Downloaded 533 times








































































































![References 1. A. Lakshman and P. Malik. Cassandra: a decentralized structured storage system. SIGOPS Oper. Syst. Rev., 44(2): 35-40, 2010 2. Cassandra.apache.org. (2016). Apache Cassandra. [online] Available at: http://cassandra.apache.org/ 3. Cattell, R. (2011). Scalable SQL and NoSQL data stores. ACM SIGMOD Record, 39(4), p.12. 4. Cockcroft, A. (2011). Benchmarking Cassandra Scalability on AWS - Over a million writes per second. [online] Techblog.netflix.com. Available at: http://techblog.netflix.com/2011/11/benchmarking-cassandra-scalability- on.html 5. Cs.uwaterloo.ca. (2016). [online] Available at: https://cs.uwaterloo.ca/~tozsu/courses/CS848/W15/presentations/Cassandra.pdf 6. Chang, F., Dean, J., Ghemawat, S., Hsieh, W., Wallach, D., Burrows, M., Chandra, T., Fikes, A. and Gruber, R. (2008). Bigtable. ACM Transactions on Computer Systems, 26(2), pp.1-26. 7. DataStax. (2016). Case Studies. [online] Available at: http://www.datastax.com/resources/casestudies](https://image.slidesharecdn.com/apachecassandrapresentation-170122113552/75/Presentation-of-Apache-Cassandra-161-2048.jpg)
![References (1) 8. Docs.datastax.com. (2016). About hinted handoff writes. [online] Available at: https://docs.datastax.com/en/cassandra/2.0/cassandra/dml/dml_about_hh_c.html 9. DataStax. (2016). Customers. [online] Available at: http://www.datastax.com/customers 10. Docs.datastax.com. (2016). Introduction to Cassandra Query Language. [online] Available at: https://docs.datastax.com/en/cql/3.1/cql/cql_intro_c.html 11. DataStax. (2014). What on earth are people using Cassandra for