Download as PDF, PPTX



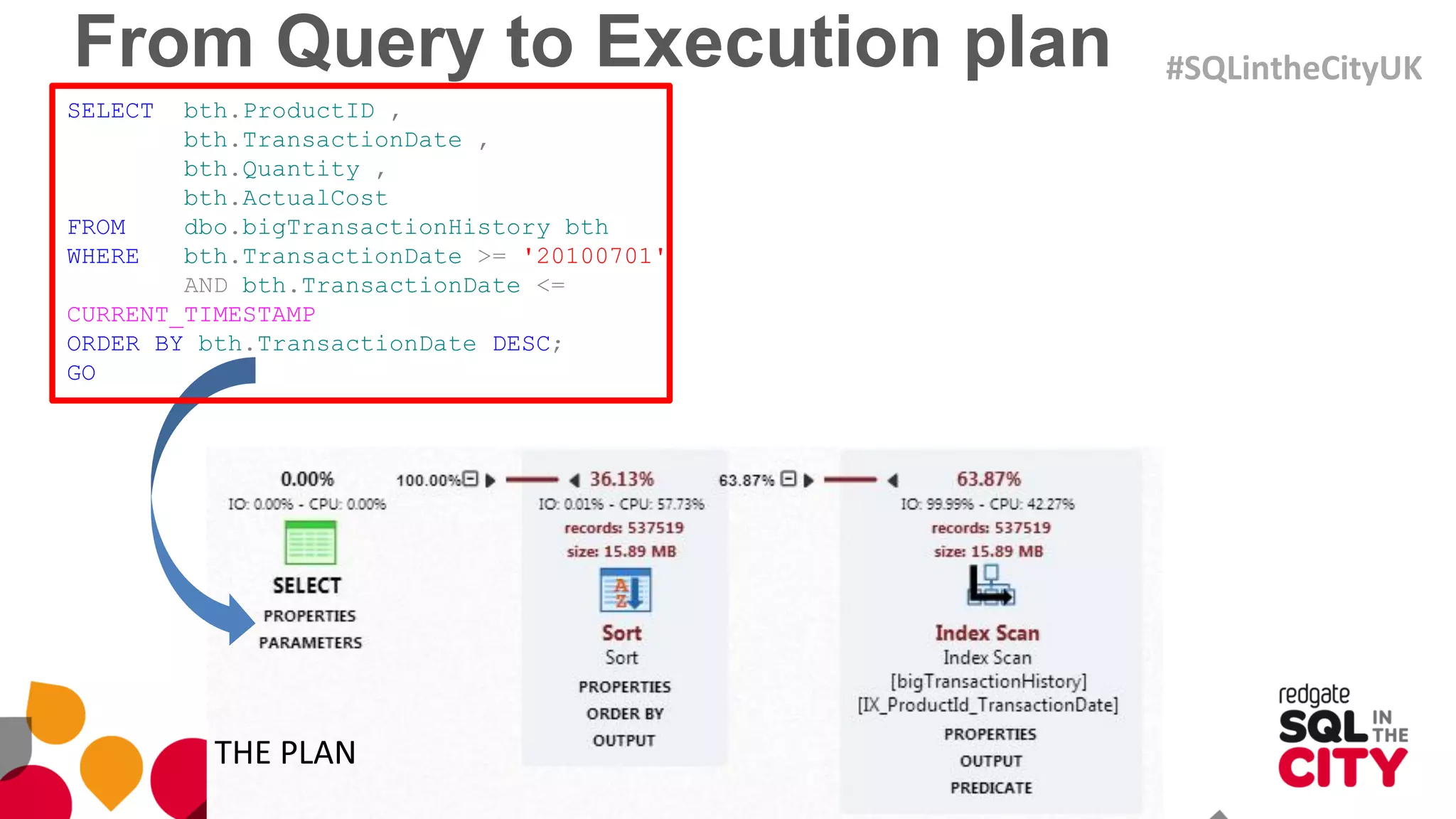
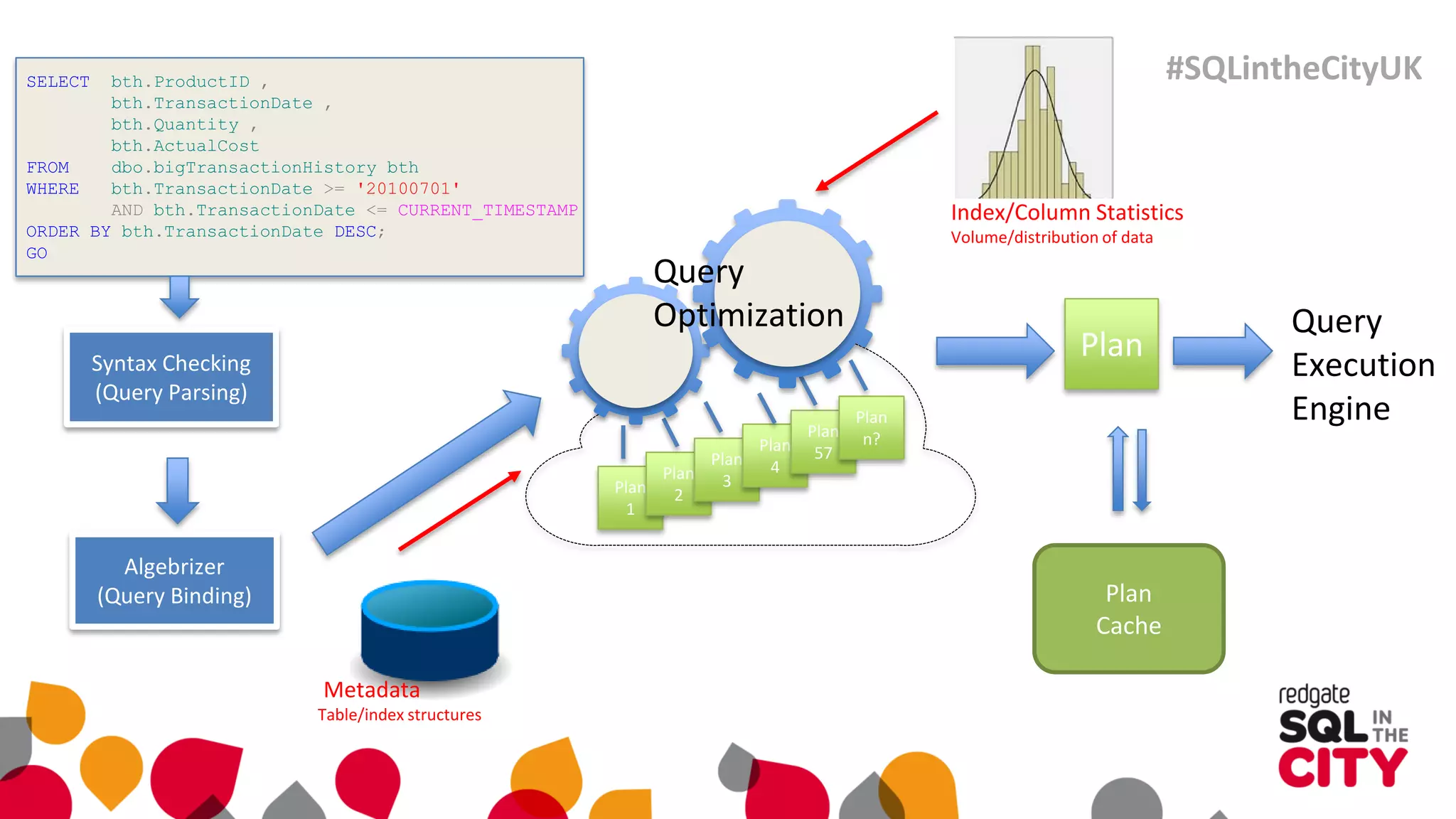
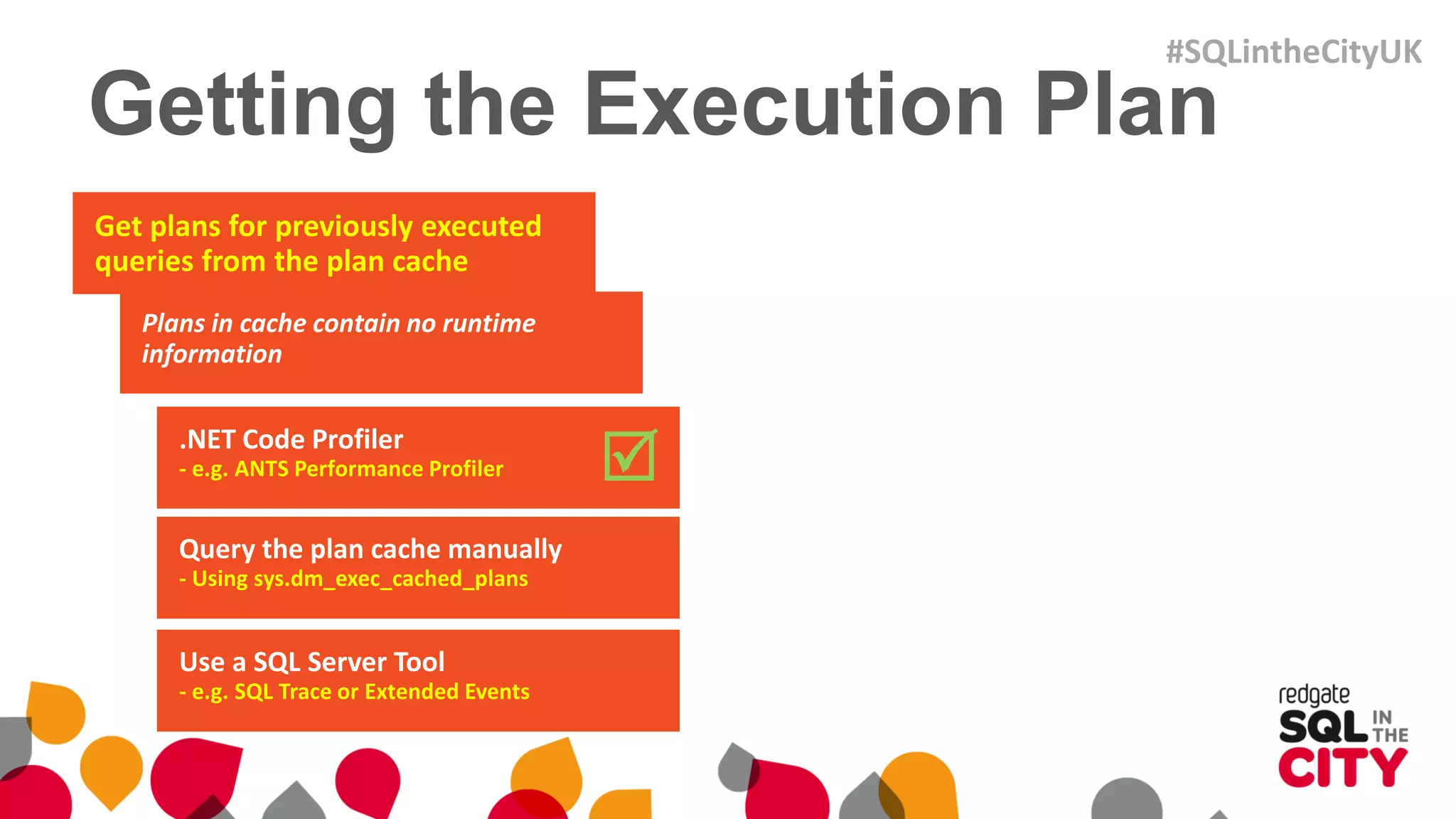

