Download to read offline






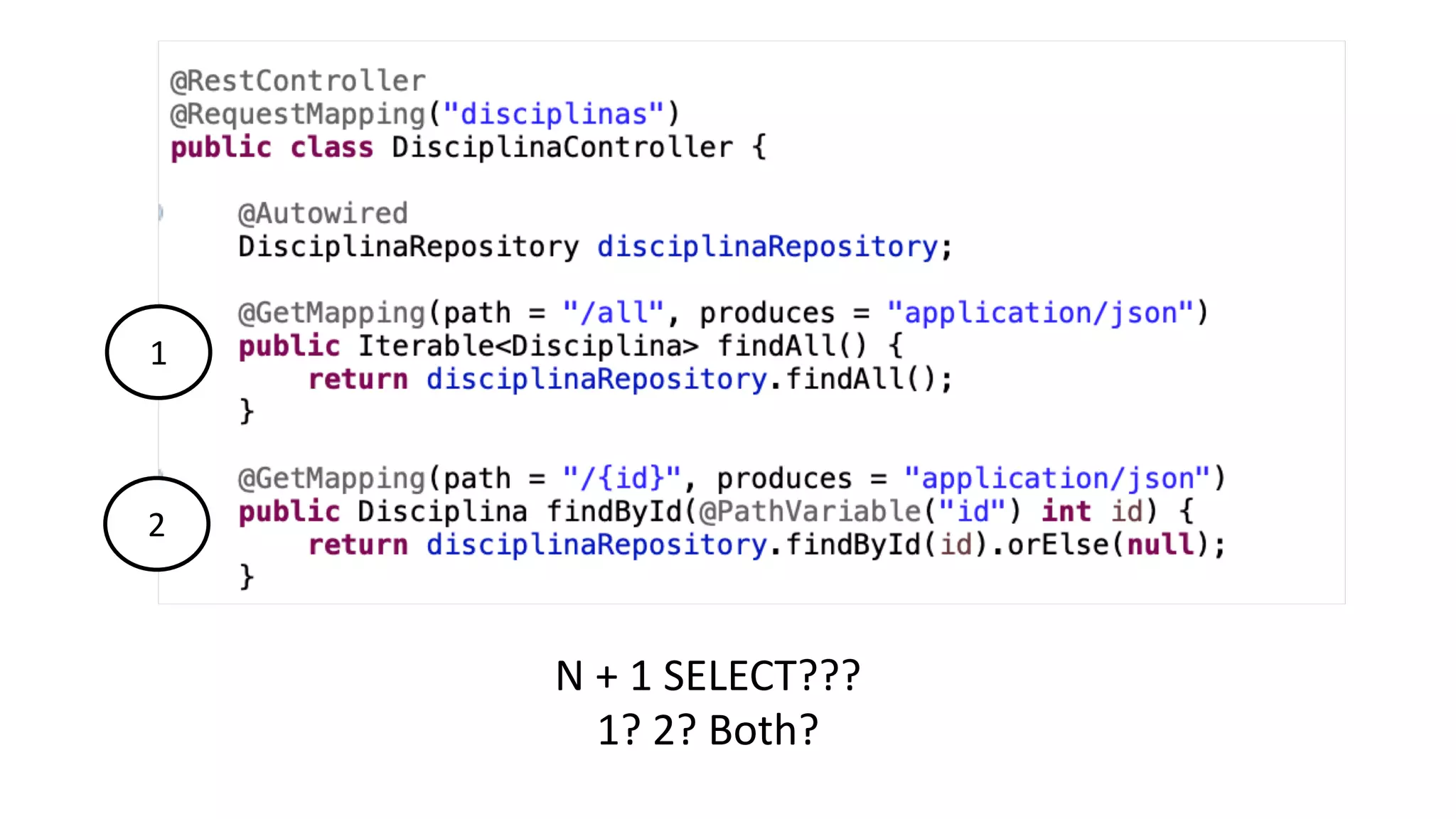
















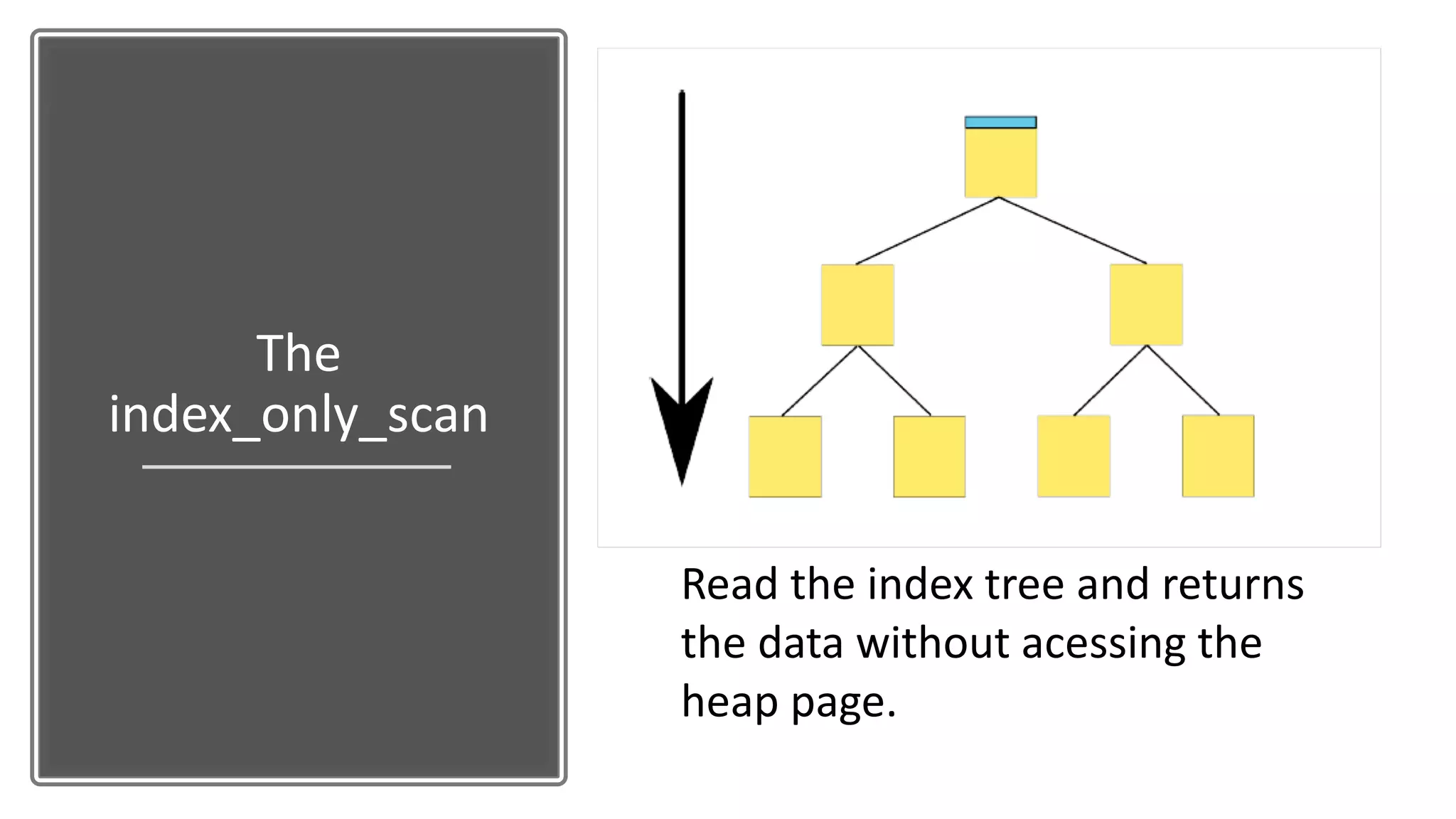