anyway?. [online] Available at: http://www.datastax.com/2014/06/what-are-people-using-cassandra-for 12. DataStax. (2012). A thrift to CQL3 upgrade guide. [online] Available at: http://www.datastax.com/dev/blog/thrift-to-cql3 13. DataStax. (2012). Virtual nodes in Cassandra 1.2. [online] Available at: http://www.datastax.com/dev/blog/virtual-nodes-in-cassandra-1-2 14. DataStax. (2012). Schema in Cassandra 1.1. [online] Available at: http://www.datastax.com/dev/blog/schema- in-cassandra-1-1](https://image.slidesharecdn.com/apachecassandrapresentation-170122113552/75/Presentation-of-Apache-Cassandra-162-2048.jpg)
![References (2) 15. DeCandia, G., Hastorun, D., Jampani, M., Kakulapati, G., Lakshman, A., Pilchin, A., Sivasubramanian, S., Vosshall, P. and Vogels, W. (2007). Dynamo. ACM SIGOPS Operating Systems Review, 41(6), p.205. 16. Docs.datastax.com. (2016). Architecture in brief. [online] Available at: https://docs.datastax.com/en/cassandra/2.0/cassandra/architecture/architectureIntro_c.html 17. Docs.datastax.com. (2016). How data is distributed across a cluster (using virtual nodes). [online] Available at: http://docs.datastax.com/en/cassandra/2.0/cassandra/architecture/architectureDataDistributeDistribute_c.html 18. Docs.datastax.com. (2016). Internode communications (gossip). [online] Available at: https://docs.datastax.com/en/cassandra/2.0/cassandra/architecture/architectureGossipAbout_c.html 19. D0.awsstatic.com. (2016). [online] Available at: https://d0.awsstatic.com/whitepapers/Cassandra_on_AWS.pdf 20. Edlich, P. (2016). NOSQL Databases. [online] Nosql-database.org. Available at: http://nosql-database.org/](https://image.slidesharecdn.com/apachecassandrapresentation-170122113552/75/Presentation-of-Apache-Cassandra-163-2048.jpg)
