
Downloaded 15 times








![Linear Search Algorithm Consider an integer type array A with size n. So list of elements from that array are, A[0], A[1], A[2], A[3],………………, A[n-1] 1. Declare and initialize one variable which contents the number to be search in an array A. ( variable key is declared) 2. Start Comparing each element from array A with the key LOOP: A[size] == key Repeat step no 2 while A[size] key 3. if key is found, display the location of element(index+1) or else display message KEY NOT FOUND 4. Terminate the program successfully](https://image.slidesharecdn.com/unit-6dsa-200212164553/75/Unit-6-dsa-SEARCHING-AND-SORTING-9-2048.jpg)
![Linear Search Algorithm printf(“accept number to search”); scanf( key ); for( i=0 ;i<n ;i++) { if( A [ i ] == key ) { printf( key is FOUND); break; } } if( i==n ) { printf(NOT FOUND); }](https://image.slidesharecdn.com/unit-6dsa-200212164553/75/Unit-6-dsa-SEARCHING-AND-SORTING-10-2048.jpg)



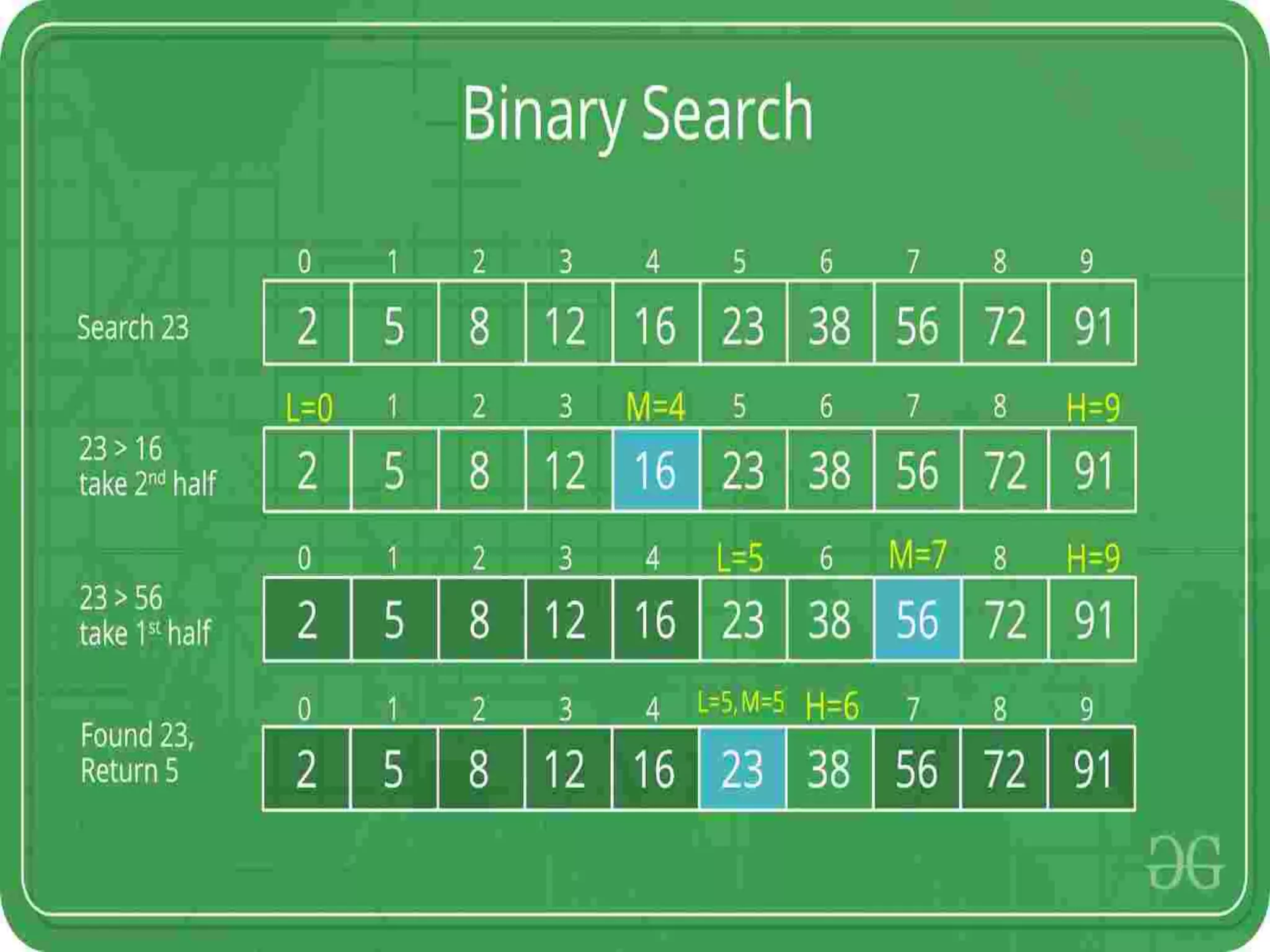
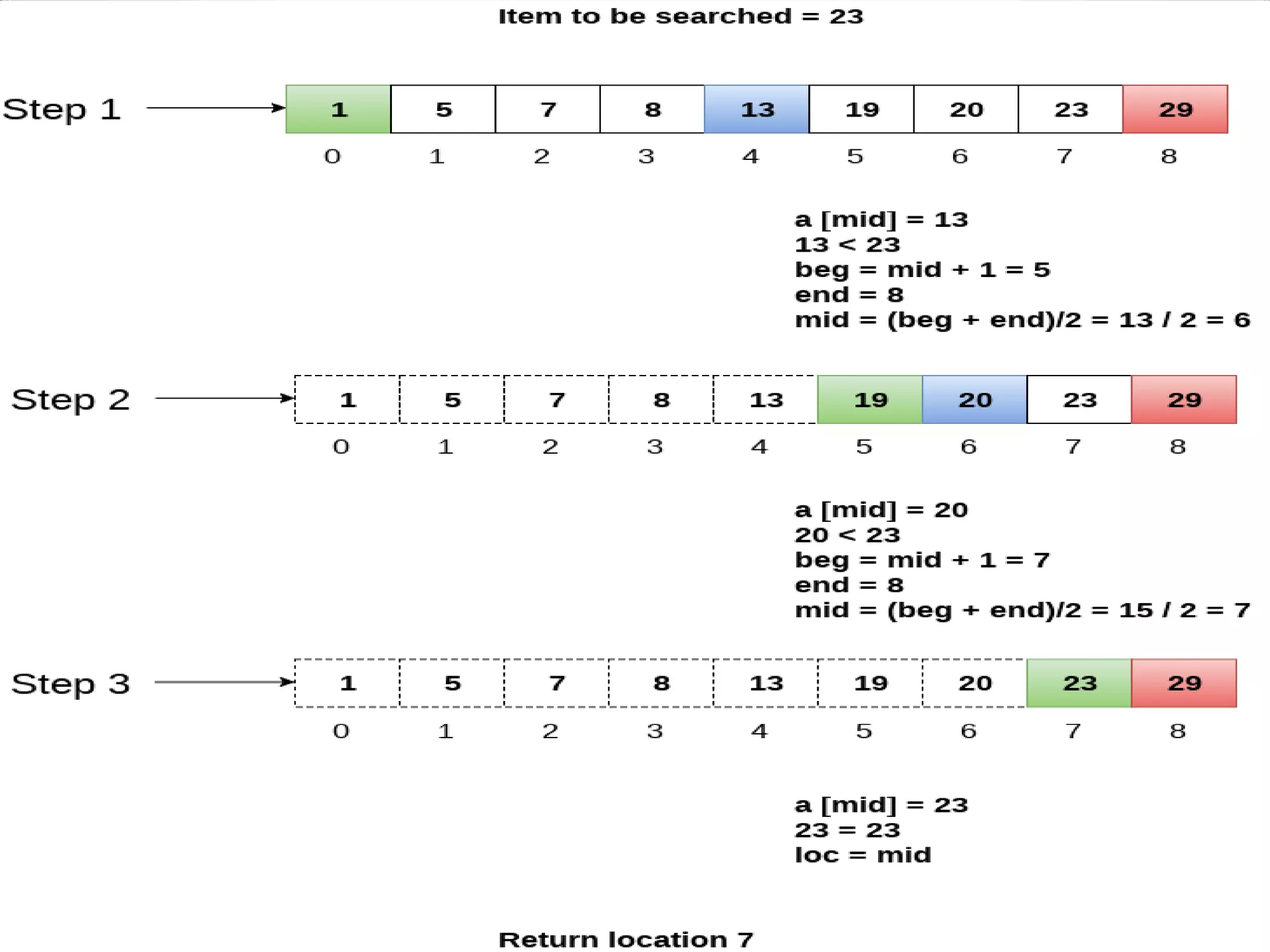
![Binary Search Assume that two variables are declared, variable first and last, they denotes beginning and ending indices of the list under consideration respectively. Step 1. Algorithm compares key with middle element from list ( A[middle] == key ), if true go to step 4 or else go to next. Step 2. if key < A[ middle ], search in left half of the list or else go to step 3 Step 3. if key > A[ middle ], search in right half of the list or go to step 1 Step 4. display the position of key else display message “NOT FOUND”](https://image.slidesharecdn.com/unit-6dsa-200212164553/75/Unit-6-dsa-SEARCHING-AND-SORTING-14-2048.jpg)
![Binary Search algorithm int i, first=0, last=n-1, middle; while( last>=first ) { middle = (first + last)/2; if( key > A[middle] ) { first = middle + 1; } else if ( key < A[middle] ) { last= middle – 1; } else { printf( FOUND ) } } if( last < first ) { printf( NOT FOUND ); }](https://image.slidesharecdn.com/unit-6dsa-200212164553/75/Unit-6-dsa-SEARCHING-AND-SORTING-15-2048.jpg)




![© Reem Al- Attas Binary Search 2. Calculate middle = (low + high) / 2. = (0 + 8) / 2 = 4. If 37 == array[middle] return middle Else if 37 < array[middle] high = middle -1 Else if 37 > array[middle] low = middle +1](https://image.slidesharecdn.com/unit-6dsa-200212164553/75/Unit-6-dsa-SEARCHING-AND-SORTING-20-2048.jpg)
![Binary Search Repeat 2. Calculate middle = (low + high) / 2. = (0 + 3) / 2 = 1. If 37 == array[middle] return middle Else if 37 < array[middle] high = middle -1 Else if 37 > array[middle] low = middle +1 9/6/201 7 © Reem Al- Attas](https://image.slidesharecdn.com/unit-6dsa-200212164553/75/Unit-6-dsa-SEARCHING-AND-SORTING-21-2048.jpg)
![Binary Search Repeat 2. Calculate middle = (low + high) / 2. = (2 + 3) / 2 = 2. If 37 == array[middle] return middle Else if 37 < array[middle] high = middle -1 Else if 37 > array[middle] low = middle +1 9/6/201 7 © Reem Al- Attas](https://image.slidesharecdn.com/unit-6dsa-200212164553/75/Unit-6-dsa-SEARCHING-AND-SORTING-22-2048.jpg)