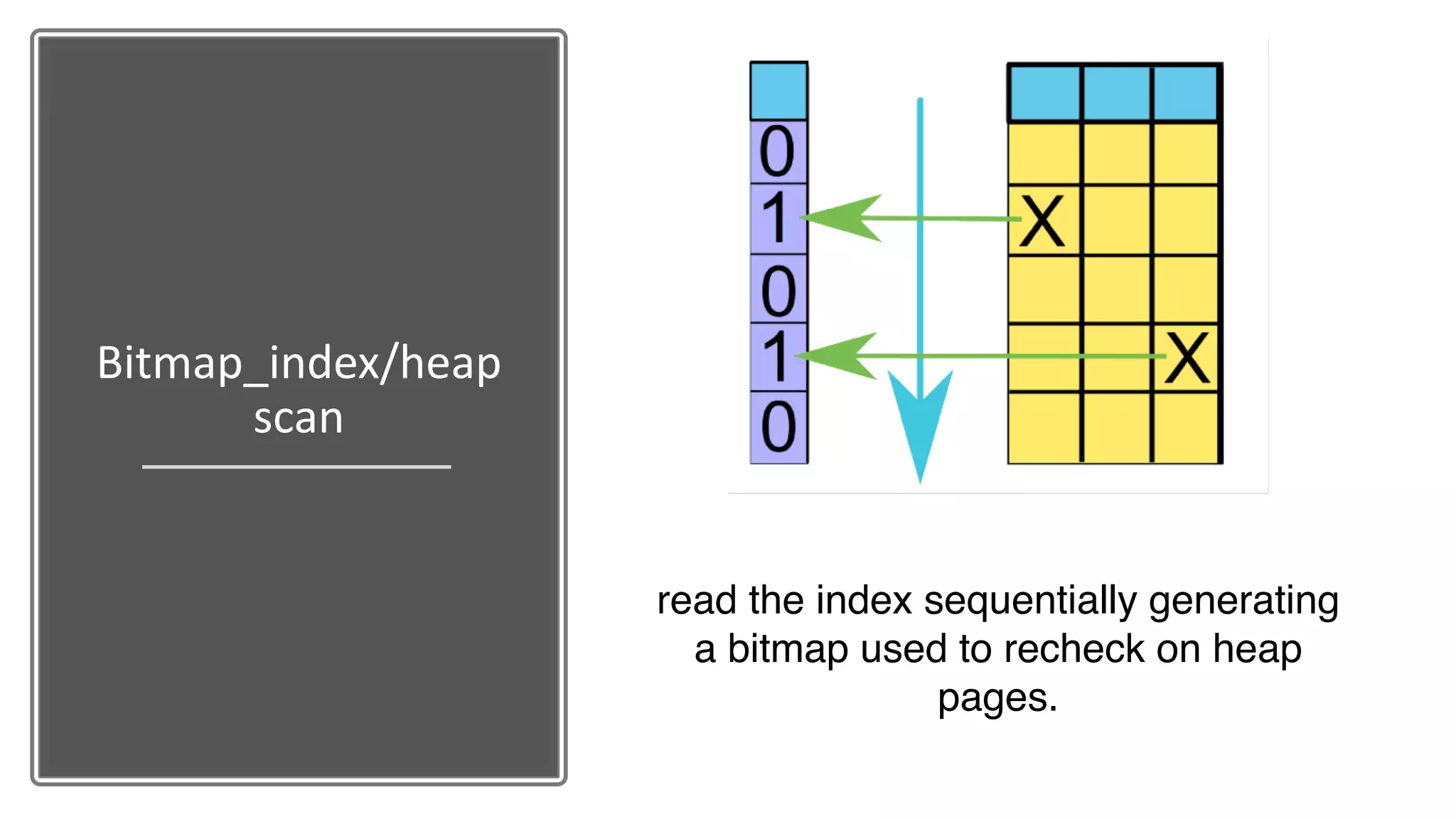
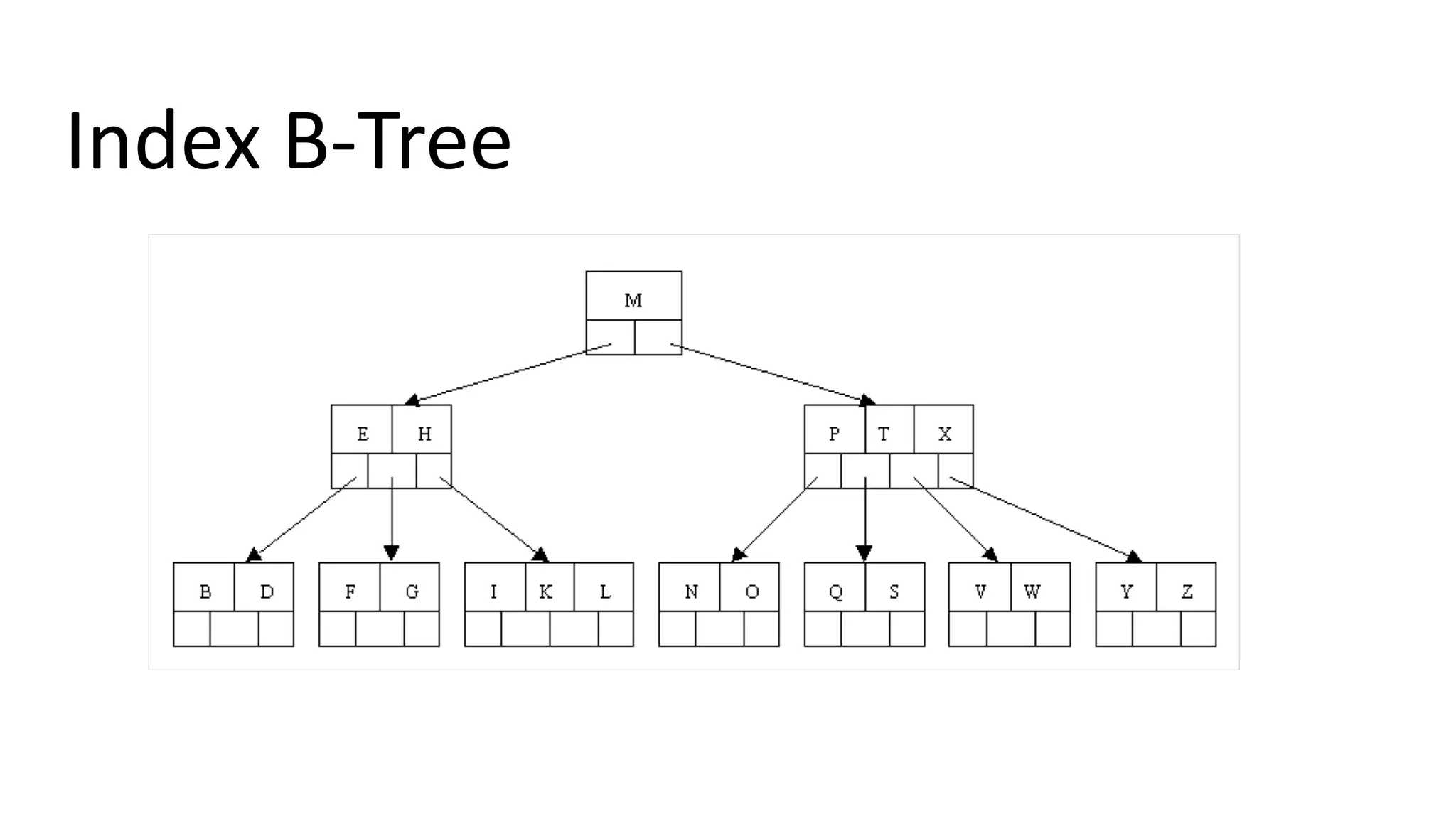

