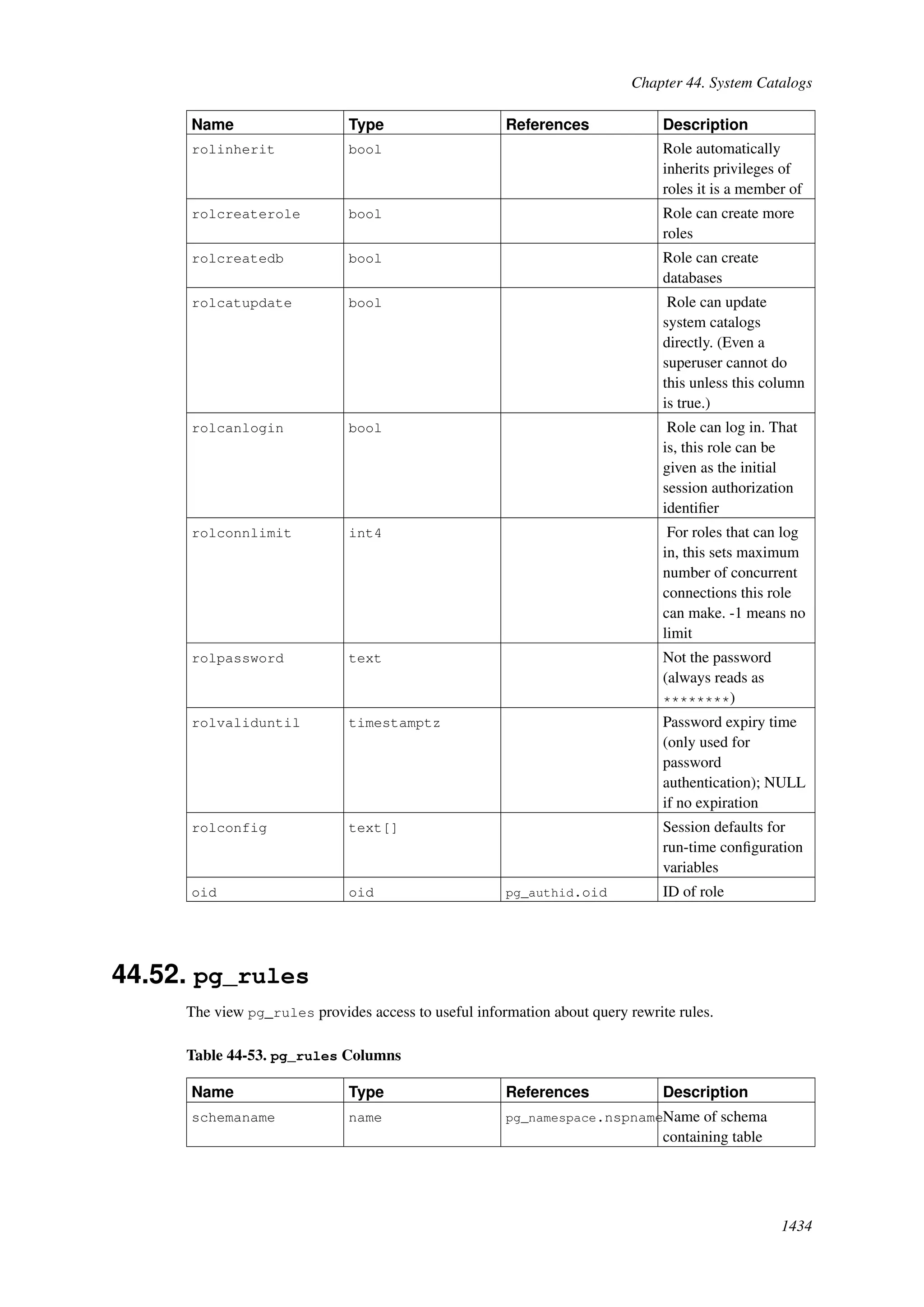
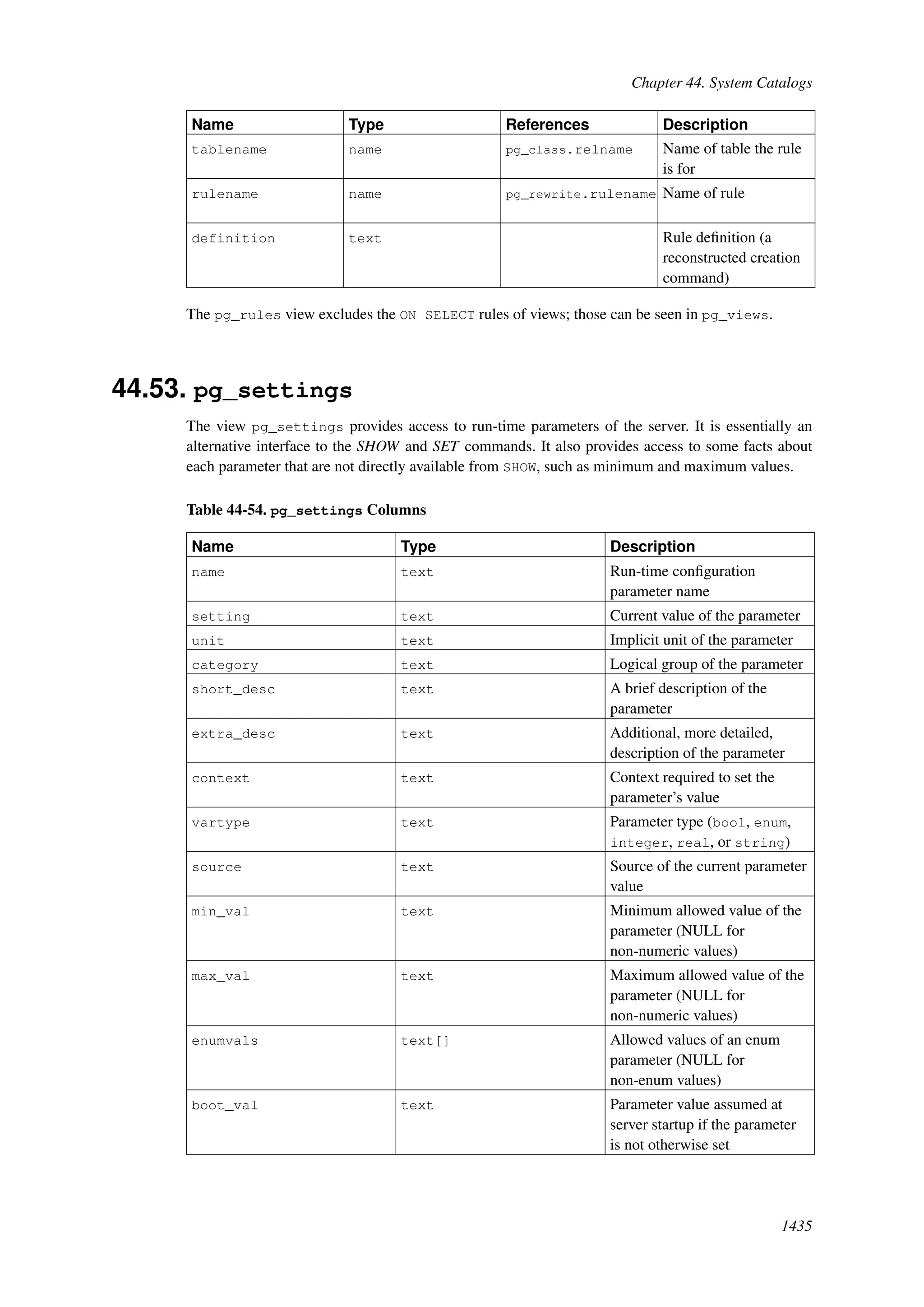
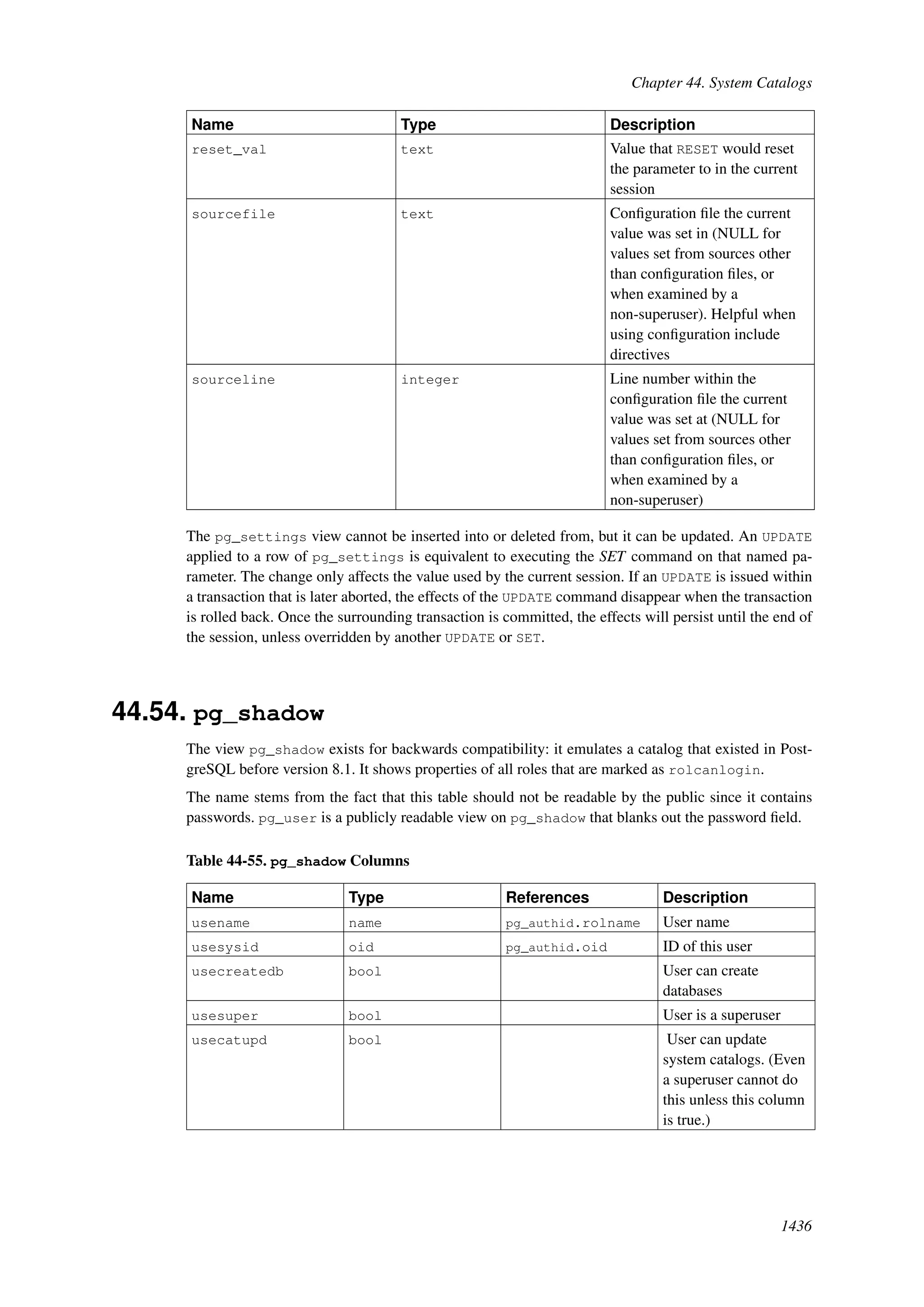
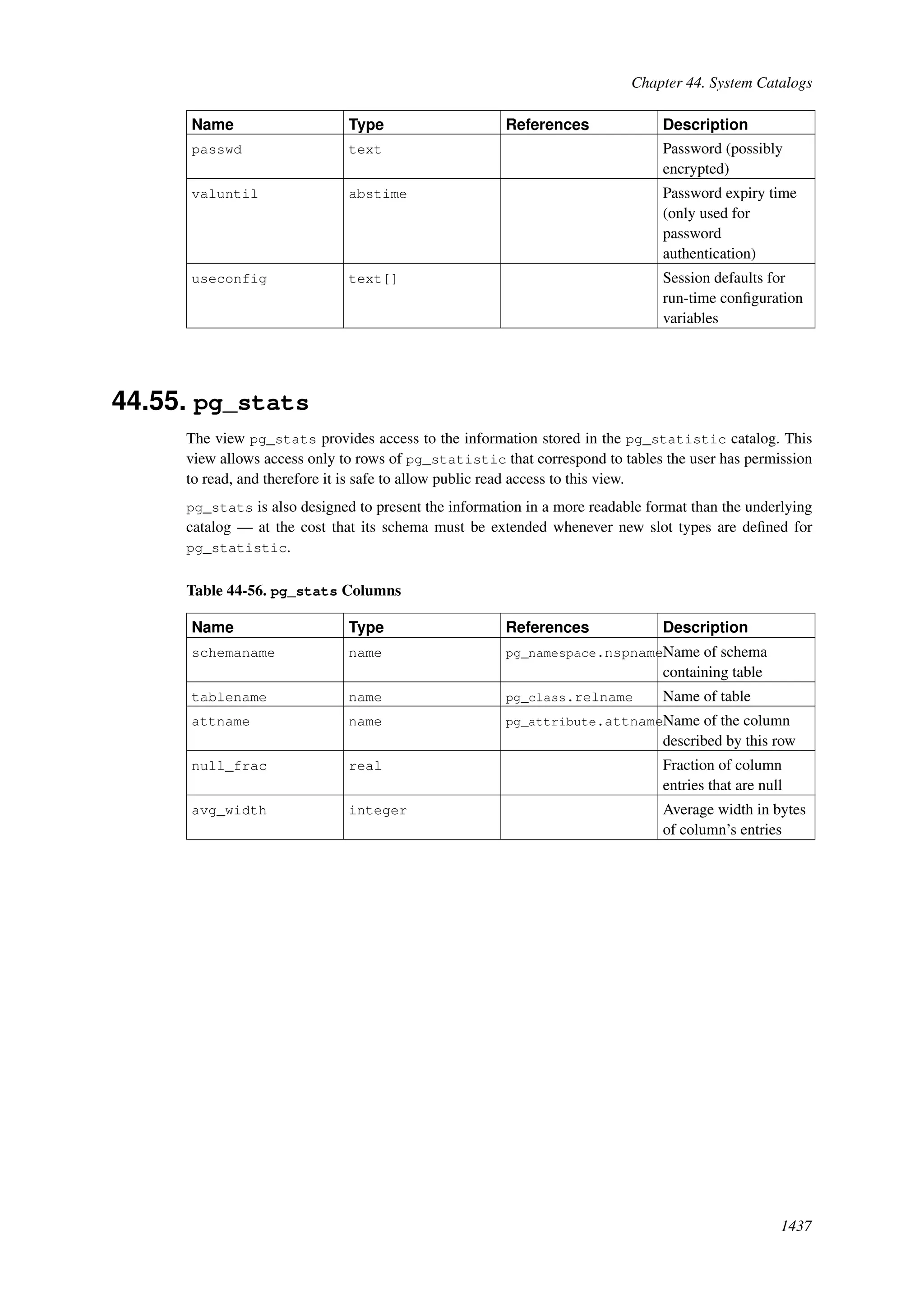
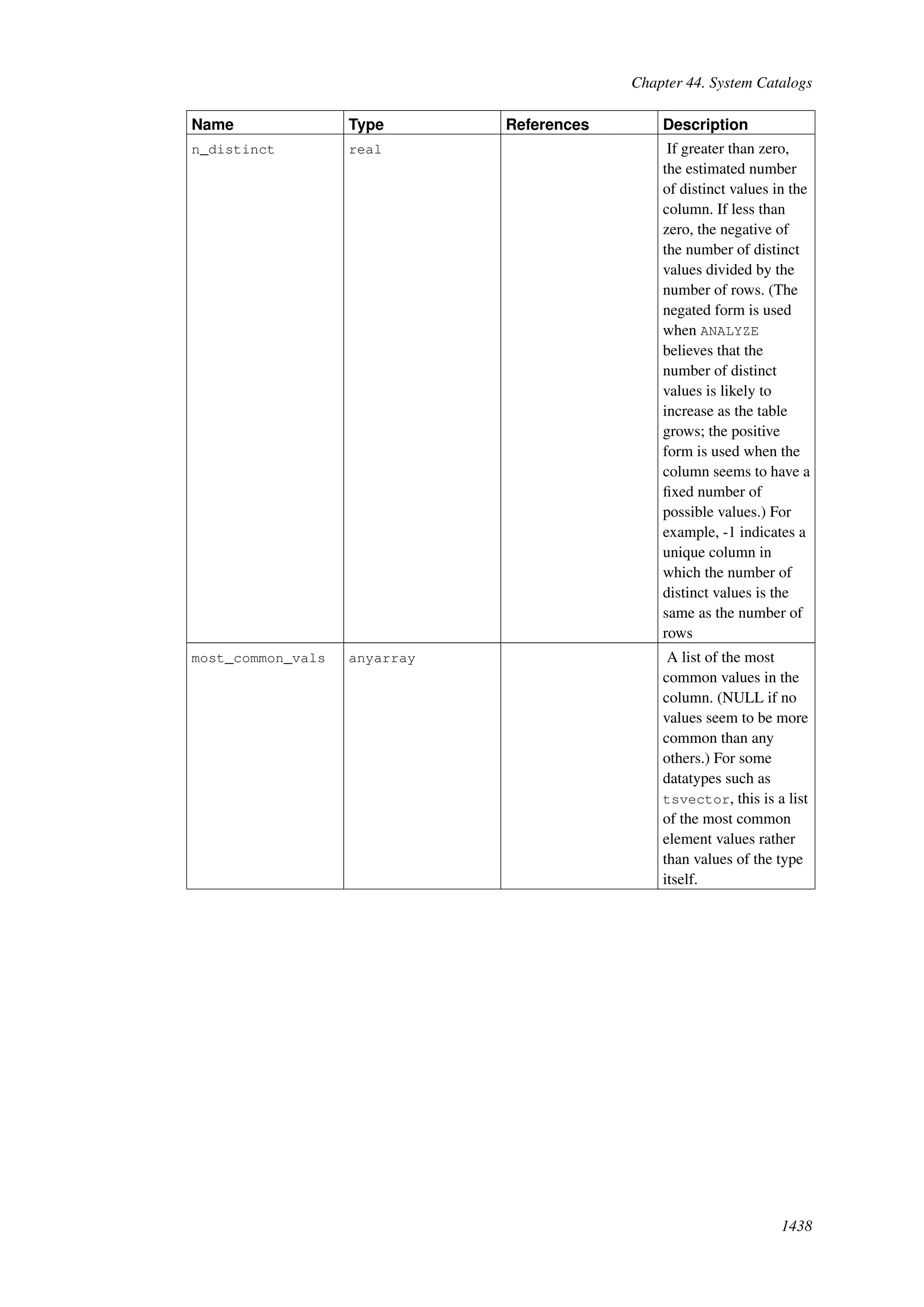
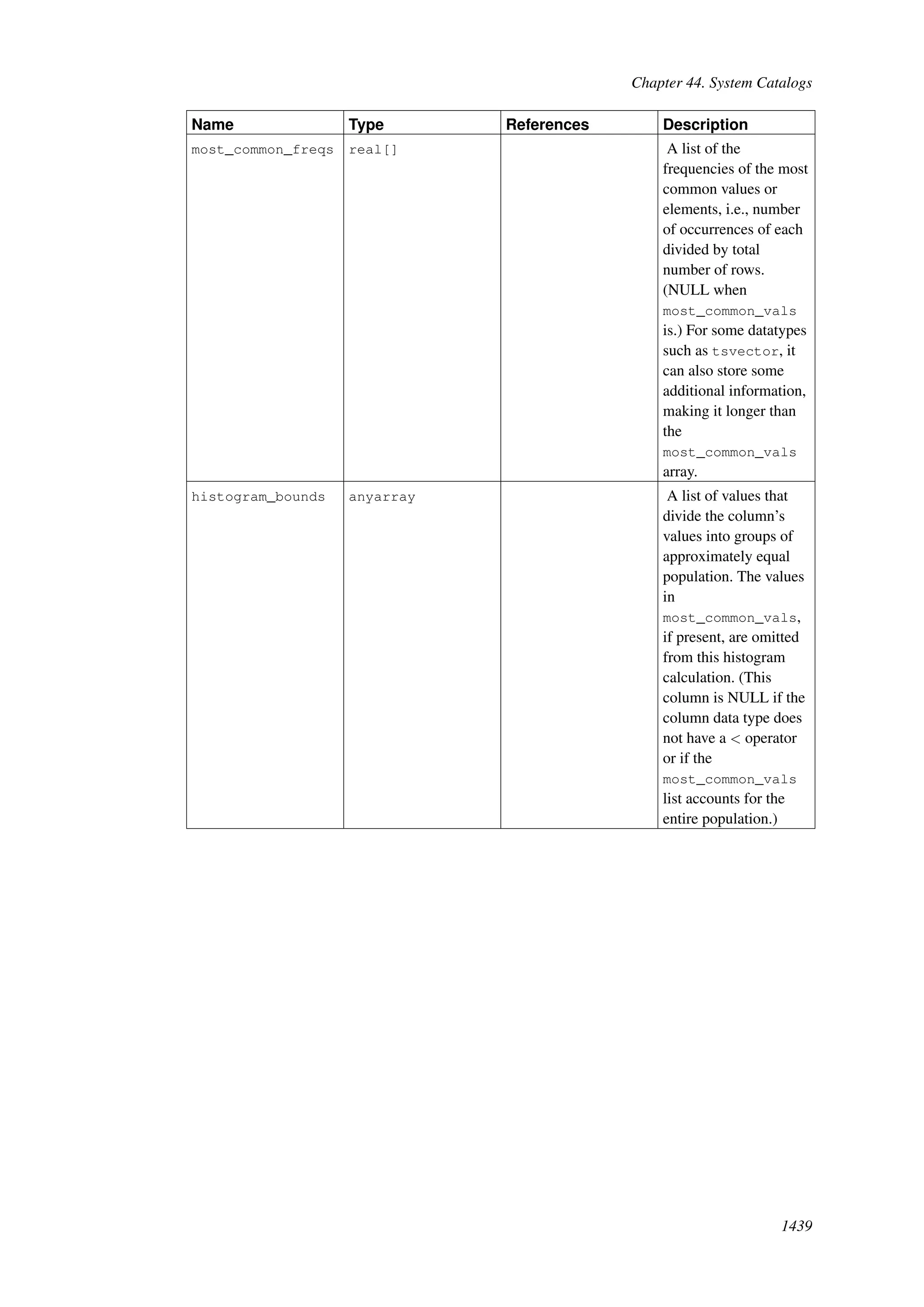
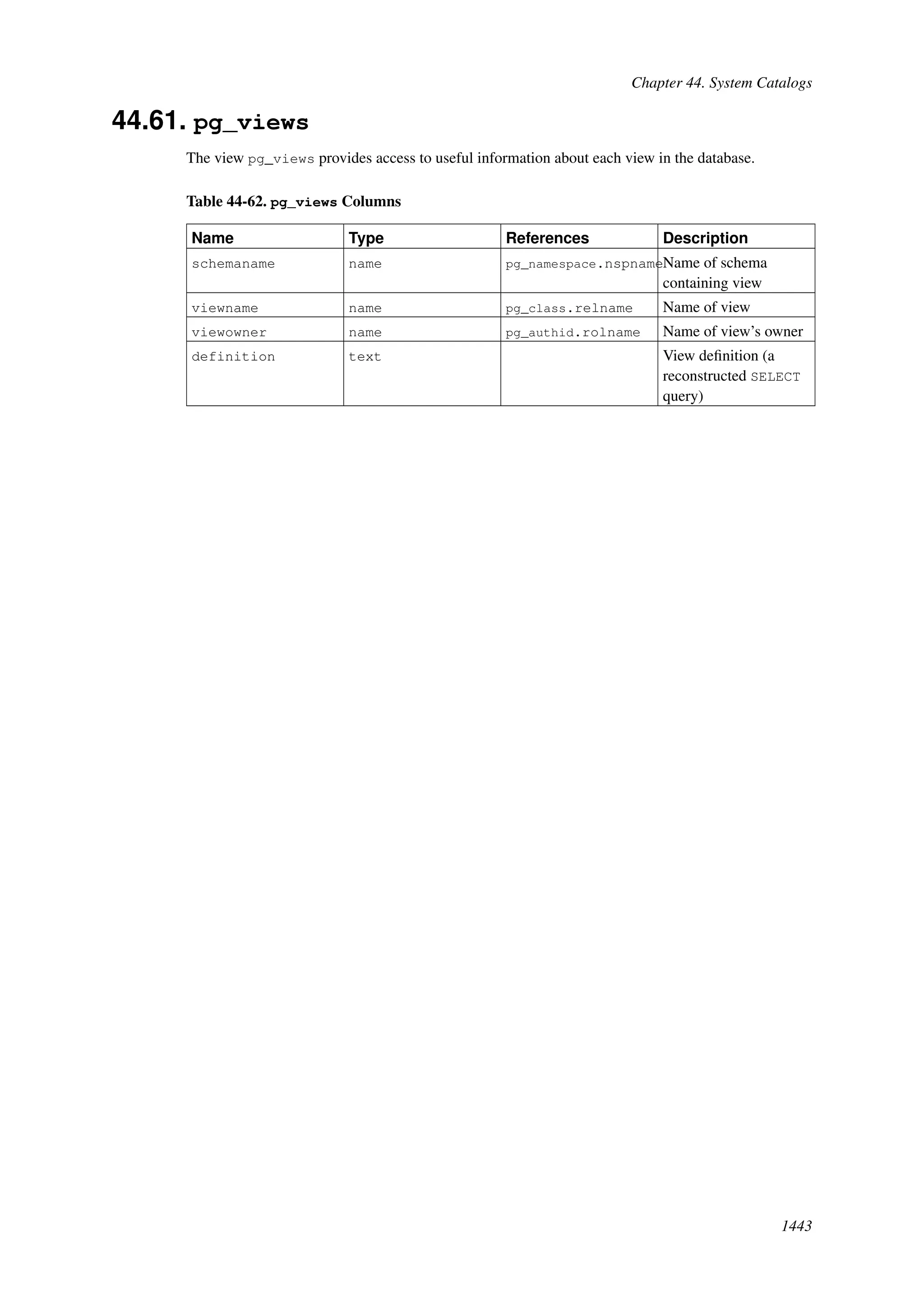
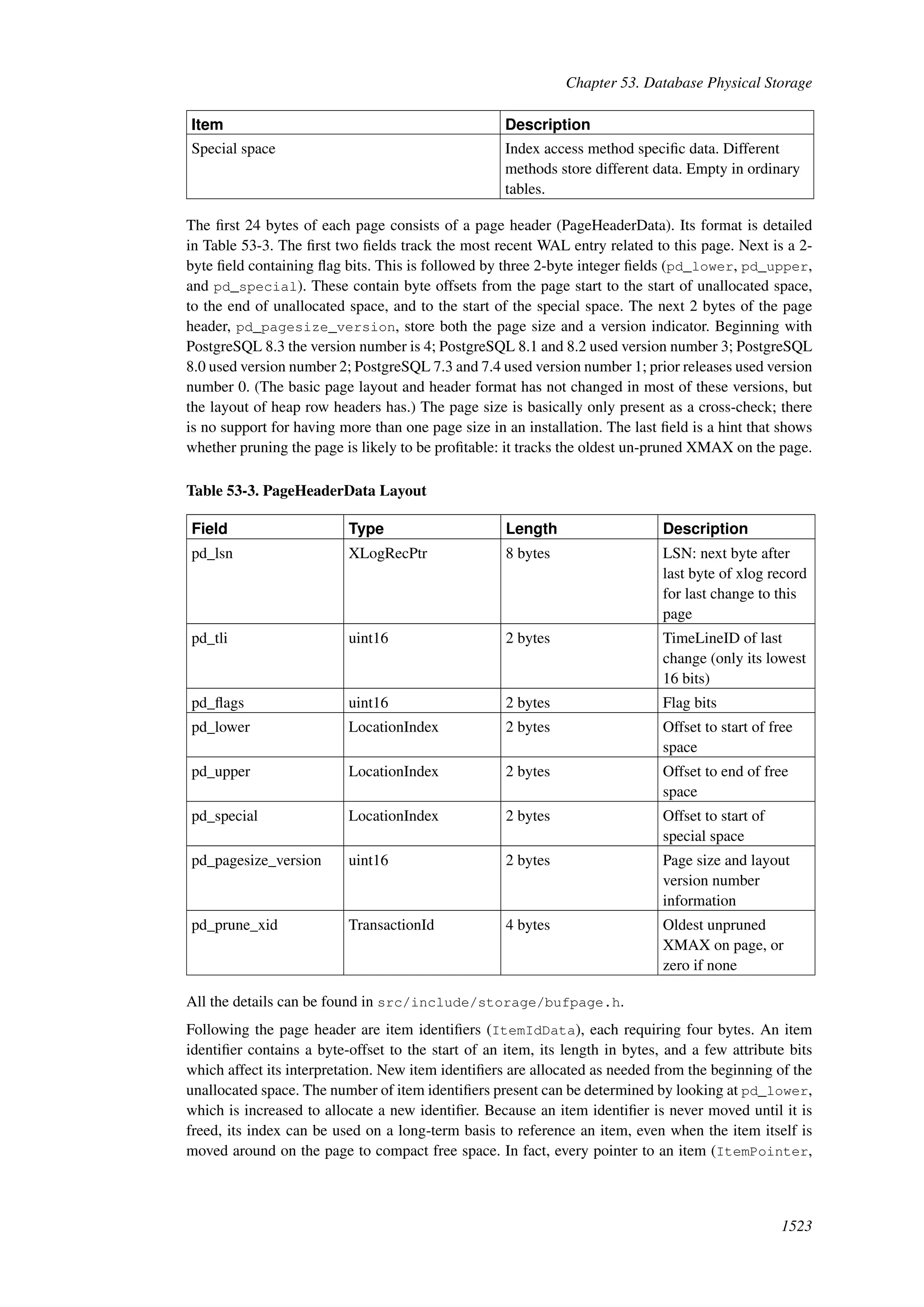
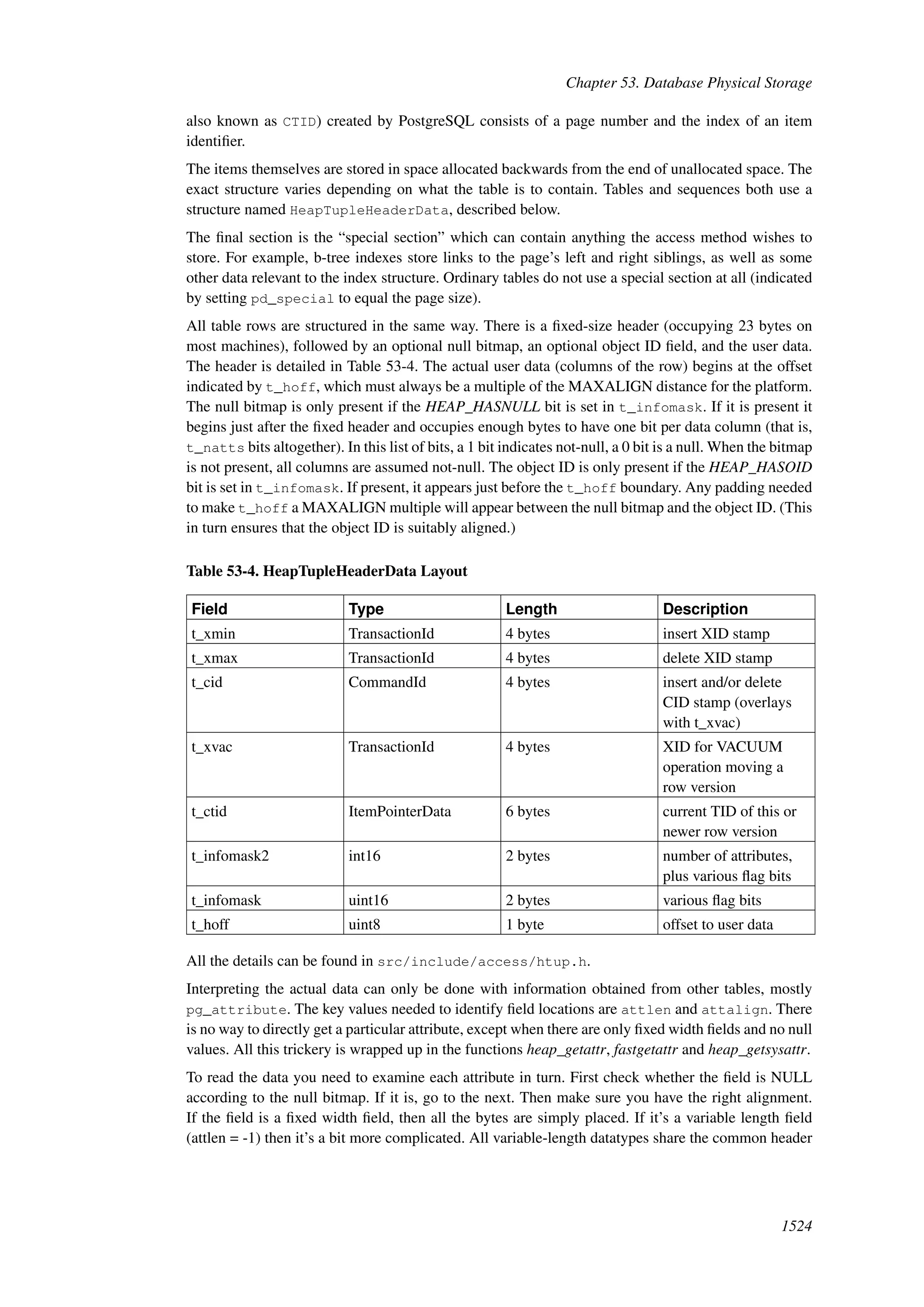
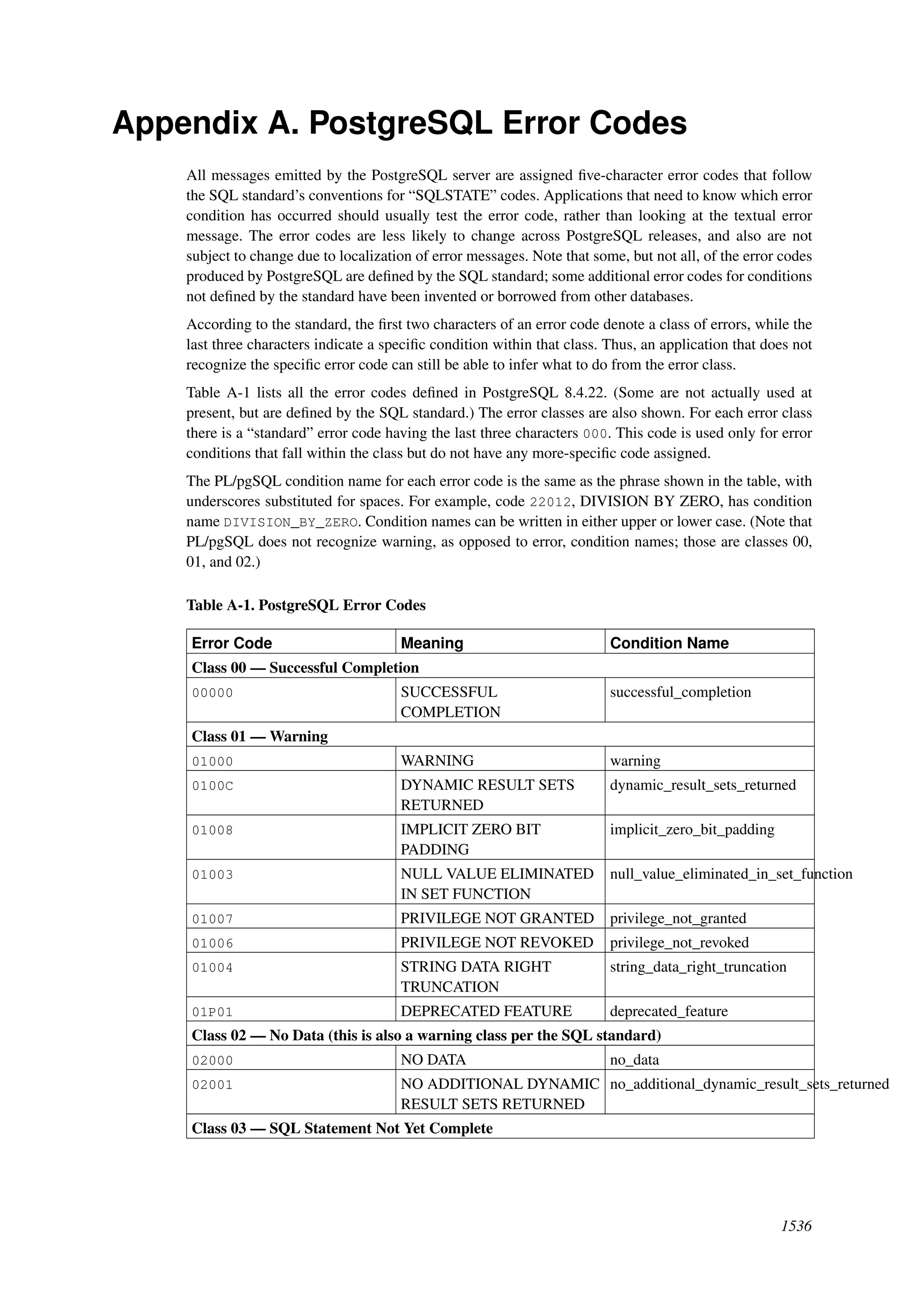
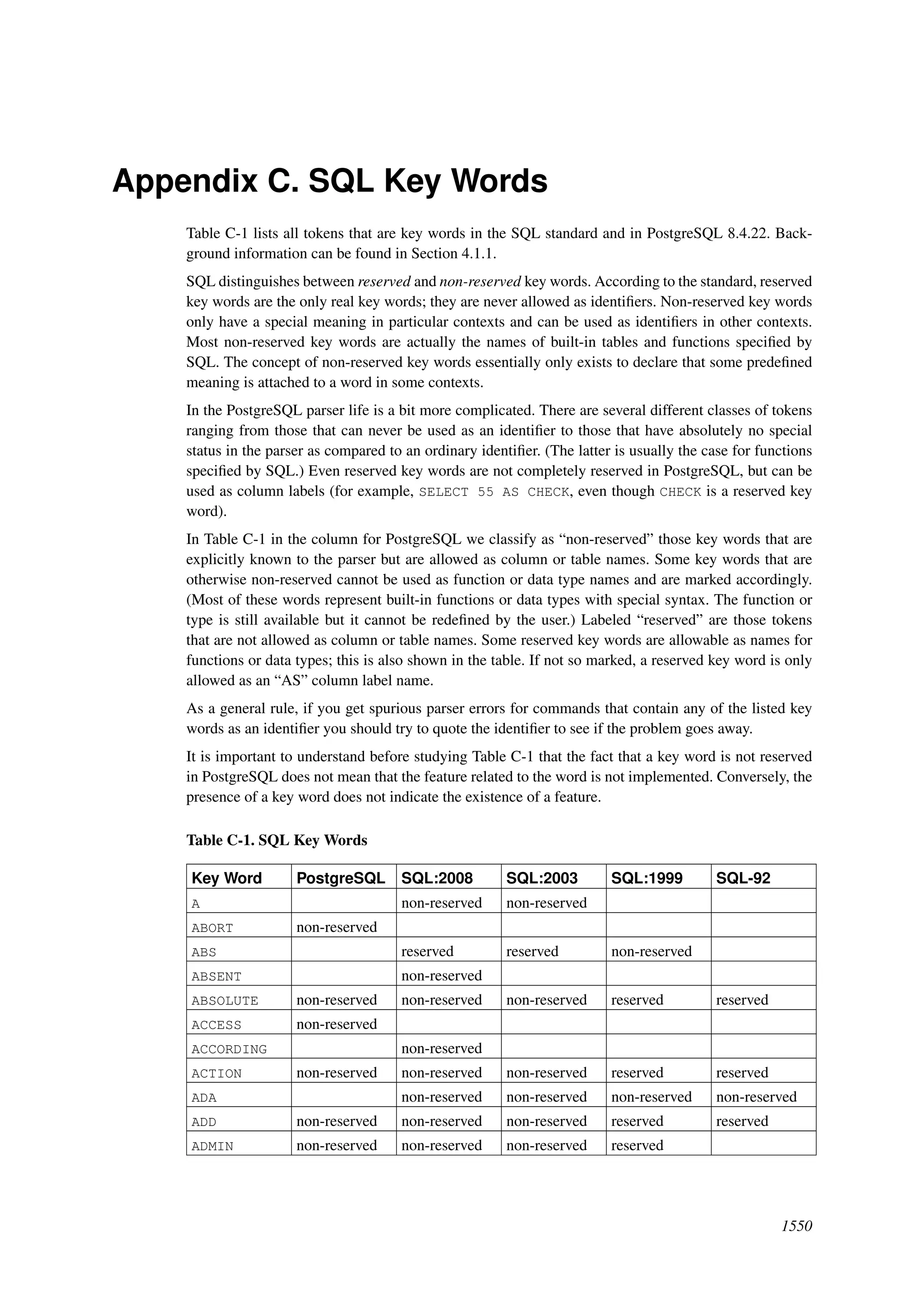
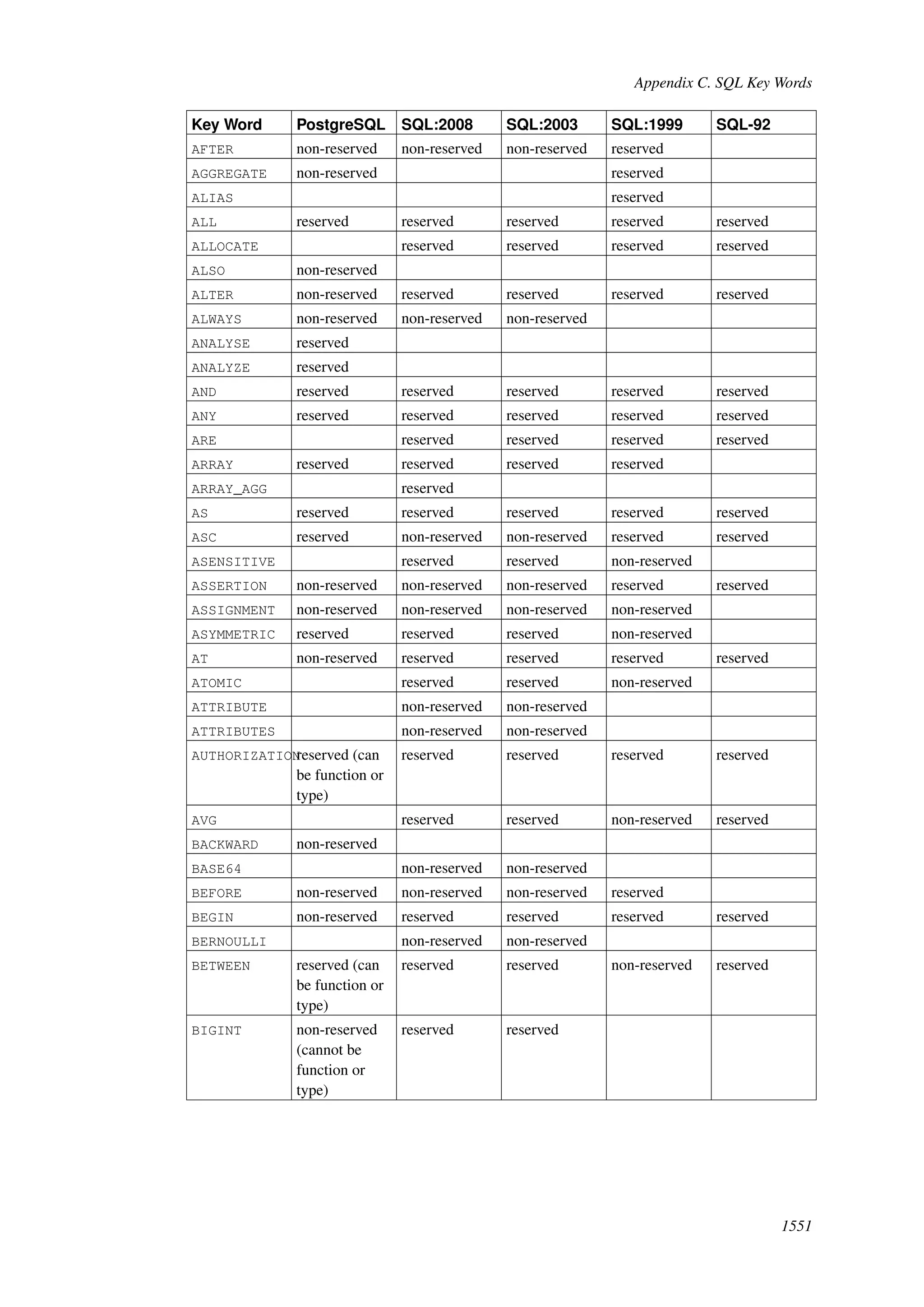
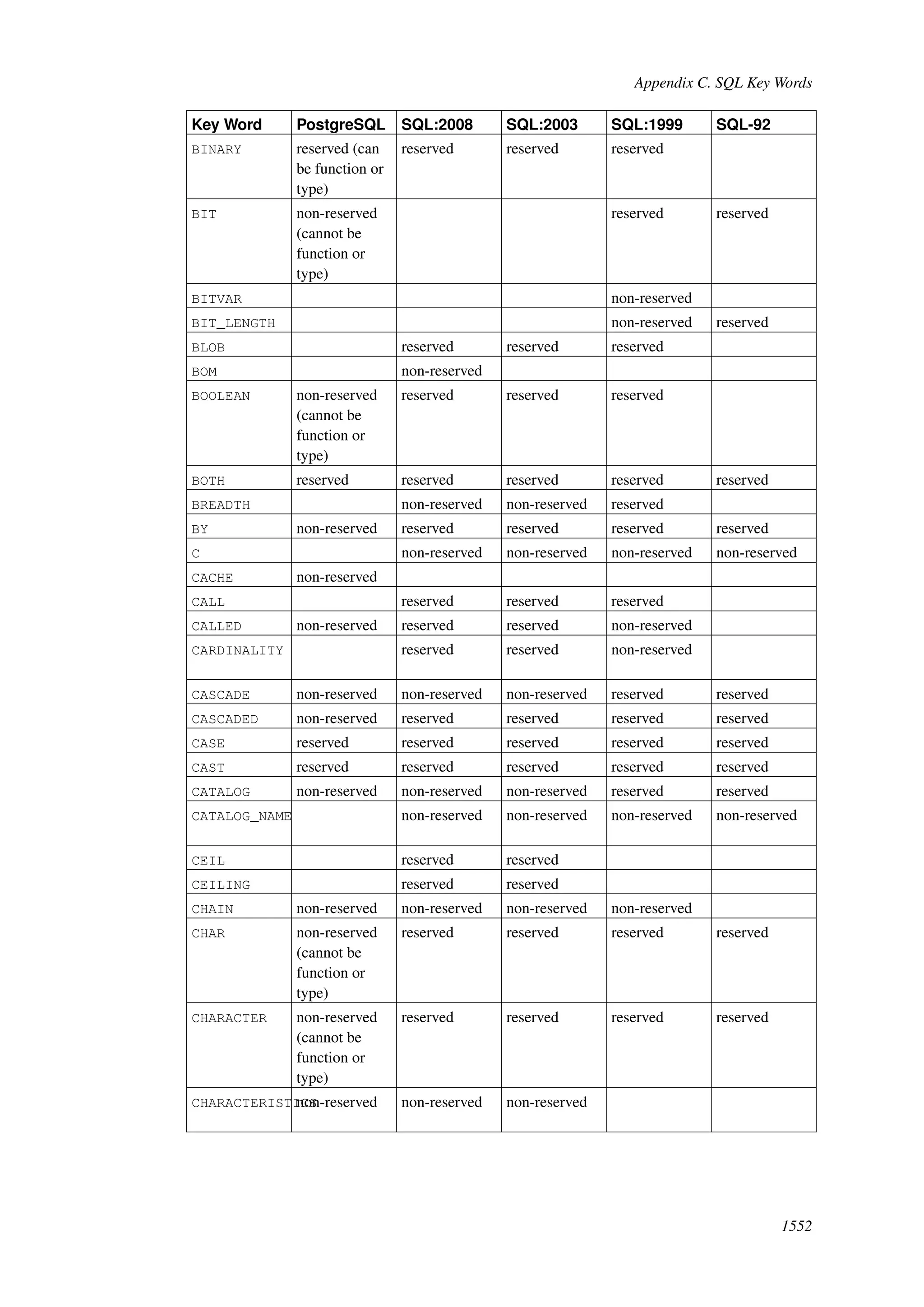
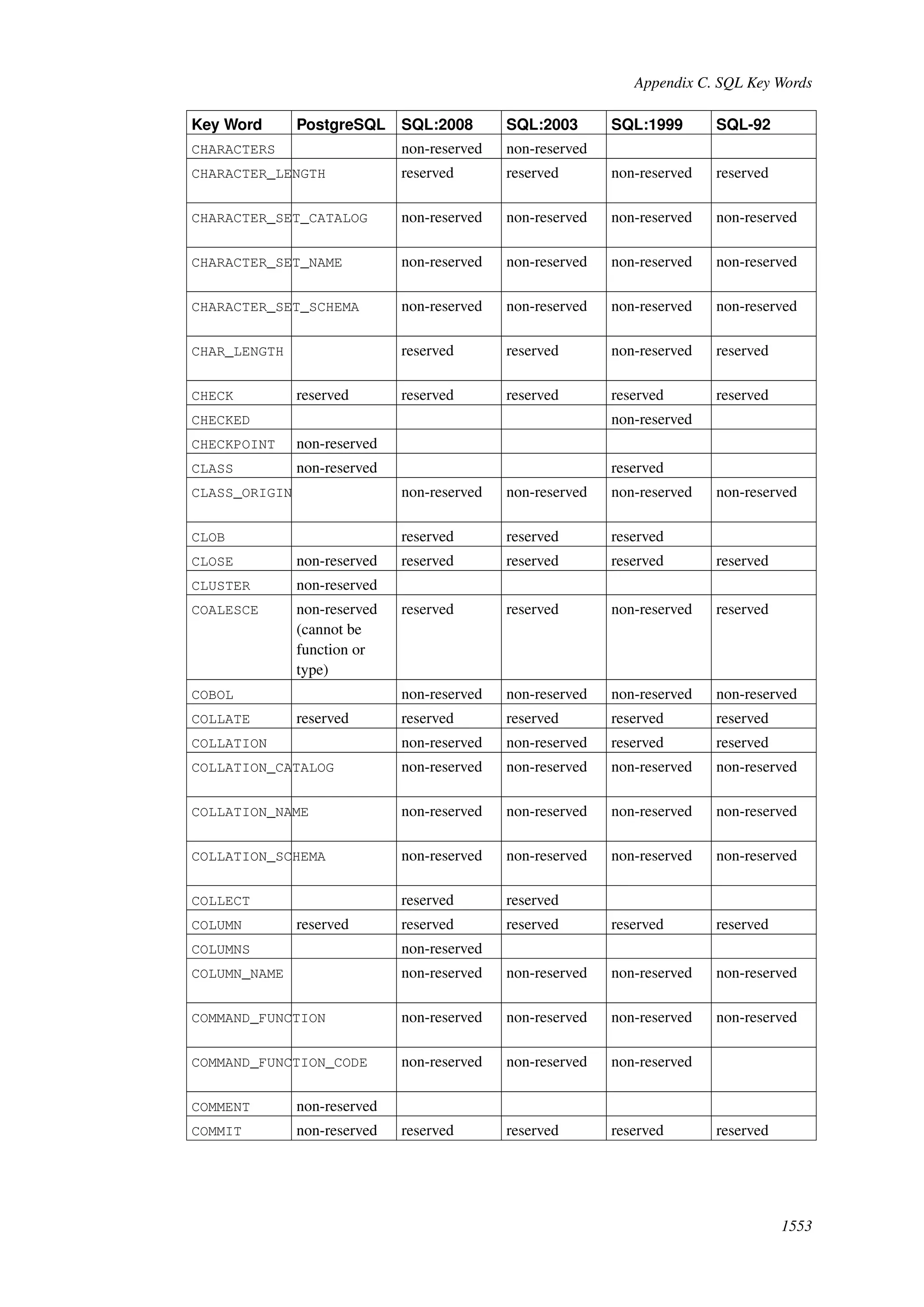
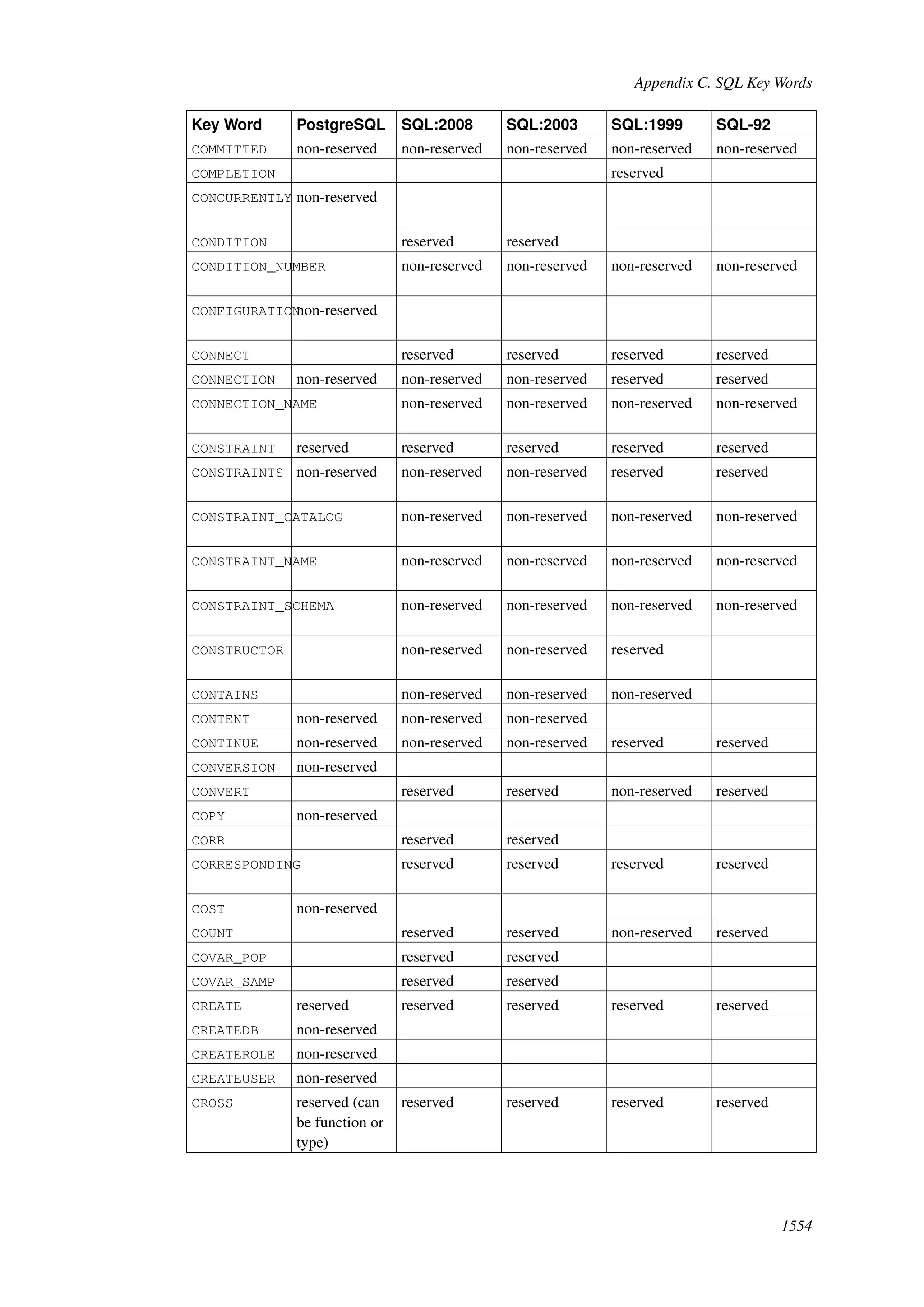
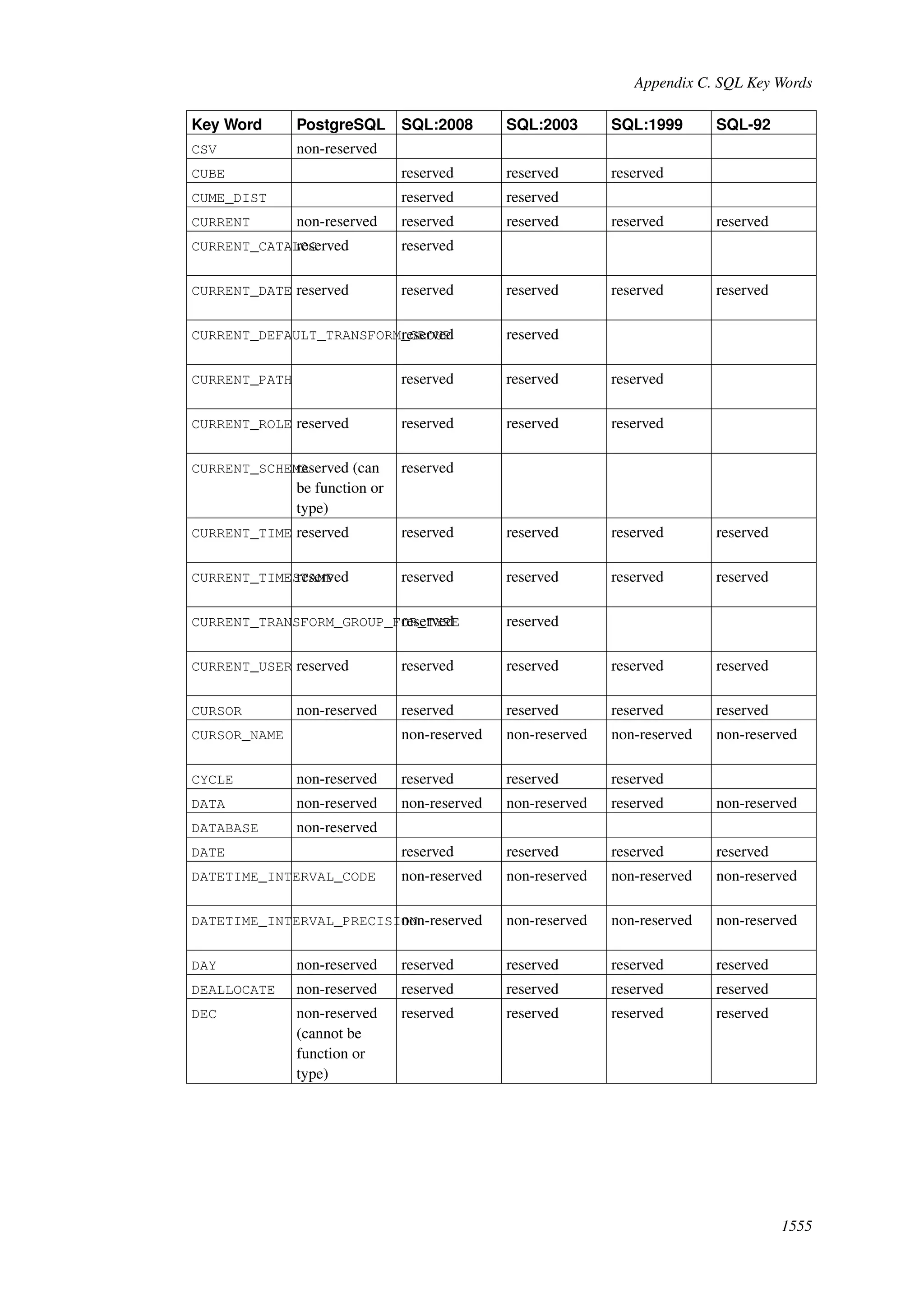
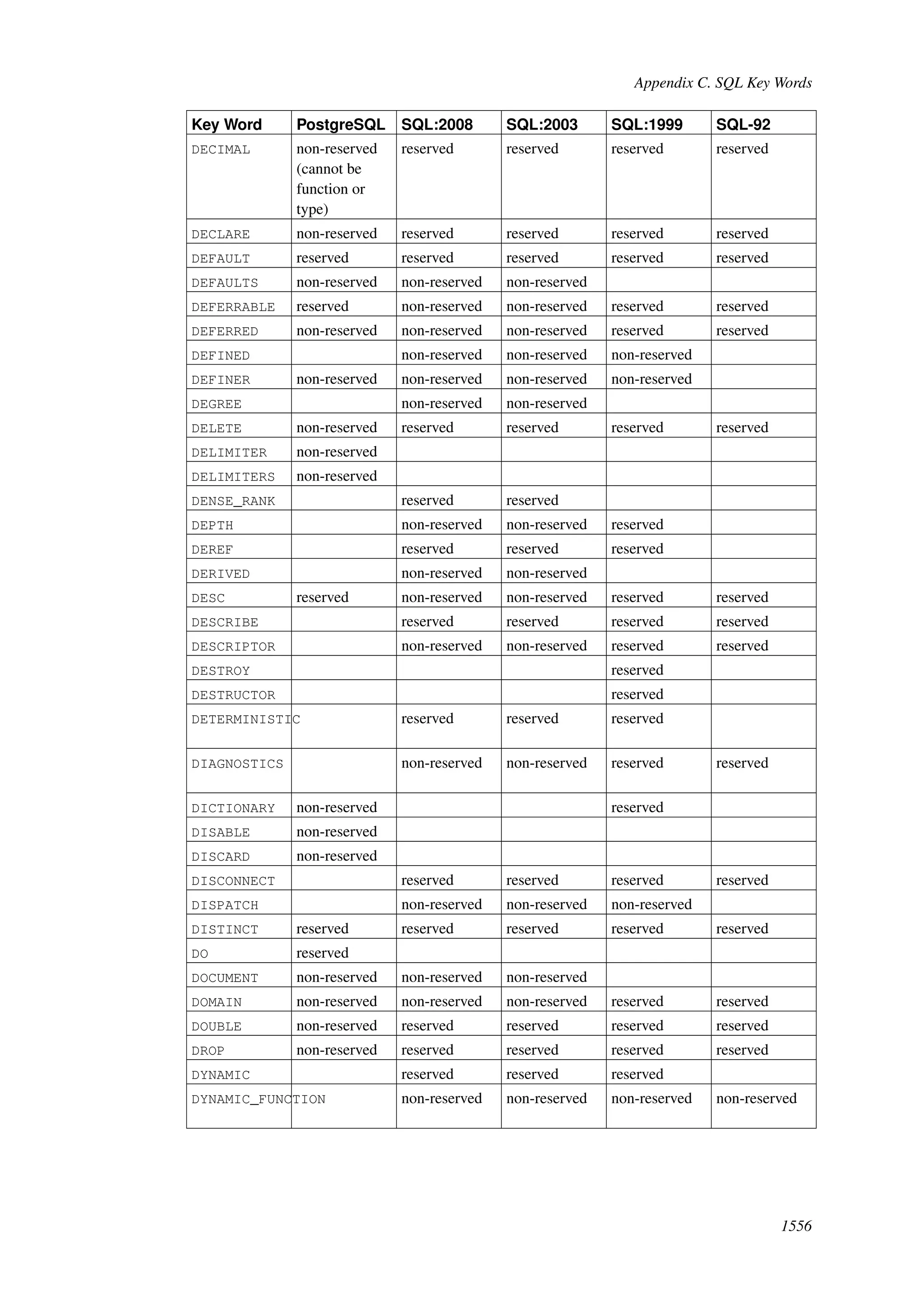
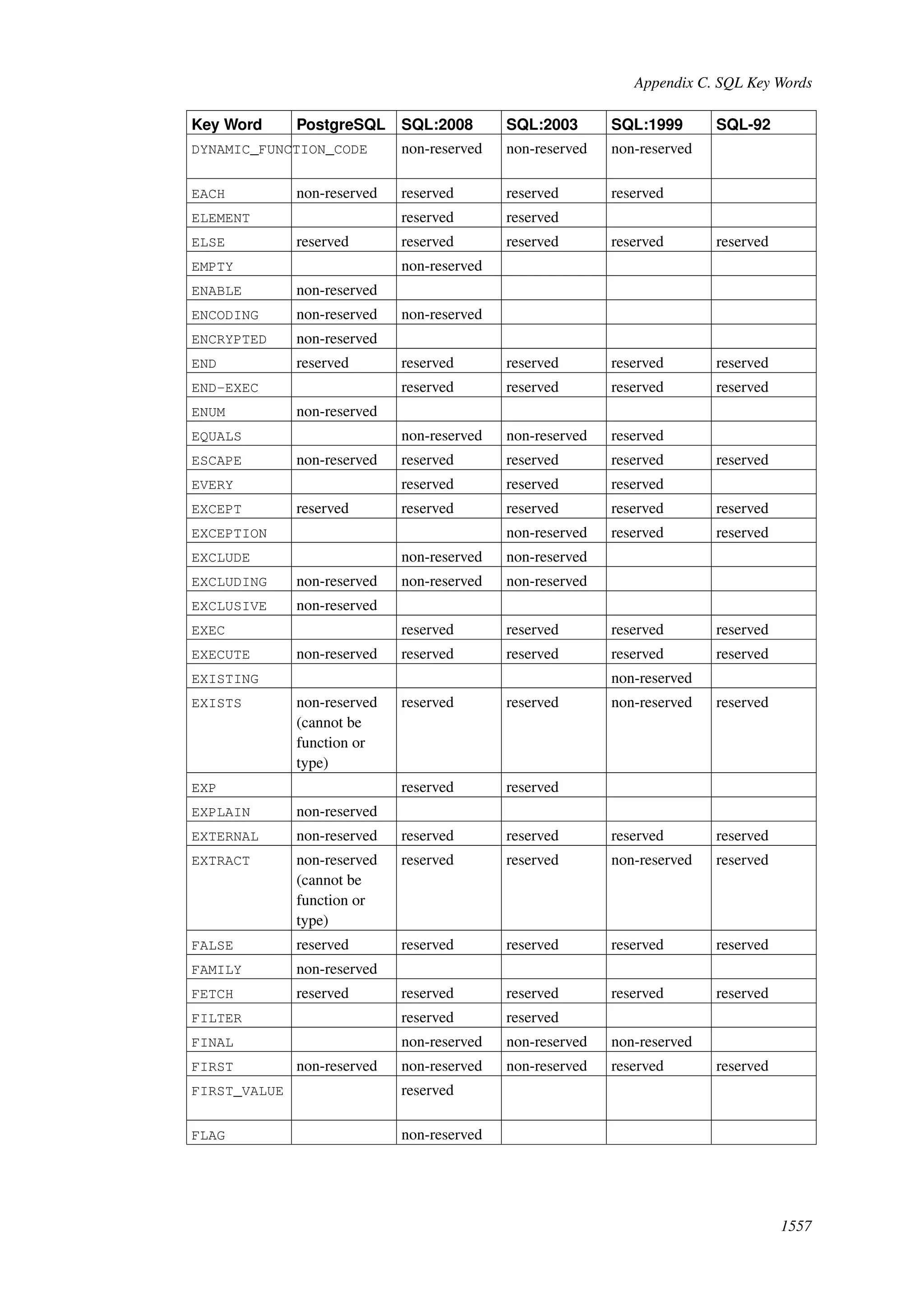
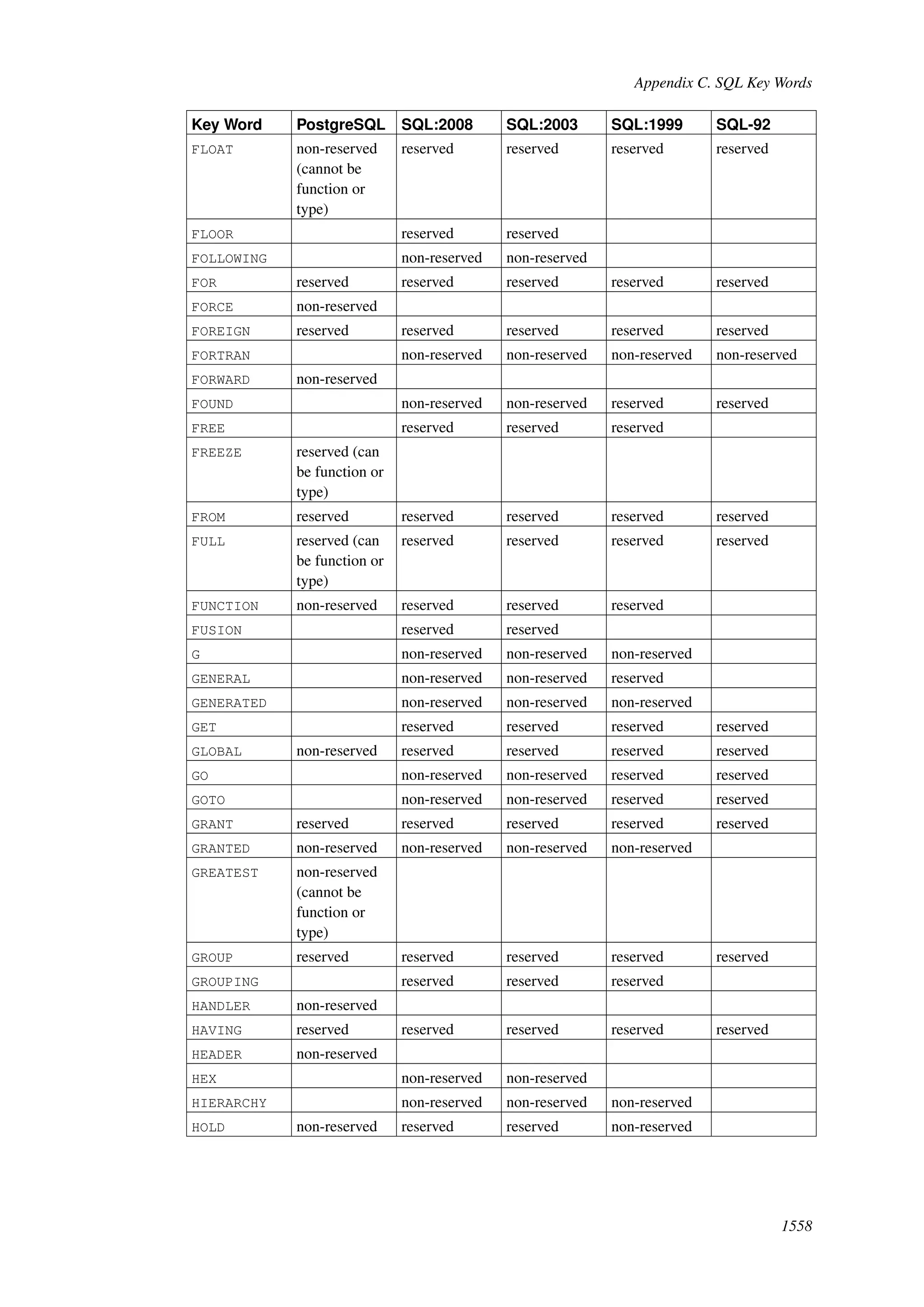
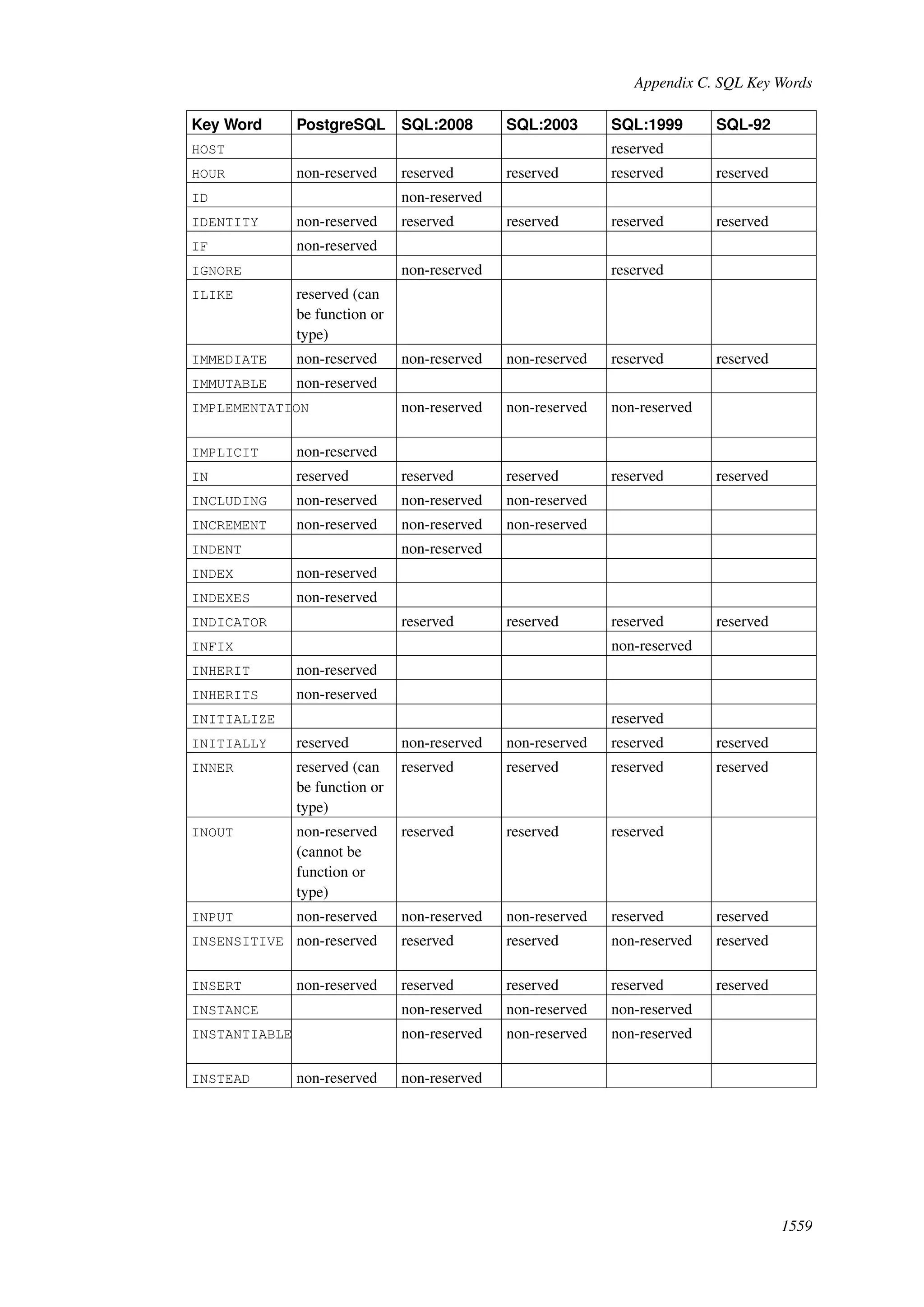
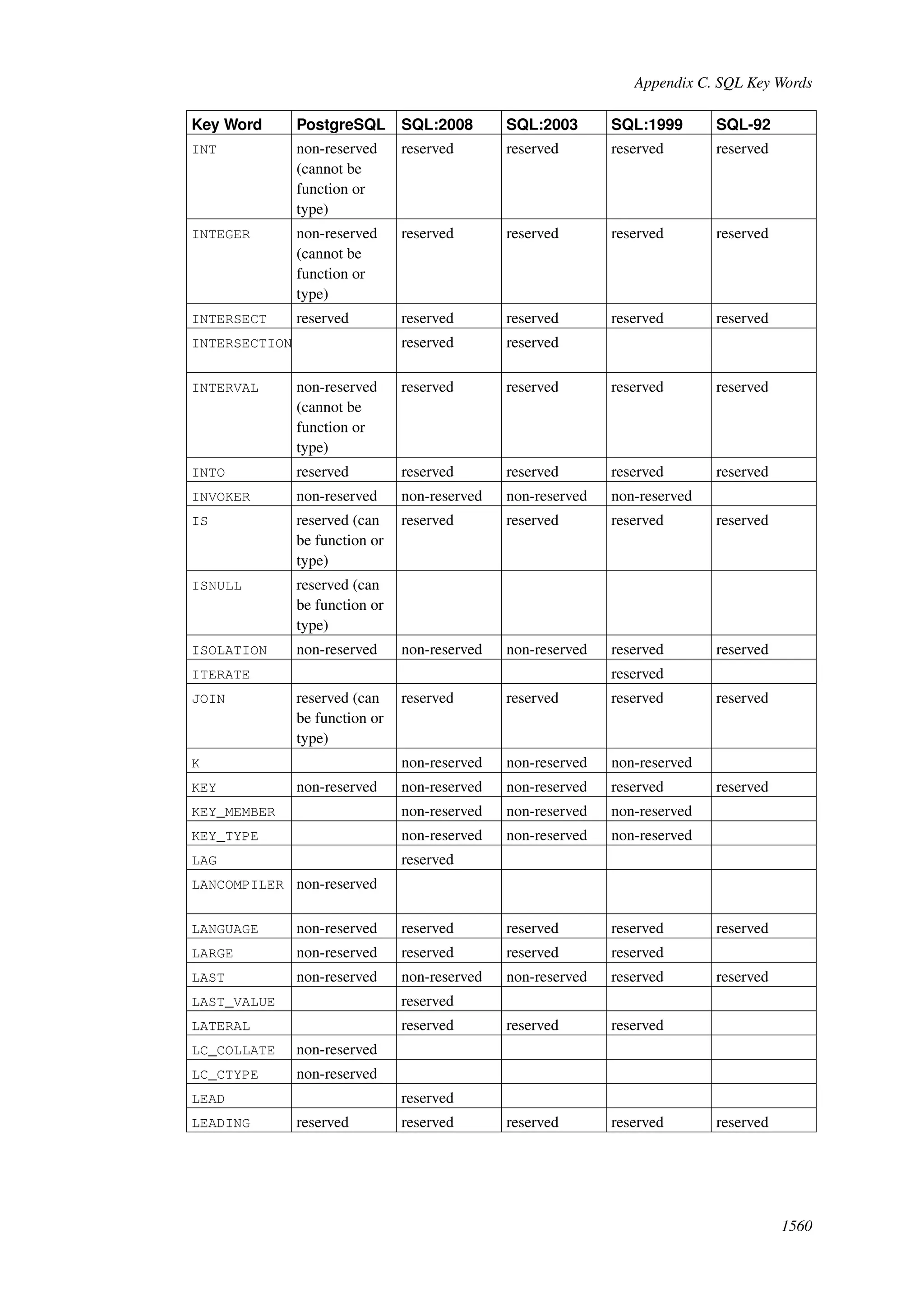
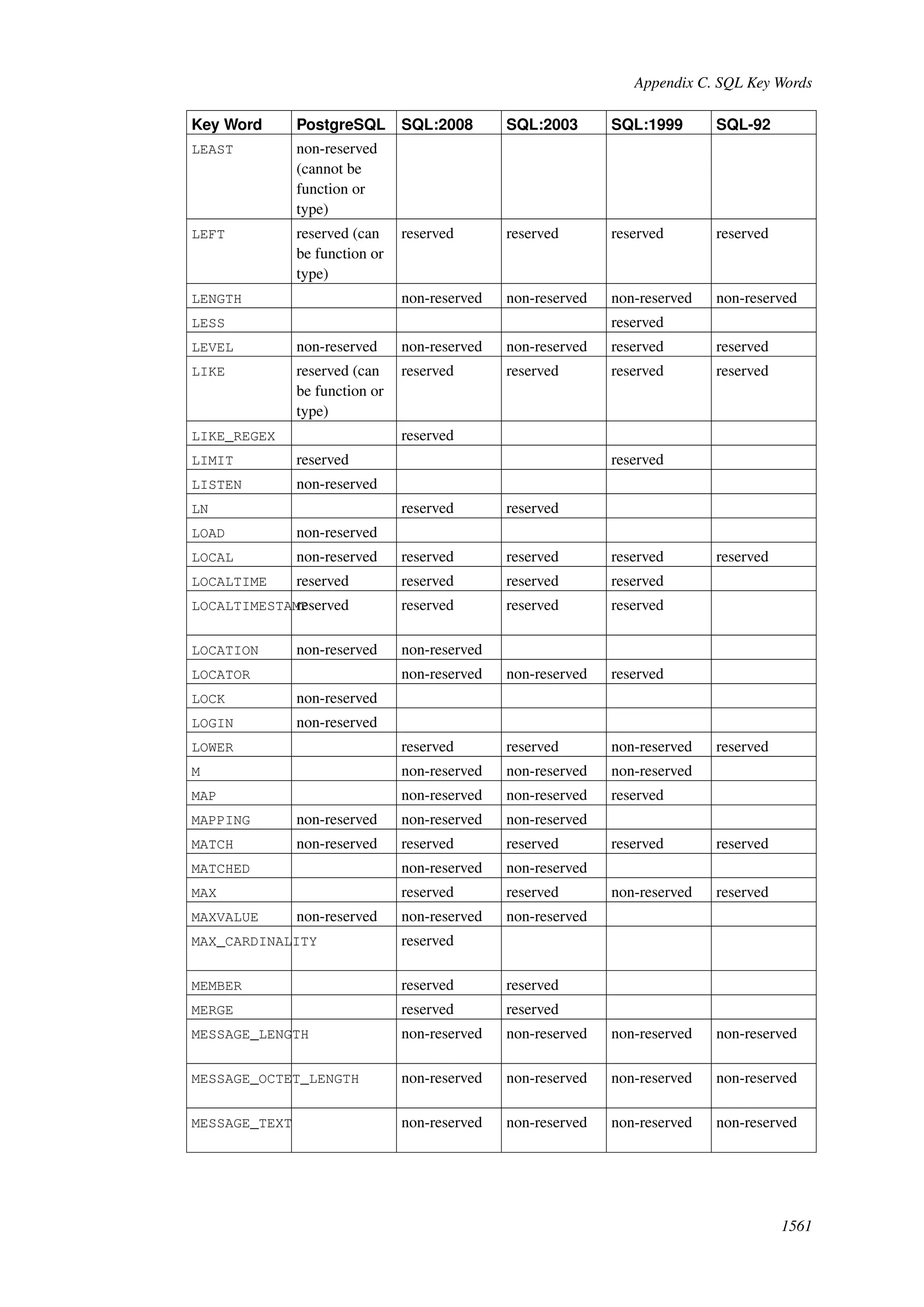
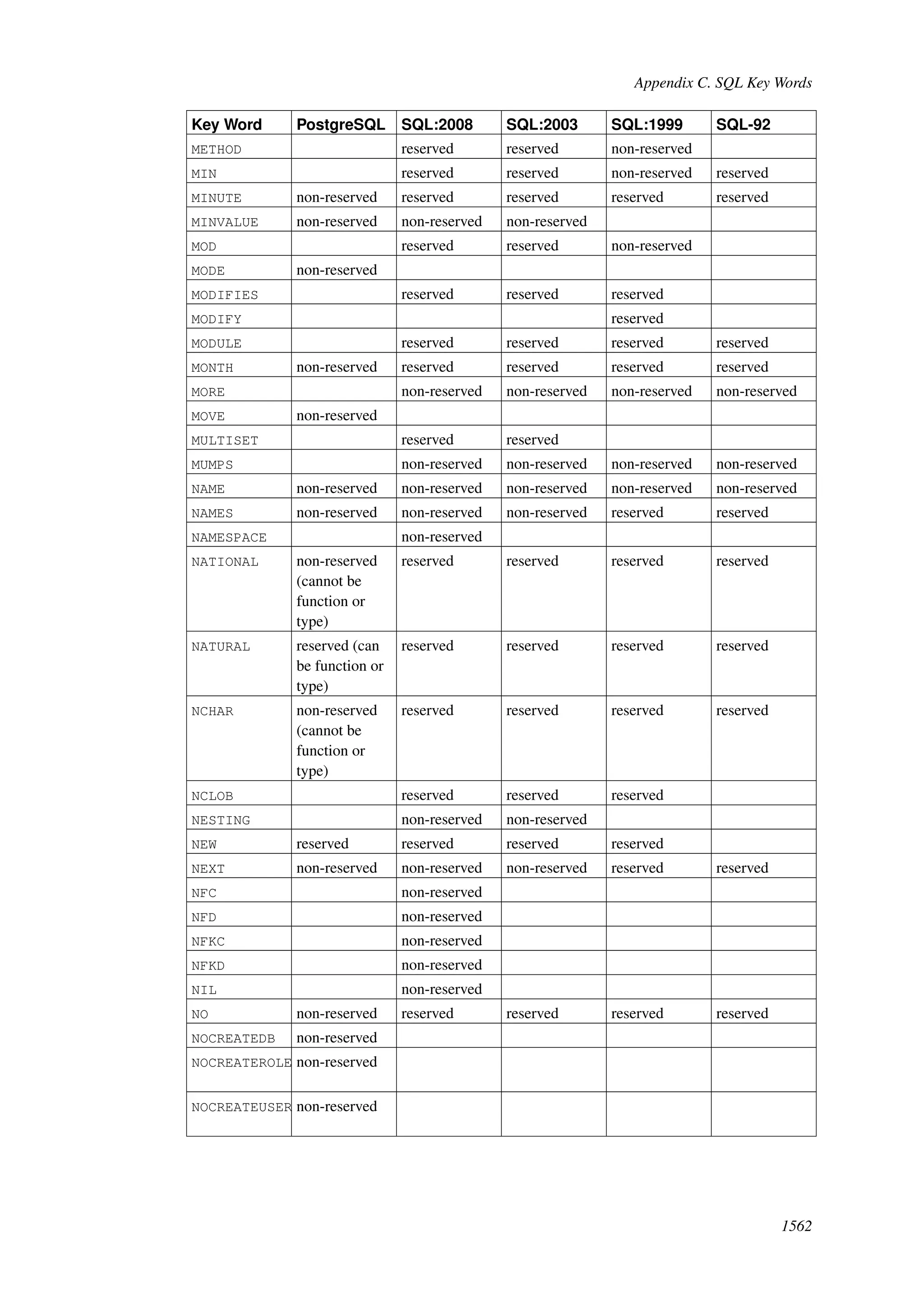
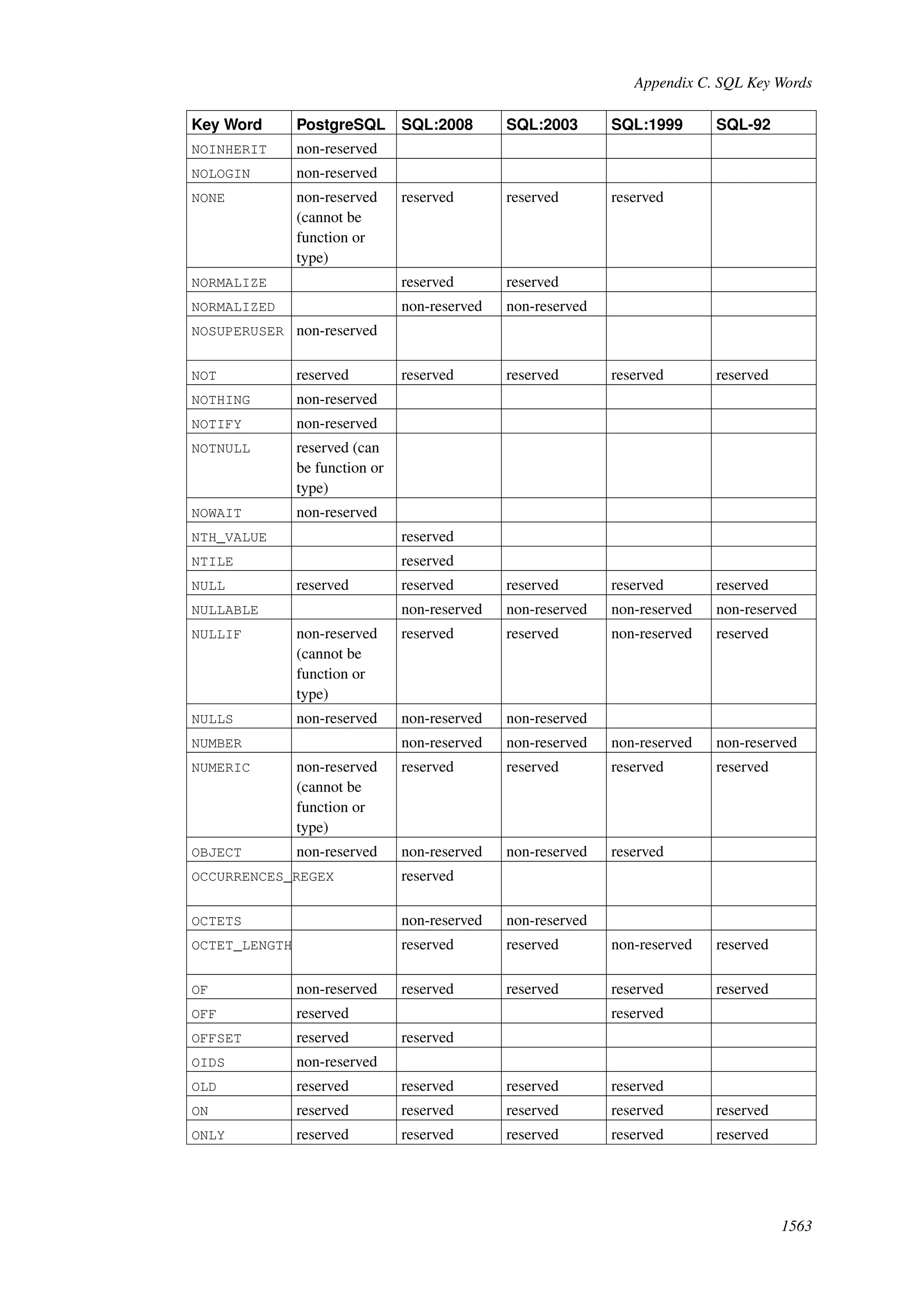
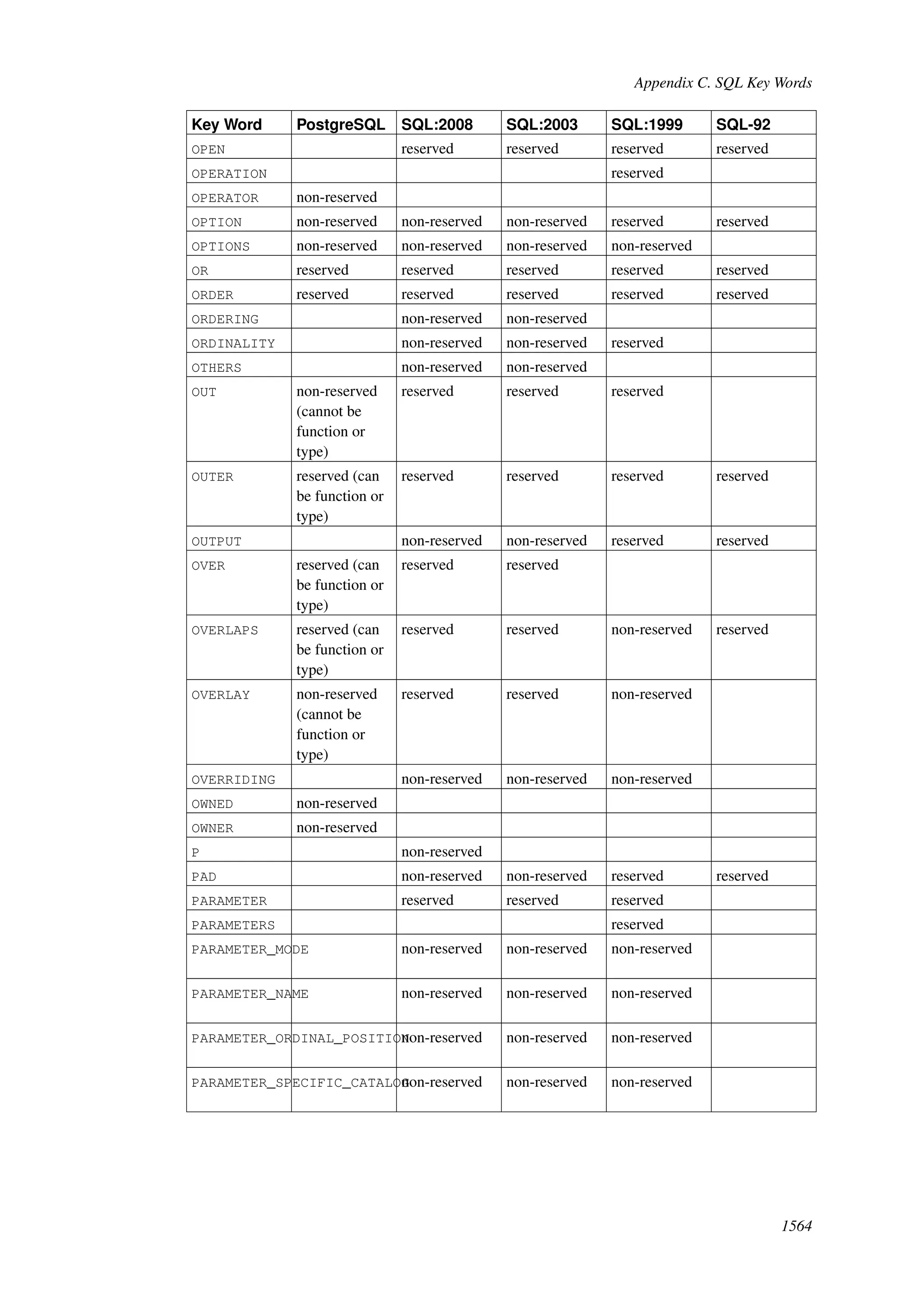
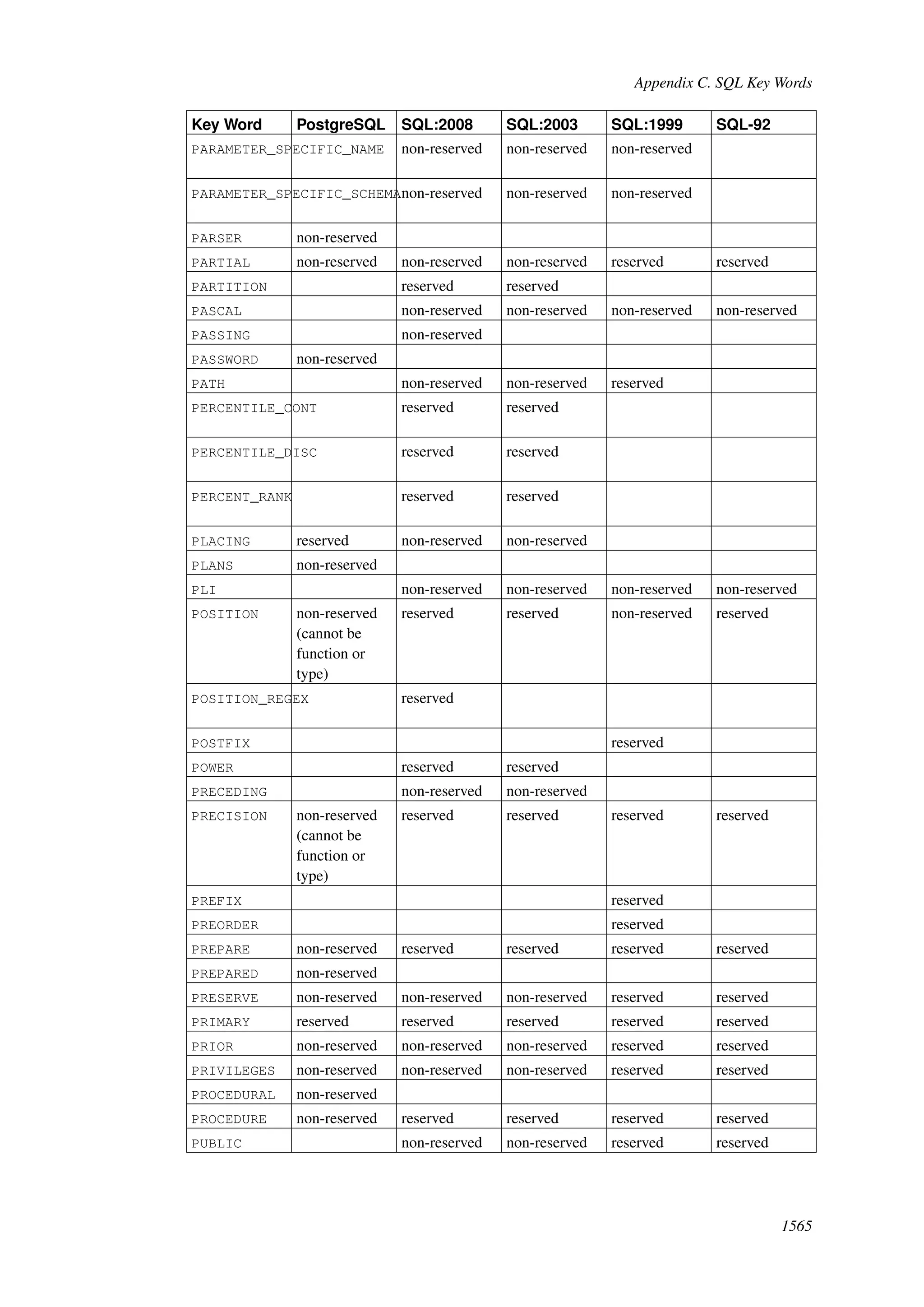
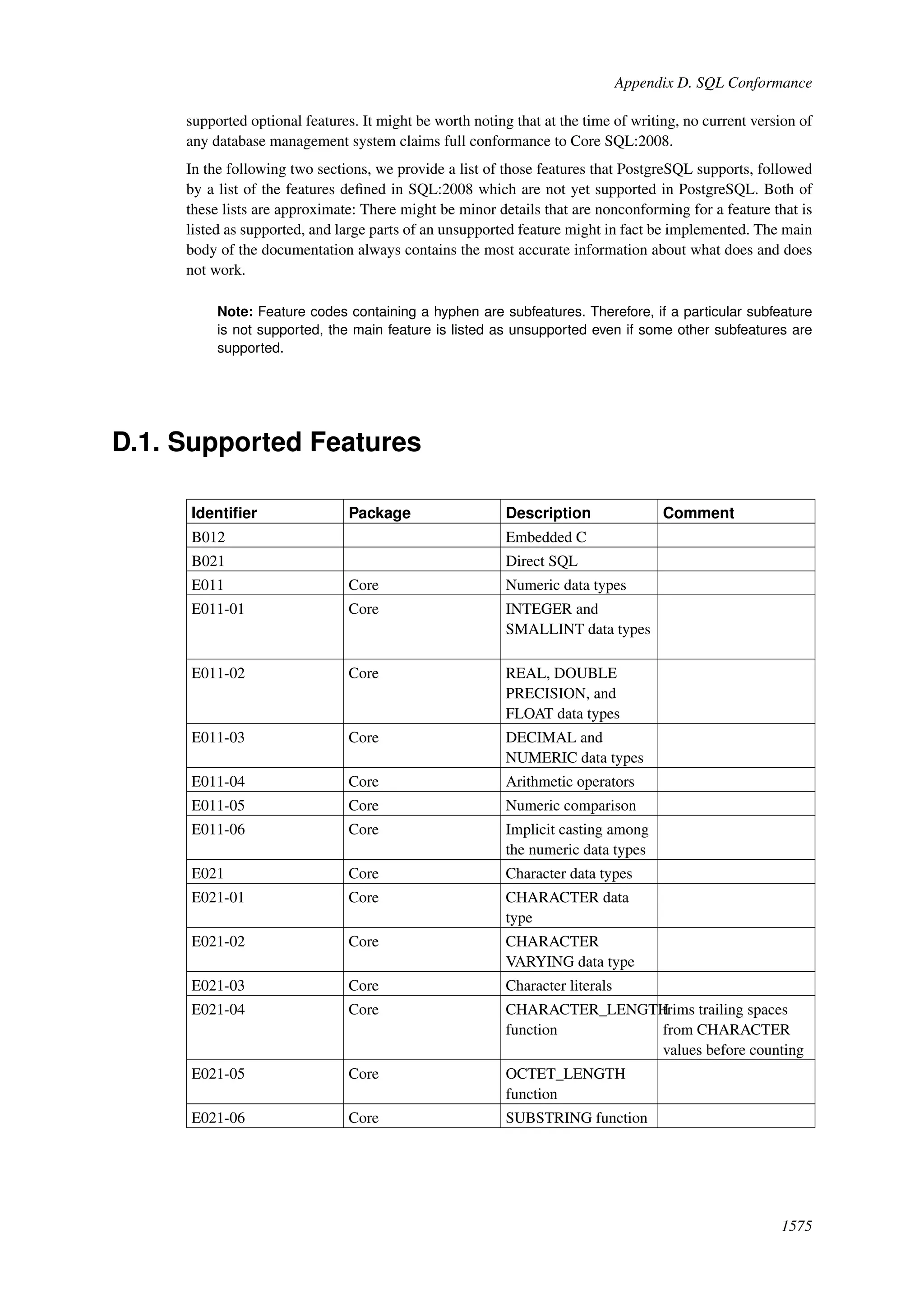
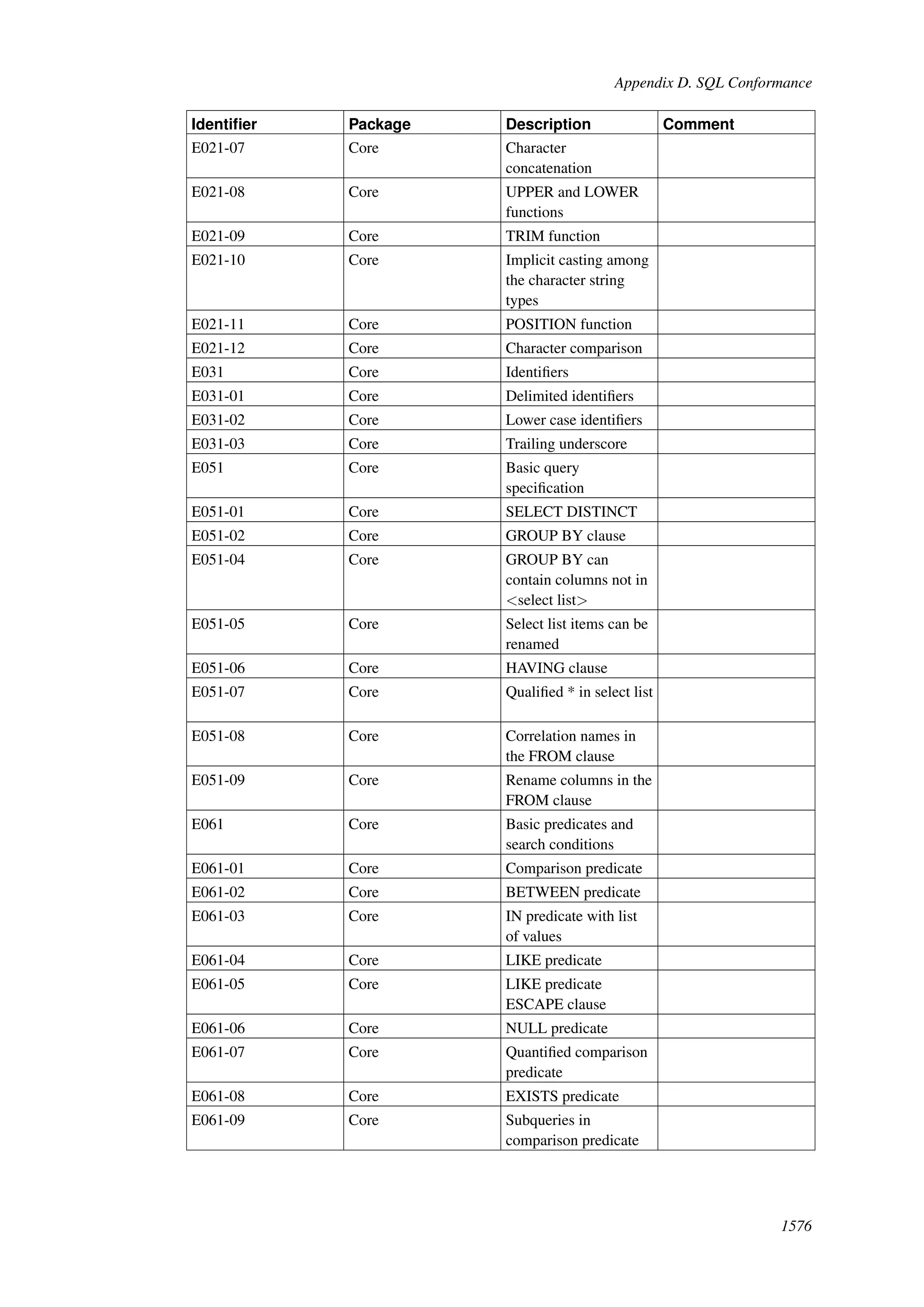
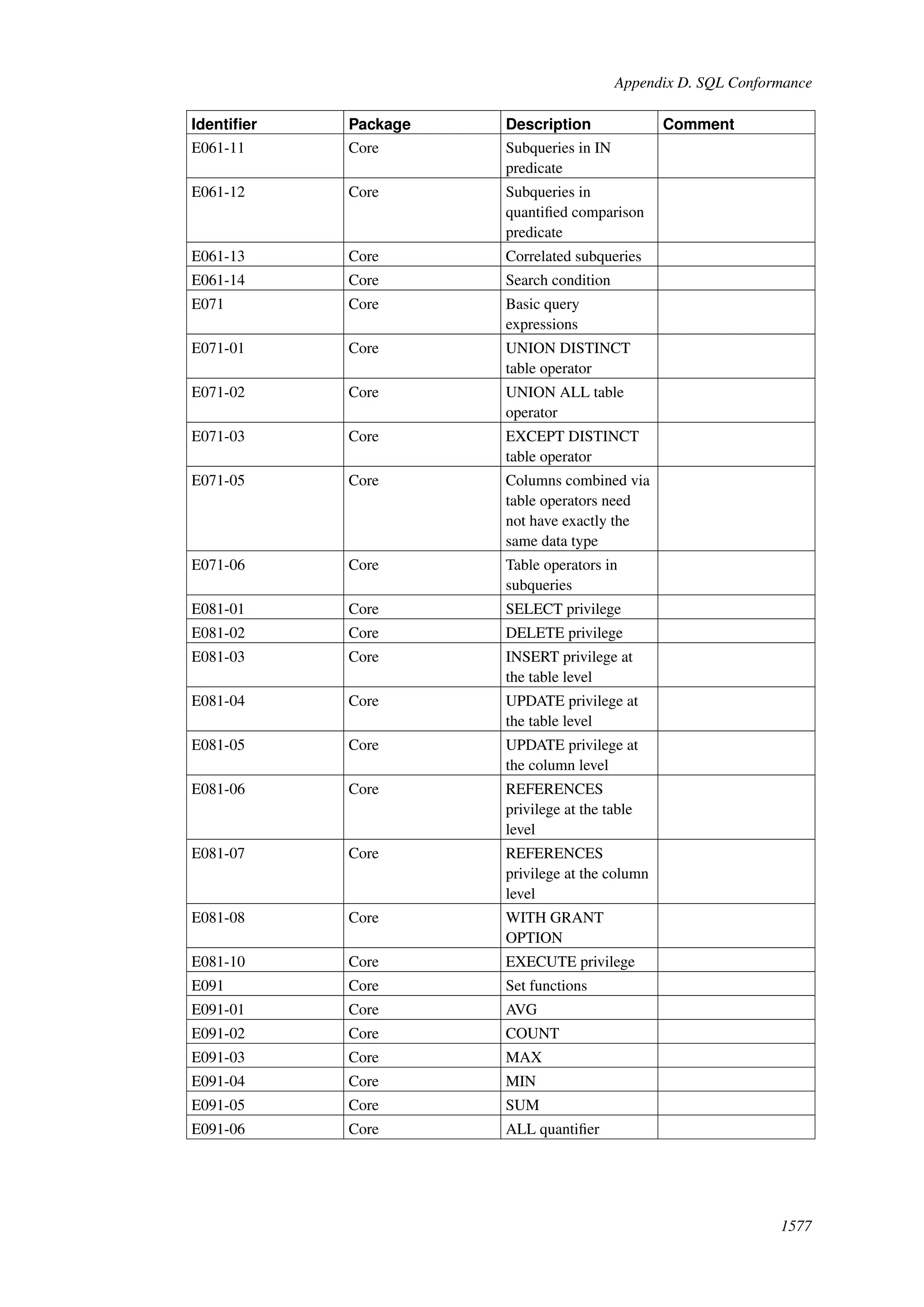
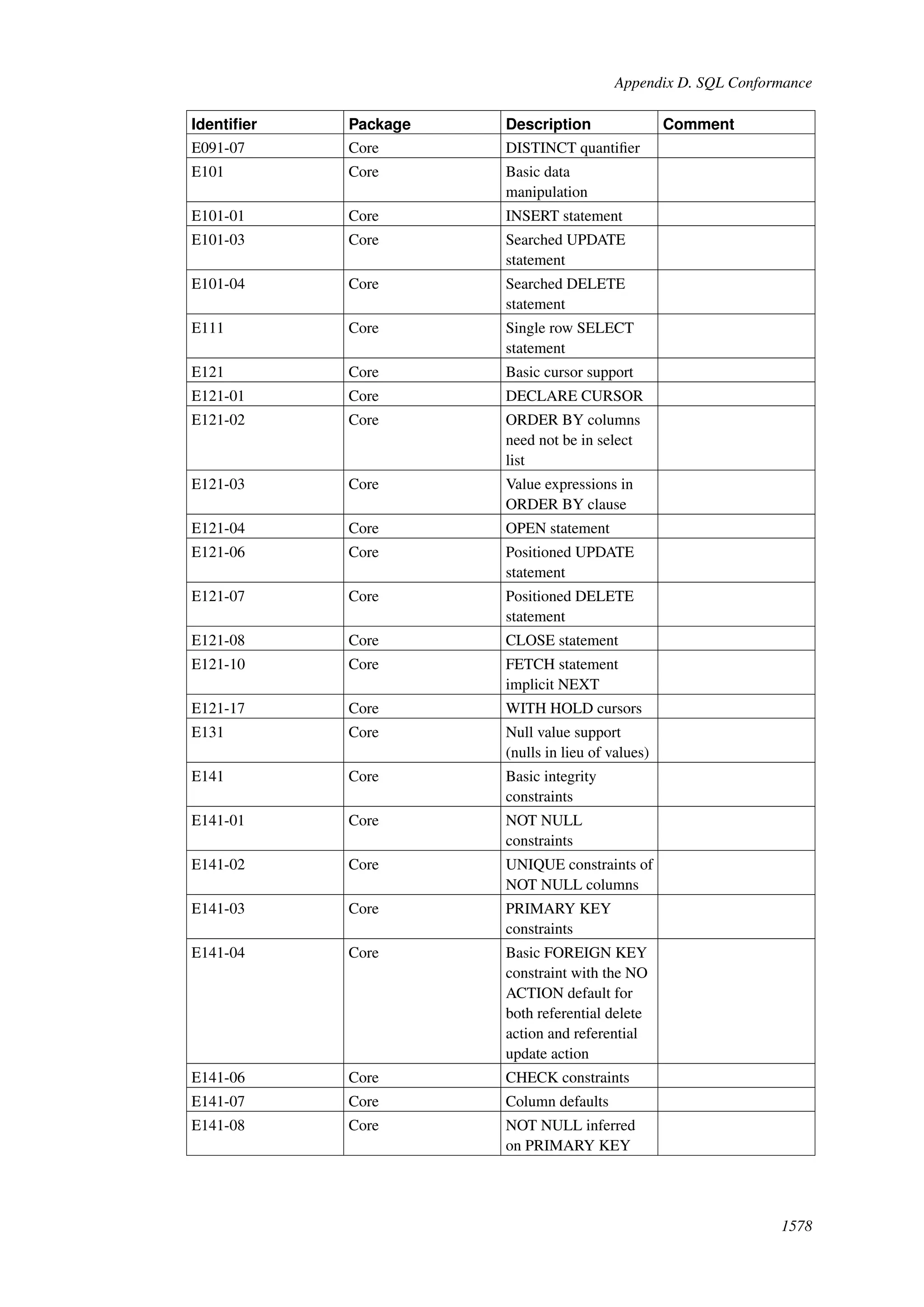
This document provides an overview and summary of the PostgreSQL 8.4.22 documentation. It discusses the license under which PostgreSQL is distributed, provides a table of contents of the manual's sections, and covers topics including SQL syntax, data types, functions, and indexes. The manual is intended to help users learn SQL and explore the advanced features of the PostgreSQL database system.


















