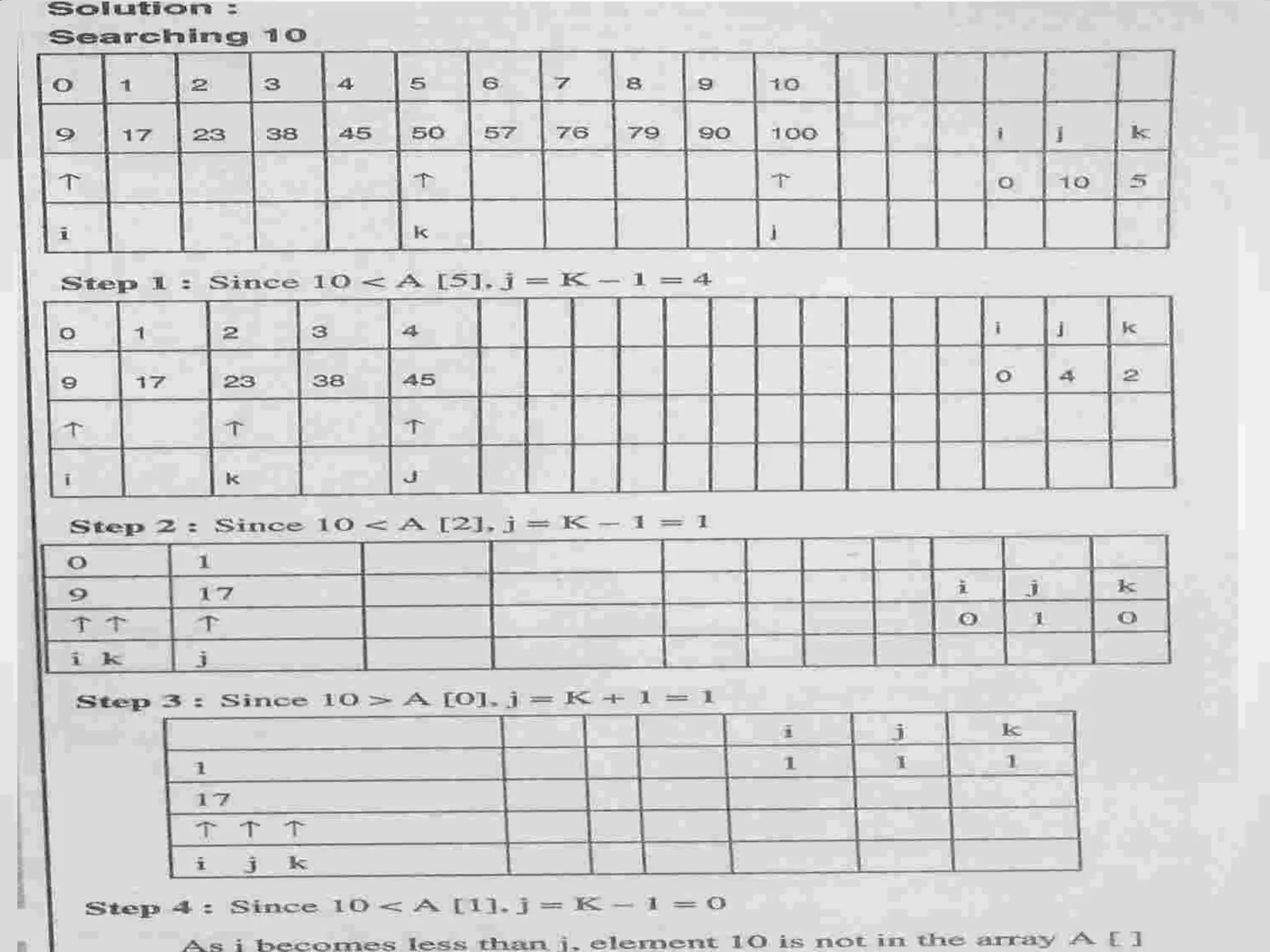
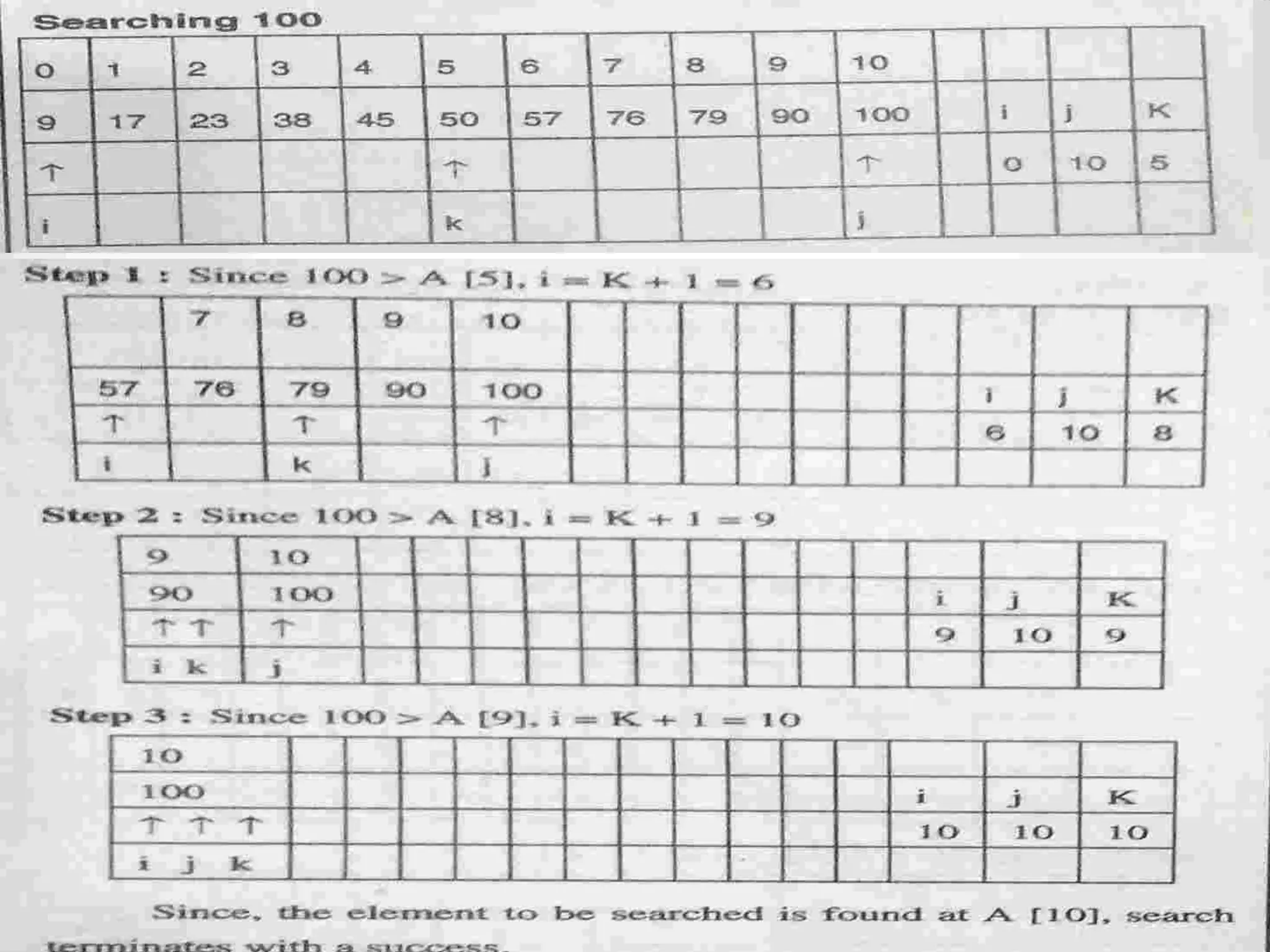





![Algorithm Given a table of records R1, R2, …, RN whose keys are in increasing order K1 < K2 < … < KN, the algorithm searches for a given argument K. Assume N+1 = Fk+1 Step 1. [Initialize] i ← Fk, p ← Fk-1, q ← Fk-2 (throughout the algorithm, p and q will be consecutive Fibonacci numbers) Step 2. [Compare] If K < Ki, go to Step 3; if K > Ki go to Step 4; and if K = Ki, the algorithm terminates successfully. Step 3. [Decrease i] If q=0, the algorithm terminates unsuccessfully. Otherwise set (i, p, q) ← (p, q, p - q) (which moves p and q one position back in the Fibonacci sequence); then return to Step 2 Step 4. [Increase i] If p=1, the algorithm terminates unsuccessfully. Otherwise set (i,p,q) ← (i + q, p - q, 2q - p) (which moves p and q two positions back in the Fibonacci sequence); and return to Step 234 Fibonacci search](https://image.slidesharecdn.com/unit-6dsa-200212164553/75/Unit-6-dsa-SEARCHING-AND-SORTING-34-2048.jpg)






















































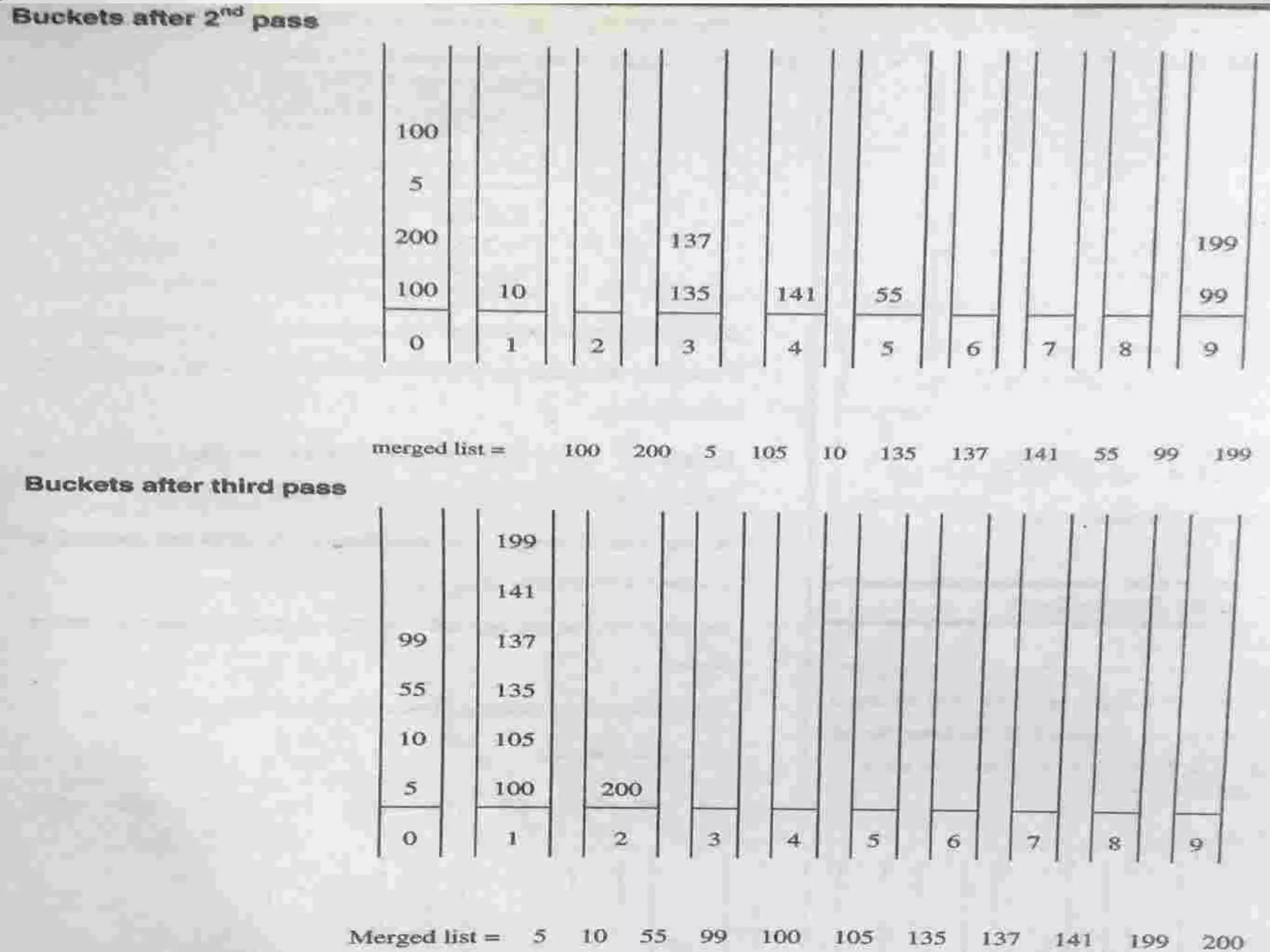
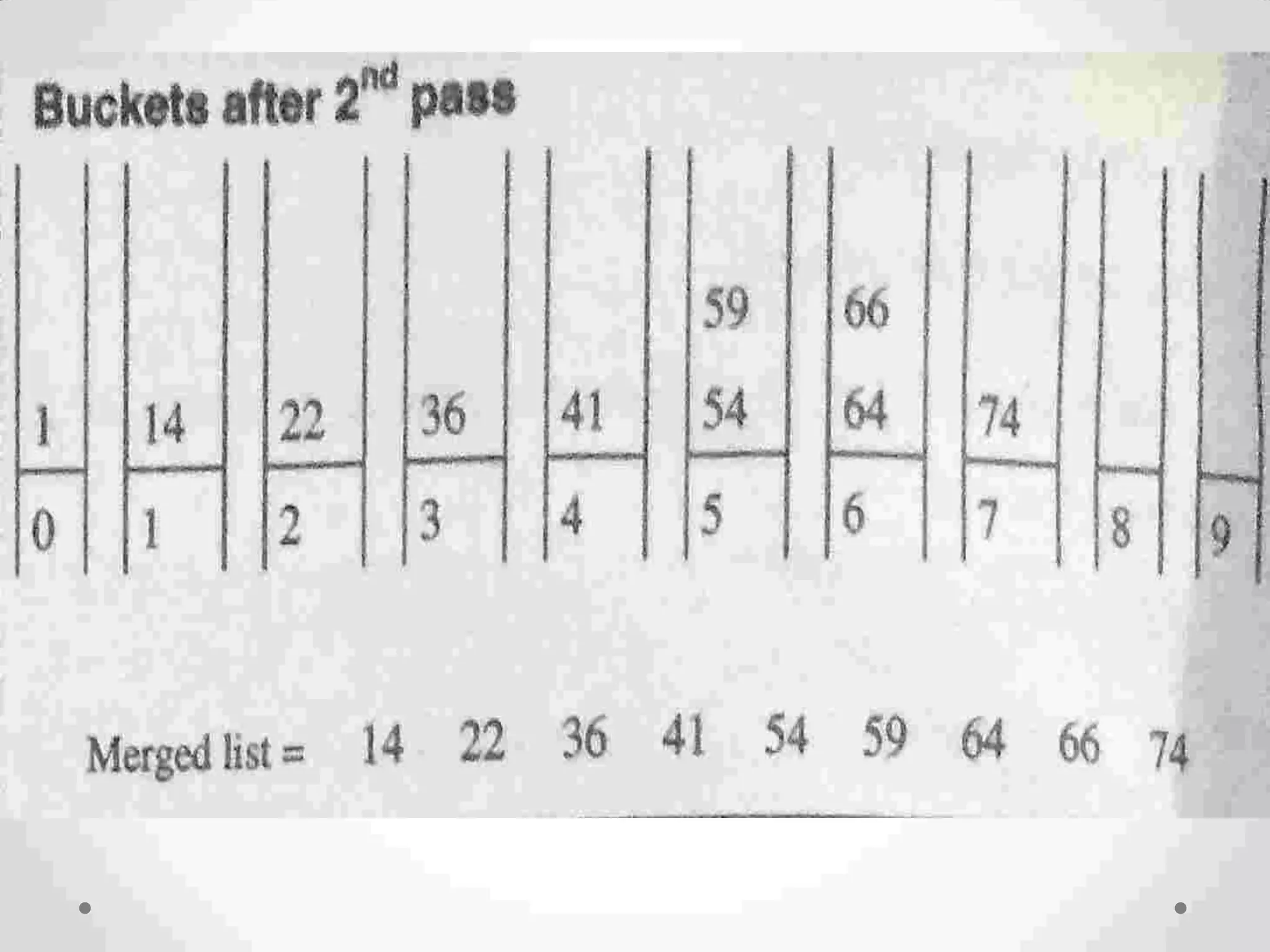
![ For example, suppose that we are sorting elements from the set of integers in the interval [0, m − 1]. The bucket sort uses m buckets or counters The ith counter/bucket keeps track of the number of occurrences of the ith element of the list 11 0 Bucket Sort](https://image.slidesharecdn.com/unit-6dsa-200212164553/75/Unit-6-dsa-SEARCHING-AND-SORTING-110-2048.jpg)





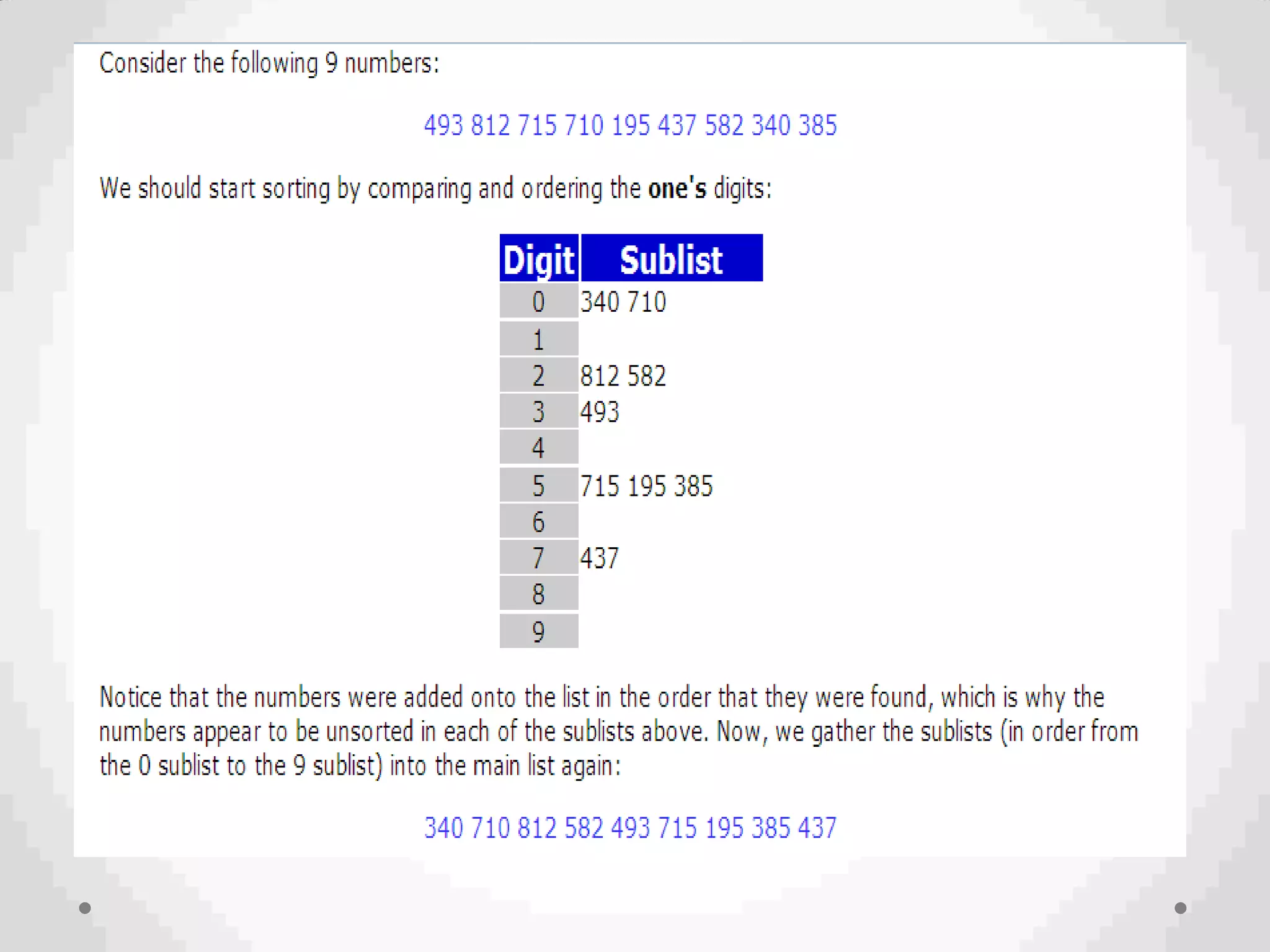
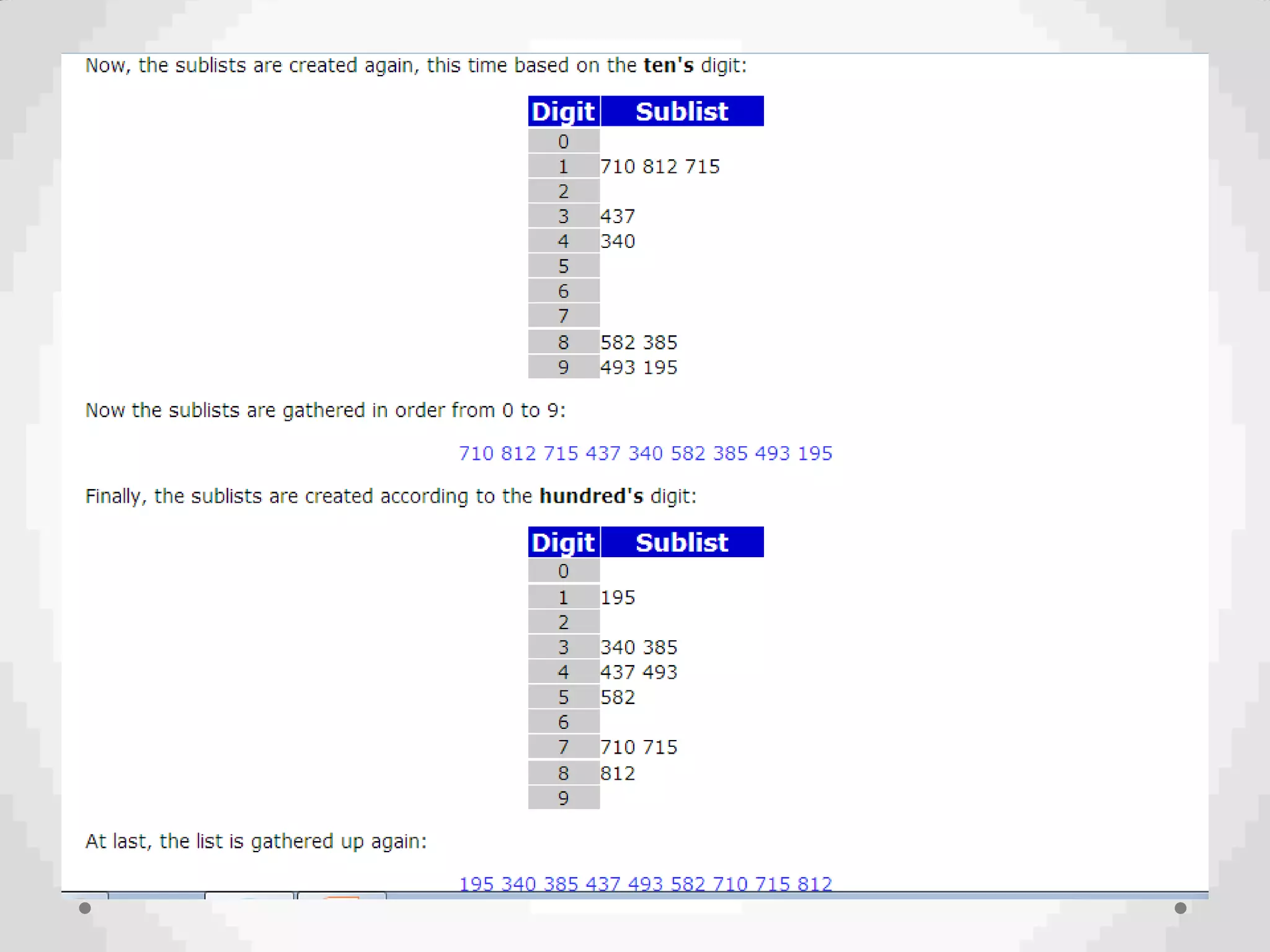















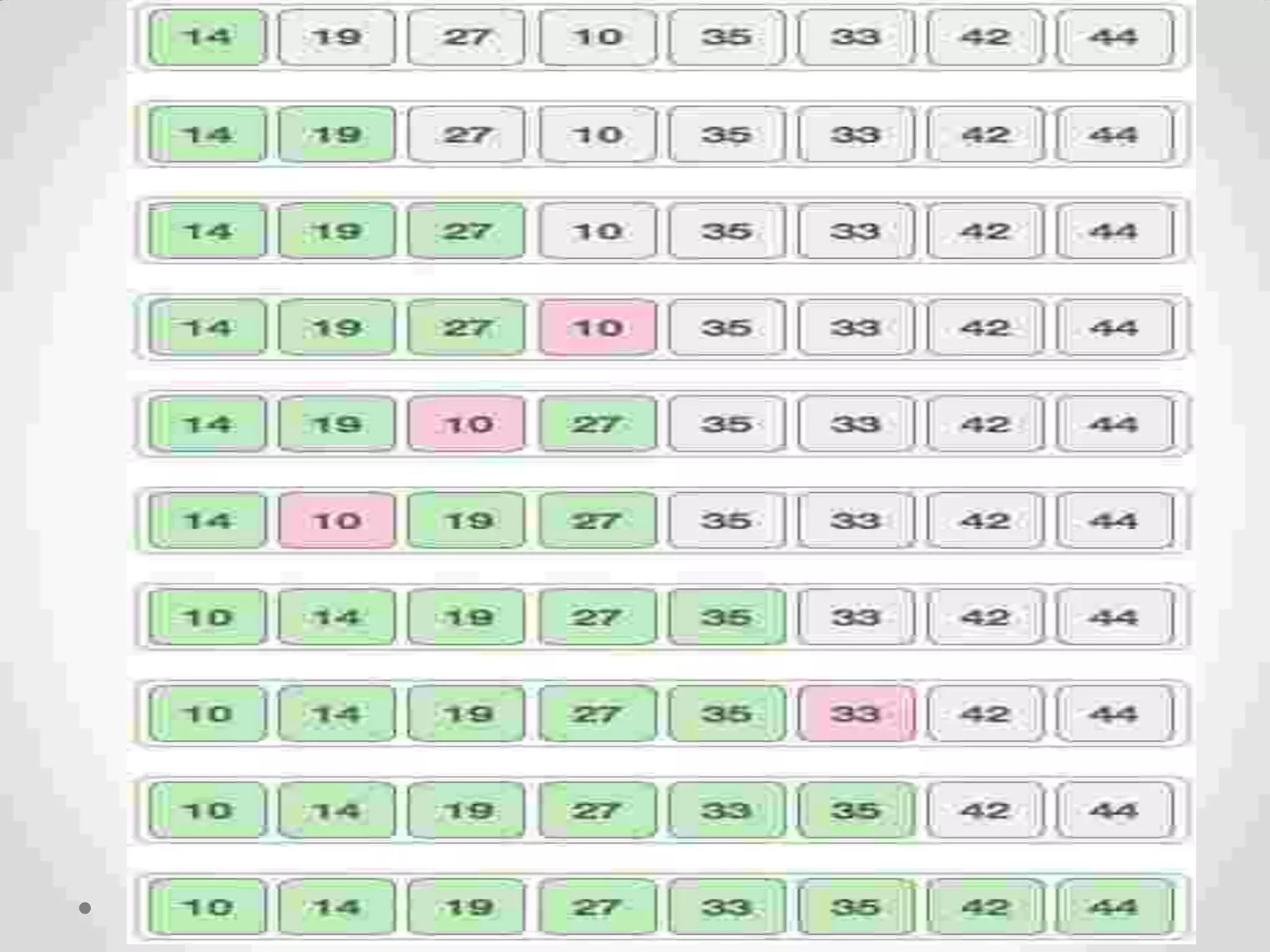
This document discusses various searching and sorting algorithms. It begins by defining searching as finding an element in a given list. Linear search and binary search are described as two common searching algorithms. Linear search has O(n) time complexity while binary search has O(log n) time complexity but requires a sorted list. The document also discusses different sorting algorithms like bubble sort, insertion sort, and merge sort, and defines key concepts related to sorting like stability, efficiency, and passes.
Introduction to searching and its importance in computer science. Techniques like linear, binary, and sentinel search are discussed.
Detailed explanation of linear search, its advantages (easy implementation, O(n) time complexity), and disadvantages (inefficiency with large lists).
An introduction to binary search, suitable for sorted lists. It discusses concepts, advantages (O(log n)), and disadvantages.
Contrasting linear and binary search regarding implementation complexity and efficiency.
Introduction to sentinel and Fibonacci search techniques, including their mechanisms and efficiencies.
