Downloaded 39 times












This document summarizes Atlassian's adoption of Databricks to manage their growing data pipelines and platforms. It discusses the challenges they faced with their previous architecture around development time, collaboration, and costs. With Databricks, Atlassian was able to build scalable data pipelines using notebooks and connectors, orchestrate workflows with Airflow, and provide self-service analytics and machine learning to teams while reducing infrastructure costs and data engineering dependencies. The key benefits included reduced development time by 30%, decreased infrastructure costs by 60%, and increased adoption of Databricks and self-service across teams.
Presenters Esha Shah and Richa Singhal introduce managing data pipelines using Databricks and outline the agenda including Atlassian overview and challenges encountered.
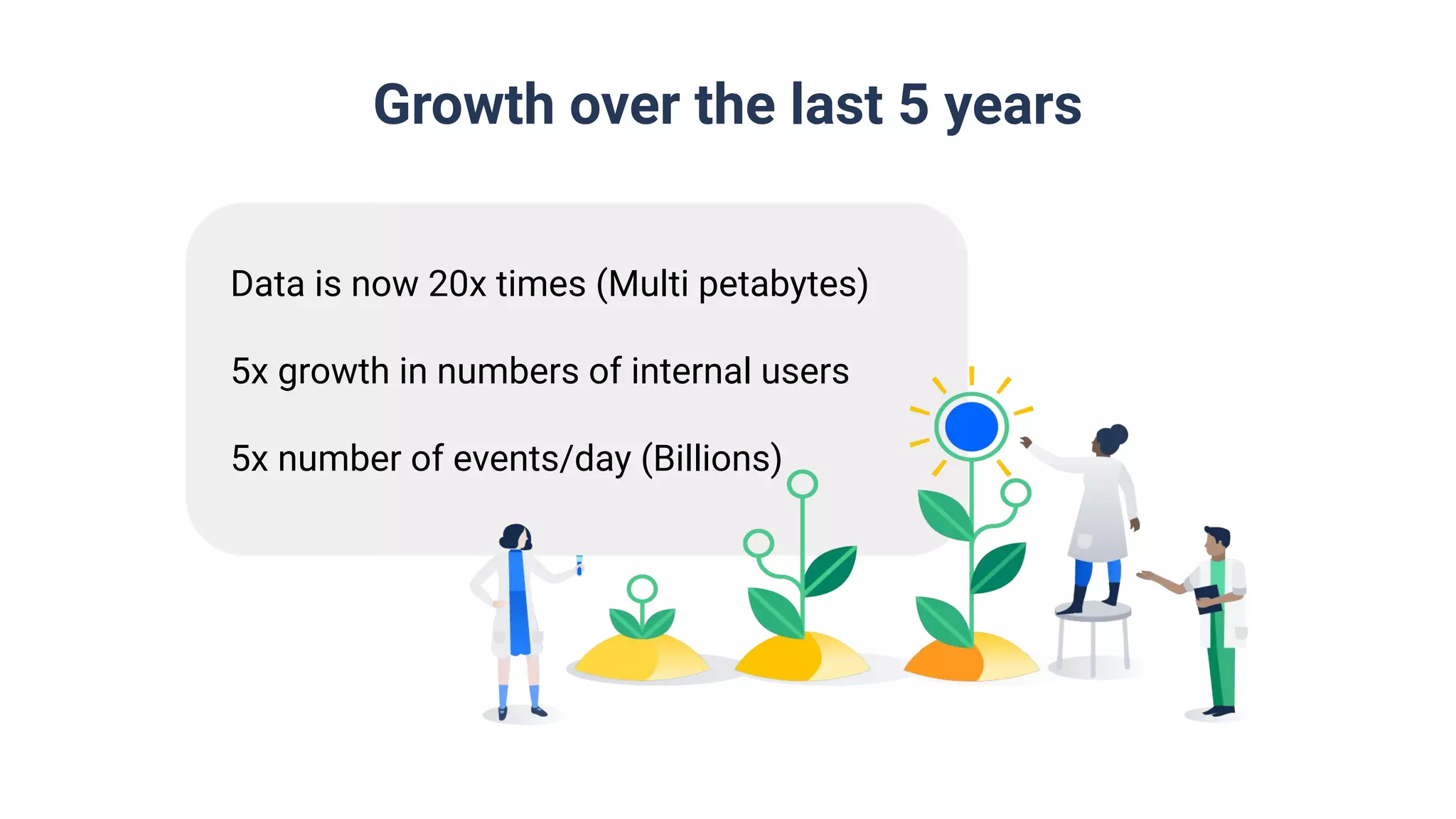
Atlassian's data has grown 20x over the last 5 years, with 5x more internal users and handling billions of events daily.
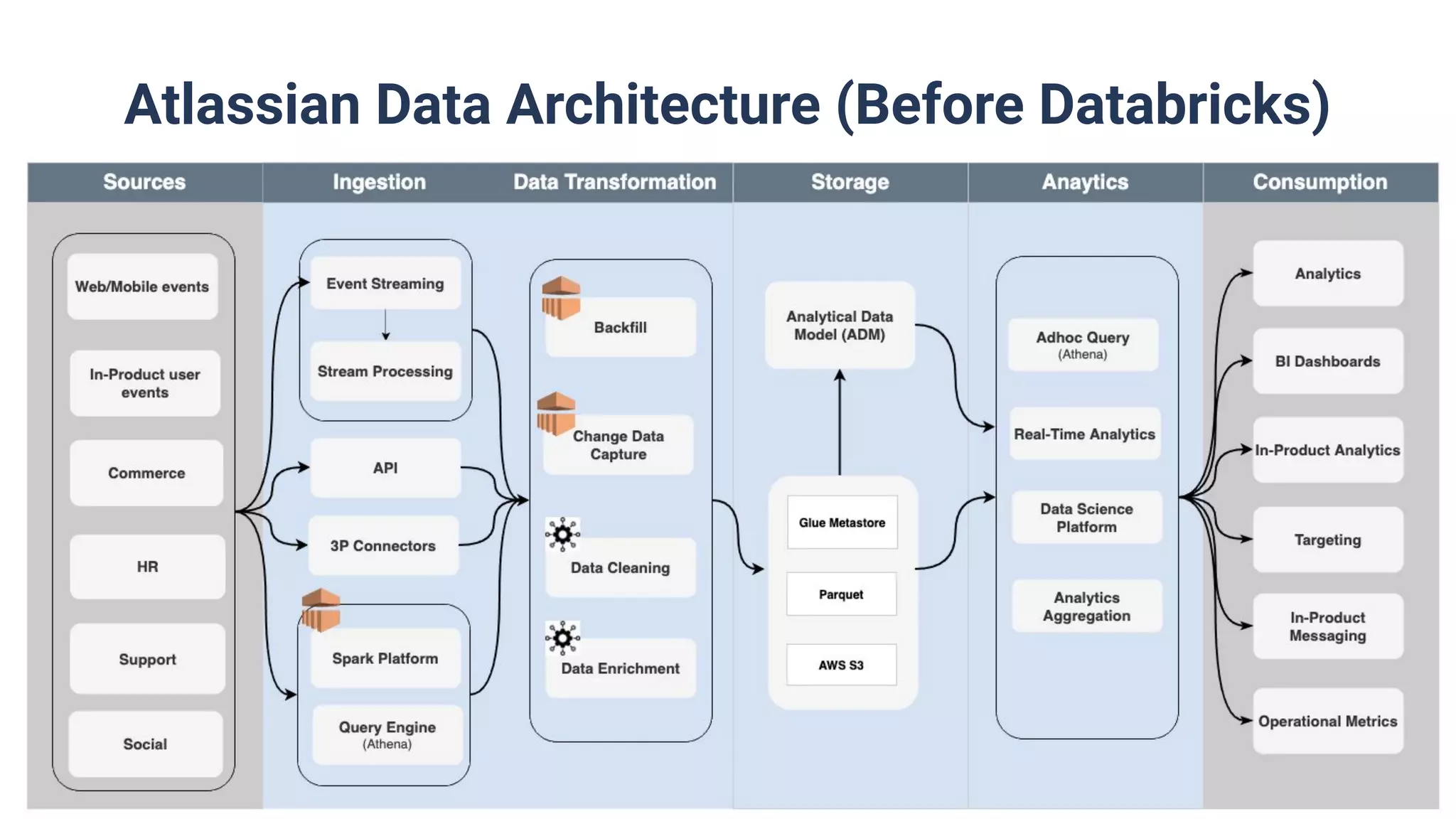
Before Databricks, Atlassian faced challenges with development, team dependencies, cluster management, and collaboration.