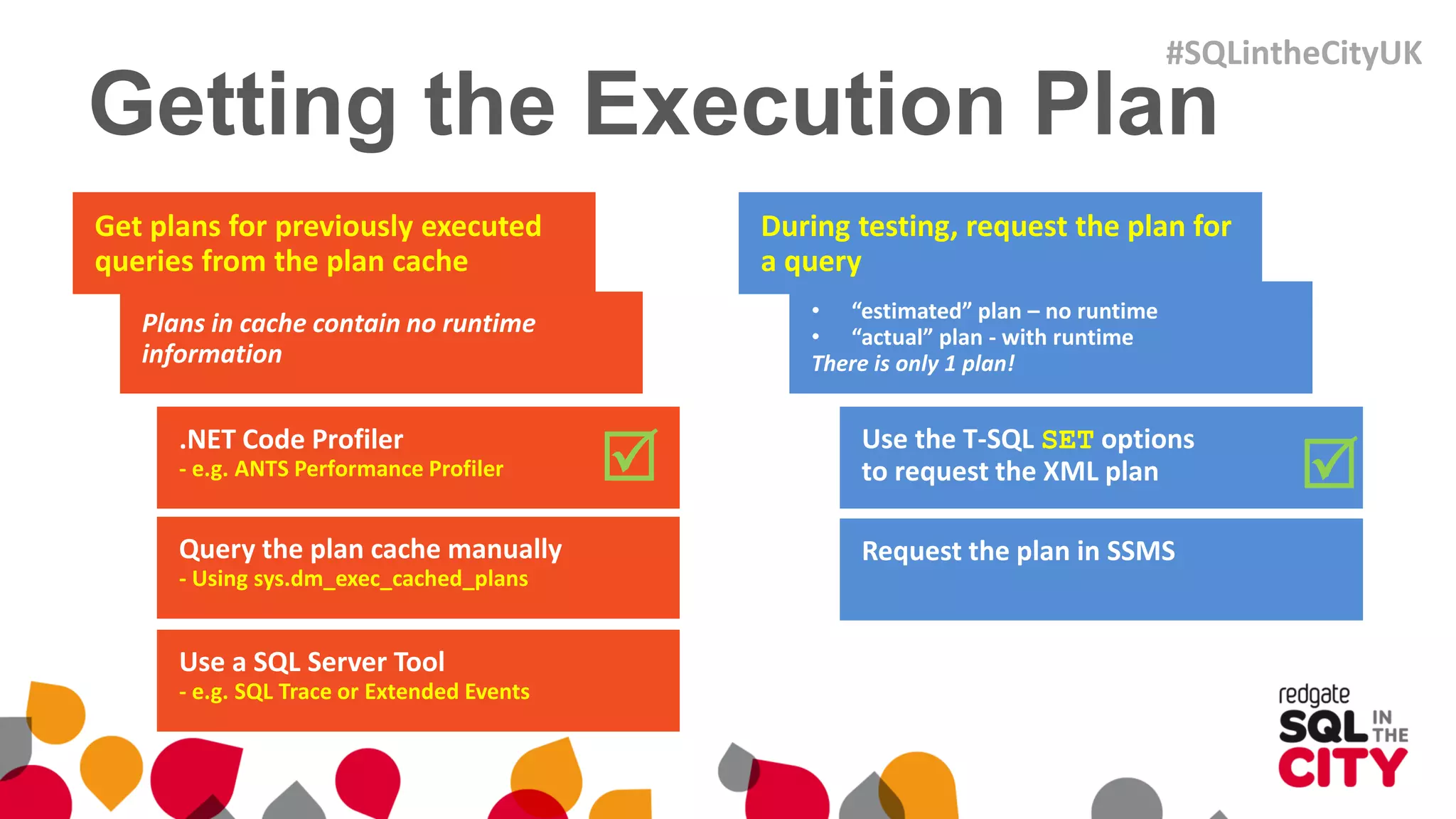





















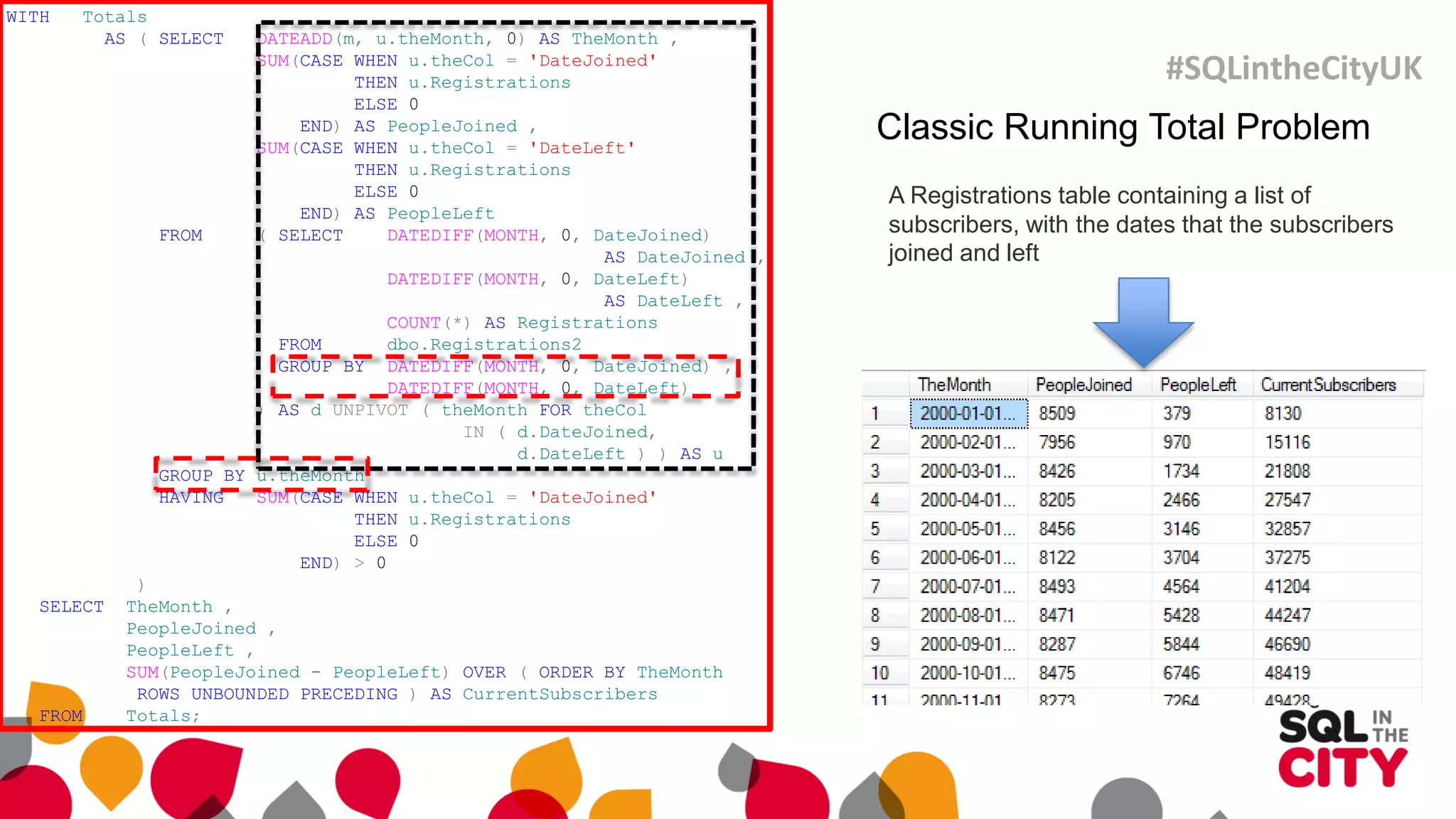
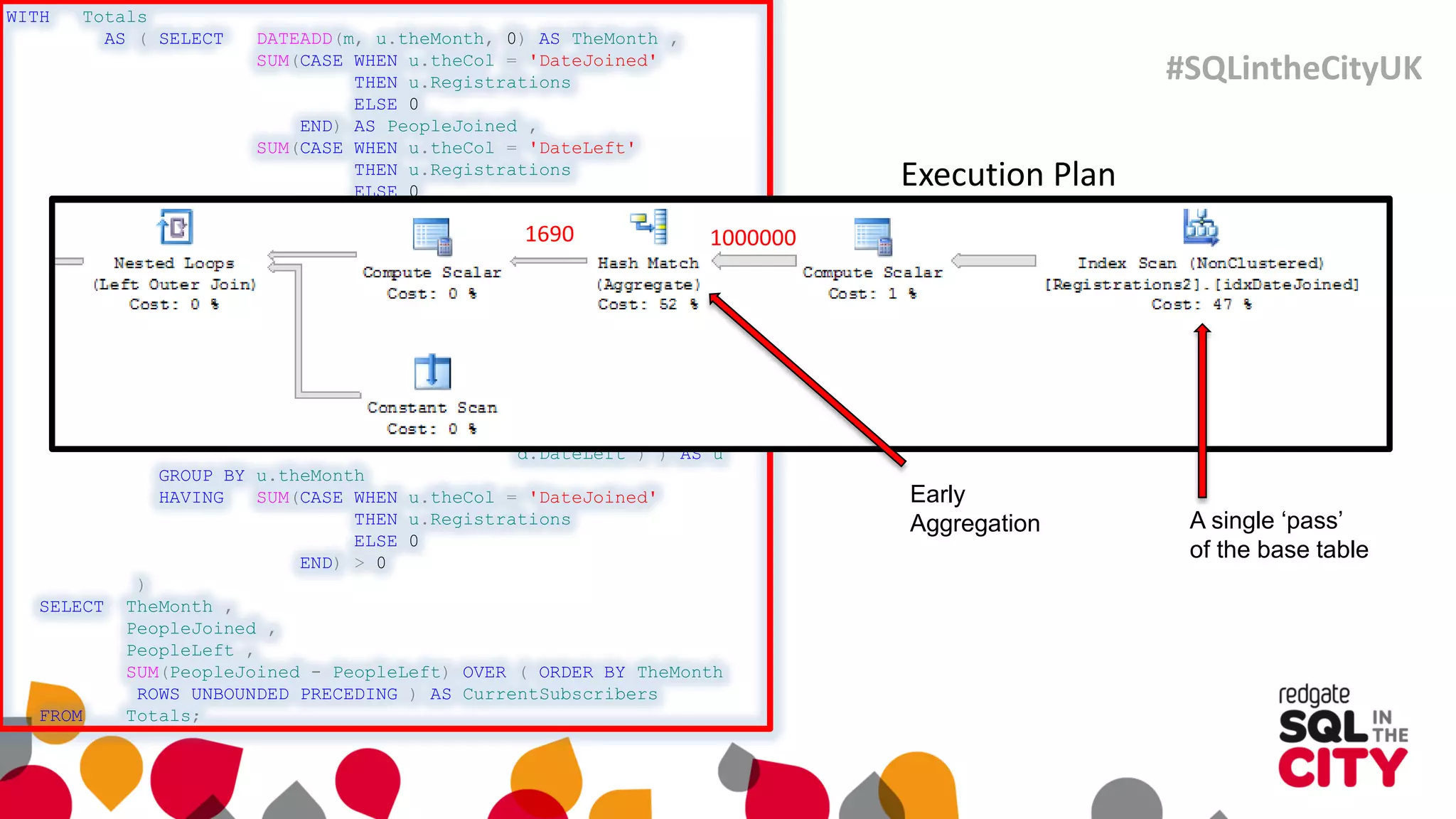