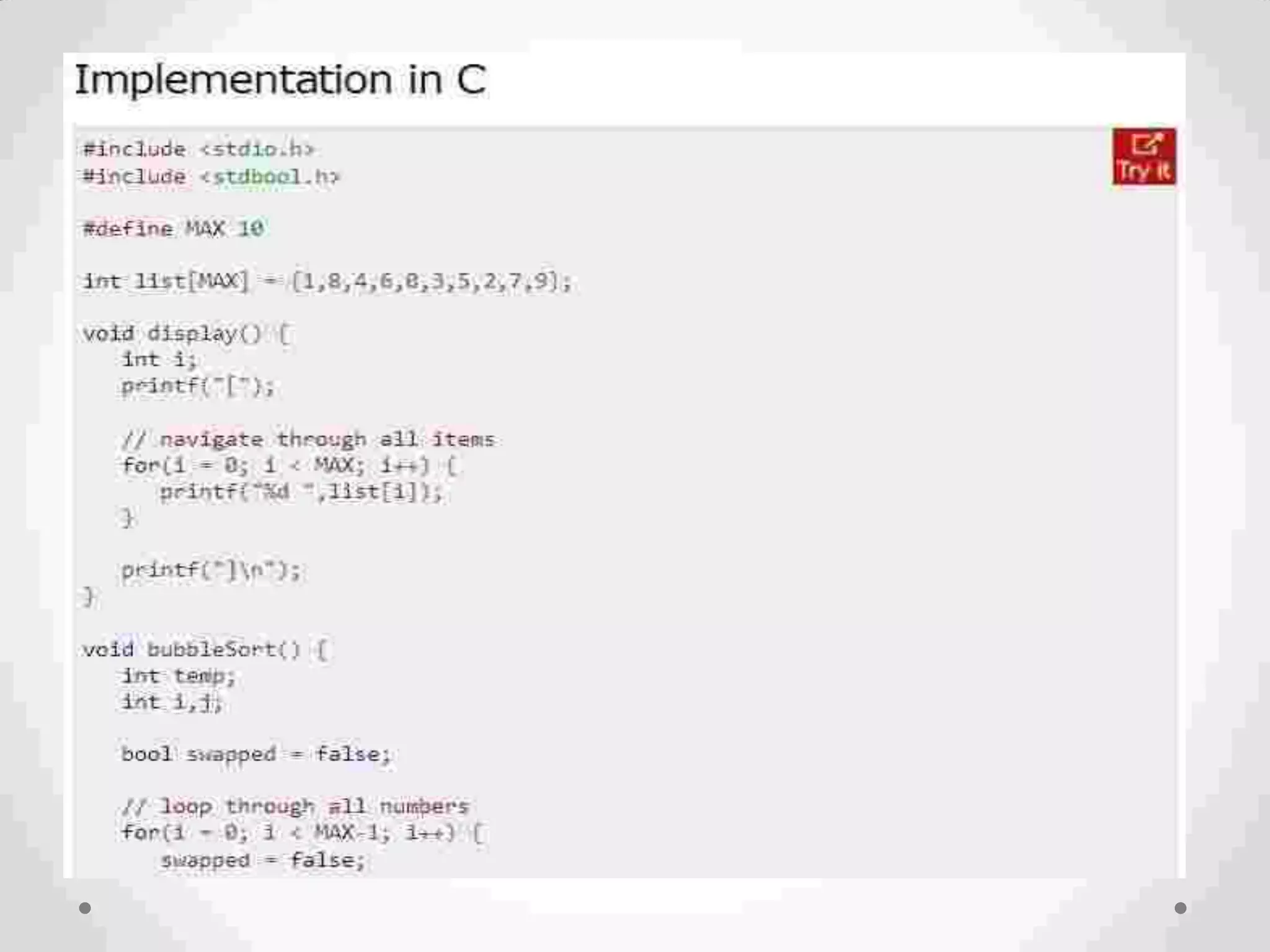
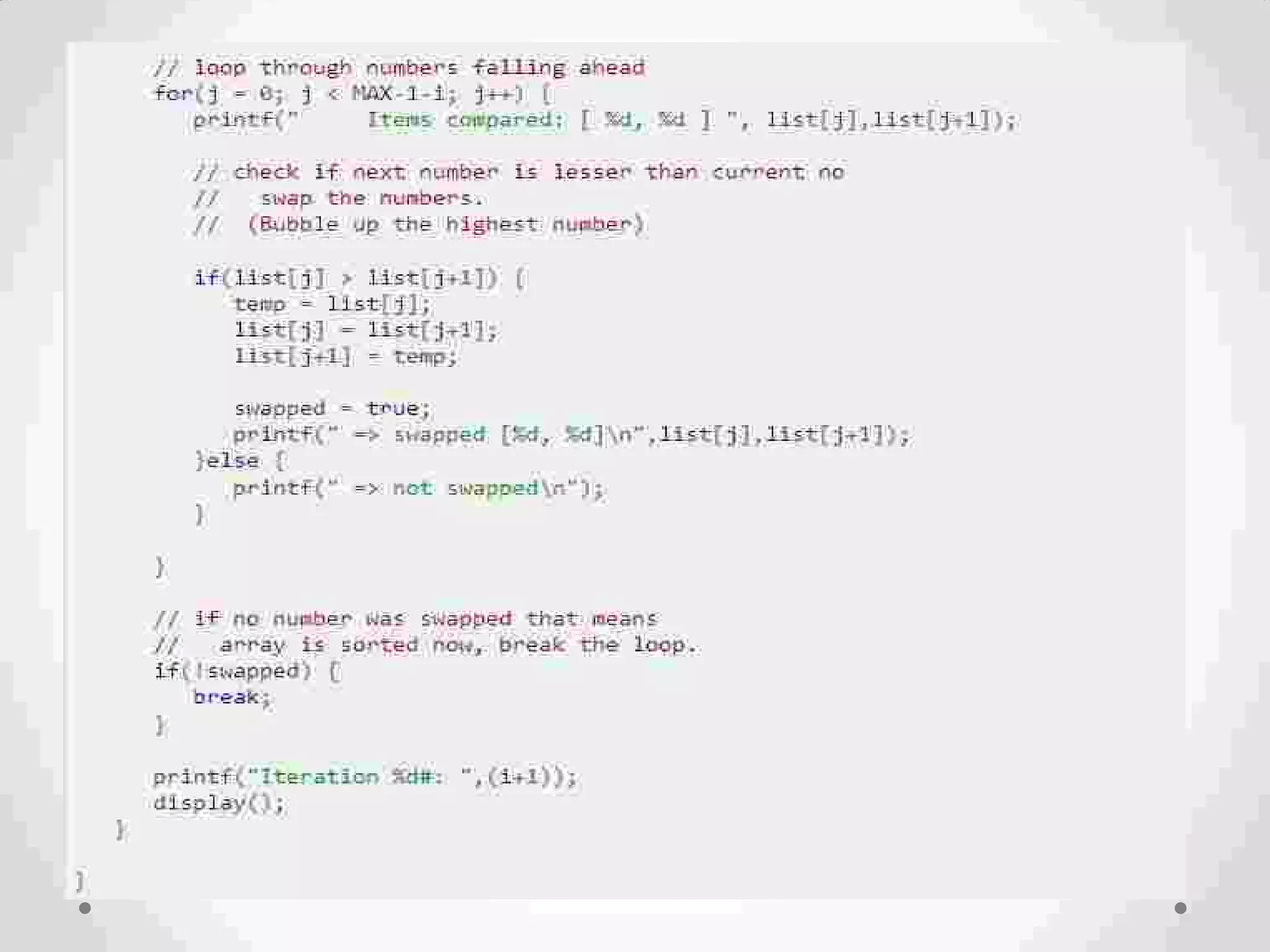
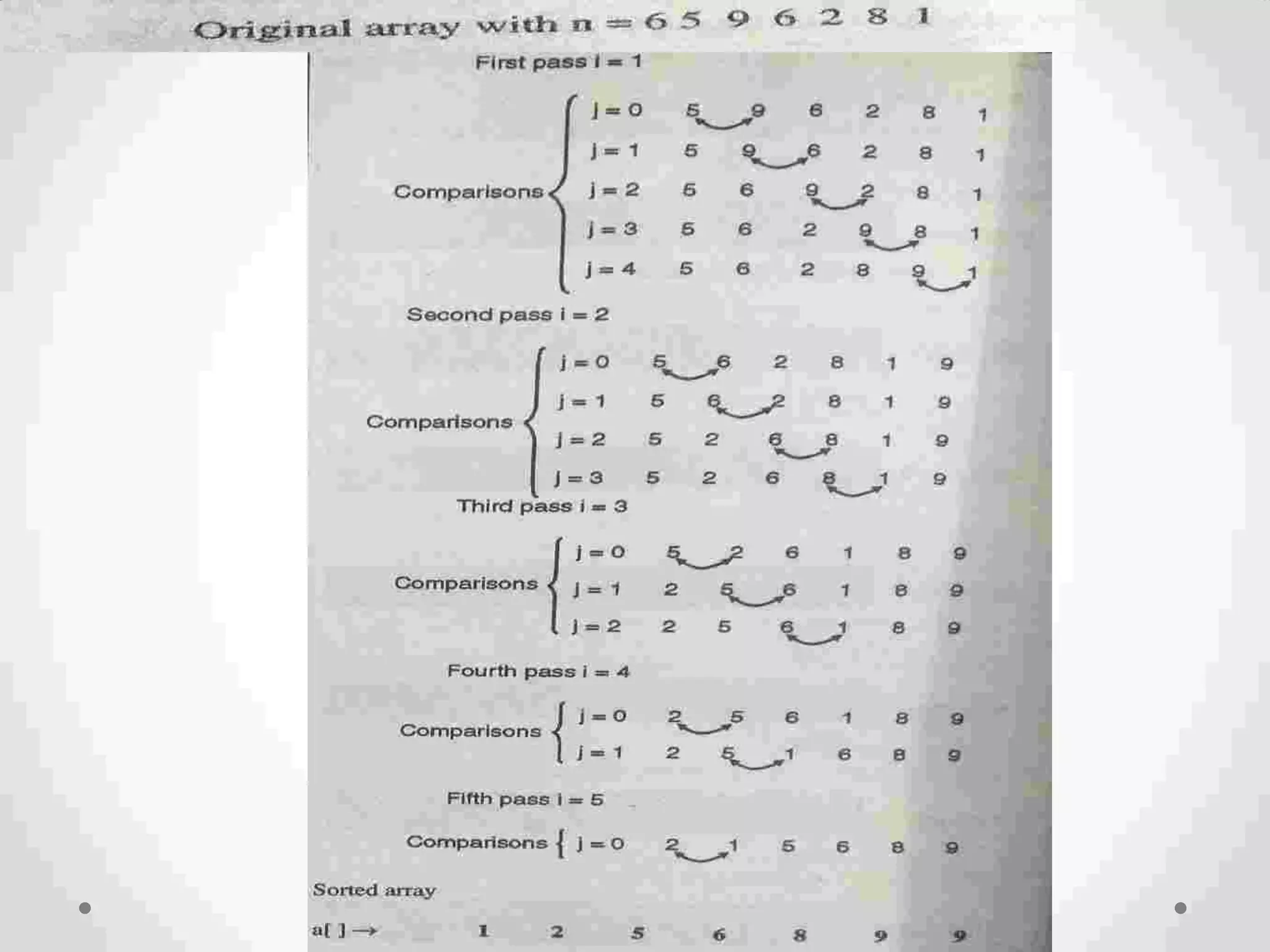
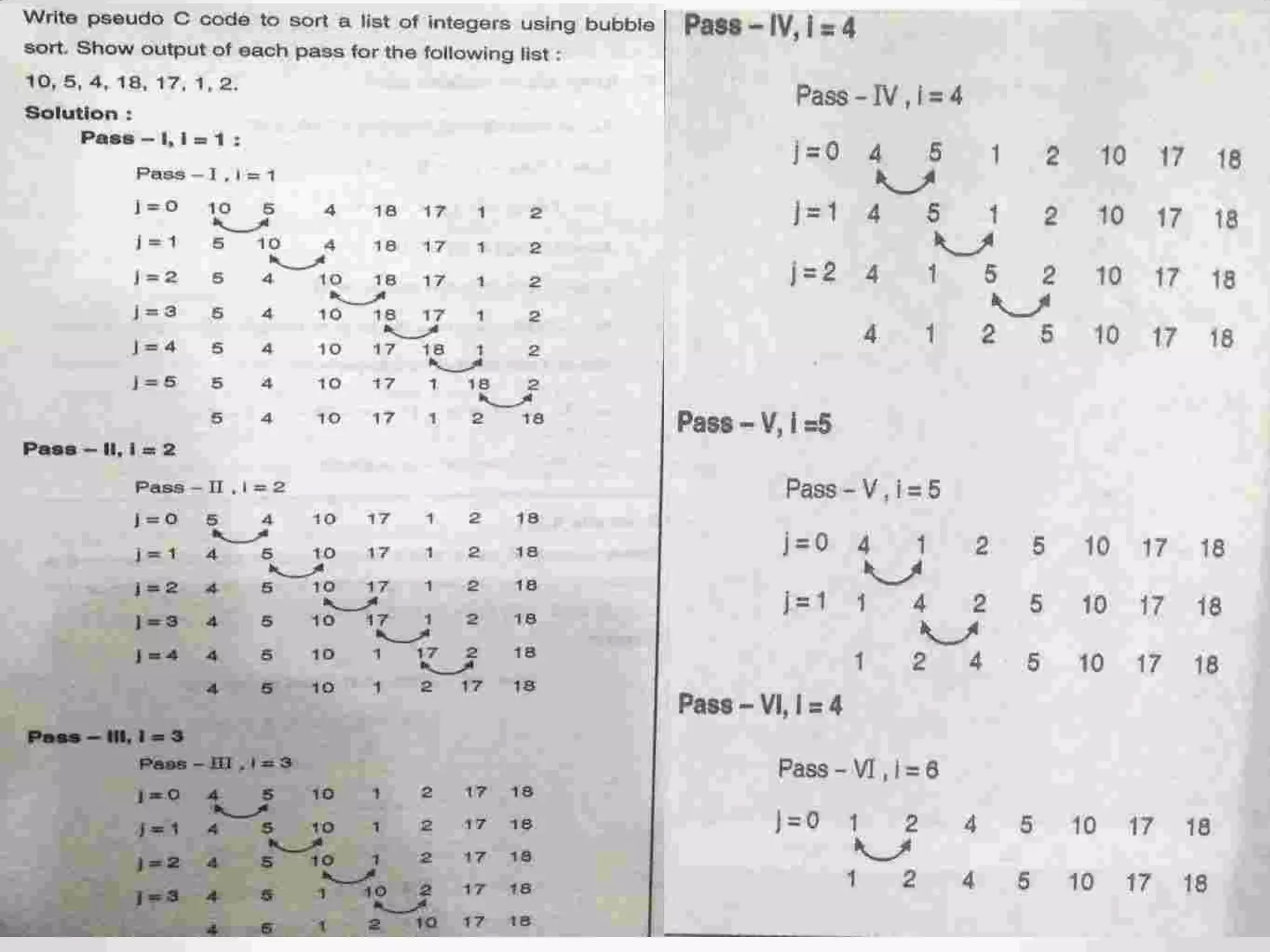
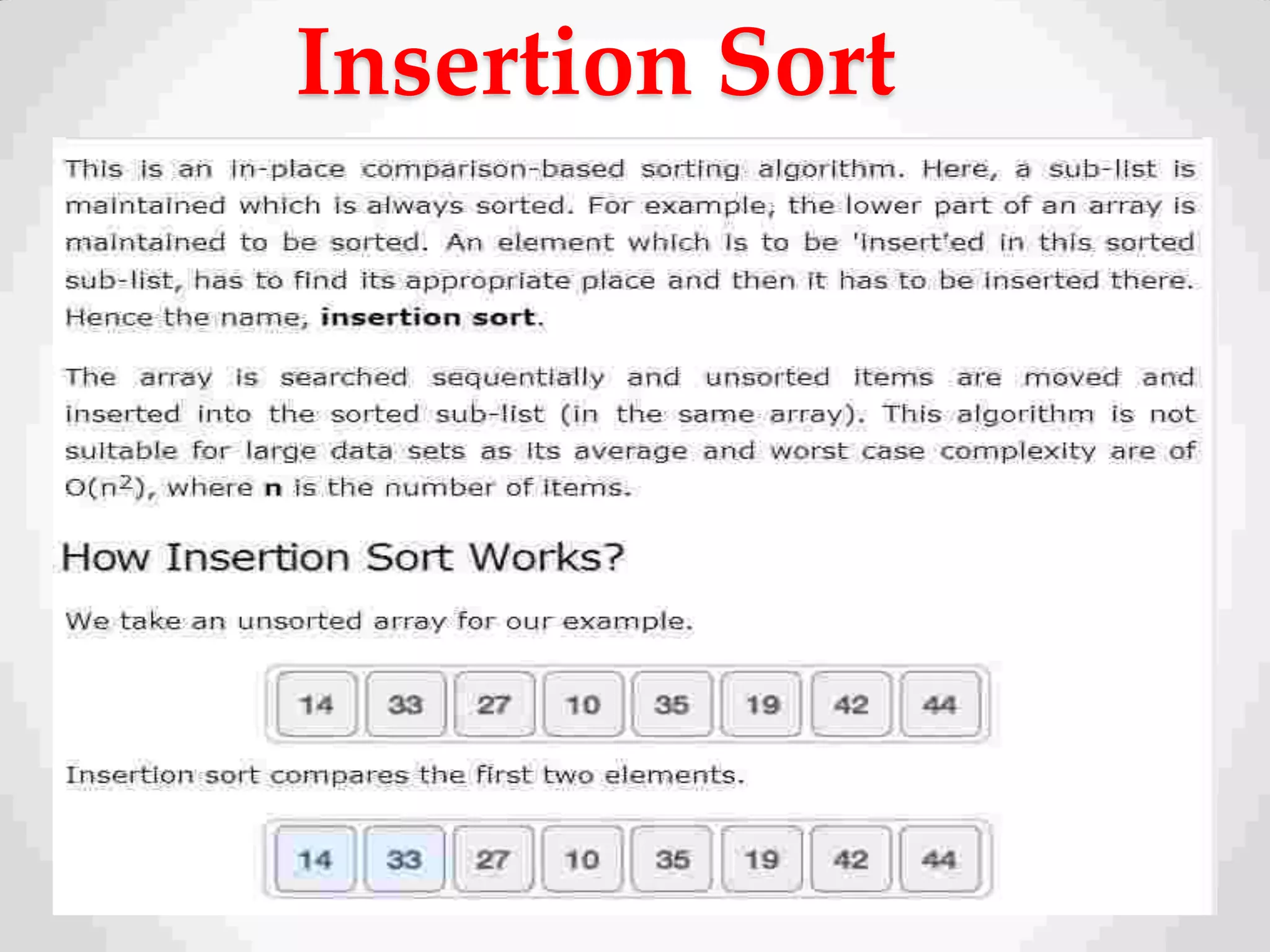
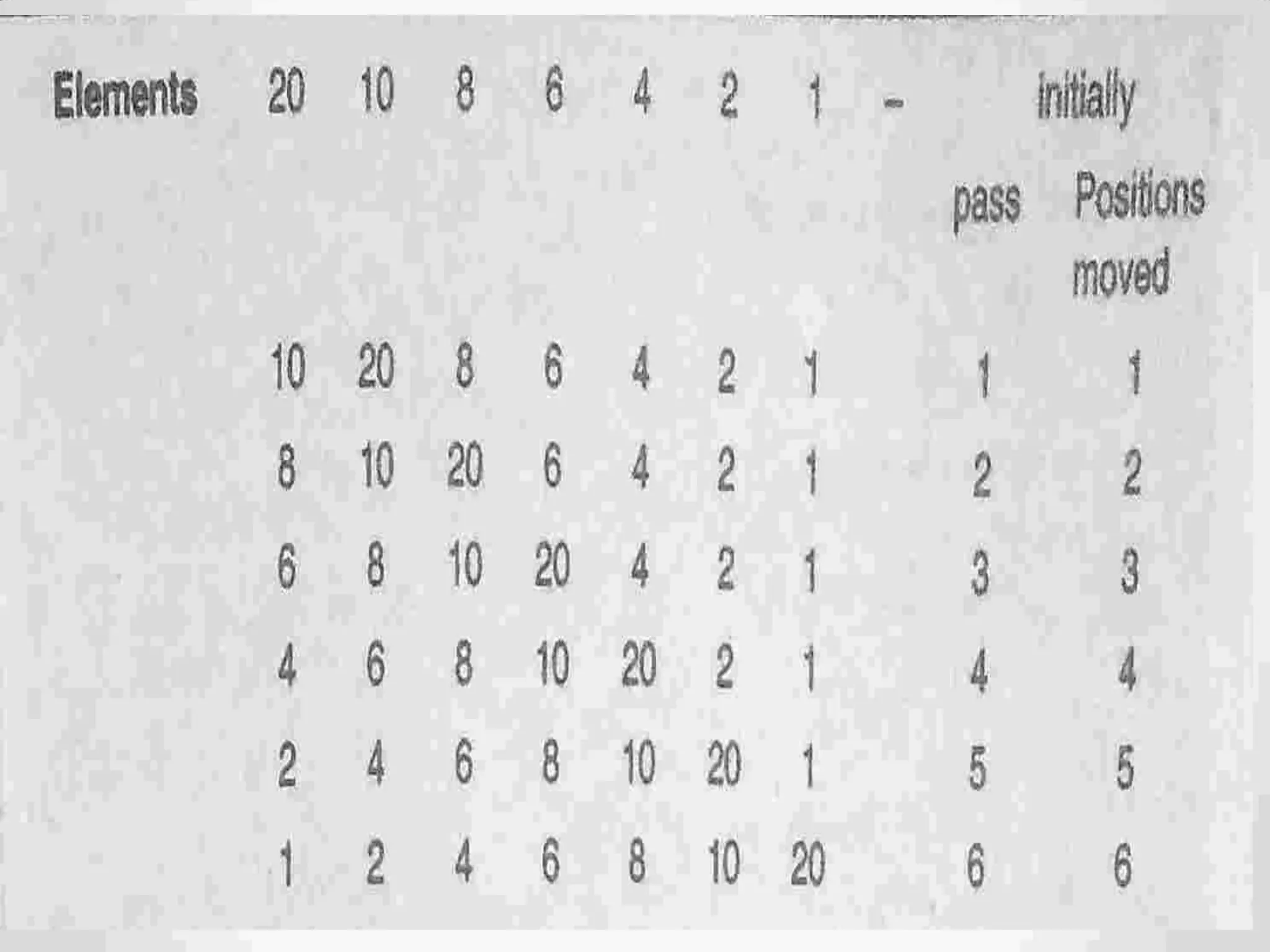
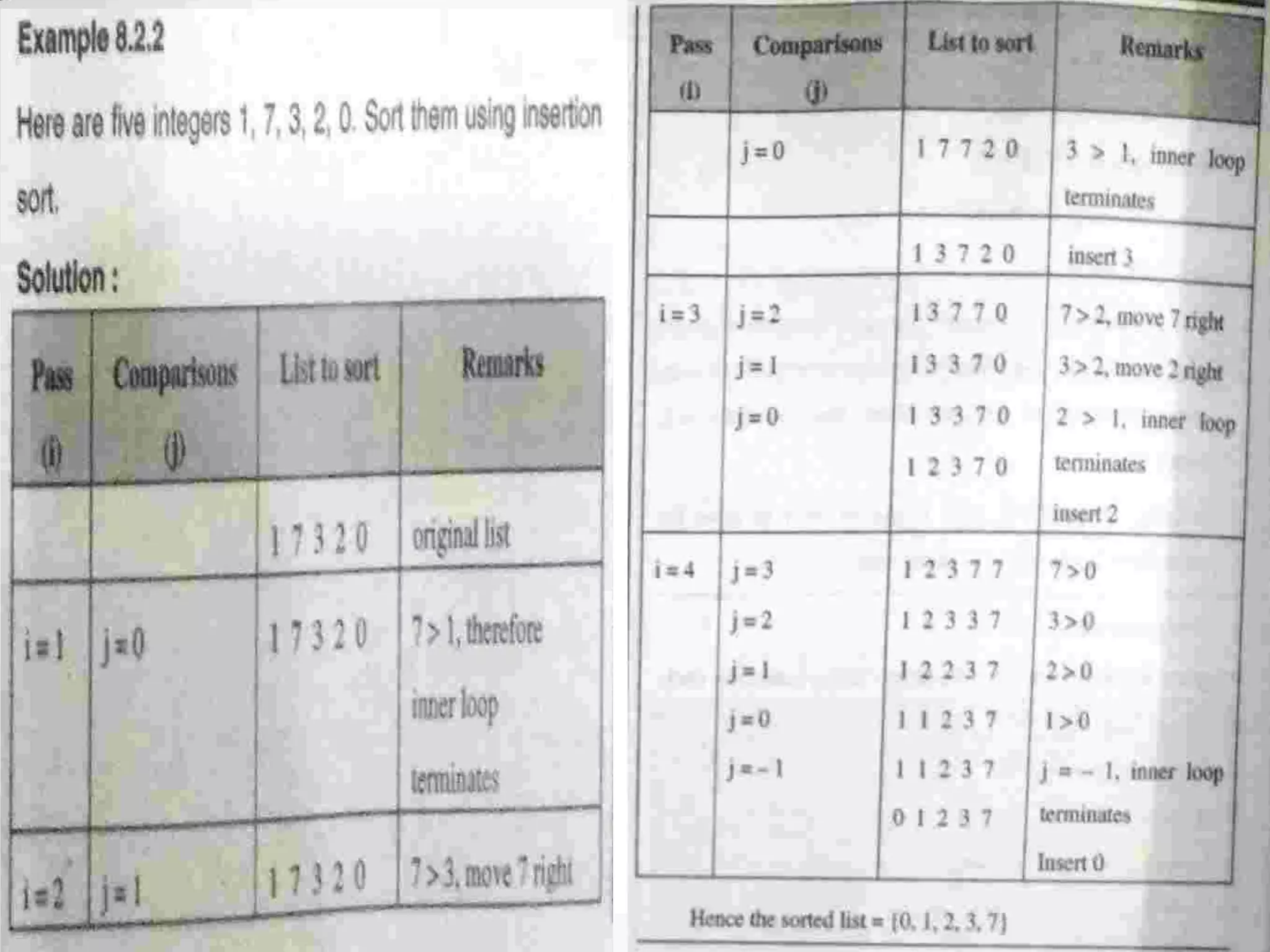
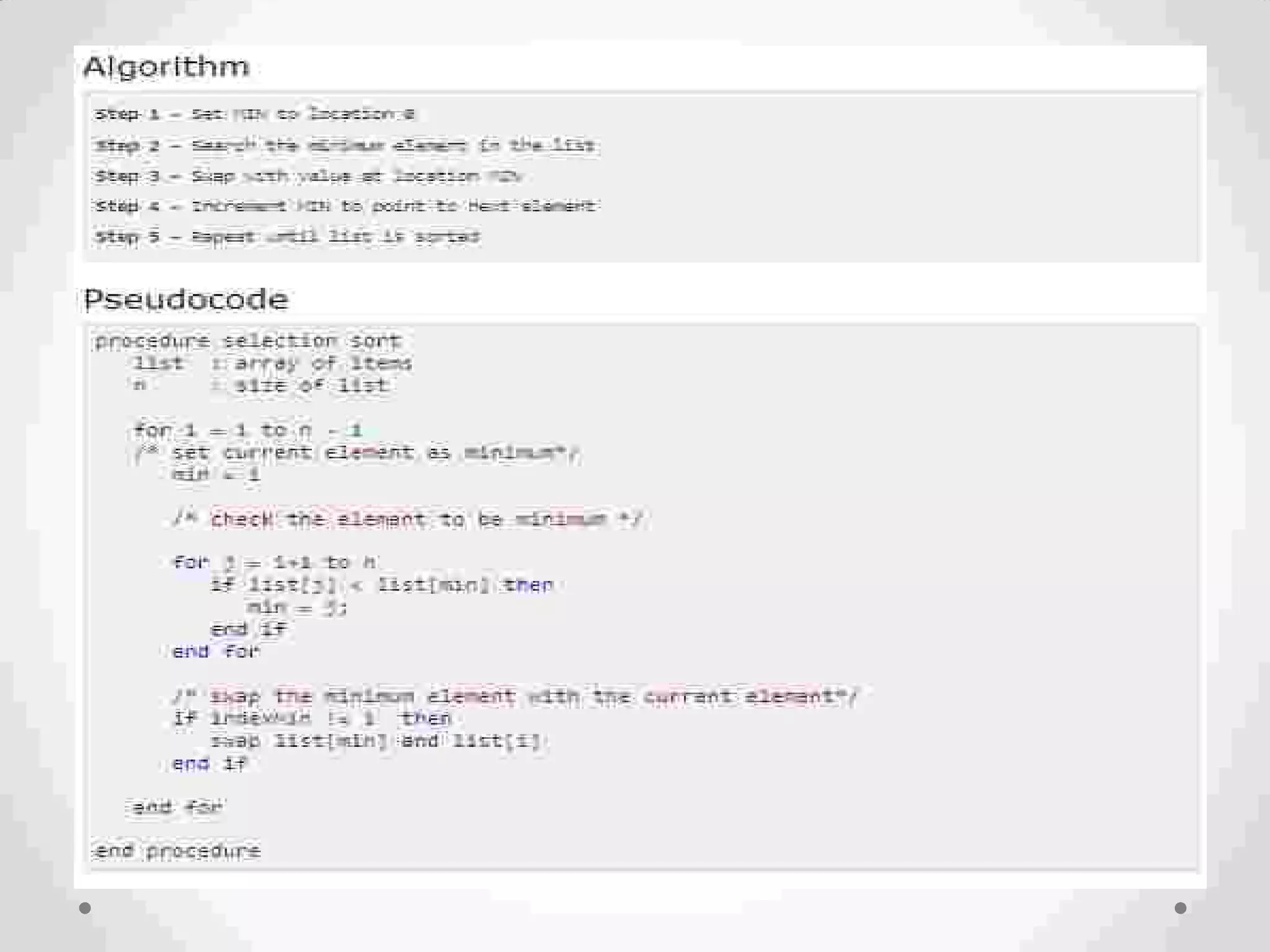
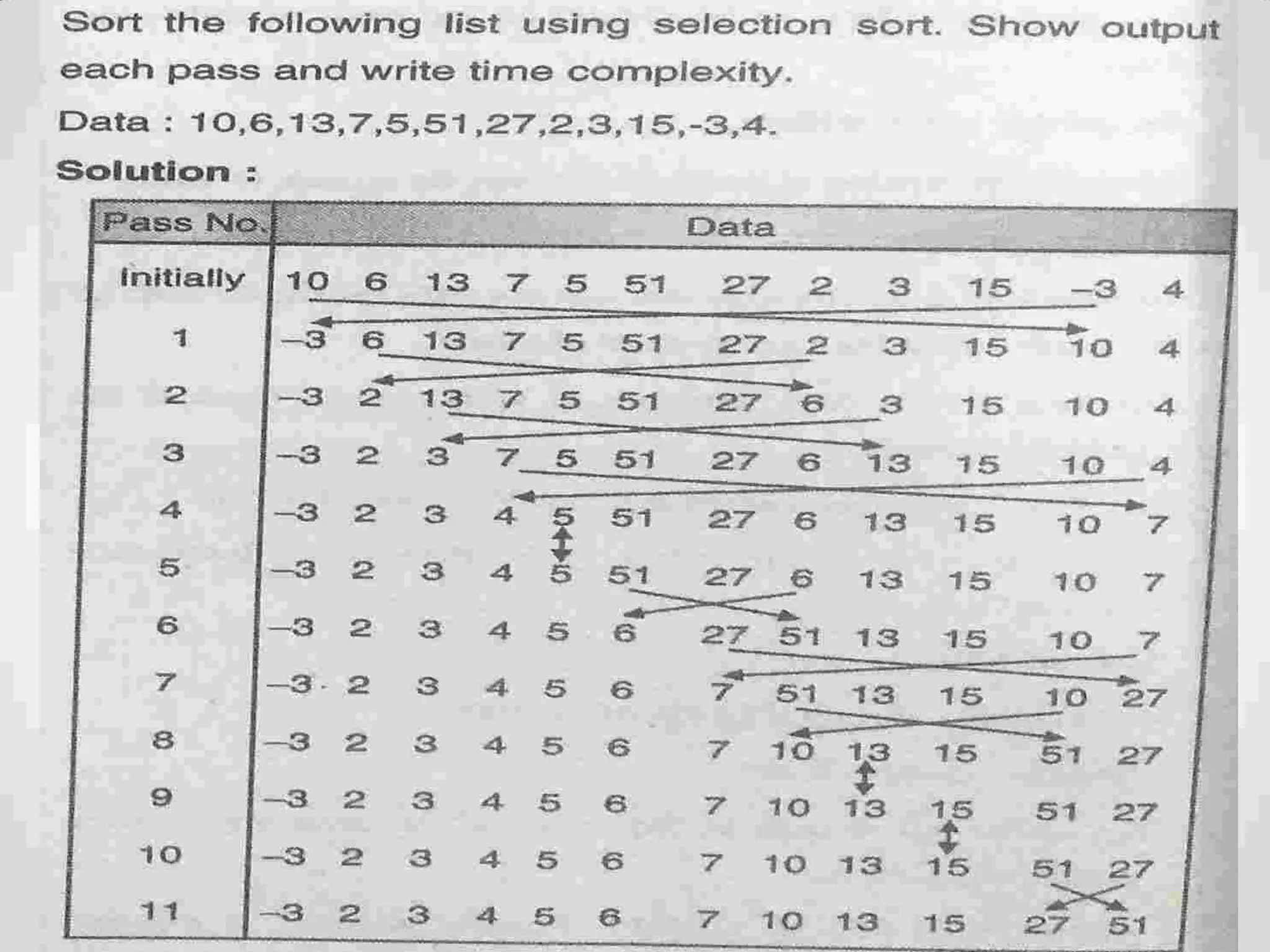
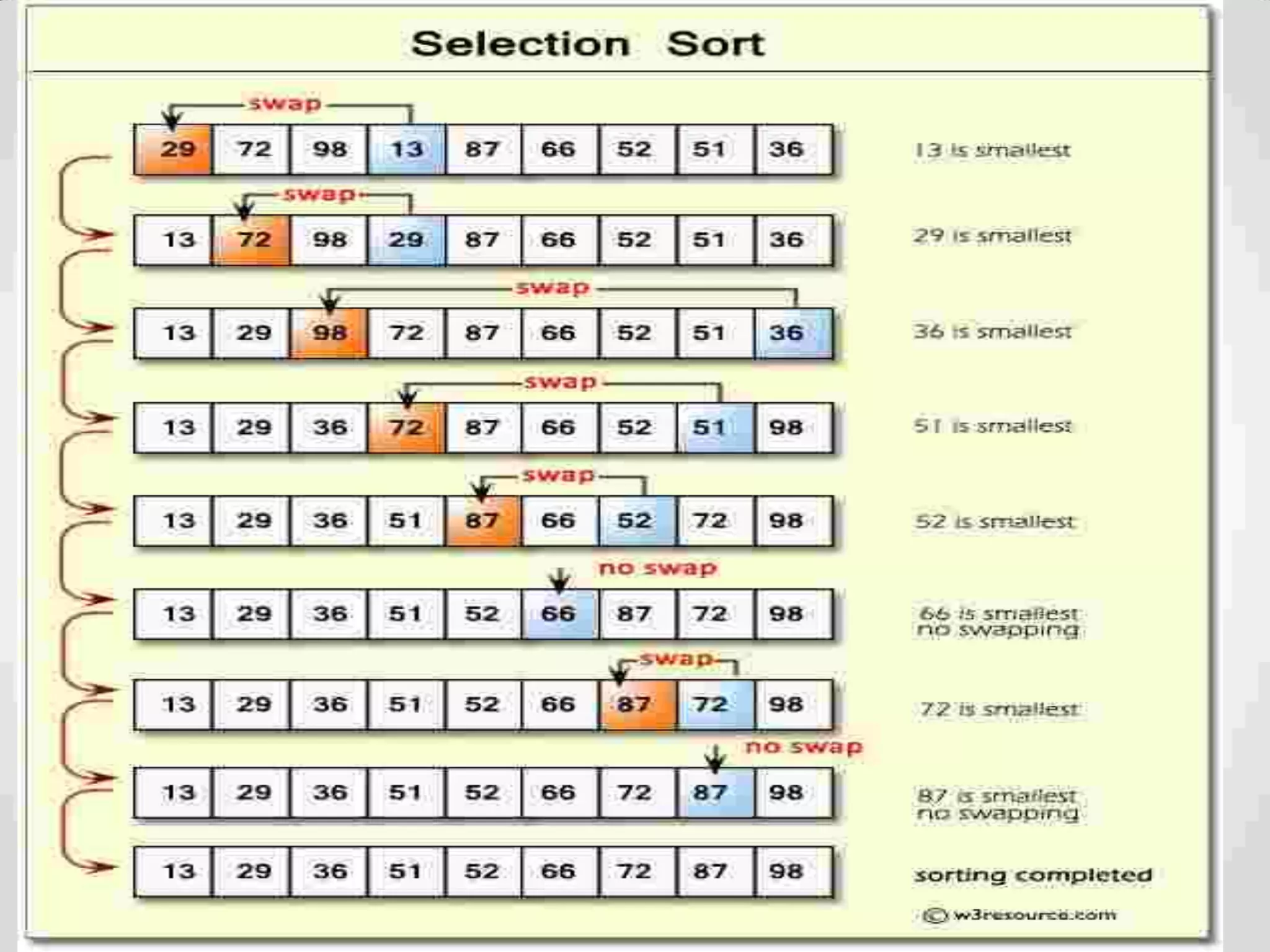