Key strategies for scaling included self-service, standardization, automation, agility, and cost optimization.
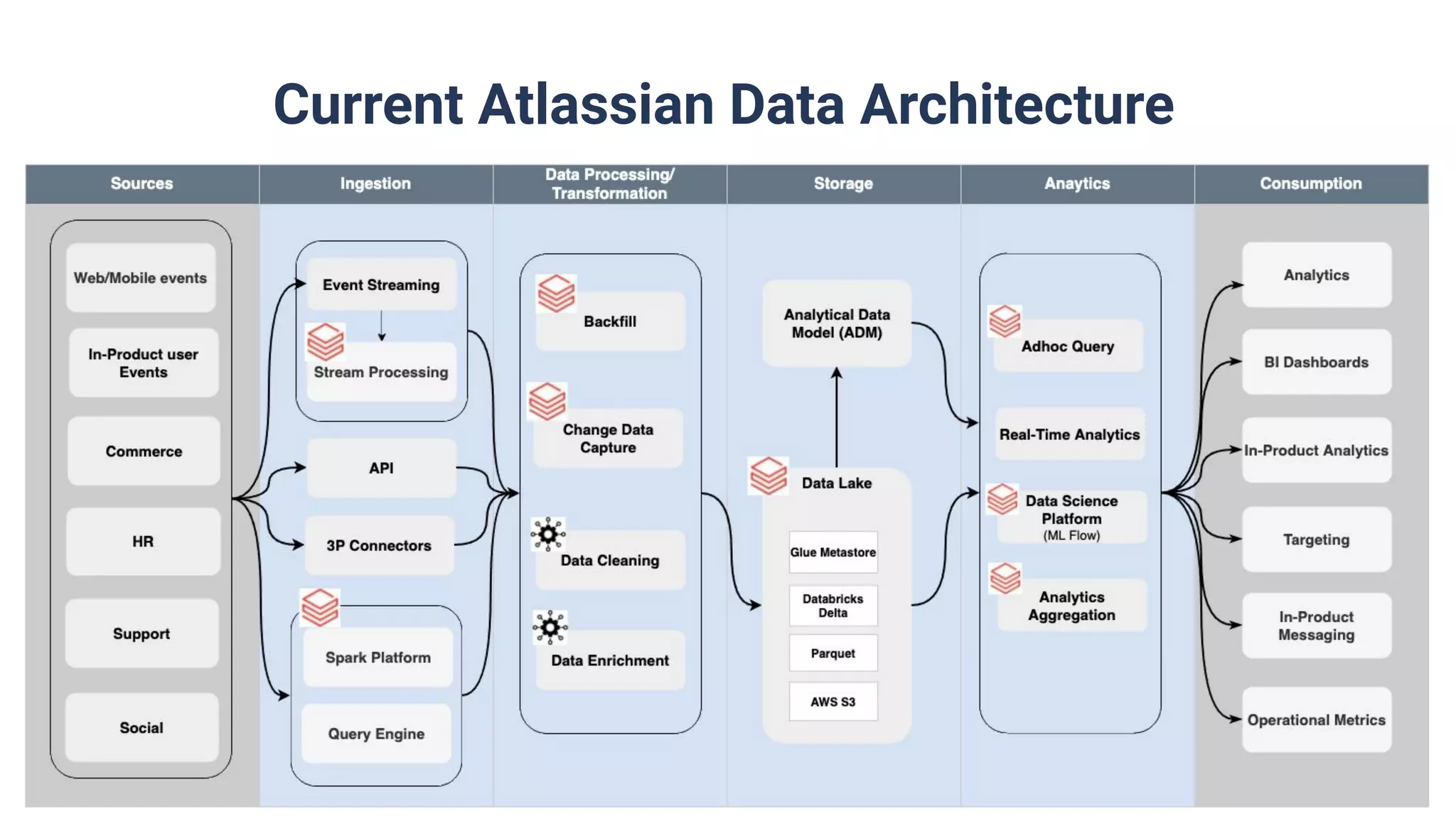
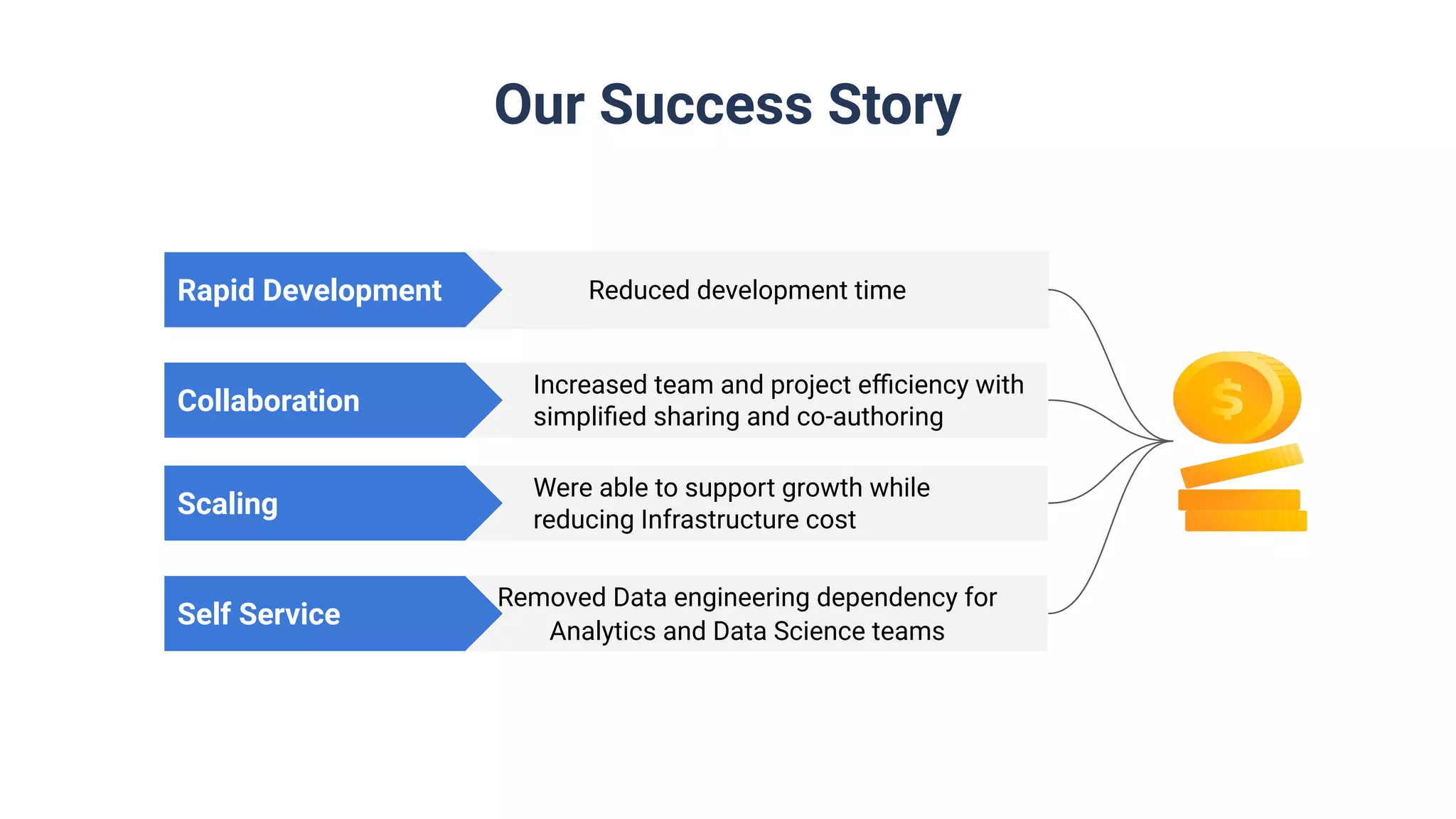
Overview of current data architecture and success metrics: reduced development time, increased efficiency, and support for growth at lower infrastructure costs.