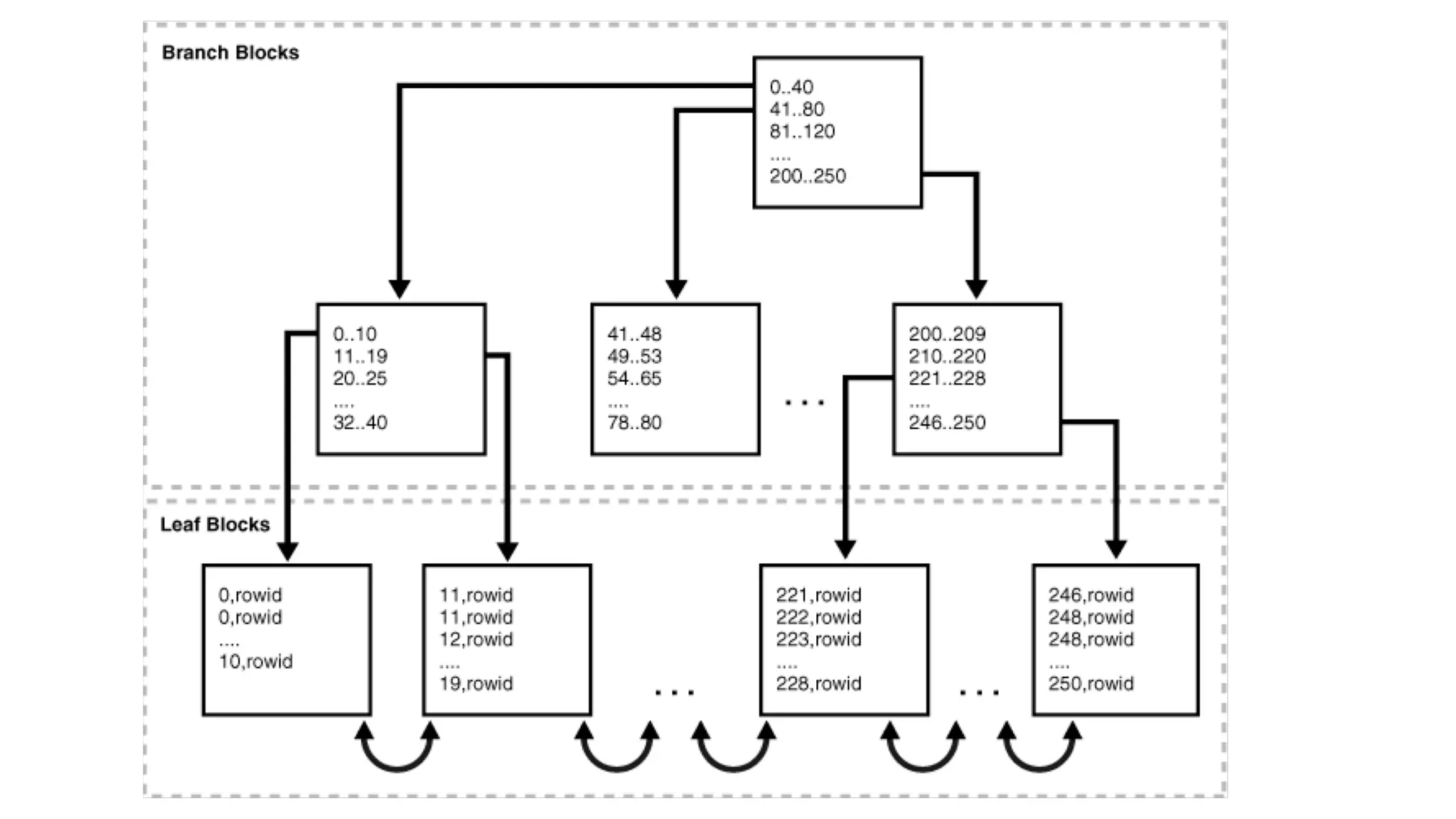

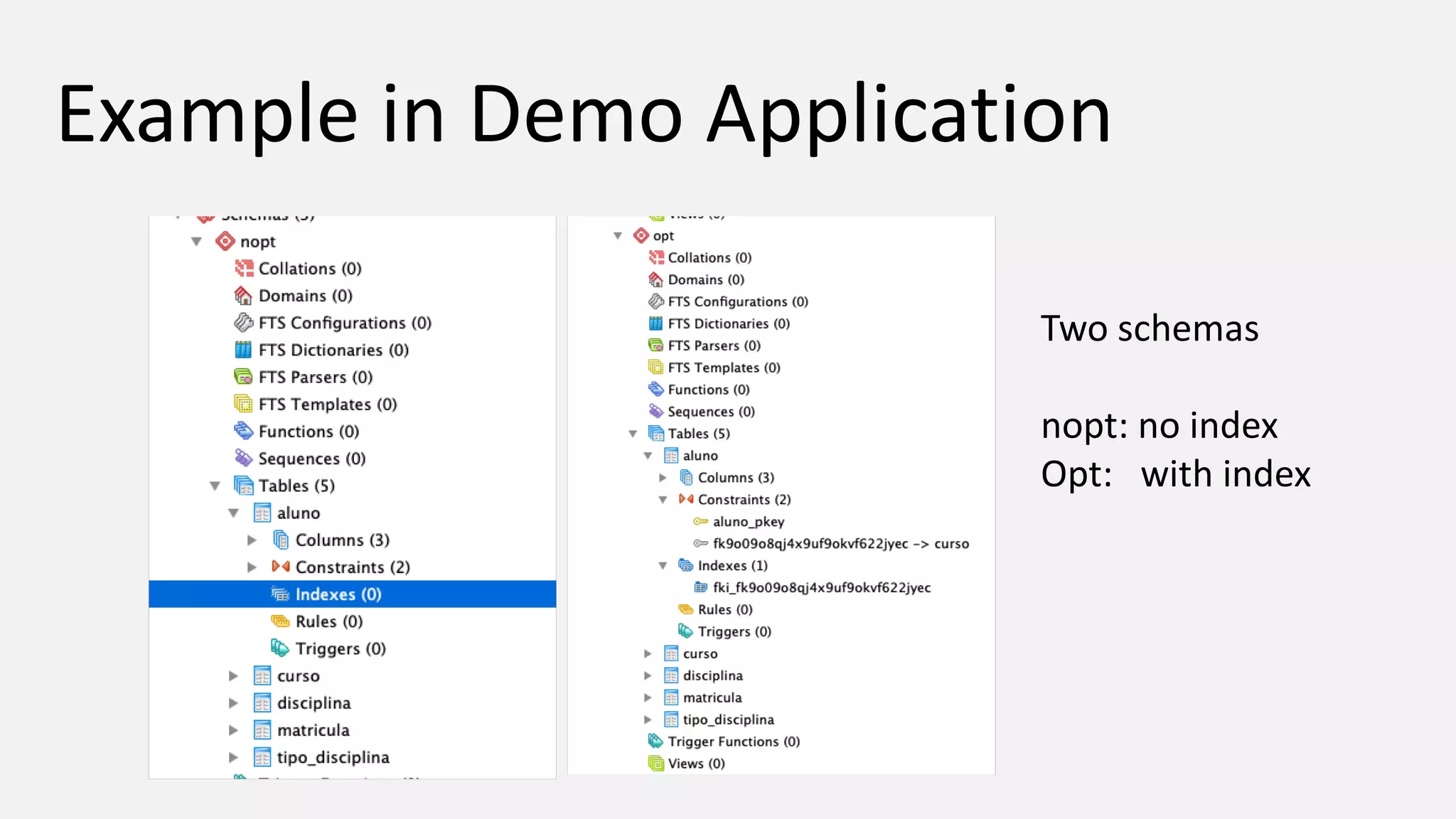
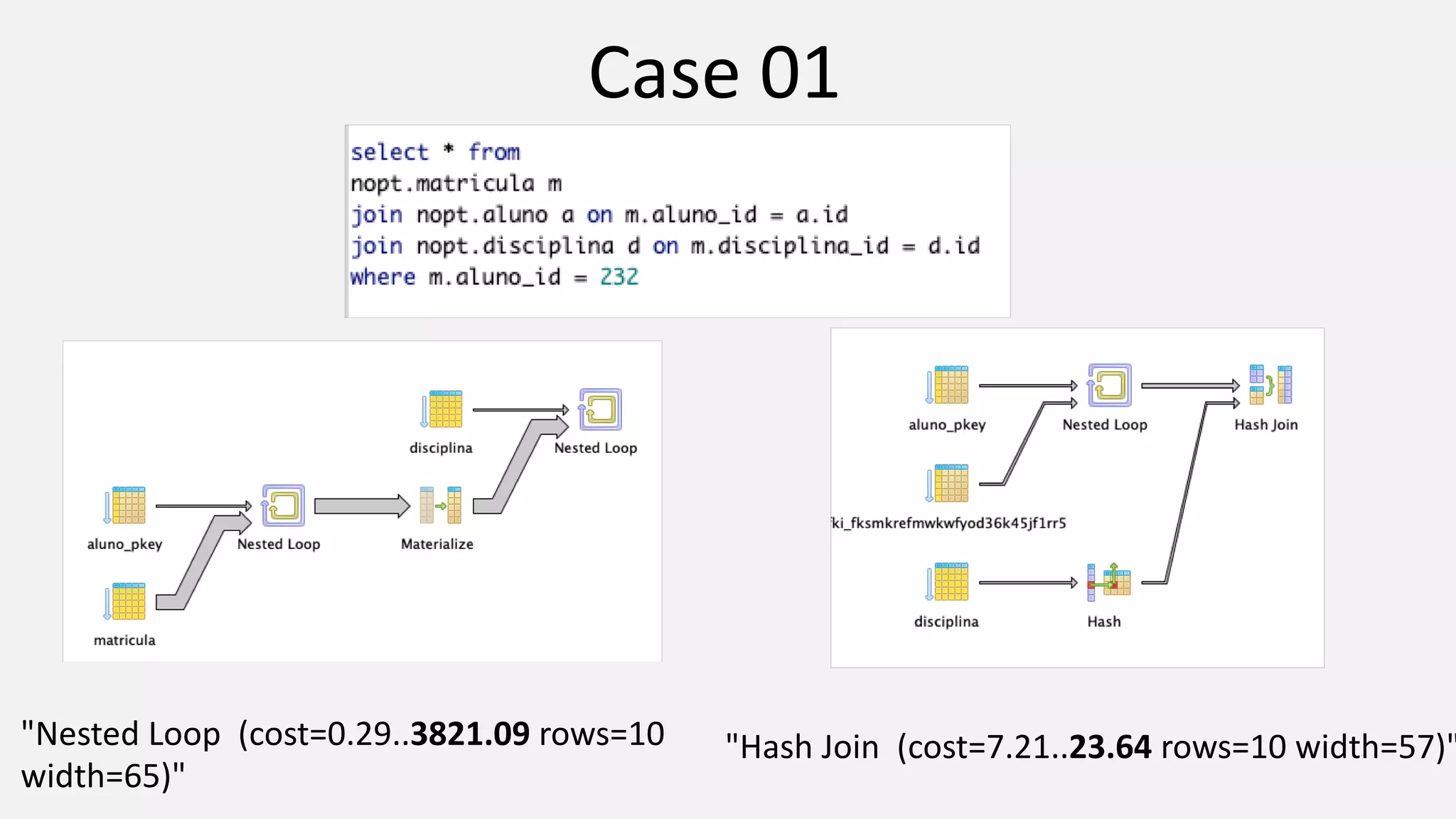