![References (3) 21. Edu.dmst.aueb.gr. (2016). Πύλη Τηλεκπαίδευσης Τμήματος Διοικητικής Επιστήμης & Τεχνολογίας: Είσοδος στο δικτυακό τόπο. [online] Available at: https://edu.dmst.aueb.gr/pluginfile.php/3614/mod_resource/content/0/BigDataSystems.pdf 22. En.wikipedia.org. (2016). Apache Cassandra. [online] Available at: https://en.wikipedia.org/wiki/Apache_Cassandra 23. En.wikipedia.org. (2016). DataStax. [online] Available at: https://en.wikipedia.org/wiki/DataStax 24. En.wikipedia.org. (2016). Log-structured merge-tree. [online] Available at: https://en.wikipedia.org/wiki/Log- structured_merge-tree 25. Exponential.io. (2016). Cassandra terminology - Exponential.io . [online] Available at: http://exponential.io/blog/2015/01/08/cassandra-terminology/](https://image.slidesharecdn.com/apachecassandrapresentation-170122113552/75/Presentation-of-Apache-Cassandra-164-2048.jpg)
![References (4) 26. Facebook.com. (2016). Cassandra – A structured storage system on a P2P Network. [online] Available at: https://www.facebook.com/notes/facebook-engineering/cassandra-a-structured-storage-system-on-a-p2p- network/24413138919/ 27. O', P. and Neil, E. (2016). The Log-Structured Merge-Tree (LSM-Tree). [online] Citeseerx.ist.psu.edu. Available at: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.44.2782 28. YouTube. (2016). Getting Started with Cassandra CQL on a Mac. [online] Available at: https://www.youtube.com/watch?v=9zQc959w6Ho 29. YouTube. (2016). Installing Apache Cassandra In Windows. [online] Available at: https://www.youtube.com/watch?v=fspXzjwfii0 30. YouTube. (2016). Part 1 - Apache Cassandra Installation From Scratch - Ubuntu. [online] Available at: