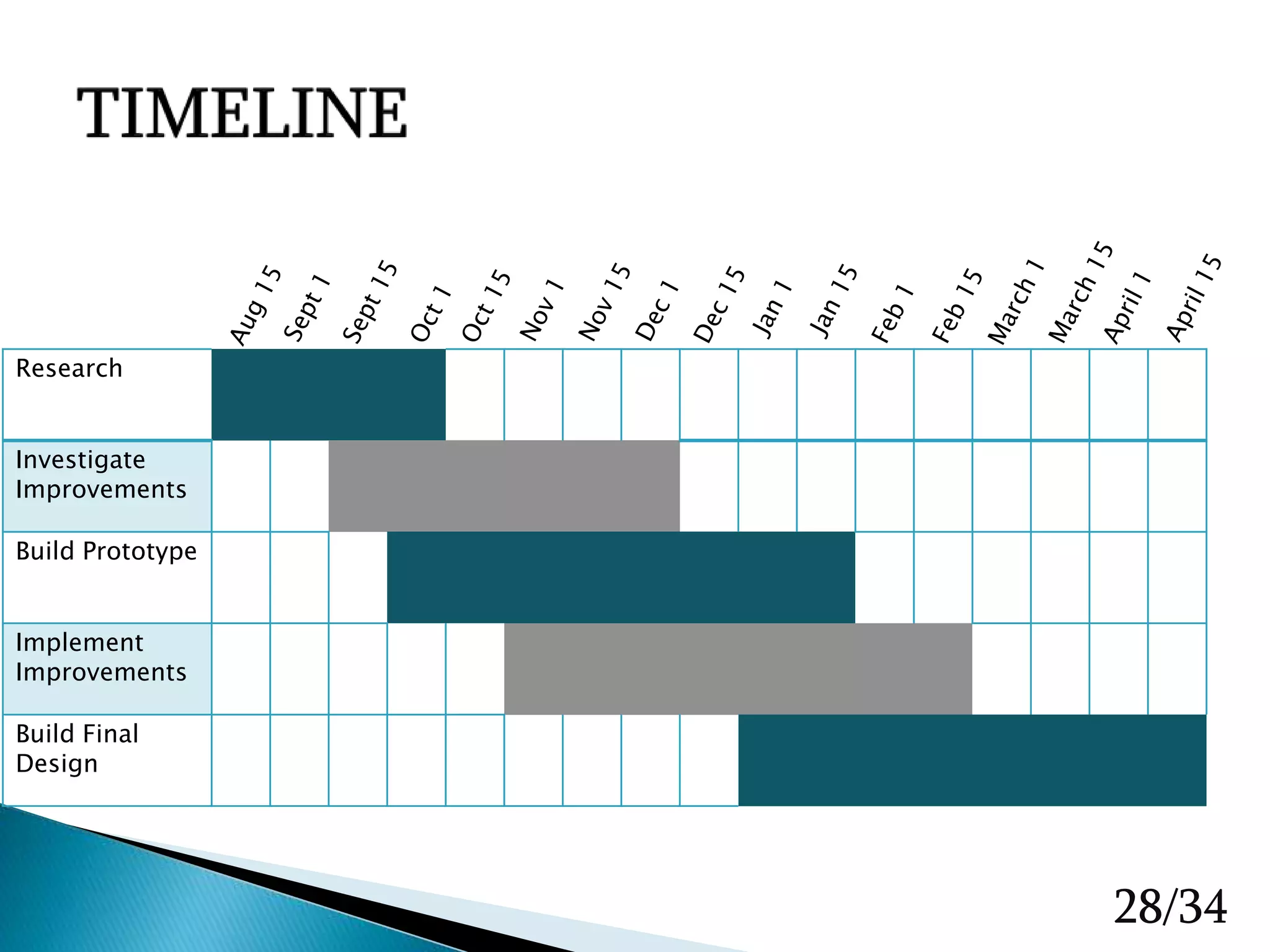
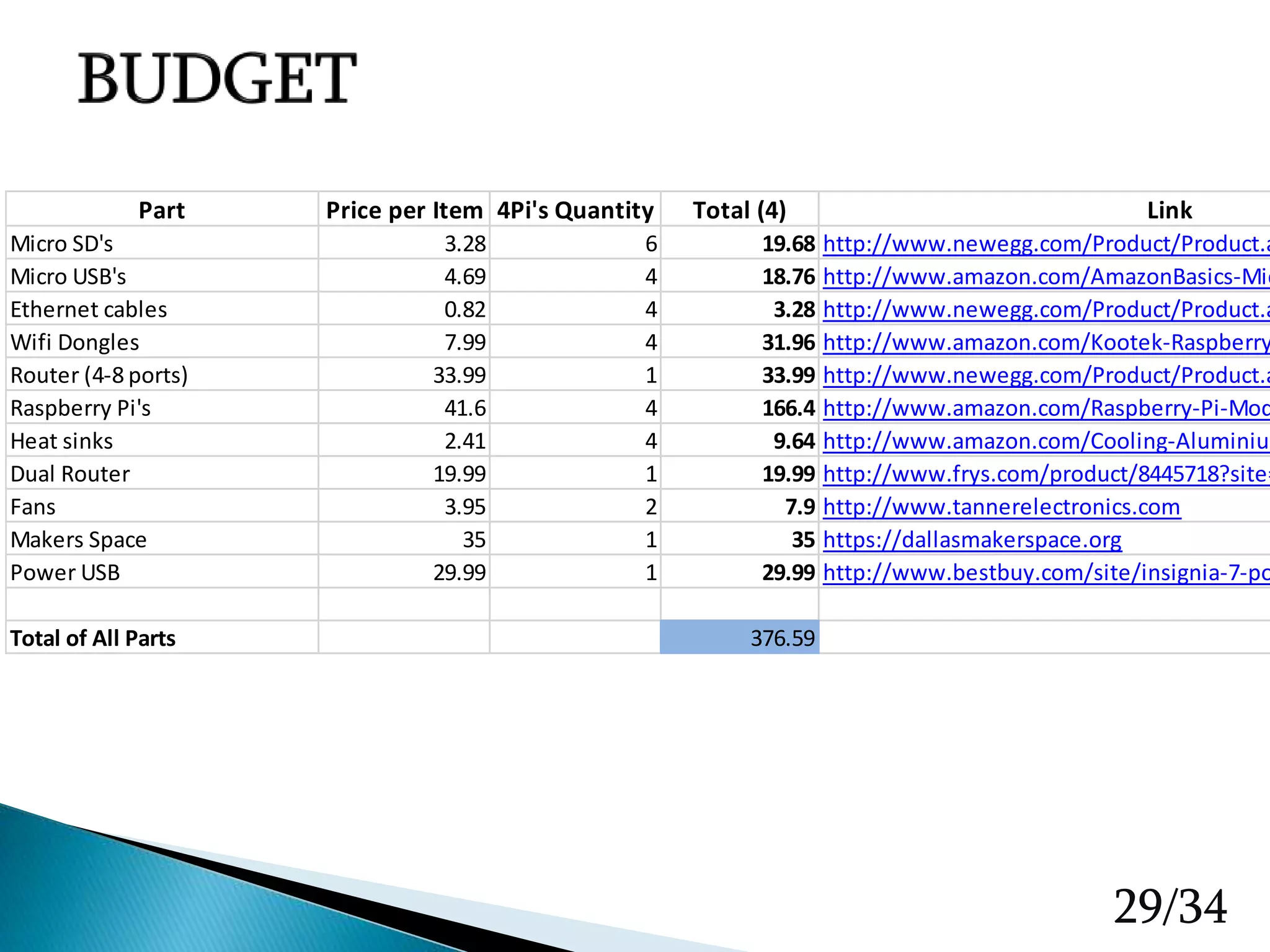
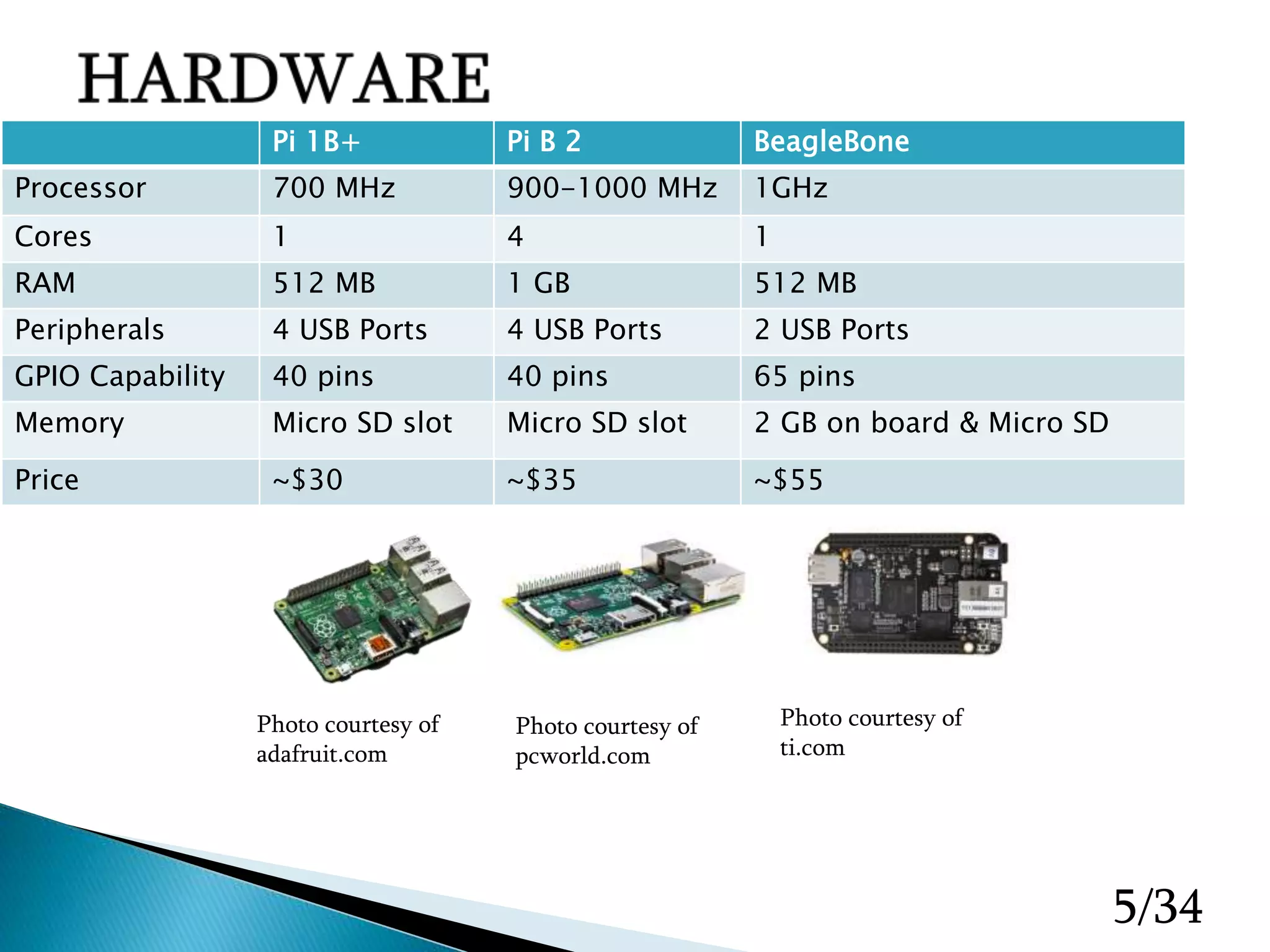
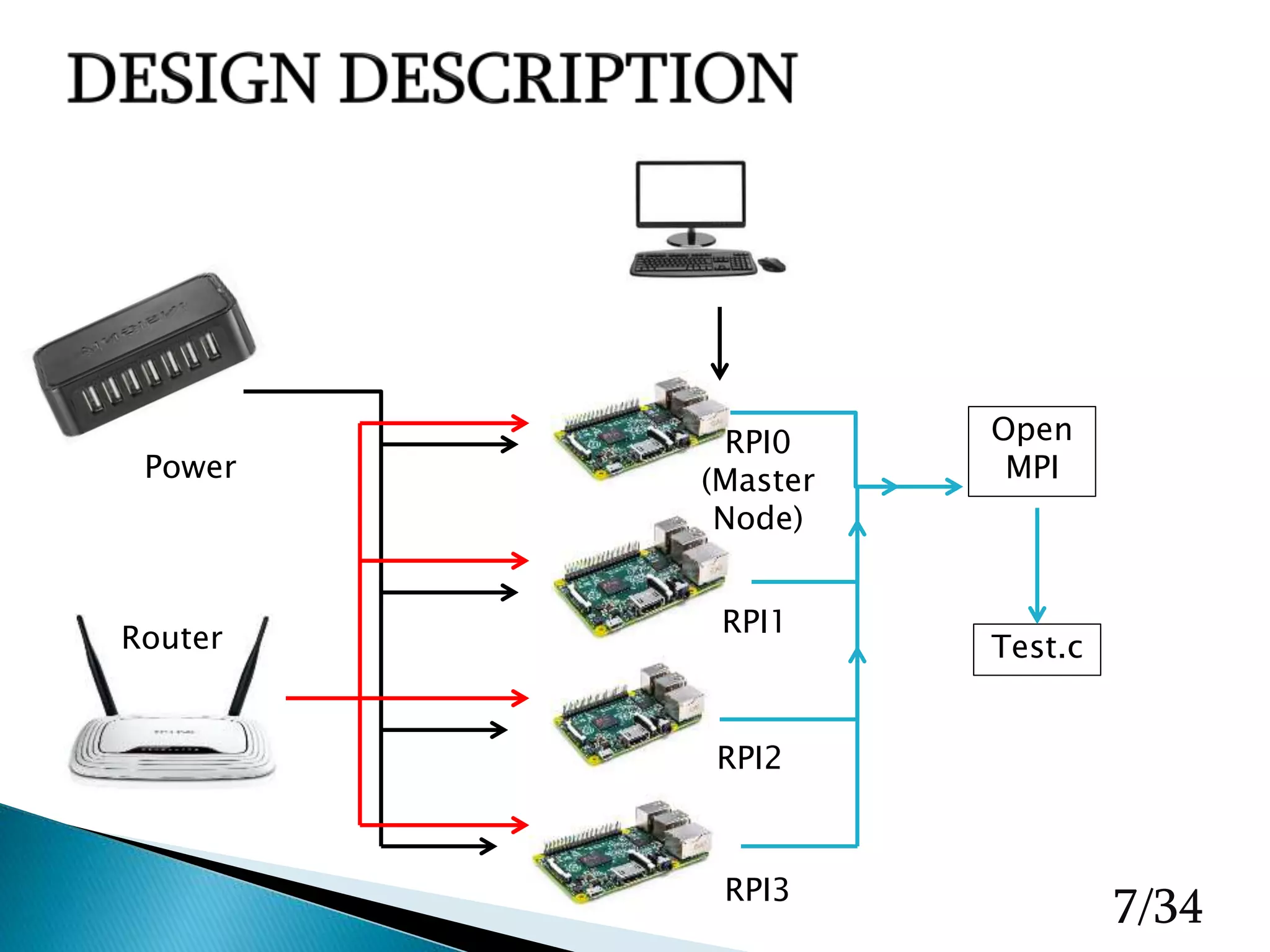
The document presents a final project on creating a Raspberry Pi-based cluster computing system, detailing hardware, design improvements, software setup, and performance testing. It discusses the use of OpenMPI for parallel processing, various configuration steps for network connectivity, and the design and build process of the cluster. The report also addresses challenges faced during implementation, such as inconsistent processing times and mounting issues, while outlining future tasks and goals for improvements.