![Preface input or output of the computer, in particular commands, program code, and screen output, is shown in a monospaced font (example). Within such passages, italics (example) indicate placeholders; you must insert an actual value instead of the placeholder. On occasion, parts of program code are emphasized in bold face (example), if they have been added or changed since the preceding example. The following conventions are used in the synopsis of a command: brackets ([ and ]) indicate optional parts. (In the synopsis of a Tcl command, question marks (?) are used instead, as is usual in Tcl.) Braces ({ and }) and vertical lines (|) indicate that you must choose one alternative. Dots (...) mean that the preceding element can be repeated. Where it enhances the clarity, SQL commands are preceded by the prompt =>, and shell commands are preceded by the prompt $. Normally, prompts are not shown, though. An administrator is generally a person who is in charge of installing and running the server. A user could be anyone who is using, or wants to use, any part of the PostgreSQL system. These terms should not be interpreted too narrowly; this book does not have fixed presumptions about system administration procedures. 4. Further Information Besides the documentation, that is, this book, there are other resources about PostgreSQL: Wiki The PostgreSQL wiki5 contains the project’s FAQ6 (Frequently Asked Questions) list, TODO7 list, and detailed information about many more topics. Web Site The PostgreSQL web site8 carries details on the latest release and other information to make your work or play with PostgreSQL more productive. Mailing Lists The mailing lists are a good place to have your questions answered, to share experiences with other users, and to contact the developers. Consult the PostgreSQL web site for details. Yourself! PostgreSQL is an open-source project. As such, it depends on the user community for ongoing support. As you begin to use PostgreSQL, you will rely on others for help, either through the documentation or through the mailing lists. Consider contributing your knowledge back. Read the mailing lists and answer questions. If you learn something which is not in the documentation, write it up and contribute it. If you add features to the code, contribute them. 5. Bug Reporting Guidelines When you find a bug in PostgreSQL we want to hear about it. Your bug reports play an important part in making PostgreSQL more reliable because even the utmost care cannot guarantee that every part 5. http://wiki.postgresql.org 6. http://wiki.postgresql.org/wiki/Frequently_Asked_Questions 7. http://wiki.postgresql.org/wiki/Todo 8. http://www.postgresql.org li](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-51-2048.jpg)

