https://www.youtube.com/watch?v=ToztU48UxYE](https://image.slidesharecdn.com/apachecassandrapresentation-170122113552/75/Presentation-of-Apache-Cassandra-165-2048.jpg)
![References (5) 31. Weinberger, M. (2016). The Facebook engineer who taught its data how to dance is solving a new complicated problem. [online] Business Insider. Available at: http://www.businessinsider.com/hedvig-avinash- lakshman-facebook-cassandra-data-storage-2015-3 32. Wiki.apache.org. (2016). FrontPage - Cassandra Wiki. [online] Available at: https://wiki.apache.org/cassandra/ 33. www.tutorialspoint.com. (2016). Cassandra Introduction. [online] Available at: https://www.tutorialspoint.com/cassandra/cassandra_introduction.htm](https://image.slidesharecdn.com/apachecassandrapresentation-170122113552/75/Presentation-of-Apache-Cassandra-166-2048.jpg)

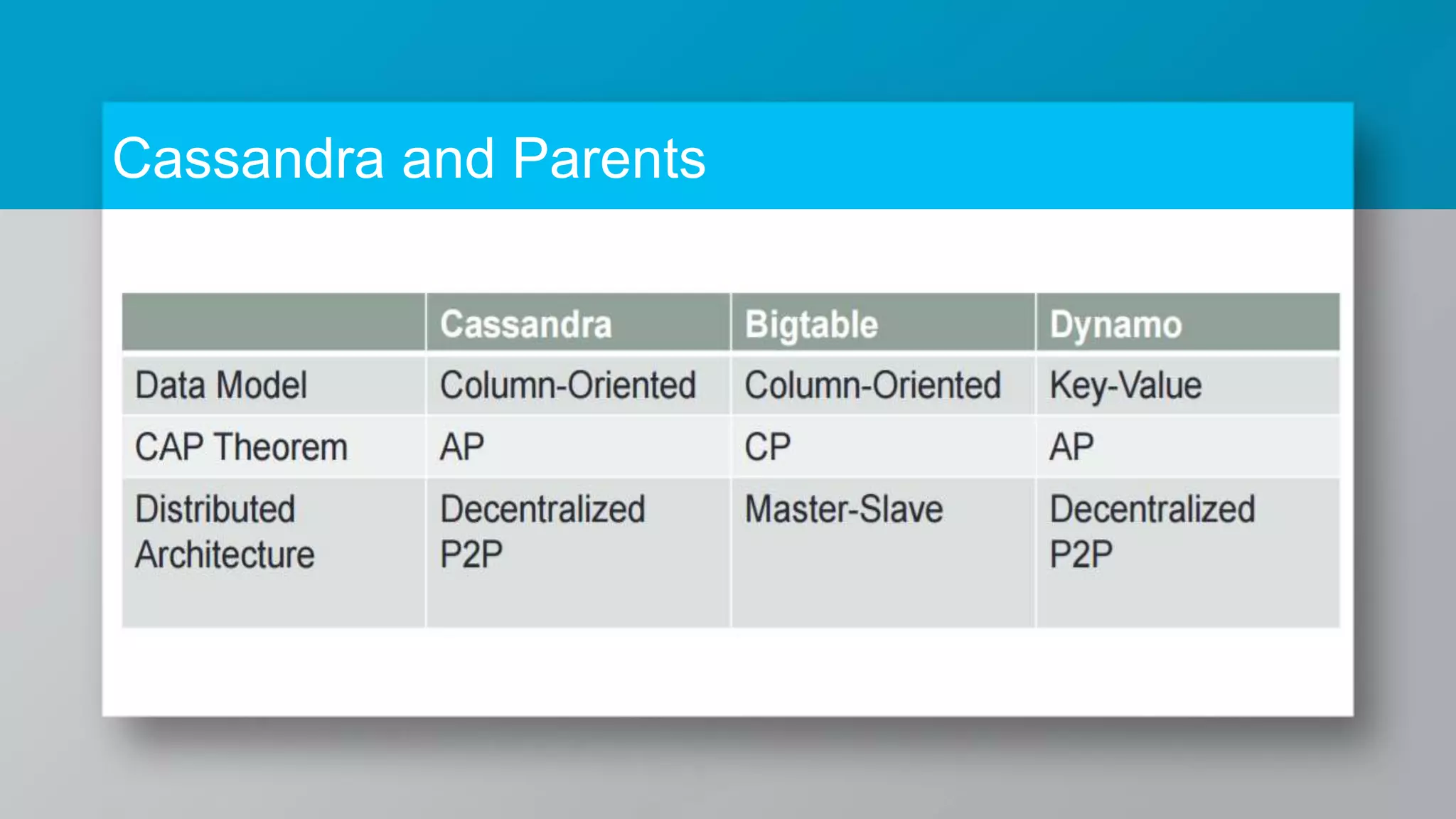
