Download as PDF, PPTX







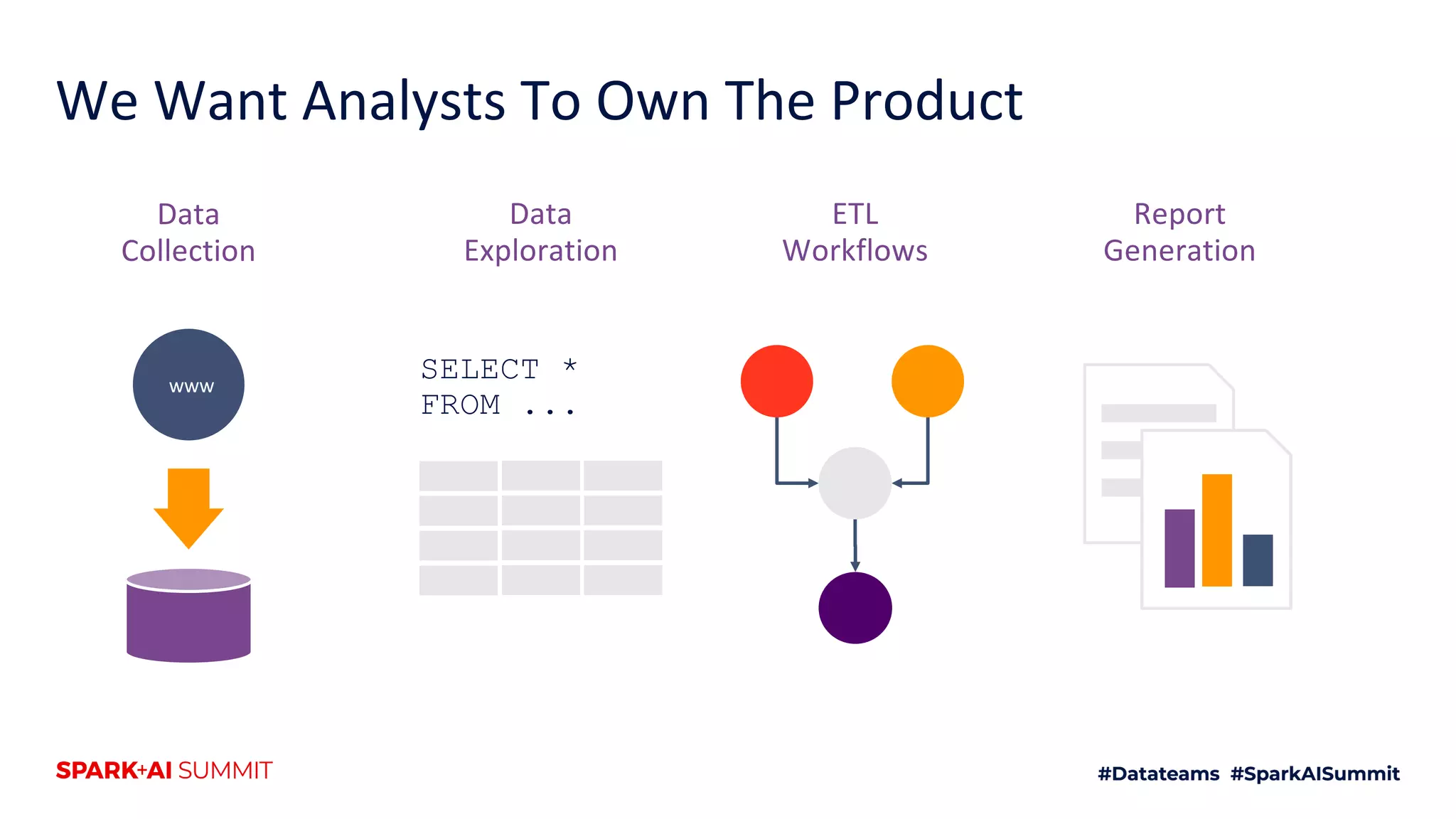


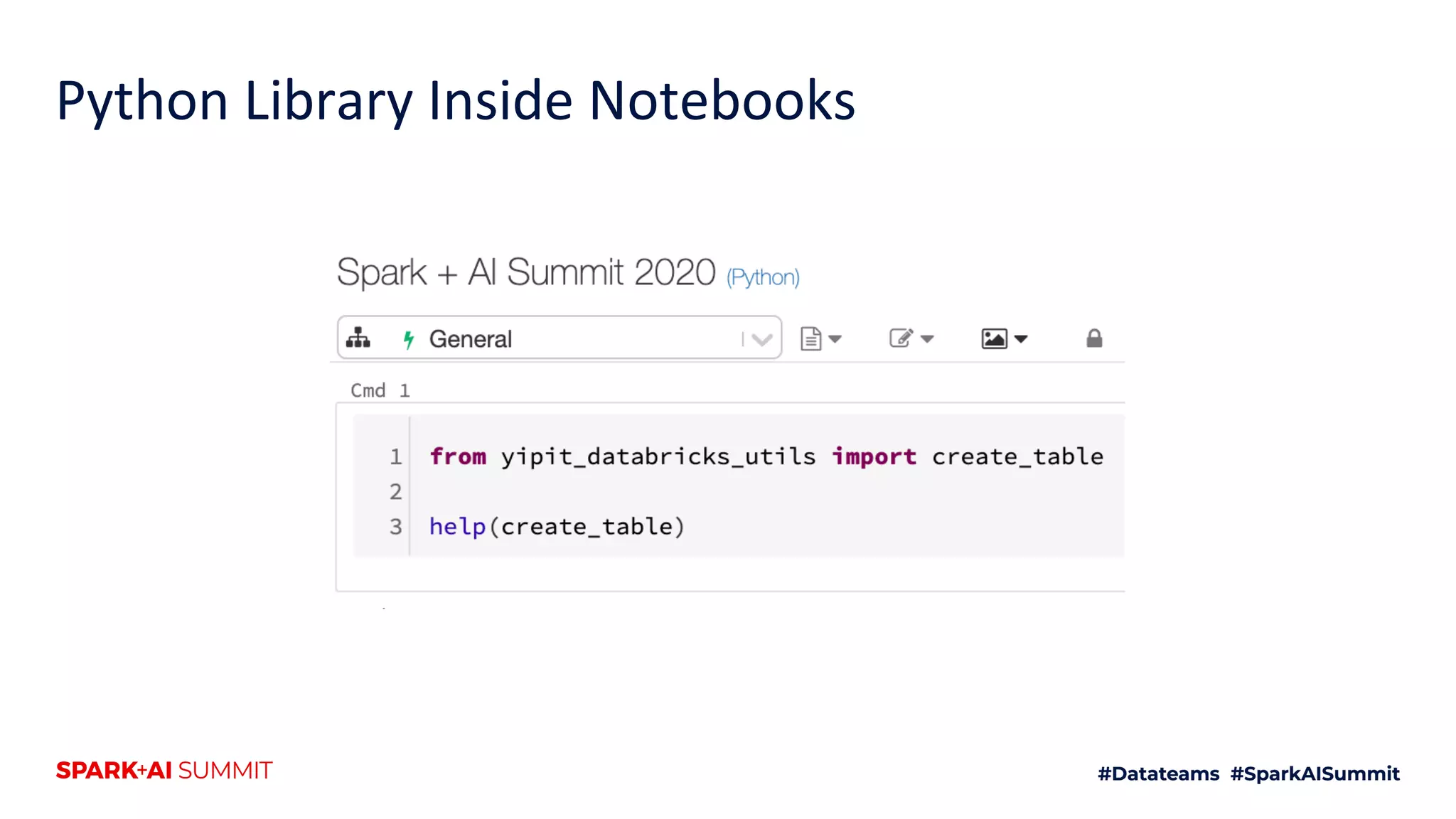