![Chapter 4. SQL Syntax number. For example, the string ’data’ could be written as U&’d0061t+000061’ The following less trivial example writes the Russian word “slon” (elephant) in Cyrillic letters: U&’0441043B043E043D’ If a different escape character than backslash is desired, it can be specified using the UESCAPE clause after the string, for example: U&’d!0061t!+000061’ UESCAPE ’!’ The escape character can be any single character other than a hexadecimal digit, the plus sign, a single quote, a double quote, or a whitespace character. The Unicode escape syntax works only when the server encoding is UTF8. When other server encod- ings are used, only code points in the ASCII range (up to 007F) can be specified. Also, the Unicode escape syntax for string constants only works when the configuration parameter standard_conforming_strings is turned on. This is because otherwise this syntax could confuse clients that parse the SQL statements to the point that it could lead to SQL injections and similar security issues. If the parameter is set to off, this syntax will be rejected with an error message. To include the escape character in the string literally, write it twice. 4.1.2.4. Dollar-Quoted String Constants While the standard syntax for specifying string constants is usually convenient, it can be difficult to understand when the desired string contains many single quotes or backslashes, since each of those must be doubled. To allow more readable queries in such situations, PostgreSQL provides another way, called “dollar quoting”, to write string constants. A dollar-quoted string constant consists of a dollar sign ($), an optional “tag” of zero or more characters, another dollar sign, an arbitrary sequence of characters that makes up the string content, a dollar sign, the same tag that began this dollar quote, and a dollar sign. For example, here are two different ways to specify the string “Dianne’s horse” using dollar quoting: $$Dianne’s horse$$ $SomeTag$Dianne’s horse$SomeTag$ Notice that inside the dollar-quoted string, single quotes can be used without needing to be escaped. Indeed, no characters inside a dollar-quoted string are ever escaped: the string content is always writ- ten literally. Backslashes are not special, and neither are dollar signs, unless they are part of a sequence matching the opening tag. It is possible to nest dollar-quoted string constants by choosing different tags at each nesting level. This is most commonly used in writing function definitions. For example: $function$ BEGIN RETURN ($1 ~ $q$[trnv]$q$); END; $function$ 28](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-85-2048.jpg)
![Chapter 4. SQL Syntax Here, the sequence $q$[trnv]$q$ represents a dollar-quoted literal string [trnv], which will be recognized when the function body is executed by PostgreSQL. But since the sequence does not match the outer dollar quoting delimiter $function$, it is just some more characters within the constant so far as the outer string is concerned. The tag, if any, of a dollar-quoted string follows the same rules as an unquoted identifier, except that it cannot contain a dollar sign. Tags are case sensitive, so $tag$String content$tag$ is correct, but $TAG$String content$tag$ is not. A dollar-quoted string that follows a keyword or identifier must be separated from it by whitespace; otherwise the dollar quoting delimiter would be taken as part of the preceding identifier. Dollar quoting is not part of the SQL standard, but it is often a more convenient way to write com- plicated string literals than the standard-compliant single quote syntax. It is particularly useful when representing string constants inside other constants, as is often needed in procedural function defini- tions. With single-quote syntax, each backslash in the above example would have to be written as four backslashes, which would be reduced to two backslashes in parsing the original string constant, and then to one when the inner string constant is re-parsed during function execution. 4.1.2.5. Bit-String Constants Bit-string constants look like regular string constants with a B (upper or lower case) immediately before the opening quote (no intervening whitespace), e.g., B’1001’. The only characters allowed within bit-string constants are 0 and 1. Alternatively, bit-string constants can be specified in hexadecimal notation, using a leading X (upper or lower case), e.g., X’1FF’. This notation is equivalent to a bit-string constant with four binary digits for each hexadecimal digit. Both forms of bit-string constant can be continued across lines in the same way as regular string constants. Dollar quoting cannot be used in a bit-string constant. 4.1.2.6. Numeric Constants Numeric constants are accepted in these general forms: digits digits.[digits][e[+-]digits] [digits].digits[e[+-]digits] digitse[+-]digits where digits is one or more decimal digits (0 through 9). At least one digit must be before or after the decimal point, if one is used. At least one digit must follow the exponent marker (e), if one is present. There cannot be any spaces or other characters embedded in the constant. Note that any leading plus or minus sign is not actually considered part of the constant; it is an operator applied to the constant. These are some examples of valid numeric constants: 42 3.5 4. .001 5e2 1.925e-3 29](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-86-2048.jpg)

![Chapter 4. SQL Syntax There are a few restrictions on operator names, however: • -- and /* cannot appear anywhere in an operator name, since they will be taken as the start of a comment. • A multiple-character operator name cannot end in + or -, unless the name also contains at least one of these characters: ~ ! @ # % ^ & | ‘ ? For example, @- is an allowed operator name, but *- is not. This restriction allows PostgreSQL to parse SQL-compliant queries without requiring spaces between tokens. When working with non-SQL-standard operator names, you will usually need to separate adjacent operators with spaces to avoid ambiguity. For example, if you have defined a left unary operator named @, you cannot write X*@Y; you must write X* @Y to ensure that PostgreSQL reads it as two operator names not one. 4.1.4. Special Characters Some characters that are not alphanumeric have a special meaning that is different from being an operator. Details on the usage can be found at the location where the respective syntax element is described. This section only exists to advise the existence and summarize the purposes of these char- acters. • A dollar sign ($) followed by digits is used to represent a positional parameter in the body of a function definition or a prepared statement. In other contexts the dollar sign can be part of an identifier or a dollar-quoted string constant. • Parentheses (()) have their usual meaning to group expressions and enforce precedence. In some cases parentheses are required as part of the fixed syntax of a particular SQL command. • Brackets ([]) are used to select the elements of an array. See Section 8.14 for more information on arrays. • Commas (,) are used in some syntactical constructs to separate the elements of a list. • The semicolon (;) terminates an SQL command. It cannot appear anywhere within a command, except within a string constant or quoted identifier. • The colon (:) is used to select “slices” from arrays. (See Section 8.14.) In certain SQL dialects (such as Embedded SQL), the colon is used to prefix variable names. • The asterisk (*) is used in some contexts to denote all the fields of a table row or composite value. It also has a special meaning when used as the argument of an aggregate function, namely that the aggregate does not require any explicit parameter. • The period (.) is used in numeric constants, and to separate schema, table, and column names. 31](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-88-2048.jpg)
![Chapter 4. SQL Syntax 4.1.5. Comments A comment is a sequence of characters beginning with double dashes and extending to the end of the line, e.g.: -- This is a standard SQL comment Alternatively, C-style block comments can be used: /* multiline comment * with nesting: /* nested block comment */ */ where the comment begins with /* and extends to the matching occurrence of */. These block com- ments nest, as specified in the SQL standard but unlike C, so that one can comment out larger blocks of code that might contain existing block comments. A comment is removed from the input stream before further syntax analysis and is effectively replaced by whitespace. 4.1.6. Lexical Precedence Table 4-2 shows the precedence and associativity of the operators in PostgreSQL. Most operators have the same precedence and are left-associative. The precedence and associativity of the operators is hard-wired into the parser. This can lead to non-intuitive behavior; for example the Boolean operators < and > have a different precedence than the Boolean operators <= and >=. Also, you will sometimes need to add parentheses when using combinations of binary and unary operators. For instance: SELECT 5 ! - 6; will be parsed as: SELECT 5 ! (- 6); because the parser has no idea — until it is too late — that ! is defined as a postfix operator, not an infix one. To get the desired behavior in this case, you must write: SELECT (5 !) - 6; This is the price one pays for extensibility. Table 4-2. Operator Precedence (decreasing) Operator/Element Associativity Description . left table/column name separator :: left PostgreSQL-style typecast [ ] left array element selection - right unary minus ^ left exponentiation * / % left multiplication, division, modulo + - left addition, subtraction 32](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-89-2048.jpg)


![Chapter 4. SQL Syntax 4.2.3. Subscripts If an expression yields a value of an array type, then a specific element of the array value can be extracted by writing expression[subscript] or multiple adjacent elements (an “array slice”) can be extracted by writing expression[lower_subscript:upper_subscript] (Here, the brackets [ ] are meant to appear literally.) Each subscript is itself an expression, which must yield an integer value. In general the array expression must be parenthesized, but the parentheses can be omitted when the expression to be subscripted is just a column reference or positional parameter. Also, multiple subscripts can be concatenated when the original array is multidimensional. For example: mytable.arraycolumn[4] mytable.two_d_column[17][34] $1[10:42] (arrayfunction(a,b))[42] The parentheses in the last example are required. See Section 8.14 for more about arrays. 4.2.4. Field Selection If an expression yields a value of a composite type (row type), then a specific field of the row can be extracted by writing expression.fieldname In general the row expression must be parenthesized, but the parentheses can be omitted when the expression to be selected from is just a table reference or positional parameter. For example: mytable.mycolumn $1.somecolumn (rowfunction(a,b)).col3 (Thus, a qualified column reference is actually just a special case of the field selection syntax.) An important special case is extracting a field from a table column that is of a composite type: (compositecol).somefield (mytable.compositecol).somefield The parentheses are required here to show that compositecol is a column name not a table name, or that mytable is a table name not a schema name in the second case. 4.2.5. Operator Invocations There are three possible syntaxes for an operator invocation: expression operator expression (binary infix operator) 35](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-92-2048.jpg)
![Chapter 4. SQL Syntax operator expression (unary prefix operator) expression operator (unary postfix operator) where the operator token follows the syntax rules of Section 4.1.3, or is one of the key words AND, OR, and NOT, or is a qualified operator name in the form: OPERATOR(schema.operatorname) Which particular operators exist and whether they are unary or binary depends on what operators have been defined by the system or the user. Chapter 9 describes the built-in operators. 4.2.6. Function Calls The syntax for a function call is the name of a function (possibly qualified with a schema name), followed by its argument list enclosed in parentheses: function_name ([expression [, expression ... ]] ) For example, the following computes the square root of 2: sqrt(2) The list of built-in functions is in Chapter 9. Other functions can be added by the user. 4.2.7. Aggregate Expressions An aggregate expression represents the application of an aggregate function across the rows selected by a query. An aggregate function reduces multiple inputs to a single output value, such as the sum or average of the inputs. The syntax of an aggregate expression is one of the following: aggregate_name (expression [ , ... ] ) aggregate_name (ALL expression [ , ... ] ) aggregate_name (DISTINCT expression) aggregate_name ( * ) where aggregate_name is a previously defined aggregate (possibly qualified with a schema name), and expression is any value expression that does not itself contain an aggregate expression or a window function call. The first form of aggregate expression invokes the aggregate across all input rows for which the given expression(s) yield non-null values. (Actually, it is up to the aggregate function whether to ignore null values or not — but all the standard ones do.) The second form is the same as the first, since ALL is the default. The third form invokes the aggregate for all distinct non-null values of the expressions found in the input rows. The last form invokes the aggregate once for each input row regardless of null or non-null values; since no particular input value is specified, it is generally only useful for the count(*) aggregate function. For example, count(*) yields the total number of input rows; count(f1) yields the number of input rows in which f1 is non-null; count(distinct f1) yields the number of distinct non-null values of f1. 36](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-93-2048.jpg)
![Chapter 4. SQL Syntax The predefined aggregate functions are described in Section 9.18. Other aggregate functions can be added by the user. An aggregate expression can only appear in the result list or HAVING clause of a SELECT command. It is forbidden in other clauses, such as WHERE, because those clauses are logically evaluated before the results of aggregates are formed. When an aggregate expression appears in a subquery (see Section 4.2.10 and Section 9.20), the aggre- gate is normally evaluated over the rows of the subquery. But an exception occurs if the aggregate’s arguments contain only outer-level variables: the aggregate then belongs to the nearest such outer level, and is evaluated over the rows of that query. The aggregate expression as a whole is then an outer reference for the subquery it appears in, and acts as a constant over any one evaluation of that subquery. The restriction about appearing only in the result list or HAVING clause applies with respect to the query level that the aggregate belongs to. Note: PostgreSQL currently does not support DISTINCT with more than one input expression. 4.2.8. Window Function Calls A window function call represents the application of an aggregate-like function over some portion of the rows selected by a query. Unlike regular aggregate function calls, this is not tied to grouping of the selected rows into a single output row — each row remains separate in the query output. However the window function is able to scan all the rows that would be part of the current row’s group according to the grouping specification (PARTITION BY list) of the window function call. The syntax of a window function call is one of the following: function_name ([expression [, expression ... ]]) OVER window_name function_name ([expression [, expression ... ]]) OVER ( window_definition ) function_name ( * ) OVER window_name function_name ( * ) OVER ( window_definition ) where window_definition has the syntax [ existing_window_name ] [ PARTITION BY expression [, ...] ] [ ORDER BY expression [ ASC | DESC | USING operator ] [ NULLS { FIRST | LAST } ] [, ...] ] [ frame_clause ] and the optional frame_clause can be one of RANGE UNBOUNDED PRECEDING RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING ROWS UNBOUNDED PRECEDING ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING Here, expression represents any value expression that does not itself contain window function calls. The PARTITION BY and ORDER BY lists have essentially the same syntax and semantics as GROUP BY and ORDER BY clauses of the whole query, except that their expressions are always just expressions and cannot be output-column names or numbers. window_name is a reference to a named window specification defined in the query’s WINDOW clause. Alternatively, a full window_definition can be given within parentheses, using the same syntax as for defining a named window in the WINDOW 37](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-94-2048.jpg)

![Chapter 4. SQL Syntax interval, time, and timestamp can only be used in this fashion if they are double-quoted, because of syntactic conflicts. Therefore, the use of the function-like cast syntax leads to inconsistencies and should probably be avoided. Note: The function-like syntax is in fact just a function call. When one of the two standard cast syntaxes is used to do a run-time conversion, it will internally invoke a registered function to perform the conversion. By convention, these conversion functions have the same name as their output type, and thus the “function-like syntax” is nothing more than a direct invocation of the underlying conversion function. Obviously, this is not something that a portable application should rely on. For further details see CREATE CAST. 4.2.10. Scalar Subqueries A scalar subquery is an ordinary SELECT query in parentheses that returns exactly one row with one column. (See Chapter 7 for information about writing queries.) The SELECT query is executed and the single returned value is used in the surrounding value expression. It is an error to use a query that returns more than one row or more than one column as a scalar subquery. (But if, during a particular execution, the subquery returns no rows, there is no error; the scalar result is taken to be null.) The subquery can refer to variables from the surrounding query, which will act as constants during any one evaluation of the subquery. See also Section 9.20 for other expressions involving subqueries. For example, the following finds the largest city population in each state: SELECT name, (SELECT max(pop) FROM cities WHERE cities.state = states.name) FROM states; 4.2.11. Array Constructors An array constructor is an expression that builds an array value using values for its member elements. A simple array constructor consists of the key word ARRAY, a left square bracket [, a list of expressions (separated by commas) for the array element values, and finally a right square bracket ]. For example: SELECT ARRAY[1,2,3+4]; array --------- {1,2,7} (1 row) By default, the array element type is the common type of the member expressions, determined using the same rules as for UNION or CASE constructs (see Section 10.5). You can override this by explicitly casting the array constructor to the desired type, for example: SELECT ARRAY[1,2,22.7]::integer[]; array ---------- {1,2,23} (1 row) 39](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-96-2048.jpg)
![Chapter 4. SQL Syntax This has the same effect as casting each expression to the array element type individually. For more on casting, see Section 4.2.9. Multidimensional array values can be built by nesting array constructors. In the inner constructors, the key word ARRAY can be omitted. For example, these produce the same result: SELECT ARRAY[ARRAY[1,2], ARRAY[3,4]]; array --------------- {{1,2},{3,4}} (1 row) SELECT ARRAY[[1,2],[3,4]]; array --------------- {{1,2},{3,4}} (1 row) Since multidimensional arrays must be rectangular, inner constructors at the same level must pro- duce sub-arrays of identical dimensions. Any cast applied to the outer ARRAY constructor propagates automatically to all the inner constructors. Multidimensional array constructor elements can be anything yielding an array of the proper kind, not only a sub-ARRAY construct. For example: CREATE TABLE arr(f1 int[], f2 int[]); INSERT INTO arr VALUES (ARRAY[[1,2],[3,4]], ARRAY[[5,6],[7,8]]); SELECT ARRAY[f1, f2, ’{{9,10},{11,12}}’::int[]] FROM arr; array ------------------------------------------------ {{{1,2},{3,4}},{{5,6},{7,8}},{{9,10},{11,12}}} (1 row) You can construct an empty array, but since it’s impossible to have an array with no type, you must explicitly cast your empty array to the desired type. For example: SELECT ARRAY[]::integer[]; array ------- {} (1 row) It is also possible to construct an array from the results of a subquery. In this form, the array construc- tor is written with the key word ARRAY followed by a parenthesized (not bracketed) subquery. For example: SELECT ARRAY(SELECT oid FROM pg_proc WHERE proname LIKE ’bytea%’); ?column? ------------------------------------------------------------- {2011,1954,1948,1952,1951,1244,1950,2005,1949,1953,2006,31} (1 row) 40](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-97-2048.jpg)





































![Chapter 7. Queries The previous chapters explained how to create tables, how to fill them with data, and how to manipu- late that data. Now we finally discuss how to retrieve the data from the database. 7.1. Overview The process of retrieving or the command to retrieve data from a database is called a query. In SQL the SELECT command is used to specify queries. The general syntax of the SELECT command is [WITH with_queries] SELECT select_list FROM table_expression [sort_specification] The following sections describe the details of the select list, the table expression, and the sort specifi- cation. WITH queries are treated last since they are an advanced feature. A simple kind of query has the form: SELECT * FROM table1; Assuming that there is a table called table1, this command would retrieve all rows and all columns from table1. (The method of retrieval depends on the client application. For example, the psql program will display an ASCII-art table on the screen, while client libraries will offer functions to extract individual values from the query result.) The select list specification * means all columns that the table expression happens to provide. A select list can also select a subset of the available columns or make calculations using the columns. For example, if table1 has columns named a, b, and c (and perhaps others) you can make the following query: SELECT a, b + c FROM table1; (assuming that b and c are of a numerical data type). See Section 7.3 for more details. FROM table1 is a simple kind of table expression: it reads just one table. In general, table expressions can be complex constructs of base tables, joins, and subqueries. But you can also omit the table expression entirely and use the SELECT command as a calculator: SELECT 3 * 4; This is more useful if the expressions in the select list return varying results. For example, you could call a function this way: SELECT random(); 7.2. Table Expressions A table expression computes a table. The table expression contains a FROM clause that is optionally followed by WHERE, GROUP BY, and HAVING clauses. Trivial table expressions simply refer to a table on disk, a so-called base table, but more complex expressions can be used to modify or combine base tables in various ways. The optional WHERE, GROUP BY, and HAVING clauses in the table expression specify a pipeline of successive transformations performed on the table derived in the FROM clause. All these transforma- 78](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-135-2048.jpg)
![Chapter 7. Queries tions produce a virtual table that provides the rows that are passed to the select list to compute the output rows of the query. 7.2.1. The FROM Clause The FROM Clause derives a table from one or more other tables given in a comma-separated table reference list. FROM table_reference [, table_reference [, ...]] A table reference can be a table name (possibly schema-qualified), or a derived table such as a sub- query, a table join, or complex combinations of these. If more than one table reference is listed in the FROM clause they are cross-joined (see below) to form the intermediate virtual table that can then be subject to transformations by the WHERE, GROUP BY, and HAVING clauses and is finally the result of the overall table expression. When a table reference names a table that is the parent of a table inheritance hierarchy, the table reference produces rows of not only that table but all of its descendant tables, unless the key word ONLY precedes the table name. However, the reference produces only the columns that appear in the named table — any columns added in subtables are ignored. Instead of writing ONLY before the table name, you can write * after the table name to explicitly specify that descendant tables are included. Writing * is not necessary since that behavior is the default (unless you have changed the setting of the sql_inheritance configuration option). However writing * might be useful to emphasize that additional tables will be searched. 7.2.1.1. Joined Tables A joined table is a table derived from two other (real or derived) tables according to the rules of the particular join type. Inner, outer, and cross-joins are available. Join Types Cross join T1 CROSS JOIN T2 For every possible combination of rows from T1 and T2 (i.e., a Cartesian product), the joined table will contain a row consisting of all columns in T1 followed by all columns in T2. If the tables have N and M rows respectively, the joined table will have N * M rows. FROM T1 CROSS JOIN T2 is equivalent to FROM T1, T2. It is also equivalent to FROM T1 INNER JOIN T2 ON TRUE (see below). Qualified joins T1 { [INNER] | { LEFT | RIGHT | FULL } [OUTER] } JOIN T2 ON boolean_expression T1 { [INNER] | { LEFT | RIGHT | FULL } [OUTER] } JOIN T2 USING ( join column list ) T1 NATURAL { [INNER] | { LEFT | RIGHT | FULL } [OUTER] } JOIN T2 The words INNER and OUTER are optional in all forms. INNER is the default; LEFT, RIGHT, and FULL imply an outer join. The join condition is specified in the ON or USING clause, or implicitly by the word NATURAL. The join condition determines which rows from the two source tables are considered to “match”, as explained in detail below. 79](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-136-2048.jpg)



![Chapter 7. Queries SELECT * FROM some_very_long_table_name s JOIN another_fairly_long_name a ON s.id = a.num The alias becomes the new name of the table reference for the current query — it is no longer possible to refer to the table by the original name. Thus: SELECT * FROM my_table AS m WHERE my_table.a > 5; is not valid according to the SQL standard. In PostgreSQL this will draw an error, assuming the add_missing_from configuration variable is off (as it is by default). If it is on, an implicit table reference will be added to the FROM clause, so the query is processed as if it were written as: SELECT * FROM my_table AS m, my_table AS my_table WHERE my_table.a > 5; That will result in a cross join, which is usually not what you want. Table aliases are mainly for notational convenience, but it is necessary to use them when joining a table to itself, e.g.: SELECT * FROM people AS mother JOIN people AS child ON mother.id = child.mother_id; Additionally, an alias is required if the table reference is a subquery (see Section 7.2.1.3). Parentheses are used to resolve ambiguities. In the following example, the first statement assigns the alias b to the second instance of my_table, but the second statement assigns the alias to the result of the join: SELECT * FROM my_table AS a CROSS JOIN my_table AS b ... SELECT * FROM (my_table AS a CROSS JOIN my_table) AS b ... Another form of table aliasing gives temporary names to the columns of the table, as well as the table itself: FROM table_reference [AS] alias ( column1 [, column2 [, ...]] ) If fewer column aliases are specified than the actual table has columns, the remaining columns are not renamed. This syntax is especially useful for self-joins or subqueries. When an alias is applied to the output of a JOIN clause, the alias hides the original name(s) within the JOIN. For example: SELECT a.* FROM my_table AS a JOIN your_table AS b ON ... is valid SQL, but: SELECT a.* FROM (my_table AS a JOIN your_table AS b ON ...) AS c is not valid; the table alias a is not visible outside the alias c. 7.2.1.3. Subqueries Subqueries specifying a derived table must be enclosed in parentheses and must be assigned a table alias name. (See Section 7.2.1.2.) For example: FROM (SELECT * FROM table1) AS alias_name 83](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-140-2048.jpg)


![Chapter 7. Queries SELECT ... FROM fdt WHERE EXISTS (SELECT c1 FROM t2 WHERE c2 > fdt.c1) fdt is the table derived in the FROM clause. Rows that do not meet the search condition of the WHERE clause are eliminated from fdt. Notice the use of scalar subqueries as value expressions. Just like any other query, the subqueries can employ complex table expressions. Notice also how fdt is referenced in the subqueries. Qualifying c1 as fdt.c1 is only necessary if c1 is also the name of a column in the derived input table of the subquery. But qualifying the column name adds clarity even when it is not needed. This example shows how the column naming scope of an outer query extends into its inner queries. 7.2.3. The GROUP BY and HAVING Clauses After passing the WHERE filter, the derived input table might be subject to grouping, using the GROUP BY clause, and elimination of group rows using the HAVING clause. SELECT select_list FROM ... [WHERE ...] GROUP BY grouping_column_reference [, grouping_column_reference]... The GROUP BY Clause is used to group together those rows in a table that have the same values in all the columns listed. The order in which the columns are listed does not matter. The effect is to combine each set of rows having common values into one group row that represents all rows in the group. This is done to eliminate redundancy in the output and/or compute aggregates that apply to these groups. For instance: => SELECT * FROM test1; x | y ---+--- a | 3 c | 2 b | 5 a | 1 (4 rows) => SELECT x FROM test1 GROUP BY x; x --- a b c (3 rows) In the second query, we could not have written SELECT * FROM test1 GROUP BY x, because there is no single value for the column y that could be associated with each group. The grouped- by columns can be referenced in the select list since they have a single value in each group. In general, if a table is grouped, columns that are not listed in GROUP BY cannot be referenced except in aggregate expressions. An example with aggregate expressions is: => SELECT x, sum(y) FROM test1 GROUP BY x; x | sum ---+----- a | 4 86](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-143-2048.jpg)
![Chapter 7. Queries b | 5 c | 2 (3 rows) Here sum is an aggregate function that computes a single value over the entire group. More informa- tion about the available aggregate functions can be found in Section 9.18. Tip: Grouping without aggregate expressions effectively calculates the set of distinct values in a column. This can also be achieved using the DISTINCT clause (see Section 7.3.3). Here is another example: it calculates the total sales for each product (rather than the total sales of all products): SELECT product_id, p.name, (sum(s.units) * p.price) AS sales FROM products p LEFT JOIN sales s USING (product_id) GROUP BY product_id, p.name, p.price; In this example, the columns product_id, p.name, and p.price must be in the GROUP BY clause since they are referenced in the query select list. (Depending on how the products table is set up, name and price might be fully dependent on the product ID, so the additional groupings could theoretically be unnecessary, though this is not implemented.) The column s.units does not have to be in the GROUP BY list since it is only used in an aggregate expression (sum(...)), which represents the sales of a product. For each product, the query returns a summary row about all sales of the product. In strict SQL, GROUP BY can only group by columns of the source table but PostgreSQL extends this to also allow GROUP BY to group by columns in the select list. Grouping by value expressions instead of simple column names is also allowed. If a table has been grouped using GROUP BY, but only certain groups are of interest, the HAVING clause can be used, much like a WHERE clause, to eliminate groups from the result. The syntax is: SELECT select_list FROM ... [WHERE ...] GROUP BY ... HAVING boolean_expression Expressions in the HAVING clause can refer both to grouped expressions and to ungrouped expressions (which necessarily involve an aggregate function). Example: => SELECT x, sum(y) FROM test1 GROUP BY x HAVING sum(y) > 3; x | sum ---+----- a | 4 b | 5 (2 rows) => SELECT x, sum(y) FROM test1 GROUP BY x HAVING x < ’c’; x | sum ---+----- a | 4 b | 5 (2 rows) Again, a more realistic example: SELECT product_id, p.name, (sum(s.units) * (p.price - p.cost)) AS profit 87](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-144-2048.jpg)


![Chapter 7. Queries 7.3.3. DISTINCT After the select list has been processed, the result table can optionally be subject to the elimination of duplicate rows. The DISTINCT key word is written directly after SELECT to specify this: SELECT DISTINCT select_list ... (Instead of DISTINCT the key word ALL can be used to specify the default behavior of retaining all rows.) Obviously, two rows are considered distinct if they differ in at least one column value. Null values are considered equal in this comparison. Alternatively, an arbitrary expression can determine what rows are to be considered distinct: SELECT DISTINCT ON (expression [, expression ...]) select_list ... Here expression is an arbitrary value expression that is evaluated for all rows. A set of rows for which all the expressions are equal are considered duplicates, and only the first row of the set is kept in the output. Note that the “first row” of a set is unpredictable unless the query is sorted on enough columns to guarantee a unique ordering of the rows arriving at the DISTINCT filter. (DISTINCT ON processing occurs after ORDER BY sorting.) The DISTINCT ON clause is not part of the SQL standard and is sometimes considered bad style because of the potentially indeterminate nature of its results. With judicious use of GROUP BY and subqueries in FROM, this construct can be avoided, but it is often the most convenient alternative. 7.4. Combining Queries The results of two queries can be combined using the set operations union, intersection, and differ- ence. The syntax is query1 UNION [ALL] query2 query1 INTERSECT [ALL] query2 query1 EXCEPT [ALL] query2 query1 and query2 are queries that can use any of the features discussed up to this point. Set operations can also be nested and chained, for example query1 UNION query2 UNION query3 which is executed as: (query1 UNION query2) UNION query3 UNION effectively appends the result of query2 to the result of query1 (although there is no guaran- tee that this is the order in which the rows are actually returned). Furthermore, it eliminates duplicate rows from its result, in the same way as DISTINCT, unless UNION ALL is used. INTERSECT returns all rows that are both in the result of query1 and in the result of query2. Dupli- cate rows are eliminated unless INTERSECT ALL is used. 90](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-147-2048.jpg)
![Chapter 7. Queries EXCEPT returns all rows that are in the result of query1 but not in the result of query2. (This is some- times called the difference between two queries.) Again, duplicates are eliminated unless EXCEPT ALL is used. In order to calculate the union, intersection, or difference of two queries, the two queries must be “union compatible”, which means that they return the same number of columns and the corresponding columns have compatible data types, as described in Section 10.5. 7.5. Sorting Rows After a query has produced an output table (after the select list has been processed) it can optionally be sorted. If sorting is not chosen, the rows will be returned in an unspecified order. The actual order in that case will depend on the scan and join plan types and the order on disk, but it must not be relied on. A particular output ordering can only be guaranteed if the sort step is explicitly chosen. The ORDER BY clause specifies the sort order: SELECT select_list FROM table_expression ORDER BY sort_expression1 [ASC | DESC] [NULLS { FIRST | LAST }] [, sort_expression2 [ASC | DESC] [NULLS { FIRST | LAST }] ...] The sort expression(s) can be any expression that would be valid in the query’s select list. An example is: SELECT a, b FROM table1 ORDER BY a + b, c; When more than one expression is specified, the later values are used to sort rows that are equal according to the earlier values. Each expression can be followed by an optional ASC or DESC keyword to set the sort direction to ascending or descending. ASC order is the default. Ascending order puts smaller values first, where “smaller” is defined in terms of the < operator. Similarly, descending order is determined with the > operator. 1 The NULLS FIRST and NULLS LAST options can be used to determine whether nulls appear before or after non-null values in the sort ordering. By default, null values sort as if larger than any non-null value; that is, NULLS FIRST is the default for DESC order, and NULLS LAST otherwise. Note that the ordering options are considered independently for each sort column. For example ORDER BY x, y DESC means ORDER BY x ASC, y DESC, which is not the same as ORDER BY x DESC, y DESC. A sort_expression can also be the column label or number of an output column, as in: SELECT a + b AS sum, c FROM table1 ORDER BY sum; SELECT a, max(b) FROM table1 GROUP BY a ORDER BY 1; both of which sort by the first output column. Note that an output column name has to stand alone, that is, it cannot be used in an expression — for example, this is not correct: SELECT a + b AS sum, c FROM table1 ORDER BY sum + c; -- wrong This restriction is made to reduce ambiguity. There is still ambiguity if an ORDER BY item is a simple name that could match either an output column name or a column from the table expression. The 1. Actually, PostgreSQL uses the default B-tree operator class for the expression’s data type to determine the sort ordering for ASC and DESC. Conventionally, data types will be set up so that the < and > operators correspond to this sort ordering, but a user-defined data type’s designer could choose to do something different. 91](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-148-2048.jpg)
![Chapter 7. Queries output column is used in such cases. This would only cause confusion if you use AS to rename an output column to match some other table column’s name. ORDER BY can be applied to the result of a UNION, INTERSECT, or EXCEPT combination, but in this case it is only permitted to sort by output column names or numbers, not by expressions. 7.6. LIMIT and OFFSET LIMIT and OFFSET allow you to retrieve just a portion of the rows that are generated by the rest of the query: SELECT select_list FROM table_expression [ ORDER BY ... ] [ LIMIT { number | ALL } ] [ OFFSET number ] If a limit count is given, no more than that many rows will be returned (but possibly less, if the query itself yields less rows). LIMIT ALL is the same as omitting the LIMIT clause. OFFSET says to skip that many rows before beginning to return rows. OFFSET 0 is the same as omitting the OFFSET clause, and LIMIT NULL is the same as omitting the LIMIT clause. If both OFFSET and LIMIT appear, then OFFSET rows are skipped before starting to count the LIMIT rows that are returned. When using LIMIT, it is important to use an ORDER BY clause that constrains the result rows into a unique order. Otherwise you will get an unpredictable subset of the query’s rows. You might be asking for the tenth through twentieth rows, but tenth through twentieth in what ordering? The ordering is unknown, unless you specified ORDER BY. The query optimizer takes LIMIT into account when generating query plans, so you are very likely to get different plans (yielding different row orders) depending on what you give for LIMIT and OFFSET. Thus, using different LIMIT/OFFSET values to select different subsets of a query result will give inconsistent results unless you enforce a predictable result ordering with ORDER BY. This is not a bug; it is an inherent consequence of the fact that SQL does not promise to deliver the results of a query in any particular order unless ORDER BY is used to constrain the order. The rows skipped by an OFFSET clause still have to be computed inside the server; therefore a large OFFSET might be inefficient. 7.7. VALUES Lists VALUES provides a way to generate a “constant table” that can be used in a query without having to actually create and populate a table on-disk. The syntax is VALUES ( expression [, ...] ) [, ...] Each parenthesized list of expressions generates a row in the table. The lists must all have the same number of elements (i.e., the number of columns in the table), and corresponding entries in each list must have compatible data types. The actual data type assigned to each column of the result is determined using the same rules as for UNION (see Section 10.5). As an example: 92](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-149-2048.jpg)


![Chapter 7. Queries just one or a few fields to see if the same point has been reached before. The standard method for handling such situations is to compute an array of the already-visited values. For example, consider the following query that searches a table graph using a link field: WITH RECURSIVE search_graph(id, link, data, depth) AS ( SELECT g.id, g.link, g.data, 1 FROM graph g UNION ALL SELECT g.id, g.link, g.data, sg.depth + 1 FROM graph g, search_graph sg WHERE g.id = sg.link ) SELECT * FROM search_graph; This query will loop if the link relationships contain cycles. Because we require a “depth” output, just changing UNION ALL to UNION would not eliminate the looping. Instead we need to recognize whether we have reached the same row again while following a particular path of links. We add two columns path and cycle to the loop-prone query: WITH RECURSIVE search_graph(id, link, data, depth, path, cycle) AS ( SELECT g.id, g.link, g.data, 1, ARRAY[g.id], false FROM graph g UNION ALL SELECT g.id, g.link, g.data, sg.depth + 1, path || g.id, g.id = ANY(path) FROM graph g, search_graph sg WHERE g.id = sg.link AND NOT cycle ) SELECT * FROM search_graph; Aside from preventing cycles, the array value is often useful in its own right as representing the “path” taken to reach any particular row. In the general case where more than one field needs to be checked to recognize a cycle, use an array of rows. For example, if we needed to compare fields f1 and f2: WITH RECURSIVE search_graph(id, link, data, depth, path, cycle) AS ( SELECT g.id, g.link, g.data, 1, ARRAY[ROW(g.f1, g.f2)], false FROM graph g UNION ALL SELECT g.id, g.link, g.data, sg.depth + 1, path || ROW(g.f1, g.f2), ROW(g.f1, g.f2) = ANY(path) FROM graph g, search_graph sg WHERE g.id = sg.link AND NOT cycle ) SELECT * FROM search_graph; 95](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-152-2048.jpg)

![Chapter 8. Data Types PostgreSQL has a rich set of native data types available to users. Users can add new types to Post- greSQL using the CREATE TYPE command. Table 8-1 shows all the built-in general-purpose data types. Most of the alternative names listed in the “Aliases” column are the names used internally by PostgreSQL for historical reasons. In addition, some internally used or deprecated types are available, but are not listed here. Table 8-1. Data Types Name Aliases Description bigint int8 signed eight-byte integer bigserial serial8 autoincrementing eight-byte integer bit [ (n) ] fixed-length bit string bit varying [ (n) ] varbit variable-length bit string boolean bool logical Boolean (true/false) box rectangular box on a plane bytea binary data (“byte array”) character varying [ (n) ] varchar [ (n) ] variable-length character string character [ (n) ] char [ (n) ] fixed-length character string cidr IPv4 or IPv6 network address circle circle on a plane date calendar date (year, month, day) double precision float8 double precision floating-point number (8 bytes) inet IPv4 or IPv6 host address integer int, int4 signed four-byte integer interval [ fields ] [ (p) ] time span line infinite line on a plane lseg line segment on a plane macaddr MAC (Media Access Control) address money currency amount numeric [ (p, s) ] decimal [ (p, s) ] exact numeric of selectable precision path geometric path on a plane point geometric point on a plane polygon closed geometric path on a plane real float4 single precision floating-point number (4 bytes) 97](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-154-2048.jpg)
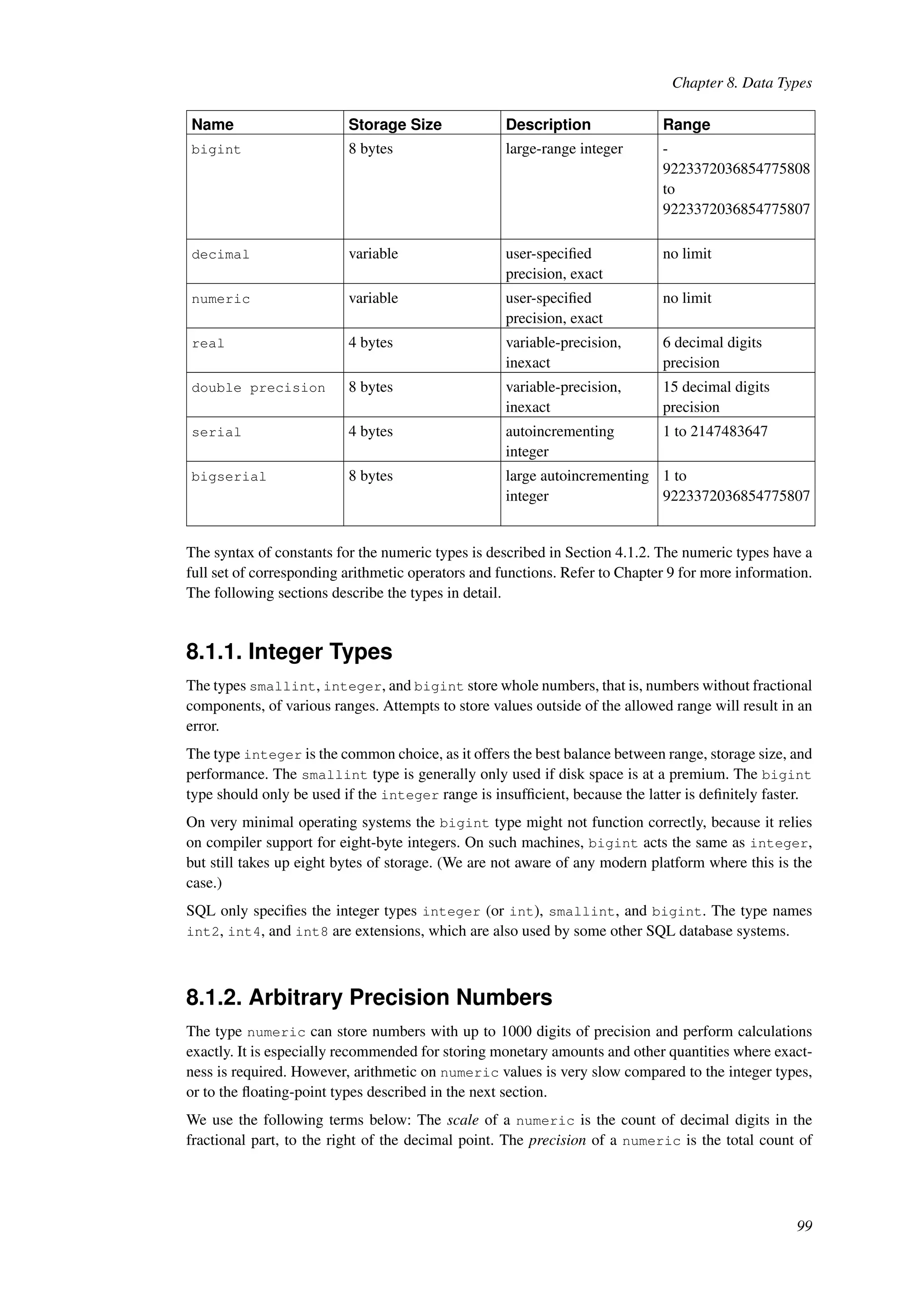
![Chapter 8. Data Types Name Aliases Description smallint int2 signed two-byte integer serial serial4 autoincrementing four-byte integer text variable-length character string time [ (p) ] [ without time zone ] time of day (no time zone) time [ (p) ] with time zone timetz time of day, including time zone timestamp [ (p) ] [ without time zone ] date and time (no time zone) timestamp [ (p) ] with time zone timestamptz date and time, including time zone tsquery text search query tsvector text search document txid_snapshot user-level transaction ID snapshot uuid universally unique identifier xml XML data Compatibility: The following types (or spellings thereof) are specified by SQL: bigint, bit, bit varying, boolean, char, character varying, character, varchar, date, double precision, integer, interval, numeric, decimal, real, smallint, time (with or without time zone), timestamp (with or without time zone), xml. Each data type has an external representation determined by its input and output functions. Many of the built-in types have obvious external formats. However, several types are either unique to Post- greSQL, such as geometric paths, or have several possible formats, such as the date and time types. Some of the input and output functions are not invertible, i.e., the result of an output function might lose accuracy when compared to the original input. 8.1. Numeric Types Numeric types consist of two-, four-, and eight-byte integers, four- and eight-byte floating-point num- bers, and selectable-precision decimals. Table 8-2 lists the available types. Table 8-2. Numeric Types Name Storage Size Description Range smallint 2 bytes small-range integer -32768 to +32767 integer 4 bytes typical choice for integer -2147483648 to +2147483647 98](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-155-2048.jpg)



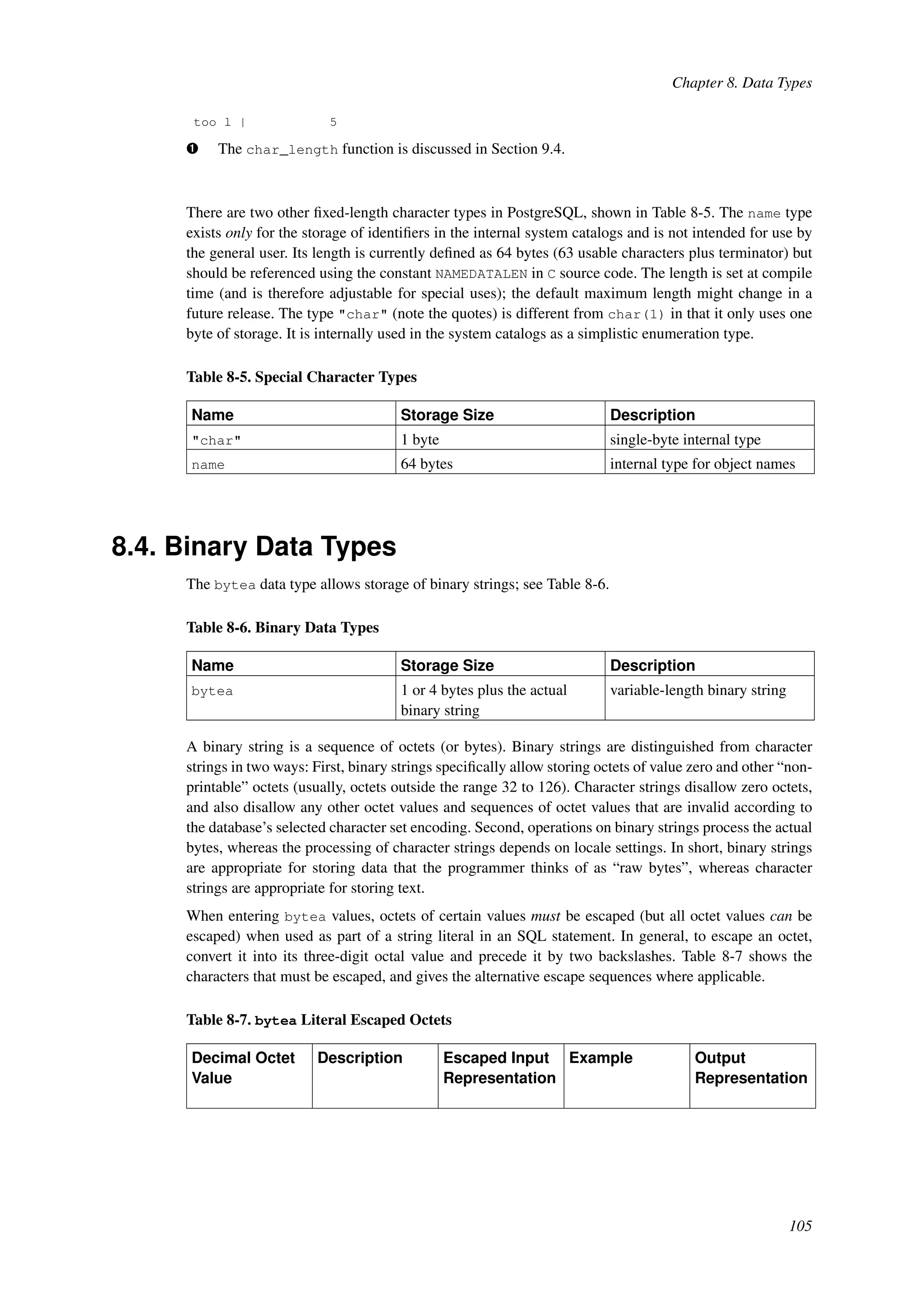
![Chapter 8. Data Types ’$1,000.00’. Output is generally in the latter form but depends on the locale. Non-quoted numeric values can be converted to money by casting the numeric value to text and then money, for example: SELECT 1234::text::money; There is no simple way of doing the reverse in a locale-independent manner, namely casting a money value to a numeric type. If you know the currency symbol and thousands separator you can use regexp_replace(): SELECT regexp_replace(’52093.89’::money::text, ’[$,]’, ”, ’g’)::numeric; Since the output of this data type is locale-sensitive, it might not work to load money data into a database that has a different setting of lc_monetary. To avoid problems, before restoring a dump into a new database make sure lc_monetary has the same or equivalent value as in the database that was dumped. Table 8-3. Monetary Types Name Storage Size Description Range money 8 bytes currency amount - 92233720368547758.08 to +92233720368547758.07 8.3. Character Types Table 8-4. Character Types Name Description character varying(n), varchar(n) variable-length with limit character(n), char(n) fixed-length, blank padded text variable unlimited length Table 8-4 shows the general-purpose character types available in PostgreSQL. SQL defines two primary character types: character varying(n) and character(n), where n is a positive integer. Both of these types can store strings up to n characters (not bytes) in length. An attempt to store a longer string into a column of these types will result in an error, unless the excess characters are all spaces, in which case the string will be truncated to the maximum length. (This somewhat bizarre exception is required by the SQL standard.) If the string to be stored is shorter than the declared length, values of type character will be space-padded; values of type character varying will simply store the shorter string. If one explicitly casts a value to character varying(n) or character(n), then an over-length value will be truncated to n characters without raising an error. (This too is required by the SQL standard.) The notations varchar(n) and char(n) are aliases for character varying(n) and character(n), respectively. character without length specifier is equivalent to character(1). 103](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-160-2048.jpg)

![Chapter 8. Data Types Depending on the front end to PostgreSQL you use, you might have additional work to do in terms of escaping and unescaping bytea strings. For example, you might also have to escape line feeds and carriage returns if your interface automatically translates these. The SQL standard defines a different binary string type, called BLOB or BINARY LARGE OBJECT. The input format is different from bytea, but the provided functions and operators are mostly the same. 8.5. Date/Time Types PostgreSQL supports the full set of SQL date and time types, shown in Table 8-9. The operations available on these data types are described in Section 9.9. Table 8-9. Date/Time Types Name Storage Size Description Low Value High Value Resolution timestamp [ (p) ] [ without time zone ] 8 bytes both date and time (no time zone) 4713 BC 294276 AD 1 microsecond / 14 digits timestamp [ (p) ] with time zone 8 bytes both date and time, with time zone 4713 BC 294276 AD 1 microsecond / 14 digits date 4 bytes date (no time of day) 4713 BC 5874897 AD 1 day time [ (p) ] [ without time zone ] 8 bytes time of day (no date) 00:00:00 24:00:00 1 microsecond / 14 digits time [ (p) ] with time zone 12 bytes times of day only, with time zone 00:00:00+1459 24:00:00-1459 1 microsecond / 14 digits interval [ fields ] [ (p) ] 16 bytes time interval -178000000 years 178000000 years 1 microsecond / 14 digits Note: Prior to PostgreSQL 7.3, writing just timestamp was equivalent to timestamp with time zone. This was changed for SQL compliance. time, timestamp, and interval accept an optional precision value p which specifies the number of fractional digits retained in the seconds field. By default, there is no explicit bound on precision. The allowed range of p is from 0 to 6 for the timestamp and interval types. Note: When timestamp values are stored as eight-byte integers (currently the default), microsec- ond precision is available over the full range of values. When timestamp values are stored as double precision floating-point numbers instead (a deprecated compile-time option), the effective 107](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-164-2048.jpg)