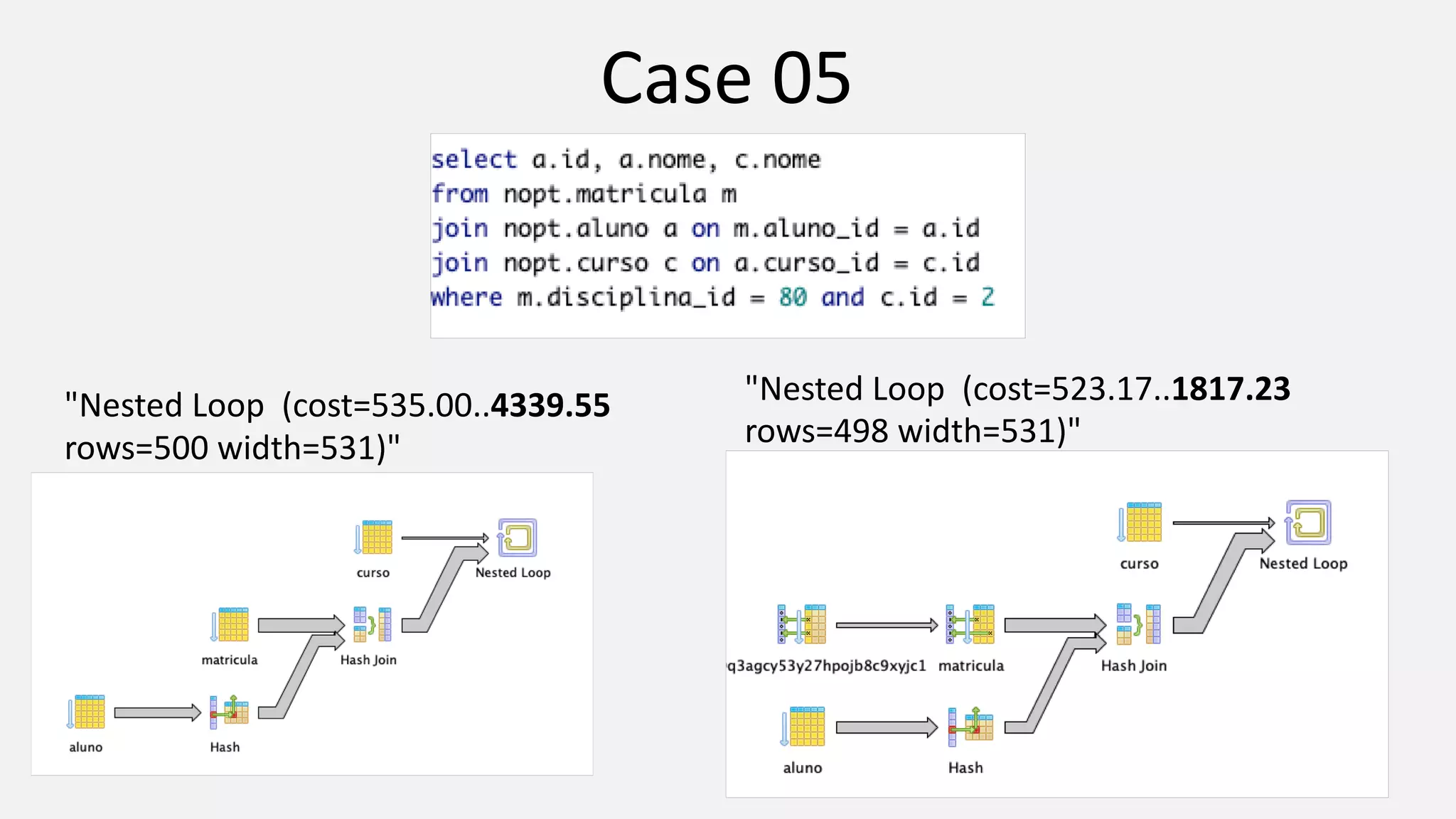







The document discusses performance optimization techniques for Java Persistence API (JPA) and SQL queries, focusing on issues like the N+1 select problem and the importance of caching, indexing, and fetch strategies. It provides practical examples and performance tips for query execution, emphasizing the use of explain commands in PostgreSQL to analyze query plans. Recommendations include using indexes for foreign keys, native queries for complex needs, and ensuring average query execution times remain under 500ms.