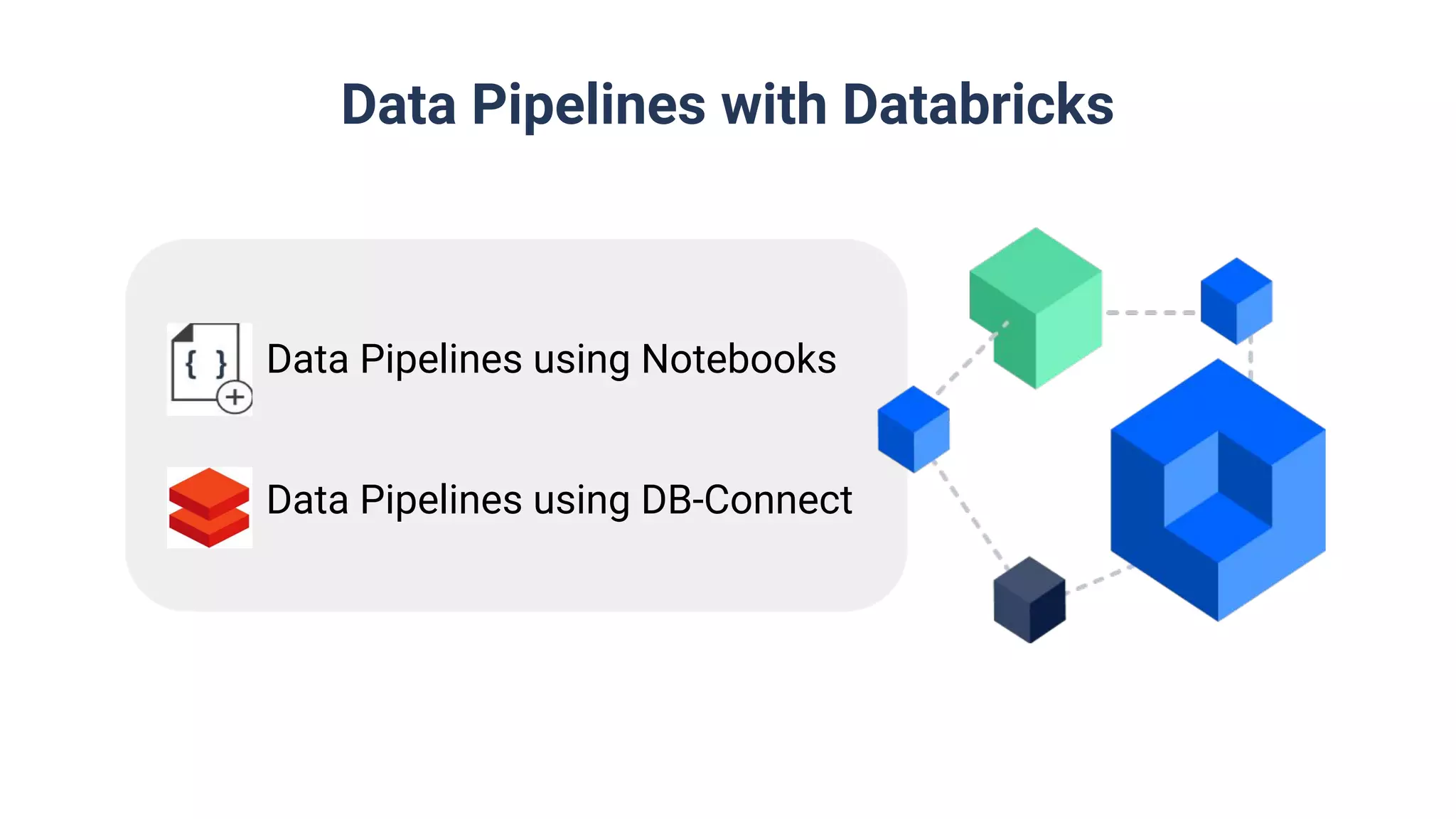
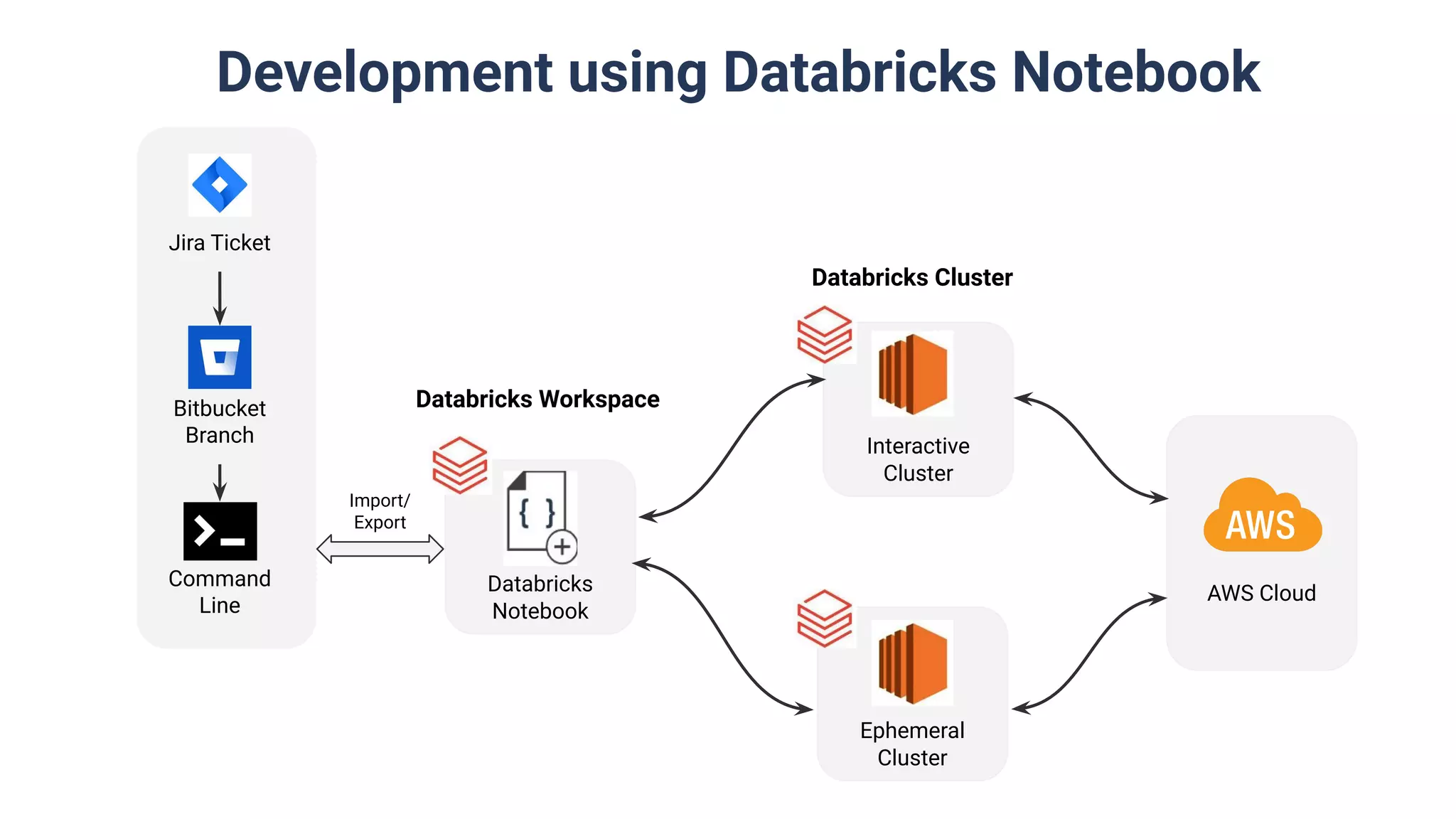
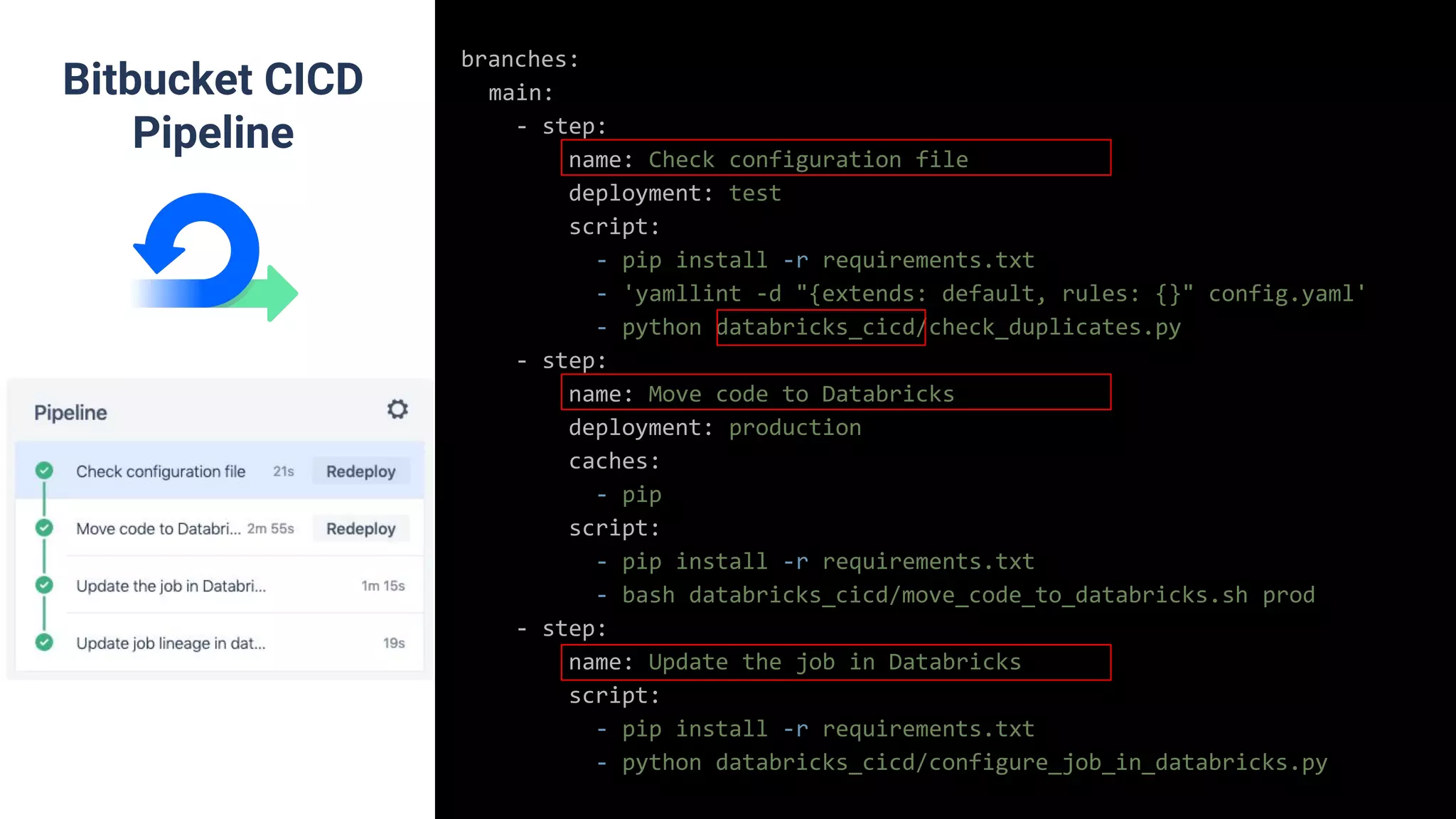
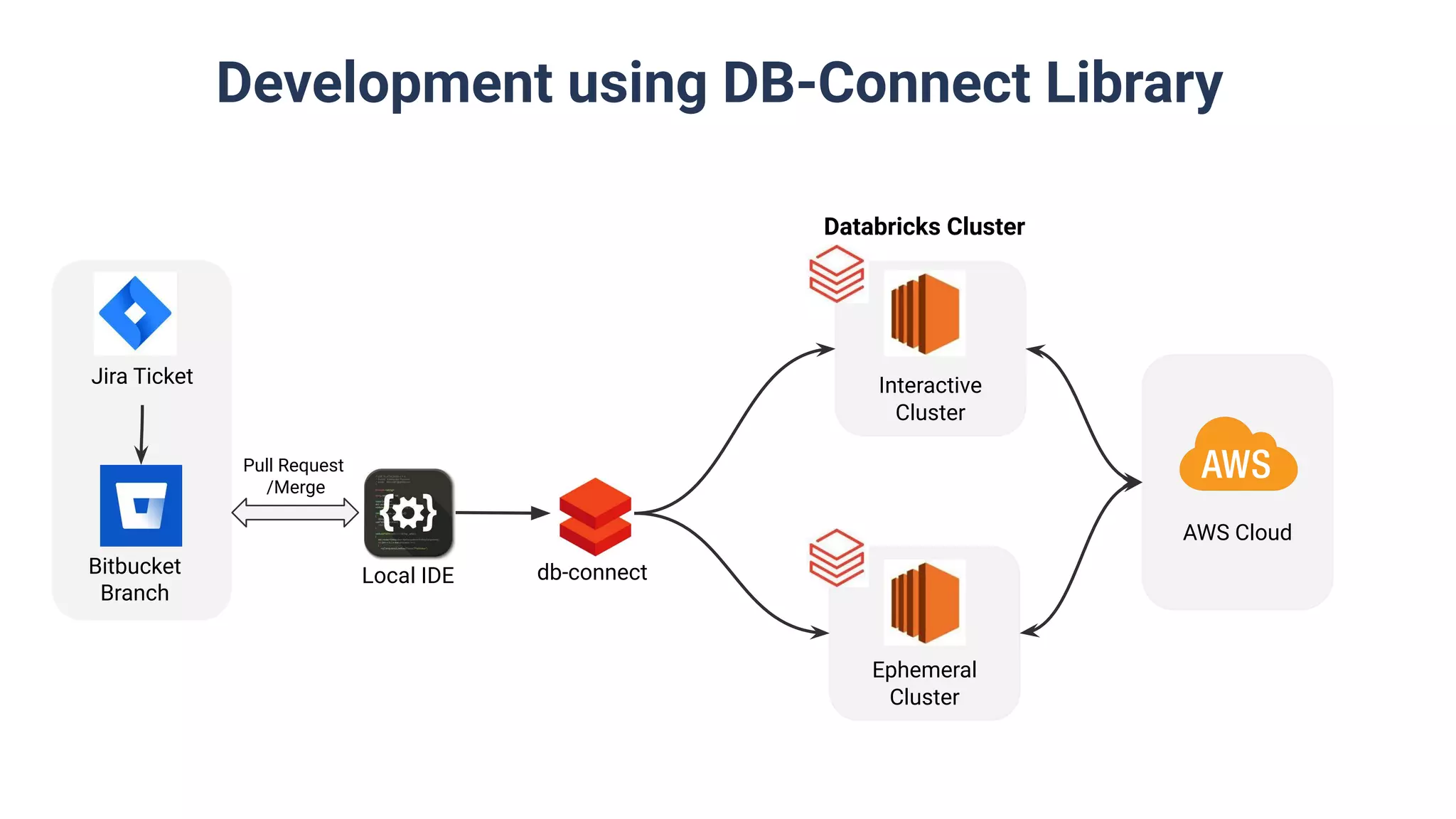
Discussion on building data pipelines using Databricks including orchestration and different methods like Databricks Notebooks and DB-Connect.