![Chapter 8. Data Types type [ (p) ] ’value’ where p is an optional precision specification giving the number of fractional digits in the seconds field. Precision can be specified for time, timestamp, and interval types. The allowed values are mentioned above. If no precision is specified in a constant specification, it defaults to the precision of the literal value. 8.5.1.1. Dates Table 8-10 shows some possible inputs for the date type. Table 8-10. Date Input Example Description 1999-01-08 ISO 8601; January 8 in any mode (recommended format) January 8, 1999 unambiguous in any datestyle input mode 1/8/1999 January 8 in MDY mode; August 1 in DMY mode 1/18/1999 January 18 in MDY mode; rejected in other modes 01/02/03 January 2, 2003 in MDY mode; February 1, 2003 in DMY mode; February 3, 2001 in YMD mode 1999-Jan-08 January 8 in any mode Jan-08-1999 January 8 in any mode 08-Jan-1999 January 8 in any mode 99-Jan-08 January 8 in YMD mode, else error 08-Jan-99 January 8, except error in YMD mode Jan-08-99 January 8, except error in YMD mode 19990108 ISO 8601; January 8, 1999 in any mode 990108 ISO 8601; January 8, 1999 in any mode 1999.008 year and day of year J2451187 Julian day January 8, 99 BC year 99 BC 8.5.1.2. Times The time-of-day types are time [ (p) ] without time zone and time [ (p) ] with time zone. time alone is equivalent to time without time zone. Valid input for these types consists of a time of day followed by an optional time zone. (See Table 8-11 and Table 8-12.) If a time zone is specified in the input for time without time zone, it is silently ignored. You can also specify a date but it will be ignored, except when you use a time zone name that involves a daylight-savings rule, such as America/New_York. In this case specifying the date is required in order to determine whether standard or daylight-savings time applies. The appropriate time zone offset is recorded in the time with time zone value. Table 8-11. Time Input 109](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-166-2048.jpg)




![Chapter 8. Data Types so have two possible UTC offsets. One should be wary that the POSIX-style time zone feature can lead to silently accepting bogus input, since there is no check on the reasonableness of the zone abbreviations. For example, SET TIMEZONE TO FOOBAR0 will work, leaving the system effectively using a rather peculiar abbreviation for UTC. Another issue to keep in mind is that in POSIX time zone names, positive offsets are used for locations west of Greenwich. Everywhere else, PostgreSQL follows the ISO-8601 convention that positive timezone offsets are east of Greenwich. In all cases, timezone names are recognized case-insensitively. (This is a change from PostgreSQL versions prior to 8.2, which were case-sensitive in some contexts but not others.) Neither full names nor abbreviations are hard-wired into the server; they are obtained from configura- tion files stored under .../share/timezone/ and .../share/timezonesets/ of the installation directory (see Section B.3). The timezone configuration parameter can be set in the file postgresql.conf, or in any of the other standard ways described in Chapter 18. There are also several special ways to set it: • If timezone is not specified in postgresql.conf or as a server command-line option, the server attempts to use the value of the TZ environment variable as the default time zone. If TZ is not defined or is not any of the time zone names known to PostgreSQL, the server attempts to deter- mine the operating system’s default time zone by checking the behavior of the C library function localtime(). The default time zone is selected as the closest match among PostgreSQL’s known time zones. (These rules are also used to choose the default value of log_timezone, if not specified.) • The SQL command SET TIME ZONE sets the time zone for the session. This is an alternative spelling of SET TIMEZONE TO with a more SQL-spec-compatible syntax. • The PGTZ environment variable is used by libpq clients to send a SET TIME ZONE command to the server upon connection. 8.5.4. Interval Input interval values can be written using the following verbose syntax: [@] quantity unit [quantity unit...] [direction] where quantity is a number (possibly signed); unit is microsecond, millisecond, second, minute, hour, day, week, month, year, decade, century, millennium, or abbreviations or plu- rals of these units; direction can be ago or empty. The at sign (@) is optional noise. The amounts of the different units are implicitly added with appropriate sign accounting. ago negates all the fields. This syntax is also used for interval output, if IntervalStyle is set to postgres_verbose. Quantities of days, hours, minutes, and seconds can be specified without explicit unit markings. For example, ’1 12:59:10’ is read the same as ’1 day 12 hours 59 min 10 sec’. Also, a com- bination of years and months can be specified with a dash; for example ’200-10’ is read the same as ’200 years 10 months’. (These shorter forms are in fact the only ones allowed by the SQL standard, and are used for output when IntervalStyle is set to sql_standard.) Interval values can also be written as ISO 8601 time intervals, using either the “format with designa- tors” of the standard’s section 4.4.3.2 or the “alternative format” of section 4.4.3.3. The format with designators looks like this: P quantity unit [ quantity unit ...] [ T [ quantity unit ...]] 114](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-171-2048.jpg)
![Chapter 8. Data Types The string must start with a P, and may include a T that introduces the time-of-day units. The available unit abbreviations are given in Table 8-16. Units may be omitted, and may be specified in any order, but units smaller than a day must appear after T. In particular, the meaning of M depends on whether it is before or after T. Table 8-16. ISO 8601 interval unit abbreviations Abbreviation Meaning Y Years M Months (in the date part) W Weeks D Days H Hours M Minutes (in the time part) S Seconds In the alternative format: P [ years-months-days ] [ T hours:minutes:seconds ] the string must begin with P, and a T separates the date and time parts of the interval. The values are given as numbers similar to ISO 8601 dates. When writing an interval constant with a fields specification, or when assigning a string to an in- terval column that was defined with a fields specification, the interpretation of unmarked quantities depends on the fields. For example INTERVAL ’1’ YEAR is read as 1 year, whereas INTERVAL ’1’ means 1 second. Also, field values “to the right” of the least significant field allowed by the fields specification are silently discarded. For example, writing INTERVAL ’1 day 2:03:04’ HOUR TO MINUTE results in dropping the seconds field, but not the day field. According to the SQL standard all fields of an interval value must have the same sign, so a leading negative sign applies to all fields; for example the negative sign in the interval literal ’-1 2:03:04’ applies to both the days and hour/minute/second parts. PostgreSQL allows the fields to have differ- ent signs, and traditionally treats each field in the textual representation as independently signed, so that the hour/minute/second part is considered positive in this example. If IntervalStyle is set to sql_standard then a leading sign is considered to apply to all fields (but only if no additional signs appear). Otherwise the traditional PostgreSQL interpretation is used. To avoid ambiguity, it’s recommended to attach an explicit sign to each field if any field is negative. Internally interval values are stored as months, days, and seconds. This is done because the number of days in a month varies, and a day can have 23 or 25 hours if a daylight savings time adjustment is involved. The months and days fields are integers while the seconds field can store fractions. Because intervals are usually created from constant strings or timestamp subtraction, this storage method works well in most cases. Functions justify_days and justify_hours are available for adjusting days and hours that overflow their normal ranges. In the verbose input format, and in some fields of the more compact input formats, field values can have fractional parts; for example ’1.5 week’ or ’01:02:03.45’. Such input is converted to the appropriate number of months, days, and seconds for storage. When this would result in a fractional number of months or days, the fraction is added to the lower-order fields using the conversion factors 1 month = 30 days and 1 day = 24 hours. For example, ’1.5 month’ becomes 1 month and 15 days. Only seconds will ever be shown as fractional on output. Table 8-17 shows some examples of valid interval input. 115](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-172-2048.jpg)




![Chapter 8. Data Types 8.8. Geometric Types Geometric data types represent two-dimensional spatial objects. Table 8-19 shows the geometric types available in PostgreSQL. The most fundamental type, the point, forms the basis for all of the other types. Table 8-19. Geometric Types Name Storage Size Representation Description point 16 bytes Point on a plane (x,y) line 32 bytes Infinite line (not fully implemented) ((x1,y1),(x2,y2)) lseg 32 bytes Finite line segment ((x1,y1),(x2,y2)) box 32 bytes Rectangular box ((x1,y1),(x2,y2)) path 16+16n bytes Closed path (similar to polygon) ((x1,y1),...) path 16+16n bytes Open path [(x1,y1),...] polygon 40+16n bytes Polygon (similar to closed path) ((x1,y1),...) circle 24 bytes Circle <(x,y),r> (center point and radius) A rich set of functions and operators is available to perform various geometric operations such as scaling, translation, rotation, and determining intersections. They are explained in Section 9.11. 8.8.1. Points Points are the fundamental two-dimensional building block for geometric types. Values of type point are specified using either of the following syntaxes: ( x , y ) x , y where x and y are the respective coordinates, as floating-point numbers. Points are output using the first syntax. 8.8.2. Line Segments Line segments (lseg) are represented by pairs of points. Values of type lseg are specified using any of the following syntaxes: [ ( x1 , y1 ) , ( x2 , y2 ) ] ( ( x1 , y1 ) , ( x2 , y2 ) ) ( x1 , y1 ) , ( x2 , y2 ) x1 , y1 , x2 , y2 where (x1,y1) and (x2,y2) are the end points of the line segment. Line segments are output using the first syntax. 120](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-177-2048.jpg)
![Chapter 8. Data Types 8.8.3. Boxes Boxes are represented by pairs of points that are opposite corners of the box. Values of type box are specified using any of the following syntaxes: ( ( x1 , y1 ) , ( x2 , y2 ) ) ( x1 , y1 ) , ( x2 , y2 ) x1 , y1 , x2 , y2 where (x1,y1) and (x2,y2) are any two opposite corners of the box. Boxes are output using the second syntax. Any two opposite corners can be supplied on input, but the values will be reordered as needed to store the upper right and lower left corners, in that order. 8.8.4. Paths Paths are represented by lists of connected points. Paths can be open, where the first and last points in the list are considered not connected, or closed, where the first and last points are considered connected. Values of type path are specified using any of the following syntaxes: [ ( x1 , y1 ) , ... , ( xn , yn ) ] ( ( x1 , y1 ) , ... , ( xn , yn ) ) ( x1 , y1 ) , ... , ( xn , yn ) ( x1 , y1 , ... , xn , yn ) x1 , y1 , ... , xn , yn where the points are the end points of the line segments comprising the path. Square brackets ([]) indicate an open path, while parentheses (()) indicate a closed path. When the outermost parentheses are omitted, as in the third through fifth syntaxes, a closed path is assumed. Paths are output using the first or second syntax, as appropriate. 8.8.5. Polygons Polygons are represented by lists of points (the vertexes of the polygon). Polygons are very similar to closed paths, but are stored differently and have their own set of support routines. Values of type polygon are specified using any of the following syntaxes: ( ( x1 , y1 ) , ... , ( xn , yn ) ) ( x1 , y1 ) , ... , ( xn , yn ) ( x1 , y1 , ... , xn , yn ) x1 , y1 , ... , xn , yn where the points are the end points of the line segments comprising the boundary of the polygon. Polygons are output using the first syntax. 121](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-178-2048.jpg)








![Chapter 8. Data Types 8.14. Arrays PostgreSQL allows columns of a table to be defined as variable-length multidimensional arrays. Ar- rays of any built-in or user-defined base type, enum type, or composite type can be created. Arrays of domains are not yet supported. 8.14.1. Declaration of Array Types To illustrate the use of array types, we create this table: CREATE TABLE sal_emp ( name text, pay_by_quarter integer[], schedule text[][] ); As shown, an array data type is named by appending square brackets ([]) to the data type name of the array elements. The above command will create a table named sal_emp with a column of type text (name), a one-dimensional array of type integer (pay_by_quarter), which represents the employee’s salary by quarter, and a two-dimensional array of text (schedule), which represents the employee’s weekly schedule. The syntax for CREATE TABLE allows the exact size of arrays to be specified, for example: CREATE TABLE tictactoe ( squares integer[3][3] ); However, the current implementation ignores any supplied array size limits, i.e., the behavior is the same as for arrays of unspecified length. The current implementation does not enforce the declared number of dimensions either. Arrays of a particular element type are all considered to be of the same type, regardless of size or number of dimensions. So, declaring the array size or number of dimensions in CREATE TABLE is simply documentation; it does not affect run-time behavior. An alternative syntax, which conforms to the SQL standard by using the keyword ARRAY, can be used for one-dimensional arrays. pay_by_quarter could have been defined as: pay_by_quarter integer ARRAY[4], Or, if no array size is to be specified: pay_by_quarter integer ARRAY, As before, however, PostgreSQL does not enforce the size restriction in any case. 8.14.2. Array Value Input To write an array value as a literal constant, enclose the element values within curly braces and separate them by commas. (If you know C, this is not unlike the C syntax for initializing structures.) You can put double quotes around any element value, and must do so if it contains commas or curly braces. (More details appear below.) Thus, the general format of an array constant is the following: ’{ val1 delim val2 delim ... }’ 130](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-187-2048.jpg)
![Chapter 8. Data Types where delim is the delimiter character for the type, as recorded in its pg_type entry. Among the standard data types provided in the PostgreSQL distribution, all use a comma (,), except for type box which uses a semicolon (;). Each val is either a constant of the array element type, or a subarray. An example of an array constant is: ’{{1,2,3},{4,5,6},{7,8,9}}’ This constant is a two-dimensional, 3-by-3 array consisting of three subarrays of integers. To set an element of an array constant to NULL, write NULL for the element value. (Any upper- or lower-case variant of NULL will do.) If you want an actual string value “NULL”, you must put double quotes around it. (These kinds of array constants are actually only a special case of the generic type constants discussed in Section 4.1.2.7. The constant is initially treated as a string and passed to the array input conversion routine. An explicit type specification might be necessary.) Now we can show some INSERT statements: INSERT INTO sal_emp VALUES (’Bill’, ’{10000, 10000, 10000, 10000}’, ’{{"meeting", "lunch"}, {"training", "presentation"}}’); INSERT INTO sal_emp VALUES (’Carol’, ’{20000, 25000, 25000, 25000}’, ’{{"breakfast", "consulting"}, {"meeting", "lunch"}}’); The result of the previous two inserts looks like this: SELECT * FROM sal_emp; name | pay_by_quarter | schedule -------+---------------------------+------------------------------------------- Bill | {10000,10000,10000,10000} | {{meeting,lunch},{training,presentation}} Carol | {20000,25000,25000,25000} | {{breakfast,consulting},{meeting,lunch}} (2 rows) Multidimensional arrays must have matching extents for each dimension. A mismatch causes an error, for example: INSERT INTO sal_emp VALUES (’Bill’, ’{10000, 10000, 10000, 10000}’, ’{{"meeting", "lunch"}, {"meeting"}}’); ERROR: multidimensional arrays must have array expressions with matching dimensions The ARRAY constructor syntax can also be used: INSERT INTO sal_emp VALUES (’Bill’, ARRAY[10000, 10000, 10000, 10000], ARRAY[[’meeting’, ’lunch’], [’training’, ’presentation’]]); 131](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-188-2048.jpg)
![Chapter 8. Data Types INSERT INTO sal_emp VALUES (’Carol’, ARRAY[20000, 25000, 25000, 25000], ARRAY[[’breakfast’, ’consulting’], [’meeting’, ’lunch’]]); Notice that the array elements are ordinary SQL constants or expressions; for instance, string literals are single quoted, instead of double quoted as they would be in an array literal. The ARRAY constructor syntax is discussed in more detail in Section 4.2.11. 8.14.3. Accessing Arrays Now, we can run some queries on the table. First, we show how to access a single element of an array. This query retrieves the names of the employees whose pay changed in the second quarter: SELECT name FROM sal_emp WHERE pay_by_quarter[1] <> pay_by_quarter[2]; name ------- Carol (1 row) The array subscript numbers are written within square brackets. By default PostgreSQL uses a one- based numbering convention for arrays, that is, an array of n elements starts with array[1] and ends with array[n]. This query retrieves the third quarter pay of all employees: SELECT pay_by_quarter[3] FROM sal_emp; pay_by_quarter ---------------- 10000 25000 (2 rows) We can also access arbitrary rectangular slices of an array, or subarrays. An array slice is denoted by writing lower-bound:upper-bound for one or more array dimensions. For example, this query retrieves the first item on Bill’s schedule for the first two days of the week: SELECT schedule[1:2][1:1] FROM sal_emp WHERE name = ’Bill’; schedule ------------------------ {{meeting},{training}} (1 row) If any dimension is written as a slice, i.e., contains a colon, then all dimensions are treated as slices. Any dimension that has only a single number (no colon) is treated as being from 1 to the number specified. For example, [2] is treated as [1:2], as in this example: SELECT schedule[1:2][2] FROM sal_emp WHERE name = ’Bill’; schedule ------------------------------------------- 132](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-189-2048.jpg)
![Chapter 8. Data Types {{meeting,lunch},{training,presentation}} (1 row) To avoid confusion with the non-slice case, it’s best to use slice syntax for all dimensions, e.g., [1:2][1:1], not [2][1:1]. An array subscript expression will return null if either the array itself or any of the subscript expres- sions are null. Also, null is returned if a subscript is outside the array bounds (this case does not raise an error). For example, if schedule currently has the dimensions [1:3][1:2] then referencing schedule[3][3] yields NULL. Similarly, an array reference with the wrong number of subscripts yields a null rather than an error. An array slice expression likewise yields null if the array itself or any of the subscript expressions are null. However, in other cases such as selecting an array slice that is completely outside the current array bounds, a slice expression yields an empty (zero-dimensional) array instead of null. (This does not match non-slice behavior and is done for historical reasons.) If the requested slice partially over- laps the array bounds, then it is silently reduced to just the overlapping region instead of returning null. The current dimensions of any array value can be retrieved with the array_dims function: SELECT array_dims(schedule) FROM sal_emp WHERE name = ’Carol’; array_dims ------------ [1:2][1:2] (1 row) array_dims produces a text result, which is convenient for people to read but perhaps inconvenient for programs. Dimensions can also be retrieved with array_upper and array_lower, which return the upper and lower bound of a specified array dimension, respectively: SELECT array_upper(schedule, 1) FROM sal_emp WHERE name = ’Carol’; array_upper ------------- 2 (1 row) array_length will return the length of a specified array dimension: SELECT array_length(schedule, 1) FROM sal_emp WHERE name = ’Carol’; array_length -------------- 2 (1 row) 8.14.4. Modifying Arrays An array value can be replaced completely: UPDATE sal_emp SET pay_by_quarter = ’{25000,25000,27000,27000}’ WHERE name = ’Carol’; 133](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-190-2048.jpg)
![Chapter 8. Data Types or using the ARRAY expression syntax: UPDATE sal_emp SET pay_by_quarter = ARRAY[25000,25000,27000,27000] WHERE name = ’Carol’; An array can also be updated at a single element: UPDATE sal_emp SET pay_by_quarter[4] = 15000 WHERE name = ’Bill’; or updated in a slice: UPDATE sal_emp SET pay_by_quarter[1:2] = ’{27000,27000}’ WHERE name = ’Carol’; A stored array value can be enlarged by assigning to elements not already present. Any positions be- tween those previously present and the newly assigned elements will be filled with nulls. For example, if array myarray currently has 4 elements, it will have six elements after an update that assigns to myarray[6]; myarray[5] will contain null. Currently, enlargement in this fashion is only allowed for one-dimensional arrays, not multidimensional arrays. Subscripted assignment allows creation of arrays that do not use one-based subscripts. For example one might assign to myarray[-2:7] to create an array with subscript values from -2 to 7. New array values can also be constructed using the concatenation operator, ||: SELECT ARRAY[1,2] || ARRAY[3,4]; ?column? ----------- {1,2,3,4} (1 row) SELECT ARRAY[5,6] || ARRAY[[1,2],[3,4]]; ?column? --------------------- {{5,6},{1,2},{3,4}} (1 row) The concatenation operator allows a single element to be pushed onto the beginning or end of a one-dimensional array. It also accepts two N-dimensional arrays, or an N-dimensional and an N+1- dimensional array. When a single element is pushed onto either the beginning or end of a one-dimensional array, the result is an array with the same lower bound subscript as the array operand. For example: SELECT array_dims(1 || ’[0:1]={2,3}’::int[]); array_dims ------------ [0:2] (1 row) SELECT array_dims(ARRAY[1,2] || 3); array_dims ------------ [1:3] (1 row) 134](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-191-2048.jpg)
![Chapter 8. Data Types When two arrays with an equal number of dimensions are concatenated, the result retains the lower bound subscript of the left-hand operand’s outer dimension. The result is an array comprising every element of the left-hand operand followed by every element of the right-hand operand. For example: SELECT array_dims(ARRAY[1,2] || ARRAY[3,4,5]); array_dims ------------ [1:5] (1 row) SELECT array_dims(ARRAY[[1,2],[3,4]] || ARRAY[[5,6],[7,8],[9,0]]); array_dims ------------ [1:5][1:2] (1 row) When an N-dimensional array is pushed onto the beginning or end of an N+1-dimensional array, the result is analogous to the element-array case above. Each N-dimensional sub-array is essentially an element of the N+1-dimensional array’s outer dimension. For example: SELECT array_dims(ARRAY[1,2] || ARRAY[[3,4],[5,6]]); array_dims ------------ [1:3][1:2] (1 row) An array can also be constructed by using the functions array_prepend, array_append, or array_cat. The first two only support one-dimensional arrays, but array_cat supports multidimensional arrays. Note that the concatenation operator discussed above is preferred over direct use of these functions. In fact, these functions primarily exist for use in implementing the concatenation operator. However, they might be directly useful in the creation of user-defined aggregates. Some examples: SELECT array_prepend(1, ARRAY[2,3]); array_prepend --------------- {1,2,3} (1 row) SELECT array_append(ARRAY[1,2], 3); array_append -------------- {1,2,3} (1 row) SELECT array_cat(ARRAY[1,2], ARRAY[3,4]); array_cat ----------- {1,2,3,4} (1 row) SELECT array_cat(ARRAY[[1,2],[3,4]], ARRAY[5,6]); 135](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-192-2048.jpg)
![Chapter 8. Data Types array_cat --------------------- {{1,2},{3,4},{5,6}} (1 row) SELECT array_cat(ARRAY[5,6], ARRAY[[1,2],[3,4]]); array_cat --------------------- {{5,6},{1,2},{3,4}} 8.14.5. Searching in Arrays To search for a value in an array, each value must be checked. This can be done manually, if you know the size of the array. For example: SELECT * FROM sal_emp WHERE pay_by_quarter[1] = 10000 OR pay_by_quarter[2] = 10000 OR pay_by_quarter[3] = 10000 OR pay_by_quarter[4] = 10000; However, this quickly becomes tedious for large arrays, and is not helpful if the size of the array is unknown. An alternative method is described in Section 9.21. The above query could be replaced by: SELECT * FROM sal_emp WHERE 10000 = ANY (pay_by_quarter); In addition, you can find rows where the array has all values equal to 10000 with: SELECT * FROM sal_emp WHERE 10000 = ALL (pay_by_quarter); Alternatively, the generate_subscripts function can be used. For example: SELECT * FROM (SELECT pay_by_quarter, generate_subscripts(pay_by_quarter, 1) AS s FROM sal_emp) AS foo WHERE pay_by_quarter[s] = 10000; This function is described in Table 9-46. Tip: Arrays are not sets; searching for specific array elements can be a sign of database misde- sign. Consider using a separate table with a row for each item that would be an array element. This will be easier to search, and is likely to scale better for a large number of elements. 8.14.6. Array Input and Output Syntax The external text representation of an array value consists of items that are interpreted according to the I/O conversion rules for the array’s element type, plus decoration that indicates the array structure. The decoration consists of curly braces ({ and }) around the array value plus delimiter characters between adjacent items. The delimiter character is usually a comma (,) but can be something else: 136](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-193-2048.jpg)
![Chapter 8. Data Types it is determined by the typdelim setting for the array’s element type. Among the standard data types provided in the PostgreSQL distribution, all use a comma, except for type box, which uses a semicolon (;). In a multidimensional array, each dimension (row, plane, cube, etc.) gets its own level of curly braces, and delimiters must be written between adjacent curly-braced entities of the same level. The array output routine will put double quotes around element values if they are empty strings, contain curly braces, delimiter characters, double quotes, backslashes, or white space, or match the word NULL. Double quotes and backslashes embedded in element values will be backslash-escaped. For numeric data types it is safe to assume that double quotes will never appear, but for textual data types one should be prepared to cope with either the presence or absence of quotes. By default, the lower bound index value of an array’s dimensions is set to one. To represent arrays with other lower bounds, the array subscript ranges can be specified explicitly before writing the array contents. This decoration consists of square brackets ([]) around each array dimension’s lower and upper bounds, with a colon (:) delimiter character in between. The array dimension decoration is followed by an equal sign (=). For example: SELECT f1[1][-2][3] AS e1, f1[1][-1][5] AS e2 FROM (SELECT ’[1:1][-2:-1][3:5]={{{1,2,3},{4,5,6}}}’::int[] AS f1) AS ss; e1 | e2 ----+---- 1 | 6 (1 row) The array output routine will include explicit dimensions in its result only when there are one or more lower bounds different from one. If the value written for an element is NULL (in any case variant), the element is taken to be NULL. The presence of any quotes or backslashes disables this and allows the literal string value “NULL” to be entered. Also, for backwards compatibility with pre-8.2 versions of PostgreSQL, the array_nulls configuration parameter can be turned off to suppress recognition of NULL as a NULL. As shown previously, when writing an array value you can use double quotes around any individual array element. You must do so if the element value would otherwise confuse the array-value parser. For example, elements containing curly braces, commas (or the data type’s delimiter character), dou- ble quotes, backslashes, or leading or trailing whitespace must be double-quoted. Empty strings and strings matching the word NULL must be quoted, too. To put a double quote or backslash in a quoted array element value, use escape string syntax and precede it with a backslash. Alternatively, you can avoid quotes and use backslash-escaping to protect all data characters that would otherwise be taken as array syntax. You can add whitespace before a left brace or after a right brace. You can also add whitespace before or after any individual item string. In all of these cases the whitespace will be ignored. However, whitespace within double-quoted elements, or surrounded on both sides by non-whitespace characters of an element, is not ignored. Note: Remember that what you write in an SQL command will first be interpreted as a string literal, and then as an array. This doubles the number of backslashes you need. For example, to insert a text array value containing a backslash and a double quote, you’d need to write: INSERT ... VALUES (E’{"","""}’); The escape string processor removes one level of backslashes, so that what arrives at the array- value parser looks like {"","""}. In turn, the strings fed to the text data type’s input routine become and " respectively. (If we were working with a data type whose input routine also treated 137](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-194-2048.jpg)




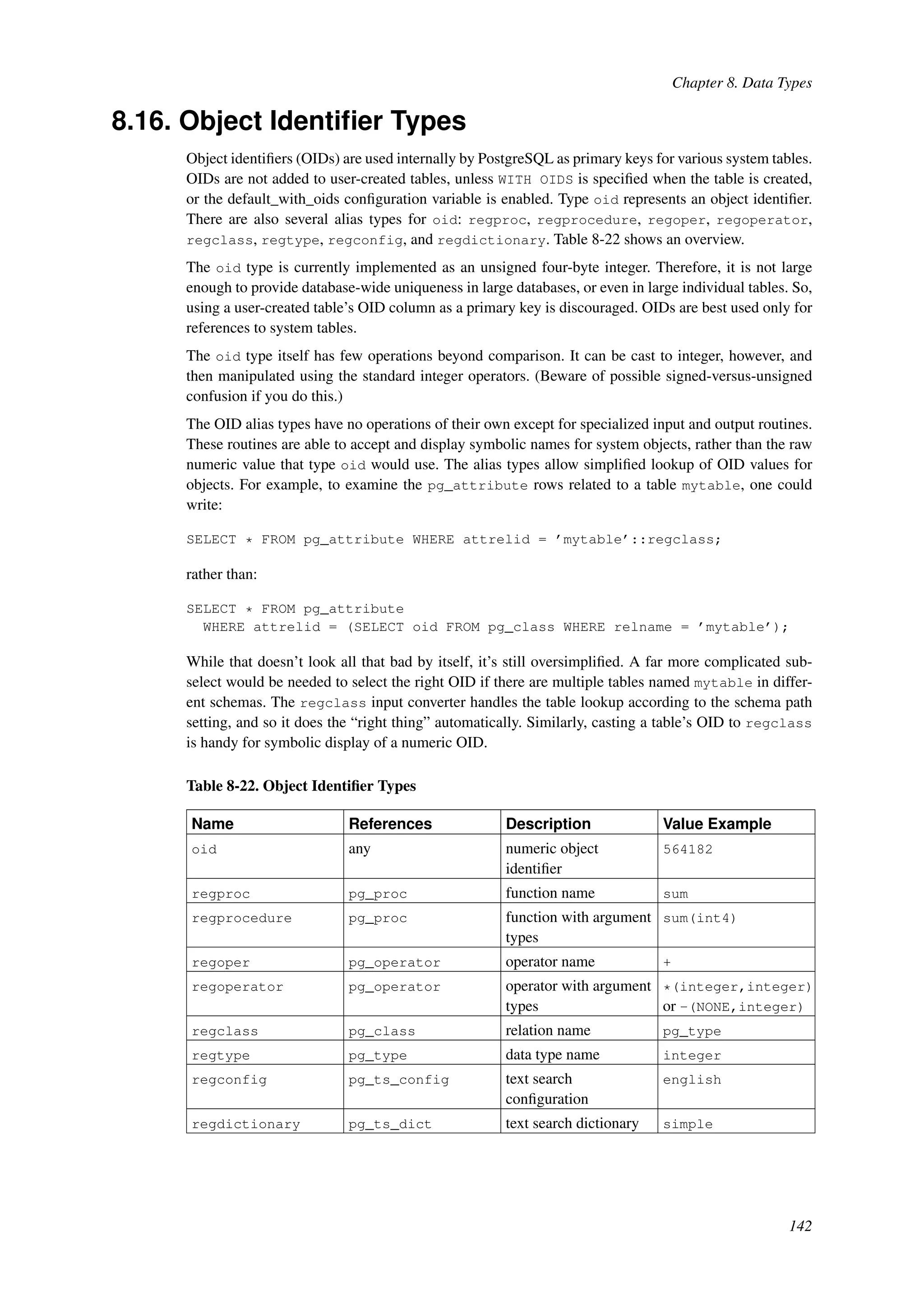

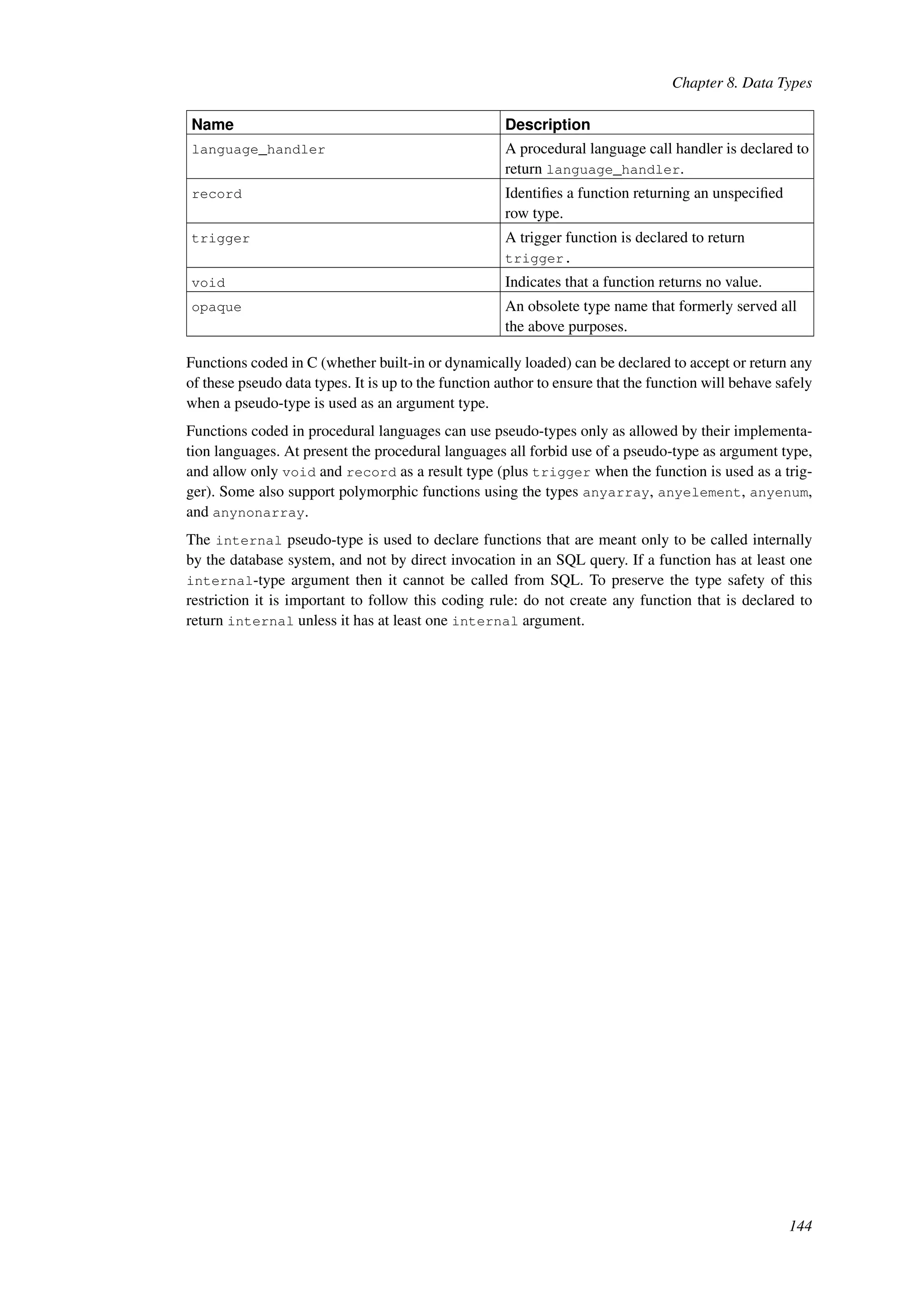


![Chapter 9. Functions and Operators Tip: Some applications might expect that expression = NULL returns true if expression evalu- ates to the null value. It is highly recommended that these applications be modified to comply with the SQL standard. However, if that cannot be done the transform_null_equals configuration variable is available. If it is enabled, PostgreSQL will convert x = NULL clauses to x IS NULL. Note: If the expression is row-valued, then IS NULL is true when the row expression itself is null or when all the row’s fields are null, while IS NOT NULL is true when the row expression itself is non-null and all the row’s fields are non-null. Because of this behavior, IS NULL and IS NOT NULL do not always return inverse results for row-valued expressions, i.e., a row-valued expression that contains both NULL and non-null values will return false for both tests. This definition conforms to the SQL standard, and is a change from the inconsistent behavior exhibited by PostgreSQL versions prior to 8.2. Ordinary comparison operators yield null (signifying “unknown”), not true or false, when either input is null. For example, 7 = NULL yields null. When this behavior is not suitable, use the IS [ NOT ] DISTINCT FROM constructs: expression IS DISTINCT FROM expression expression IS NOT DISTINCT FROM expression For non-null inputs, IS DISTINCT FROM is the same as the <> operator. However, if both inputs are null it returns false, and if only one input is null it returns true. Similarly, IS NOT DISTINCT FROM is identical to = for non-null inputs, but it returns true when both inputs are null, and false when only one input is null. Thus, these constructs effectively act as though null were a normal data value, rather than “unknown”. Boolean values can also be tested using the constructs expression IS TRUE expression IS NOT TRUE expression IS FALSE expression IS NOT FALSE expression IS UNKNOWN expression IS NOT UNKNOWN These will always return true or false, never a null value, even when the operand is null. A null input is treated as the logical value “unknown”. Notice that IS UNKNOWN and IS NOT UNKNOWN are effectively the same as IS NULL and IS NOT NULL, respectively, except that the input expression must be of Boolean type. 9.3. Mathematical Functions and Operators Mathematical operators are provided for many PostgreSQL types. For types without standard mathe- matical conventions (e.g., date/time types) we describe the actual behavior in subsequent sections. Table 9-2 shows the available mathematical operators. Table 9-2. Mathematical Operators Operator Description Example Result 147](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-204-2048.jpg)
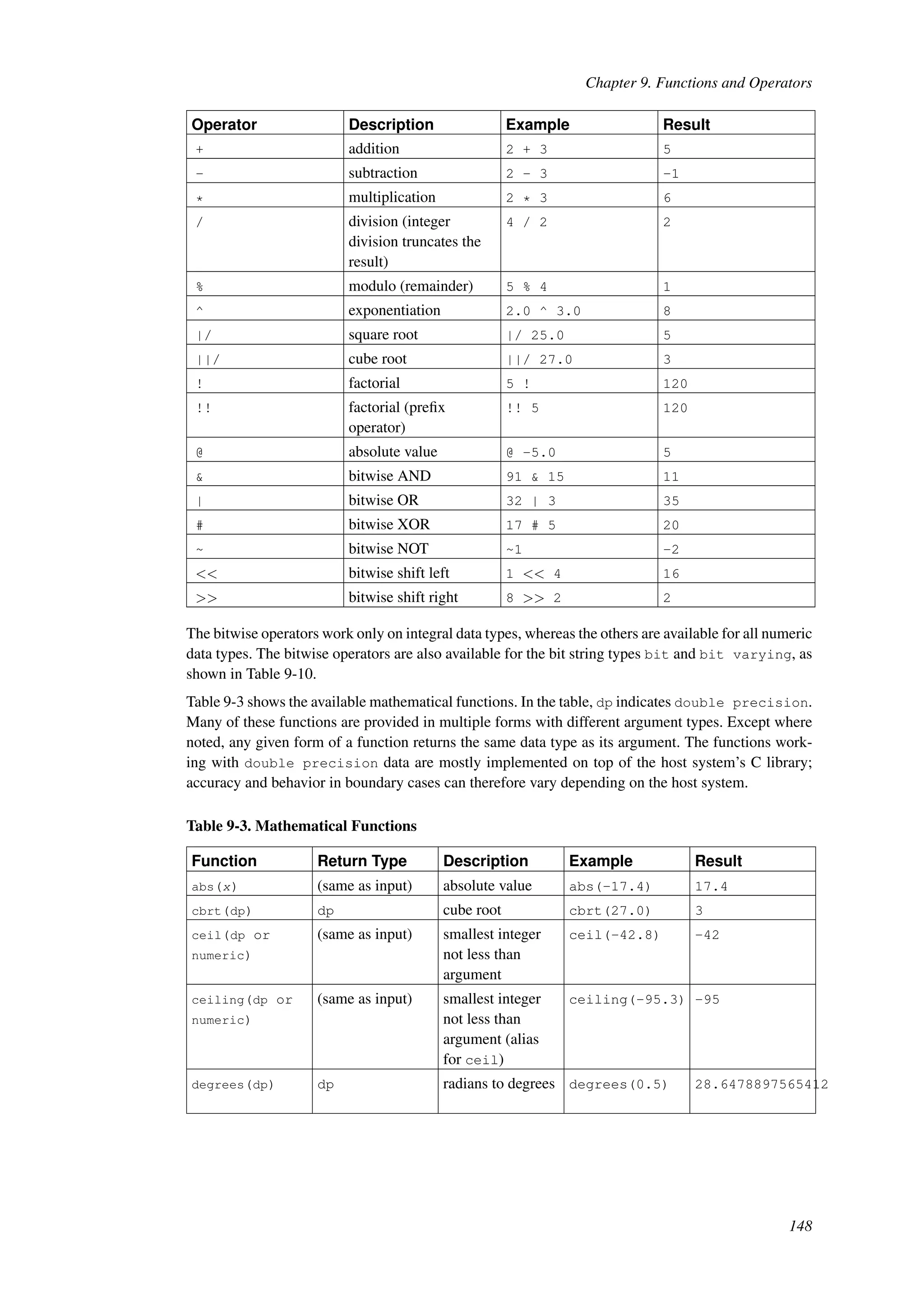
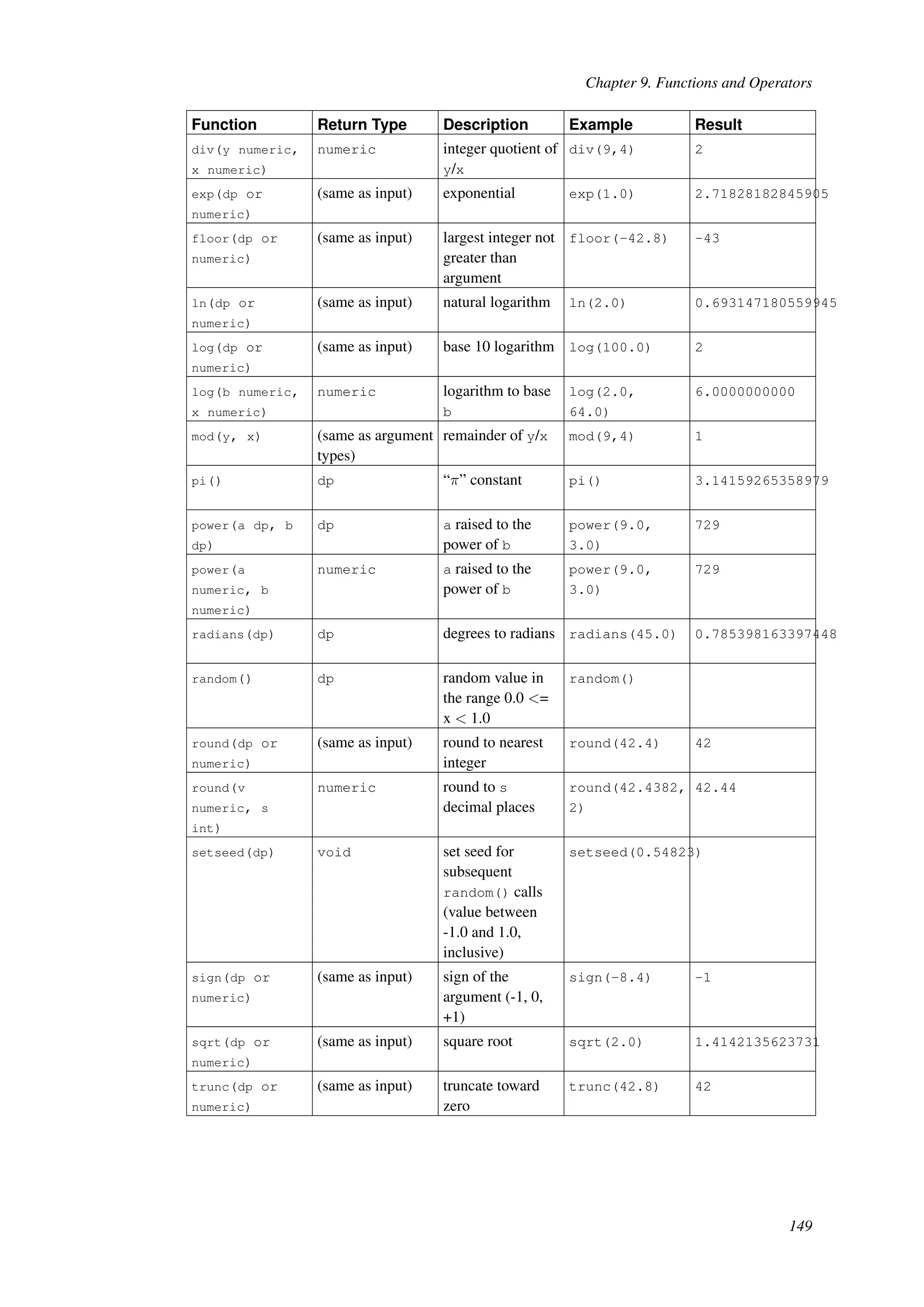

