The document discusses replication in distributed systems, highlighting its definition, benefits, and necessity for maintaining consistency among redundant resources. It describes various replication techniques such as active and passive replication, different replication models including master-slave and peer-to-peer, and the challenges of ensuring consistency during updates. Additionally, it covers consistency models, including strict and causal consistency, and their implications for performance in distributed systems.
What is Replication? ●It involves sharing of information so as to ensure consistency between redundant resources (software or hardware components) to improve reliability, fault-tolerance or accessibility. ● Benefits of this technique: ○ Performance Enhancement: More load can be tolerated because workload is shared among several processes. ○ Increased Availability: Helps a service overcome individual server failures. ○ Fault Tolerance: Ensures correctness in addition to availability.
3.
Need for Replication ●From the client's point of view, there is a single logical copy of the data. If a client makes an update to one replica, that change should be reflected at all other replicas. Consider the following scenario -- we have a bank with two replicated servers. A user may connect to either one. Initially, account A has $5 and account B has 0. ○ The user connects to server 1 and updates account A to contain $10. ○ The user transfers $5 from account A to account B via server 2. ○ Server 1 fails before data is propagated. ○ Account A has a balance of 0 and account B has a balance of $5. ● This example violates sequential consistency.
4.
How to solveit? ● The basic model for managing replicated data includes the following components: ○ Clients issue requests to a front end ○ The front end provides transparency by hiding the fact that data is replicated. ○ The front end contacts one or more replica managers to retrieve/store the data ○ The replica managers interact to ensure that data is consistent. ● There are several models for providing replication: passive, active, and lazy.
5.
REPLICATION TECHNIQUES The main ideain replication is to keep several copies of the same resources at various different servers. ● Optimistic Technique – These schemes assume faults are rare and implement recovery schemes to deal with inconsistency. ● Pessimistic Technique – These schemes assume faults are more common, and attempt to ensure consistency of every access.
6.
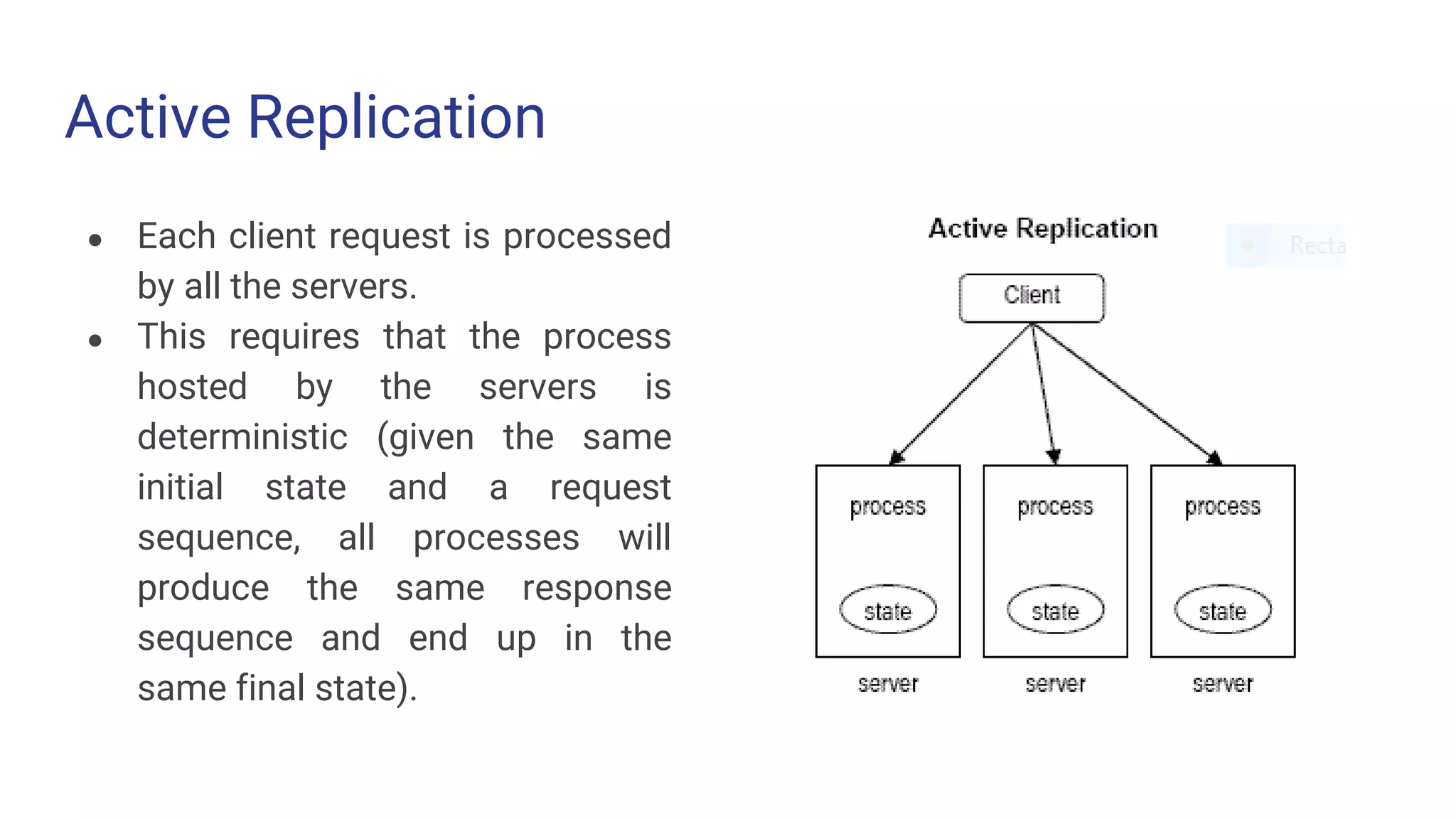
Active Replication ● Eachclient request is processed by all the servers. ● This requires that the process hosted by the servers is deterministic (given the same initial state and a request sequence, all processes will produce the same response sequence and end up in the same final state).