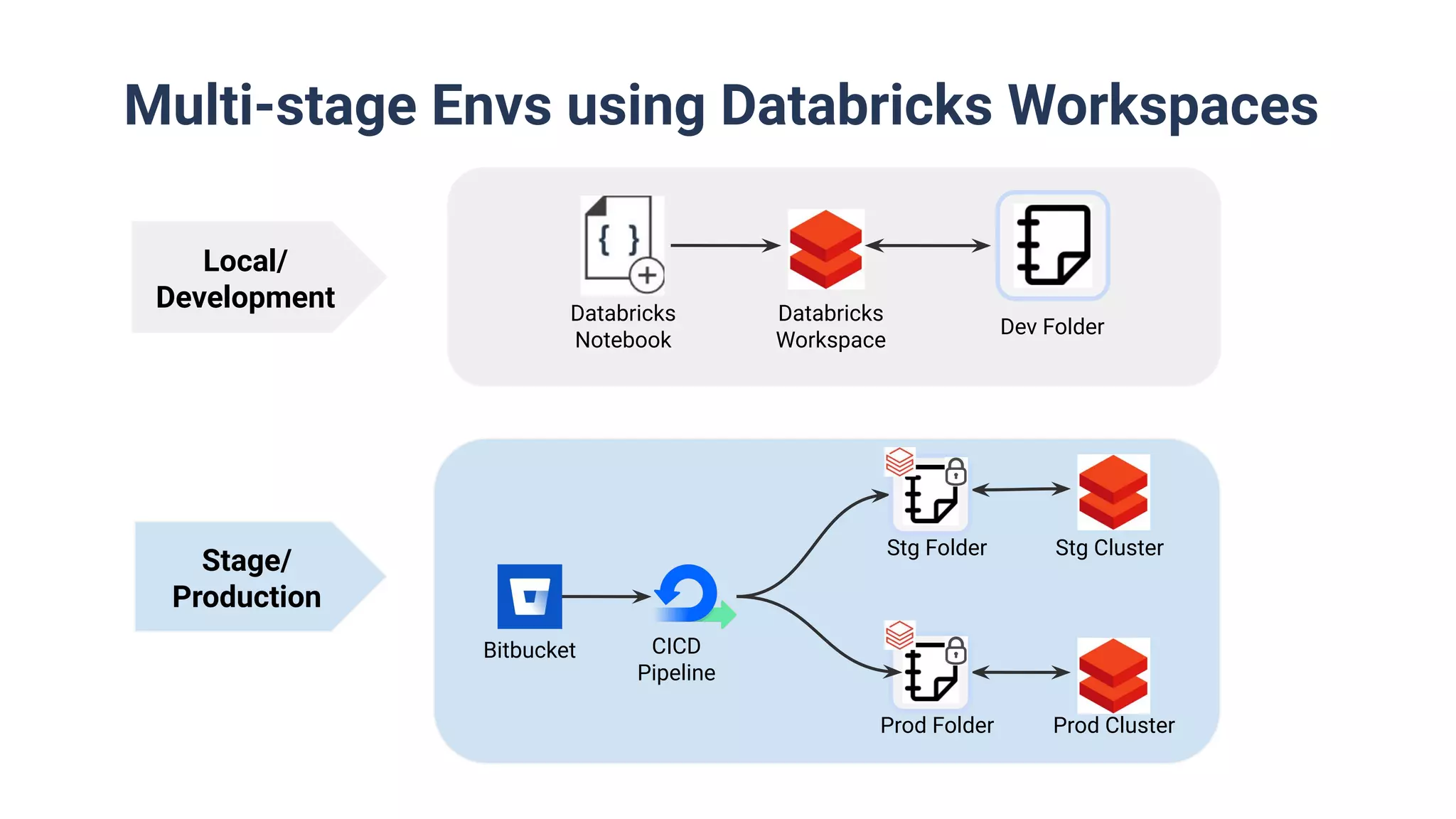
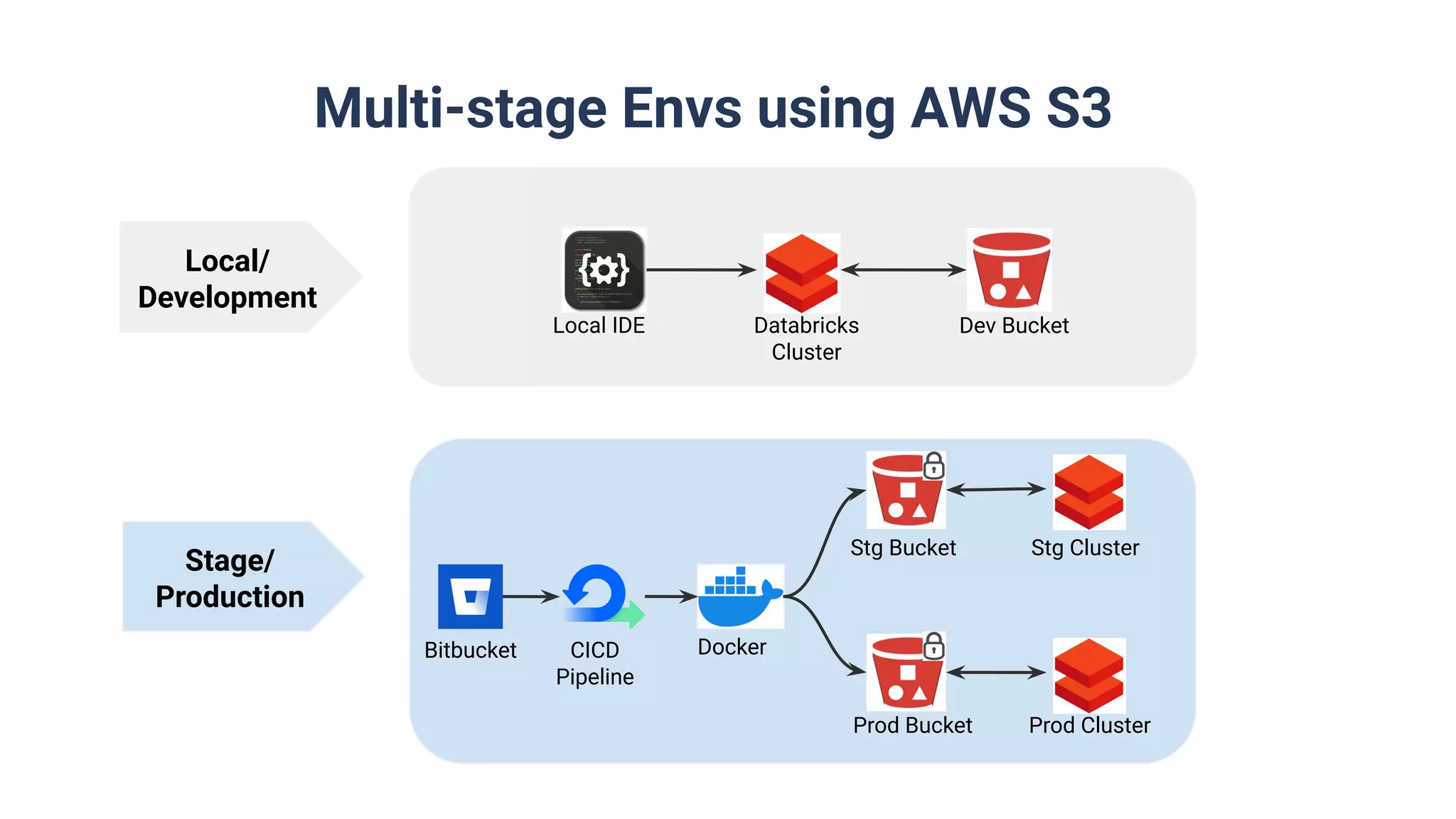
Utilization of Databricks Notebooks and DB-Connect, including multi-stage environments for release pipelines.