![Chapter 9. Functions and Operators Note: Before PostgreSQL 8.3, these functions would silently accept values of several non-string data types as well, due to the presence of implicit coercions from those data types to text. Those coercions have been removed because they frequently caused surprising behaviors. However, the string concatenation operator (||) still accepts non-string input, so long as at least one input is of a string type, as shown in Table 9-5. For other cases, insert an explicit coercion to text if you need to duplicate the previous behavior. Table 9-5. SQL String Functions and Operators Function Return Type Description Example Result string || string text String concatenation ’Post’ || ’greSQL’ PostgreSQL string || non-string or non-string || string text String concatenation with one non-string input ’Value: ’ || 42 Value: 42 bit_length(string)int Number of bits in string bit_length(’jose’)32 char_length(string) or character_length(string) int Number of characters in string char_length(’jose’)4 lower(string) text Convert string to lower case lower(’TOM’) tom octet_length(string)int Number of bytes in string octet_length(’jose’)4 overlay(string placing string from int [for int]) text Replace substring overlay(’Txxxxas’ placing ’hom’ from 2 for 4) Thomas position(substring in string) int Location of specified substring position(’om’ in ’Thomas’) 3 substring(string [from int] [for int]) text Extract substring substring(’Thomas’ from 2 for 3) hom substring(string from pattern) text Extract substring matching POSIX regular expression. See Section 9.7 for more information on pattern matching. substring(’Thomas’ from ’...$’) mas 151](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-208-2048.jpg)
![Chapter 9. Functions and Operators Function Return Type Description Example Result substring(string from pattern for escape) text Extract substring matching SQL regular expression. See Section 9.7 for more information on pattern matching. substring(’Thomas’ from ’%#"o_a#"_’ for ’#’) oma trim([leading | trailing | both] [characters] from string) text Remove the longest string containing only the characters (a space by default) from the start/end/both ends of the string trim(both ’x’ from ’xTomxx’) Tom upper(string) text Convert string to uppercase upper(’tom’) TOM Additional string manipulation functions are available and are listed in Table 9-6. Some of them are used internally to implement the SQL-standard string functions listed in Table 9-5. Table 9-6. Other String Functions Function Return Type Description Example Result ascii(string) int ASCII code of the first character of the argument. For UTF8 returns the Unicode code point of the character. For other multibyte encodings, the argument must be an ASCII character. ascii(’x’) 120 btrim(string text [, characters text]) text Remove the longest string consisting only of characters in characters (a space by default) from the start and end of string btrim(’xyxtrimyyx’, ’xy’) trim 152](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-209-2048.jpg)
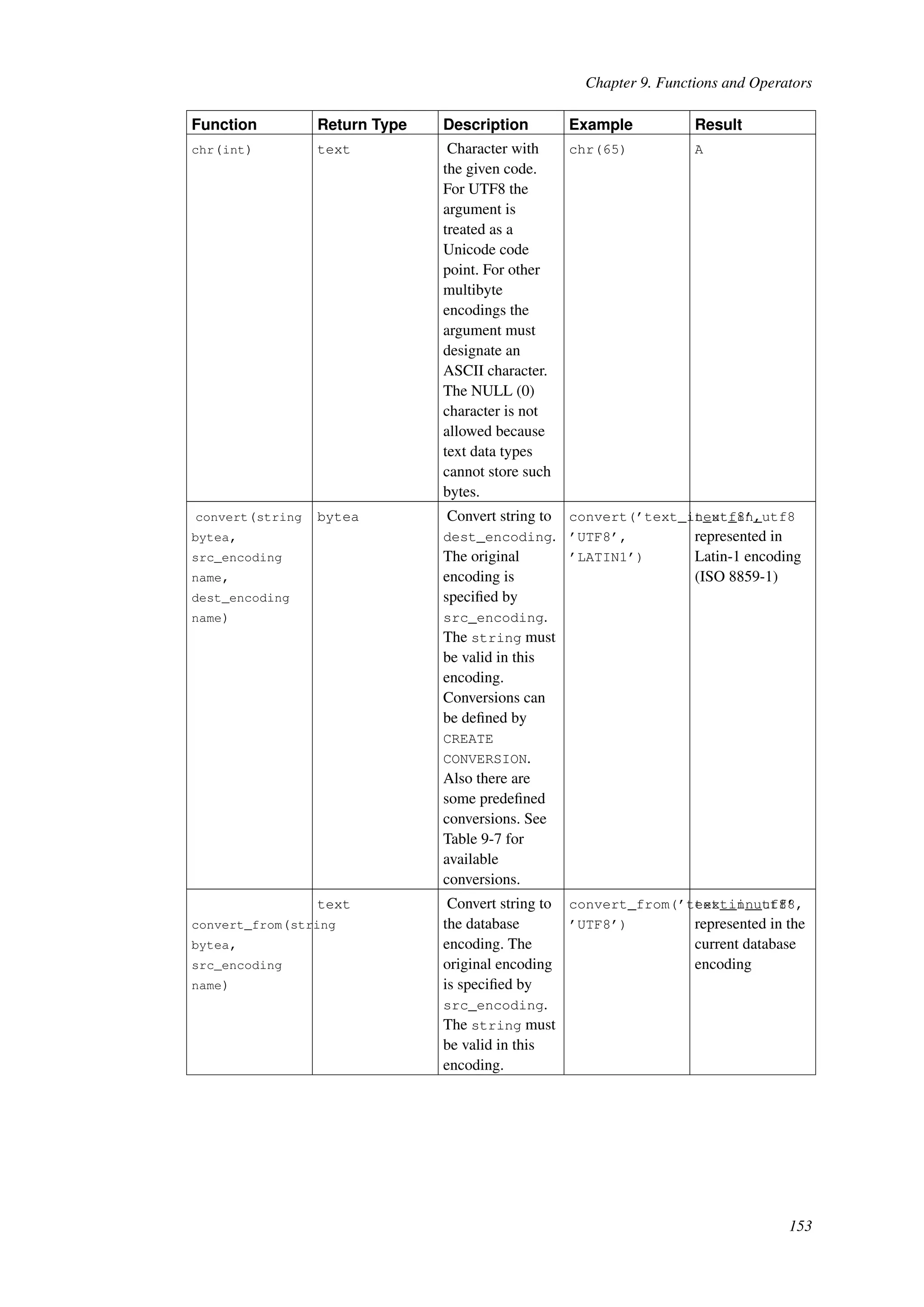
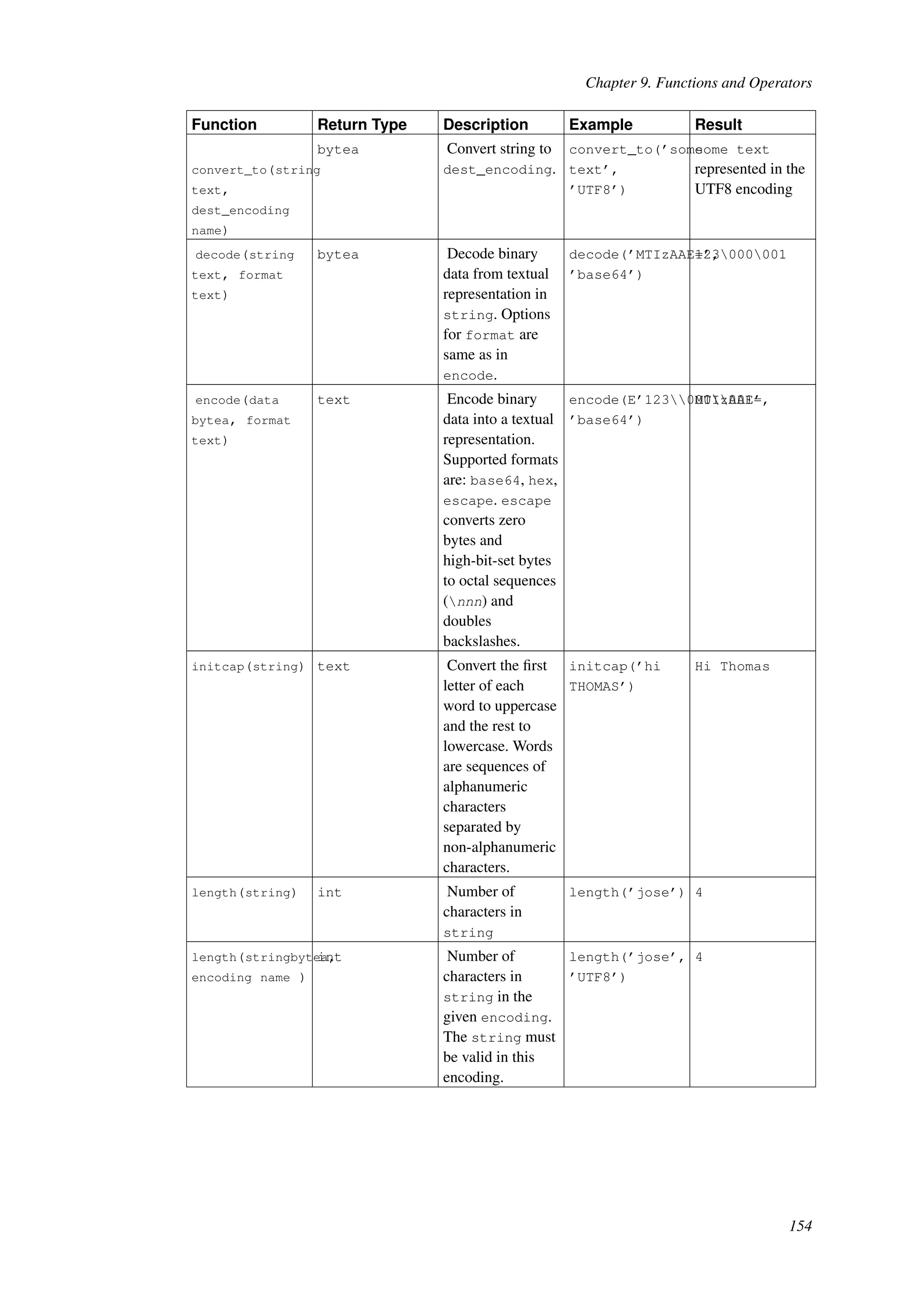
![Chapter 9. Functions and Operators Function Return Type Description Example Result lpad(string text, length int [, fill text]) text Fill up the string to length length by prepending the characters fill (a space by default). If the string is already longer than length then it is truncated (on the right). lpad(’hi’, 5, ’xy’) xyxhi ltrim(string text [, characters text]) text Remove the longest string containing only characters from characters (a space by default) from the start of string ltrim(’zzzytrim’, ’xyz’) trim md5(string) text Calculates the MD5 hash of string, returning the result in hexadecimal md5(’abc’) 900150983cd24fb0 d6963f7d28e17f72 pg_client_encoding()name Current client encoding name pg_client_encoding()SQL_ASCII quote_ident(string text) text Return the given string suitably quoted to be used as an identifier in an SQL statement string. Quotes are added only if necessary (i.e., if the string contains non-identifier characters or would be case-folded). Embedded quotes are properly doubled. See also Example 38-1. quote_ident(’Foo bar’) "Foo bar" 155](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-212-2048.jpg)
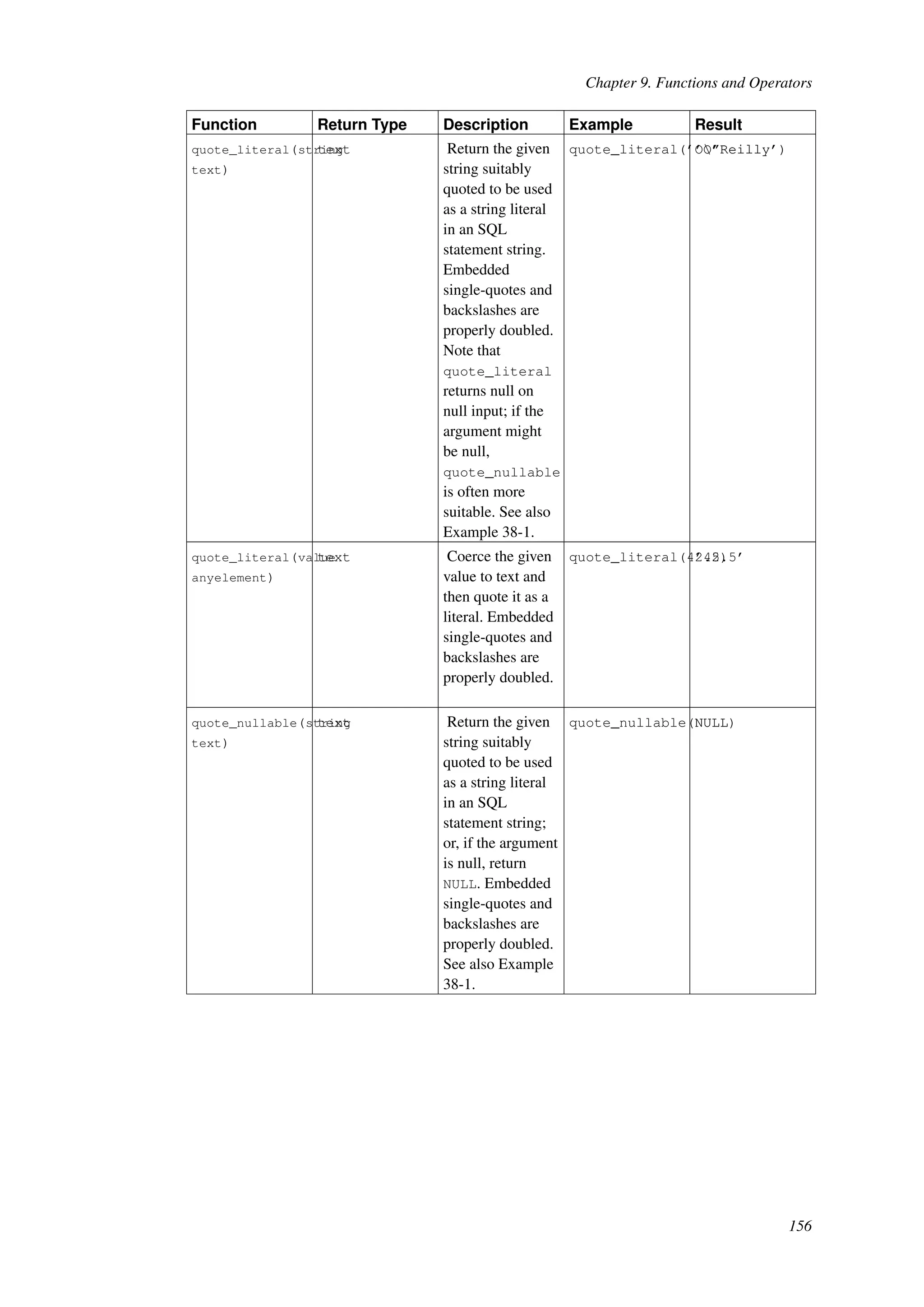
![Chapter 9. Functions and Operators Function Return Type Description Example Result quote_nullable(value anyelement) text Coerce the given value to text and then quote it as a literal; or, if the argument is null, return NULL. Embedded single-quotes and backslashes are properly doubled. quote_nullable(42.5)’42.5’ regexp_matches(string text, pattern text [, flags text]) setof text[] Return all captured substrings resulting from matching a POSIX regular expression against the string. See Section 9.7.3 for more information. regexp_matches(’foobarbequebaz’, ’(bar)(beque)’) {bar,beque} regexp_replace(string text, pattern text, replacement text [, flags text]) text Replace substring(s) matching a POSIX regular expression. See Section 9.7.3 for more information. regexp_replace(’Thomas’, ’.[mN]a.’, ’M’) ThM regexp_split_to_array(string text, pattern text [, flags text ]) text[] Split string using a POSIX regular expression as the delimiter. See Section 9.7.3 for more information. regexp_split_to_array(’hello world’, E’s+’) {hello,world} regexp_split_to_table(string text, pattern text [, flags text]) setof text Split string using a POSIX regular expression as the delimiter. See Section 9.7.3 for more information. regexp_split_to_table(’hello world’, E’s+’) helloworld (2 rows) repeat(string text, number int) text Repeat string the specified number of times repeat(’Pg’, 4) PgPgPgPg 157](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-214-2048.jpg)
![Chapter 9. Functions and Operators Function Return Type Description Example Result replace(string text, from text, to text) text Replace all occurrences in string of substring from with substring to replace(’abcdefabcdef’, ’cd’, ’XX’) abXXefabXXef rpad(string text, length int [, fill text]) text Fill up the string to length length by appending the characters fill (a space by default). If the string is already longer than length then it is truncated. rpad(’hi’, 5, ’xy’) hixyx rtrim(string text [, characters text]) text Remove the longest string containing only characters from characters (a space by default) from the end of string rtrim(’trimxxxx’, ’x’) trim split_part(string text, delimiter text, field int) text Split string on delimiter and return the given field (counting from one) split_part(’abc~@~def~@~ghi’, ’~@~’, 2) def strpos(string, substring) int Location of specified substring (same as position(substring in string), but note the reversed argument order) strpos(’high’, ’ig’) 2 substr(string, from [, count]) text Extract substring (same as substring(string from from for count)) substr(’alphabet’, 3, 2) ph to_ascii(string text [, encoding text]) text Convert string to ASCII from another encoding (only supports conversion from LATIN1, LATIN2, LATIN9, and WIN1250 encodings) to_ascii(’Karel’)Karel 158](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-215-2048.jpg)
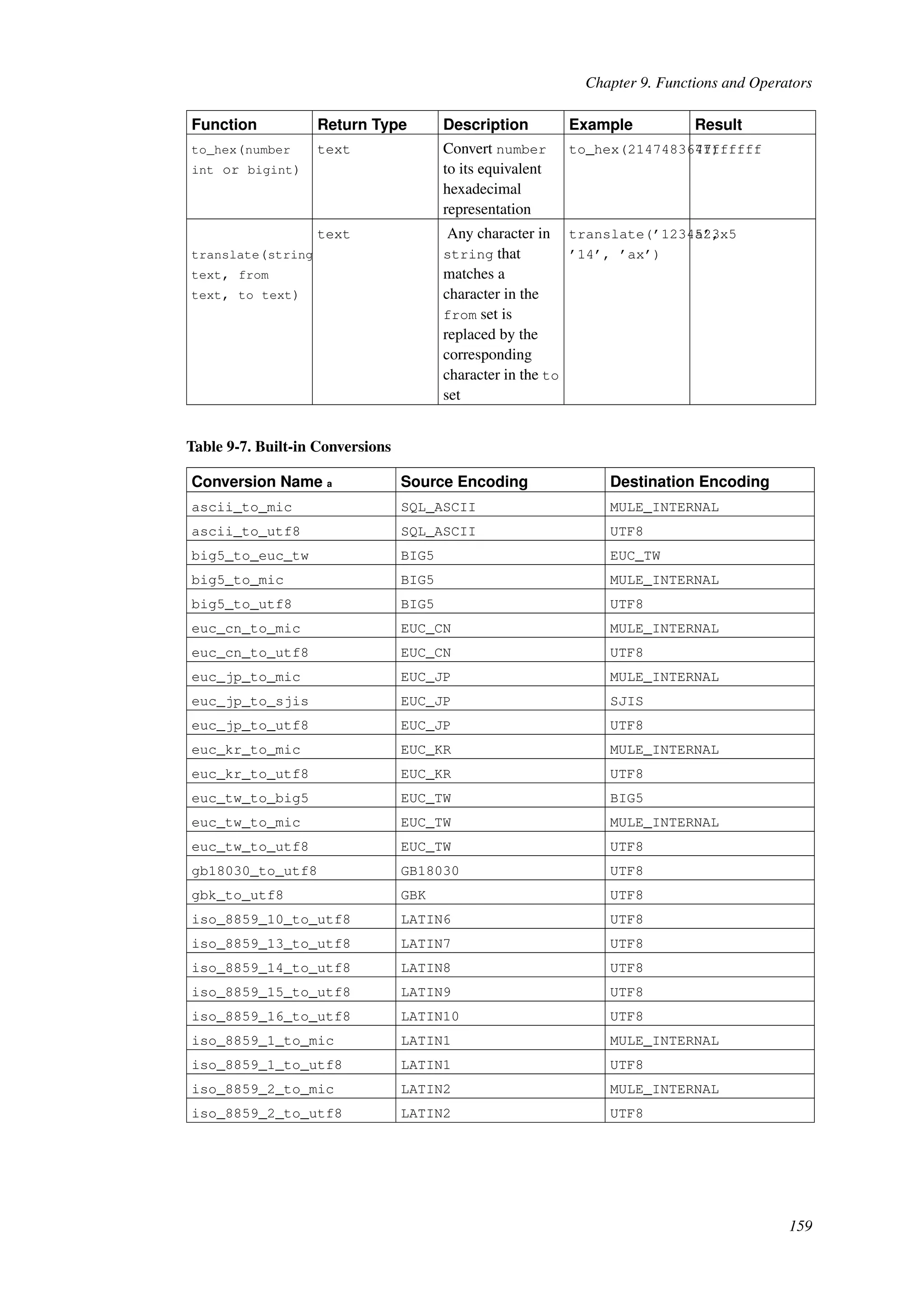
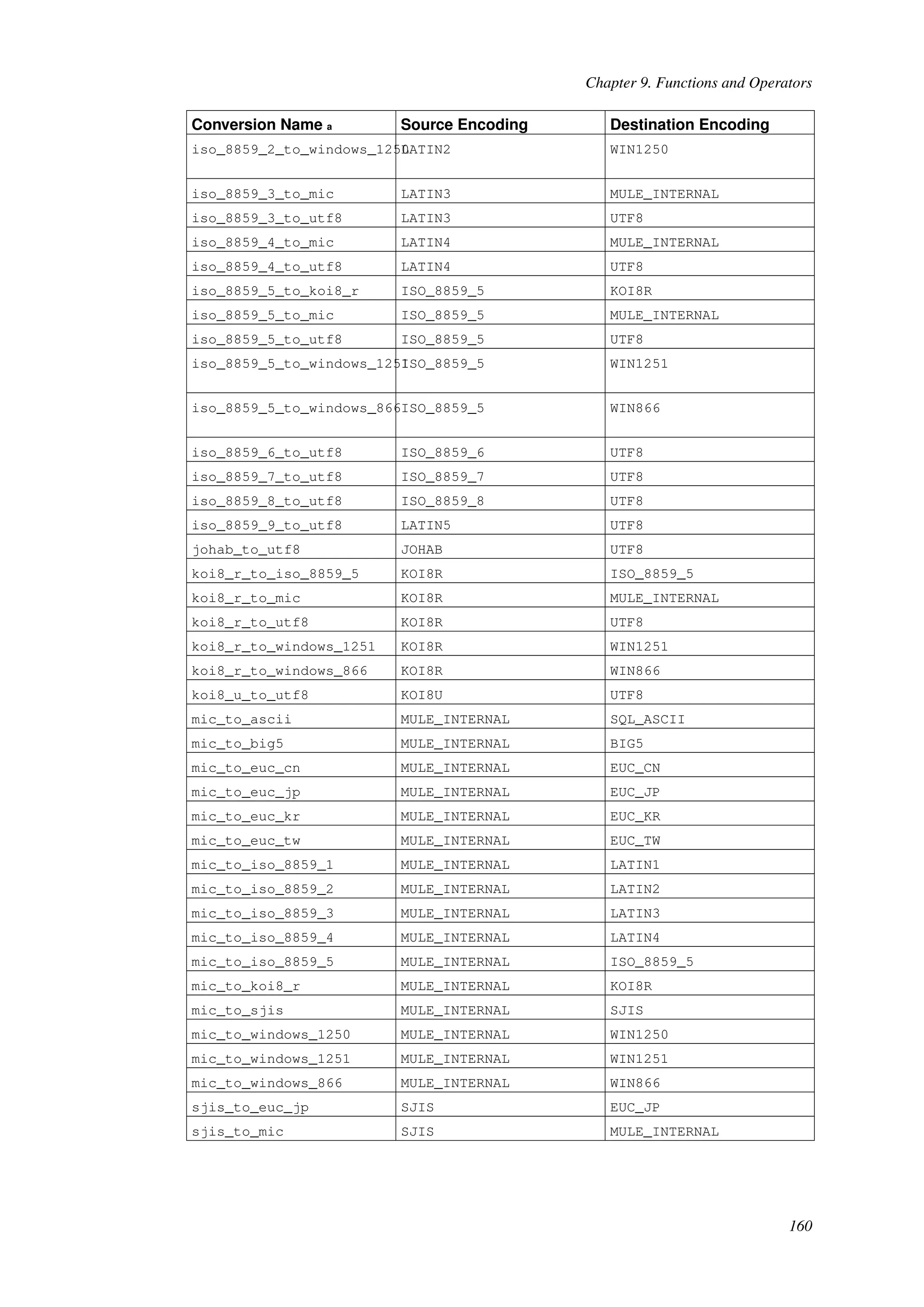
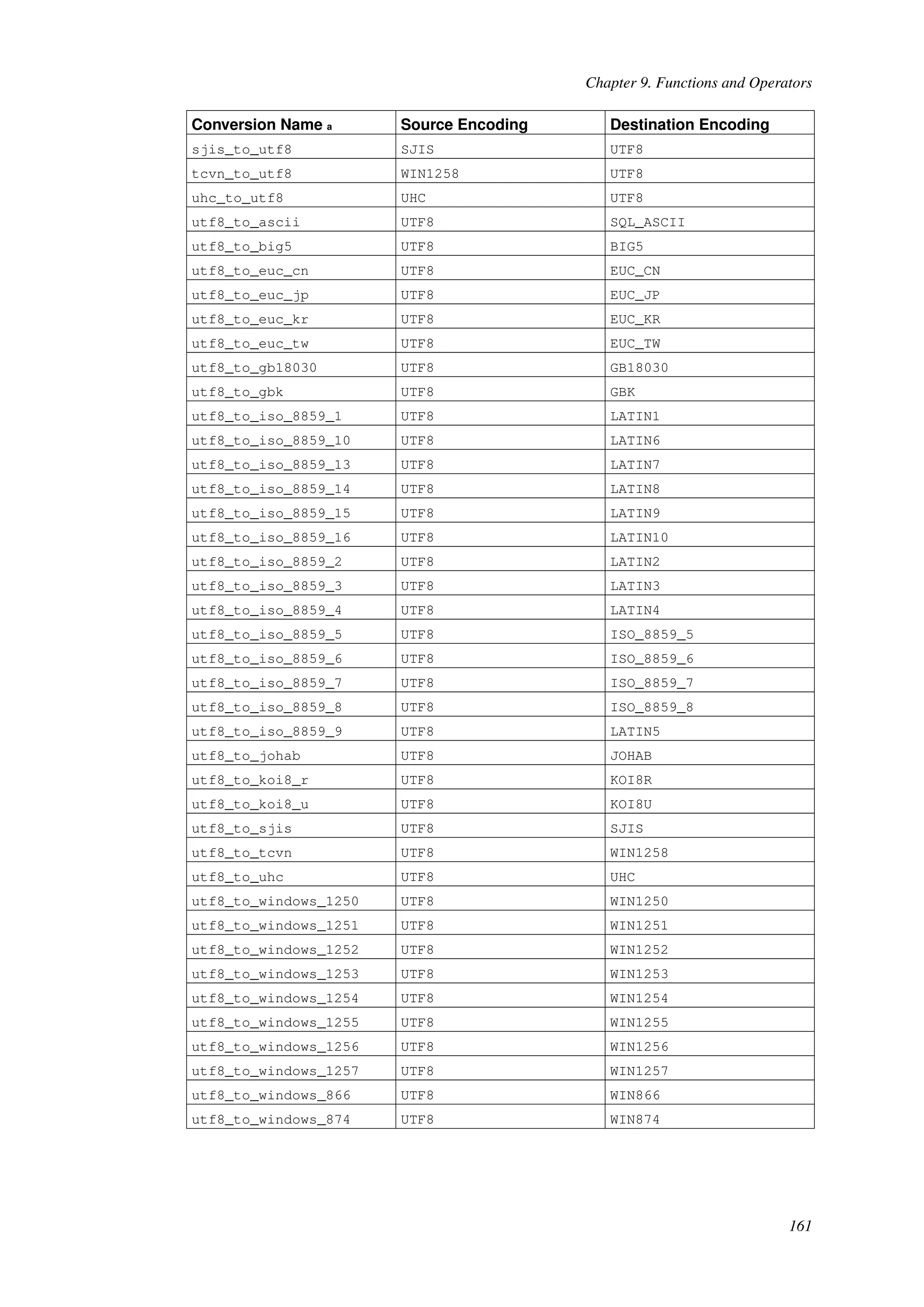

![Chapter 9. Functions and Operators Table 9-8. SQL Binary String Functions and Operators Function Return Type Description Example Result string || string bytea String concatenation E’Post’::bytea || E’047gres000’::bytea Post’gres000 get_bit(string, offset) int Extract bit from string get_bit(E’Th000omas’::bytea, 45) 1 get_byte(string, offset) int Extract byte from string get_byte(E’Th000omas’::bytea, 4) 109 octet_length(string)int Number of bytes in binary string octet_length(E’jo000se’::bytea)5 position(substring in string) int Location of specified substring position(E’000om’::bytea in E’Th000omas’::bytea) 3 set_bit(string, offset, newvalue) bytea Set bit in string set_bit(E’Th000omas’::bytea, 45, 0) Th000omAs set_byte(string, offset, newvalue) bytea Set byte in string set_byte(E’Th000omas’::bytea, 4, 64) Th000o@as substring(string [from int] [for int]) bytea Extract substring substring(E’Th000omas’::bytea from 2 for 3) h000o trim([both] bytes from string) bytea Remove the longest string containing only the bytes in bytes from the start and end of string trim(E’000’::bytea from E’000Tom000’::bytea) Tom Additional binary string manipulation functions are available and are listed in Table 9-9. Some of them are used internally to implement the SQL-standard string functions listed in Table 9-8. Table 9-9. Other Binary String Functions Function Return Type Description Example Result btrim(string bytea, bytes bytea) bytea Remove the longest string consisting only of bytes in bytes from the start and end of string btrim(E’000trim000’::bytea, E’000’::bytea) trim 163](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-220-2048.jpg)

![Chapter 9. Functions and Operators Operator Description Example Result ~ bitwise NOT ~ B’10001’ 01110 << bitwise shift left B’10001’ << 3 01000 >> bitwise shift right B’10001’ >> 2 00100 The following SQL-standard functions work on bit strings as well as character strings: length, bit_length, octet_length, position, substring. In addition, it is possible to cast integral values to and from type bit. Some examples: 44::bit(10) 0000101100 44::bit(3) 100 cast(-44 as bit(12)) 111111010100 ’1110’::bit(4)::integer 14 Note that casting to just “bit” means casting to bit(1), and so will deliver only the least significant bit of the integer. Note: Prior to PostgreSQL 8.0, casting an integer to bit(n) would copy the leftmost n bits of the integer, whereas now it copies the rightmost n bits. Also, casting an integer to a bit string width wider than the integer itself will sign-extend on the left. 9.7. Pattern Matching There are three separate approaches to pattern matching provided by PostgreSQL: the traditional SQL LIKE operator, the more recent SIMILAR TO operator (added in SQL:1999), and POSIX-style regular expressions. Aside from the basic “does this string match this pattern?” operators, functions are available to extract or replace matching substrings and to split a string at matching locations. Tip: If you have pattern matching needs that go beyond this, consider writing a user-defined function in Perl or Tcl. 9.7.1. LIKE string LIKE pattern [ESCAPE escape-character] string NOT LIKE pattern [ESCAPE escape-character] The LIKE expression returns true if the string matches the supplied pattern. (As expected, the NOT LIKE expression returns false if LIKE returns true, and vice versa. An equivalent expression is NOT (string LIKE pattern).) If pattern does not contain percent signs or underscores, then the pattern only represents the string itself; in that case LIKE acts like the equals operator. An underscore (_) in pattern stands for (matches) any single character; a percent sign (%) matches any sequence of zero or more characters. Some examples: ’abc’ LIKE ’abc’ true ’abc’ LIKE ’a%’ true 165](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-222-2048.jpg)
![Chapter 9. Functions and Operators ’abc’ LIKE ’_b_’ true ’abc’ LIKE ’c’ false LIKE pattern matching always covers the entire string. Therefore, to match a sequence anywhere within a string, the pattern must start and end with a percent sign. To match a literal underscore or percent sign without matching other characters, the respective char- acter in pattern must be preceded by the escape character. The default escape character is the back- slash but a different one can be selected by using the ESCAPE clause. To match the escape character itself, write two escape characters. Note that the backslash already has a special meaning in string literals, so to write a pattern constant that contains a backslash you must write two backslashes in an SQL statement (assuming escape string syntax is used, see Section 4.1.2.1). Thus, writing a pattern that actually matches a literal backslash means writing four backslashes in the statement. You can avoid this by selecting a different escape character with ESCAPE; then a backslash is not special to LIKE anymore. (But backslash is still special to the string literal parser, so you still need two of them to match a backslash.) It’s also possible to select no escape character by writing ESCAPE ”. This effectively disables the escape mechanism, which makes it impossible to turn off the special meaning of underscore and percent signs in the pattern. The key word ILIKE can be used instead of LIKE to make the match case-insensitive according to the active locale. This is not in the SQL standard but is a PostgreSQL extension. The operator ~~ is equivalent to LIKE, and ~~* corresponds to ILIKE. There are also !~~ and !~~* operators that represent NOT LIKE and NOT ILIKE, respectively. All of these operators are PostgreSQL-specific. 9.7.2. SIMILAR TO Regular Expressions string SIMILAR TO pattern [ESCAPE escape-character] string NOT SIMILAR TO pattern [ESCAPE escape-character] The SIMILAR TO operator returns true or false depending on whether its pattern matches the given string. It is similar to LIKE, except that it interprets the pattern using the SQL standard’s definition of a regular expression. SQL regular expressions are a curious cross between LIKE notation and common regular expression notation. Like LIKE, the SIMILAR TO operator succeeds only if its pattern matches the entire string; this is unlike common regular expression behavior where the pattern can match any part of the string. Also like LIKE, SIMILAR TO uses _ and % as wildcard characters denoting any single character and any string, respectively (these are comparable to . and .* in POSIX regular expressions). In addition to these facilities borrowed from LIKE, SIMILAR TO supports these pattern-matching metacharacters borrowed from POSIX regular expressions: • | denotes alternation (either of two alternatives). • * denotes repetition of the previous item zero or more times. • + denotes repetition of the previous item one or more times. • Parentheses () can be used to group items into a single logical item. • A bracket expression [...] specifies a character class, just as in POSIX regular expressions. 166](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-223-2048.jpg)

![Chapter 9. Functions and Operators of the string. Some examples: ’abc’ ~ ’abc’ true ’abc’ ~ ’^a’ true ’abc’ ~ ’(b|d)’ true ’abc’ ~ ’^(b|c)’ false The POSIX pattern language is described in much greater detail below. The substring function with two parameters, substring(string from pattern), provides ex- traction of a substring that matches a POSIX regular expression pattern. It returns null if there is no match, otherwise the portion of the text that matched the pattern. But if the pattern contains any paren- theses, the portion of the text that matched the first parenthesized subexpression (the one whose left parenthesis comes first) is returned. You can put parentheses around the whole expression if you want to use parentheses within it without triggering this exception. If you need parentheses in the pattern before the subexpression you want to extract, see the non-capturing parentheses described below. Some examples: substring(’foobar’ from ’o.b’) oob substring(’foobar’ from ’o(.)b’) o The regexp_replace function provides substitution of new text for substrings that match POSIX regular expression patterns. It has the syntax regexp_replace(source, pattern, replacement [, flags ]). The source string is returned unchanged if there is no match to the pattern. If there is a match, the source string is returned with the replacement string substituted for the matching substring. The replacement string can contain n, where n is 1 through 9, to indicate that the source substring matching the n’th parenthesized subexpression of the pattern should be inserted, and it can contain & to indicate that the substring matching the entire pattern should be inserted. Write if you need to put a literal backslash in the replacement text. (As always, remember to double backslashes written in literal constant strings, assuming escape string syntax is used.) The flags parameter is an optional text string containing zero or more single-letter flags that change the function’s behavior. Flag i specifies case-insensitive matching, while flag g specifies replacement of each matching substring rather than only the first one. Other supported flags are described in Table 9-19. Some examples: regexp_replace(’foobarbaz’, ’b..’, ’X’) fooXbaz regexp_replace(’foobarbaz’, ’b..’, ’X’, ’g’) fooXX regexp_replace(’foobarbaz’, ’b(..)’, E’X1Y’, ’g’) fooXarYXazY The regexp_matches function returns all of the captured substrings resulting from matching a POSIX regular expression pattern. It has the syntax regexp_matches(string, pattern [, flags ]). If there is no match to the pattern, the function returns no rows. If there is a match, the function returns a text array whose n’th element is the substring matching the n’th parenthesized subexpression of the pattern (not counting “non-capturing” parentheses; see below for details). If the pattern does not contain any parenthesized subexpressions, then the result is a single-element text array containing 168](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-225-2048.jpg)
![Chapter 9. Functions and Operators the substring matching the whole pattern. The flags parameter is an optional text string containing zero or more single-letter flags that change the function’s behavior. Flag g causes the function to find each match in the string, not only the first one, and return a row for each such match. Other supported flags are described in Table 9-19. Some examples: SELECT regexp_matches(’foobarbequebaz’, ’(bar)(beque)’); regexp_matches ---------------- {bar,beque} (1 row) SELECT regexp_matches(’foobarbequebazilbarfbonk’, ’(b[^b]+)(b[^b]+)’, ’g’); regexp_matches ---------------- {bar,beque} {bazil,barf} (2 rows) SELECT regexp_matches(’foobarbequebaz’, ’barbeque’); regexp_matches ---------------- {barbeque} (1 row) The regexp_split_to_table function splits a string using a POSIX regular expression pattern as a delimiter. It has the syntax regexp_split_to_table(string, pattern [, flags ]). If there is no match to the pattern, the function returns the string. If there is at least one match, for each match it returns the text from the end of the last match (or the beginning of the string) to the beginning of the match. When there are no more matches, it returns the text from the end of the last match to the end of the string. The flags parameter is an optional text string containing zero or more single-letter flags that change the function’s behavior. regexp_split_to_table supports the flags described in Table 9-19. The regexp_split_to_array function behaves the same as regexp_split_to_table, except that regexp_split_to_array returns its result as an array of text. It has the syntax regexp_split_to_array(string, pattern [, flags ]). The parameters are the same as for regexp_split_to_table. Some examples: SELECT foo FROM regexp_split_to_table(’the quick brown fox jumped over the lazy dog’, E’ foo -------- the quick brown fox jumped over the lazy dog (9 rows) 169](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-226-2048.jpg)

![Chapter 9. Functions and Operators A branch is zero or more quantified atoms or constraints, concatenated. It matches a match for the first, followed by a match for the second, etc; an empty branch matches the empty string. A quantified atom is an atom possibly followed by a single quantifier. Without a quantifier, it matches a match for the atom. With a quantifier, it can match some number of matches of the atom. An atom can be any of the possibilities shown in Table 9-12. The possible quantifiers and their meanings are shown in Table 9-13. A constraint matches an empty string, but matches only when specific conditions are met. A constraint can be used where an atom could be used, except it cannot be followed by a quantifier. The simple constraints are shown in Table 9-14; some more constraints are described later. Table 9-12. Regular Expression Atoms Atom Description (re) (where re is any regular expression) matches a match for re, with the match noted for possible reporting (?:re) as above, but the match is not noted for reporting (a “non-capturing” set of parentheses) (AREs only) . matches any single character [chars] a bracket expression, matching any one of the chars (see Section 9.7.3.2 for more detail) k (where k is a non-alphanumeric character) matches that character taken as an ordinary character, e.g., matches a backslash character c where c is alphanumeric (possibly followed by other characters) is an escape, see Section 9.7.3.3 (AREs only; in EREs and BREs, this matches c) { when followed by a character other than a digit, matches the left-brace character {; when followed by a digit, it is the beginning of a bound (see below) x where x is a single character with no other significance, matches that character An RE cannot end with . Note: Remember that the backslash () already has a special meaning in PostgreSQL string literals. To write a pattern constant that contains a backslash, you must write two backslashes in the statement, assuming escape string syntax is used (see Section 4.1.2.1). Table 9-13. Regular Expression Quantifiers Quantifier Matches * a sequence of 0 or more matches of the atom 171](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-228-2048.jpg)
![Chapter 9. Functions and Operators Quantifier Matches + a sequence of 1 or more matches of the atom ? a sequence of 0 or 1 matches of the atom {m} a sequence of exactly m matches of the atom {m,} a sequence of m or more matches of the atom {m,n} a sequence of m through n (inclusive) matches of the atom; m cannot exceed n *? non-greedy version of * +? non-greedy version of + ?? non-greedy version of ? {m}? non-greedy version of {m} {m,}? non-greedy version of {m,} {m,n}? non-greedy version of {m,n} The forms using {...} are known as bounds. The numbers m and n within a bound are unsigned decimal integers with permissible values from 0 to 255 inclusive. Non-greedy quantifiers (available in AREs only) match the same possibilities as their correspond- ing normal (greedy) counterparts, but prefer the smallest number rather than the largest number of matches. See Section 9.7.3.5 for more detail. Note: A quantifier cannot immediately follow another quantifier, e.g., ** is invalid. A quantifier cannot begin an expression or subexpression or follow ^ or |. Table 9-14. Regular Expression Constraints Constraint Description ^ matches at the beginning of the string $ matches at the end of the string (?=re) positive lookahead matches at any point where a substring matching re begins (AREs only) (?!re) negative lookahead matches at any point where no substring matching re begins (AREs only) Lookahead constraints cannot contain back references (see Section 9.7.3.3), and all parentheses within them are considered non-capturing. 9.7.3.2. Bracket Expressions A bracket expression is a list of characters enclosed in []. It normally matches any single character from the list (but see below). If the list begins with ^, it matches any single character not from the rest of the list. If two characters in the list are separated by -, this is shorthand for the full range of characters between those two (inclusive) in the collating sequence, e.g., [0-9] in ASCII matches any decimal digit. It is illegal for two ranges to share an endpoint, e.g., a-c-e. Ranges are very collating-sequence-dependent, so portable programs should avoid relying on them. To include a literal ] in the list, make it the first character (after ^, if that is used). To include a literal -, make it the first or last character, or the second endpoint of a range. To use a literal - as 172](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-229-2048.jpg)
![Chapter 9. Functions and Operators the first endpoint of a range, enclose it in [. and .] to make it a collating element (see below). With the exception of these characters, some combinations using [ (see next paragraphs), and escapes (AREs only), all other special characters lose their special significance within a bracket expression. In particular, is not special when following ERE or BRE rules, though it is special (as introducing an escape) in AREs. Within a bracket expression, a collating element (a character, a multiple-character sequence that col- lates as if it were a single character, or a collating-sequence name for either) enclosed in [. and .] stands for the sequence of characters of that collating element. The sequence is treated as a single ele- ment of the bracket expression’s list. This allows a bracket expression containing a multiple-character collating element to match more than one character, e.g., if the collating sequence includes a ch collating element, then the RE [[.ch.]]*c matches the first five characters of chchcc. Note: PostgreSQL currently does not support multi-character collating elements. This information describes possible future behavior. Within a bracket expression, a collating element enclosed in [= and =] is an equivalence class, stand- ing for the sequences of characters of all collating elements equivalent to that one, including itself. (If there are no other equivalent collating elements, the treatment is as if the enclosing delimiters were [. and .].) For example, if o and ^ are the members of an equivalence class, then [[=o=]], [[=^=]], and [o^] are all synonymous. An equivalence class cannot be an endpoint of a range. Within a bracket expression, the name of a character class enclosed in [: and :] stands for the list of all characters belonging to that class. Standard character class names are: alnum, alpha, blank, cntrl, digit, graph, lower, print, punct, space, upper, xdigit. These stand for the character classes defined in ctype. A locale can provide others. A character class cannot be used as an endpoint of a range. There are two special cases of bracket expressions: the bracket expressions [[:<:]] and [[:>:]] are constraints, matching empty strings at the beginning and end of a word respectively. A word is defined as a sequence of word characters that is neither preceded nor followed by word characters. A word character is an alnum character (as defined by ctype) or an underscore. This is an extension, compatible with but not specified by POSIX 1003.2, and should be used with caution in software in- tended to be portable to other systems. The constraint escapes described below are usually preferable; they are no more standard, but are easier to type. 9.7.3.3. Regular Expression Escapes Escapes are special sequences beginning with followed by an alphanumeric character. Escapes come in several varieties: character entry, class shorthands, constraint escapes, and back references. A followed by an alphanumeric character but not constituting a valid escape is illegal in AREs. In EREs, there are no escapes: outside a bracket expression, a followed by an alphanumeric character merely stands for that character as an ordinary character, and inside a bracket expression, is an ordinary character. (The latter is the one actual incompatibility between EREs and AREs.) Character-entry escapes exist to make it easier to specify non-printing and other inconvenient char- acters in REs. They are shown in Table 9-15. Class-shorthand escapes provide shorthands for certain commonly-used character classes. They are shown in Table 9-16. A constraint escape is a constraint, matching the empty string if specific conditions are met, written as an escape. They are shown in Table 9-17. 173](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-230-2048.jpg)
![Chapter 9. Functions and Operators A back reference (n) matches the same string matched by the previous parenthesized subexpression specified by the number n (see Table 9-18). For example, ([bc])1 matches bb or cc but not bc or cb. The subexpression must entirely precede the back reference in the RE. Subexpressions are numbered in the order of their leading parentheses. Non-capturing parentheses do not define subex- pressions. Note: Keep in mind that an escape’s leading will need to be doubled when entering the pattern as an SQL string constant. For example: ’123’ ~ E’^d{3}’ true Table 9-15. Regular Expression Character-Entry Escapes Escape Description a alert (bell) character, as in C b backspace, as in C B synonym for backslash () to help reduce the need for backslash doubling cX (where X is any character) the character whose low-order 5 bits are the same as those of X, and whose other bits are all zero e the character whose collating-sequence name is ESC, or failing that, the character with octal value 033 f form feed, as in C n newline, as in C r carriage return, as in C t horizontal tab, as in C uwxyz (where wxyz is exactly four hexadecimal digits) the UTF16 (Unicode, 16-bit) character U+wxyz in the local byte ordering Ustuvwxyz (where stuvwxyz is exactly eight hexadecimal digits) reserved for a hypothetical Unicode extension to 32 bits v vertical tab, as in C xhhh (where hhh is any sequence of hexadecimal digits) the character whose hexadecimal value is 0xhhh (a single character no matter how many hexadecimal digits are used) 0 the character whose value is 0 (the null byte) xy (where xy is exactly two octal digits, and is not a back reference) the character whose octal value is 0xy 174](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-231-2048.jpg)
![Chapter 9. Functions and Operators Escape Description xyz (where xyz is exactly three octal digits, and is not a back reference) the character whose octal value is 0xyz Hexadecimal digits are 0-9, a-f, and A-F. Octal digits are 0-7. The character-entry escapes are always taken as ordinary characters. For example, 135 is ] in ASCII, but 135 does not terminate a bracket expression. Table 9-16. Regular Expression Class-Shorthand Escapes Escape Description d [[:digit:]] s [[:space:]] w [[:alnum:]_] (note underscore is included) D [^[:digit:]] S [^[:space:]] W [^[:alnum:]_] (note underscore is included) Within bracket expressions, d, s, and w lose their outer brackets, and D, S, and W are illegal. (So, for example, [a-cd] is equivalent to [a-c[:digit:]]. Also, [a-cD], which is equivalent to [a-c^[:digit:]], is illegal.) Table 9-17. Regular Expression Constraint Escapes Escape Description A matches only at the beginning of the string (see Section 9.7.3.5 for how this differs from ^) m matches only at the beginning of a word M matches only at the end of a word y matches only at the beginning or end of a word Y matches only at a point that is not the beginning or end of a word Z matches only at the end of the string (see Section 9.7.3.5 for how this differs from $) A word is defined as in the specification of [[:<:]] and [[:>:]] above. Constraint escapes are illegal within bracket expressions. Table 9-18. Regular Expression Back References Escape Description m (where m is a nonzero digit) a back reference to the m’th subexpression 175](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-232-2048.jpg)


![Chapter 9. Functions and Operators The above rules associate greediness attributes not only with individual quantified atoms, but with branches and entire REs that contain quantified atoms. What that means is that the matching is done in such a way that the branch, or whole RE, matches the longest or shortest possible substring as a whole. Once the length of the entire match is determined, the part of it that matches any particu- lar subexpression is determined on the basis of the greediness attribute of that subexpression, with subexpressions starting earlier in the RE taking priority over ones starting later. An example of what this means: SELECT SUBSTRING(’XY1234Z’, ’Y*([0-9]{1,3})’); Result: 123 SELECT SUBSTRING(’XY1234Z’, ’Y*?([0-9]{1,3})’); Result: 1 In the first case, the RE as a whole is greedy because Y* is greedy. It can match beginning at the Y, and it matches the longest possible string starting there, i.e., Y123. The output is the parenthesized part of that, or 123. In the second case, the RE as a whole is non-greedy because Y*? is non-greedy. It can match beginning at the Y, and it matches the shortest possible string starting there, i.e., Y1. The subexpression [0-9]{1,3} is greedy but it cannot change the decision as to the overall match length; so it is forced to match just 1. In short, when an RE contains both greedy and non-greedy subexpressions, the total match length is either as long as possible or as short as possible, according to the attribute assigned to the whole RE. The attributes assigned to the subexpressions only affect how much of that match they are allowed to “eat” relative to each other. The quantifiers {1,1} and {1,1}? can be used to force greediness or non-greediness, respectively, on a subexpression or a whole RE. Match lengths are measured in characters, not collating elements. An empty string is considered longer than no match at all. For example: bb* matches the three middle characters of abbbc; (week|wee)(night|knights) matches all ten characters of weeknights; when (.*).* is matched against abc the parenthesized subexpression matches all three characters; and when (a*)* is matched against bc both the whole RE and the parenthesized subexpression match an empty string. If case-independent matching is specified, the effect is much as if all case distinctions had vanished from the alphabet. When an alphabetic that exists in multiple cases appears as an ordinary character outside a bracket expression, it is effectively transformed into a bracket expression containing both cases, e.g., x becomes [xX]. When it appears inside a bracket expression, all case counterparts of it are added to the bracket expression, e.g., [x] becomes [xX] and [^x] becomes [^xX]. If newline-sensitive matching is specified, . and bracket expressions using ^ will never match the newline character (so that matches will never cross newlines unless the RE explicitly arranges it) and ^and $ will match the empty string after and before a newline respectively, in addition to matching at beginning and end of string respectively. But the ARE escapes A and Z continue to match beginning or end of string only. If partial newline-sensitive matching is specified, this affects . and bracket expressions as with newline-sensitive matching, but not ^ and $. If inverse partial newline-sensitive matching is specified, this affects ^ and $ as with newline-sensitive matching, but not . and bracket expressions. This isn’t very useful but is provided for symmetry. 178](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-235-2048.jpg)
![Chapter 9. Functions and Operators 9.7.3.6. Limits and Compatibility No particular limit is imposed on the length of REs in this implementation. However, programs in- tended to be highly portable should not employ REs longer than 256 bytes, as a POSIX-compliant implementation can refuse to accept such REs. The only feature of AREs that is actually incompatible with POSIX EREs is that does not lose its special significance inside bracket expressions. All other ARE features use syntax which is illegal or has undefined or unspecified effects in POSIX EREs; the *** syntax of directors likewise is outside the POSIX syntax for both BREs and EREs. Many of the ARE extensions are borrowed from Perl, but some have been changed to clean them up, and a few Perl extensions are not present. Incompatibilities of note include b, B, the lack of special treatment for a trailing newline, the addition of complemented bracket expressions to the things affected by newline-sensitive matching, the restrictions on parentheses and back references in lookahead constraints, and the longest/shortest-match (rather than first-match) matching semantics. Two significant incompatibilities exist between AREs and the ERE syntax recognized by pre-7.4 releases of PostgreSQL: • In AREs, followed by an alphanumeric character is either an escape or an error, while in previous releases, it was just another way of writing the alphanumeric. This should not be much of a problem because there was no reason to write such a sequence in earlier releases. • In AREs, remains a special character within [], so a literal within a bracket expression must be written . While these differences are unlikely to create a problem for most applications, you can avoid them if necessary by setting regex_flavor to extended. 9.7.3.7. Basic Regular Expressions BREs differ from EREs in several respects. In BREs, |, +, and ? are ordinary characters and there is no equivalent for their functionality. The delimiters for bounds are { and }, with { and } by themselves ordinary characters. The parentheses for nested subexpressions are ( and ), with ( and ) by themselves ordinary characters. ^ is an ordinary character except at the beginning of the RE or the beginning of a parenthesized subexpression, $ is an ordinary character except at the end of the RE or the end of a parenthesized subexpression, and * is an ordinary character if it appears at the beginning of the RE or the beginning of a parenthesized subexpression (after a possible leading ^). Finally, single-digit back references are available, and < and > are synonyms for [[:<:]] and [[:>:]] respectively; no other escapes are available in BREs. 9.8. Data Type Formatting Functions The PostgreSQL formatting functions provide a powerful set of tools for converting various data types (date/time, integer, floating point, numeric) to formatted strings and for converting from formatted strings to specific data types. Table 9-20 lists them. These functions all follow a common calling convention: the first argument is the value to be formatted and the second argument is a template that defines the output or input format. 179](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-236-2048.jpg)
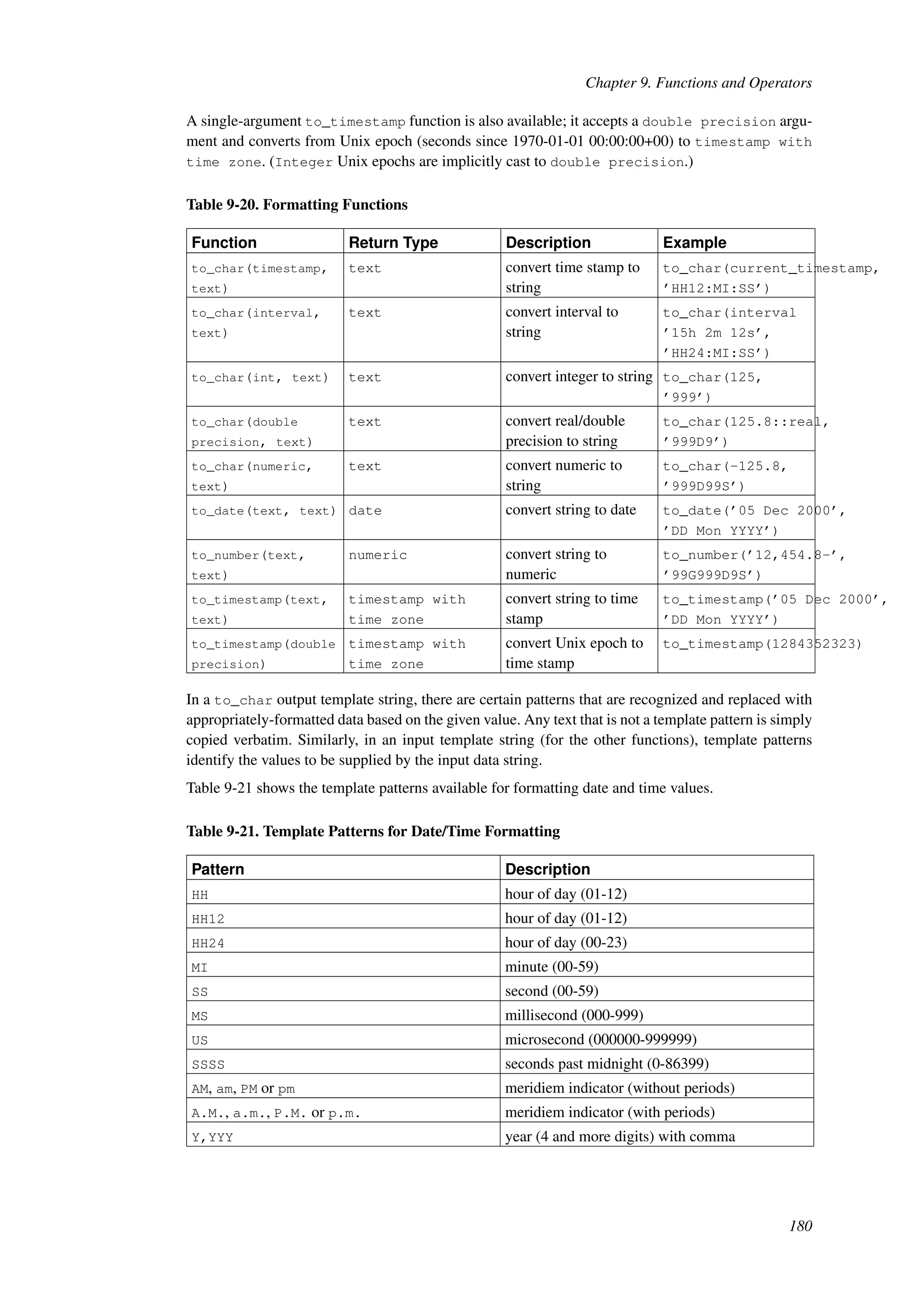
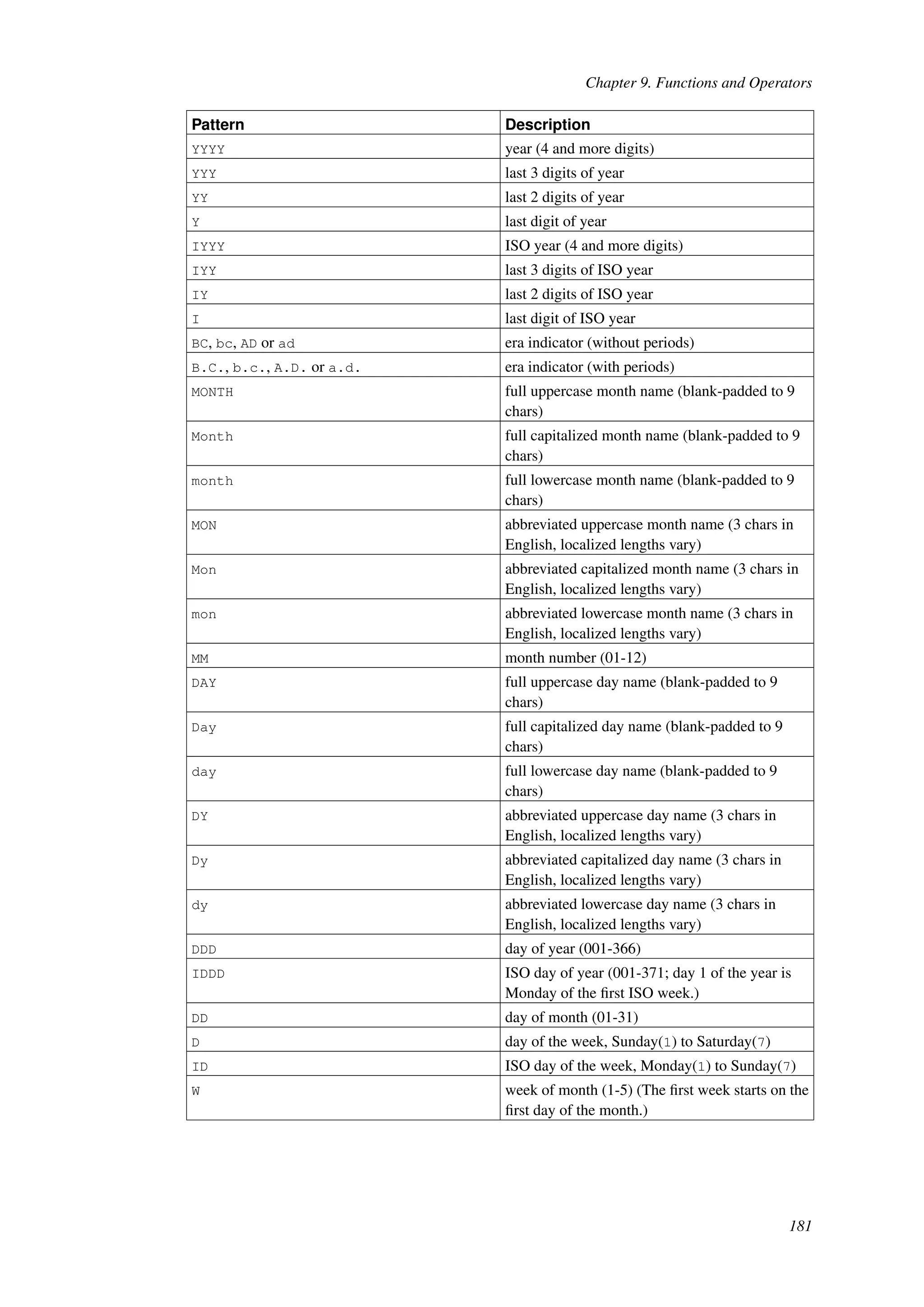
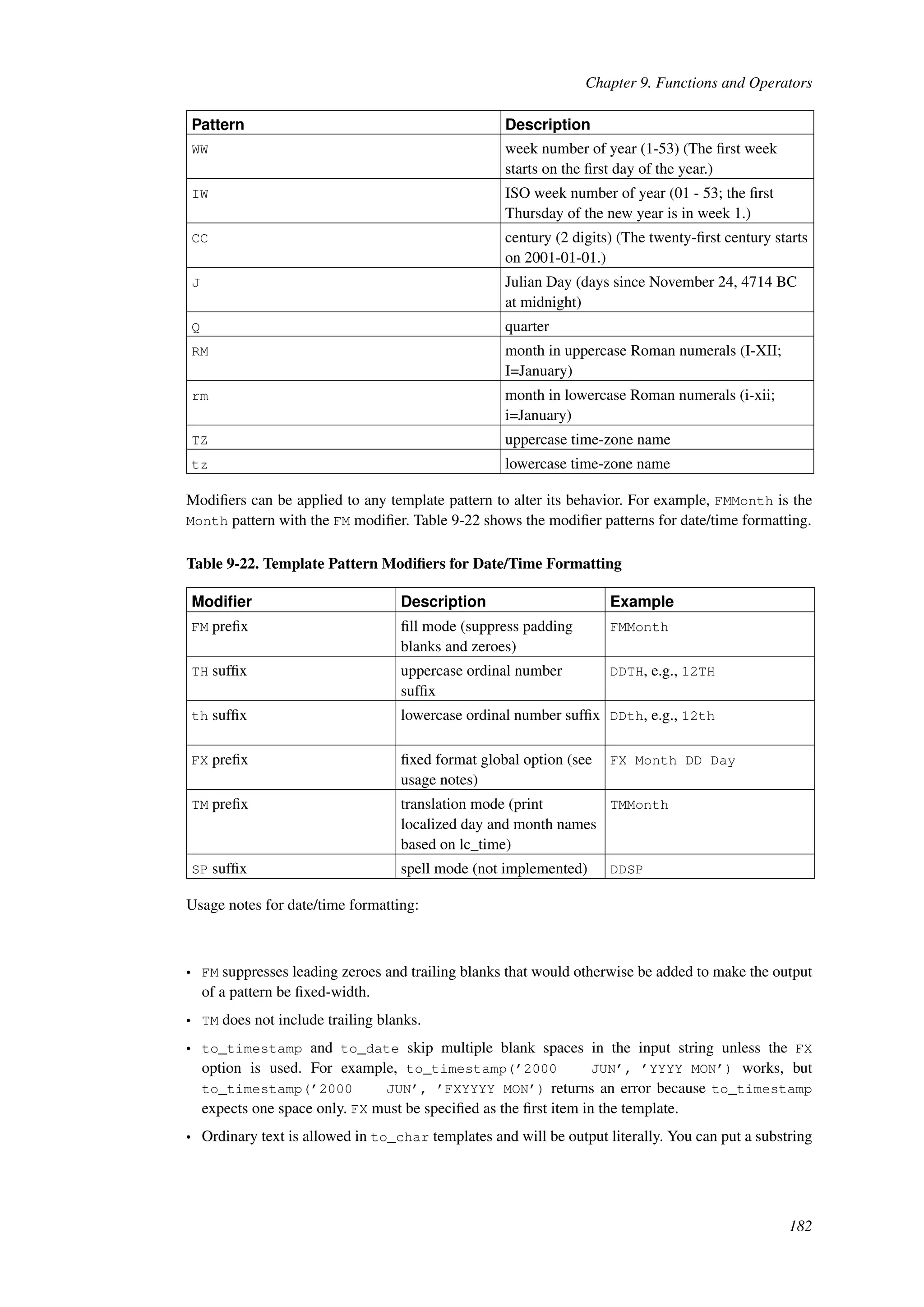