![15/34 1. # include <stdio.h> //Standard Input/output library 2. # include <mpi.h> 3. int main(int argc, char** argv) 4. { 5. //MPI variables 6. int num_processes; 7. int curr_rank; 8. char proc_name[MPI_MAX_PROCESSOR_NAME]; 9. int proc_name_len; 10. //intialize MPI 11. MPI_Init(&argc, &argv); 12. //get the number of processes 13. MPI_Comm_size(MPI_COMM_WORLD, &num_processes); 14. 15. //Get the rank of the current process 16. MPI_Comm_rank(MPI_COMM_WORLD, &curr_rank); 17. // Get the processor name for the current thread 18. MPI_Get_processor_name(proc_name, &proc_name_len); 19. //Check that we're running this process. 20. printf("Calling process %d out of %d on %srn", curr_rank, num_processes, proc_name); 21. //Wait for all threads ot finish 22. MPI_Finalized(); 23. return 0; 24. } •Creates user specified dummy processes of equal size •Allocates the processes dynamically to each nodes •Displays the process number upon completion](https://image.slidesharecdn.com/presentation1spring2016finalcopy-200223190841/75/Senior-Design-Raspberry-Pi-Cluster-Computing-15-2048.jpg)
![ #include <stdio.h> #include <math.h> #include <mpi.h> #define TOTAL_ITERATIONS 10000 int main(int argc, char *argv[]) { //MPI variables int num_processes; int curr_rank; // keep track of the current for-loop iterations int total_iter; int step_iter; //variables used to calculate pi double pi; // the final value double curr_pi, h, sum, x; //step variables //start up MPI MPI_Init(&argc, &argv); MPI_Comm_size(MPI_COMM_WORLD, &num_processes); MPI_Comm_rank(MPI_COMM_WORLD, &curr_rank); //Iterate TOTAL_ITERATIONS to calculate PI within a certain error margin for(total_iter = 2; total_iter < TOTAL_ITERATIONS; total_iter++); { 16/34](https://image.slidesharecdn.com/presentation1spring2016finalcopy-200223190841/75/Senior-Design-Raspberry-Pi-Cluster-Computing-16-2048.jpg)