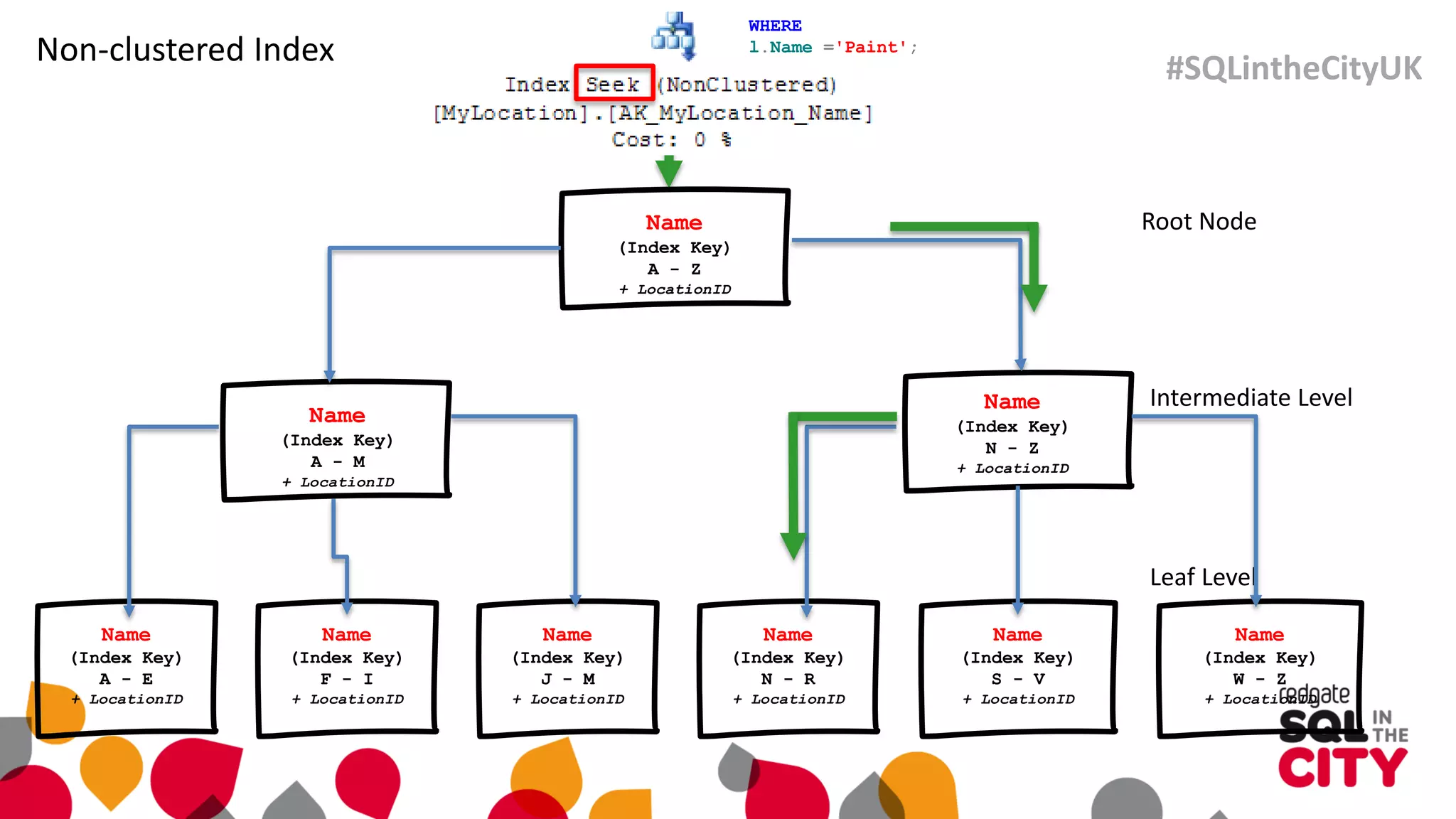
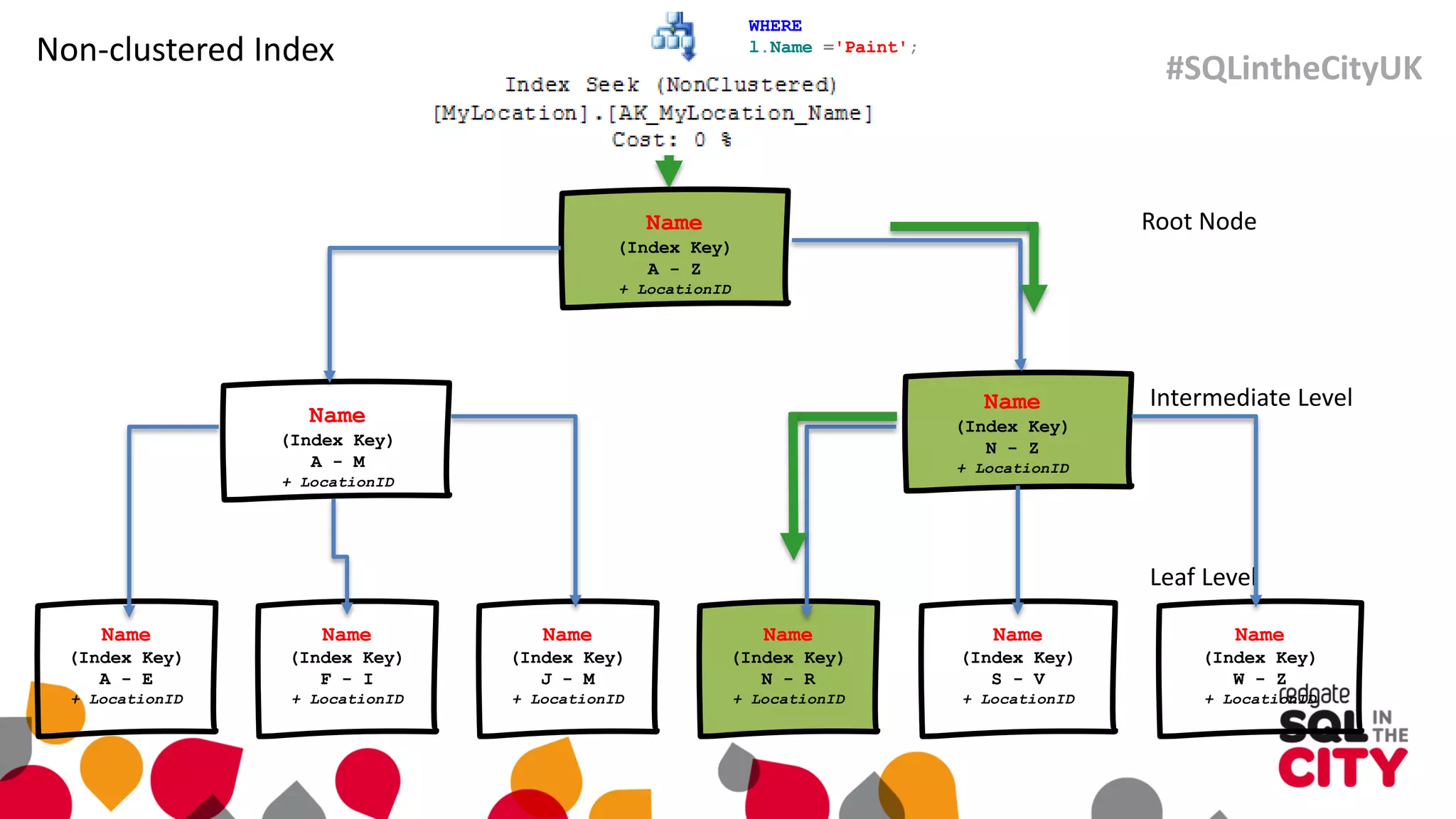
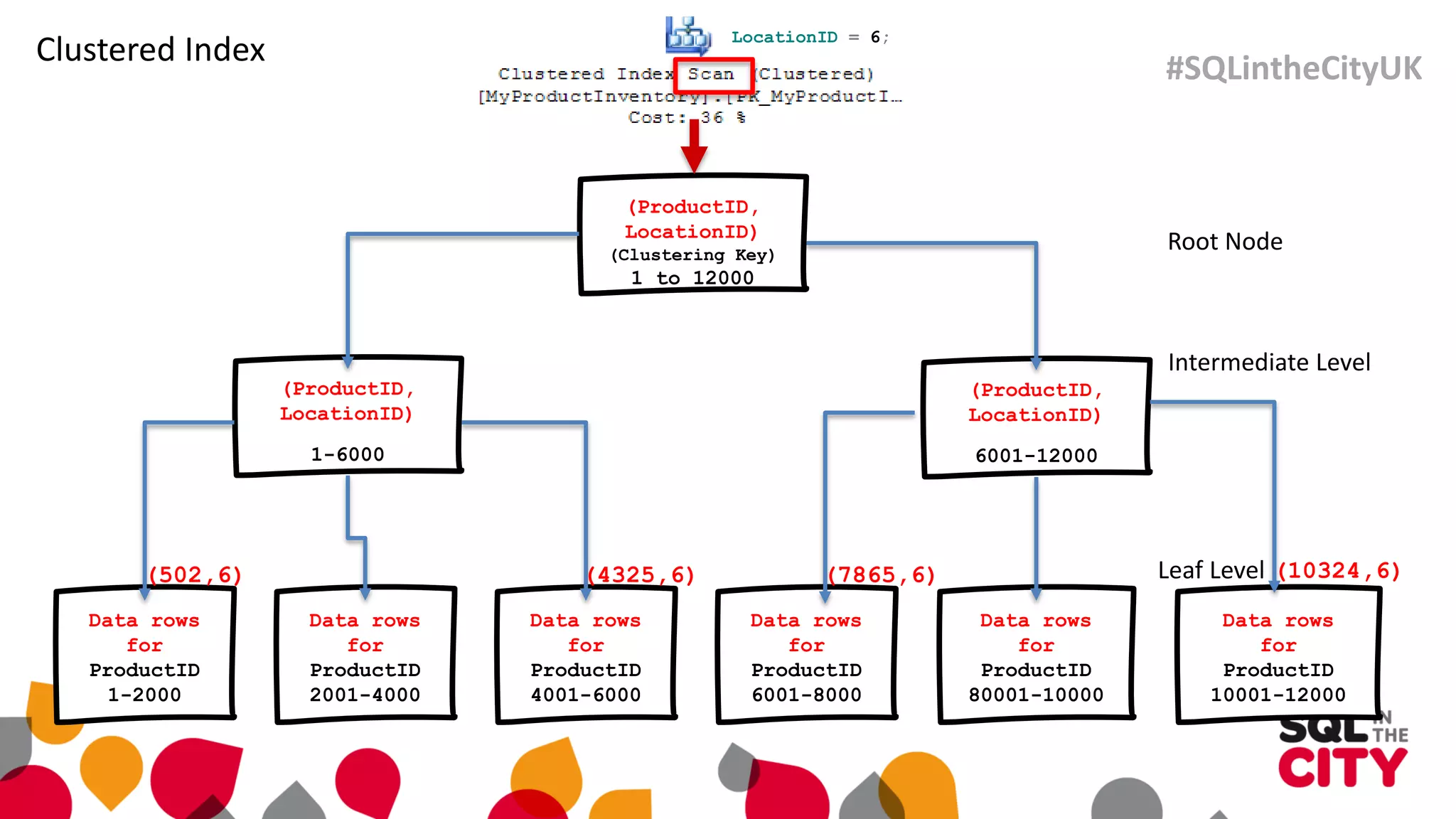
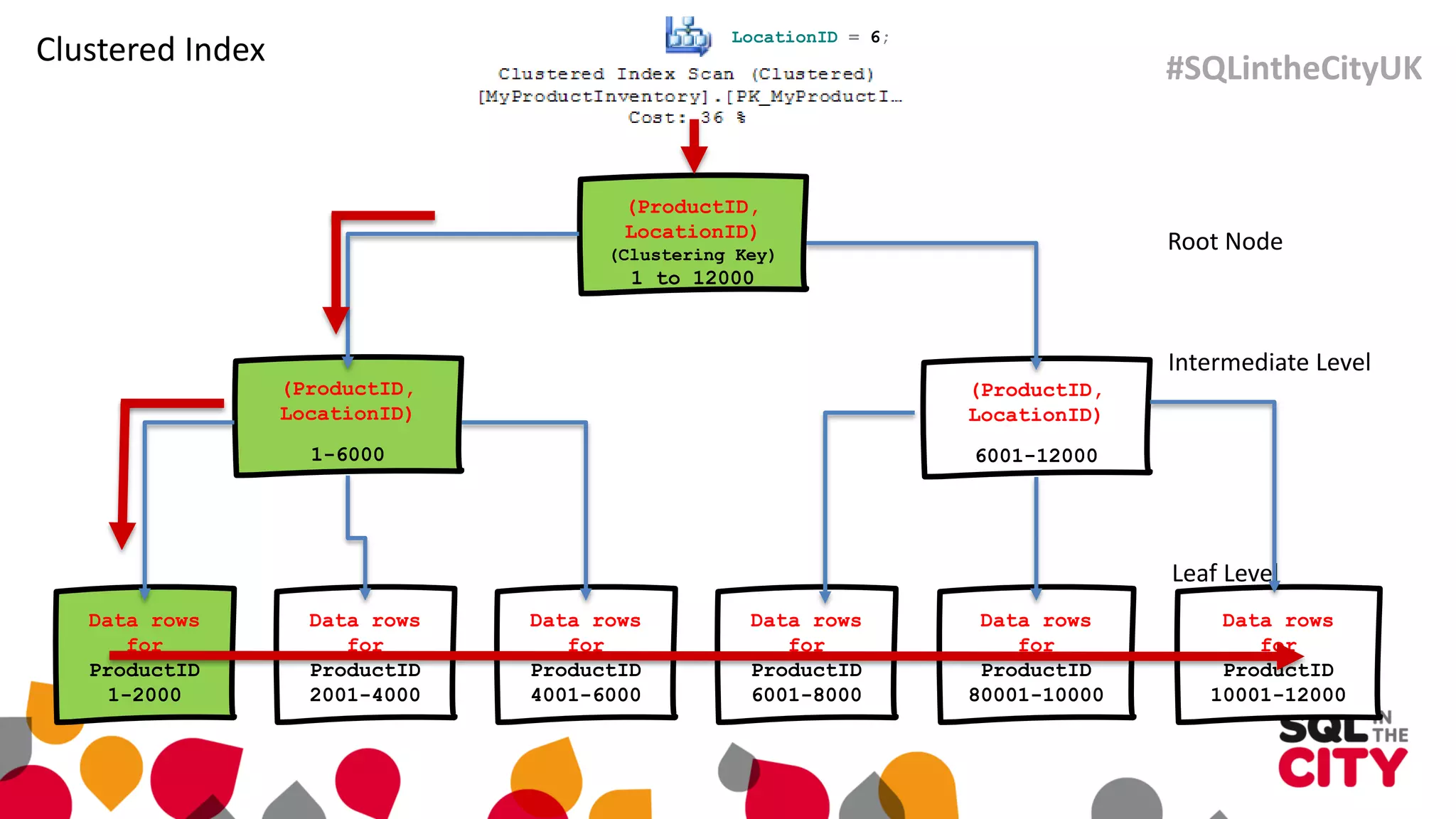