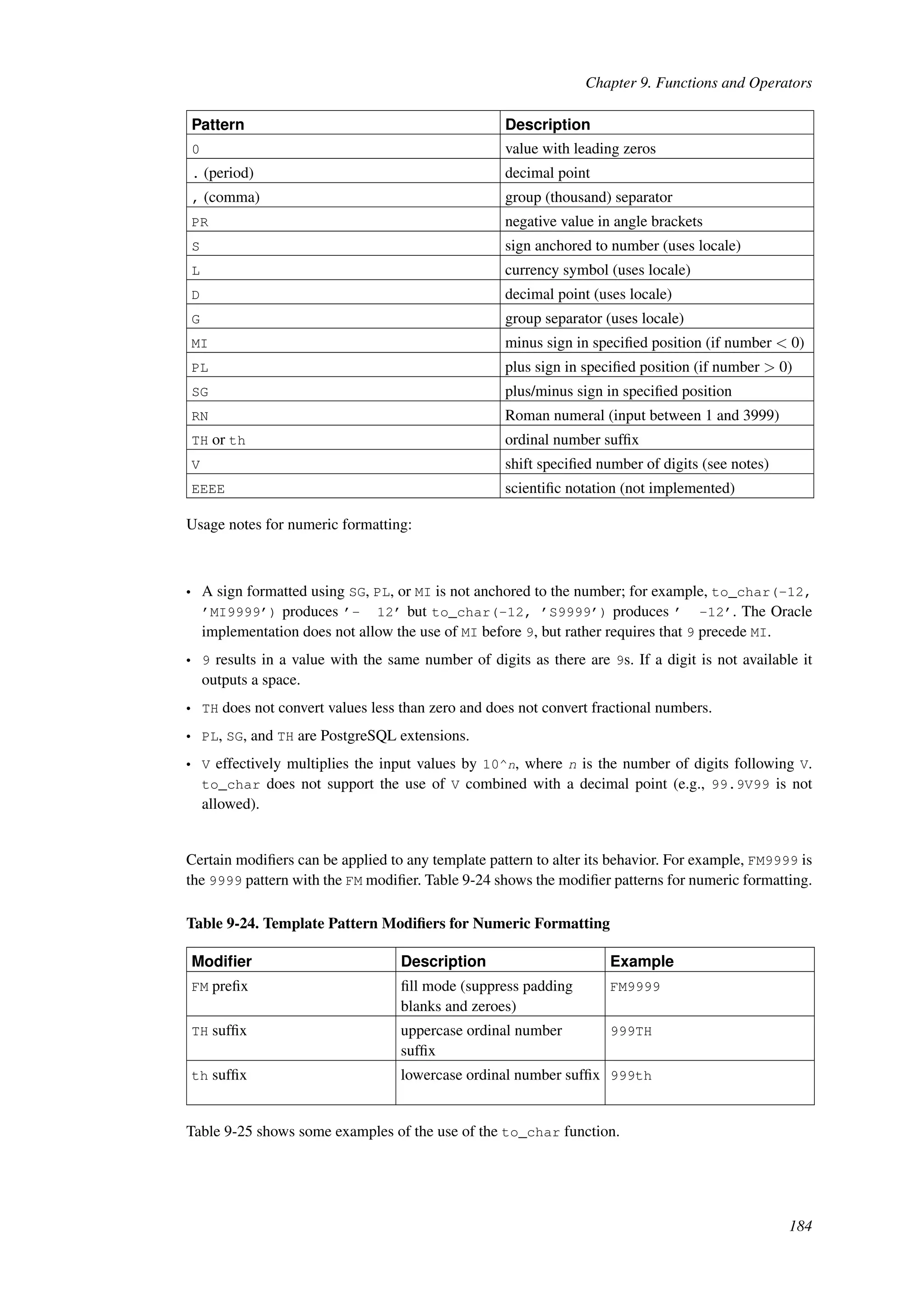
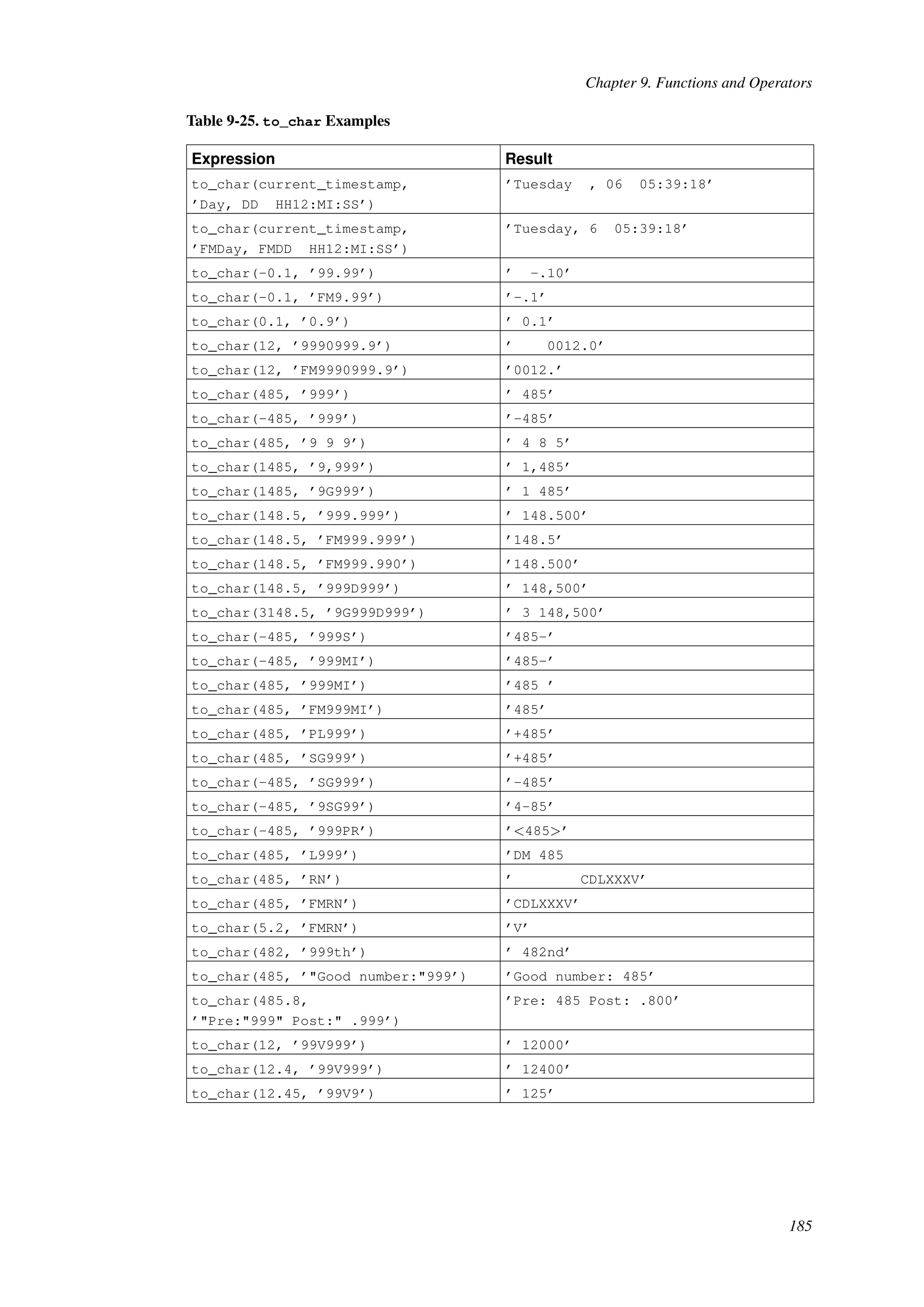
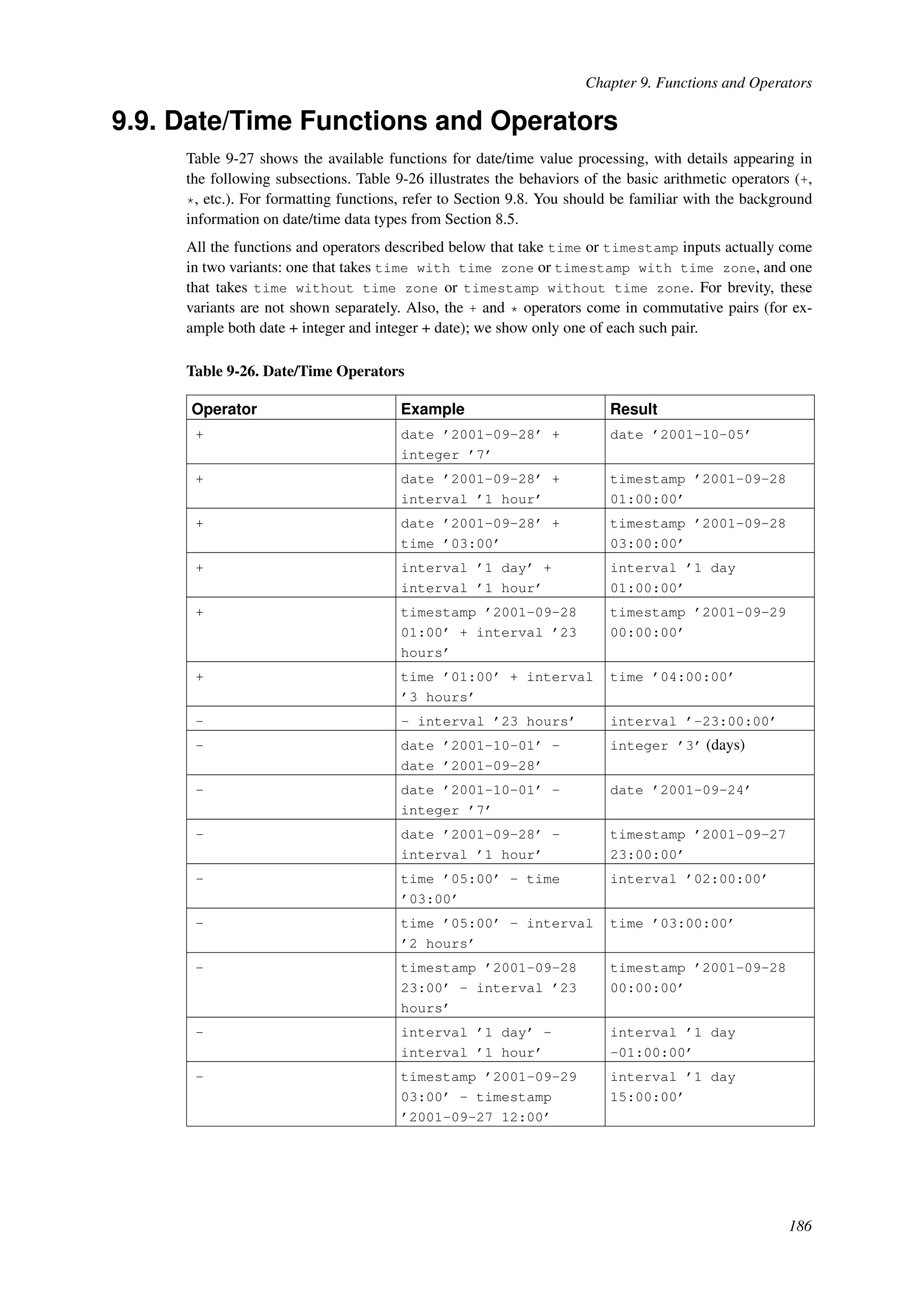
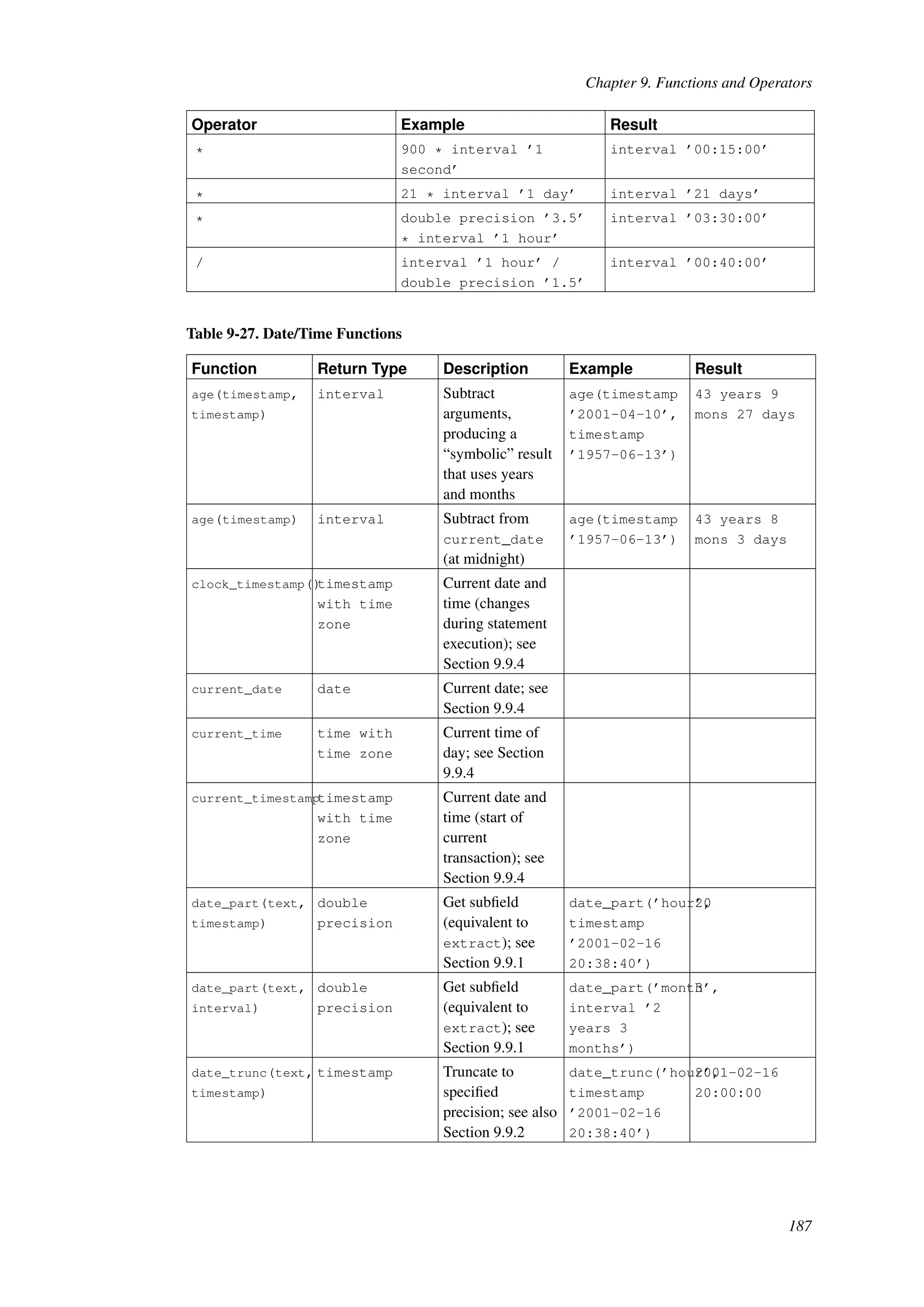
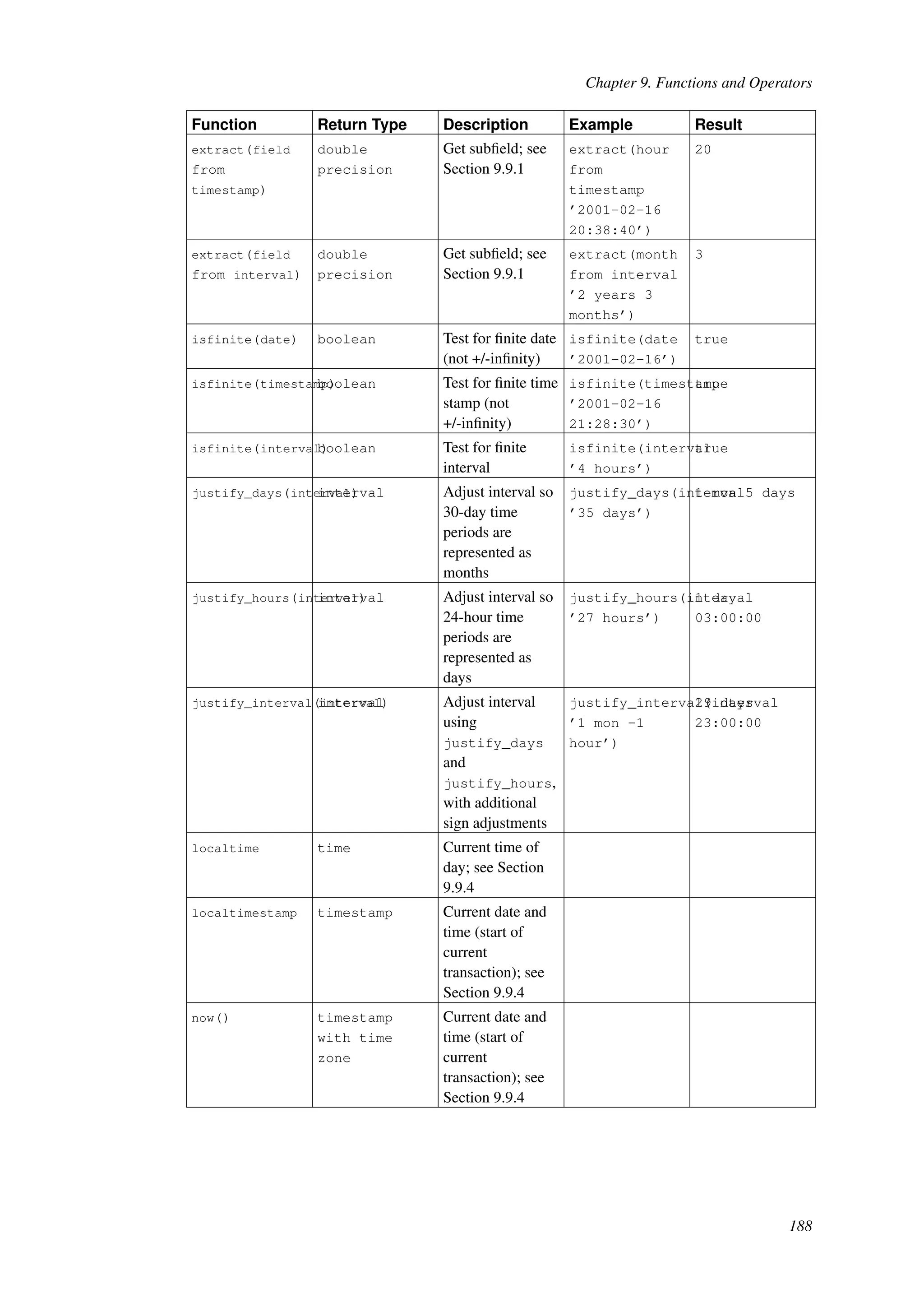


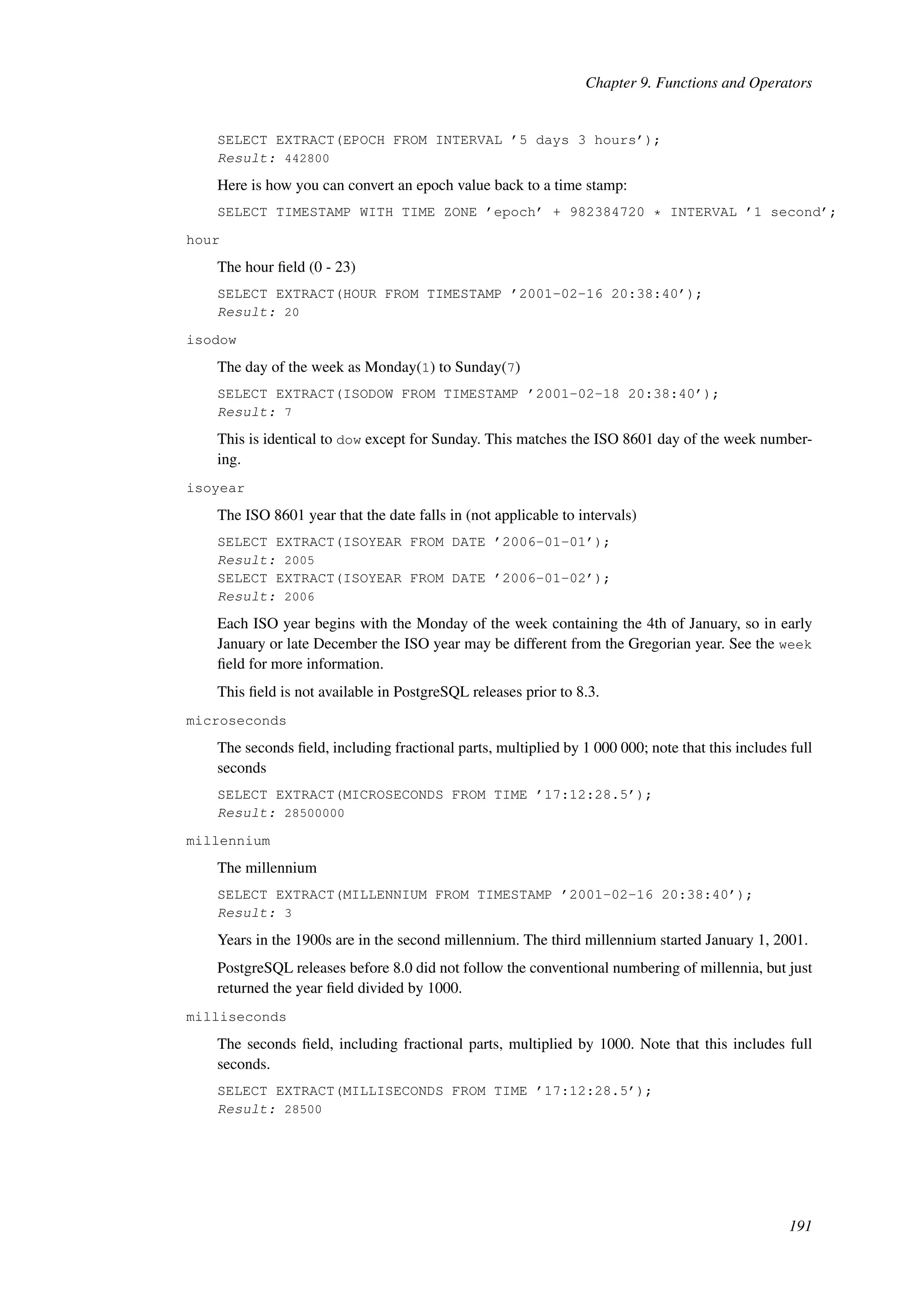





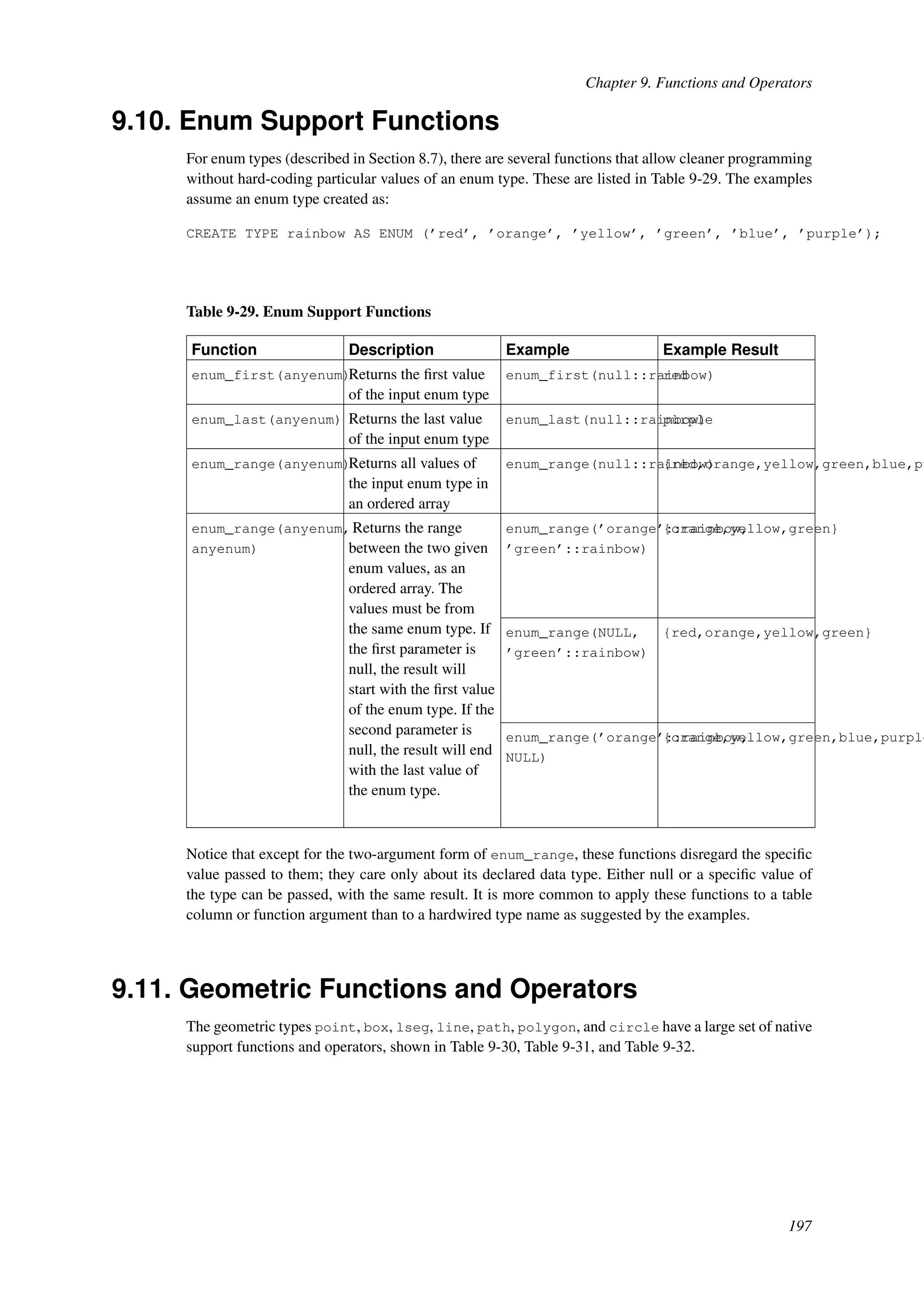
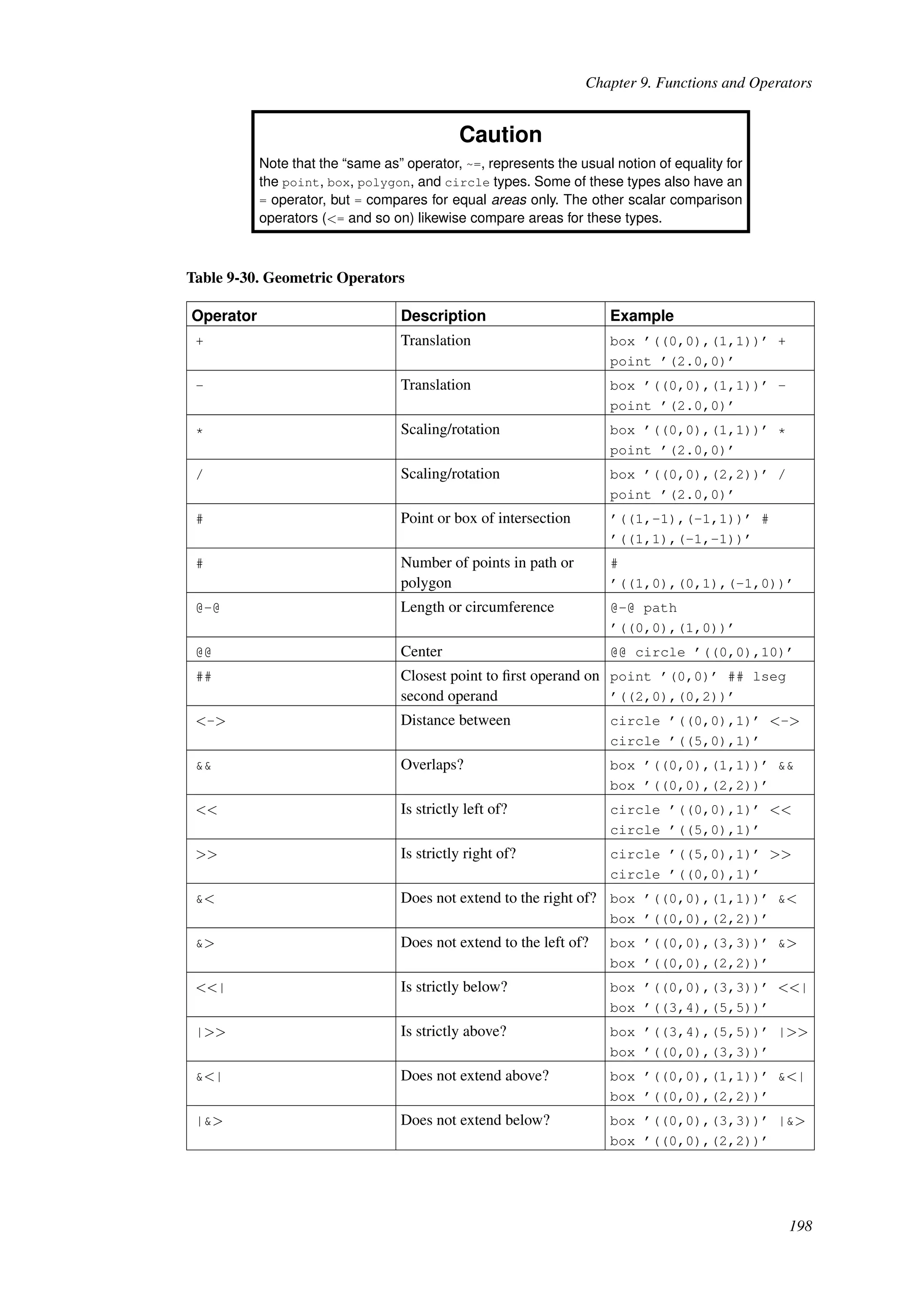
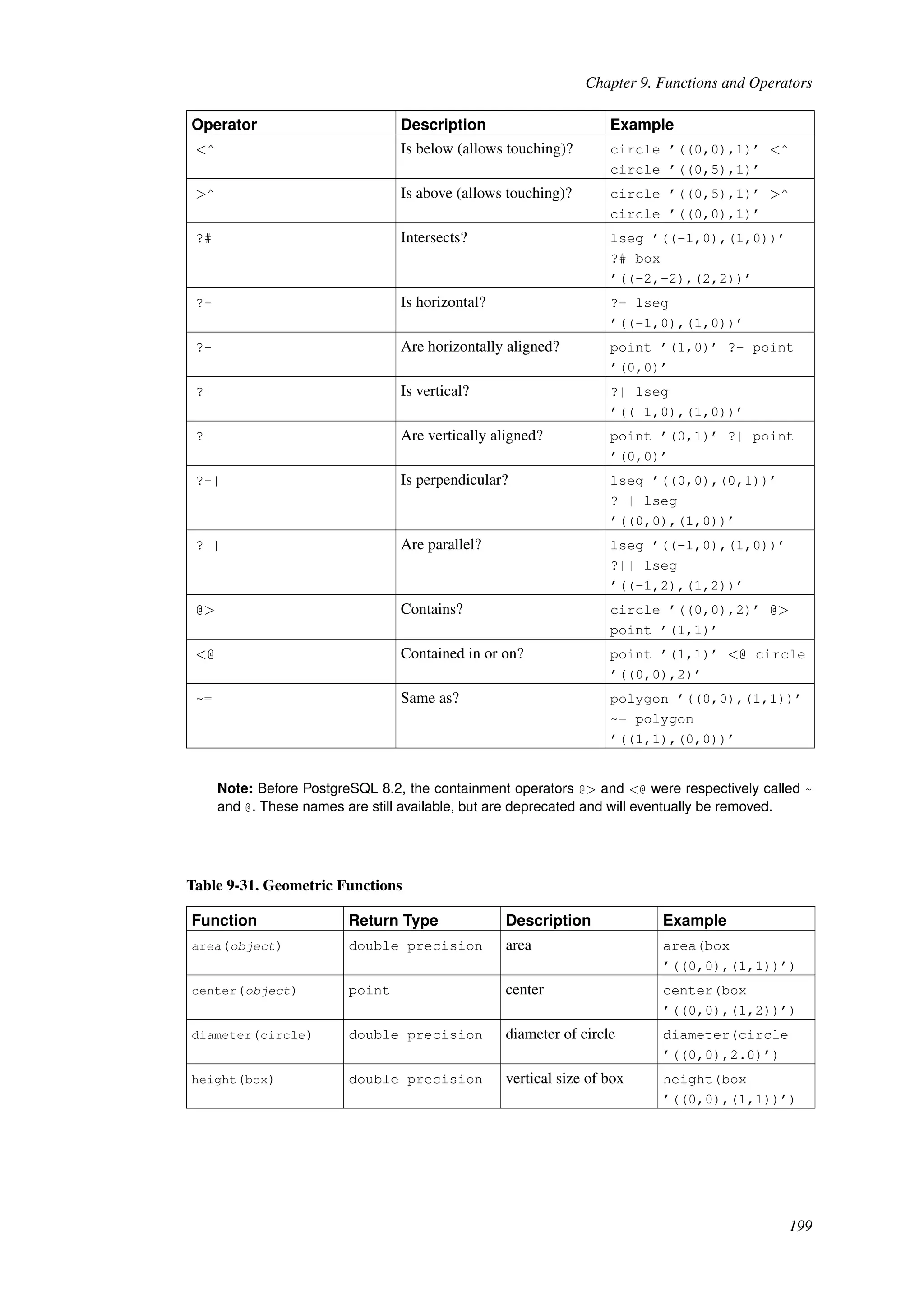
![Chapter 9. Functions and Operators Function Return Type Description Example isclosed(path) boolean a closed path? isclosed(path ’((0,0),(1,1),(2,0))’) isopen(path) boolean an open path? isopen(path ’[(0,0),(1,1),(2,0)]’) length(object) double precision length length(path ’((-1,0),(1,0))’) npoints(path) int number of points npoints(path ’[(0,0),(1,1),(2,0)]’) npoints(polygon) int number of points npoints(polygon ’((1,1),(0,0))’) pclose(path) path convert path to closed pclose(path ’[(0,0),(1,1),(2,0)]’) popen(path) path convert path to open popen(path ’((0,0),(1,1),(2,0))’) radius(circle) double precision radius of circle radius(circle ’((0,0),2.0)’) width(box) double precision horizontal size of box width(box ’((0,0),(1,1))’) Table 9-32. Geometric Type Conversion Functions Function Return Type Description Example box(circle) box circle to box box(circle ’((0,0),2.0)’) box(point, point) box points to box box(point ’(0,0)’, point ’(1,1)’) box(polygon) box polygon to box box(polygon ’((0,0),(1,1),(2,0))’) circle(box) circle box to circle circle(box ’((0,0),(1,1))’) circle(point, double precision) circle center and radius to circle circle(point ’(0,0)’, 2.0) circle(polygon) circle polygon to circle circle(polygon ’((0,0),(1,1),(2,0))’) lseg(box) lseg box diagonal to line segment lseg(box ’((-1,0),(1,0))’) 200](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-257-2048.jpg)
![Chapter 9. Functions and Operators Function Return Type Description Example lseg(point, point) lseg points to line segment lseg(point ’(-1,0)’, point ’(1,0)’) path(polygon) path polygon to path path(polygon ’((0,0),(1,1),(2,0))’) point(double precision, double precision) point construct point point(23.4, -44.5) point(box) point center of box point(box ’((-1,0),(1,0))’) point(circle) point center of circle point(circle ’((0,0),2.0)’) point(lseg) point center of line segment point(lseg ’((-1,0),(1,0))’) point(polygon) point center of polygon point(polygon ’((0,0),(1,1),(2,0))’) polygon(box) polygon box to 4-point polygon polygon(box ’((0,0),(1,1))’) polygon(circle) polygon circle to 12-point polygon polygon(circle ’((0,0),2.0)’) polygon(npts, circle) polygon circle to npts-point polygon polygon(12, circle ’((0,0),2.0)’) polygon(path) polygon path to polygon polygon(path ’((0,0),(1,1),(2,0))’) It is possible to access the two component numbers of a point as though the point were an array with indexes 0 and 1. For example, if t.p is a point column then SELECT p[0] FROM t retrieves the X coordinate and UPDATE t SET p[1] = ... changes the Y coordinate. In the same way, a value of type box or lseg can be treated as an array of two point values. The area function works for the types box, circle, and path. The area function only works on the path data type if the points in the path are non-intersecting. For example, the path ’((0,0),(0,1),(2,1),(2,2),(1,2),(1,0),(0,0))’::PATH will not work; however, the following visually identical path ’((0,0),(0,1),(1,1),(1,2),(2,2),(2,1),(1,1),(1,0),(0,0))’::PATH will work. If the concept of an intersecting versus non-intersecting path is confusing, draw both of the above paths side by side on a piece of graph paper. 9.12. Network Address Functions and Operators Table 9-33 shows the operators available for the cidr and inet types. The operators <<, <<=, >>, and >>= test for subnet inclusion. They consider only the network parts of the two addresses (ignoring any host part) and determine whether one network is identical to or a subnet of the other. 201](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-258-2048.jpg)
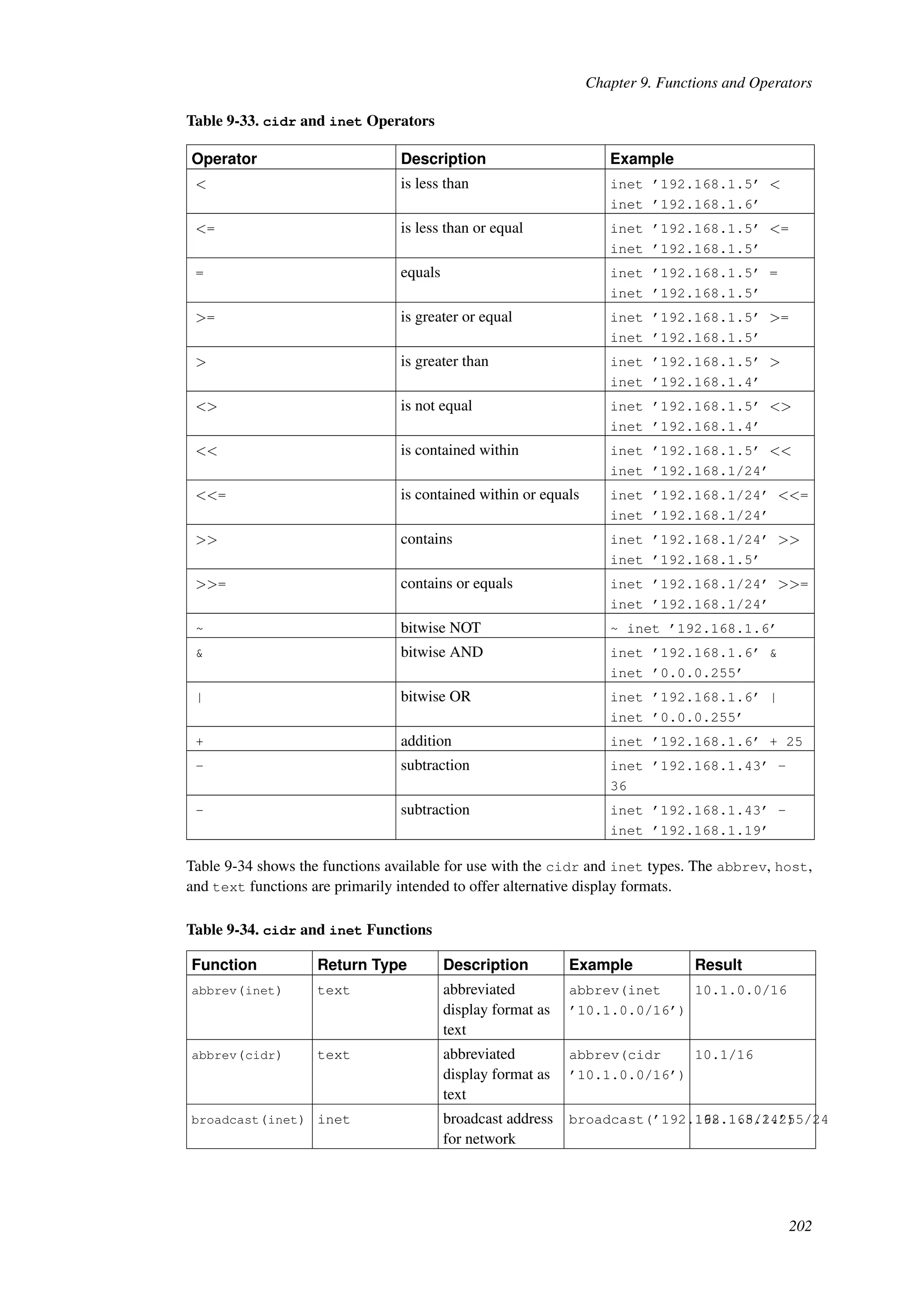

![Chapter 9. Functions and Operators Table 9-36. Text Search Operators Operator Description Example Result @@ tsvector matches tsquery ? to_tsvector(’fat cats ate rats’) @@ to_tsquery(’cat & rat’) t @@@ deprecated synonym for @@ to_tsvector(’fat cats ate rats’) @@@ to_tsquery(’cat & rat’) t || concatenate tsvectors ’a:1 b:2’::tsvector || ’c:1 d:2 b:3’::tsvector ’a’:1 ’b’:2,5 ’c’:3 ’d’:4 && AND tsquerys together ’fat | rat’::tsquery && ’cat’::tsquery ( ’fat’ | ’rat’ ) & ’cat’ || OR tsquerys together ’fat | rat’::tsquery || ’cat’::tsquery ( ’fat’ | ’rat’ ) | ’cat’ !! negate a tsquery !! ’cat’::tsquery !’cat’ @> tsquery contains another ? ’cat’::tsquery @> ’cat & rat’::tsquery f <@ tsquery is contained in ? ’cat’::tsquery <@ ’cat & rat’::tsquery t Note: The tsquery containment operators consider only the lexemes listed in the two queries, ignoring the combining operators. In addition to the operators shown in the table, the ordinary B-tree comparison operators (=, <, etc) are defined for types tsvector and tsquery. These are not very useful for text searching but allow, for example, unique indexes to be built on columns of these types. Table 9-37. Text Search Functions Function Return Type Description Example Result to_tsvector([ config regconfig , ] document text) tsvector reduce document text to tsvector to_tsvector(’english’, ’The Fat Rats’) ’fat’:2 ’rat’:3 204](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-261-2048.jpg)
![Chapter 9. Functions and Operators Function Return Type Description Example Result length(tsvector) integer number of lexemes in tsvector length(’fat:2,4 cat:3 rat:5A’::tsvector) 3 setweight(tsvector, "char") tsvector assign weight to each element of tsvector setweight(’fat:2,4 cat:3 rat:5B’::tsvector, ’A’) ’cat’:3A ’fat’:2A,4A ’rat’:5A strip(tsvector) tsvector remove positions and weights from tsvector strip(’fat:2,4 cat:3 rat:5A’::tsvector) ’cat’ ’fat’ ’rat’ to_tsquery([ config regconfig , ] query text) tsquery normalize words and convert to tsquery to_tsquery(’english’, ’The & Fat & Rats’) ’fat’ & ’rat’ plainto_tsquery([ config regconfig , ] query text) tsquery produce tsquery ignoring punctuation plainto_tsquery(’english’, ’The Fat Rats’) ’fat’ & ’rat’ numnode(tsquery) integer number of lexemes plus operators in tsquery numnode(’(fat & rat) | cat’::tsquery) 5 querytree(query tsquery) text get indexable part of a tsquery querytree(’foo & ! bar’::tsquery) ’foo’ ts_rank([ weights float4[], ] vector tsvector, query tsquery [, normalization integer ]) float4 rank document for query ts_rank(textsearch, query) 0.818 ts_rank_cd([ weights float4[], ] vector tsvector, query tsquery [, normalization integer ]) float4 rank document for query using cover density ts_rank_cd(’{0.1, 0.2, 0.4, 1.0}’, textsearch, query) 2.01317 205](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-262-2048.jpg)
![Chapter 9. Functions and Operators Function Return Type Description Example Result ts_headline([ config regconfig, ] document text, query tsquery [, options text ]) text display a query match ts_headline(’x y z’, ’z’::tsquery) x y <b>z</b> ts_rewrite(query tsquery, target tsquery, substitute tsquery) tsquery replace target with substitute within query ts_rewrite(’a & b’::tsquery, ’a’::tsquery, ’foo|bar’::tsquery) ’b’ & ( ’foo’ | ’bar’ ) ts_rewrite(query tsquery, select text) tsquery replace using targets and substitutes from a SELECT command SELECT ts_rewrite(’a & b’::tsquery, ’SELECT t,s FROM aliases’) ’b’ & ( ’foo’ | ’bar’ ) get_current_ts_config()regconfig get default text search configuration get_current_ts_config()english tsvector_update_trigger()trigger trigger function for automatic tsvector column update CREATE TRIGGER ... tsvector_update_trigger(tsvcol, ’pg_catalog.swedish’, title, body) tsvector_update_trigger_column()trigger trigger function for automatic tsvector column update CREATE TRIGGER ... tsvector_update_trigger_column(tsvcol, configcol, title, body) Note: All the text search functions that accept an optional regconfig argument will use the con- figuration specified by default_text_search_config when that argument is omitted. The functions in Table 9-38 are listed separately because they are not usually used in everyday text searching operations. They are helpful for development and debugging of new text search configura- tions. Table 9-38. Text Search Debugging Functions Function Return Type Description Example Result 206](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-263-2048.jpg)
![Chapter 9. Functions and Operators Function Return Type Description Example Result ts_debug([ config regconfig, ] document text, OUT alias text, OUT description text, OUT token text, OUT dictionaries regdictionary[], OUT dictionary regdictionary, OUT lexemes text[]) setof record test a configuration ts_debug(’english’, ’The Brightest supernovaes’) (asciiword,"Word, all ASCII",The,{english_stem},en ... ts_lexize(dict regdictionary, token text) text[] test a dictionary ts_lexize(’english_stem’, ’stars’) {star} ts_parse(parser_name text, document text, OUT tokid integer, OUT token text) setof record test a parser ts_parse(’default’, ’foo - bar’) (1,foo) ... ts_parse(parser_oid oid, document text, OUT tokid integer, OUT token text) setof record test a parser ts_parse(3722, ’foo - bar’) (1,foo) ... ts_token_type(parser_name text, OUT tokid integer, OUT alias text, OUT description text) setof record get token types defined by parser ts_token_type(’default’)(1,asciiword,"Word, all ASCII") ... ts_token_type(parser_oid oid, OUT tokid integer, OUT alias text, OUT description text) setof record get token types defined by parser ts_token_type(3722)(1,asciiword,"Word, all ASCII") ... 207](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-264-2048.jpg)
![Chapter 9. Functions and Operators Function Return Type Description Example Result ts_stat(sqlquery text, [ weights text, ] OUT word text, OUT ndoc integer, OUT nentry integer) setof record get statistics of a tsvector column ts_stat(’SELECT vector from apod’) (foo,10,15) ... 9.14. XML Functions The functions and function-like expressions described in this section operate on values of type xml. Check Section 8.13 for information about the xml type. The function-like expressions xmlparse and xmlserialize for converting to and from type xml are not repeated here. Use of many of these functions requires the installation to have been built with configure --with-libxml. 9.14.1. Producing XML Content A set of functions and function-like expressions are available for producing XML content from SQL data. As such, they are particularly suitable for formatting query results into XML documents for processing in client applications. 9.14.1.1. xmlcomment xmlcomment(text) The function xmlcomment creates an XML value containing an XML comment with the specified text as content. The text cannot contain “--” or end with a “-” so that the resulting construct is a valid XML comment. If the argument is null, the result is null. Example: SELECT xmlcomment(’hello’); xmlcomment -------------- <!--hello--> 9.14.1.2. xmlconcat xmlconcat(xml[, ...]) The function xmlconcat concatenates a list of individual XML values to create a single value con- taining an XML content fragment. Null values are omitted; the result is only null if there are no nonnull arguments. 208](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-265-2048.jpg)
![Chapter 9. Functions and Operators Example: SELECT xmlconcat(’<abc/>’, ’<bar>foo</bar>’); xmlconcat ---------------------- <abc/><bar>foo</bar> XML declarations, if present, are combined as follows. If all argument values have the same XML version declaration, that version is used in the result, else no version is used. If all argument values have the standalone declaration value “yes”, then that value is used in the result. If all argument values have a standalone declaration value and at least one is “no”, then that is used in the result. Else the result will have no standalone declaration. If the result is determined to require a standalone declaration but no version declaration, a version declaration with version 1.0 will be used because XML requires an XML declaration to contain a version declaration. Encoding declarations are ignored and removed in all cases. Example: SELECT xmlconcat(’<?xml version="1.1"?><foo/>’, ’<?xml version="1.1" standalone="no"?><ba xmlconcat ----------------------------------- <?xml version="1.1"?><foo/><bar/> 9.14.1.3. xmlelement xmlelement(name name [, xmlattributes(value [AS attname] [, ... ])] [, content, ...]) The xmlelement expression produces an XML element with the given name, attributes, and content. Examples: SELECT xmlelement(name foo); xmlelement ------------ <foo/> SELECT xmlelement(name foo, xmlattributes(’xyz’ as bar)); xmlelement ------------------ <foo bar="xyz"/> SELECT xmlelement(name foo, xmlattributes(current_date as bar), ’cont’, ’ent’); xmlelement ------------------------------------- <foo bar="2007-01-26">content</foo> 209](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-266-2048.jpg)
![Chapter 9. Functions and Operators Element and attribute names that are not valid XML names are escaped by replacing the offending characters by the sequence _xHHHH_, where HHHH is the character’s Unicode codepoint in hexadeci- mal notation. For example: SELECT xmlelement(name "foo$bar", xmlattributes(’xyz’ as "a&b")); xmlelement ---------------------------------- <foo_x0024_bar a_x0026_b="xyz"/> An explicit attribute name need not be specified if the attribute value is a column reference, in which case the column’s name will be used as the attribute name by default. In other cases, the attribute must be given an explicit name. So this example is valid: CREATE TABLE test (a xml, b xml); SELECT xmlelement(name test, xmlattributes(a, b)) FROM test; But these are not: SELECT xmlelement(name test, xmlattributes(’constant’), a, b) FROM test; SELECT xmlelement(name test, xmlattributes(func(a, b))) FROM test; Element content, if specified, will be formatted according to its data type. If the content is itself of type xml, complex XML documents can be constructed. For example: SELECT xmlelement(name foo, xmlattributes(’xyz’ as bar), xmlelement(name abc), xmlcomment(’test’), xmlelement(name xyz)); xmlelement ---------------------------------------------- <foo bar="xyz"><abc/><!--test--><xyz/></foo> Content of other types will be formatted into valid XML character data. This means in particular that the characters <, >, and & will be converted to entities. Binary data (data type bytea) will be represented in base64 or hex encoding, depending on the setting of the configuration parameter xmlbinary. The particular behavior for individual data types is expected to evolve in order to align the SQL and PostgreSQL data types with the XML Schema specification, at which point a more precise description will appear. 9.14.1.4. xmlforest xmlforest(content [AS name] [, ...]) The xmlforest expression produces an XML forest (sequence) of elements using the given names and content. Examples: SELECT xmlforest(’abc’ AS foo, 123 AS bar); 210](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-267-2048.jpg)
![Chapter 9. Functions and Operators xmlforest ------------------------------ <foo>abc</foo><bar>123</bar> SELECT xmlforest(table_name, column_name) FROM information_schema.columns WHERE table_schema = ’pg_catalog’; xmlforest ----------------------------------------------------------------------------------------- <table_name>pg_authid</table_name><column_name>rolname</column_name> <table_name>pg_authid</table_name><column_name>rolsuper</column_name> ... As seen in the second example, the element name can be omitted if the content value is a column reference, in which case the column name is used by default. Otherwise, a name must be specified. Element names that are not valid XML names are escaped as shown for xmlelement above. Simi- larly, content data is escaped to make valid XML content, unless it is already of type xml. Note that XML forests are not valid XML documents if they consist of more than one element, so it might be useful to wrap xmlforest expressions in xmlelement. 9.14.1.5. xmlpi xmlpi(name target [, content]) The xmlpi expression creates an XML processing instruction. The content, if present, must not con- tain the character sequence ?>. Example: SELECT xmlpi(name php, ’echo "hello world";’); xmlpi ----------------------------- <?php echo "hello world";?> 9.14.1.6. xmlroot xmlroot(xml, version text | no value [, standalone yes|no|no value]) The xmlroot expression alters the properties of the root node of an XML value. If a version is spec- ified, it replaces the value in the root node’s version declaration; if a standalone setting is specified, it replaces the value in the root node’s standalone declaration. SELECT xmlroot(xmlparse(document ’<?xml version="1.1"?><content>abc</content>’), version ’1.0’, standalone yes); xmlroot 211](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-268-2048.jpg)
![Chapter 9. Functions and Operators ---------------------------------------- <?xml version="1.0" standalone="yes"?> <content>abc</content> 9.14.1.7. xmlagg xmlagg(xml) The function xmlagg is, unlike the other functions described here, an aggregate function. It con- catenates the input values to the aggregate function call, like xmlconcat does. See Section 9.18 for additional information about aggregate functions. Example: CREATE TABLE test (y int, x xml); INSERT INTO test VALUES (1, ’<foo>abc</foo>’); INSERT INTO test VALUES (2, ’<bar/>’); SELECT xmlagg(x) FROM test; xmlagg ---------------------- <foo>abc</foo><bar/> To determine the order of the concatenation, something like the following approach can be used: SELECT xmlagg(x) FROM (SELECT * FROM test ORDER BY y DESC) AS tab; xmlagg ---------------------- <bar/><foo>abc</foo> Again, see Section 9.18 for additional information. 9.14.1.8. XML Predicates xml IS DOCUMENT The expression IS DOCUMENT returns true if the argument XML value is a proper XML document, false if it is not (that is, it is a content fragment), or null if the argument is null. See Section 8.13 about the difference between documents and content fragments. 9.14.2. Processing XML To process values of data type xml, PostgreSQL offers the function xpath, which evaluates XPath 1.0 expressions. xpath(xpath, xml[, nsarray]) The function xpath evaluates the XPath expression xpath against the XML value xml. It returns an array of XML values corresponding to the node set produced by the XPath expression. 212](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-269-2048.jpg)
![Chapter 9. Functions and Operators The second argument must be a well formed XML document. In particular, it must have a single root node element. The third argument of the function is an array of namespace mappings. This array should be a two- dimensional array with the length of the second axis being equal to 2 (i.e., it should be an array of arrays, each of which consists of exactly 2 elements). The first element of each array entry is the namespace name, the second the namespace URI. Example: SELECT xpath(’/my:a/text()’, ’<my:a xmlns:my="http://example.com">test</my:a>’, ARRAY[ARRAY[’my’, ’http://example.com’]]); xpath -------- {test} (1 row) 9.14.3. Mapping Tables to XML The following functions map the contents of relational tables to XML values. They can be thought of as XML export functionality: table_to_xml(tbl regclass, nulls boolean, tableforest boolean, targetns text) query_to_xml(query text, nulls boolean, tableforest boolean, targetns text) cursor_to_xml(cursor refcursor, count int, nulls boolean, tableforest boolean, targetns text) The return type of each function is xml. table_to_xml maps the content of the named table, passed as parameter tbl. The regclass type accepts strings identifying tables using the usual notation, including optional schema qualifications and double quotes. query_to_xml executes the query whose text is passed as parameter query and maps the result set. cursor_to_xml fetches the indicated number of rows from the cursor specified by the parameter cursor. This variant is recommended if large tables have to be mapped, because the result value is built up in memory by each function. If tableforest is false, then the resulting XML document looks like this: <tablename> <row> <columnname1>data</columnname1> <columnname2>data</columnname2> </row> <row> ... </row> ... </tablename> If tableforest is true, the result is an XML content fragment that looks like this: <tablename> 213](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-270-2048.jpg)