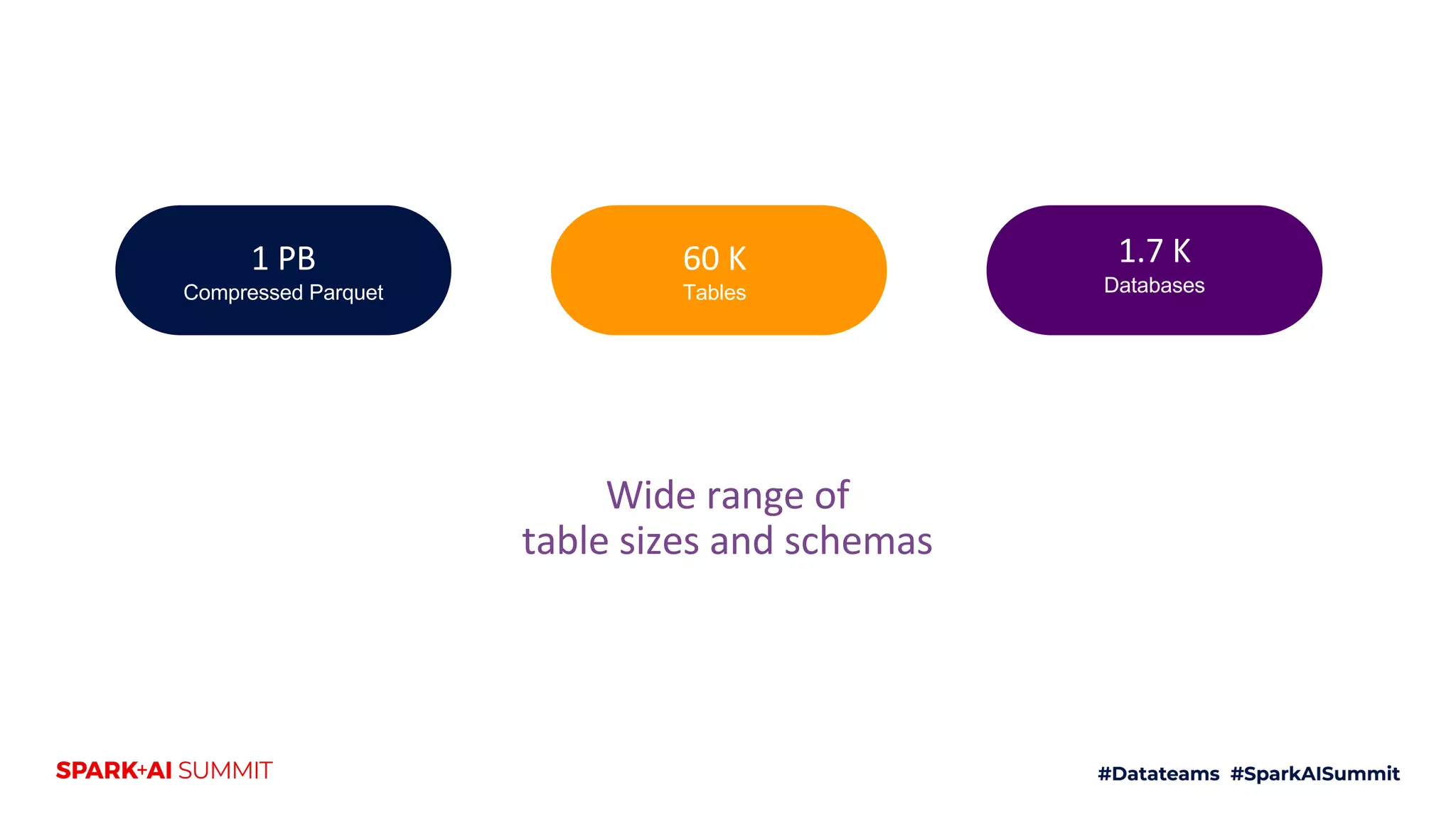


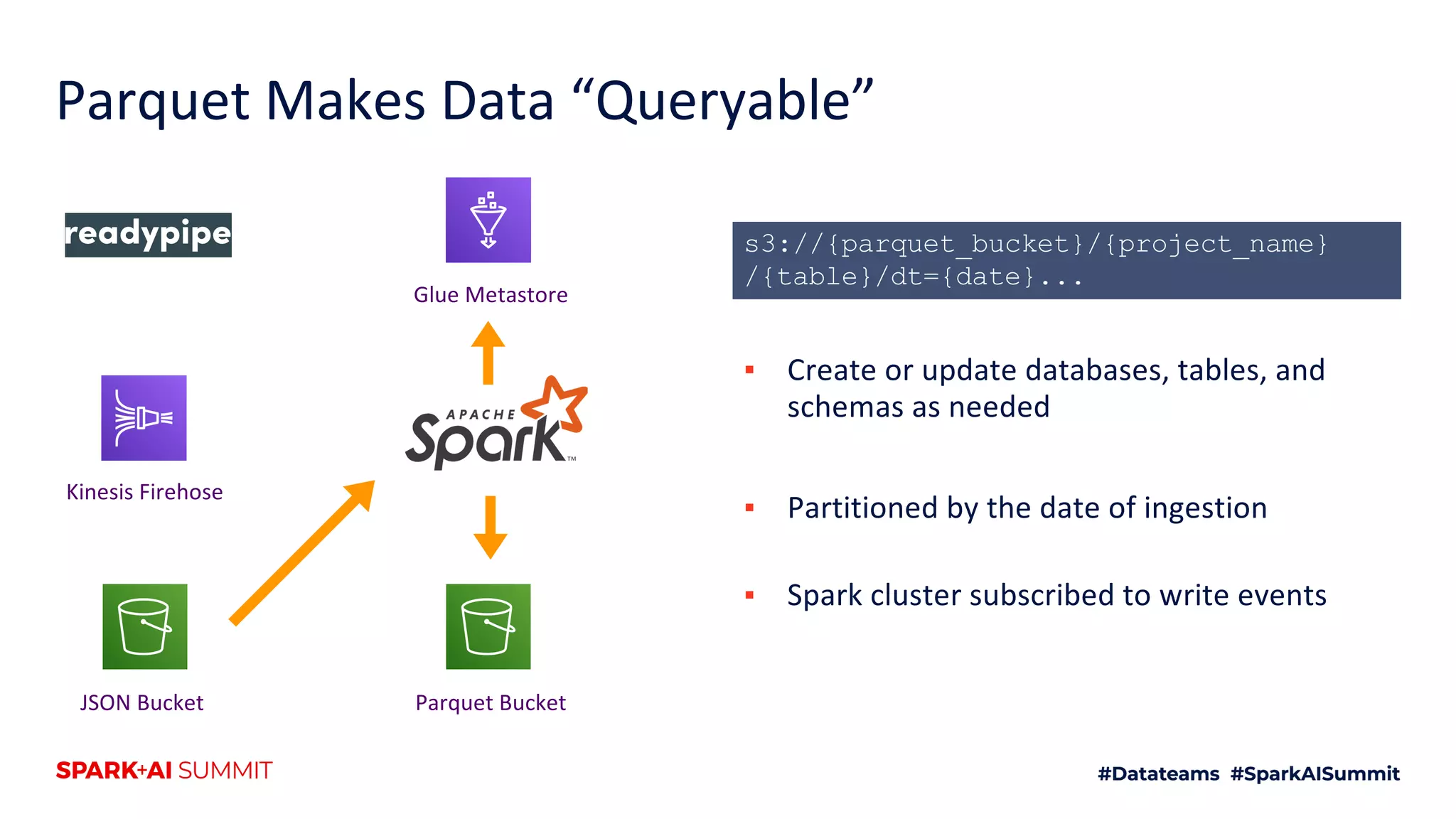

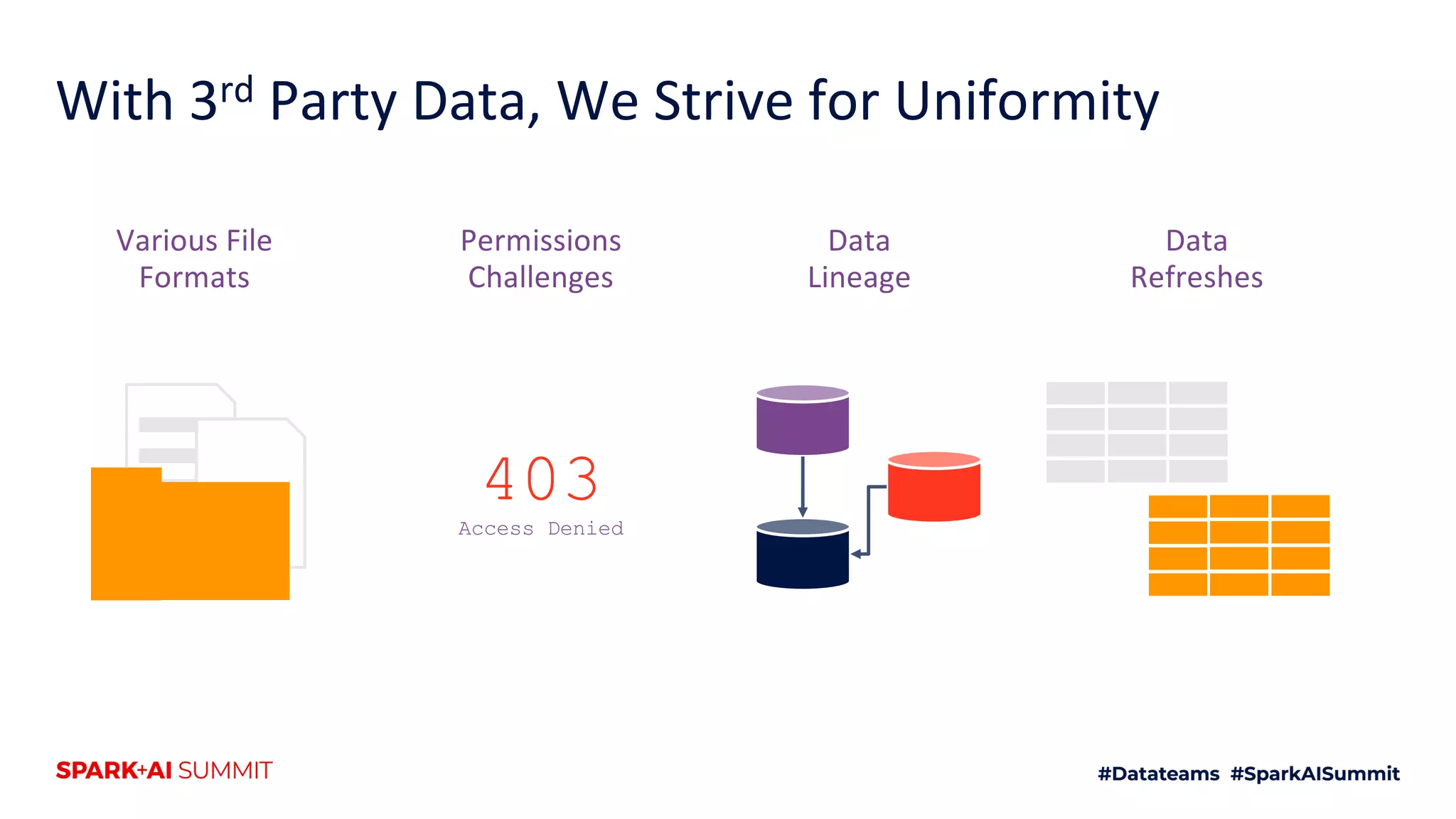
