- Code has been run on Google Colab which provides free GPU memory
-
Natural Language Processing(自然语言处理)
-
- IMDB(English Data)
-
-
SNLI(English Data)
-
微众银行智能客服(Chinese Data)
-
-
Spoken Language Understanding(对话理解)
- ATIS(English Data)
-
-
青云语料(Chinese Data)
-
Python Inference(基于 Python 的推理)
-
Java Inference(基于 Java 的推理)
-
-
-
Multi-turn Dialogue Rewriting(多轮对话改写)
-
微信 AI 研发数据(Chinese Data)
-
Python Inference(基于 Python 的推理)
-
Java Inference(基于 Java 的推理)
-
-
-
- Facebook AI Research Data(English Data)
-
- bAbI(Engish Data)
-
-
Word Extraction
-
Word Segmentation
-
-
-
Knowledge Graph(知识图谱)
-
- Movielens 1M(English Data)
└── finch/tensorflow2/text_classification/imdb │ ├── data │ └── glove.840B.300d.txt # pretrained embedding, download and put here │ └── make_data.ipynb # step 1. make data and vocab: train.txt, test.txt, word.txt │ └── train.txt # incomplete sample, format <label, text> separated by \t │ └── test.txt # incomplete sample, format <label, text> separated by \t │ └── train_bt_part1.txt # (back-translated) incomplete sample, format <label, text> separated by \t │ ├── vocab │ └── word.txt # incomplete sample, list of words in vocabulary │ └── main └── attention_linear.ipynb # step 2: train and evaluate model └── attention_conv.ipynb # step 2: train and evaluate model └── fasttext_unigram.ipynb # step 2: train and evaluate model └── fasttext_bigram.ipynb # step 2: train and evaluate model └── sliced_rnn.ipynb # step 2: train and evaluate model └── sliced_rnn_bt.ipynb # step 2: train and evaluate model -
Task: IMDB(English Data)
Training Data: 25000, Testing Data: 25000, Labels: 2-
Model: TF-IDF + Logistic Regression
-
Model: FastText
-
Model: Feedforward Attention
-
Model: Sliced RNN
-
TensorFlow 2
-
<Notebook> Sliced LSTM + Back-Translation -> 91.7 % Testing Accuracy
-
<Notebook> Sliced LSTM + Back-Translation + Char Embedding -> 92.3 % Testing Accuracy
-
<Notebook> Sliced LSTM + Back-Translation + Char Embedding + Label Smoothing
-> 92.5 % Testing Accuracy
-
<Notebook> Sliced LSTM + Back-Translation + Char Embedding + Label Smoothing + Cyclical LR
-> 92.6 % Testing Accuracy
This result (without transfer learning) is higher than CoVe (with transfer learning)
-
└── finch/tensorflow2/text_matching/snli │ ├── data │ └── glove.840B.300d.txt # pretrained embedding, download and put here │ └── download_data.ipynb # step 1. run this to download snli dataset │ └── make_data.ipynb # step 2. run this to generate train.txt, test.txt, word.txt │ └── train.txt # incomplete sample, format <label, text1, text2> separated by \t │ └── test.txt # incomplete sample, format <label, text1, text2> separated by \t │ ├── vocab │ └── word.txt # incomplete sample, list of words in vocabulary │ └── main └── dam.ipynb # step 3. train and evaluate model └── esim.ipynb # step 3. train and evaluate model └── ...... -
Task: SNLI(English Data)
Training Data: 550152, Testing Data: 10000, Labels: 3-