7.
Active Replication ● Inorder to make all the servers receive the same sequence of operations, an atomic broadcast protocol must be used. ● An atomic broadcast protocol guarantees that either all servers receive a message or none, plus that they all receive messages in the same order. ● Disadvantage – In practice most of the real world servers are non – deterministic. Still active replication is the preferable choice when dealing with real time systems that require quick response even under the presence of faults or with systems that must handle byzantine faults.
8.
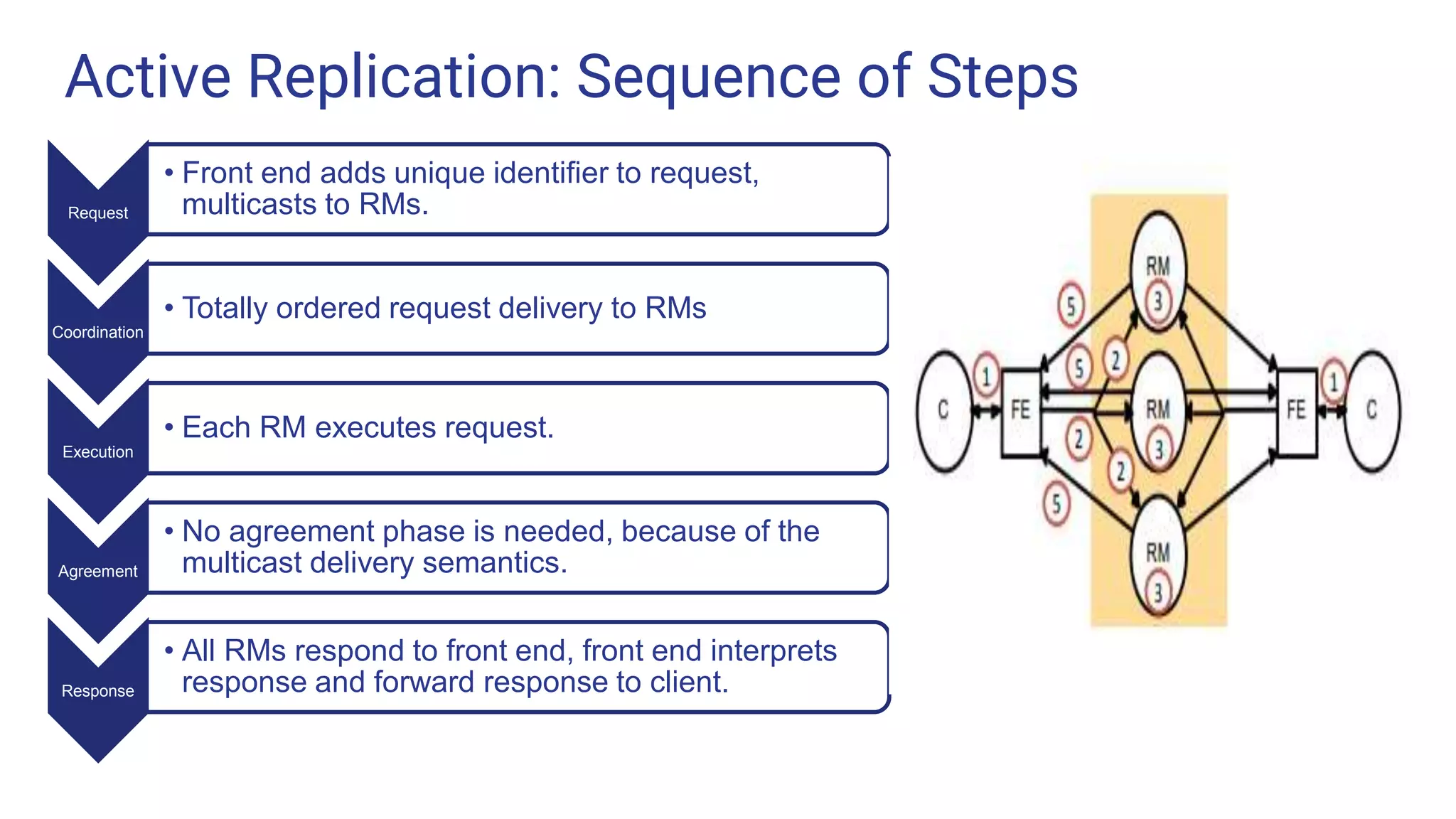
Active Replication: Sequenceof Steps Request • Front end adds unique identifier to request, multicasts to RMs. Coordination • Totally ordered request delivery to RMs Execution • Each RM executes request. Agreement • No agreement phase is needed, because of the multicast delivery semantics. Response • All RMs respond to front end, front end interprets response and forward response to client.
9.
Passive Replication ● Thereis only one server that processes client requests. ● After processing a request, the primary server updates the state on the other servers and sends back the response to the client. ● If the primary server fails, one of the backup servers takes its place. ● This may be used for non – deterministic processes. ● Disadvantage – In case of failure the response is delayed.