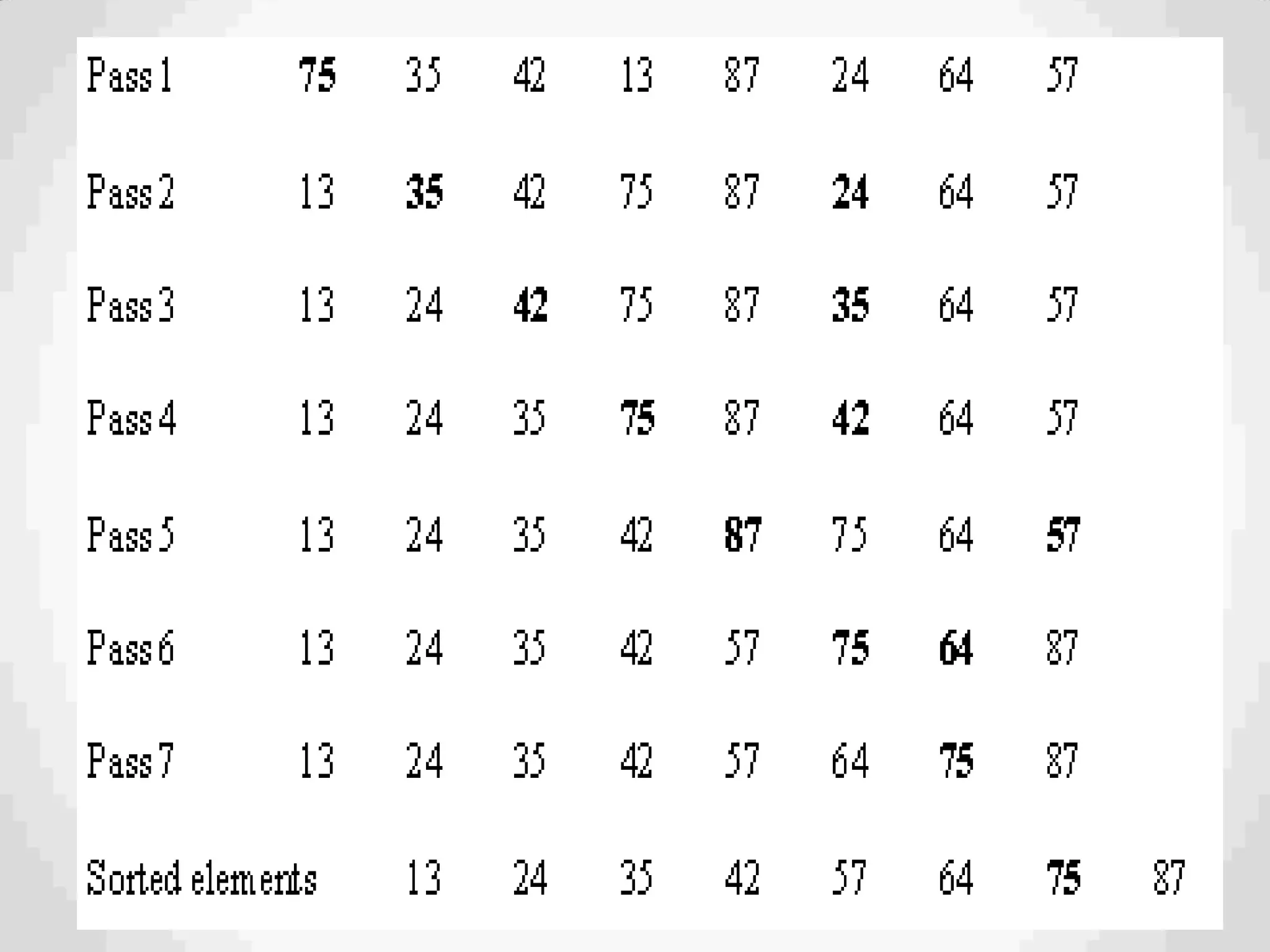
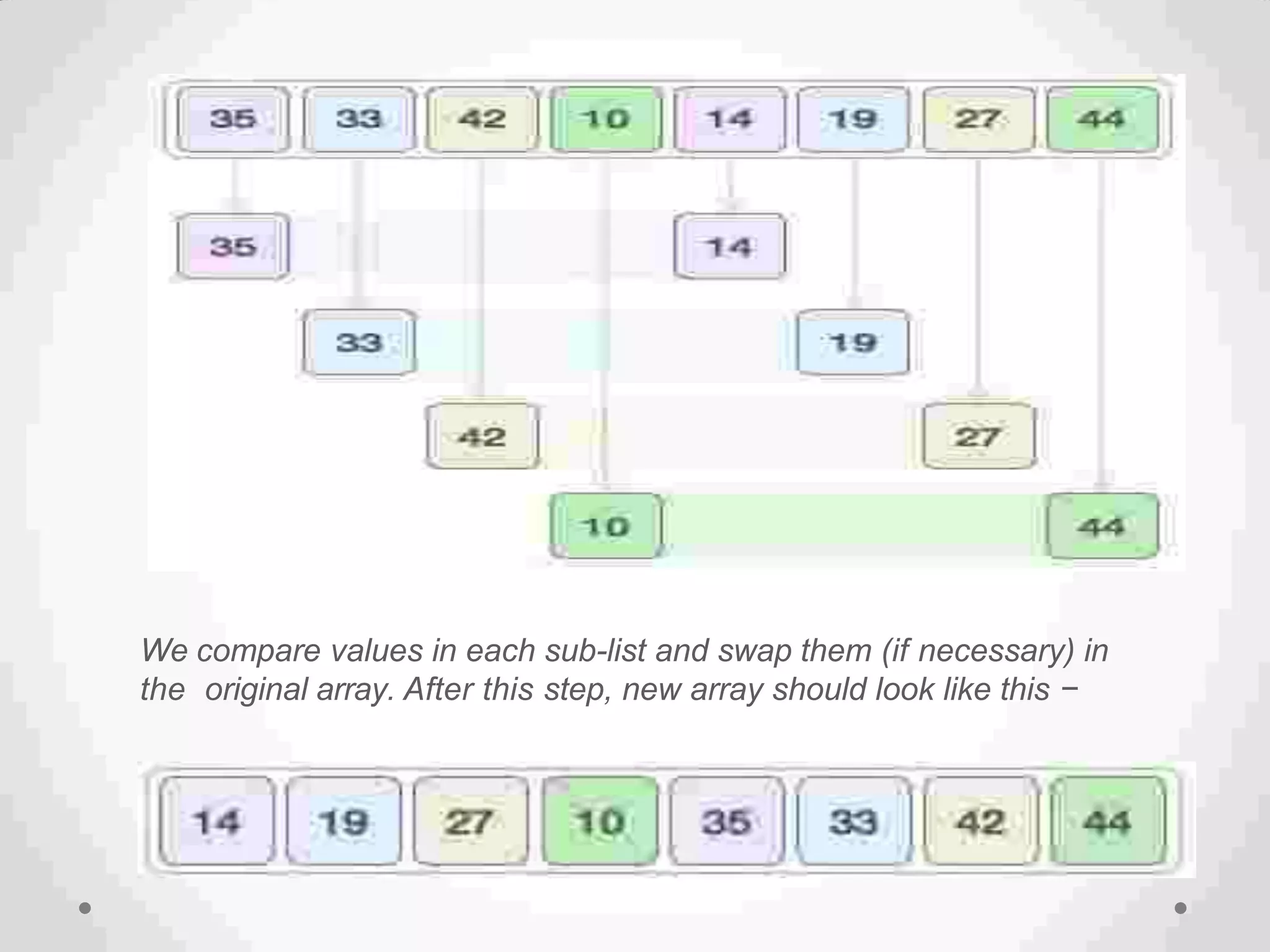
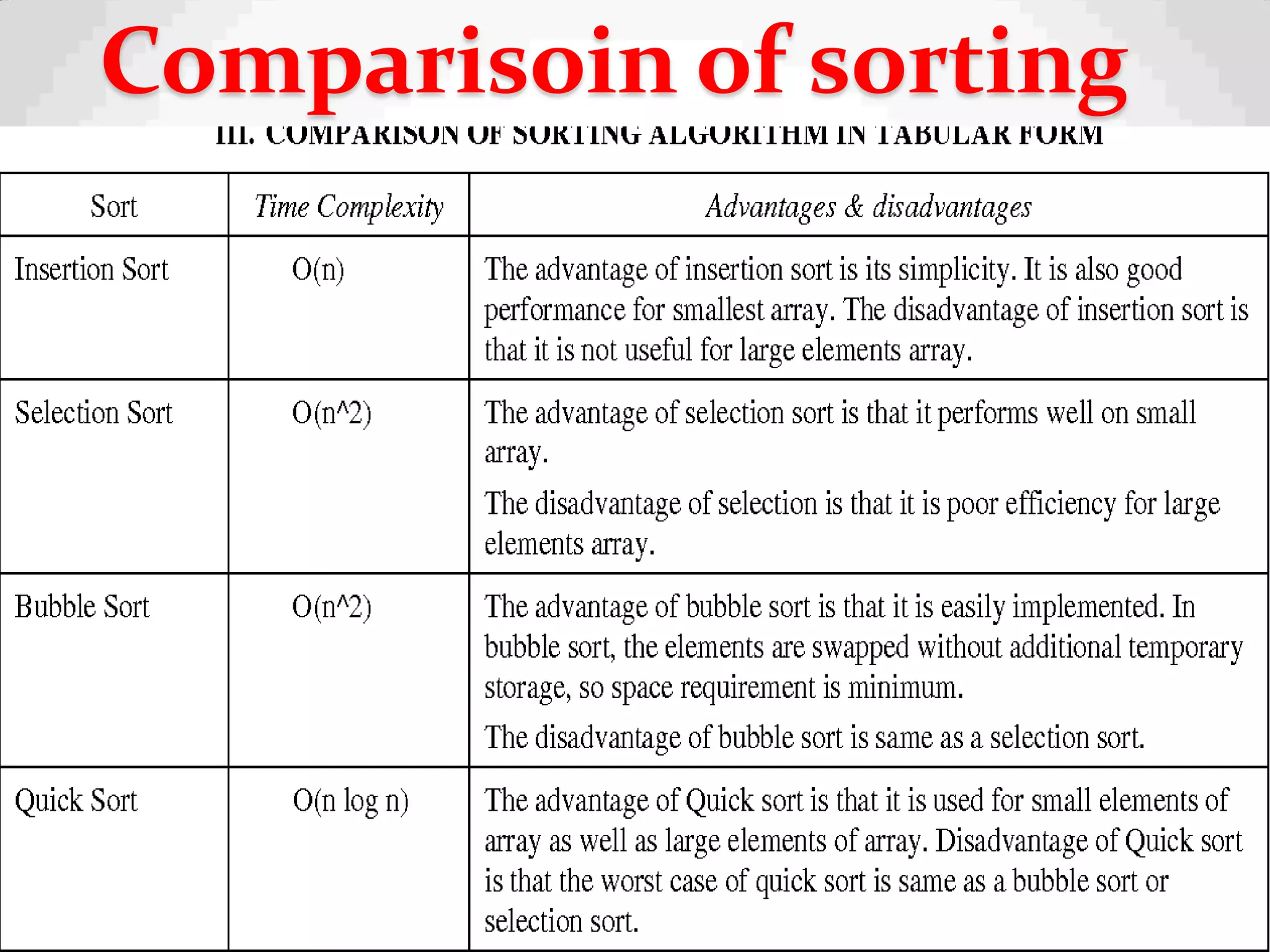
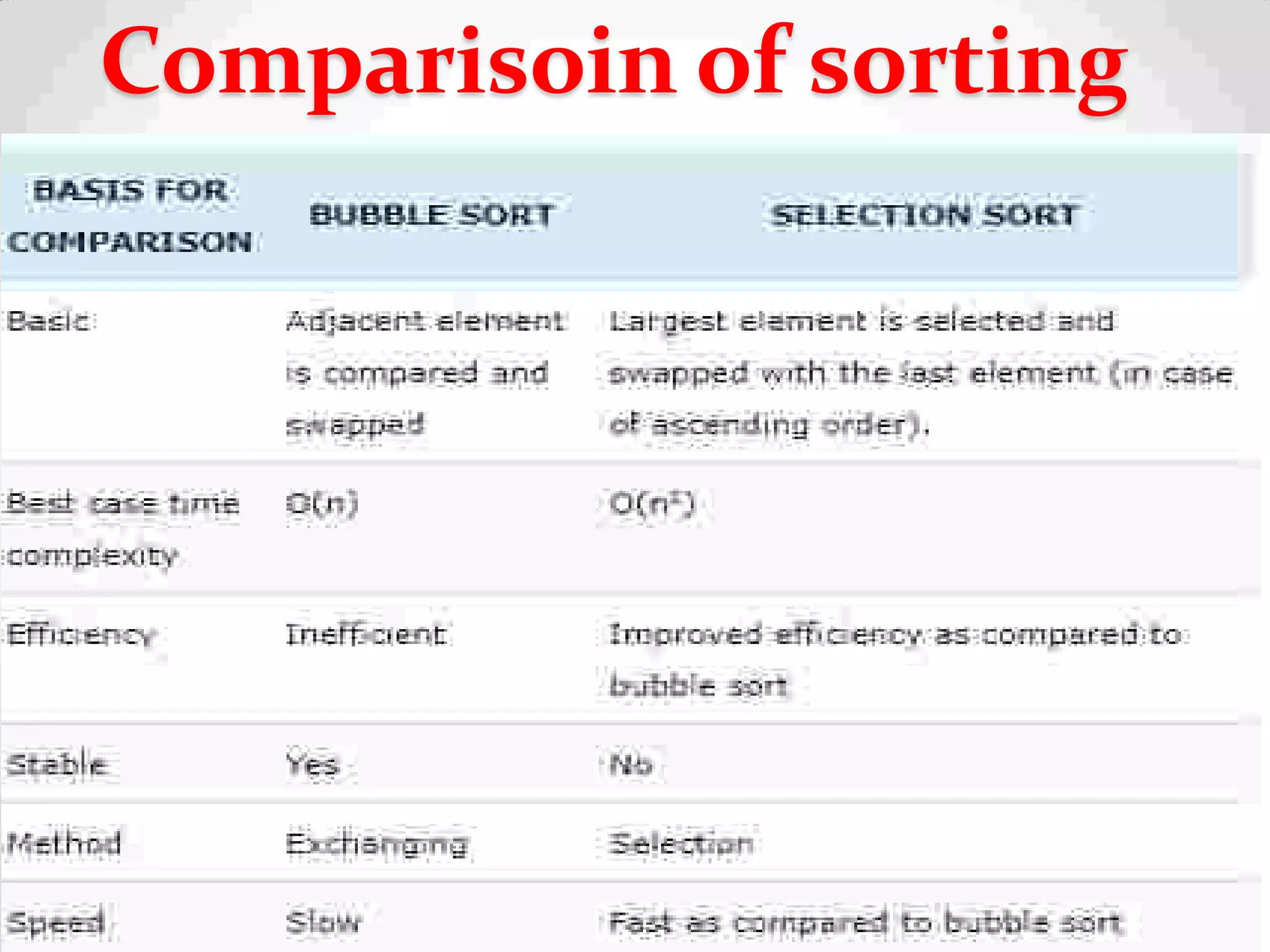
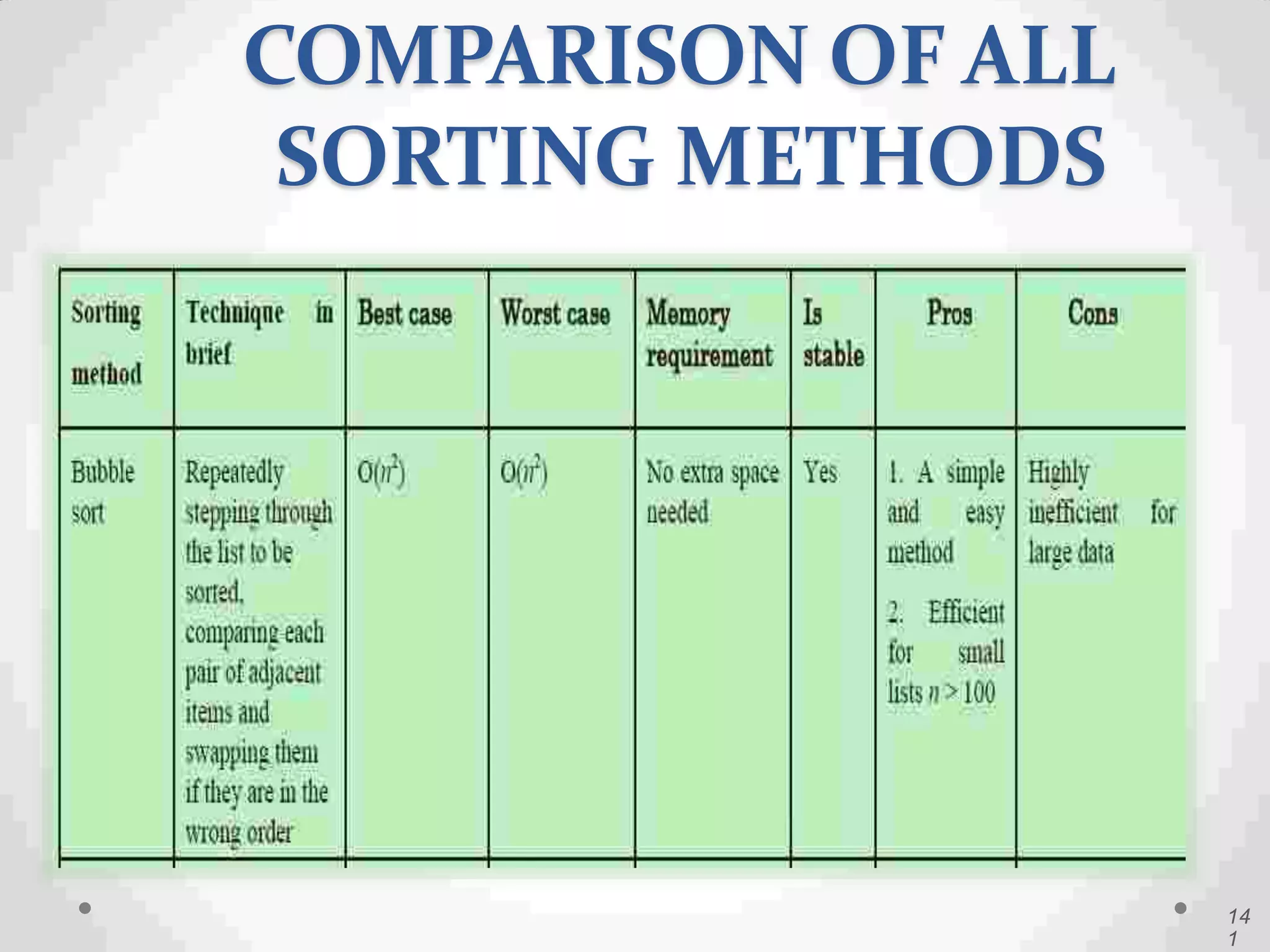
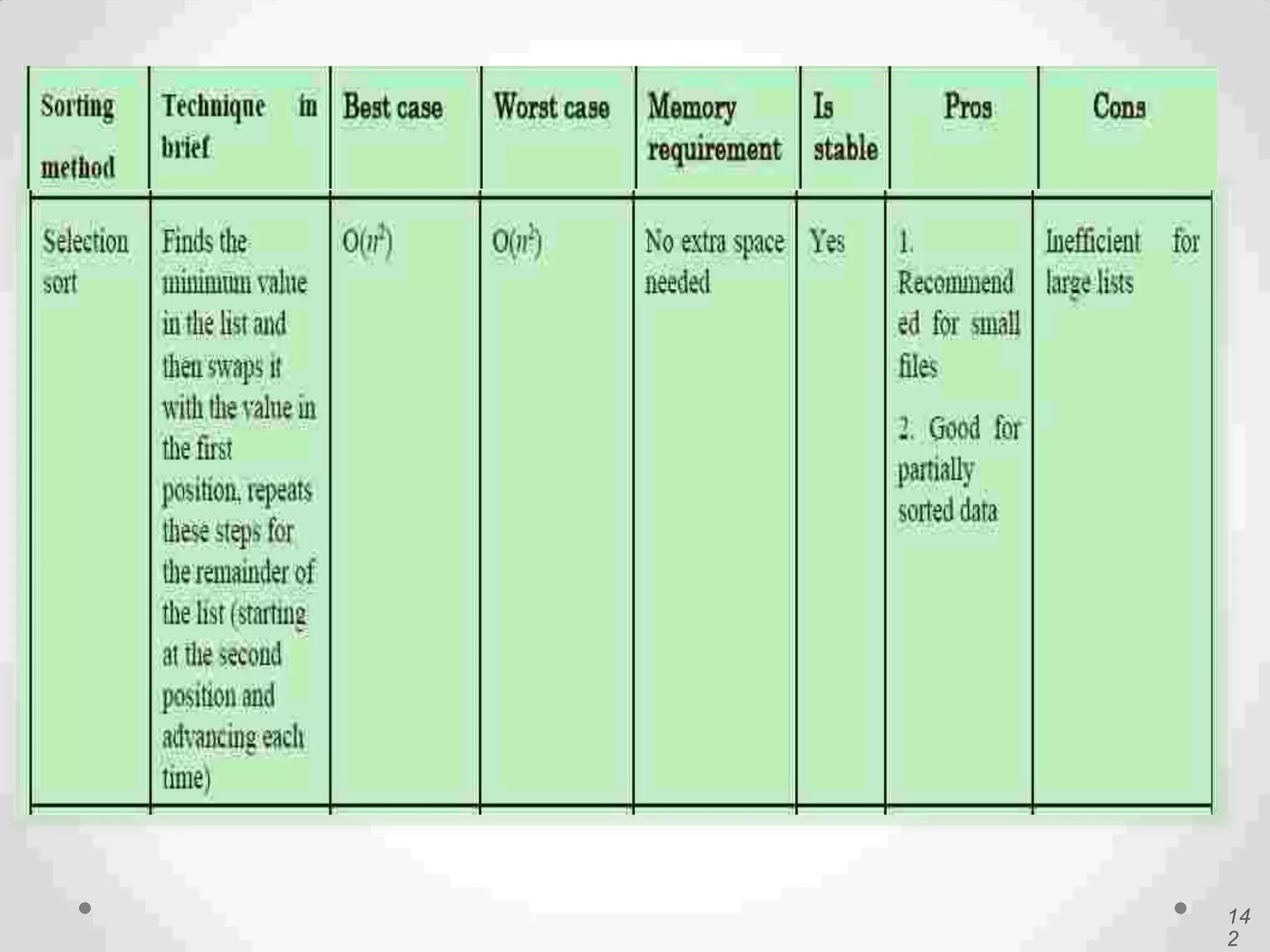
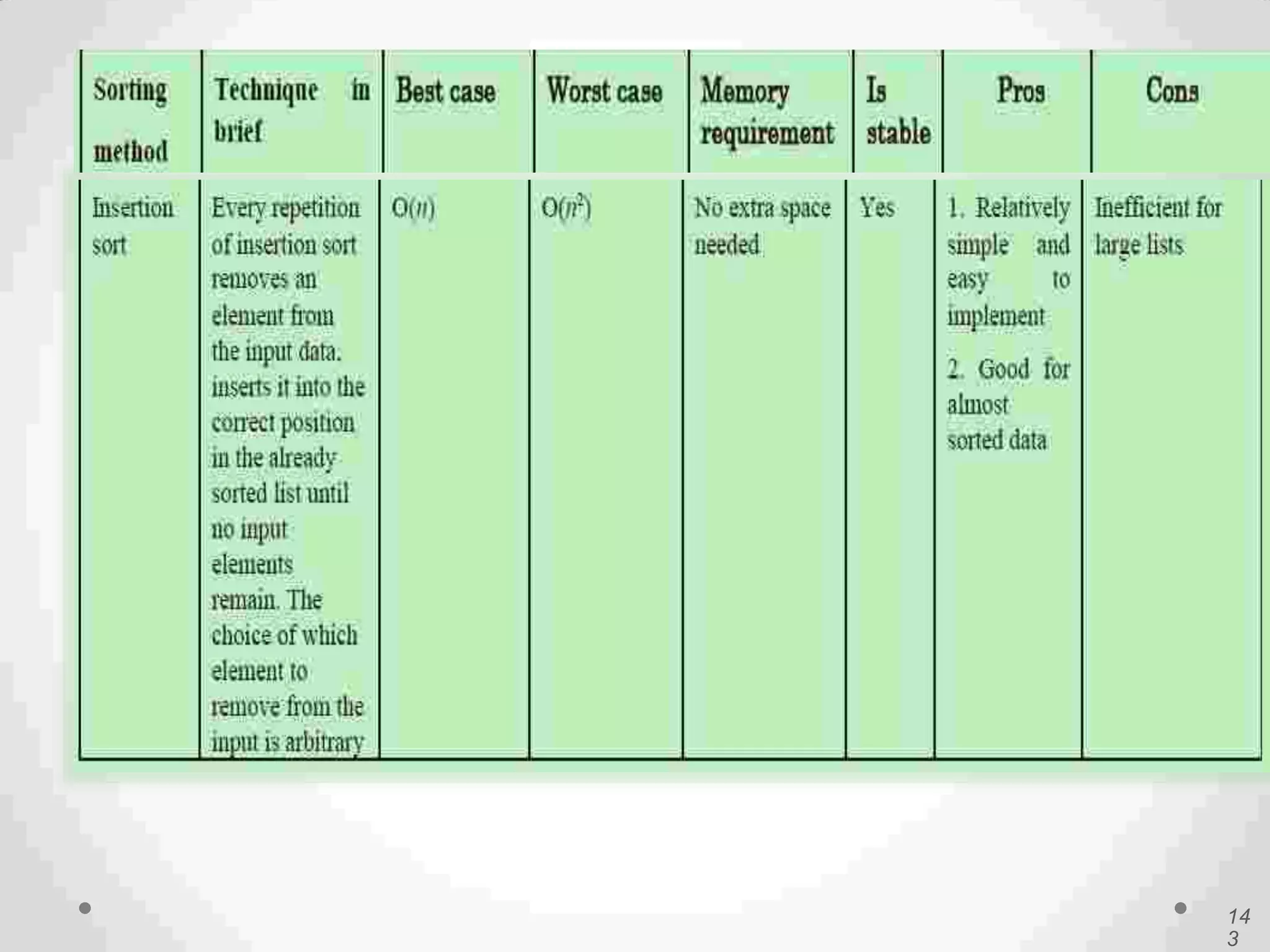
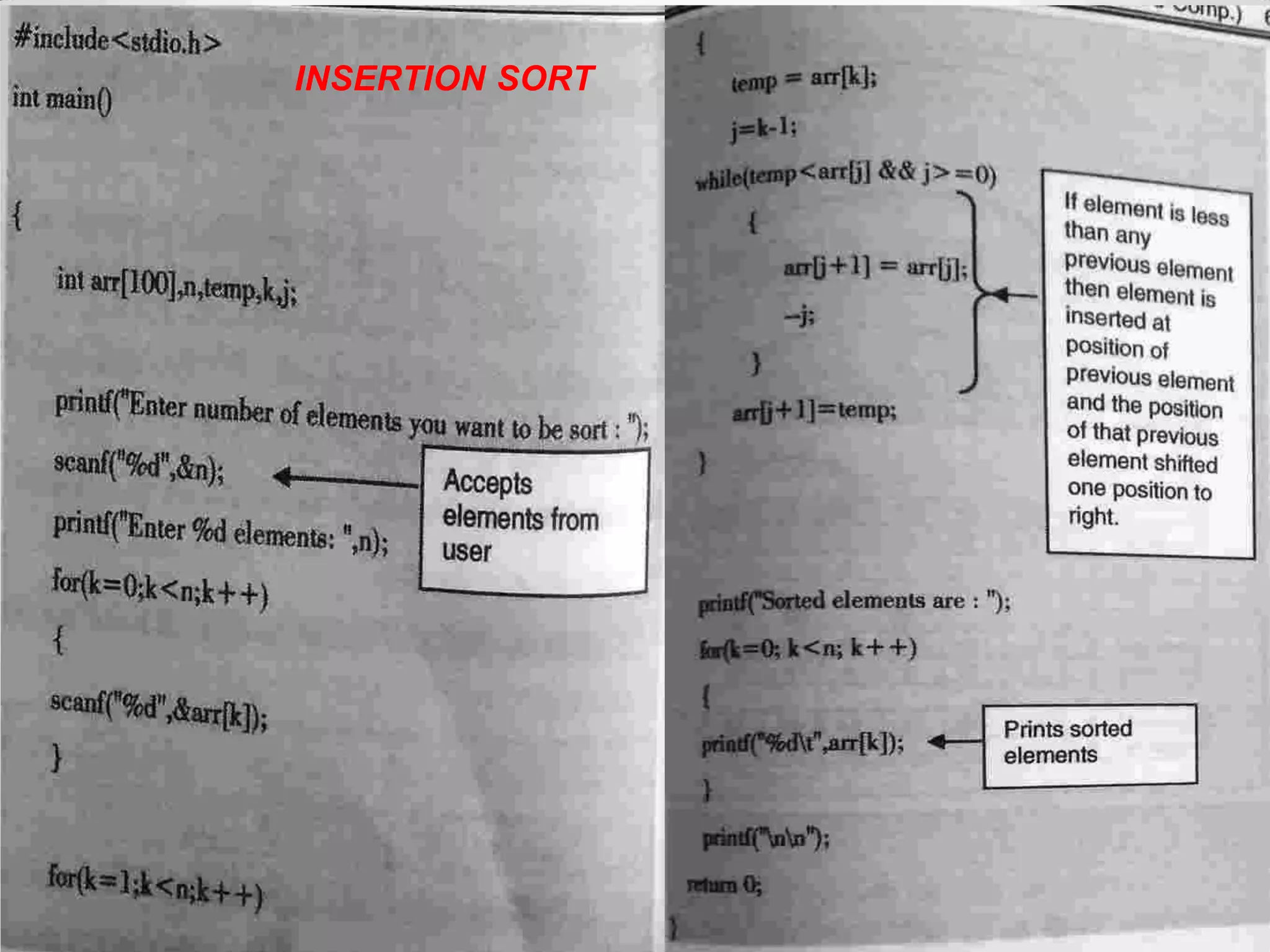