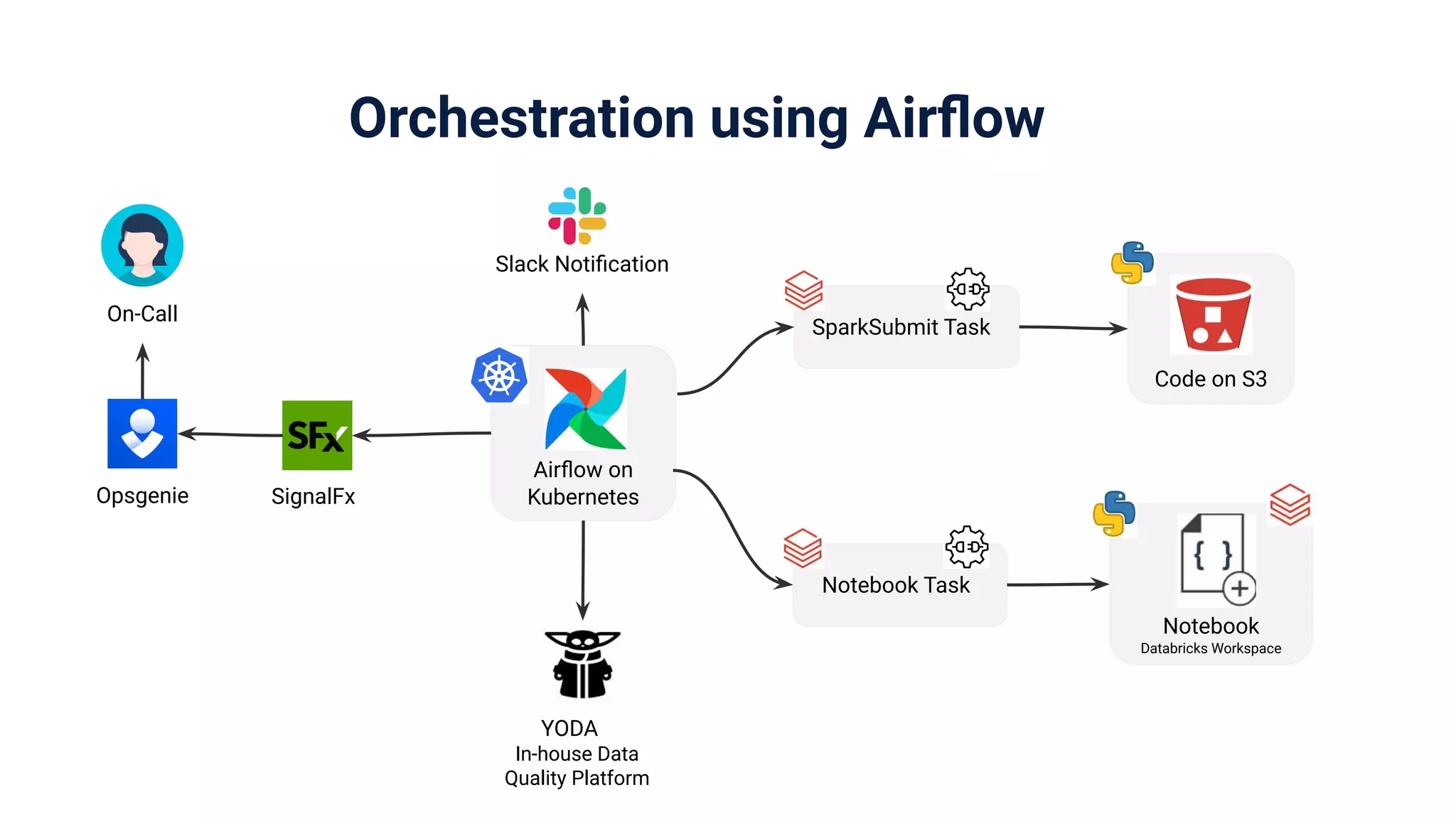
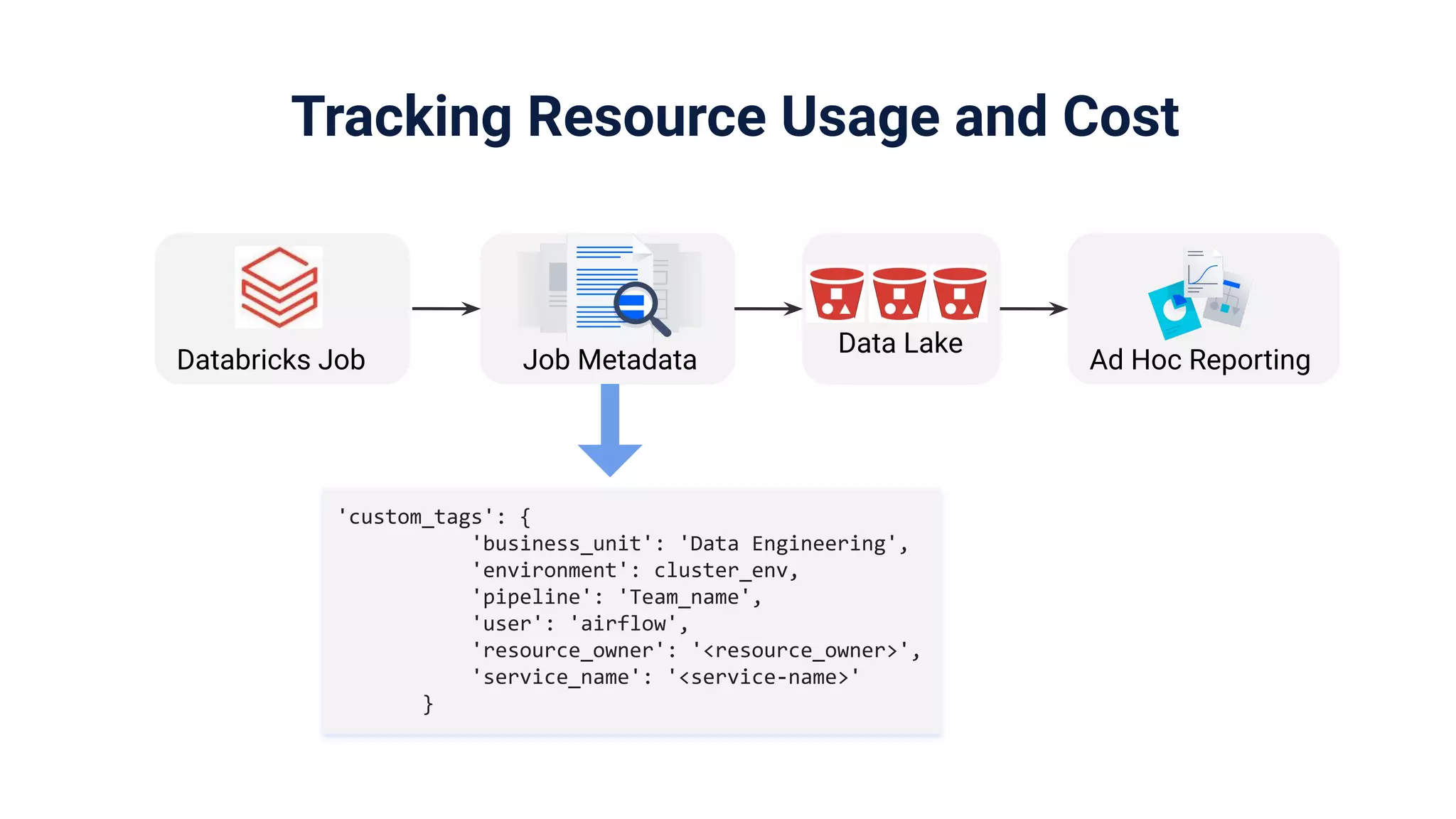
Focus on orchestration using Airflow on Kubernetes for resource tracking, job metadata, and quality management.
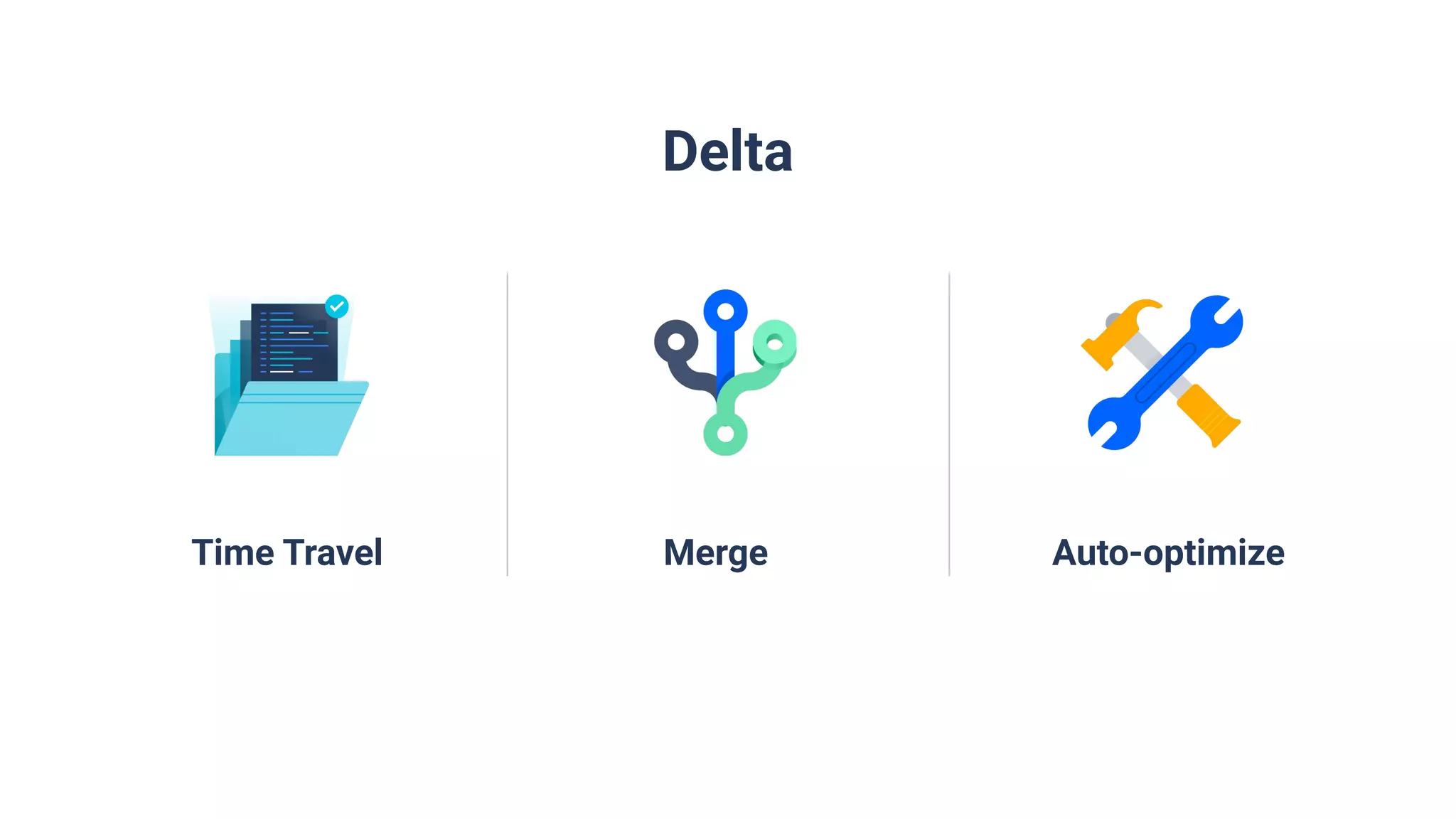
Utilization of Databricks Delta for advanced data handling features such as time travel and auto optimization.