10.
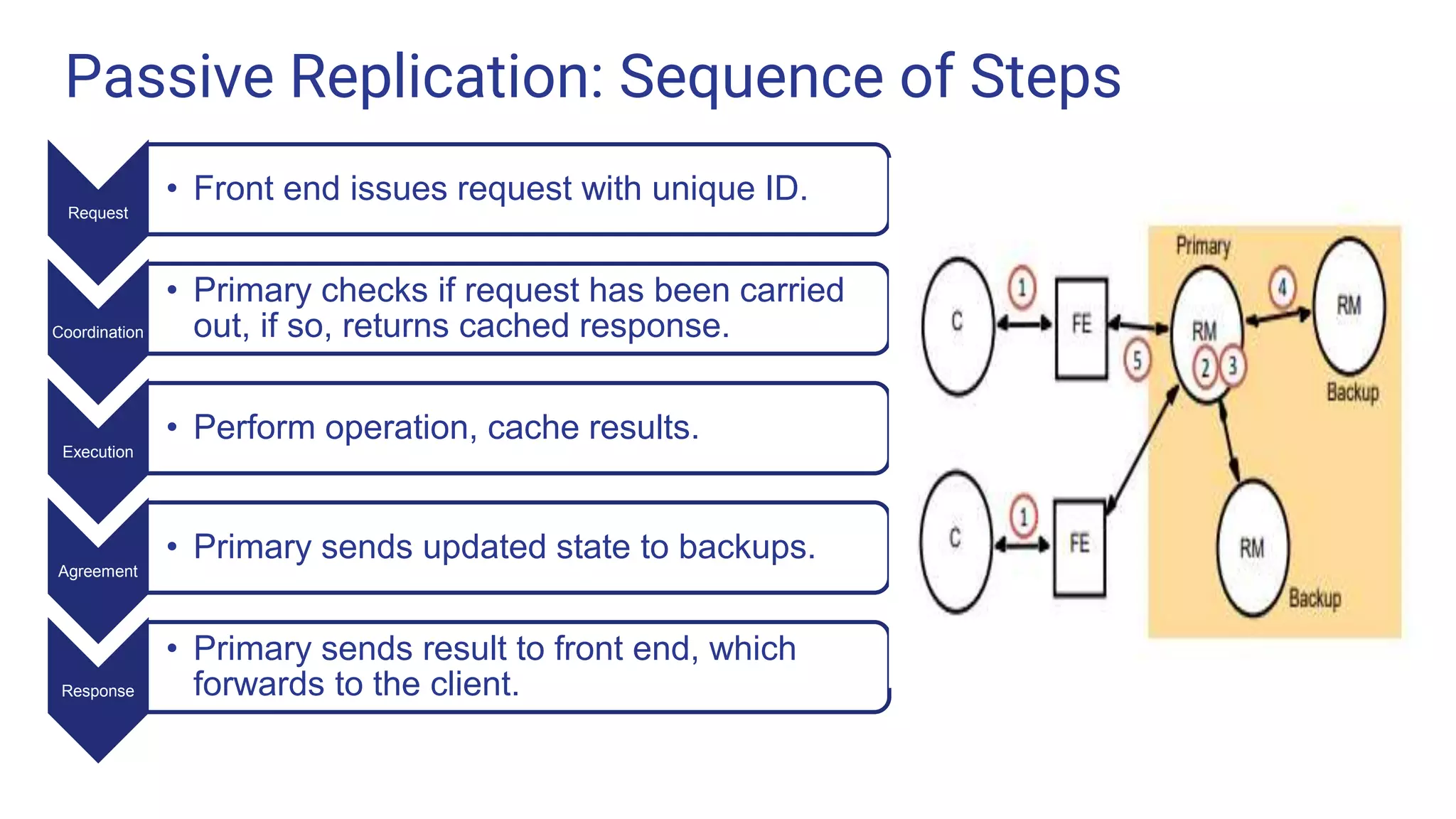
Passive Replication: Sequenceof Steps Request • Front end issues request with unique ID. Coordination • Primary checks if request has been carried out, if so, returns cached response. Execution • Perform operation, cache results. Agreement • Primary sends updated state to backups. Response • Primary sends result to front end, which forwards to the client.
11.
Data Replication ● Itis the process of storing data in more than one site or node. ● Ensures availability of data. ● There can be two types of replication: ○ Full Replication – A copy of the whole database is stored at every site. ○ Partial Replication – Some fragment of the database are replicated.
12.
● Advantages: ○ Availability ○Increased Parallelism ○ Less Data Movement over Network ● Disadvantages: ○ Increased overhead on update. ○ Require more disk space. ○ Concurrency control and recovery techniques will be more advanced and hence more expensive.
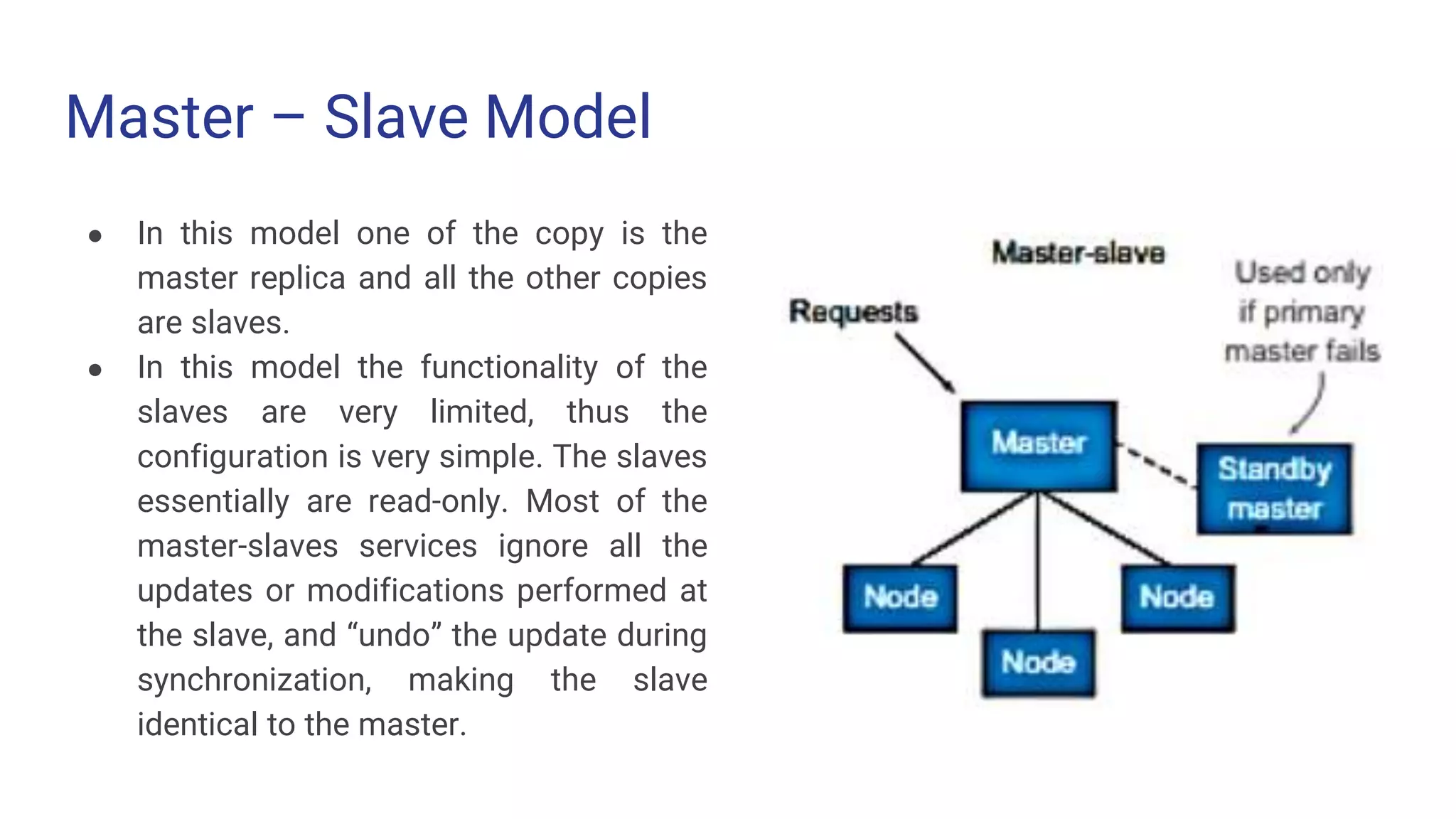
Master – SlaveModel ● In this model one of the copy is the master replica and all the other copies are slaves. ● In this model the functionality of the slaves are very limited, thus the configuration is very simple. The slaves essentially are read-only. Most of the master-slaves services ignore all the updates or modifications performed at the slave, and “undo” the update during synchronization, making the slave identical to the master.