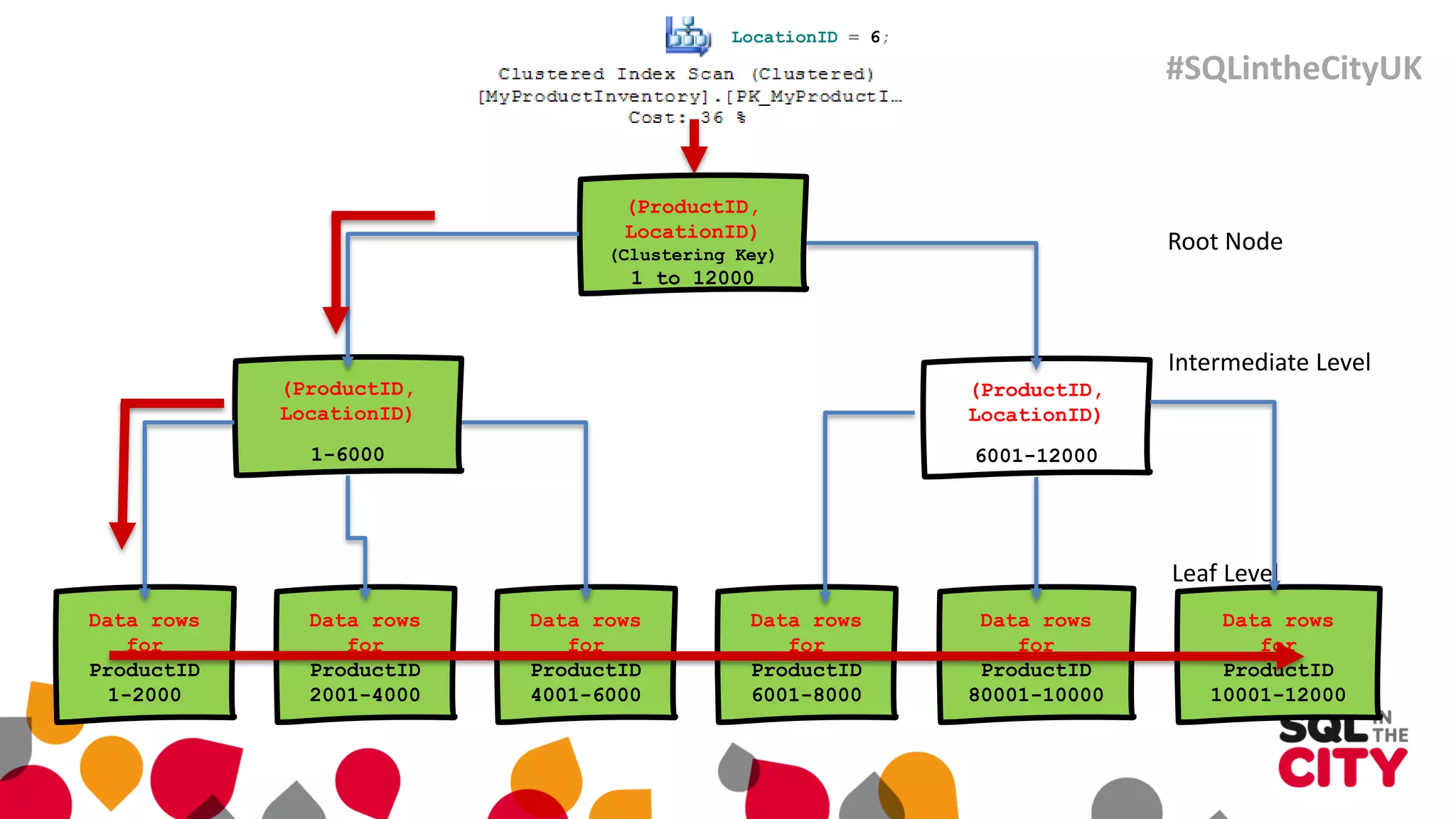

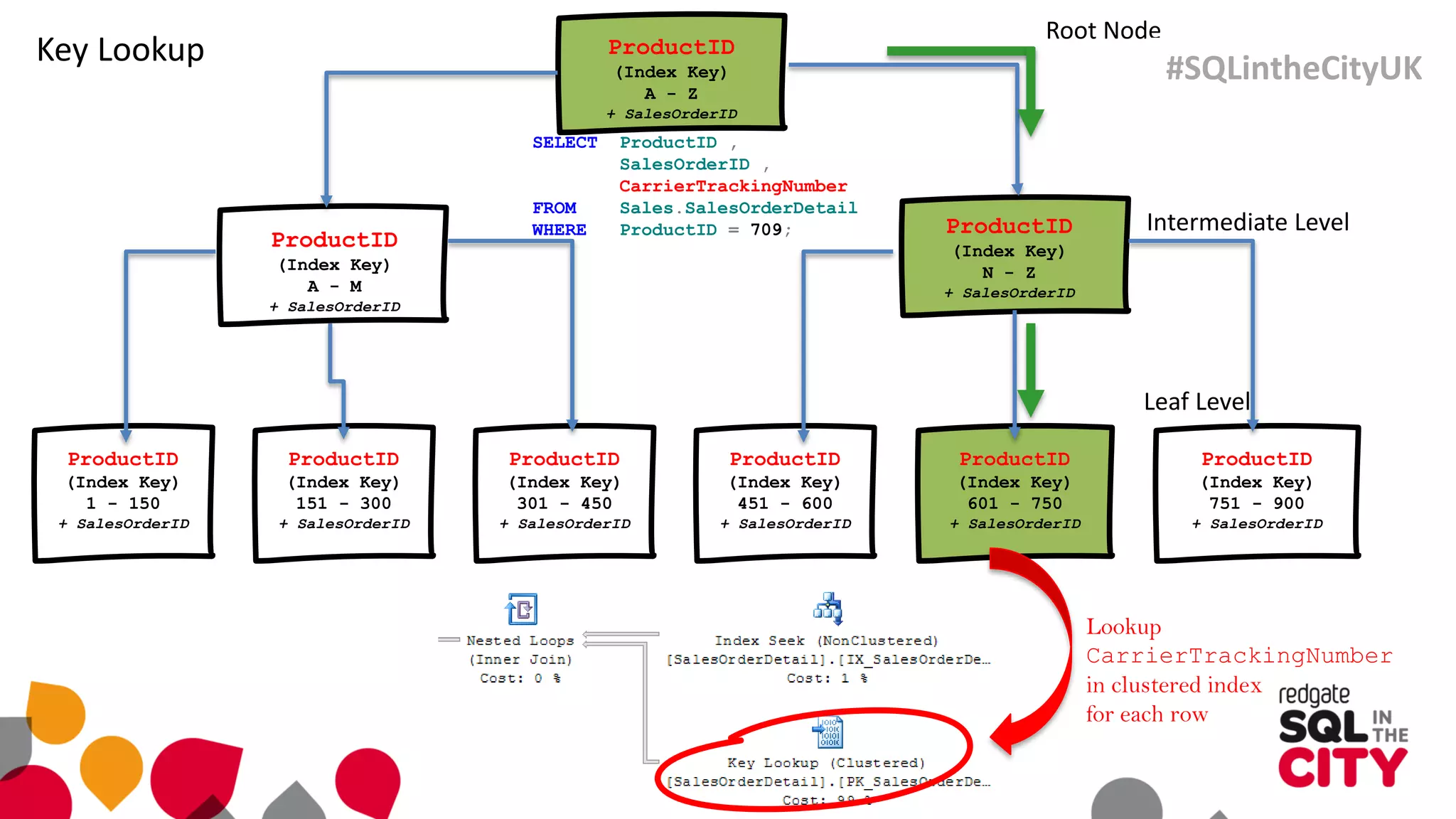







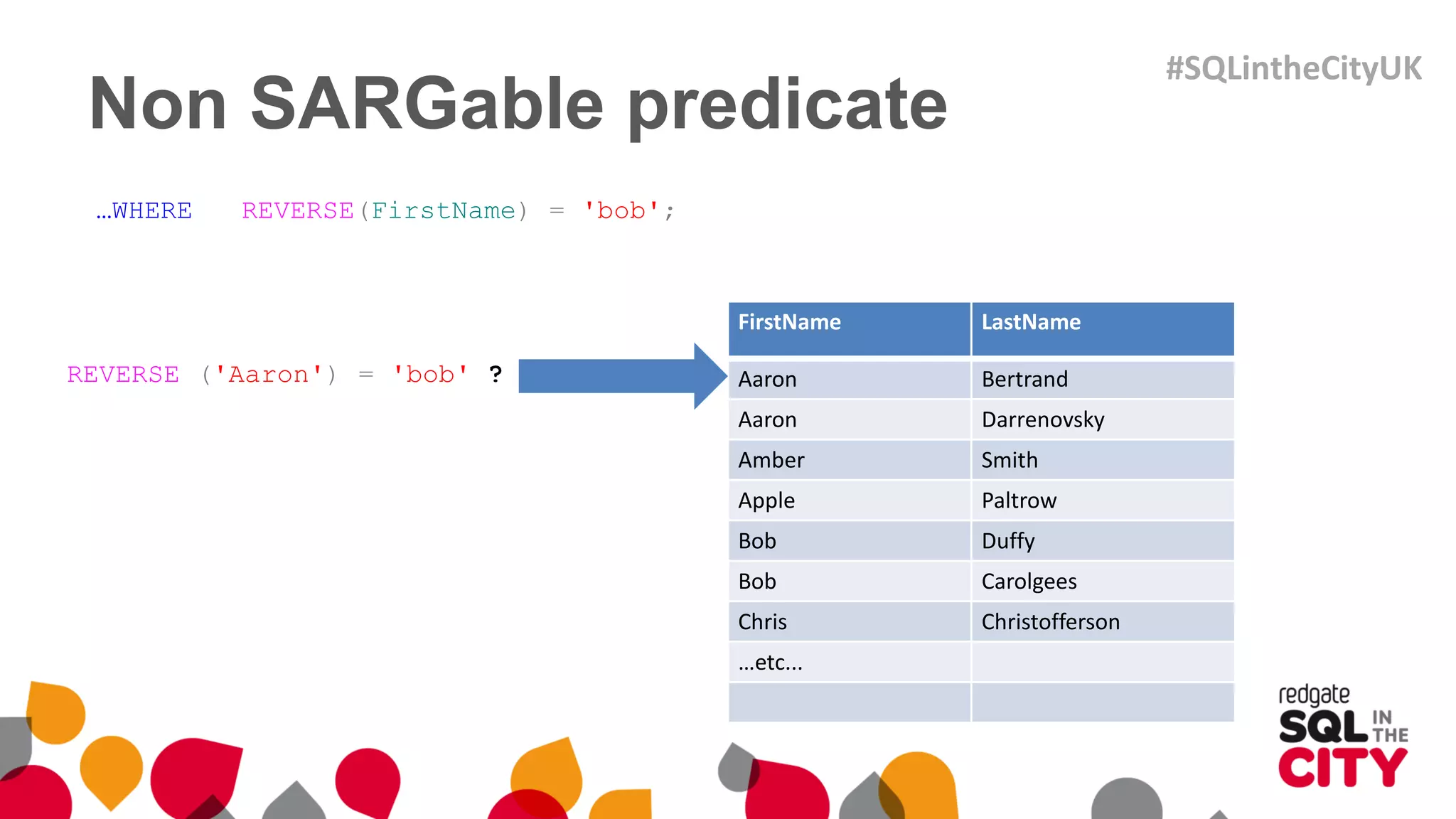