![Chapter 9. Functions and Operators <xsl:template match="/*"> <xsl:variable name="schema" select="//xsd:schema"/> <xsl:variable name="tabletypename" select="$schema/xsd:element[@name=name(current())]/@type"/> <xsl:variable name="rowtypename" select="$schema/xsd:complexType[@name=$tabletypename]/xsd:sequence/xsd: <html> <head> <title><xsl:value-of select="name(current())"/></title> </head> <body> <table> <tr> <xsl:for-each select="$schema/xsd:complexType[@name=$rowtypename]/xsd:sequenc <th><xsl:value-of select="."/></th> </xsl:for-each> </tr> <xsl:for-each select="row"> <tr> <xsl:for-each select="*"> <td><xsl:value-of select="."/></td> </xsl:for-each> </tr> </xsl:for-each> </table> </body> </html> </xsl:template> </xsl:stylesheet> 9.15. Sequence Manipulation Functions This section describes functions for operating on sequence objects, also called sequence generators or just sequences. Sequence objects are special single-row tables created with CREATE SEQUENCE. Sequence objects are commonly used to generate unique identifiers for rows of a table. The sequence functions, listed in Table 9-39, provide simple, multiuser-safe methods for obtaining successive se- quence values from sequence objects. Table 9-39. Sequence Functions Function Return Type Description currval(regclass) bigint Return value most recently obtained with nextval for specified sequence lastval() bigint Return value most recently obtained with nextval for any sequence 216](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-273-2048.jpg)


![Chapter 9. Functions and Operators 9.16.1. CASE The SQL CASE expression is a generic conditional expression, similar to if/else statements in other programming languages: CASE WHEN condition THEN result [WHEN ...] [ELSE result] END CASE clauses can be used wherever an expression is valid. Each condition is an expression that returns a boolean result. If the condition’s result is true, the value of the CASE expression is the result that follows the condition, and the remainder of the CASE expression is not processed. If the condition’s result is not true, any subsequent WHEN clauses are examined in the same manner. If no WHEN condition yields true, the value of the CASE expression is the result of the ELSE clause. If the ELSE clause is omitted and no condition is true, the result is null. An example: SELECT * FROM test; a --- 1 2 3 SELECT a, CASE WHEN a=1 THEN ’one’ WHEN a=2 THEN ’two’ ELSE ’other’ END FROM test; a | case ---+------- 1 | one 2 | two 3 | other The data types of all the result expressions must be convertible to a single output type. See Section 10.5 for more details. There is a “simple” form of CASE expression that is a variant of the general form above: CASE expression WHEN value THEN result [WHEN ...] [ELSE result] END The first expression is computed, then compared to each of the value expressions in the WHEN clauses until one is found that is equal to it. If no match is found, the result of the ELSE clause (or a null value) is returned. This is similar to the switch statement in C. The example above can be written using the simple CASE syntax: 219](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-276-2048.jpg)
![Chapter 9. Functions and Operators SELECT a, CASE a WHEN 1 THEN ’one’ WHEN 2 THEN ’two’ ELSE ’other’ END FROM test; a | case ---+------- 1 | one 2 | two 3 | other A CASE expression does not evaluate any subexpressions that are not needed to determine the result. For example, this is a possible way of avoiding a division-by-zero failure: SELECT ... WHERE CASE WHEN x <> 0 THEN y/x > 1.5 ELSE false END; Note: As described in Section 34.6, functions and operators marked IMMUTABLE can be evaluated when the query is planned rather than when it is executed. This means that constant parts of a subexpression that is not evaluated during query execution might still be evaluated during query planning. 9.16.2. COALESCE COALESCE(value [, ...]) The COALESCE function returns the first of its arguments that is not null. Null is returned only if all arguments are null. It is often used to substitute a default value for null values when data is retrieved for display, for example: SELECT COALESCE(description, short_description, ’(none)’) ... Like a CASE expression, COALESCE only evaluates the arguments that are needed to determine the result; that is, arguments to the right of the first non-null argument are not evaluated. This SQL- standard function provides capabilities similar to NVL and IFNULL, which are used in some other database systems. 9.16.3. NULLIF NULLIF(value1, value2) The NULLIF function returns a null value if value1 equals value2; otherwise it returns value1. This can be used to perform the inverse operation of the COALESCE example given above: SELECT NULLIF(value, ’(none)’) ... 220](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-277-2048.jpg)
![Chapter 9. Functions and Operators If value1 is (none), return a null, otherwise return value1. 9.16.4. GREATEST and LEAST GREATEST(value [, ...]) LEAST(value [, ...]) The GREATEST and LEAST functions select the largest or smallest value from a list of any number of expressions. The expressions must all be convertible to a common data type, which will be the type of the result (see Section 10.5 for details). NULL values in the list are ignored. The result will be NULL only if all the expressions evaluate to NULL. Note that GREATEST and LEAST are not in the SQL standard, but are a common extension. Some other databases make them return NULL if any argument is NULL, rather than only when all are NULL. 9.17. Array Functions and Operators Table 9-40 shows the operators available for array types. Table 9-40. Array Operators Operator Description Example Result = equal ARRAY[1.1,2.1,3.1]::int[] = ARRAY[1,2,3] t <> not equal ARRAY[1,2,3] <> ARRAY[1,2,4] t < less than ARRAY[1,2,3] < ARRAY[1,2,4] t > greater than ARRAY[1,4,3] > ARRAY[1,2,4] t <= less than or equal ARRAY[1,2,3] <= ARRAY[1,2,3] t >= greater than or equal ARRAY[1,4,3] >= ARRAY[1,4,3] t @> contains ARRAY[1,4,3] @> ARRAY[3,1] t <@ is contained by ARRAY[2,7] <@ ARRAY[1,7,4,2,6] t && overlap (have elements in common) ARRAY[1,4,3] && ARRAY[2,1] t || array-to-array concatenation ARRAY[1,2,3] || ARRAY[4,5,6] {1,2,3,4,5,6} 221](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-278-2048.jpg)
![Chapter 9. Functions and Operators Operator Description Example Result || array-to-array concatenation ARRAY[1,2,3] || ARRAY[[4,5,6],[7,8,9]] {{1,2,3},{4,5,6},{7,8,9}} || element-to-array concatenation 3 || ARRAY[4,5,6] {3,4,5,6} || array-to-element concatenation ARRAY[4,5,6] || 7 {4,5,6,7} Array comparisons compare the array contents element-by-element, using the default B-Tree com- parison function for the element data type. In multidimensional arrays the elements are visited in row-major order (last subscript varies most rapidly). If the contents of two arrays are equal but the dimensionality is different, the first difference in the dimensionality information determines the sort order. (This is a change from versions of PostgreSQL prior to 8.2: older versions would claim that two arrays with the same contents were equal, even if the number of dimensions or subscript ranges were different.) See Section 8.14 for more details about array operator behavior. Table 9-41 shows the functions available for use with array types. See Section 8.14 for more informa- tion and examples of the use of these functions. Table 9-41. Array Functions Function Return Type Description Example Result array_append(anyarray, anyelement) anyarray append an element to the end of an array array_append(ARRAY[1,2], 3) {1,2,3} array_cat(anyarray, anyarray) anyarray concatenate two arrays array_cat(ARRAY[1,2,3], ARRAY[4,5]) {1,2,3,4,5} array_ndims(anyarray) int returns the number of dimensions of the array array_ndims(ARRAY[[1,2,3], [4,5,6]]) 2 array_dims(anyarray) text returns a text representation of array’s dimensions array_dims(ARRAY[[1,2,3], [4,5,6]]) [1:2][1:3] array_fill(anyelement, int[], [, int[]]) anyarray returns an array initialized with supplied value and dimensions, optionally with lower bounds other than 1 array_fill(7, ARRAY[3], ARRAY[2]) [2:4]={7,7,7} array_length(anyarray, int) int returns the length of the requested array dimension array_length(array[1,2,3], 1) 3 222](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-279-2048.jpg)
![Chapter 9. Functions and Operators Function Return Type Description Example Result array_lower(anyarray, int) int returns lower bound of the requested array dimension array_lower(’[0:2]={1,2,3}’::int[], 1) 0 array_prepend(anyelement, anyarray) anyarray append an element to the beginning of an array array_prepend(1, ARRAY[2,3]) {1,2,3} array_to_string(anyarray, text) text concatenates array elements using supplied delimiter array_to_string(ARRAY[1, 2, 3], ’~^~’) 1~^~2~^~3 array_upper(anyarray, int) int returns upper bound of the requested array dimension array_upper(ARRAY[1,2,3,4], 1) 4 string_to_array(text, text) text[] splits string into array elements using supplied delimiter string_to_array(’xx~^~yy~^~zz’, ’~^~’) {xx,yy,zz} unnest(anyarray) setof anyelement expand an array to a set of rows unnest(ARRAY[1,2])12 (2 rows) See also Section 9.18 about the aggregate function array_agg for use with arrays. 9.18. Aggregate Functions Aggregate functions compute a single result from a set of input values. The built-in aggregate func- tions are listed in Table 9-42 and Table 9-43. The special syntax considerations for aggregate functions are explained in Section 4.2.7. Consult Section 2.7 for additional introductory information. Table 9-42. General-Purpose Aggregate Functions Function Argument Type Return Type Description array_agg(expression) any array of the argument type input values concatenated into an array avg(expression) smallint, int, bigint, real, double precision, numeric, or interval numeric for any integer-type argument, double precision for a floating-point argument, otherwise the same as the argument data type the average (arithmetic mean) of all input values bit_and(expression) smallint, int, bigint, or bit same as argument data type the bitwise AND of all non-null input values, or null if none 223](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-280-2048.jpg)
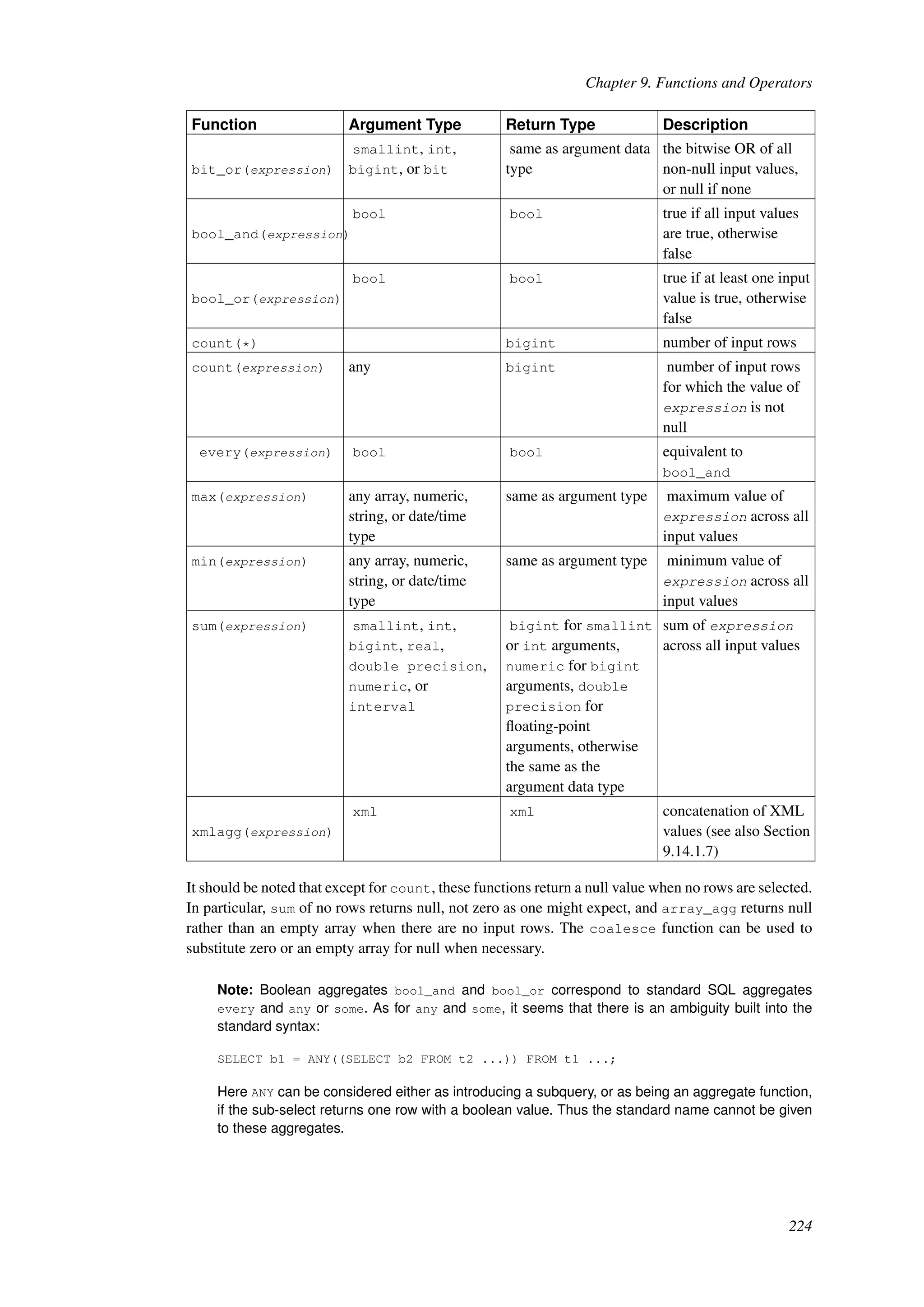
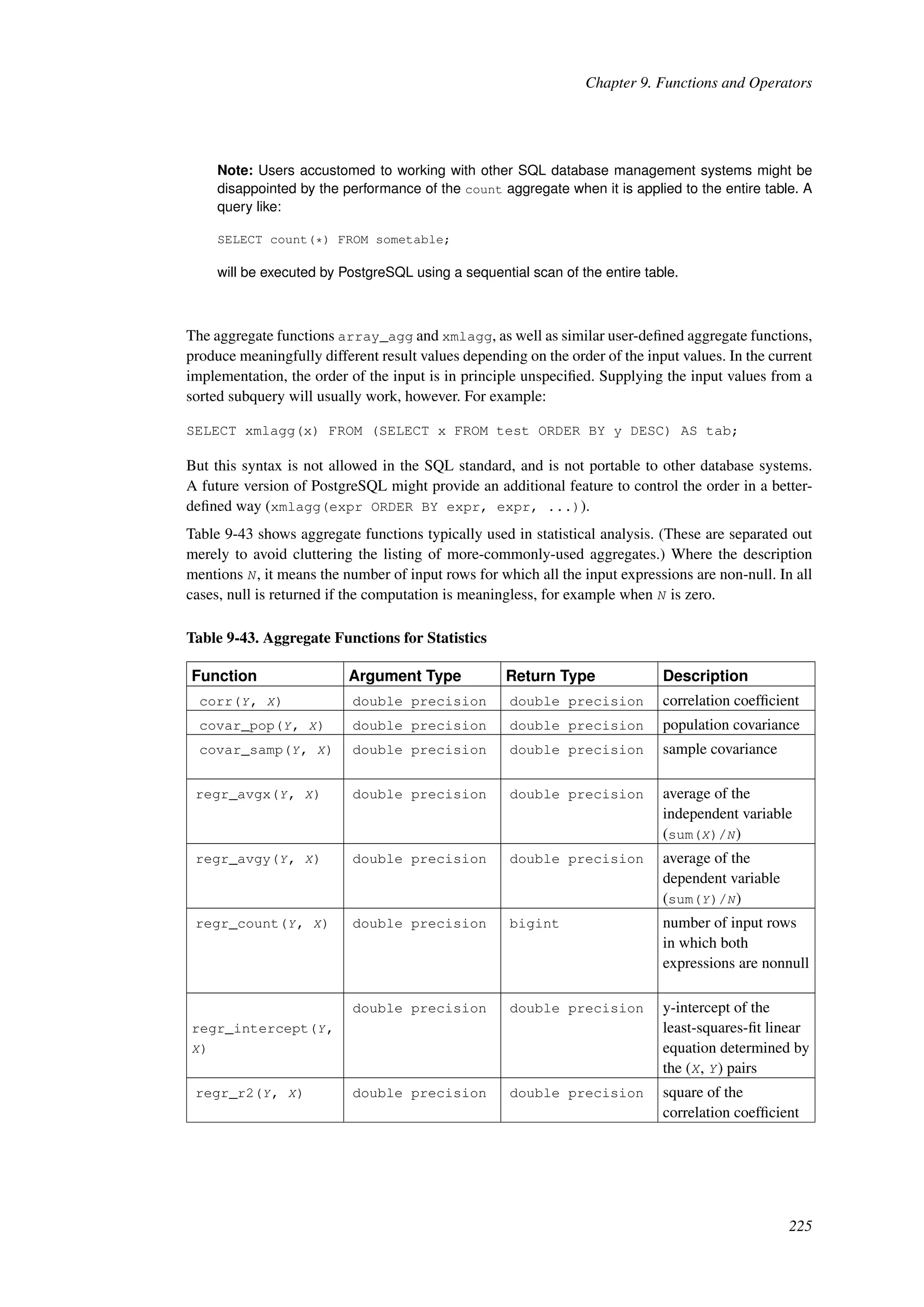
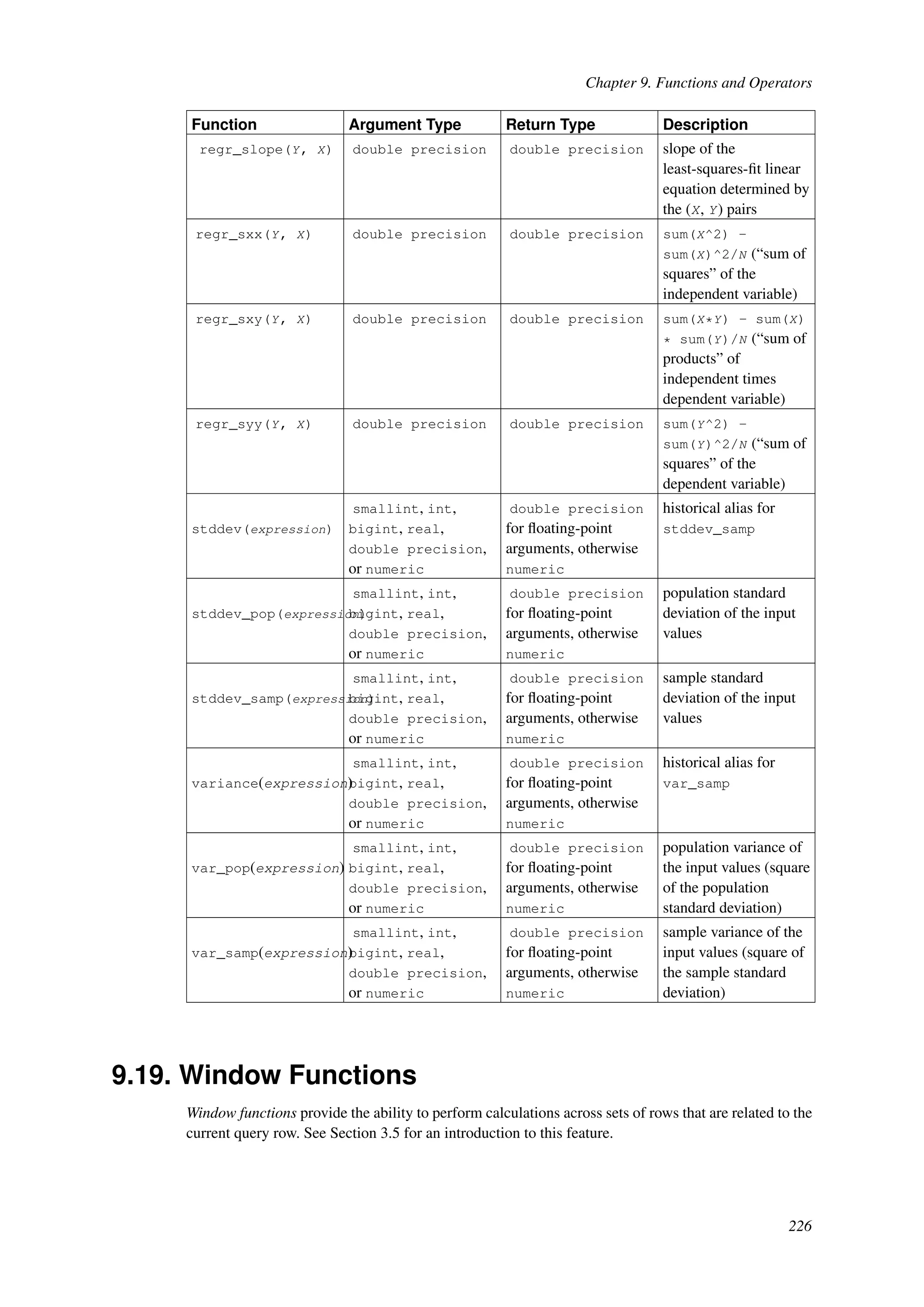
![Chapter 9. Functions and Operators The built-in window functions are listed in Table 9-44. Note that these functions must be invoked using window function syntax; that is an OVER clause is required. In addition to these functions, any built-in or user-defined aggregate function can be used as a window function (see Section 9.18 for a list of the built-in aggregates). Aggregate functions act as window functions only when an OVER clause follows the call; otherwise they act as regular aggregates. Table 9-44. General-Purpose Window Functions Function Return Type Description row_number() bigint number of the current row within its partition, counting from 1 rank() bigint rank of the current row with gaps; same as row_number of its first peer dense_rank() bigint rank of the current row without gaps; this function counts peer groups percent_rank() double precision relative rank of the current row: (rank - 1) / (total rows - 1) cume_dist() double precision relative rank of the current row: (number of rows preceding or peer with current row) / (total rows) ntile(num_buckets integer) integer integer ranging from 1 to the argument value, dividing the partition as equally as possible lag(value any [, offset integer [, default any ]]) same type as value returns value evaluated at the row that is offset rows before the current row within the partition; if there is no such row, instead return default. Both offset and default are evaluated with respect to the current row. If omitted, offset defaults to 1 and default to null lead(value any [, offset integer [, default any ]]) same type as value returns value evaluated at the row that is offset rows after the current row within the partition; if there is no such row, instead return default. Both offset and default are evaluated with respect to the current row. If omitted, offset defaults to 1 and default to null 227](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-284-2048.jpg)
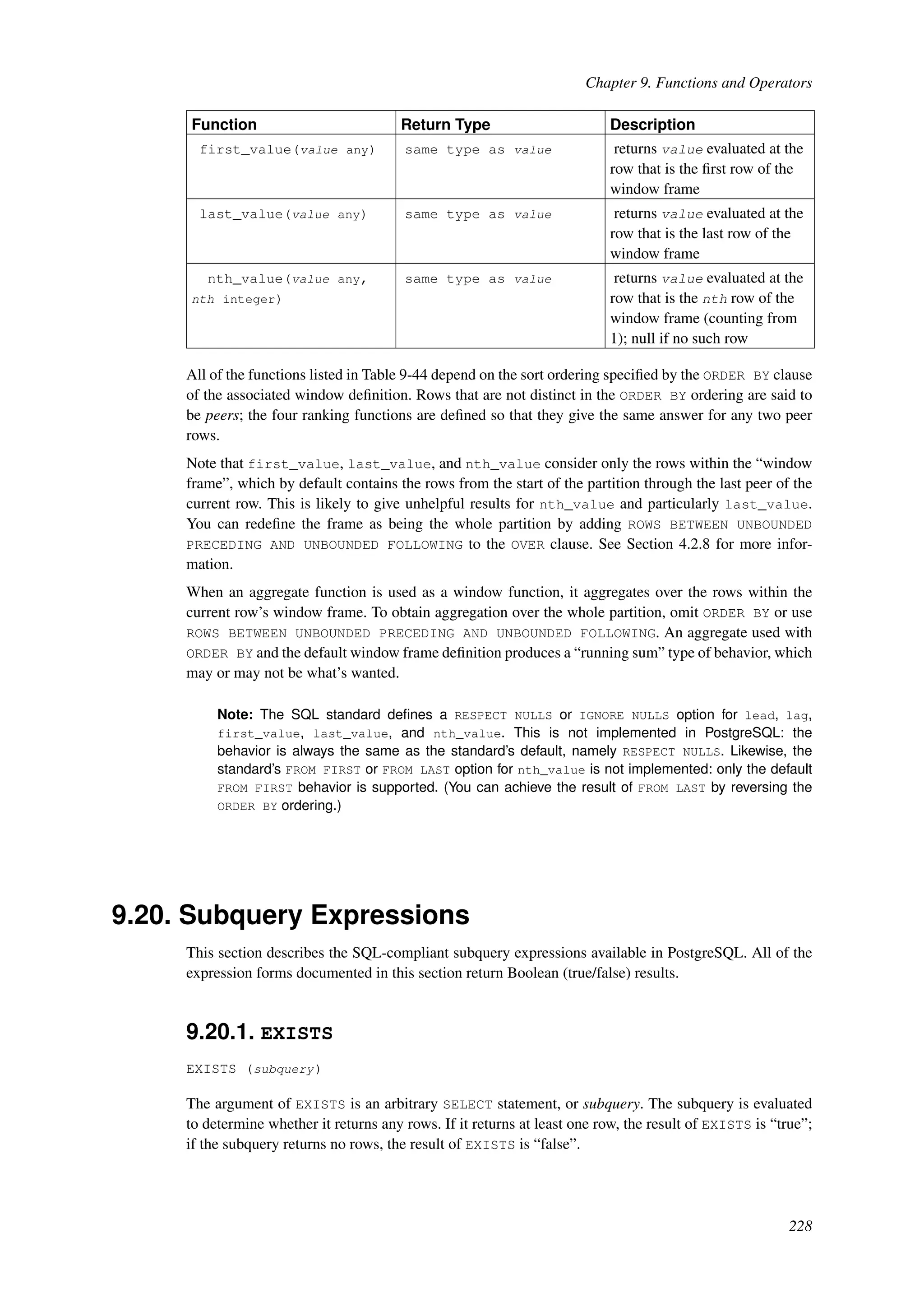


![Chapter 9. Functions and Operators 9.20.5. ALL expression operator ALL (subquery) The right-hand side is a parenthesized subquery, which must return exactly one column. The left-hand expression is evaluated and compared to each row of the subquery result using the given operator, which must yield a Boolean result. The result of ALL is “true” if all rows yield true (including the case where the subquery returns no rows). The result is “false” if any false result is found. The result is NULL if the comparison does not return false for any row, and it returns NULL for at least one row. NOT IN is equivalent to <> ALL. As with EXISTS, it’s unwise to assume that the subquery will be evaluated completely. row_constructor operator ALL (subquery) The left-hand side of this form of ALL is a row constructor, as described in Section 4.2.12. The right-hand side is a parenthesized subquery, which must return exactly as many columns as there are expressions in the left-hand row. The left-hand expressions are evaluated and compared row-wise to each row of the subquery result, using the given operator. The result of ALL is “true” if the comparison returns true for all subquery rows (including the case where the subquery returns no rows). The result is “false” if the comparison returns false for any subquery row. The result is NULL if the comparison does not return false for any subquery row, and it returns NULL for at least one row. See Section 9.21.5 for details about the meaning of a row-wise comparison. 9.20.6. Row-wise Comparison row_constructor operator (subquery) The left-hand side is a row constructor, as described in Section 4.2.12. The right-hand side is a paren- thesized subquery, which must return exactly as many columns as there are expressions in the left- hand row. Furthermore, the subquery cannot return more than one row. (If it returns zero rows, the result is taken to be null.) The left-hand side is evaluated and compared row-wise to the single sub- query result row. See Section 9.21.5 for details about the meaning of a row-wise comparison. 9.21. Row and Array Comparisons This section describes several specialized constructs for making multiple comparisons between groups of values. These forms are syntactically related to the subquery forms of the previous section, but do not involve subqueries. The forms involving array subexpressions are PostgreSQL extensions; the rest are SQL-compliant. All of the expression forms documented in this section return Boolean (true/false) results. 9.21.1. IN expression IN (value [, ...]) 231](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-288-2048.jpg)
![Chapter 9. Functions and Operators The right-hand side is a parenthesized list of scalar expressions. The result is “true” if the left-hand expression’s result is equal to any of the right-hand expressions. This is a shorthand notation for expression = value1 OR expression = value2 OR ... Note that if the left-hand expression yields null, or if there are no equal right-hand values and at least one right-hand expression yields null, the result of the IN construct will be null, not false. This is in accordance with SQL’s normal rules for Boolean combinations of null values. 9.21.2. NOT IN expression NOT IN (value [, ...]) The right-hand side is a parenthesized list of scalar expressions. The result is “true” if the left-hand expression’s result is unequal to all of the right-hand expressions. This is a shorthand notation for expression <> value1 AND expression <> value2 AND ... Note that if the left-hand expression yields null, or if there are no equal right-hand values and at least one right-hand expression yields null, the result of the NOT IN construct will be null, not true as one might naively expect. This is in accordance with SQL’s normal rules for Boolean combinations of null values. Tip: x NOT IN y is equivalent to NOT (x IN y) in all cases. However, null values are much more likely to trip up the novice when working with NOT IN than when working with IN. It is best to express your condition positively if possible. 9.21.3. ANY/SOME (array) expression operator ANY (array expression) expression operator SOME (array expression) The right-hand side is a parenthesized expression, which must yield an array value. The left-hand expression is evaluated and compared to each element of the array using the given operator, which must yield a Boolean result. The result of ANY is “true” if any true result is obtained. The result is “false” if no true result is found (including the case where the array has zero elements). If the array expression yields a null array, the result of ANY will be null. If the left-hand expression yields null, the result of ANY is ordinarily null (though a non-strict comparison operator could possibly 232](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-289-2048.jpg)


![Chapter 9. Functions and Operators 3 1 (3 rows) SELECT * FROM generate_series(4,3); generate_series ----------------- (0 rows) -- this example relies on the date-plus-integer operator SELECT current_date + s.a AS dates FROM generate_series(0,14,7) AS s(a); dates ------------ 2004-02-05 2004-02-12 2004-02-19 (3 rows) SELECT * FROM generate_series(’2008-03-01 00:00’::timestamp, ’2008-03-04 12:00’, ’10 hours’); generate_series --------------------- 2008-03-01 00:00:00 2008-03-01 10:00:00 2008-03-01 20:00:00 2008-03-02 06:00:00 2008-03-02 16:00:00 2008-03-03 02:00:00 2008-03-03 12:00:00 2008-03-03 22:00:00 2008-03-04 08:00:00 (9 rows) Table 9-46. Subscript Generating Functions Function Return Type Description generate_subscripts(array anyarray, dim int) setof int Generate a series comprising the given array’s subscripts. generate_subscripts(array anyarray, dim int, reverse boolean) setof int Generate a series comprising the given array’s subscripts. When reverse is true, the series is returned in reverse order. generate_subscripts is a convenience function that generates the set of valid subscripts for the specified dimension of the given array. Zero rows are returned for arrays that do not have the requested dimension, or for NULL arrays (but valid subscripts are returned for NULL array elements). Some examples follow: -- basic usage select generate_subscripts(’{NULL,1,NULL,2}’::int[], 1) as s; s --- 235](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-292-2048.jpg)
![Chapter 9. Functions and Operators 1 2 3 4 (4 rows) -- presenting an array, the subscript and the subscripted -- value requires a subquery select * from arrays; a -------------------- {-1,-2} {100,200} (2 rows) select a as array, s as subscript, a[s] as value from (select generate_subscripts(a, 1) as s, a from arrays) foo; array | subscript | value -----------+-----------+------- {-1,-2} | 1 | -1 {-1,-2} | 2 | -2 {100,200} | 1 | 100 {100,200} | 2 | 200 (4 rows) -- unnest a 2D array create or replace function unnest2(anyarray) returns setof anyelement as $$ select $1[i][j] from generate_subscripts($1,1) g1(i), generate_subscripts($1,2) g2(j); $$ language sql immutable; CREATE FUNCTION postgres=# select * from unnest2(array[[1,2],[3,4]]); unnest2 --------- 1 2 3 4 (4 rows) 9.23. System Information Functions Table 9-47 shows several functions that extract session and system information. In addition to the functions listed in this section, there are a number of functions related to the statistics system that also provide system information. See Section 26.2.2 for more information. 236](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-293-2048.jpg)
![Chapter 9. Functions and Operators Name Return Type Description Table 9-47. Session Information Functions Name Return Type Description current_catalog name name of current database (called “catalog” in the SQL standard) current_database() name name of current database current_schema[()] name name of current schema current_schemas(boolean) name[] names of schemas in search path, optionally including implicit schemas current_user name user name of current execution context current_query() text text of the currently executing query, as submitted by the client (might contain more than one statement) pg_backend_pid() int Process ID of the server process attached to the current session inet_client_addr() inet address of the remote connection inet_client_port() int port of the remote connection inet_server_addr() inet address of the local connection inet_server_port() int port of the local connection pg_my_temp_schema() oid OID of session’s temporary schema, or 0 if none pg_is_other_temp_schema(oid)boolean is schema another session’s temporary schema? pg_postmaster_start_time() timestamp with time zone server start time pg_conf_load_time() timestamp with time zone configuration load time session_user name session user name user name equivalent to current_user version() text PostgreSQL version information Note: current_catalog, current_schema, current_user, session_user, and user have spe- cial syntactic status in SQL: they must be called without trailing parentheses. (In PostgreSQL, parentheses can optionally be used with current_schema, but not with the others.) The session_user is normally the user who initiated the current database connection; but supe- rusers can change this setting with SET SESSION AUTHORIZATION. The current_user is the user identifier that is applicable for permission checking. Normally it is equal to the session user, but 237](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-294-2048.jpg)
![Chapter 9. Functions and Operators it can be changed with SET ROLE. It also changes during the execution of functions with the attribute SECURITY DEFINER. In Unix parlance, the session user is the “real user” and the current user is the “effective user”. current_schema returns the name of the schema that is first in the search path (or a null value if the search path is empty). This is the schema that will be used for any tables or other named objects that are created without specifying a target schema. current_schemas(boolean) returns an array of the names of all schemas presently in the search path. The Boolean option determines whether or not implicitly included system schemas such as pg_catalog are included in the returned search path. Note: The search path can be altered at run time. The command is: SET search_path TO schema [, schema, ...] inet_client_addr returns the IP address of the current client, and inet_client_port returns the port number. inet_server_addr returns the IP address on which the server accepted the current connection, and inet_server_port returns the port number. All these functions return NULL if the current connection is via a Unix-domain socket. pg_my_temp_schema returns the OID of the current session’s temporary schema, or zero if it has none (because it has not created any temporary tables). pg_is_other_temp_schema returns true if the given OID is the OID of another session’s temporary schema. (This can be useful, for example, to exclude other sessions’ temporary tables from a catalog display.) pg_postmaster_start_time returns the timestamp with time zone when the server started. pg_conf_load_time returns the timestamp with time zone when the server configuration files were last loaded. (If the current session was alive at the time, this will be the time when the session itself re-read the configuration files, so the reading will vary a little in different sessions. Otherwise it is the time when the postmaster process re-read the configuration files.) version returns a string describing the PostgreSQL server’s version. Table 9-48 lists functions that allow the user to query object access privileges programmatically. See Section 5.6 for more information about privileges. Table 9-48. Access Privilege Inquiry Functions Name Return Type Description has_any_column_privilege(user, table, privilege) boolean does user have privilege for any column of table has_any_column_privilege(table, privilege) boolean does current user have privilege for any column of table has_column_privilege(user, table, column, privilege) boolean does user have privilege for column has_column_privilege(table, column, privilege) boolean does current user have privilege for column has_database_privilege(user, database, privilege) boolean does user have privilege for database 238](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-295-2048.jpg)
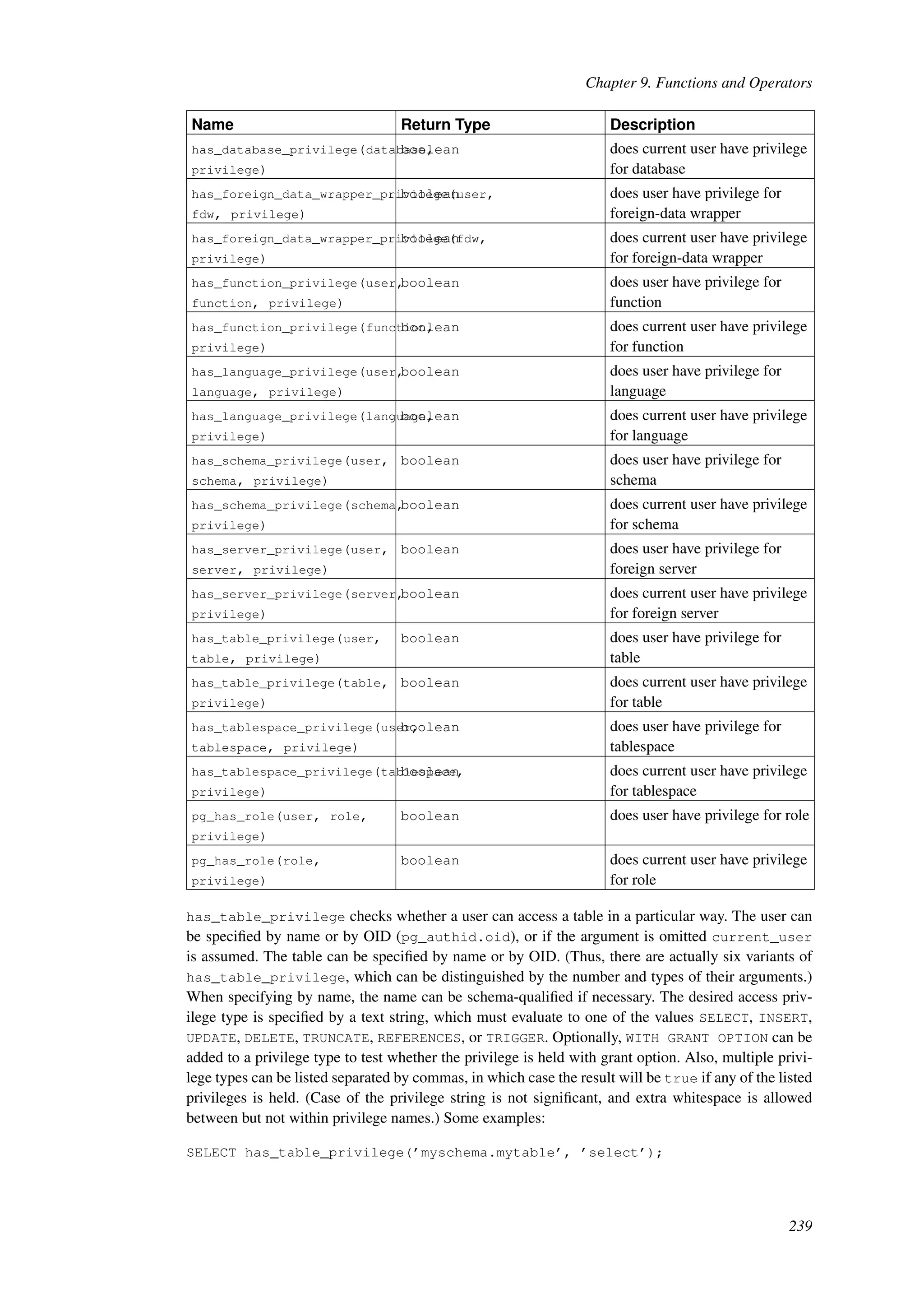


![Chapter 9. Functions and Operators Table 9-50. System Catalog Information Functions Name Return Type Description format_type(type_oid, typemod) text get SQL name of a data type pg_get_keywords() setof record get list of SQL keywords and their categories pg_get_constraintdef(constraint_oid)text get definition of a constraint pg_get_constraintdef(constraint_oid, pretty_bool) text get definition of a constraint pg_get_expr(expr_text, relation_oid) text decompile internal form of an expression, assuming that any Vars in it refer to the relation indicated by the second parameter pg_get_expr(expr_text, relation_oid, pretty_bool) text decompile internal form of an expression, assuming that any Vars in it refer to the relation indicated by the second parameter pg_get_functiondef(func_oid)text get definition of a function pg_get_function_arguments(func_oid)text get argument list of function’s definition (with default values) pg_get_function_identity_arguments(func_oid)text get argument list to identify a function (without default values) pg_get_function_result(func_oid)text get RETURNS clause for function pg_get_indexdef(index_oid) text get CREATE INDEX command for index pg_get_indexdef(index_oid, column_no, pretty_bool) text get CREATE INDEX command for index, or definition of just one index column when column_no is not zero pg_get_ruledef(rule_oid) text get CREATE RULE command for rule pg_get_ruledef(rule_oid, pretty_bool) text get CREATE RULE command for rule pg_get_serial_sequence(table_name, column_name) text get name of the sequence that a serial or bigserial column uses pg_get_triggerdef(trigger_oid)text get CREATE [ CONSTRAINT ] TRIGGER command for trigger pg_get_userbyid(role_oid) name get role name with given OID 242](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-299-2048.jpg)
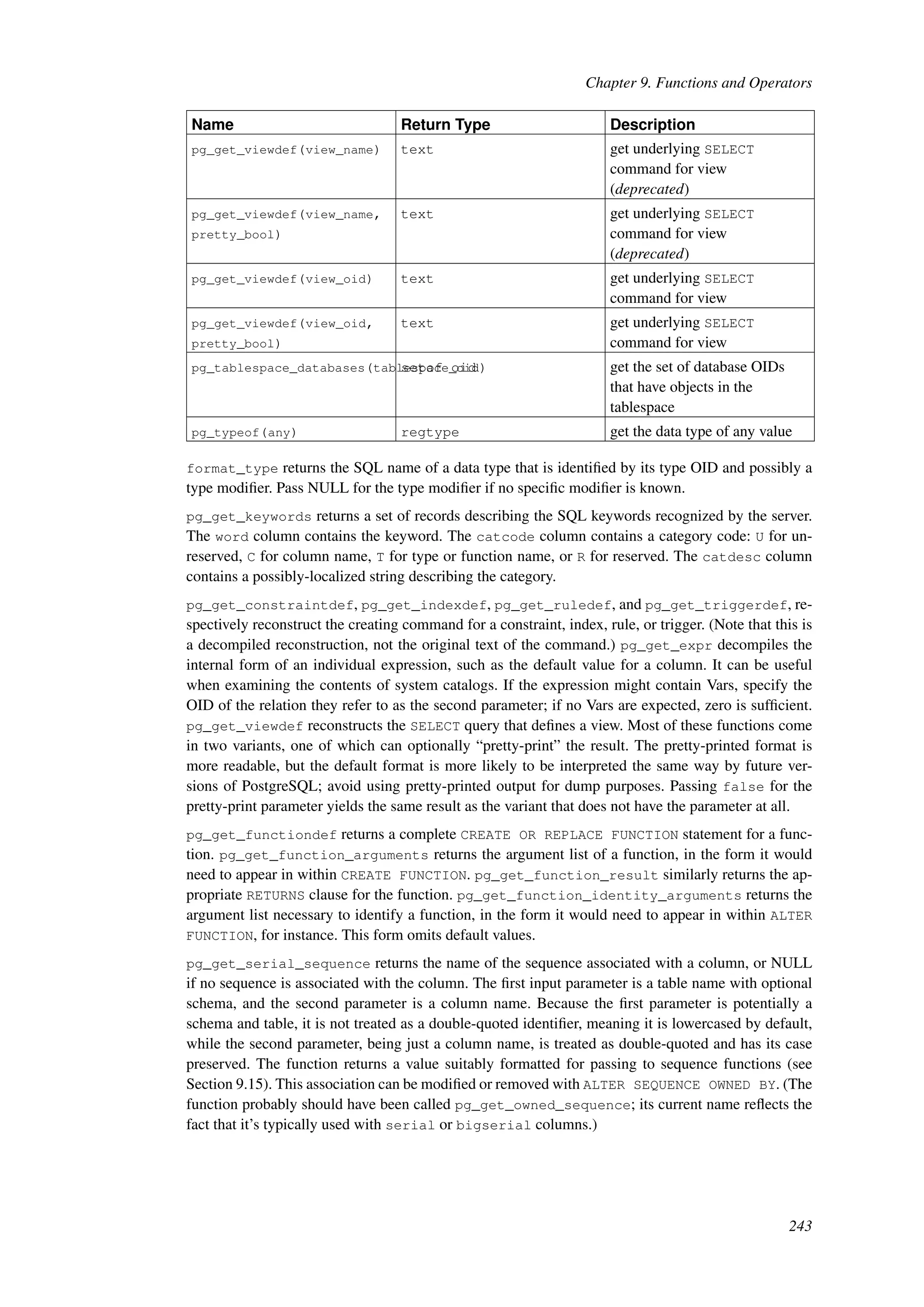

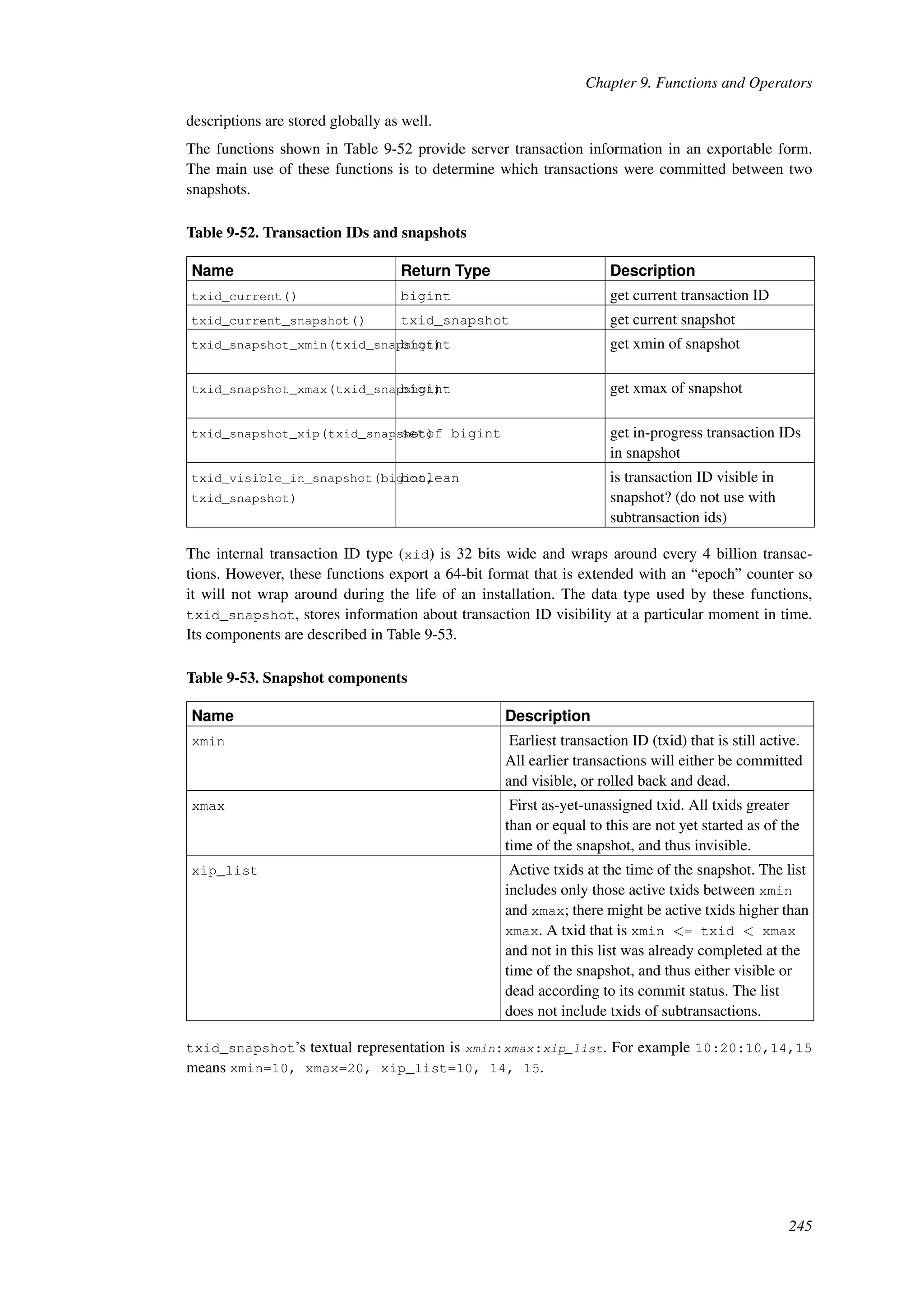
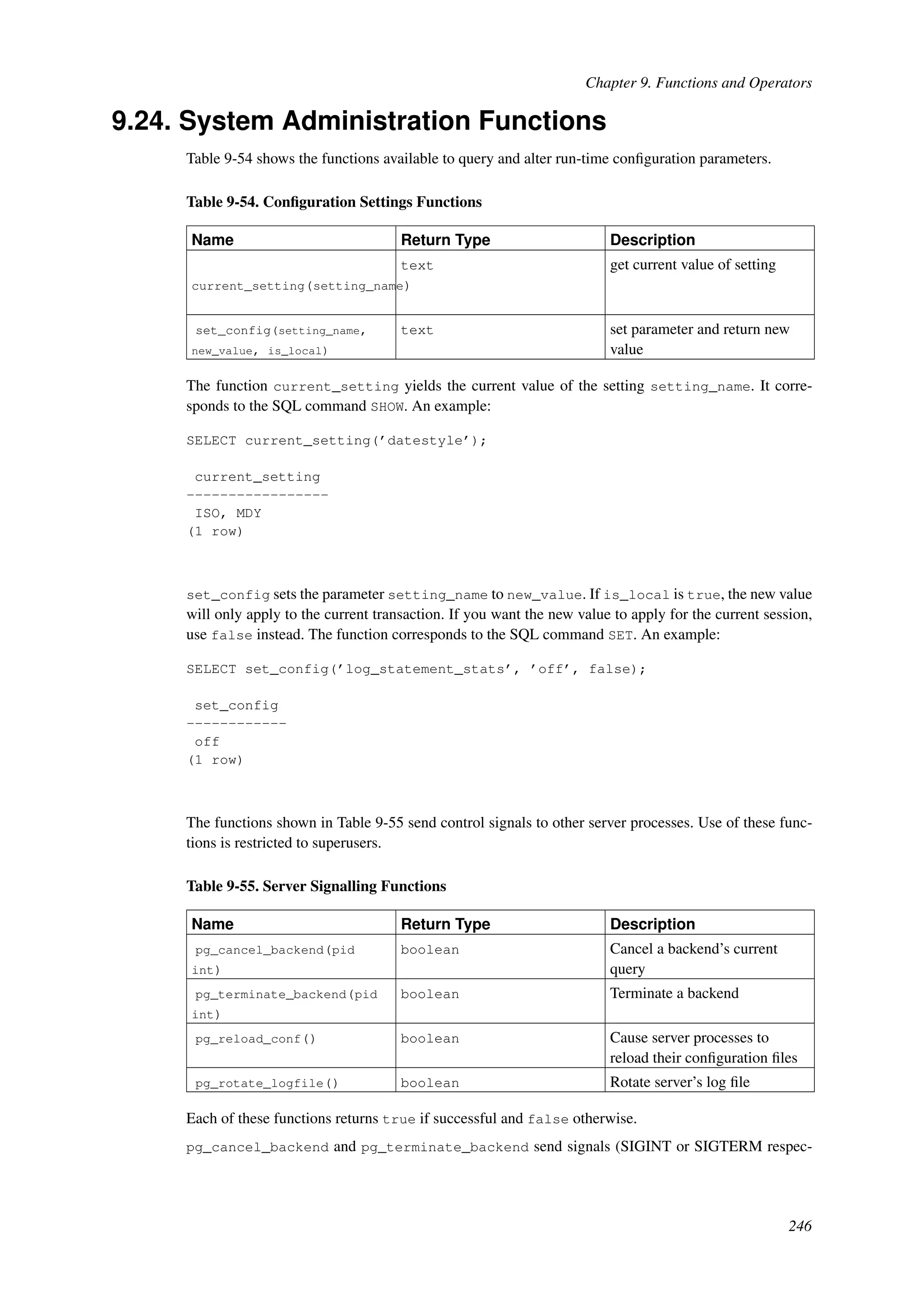
![Chapter 9. Functions and Operators tively) to backend processes identified by process ID. The process ID of an active backend can be found from the procpid column of the pg_stat_activity view, or by listing the postgres pro- cesses on the server (using ps on Unix or the Task Manager on Windows). pg_reload_conf sends a SIGHUP signal to the server, causing configuration files to be reloaded by all server processes. pg_rotate_logfile signals the log-file manager to switch to a new output file immediately. This works only when the built-in log collector is running, since otherwise there is no log-file manager subprocess. The functions shown in Table 9-56 assist in making on-line backups. Use of the first three functions is restricted to superusers. Table 9-56. Backup Control Functions Name Return Type Description pg_start_backup(label text [, fast boolean ]) text Prepare for performing on-line backup pg_stop_backup() text Finish performing on-line backup pg_switch_xlog() text Force switch to a new transaction log file pg_current_xlog_location() text Get current transaction log write location pg_current_xlog_insert_location() text Get current transaction log insert location pg_xlogfile_name_offset(location text) text, integer Convert transaction log location string to file name and decimal byte offset within file pg_xlogfile_name(location text) text Convert transaction log location string to file name pg_start_backup accepts an arbitrary user-defined label for the backup. (Typically this would be the name under which the backup dump file will be stored.) The function writes a backup label file (backup_label) into the database cluster’s data directory, performs a checkpoint, and then returns the backup’s starting transaction log location as text. The user can ignore this result value, but it is provided in case it is useful. postgres=# select pg_start_backup(’label_goes_here’); pg_start_backup ----------------- 0/D4445B8 (1 row) There is an optional boolean second parameter. If true, it specifies executing pg_start_backup as quickly as possible. This forces an immediate checkpoint which will cause a spike in I/O operations, slowing any concurrently executing queries. pg_stop_backup removes the label file created by pg_start_backup, and creates a backup history file in the transaction log archive area. The history file includes the label given to pg_start_backup, the starting and ending transaction log locations for the backup, and the starting and ending times of 247](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-304-2048.jpg)