Definition of sorting, importance, internal vs. external sorting algorithms, and sorting efficiency considerations. Overview of internal sorting algorithms such as Bubble, Selection, and Insertion sort, including their efficiency and usage.
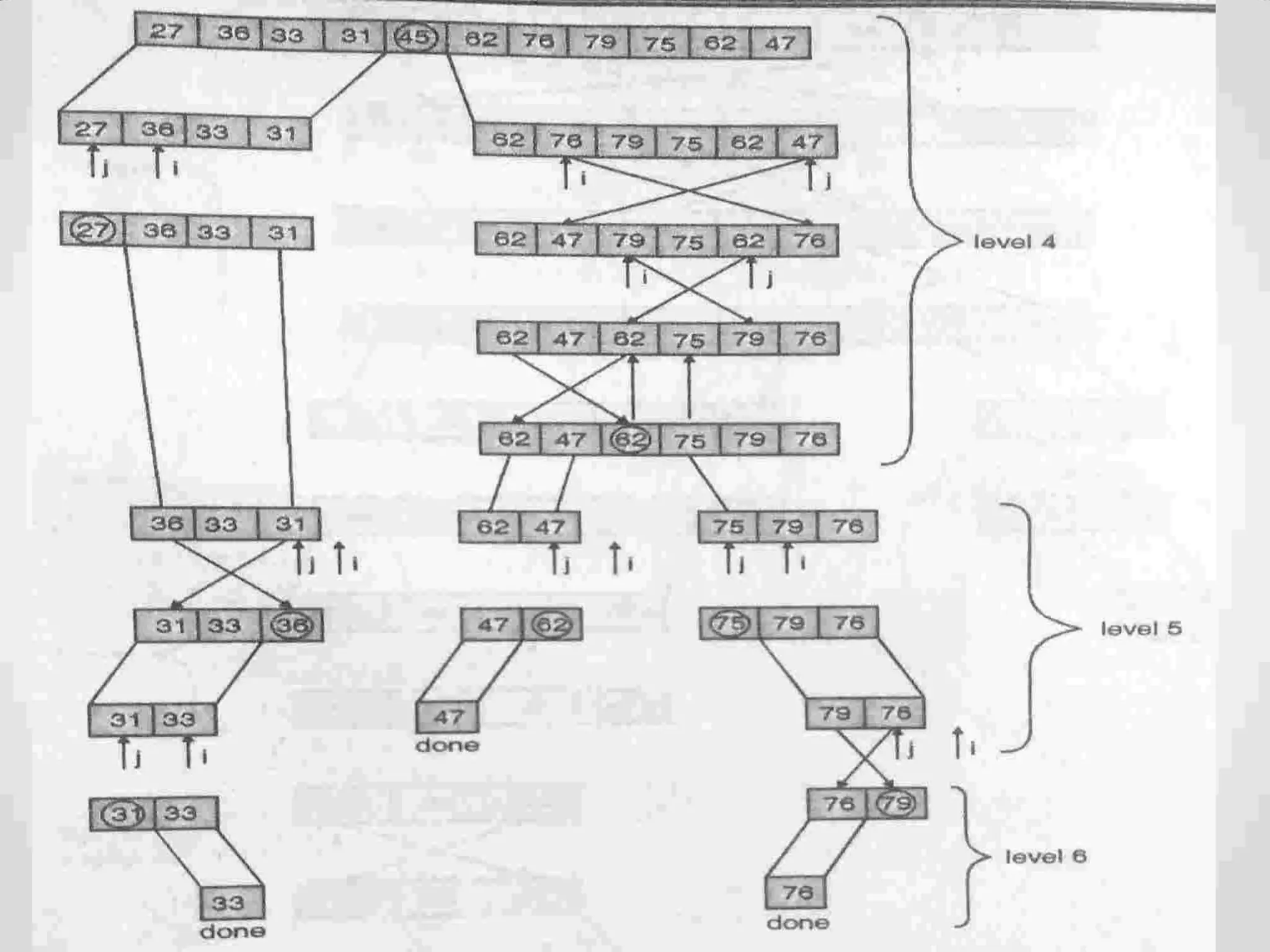
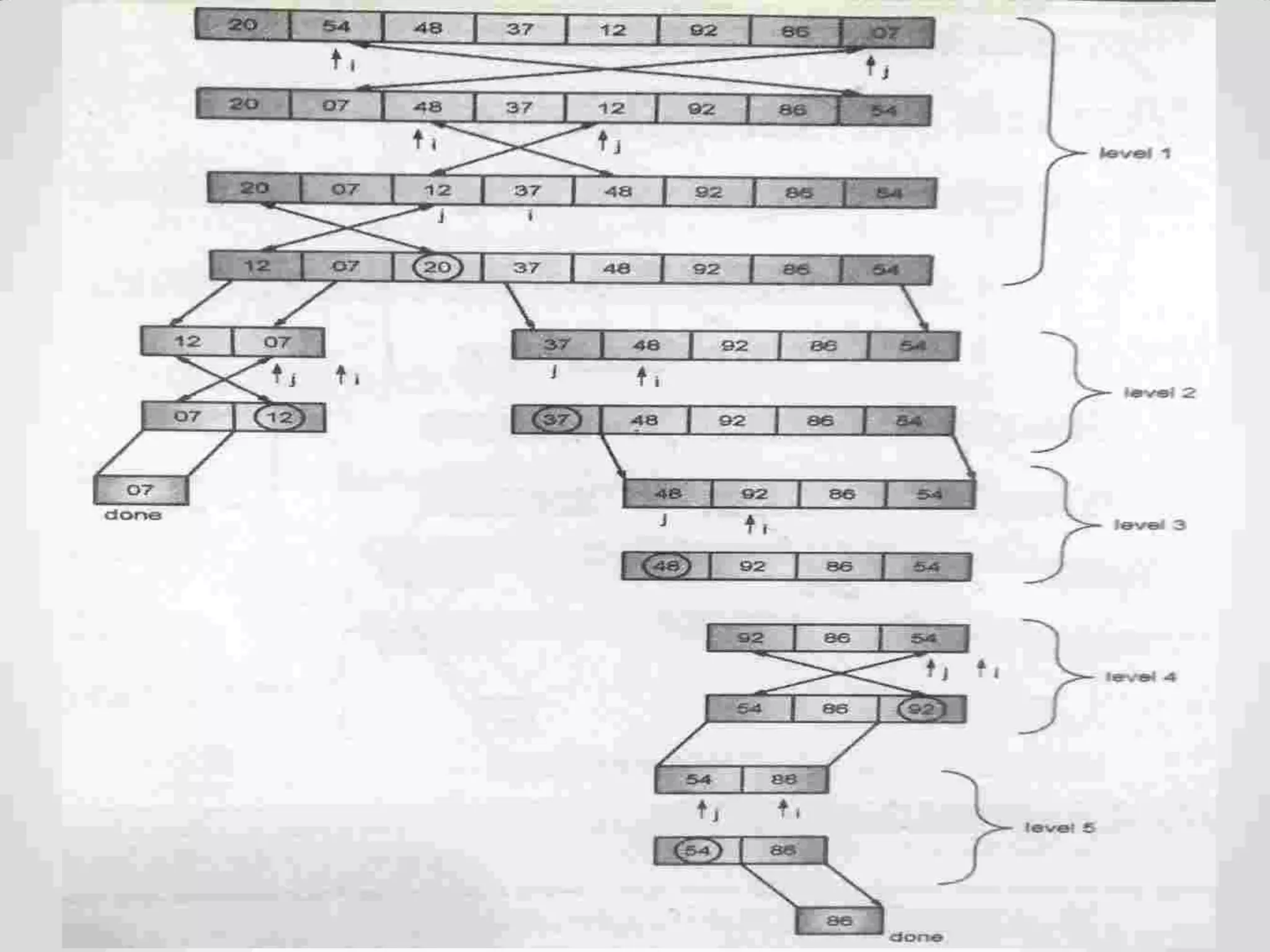
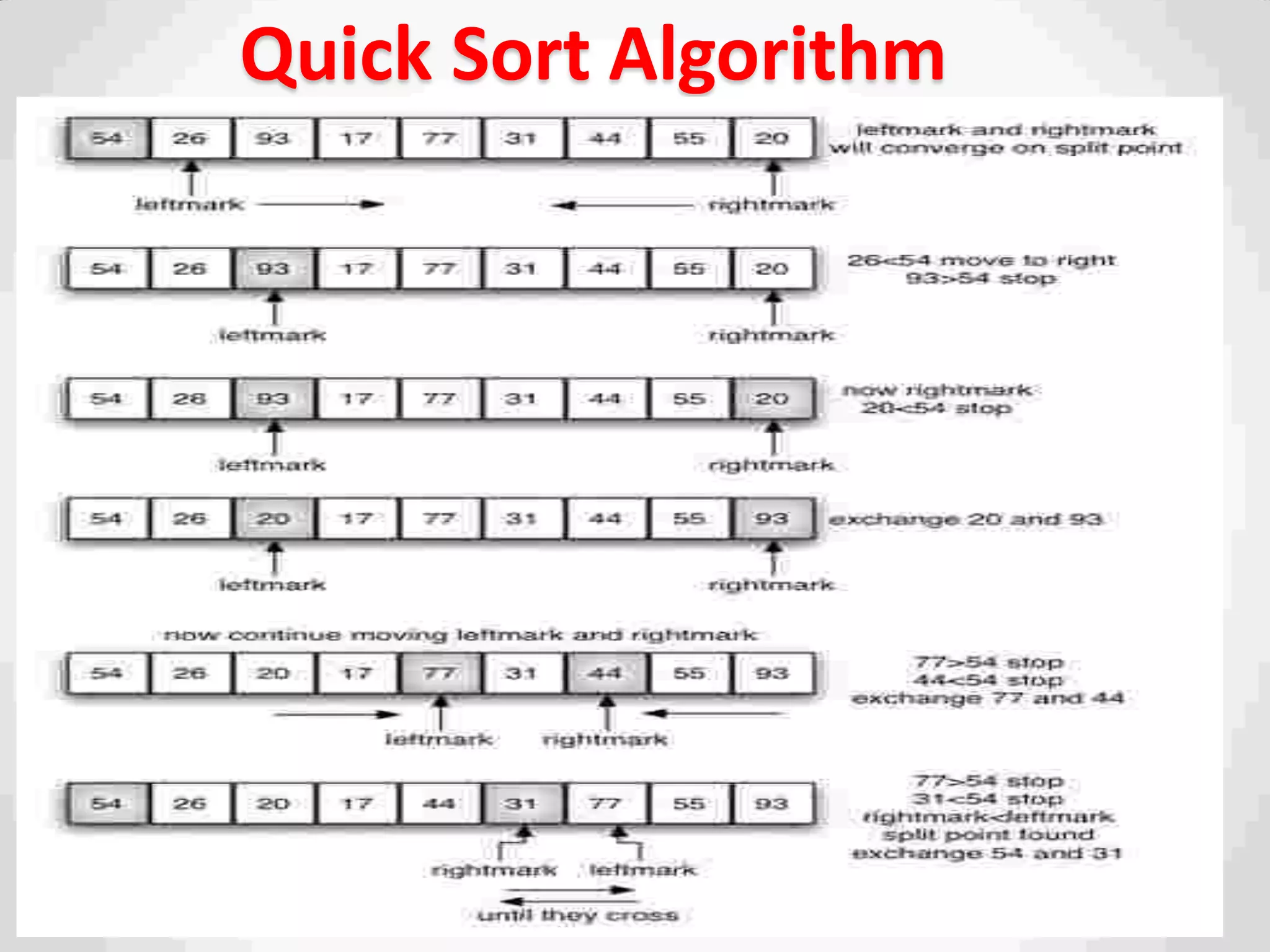
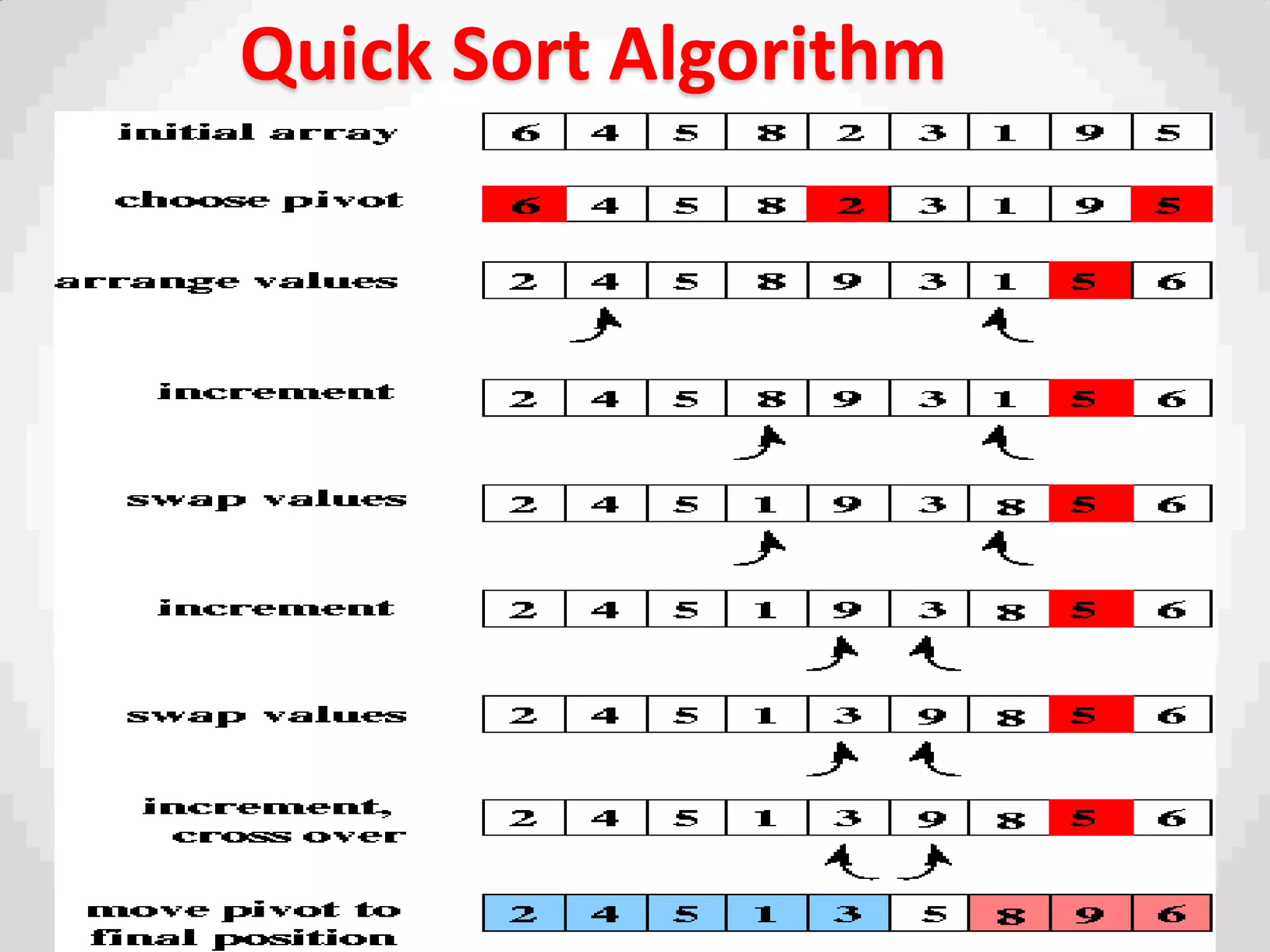
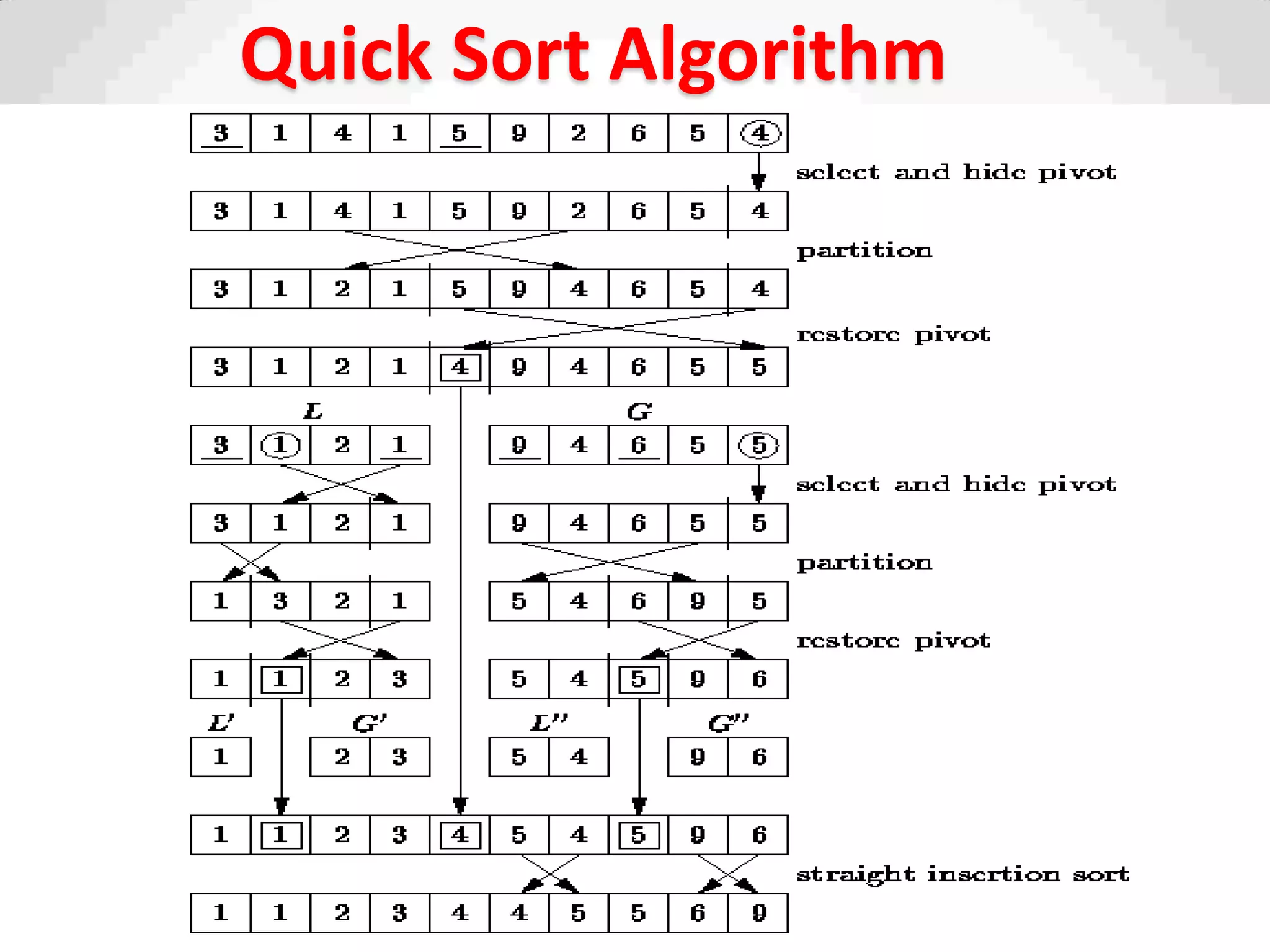
