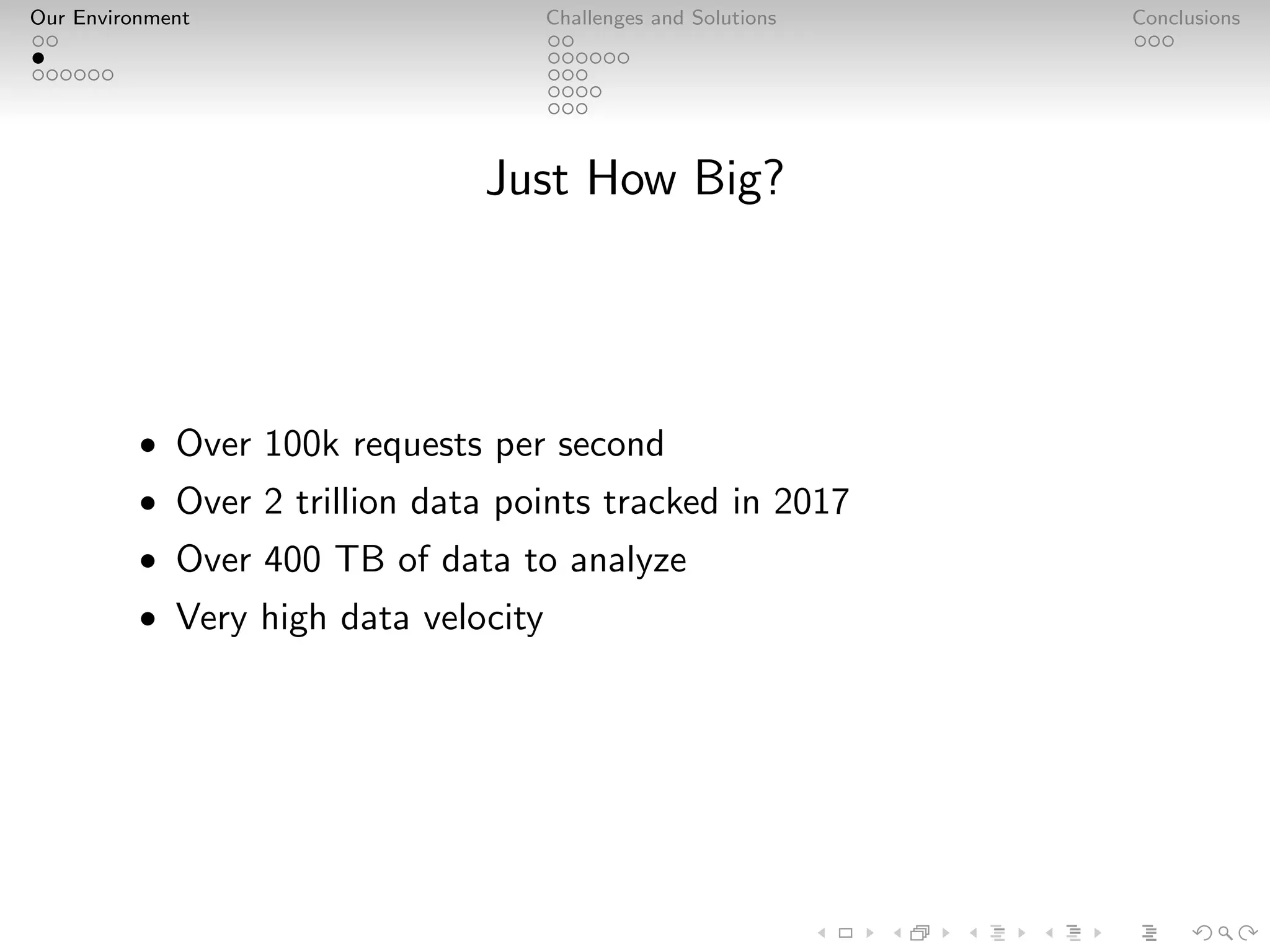
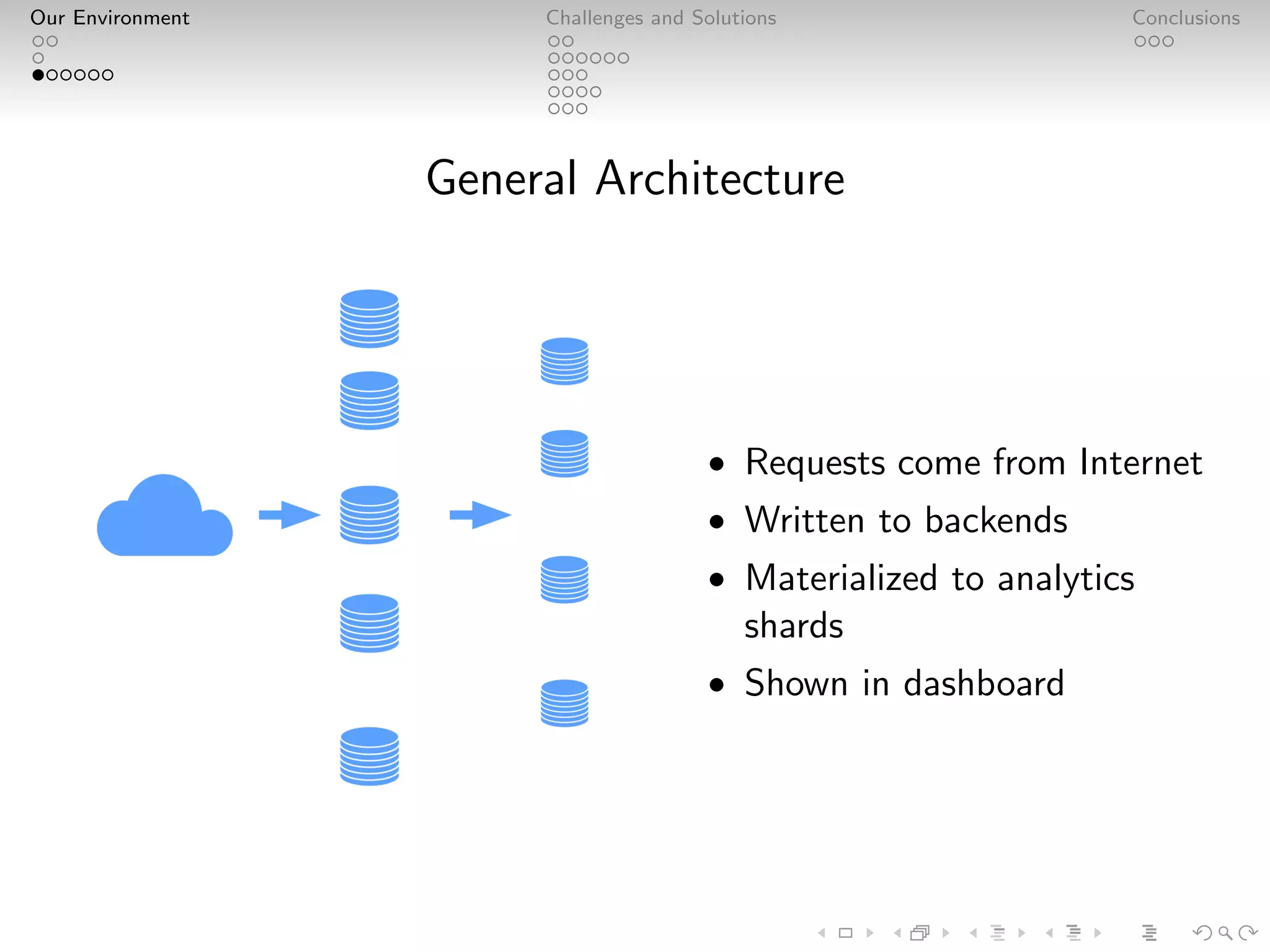
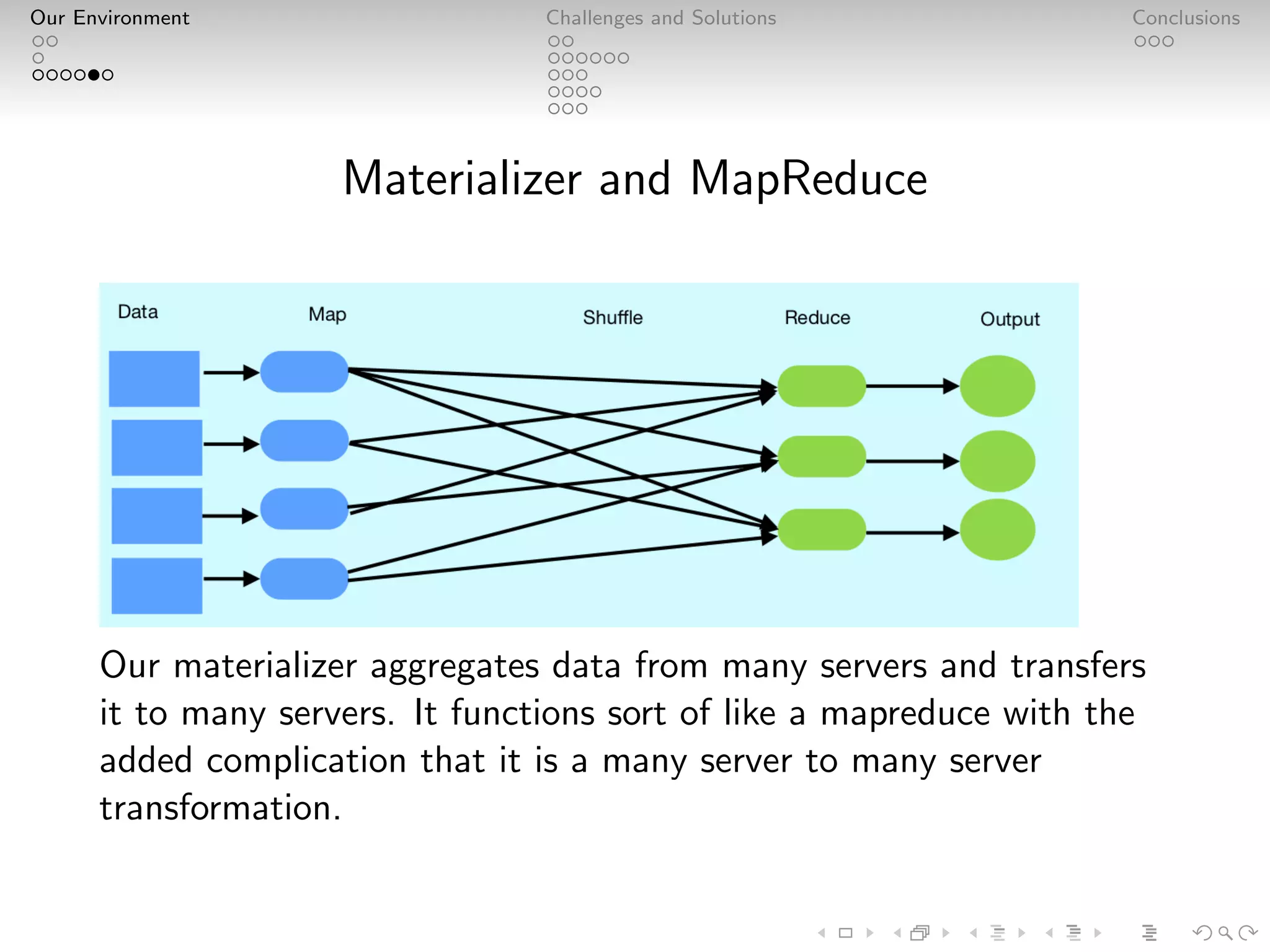
Adjust is a leader in mobile advertisement attribution, managing massive data volumes with their PostgreSQL and Kafka environment. They handle over 2 trillion data points and 100k requests per second, focusing on performance optimization, analytics, and fraud prevention. Adjust's infrastructure emphasizes careful design, custom solutions, and staff expertise to ensure reliable, near-real-time analytics for advertisers.