TensorFlow 2
-
Model: DAM
-
<Notebook> DAM -> 85.3% Testing Accuracy
The accuracy of this implementation is higher than UCL MR Group's implementation (84.6%)
-
-
Model: Match Pyramid
-
<Notebook> Pyramid -> 87.1% Testing Accuracy
The accuracy of this model is 0.3% below ESIM, however the speed is 1x faster than ESIM
-
-
Model: ESIM
-
<Notebook> ESIM -> 87.4% Testing Accuracy
The accuracy of this implementation is comparable to UCL MR Group's implementation (87.2%)
-
-
Model: RE2
-
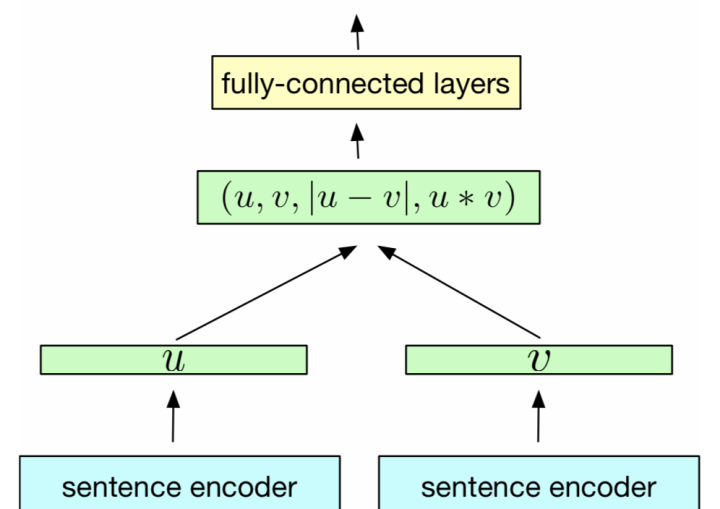
└── finch/tensorflow2/text_matching/chinese │ ├── data │ └── make_data.ipynb # step 1. run this to generate char.txt and char.npy │ └── train.csv # incomplete sample, format <text1, text2, label> separated by comma │ └── test.csv # incomplete sample, format <text1, text2, label> separated by comma │ ├── vocab │ └── cc.zh.300.vec # pretrained embedding, download and put here │ └── char.txt # incomplete sample, list of chinese characters │ └── char.npy # saved pretrained embedding matrix for this task │ └── main └── pyramid.ipynb # step 2. train and evaluate model └── esim.ipynb # step 2. train and evaluate model └── ...... -
Task: 微众银行智能客服(Chinese Data)
Training Data: 100000, Testing Data: 10000, Labels: 2-
Model
-
TensorFlow 2
These results are higher than the results here and the result here
-
TensorFlow 1 + bert4keras
-
<Notebook> BERT -> 85.0% Testing Accuracy
Weights downloaded from here
-
-
-
Data: 2373 Lines of Book Titles(English Data)
-
Model: TF-IDF + LDA
-
PySpark
-
Sklearn + pyLDAvis
-
-
└── finch/tensorflow2/spoken_language_understanding/atis │ ├── data │ └── glove.840B.300d.txt # pretrained embedding, download and put here │ └── make_data.ipynb # step 1. run this to generate vocab: word.txt, intent.txt, slot.txt │ └── atis.train.w-intent.iob # incomplete sample, format <text, slot, intent> │ └── atis.test.w-intent.iob # incomplete sample, format <text, slot, intent> │ ├── vocab │ └── word.txt # list of words in vocabulary │ └── intent.txt # list of intents in vocabulary │ └── slot.txt # list of slots in vocabulary │ └── main └── bigru.ipynb # step 2. train and evaluate model └── bigru_self_attn.ipynb # step 2. train and evaluate model └── transformer.ipynb # step 2. train and evaluate model └── transformer_elu.ipynb # step 2. train and evaluate model -
Task: ATIS(English Data)

Training Data: 4978, Testing Data: 893-
Model: Bi-directional RNN
-
TensorFlow 2
-
97.4% Intent Acc, 95.4% Slot Micro-F1 on Testing Data
-
<Notebook> Bi-GRU + Self-Attention
97.6% Intent Acc, 95.7% Slot Micro-F1 on Testing Data
-
-
-
Model: ELMO Embedding
-
TensorFlow 1
-
97.5% Intent Acc, 96.1% Slot Micro-F1 on Testing Data
-
-