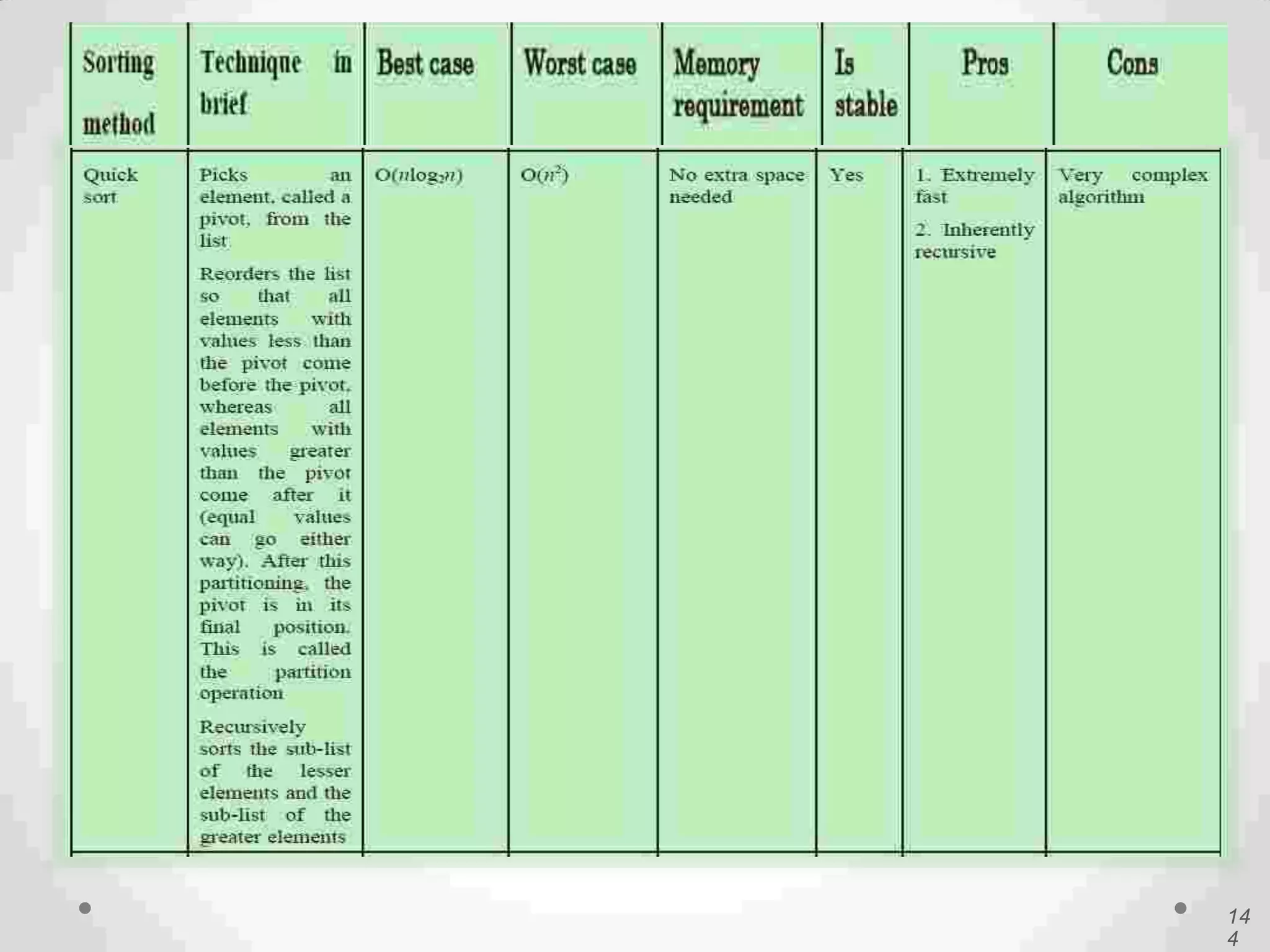
Description of Quick Sort as an efficient sorting algorithm using divide-and-conquer strategy.
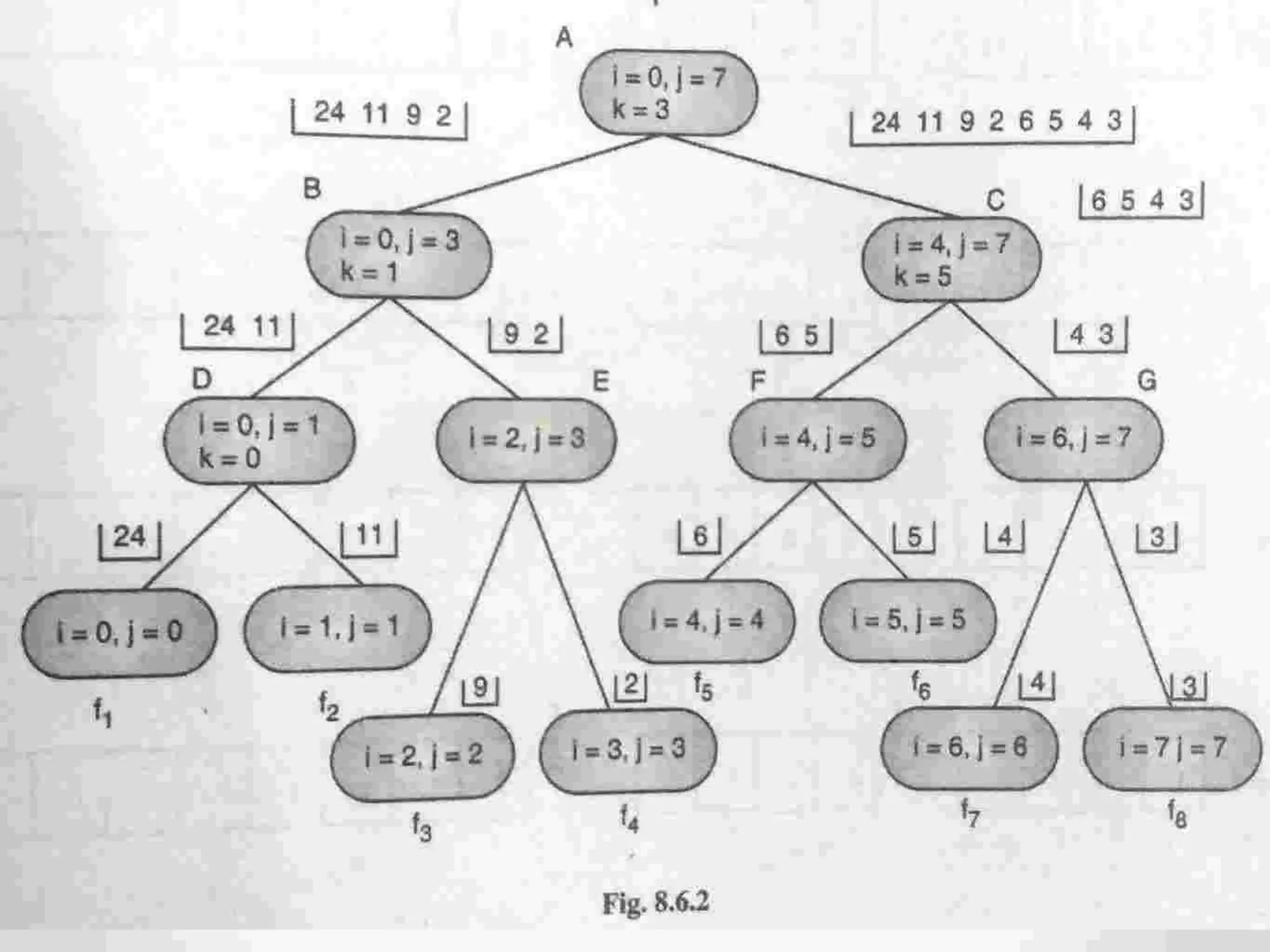
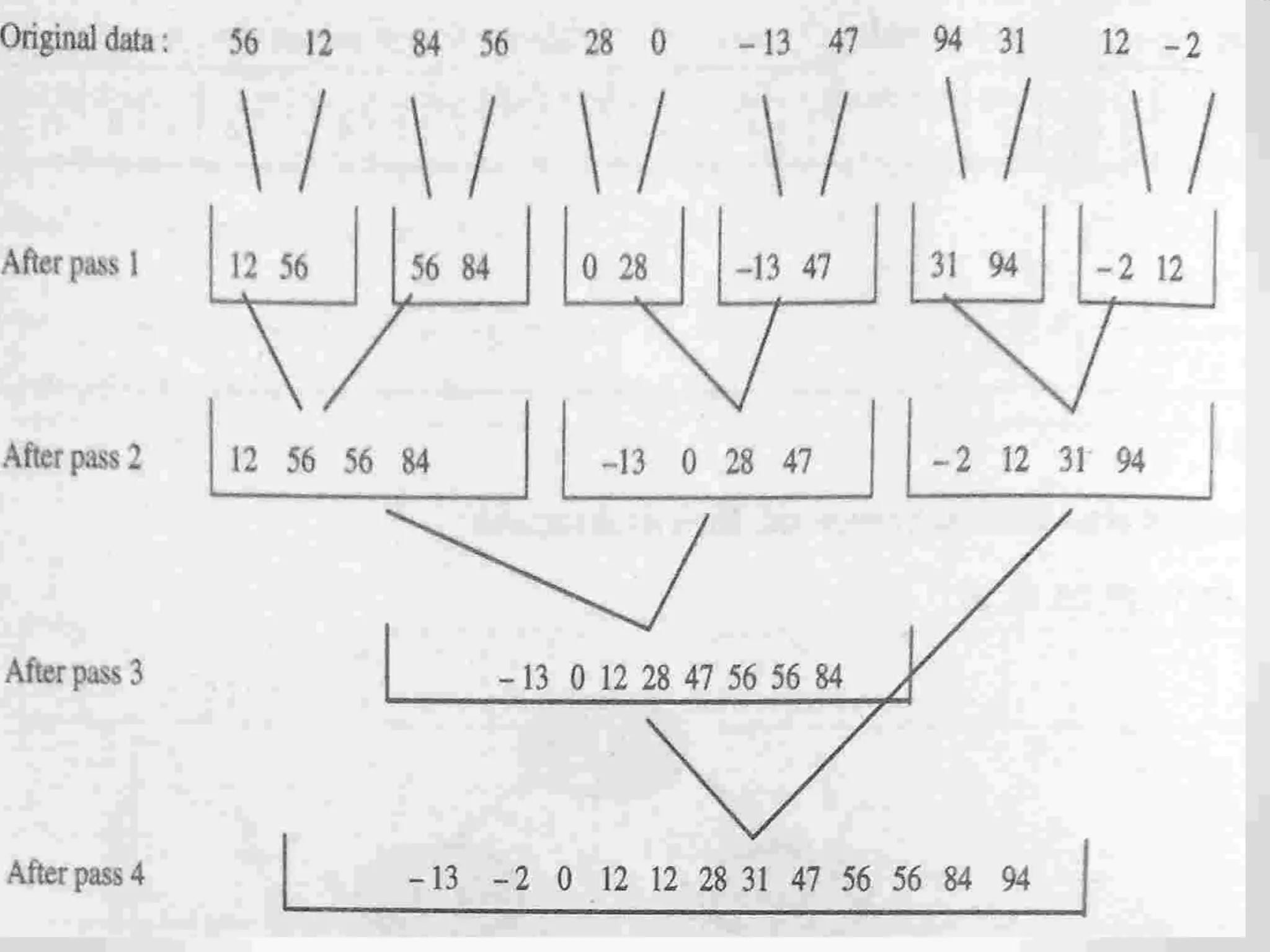
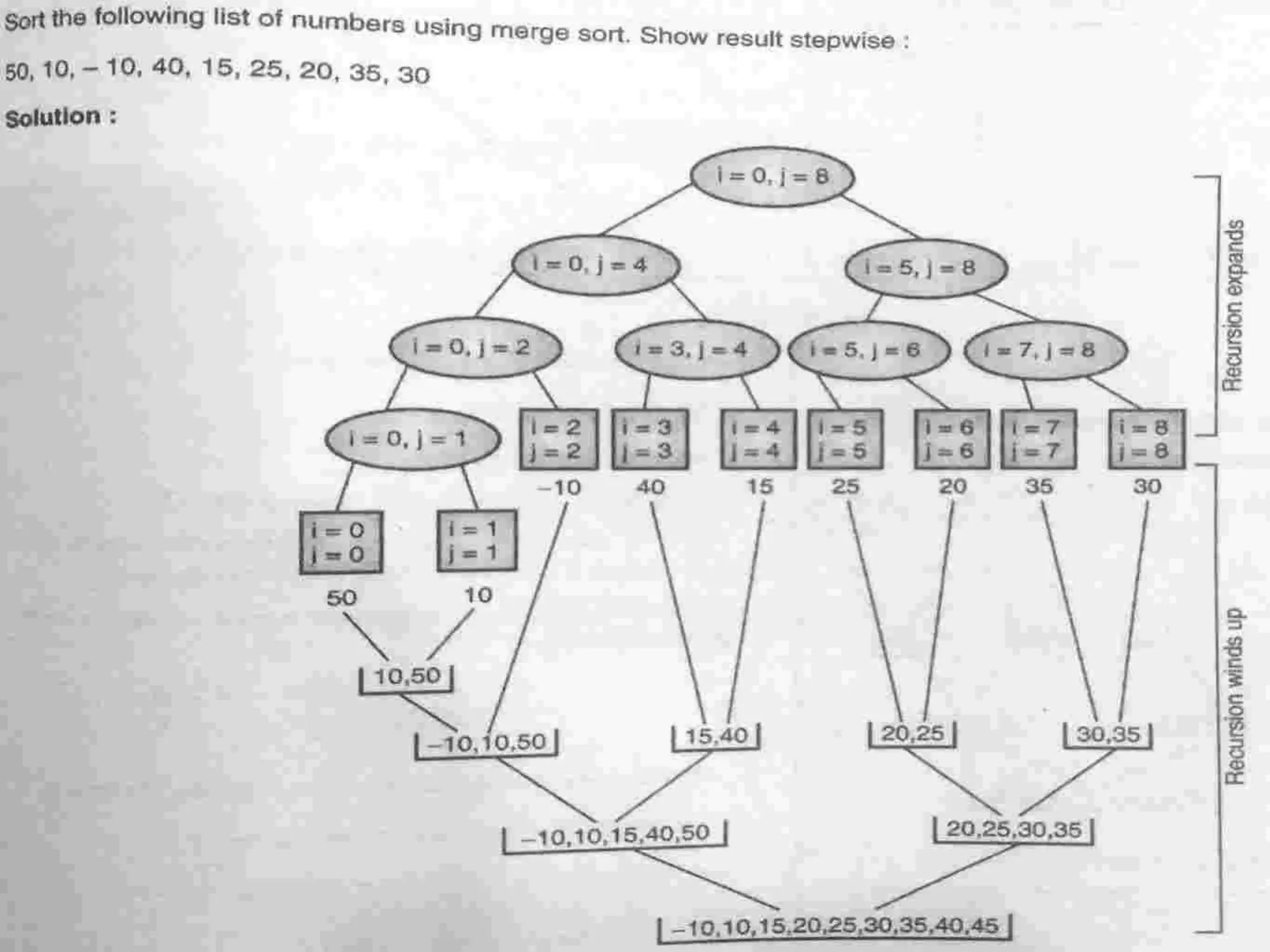
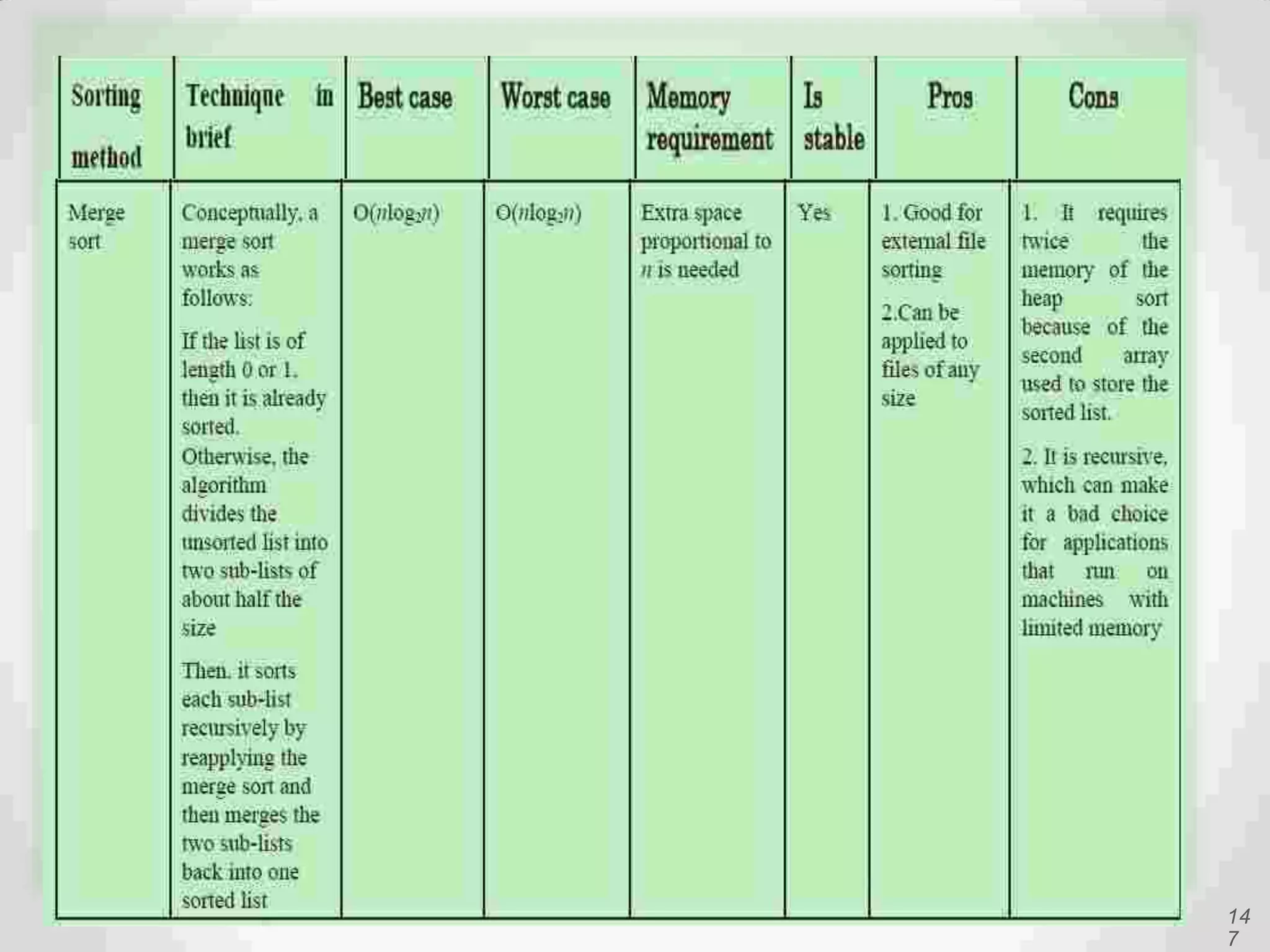
Explains Merge Sort's divide-and-conquer approach, its efficiency, and how it merges sorted lists.