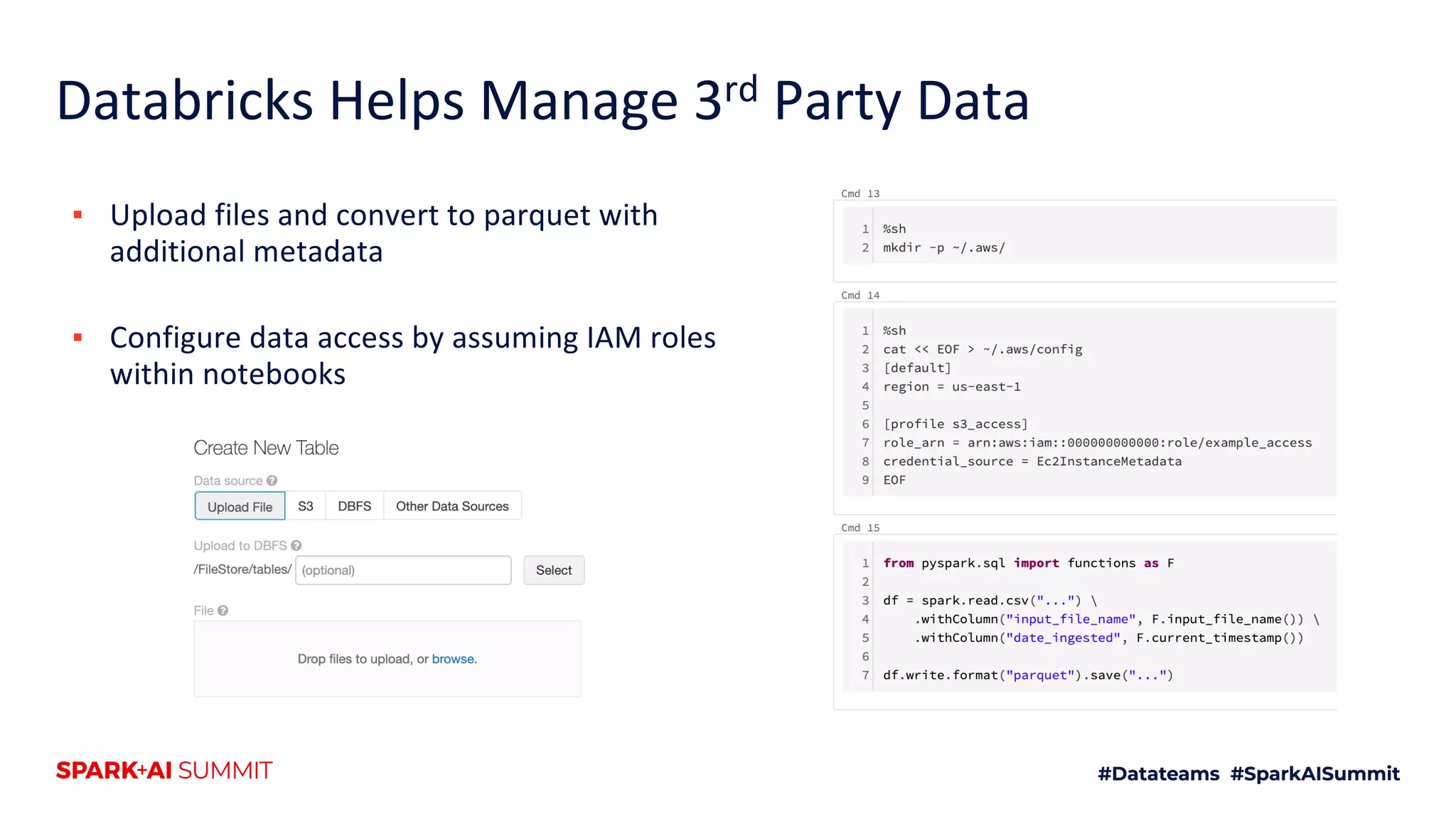



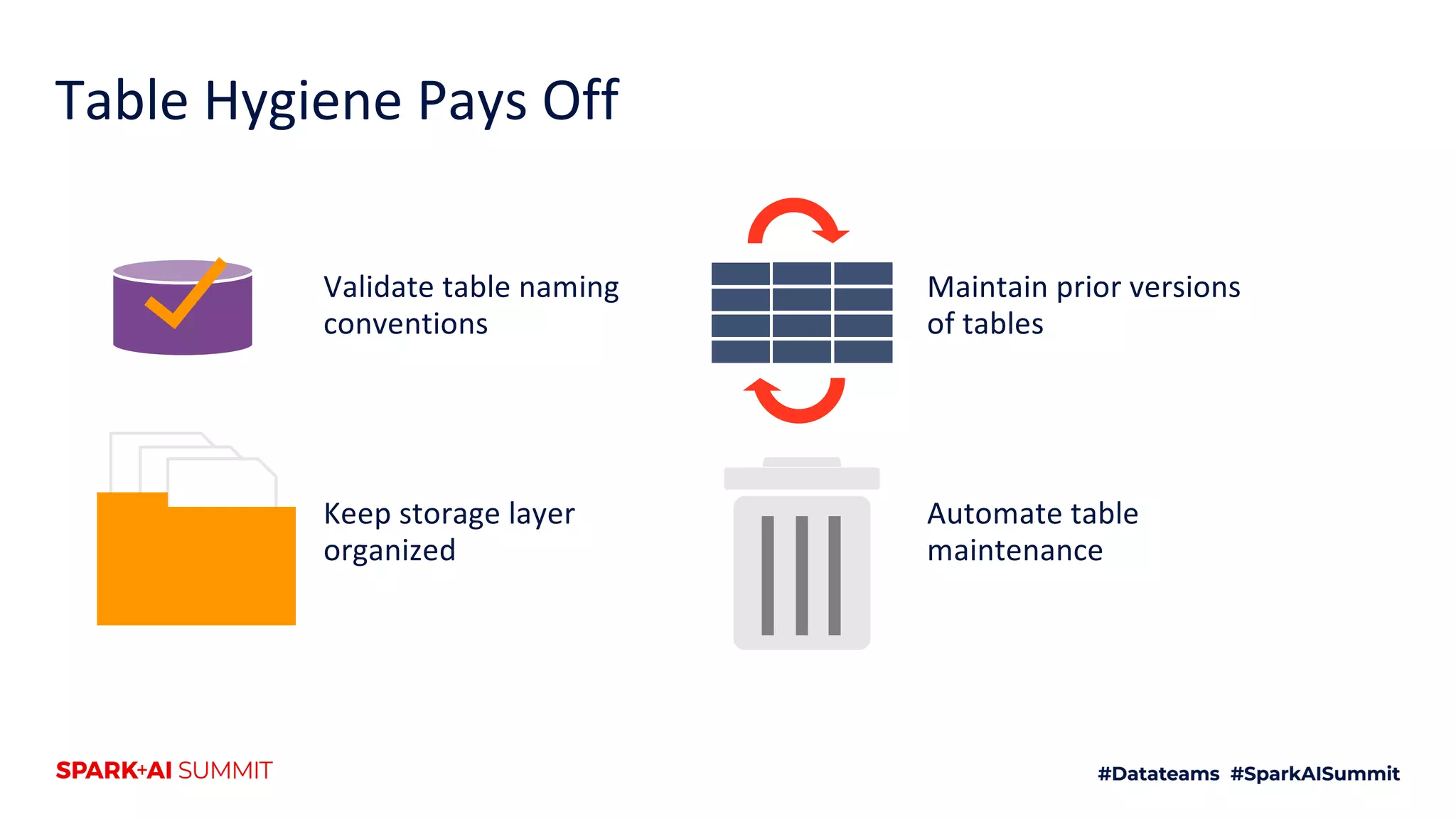







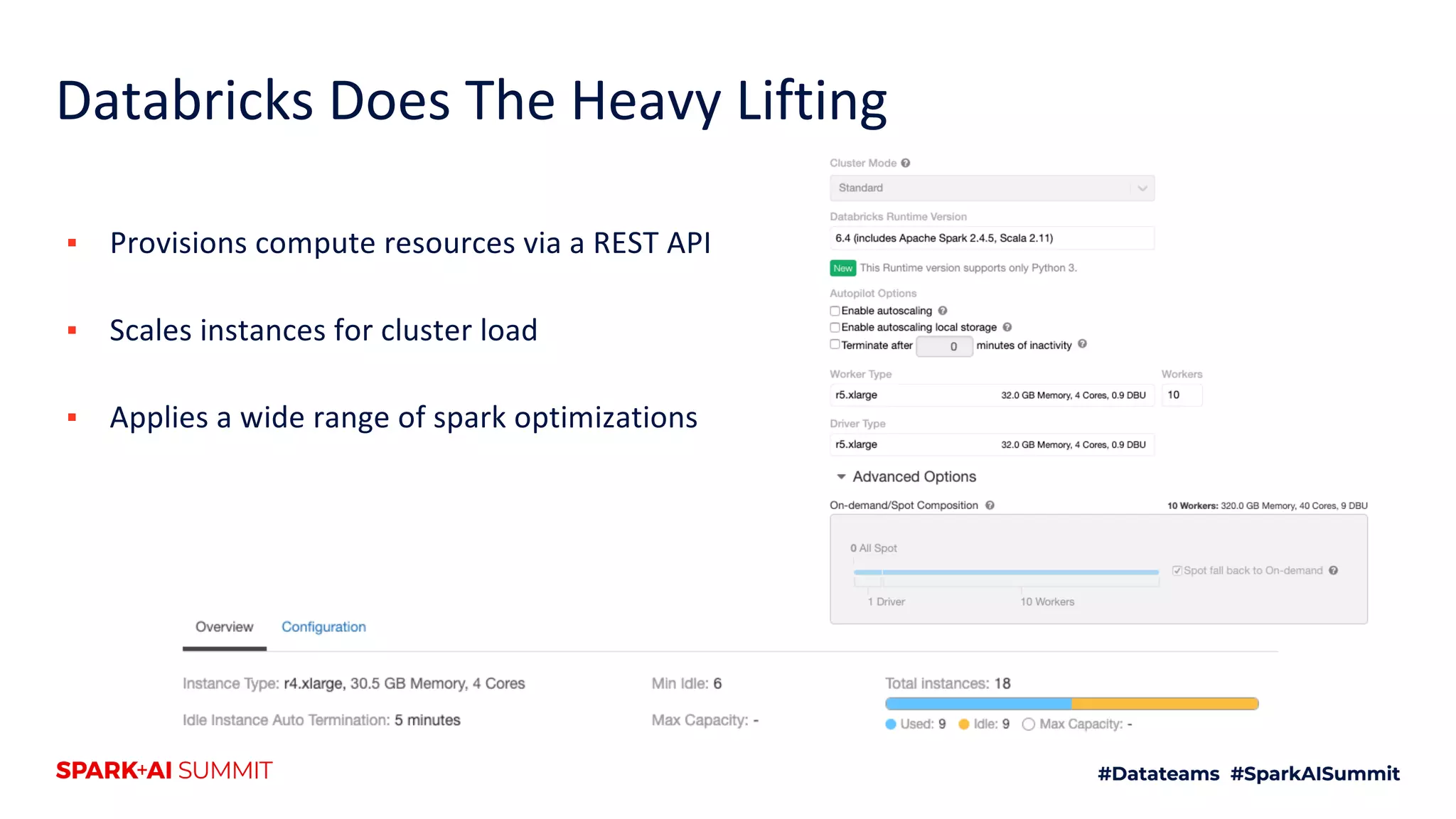