└── finch/tensorflow1/free_chat/chinese_qingyun │ ├── data │ └── raw_data.csv # raw data downloaded from external │ └── make_data.ipynb # step 1. run this to generate vocab {char.txt} and data {train.txt & test.txt} │ └── train.txt # processed text file generated by {make_data.ipynb} │ ├── vocab │ └── char.txt # list of chars in vocabulary for chinese │ └── cc.zh.300.vec # fastText pretrained embedding downloaded from external │ └── char.npy # chinese characters and their embedding values (300 dim) │ └── main └── lstm_seq2seq_train.ipynb # step 2. train and evaluate model └── lstm_seq2seq_export.ipynb # step 3. export model └── lstm_seq2seq_infer.ipynb # step 4. model inference └── transformer_train.ipynb # step 2. train and evaluate model └── transformer_export.ipynb # step 3. export model └── transformer_infer.ipynb # step 4. model inference -
Task: 青云语料(Chinese Data)
Training Data: 107687, Testing Data: 3350-
Data
-
Model: RNN Seq2Seq + Attention
-
TensorFlow 1
-
LSTM + Attention + Beam Search -> 3.540 Testing Perplexity
-
-
Model Inference
-
-
Model: Transformer
-
TensorFlow 1 + texar
-
Transformer (6 Layers, 8 Heads) -> 3.540 Testing Perplexity
-
-
Model Inference
-
-
└── FreeChatInference │ ├── data │ └── transformer_export/ │ └── char.txt │ └── libtensorflow-1.14.0.jar │ └── tensorflow_jni.dll │ └── src └── ModelInference.java 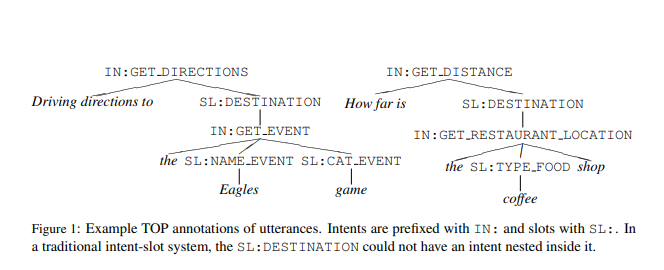
└── finch/tensorflow2/semantic_parsing/tree_slu │ ├── data │ └── glove.840B.300d.txt # pretrained embedding, download and put here │ └── make_data.ipynb # step 1. run this to generate vocab: word.txt, intent.txt, slot.txt │ └── train.tsv # incomplete sample, format <text, tokenized_text, tree> │ └── test.tsv # incomplete sample, format <text, tokenized_text, tree> │ ├── vocab │ └── source.txt # list of words in vocabulary for source (of seq2seq) │ └── target.txt # list of words in vocabulary for target (of seq2seq) │ └── main └── lstm_seq2seq_tf_addons.ipynb # step 2. train and evaluate model └── ...... -
Task: Semantic Parsing for Task Oriented Dialog(English Data)
Training Data: 31279, Testing Data: 9042-
Model: RNN Seq2Seq + Attention
-
TensorFlow 2
-
<Notebook> LSTM + Attention + Beam Search ->
72.4% Exact Match Accuracy on Testing Data
-
<Notebook> LSTM + Attention + Beam Search + Cyclical LR + Label Smoothing ->
74.1% Exact Match Accuracy on Testing Data
-
-
└── finch/tensorflow2/knowledge_graph_completion/wn18 │ ├── data │ └── download_data.ipynb # step 1. run this to download wn18 dataset │ └── make_data.ipynb # step 2. run this to generate vocabulary: entity.txt, relation.txt │ └── wn18 # wn18 folder (will be auto created by download_data.ipynb) │ └── train.txt # incomplete sample, format <entity1, relation, entity2> separated by \t │ └── valid.txt # incomplete sample, format <entity1, relation, entity2> separated by \t │ └── test.txt # incomplete sample, format <entity1, relation, entity2> separated by \t │ ├── vocab │ └── entity.txt # incomplete sample, list of entities in vocabulary │ └── relation.txt # incomplete sample, list of relations in vocabulary │ └── main └── distmult_1-N.ipynb # step 3. train and evaluate model -