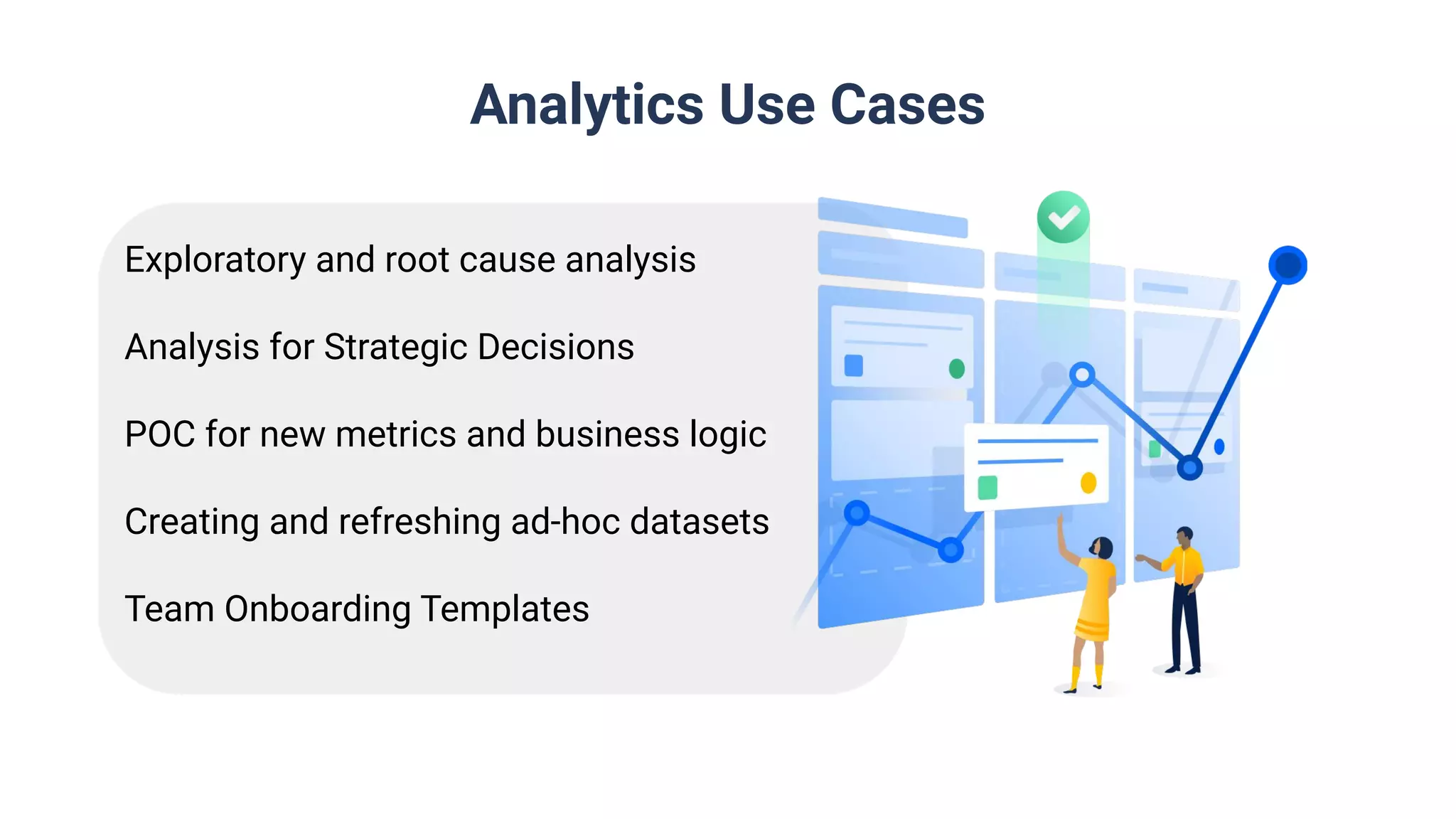
Application of Databricks for analytics including exploratory analysis, strategy decisions, and collaborative self-service analytics.
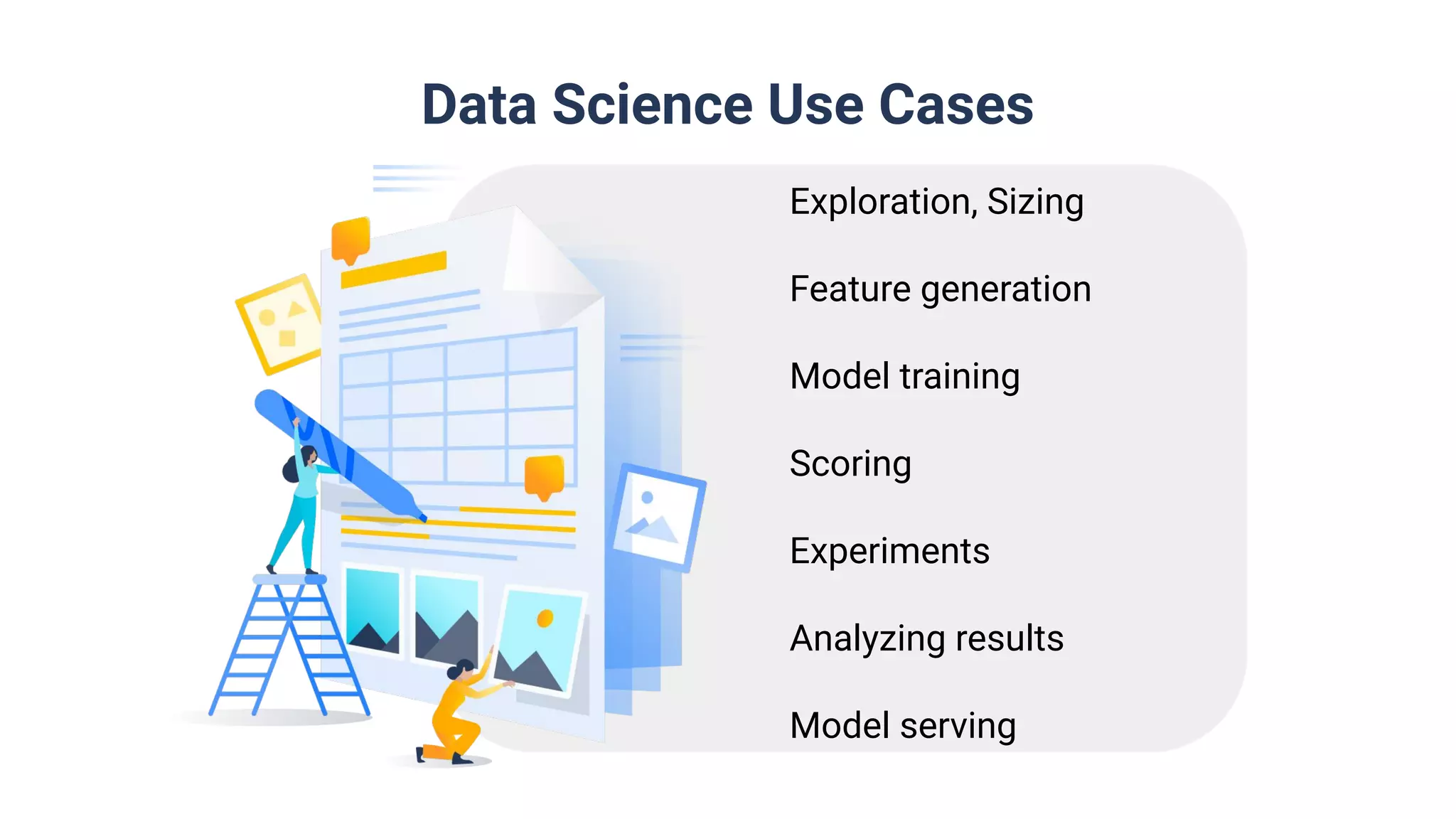
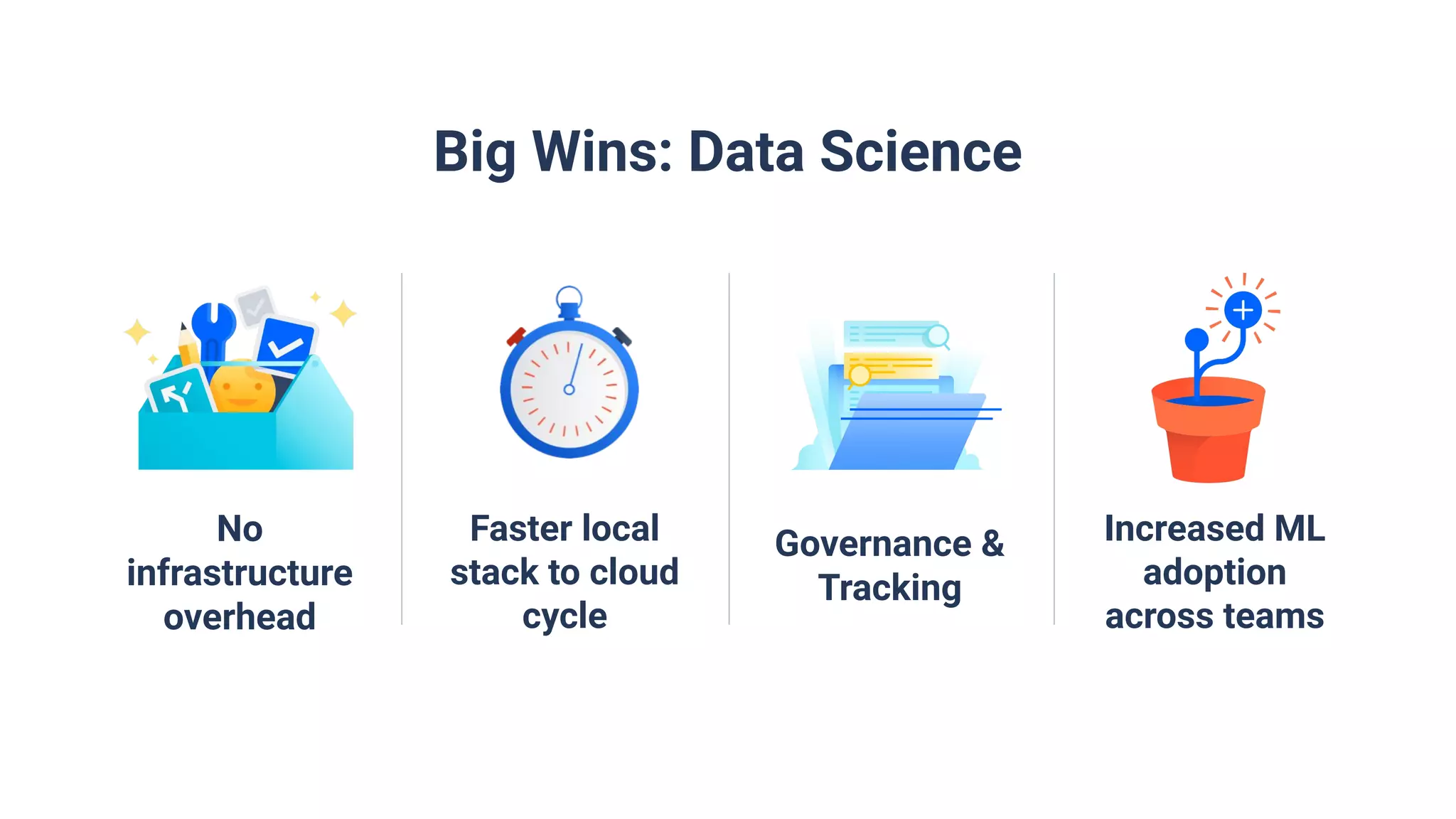
Utilization in data science encompassing model