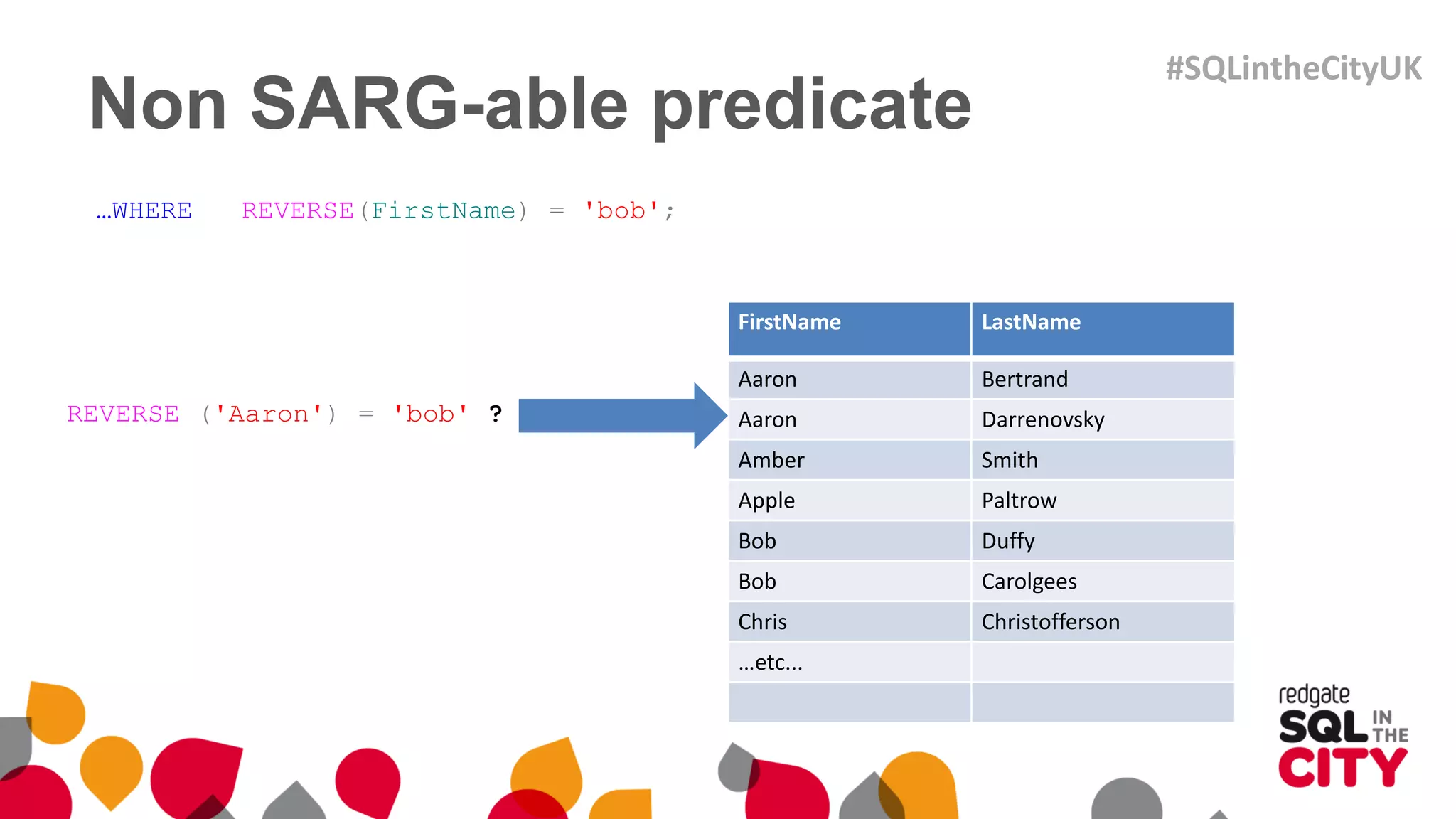









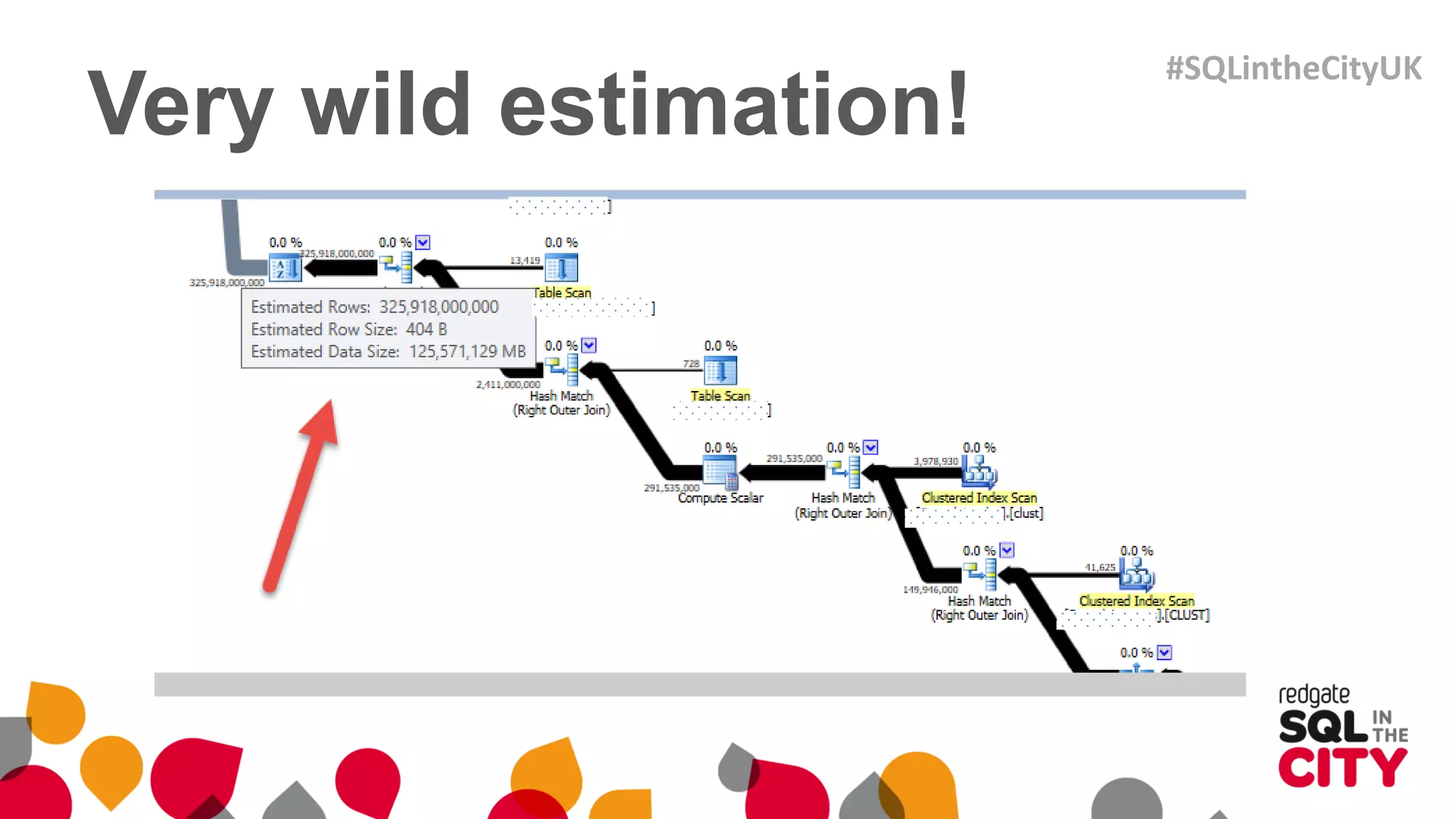



The document discusses techniques for uncovering SQL Server query problems using execution plans, emphasizing the importance of understanding execution plans to optimize query performance. It highlights common issues such as poor indexing, excessive logical reads, non-sargable predicates, and the need for specific SQL queries tailored to defined purposes. By focusing on critical queries and using execution plans effectively, developers can improve SQL performance and resolve issues efficiently.