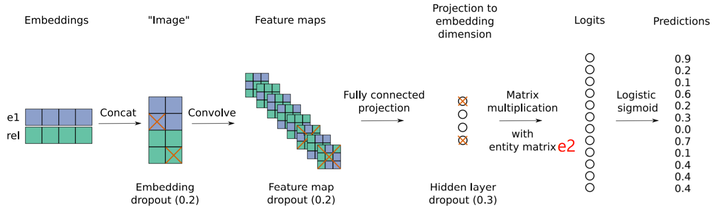
Task: WN18
Training Data: 141442, Testing Data: 5000-
We use 1-N Fast Evaluation to largely accelerate evaluation process
MRR: Mean Reciprocal Rank
-
Model: DistMult
-
TensorFlow 2
-
-
Model: TuckER
-
TensorFlow 2
-
-
Model: ComplEx
-
TensorFlow 2
-
-
Data Scraping
-
SPARQL
-
Neo4j + Cypher

└── finch/tensorflow1/question_answering/babi │ ├── data │ └── make_data.ipynb # step 1. run this to generate vocabulary: word.txt │ └── qa5_three-arg-relations_train.txt # one complete example of babi dataset │ └── qa5_three-arg-relations_test.txt # one complete example of babi dataset │ ├── vocab │ └── word.txt # complete list of words in vocabulary │ └── main └── dmn_train.ipynb └── dmn_serve.ipynb └── attn_gru_cell.py -
Task: bAbI(English Data)
-
Word Extraction
-
Chinese
-
-
Word Segmentation
-
Chinese
-
Custom TensorFlow Op added by applenob
-
-

└── finch/tensorflow1/recommender/movielens │ ├── data │ └── make_data.ipynb # run this to generate vocabulary │ ├── vocab │ └── user_job.txt │ └── user_id.txt │ └── user_gender.txt │ └── user_age.txt │ └── movie_types.txt │ └── movie_title.txt │ └── movie_id.txt │ └── main └── dnn_softmax.ipynb └── ...... -
Task: Movielens 1M(English Data)
Training Data: 900228, Testing Data: 99981, Users: 6000, Movies: 4000, Rating: 1-5-
Model: Fusion
-
TensorFlow 1
MAE: Mean Absolute Error
-
└── finch/tensorflow1/multi_turn_rewrite/chinese/ │ ├── data │ └── make_data.ipynb # run this to generate vocab, split train & test data, make pretrained embedding │ └── corpus.txt # original data downloaded from external │ └── train_pos.txt # processed positive training data after {make_data.ipynb} │ └── train_neg.txt # processed negative training data after {make_data.ipynb} │ └── test_pos.txt # processed positive testing data after {make_data.ipynb} │ └── test_neg.txt # processed negative testing data after {make_data.ipynb} │ ├── vocab │ └── cc.zh.300.vec # fastText pretrained embedding downloaded from external │ └── char.npy # chinese characters and their embedding values (300 dim) │ └── char.txt # list of chinese characters used in this project │ └── main └── baseline_lstm_train.ipynb └── baseline_lstm_export.ipynb └── baseline_lstm_predict.ipynb -
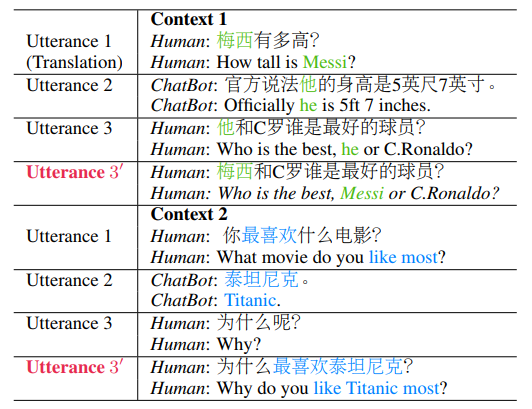
Task: Multi-turn Dialogue Rewriting(Chinese Data)
Training Data (Positive): 18986, Testing Data (Positive): 1008 Training Data = 2 * 18986 because of 1:1 Negative Sampling-
Model: RNN Seq2Seq + Attention + Dynamic Memory
-
TensorFlow 1
-
<Notebook> LSTM Seq2Seq + Attention + Memory + Beam Search
-> BLEU-1: 94.6, BLEU-2: 89.1, BELU-4: 78.5, EM: 56.2%
This result (without BERT) is comparable to the result here with BERT
-
-
└── MultiDialogInference │ ├── data │ └── baseline_lstm_export/ │ └── char.txt │ └── libtensorflow-1.14.0.jar │ └── tensorflow_jni.dll │ └── src └── ModelInference.java 
-
Rule-based System(基于规则的系统)