training, scoring, experiment analysis, and increased ML adoption.
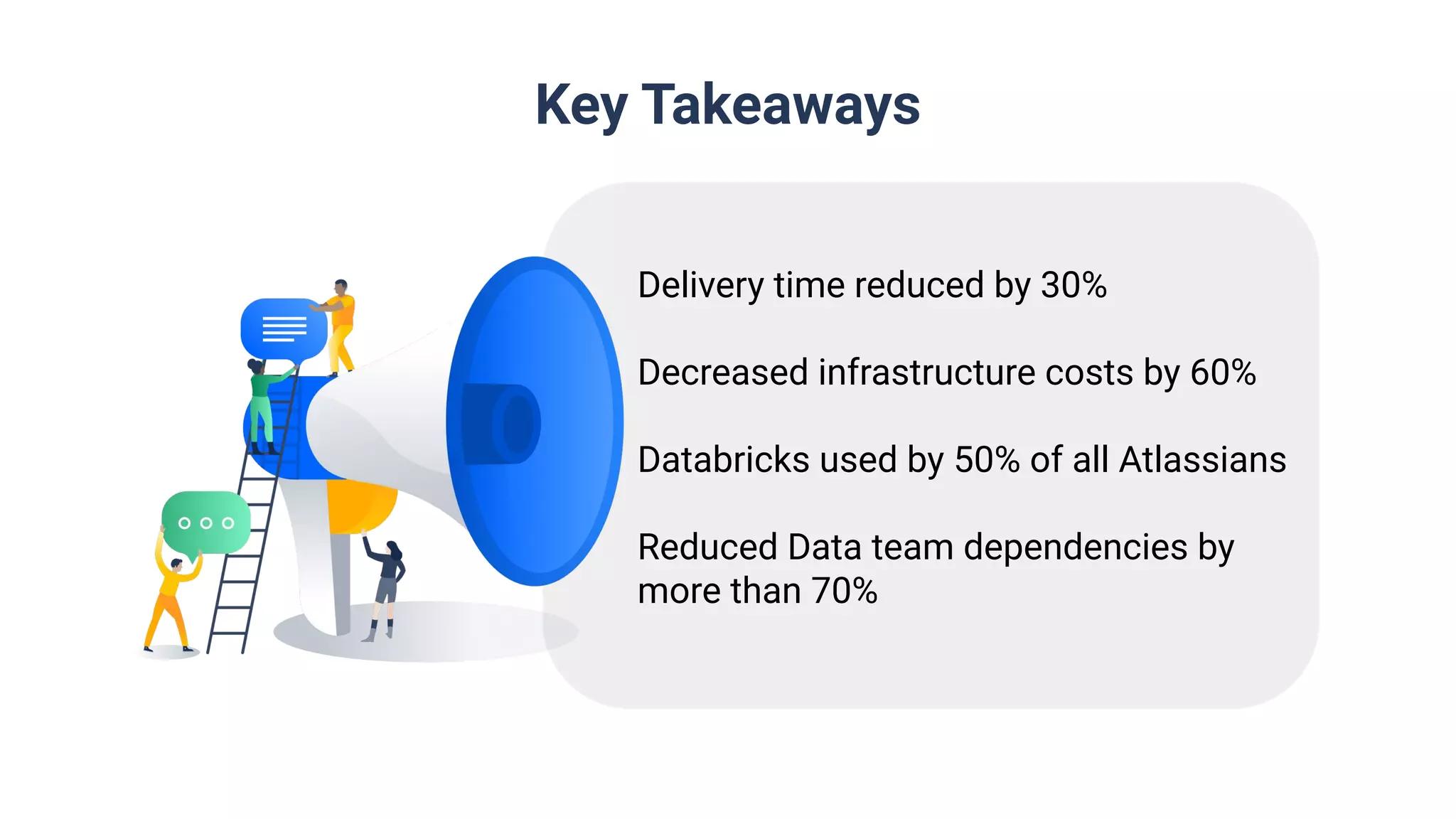
Summary with key takeaways: 30% reduction in delivery time, 60% decrease in infrastructure costs, and significant company-wide adoption of Databricks.
Thanking attendees followed by a request for feedback on the session.