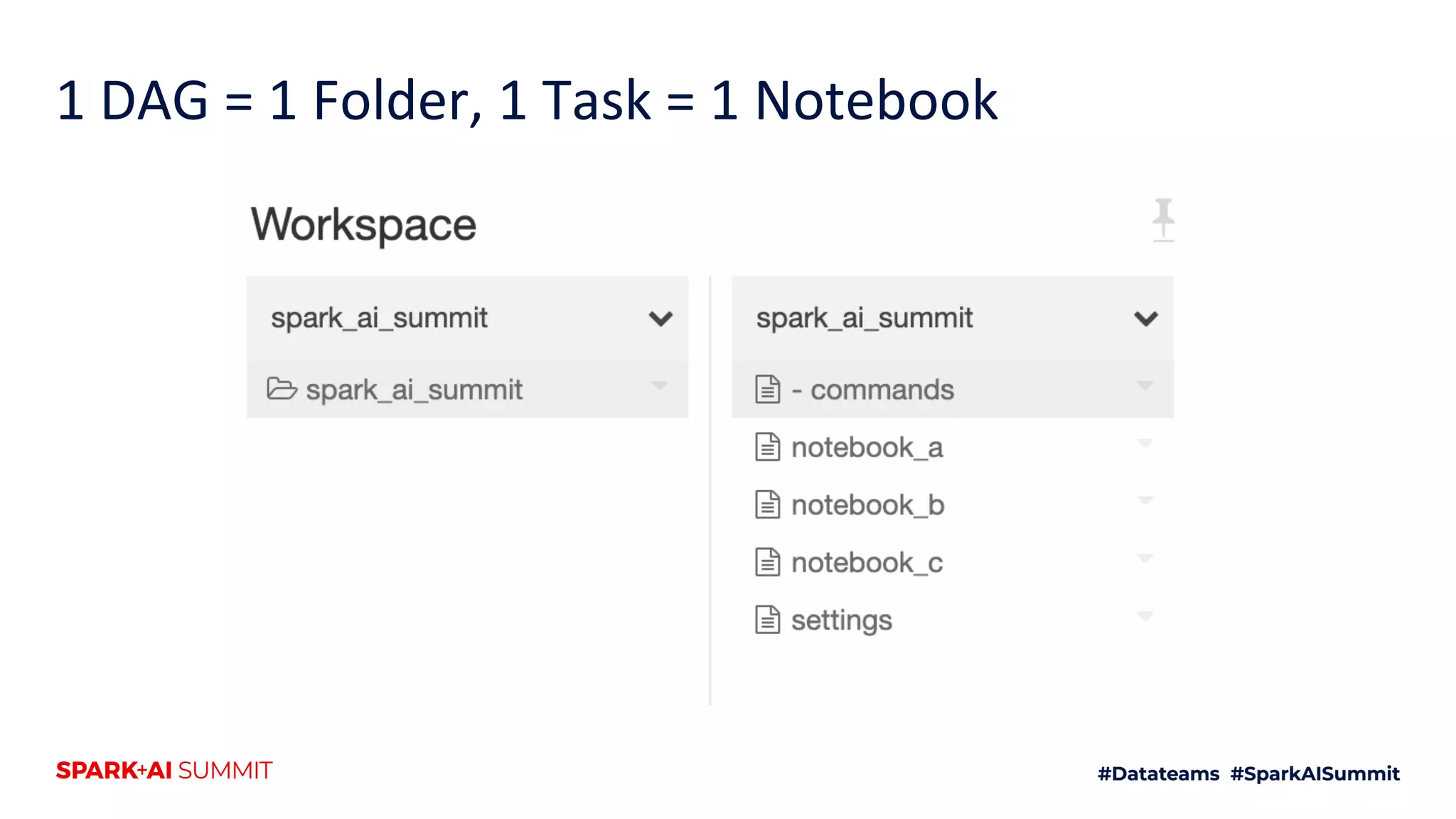





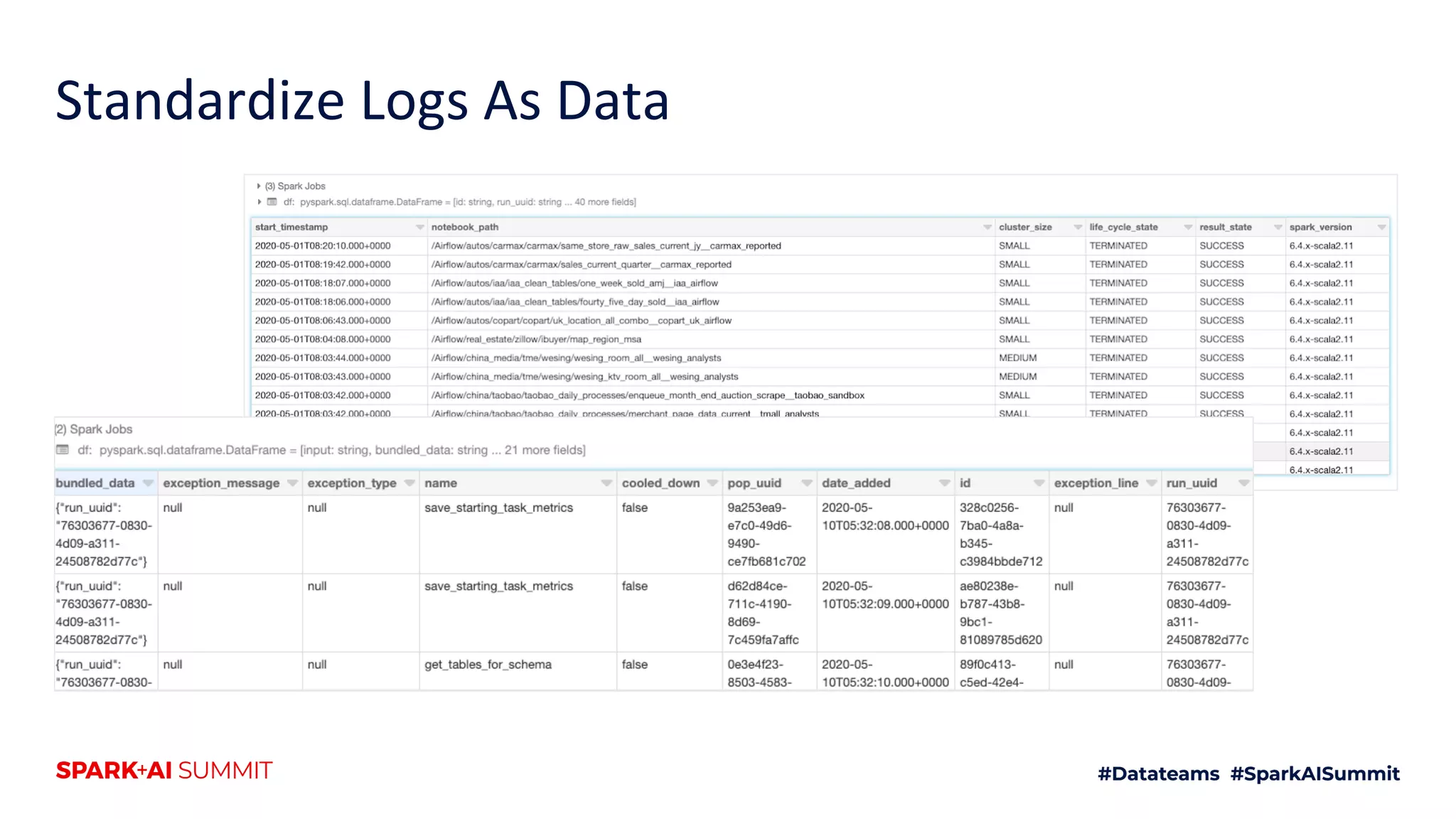
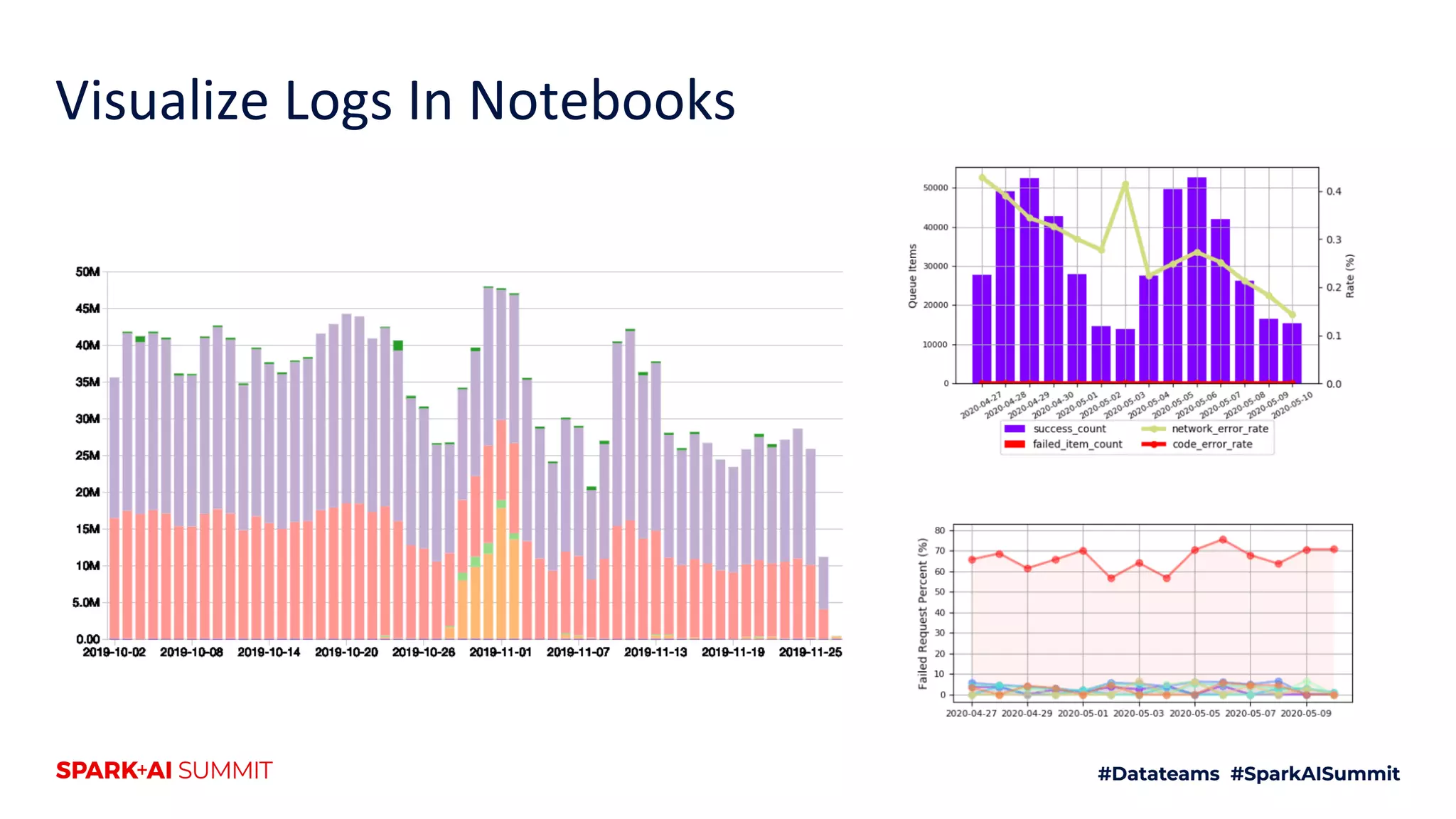























The document discusses the use of Databricks as an analytics platform, highlighting features such as ETL workload management, various data types supported, and the integration of 3rd party data. It also emphasizes the importance of automation using tools like Airflow for workflow management, along with best practices for data handling and storage. Additionally, the document outlines YipitData's research offerings and encourages feedback and job applications.