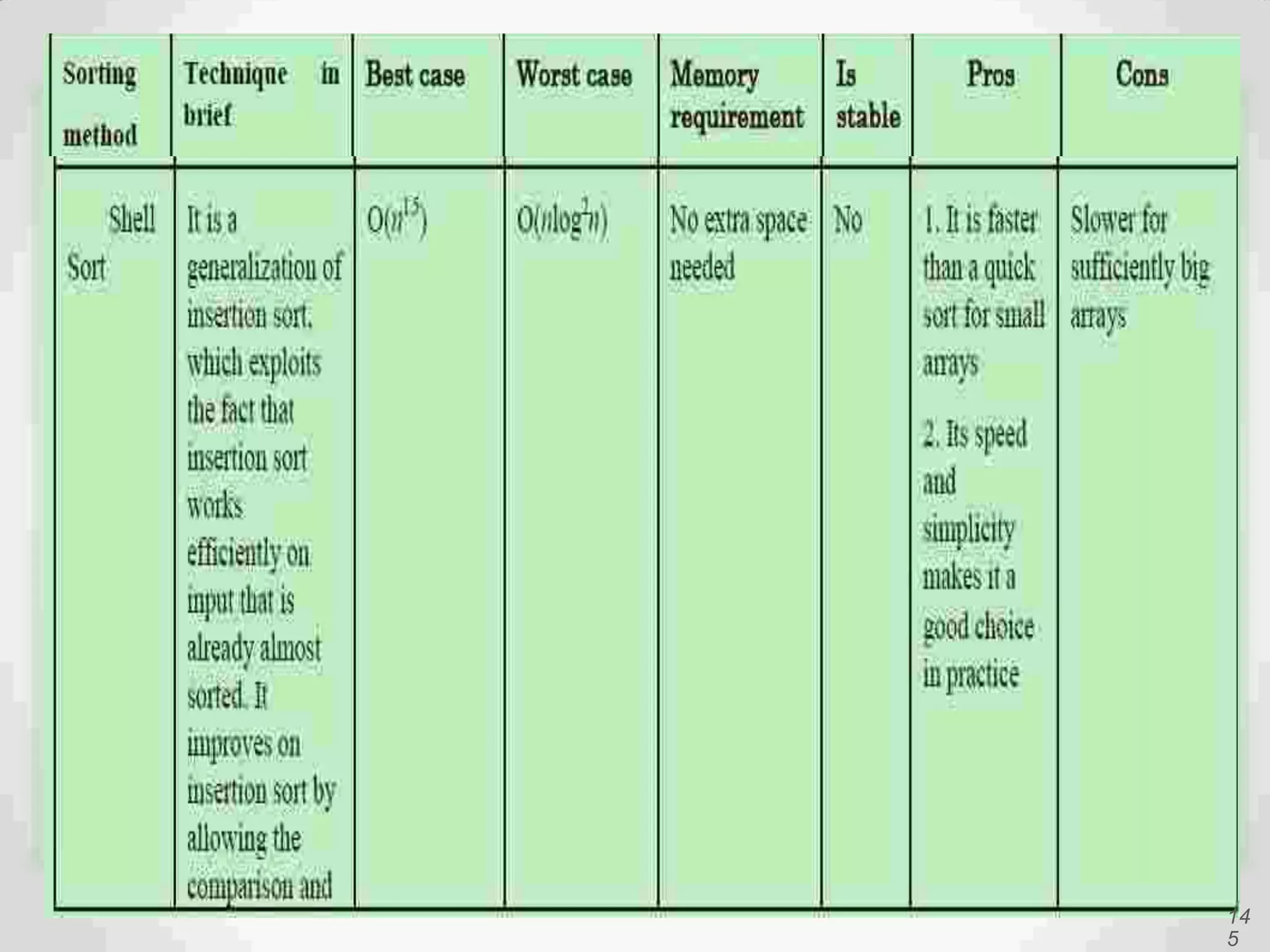
Details of Shell Sort, interval-based sorting, and efficiency considerations.
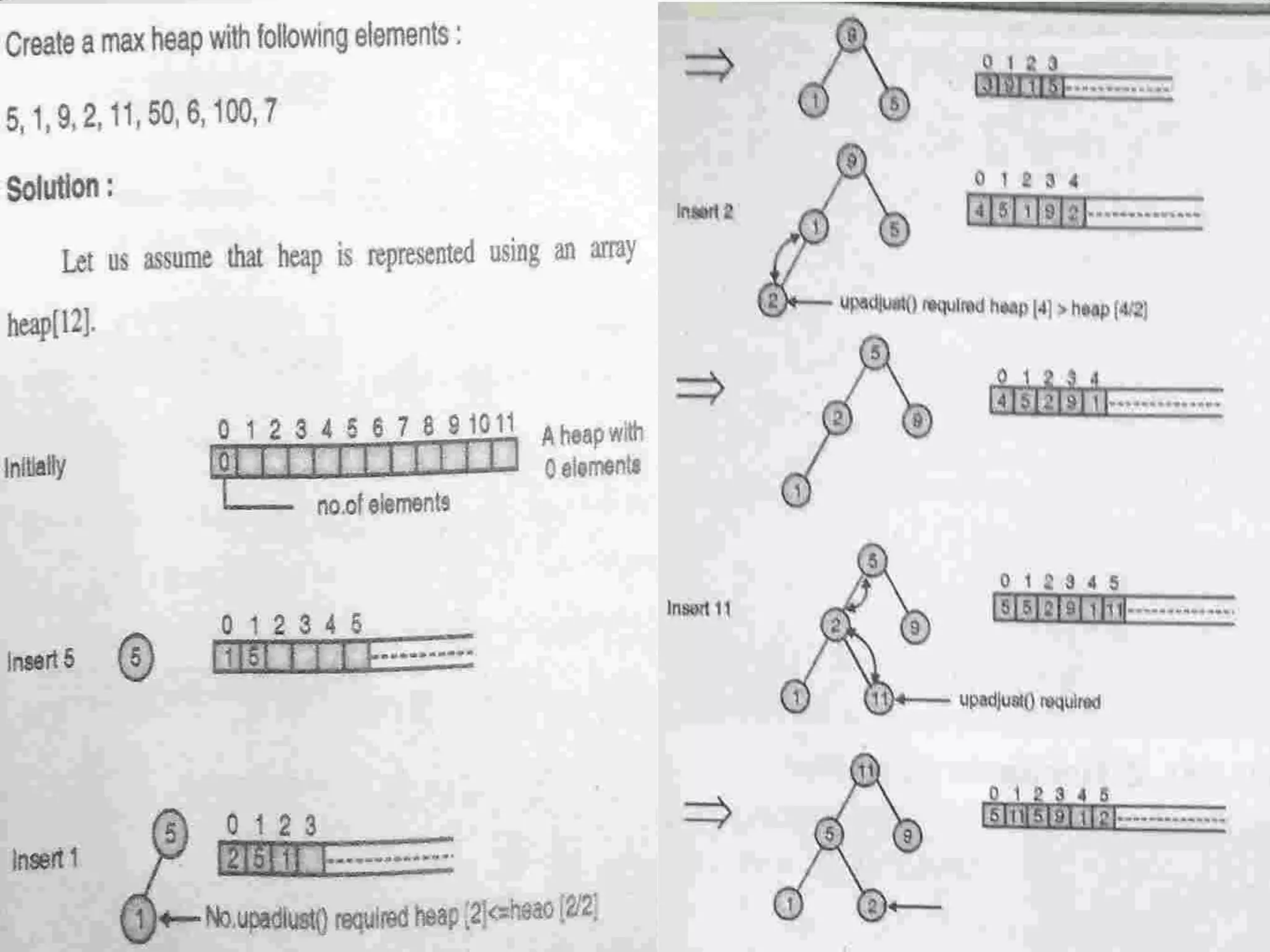
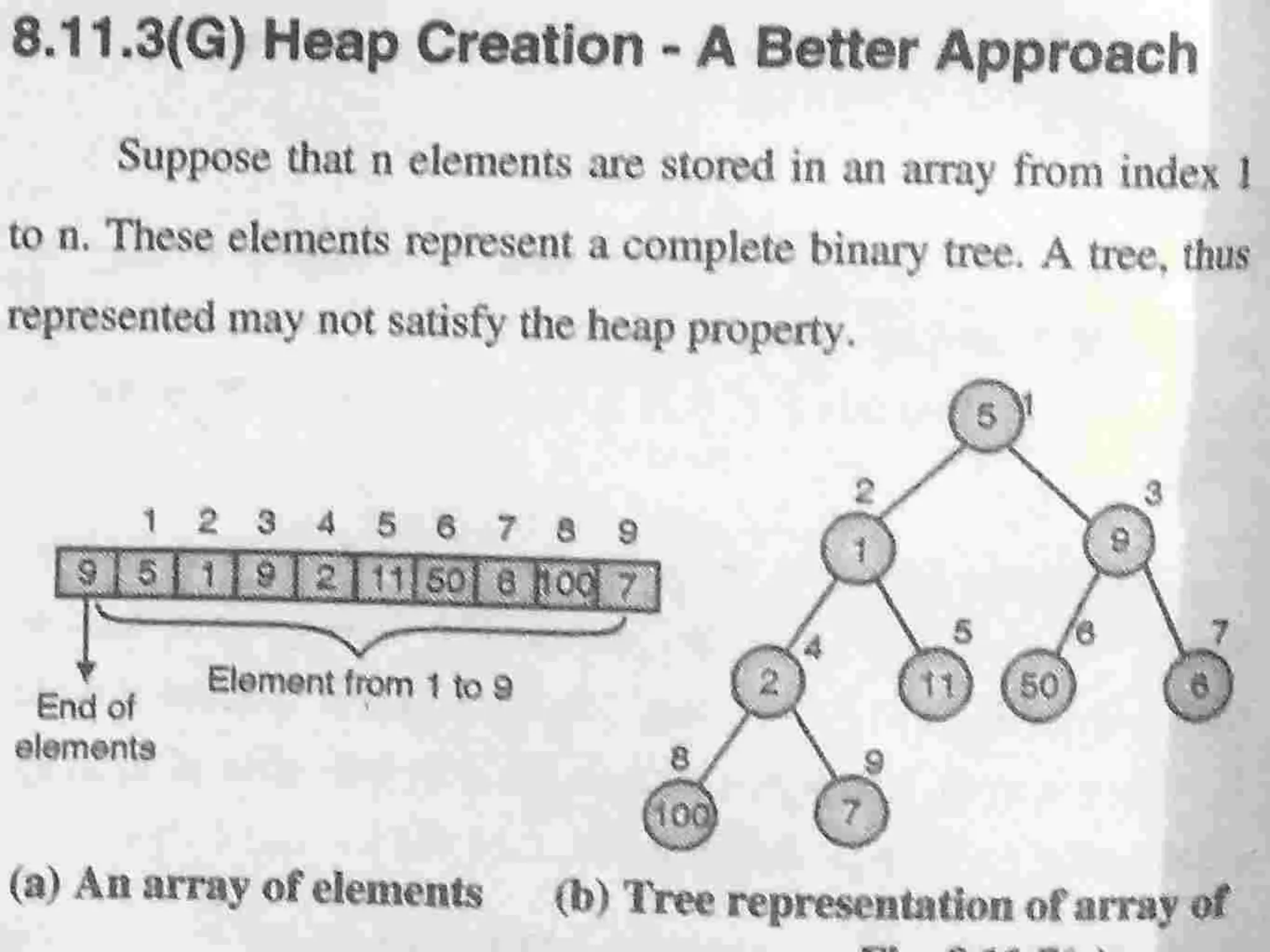
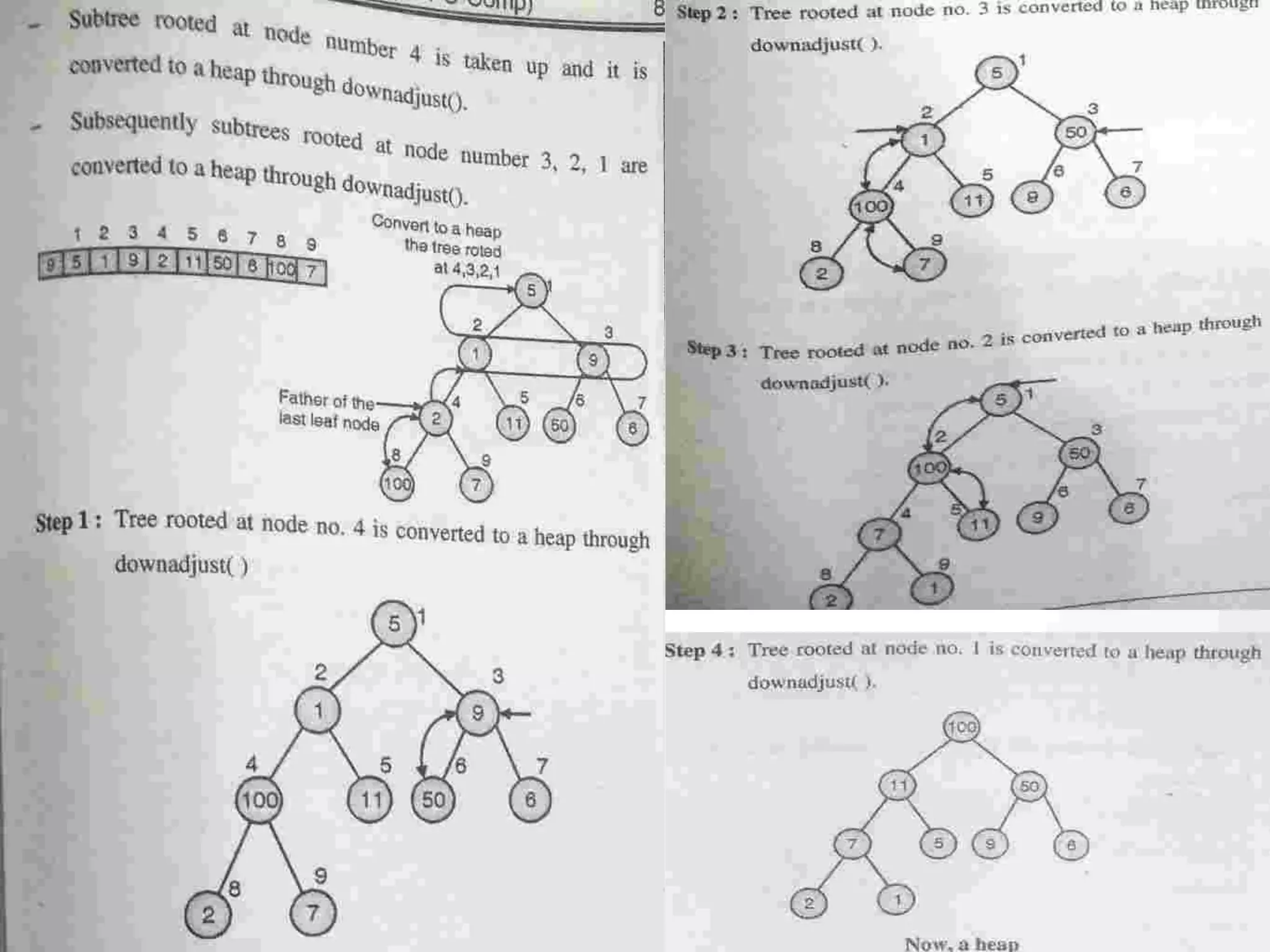
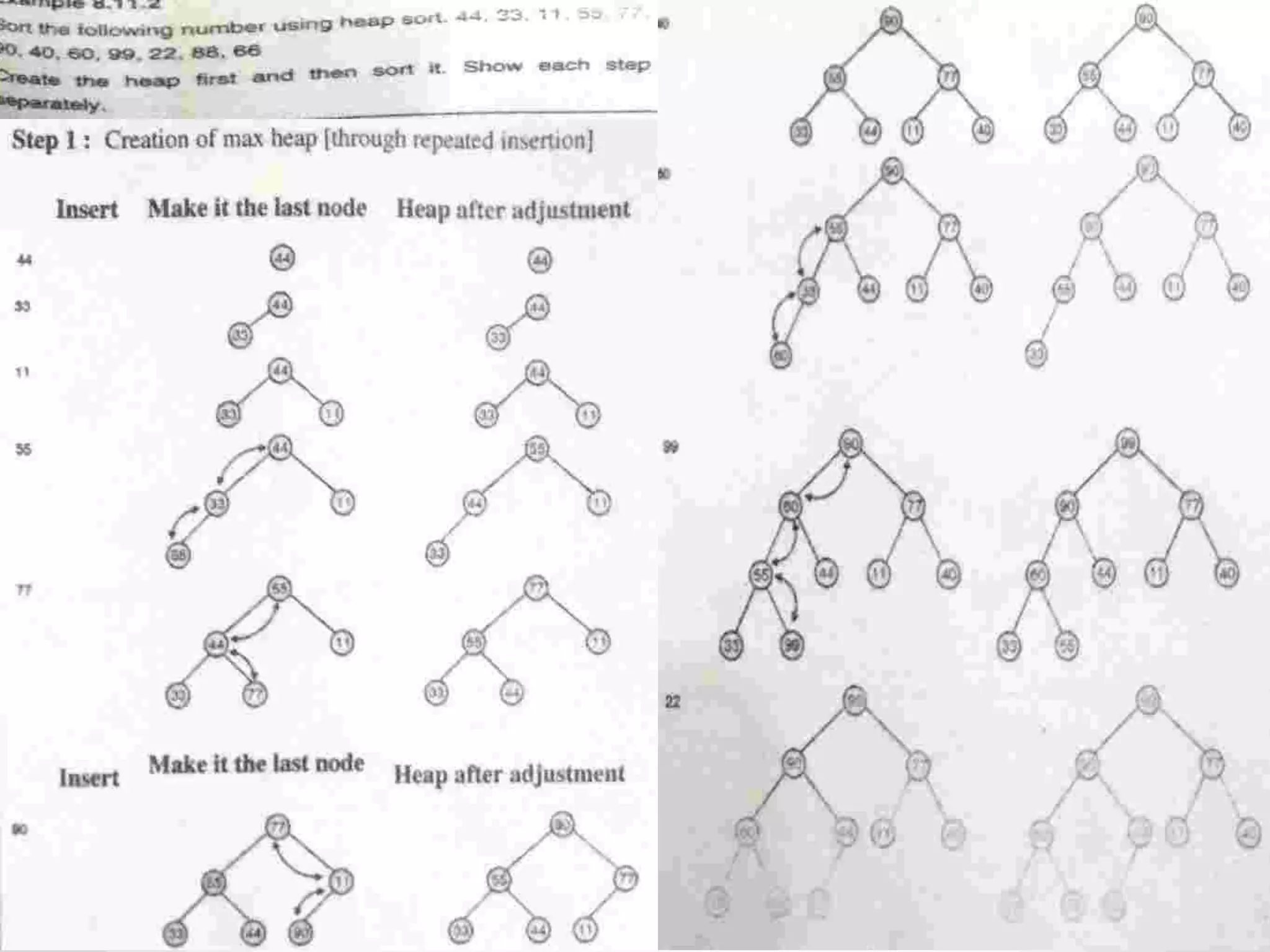
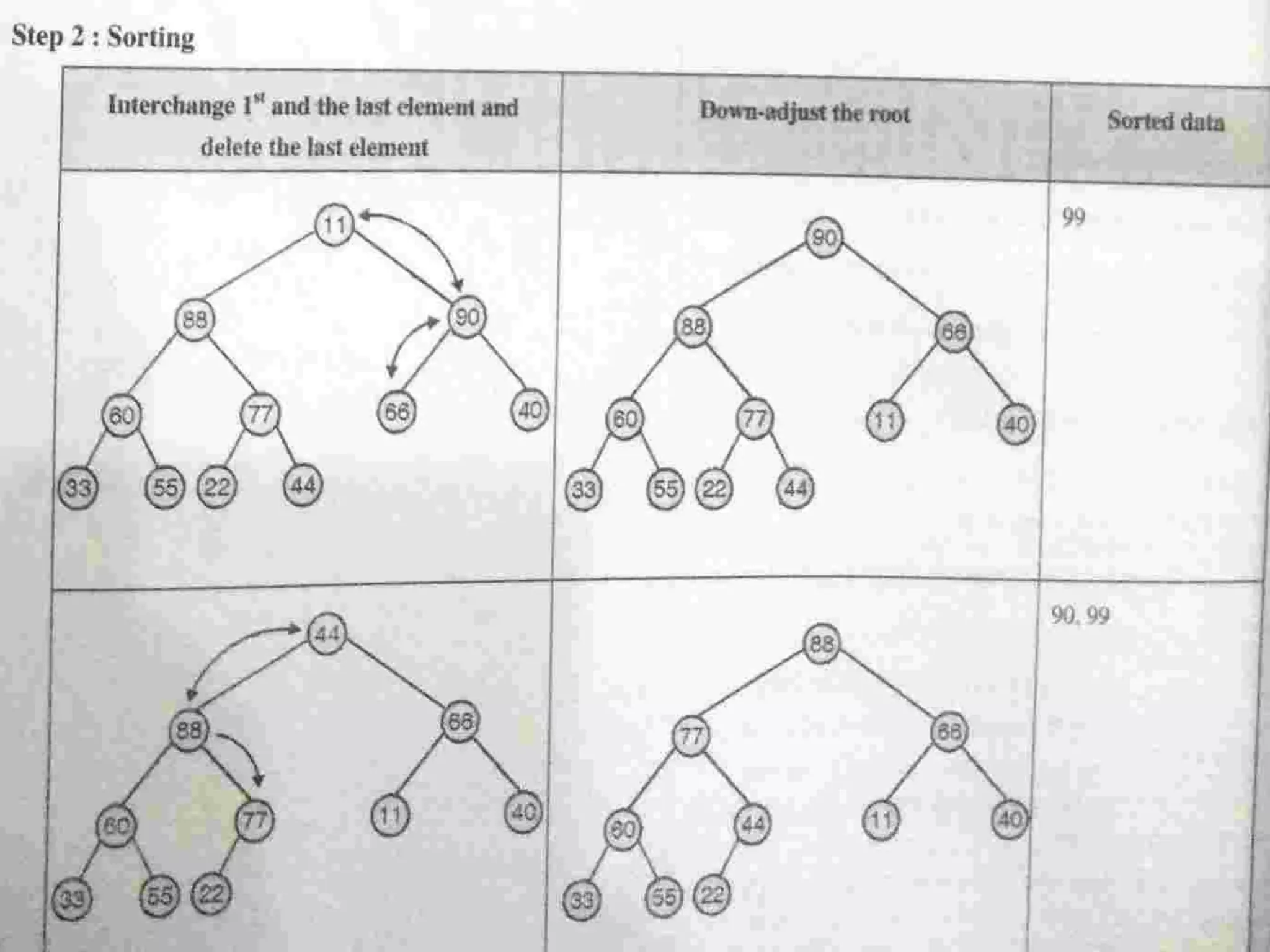
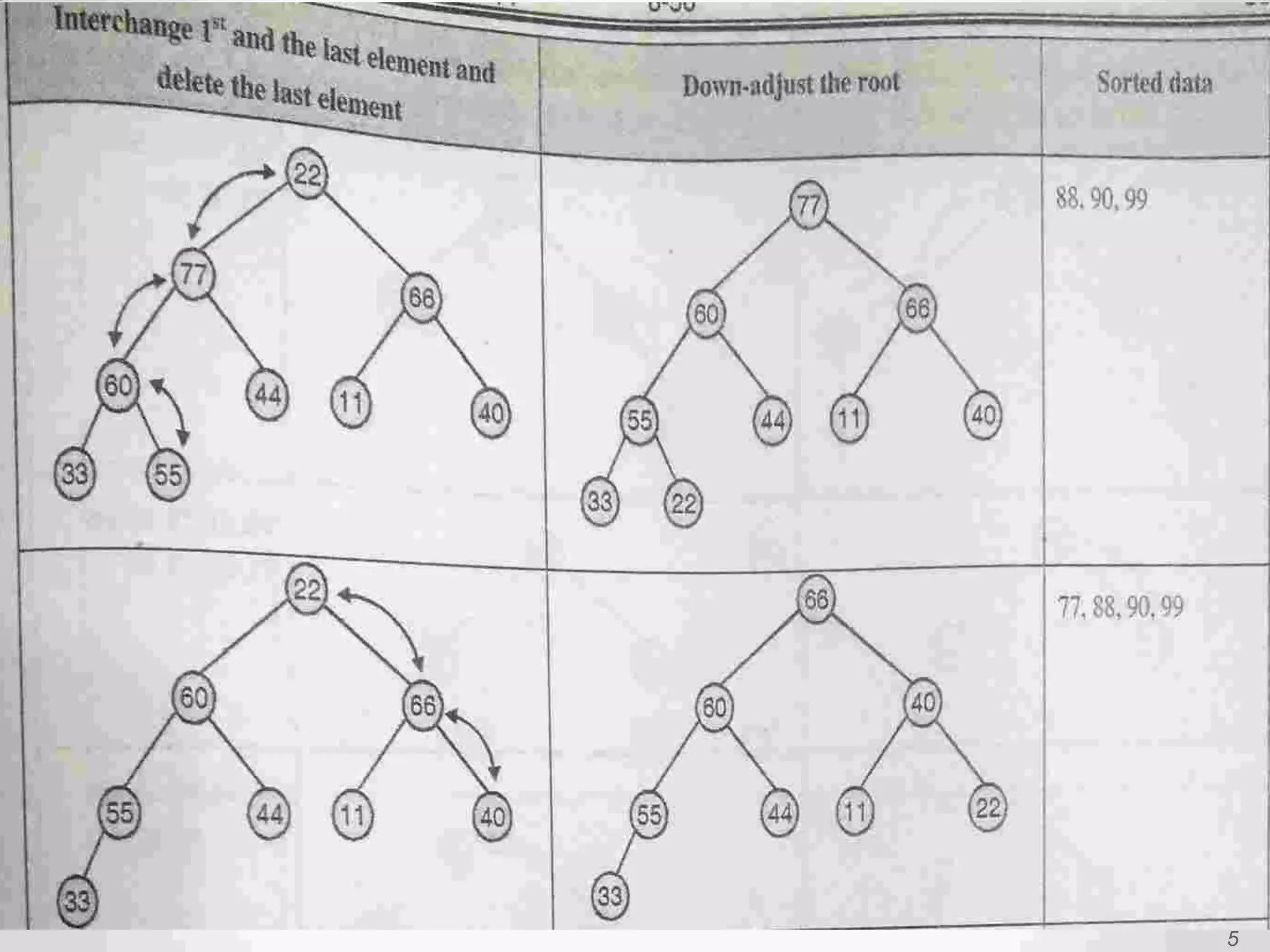
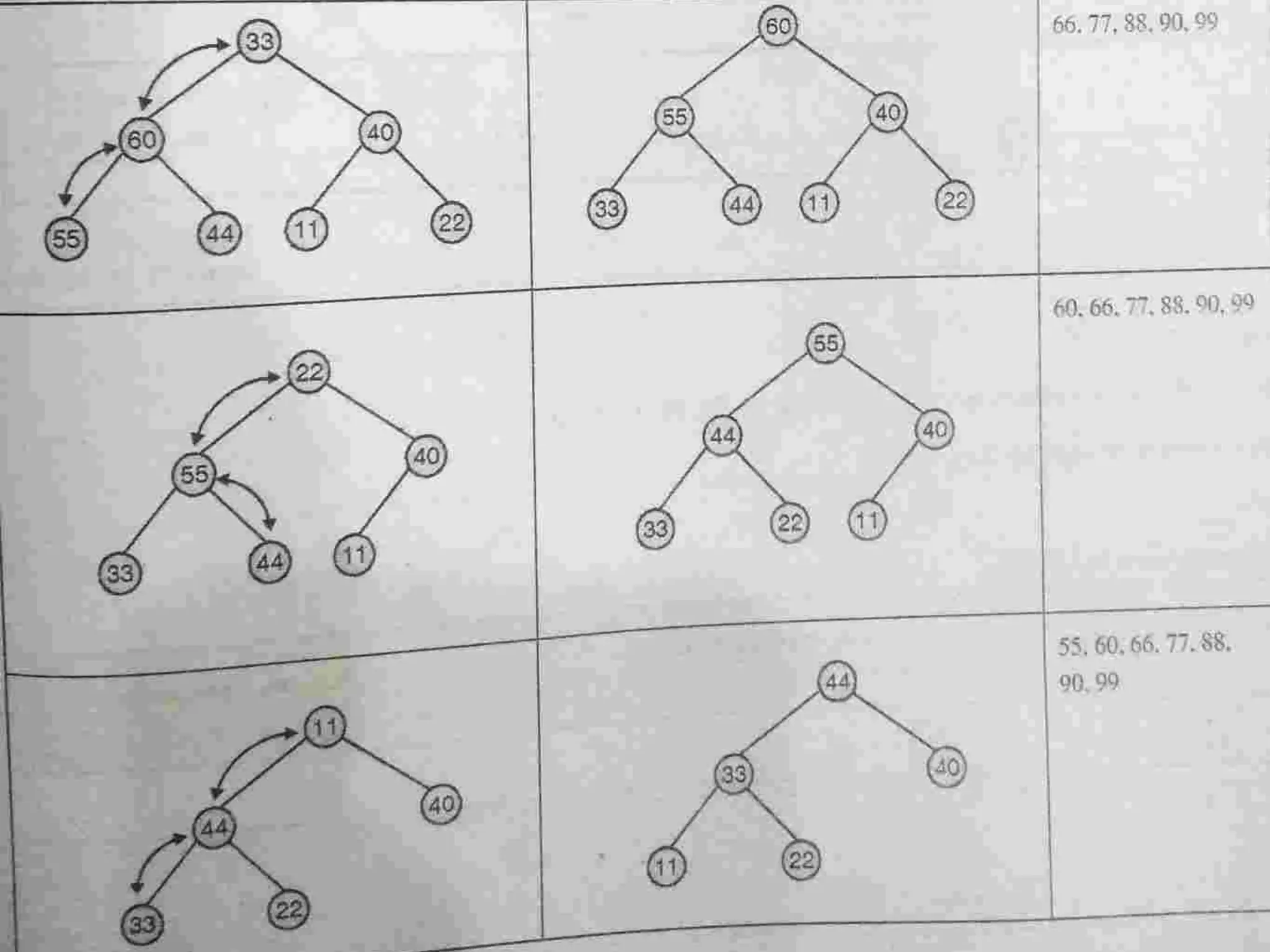