15.
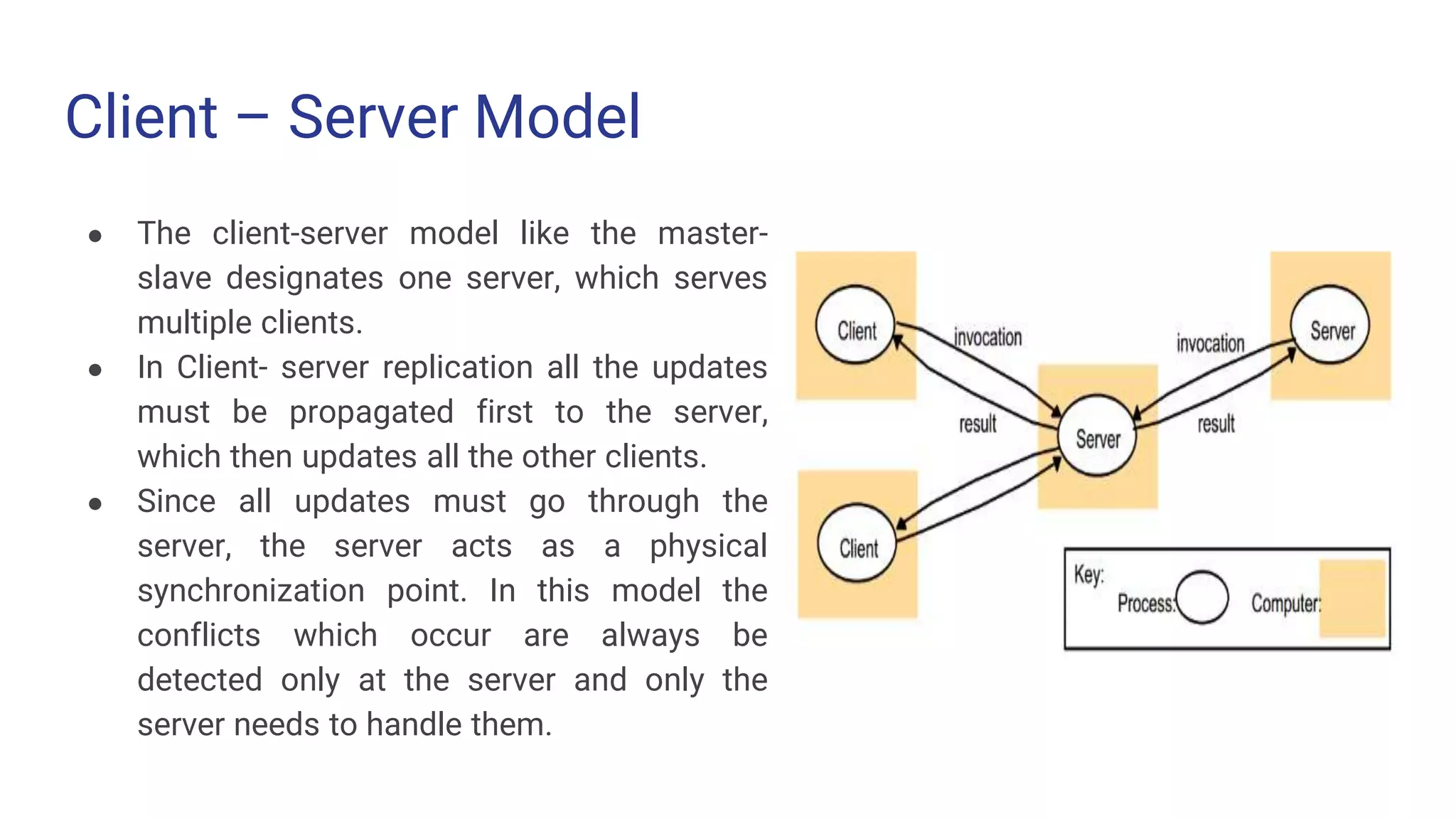
Client – ServerModel ● The client-server model like the master- slave designates one server, which serves multiple clients. ● In Client- server replication all the updates must be propagated first to the server, which then updates all the other clients. ● Since all updates must go through the server, the server acts as a physical synchronization point. In this model the conflicts which occur are always be detected only at the server and only the server needs to handle them.
16.
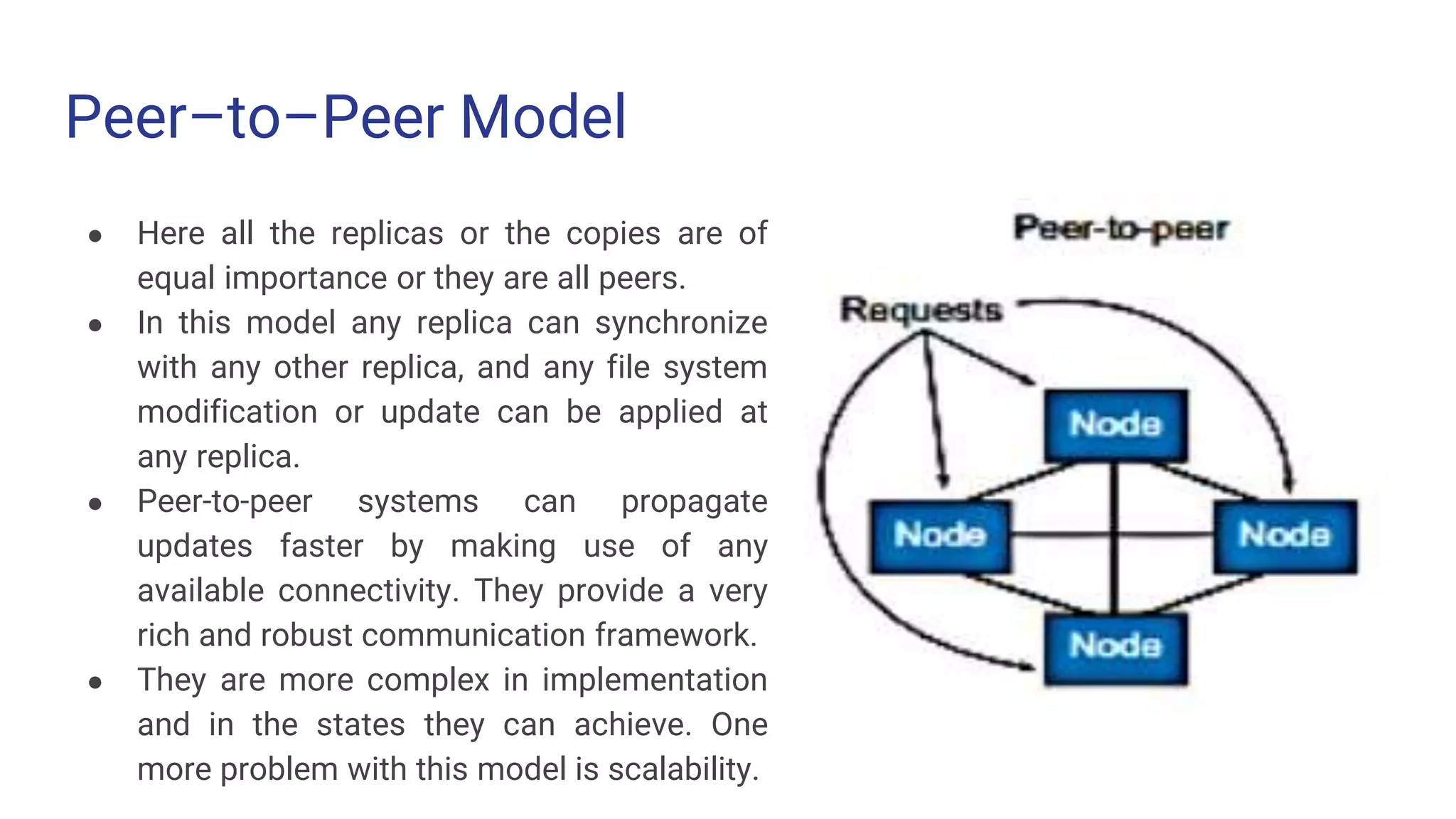
Peer–to–Peer Model ● Hereall the replicas or the copies are of equal importance or they are all peers. ● In this model any replica can synchronize with any other replica, and any file system modification or update can be applied at any replica. ● Peer-to-peer systems can propagate updates faster by making use of any available connectivity. They provide a very rich and robust communication framework. ● They are more complex in implementation and in the states they can achieve. One more problem with this model is scalability.
17.
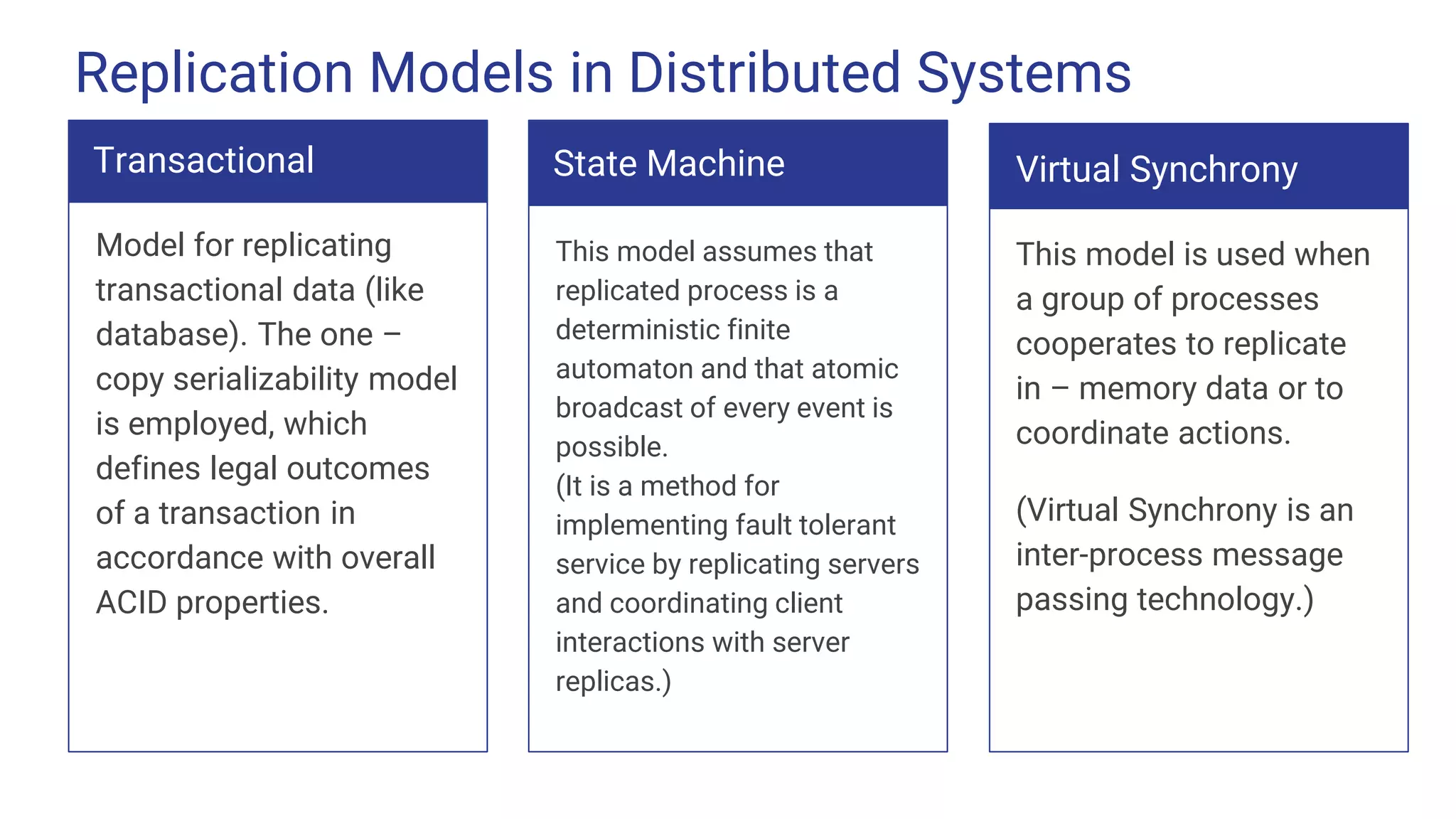