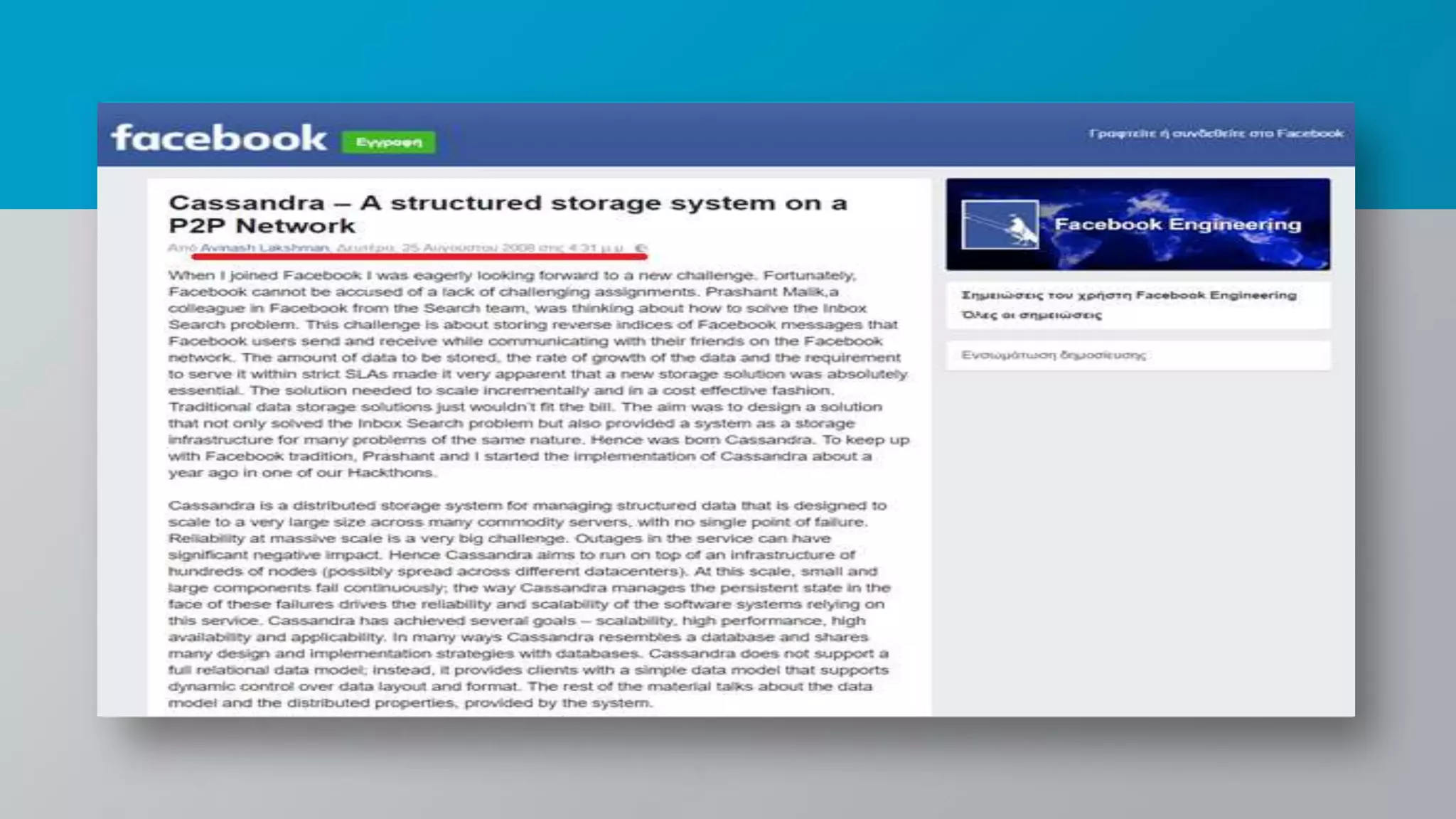
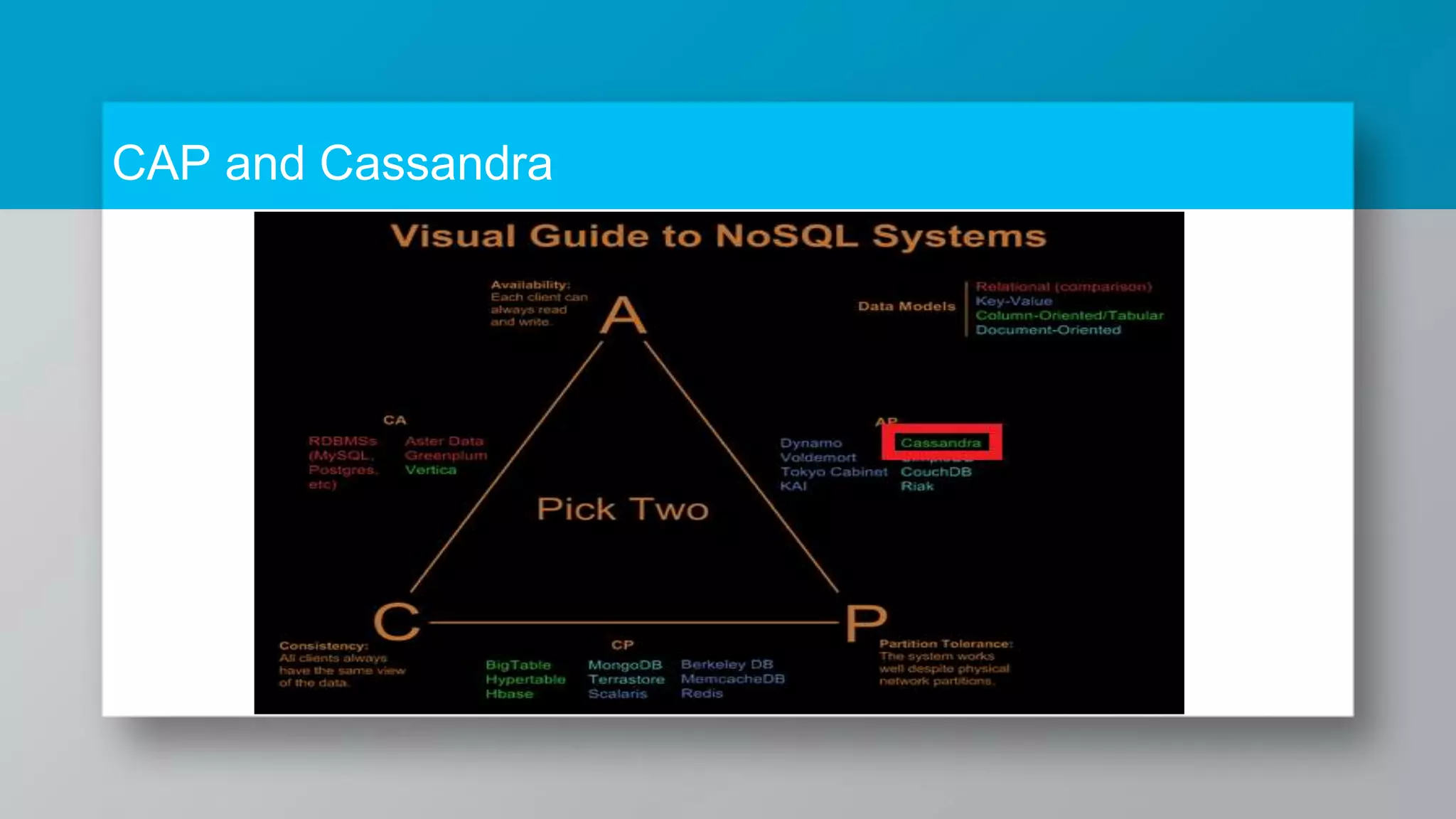
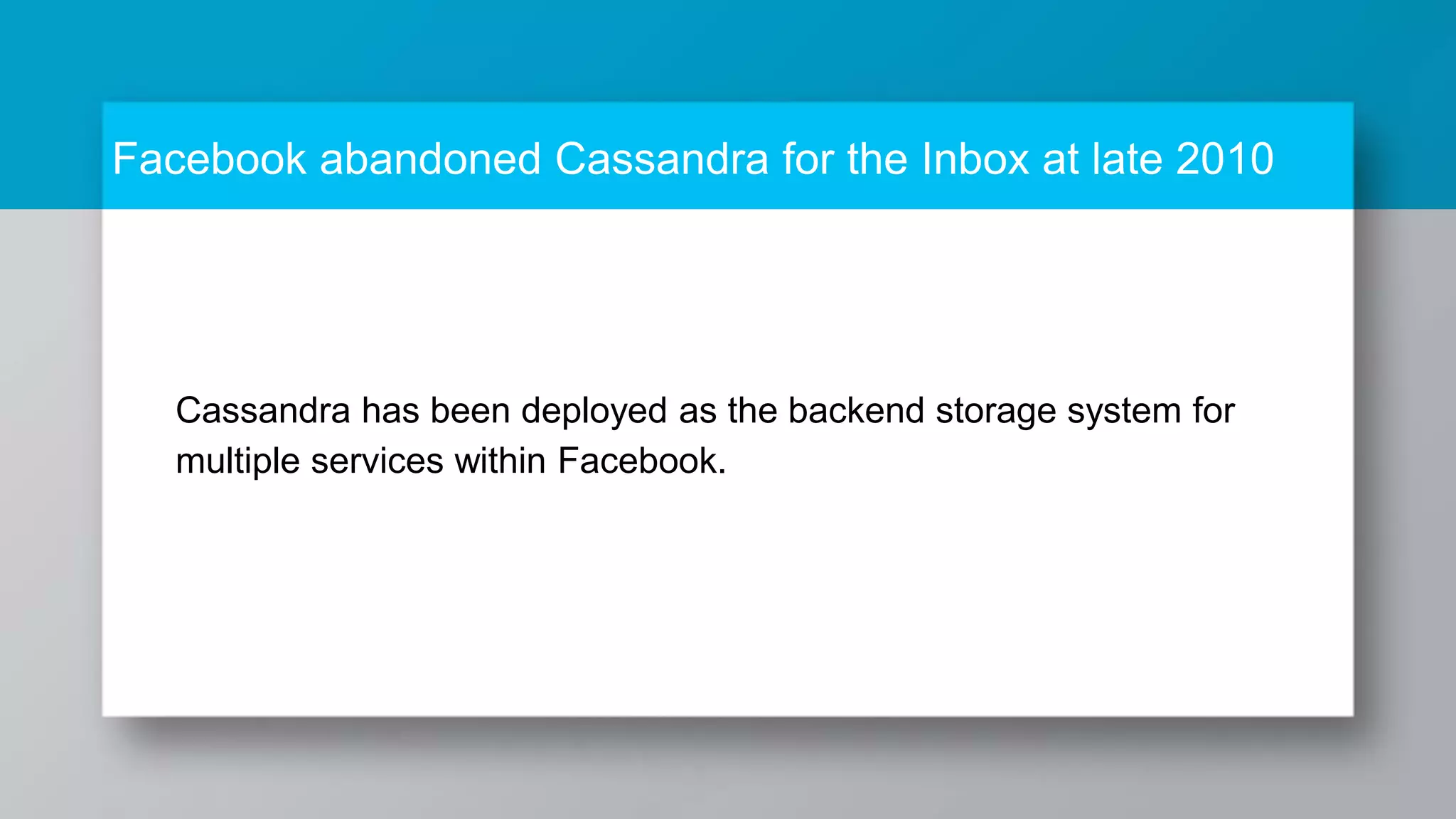
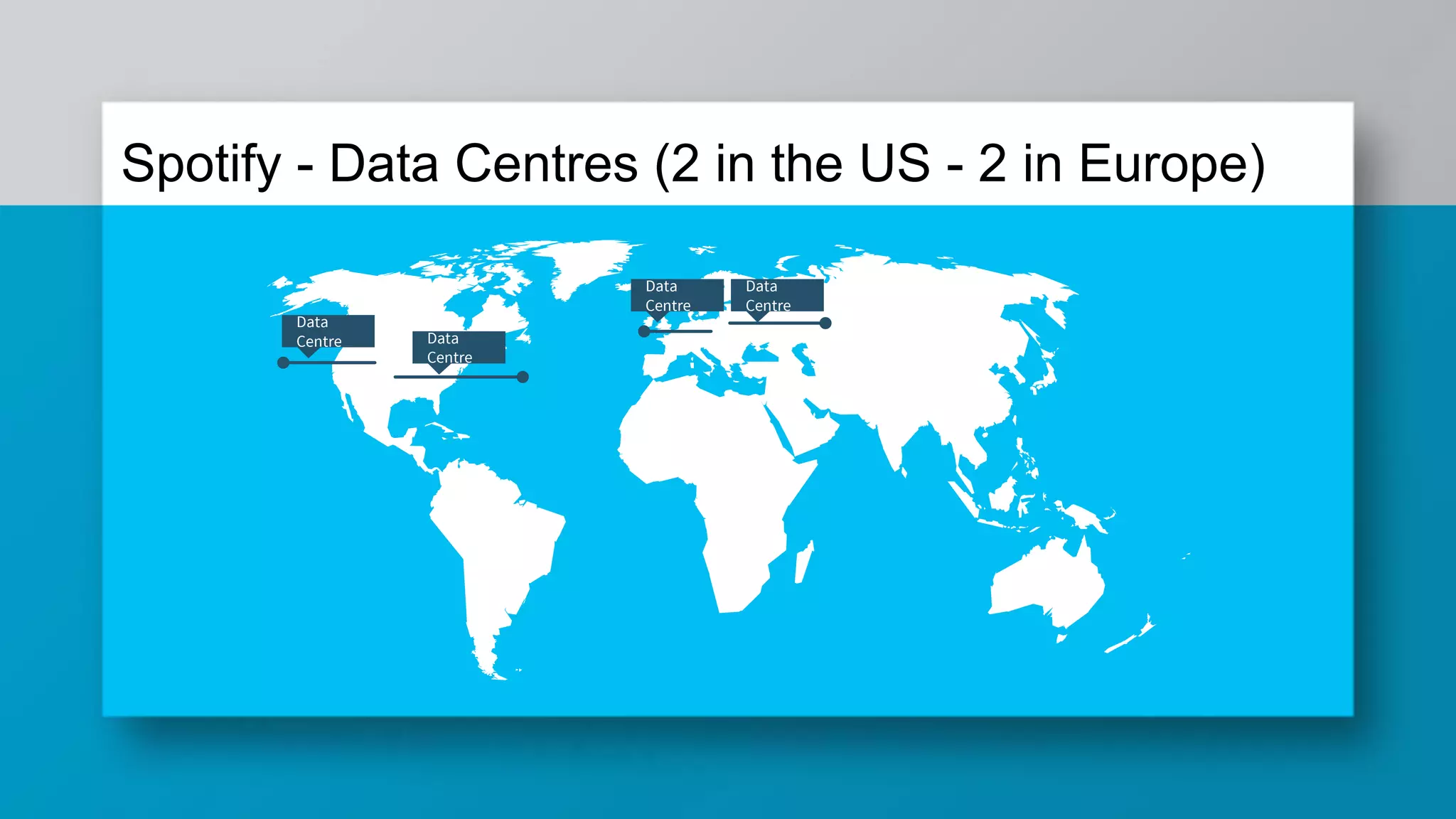
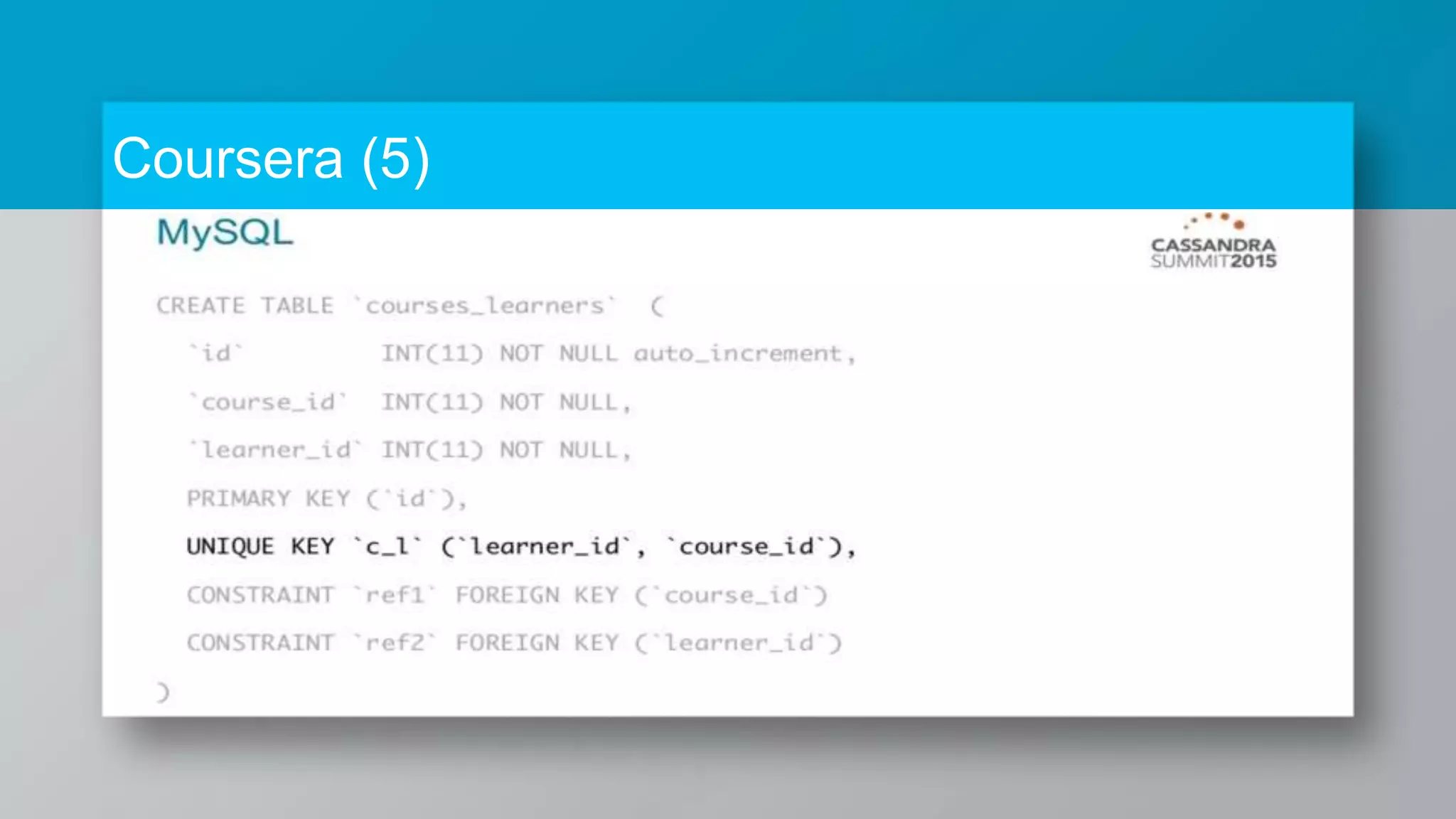
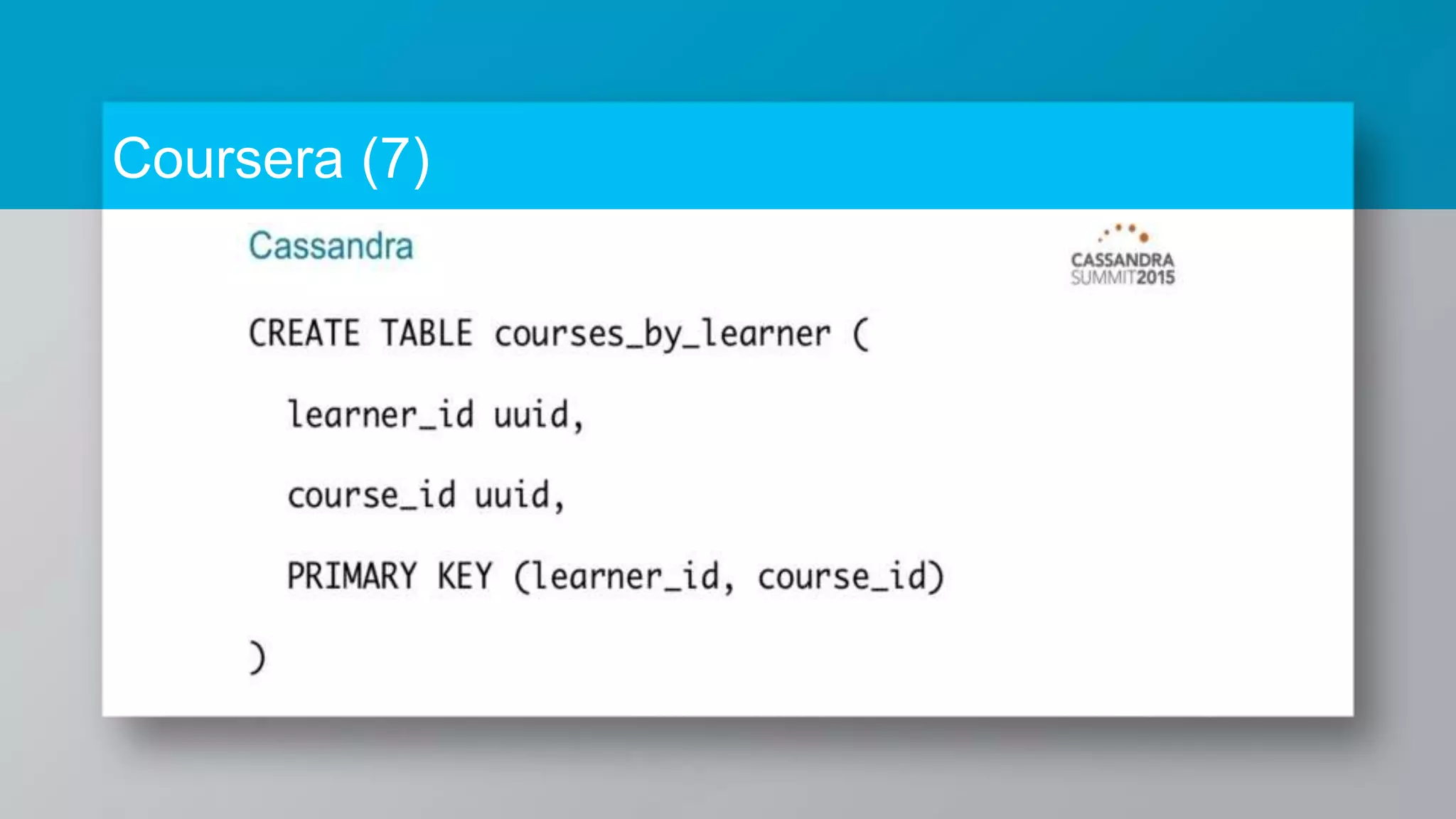
The document provides a comprehensive overview of Apache Cassandra, a distributed NoSQL database designed for managing large volumes of structured data across many servers while ensuring high availability and fault tolerance. It details Cassandra's architecture, origins from Amazon's Dynamo and Google's Bigtable, strengths, weaknesses, and use cases for various applications like messaging, fraud detection, and analytics. Additionally, it outlines its scalability, ease of use, and support for diverse programming languages, illustrated by case studies from companies like Facebook, Instagram, and Netflix.