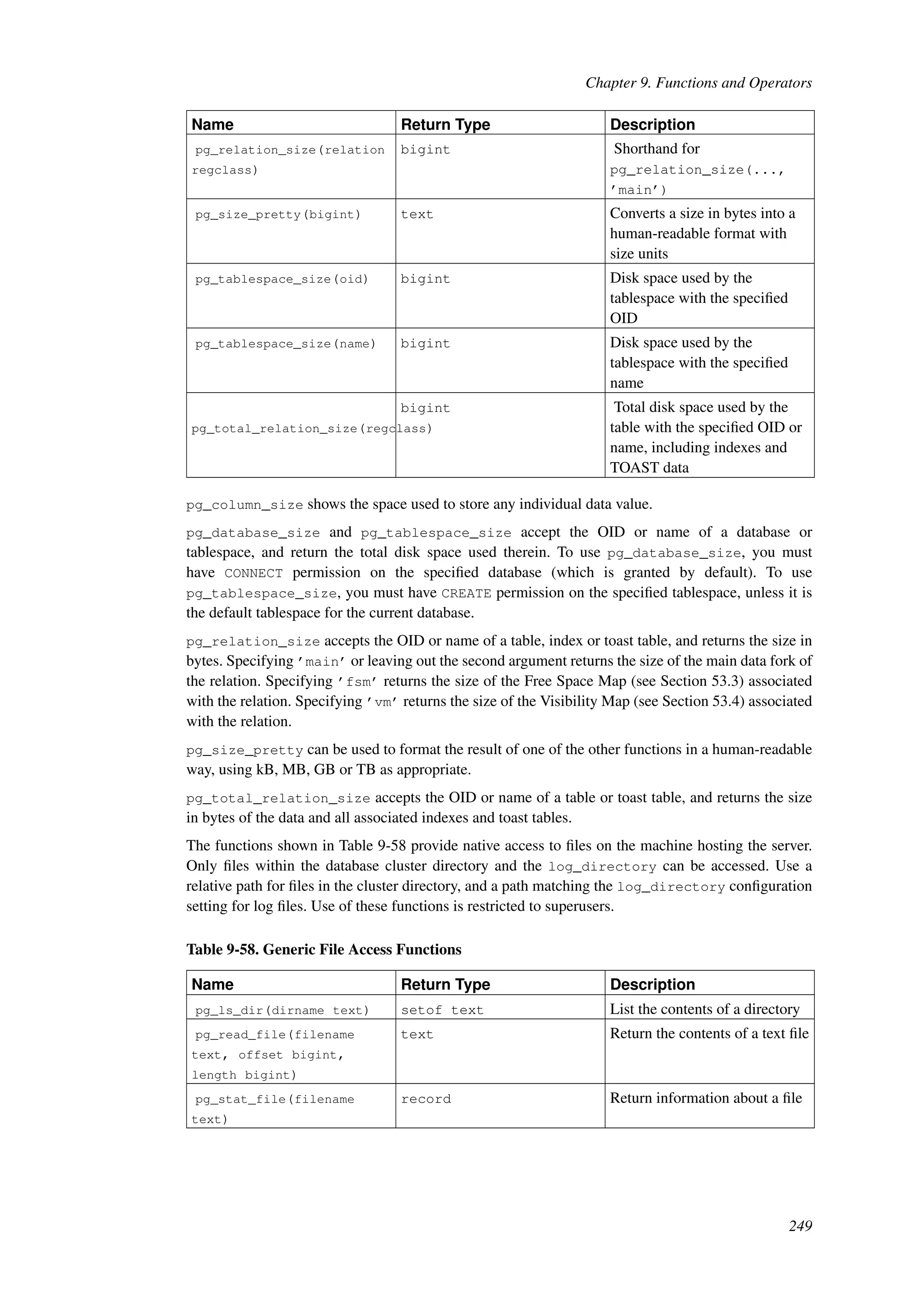
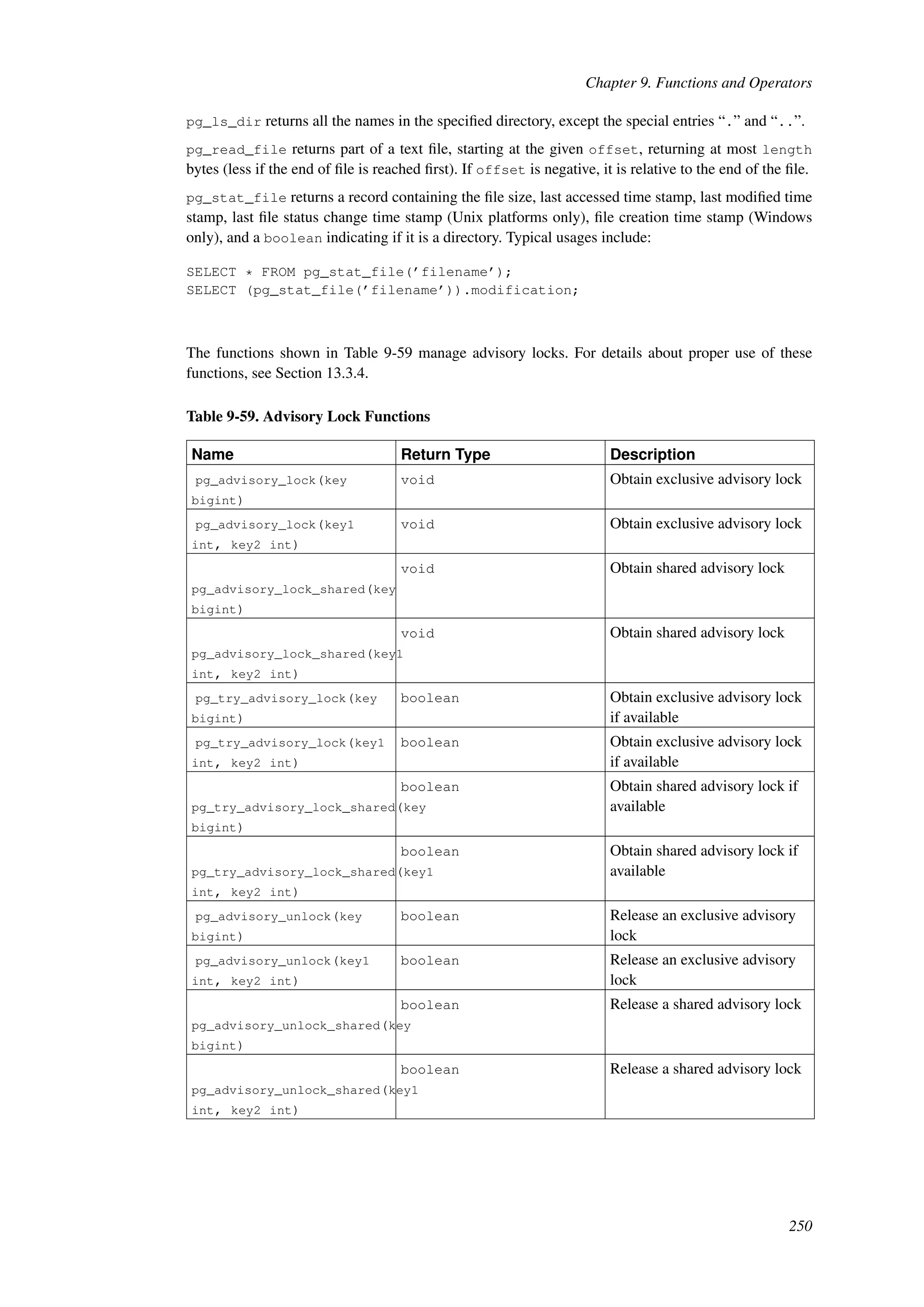
















![Chapter 11. Indexes 11.3, it would be almost useless for queries involving only y, so it should not be the only index. A combination of the multicolumn index and a separate index on y would serve reasonably well. For queries involving only x, the multicolumn index could be used, though it would be larger and hence slower than an index on x alone. The last alternative is to create all three indexes, but this is probably only reasonable if the table is searched much more often than it is updated and all three types of query are common. If one of the types of query is much less common than the others, you’d probably settle for creating just the two indexes that best match the common types. 11.6. Unique Indexes Indexes can also be used to enforce uniqueness of a column’s value, or the uniqueness of the combined values of more than one column. CREATE UNIQUE INDEX name ON table (column [, ...]); Currently, only B-tree indexes can be declared unique. When an index is declared unique, multiple table rows with equal indexed values are not allowed. Null values are not considered equal. A multicolumn unique index will only reject cases where all indexed columns are equal in multiple rows. PostgreSQL automatically creates a unique index when a unique constraint or primary key is de- fined for a table. The index covers the columns that make up the primary key or unique constraint (a multicolumn index, if appropriate), and is the mechanism that enforces the constraint. Note: The preferred way to add a unique constraint to a table is ALTER TABLE ... ADD CONSTRAINT. The use of indexes to enforce unique constraints could be considered an implementation detail that should not be accessed directly. One should, however, be aware that there’s no need to manually create indexes on unique columns; doing so would just duplicate the automatically-created index. 11.7. Indexes on Expressions An index column need not be just a column of the underlying table, but can be a function or scalar expression computed from one or more columns of the table. This feature is useful to obtain fast access to tables based on the results of computations. For example, a common way to do case-insensitive comparisons is to use the lower function: SELECT * FROM test1 WHERE lower(col1) = ’value’; This query can use an index if one has been defined on the result of the lower(col1) function: CREATE INDEX test1_lower_col1_idx ON test1 (lower(col1)); If we were to declare this index UNIQUE, it would prevent creation of rows whose col1 values differ only in case, as well as rows whose col1 values are actually identical. Thus, indexes on expressions can be used to enforce constraints that are not definable as simple unique constraints. As another example, if one often does queries like: 268](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-325-2048.jpg)


![Chapter 11. Indexes example a prepared query with a parameter might specify “x < ?” which will never imply “x < 2” for all possible values of the parameter. A third possible use for partial indexes does not require the index to be used in queries at all. The idea here is to create a unique index over a subset of a table, as in Example 11-3. This enforces uniqueness among the rows that satisfy the index predicate, without constraining those that do not. Example 11-3. Setting up a Partial Unique Index Suppose that we have a table describing test outcomes. We wish to ensure that there is only one “successful” entry for a given subject and target combination, but there might be any number of “unsuccessful” entries. Here is one way to do it: CREATE TABLE tests ( subject text, target text, success boolean, ... ); CREATE UNIQUE INDEX tests_success_constraint ON tests (subject, target) WHERE success; This is a particularly efficient approach when there are few successful tests and many unsuccessful ones. Finally, a partial index can also be used to override the system’s query plan choices. Also, data sets with peculiar distributions might cause the system to use an index when it really should not. In that case the index can be set up so that it is not available for the offending query. Normally, PostgreSQL makes reasonable choices about index usage (e.g., it avoids them when retrieving common values, so the earlier example really only saves index size, it is not required to avoid index usage), and grossly incorrect plan choices are cause for a bug report. Keep in mind that setting up a partial index indicates that you know at least as much as the query planner knows, in particular you know when an index might be profitable. Forming this knowledge requires experience and understanding of how indexes in PostgreSQL work. In most cases, the advan- tage of a partial index over a regular index will be minimal. More information about partial indexes can be found in The case for partial indexes , Partial indexing in POSTGRES: research project, and Generalized Partial Indexes (cached version) . 11.9. Operator Classes and Operator Families An index definition can specify an operator class for each column of an index. CREATE INDEX name ON table (column opclass [sort options] [, ...]); The operator class identifies the operators to be used by the index for that column. For example, a B- tree index on the type int4 would use the int4_ops class; this operator class includes comparison functions for values of type int4. In practice the default operator class for the column’s data type is usually sufficient. The main reason for having operator classes is that for some data types, there could be more than one meaningful index behavior. For example, we might want to sort a complex-number data type either by absolute value or by real part. We could do this by defining two operator classes for the data type and then selecting the proper class when making an index. The operator class determines 271](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-328-2048.jpg)







![Chapter 12. Full Text Search Indexes can even concatenate columns: CREATE INDEX pgweb_idx ON pgweb USING gin(to_tsvector(’english’, title || ’ ’ || body)); Another approach is to create a separate tsvector column to hold the output of to_tsvector. This example is a concatenation of title and body, using coalesce to ensure that one field will still be indexed when the other is NULL: ALTER TABLE pgweb ADD COLUMN textsearchable_index_col tsvector; UPDATE pgweb SET textsearchable_index_col = to_tsvector(’english’, coalesce(title,”) || ’ ’ || coalesce(body,”)); Then we create a GIN index to speed up the search: CREATE INDEX textsearch_idx ON pgweb USING gin(textsearchable_index_col); Now we are ready to perform a fast full text search: SELECT title FROM pgweb WHERE textsearchable_index_col @@ to_tsquery(’create & table’) ORDER BY last_mod_date DESC LIMIT 10; When using a separate column to store the tsvector representation, it is necessary to create a trigger to keep the tsvector column current anytime title or body changes. Section 12.4.3 explains how to do that. One advantage of the separate-column approach over an expression index is that it is not necessary to explicitly specify the text search configuration in queries in order to make use of the index. As shown in the example above, the query can depend on default_text_search_config. Another advantage is that searches will be faster, since it will not be necessary to redo the to_tsvector calls to verify index matches. (This is more important when using a GiST index than a GIN index; see Section 12.9.) The expression-index approach is simpler to set up, however, and it requires less disk space since the tsvector representation is not stored explicitly. 12.3. Controlling Text Search To implement full text searching there must be a function to create a tsvector from a document and a tsquery from a user query. Also, we need to return results in a useful order, so we need a function that compares documents with respect to their relevance to the query. It’s also important to be able to display the results nicely. PostgreSQL provides support for all of these functions. 12.3.1. Parsing Documents PostgreSQL provides the function to_tsvector for converting a document to the tsvector data type. to_tsvector([ config regconfig, ] document text) returns tsvector 279](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-336-2048.jpg)
![Chapter 12. Full Text Search to_tsvector parses a textual document into tokens, reduces the tokens to lexemes, and returns a tsvector which lists the lexemes together with their positions in the document. The document is processed according to the specified or default text search configuration. Here is a simple example: SELECT to_tsvector(’english’, ’a fat cat sat on a mat - it ate a fat rats’); to_tsvector ----------------------------------------------------- ’ate’:9 ’cat’:3 ’fat’:2,11 ’mat’:7 ’rat’:12 ’sat’:4 In the example above we see that the resulting tsvector does not contain the words a, on, or it, the word rats became rat, and the punctuation sign - was ignored. The to_tsvector function internally calls a parser which breaks the document text into tokens and assigns a type to each token. For each token, a list of dictionaries (Section 12.6) is consulted, where the list can vary depending on the token type. The first dictionary that recognizes the token emits one or more normalized lexemes to represent the token. For example, rats became rat because one of the dictionaries recognized that the word rats is a plural form of rat. Some words are recognized as stop words (Section 12.6.1), which causes them to be ignored since they occur too frequently to be useful in searching. In our example these are a, on, and it. If no dictionary in the list recognizes the token then it is also ignored. In this example that happened to the punctuation sign - because there are in fact no dictionaries assigned for its token type (Space symbols), meaning space tokens will never be indexed. The choices of parser, dictionaries and which types of tokens to index are determined by the selected text search configuration (Section 12.7). It is possible to have many different configurations in the same database, and predefined configurations are available for various languages. In our example we used the default configuration english for the English language. The function setweight can be used to label the entries of a tsvector with a given weight, where a weight is one of the letters A, B, C, or D. This is typically used to mark entries coming from different parts of a document, such as title versus body. Later, this information can be used for ranking of search results. Because to_tsvector(NULL) will return NULL, it is recommended to use coalesce whenever a field might be null. Here is the recommended method for creating a tsvector from a structured document: UPDATE tt SET ti = setweight(to_tsvector(coalesce(title,”)), ’A’) || setweight(to_tsvector(coalesce(keyword,”)), ’B’) || setweight(to_tsvector(coalesce(abstract,”)), ’C’) || setweight(to_tsvector(coalesce(body,”)), ’D’); Here we have used setweight to label the source of each lexeme in the finished tsvector, and then merged the labeled tsvector values using the tsvector concatenation operator ||. (Section 12.4.1 gives details about these operations.) 12.3.2. Parsing Queries PostgreSQL provides the functions to_tsquery and plainto_tsquery for converting a query to the tsquery data type. to_tsquery offers access to more features than plainto_tsquery, but is less forgiving about its input. to_tsquery([ config regconfig, ] querytext text) returns tsquery 280](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-337-2048.jpg)
![Chapter 12. Full Text Search to_tsquery creates a tsquery value from querytext, which must consist of single tokens sep- arated by the Boolean operators & (AND), | (OR) and ! (NOT). These operators can be grouped using parentheses. In other words, the input to to_tsquery must already follow the general rules for tsquery input, as described in Section 8.11. The difference is that while basic tsquery input takes the tokens at face value, to_tsquery normalizes each token to a lexeme using the specified or default configuration, and discards any tokens that are stop words according to the configuration. For example: SELECT to_tsquery(’english’, ’The & Fat & Rats’); to_tsquery --------------- ’fat’ & ’rat’ As in basic tsquery input, weight(s) can be attached to each lexeme to restrict it to match only tsvector lexemes of those weight(s). For example: SELECT to_tsquery(’english’, ’Fat | Rats:AB’); to_tsquery ------------------ ’fat’ | ’rat’:AB Also, * can be attached to a lexeme to specify prefix matching: SELECT to_tsquery(’supern:*A & star:A*B’); to_tsquery -------------------------- ’supern’:*A & ’star’:*AB Such a lexeme will match any word in a tsvector that begins with the given string. to_tsquery can also accept single-quoted phrases. This is primarily useful when the configuration includes a thesaurus dictionary that may trigger on such phrases. In the example below, a thesaurus contains the rule supernovae stars : sn: SELECT to_tsquery(”’supernovae stars” & !crab’); to_tsquery --------------- ’sn’ & !’crab’ Without quotes, to_tsquery will generate a syntax error for tokens that are not separated by an AND or OR operator. plainto_tsquery([ config regconfig, ] querytext text) returns tsquery plainto_tsquery transforms unformatted text querytext to tsquery. The text is parsed and nor- malized much as for to_tsvector, then the & (AND) Boolean operator is inserted between surviving words. Example: SELECT plainto_tsquery(’english’, ’The Fat Rats’); plainto_tsquery ----------------- ’fat’ & ’rat’ Note that plainto_tsquery cannot recognize Boolean operators, weight labels, or prefix-match labels in its input: 281](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-338-2048.jpg)
![Chapter 12. Full Text Search SELECT plainto_tsquery(’english’, ’The Fat & Rats:C’); plainto_tsquery --------------------- ’fat’ & ’rat’ & ’c’ Here, all the input punctuation was discarded as being space symbols. 12.3.3. Ranking Search Results Ranking attempts to measure how relevant documents are to a particular query, so that when there are many matches the most relevant ones can be shown first. PostgreSQL provides two predefined ranking functions, which take into account lexical, proximity, and structural information; that is, they consider how often the query terms appear in the document, how close together the terms are in the document, and how important is the part of the document where they occur. However, the concept of relevancy is vague and very application-specific. Different applications might require additional information for ranking, e.g., document modification time. The built-in ranking functions are only examples. You can write your own ranking functions and/or combine their results with additional factors to fit your specific needs. The two ranking functions currently available are: ts_rank([ weights float4[], ] vector tsvector, query tsquery [, normalization integer ]) returns float4 Standard ranking function. ts_rank_cd([ weights float4[], ] vector tsvector, query tsquery [, normalization integer ]) returns float4 This function computes the cover density ranking for the given document vector and query, as described in Clarke, Cormack, and Tudhope’s "Relevance Ranking for One to Three Term Queries" in the journal "Information Processing and Management", 1999. This function requires positional information in its input. Therefore it will not work on “stripped” tsvector values — it will always return zero. For both these functions, the optional weights argument offers the ability to weigh word instances more or less heavily depending on how they are labeled. The weight arrays specify how heavily to weigh each category of word, in the order: {D-weight, C-weight, B-weight, A-weight} If no weights are provided, then these defaults are used: {0.1, 0.2, 0.4, 1.0} Typically weights are used to mark words from special areas of the document, like the title or an initial abstract, so they can be treated with more or less importance than words in the document body. Since a longer document has a greater chance of containing a query term it is reasonable to take into account document size, e.g., a hundred-word document with five instances of a search word is probably more relevant than a thousand-word document with five instances. Both ranking functions take an integer normalization option that specifies whether and how a document’s length should 282](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-339-2048.jpg)

![Chapter 12. Full Text Search Weak Lensing Distorts the Universe | 0.450010798361481 Ranking can be expensive since it requires consulting the tsvector of each matching document, which can be I/O bound and therefore slow. Unfortunately, it is almost impossible to avoid since practical queries often result in large numbers of matches. 12.3.4. Highlighting Results To present search results it is ideal to show a part of each document and how it is related to the query. Usually, search engines show fragments of the document with marked search terms. PostgreSQL provides a function ts_headline that implements this functionality. ts_headline([ config regconfig, ] document text, query tsquery [, options text ]) returns ts_headline accepts a document along with a query, and returns an excerpt from the document in which terms from the query are highlighted. The configuration to be used to parse the document can be specified by config; if config is omitted, the default_text_search_config configuration is used. If an options string is specified it must consist of a comma-separated list of one or more option=value pairs. The available options are: • StartSel, StopSel: the strings with which to delimit query words appearing in the document, to distinguish them from other excerpted words. You must double-quote these strings if they contain spaces or commas. • MaxWords, MinWords: these numbers determine the longest and shortest headlines to output. • ShortWord: words of this length or less will be dropped at the start and end of a headline. The default value of three eliminates common English articles. • HighlightAll: Boolean flag; if true the whole document will be used as the headline, ignoring the preceding three parameters. • MaxFragments: maximum number of text excerpts or fragments to display. The default value of zero selects a non-fragment-oriented headline generation method. A value greater than zero selects fragment-based headline generation. This method finds text fragments with as many query words as possible and stretches those fragments around the query words. As a result query words are close to the middle of each fragment and have words on each side. Each fragment will be of at most MaxWords and words of length ShortWord or less are dropped at the start and end of each fragment. If not all query words are found in the document, then a single fragment of the first MinWords in the document will be displayed. • FragmentDelimiter: When more than one fragment is displayed, the fragments will be separated by this string. Any unspecified options receive these defaults: StartSel=<b>, StopSel=</b>, MaxWords=35, MinWords=15, ShortWord=3, HighlightAll=FALSE, MaxFragments=0, FragmentDelimiter=" ... " For example: SELECT ts_headline(’english’, 284](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-341-2048.jpg)




![Chapter 12. Full Text Search 12.4.3. Triggers for Automatic Updates When using a separate column to store the tsvector representation of your documents, it is neces- sary to create a trigger to update the tsvector column when the document content columns change. Two built-in trigger functions are available for this, or you can write your own. tsvector_update_trigger(tsvector_column_name, config_name, text_column_name [, ... ]) tsvector_update_trigger_column(tsvector_column_name, config_column_name, text_column_name These trigger functions automatically compute a tsvector column from one or more textual columns, under the control of parameters specified in the CREATE TRIGGER command. An example of their use is: CREATE TABLE messages ( title text, body text, tsv tsvector ); CREATE TRIGGER tsvectorupdate BEFORE INSERT OR UPDATE ON messages FOR EACH ROW EXECUTE PROCEDURE tsvector_update_trigger(tsv, ’pg_catalog.english’, title, body); INSERT INTO messages VALUES(’title here’, ’the body text is here’); SELECT * FROM messages; title | body | tsv ------------+-----------------------+---------------------------- title here | the body text is here | ’bodi’:4 ’text’:5 ’titl’:1 SELECT title, body FROM messages WHERE tsv @@ to_tsquery(’title & body’); title | body ------------+----------------------- title here | the body text is here Having created this trigger, any change in title or body will automatically be reflected into tsv, without the application having to worry about it. The first trigger argument must be the name of the tsvector column to be updated. The second argument specifies the text search configuration to be used to perform the conversion. For tsvector_update_trigger, the configuration name is simply given as the second trigger argument. It must be schema-qualified as shown above, so that the trigger behavior will not change with changes in search_path. For tsvector_update_trigger_column, the second trigger argument is the name of another table column, which must be of type regconfig. This allows a per-row selection of configuration to be made. The remaining argument(s) are the names of textual columns (of type text, varchar, or char). These will be included in the document in the order given. NULL values will be skipped (but the other columns will still be indexed). A limitation of these built-in triggers is that they treat all the input columns alike. To process columns differently — for example, to weight title differently from body — it is necessary to write a custom trigger. Here is an example using PL/pgSQL as the trigger language: CREATE FUNCTION messages_trigger() RETURNS trigger AS $$ begin new.tsv := setweight(to_tsvector(’pg_catalog.english’, coalesce(new.title,”)), ’A’) || 289](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-346-2048.jpg)
![Chapter 12. Full Text Search setweight(to_tsvector(’pg_catalog.english’, coalesce(new.body,”)), ’D’); return new; end $$ LANGUAGE plpgsql; CREATE TRIGGER tsvectorupdate BEFORE INSERT OR UPDATE ON messages FOR EACH ROW EXECUTE PROCEDURE messages_trigger(); Keep in mind that it is important to specify the configuration name explicitly when creating tsvector values inside triggers, so that the column’s contents will not be affected by changes to default_text_search_config. Failure to do this is likely to lead to problems such as search results changing after a dump and reload. 12.4.4. Gathering Document Statistics The function ts_stat is useful for checking your configuration and for finding stop-word candidates. ts_stat(sqlquery text, [ weights text, ] OUT word text, OUT ndoc integer, OUT nentry integer) returns setof record sqlquery is a text value containing an SQL query which must return a single tsvector column. ts_stat executes the query and returns statistics about each distinct lexeme (word) contained in the tsvector data. The columns returned are • word text — the value of a lexeme • ndoc integer — number of documents (tsvectors) the word occurred in • nentry integer — total number of occurrences of the word If weights is supplied, only occurrences having one of those weights are counted. For example, to find the ten most frequent words in a document collection: SELECT * FROM ts_stat(’SELECT vector FROM apod’) ORDER BY nentry DESC, ndoc DESC, word LIMIT 10; The same, but counting only word occurrences with weight A or B: SELECT * FROM ts_stat(’SELECT vector FROM apod’, ’ab’) ORDER BY nentry DESC, ndoc DESC, word LIMIT 10; 12.5. Parsers Text search parsers are responsible for splitting raw document text into tokens and identifying each token’s type, where the set of possible types is defined by the parser itself. Note that a parser does 290](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-347-2048.jpg)
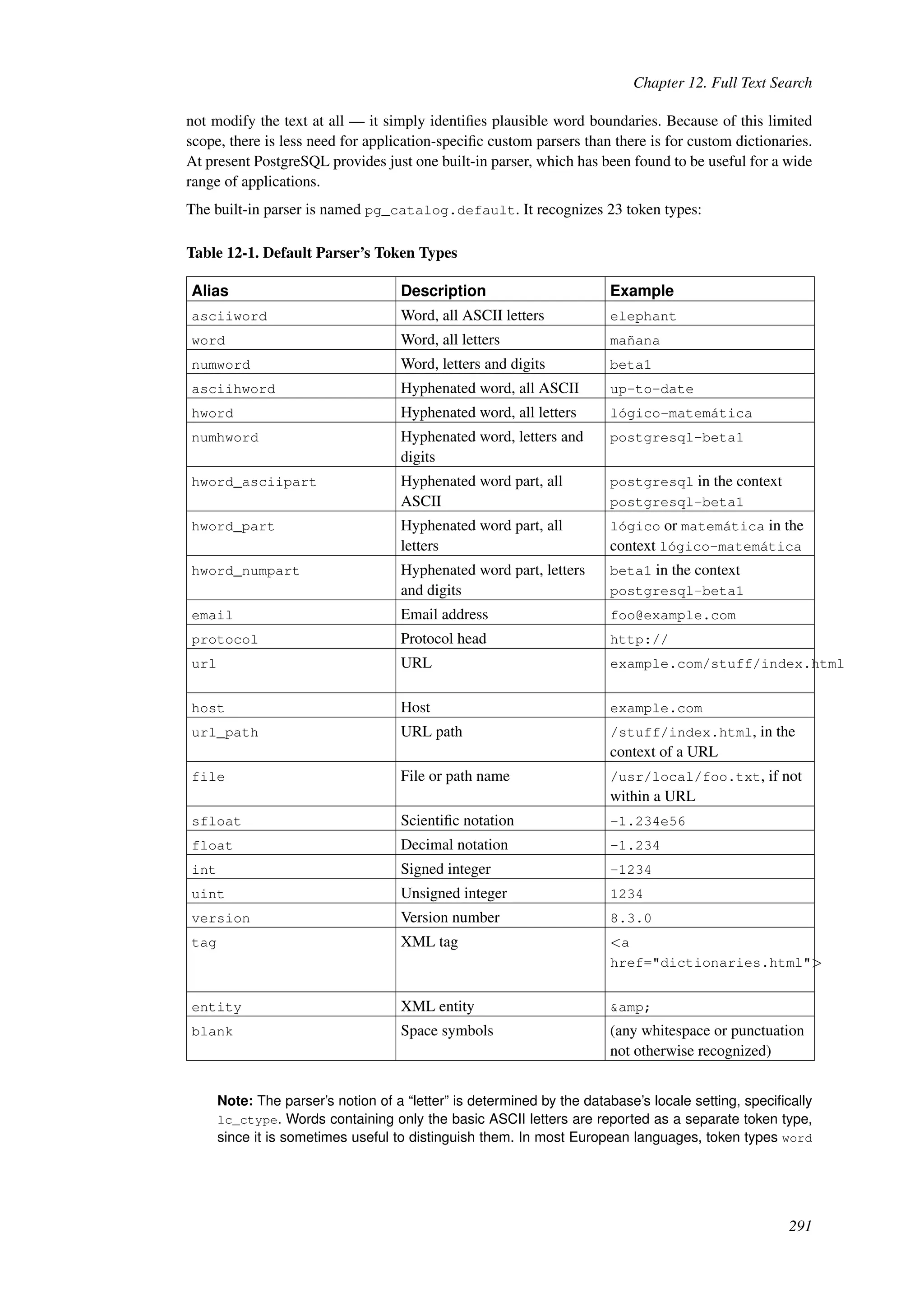









![Chapter 12. Full Text Search SELECT * FROM ts_debug(’public.pg’, ’ PostgreSQL, the highly scalable, SQL compliant, open source object-relational database management system, is now undergoing beta testing of the next version of our software. ’); The next step is to set the session to use the new configuration, which was created in the public schema: => dF List of text search configurations Schema | Name | Description ---------+------+------------- public | pg | SET default_text_search_config = ’public.pg’; SET SHOW default_text_search_config; default_text_search_config ---------------------------- public.pg 12.8. Testing and Debugging Text Search The behavior of a custom text search configuration can easily become confusing. The functions de- scribed in this section are useful for testing text search objects. You can test a complete configuration, or test parsers and dictionaries separately. 12.8.1. Configuration Testing The function ts_debug allows easy testing of a text search configuration. ts_debug([ config regconfig, ] document text, OUT alias text, OUT description text, OUT token text, OUT dictionaries regdictionary[], OUT dictionary regdictionary, OUT lexemes text[]) returns setof record ts_debug displays information about every token of document as produced by the parser and processed by the configured dictionaries. It uses the configuration specified by config, or default_text_search_config if that argument is omitted. ts_debug returns one row for each token identified in the text by the parser. The columns returned are 301](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-358-2048.jpg)
![Chapter 12. Full Text Search • alias text — short name of the token type • description text — description of the token type • token text — text of the token • dictionaries regdictionary[] — the dictionaries selected by the configuration for this token type • dictionary regdictionary — the dictionary that recognized the token, or NULL if none did • lexemes text[] — the lexeme(s) produced by the dictionary that recognized the token, or NULL if none did; an empty array ({}) means it was recognized as a stop word Here is a simple example: SELECT * FROM ts_debug(’english’,’a fat cat sat on a mat - it ate a fat rats’); alias | description | token | dictionaries | dictionary | lexemes -----------+-----------------+-------+----------------+--------------+--------- asciiword | Word, all ASCII | a | {english_stem} | english_stem | {} blank | Space symbols | | {} | | asciiword | Word, all ASCII | fat | {english_stem} | english_stem | {fat} blank | Space symbols | | {} | | asciiword | Word, all ASCII | cat | {english_stem} | english_stem | {cat} blank | Space symbols | | {} | | asciiword | Word, all ASCII | sat | {english_stem} | english_stem | {sat} blank | Space symbols | | {} | | asciiword | Word, all ASCII | on | {english_stem} | english_stem | {} blank | Space symbols | | {} | | asciiword | Word, all ASCII | a | {english_stem} | english_stem | {} blank | Space symbols | | {} | | asciiword | Word, all ASCII | mat | {english_stem} | english_stem | {mat} blank | Space symbols | | {} | | blank | Space symbols | - | {} | | asciiword | Word, all ASCII | it | {english_stem} | english_stem | {} blank | Space symbols | | {} | | asciiword | Word, all ASCII | ate | {english_stem} | english_stem | {ate} blank | Space symbols | | {} | | asciiword | Word, all ASCII | a | {english_stem} | english_stem | {} blank | Space symbols | | {} | | asciiword | Word, all ASCII | fat | {english_stem} | english_stem | {fat} blank | Space symbols | | {} | | asciiword | Word, all ASCII | rats | {english_stem} | english_stem | {rat} For a more extensive demonstration, we first create a public.english configuration and Ispell dictionary for the English language: CREATE TEXT SEARCH CONFIGURATION public.english ( COPY = pg_catalog.english ); CREATE TEXT SEARCH DICTIONARY english_ispell ( TEMPLATE = ispell, DictFile = english, AffFile = english, StopWords = english ); ALTER TEXT SEARCH CONFIGURATION public.english ALTER MAPPING FOR asciiword WITH english_ispell, english_stem; 302](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-359-2048.jpg)

![Chapter 12. Full Text Search 1 | number ts_token_type(parser_name text, OUT tokid integer, OUT alias text, OUT description text) returns setof record ts_token_type(parser_oid oid, OUT tokid integer, OUT alias text, OUT description text) returns setof record ts_token_type returns a table which describes each type of token the specified parser can recog- nize. For each token type, the table gives the integer tokid that the parser uses to label a token of that type, the alias that names the token type in configuration commands, and a short description. For example: SELECT * FROM ts_token_type(’default’); tokid | alias | description -------+-----------------+------------------------------------------ 1 | asciiword | Word, all ASCII 2 | word | Word, all letters 3 | numword | Word, letters and digits 4 | email | Email address 5 | url | URL 6 | host | Host 7 | sfloat | Scientific notation 8 | version | Version number 9 | hword_numpart | Hyphenated word part, letters and digits 10 | hword_part | Hyphenated word part, all letters 11 | hword_asciipart | Hyphenated word part, all ASCII 12 | blank | Space symbols 13 | tag | XML tag 14 | protocol | Protocol head 15 | numhword | Hyphenated word, letters and digits 16 | asciihword | Hyphenated word, all ASCII 17 | hword | Hyphenated word, all letters 18 | url_path | URL path 19 | file | File or path name 20 | float | Decimal notation 21 | int | Signed integer 22 | uint | Unsigned integer 23 | entity | XML entity 12.8.3. Dictionary Testing The ts_lexize function facilitates dictionary testing. ts_lexize(dict regdictionary, token text) returns text[] ts_lexize returns an array of lexemes if the input token is known to the dictionary, or an empty array if the token is known to the dictionary but it is a stop word, or NULL if it is an unknown word. Examples: 304](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-361-2048.jpg)

![Chapter 12. Full Text Search A GiST index is lossy, meaning that the index may produce false matches, and it is necessary to check the actual table row to eliminate such false matches. (PostgreSQL does this automatically when needed.) GiST indexes are lossy because each document is represented in the index by a fixed-length signature. The signature is generated by hashing each word into a random bit in an n-bit string, with all these bits OR-ed together to produce an n-bit document signature. When two words hash to the same bit position there will be a false match. If all words in the query have matches (real or false) then the table row must be retrieved to see if the match is correct. Lossiness causes performance degradation due to unnecessary fetches of table records that turn out to be false matches. Since random access to table records is slow, this limits the usefulness of GiST indexes. The likelihood of false matches depends on several factors, in particular the number of unique words, so using dictionaries to reduce this number is recommended. GIN indexes are not lossy for standard queries, but their performance depends logarithmically on the number of unique words. (However, GIN indexes store only the words (lexemes) of tsvector values, and not their weight labels. Thus a table row recheck is needed when using a query that involves weights.) In choosing which index type to use, GiST or GIN, consider these performance differences: • GIN index lookups are about three times faster than GiST • GIN indexes take about three times longer to build than GiST • GIN indexes are moderately slower to update than GiST indexes, but about 10 times slower if fast-update support was disabled (see Section 52.3.1 for details) • GIN indexes are two-to-three times larger than GiST indexes As a rule of thumb, GIN indexes are best for static data because lookups are faster. For dynamic data, GiST indexes are faster to update. Specifically, GiST indexes are very good for dynamic data and fast if the number of unique words (lexemes) is under 100,000, while GIN indexes will handle 100,000+ lexemes better but are slower to update. Note that GIN index build time can often be improved by increasing maintenance_work_mem, while GiST index build time is not sensitive to that parameter. Partitioning of big collections and the proper use of GiST and GIN indexes allows the implemen- tation of very fast searches with online update. Partitioning can be done at the database level using table inheritance, or by distributing documents over servers and collecting search results using the contrib/dblink extension module. The latter is possible because ranking functions use only local information. 12.10. psql Support Information about text search configuration objects can be obtained in psql using a set of commands: dF{d,p,t}[+] [PATTERN] An optional + produces more details. The optional parameter PATTERN can be the name of a text search object, optionally schema-qualified. If PATTERN is omitted then information about all visible objects will be displayed. PATTERN can be a regular expression and can provide separate patterns for the schema and object names. The following examples illustrate this: 306](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-363-2048.jpg)
![Chapter 12. Full Text Search => dF *fulltext* List of text search configurations Schema | Name | Description --------+--------------+------------- public | fulltext_cfg | => dF *.fulltext* List of text search configurations Schema | Name | Description ----------+---------------------------- fulltext | fulltext_cfg | public | fulltext_cfg | The available commands are: dF[+] [PATTERN] List text search configurations (add + for more detail). => dF russian List of text search configurations Schema | Name | Description ------------+---------+------------------------------------ pg_catalog | russian | configuration for russian language => dF+ russian Text search configuration "pg_catalog.russian" Parser: "pg_catalog.default" Token | Dictionaries -----------------+-------------- asciihword | english_stem asciiword | english_stem email | simple file | simple float | simple host | simple hword | russian_stem hword_asciipart | english_stem hword_numpart | simple hword_part | russian_stem int | simple numhword | simple numword | simple sfloat | simple uint | simple url | simple url_path | simple version | simple word | russian_stem dFd[+] [PATTERN] List text search dictionaries (add + for more detail). => dFd List of text search dictionaries Schema | Name | Description ------------+-----------------+------------------------------------------------------ 307](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-364-2048.jpg)
![Chapter 12. Full Text Search pg_catalog | danish_stem | snowball stemmer for danish language pg_catalog | dutch_stem | snowball stemmer for dutch language pg_catalog | english_stem | snowball stemmer for english language pg_catalog | finnish_stem | snowball stemmer for finnish language pg_catalog | french_stem | snowball stemmer for french language pg_catalog | german_stem | snowball stemmer for german language pg_catalog | hungarian_stem | snowball stemmer for hungarian language pg_catalog | italian_stem | snowball stemmer for italian language pg_catalog | norwegian_stem | snowball stemmer for norwegian language pg_catalog | portuguese_stem | snowball stemmer for portuguese language pg_catalog | romanian_stem | snowball stemmer for romanian language pg_catalog | russian_stem | snowball stemmer for russian language pg_catalog | simple | simple dictionary: just lower case and check for stop pg_catalog | spanish_stem | snowball stemmer for spanish language pg_catalog | swedish_stem | snowball stemmer for swedish language pg_catalog | turkish_stem | snowball stemmer for turkish language dFp[+] [PATTERN] List text search parsers (add + for more detail). => dFp List of text search parsers Schema | Name | Description ------------+---------+--------------------- pg_catalog | default | default word parser => dFp+ Text search parser "pg_catalog.default" Method | Function | Description -----------------+----------------+------------- Start parse | prsd_start | Get next token | prsd_nexttoken | End parse | prsd_end | Get headline | prsd_headline | Get token types | prsd_lextype | Token types for parser "pg_catalog.default" Token name | Description -----------------+------------------------------------------ asciihword | Hyphenated word, all ASCII asciiword | Word, all ASCII blank | Space symbols email | Email address entity | XML entity file | File or path name float | Decimal notation host | Host hword | Hyphenated word, all letters hword_asciipart | Hyphenated word part, all ASCII hword_numpart | Hyphenated word part, letters and digits hword_part | Hyphenated word part, all letters int | Signed integer numhword | Hyphenated word, letters and digits numword | Word, letters and digits protocol | Protocol head sfloat | Scientific notation tag | XML tag uint | Unsigned integer 308](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-365-2048.jpg)
![Chapter 12. Full Text Search url | URL url_path | URL path version | Version number word | Word, all letters (23 rows) dFt[+] [PATTERN] List text search templates (add + for more detail). => dFt List of text search templates Schema | Name | Description ------------+-----------+----------------------------------------------------------- pg_catalog | ispell | ispell dictionary pg_catalog | simple | simple dictionary: just lower case and check for stopword pg_catalog | snowball | snowball stemmer pg_catalog | synonym | synonym dictionary: replace word by its synonym pg_catalog | thesaurus | thesaurus dictionary: phrase by phrase substitution 12.11. Limitations The current limitations of PostgreSQL’s text search features are: • The length of each lexeme must be less than 2K bytes • The length of a tsvector (lexemes + positions) must be less than 1 megabyte • The number of lexemes must be less than 264 • Position values in tsvector must be greater than 0 and no more than 16,383 • No more than 256 positions per lexeme • The number of nodes (lexemes + operators) in a tsquery must be less than 32,768 For comparison, the PostgreSQL 8.1 documentation contained 10,441 unique words, a total of 335,420 words, and the most frequent word “postgresql” was mentioned 6,127 times in 655 documents. Another example — the PostgreSQL mailing list archives contained 910,989 unique words with 57,491,343 lexemes in 461,020 messages. 12.12. Migration from Pre-8.3 Text Search Applications that used the contrib/tsearch2 add-on module for text searching will need some adjustments to work with the built-in features: • Some functions have been renamed or had small adjustments in their argument lists, and all of them are now in the pg_catalog schema, whereas in a previous installation they would have been in public or another non-system schema. There is a new version of contrib/tsearch2 (see Section F.35) that provides a compatibility layer to solve most problems in this area. • The old contrib/tsearch2 functions and other objects must be suppressed when loading pg_dump output from a pre-8.3 database. While many of them won’t load anyway, a few will and 309](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-366-2048.jpg)


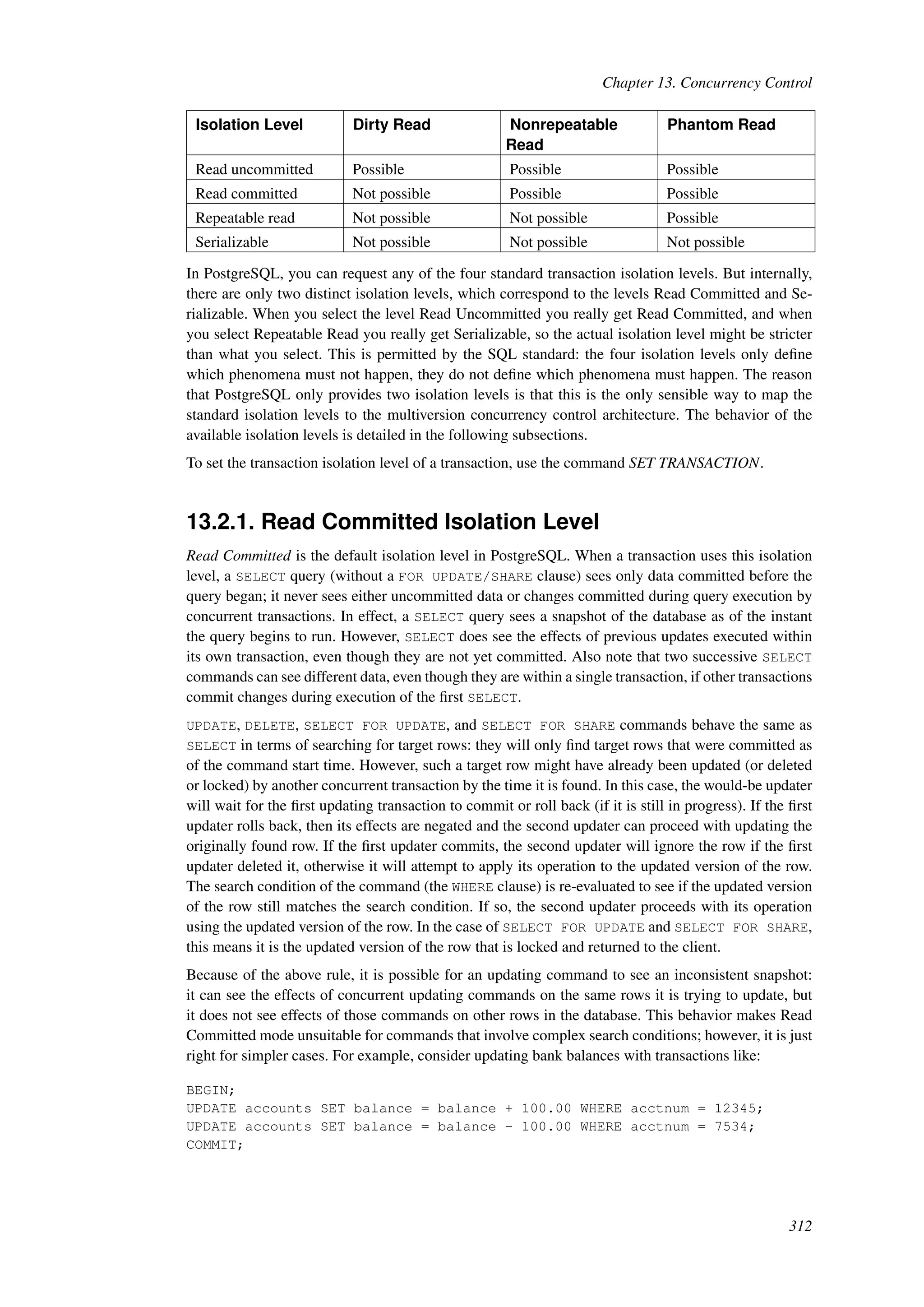




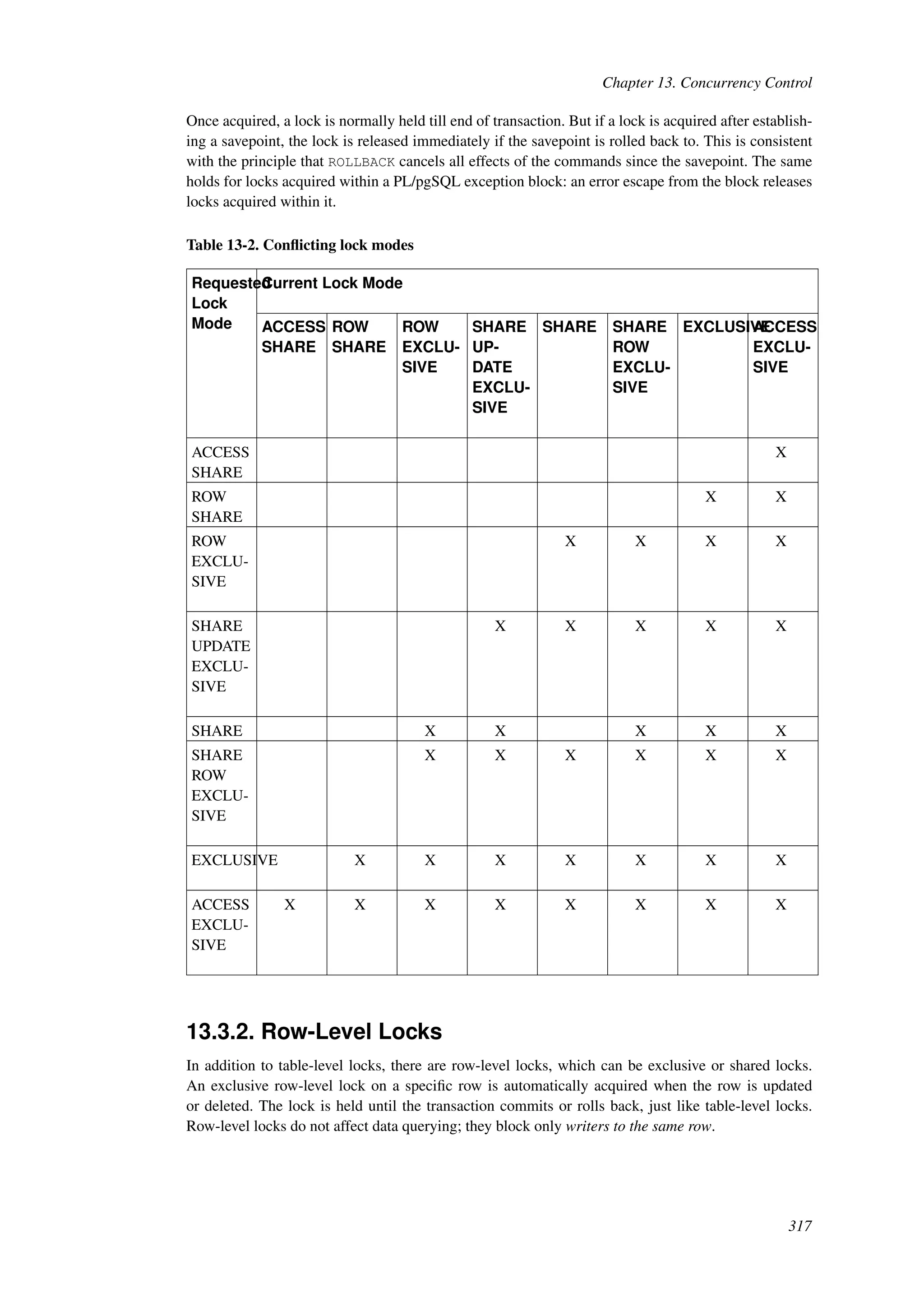









![Chapter 14. Performance Tips 14.2. Statistics Used by the Planner As we saw in the previous section, the query planner needs to estimate the number of rows retrieved by a query in order to make good choices of query plans. This section provides a quick look at the statistics that the system uses for these estimates. One component of the statistics is the total number of entries in each table and index, as well as the number of disk blocks occupied by each table and index. This information is kept in the table pg_class, in the columns reltuples and relpages. We can look at it with queries similar to this one: SELECT relname, relkind, reltuples, relpages FROM pg_class WHERE relname LIKE ’tenk1%’; relname | relkind | reltuples | relpages ----------------------+---------+-----------+---------- tenk1 | r | 10000 | 358 tenk1_hundred | i | 10000 | 30 tenk1_thous_tenthous | i | 10000 | 30 tenk1_unique1 | i | 10000 | 30 tenk1_unique2 | i | 10000 | 30 (5 rows) Here we can see that tenk1 contains 10000 rows, as do its indexes, but the indexes are (unsurpris- ingly) much smaller than the table. For efficiency reasons, reltuples and relpages are not updated on-the-fly, and so they usually contain somewhat out-of-date values. They are updated by VACUUM, ANALYZE, and a few DDL com- mands such as CREATE INDEX. A stand-alone ANALYZE, that is one not part of VACUUM, generates an approximate reltuples value since it does not read every row of the table. The planner will scale the values it finds in pg_class to match the current physical table size, thus obtaining a closer approximation. Most queries retrieve only a fraction of the rows in a table, due to WHERE clauses that restrict the rows to be examined. The planner thus needs to make an estimate of the selectivity of WHERE clauses, that is, the fraction of rows that match each condition in the WHERE clause. The information used for this task is stored in the pg_statistic system catalog. Entries in pg_statistic are updated by the ANALYZE and VACUUM ANALYZE commands, and are always approximate even when freshly updated. Rather than look at pg_statistic directly, it’s better to look at its view pg_stats when examining the statistics manually. pg_stats is designed to be more easily readable. Furthermore, pg_stats is readable by all, whereas pg_statistic is only readable by a superuser. (This prevents unprivileged users from learning something about the contents of other people’s tables from the statistics. The pg_stats view is restricted to show only rows about tables that the current user can read.) For example, we might do: SELECT attname, n_distinct, most_common_vals FROM pg_stats WHERE tablename = ’road’; attname | n_distinct | ---------+------------+------------------------------------------------------------------ name | -0.467008 | {"I- 580 Ramp","I- 880 thepath | 20 | {"[(-122.089,37.71),(-122.0886,37.711)]"} (2 rows) 327](https://image.slidesharecdn.com/postgresql-8-150203190554-conversion-gate02/75/Postgresql-8-4-a4-384-2048.jpg)