Replication Models inDistributed Systems Transactional Model for replicating transactional data (like database). The one – copy serializability model is employed, which defines legal outcomes of a transaction in accordance with overall ACID properties. State Machine This model assumes that replicated process is a deterministic finite automaton and that atomic broadcast of every event is possible. (It is a method for implementing fault tolerant service by replicating servers and coordinating client interactions with server replicas.) Virtual Synchrony This model is used when a group of processes cooperates to replicate in – memory data or to coordinate actions. (Virtual Synchrony is an inter-process message passing technology.)
18.
Replication for WorldWide Web Access ● The ever-increasing demand for the World Wide Web had not come without its share of problems. The primary amongst them being the inability of resources to cope up with the ever increasing demands. ● All this has resulted in high latencies, low throughputs and huge amounts of network traffic. ● Basic idea behind replication is to keep several copies of the same resource at different servers. ● The benefits associated with replication are reduced access times, balanced load etc.
Consistency Problem Replication improvesreliability and performance … but when a replica is updated, it becomes different from the others … so we need to propagate updates in a way that temporal inconsistencies are not noticed … however this may degrade performance severely
21.
Strict Consistency ● Everyread of x returns a value corresponding to the result of the most recent write to x. ● True replication transparency, every process receives a response that is consistent with the real time. ● All writes are instantaneously visible to all process. ● Assumes absolute global time ○ Due to message latency, strict consistency is difficult to implement. ● In general, A:write t(x,a) then B:read t’(x,a); t’>t
22.
Sequential Consistency (weakerthan strict consistency) ● “The result of any execution is the same as if the (read and write) operations by all processes on the data store were executed in some sequential order and the operations of each individual process appear in this sequence in the order specified by its program” (Lamport 1979). ● A write to a variable does not have to be seen instantaneously, however, writes to variables by different processes have to be seen in same order by all processes. ● All processes see the same interleaving of operations.
23.
Linearizability (weaker thanstrict consistency, stronger than sequential consistency) ● Interleaving of reads and writes into a single total order that respects the local ordering of the operations of every process. ○ A trace is consistent when every read returns the latest write preceding the read. ● A trace is linearizable when ○ It is consistent. ○ If t1 , t2 are the times at which pi and pj perform operations, and t1 < t2 , then the consistent trace must satisfy the condition that t1 < t2. ● The linearizable trace is A:W(x,1), B:W(y,1), A:R(y,1), B:R(x,1).
24.
Causal Consistency ● Allwrites that are causally related must be seen by every process in the same order, and reads must be consistent with this order. ● Writes that are not causally related to one another (concurrent) can be seen in any order. ● No constraints on the order of values read by a process if writes are not causally related.
25.
Causal Consistency ● Forexample, consider a chat between three people, where Attiya asks “shall we have lunch?”, and Barbarella & Cyrus respond with “yes”, and “no”, respectively. Causal consistency allows Attiya to observe “lunch?”, “yes”, “no”; and Barbarella to observe “lunch?”, “no”, “yes”. However, no participant ever observes “yes” or “no” prior to the question “lunch?”
26.
Summary ● Passive replication(implements linearizability): A single primary replica manager and one or more backup replica managers. ● Active replication (implements sequential consistency): Independent replica managers executing all operations. ● Consistency models: Data-centric models (strict, linearizability, sequential, causal), differs: ○ In how restrictive they are ○ How complex their implementations are ○ Ease of programming ○ Performance