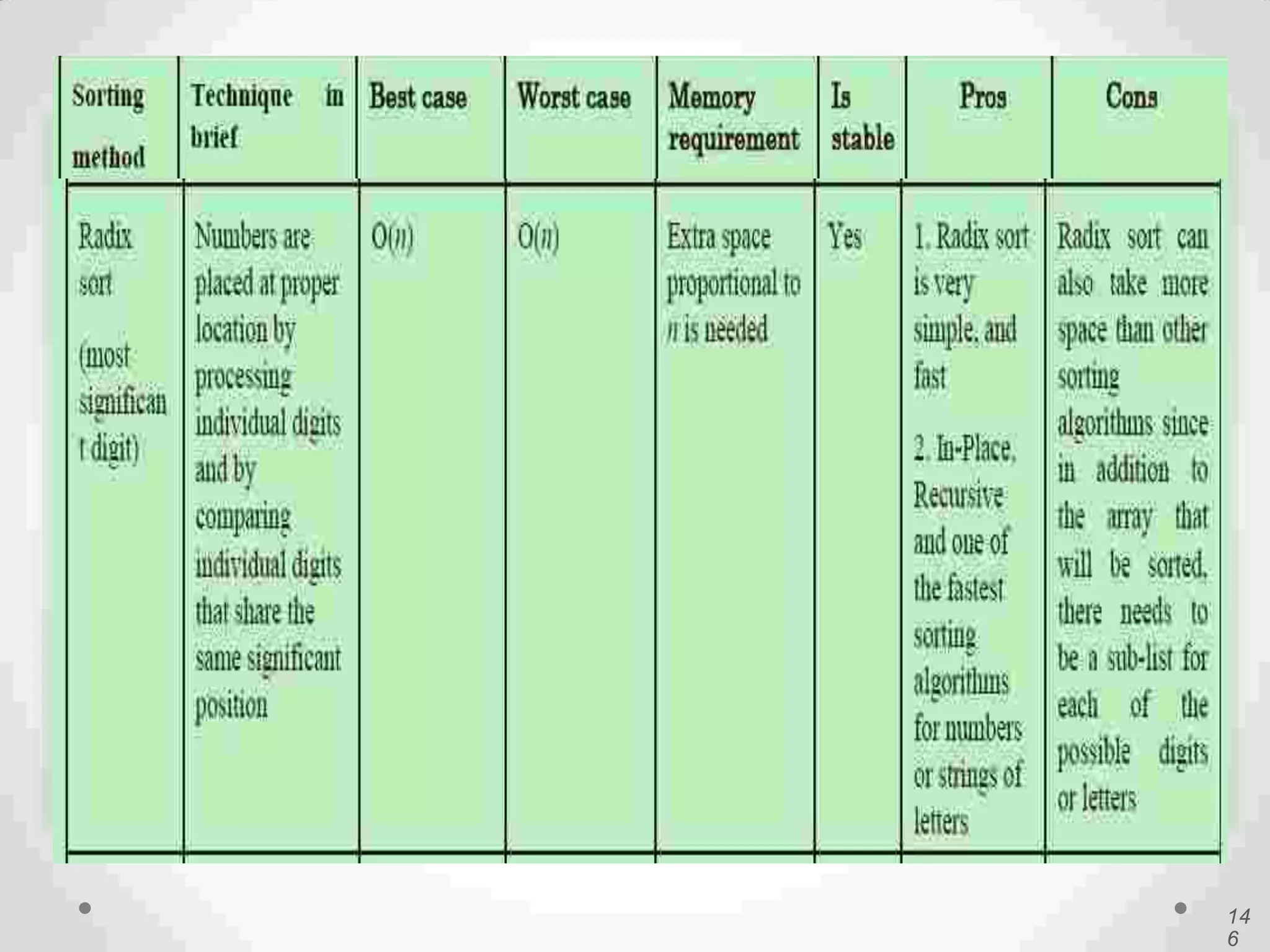
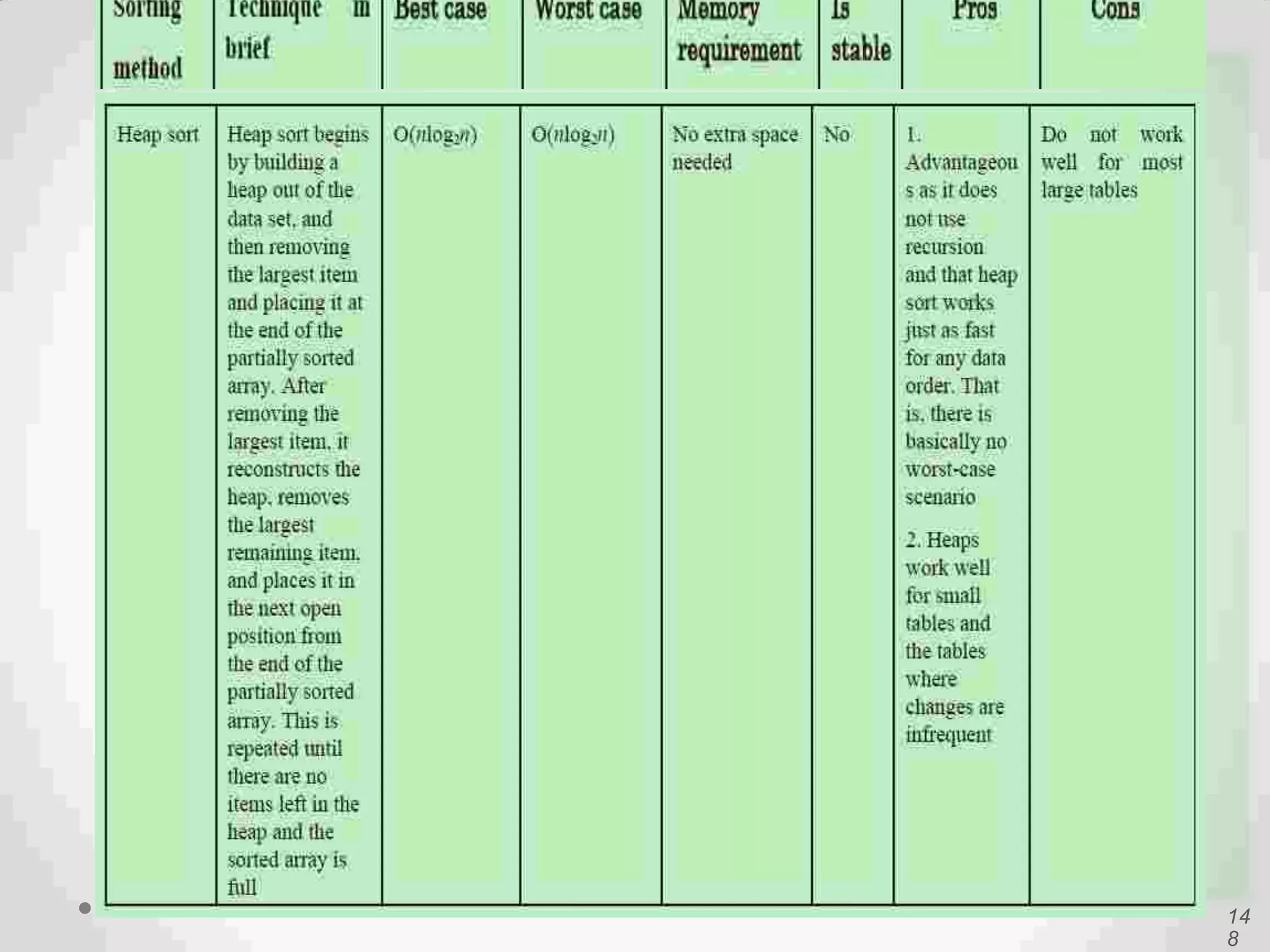
Introduction to Bucket and Radix Sort, their methodologies, and efficiency metrics.Describes Heap Sort, its algorithm, efficiency, and worst-case performance.
Visual and conceptual comparison of various sorting methods including performance and complexity.
Wrap-up of the presentation by Prof. Anand Gharu.